國
立 交 通 大 學
電信工程學系
博 士 論 文
非監督式中文語音韻律標記及韻律模式
Unsupervised Joint Prosody Labeling and
Modeling for Mandarin Speech
研究生: 江振宇
指導教授: 陳信宏博士
王逸如博士
非監督式中文語音韻律標記及韻律模式
Unsupervised Joint Prosody Labeling and
Modeling for Mandarin Speech
研 究 生:江振宇 Student:
Chen-Yu
Chiang
指導教授:陳信宏 博士
Advisors: Dr. Sin-Horng Chen
王逸如 博士 Dr. Yih-Ru Wang
國立交通大學
電信工程學系
博士論文
A Dissertation Submitted to Institute of
Communication Engineering
College of Electrical and Computer Engineering
National Chiao Tung University
in Partial Fulfillment of the Requirements
for the Degree of Doctor of Philosophy
in
Communication Engineering
Hsinchu, Taiwan
推 薦 函
中華民國九十八年二月十一日
一、 事由:本校電信研究所博士班研究生 江振宇 提出論文以參加
國立交通大學博士班論文口試。
二、 說明:本校電信研究所博士班研究生 江振宇 已完成本校電信
研究所規定之學科課程及論文研究之訓練。
有關學科部分,江君已修滿十八學分之規定(請查閱學籍資料)
並通過資格考試。
有關論文部分,江君已完成其論文初稿,相關之論文亦分別發
表或即將發表於國際期刊(請查閱附件)並滿足論文計點之要
求。
總而言之,江君已具備國立交通大學電信研究所應有之教育及
訓練水準,因此特推薦
江君參加國立交通大學電信工程學系博士班論文口試。
交通大學電信工程學系教授 陳信宏
交通大學電信工程學系副教授 王逸如
非監督式中文語音韻律標記及韻律模式
研究生:江振宇
指導教授:陳信宏 博士
王逸如 博士
國立交通大學電信工程學系
中文摘要
韻律模式可使用在許多語音處理應用上,如語音合成及語音辨認。一般傳統 建構韻律模式的方法,是先對語音信號標示出韻律標記以表示重要的韻律訊息, 進而建構韻律模式。傳統韻律標記的方法是以人工觀察並聆聽語音信號進行標 記,此方法之缺點為:(1)因為不同標記人的主觀認定不同造成標記結果不一 致,(2)即使是同一個標記人進行標記,長時間進行下來,亦難以保持一致性, (3)耗時。上述所論及的不一致性,進而可能使得韻律模式在語音處理應用上 的表現不佳。為了改善以上缺點,在本研究中,我們設計出一個包含四個子模型 的「非監督式中文韻律標記及韻律模式」(Unsupervised joint prosody labeling and modeling, UJPLM)演算法,自動化地對語料同時進行韻律模式以及韻律標記,試 圖更客觀且一致地標記出韻律標記。本研究標記的韻律標記為停頓標記及韻律狀 態,其中停頓標記表示韻律單位的邊界,而韻律狀態的序列代表上層韻律單位(韻 律詞、韻律短語以及呼吸組/韻律句組)的音高變化。實驗語料由一位專業女播音 員朗讀中文文稿,文稿內容則從「中央研究院詞庫小組-中文句結構樹資料庫」 中選出的短篇文章。透過分析訓練出的模型參數,我們探討此語者之:(1)音 節的音高輪廓變化、韻律標記及語言參數的關係,(2)停頓標記、韻律參數及 語言參數的關係,(3)由韻律狀態所表示的上層韻律單位之音高變化。藉由停 頓標記和其對應詞關係之深入分析,除了探討韻律參數與語言參數的連結,同時 也驗證本研究所提出方法之標記能力。另外,經由和人工停頓標記之比較,發現 以本研究方法標記出來的停頓標記,其對應的韻律參數擁有較一致的統計特性,觀地)描述語者之韻律特性。基於UJPLM演算法,本研究接著提出「進階非監 督式中文韻律標記及韻律模式」(Advanced-UJPLM, A-UJPLM)演算法,增加一個 次要停頓韻律標記及同時對於音高、音長和音強進行模式建立。實驗結果顯示此 方法可以更豐富地描述語者之韻律特性,停頓標記的結果顯示在主要停頓及無停 頓的標示上,與UJPLM標示的結果相當一致,而A-UJPLM能夠標記出較多的次 要停頓,使得次要停頓標記結果與人工標記結果更一致。最後本研究提出一個以 A-UJPLM演算法為基礎之語音合成韻律產生法,實驗結果顯示此方法產生之韻 律參數大致符合實際語音的韻律參數,驗證A-UJPLM演算法在韻律標記及韻律 模式上擁有不錯的表現。
Unsupervised Joint Prosody Labeling and
Modeling for Mandarin Speech
Student: Chen-Yu Chiang
Advisors: Dr. Sin-Horng Chen
Dr. Yih-Ru Wang
Department of Communication Engineering, National Chiao Tung University Hsinchu, Taiwan, Republic of China
Abstract
An unsupervised joint prosody labeling and modeling method (UJPLM) for Mandarin speech is proposed, a new scheme intended to construct statistical prosodic models and to label prosodic tags consistently for Mandarin speech. Two types of prosodic tags are determined by four prosodic models designed to illustrate the hierarchy of Mandarin prosody: the break of a syllable juncture to demarcate prosodic constituents and the prosodic state of a syllable to represent any prosodic domain’s pitch level variation resulting from its upper-layered prosodic constituents’ influences. The performance of the proposed method was evaluated using an unlabeled read-speech corpus articulated by an experienced female announcer. Texts of the corpus were selected from The Sinica Treebank Corpus. Experimental results showed that the estimated parameters of the four prosodic models were able to explore and describe the structures and patterns of Mandarin prosody. Besides, certain corresponding relationships between the break indices labeled and the associated words were found, and manifested the connections between prosodic and linguistic parameters, a finding further verifying the capability of the method presented. A quantitative comparison in labeling results between the proposed method and human labelers indicated that the former was more consistent and discriminative than the latter in prosodic feature distributions, a merit of the method developed here on the
UJPLM (A-UJPLM) method was designed based on UJPLM to jointly label seven prosodic tags and model syllable pitch contour, duration and energy level. Experimental results showed that A-UJPLM performed quite well. The break labeling result showed that A-UJPLM inserted more minor breaks than UJPLM to result in a more consistent labeling of minor breaks to the human labeling. Lastly, an application of A-UJPLM to the prosody generation for Mandarin TTS is proposed. Experimental results showed that the proposed method performed well. Most predicted values of syllable pitch mean, duration and energy level matched well to their original counterparts. This also reconfirmed the effectiveness of the A-UJPLM method.
