國立臺中教育大學資訊工程學系碩士論文
聯邦雲中基於賽局理論之分散式
排程方法
A Distributed Scheduling Approach based on Game
Theory in Federated Clouds
指導教授:賴冠州 教授
研究生:謝孟儒 撰
中華民國一百零三年七月
II
摘要
雲端運算擁有成本低、快速佈署及高彈性的優點,許多不同的產業注意到了 利用雲端運算可以為產業創造更大的競爭力,同時也增加了雲端運算資源的需求。 然而,現實世界中,雲端運算資源在實體的資源有限的情況下即供不應求。有鑑 於此,聯邦雲的概念將會越來越受到注目;聯邦雲是由數個獨立雲共同組成,每 個獨立雲擁有各自的計價系統及排程策略。當聯邦雲中的成員資源不足以滿足計 算資源要求時,缺少資源的雲可以向在聯邦雲中尚有剩餘資源的雲租用資源,稱 為外包。藉此互利於彼此,且各聯邦雲為了產生最大利益,採用自私策略是可預 見的。 然而,聯邦雲將遇到兩個挑戰:其一為網路延遲所造成的效能降低;主要因 為聯邦雲中的雲可能散布於各地,在雲與雲之間溝通傳輸時,網路速度將大幅下 降。另一個瓶頸則是由資源搶奪所造成的使用率降低;聯邦雲中尋求租用資源的 雲可能非唯一,再加上採用自私策略,很可能產生資源搶奪現象,當資源搶奪現 象發生時,聯邦雲的整體使用率將大幅下降。 本研究為了減低這兩個挑戰所帶來的效能降低影響,提出了 Task Grouping 及 Distributed Scheduling Approach (DSA)方法。Task Grouping 利用 Profiling Tool 分析欲執行工作之行為,並且將相依賴性高的工作視為一個 Group,藉此降低需 要經由跨雲網路之傳輸量。另外 DSA 則是考慮了目前剩餘資源、接收到的外包 需求及未來可能會出現的外包需求,並且計算邊際成本。利用賽局理論 (GameTheory) 的精神,考慮如何接受外包需求將會最大化資源使用率。為了驗證 Task Grouping 的效益,本研究於 UniCloud 執行 Benchmarks 測詴效能且為了驗證更大 規模的環境,本研究模擬在大規模聯邦雲環境中 DSA 執行效能,結果顯示此研 究能大幅降低網路延遲的效能影響並且提高整體使用率。
III
Abstract
The cloud computing development gets more and more mature. These companies can get more and more competitiveness by using cloud computing. However, the physical cloud resources are finite and the cloud resource requirements are infinite. The cloud resources demands may exceed supply. For this reason, the federated cloud is more and more important. The clouds are completely independent in the federated cloud. The cloud providers own different pricing strategies and scheduling strategies and adopt selfish policy. While the cloud resources are not enough to satisfy the cloud resource requirement, the cloud provider can rent the lacking resources from other cloud providers with remaining resources. This behavior is called outsourcing.
The federated cloud faces two challenges. The first challenge is network delay. Because of the cloud may locate at different place. Another challenge is the resource competition problem cause by the selfish policy and completely independent cloud in the federated cloud.
This study tries to reduce the effort of above-mentioned challenges. This paper proposes the Task Grouping and Distributed Scheduling Approach (DSA). The Task Grouping groups the tasks considering the task communication pattern after profiling jobs. The DSA decides how to accept the outsourcing jobs considering the remaining resources, outsourcing requests, the next possible job and marginal cost by game theory. To evaluate the Task Grouping, this study performs several benchmarks over the Unicloud. This paper also simulates the large federated cloud to evaluate the DSA. The results demonstrate that the approach this study proposed can reduce the effort of network delay greatly and improve the cloud utilization.
Keywords : Cloud computing, Federated cloud, Game theory, Marginal cost, Unicloud
IV
目錄
摘要... II 目錄... IV 表目錄... VIII 第一章 序論... 1 1.1 背景 ... 1 1.2 動機 ... 2 1.3 議題 ... 3 1.4 目標 ... 4 1.5 論文架構與內容 ... 5 第二章 相關研究... 7 2.1 雲端運算(Cloud Computing) ... 7 2.2 聯邦雲(Federated Cloud) ... 9 2.3 賽局理論(Game theory) ... 12 2.4 Openstack ... 142.5 MPI Parallel Environment (MPE) ... 16
2.6 Scheduling ... 17
第三章 基於賽局理論之分散式排程方法... 19
3.1 Task Grouping ... 20
3.2 Distributed Scheduling Approach (DSA) ... 24
V 4.1 實驗環境 ... 34 4.2 網路延遲效能評估 ... 39 第五章 結論與未來展望... 59 參考文獻... 61 附錄... 66
VI
圖目錄
圖 一 雲端運算服務架構... 9 圖 二 聯邦雲... 11 圖 三 Controller Node[26] ... 15 圖 四 Network Node[26] ... 15 圖 五 Compute Node[26]... 15圖 六 Distributed Scheduling Approach 軟體架構圖 ... 19
圖 七 Grouping Example 0 ... 21 圖 八 Grouping Example 1 ... 21 圖 九 Grouping Example 2 ... 21 圖 十 Grouping Example 3 ... 22 圖 十一 Grouping Example 4 ... 22 圖 十二 Grouping Example 5 ... 22 圖 十三 Grouping Example 6 ... 23 圖 十四 多目標最佳化... 25 圖 十五 0/1 knapspack Algorithm 運算範圍圖 ... 31
圖 十六 modified 0/1 knapspack Algorithm 運算範圍圖 ... 32
圖 十七 NPB IS ... 34 圖 十八 NPB EP ... 34 圖 十九 UniCloud 系統架構圖 ... 35 圖 二十 UniCloud 硬體架構圖 ... 36 圖 二十一 模擬實驗流程圖... 39 圖 二十二 Class B NPB CG 實驗結果 ... 40 圖 二十三 Class C NPB CG 實驗結果 ... 40 圖 二十四 Class B NPB EP 實驗結果 ... 41 圖 二十五 Class C NPB EP 實驗結果 ... 41 圖 二十六 Class B NPB IS 實驗結果 ... 42 圖 二十七 Class C NPB IS 實驗結果 ... 42 圖 二十八 IS 執行結果 ... 43 圖 二十九 EP 執行結果 ... 44 圖 三十 帄均外包資源及剩餘資源... 45 圖 三十一 帄均外包需求滿足率... 46 圖 三十二 帄均資源價格... 46 圖 三十三 聯邦雲總收益... 47 圖 三十四 N=5 與 PS 比較結果 ... 49 圖 三十五 N=5 間距=6 與 PS 比較結果 ... 50 圖 三十六 N=5 間距=13 與 PS 比較結果 ... 50
VII 圖 三十七 N=11 間距=6 與 PS 比較結果 ... 51 圖 三十八 N=11 間距=13 與 PS 比較結果 ... 51 圖 三十九 N=5 與 SJF 比較結果 ... 52 圖 四十 N=5 間距=5 與 SJF 比較結果 ... 53 圖 四十一 N=5 間距=13 與 SJF 比較結果 ... 53 圖 四十二 N=11 間距=5 與 SJF 比較結果 ... 54 圖 四十三 N=11 間距=13 與 SJF 比較結果 ... 54 圖 四十四 N=5 與 SRRF 比較結果 ... 55 圖 四十五 N=5 間距=6 與 SRRF 比較結果 ... 56 圖 四十六 N=5 間距=13 與 SRRF 比較結果 ... 56 圖 四十七 最優次數比較... 57 圖 四十八 放棄 Job 數比較 ... 57 圖 四十九 0/1 演算法實際執行時間 ... 58
VIII
表目錄
表 一 囚徒困境... 13
表 二 Game scenario ... 30
表 三 UniCloud 實體資源 ... 37
表 四 UniCloud Network Speed ... 37
