國立臺灣大學電機資訊學院資訊工程學系 碩士論文
Department of Computer Science and Information Engineering College of Electrical Engineering and Computer Science
National Taiwan University Master Thesis
在有限記憶體下學習的區塊最小化框架
Block Minimization Framework for Learning with Limited Memory
林善偉 Shan-Wei Lin
指導教授:林守德博士 Advisor: Shou-De Lin, Ph.D.
中華民國 105 年 07 月 July, 2016
摘要
我們考慮在有限記憶體中的最小經驗風險 (Empirical Risk Minimiza- tion) 問題。我們提出一個區塊最小化框架來解決有限記憶體中的四種 情況。第一種情況是資料 (data) 比模型 (model) 大而且對偶函式不是平 滑的。這個情況在現在的大資料的趨勢當中很容易遇到,當問題的正 則項 (regularizer) 是二範數 (norm) 的平方時,就會是這種情況,像是 二範數支持向量機 (support vector machine)、二範數邏輯回歸 (logistic regression) 以及二範數線性回歸。第二種情況是資料比模型大但是在 對偶函式中存在一項是無法被區塊分割且不平滑的,這種情形發生在 範數不是二範數的平方時,這種問題包括一範數線性回歸問題、矩陣 填補中的核範數 (nuclear norm) 以及群範數 (group norm) 家族。第三種 情況是模型比資料大,而且問題函式在不可切成區塊的部分是平滑的,
這種情況會出現在極端分類問題 (extreme classification) 裡,因為這種 問題有非常多類 (class) 以及非常高維度的特徵 (feature) 向量,稀疏編 碼 (sparse coding) 也會出現特徵值比資料多的情況,也就是模型比資料 大。第四種情況是模型比資料大,但是問題函式中有不可區塊分割的 部分同時也不平滑,支持向量機的合頁損失 (hinge loss) 函式就會造成 這種情況。在這篇論文裡,我們假設資料或是模型其中之一因為太大 而不能全部放進記憶體當中,而另外一個可以放進記憶體中。當資料 比較大的時候,我們用對偶區塊最小化方法來解,當模型比較大的時 候,我們則用原始 (primal) 區域最小化。在原始區域最小化當中,我
們把模型分割成很多個區塊,把這些區塊存在硬碟中,每次讀取一個 區塊來解,並且只更新這個區塊的參數。而在對偶最小化問題時,我 們把資料切成很多塊,把這些區塊存在硬碟,一次讀取一個區塊的資 料來做最小化。當有無法被區域分開而且不平滑的項存在時,我們使 用拉格朗日增強法使得那一項變成平滑項,來保證最後會收斂到全局 最佳解 (global optimum)。當在做原始區塊最小化時,我們在對偶問題 加上一個強凸 (strongly convex) 項,使得原始問題變的平滑; 而在做對 偶區塊最小化時,我們在原始問題加上一項強凸項,使得對偶問題變 平滑。而這多加的一項在演算法接近最佳解的時候會消失,所以我們 的方法會收斂到和那些在足夠記憶體下的方法一樣的解。我們的這個 框架是靈活的,因為給定一個在足夠記憶體下的解決方法,我們可以 只在解決方法上加上一項,就能很容易的把這個解決方法用在有限記 憶體之下。
Abstract
We consider the regularized Empirical Risk Minimization (ERM) in the limited memory environment. We provide a block minimization framework to deal with four situations when training with limited memory. First, when data is larger than the model and the terms in dual objective function are ei- ther smooth or block separable. This situation happens frequently in the re- cently big data trend with L2-regularizer, including L2 Support Vector Ma- chine (SVM), L2 Logistic Regression, and L2 Linear Regression. Second, when data is larger than the model and the non-separable part of dual ob- jective function is non-smooth. It could happen when the regularizer is not L2 norm, including L1-regularizer in Lasso problem, nuclear norm in ma- trix completion problem, and a family of structure group norms. Third, when model is larger than the data and the terms in primal objective function are either smooth or block separable. This situation appears sometime in the ex- treme classification problem, which will have large model due to large number of classes and large number of features. Sparse coding is another area that the number of features is larger than the number of samples. Fourth, when model is larger than the data and the non-separable part of primal objective function is non-smooth. Multi-class SVM is an example of this situation, Hinge Loss causes the non-smoothness of the primal objective function. In this paper, we assume that either model or data is too large to fit into memory, and that the
other one can fit into memory. We use dual block minimization to solve the problem when the data size is larger than the memory size, using primal block minimization to solve it when the model size is larger than the memory. To be specific, in the primal block minimization framework, we split the model into several blocks, store the model in the disk, sequentially load part of the model into memory and update this part only, write this part back to the disk, and read the next part. In the dual block minimization framework, we split data in to blocks and store it in the disk, sequentially load part of the data into memory, update the parameters base on this partial data, than load the next block of data. Also, we apply Augmented Lagrangian technique to force the smoothness of the corresponding objective function when it is non-smooth and non-block-separable to achieve global convergence for the general con- vex ERM problem. In particular, in the primal block minimization case, we add a strongly convex term to the dual objective in order to force the primal objective function to be smooth. In the dual block minimization case, we add a strongly convex term to the primal problem. This additional term will disappear when the model converge to near the optimal point. Therefore, this algorithm will converge to the same point achieved by the algorithm with suf- ficient memory. This framework is flexible in the sense that, given a solver working under sufficient memory, one can integrate it into our framework with additional term in the update rule if necessary and obtain a solver glob- ally convergent under limited memory condition.
