A Fast Search Algorithm for Vector Quantization Using
Means and Variances of Codewords
Chang-Hsing Lee and Ling—Hwei Chen
Department of Computer and Information Science, National Chiao Tung University, Hsinchu, Taiwan 30050, R. 0. C.
ABSTRACT
Vector Quantization has been applied to low-bit-rate speech and image compression. One of
the most serious problems for vector quantization is the high computational complexity of
searching for the closest codeword in the codebook design and encoding processes. To overcome
this problem, a fast algorithm, under the assumption that the distortion is measured by the squared Euclidean distance, will be proposed to search for the closest codeword to an input
vector. Using the means and variances of codewords, the algorithm can reject many codewords that are impossible to be candidates for the closest codeword to the input vector and hence save a great deal of computation time. Experimental results confirm the effectiveness of the proposed method.
1. INTRODUCTION
Vector quantization (VQ) is a very efficient approach to low-bit-rate image compression12. In
VQ, the images to be encoded are first decomposed into vectors (i.e., blocks) and then
sequentially encoded vector by vector. Each vector is compared with the codewords in thecodebook to find the best matching codeword. The key aspect of VQ is to design a good
codebook, Y={y1
i=l
,2, .. . , N},whichcontains the most representative codewords and will be used by the encoder and the decoder. In the encoding process, the encoder designs a mapping Q and assigns an index I to each k-dimensional input vector x=(xj,x2, . . ., xk), with Q(x)=y=(y1j,Yi2' .. . Yk).In this paper, we will only consider the mapping Q, which is designed to map x to y with y satisfying the following condition:
d2 (x,
y)
=
mm d2 (x,Yj) for j =I
,2,.. ., N, (1)where d2 (x, Yj) is the distortion of representing the input vector x by the codeword Yj and is
measured by the squared Euclidean distance, i.e.,
k
d2 (x,Yj)=
(x
-y1)2 (2)The decoder has the same codebook as the encoder. In the decoding process, for each index i, the
decoder merely performs a simple table look-up operation to obtain y and then uses y to
reconstruct the input vector x. Compression is achieved by transmitting or storing the index of a codeword rather than the codeword itself.
From the above description, we see that the compression ratio of VQ is determined by the codebook size and the dimension of the input vectors, and the distortion is dependent on the
codebook size and the selection ofcodewords. Hence, a good codebook design is the main task of
VQ. Many algorithms for optimal codebook design have been proposed37. Among these, the
most popular was developed by Linde, Buzo and Gray3 and is referred to as the LBG algorithm. This algorithm is basically an iterative process to minimize the overall distortion of representing the training vectors by their corresponding codewords. Since a full codebook search is needed to find the closest codeword for each training vector, the algorithm is time consuming. To reduce
the computation time needed for such an exhaustive search through the codebook, many fast
algorithms have been proposed822. Some of them achieve the goal of decreasing the search time
at the expense of the coding quality. Some can reduce the search time without producing any extra error, but are still not fast enough. In the following section, we will introduce such an
algorithm.
2. PREVIOUS WORKS
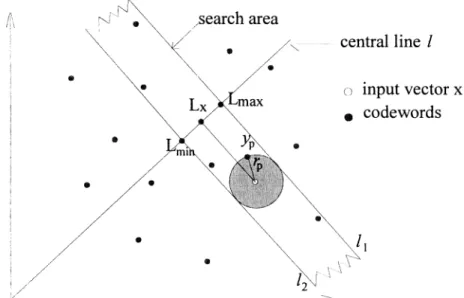
Guan et 21 proposed an equal-average nearest neighbor search (ENNS) algorithm which
uses hyperplanes orthogonal to the central line 1 to partition the search space. Each coordinate
value of any point p=(pj, P2 .. ., Pk) on 1 has the same value, i.e., p1 =
Pj
4 1= 1,2, .. ., k. Eachpoint on a fixed hyperplane H, which is orthogonal to the central line 1 and intersects 1 at point
LH=(rnH, mH, .. . , mH),will have the same mean value mH, such a hyperplane is called an
equal-average hyperplane. For an input vector x=(xj, x2, .. ., xk), the algorithm first calculates its mean
value m with
m=— xj.