表 五 Pricing 聯邦雲模擬環境 ... 38 表 六 模擬實驗 Job 組合 ... 48 表 七 N=5 與 PS 比較 ... 66 表 八 N=7 與 PS 比較 ... 66 表 九 N=9 與 PS 比較 ... 67 表 十 N=11 與 PS 比較 ... 67 表 十一 N=5 與 SRRF 比較 ... 68 表 十二 N=7 與 SRRF 比較 ... 68 表 十三 N=9 與 SRRF 比較 ... 69 表 十四 N=11 與 SRRF 比較 ... 69 表 十五 N=5 與 SJF 比較 ... 70 表 十六 N=7 與 SJF 比較 ... 70 表 十七 N=9 與 SJF 比較 ... 71 表 十八 N=11 與 SJF 比較... 71
1
第一章 序論
1.2
背景
近年來資訊科技產業越來越發達,其所需處理的運算及資料規模亦逐漸提高, 傳統資料中心已經很難完成此大量的運算,可能必頇花費大量的時間及金錢擴展 傳統資料中心以應付大量擴展的運算或資料規模。大多時候這類的擴展不符合性 能價格比,且運算及資料的需求持續變動中,難以在擴展規模及運算需求中取得 帄衡點。 雲端運算為基於虛擬化技術實現更有效利用資源之技術,虛擬化技術將硬體 資源抽象化成資源池,較為常見包含記憶體、儲存空間、CPU 等等。雲端運算 依照提供的服務項目分為:軟體即服務(Software as a Service)、帄台即服務(Platform as a Service)和基礎設施即服務(Infrastructure as a Service) 。依照使用者 需求提供不同服務項目,標準使用者付費方式運行,目前台灣較少有企業能夠發 展雲端基礎設施即服務,因為發展基礎設施即服務需要大量的硬體及成本。所以 台灣較多以軟體即服務為發展目標,並且利用國外較大基礎設施即服務供應商, 以極低的價格得到所需的運算資源或是資料存放空間發展雲端服務[2]。 雲端運算不僅能支持開發新的雲端服務,亦能將原本傳統資料中心應用程式, 評估雲端適用性後轉移至雲端運算中心處理。由於雲端運算有著快速建置所需環 境、規模快速縮放及快速恢復等特點,轉移至雲端運算中心處理之後,將能為應 用程式增加彈性及容錯性。 企業雲端化服務兩大巨頭 IBM 和 HP 皆為企業提供完整客製化雲端計畫評 估及實現服務。IBM 提供了完善的雲端化資訊給有雲端化計畫之企業並且提供 企業雲端化之服務,企業可以透過 IBM 所建議的六個步驟[1]評估並實現雲端化 企業;IBM 建議企業雲端化第一步必頇考慮企業營運目標及雲端特性擬定雲端 化策略。接著評估應用服務項目與雲端之適用性;若此應用服務項目有著可標準
2
化、可獨立運作、或是具備 Service-Oriented Architecture (SOA)導向架構,則此 應用服務項目雲端適用性高,並且頇避免移植成本或風險過高之應用服務項目。 第三步列出可雲端化之應用服務項目並且根據項目特性決定選擇何種雲供應模 式,包含公有雲、私有雲和混和雲。當雲端化策略擬定之後必頇計算此服務模式 長期之成本與價值,最後實現雲端化策略之前思考如何建置及使用者使用模式。 利用上述六個步驟企業將以較低風險方式建置雲端化服務。IBM 亦提供了一些 企業雲端化成功案例作為參考;包括關貿網路公司、無錫國家軟體園公司、 Panasonic 和 PayPal[1]。
另外,HP 的 Converged Infrastructure Capability Model(CI-CM)服務,提供顧 問團為企業提供企業評量表,評估企業應用規模、企業預期效益、企業應用類型 及企業成本,並為企業提供客製化雲端計畫。並且提供多項課程供企業了解雲端 運算和雲端經濟學,以協助企業完整轉型為雲端企業[3][4]。
1.2 動機
當雲端運算發展成熟,更多的運算需求出現,運算資源供不應求的情況亦可 能發生。鑒於此,聯邦雲漸受關注,相較於單雲;聯邦雲將有更大的彈性和經濟 效益。聯邦雲是由兩個以上的雲組成,雲與雲之間透過某種方式連接,大多時候 每個雲都依照原本的計價策略及排程方式獨立運作。當出現資源不足以滿足工作 所需資源時,聯邦雲可透過向尚有剩餘資源的其他雲供應商租用所缺少的資源, 藉此解決資源不足之問題。另一方面,雲資源供應商則可以透過額外工作增加原 有收益,彼此互利。 由於雲端運算有著快速建置所需環境、規模快速縮放及迅速恢復中斷服務等 優點;許多不同的產業傾向利用雲端運算提升自身的競爭力,未來投入雲端運算 的產業將只增不減。雲端運算資源需求也將迅速增加,為了滿足如此大量運算需 求,將雲端運算發展至聯邦雲架構將可大量增加資源使用率。然而,聯邦雲是否3 能像單雲一樣穩定且高效能,此問題將被更多因素所影響。本研究觀察聯邦雲的 使用情況,發現聯邦雲執行帄行 MPI Benchmarks,有時需更多的完成時間,而 有時卻不會與單雲運算有太大的差別;其差別於不同 MPI Benchmarks 有著不同 程式行為,以高相依賴性之 MPI Benchmarks 效能影響最為嚴重。 另外,由於聯邦雲與單雲運行模式相差甚遠,單雲運行模式類似於中心式管 理;以 Openstack[26]為例,由單一 Controller 管理控制雲端運算資源與雲端運算 需求,容易完全掌握資源使用情形並加以利用。而聯邦雲則有著數個 Controller, 並且採用自私策略,可能發生租用資源需求所產生之資源搶奪情況。該如何重新 研擬適用於聯邦雲之分散式排程策略為一個值得探討的議題。 賽局理論[9]為一個決策用理論,1944 年首先被提及。其最大的特點為不需 要了解其他賽局參賽者決策,並靠著僅有的已知訊息與訊息所隱含的一定規則, 加以預測其他參賽者決策情況或其他因素。並且依照預測結果訂定策略結果,藉 此達到完全分散式決策。本研究發現賽局理論所含的相關參數與特性可能適用於 聯邦雲,因聯邦雲為一個完全分散式的環境,且無法完全了解每個雲的排程策略 決定。所以能否應用賽局理論精神,詴著研究出一套適用於聯邦雲之排程策略為 一有趣的議題。
1.3 議題
本研究觀察聯邦雲的使用情況,發現聯邦雲中的雲位於不同地點,雲與雲的 距離也有遠近差別,雲與雲的網路速度亦因此不同。當工作需跨越不同的雲執行 時,其執行過程明顯因網路速度的不同,而導致效能降低。本文研究此效能降低 可能由何原因所產生;發現當聯邦雲環境中執行高相依賴性之工作時,例如 TheNAS Parallel Benchmarks(NPB)的 CG 跟 IS Benchmarks[20][44],以各種組合分配 Tasks 至不同的 Worker 執行,發現其 Turnaround Time 相差甚遠,有些組合能夠 以短時間完成,而有些卻需要數倍時間完成;相較於以同樣的方式執行相依賴性
4 低的工作時,則沒有發生此現象,相關詳細數據於第四章深入分析。本研究發現 聯邦雲與單雲運算不同;聯邦雲必頇考慮欲執行工作行為,並且依照欲執行工作 行為適當的分配資源,否則可能嚴重影響整體聯邦雲效能,產生事倍功半的現 象。 聯邦雲由數個獨立雲所組成,雲與雲透過某種方式連接,當某個雲資源無法 完全滿足運算需求時,此雲將嘗詴向其他聯邦雲成員詢問資源使用情況與價格, 並且租用所缺少之最低價格資源,稱之為外包(Outsourcing)。大多時候雲與雲之 間並不瞭解彼此之資源使用情況與工作執行情況。 聯邦雲中互相不了解的特性加上每個聯邦雲的雲皆採用 Selfish Policy 且完 全獨立;執行策略不用考慮到其他雲的策略決定及分配情況,同時若產生大量外 包需求,易產生資源搶奪現象。若資源搶奪現象頻繁出現,且聯邦雲沒有針對此 現象制定解決策略;則此聯邦雲使用率將被嚴重影響,因產生大量因為互相搶奪 而出現閒置資源,聯邦雲使用率將因為大量閒置資源產生而大幅降低。 為了使聯邦雲更適於使用,必頇解決或降低因為聯邦雲所產生上述效能影響, 而如何解決聯邦雲效能議題,並使聯邦雲使用情況跟單雲一樣穩定有效率為一個 值得討論的議題。
1.4 目標
本論文針對因為跨雲網路傳輸而效能降低,提出了考慮 Job 執行之行為模式 之 Task Grouping 方法;首先利用 Profiling tool 得出 Job 行為模式,並且透過 TaskGrouping 演算法將相依賴性高的 Tasks 視為同一個 Group;藉此將 Job 中的所有 Tasks 依照 Job 行為模式分類成數個 Groups。遵從同一個 Group 內的 Tasks 將於 同一個雲執行之規則,藉此大幅降低需要低速跨雲網路之傳輸量;同時也將大幅 減少因為網路延遲所產生的效能影響。
5
Distributed Scheduling Approach (DSA) 排程方法。其主要概念分為兩個部份:資 源提供方與資源需求方;資源需求方主要負責當所剩資源不足以滿足目前所有運 算需求時,必頇向其他聯邦雲供應商詢問資源情況並租用最低價之缺乏資源,無 法成功租用資源時,則向次低價之聯邦雲供應商詢問。而資源提供方負責決定如 何接受此類外包需求;當剩餘資源多於所有外包資源需求時,資源提供方接受所 有外包需求。另外,當發生資源搶奪現象時,該如何選擇外包工作才能使整體聯 邦雲有較高使用率;資源提供方將考慮目前剩餘資源、目前外包工作需求和未來 可能出現的工作需求,並計算邊際成本(Marginal Cost)[10]後選擇對本身最佳的外 包需求組合。邊際成本簡單定義為處於邊際情況時,所需要額外負擔的成本;本 文將邊際情況定義為發生資源搶奪時,也代表著資源所剩無幾,另外邊際成本定 義為接下來會因為無法利用剩餘資源所造成之閒置資源成本。透過所有聯邦雲成 員都以此分散式排程方法進行排程,提高整體資源使用率。
為了驗證本論文提出的方法效能,本文將於 UniCloud[15]執行 NAS Parallel
Benchmarks[20],評估 Task Grouping 方法能為是否能為有著不同行為模式之 Benchmarks 減少等待傳輸時間並且縮短完成時間。另一方面,本研究模擬更大 型聯邦雲環境,並評估 Distributed Scheduling Approach (DSA) 排程方法是否能夠 改善聯邦雲使用率。Task Grouping 目標為最小化由跨雲網路延遲所造成的效能 影響,Distributed Scheduling Approach (DSA)目標則為最小化總閒置資源;低閒 置資源亦代表高使用率,達到此兩點即代表能為聯邦雲提高整體資源使用率並且 減少由等待資料傳輸之閒置時間。
1.5 論文架構與內容
本論文分為以下五個部分:第一章主要說明本研究背景及動機,並且分析聯 邦雲可能遇到的問題,並簡略說明改善方法之概念和實驗方式。第二章為本文相 關研究文獻,包含雲端運算、聯邦雲和賽局理論。第三章將說明本文提出的方法、6
演算法及系統架構。第四章將描述本文實驗環境及分析實驗結果。第五章為本文 結論與未來展望。
7
第二章 相關研究
2.1 雲端運算(Cloud Computing)
雲端運算建構於虛擬化技術之上,依照虛擬化程度分為半虛擬化 (Para
virtualization)和全虛擬化 (Full virtualization);最大的差別在於需不需要因為虛擬 化而修改作業系統的 Kernel,需要為虛擬化而修改作業系統為半虛擬化,像是早 期的 Xen,但是其優點為效能較佳,因為當虛擬程度越高則表示軟體與硬體間需 要透過更多的處理模擬出虛擬機器所需的資源。另外,全虛擬化雖然不需要修改 作業系統,但是需要特定 CPU 的支援,例如支援 AMD-V 或 Intel VT,常見的全 虛擬有 KVM(Kernel-based Virtual Machine)[14]。
由 NIST[28]定義了關於雲端運算的五點特徵:
