1997 IEEE International Symposium on Circuits
and
Systems, June 9-12,1997,Hong Kong
A
NOVEL SCALABLE
ARCHITECTURE w I m MEMORY INTERLEAVING
ORGANIZATION FOR FULL SEARCH BLOCK-MATCHING ALGORITHM
Yeong-Kang Lai, Liang-Gee Chen, Tsung-Hun. Tsai, and Po-Cheng Wu
Department of Electrical Enigineering National Taiwan University
Taipei, Taiwan, R. 0. C. China
ABSTRACT
This paper describes a high-throughput scalalble architec- ture for full-search block-matching algorithm (FSBMA). T h e number of processing elements (PES) is scalable ac- cording to the variable algorithm parameters and the per- formance required for different applications. By use of the efficient PE-rings and the intelligent memory-interleaving organization, the efficiency of the architecture can be in- creased. Techniques for reducing interconnections and ex- ternal memory accesses are also presented. Our results demonstrate t h a t the scalable PE-ringed architecture is a flexible and high-performance solution for
FSBMA.
1. INTRODUCTION
Among various video compression techniques, the motion- compensated hybrid coding is the most popular one and is adopted by several standards and proposals [I]-[3]. Block matching algorithm for motion estimation is nowadays used in a wide variety of applications. It removes the temporal redundancy within frame sequences, thus it provides these coding systems with significant bit-rate reduction. Howev- er, it also requires a large amount of computation and a heavy memory bandwidth.
The different performance requirements are needed for different real-time video applications. T h e performance re- quirements can be evaluated by some essential parameters such as the block size, the search area size, the frame size, and the frame rate. T o meet real-time video application, the number of P E S depends on the performance requirements. For numerous application domains, optimal block-matching parameters have not been specified yet. Furthermore, flex- ibility in parameters is explicitly favored for emulation of algorithms in an early phase of system development. Hence, there exists a substantial need for a flexible motion estima- tor, allowing the user t o select his own parameters and t o check the influence of parameter variations.
Several dedicated hardware implementations have been realized for full-search (FS) or full-search-based block matching algorithms [4]-[ll]. Principally, these realizations are systolic arrays, laid out for a specific set of parameter values. Hence they usually offer only a limited flexibility, or even no flexibility a t all. Moreover, the parallel architec- ture with multiple PES can efficiently increase throughput. However, the number of input pins, the difficulties on d a t a addressing, and interconnection complexity between mem- ory modules and PES make it hard t o implement. We pro- pose the novel scalable PE-ringed architecture effectively t o solve all these problems.
In the presented paper, a scalable, parametrizable and
0-7803-3583-XI97 $10.00 01997
IEEE
O B I B 2 B i 04 05 0 6 0 7 B8 BY B I O B l i 812813 B l 4 B i 16017HIX . ~ B l i l B l l.I-.
12 013 1174 O M 047 48 B4Y H i l l BA2 B h i 64 865 1166 B7Y BXI a(0.0)a(0,l)a(o.Z) . , , , . .q7,o)a(l,l)a(l,z) a(2,0)a(2.l)a(2.2). . . , , , . 224 0225 8226. . 240 BZ4l 0242 ~~ -8 16x1 6 template block from current frameX
'
31 x31 search area from previous frame
7
Figure: 1. Template block and search area for 256 possible displacement
( N
= 16,p = 8).yet efficient full search block-matching architecture is de- scribed. The proposed approach offers the various d a t a flow of different parameters and thus achieves an efficiency close t o 1 0 0 ]percent. It also utilizes the data-reuse t o reduces the number of input pins. Section 2 shows the overall scalable architecture. In Section 3 , we present some techniques of memor:y bandwidth reduction, d a t a arrangement, and inter- connection simplification. In Section 4, the performance of the proposed VLSI architecture along with various conven- tional full search block-matching architectures is analyzed. Finally, Section 5 gives a conclusion.
2. THE PROPOSED VLSI ARCHITECTURE
The procedure of a block-matching algorithm is t o find the best matched displaced block from the previous frame Ft-1, within a search range, for each
N
x N block in the present frame .Ft. A straightforward method, the full search, ex-haustively matches all possible candidates t o find the dis- placement (called motion vector) with a minimal distortion. As a c.riterion of distortion, the mean absolute difference (MAD) is calculated for each candidate location ( U , v ) :
H MM columns and H P E columns from the above PE from memory module current block - DIXBIS v MM l O W S v PE rows
...
...
time-sharing common bus I
motion vector
Figure 2 . The scalable PE-ringed architecture.
N-1 N-1
= IFt(z
+
I , Y+
m ) - Ft-i(z+
I + U , Y + m +.)I
1=0 m = O
(1) where ( z , y ) is the coordinate of the upper-left pixel of the current block in F,, and the values of U and TJ are limited
t o between - p t o p - 1. Fig. 1 illustrates the procedure of FSBMA. T h e candidate blocks are labeled by BO N B255.