I'j=1
It
then finds the codeword Yp which has the minimum mean difference from x and calculates thedistance r
betweenx and yr,. It is obvious that any other codeword which is closer to x than Yphas to be located inside the hypersphere centered at x with radius r.
By projecting the hypersphere on 1, two boundary projection points, Lmax=(mmax, mmax, .. ., mmax) andLmin(mmin, ...,mmjn)on 1 can be found, where
mmax =
m
+ (3)and
mmjn=mx-.
(4)The hypersphere is bounded by two equal-average hyperplanes with mean values mmax and mmjn.
Hence, the algorithm only searches those codewords with mean values ranging from mmjn to
mmax. Fig. 1 shows the geometric interpretation of the method for a 2-dimensional case, the
search area is bounded by two lines l and 12, which are perpendicular to the central line 1 at Lmax
and Lmjn, respectively.
central line 1
C) inputvector x
,
codewordsFig. 1 An example of the ENNS algorithm fora 2-dimensional case.
As described above, the ENNS algorithm uses mean value as a feature to reject unlikely
codewords and thus saves much of computation time. However, two vectors with similar mean
values may have a large distance. For example, one vector represents an almost homogeneous
block, i.e., entities in the vector are almost the same; the other represents an edge block, i.e., some entities will be larger than others. The distance between these two types of vectors will be large. To treat this phenomenon, we have proposed a new search method22, called the mean-or-variance (MOV) method, to reduce the search area of the ENNS algorithm. Since the variance of a vector is a simple measure to detect whether a vector is homogeneous, this method uses both the mean value and the variance of a vector as two significant features to reject many unlikely codewords. Define the mean value and variance of a k-dimensional vector x as
and 1
m =
xj,
kj=l
2 kvx=
(xj-m)2.
j=1We have proved22 that for a codeword y, the distortion between x and y, d2 (x,
y),
will satisfy and d2 (x,y)
k(m
-d2(x, y) (V -
V1)2. (5) (6) SPIE Vol. 2501 /621 area '1Therefore, if is a known current minimum distortion of x represented by a certain codeword.
For any codeword y, if k(m -
m)2
dmin or (V -
V)2
dmin,theny will not be the closestcodeword to x and it is unnecessary to calculate d2 (x, y). The MOV method was developed
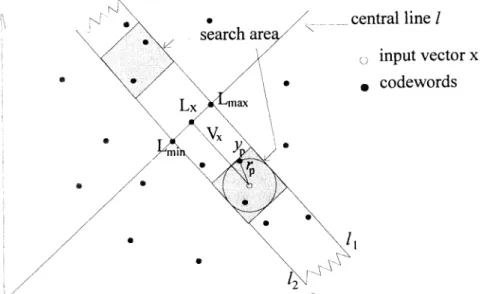
according to the above idea. Fig. 2 depicts the geometric interpretation of the MOV method for a
2-dimensional case. Comparing Fig. 1 and Fig. 2, we can see that the search area, which is originally an area bounded by two lines l and 12 perpendicular to the central line 1, has been
reduced to be the two shaded squares. In the next section, we will describe the proposed
algorithm, which is faster than the MOV method.
\-
—---- centralline 1 C inputvector x,
codewordsFig. 2 An example to illustratethe mean-or-variancemethod for a 2-dimensional case. 3. THE MEAN-AND-VARIANCE METHOD
In this section, we will propose another inequality, which can reject more codewords than the MOV method, to speed up the closest codeword search process. This method, called the mean-and-variance (MAV) method, also uses the mean value and variance of a vector as two significant features. In the MOV method, if dmin is a known current minimum distortion of x represented by
a certain codeword. For any codeword y, if k(m -
m)2
dmin or (V -
V)2
dmin, theny
will not be the closest codeword to x and it is unnecessary to calculate d2 (x, ye). However, we have proved that the following inequality is true:
d2 (x, y) (V -
V)2
+k(m
-
m)2.
(7)(The proof of Inequality (7) is given in Appendix A.) Therefore, those
codewords with (V
-V)2
+k(m
- m1)2 larger than the known current minimum distortion dmin will be rejected.Comparing Inequalities (5), (6) and (7), we can see that the new proposedmethod can reject more
622/SP!EV0!.2501
e
S
5
codewords and thus without evaluating d2 (x, ye),this makes the algorithm to be more efficient.
