Improved syllable-based continuous
Mandarin speech recognition using
intersyllable boundary models
Saga Chang and Sin-Horng Chen
~~
acc 87.1 “Yo
Indexing term: Speech recognition
A novel approach to compensate for the intersyllable coarticulation effect on continuous Mandarin speech recognition by supplementing the syllable HMM models with intersyllable boundary models is proposed. Experimental results show that the syllable recognition errors of a speaker-dependent recognition task are reduced by 24%.
Introduction: One of the most important problems in continuous speech recognition is how to accurately model the acoustic varia- bilities caused by coarticulation to obtain high recognition accu- racy. For English speech recognition, it has been found that using context-dependent phone models is an effective way to solve the problem [I], For Mandarin speech recognition, a simpler approach can be adopted to take advantage of the simple phonetic structure of Mandarin syllables. Because there are only 41 1 phonetically dis- tinguishable base syllables, it is wise to adopt the context-inde- pendent (CI) syllable-based speech recognition approach so that only intersyllable coarticulation is needed to be additionally con- sidered. We therefore propose in this Letter a novel approach for improving the CI syllable-based continuous Mandarin speech rec- ognition method by incorporating some intersyllable boundary models to compensate for the intersyllable coarticulation effect.
Intersyllable boundary models: For each pair of consecutive sylla- bles, a fixed-length feature vector sequence located symmetrically across the intersyllable boundary is extracted for constructing the corresponding intersyllable boundary model. Since the acoustic characteristics in the transition region between two syllables are, in general, not stationary, a segment-based statistical model 12, 31 is adopted to deal with the nonstationarity of the feature vector sequence. Specifically, instead of modelling the feature vector of each frame independently as a Gaussian distribution, we represent, in an intersyllable boundary model, the feature vector sequence of the whole segment by a reference template with the residual vec- tors treated as independently and identically distributed white Gaussian noise with zero mean vector and diagonal covariance matrix
R.
In this model, feature vectors are regarded as a nonsta- tionary Gaussian vector process with the mean vector sequence equal to a reference template and the common diagonal covari- ance matrixR
estimated from residual vectors.Two methods for generating reference templates of intersyllable boundary models are proposed. One is to employ matrix quantisa- tion to find some representative reference templates for each sylla- ble pair by taking each feature vector sequence as a matrix. The other uses contour quantisation [4] to first take the time sequence of each component of the feature vector sequence as a contour and represent it by the first few lower-order coefficients of all orthonormal polynomial expansion, and then collect coeficents of all components to form a new feature vector and apply vector quantisation to find some codewords. Reference templates for each syllable pair are generated from these codewords by orthon- ormal polynomial expansions. Here, the first three discrete Legen- dre polynomials were chosen as the basic functions [2] of the orthonormal polynomial expansion. These basis functions are nor- malised in length to [0,1] and expressed as
corr sub del ins
/o % /a %
80.6 18.9 0.5 2.5
% ( ; ) = I
7 + 1
7 - 1
ELECTRONICS LEnERS 25th
May
1995
Vol. 31
for t = 1, 2 , _._ ‘c, where z is the length of the feature vector sequence.
If we construct one model for each syllable pair, there will be 411 x 411 intersyllable boundary models. However, as the training data are usually very limited in practical applications, the number of intersyllable boundary models should somehow be greatly reduced. Here we solve the problem by simply assuming that the acoustic variability of an intersyllable boundary segment results solely from the two phones located nearest to the boundary. According to the phonetic structure of Mandarin syllables, there are in total 11 types of ending phones and 27 types of starting phones. Hence, only 297 intersyllable boundary models are needed. Furthermore, silence must be considered separately. By treating silence as an ending phone for the following syllable and a starting phone for the preceding syllable, we construct 38 addi- tional models.
