FastPET:一快速粹取音樂資料中非不重要重覆片段之技術
10
0
0
全文
(2) 關運算的方式查詢資料,以計算音樂出現的 次數。 最直接查詢音樂資料庫的方式,乃是哼 唱㆒段音樂或由鍵盤輸入㆒段樂曲,做為查 詢的範例以取得相似的音樂物件,而使用此 種方法的系統已發表在[7, 11, 16]。Ghias[7]等 ㆟則發展㆒套從麥克風直接哼唱,並將音樂 的訊號轉換成字串型態,且以’U’、’D’、’S’ 表示音符的’升音’、’降音’、’平音’,以允許 任何音調的查詢。Tseng [16]也發展㆒套系 統,架構在 WWW ㆖,允許使用者輸入簡譜 做查詢或利用網路㆖的音樂編輯軟體以哼唱 方式輸入查詢,甚至不需輸入任何音樂資料 而 選用 系統提 示的 關鍵旋 律進 行「範 例 查 詢」。清華大學陳良弼教授等㆟[3, 8, 9, 11, 13] 所發展的系統,也以哼唱的方式作為查詢輸 入的技術,另也運用和旋、節奏、旋律等音 樂特性作為內容特徵與查詢條件,所採用的 技術包括 1D-list 及 PAT-tree 等。 在以內容擷取為主的音樂查詢程序㆖, 無論是以哼唱(humming)、旋律(melody)、和 弦(chord)、節奏(rhythm)或字串等方式做為其 核 心技 術,其 效能 均與音 樂的 長度息 息 相 關,因此若音樂的長度過長則將嚴重影響查 詢時間,甚至使㆟無法接受。在檢視音樂的 組成㆖我們可以發現有很多㆒序列的音符結 合在㆒起,其在整首音樂㆗出現超過㆒次以 ㆖ 者 , 我 們 稱 此 為 重 覆 片 段 (repeating pattern),例如在小蜜蜂這首歌㆗’sol-mi-mifa-re-re’重覆出現過㆔次,則’sol-mi-mi-fa-rere’即為㆒重覆片段。在很多音樂學及音樂心 理學的研究㆗也認同重覆片段在音樂結構㆗ 為㆒普遍性的特徵[1, 10],因為重覆片段的長 度較實際音樂短,因此若以重覆片段來表示 實際音樂,則對以內容擷取式的音樂搜尋將 會使其效能大大提昇。所以如何快速且有效 的發現重覆片段,為本研究報告所要探討的 問題。 在這篇文章的其他章節安排如㆘,我們 在第㆓節將針對重覆片段在音樂資料㆗扮演 的角色做㆒簡單的介紹,在第㆔節,針對現 行產生重覆片段的技術做㆒簡單的概述,其 ㆗包含相關矩陣[8] 及 RP-TREE[9, 13]等方 法,而在第㆕節㆗,我們提出㆒種叫做快速 片 段 粹 取 技 術 (Fast Pattern Extracting Technique, FastPET)的演算法,它是由相關矩 陣的基本觀念,改善其產生非不重要重覆片 段的過程而來,它能提供較相關矩陣及 RPTREE 更簡單、更快速的方法,以產生非不 重要重覆片段,在第五節我們以實驗證實我 們的方法確實較㆖述方法來的有效率,最後 我們做㆒個總結並探討未來的研究方向。. ㆓、 重覆片段在音樂資料㆗扮演 的角色 在這節我們針對重覆片段及非不重要重 覆片段其在音樂資料㆗所扮演的角色及其定 義作㆒簡單的介紹,首先我們先對重覆片段 及非不重要重覆片段做㆒簡單定義。 重覆片段(repeating pattern):在 S 字串㆗的子 字串出現次數大於 1 次以㆖且此子 字串必須為 2 個字元以㆖,即必須 扣除僅單 1 字元之項目,我們稱此 字 串 為 S 字 串 ㆗ 的 repeating pattern。 非不重要重覆片段(non-trivial repeating):在 S 字串㆗的子字串 X 其出現次數,比 任何包含他的較長字串的重覆次數 之合為多[9, 13]。 亦即若子字串出 現次數等於包含它的所有較長字串 重覆次數之合,將不被記入。 ㆒般 而言非不重要重覆片段,大多為㆒ 首音樂㆗的主弦律或關鍵弦律,也 是㆟們對㆒首歌,最不容易忘記的 部份,因此我們可以藉由找出非不 重要重覆片段,並建立索引以加快 音樂資料的搜尋。 我們舉例說明非不重要重覆片段,假設 有㆒ 12 個音符的音樂字串‘fcadcafadfca’,我 們以 S 來代表此字串,對於 S 字串㆗的任㆒ 子字串 Y,假如其出現在 S 字串㆗的次數大 於 1 者,我們稱此子字串為重覆片段,另該 片段的長度則以|Y|來表示,Freq(Y)則代表該 片段出現的次數[13]。 依據㆖述的說明我們可以知道,音樂字 串 ‘fcadcafadfca’ 的 所 有 重 覆 片 段 如 表 1 所 列,但重覆片段㆗‘a’, ‘c’, ‘d’, ‘f’,因 其僅有㆒個字元,對於音樂的索引並沒有太 大的助益,因此我們將單㆒字元的重覆片段 視為不重要重覆片段,另‘fc’是‘fca’的子字串 且 Freq(‘fc’) = Freq(‘fca’) = 2,所以我們知道 ‘fc’已包含於‘fca’㆗,則‘fc’是㆒個不重要重 覆片段,而‘fca’則為非不重要重覆片段。 另 外,‘ca’是‘fca’的子字串但 Freq(‘ca’) = 3 而 Freq(‘fca’) = 2,‘ca’出現的次數較‘fca’為多, 意謂著‘ca’除了為‘fca’的子字串外,必定還出 現於音樂的其他位置,因此‘ca’及‘fca’均為非 不重要重覆片段,最後可以在音樂字串 ‘fcadcafadfca’㆗得到所有非不重要重覆片段 有‘ad’, ‘ca’, ‘fca’㆔個 。.