Fig. 3 depicts the geometric interpretation of the MAV method for a 2-dimensional case.
Comparing Fig. 2 and Fig. 3, we can see that the search area, which is originally the two shaded squares, has been reduced to be the two shaded circles.
- -- centralline 1
N
0 inputvector x S codewords
11
Fig. 3 An example to illustrate the mean-and-variancemethod for a 2-dimensional case. A detailed description of how to apply the proposed algorithm to design a codebook is given
below.
Step 0 Initialization: Given N =codebooksize, n =thenumber of training vectors, k =thevector dimension, Y0 initial codebook, c =distortion threshold. Set iteration counter c 0,
initial total distortion D1 = x.
Step 1 Compute the mean value of each codeword in the codebook Y, and sort Y according to
increasing order of the codeword means, i.e., the sorted codebook Y is
m,1 m(+l), 1 i N-i },
wherem1 is the mean value of the codeword y.Step 2 Compute the squared root of the variance, of each codeword y.
Step 3 For each training vector Xt,findthe closest codeword Yi(t) in the codebook Y. and assign
x
toclass i(t). The procedure includes the following sub-steps:Step 3.1 Input a training vector Xt=(Xtj,Xt2, ..., Xtk), compute its mean value and its
square root of variance
Step 3.2 Find the codeword y, which has the minimum mean difference from x(using
binary search), i.e.,
-
mI
m, -
for all i p.+ •r+_ i2. — j21
L)eLlL) — (4mm — Cl Xt,
Step
3.3 Find the closest codeword Yi(i) in Y and assign x
to class 1(t). The searchprocedure is as follows: Set d = 1;
while((p+d N and k(mt - m(+d))2< diin) or•
(p-d 1 and k(mt - mY(Pd)) < dmin))begin
if(p+d N and k(mt - m(+d))2< )begin
if(k(mt -mY(P+d))2+
(Vt
-Vy(p+d))2< )begin if( d2 (Xt,Yp+d)< )begin
,2 2 amin d (xt,yp+d); 1(t) =p+d; end; end; end;
if(p-d 1 and k(mt -
m(d))2
<)
beginif(k(rnt -mY(Pd))2+
(V
-Vy(pd))2<
)
beginif( d2 (Xt,Yp-d)< )begin
dmjn =
d
(Xt, Yp-d) 1(t) = p-d; end; end; end; end; {ofwhile}Step 4 Compute the overall distortion for the c-th iteration, D. Here D is defined to be
D =
d2(Xt,Yi(t))•Step 5 If (D -
D)/D
C
, haltwith final codebook being Y. Otherwise, go to Step 6.Step 6 Compute the centroid of each class. The centroids are regarded as the codewords of
a new codebook. Set c =c+1 and go to Step 1 for next iteration.
The encoder has to find the closest codeword in a predesigned codebook for each input vector and then uses the codeword as the reproduction one of the corresponding input vector. Therefore,
it can use the MAV to find the closest codeword to each input vector. The details of this
procedure are similar to those in Step 3 of the codebook design algorithm described above.
4. EXPERIMENTAL RESULTS
To examine the efficiency of the proposed algorithm, we performed some experiments on a Sun SPARC-station-IPC using several 512x512 monochrome images with 256 gray levels. Each image is divided into 4x4 blocks, so that the training sequence contains 16384 16-dimensional
vectors. The proposed algorithm was compared with the LBG algorithm and the MOV
algorithm22 in terms of the execution time required in codebook design and image encoding. Table 1 shows the execution time required to design a codebook using the well-known image
Lena. Table 2 shows the time needed to encode an image given the previously designed
codebook. The codebook was used to encode the four images (Lena, Peppers, Jet, and Baboon).
From these two tables, we see the effectiveness of the proposed algorithm in both codebook
design and image encoding.
Table 1
Comparison of execution time (in seconds) for codebook design. Values in parentheses denote the ratio of execution time of the current algorithm to that of the LBG algorithm.