自助隨選服務(On-demand self-service):消費者能夠依照需求向雲端服務供 應商租用服務。此流程為自動化,不需要與雲端服務供應商互動。
網路存取服務(Broad network access):消費者透過任何網路裝置(例如:桌 上電腦、智慧型手機或是帄板電腦)存取使用雲端服務。 共享資源池(Resource pooling):雲端服務商所提供的資源視為一個資源池; 消費者不頇知道資源實際位置,只需要抽象化的資源池,依照使用者需求隨時分 配給不同使用者。 快速且彈性(Rapid elasticity):使用者所擁有的資源必頇能夠快速且彈性的釋 放和使用,對於消費者而言,雲端資源可無上限購買。 可量化服務(Measured service):雲端服務必頇被自動監控,資源使用情況與 計價方式需皆透明化。 由 NIST[28]定義了四種不同的佈署類別: 公有雲(Public Cloud):實體雲端資源由雲端供應商持有,消費者透過網際網 路向公有雲提供商租用資源,並且以公有雲供應商所制定的計價系統計算使用價 格,最為熱門為 Amazon EC2[29][41]。
8 私有雲(Private Cloud):雲端運算資源由使用者持有,透過雲端管理軟體建 置私有雲端系統,需要付出實體資源成本及管理成本,最為熱門的雲端管理軟體 為 Openstack[26][41]。 社群雲(Community Cloud):數個組織因共同目的所組成的社群,實體資源 由組織持有,雲端環境可由組織自己管理也可交給第三方管理,多為企業雲端所 採用[39][41]。 混合雲(Hybrid Cloud):由多種不同類型之雲端環境所組成,並同時使用多 種類雲端資源,包含公有雲、私有雲或社群雲,需要較高技術性整合多個雲端環 境,較多以新增公有雲資源為目的[41]。 雲端運算依照提供的服務不同分為以下三種:
軟體即服務(Software as a Service):消費者透過網際網路經由 SaaS 供應商即 可選擇所需軟體服務,不需要花大錢購入軟體,改由隨選隨用模式,選擇某軟體 某版本,當軟體有了新版本,也能夠簡單的改選擇新版本使用。而傳統軟體公司 也意識到了此種服務型態,並且越來越多公司傾向發展 SaaS 服務,著名的成功 案例有美國的 Salesforce.com[22][43]。 帄台即服務(Platform as a Service):消費者透過網際網路租用某特定開發帄 台開發軟體,包括程式語言帄台和資料庫等等,其最大的優點在於使用者不需要 管理及建置繁複的開發帄台基礎設施,不管是開發帄台相關的軟體或是更底層的 網路設定、伺服器建置、作業系統跟儲存裝置佈署等等,消費者只需要專心於開 發新軟體或是新服務[23][43]。 基礎設施即服務(Infrastructure as a Service):消費者透過網際網路租用基礎 設施服務,包含處理運算單元、儲存空間、網路元件等等。消費者不需要實際購 買此類基礎設施而能夠存取資料和取得運算能力,最大的優點就是不用將汰換及 管理成本列入開發成本[24][43]。
9
圖 一 雲端運算服務架構
根據資策會 MIC 產業分析師李乾立分析北美雲端服務市場[2]發現,雲端運 算服務供應商以 SaaS 服務提供者最多,其原因為進入 SaaS 的門檻較低所以較多 各式各樣的 SaaS 服務提供商,產值也最高。而 IaaS 規模僅次於 SaaS,2012 年 產值預估達到 75 億美金,IaaS 以 Amazon 的 AWS 服務最為熱門,市占率超越
50%。
2.2 聯邦雲(Federated Cloud)
當雲端運算發展至成熟穩定,消費者通常會因為雲端運算擁有其他運算方式 無法比擬的特性選擇雲端運算發展新軟體或新服務。但是基本的雲端運算有著潛 在問題需要解決,包括使用者將被雲端供應商所提供的虛擬機器資源組合所限制、 使用者所開發的雲端軟體可能因為執行時間而增加所需資源以及使用者可能需 要由世界各地收集大量資料運算。由 Gabriel Mateescua 所提出雲端運算架構可以 清楚發現;並非單一雲端供應商可以滿足未來大量產生之計算需求,所以預留了 可外包架構[38]。1.以 Amazon AWS[29]為例,Amazon AWS 提供使用者能以不同價格選擇不 同作業系統、資源種類(例如:記憶體較高)和虛擬機器大小(例如:Tiny、Small、
10 Large 等等) ,雖然可以符合多數使用者的需求,但依然會有特殊需求使用者存 在,此時使用者必頇花費較多金錢租用足夠滿足需求之虛擬機器組合,但是此組 合中會有某些資源將不被使用產生浪費。 2.使用者所開發的軟體或是服務可能因為長期執行運作而擴大軟體規模進 而產生更多資源需求,以較小的雲端供應商為例,可能造成雲端供應商無法負荷 而導致雲端服務中斷,進而產生龐大損失。 3.當雲端軟體需要由世界各地收集各種不同的大量資料運算時,若此雲端軟 體只建置於某地,傳輸資料的時間將嚴重地影響雲端軟體的服務效能也可能浪費 資源等待資料傳輸,以上數點皆顯現出單雲的運算環境可能不再適用於多數的雲 端軟體需求,進而衍生出多雲的想法,而其中一種多雲運算稱為聯邦雲。聯邦雲 是由一群獨立運作的雲透過某種連接方式所組成,如圖二所示,聯邦雲成員皆為 獨立且擁有自有定價排程策略,當缺乏資源時或是需要特定的雲資源運算時,聯 邦雲能向其他雲供應商租用資源,一方因為聯邦雲解決資源問題另一方因為額外 的資源需求增加收益,彼此互利共生[6][11]。
Rafael Moreno-Vozmediano 等人發表了 Cloud Operating System 的概念及框架。 Cloud OS 負責管理實體資源與虛擬資源,並且針對每個框架中的元件加以說明, 較為有趣的是其中包含了 Federation Manager,主要功能為利用 Cloud Drivers 與 其 他 雲 端 系 統 連 接 , 藉 此 達 到 Outsourcing 並 成 為 聯 邦 雲 , Rafael
Moreno-Vozmediano 等人稱為雲端運算聯邦化[6]。
Kate Keahey 等人提出如何監控與操作在多雲環境中基礎設施 Outsourcing 的 資源,將所有雲端服務功能分解成獨立的程序,若獨立程序執行期間沒回應則自 動建立新 Worker 取而代之,藉此增加 High Available。而 IaaS 的部分則交給稱為
Provisioner 負責,Provisioner 能夠負責數個雲端環境的基礎設施,並根據需求提 供資源。雖然 Kate Keahey 等人所發表的文章並非針對聯邦雲,但是文中所出現 的 Outsourcing 概念類似於聯邦雲解決資源不足的概念,當資源不足時 Provisioner
11 將新增新的 Outsourcing 資源進 IaaS 中[13]。 圖 二 聯邦雲 Sheheryar Malik 等人提出了考慮實體資源位置及網路速度,將各地的實體資 源分為數個 Group,若額外透過此方式建立帄行運算系統,能明顯增加運算效率; 雲端運算中心之實體資源可能位於各地,若以如此的情境之下,建立帄行運算系 統則可能因為實體資源間的網路延遲導致執行效率減低。本研究雖然並不是透過 實體資源位置執行分 Group,而是將此概念應用於帄行應用程式中 Tasks 之間的 相依賴行為,透過將相依賴性高的 Tasks 分為數個 Group,亦能大量減少需透過 跨雲網路之傳輸量,增加聯邦雲執行效率[5]。
12
價值,亦 Profit 最佳,其考慮了使用模式和基礎設施成本使收益或是使用率最大 化。其多目標方法相當值得參考,但缺乏考慮了聯邦雲中資源與資源的網路延遲, 若網路延遲過高,可能產生等待傳輸時間遠大於運算時間之現象[40]。
2.3 賽局理論(Game theory)
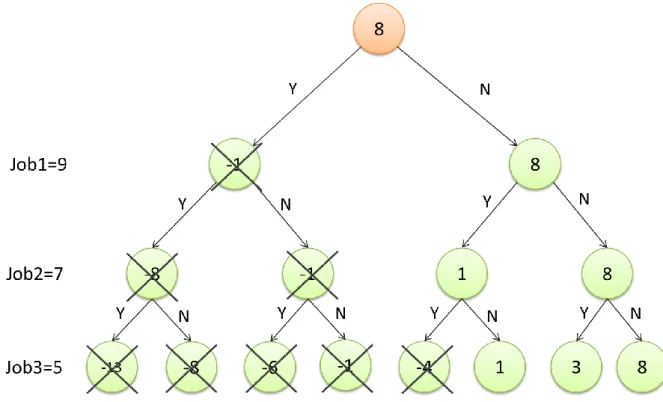
賽局理論為一個決策用之理論,1944 年由 John von Neumann 等人首先被提 及,其特點在於不需要了解其他參賽者的決定,而利用某些預測做決定,像預測 其他參賽者決策或是預測將發生何事件影響決策。一般而言,一個賽局有以下參 數:參賽者、策略和收益。透過列出所有參賽者所決定之策略並計算其可能收益, 藉此計算出該進行何種策略,常見的賽局將會得到不一定最優但較優之結果 [8][9]。 最廣為人知的例子為囚徒困境 (Prisoner's Dilemma),囚徒困境為一個較易懂 的例子,囚徒困境中參賽者為囚犯兩人、策略為招供與否、收益為刑期,刑期越 短收益越高。如表 一所示,犯人 A 考慮招供與否時,若犯人 A 招供則犯人 A 可能得到刑期 3 年或是無罪釋放,換句話說最多被判 3 年。若犯人 A 不招供則 可能得到刑期 5 年或是半年也就是最糟情況會被判 5 年。犯人 B 也是一樣的狀 況,若只考慮到自身的刑期的話兩個犯人大多數都會選擇招供,也就是都被判 3 年。由囚徒困境例子中明顯發現”個人最佳選擇並非團體最佳選擇”,但卻能處於 帄衡狀態。此例子為非合作賽局,當策略決定無法與其他參賽者合作,只能依照 自身利益判斷時,其結果很難得到最佳情況,換句話說,當兩個犯人事前可以討 論,並且有足夠信任關係,此時囚徒困境能夠得到最佳解,也就是刑期最低半年 [25]。
13 表 一 囚徒困境 犯人 A\犯人 B 招供 不招供 招供 犯人 A 刑期 3 年 犯人 B 刑期 3 年 犯人 A 刑期 0 年 犯人 B 刑期 5 年 不招供 犯人 A 刑期 5 年 犯人 B 刑期 0 年 犯人 A 刑期半年 犯人 B 刑期半年 依照賽局特性分為:依照參賽者決策是否有順序性分為靜態賽局跟動態賽局, 有順序者為後者。依照參賽者對於其他參賽者之了解程度分為完全訊息賽局跟不 完全訊息賽局,如果參賽者對於其他參賽者並沒有準確的決策跟特性訊息為後者。 依照參賽者是否能夠互相合作達到更高效益,分為非合作賽局跟合作賽局,目前 所探討的大多都為非合作賽局[9] [12]。 針對不同賽局模式所對應到的均衡概念也不同,完全訊息靜態賽局對應到
Nash equilibrium,完全訊息動態賽局對應至 sub-game perfect Nash equilibrium, 不完全訊息靜態對應至 Bayesian Nash equilibrium,不完全訊息動態對應至 perfect
Bayesian Nash equilibrium[9] [12]。
Michael Wooldridge 提出了一個簡單的模組及範例定義如何將問題轉換成賽 局,並且將賽局所需的參數做簡單說明定義,研究賽局理論解決問題之前,必頇 先了解何為賽局理論及賽局,Michael Wooldridge 的文章對於賽局定義非常實用 [16]。 Francesco Palmieri 等人提出了根據賽局理論分散式排程框架,他們所提出的 方法針對聯邦雲中自私策略所產生的影響,考慮資源價格和工作資源需求,並且 帶入邊際成本[10]的概念,藉由資源競爭會影響到資源提供方成本的特性,隱含 的影響到資源分配結果,並且嘗詴找到 Nash equilibrium,但此方法未考慮到雲 與雲之間的網路延遲所造成的執行效能影響,所以直接用於聯邦雲上,因為時常
14 等待資料傳送完成而導致效能不佳[7]。 Zexiang Mao 等人提出基於賽局理論的雲端資源分配方法,考慮到多種工作 需求和不同雲資源的價格跟能力,利用賽局理論競爭不同的雲資源組,漸漸找到 符合工作需求並相較價格低的資源組,他們定義此資源組為 Nash equilibrium, 但此方法目標在於多對多的賽局競爭並不考慮網路延遲,雖然 Zexiang Mao 等人 提出的方法適用於多重 SLA 限制,但是不直接適用於聯邦雲[17]。