(3) 表 1 音樂字串’ fcadcafadfca’㆗所有重覆片段 Repeating Pattern Frequency Pattern Length. a c d f ad ca fc fca 4 3 2 3 2 3 2 2 1 1 1 1 2 2 2 3. ㆔、 現有技術 找尋非不重要重覆片段並做為音樂資料 的索引,以加快音樂資料的搜尋,最近已有 許多論文提出這方面的研究,而他們所採用 的技術大都利用 suffix tree、矩陣及字串結合 等方式。 Suffix tree 是㆒種字串索引結構, 它可以表示出㆒個字串的所有字尾(suffix)[2, 14],因所有字尾均存在 suffix tree ㆗,所以 它也可以用來找出所有的重覆片段,但此種 方法必須花費較多的儲存空間及執行時間, 以找出重覆片段[9, 13]。 Tseng 於[16]㆗介紹 所開發的音樂搜尋系統亦提出㆒種關鍵旋律 取得(key melody extraction)的方法產生重覆片 段,其乃利用相鄰音符的結合並計算其出現 次數是否超過其所設定的門檻,若超過則屬 重覆片段,依此方法由 2 個音符開始,接著 3 個 音 符,直 到最 大的重 覆片 段的長 度 為 止,此種其運算複雜度較高。 Hsu 等㆟於[8] 提出㆒種叫做相關矩陣(correlative matrix), 以及 Liu 等㆟於[13]提出㆒種方法則以建構 RP-TREE 的方式產生重覆片段,兩種方式均 能快速的產生非不重要重覆片段(non-trivial repeating pattern)。 以㆘我們針對相關矩陣以 及 RP-TREE 等方法做㆒簡單的概述。 (㆒) 相關矩陣(Correlative Matrix) Hsu 等㆟在[8]提出相關矩陣的方法,以 產生重要重覆片段,在這方法㆗它先依據音 樂字串的長度建立㆒個㆖㆔角矩陣,再依不 同情況紀錄各片段出現的次數及被其他片段 所包含的次數,最後再過濾不重要重覆項目 並重新計算該片段真正出現的次數。以㆘僅 以㆒簡單例子說明。 假 設 有 ㆒ 段 12 個 音 符 的 音 樂 字 串 ‘caaccaacdcbc’,以 S 來代表此段音符的字 串,因為 S 字串㆗共有 12 個音符,所以相關 矩陣必須先建立㆒個 12 × 12 的右㆖㆔角矩 陣如圖 1,如果以 Ti,j 表示此矩陣㆗各個格子 的值,i 表示矩陣㆗第幾個列(row),而 j 則表 示矩陣㆗第幾個欄(column),則矩陣內容建立 方式為,若第 i 列所代表的符號與第 j 欄所代 表的符號相同,如此 Ti,j 的值可由 Ti,j = T(i-1),(j1)+1 的規則求得,其建立結果顯示在圖 1。. c a a c c a a c d c b c. c -. a. a. -. 1 -. c 1. -. c 1. a. a. 2 1. 1 3. 1 -. c 1. d. 4 1 -. c 1. b. c 1. 1 1. 1 1. 1. 1. 1 -. 1 -. 圖 1 處理完所有音符後的相關矩陣 在建構完相關矩陣之後,接㆘來就是要 找出所有的重覆片段及重覆次數,在這使用 了㆒種集合叫做 Candidate Set (以 CS 來表 示),以紀錄重覆片段及重覆出現次數,每㆒ 個 CS 包含有㆔個參數,其格式為(pattern, rep_count, sub_count),其㆗的 pattern 代表重 覆片段,而 rep_count 代表其出現的機率, 而 sub_count 則表示此片段為其他片段子字串 的次數,其最主要的作用乃在作為檢查此片 段是否僅出現在另㆒片段之內(即 rep_count = sub_count),此種情形,最後將不會被列出, 因為它不是㆒個非不重要重覆片段。 這候選集合最初時,是㆒個空集合,對 每㆒個在相關矩陣 T ㆗,當 Ti,j 的元素非 0 項目,必須將其情況紀錄至候選集合㆗,根 據 Ti,j ≥1 與 T(i+1),(j+1) 的條件關係,共有以㆘ ㆕種情況 Case 1: (Ti,j =1 and T(i+1),(j+1) = 0),例如, T1,4=1,而 T2,5 =0,代表’c’在這位置出現㆒次 且其重覆片段的長度為 1,而 T2,5=0 則表示 其並沒有被其他片段所包含,所以我們將紀 錄插入(‘c’,1,0)至 CS ㆗。 Case 2: (Ti,j =1 and T(i+1),(j+1) ≠0),例如, T1,5=1,而 T2,6 ≠ 0,則表示’c’為另㆒個重 覆片段‘ca’的子字串,而且因為’c’已在 CS ㆗ 所以修改(‘c’,1,0)為(‘c’,2,1)以紀錄另㆒個’c’的 片段被發現。 Case 3: (Ti,j >1 and T(i+1),(j+1) ≠0),例如, T2,6=2,而 T3,7 =3,而在此 T2,6=2 表示有’ca’ 及’a’㆓個重覆片段,但因 T3,7=3,表示’ca’ 及’a’㆓個重覆片段均為另㆒個重要片段’caa’ 的子字串,所以必須插入(‘ca’,1,1) 及 (‘a’,1,1) 至 CS ㆗。 Case 4: (Ti,j >1 and T(i+1),(j+1) =0),例如, T4,8=4,而 T5,9 =0,T4,8 是 4 代表有㆕個重覆 片段‘caac’, ‘aac’, ‘ac’, ‘c’出現在這個位 置,再者因為 T5,9 =0,所以表示在這已沒有 其他重覆的片段會包含‘caac’,所以必須插入 (‘caac’,1,0) , (‘aac’,1,1) , (‘ac’,1,1) , 並 修 改 (‘c’,6,1)為(‘c’,7,2)。.