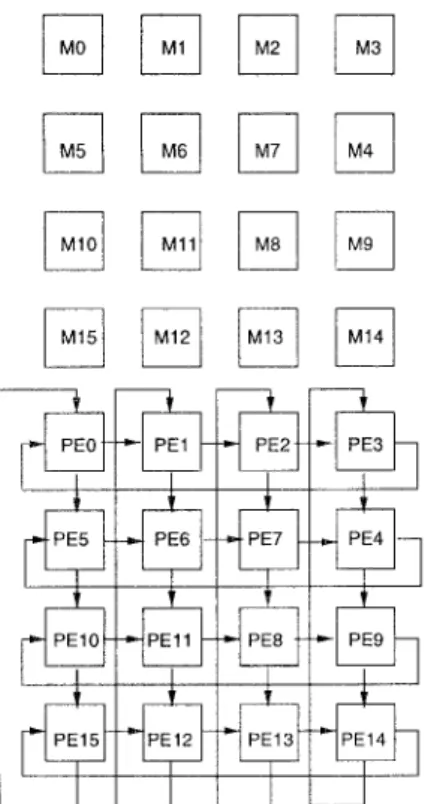
Fig. 2 shows the scalable PE-ringed architecture t o per- form the FSBMA. T o exploit the parallelism in FSBMA, the proposed architecture is consists of H x V identical on-chip Memory Modules (MMs) and H x V identical processing el- ements (PES). T h e P E S are connected in a ringed fashion. Each of the P E S is composed of an absolute difference unit, an accumulator, and a final-result latch in a pipelined fash- ion. T h e detailed hardware architecture of a PE is shown in Fig. 3. According t o the performance requirements of dif- ferent real-time video applications, the number of the MMs and the PES, i.e., H x V , is determined by the following evaluation equation. Assume t h a t the cycle time is Tp for
t h e N x N current block with the search range of - p t o p - 1. ( 2 ) x ( 2 ~ ) ’ x N 2 x Tp 1
f r
< -
H x V T =where T denotes the total block-matching time of all blocks in a frame (frame size: W X L). It should be small- er than frame period, l / f r . The search area pixels t o be computed are first stored in the MMs. T h e current block pixels are sequentially input and broadcasted t o all P E S in
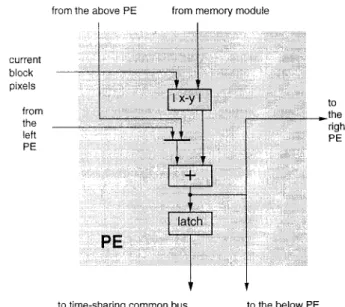
current block pixels from the left PE
to time-sharing common bus to the below PE to .the
right PE
Figure 3. Architecture of PE.
a raster-scan order. The upper-left H x V of the all candi- date blocks are first computed. After 256 clock cycles, the MAD of each candidate block is produced in each PE and transferred to PE’s final-result latch. These H x V latched MADS can then be sent t o the minimum extractor t o get a minimum MAD. During the comparisons, the PES continue t o perform the block-matchings of the next H x V candi- date blocks. It does not consume extra cycles t o fill u p the pipeline operations.
3. T E C H N I Q U E S FOR DATA M A N A G E M E N T This architecture is based on some d a t a management tech- niques: (1) On-chip memory configuration for data-reuse, ( 2 ) Memory interleaving organization for parallel d a t a ac- cesses, and (3) Propagation of the accumulated partial- results for eliminating the interconnection overheads be- tween the PES and the MMs, These techniques are de- scribed in the following subsections. Fig. 4 shows a simple example t o illustrate the operation of the proposed archi- tecture. In terms of (Z), we assume t h a t the 4x4 MMs and 4x4 PES are needed t o meet a certain real-time application.
3.1. On-chip Memory C o n f i g u r a t i o n for Data- The memory bandwidth is the main bottleneck t o support the high performance motion estimators. However, pixels are repeatedly used several times t o evaluate different can- didate blocks. To avoid the extremely high bandwidth re- quirements for chip 1/0 and memory systems, we utilize the overlap between the search areas of the adjacent current blocks (see Fig. 5) and propose the scheme of three half- search-area (HSA) segments. Each of the memory mod- ules is partitioned into three HSA segments, as shown in Fig. 6(a). One HSA block (31 x 16 pixels) is interleaved t o reside the same labeled segments in the 4 x 4 MMs. Fig. 6(b) illustrates the operations of the three HSA segments. When executing task 0 (matching current block 0 ) , the PES access the search area pixels from the segments 0 and 1. During performing the FS of current block 0, the HSA segment 2 in all memory modules is being filled by the right-half of the search area for task 1 (HSA C). When executing task 1 (matching current block l), the search area pixels from the
L I I ' I ' i ' I '
l
Figure 4. A simple architecture e x a m p l e for
N
= 4, p = 2, H = 4, and V = 4.(some interconnections are o m i t t e d . )HSA blocks (31 x 16) ~ w r s n l blocks (16 x 16)
P
a
I I 1 I I I
A R C D E F G H - - .