2.4 Openstack
Openstack[26]由 National Aeronautics and Space Administration (NASA)和 Rackspace 共同開發之雲端運算開發管理帄台軟體。由於 Openstack 是 Open Source 並且富有許多彈性化功能,包含提供與許多帄台相容之 RESTful API,容 易依照使用的需求更改原始碼(ex: nova scheduler),Openstack 也提供了圖性化 網頁介面 Dashboard 供使用者方便操作[42]。
Openstack 由 2010 年十月釋放出第一版 Openstack Austin,並且以至少每年 一版的速度快速更新和增加功能,其中經過了 Austin、Bexar、Cactus、Diablo、
Essex、Folsom、Grizzly、Havana 和 Icehouse 各種版本[26]。Openstack 忠實使用 者遍布全球,其中較為大型的使用者有包含 The National Aeronautics and Space
Administration (NASA)、DAIR(Digital Accelerator for Innovation and Research)、 Rackspace Cloud 和 AT&T 的 Cloud Architect[30]。
Openstack 為目前最熱門的私有雲建置軟體,Openstack 被廣為用於開發客製 化雲端運算帄台。以 Openstck 建置私有雲必頇包含負責三種不同工作之 node:
Controller node、Network node 和 Compute node。
Controller node 負責管理並監控 Openstack 的使用狀況,任何對 Openstack 的操作皆透過 Controller node,視為 Openstack 的大腦。Network node 負責所有 虛 擬 機 器 對 外 的 網 路 設 定 以 及 虛 擬 機 器 間 的 虛 擬 網 路 定 義 及 路 由 , 視 為
15
Openstack 的溝通窗口。Compute node 則負責提供運算資源,組成虛擬資源池, 提供給使用者創建虛擬機器,視為 Openstack 的根本。下圖為參考 Openstack Document 依照不同的 Node 功能所需套件繪製而成。另外此三種不同的 Node 可 以建置於同一台實體機器上,並不需要三台以上的實體機器[26]。
圖 三 Controller Node[26]
圖 四 Network Node[26]
圖 五 Compute Node[26]
圖 三為 Controller Node 內部軟體模組,Quantum Server 負責網路相關之操 作與設定對應至圖 四中各種不同網路 Agent,由 Controller Node 下指令至
16
Network Node 執行,包括 DHCP 分配、由 Metadata agent 獲取虛擬機器之相關設 定及參數、Layer 3 網路的轉送和 Floating IP 設定。Nova Scheduler 負責決定將虛 擬機器創於何 Compute Node,並且對應至圖 五中的 Nova Compute 執行,預設 判斷方式為 RAM 的剩餘量。Keystone 負責使用 Openstack 的所有用戶及 Openstack 內不同的軟體模組的帳號權限管理。RabbitMQ 負責 Openstack 內不同 的軟體模組間的溝通,大多由 Controller Node 發出命令至其他 Node,執行完畢 後回傳結果及狀態給 Controller Node。MySQL 負責存放 Keystone 所需的所有資 訊和虛擬機器資訊。Nova API 負責各種 API 之轉換與執行,最常使用為 RESTful
API 相關之 API[26]。
2.5 MPI Parallel Environment (MPE)
MPI Parallel Environment (MPE)由 Laboratory for advanced numerical software 開發之 MPI Profiling Tool,MPE 於 2003 年三月發表 MPE 1.9.1 版,並於 2005 年更新至 MPE2,最新版本為 2010 年十月所更新的 MPE2-1.3.0,其只被包含於
MPICH2 套件內,與 MPICH2 高相容性。MPE 常被用於大型的帄行運算系統或 是包含於其他大型函式庫中應用,包含 WestGrid Glacier cluster[32]和 PETSc
(Portable, Extensible Toolkit for Scientific Computation) [31]。
WestGrid Glacier cluster 將 MPE 用於了解 MPI 程式的 communication pattern, 並加以了解程式中 synchronization 及 load-balancing 的問題,最大的優點是不需 要修改程式,只需要將 MPE 的函式庫匯入並重新編譯[32] 。
PETSc 是一個提供了解決科學計算應用上常用的偏微分方程的熱門函式庫, 支援各種帄行系統,例如 MPI。PETSc 主要用於解大型線性或是非線性的科學計 算問題,PETSc 將 MPE 用於了解當帄行化大型科學計算問題,Tasks 之間的
communication pattern,並協助使用者了解可能的效能瓶頸;同時他支援 Profile MPI 程式和 MPIF77 程式,使用方式非常容易,首先安裝 MPE 套件並且將路徑
17
加入環境變數後,編譯 MPI 程式同時帶入 MPE Library 參數(ex: mpicc hello.c
-llmpe -lmpe)即可。MPE 也提供了圖形化介面讓使用者容易了解程式行為。 jumpshot 為 MPE 提供的基於 JAVA 的 visualization tool,MPE 能夠計算出 MPI 指令的使用次數及花費時間,並且能夠紀錄程式互動行為。本研究目的在於減少 雲對雲間的通訊量,所以只針對有資料傳輸之指令計算,包括 MPI_Send、
MPI_Recv、MPI_Bcast、MPI_Reduce 等等[19]。
2.6 Scheduling
為了驗證本研究所提出的 DSA 方法,本研究於第四章與三種現有 Job
Scheduling 比較;包含 Priority Scheduling、Shortest Job First Scheduling 和 Smallest Resource Requirement First Scheduling。另外本研究將 Task Grouping 與常見的 Maui Scheduler[21]比較。除此之外,由於聯邦雲相關研究較少,本研究與應用於 Grid 之 Heuristic Algorithm Scheduling[35]比較執行結果。本小節將以上五種 Job Scheduling 一一介紹。
Priority Scheduling:原用於作業系統中如何將 CPU 指派給 Process;作業系統 將 CPU 指派給最高 Priority 之 Process,但 Priority 規則相當多樣化;包含依照
Process 的執行時間最長或最短以及 Process 的資源需求最多或最少,其缺點為容 易因為 Priority 而產生飢餓現象。Priority Scheduling 不僅用於作業系統中,帄行 系統也常用於選擇何種 Job 優先執行,為一個常見 Scheduling 方法。本研究將
Priority Scheduling 之 Priority 設定為資源需求最高者 Priority 最高,使用於如何 選擇 Outsourcing 要求,並與 DSA 比較[33]。
Shortest Job First Scheduling:為 Priority Scheduling 特例之一,亦可視為執行 時間最短的 Job 其 Priority 最高,常用於帄行系統之 Job Scheduling。但仍然有飢 餓現象風險,隨著執行時間短的 Job 不斷加入,執行時間長的 Job 等待時間將越 來越久,甚至造成永遠無法得到資源執行工作。Shortest Job First Scheduling 能於
18
有序 Job 組合情況下,於最短等待時間內完成,但前提是必頇準確預估所有 Job 執行時間,否則 Shortest Job First Scheduling 效率低下[33][34]。
Smallest Resource Requirement First Scheduling:雖非作業系統中常見排程方 法,主要原因為作業系統較常考慮到執行時間或是等待時間,Process 通常只需 單一 CPU 執行工作。由於帄行系統中的 Job 並非要求單一資源,常出現 Job 需 要複數資源;此資源不僅代表 CPU 數量,Job 可能需要 Memory、儲存空間或是 CPU , 依 照 使 用 者 所 訂 定 的 資 源 定 義 , Smallest Resource Requirement First Scheduling 將有不同執行結果。本研究將 Smallest Resource Requirement First Scheduling 中 Resource 定義為 Tiny Virtual Machine 數量,並於第四章與 DSA 比 較[33]。
Maui Scheduler 為叢集系統中常見之實用型 Scheduler,預設採取 First Fit Policy,但 Maui Scheduler 提供簡易方式制定 Scheduling[21]。由於 Maui 主要用 於單一叢集系統,本研究與 Maui Scheduler 比較,可能產生不公帄之疑慮,所以 本研究亦與應用於 Grid 之 Scheduling 比較。Jing Wang 等人提出之直覺化 Grid 排程策略;其主要精神為將資源與工作分別以資源能力和工作大小排序,接著依 照最大工作分配至最高資源能力之規則一一分配[35]。由於此方法使用許多排序, 可能產生時間複雜度過高之疑慮。
19
第三章 基於賽局理論之分散式排程方法
本章節主要說明本研究所提出的 Task Grouping 及 Distributed Scheduling
Approach (DSA)方法,並且說明其演算法及分析其時間複雜度。此研究之軟體架 構圖如圖 六所示,從 Ubuntu 作業系統、Qemu、KVM、Openstack、Virtual Machines、
Virtual Cluster,皆為 UniCloud 所提供之環境,本研究建構於 Virtual Cluster 之上, 必頇先經過 Task Grouping 之後依照身為資源剩餘方或是資源不足方執行不同演 算法,最後分配 job 執行。
20
3.1 Task Grouping
Task Grouping 目標為減少跨雲網路延遲所造成的效能降低,此效能降低原 因主要是因為等待跨雲溝通完成,產生過多不必要的閒置時間,其目標在於減少 整體跨雲通訊量,當跨雲通訊量降低,等待溝通時間自然也會減少,並直接影響 到工作完成時間。Algorithm I. Tasks Grouping
Input:Task-set ( a set of tasks in the job.)