Keywords: Machine Learning, Limited Memory, Augmented Lagrangian, Empirical Risk Minimization.
Contents
摘要 iii
Abstract v
1 Introduction 1
2 Problem Setup 5
3 Primal and Dual Block Minimization 9
3.1 Data Size is Larger than The Memory Size . . . 9
3.2 Model Size is Larger than The Memory Size . . . 12
3.2.1 Solve Block SubProblem in Primal . . . 14
4 Augmented Block Minimization 15 4.1 Algorithm . . . 16
4.1.1 Dual Augmented Block Minimization . . . 17
4.1.2 Primal Augmented Block Minimization . . . 18
4.2 Analysis . . . 22
4.3 Practical Issue . . . 26
4.3.1 Solving Sub-Problem Inexactly . . . 26
4.3.2 Random Selection w/o Replacement . . . 27
4.3.3 Storage of Dual Variables . . . 27
5 Experiment 29
5.1 When Data is Larger than Memory . . . 29 5.2 When Model is Larger than Memory . . . 35
6 Conclusion 41
Bibliography 43
A ADMM under Limited Memory 1
List of Figures
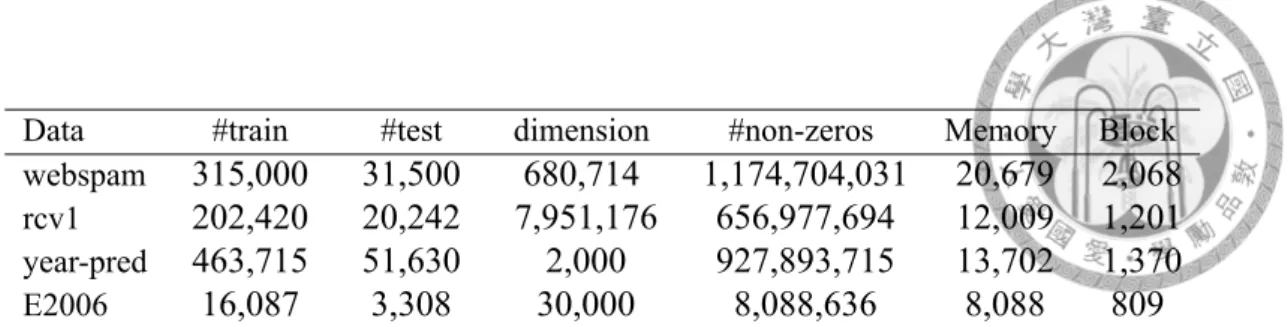
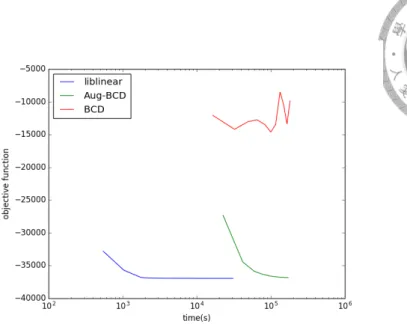
5.1 Objective Value for Webspam data set . . . 31
5.2 Error for Webspam data set . . . 32
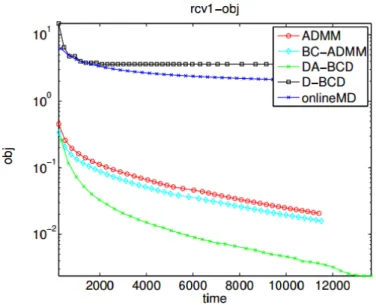
5.3 Objective Value for Rcv1 data set . . . 32
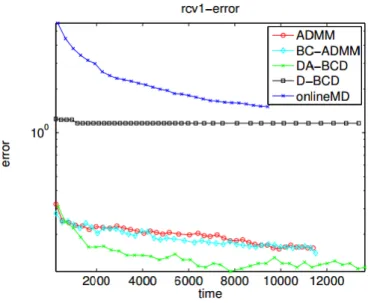
5.4 Error for Rcv1 data set . . . 33