+_I
--
ssarch area of c u m n l block 0 (task 0) search area of current block 1 (task 1)1
- search area of current black 2 (lark 2)
F i g u r e 5 . Overlapped search areas of a d j a c e n t cur-
rent blocks.
segments 1 and 2 of the 4 x 4 MMs are accessed by the PES, and the new d a t a (HSA D) are input to segment 0. In this cyclic manner, the 31 x 16 new pixels can be easily accessed from system memory during performing the block-matching of the current block by only one input port.
3.2. M e m o r y I n t e r l e a v i n g O r g a n i z a t i o n
T h e on-chip memory is used t o reduce the 1oa.d for chip
1/0 and memory system. The next problem is: how to provide all required d a t a for the H x V P E S simultaneously. Our approach is t o divide the memory into H x V memory modules, and to interleave the input pixels to these H x V modules. An example are shown in Fig. 7. The label (0 N 15) for each pixel indicates the module t h a t stores
the pixel. This memory interleaving organization provides
a solution for parallel d a t a accesses, but it stipulates t h a t each of P E S is able t o access the corresponding memory module in parallel. HSA segment 0 HSA segment 1 HSA segrnent 2 memory module i
I
segment21
contents of segments TO T1 T2 T3 T4 T5 T6 A I n / D D m G G B B m E E M H m C C I F / F F m * timeH full search for current block Ti: task i
F i g u r e 16. ( a ) The three partitioned HSA s e g m e n t s . (b) Contents of the three HSA s e g m e n t s ( w r i t e op- erations are m a r k e d b y small f r a m e s ) .
3.3. P r o p a g a t i o n of the accumulated partial-
In most of multiple
PES
designs, a fully connected intercon- nection is demanded between the multiple PES and multipleMMs. However, the interconnection gives the extra delay and consumes larger routing space due to large numbers of buses, multiplexers and tri-state buffers. To overcome the drawback, the adjacent P E S are connected in the horizon- tal rings and the vertical rings, and we arrange the d a t a flow from the memory modules to the P E S and redistribute the PES operations. This method allows the operations be- longing i o a candidate block t o be performed by the several PES. Then, for every clock cycle, P E propagates the accu- mulated partial-result to t h e adjacent
PE
t o form the next partial-result of the block candidate. After 256 clock cycles, the final result of each candidate block is produced in each P E . The d a t a flow is shown in Table 1. By use of the prop- agation of the accumulated partial-results, each of the P E S is only connected to one memory module. This eliminates the complicated interconnection and the switching circuitry between the P E S and the memory modules.results
4. P E R F O R M A N C E A N A L Y S I S
In this section, we analyze the performance of the proposed VLSI architecture for the full search block-matching algo- rithm. Table 2 presents a comparison between the pro- posed and previous architectures. T h e 2-D array provides high-speed motion estimators with very high costs. T h e 1-
D array is an efficient low-cost design for some low-speed applications. However, the proposed architecture gives a satisfactory solution taking into account scalability, input ports and computation speed.
5. C O N C L U S I O N
A scalable PE-ringed architecture for F S B M A has been de- scribed. The number of processing elements (PES) is scal- able according to the variable algorithm parameters and the
Architecture No. of t h e PES
No. ofinDut d a t a Dins
proposed architecture 2-D array [4] 1-D array [5]
128
I
641
32[
16 1281
641
321
16 1281
641
32I
16 16 I 16 I 16 I 16 24 I 24 I 24 1 24 136 I 72 I 40 I 24Figure 7. An example for the distribution of search area pixels to 4 x 4-memory modules.
performance required for different applications. A config- uration of random-access on-chip memory modules solves t h e problems of chip 1/0 and memory bandwidth require- ment. Input d a t a are arranged in the memory modules by memory interleaving organization. Combined with a tech- nique of t h e propagation of accumulated partial results, the interleaved memory module provides every PE with its re- quired d a t a simultaneously without introducing complicat- ed interconnections and switching circuitry. In summary, t h e proposed architectures have t h e following desirable fea- tures: (1) low hardware cost, ( 2 ) high throughput rate, ( 3 )
low latency delay, (4) low 1/0 and memory bandwidth re- quirements, and (5) 100 percent computation efficiency.