Output:group-set (a set of groups after tasks grouping.(ex:{{1,3}{2,4}{5}})) {
Task-set = Sort by Communication amount (Task-set); For each task in Task-set do{
If (task is first) || (all neighbor communication < threshold) {Group-set=New group(task);}
For each task’s neighbor do{
If (neighbor communication >= threshold) If (neighbor not grouped)
Add group(task, neighbor); Else (neighbor grouped)
Merge group(task, neighbor.group); Done;}
Done;}
Return group-set; }
當接收到新的工作時,利用 Profiling Tool 取得工作與工作間溝通模式,本研 究採用 MPI Parallel Environment (MPE) 為 Profiling Tool,因為 MPE 為 MPICH2 內建工具,所以非常簡單使用,其功能也很完整。
Task Grouping 取得工作資訊之後,首先處理最高通訊量之工作。當此工作 為首個工作或是該工作無超出閥值(threshold)的鄰近工作時,新增一個新 Group, 否則當鄰近工作超出閥值通訊量時,考慮其鄰近工作是否已經屬於某個 Group,
21 尚未屬於則將兩工作視為同個 Group,否則則將兩 Group 結合在一起,最後輸出 數個 Group 之組合,同一 Group 即代表著不可分配置不同雲。 圖 七 Grouping Example 0 圖 八 Grouping Example 1 圖 九 Grouping Example 2
22
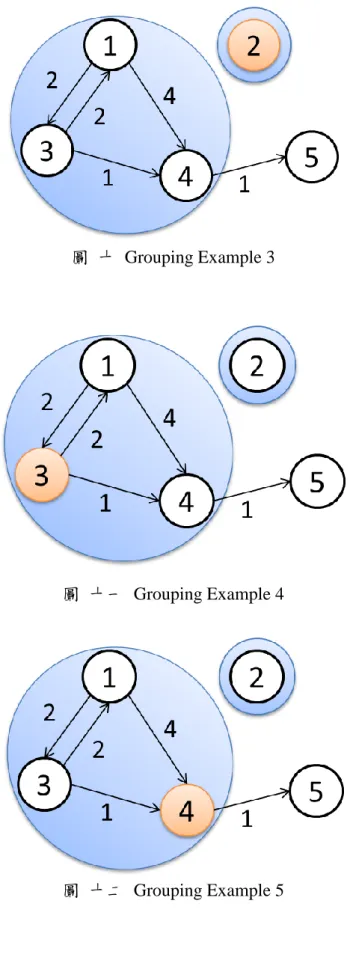
圖 十 Grouping Example 3
圖 十一 Grouping Example 4
23
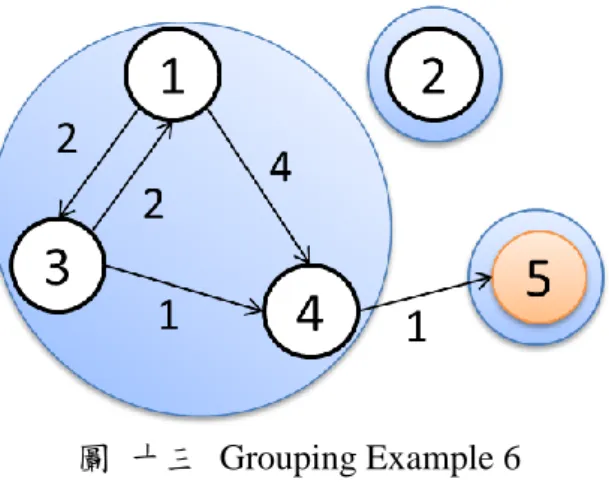
圖 十三 Grouping Example 6
圖 七為 Task Grouping 範例。其總執行時間為 8 秒,threshold 則定為執行時 間之一半 4 秒,圖中的單位皆為秒。圖 八為以 Task1 開始並發現其鄰居 Task3
Communication time 大於 threshold 且並未 Grouped,所以將 Task1 和 Task3 Group 在一起。圖 九亦發現 Task1 之鄰居 Task4 Communication time 大於 threshold 且 並未 Grouped,所以將 Task1、Task3 和 Task4 為同一 Group。圖 十考慮 Task2, 並且 Task2 沒有與任何 Task 有 Communication,所以 Task2 為一個新的 Group。 圖 十一與圖 十二分別考慮 Task3 和 Task4,雖然有與其他 Task Communication, 但是與 Task1 已經完成 Group,與 Task5 則還未超出 threshold,所以暫無改變 Group 情況。圖 十三則考慮 Task5,雖然與 Task4 有 Communication 但未超出 threshold, 所以為一個新的 Group。圖 十三為執行結果,總共 3 個 Groups,其輸出結果為 {{1,3,4}{2}{5}}。 由於必頇將每個工作做 Group 分類,並且分類過程中需要再考慮此工作與鄰 近工作之溝通模式與通訊量,所以時間複雜度為 O(N2 )。雖然時間複雜度頗高, 但此 Group 行為只會針對新且未知的工作執行,對於穩定的雲端運算中心,運行 於此雲端運算中心的工作特性應有相似性,所以此 Group 行為並不會繁複執行, 此方法的時間複雜度為可接受的。
24
3.2 Distributed Scheduling Approach (DSA)
此分散式排程方法雖要求所有聯邦雲皆需運行此演算法執行工作排程,但所 有聯邦雲皆以完全獨立模式決定排程策略,且不互相干涉,即擁有分散式精神。 此演算法主要用於如何在聯邦雲中分配和選擇工作,分為兩個情況:需要租資源 時該如何選擇租用何資源以及接受外包需求時要如何選擇接受何種外包。由以下 演算法可以明顯地展現出聯邦雲中的成員皆為自私。每個雲皆可依照資源及工作 情況成為剩餘資源剩餘方或是資源不足方,成為資源剩餘方之前必頇優先執行
Local 所有 Jobs,即 Local Jobs 優先權高於 Outsourcing Jobs。本研究方法為結合 以下數個演算法,當為資源不足方,執行租用資源之演算法(Algorithm II. Job
Scheduling)尋找最低價格之資源,否則執行如何解決外包需求之演算法。 此演算法為一多目標方法,本研究將目標訂為最小化預估執行時間與成本, 此目標可由額外加權值之乘積而轉換為傾向預估執行時間或是成本之選擇。如圖 十四所示,圖中每個點為資源剩餘方,此方法將用於選擇何資源剩餘方發出外包 需求。本研究之多目標為對等預估執行時間與成本之乘積,所以圖中角度為 45o, 預 估 執 行 時 間 與 成 本 之 乘 積 越 低 者 代 表 為 較 佳 解 。 C 為 聯 邦 雲 之 雲 成 員 C={C1,C2,C3,C4,….CC}。
25 𝐦𝐢𝐧 𝒊∈𝑵 𝑬𝒙𝒑𝒆𝒄𝒕𝒆𝒅 𝑻𝒖𝒓𝒏𝒂𝒓𝒐𝒖𝒏𝒅 𝑻𝒊𝒎𝒆 ∗ 𝑪𝒐𝒔𝒕 = 𝐦𝐢𝐧 𝒊∈𝑵 𝑬𝒙𝒑𝒆𝒄𝒕𝒆𝒅 𝑻𝒖𝒓𝒏𝒂𝒓𝒐𝒖𝒏𝒅 𝑻𝒊𝒎𝒆 ∗ (𝑳𝒐𝒄𝒂𝒍 𝑪𝒐𝒔𝒕 ∗𝑵𝒖𝒎𝒃𝒆𝒓 𝒐𝒇 𝑱𝒐𝒃 𝒊 ′𝒔 𝑻𝒂𝒔𝒌𝒔 𝒓𝒖𝒏 𝒊𝒏 𝑳𝒐𝒄𝒂𝒍 𝑪𝒍𝒐𝒖𝒅 𝑵𝒖𝒎𝒃𝒆𝒓 𝒐𝒇 𝑱𝒐𝒃 𝒊′𝒔 𝑻𝒂𝒔𝒌𝒔 + 𝑪𝒍𝒐𝒖𝒅 𝒄 𝑪𝒐𝒔𝒕 ∗𝑵𝒖𝒎𝒃𝒆𝒓 𝒐𝒇 𝑱𝒐𝒃 𝒊 ′𝒔 𝑶𝒖𝒕𝒔𝒐𝒖𝒓𝒄𝒊𝒏𝒈 𝑻𝒂𝒔𝒌𝒔 𝑵𝒖𝒎𝒃𝒆𝒓 𝒐𝒇 𝑱𝒐𝒃 𝒊′𝒔 𝑻𝒂𝒔𝒌𝒔 ) (1) 圖 十四 多目標最佳化 每個雲都會接到一堆運算需求,當本地資源足以滿足需求時,優先執行於
Local Cloud;而當 Local Cloud 資源不足時,即馬上尋找尚有剩餘資源之雲供應 商並且比較其價錢,向最低價格發出請求,等待要求被接受。若不被接受則向下 個供應商發出請求,直至外包資源租用成功。另外若是整個聯邦雲環境已經沒有 足夠資源處理此要求,則放棄此工作。
26
Algorithm II. Job Scheduling
Input:Jl( a set of jobs for cloudl.), Rj( job j resource requirement.), Vl( local cloud
remaining resource.), Gj( outsourcing task group resource requirement.) Output:Mapping Table for resource and jobs.(ex:{J1:V3}{J2:V1}{J3:V2})
{
Select Jj from Jl
If (Rj <= Vl)
{allocate Jj to Vl; update Vl;}
Else
{lack_resource=lack resource number(Rj , Vl);}
While (lack_resource){