致謝
首先,最需要感謝影響我至深的指導教授:陳信宏老師及王逸如老師,在 七年多的指導過程中,他們給予我許多參與國外學術交流和學習的機會,更感謝 兩位老師平日生活上的諄諄教誨與不吝分享,讓我從中獲益良多。此外,也謝謝 余秀敏老師及潘荷仙老師的大力協助,使本研究的內容更臻於完善,並且開拓我 的研究視野。同時,亦需要感謝廣瀬 啓吉老師 (Professor Keikichi Hirose) 和廖 元甫老師,於為期三個月在東京大學的訪問研究時,給予我許多磨鍊的機會,使 我獲得更多成長。最後,非常感謝王小川老師、王駿發老師、李琳山老師、張文 輝老師、鄭秋豫老師五位口試委員對本研究的肯定和建議,對我而言是種莫大的 鼓勵。 回首在實驗室的點滴,總是一片歡愉的氣氛;感謝羅文輝學長、郭威志學長 以及賴玟杏學姊,在研究與生活上的提攜與指引,常不厭其煩地讓我請教;也感 謝智合、阿德、希群和巴金,大家不只在研究上相互鼓勵與切磋,還讓你們忍受 我多年來持續的冷笑話;還要謝謝振豐、小傅、銘彥、友駿、宏宇、胤賢、小鄧、 啟風、小迷彩、小廣、阿宅、柯達、普烏、小宋、杜Q、小帥哥等這群一起在實 驗室同甘共苦的可愛學弟們,有了你們讓生活更加精采! 最後,特別感謝一直支持我的家人,謝謝爸媽從小的養育和栽培,沒有你們 就無法有今日的我;還有宇君,有妳一路相伴,讓我在生活、研究的路上並不孤 單,給予我最溫暖、窩心的守護。你們的支持及鼓勵是我生命中最大的力量,在 此僅將此論文獻給你們!
Contents
中文摘要
... i
Abstract... iii
致謝
...v
Contents ... vi
List of Tables ... ix
List of Figures... xi
Chapter 1 Introduction ...1
1.1
Background... 1
1.2
Motivation ... 4
1.3
Overview of Unsupervised Joint Prosody Labeling and
Modeling... 5
1.3.1
Previous Works ... 5
1.3.2
Prosody Hierarchy and Prosody Tags... 9
1.3.3
The Four Prosodic Models ... 11
1.3.4
Experimental Database... 12
1.4
Organization of the Dissertation... 13
Chapter 2 Unsupervised Joint Prosody Labeling and
Modeling ...14
2.1 Introduction ... 14
2.2 The Design of the Four Models... 14
2.3 Joint Prosody Labeling and Modeling... 19
2.3.1 Initialization ... 19
2.3.2 Iteration ... 21
2.4 Experimental Results... 22
2.4.1 The Syllable Pitch Contour Model ... 22
2.4.3 The Prosodic State Model... 28
2.4.4 The Break-Syntax Model... 29
2.5 Analyses of the Labeled Breaks and Prosodic
Constituents ... 32
2.5.1 Analyses of the Labeled Break Types ... 32
2.5.2 Analyses of Prosodic Constituents ... 40
2.5.3 Pitch Patterns of Prosodic Constituents ... 42
2.5.4 Comparison with Human Labeling... 44
2.5.5 A Labeling Example ... 49
2.6 Conclusions ... 51
Chapter 3 Advanced Unsupervised Joint Prosody
Labeling and Modeling...52
3.1 Introduction ... 52
3.2 The New Prosodic Model ... 52
3.2.1 Features and Parameters Used in the New Prosodic Model .. 52
3.2.2 Design of the New Prosodic Model ... 54
3.3 Model Training by the A-UJPLM Method... 56
3.3.1 Initialization ... 57
3.3.2 Iteration ... 58
3.4 Experimental Results... 59
3.3.1 The Syllable Prosodic Model... 60
3.3.2 The Break-Acoustics Model ... 63
3.3.3 The Prosodic State Model... 64
3.3.4 The Break-Syntax Model... 66
3.4 Analyses of the Labeled Breaks and Prosodic
Constituents ... 69
3.4.1 Comparison Between A-UJPLM and UJPLM... 69
3.4.2 Patterns of Prosodic Constituents ... 71
3.4.3 A Labeling Example ... 75
3.5 Conclusions ... 77
Chapter 4 An Application to Prosody Generation for
TTS...78
4.1 Introduction ... 78
4.2 The Proposed Break Prediction Method... 80
4.3 Prosodic Feature Prediction... 87
4.4 Conclusions ... 91
Chapter 5 Conclusions and Future Works...92
5.1 Conclusions ... 92
5.2 Future Works ... 94
Bibliography ...95
Appendix A...102
Appendix B ...104
Appendix C...105
C.1 The question set
Θ ... 105
1C.2 The question set
Θ ... 106
2Appendix D...109
D.1 The question set
Θ ... 109
3D.2 The question set
Θ ... 109
4Publication List ...111
List of Tables
Table 1.1: The content of the Sinica Treebank corpus ...13
Table 2.1: The APs (log-F0 levels, βp(1)) and the distribution (P p ) of the 16 ( ) prosodic states...23
Table 2.2: Statistics of break types labeled for 121 prefixes and 195 suffixes...33
Table 2.3: Statistics of break types labeled for the DE words...34
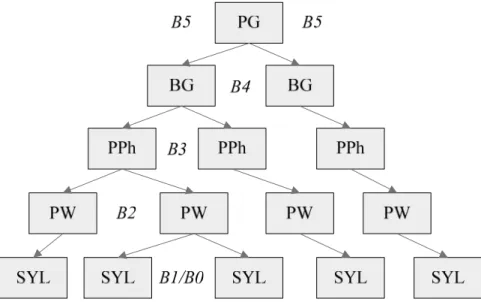
Table 2.4: Statistics of break types labeled for the word sets of Ng, Di, and T. ...36
Table 2.5: Statistics of break types labeled for word set of VE...36
Table 2.6: Statistics of break types labeled for word sets of Caa and Cb...38
Table 2.7: Statistics of break types labeled for word sets of P07 and P21. ...40
Table 2.8: Statistics of three types of prosodic constituents. Value in parentheses denotes standard deviation...40
Table 2.9: Count of short PPh instances with respect to the existence of PM at their two endings. ...42
Table 2.10: Correlations between unsupervised and human labeled breaks ...46
Table 2.11: Distances measuring the difference between two acoustic feature distributions that belong to different break indices labeled by the same method: (a) the proposed method, and (b) human labeling. Upper and lower triangular matrices represent KL2 distances for pause duration and normalized pitch jump, respectively...49
Table 3.1: The notations of prosodic tags, prosodic features and linguistic features..54
Table 3.2: APs of five tones...60
Table 3.3: APs of prosodic states...62
Table 3.4: TREs of the prosodic modelings for syllable pitch contour, duration and energy level w.r.t. the use of different combinations of affecting factors. ...63
Table 3.5: Cooccurrence matrix for the break types labeled by A-UJPLM and by UJPLM...69
denotes standard deviation...70 Table 3.7: Cooccurrence matrix of break tags labeled by A-UJPLM and human...71 Table 3.8: Total residual errors (TREs) w.r.t. the use of different combinations of
affecting factors for pitch/duration/energy level modeling ...75 Table 4.1: Summary of linguistic features used and their abbreviations...81 Table 4.2: The confusion matrix of the target and predicted break types (%) using the baseline all-in-one CART-based method for (a) the inside and (b) outside tests. ...83 Table 4.3: The confusion matrix of the break prediction for the baseline method
evaluated using 3 broad classes of break: (a) The inside and (b) outside tests. (NB: non-break, MiB: minor break, MB: major break) ...83 Table 4.4: The confusion matrix of target and predicted reduced three classes break types using the two-stage approach: (a) inside test (b) outside test...85 Table 4.5: The confusion matrix of target and predicted seven break types using the two-stage approach: (a) inside test and (b) outside test...85 Table 4.6: The confusion matrix of target and predicted reduced three classes break types using the Markov model: (a) inside test (b) outside test. ...86 Table 4.7: TREs of the prosodic feature prediction results. ...89 Table 4.8: TREs of the prosodic feature prediction using correct break labels...89 Table B.1: The contextual linguistic features considered in this study. Note that the
List of Figures
Figure 1.1: A commonly agreed and used prosody hierarchy structure that consists of four layers, including, syllable layer (SYL), prosodic word layer (PW), prosodic phrase layer (PP), and intonation phrase (IP). (Note: this figure
is excerpted and modified from Ref. [6])...2
Figure 1.2: A conceptual prosody hierarchy of Mandarin speech proposed by Tseng et al. in Ref. [8]...9
Figure 2.1: The relationship of observed syllable pitch contour with its APs...17
Figure 2.2: The decision tree for initial break type labeling...20
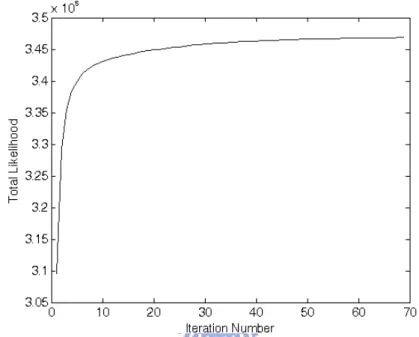
Figure 2.3: The plot of total log-likelihood versus iteration number. ...22
Figure 2.4: The APs of five tones ...23
Figure 2.5: The (a) forward and (c) backward coarticulation patterns, f, B tp β and b, B tp β , for B0 (point line), B1(solid line), and B4(dashed line); and the (b) onset and (d) offset patterns, , b f B t β and , e b B t β , for B and b B . Here tp = (i, j) e and t = i or j...25
Figure 2.6: The pdfs of (a) pause duration and (b) energy-dip level for the root nodes of these 6 break types. Numbers in () denote the mean values...26
Figure 2.7: The decision trees of the break-acoustics model for (a) B4, (b) B3, (c) B2-2, (d) B2-1, and (e) B1. The numbers in a bracket denote average pause duration in ms (left), energy-dip level in dB (middle) and sample count (right) of the associated node. Solid line indicates positive answer to the question and dashed line indicates negative answer...27