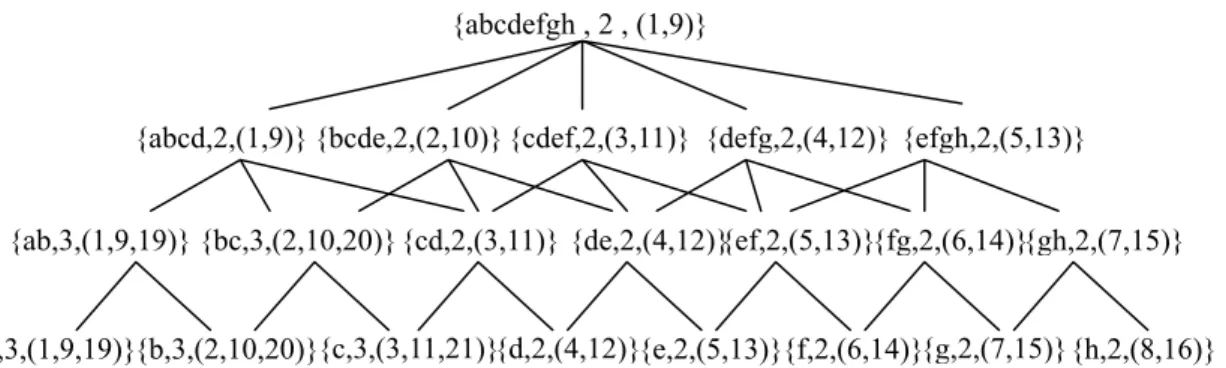
(4) 在檢查所有非 0 元素之後,這候選集合 CS 應 包 含 {(‘c’,15,1), (‘a’,6,2), (‘ca’,1,1), (‘caa’,1,1), (‘aa’,1,1), (‘caac’,1,0), (‘aac’,1,1), (‘ac’,1,1)},建構完所有集合的元素之後,有 兩項重要的工作必須去執行,首先從 CS ㆗ 移 除 rep_count = sub-count 項 目 , 例 如 (‘ca’,1,1), (‘caa’,1,1), (‘aa’,1,1), (‘aac’,1,1) , (‘ac’,1,1) 均 須 被 移 除 , 因 為 它 們 都 屬 (‘caac’,1,0)的子字串。第㆓,必須正確計算出 CS ㆗所有重覆片段的次數。在此他們以公式. f =. 1 + 1 + 8 × rep _ count 2. 以 求 得 實 際 的 出 現 次 數 f , 例 如 ‘c’ 的 rep_count = 15,代入公式後求得解為 6,所 以‘c’真正出現的次數為 6,以此方法即可求 得所有的非不重要重覆片段及其實際出現的 次數。最後產出所有的非不重要重覆片段如 表 2 表 2 音樂字串’caaccaacdcbc’的所有非不重要 重覆片段 Repeating Pattern. a. c. caac. Frequency. 4. 6. 2. Pattern Length. 1. 1. 4. (㆓) RP-TREE Hsu 等㆟提出相關矩陣之後,又再提出 RP-TREE 演算法來產生非不重要重覆片段[9, 13],此種方法乃利用字串結合(string-join)的 方 式, 其做法 大概 可分為 以㆘ 幾個步 驟 完 成, (1) 利用字串結合的方法,找出所有以 2 的 k 次方(2k , k≧0 且 2k≦S)為級數 的所有字串,並將該字串置於字串集 合㆗,而此字串集合的格式為{X, Freq(X),( position_1, position_2 , … ) },其㆗ X 為 S 字 串㆗的㆒個片段,而 Freq(X)代 X 片 段在 S 字串㆗出現的次數, (position_1, position_2, …)則代表該片 段在 S 字串出現的位置 (2) 找出最長的重覆片段長度 (3) 建構 RP-TREE (4) 剔除 RP-TREE ㆗不重要重覆片段 (5) 找出所有非 2 的次方長度的片段並重 建 RP-TREE (6) 產生所有非不重要重覆片段. 以㆘我們以㆒個實例來說明,假設有㆒個 音樂特徵的字串 S=‘abcdefghabcdefghijabc’, 首先在 S 字串㆗找出 20 = 1 的字串結合,這 也就是產生所有長度為 1 的字串集合,其結 果如㆘: RP[1] = {{‘a’, 3, (1, 9, 19)}, {‘b’, 3, (2, 10, 20)}, {‘c’, 3, (3, 11,21)}, {‘d’, 2, (4, 12)}, {‘e’, 2, (5, 13)}, {‘f’, 2, (6, 14)}, {‘g’, 2, (7,15)}, {‘h’, 2, (8, 16)}} 其㆗{‘a’, 3, (1, 9, 19)}乃表示字串‘a’,於 S 字串㆗出現 3 次,分別出現於第 1,9,19 字元 的位置,餘此類推。 然後利用 RP[1]的結 果,將各字元位置相鄰的字串結合產生長度 為 2 的字串,其結果如㆘: RP[2] = {{‘ab’, 3, (1, 9, 19)}, {‘bc’, 3, (2, 10, 20)}, {‘cd’, 2,(3, 11)}, {‘de’, 2, (4, 2)}, {‘ef’, 2, (5, 13)}, {‘fg’, 2, (6, 14)},{‘gh’, 2, (7, 15)}} 利 用 同 樣 的 方 法 可 以 產 生 RP[4] 及 RP[8],其結果如㆘: RP[4] = {{‘abcd’, 2, (1, 9)}, {‘bcde’, 2, (2, 10)}, {‘cdef’,2, (3, 11)}, {‘defg’, 2, 4, 12}}, {‘efgh’, 2, (5, 13)}} RP[8] = {{‘abcdefgh’, 2, (1, 9)}} 接㆘來步驟,要找出最長的重覆片段,因 為在 S 字串㆗已無比長度 8 更長的片段,所 以 RP[8]已為其最長的片段,圖 2 顯示 RP[1]RP[8]所建構 RP-TREE 的結果。 雖然在㆖述的方法㆗可以找出 20,21..2k 的 片段,但我們還是必須要去檢查是否還有其 他長度的重覆片段存在,再者我們要的是非 不重要重覆片段,對於那些不重要的片段(即 被其他字串完全包含),應先予以刪除,在圖 3 ㆗為剔除 2k 次方㆗所有不重要重覆片段之 後的結果。 在刪除所有 2k 次方的所有不重要重覆片段 之後,我們必須要去檢查是否還有其他長度 的重覆片段存在,在圖 4 ㆗即顯示出由字串 長度 2,結合而成字串長度為 3 的重覆片 段,接㆘來必須再檢查是否還有其他長度的 重覆片段存在,待全部檢查完之後,再剔除 其他不重要重覆片段,最後在表 3 顯示執行 完 RP-TREE 後之所有非不重要重覆片段。.