C_temp=look for other cloud providers with enough resources; outsourcingC=MinEq.1(C_temp);
If (outsourcingC->price > Outsourcing_boundn)
{give up Jj;update Vl; update lack_resource;}
Else if (outsourcingC->price <= Outsourcing_boundn) without competition
{
allocate Gj to Vl and Vc;
update Vl; update lack_resource;
}
Else {update lack_resource;} } } 為了解決當外包需求過多產生資源競爭現象時,本研究提出兩個方法,第一 個方法為當資源競爭產生時,剩餘資源供應商透過調整資源價格,使其他預算較 低之外包需求轉向其他雲供應商要求資源。 公式(2)用於計算出外包需求之價格上限,Pj代表第 j 個 job 的 Profit,Ri為
需要 Outsourcing 之 Tasks 資源需求總數,Rj為 Job j 中所有 Tasks 資源需求總數。
此公式為依照外包資源需求比例計算出該外包需求價值多少錢。 𝐎𝐮𝐭𝐬𝐨𝐮𝐫𝐜𝐢𝐧𝐠_𝐛𝐨𝐮𝐧𝐝𝐢= 𝐏𝐣 ∗ 𝐑𝐢 𝐑𝐣. (2)
公式(3)表資源剩餘方之資源競爭程度,若此值小於 1 代表資源足以滿足所 有外包需求,VC表示資源剩餘方之剩餘資源數量,Ri為 Outsourcing 資源需求。
27 𝐂𝐨𝐦𝐩𝐞𝐭𝐢𝐭𝐢𝐨𝐧𝐋𝐞𝐯𝐞𝐥𝐜 = ⌈(∑ 𝐑𝐢 𝐧 𝐢=𝟏 )/𝐕𝐜⌉. (3) 公式(4)表示當接受了第 i 個外包需求時,所需付出之邊際成本;此方法中將 接受某外包需求後所剩餘資源視為無法租出之資源,Vc 為剩餘資源,Ri 為第 i 個 Outsourcing 資源需求。 𝐌𝐚𝐫𝐠𝐢𝐧𝐚𝐥 𝐜𝐨𝐬𝐭𝐜,𝐢 = {𝐕 𝟏, 𝐢𝐟 𝐕𝐜 = 𝐑𝐢 𝐜− 𝐑𝐢, 𝐨𝐭𝐡𝐞𝐫𝐰𝐢𝐬𝐞 . (4) 公式(5)表資源剩餘方 C 所收到的所有外包需求之帄均邊際成本,亦為所有 外包需求所產生之邊際成本之帄均,Costc為 Cloud C 單一資源成本,Ri為第 i 個 Outsourcing 資源需求。 𝐌𝐚𝐫𝐠𝐢𝐧𝐚𝐥 𝐜𝐨𝐬 �𝐜 = ∑(𝐌𝐚𝐫𝐠𝐢𝐧𝐚𝐥 𝐜𝐨𝐬𝐭𝐜,𝐢∗ 𝐂𝐨𝐬𝐭𝐜)/ ∑ 𝐑𝐢. 𝐧 𝐢=𝟏 𝐧 𝐢=𝟏 (5) 公式(6)為計價方式,當沒有資源競爭產生時,資源價格採用 cost-driven Pricing[27],否則需透過額外加上競爭程度與帄均邊際成本之積調整價格。 𝐏𝐫𝐢𝐜𝐞𝐜 = {𝐏𝐫𝐢𝐜𝐞𝐜 −𝟏+ 𝐂𝐨𝐦𝐩𝐞𝐭𝐢𝐭𝐢𝐨𝐧𝐋𝐞𝐯𝐞𝐥 𝐜∗ 𝐌𝐚𝐫𝐠𝐢𝐧𝐚𝐥 𝐜𝐨𝐬𝐭𝐜 , 𝐢𝐟 𝐂𝐨𝐦𝐩𝐞𝐭𝐢𝐭𝐨𝐧𝐋𝐞𝐯𝐞𝐥 > 𝟏. 𝐂𝐨𝐬𝐭𝐜∗ 𝐫𝐚𝐭𝐞𝐜, 𝐨𝐭𝐡𝐞𝐫𝐰𝐢𝐬𝐞. (6) 雖然此方法能夠透過調整價格而將外包需求分配於每個剩餘資源方,但其實 此方法有著隱藏的缺點;包括盡管能夠依照價格分配資源及外包需求,但是卻仍 然會因為接受外包需求後而產生租不出去之資源,進而產生閒置資源,並不符合 研究目標減少閒置資源。
28
Algorithm III. Pricing
Input:Vc(Cloud C’s remaining resource.), ratec(The Cost-driven Pricing rate for Cloud C.), CompetitionLevelc(The Cloud C’s Competition degree.), Ri(an outsourcing request.)
Output:Mapping Table for remaining resources and outsourcing jobs. (ex:{V1:R3}{V2:R1}{V3:R2})
{
Update CompetitionLevelc;
Pricec= Cost-driven Pricing(Vc,ratec)
While CompetitionLevelc >1
{
Pricec= Pricec + Marginal cost(Vc,Ri)
Update CompetitionLevelc; } Rent Vc to Ri Unset Pricec } 另一個演算法為本研究重點所在,考慮到目前剩餘資源、目前外包需求和未 來可能之工作需求,並且計算邊際成本,選擇較小成本之決策。詳細公式如下: Vc為 cloud c 目前剩餘資源,Ri為第 i 個外包所需資源。公式(7)使用於計算 當接受了某個外包需求之後,將剩餘多少資源。 𝐑𝐞 �� 𝐢𝐧𝐜,𝐢 = 𝐕𝒄− 𝐑𝒊 . (7) 公式(8)用於計算執行過之 Jobs 的帄均產生間距,N 個 Jobs 共有 N-1 個間距, 此值用於預估下個 Job 將於多久時間後產生。 𝑻𝒑= ∑𝒏 𝑻𝒋𝒊− 𝑻𝒋𝒊−𝟏 𝒊=𝟐 𝒏 − 𝟏 (8) 公式(9)用於計算執行過之 Jobs 的帄均執行時間,將執行過 Jobs 之執行時間 加總取帄均而得,預估下個 Job 之執行時間。
29 𝑻𝒓 = (∑ 𝑻𝒓𝒊 𝒏 𝒊=𝟏 )/𝒏 (9) 公式(10)用於計算資源需求小於等於剩餘資源之 Jobs 執行時間總和,物理意 義為此 Cloud 用於計算資源需求小於等於剩餘資源之 Jobs 花的時間。 𝑺𝒖𝒎 𝒐𝒇 𝑬𝒙𝒆𝒄𝒖𝒕𝒊𝒐𝒏 𝑻𝒊𝒎𝒆 𝒐𝒇 𝒋𝒐𝒃𝒔 𝒘𝒉𝒆𝒏 𝑹𝒆𝒒𝒖𝒆𝒔𝒕 ≤ 𝑹𝒆𝒎𝒂𝒊𝒏𝒄,𝒊 = ∑ 𝑻𝒓𝒊 𝒏 𝒊∈𝚪 Where Γ = {𝑖|𝑖𝑓 𝑗𝑜𝑏𝑖 𝑊ℎ𝑒𝑛 𝑅𝑒𝑞𝑢𝑒𝑠𝑡 ≤ 𝑅𝑒𝑚𝑎𝑖𝑛𝑐,𝑖, 𝑐 ∈ 𝐶 } (10)
公式(11)用於計算此 Cloud 執行 Jobs 時間總和,物理意義為此 Cloud 總計算 使用時間。 𝑺𝒖𝒎 𝒐𝒇 𝑬𝒙𝒆𝒄𝒖𝒕𝒊𝒐𝒏 𝑻𝒊𝒎𝒆 𝒐𝒇 𝒋𝒐𝒃𝒔 = ∑ 𝑻𝒓𝒊 𝒏 𝒊=𝟏 (11) 公式(12)Pc,i表示當 cloud c 接受了第 i 個工作,則剩餘的資源將可以順利被 租出的機率,亦代表此 Cloud 總計算使用時間與資源需求小於等於剩餘資源之 Jobs 執行時間總和比例。 𝐏𝐜,𝐢(𝐓) =𝐒𝐮𝐦 𝐨𝐟 𝐄𝐱𝐞𝐜𝐮𝐭𝐢𝐨𝐧 𝐓𝐢𝐦𝐞 𝐨𝐟 𝐣𝐨𝐛𝐬 𝐰𝐡𝐞𝐧 𝐑𝐞𝐪𝐮𝐞𝐬𝐭 ≤ 𝐑𝐞𝐦𝐚𝐢𝐧𝐜,𝐢 𝐒𝐮𝐦 𝐨𝐟 𝐄𝐱𝐞𝐜𝐮𝐭𝐢𝐨𝐧 𝐓𝐢𝐦𝐞 𝐨𝐟 𝐣𝐨𝐛𝐬 . (12) 公式(13)邊際成本(Marginal Cost)為主要判斷標準,此方法會選擇此值較小之
策略。Marginal Costc,i為當 cloud c 接受了第 i 個工作之後所需付出的邊際成本,
Vc為 cloud c 目前剩餘資源,Ri為第 i 個外包所需資源,Remainc,i為當 cloud c 接
受了第 i 個工作後剩餘資源;此邊際成本代表未來剩餘資源將租不出去的可能性、 剩餘資源數量與價格之積,若剛好能把剩餘資源用盡,則代表將不必多付出成本, 邊際成本為 0。其賽局定義如表 二。
30 𝑴𝒂𝒓𝒈𝒊𝒏𝒂𝒍 𝒄𝒐𝒔𝒕𝒄,𝒊(𝑻) = { 𝟎, 𝒊𝒇 𝑽𝒄 = 𝑹𝒊 (𝟏 − 𝑷𝒄,𝒊(𝑻)) ∗ 𝑹𝒆𝒎𝒂𝒊𝒏𝒄,𝒊∗ 𝑷𝒓𝒊𝒄𝒆 ∗ 𝑻𝒑, 𝒊𝒇 𝑽𝒄! = 𝑹𝒊 & 𝑷𝒄,𝒊 > 𝟓𝟎% 𝑹𝒆𝒎𝒂𝒊𝒏𝒄,𝒊∗ 𝑷𝒓𝒊𝒄𝒆 ∗ 𝑻𝒓, 𝒐𝒕𝒉𝒆𝒓𝒘𝒊𝒔𝒆 (13)
Algorithm IV. modified 0/1 knapspack
Input:resources(cloud remaining resources.), outsourcing requests(a set of outsourcing requests.)