Figure 2.8: The most significant prosodic state transitions for (a) B0, B1 and B2-1, and (b) B2-2, B3 and B4. Here, the number in each node represents the index of the prosodic state. Note that bold and thin lines denote the primary and secondary state transitions, respectively. ...28
Figure 2.9: The decision tree of the break-syntax model. The bar plot associated with a node denotes the distributions of these six break types (B0, B1, B2-1, B2-2, B3, B4, from left to right) and the number is the total sample count of the node...30
Figure 2.10: The more detailed structures of sub-trees of (a) T3, (b) T4, (c) T5 and (d) T6. Solid line indicates positive answer to the question and dashed line indicates negative answer. ...31
Figure 2.11: Histograms of lengths for BG/PG, PPh, and PW. ...41 Figure 2.12: The log-F0 patterns of (a) BG/PG, (b) PPh, and (c) PW. The special
symbol “□” in (a) indicates the ending syllable of a log-F0 pattern...44 Figure 2.13: The histograms of length of the prosodic constituents formed by (a) the human labelers and (b) the proposed methods. The numbers in () represent the average length of prosodic constituents. ...46 Figure 2.14: The histograms of (a) pause duration (in sec) and (b) normalized pitch jump (in log-F0) for syllable-juncture instances belonging to sub-groups with different break-index pairs labeled by the two methods...48 Figure 2.15: An example of the automatic prosody labeling. (a) Syntactic trees with prosodic tags: upper case B and lower case b for break-index labeled by our method and the human labeler, respectively; and (b) syllable log-F0 means: observed (open circle) and prosodic state+global mean (close circle). Solid/dash/dot lines represent B3/B2-1/B2-2 respectively. The utterance is “yi-ju(according to) xing-zheng-yuan(the Executive Yuan)
zhu-ji-chu(Directorate-General of Budget, Accounting and Statistics) de(DE) tong-ji(statistics), shi-yue-fen(October) yi(1st) dao(to) er-shi-ri(20th), wo-guo(our country) chu-kou(export) ji(and) jin-kou(import) jin-e(the amount of money) bi-qi(in comparison with) qu-nian(last year) tong-qi(the same period) jun(both) you(to have some) zeng-jia(increase).” ...50
Figure 3.1: The decision tree for initial break type labeling...57 Figure 3.2: The plot of total log-likelihood versus iteration number. ...59 Figure 3.3: Decision tree analysis of duration APs of base-syllable type. Number in () represents the average length (ms) of the APs in the leaf node. Solid line indicates positive answer to the question and dashed line indicates negative answer...61 Figure 3.4: Decision tree analysis of energy-level APs of final. Number in ()
represents the average energy level (dB) of the APs in the leaf node. Solid line indicates positive answer to the question and dashed line indicates negative answer. ...61 Figure 3.5: Distributions of normalized prosodic features and the APs of prosodic
states (vertical lines). ...62 Figure 3.6: The pdfs of (a) pause duration, (b) energy-dip level for the root nodes, (c) normalized pitch jump, (d) normalized duration lengthening factor 1 and (e) normalized duration lengthening factor 2 of these seven break types. Numbers in () denote the mean values...64 Figure 3.7: The most significant pitch prosodic state transitions, P p p( n| n−1,Bn−1), for each break types. Notice that the darker lines represent the more primary prosodic state transitions...65
Figure 3.8: The most significant duration prosodic state transitions, P q q( |n n−1,Bn−1), for each break types. Notice that the darker lines represent the more
primary prosodic state transitions. ...65
Figure 3.9: The most significant energy prosodic state transitions, P q q( |n n−1,Bn−1), for each break types. Notice that the darker lines represent the more primary prosodic state transitions. ...66
Figure 3.10: The decision tree of the break-syntax model. The bar plot associated with a node denotes the distributions of these six break types (B0, B1, B2-1, B2-2, B3, B4, from left to right) and the number is the total sample count of the node...67
Figure 3.11: The more detailed structures of sub-trees of (a) T3, (b) T4, (c) T6 and (d) T5. Solid line indicates positive answer to the question and dashed line indicates negative answer. ...68
Figure 3.12: Histograms of lengths for BG/PG, PPh and PW. ...70
Figure 3.13: The log-F0 patterns of BG/PG, PPh and PW...73
Figure 3.14: The duration patterns of BG/PG, PPh and PW. ...73
Figure 3.15: The energy level patterns of BG/PG, PPh and PW. ...74
Figure 3.16: An example of the automatic prosody labeling by A-UJPLM. Upper, middle and lower panels represent observed (open circle) and prosodic state+global mean (solid diamond) of syllable log-F0 means, syllable duration and syllable energy level, respectively. The utterance is “yi-ju(according to) xing-zheng-yuan(the Executive Yuan) zhu-ji-chu(Directorate-General of Budget, Accounting and Statistics) de(DE) tong-ji(statistics), shi-yue-fen(October) yi(1st) dao(to) er-shi-ri(20th), wo-guo(our country) chu-kou(export) ji(and) jin-kou(import) jin-e(the amount of money) bi-qi(in comparison with) qu-nian(last year) tong-qi(the same period) jun(both) you(to have some) zeng-jia(increase).” ...76
Figure 4.1: The proposed prosody generation method. ...79
Figure 4.2: All-in-one CART for break prediction...82
Figure 4.3: A block diagram of the two-stage break prediction method. ...84 Figure 4.4: An example of the prosodic feature prediction by the A-UJPLM-based
approach. The panels from up to bottom represent, respectively, syllable log-F0 means, syllable duration, syllable energy level and inter-syllable pause duration. Solid lines, open circles, and closed circles denote, correspondingly, the original features, the predicted features using predicted breaks, and the predicted features using correct break labels. Vertical dash lines represent erroneous major/minor break prediction
Chapter 1 Introduction
1.1 Background
The term prosody refers to certain inherent suprasegmental properties that carry melodic, timing, and pragmatic information of continuous speech, encompassing accentuation, intonation, rhythm, speaking rate, prominences, pauses, and attitudes or emotions intended to express. Prosodic features are physically encoded in the variations in pitch contour, energy level, duration, and silence of spoken utterances. Prosodic studies have indicated that these prosodic features are not produced arbitrarily, but rather realized after a hierarchically organized structure which demarcates speech flows into domains of varying lengths by boundary or break cues such as pre- and post-boundary lengthening, pitch and energy change, pauses, etc. Therefore, prosodic structure in English, for example, functions to set up syntagmatic contrasts to mark a prosodic word, an intermediate phrase, or an intonational boundary [1-3]. On the other hand, the prosodic structure of Mandarin Chinese also parses continuous speech into different prosodic constituents by breaks that reflect different levels of Chinese linguistic processing: phonetic, lexical, syntactic, and pragmatic. As a result, successive words with related prosodic feature variations are aggregated to form prosodic phrases, and contiguous prosodic phrases are, in turn, integrated to form prosodic phrases of a higher level.