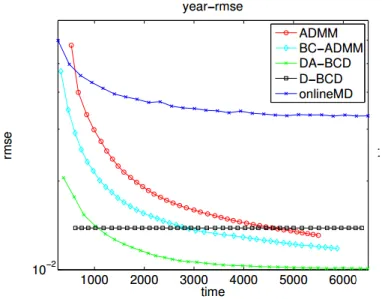
5.5 Objective Value for Year-pred data set . . . 33
5.6 RMSE for Year-pred data set . . . 34
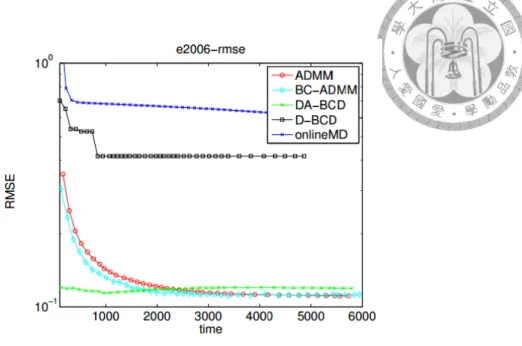
5.7 Objective Value for E2006 data set . . . 34
5.8 RMSE for E2006 data set . . . 35
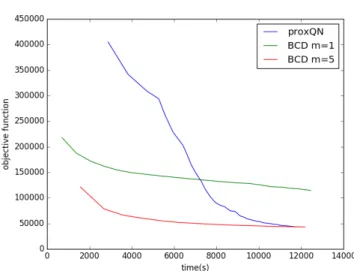
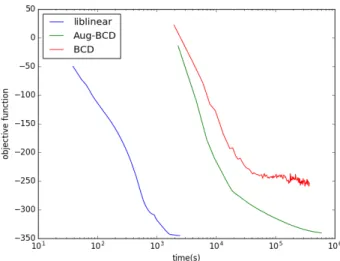
5.9 Objective Value for LSHTC1 data set on LR . . . 37
5.10 Objective Value for aloi.bin data set on LR . . . 37
5.11 Objective Value for LSHTC1 data set on SVM . . . 38
5.12 Objective Value for aloi.bin data set on SVM . . . 39
List of Tables
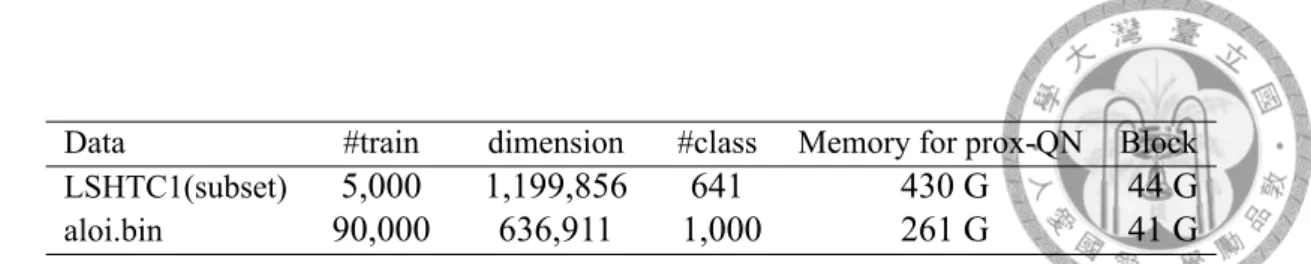
5.1 Data Statistic for Dual Augmented BCD . . . 30 5.2 Data Statistic for L1-regularized Multi-class Logistic Regression . . . 36 5.3 Data Statistic for L2-regularized Multi-class SVM . . . 36
Chapter 1 Introduction
Nowadays, there are many applications of machine learning and data mining trained by data with huge scale. It has been observed that model’s performance can be boosted by increasing both the number of samples and the number of features. With the help of crowd- sourcing, data with million number of features and number of samples was generated[3].