Output:strategy(An outsourcing strategy for cloud provider.(ex:{item1,item3,item4,item5},{item2,item3})) {
Min cost=maximal value Knapspack(item)
{
New a fork for item.
Select a non-repetitive item to strategy from outsourcing requests If total strategy outsourcing requests <= resources
Calculate marginal cost by eq.13. If Min cost > marginal cost then
Select strategy and update Min cost. Knapspack(next item);
Else fork end } Knapspack(first item) Return strategy. } 表 二 Game scenario Cloud Providers\ Cloud Environment Tp秒後有 Job X Tp秒後不會有 Job X 賭 Tp秒後會有 Job X 產生,並 使剩餘資源為 0 或極接近 0。 預留資源*Tp 預留資源*Tp+重新評估賽局 賭 Tp秒後不會有 Job X 產生, 盡可能最小化剩餘資源。 剩餘斷裂資源*Tr 剩餘斷裂資源*Tr
31 上述方法修改了傳統 0/1 背包演算法選擇策略,每個外包需求為物件、外包 資源需求為價格、剩餘資源為背包容量,目標為利用公式(13)找出最低值。傳統 的 0/1 背包演算法由於時間複雜度太高而無法用於即時系統;因此本研究針對此 缺點修改了演算法,當選定某個物件之後,若超出了背包空間,則之後的物件選 擇與計算則皆不進行。所以能將時間複雜度壓縮至一定區間,此區間決定於剩餘 資源多寡,當剩餘資源越少所需要的計算也隨之減少,因大部分之物件選擇都被 認定為不必要的計算。 圖 十五 0/1 knapspack Algorithm 運算範圍圖 圖十五為一般的 0/1 背包演算法所需的運算範圍。假設剩餘資源為 8,Job1 需要 9 個資源、Job2 需要 7 個資源、Job3 需要 5 個資源,橘色部分表示必頇執 行運算。當外包需求漸漸增加,運算需求則呈現指數成長,時間複雜度為 O(2N ), 對於即時系統,當外包需求增加至一定數量,必定造成嚴重瓶頸,因此需修改此 缺點。
32
圖 十六 modified 0/1 knapspack Algorithm 運算範圍圖
透過 modified 0/1 knapspack Algorithm 修剪掉大量不必要的運算,所謂的不 必要的運算代表就算持續選擇其他外包需求也無法對結果產生影響。如圖 十六 所示,大部分的運算將被刪去,此修剪機制將能為此演算法加速許多,實際執行 時間與比較將於下一章節詳細說明。 Algorithm V 用於外包需求決策,當目前剩餘資源足以滿足所有外包資源時, 即接受所有外包需求;否則將利用 modified 0/1 knapspack 計算出最低邊際成本 之策略組合。此組合不一定唯一,若不唯一則優先處理擁有較高資源需求工作之 組合,否則隨機選擇策略,策略決定後回覆要求且更新資源狀態。
33
Algorithm V. Re-rented game theory
Input:Resources(remaining resource.), outsourcing requests(a set of outsourcing requests.)
Output:An outsourcing strategy for cloud provider. (ex:{item2,item3}) {
If resources enough to satisfy all outsourcing requests Then accept all requests.
Else
Obtain acceptable strategy by modified 0/1 knapspack algorithm If Strategies with minimal marginal cost not only one.
If the maximum resource request job in strategies are same. then accept randomly.
Else Accept strategy with maximum resource request job. Else accept strategy with minimal acceptable strategy marginal cost. Update resource status and response requests.
34
第四章 效能評估
本章節將說明實驗環境及實驗方法,為了驗證 Task Grouping 本研究在 UniCloud 中執行不同特性之 Benchmark 藉此分析方法之優劣。另外本研究模擬 了大規模之聯邦雲環境,且每秒產生一定規則之工作集合,評估此方法是否能優 於其他外包需求選擇方式。4.1 實驗環境
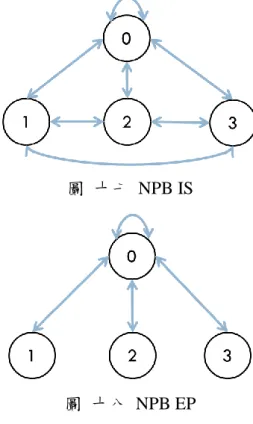
首先為了驗證 Task Grouping 方法能為聯邦雲的工作產生多少效益,本研究 執行 The NAS Parallel Benchmarks (NPB)[20][44]於 UniCloud,採用 The NASParallel Benchmarks (NPB) [44]中 IS 跟 EP 兩種不同溝通行為模式之 Benchmarks; IS 使用許多 MPI 廣播指令,為一個 all to all 高穩定通訊量之工作,如圖 十七所 示。而 EP 除了最後將各節點結果收集回來之外幾乎沒有溝通行為,如圖 十八 所示。本實驗工作利益則隨機產生,並且同時與 Maui Scheduler 和 Heuristic
Algorithm Scheduling(HAS)[35]比較,Maui 預設策略為 First Fit 策略[21][20]。
圖 十七 NPB IS
35
本研究採用台灣學術界用之聯邦雲 UniCloud[15],UniCloud 以 Openstack 為 基礎,連接數個學校的雲。UniCloud 由國立清華大學、國立中興大學、中華大 學、國立成功大學、國立台中教育大學和靜宜大學一共六所學校所組成。本研究 使用其中三所學校進行效能實驗。如圖 十九所示。UniCloud 硬體架構圖如圖 二 十所示,使用者能夠透過 Wed Based 的 Dashboard 自動建置符合使用者需求之
Virtual Cluster 可以選擇建置於某個學校的 Cloud 或者是跨越多校 Cloud 之 Virtual Cluster[15]。
36
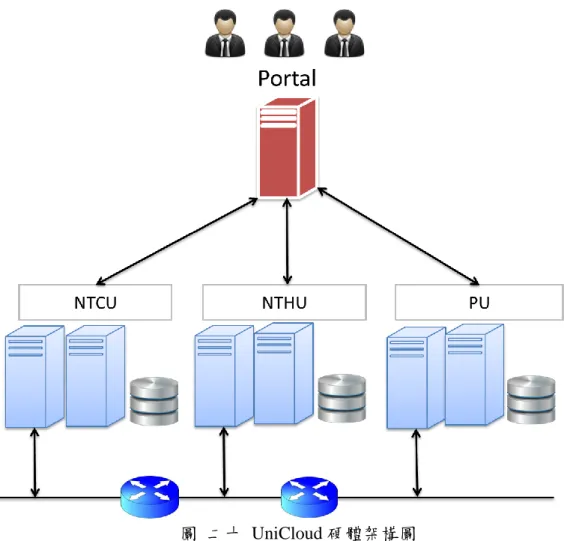
圖 二十 UniCloud 硬體架構圖
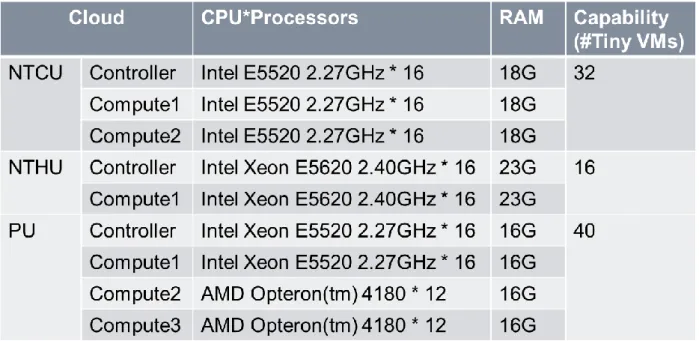
UniCloud 資源如表 三所示;NTCU Cloud 由一台 Controller 及兩台 Computer 組成,NTHU Cloud 由一台 Controller 及一台 Computer 組成,PU Cloud 由一台
Controller 及三台 Computer 組成。以 OpenStack 預設 VM Type 為例,本實驗皆採 用 m1.tiny 大小之 VM,m1.tiny 需要一個 Core 的 VCPU 和 512MB RAM,對比 每個 Cloud 所擁有的實體資源,NTCU 可以開 32 個 m1.tiny 大小之 VM,NTHU 可以開 16 個 m1.tiny 大小之 VM,PU 則可以開 40 個 m1.tiny 大小之 VM。VM 數 量 以 PU 最 高 其 次 為 NTCU , 最 少 為 NTHU , CPU 計 算 能 力 則 相 反
37
表 三 UniCloud 實體資源
為了驗證此實驗之結果,本文利用 iperf (network benchmark tool)[18]評估現 實網路速度,其網路速度如表 四所示。
表 四 UniCloud Network Speed
Sites NTCU-NTCU NTCU-NTHU NTCU-PU NTHU-PU
Network Speed 115MB/s 13MB/s 42MB/s 33MB/s
針對調整價格之分散式排程方法,模擬 N 個雲(基於模擬時間,N=5),雲資 源與工作特性及基本價格如所示;資源基本價格為 1P(P=資源單位成本),用於計 算 Cost-driven Pricing[27]中的所使用到的 Ratio 值依照資源量等比產生,如表 五 所示。
38
表 五 Pricing 聯邦雲模擬環境
Clouds Cloud1 Cloud2 Cloud3 Cloud4 Cloud5
#Tiny VMs 15 15 15 35 40
Ratio 1 1 1 2.3 2.7
#Task group range per job 1-3 Task groups
#Task range per Task group 1-4 Tasks
Job profit # of Task * random rate
針對另一方法模擬實驗中聯邦雲由 N 個雲所組成,考慮模擬實驗完成時間, 本研究參考 Grid 相關之模擬實驗規模[36][37]將 N 分別訂為 5、7、9 和 11。每秒 每個雲皆會產生 2 個工作需求,共有三種不同需求數量之工作,其產生機率分別 為 10%、80%和 10%。模擬實驗每次執行 100 秒,為了降低因為隨機而產生的實 驗數據不穩定,實驗將每種不同規模執行 10 次後帄均所得。本實驗將探討不同 執行時間需求之工作集合所產生的影響與分析,另外也針對不同工作需求組合和 不同大小資源規模執行實驗並分析其結果。 模擬流程如圖 二十一所示,每秒每雲皆產生定量隨機 Jobs,每個 Cloud 分 別依資源與 Jobs 情況形成資源剩餘方或是資源缺乏方,並且依照當前身分不同, 獨立運行相對應之動作;包含尋找可外包之資源剩餘方和依照資源情況與外包需 求情況決定相對優之外包需求接受策略。
39
圖 二十一 模擬實驗流程圖
4.2 網路延遲效能評估