Many literatures on Chinese prosody have shown that the prosody of Mandarin speech can be organized into hierarchical structures [4-7]. Figure 1.1 displays a commonly agreed and used prosody hierarchy structure consists of four layers, including, from the lowest layer to the highest one, syllable layer, prosodic word layer, prosodic phrase layer (or intermediate phrase), and intonation phrase. As far as the major prosodic information relevant to each of the layers is concerned, given that Mandarin is a monosyllabic and tonal language, where each syllable with its inherent tone contains a lexical meaning, and each tone carries a lexically contrastive role, the features of every syllabic tone of an utterance are the most important prosodic information for the lowest layer; besides, tone along with syllable constituents affects syllable duration and energy level as well. As for the second prosodic layer, a
prosodic word refers to di-syllabic and multi-syllabic words or phrases composed of words syntactically and semantically closely related or most frequently collocated, so the words or phrases are uttered as a single unit as in 霧(wu) “fog” + 的(de) + 形成 (xing-cheng) “to form” (the formation of fog). As for the third prosodic layer, prosodic phrase is composed of one or several prosodic words and it usually ends with a perceptible but unobvious break. Finally, intonation phrase is at the top layer of the Mandarin prosodic structure. It determines the pitch contour of the intonation of a sentence containing one or several prosodic phrases and it ends with an obvious break. Basically, the four-layer prosodic structure interprets the pitch and duration variations of syllable well for sentential utterances. Some recent studies [8,9] proposed to integrate prosodic phrases into prosodic phrase groups to interpret the contributions of higher-level discourse information to the wider-range and larger variations on the prosodic features of utterances of long texts. In the science of speech processing, to model prosody is to exploit a framework or a computational model to represent a hierarchy of prosodic phrases of speech and to describe its relationship with the syntactic structure of the associated text.
Figure 1.1: A commonly agreed and used prosody hierarchy structure that consists of four layers, including, syllable layer (SYL), prosodic word layer (PW), prosodic phrase layer (PP), and intonation phrase (IP). (Note: this figure is excerpted and modified from Ref. [6])
In the past, many prosody modeling methods have been proposed for various applications, including generation of prosodic information for text-to-speech (TTS) [10-12], segmentation of untranscribed speech into sentences or topics [13-15], generation of punctuations from speech [16-18], detection of interrupt points in spontaneous speech [13,19-21], automatic speech recognition (ASR) [22-28], and so forth. It can be found from those prosody modeling studies that four main issues have been intensively addressed. The first one is concerning representing a hierarchical prosodic phrase structure indirectly by tags marking important prosodic events.
Among various prosodic events explored in the relevant literature [29-35], break type and tone pattern are the most important ones: the break types of all word boundaries can determine the hierarchical prosodic phrase structure of an utterance, and the tonal patterns of all syllables/words can indicate the accented syllables/words of an utterance, and may specify the pitch contour patterns of the prosodic constituents. Several prosody representation systems have been proposed in the past. They include ToBI (Tones and Breaks Indices, a standard prosody transcription system for American English utterances) [29], PROSPA [31], INTSINT [32], and TILT [33]. Among them, ToBI and its modifications to other languages, such as Pan-Mandarin ToBI [34] and C-ToBI [35], are most popular conventions for Mandarin Chinese prosodic tagging. The second main issue is about realizing the constituents of a hierarchical prosodic phrase structure by using prosodic feature patterns. This is mainly used in TTS for the generation of prosodic information from prosodic tags. A common approach is to use a multi-component representation model to superimpose several prototypical contours of multi-level prosodic phrases for each prosodic feature [36-38]. In Ref. [36], three components of sentence-specific contours, word-specific contours, and tone-specific contours are superimposed to form the synthesized contours of pitch and syllable duration for Mandarin TTS.
The third main issue is relating to exploring the relationship between prosodic tags (or boundary types) and the acoustic features surrounding the associated word juncture. Patterns of pause duration, pitch, and energy around word junctures are modeled for each prosodic tag or boundary type to help speech segmentation [13-15], topic identification [15], punctuation generation [16-18], interrupt point detection [13,19-21], and ASR [22-28] based on word-based features. The last issue is upon modeling the relationship between prosodic structure and syntactic structure. It is known that prosodic structure is closely related to syntactic structure although they are not identical. Usually, only the relationship between a prosodic tag, such as break or prominence, and contextual linguistic features of syntactic structure is built. A good break-syntax model should be very useful in predicting breaks of various levels from input text for TTS. Main methods of building a break-syntax model for TTS are hierarchical stochastic model [39,40], N-gram model [41], classification and regression tree (CART) [40,42-45], Markov model [46], artificial neural networks
approach, emission probabilities can be generated by CART [44] or maximum entropy model [51].
1.2 Motivation
Prosody modeling has been proved to be useful in above-mentioned applications, and the most commonly adopted approach by the previous studies is a supervised one to construct prosodic model from an annotated speech database with tags marking prosodic events being pre-labeled manually. However, the supervised prosody modeling based on human labeling unavoidably arises such problems as diseconomy due to labeler training and manual labeling labor, and inter-labelers’ and intra-labeler’s inconsistency caused by individual subjectivity and fatigue during long time labeling, respectively. This inconsistency may mislead prosody modeling to obtain erroneous results, and hence lead to unwanted degradation of modeling performance. Even in the studies where prosody labeling can be automatically done by machine, their model is still trained with a manually-annotated speech corpus [52-57], so the performance of machine labeling is still subject to the quality of human prosody labeling.