syllable 1 syllable 2 syllable 3 sy I lable
sequence
I state syllable intersyllable HMM model boundaymodel
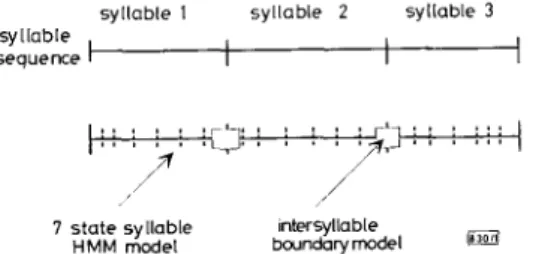
Fig. 1 Schematic diagram for representing speech signal by sequence of syllable H M M models overlaid with sequence of intersyllable boundary models
Proposed speech recognition approach: By supplementing these 335 intersyllable boundary models to a set of 411 CI syllable HMM models, we can represent a speech signal by a sequence of syllable HMM models overlaid with a sequence of intersyllable boundary models. Fig. 1 shows a schematic diagram of the representation. Using this representation of the speech signal, the task of continu- ous Mandarin speech recognition is then to find the best syllable string for a testing utterance based on the given sets of CI syllable HMM models and intersyllable boundary models.
In the training phase, a set of 411 initial CI syllable HMM models is fust generated by the segmental k-means training algo- rithm. We then use the results of syllable segmentations of all training utterances to extract intersyllable boundary segments for training a set of 335 initial intersyllable boundary models. An iter- ative training procedure is then applied to alternatively segmenting all training utterances into syllable sequences by using a modified Viterbi algorithm and updating both sets of CI syllable HMM models and intersyllable boundary models. The only modification of the Viterbi algorithm is to add an additional score at the instant of the decision to make a syllable transition. This is the score of matching the input vector sequence across the boundary with an intersyllable boundary model of the syllable pair involving the syl- lable transition. A normalisation of the local score is then applied in order not to favour the path with syllable transitions. Repeat- edly applying the procedure of segmentation and model updating, we can obtain two well-trained sets of 411 CI syllable HMM mod- els and 335 intersyllable boundary models.
In the testing phase, a one-stage search algorithm is applied to find the best sequences of CI syllable HMM models and the over- laid intersyllable boundary models for the input utterance. As with the training algorithm, the one-stage search algorithm is also mod- ified by considering the effect of the additional intersyllable boundary models. The syllable sequence associated with the best sequence of CI syllable HMM models is taken as the recognition output.
Table 1: Recognition result using CI syllable HMM models
Experiments: The effectiveness of the proposed method was tested with simulations using a continuous Mandarin speech database uttered by a single male speaker. The database contains 35231 syl-
lables in total including 28197 training syllables and 7034 testing syllables. All speech signals were sampled at a rate of l0kHz and pre-emphasised with digital filter with function 1 - 0.952-I. The signals were then analysed for each Hamming-windowed frame of 20ms with 10 msframe shift. The recognition features consist of 12 me1 cepstrnms, 12delta cepstrums, and the delta energy. First, the conventional HMM method based on 411 7state CI syllable HMM models and a 1 state silence model was tested. The number of Gaussian mixtures in each state of a syllable HMM model var- ies from one to five depending on the number of training data. Table 1 shows the recognition results. A syllable accuracy rate of 77.1 YO was achieved. Then, the proposed recognition method was tested.