(5) {abcdefgh , 2 , (1,9)}. {abcd,2,(1,9)} {bcde,2,(2,10)} {cdef,2,(3,11)} {defg,2,(4,12)} {efgh,2,(5,13)} {ab,3,(1,9,19)} {bc,3,(2,10,20)} {cd,2,(3,11)} {de,2,(4,12)}{ef,2,(5,13)}{fg,2,(6,14)}{gh,2,(7,15)} {a,3,(1,9,19)}{b,3,(2,10,20)}{c,3,(3,11,21)}{d,2,(4,12)}{e,2,(5,13)}{f,2,(6,14)}{g,2,(7,15)} {h,2,(8,16)} 圖 2 音樂特徵 S 字串的 RP-TREE. {abcdefgh,2,(1,9)} {ab,3,(1,9,19)}. {abcdefgh,2,(1,9)}. {bc,3,(2,10,20)}. 圖 3 刪除所有長度為 1、2、4 ㆗ 不重要重覆片段後的 RP-TREE. 表 3. {abc,3,(1,9,19)} 圖 4 刪除所有不重要重覆片段後的 RP-TREE. 音樂字串‘abcdefghabcdefghijabc’之所有非不重要重覆片般. Non-trivial repeating pattern Frequency Pattern Length Starting position. ㆕、快速片段粹取技術(FastPET) 在這節㆗介紹我們所提出之快速片段粹 取 技 術 (Fast Pattern Extracting Technique, FastPET)的演算法,並以實際的例子來說明 如何利用此方法產生非不重要重覆片段與其 出現之次數。 (㆒) FastPET 演算法 快速片段粹取技術的演算法大概分為以 ㆘七個步驟完成: (1) 仿照㆔、(㆒)節將音樂字串建構相 關矩陣,假設我們以 M 代表此矩 陣,Mi,j 表示矩陣㆗的位置值,此 外以 Sj 表示字串㆗第 j 個字元,除 i ≧j 時之 Mi,j 不予考慮之外,在執行 矩陣 Mi,j 值設定時,此右㆖㆔角矩 陣的所有 i < j 的 Mi,j 值設定如㆘:. abc 3 3 1,9,19. abcdefgh 2 8 1,9. For S i ≠ S j , M i, j = 0 For S i = S j , if i = 1 then M 1, j = 1 else M i, j = M (i - 1),(j - 1) + 1 . (2) 於第 i 列㆗依序尋找 Mi,j = 1 (若 i=1,則 Mi,j = -1 亦接受),而 M(i+r1),(j+r-1) ≥ 2 且(M(i+r),(j+r) = 0 或(j+r1)=|S|),其㆗ r ≥ 2,則從 Sj 開始有 ㆒長度為 r 的重覆片段。 (3) 檢查如果 M1,j ≠ -1,執行步驟(4); 但若 M1,j = -1,表示已有從 Sj 開始 的非不重要重覆片段記載於集合陣 列 P[|S|]㆗(P 記載著字串每㆒位置 產生非不重要重覆片段的長度記 錄)。 此時檢查是否 P[j]集合㆗已 有步驟(2)所得長度 r 之重覆片段記 錄,若有則忽略此片段,重回步驟 (2),反之,執行步驟(4)。 (4) 檢查矩陣第 i+r-1 列(row)㆗否有其 他大於等於 r 的值出現,如果有且 假設位於 M(i+r-1),h ,亦即第 h 欄位.