To tackle the problems arising from the supervised prosody modeling with manual labeling, this dissertation presents a new unsupervised approach of prosody modeling to jointly perform prosody modeling and labeling for Mandarin speech based on an unlabeled speech database. It is an extension of the previous work by Chen et al. [58,59] which will be introduced in Section 1.3. The basic idea of this work is to properly model the observed features and then let the modeled-features objectively determine prosodic tags by themselves rather than by human perception with audio and visual aid in conventional prosody labeling works. The task automatically determines two types of prosodic tags for all utterances of a corpus and to build four prosodic models simultaneously. The two types of prosodic tags are: (1) the break types of inter-syllable locations (or syllable junctures) which can be used to demarcate the constituents of a hierarchy of Mandarin speech prosody; and (2) the prosodic states of syllables which can be used to construct the pitch contour, syllable duration and energy level patterns of the prosodic constituents. The four prosodic models are introduced to describe the various relationships between the two types of prosodic tags and all available information sources including acoustic prosodic
features and syntactic structure features. Three advantages of the proposed method can be found. First, prosody modeling and labeling are accomplished jointly and automatically without using human-labeled training corpus. Second, all information sources, including acoustic and linguistic features, are systematically used (via introducing the four prosodic models) in the prosody labeling. We therefore expect that the result of the prosodic labeling is more consistent than that done by human, which will in turn make the four prosodic models more accurate. Third, the four prosodic models constructed address all the four main issues of prosody modeling discussed above. So they are useful models and may be directly used or extended to be used in those applications mentioned above.
1.3 Overview of Unsupervised Joint Prosody Labeling and
Modeling
Since the proposed unsupervised joint prosody labeling and modeling method is an extension of the previous works by Chen et al. [58,59], these previous works will be introduced in Subsection 1.3.1 to give a clearer concept of the prosodic states defined. Then the prosody hierarchy adopted in this study and its relationship to the defined prosody tags, i.e. break types and prosodic states, are described in Subsection 1.3.2. In Subsection 1.3.3, we present the general concept of the four prosodic models which are the core of this dissertation. Lastly, the database used in our experiments is introduced in Subsection 1.3.4.
1.3.1 Previous Works
Two statistical prosody models for Mandarin speech using unlabeled speech corpora were proposed by Chen et al. [58,59]. These two models consider several affecting factors on the variations in syllable pitch contour and syllable duration, respectively, including lexical tones, initial-final or base-syllable type, and prosodic state. Here, prosodic state is conceptually defined as the state in a prosodic phrase and used as a substitution for the effects from high-level linguistic features, such as a word, a phrase or a syntactic tree. Prosodic states are also assumed to account for the prosodic variation contributed by para-linguistic features, such as intention, attitude
emotional conditions of the speaker. They therefore treat the high-level linguistic features, para-linguistic features and non-linguistic features as high-level affecting factors on prosodic variation. On the other hands, low-level affecting factors refer to some syllable-level linguistic features which represent intrinsic characteristics of Mandarin prosody, such as lexical tones and base-syllable type, and so forth. For the syllable duration model, a companding factor (CF) is hence defined to control the compression/increase or stretch/increase of syllable duration/pitch associated with each of the above low- and high-level affecting factors. Based on the assumption that all CFs are combined multiplicatively or additively, the multiplicative and additive syllable duration models are expressed respectively by
n n n n n n n t y j l s Z =X γ γ γ γ γ (1.1) and n n n n n n n t y j l s Z =X + + + + + (1.2) γ γ γ γ γ where Z and n X are the observed and normalized durations of the n-th syllable; n
x
γ represents duration CF of the affecting factors x; tn, yn, jn, ln and sn respectively represent the lexical tone, duration prosodic state, base-syllable type, utterance, and speaker of the n-th syllable; and the residual X is modeled by a n
normal distribution with mean μ and variance v, i.e.
2 2 2 2 2
( , | ) ( ; , )
n n n n n n n n n n
n n n t y j l s t y j l s
p Z y λ = Ν Z μγ γ γ γ γ vγ γ γ γ γ . Notice that the prosodic state is treated as a latent variable hence the Expectation-Maximization (EM) algorithm is introduced to train the multiplicative or additive syllable duration models based on the maximum likelihood (ML) criterion. After training, each syllable can be labeled a prosodic state index by
* max ( | , )
n
n y n n
y = p y Z λ (1.3) Then, the CF sequence of prosodic state { *
n
y
γ } of each utterance can represent the syllable-duration variation of the utterance primarily resulted from high-level linguistic features.
Based on the same idea, the syllable pitch mean and shape models are respectively expressed by n n n n n n n n t pt ft i f p Y =X +β +β +β +β +β +β (1.4) and n n n n n n = n+ tc + q + s + i + f Z X b b b b b (1.5)
where Y /n Z and n X /n X are observed and normalized pitch mean/shape of the n
n-th syllable; βx/b represents the pitch mean/shape CF of the affecting factors x; n
pt , ft , n i , n f , n p , n tc and n q are, correspondingly, previous lexical tone, n
following lexical tone, initial type, final type, pitch mean prosodic state, tone combination and pitch shape prosodic state of the n-th syllable. The training and labeling of the pitch mean/shape models are similar to the way in syllable duration modeling.
The main purpose of using prosodic state to replace conventional high-level linguistic information is to decompose the effects of low-level and high-level linguistic features on speech prosody. Through this modeling approach, some unsolved problems, such as the inconsistency between prosodic and syntactic structures, the ambiguity of word segmentation and word chunking for Mandarin Chinese, can be avoided. Hence, this modeling scheme can more focus on modeling the global effect of mapping high-level linguistic features to the prosodic state and break indices, since interference caused by low-level linguistic feature has been properly removed. The following are some key observations and conclusions of the proposed models evaluated by a speech corpus consisted of paragraphic utterance of five speakers:
1. The variances of syllable duration, pitch mean and pitch shape were greatly reduced as the observed prosodic features are normalized with the CFs for considered affecting factors.
2. The quantitative influence of each affecting factor is directly obtained from their corresponding CFs.
3. The obtained CFs for low-level linguistic features generally agreed with the prior knowledge of Mandarin prosody.
4. By investigating the relationship between the labeled prosodic states and their associated texts, the prosodic states labeled seemed to be linguistically meaningful. For example, the prosodic states with larger CFs are usually labeled on the last syllable of a sentence illustrating syllable duration lengthening effect; pattern of a prosodic phrase is more apparent when it is represented by a sequence of pitch mean prosodic state CFs than when observed in original pitch mean.
5. Experiments on prosody generation for Mandarin TTS system showed that the hybrid-regression model that normalized the observed prosodic features with CFs for syllable level linguistic features in advanced achieved a better prediction result than a conventional regression method that take observed prosodic features and all levels of linguistic features as targets and inputs. The results implied the proposed models can properly decompose the influences of high-level and low-level linguistic features on prosody.
6. A simple rule-based break labeling method is proposed. Large and medium sudden low-to-high pitch prosodic state transitions indicated minor and major breaks boundaries.
As discussed above, the two models proposed by Chen et al. could generate
linguistically meaningful prosodic state tags and they can give a better representation of prosodic phrase patterns. However, a well-defined prosody hierarchy is not considered in these previous studies. Besides, the relationship between prosodic states and high-level linguistic features are still untouched. Some important acoustic features related to prosodic breaks are also not incorporated in those models. We therefore intend the new proposed unsupervised joint prosody labeling and modeling method in this dissertation to address those missing research fields mentioned above based on the previous works by Chen et al.