Codebook size LBG MOV MAV
128 2815 266(0.094) 236(0.084)
256 5608 383(0.068) 337(0.060)
512 11263 576(0.051) 506(0.045)
1024 22732 925(0.041) 820(0.036)
Table 2
Comparison of execution time (in seconds) forimage encoding. Codebook
size
Method Encoded image
Lena Peppers Jet Baboon
128 Fullsearch 140.9 140.1 125.1 137.5 MOV 11.5(0.082) 11.9(0.085) 11.4(0.091) 32.2(0.233) MAV 10.9(0.077) 11.0(0.079) 10.5(0.084) 24.8(0.180) 256 Full search 278.6 279.5 249.7 275.0 MOV 1 7.2(0.062) 1 8.8(0.067) 1 7.4(0.070) 54.1(0.197) MAV 1 5.6(0.056) 1 6.4(0.059) 1 5.0(0.060) 43.0(0.156) 512 Fullsearch 557.6 558.1 499.3 547.8 MOV 26.7(0.048) 30.2(0.054) 26.7(0.053) 96.2(0.176) MAV 23 .6(0.042) 26.2(0.047) 23 .2(0.046) 76.3(0.139) 1 024 Fullsearch 1108.5 1108.5 992.7 1087.9 MOV 40.7(0.03 7) 5 1 .1(0.046) 43 .6(0.044) 174.6(0.160) MAV 37.3(0.034) 44.6(0.040) 38.5(0.039) 139.3(0.128) 5. CONCLUSIONS
In this paper. we have proposed a fast closest codeword search algorithm, called the MAV
algorithm, for vector quantization. This algorithm uses two significant features of a vector, mean value and variance, to reject a lot of codewords which are definitely not candidates for the closest codeword to the input vector. It can speed up the search process in conventional VQ codebook
design and encoding. The performance of the proposed algorithm has been evaluated in both codebook design and image encoding. The results obtained show that the proposed algorithm
outperforms the ENNS and the MOV algorithms and reduces a great deal of computation time required by the LBG algorithm. Furthermore, it is worth mentioning that the proposed algorithm does not introduce any extra error than the LBG algorithm.
6. ACKNOWLEDGMENT
This research was supported in part by the National Science Council of R. 0. C. under contract
NSC-83-0404-E009-1 17.
7. REFERENCES
[1] R. M. Gray, 'Vector quantization," IEEEASSP Magazine, vol. 1, pp. 4-29, Apr. 1984.
[2] N. M. Nasrabadi and R. A. King, 'Image coding using vector quantization: A review,'
IEEE Trans. Commun., vol. COM-36, no. 8, pp. 957-971, Aug. 1988.
[3] Y. Linde, A. Buzo, and R. M. Gray "An algorithm for vector quantizer design," IEEE
Trans. Commun., vol. COM-28, no. 1, pp. 84-95, Jan. 1980.
[4] W. H. Equitz, "A new vector quantization clustering algorithm," IEEE Trans. Acoust.,
Speech, andSignal Processing, vol. 37, no. 10, pp. 1568-1575, Oct. 1989.
[5] B. Marangelli, "A vector quantizer with minimum visible distortion," IEEE Trans. Signal Processing,vol. 39, no. 12, pp. 2718-2721, Dec. 1991.
[6] K. Zeger, J. Vaisey, and A. Gersho, "Globally optimal vector quantizer design by stochastic
relaxation,"IEEE Trans. SignalProcessing, vol.40, no. 2,pp.310-322, Feb. 1992.
[7] K. Rose, E. Gurewitz, and G. C. Fox, "Vector quantization by deterministic annealing,"
IEEE Trans. Inform. Theory, vol. IT-38, no. 4, pp. 1249-1257, Jul. 1992.
[8] C. D. Bei and R. M. Gray "An improvement of the minimum distortion encoding algorithm for vector quantization," IEEE Trans. Commun., vol. COM-33, no. 10, pp. 1 132-1133, Oct.
1985.
[9] K. K. Paliwal and V. Ramasubramanian, "Effect of ordering the codebook on the efficiency
of the partial distance search algorithm for vector quantization," IEEE Trans. Commun. ,vol.
COM-37, no. 5, pp. 538-540,May. 1989.