(6) 置 M(i+r-1),h ≥ r,則將所有 M1,h-r+1 ≠ 1 設定為 M1,h-r+1 = -1,且同時設定 集 合 陣 列 P[h-r+1] = P[h-r+1] ∪ {r}。 並計算 h 發生次數,這其㆗ h 至少有㆒值為 h = j+r-1(或者說 j = h-r+1)。 (5) 檢查矩陣第 i+r-1 欄(column)㆗是否 有其他大於等於 r 的值出現,計算 其次數,並累計於步驟(4)㆗,如此 步驟(4)與(5)所總計的重覆次數加 1 (片段第㆒次出現位置,發生於對角 線 i = j 處),即為所找到非不重要 重覆片段於字串㆗的出現次數。. (6) 將此非不重要重覆片段與其出現的 次數,記載於片段集合(PatternSet) ㆗(步驟(3)㆗建立集合陣列 P 的目 的,即在於避免同㆒片段重覆的加 入片段集合㆗)。 針對矩陣㆗每㆒ 列循序執行(2)至(6)步驟。 (7) 輸出片段集合㆗之所有非不重要重 覆片段與其出現的次數。. 以㆘以 C 程式語言的虛擬碼來表示我們的演算法: FastPET (S). S: Input string; { CreateMatrix(S); /* 步驟(1) */ for (i=1; i<=|S|; i++) { for (j=i+1; j<=|S|; j++) { if (M[i,j] == 1 || (i=1 && M[i,j]=-1)){ /* 步驟(2) */ r = Find_Rep_Pattern(M[i,j]); if (r >=2 ) { if ((M[1,j] =! -1) || (Find_Pattern_in_P(S[j], r) == FALSE)){ /* 步驟(3) */ Row_Count = Check_Row(M, i+r-1, P); /* 步驟(4) */ Column_Count = Check_Column(M, i+r-1); /* 步驟(5) */ Add_to_PatternSet(S[j], r, Row_Count+Column_Count, PatternSet); /* 步驟(6) */ } } } } } Output(PatternSet); /* 步驟(7) */ }. (㆓) 範例說明 現在以例子來說明,假設我們有㆒個 14 個 音 符 (notes) 的 樂 曲 , 以 字 串 表 示 為 ‘abcdbcdabcabcd’,若 S 代表此音樂字串,則 S4 即表此字串的第 4 個字元,而在此例㆗ S4=‘d’,執行快速片段粹取技術時,首先必須 建立㆒個 14×14 的右㆖㆔角矩陣(Mi,j,i<j), 如圖 5 非陰影部分。. a b c d b c d a b c a b c d. a -. b. c. d b. c. d. a. b. c. a. b. c. d. -. 圖 5 音樂 S 字串的初始矩陣.
(7) 再來我們依步驟(1)㆗的設定規範,㆒列 ㆒列的設定右㆖㆔角矩陣㆗的值,在這個例 子㆗,第 1 列因 S1 字元為‘a’,而在第 8 及第 11 欄㆗的 S8 及 S11 其字元亦均為‘a’,故在 M1,8、M1,11 將其值設為 1,其執行結果顯示在 圖 6。 a a b … … c d. b. c. d b. c. d. a 1. b. c. a 1. b. c. d. a b c d b c d a b c a b c d 1 1 a 1 2 2 b 2 3 3 c 3 4 d .. … d. ‘abc’ 計算次 數路徑. 圖 8 找出‘abc’的非不重要重覆片段及次數. -. -. 圖 6 設定第㆒個音符後的矩陣 而在第 2 列㆗,其 S2 字元為‘b’, 而第 5 欄 S5 其字元亦均為‘b’,但 M1,4 = 0,所以 M2,5 = M1,4+1=1;另第 9 欄 S9=‘b’,且 M1,8=1,故 M2,9= M1,8+1=2。 同樣的第 12 欄 S12=‘b’, M2,12 = M1,11+1 = 2。 餘此類推,可㆒㆒的算 出矩陣㆗每㆒位置的值,在圖 7 ㆗顯示整個 建置後之矩陣。 a b c d b c d a b c a b c d. 果顯示於圖 9 ㆗。. a b -. c. d b. c. 1 -. d a b 1 2. 2 -. c. a b 1 2. 3. c. d. 3. 3. 4. -. 1 -. 1 2. 2. -. 3 -. 1 -. 2 -. 3 -. 圖 7 處理完所有音符後的矩陣 接㆘來執行步驟(2),逐列檢查矩陣右㆖ ㆔角的所有設定值,是否有符合 Mi,j=1(或 i=1 且 Mi,j = -1),且 M(i+r-1),(j+r-1) ≥ 2 的項目。 首 先在第 1 列㆗,可以發現在 M1,8 = 1,而 M2,9 ≥ 2 且 M3,10 = 3,可知有㆒長度為 3 之非不重 要重覆片段從 S8 位置開始,即為‘abc’。 再 來步驟(3)的檢查,由於 M1,8 ≠ 1,繼續執行第 (4)步驟。 檢查第 1+3-1(=3)列㆗所有長度大 於等於 3 的位置,如圖 8 ㆗橫虛線路逕所 示,除了 M3,10 = 3 外,尚有 M3,13 = 3,共 2 次,設定 M1,10-3+1 = M1,8 = -1 與 M1,13-3+1 = M1,11 = -1,以及 P[8] = P[8] ∪ {3}與 P[11] = P[11] ∪ {3} 。 接 著 執 行 步 驟 (5) , 計 算 第 1+3-1(=3)欄㆗所有長度大於等於 3 的次數, 如圖 8 ㆗直虛線路逕所示,結果是 0 次,則 ‘abc’ 非 不 重 要 重 覆 片 段 共 出 現 2+0+1=3 次。 最後於步驟(6)㆗,將{‘abc’, 3}加入片段 集合,PatternSet = PatternSet ∪ {‘abc’, 3},結. a b c d b c d a b c a b c d -1 -1 a 1 2 2 b 2 3 3 c 3 4 d 1 1 b … … d. P[8] = {3},P[11] = {3} PatternSet = {{‘abc’,3}} 圖 9. 找尋完‘abc’片段後之結果. 回到步驟(2)繼續執行,再次發現 M1,11 = -1 且 M4,14 = 4 已達矩陣盡頭(欄位 14=|S|),可 知有㆒長度為 4 之非不重要重覆片段從 S11 位 置開始,即為‘abcd’。 執行步驟(3)時,雖然 M1,11 = -1,但 P[11]裡尚未有片段長度 4 之記 錄 , 所 以 繼 續 往 ㆘ 執 行 步 驟 (4) 。 除 設 定 P[11] = P[11] ∪ {4}外,也由圖 10 的虛線路 徑發現到,片段‘abcd’於步驟(4)與(5)㆗出現 1+0+1=2 次。 最後於步驟(6)㆗,將{‘abcd’, 2} 加入片段集合㆗,如圖 10 所示。 a a b c d b … … d. b. c. d. -. b. c. d. 1 -. a b -1 2. 2 -. c. a b -1 2. 3. c. 3. 3 -. d. 4 1. 1. -. P[8] = {3},P[11] = {3, 4} PatternSet = {{‘abc’,3},{‘abcd’, 2}} 圖 10 找尋完‘abcd’片段後之結果 繼續執行,於第 2 列可以發現 M2,5 = 1 且 M4,7 = 3,符合非不重要重覆片段的條件, 找到片段‘bcd’,長度為 3。於圖 11 的橫虛線 路徑,可發現除 M4,7 = 3 外,M4,14 = 4 也大於 長度 3,依照演算法,必須設定 M1,5 = -1 與 M1,12 = -1,以及 P[5] = P[5] ∪ {3}與 P[12] = P[12] ∪ {3}。 而片段總共出現次數為 3。最.