1.3.2 Prosody Hierarchy and Prosody Tags
Recently, Tseng et al. [8] proposed to integrate contiguous prosodic phrases into
prosodic phrase groups to interpret the contributions of higher-level discourse information to the wider-range and larger variations in syllable pitch and duration of long utterances in paragraphs. Figure 1.2 displays the hierarchical prosodic phrase grouping (HPG) model of Mandarin speech proposed by Tseng. It is a five-layer structure. The first three layers in the hierarchy are the same as those of the four-layer prosodic structure introduced in Section 1.1, which are referred to as Syllable (SYL), Prosodic Word (PW), and Prosodic Phrase (PPh) in the system of Tseng et al., respectively. The fourth layer, Breath Group (BG), is formed by combining a sequence of PPhs, and a sequence of BGs, in turn, constitutes the fifth layer, Prosodic Phrase Group (PG). The above five prosodic units are delimited by different type of the six breaks proposed by Tseng et al. Firstly, B0 and B1 are defined for SYL boundaries within PW. Here, B0 represents reduced syllabic boundary and B1
represents normal syllabic boundary. Usually no identifiable pauses exist for both B0
and B1. Secondly, B4 and B5 are defined for BG and PG boundaries, respectively. B4
is a breathing pause and B5 is a complete speech paragraph end characterized by final
lengthening coupled with weakening of speech sounds. Thirdly, B2 and B3 are
perceivable boundaries defined for PW and PPh boundaries, respectively.
Figure 1.2: A conceptual prosody hierarchy of Mandarin speech proposed by Tseng et al. in Ref. [8].
In this dissertation, we adopt the prosodic structure of Tseng et al. because our
speech database also consists of long Mandarin utterances of paragraphs. However, we modify the break type labeling scheme of HPG model by dividing B2 into two
types, B2-1 and B2-2, and combining B4 and B5 into one denoted simply by B4. Here, B2-2 represents syllabic boundary of B2 perceived by pause, while B2-1 is B2 with F0
movement. The reason of dividing B2 into B2-1 and B2-2 is due to the difference of
their acoustic cues to be modeled. On the contrary, the combination of B4 and B5 is
owing to the similarity of their acoustic characteristics. So, the break-type tags used is in Λ {= B0, B1, B2-1, B2-2, B3, B4}. These six break-type tags can be used to delimit
four types of prosodic units: SYL, PW, PPh, and BG/PG. These four units are the constituents of our hierarchical prosodic structure.
To further specify the four-layer prosodic structure, a representation of its constituents using prosodic features is needed. Two main approaches of representation can be considered. One is direct representation approach to represent each individual prosodic constituent by multiple prototypical patterns for each prosodic feature of syllable pitch contour, duration, or energy level [8,10,11]. The other is indirect representation approach by using some tags which carry the information of prosodic constituents and are treated as hidden, i.e. the prosodic states. Due to the following two reasons, we do not adopt direct representation approach in the prosody modeling and labeling study. First, the technique of direct representation approach is still not mature enough to produce a good direct representation for the hierarchy of Mandarin speech prosody. The modeling errors, defined as the ratio of mean square errors of direct representations to the variances of the raw data, are still as high as about 30% for the multi-layer representations of syllable duration, and energy using the HPG model [8]. Second, a good direct representation is not easy to be realized for the case of joint prosody modeling and labeling using an unlabeled speech corpus in which the prosodic structures of all utterances are not well determined in advance. Degeneration may occur because break labeling errors may produce inaccurate representation patterns of prosodic constituents, which in turn may cause more break labeling errors to occur. Instead, we adopt an indirect representation approach to employ the defined prosodic states discussed in Subsection 1.3.1 to represent the aggregative contributions of the constituents of the upper three layers on syllable pitch level. Similar to the definition of the previous works by Chen et al., the
prosodic state tag is defined as a quantized and normalized syllable pitch level, duration and energy level with the effects from base-syllable or final types, the current tone and the two nearest neighboring tones being properly eliminated. So it carries mainly the prosodic information of the upper three layers of the prosodic structure, i.e. PW, PPh, and BG/PG. We call it prosodic state to roughly mean the state in a prosodic phrase (PW, PPh, or BG/PG). Two advantages of using the prosodic-state tag can be found. First, the tag is defined for each individual syllable so that the effect of a labeling error is limited to the current syllable only. No degeneration in the joint prosody modeling and labeling process will occur. Second, the tag carries the full prosodic information in the upper three layers of the prosodic structure. In experimental results, we will show the capability of the prosodic-state tag on constructing the pitch contour patterns of PW, PPh, and BG/PG. It is worth to note that the pitch prosodic state, duration prosodic state and energy prosodic state are correspondingly defined for syllable pitch mean, syllable duration, and syllable energy level variations of high-level prosodic constituents ( i.e. PW, PPh, and PG/BG). In this dissertation, for simplicity, we first only consider the pitch prosodic state in unsupervised joint prosody labeling and modeling. Then the duration prosodic state and the energy prosodic state are added to the proposed method to perform an advanced unsupervised joint prosody labeling and modeling.
1.3.3 The Four Prosodic Models
The four prosodic models are designed to model the prosody hierarchy illustrated in Subsection 1.3.2 and perform unsupervised joint prosody labeling and modeling given with both acoustic and linguistic features. Two types of acoustic features can be considered. One is the prosodic features which carry the information of prosodic constituents. Primary features of this type include syllable pitch contour, syllable duration, and syllable energy level. Another is the acoustic features used to specify the break type of syllable juncture. Primary features of this type include pause duration and energy-dip level of syllable juncture, energy and pitch jumps across syllable juncture, lengthening factor of syllable duration, etc. The linguistic features used span a wide range from syllable level, word level to syntactic tree level.
variations in syllable prosodic features, including syllable pitch contours, duration and energy level, controlled by several major affecting factors, such as syllable-level linguistic features and prosodic tags. The next one, referred to as the break-acoustics model, describes the relationship between the break type of a syllable juncture and nearby acoustic features, such as pause duration and energy-dip level of syllable juncture. The third one describes the relationship between the break type of a syllable juncture and contextual linguistic features. It is referred to as the break-syntax model. Finally, the last model describes the relationship between the prosodic states of syllables and the break types of neighboring syllable junctures, and is referred to as the prosodic state model. We can then regard the proposed unsupervised joint prosody labeling and modeling method which is based on the four prosodic models as a clustering problem. With proper initializations of break types and prosodic states, a designed sequential optimization training algorithm is conducted to iteratively estimate parameters of the four prosodic models, and find all prosodic tags using an unlabeled speech corpus.
1.3.4 Experimental Database
An unlabeled read Mandarin speech database was used to evaluate the proposed unsupervised joint prosody labeling and modeling method. The database contained 425 utterances with 56237 syllables uttered by a female professional announcer in a sound-proof booth. All speech signals were digitally recorded in a form of 16kHz sampling rate and 16-bit resolution. Its associated texts were all short paragraphs composed of several sentences selected from the Sinica Treebank Version 3.0 [60]. There are six files in the Sinica Treebank Version 3.0 as listed in Table 1.1. All the texts used in this study were extracted from the “news.check” file. Those texts were automatically parsed and manually checked. The tone and base-syllable type of each syllable were transcribed by a linguistic processor with a 130,000-word lexicon and then manually error-corrected. All syllable segmentation and F0 detection were first done automatically using the Hidden Markov Model Toolkit (HTK) [61] and WaveSurfer [62], respectively, and then error corrected manually. The database is further divided into two parts: a training set of 379 utterances with 52192 syllables and a test set of 46 utterances with 4801 syllables.