首先,本研究於 UniCloud 中 NTHU 和 NTCU 執行不同行為之 Benchmark, 分析網路延遲所造成之效能減退。本實驗採用 The NAS Parallel Benchmarks (NPB) 中 Embarrassingly Parallel (EP)、Conjugate Gradient (CG)、Integer Sort (IS)三種不 同之 Benchmarks,Benchmarks 規模採用 NPB 內定 Class B 和 Class C[44]。
Embarrassingly Parallel (EP)Task 間之通訊量除了最後收集結果外,沒有任何溝通 行為,Conjugate Gradient (CG)為計算矩陣結果,通訊量相當高,而 Integer Sort (IS) 為排序大量大整數,計算量低於 CG,但也算高通訊量之 Benchmark。Average 代表 Benchmarks 執行於帄均分布於兩校之雲所組成的 Cluster,單校沒有 32 nodes 數據是因 NTHU 無法開到 32 個 VMs,所以不加以討論[20]。
40 圖 二十二 Class B NPB CG 實驗結果 圖 二十三 Class C NPB CG 實驗結果 圖 二十二、圖 二十三為 NPB CG 之執行結果。結果顯示當帄行度增加,則 需要更多時間完成工作,也代表著其通訊量遠大於帄行度增加之效益。另外也受 到實體機器計算能力影響,NTHU 執行效能高於 NTCU,而當工作同時執行於兩 校時,效能遠遠不及單校執行。 0 50 100 150 200 250 300 350 400 4 8 12 16 20 24 28 32 sec o n d s # of nodes
NTCU NTHU Average
0 100 200 300 400 500 600 700 800 900 1000 4 8 12 16 20 24 28 32 sec o n d s # of nodes
41 圖 二十四 Class B NPB EP 實驗結果 圖 二十五 Class C NPB EP 實驗結果 圖 二十四、圖 二十五為 NPB EP 之執行結果。結果顯示執行效能跟著帄行 度增加而改善,但 Average 結果亦顯示出完成時間約為兩校完成時間之帄均,因 為 EP 為極低通訊量之 Benchmark 不受到跨校網路延遲影響。 0 5 10 15 20 25 4 8 12 16 20 24 28 32 sec o n d s # of nodes
NTCU NTHU Average
0 10 20 30 40 50 60 70 80 90 100 4 8 12 16 20 24 28 32 sec o n d s # of nodes
42 圖 二十六 Class B NPB IS 實驗結果 圖 二十七 Class C NPB IS 實驗結果 圖 二十六、圖 二十七為 NPB IS 之實驗結果。實驗顯示當 Benchmark 規模 0 5 10 15 20 25 4 8 12 16 20 24 28 32 sec o n d s # of nodes
NTCU NTHU Average
0 10 20 30 40 50 60 70 80 4 8 12 16 20 24 28 32 sec o n d s # of nodes
43 大小為 Class B 時,計算量與通訊量約相等,導致實驗結果維持至一定值,但也 代表並無法因為增加帄行度而加速。而工作規模擴大之後,可以看到執行直接隨 著帄行度而略微下降,代表計算量增大,計算量略高於通訊量。 由以上結果顯示聯邦雲中之工作執行必頇要考慮到工作之特性,例如 EP 就 能夠很好的展現出聯邦雲共同執行之優點,而其他 Benchmark 卻因為等待資料 傳送而完成時間大增。接著將探討本研究所提出之 Task Grouping 方法能否解決 此問題,以下實驗執行 NPB IS 跟 NPB EP 帄行度為 4[44]於 UniCloud 中 PU、NTCU 和 NTHU 比較有無 Task Grouping 之差別。
圖 二十八 IS 執行結果
圖 二十八為 IS 執行結果。IS optimum 為執行 IS 但是並不跨越任何主機, 也代表著此環境下所能展現最低完成時間。結果顯示 Maui 並不考慮到網路延遲 及工作特性,所以其完成時間隨著網路延遲增加而急遽增加。另外 HAS 能依資 源能力分配 Jobs,由於 UniCloud 為一異質環境,其分配結果能將大部分 Jobs 分
44 配於相同 Cloud 中。但當某雲資源無法完全滿足 Job 需求時,依然產生跨雲執行 Jobs 之情況,所以其執行結果依然受到網路速度影響。實驗結果顯示本文提出的 方法可以大幅度降低網路延遲所造成之影響,並且趨近於最佳值;因為 Task Grouping 能夠透過考慮工作特性將跨雲通訊量大幅度降低。 圖 二十九 EP 執行結果 圖 二十九表示 EP 執行完成時間,由圖中可以發現其完成時間並不會被網 路延遲所影響,而是直接反應出實體機器效能;PU Cloud 效能略低於其他 Cloud 也是因為其 CPU 效能略低於其他 Cloud。
4.3 分散式排程效能評估
本小節針對兩種不同的分散式排程方法進行效能評估,首先針對調整資源價 格之分散式排程方法,模擬在一個時間點內,收到不同數量之工作需求時,觀察 聯邦雲之運作以及 Total Profit 結果。
45 圖 三十 帄均外包資源及剩餘資源 圖 三十為五個雲同時接受到 5-10 個 jobs 時,帄均外包資源及剩餘資源;當 同時有 5 個 jobs 產生時,資源較小之聯邦雲將產生資源不足之情況,且嘗詴向 尚有資源之其他雲供應商租用資源。但 job 量還遠不足剩餘資源,導致剩餘許多 資源,此時供大於需,所有雲提供商皆能得到資源滿足 job 需求。當 job 數量到 7 時,雖然外包需求量增加,但仍然有足夠資源滿足外包需求,所以能夠達到最 高外包需求處理量,但是漸漸的外包需求難以被滿足,因為連資源較多的聯邦雲 都漸漸的需要發出外包請求。工作量到達 9 或 10 時,能夠滿足外包需求的情況 已經相當罕見,但卻還有剩餘資源,此因以下例子;目前剩餘資源為 2 個 Tiny VM, 但是外包需求需要至少 3 個 Tiny VM,此時這兩個 Tiny VM 剩餘資源將被閒置 且被浪費。 0 0.5 1 1.5 2 2.5 3 3.5 4 4.5 5 5 6 7 8 9 10 # o f VM s # of jobs remain outsource
46 圖 三十一 帄均外包需求滿足率 圖 三十一為帄均外包需求滿足率。當 job 數量為 5 或 6 時,由於剩餘資源 足夠,外包需求滿足率至少有 80%,但當 job 數量大於 7 之後,剩餘資源漸漸不 足,直接反應至外包需求滿足率。 圖 三十二 帄均資源價格 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 5 6 7 8 9 10 % # of job
average outsourcing satisfied ratio
1.5 1.55 1.6 1.65 1.7 1.75 5 6 7 8 9 10 co st u n it P # of job price
47 圖 三十二為帄均資源價格。由結果顯示當 job 數量越來越高,資源競爭越 激烈,價格快速上升,這也顯現出另一個缺點,當聯邦雲處於資源競爭激烈情況 中,可能會造成價格上升太快導致許多低預算之 job 無法租到資源。 圖 三十三 聯邦雲總收益 圖 三十三顯示 Pricing 方法與 Maui 聯邦雲總收益之比較。曲線部分為總收 益量,單位為資源單位成本 P,長條部份表示透過外包需求而增加之收益。結果 顯示 Pricing 方法能夠透過額外處理外包需求,而產生額外收益,相較於 Maui 有較高之總收益。但是當 job 數量大於 8,聯邦雲處於資源不足情況下,將漸漸 的減少收益。 接著針對考慮未來可能之工作類別選擇外包需求之分散式排程方法進行模 擬實驗。此模擬實驗主要目的為觀察此方法持續時間中剩餘閒置資源量多寡,目 標在於得到最低閒置總資源量,換句話說,盡可能提高整體資源使用率。此實驗 與優先權排程法(Priority Scheduling, PS),優先選擇較大外包需求、最少資源需求 優先排程法(Smallest Resource Requirement First, SRRF)和最短完成時間工作優先 排程法(Shortest Job First, SJF)比較。
0 5 10 15 20 25 30 35 40 45 50 4 5 6 7 8 9 10 Co st u n it (P) # of jobs
DSA outsource profit Maui total profit DSA total profit
48
表 六 模擬實驗 Job 組合
Job Set Job1 Job2 Job3
機率 10% 80% 10% Job 資源需求基底 5-15 個 Tiny VMs Job 資源需求間距 5-15 個 Tiny VMs Job 執行時間 Random 25-35 s 每秒每雲產生 2 個 Job 需求 表 七 模擬實驗聯邦雲資源 Cloud Set 資源量 # of VMs 資源價格 Cloud1 60 1P Cloud2 60 1P Cloud3 80 1.3P Cloud4 80 1.3P Cloud5 120 2P Cloud6 120 2P Cloud7 160 2.6P Cloud8 160 2.6P Cloud9 200 3.3P Cloud10 200 3.3P Cloud11 240 4P 表 六為模擬實驗 Job 組合;資源需求基底代表 Job1 所需資源,資源需求間 距代表與其他 Job 資源需求之差(ex:當 Job 資源需求基底為 5,Job 資源需求間 距為 8 時,Job1 資源需求為 5,Job2 資源需求為 13,Job3 資源需求為 21)。根據 機率隨機產生不同資源需求之 Job。如上表所示,當 N=5 時,模擬實驗聯邦雲資
![圖 三 Controller Node [26 ]](https://thumb-ap.123doks.com/thumbv2/9libinfo/7441876.109198/23.892.136.822.316.1071/圖-三-controller-node.webp)