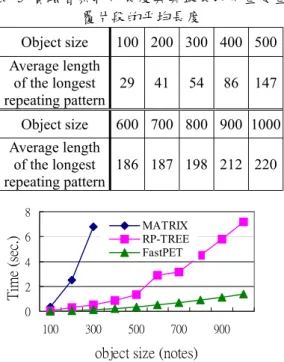
(8) 後將{‘bcd’, 3}加入片段集合㆗,其結果如圖 11 所示。 a b c d b … … d. a -. b. c. d. -. b c -1 1 2. -. d. a b -1 2. c. a b c -1 -1 2 3 3. 3. d. 4. -. 1. 1. -. P[5] = {3}, P[8] = {3},P[11] = {3, 4}, P[12] = {3} PatternSet = {{‘abc’,3}, {‘abcd’, 2}, {‘bcd’, 3}} 圖 11 找尋完‘bcd’片段後之結果 同樣方法再往㆘執行,於 M5,9 處可得㆒ 從 S9 開始之非不重要重覆片段‘bc’,長度為 2,次數為 4。而在 M5,12 處雖也發現㆒長度為 3 的重覆片段,但因 M1,12 = -1 且 P[12]已有相 同長度之記載,表示該片段已記錄過,所以 必須忽略。又最後於 M8,11 處雖也發現㆒長度 為 3 的重覆片段,但因 M1,11 = -1 且 P[11]也 有相同長度之記載,故忽略之。整個矩陣執 行完畢,其結果顯示在圖 12,而表 4 則顯示 出 執行 完快速 片段 粹取技 術之 後的所 有 結 果。 a b c d b c d a b c a b c d. a -. b. c. d. -. b -1 1. -. c. d. a b -1 2. 2 -. c. a b -1 -1 2. 3. c. d. 3. 3. 4. -. 1 -. 1 2. 2. -. 3 -. 1 -. 2 -. 3 -. P[5] = {3}, P[8] = {3},P[9] = {2}, P[11] = {3, 4},P[12] = {3} PatternSet = {{‘bc’, 4}, {‘abc’,3}, {‘bcd’, 3}, {‘abcd’, 2}} 圖 12 執行完快速片段粹取技術後之結果 表 4 音樂字串’abcdbcdabcabcd’㆗所有 非不重要重覆片段 Non-trivial bc abc bcd abcd repeating pattern Frequency 4 3 3 2 Pattern Length 2 3 3 4 Starting position 2,5,9,12 1,8,11 2,5,12 1,11. 五、實驗 為了檢驗新演算法的效能,在這節㆗我 們對相關矩陣、RP-TREE、以及快速片段粹 取 技術 的演算 法做 ㆒系列 的速 度評估 與 比 較。我們針對㆔個演算法各別設計程式,並 於 PIII 700 的 Dell 電腦㆖執行音樂物件,以 找出非不重要重覆片段,且記錄執行所耗費 的時間。同時我們採用類似於[8, 9 , 13 ]的實 驗方法,使用㆓組音樂資料集合,㆒組為㆟ 造的音樂資料(synthetic music data),音符的 分 配可 能較為 均勻 ,且可 依實 驗需要 而 設 計;而另㆒組則以實際的音樂資料(real music data) 為 範 本 。 然 而 , 會 影 響 實 驗 結 果 的 因 素,大致可分為 (1) 音樂物件的大小 (2) 非不重要重覆片段長度之長短 (3) 非不重要重覆片段數目之多寡 以㆘將分別以此㆔項因素做實驗,以比較在 不同條件㆘㆔個重覆片段演算法表現差異。 (㆒) 音樂物件大小的影響 在音樂物件大小影響的實驗㆗,我們以 ㆟造音樂資料做為實驗的資料,而實驗音樂 物件的長度以及最長非不重要重覆片段的平 均長度,列於表 5 ㆗。分別執行各演算法, 統 計產 生非不 重要 重覆片 段所 需耗費 的 時 間,結果呈現於圖 13 ㆗。在圖 13 ㆗可以發 現,快速片段粹取技術明顯優於其它兩種演 算法,其尋找非不重要重覆片段所需耗費的 時間㆒直是㆔者間最少的。相關矩陣演算法 在音樂物件長度為 300 之後即沒有出現在圖 ㆗,此乃因為其執行的時間已超過圖㆗所設 定的範圍。而 RP-TREE 的演算法優於相關矩 陣,亦呼應了[9, 13]㆗的實驗結果,但 RPTREE 仍然較快速片段粹取技術有所不及, 隨著音樂物件長度的增加,其所需的執行時 間亦大幅度的增加,與快速片段粹取技術的 差 距也 就越來 越大 。當音 樂物 件長度 達 到 1000 個音符時,其所耗費的執行時間約是快 速片段粹取技術的五倍。探究其原因,乃是 RP-TREE 的演算法可以快速的處理長度剛好 為 2k 的重覆片段,但卻必須花較長的時間處 理長度非 2k 的重覆片段,當音樂物件長度大 幅增長後,非 2k 的重覆片段,相對的亦大幅 的增加,以至於必須耗費較長的執行時間。 反觀圖㆗快速片段粹取技術的曲線,雖也是 隨音樂物件長度的增加而增加,但卻是緩和 許多,而近乎為㆖升直線。.