Table 1.1: The content of the Sinica Treebank corpus
File name Content
news.check, travel.check News papers, books, or internet articles ko.check, ev.check Elementary school text books
oral.check Text from phonetic balanced speech
sino.check Text from Taiwan Panorama
1.4 Organization of the Dissertation
The dissertation is organized as follows. Chapter 1 gives the background, motivation, review of related previous works and description on the experimental databases used in this study. Chapter 2 presents the proposed unsupervised joint prosody labeling and modeling method which employs four prosodic models to describe relationship between prosodic tags, acoustic features and associated linguistic features. For simplicity we only consider the modeling of syllable pitch contour in this chapter and will extend the modeling to include the other two syllable prosodic features, i.e. syllable duration and syllable energy level, in Chapter 3. The experimental results on the training set of the Sinica Treebank corpus are discussed. Then, an extension to joint modeling of syllable pitch contour, duration and energy level is presented in Chapter 3. An application of the proposed model to prosody generation for TTS is discussed in Chapter 4. Some conclusions and related future research topics are given in the last chapter.
Chapter 2 Unsupervised Joint Prosody Labeling
and Modeling
2.1 Introduction
The proposed method first treats the problem as a model-based prosody labeling problem to define four prosodic models to describe various relationships between the prosodic tags to be labeled and the available information sources of acoustic and syntactic features. It then extends the formulation for the joint prosody labeling and modeling problem and applies a sequential optimization procedure to jointly label prosodic tags and estimate the model parameters using an unlabeled speech corpus. This chapter is organized as follows. Section 2.2 presents the four prosodic models which is the core of this dissertation. The training algorithm for the four prosodic models is given in Section 2.3. Sections 2.4 and 2.5 give the experimental results and the detail analysis of model-labeled break, respectively. Lastly, some conclusions and remarks are given in Section 2.6.
2.2 The Design of the Four Models
The prosody labeling problem can be generally formulated as a parametric optimization problem to find the best prosodic tag sequence T given with the ∗ acoustic feature sequence A of the input speech utterance and the linguistic feature sequence L of the associated text:
argmax ( | , )=argmax ( , | )P P ∗=
T T
T T A L T A L (2.1)
Two types of prosodic tags which carry the information of prosodic structure of Mandarin speech are considered in this study. One is the break type of syllable juncture. A set of six break types, defined in Subsection 1.3.2, is used. It is denoted as {B0, B1, B2-1, B2-2, B3, B4}. These six break types are used to define a hierarchy of
speech prosody comprising four constituents of SYL, PW, PPh, and BG/PG. Another is the prosodic state of syllable defined as a quantized and normalized syllable pitch level with the effects of the current tone and the two nearest neighboring tones being
properly eliminated. As discussed in Subsection 1.3.2, it is an indirect representation of the prosodic constituents to carry the pitch level information of PW, PPh, and BG/PG. So, T can be refined to comprise a break-type sequence B and a prosodic state sequence p.
Two types of acoustic features can be considered. One is the prosodic features which carry the information of prosodic constituents. Acoustic features of this type are assumed to be closely related to the prosodic-state tags and loosely related to or independent of the break-type tags. Primary features of this type include syllable pitch contour, syllable duration, and syllable energy level. For simplicity we only consider syllable pitch contour in this chapter and will extend the study to include the other two in next chapter. Another is the acoustic features used to specify the break type of syllable juncture. Acoustic features of this type are assumed to be closely related to the break-type tags, and loosely related to or independent of the prosodic-state tags. Primary features of this type include pause duration and energy-dip level of syllable juncture, energy and pitch jumps across syllable juncture, lengthening factor of syllable duration, etc. Among them, pitch jump has been implicitly considered via the use of prosodic-state tag, energy jump is somewhat a redundant feature as energy-dip level is used, and lengthening factor will be considered together with the syllable duration modeling in next chapter. We therefore only consider the two features of pause duration and energy-dip level here. From above discussions, A can be refined to comprise a syllable pitch contour sequence sp, a pause duration sequence pd, and an energy-dip level sequence ed.
The linguistic features used span a wide range from syllable level, such as syllable tone and initial type; word level, such as syllable juncture type (intra-word and inter-word), word length, part of speech (POS), and type of punctuation mark (PM); to syntactic tree level, such as size of syntactic phrase and syntactic juncture type (intra-phrase and inter-phrase). Since syllable tone is an important linguistic feature and mainly used in the modeling of syllable pitch contour, we separate it from other linguistic features. So, L is refined to include a syllable tone sequence t and a reduced linguistic feature set l.
Based on above discussions, we rewrite ( , | )P T A L by
( , | ) ( , , , , | , ) ( , , | , , , ) ( , | , )
where P sp pd ed B p l t( , , | , , , ) is a general prosodic feature model describing the variations in acoustic prosodic features ( ,sp pd ed ) controlled by the prosodic tags , (B,p) representing the prosodic structure and the linguistic features (l, t) representing the syntactic structure; and P B p l t( , | , ) is a general prosody-syntax model which describes the relationship between (B,p) and (l, t).
Since the break type tag sequence, B, has already carried the prosodic cues related to syllable junctures, we therefore assume that the observed syllable-based acoustic feature, sp, and the juncture-based acoustic features, ( pd ed ), are , independent as B is given. So we split ( ,P sp pd ed B p l t into two terms: , | , , , )
( , , | , , , ) ( , , , ) ( , , , , )
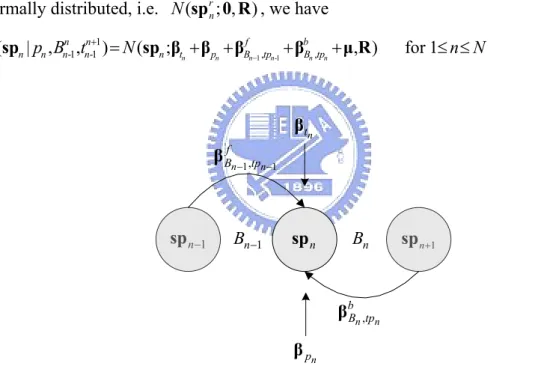
P sp pd ed B p l t ≈ P sp|B p l t P pd ed|B p l t (2.3) Here (P sp|B p l t is a syllable pitch contour model describing the variation in , , , ) syllable pitch contour controlled by (B p l t ) and (, , , P pd ed|B p l t is a break- , , , , ) acoustics model describing the acoustic cues of syllable junctures for different break types. The syllable pitch contour model is realized using a modified version of the syllable pitch contour model proposed previously by Chen et al [58]. It models the pitch contour of each syllable separately and considers four main affecting factors, including the current prosodic state p , the current tone n tn, and the coarticulations from the two nearest neighboring tones, tn−1 and tn+1, conditioned, respectively, on the break types, Bn-1 and Bn, of the syllable junctures on both sides. Specifically, the model is expressed by 1 -1 -1 1 ( , , , ) ( , , ) N ( | , n ,n ) n n n n n P P P p B t+ = ≈ ≈
∏
sp|B p l t sp|B p t sp (2.4) where 1, -1 , for 1 n n n n n n r f b n= n+ t + p + B− tp + B tp + ≤ ≤n N sp sp β β β β μ (2.5)is the observed pitch contour of n-th syllable (referred to as syllable n hereafter) represented by the first four orthogonally-transformed parameters of syllable log-F0 contour [63]; -1=( -1, ) n n n n B B B ; 1 -1 ( , ,-1 1) n n n n n t+ = t t t+ ; r n
sp is the normalized (or residual)
version of sp ; n βx represents the affecting pattern (AP) of affecting factor x. Here AP means the effect of a factor on increase or decrease of the observed syllable pitch contour vector sp . n n t β and n p
respectively; tpn is tone pair 1 +1 ( , ) n n n n t + = t t ; 1, -1 n n f B− tp β and , n n b B tp
β are the APs of
forward and backward coarticulation contributed from syllable n-1 and syllable n+1, respectively; and μ is the AP of global mean. For taking care of utterance boundaries, two special break types, Bb and Be, are assigned to the two ending locations of all utterances, i.e., B0 =Bb and BN =Be; and two special APs of coarticulation, 1 0 0 , , b f f B t = B tp β β and , , e N N N b b B t = B tp
β β , are accordingly adopted to represent the effects of utterance onset and offset, respectively.