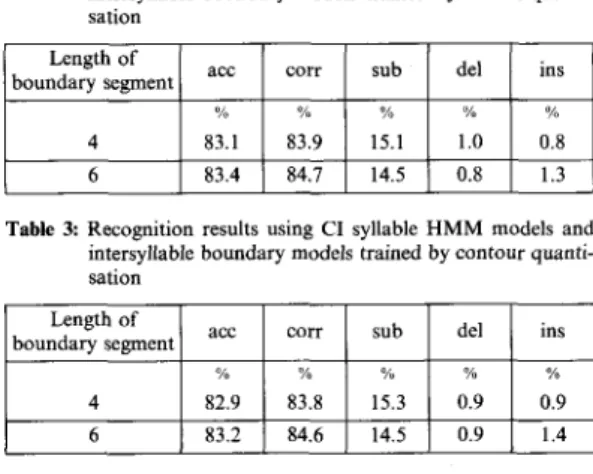
Table 2: Recognition results using CI syllable HMM models and intersyllable boundary models trained by matrix quanti- sation
Length of
boundary segment acc corr sub
% % % del ins /o % 4 6 83.1 83.9 15.1 1.0 0.8 83.4 84.7 14.5 0.8 1.3 Length of
boundary segment acc corr sub del
% /o 0% h
0 IEE 1995
Electronics Letters Online No: I9950629
4 April I995
ins %
Saga Chang and Sin-Horng Chen (Department of Communication Engineering and Center for Telecommunications Research, National Chiao Tung University, Hsinchu, Taiwan. Republic of China)
4
References
1 LEE, C H , RABINER, L R , PIERACCINI, R , and WILPON, I G : ‘Acoustic
modeling for large vocabulary speech recognition’, Comput. Speech Lung., 1990, 4, pp. 127-165
82.9 83.8 15.3 0.9 0.9
2 CHANG, s., and CHEN, S.H.: ‘A modified hidden semi-Markov model
for multi-speaker Mandarin syllable recognition’, J. Chin. Inst. Electrical Engineering, 1994, 1, (2), pp, 95-104
3 DENG, L.: ‘A generalized hidden Markov model with state-
conditioned trend functions of time for the speech signal’, Signal Process., 1992, 21, pp. 65-78
4 CHANG, s., CHEN, s.H., CHUNG, C.J., and HONG, v.: ‘A low data rate
LPC Vocoder using contour quantization’. Proc. EUSIPCO-92: Sixth European Signal Processing Conf., 1992, pp. 459462
6 83.2
Improving the input-queueing switch under
bursty traffic
Jiunn-Jian Li
84.6 14.5 0.9 1.4
Indexing ferns: Queueing theory, Switching theory
A new window scheme for improving the performance of nonblocking switches with input queueing under bursty traffic is proposed. The maximum throughput for the proposed scheme is measured and the scheme is shown to alleviate the effect of burst traffic on input queueing.
Introduction: The maximum throughput of a nonblocking switch with FIFO buffers on the input ports is limited by the head of line (HOL) blocking and approaches -0.60 for large switch size N with random traffic. The window policy [l] can be used to reduce the HOL blocking by allowing the non-HOL cells to contend for the outputs, In the beginning of a time slot, the input port not selected to transmit its HOL cell has its second cell contending for the remaining idle outputs. The contending process repeats up to w times until a cell wins the contention, where w is referred to as the window size. In the window policy, each input buffer must be a first-in random-out (FIRO) queue.
A window size w = 1 corresponds to input queueing with FIFO buffers. As w increases, the throughput performance improves on a random traffic assumption. Note that the improvement dimin- ishes quickly under bursty traffic. This is because the bursty traffic conditions make it likely that the first w cells in each input queue have the same destination.
In this Letter, an approach to alleviate the influence of bursty traffic on the window policy is proposed. Each input port employs an FIRO queue and b registers, called burst head pointers (BHPs). If there are k bursts in an input queue, BHP i (1 5 i L k ) points to the leading cell of the ith burst and the remaining (b -
k)
BHPs remain idle. The cell pointed to by the ith BHP is labelled [BHPJ. Fig. 1 illustrates the proposed scheme, where b = 3 and BHPs point to the leading cells of the first three bursts (whose destina- tions are y , z and x, respectively).F I R 0
Operation: The proposed scheme is very similar in operation to the window policy [l]. At the beginning of each time slot, if the cell [BHPJ, 1 5 i 5 b , is blocked, a chance is given to the cell [BHP,,,], until either a cell is selected or the cell [BHPJ is reached, which- ever comes first. Thus, the b cells pointed to by the BHPs form a ‘window’ in an input queue.
Maintaining the BHPs is easy. The contents of BHPs do not change except in the cases described below. Suppose there are k bursts in the target input queue.