[10] C. H. Hsieh, P. C. Lu, and J. C. Chang "Fast codebook generation algorithm for vector
quantization of images," Pattern Recognition Letters, vol. 12, pp. 605-609, 1991.
[11] D. Y. Cheng, A. Gersho, B. Ramamurthi, and Y. Shoham, "Fast search algorithms for
vector quantization and pattern matching," in Proc. IEEE ICASSP, 1984, pp. 9.11.1-9.11.4. [12] D. Y. Cheng and A. Gersho "A fast codebook search algorithm for nearest-neighbor pattern
matching," in Proc.IEEE IGASSP, 1986, pp. 265-268.
[3] A. Lowry, S. Hossain, and W. Millar, "Binary search trees for vector quantization," in Proc. IEEEICASSP, 1987, pp. 2205-2208.
[14] V. Rarnasubramanian and K. K. Paliwal, "An optimized k-d tree algorithm for fast vector
quantizationof speech," in Proc. European Signal Processing Conf, 1988, pp. 875-878.
[ 15] V. Ramasubramanian and K. K. Paliwal, "Fast k-dimensional tree algorithms for nearest
neighbor search with application to vector quantization encoding," IEEE Trans. Signal
Processing, vol. 40, no.3, pp. 5 1 8-53 1 , Mar. 1992.
[16] M. R. Soleymani and S. D. Morgera, "A high-speed search algorithm for vector
quantization," in Proc. IEEE ICASSP, 1987, pp. 45.6. 1-3.
[1 7] V. Ramasubramanian and K. K. Paliwal, "An efficient approximation-elimination algorithm
for fast nearest-neighbor search based on a spherical distance coordinate formulation,"
Pattern Recognition Letters, vol. 13, pp. 471-480, 1992.
[1 8] E. Vidal, "An algorithm for finding nearest neighbors in (approximately) constant average time complexity," Pattern Recognition Letters, vol. 4, pp. 145-1 57, 1986.
[19] M. T. Orchard, "A fast nearest-neighbor search algorithm," in Proc. IEEE ICASSP, 1991, pp. 2297-2300.
[20] C. M. Huang, Q. Bi, G. S. Stiles, and R. W. Harris, "Fast full search equivalent encoding
algorithms for image compression using vector quantization," IEEE. Trans. Image
Processing, vol.1, no. 3, pp. 413-416, Jul. 1992.
[2 1] L. Guan and M. Kamel, "Equal-average hyperplane partitioning method for vector
quantization of image data," Pattern Recognition Letters, vol. 13, pp. 693-699, 1992.
[22] C. H. Lee and L. H. Chen, "Fast closest codeword search algorithm for vector quantization," lEE Proc.- Vision,
Image and Signal Processing, vol. 141, no. 3,June 1994, pp. 143-148.
APPENDIX A
Proof of Inequality (7): To prove Inequality (7), we have to prove the following inequality first:
k
V
(x -
-m1). (A. 1)j=1
Fromthe well-known Cauchy-Schwarz Inequality, we can easily get
k k k
(V V1)2 =
(xj-rn)2x -m1)2[
(xj-mx)(yy-m1)]2.j=1 j=1 j=1
Fromthe above inequality, we can derive Inequality (A. 1).
k k Since (xj- = (xj-
m
+m
-m1+ -j=1 j=1 k k k = (x1-m,32+(m
-m)2
+ (m,j-y)2
+
j=1 j=1 j=1 k k 2 > (x1-m)(m
-m)
+2(m -
m)(m1
-y)
+
j=1 j=1 SPIE Vol. 2501 1627k
2 (m -
y)(x1-m)
j=1 k=
(V)2
+ k(rn -
m)2
+ (V)2 + 2(m -
m)
(x -
m)
+ j=1 k k2(m -
m)
(m -
yj)
-2 (x3 -m)(y - m)
j=1 j=1 k=
(V)2
+ (V)2 + k(m -
m)2
-2
(x1-m)(y -
(A.2) j=1Andsince (V -V1)2
+ k(m -
m)2
=
(V)2
+ (V)2 + k(m -
m)2
-2V
(A.3)Comparing Eqs. (A.2) and (A.3) and from Inequality (A.l),we can prove Inequality (7).