n
p
β is set to have nonzero
value only in its first dimension in order to restrict the influence of prosodic state merely on the log-F0 level of the current syllable. Figure 2.1 displays the relationship
of sp with these affecting factors. By assuming that n sp is zero-mean and rn
normally distributed, i.e. ( r; , )
n N sp 0 R , we have 1 -1 1 -1 -1 , , ( | , , ) ( ; , ) for 1 n n n n n n n n f b n n n n n t p B tp B tp P sp p B t + =N sp β +β +β − +β +μ R ≤ ≤n N (2.6) 1 n− sp Bn−1 spn Bn spn+1 1, 1 n n f B− tp − β , n n b B tp β n t β n p β
Figure 2.1: The relationship of observed syllable pitch contour with its APs. It is noted that the effect from l is assumed to be implicitly included in the effect of p and hence is neglected. We also note that the coarticulation effect is elegantly treated to consider different degrees of coupling between two neighboring syllables via letting it depend on the break type of the syllable juncture.
The break-acoustics model P pd ed|B p l t is further elaborated via assuming ( , , , , ) that (pd ed ) is independent of (p,t) which mainly carries information of prosodic , constituents rather than that of syllable juncture. So we have
1 1 ( , , , , ) ( , , ) N ( n, n| , )n n n P P − P pd ed B = ≈ ≈
∏
pd ed|B p l t pd ed|B l l (2.7)where pdn and edn are the pause duration and energy-dip level of the juncture following syllable n (referred to as juncture n hereafter); and l is the contextual n
linguistic feature vector around juncture n. For mathematically tractable, ( n, n | n, )n
P pd ed B l is further simplified and realized by the product of a gamma
distribution for pause duration and a normal distribution for energy-dip level: 2 , , , , ( , | , ) ( ; , ) ( ; , ) n n n n n n n n n n n n n B B n B B P pd ed B l =g pd α l β l N ed μ l σ l (2.8)
In this study, g pd( n;αBn n,l ,βBn n,l ) and 2 , ,
( n; Bn n, Bn n)
N ed μ l σ l are concurrently generated by the decision tree method for each break type.
Similarly, we simplify the general prosody-syntax model ( , | , )P B p l t via assuming the independency of ( , )B p and t, and decomposing it into two models, i.e.
( , | , ) ( , | ) ( | , ) ( | ) ( | ) ( | )
P B p l t ≈P B p l =P p B l P B l ≈P p B P B l (2.9)
where ( | )P p B is a prosodic state model describing the dynamics of p given with B, and ( | )P Bn ln is a break-syntax model describing the relationship between B and the contextual linguistic feature sequence l. In this study, we realize P p B by a ( | ) Markov model: 1 1 1 2 ( | ) ( ) N ( |n n , n ) n P P p P p p− B− = ⎡ ⎤ ≈ ⎢ ⎥ ⎣
∏
⎦ p B (2.10) where P p( )1 is the initial prosodic-state probability for syllable 1 and1 1 ( |n n , n )
P p p− B− is the prosodic-state transition probability from syllable n-1 to
syllable n given Bn−1. We also simplify P B l by separately modeling it for each ( | ) syllable juncture: 1 1 ( | )=N ( | )n n n P − P B =
∏
B l l . (2.11) Here ( | )P Bn ln is implemented by the decision tree method.2.3 Joint Prosody Labeling and Modeling
A sequential optimization procedure based on the ML criterion is proposed to jointly label the prosodic tags for all utterances of the training corpus and to estimate the parameters of the four prosodic models. It is divided into two main parts: initialization and iteration. The initialization part determines initial prosodic tags of all utterances and estimates initial parameters of the four prosodic models by a specially designed procedure. The iteration part first defines an objective likelihood function for each utterance by
(
)
1 -1 1 1 1 1 1 2 1 1 ( | , , ) ( ) ( | , ) ( , | , ) ( | ) N N n n n n n n n n n n n N n n n n n n n Q P p B t P p P p p B P pd ed B P B + − − − = = − = ⎛ ⎞⎛ ⎞ = ⎜ ⎟⎜ ⎟ ⎝ ⎠⎝ ⎠ ⎛ ⎞ ⎜ ⎟ ⎝ ⎠∏
∏
∏
sp l l . (2.12)It then applies a multi-step iterative procedure to update the labels of prosodic tags and the parameters of the four prosodic models sequentially and iteratively. In the following subsections, we discuss the sequential optimization procedure in detail.
2.3.1 Initialization
The initialization part is further divided into two sub-parts: (a) a specially designed procedure to determine initial break labels of all syllable junctures; and (b) a ML estimation process to estimate initial parameters of the four prosodic models and to determine the initial prosodic-state labels of all syllables using the information of initial break labels determined in the first sub-part.
(a) Initial labeling of break indices
The initial break index of each syllable juncture is determined by a decision tree (see Figure 2.2) designed based on a prior knowledge about break labeling/modeling gained in previous studies [8,28,40,52-58,64,65]. It is known that pause duration is the most important acoustic cue to specify breaks. Most word junctures with PM have long pauses so that they are most likely labeled as major break, or in our case B3 and
B4. On the other hand, most intra-word syllable junctures have very short pause duration so that they are generally labeled as non-break, or in our case B0 and B1. Moreover, B0 represents tightly coupled syllable juncture so that it is distinguished
from B1 by having very short pitch pause duration and high energy-dip level. In-between these extreme situations, non-PM inter-word junctures with medium pause duration and with medium pitch jump are likely labeled as B2-2 and B2-1, respectively. By using the prior knowledge, we develop the algorithms to determine all thresholds of the decision tree (Th1~ Th6) in a systematic way to avoid doing it manually or by trial and error. Detail of the algorithms is given in Appendix A.
1 n pd ≥Th 2 n pd ≥Th 3 n pd ≥Th 6 and n ed ≥Th 6 and n ed ≥Th Figure 2.2: The decision tree for initial break type labeling.
(b) Estimation of the initial parameters of the four prosodic models and prosodic-state indices
The initializations of the break-acoustics model and the break-syntax model can be done independently with initial break indices of all syllable junctures being given. We realize them by the CART algorithm [66]. For the initialization of the break-acoustics model, the CART algorithm with the node splitting criterion of maximum likelihood gain is adopted to classify pause duration pdn and energy-dip level edn for each break type B according to a question set Θ derived from the 1 contextual linguistic features ln. Each leave node represents the product of a gamma distribution ( ; , , , )
n n
n B B
g pd α l β l and a normal distribution 2
, ,
( ; , )
n n
n B B
N ed μ l σ l .For the initialization of the break-syntax model ( | )P Bn ln , a decision tree is built by using another question set Θ derived also from 2 ln to classify break types. The details of
n
l , Θ , and 1 Θ used in this study are listed in Appendixes B, C.1, and C.2, 2 respectively.
![Figure 2.4 displays the APs of five tones. We find from the figure that the APs of the first four tones conformed well to the standard tone patterns found by Chao [67]](https://thumb-ap.123doks.com/thumbv2/9libinfo/8756392.207001/42.892.156.750.242.775/figure-displays-tones-figure-tones-conformed-standard-patterns.webp)