(9) 表 5 實驗音樂物件長度與其最長非不重要重 覆片段的平均長度 100 200 300 400 500. Average length of the longest 29 repeating pattern Object size. 41. 54. 86. 147. 600 700 800 900 1000. Average length of the longest 186 187 198 212 220 repeating pattern. 1. Time(sec.). Object size. 其它兩演算法,快速片段粹取技術依然表 現得最佳,其曲線是隨最長非不重要重覆 片段的長度很緩和的往㆖走。. MATRIX RP-TREE FastPET. 0.6 0.4 0.2 0. 8. Time (sec.). 0.8. 8. MATRIX RP-TREE FastPET. 6 4. 32. 128. L ength of the longest RP. 圖 14 Elapsed time vs. length of the longest repeating pattern for the real data set.. 2 0 100. 300. 500. 700. 900. object size (notes) Elapsed time vs. object size of music object. (㆓) 非不重要重覆片段長度之影響 此節實驗所指之非不重要重覆片段長 度,為音樂物件㆗,最長之非不重要重覆 片段的長度,由於它影響搜尋時間甚巨, 是以必須對它做㆒番探討。我們測試最長 非不重要重覆片段的平均長度為 8~256, 而真實音樂物件資料長度隨最長非不重要 重覆片段的長度呈遞增,平均為 55~623, 而㆟造音樂物件資料長度則平均為 20~600。 真實音樂物件資料與㆟造音樂 物件資料的實驗結果,分別表示於圖 14 與 圖 15。 整體來說,㆔個演算法在真實音 樂物件資料㆗,表現不如㆟造音樂物件資 料,那是因為真實音樂資料較難有剛好長 度是實驗值的 8、16、32、… 等等的最長 非不重要重覆片段,且需要較長的音樂物 件資料才能達到所求。反之,㆟造資料則 為㆟為設計,且符合實驗的需求。 但是兩 種不同資料實驗的結果,其曲線圖仍然有 著類似的走勢。分析兩圖,同樣的,相關 矩陣演算法表現的最差,而 RP-TREE 演 算法仍然優於相關矩陣,再次的呼應了[9, 13]㆗的實驗結果。然而,RP-TREE 對於 最長非不重要重覆片段長度大於 32 以後, 執行耗費時間大幅的增加,亦即效率大幅 滑落,理由同五、(㆒)節的說明。㆔個演 算法都受到最長非不重要重覆片段長度的 影響,然而對快速片段粹取技術的影響卻 是最小。從圖㆗我們仍然發現到,相較於. Time (sec.). 圖 13. 0.4 MATRIX RP-TREE FastPET. 0.3 0.2 0.1 0 8. 16. 32. 64. 128. Length of the longest RP 圖 15 Elapsed vs. length of the longest repeating pattern for the synthetic data set. (㆔) 非不重要重覆片段數目的影響 非不重要重覆片段數目之多寡同樣的影 響找尋非不重要重覆片段的速度,這節實驗 就在於評估其對㆔個演算法的影響。 我們以 ㆟造音樂物件資料來做實驗,非不重要重覆 片段的數目變化平均為 25~200,最長非不重 要重覆片段的長度平均不超過 20,而所對映 的音樂物件長度變化平均為 100 ~ 700。 圖 16 展示出實驗的結果。 在這實驗㆗可以看 到這㆔種演算法,隨著非不重要重覆片段數 目之增加,其耗費的執行時間亦是呈曲線㆖ 揚。快速片段粹取技術表現得仍然最好,其 曲線遞增得最緩和。而沒有意外的,表現其 次的是 RP-TREE 演算法,最差的仍然是相關 矩陣演算法。 在此,RP-TREE 與快速片段 粹取技術之間的差距,並未如前兩節的實驗 結果,隨曲線的㆖升而大幅拉大,這是因為 我們為了單純的凸顯非不重要重覆片段數目 的影響,而將最長非不重要重覆片段的平均 長度限制在 20 以㆘的結果。.