REFERENCES
[l] C C I T T SGXV Working P a r t y XV/1 Specialists Group on Coding for Visual Telephony, Document #584, Nov.
1989.
[2]
ISO/IEC/JTCl/SC29/WGll/Draft/CD
13818-2,“Recommendation H.262,” November, 1993.
[3]
ISO/IEC/JTCl/SC29/WGll/Draft/CD
13818-1,“MPEG-2 Systems,” November, 1993.
[4] Luc De Vos and Michael Stegherr,
,
“Parameterisable VLSI Architectures for the Full-Search Block-Matching Algorithm,”
I E E E Transactions o n Circuit and Sys- tem., vol. 36 no. 10, p p 1309-1316, Oct. 1989. [5] K . M. Yang, M. T . Sun, and L. Wu, “ A family of VLSIdesigns for t h e motion compensation block-matching algorithm,” I E E E Transactions o n Circuit and S y s t e m
for Video Technology., vol. 36, no. 10, pp.1317-1325,
Oct. 1989.
Clock cycles per block matching
Table 1. Data flow for FSBMA ( N = 1 6 , p = 8 )
T i m e I D a t e S e q u e n c e I PBO I P B l I . I P B 1 4 1 P B 1 6 O X 1 6 4 0 I 512 1024 2048 4096 512 1024 2048 4096 512 1024 2048 4096 ... ... ... ... ... ... . ( 0 , 1 4 ) B 2 O X 16+14 OX16+16 .(0,16) B 1 1X 16+0 . ( 1 , 0 ) B 4 8 1X 1 6 + 1 .(l,l) BKl ... ... ... ... ... ... 1 x 1 6 1 1 4 a ( 1 . 1 4 ) BKO 1 X 1 6 + 1 6 & ( 1 , 1 6 ) 8 4 9 ... ... ... ... ... ... ... ... ... ... ... ... 14X 16+0 r(14,O) 8 3 2 14X 16+1 4 1 4 . 1 ) 8 3 6 1 4 X 1 6 + 1 4 1 4 x 1 6 + 1 6 16X 16+0 16X 16+1 B 4 9 ... ... ... a ( 1 4 , 1 4 ) 8 3 4 B 3 6 . B 1 6 B 1 7 .(14,16) B 3 3 8 3 4 . B 1 9 8 1 6 a(16.0) B16 B l t . B 1 B 3 ~ ( 1 6 ~ 1 ) B 1 9 B 1 6 . B 1 B 2 ... ... B 6 0 ... ... 1 6 1 1 6 + 1 4 1 6 X 1 6 + 1 6 ... ... ... B 3 1 ... ... . . . ... ... ... . . . ... a ( l K , l 4 ) B 1 1 B 1 9 . BO B 1 E l ? B l 8 . B 3 BO a( 1 6 , l S ) I ... I ... I . . . I . . . I . I ... I I ... I ... I ... l . . . I . I ... I ...
I
” ’I
”I
...I
N B X T1 . 1
...1
... ... ... ... I ( ” I[6] Y. S. Jehng, L. G. Chen,and T. D. Chiueh, “ An ef-
ficient and simple VLSI tree architecture for motion estimation algorithm,’’ I E E E Transactions o n Signal
Proc., vol. 41, no. 2 , Feb. 1993.
[7] H. M. Jong, L. G. Chen, and T. D. Chiueh, I‘ Paral- lel Architecture for 3-Step Hierarchical Search Block- Matching Algorithm,” I E E E Transactions o n Circuit and S y s t e m for Video Technology., vol. 4 , no. 4, Aug.
1994.
[8] Shifan Chang, Juin-Haur Hwang, and Chein-Wei Jen
,
“Scalable Array Architecture for Full Search Block Matching,”
I E E E Transactions o n Circuit and S y s t e mf o r Video Technology., vol. 5 no. 4 , pp 332-353, Aug.
1995.
[9] Luc De Vos and Matthias Schobinger
,
“VLSI Architec- ture for a Flexible Block Matching Processor,”
IEEE
Transactions o n Circuit and S y s t e m for Video Tech- nology., vol. 5 no. 5, pp 417-428, Oct. 1995.[lo] Santanu D u t t a and Wayne W o l f , “A Flexible Paral- lel Architecture Adapted t o Block-Matching Motion-
Estimation Algorithms
,”
IEEE Transactions on Cir- cuit and S y s t e m for Video Technology., vol. 6 no. 1, p p74-86, Feb. 1996.
[ll] Gangan G u p t a and Chaitali Chakrabarti
,
“Archi- tectures for Hierarchical Other Block Matching Algo- rithms,”
I E E E Transactions o n Circuit and S y s t e mfor Video Technology., vol. 5 no. 6, p p 477-489, Dec.
1995.