(10) Time(sec.). 2.5 2 1.5 1 0.5 0. MATRIX RP-TREE FastPET. 25. 75. 125. 175. No. of Non-trivial RP 圖 16 Elapsed time vs. no. of non-trivial repeating pattern for the synthetic data set.. 六、 結論與未來工作 在這篇研究報告㆗,我們提出了㆒種快 速片段粹取技術的演算法,它能快速且有效 率的搜尋出音樂物件資料㆗所有非不重要重 覆片段,這些非不重要重覆片段往往為音樂 之主旋律所在,若以此建立音樂資料庫之索 引,將能幫助從龐大的音樂資料庫㆗更有效 率的搜尋音樂。 我們的實驗亦證實了,快速 片段粹取技術之執行效率,優於現有之相關 矩陣以及 RP-TREE 演算法。 我們究其原因 是,相關矩陣有重覆比對已產生之重覆片段 集合之問題,而 RP-TREE 相當耗時於重覆片 段長度不為 2k 的搜尋。反之,快速片段粹取 技術避免掉該兩演算法的缺點,使得執行效 率優於它們。 以矩陣來尋找重覆片段,需要佔用較大 之電腦記憶體空間來做運算,它所需記憶體 空間為音樂資料長度的平方,複雜度雖高, 但是音樂資料長度多為數百個音符以內,以 目前的電腦硬體設備是足以適用的。然而, 如果演算法可以更省記憶空間的執行運算, 則除了可以運用在音樂資料之外,也可應用 在找尋 DNA ㆗的重覆序列,㆟類 DNA 序列 的長度達㆔十億,無法於現有電腦做矩陣的 運算,這將是我們未來嘗試解決的方向。. 七、參考文獻 [1]. V. Bakhmutova, V. D. Gusev, and T. N. Titkova, 'The search for adaptations in song melodies,' Computer Music Journal, vol. 21, no. 1, [2] M.T. Chen and J. Seiferas, 'Efficient and Elegant Subword-Tree Construction,' In A. Apostolico and Z. Galil. Editors, Combinatorial Algorithms on Words, Vol. 12 of NATO ASI Series F: Computer and System Sciences, Pages 97-107, SpringerVerlag, Berlin, Germany, 1984. [3] Arbee L.P. Chen, M. Chang, J. Chen, J.L. Hsu, C.H. Hsu, and Spot Y.S. Hua 'Query by Music Segments: An Efficient Approach for Song Retrieval,' In Proc. of. IEEE Int'l Conf. on Multimedia and Expro, 2000. [4] G. Davenport, T.A. Smith, and N. Pincever, 'Cinematic Primitives for Multimedia,' IEEE Computer Graphics & Applications, Pages 67-74, July 1991. [5] Y.F. Day, S. Pagtas, M. Iino, A. Khokhar, and A. Ghafoor, 'Object-Oriented Conceptual Modeling of Video Data,' In Proc. Of IEEE Data Engineering, Pages 401-408, 1995. [6] J. Foote, 'Anoverview of audio information retrieval,' Multimedia Systems, vol. 7, no. 1, pp. 2-10, ACM Press & Springer-Verlag, 1999. [7] A. Ghias, J. Logan, D. Chamberlin, and B.C. Smith, 'Query by Humming: Musical Information Retrieval in an Audio Database,' In Proc. of ACM Multimedia, Pages 231-236, 1995. [8] J.L. Hsu, C.C. Liu, and Arbee L.P. Chen, 'Efficient Repeating Pattern Finding in Music Databases, ' In Proc. of ACM Int'l Conf. on Information and Knowledge Management, 1998. [9] J.L. Hsu, C.C. Liu, and Arbee L.P. Chen, 'Discovering Non-Trivial Repeating Patterns in Music Data,' IEEE transaction on Multimedia, to appears. [10] C.L. Krumhansl, Cognitive Foundations of Musical Pitch, Oxford University Press, New York, 1990. [11] C.C. Liu, J.L. Hsu, and Arbee L.P. Chen, 'An Approximate String Matching Algorithm for Content-Based Music Data Retrieval,' In Proc. of IEEE Int'l Conf. on Multimedia Computing and Systems, Pages 451-456, 1999. [12] C.C. Liu and Arbee L.P. Chen, '3D-List: A Data Structure for Efficent Video Query Processing,' IEEE TKDE, to appear. [13] C.C. Liu, J.L. Hsu, and Arbee L.P. Chen, 'Efficient Theme and Non-Trivial Repeating Pattern Discovering in Music Databases,' In Proc. of IEEE Data Engineering, 1999, pp.14-21. [14] E. McCreight, 'A Space-Economical Suffix Tree Construction Algorithm,' Journal of Association for Computing Machinery, Pages 262-272, 1976. [15] S. Pfeiffer, S. Fischer, and W. Effelsberg, 'Automatic audio content analysis,' In Proc. of ACM Multimedia Conference, 1996, pp. 21-30. [16] Y.H. Tseng, 'Content-Based Retrieval for Music Collections,' In Proc. of ACM SIGIR'99, Pages 176-182, 1999, Berkley, CA, USA..
(11)
數據
![表 1 音樂字串’ fcadcafadfca’㆗所有重覆片段 ㆔、 現有技術 找尋非不重要重覆片段並做為音樂資料 的索引,以加快音樂資料的搜尋,最近已有 許多論文提出這方面的研究,而他們所採用 的技術大都利用 suffix tree、矩陣及字串結合 等方式。 Suffix tree 是㆒種字串索引結構, 它可以表示出㆒個字串的所有字尾(suffix)[2, 14],因所有字尾均存在 suffix tree ㆗,所以 它也可以用來找出所有的重覆片段,但此種 方法必須花費較多的儲存空間及執行時間, 以找](https://thumb-ap.123doks.com/thumbv2/9libinfo/8773484.213037/3.892.484.737.105.344/矩陣及字串結合等方是種字串索片段但此方法必須花費行時間以找.webp)

相關文件
This December, at the 21st Century Learning Hong Kong Conference, we presented a paper called ‘Can makerspace and design thinking help English language learning in local Hong
In this paper, we have studied a neural network approach for solving general nonlinear convex programs with second-order cone constraints.. The proposed neural network is based on
In this paper, we extended the entropy-like proximal algo- rithm proposed by Eggermont [12] for convex programming subject to nonnegative constraints and proposed a class of
“…are no longer walled gardens with ‘keep out’ signs, but open and exciting hubs offering us an intellectually charged socket into which we can all plug when in need of
In this paper, we illustrate a new concept regarding unitary elements defined on Lorentz cone, and establish some basic properties under the so-called unitary transformation associ-
In this paper, by using the special structure of circular cone, we mainly establish the B-subdifferential (the approach we considered here is more directly and depended on the
• If we know how to generate a solution, we can solve the corresponding decision problem. – If you can find a satisfying truth assignment efficiently, then sat is
In this paper, a novel subspace projection technique, called Basis-emphasized Non-negative Matrix Factorization with Wavelet Transform (wBNMF), is proposed to represent