As a consequence, data size can easily exceed the size of memory, we cannot load whole data or model into memory and have to use the secondary storage when training a model.
Therefore, we have to consider the expensive I/O time and balance with computational time during training.
There are two disparate ways will be considered when training a model with huge data, online and distributed learning. In the online learning scenario, each sample is processed only once in a stochastic manner without being stored. The drawback of online learning is that it require large number of epochs to converge to the same level of batch method. If we want to obtain a useful result, we still have to memorize all the data in disk and process it to memory several times during training, and the algorithm spends most of the time in I/O instead of computation at each epoch; therefore, the bottleneck in the online learning setting is I/O[2, 22, 25]. The problem of slow convergence for an online algorithm will be- come even much worse for non-smooth or non-strongly convex objective function [16, 18]
than the strongly convex problem like L2-regularized SVM [15]. In the distributed learn- ing setting, there are many cores or machines that can process data at the same time and jointly fit the data into memory. However, in the real case, there may not have sufficient number of machines to store the whole data into memory. In this situation, the algorithm can only process a block of data at a time. Therefore, we will also encounter large number of I/O and have to consider the I/O time in the distributed learning setting[25].
Recently, several algorithms have been proposed to solve large-scale linear Support Vector Machine (SVM) in the limited memory setting[2, 22, 25]. These approaches are based on a dual Block Coordinate Descent (dual-BCD) algorithm, which split the original problem into several block sub-problems, each sub-problem only requires a block of data loaded into memory. As a result, the machine will process a block of data from disk to memory when changing the block sub-problem, allowing more computation between two I/O and balance the computation time and the I/O time. This approach was proved linear conver- gent to global optimum, and showed fast convergence in the experiment. However, the global convergence for dual-BCD method base on the assumption that the non-separable part of the dual problem is smooth, which is not the case in the general Empirical Risk Minimization (ERM) problem except the regularizer is L2-norm.
Another scenario in the limited memory setting is that the model size is larger than the memory size, we assume that the data size is smaller than the memory size. This scenario may happen in the extreme classification problem, the model can easily become very large when both number of features and the number of classes are large. Another application is Sparse Coding, which usually has extremely large number of features and smaller number of samples[7], and some problems require the memory size equal to square of the num- ber of features, such as inverse covariance estimation problem. Traditional algorithms which requires the whole model to process is infeasible. We can apply the same technique discuss above, except that we apply BCD based on the primal problem instead of dual problem. The primal BCD method separates model into blocks and update one block at
a time, we only need a block of model loaded in the memory to perform the algorithm.
This method achieves linearly convergent when the loss function is strongly convex[14].
However, primal-BCD will not converge to the global optimum if the non-separable part of the primal objective function is non-smooth.
In this paper, we propose a general framework to solve the regularized Empirical Risk Minimization problem (ERM) in the limited memory setting, which include the situation that the data is larger than the memory and that the model is larger than the memory. ERM problem covers most of supervised learning problems ranging from classification, regres- sion, ranking and recommendation, many of them have non-separable and non-smooth part in primal objective function or dual objective function, leading to the result that BCD method cannot converge to global optimum. Then we discuss the convergence issue and then apply Proximal Point method to allow the algorithm’s global convergence.
We conduct experiments on the L1-regularized classification and regression problems when data is larger to corroborate our theory, which shows the proposed augmented tech- nique improve the convergence dramatically. We also provide another general framework in limited memory setting adapted from a famous distributed method Alternating Direc- tion Method of Multiplier (ADMM)[1]. The experiments show that the adaptive ADMM is efficient but not as efficient as the proposed framework specially designed for limited memory setting.
We experiment on multi-class classification problems with both smooth loss function and non-smooth loss function when model size is larger than the data size and the memory size, which will happen when the number of features is larger than the number of samples and the number of classes is huge. we show that one can reduce the memory usage almost linearly with the number of blocks during training, and the proposed algorithm indeed converge to the same point that the original algorithm converge to.
Note that we didn’t compare our method with the recently proposed distributed learning algorithms (CoCoA etc.)[9, 8], because they can only apply to L2 regularized ERM prob-
lems or designed for some specific loss function, such as L1-logistic regression[20].
The recently proposed distributed learning algorithm PROXCoCoA+[17] which can deal with more general regularizer is similar to our framework. However, their framework aims to deal with the ERM problem in the distributed system, instead of saving memory as the framework we proposed. Furthermore, if we adopt PROXCoCoA+ to limited memory setting like ADMM, it will be the same with our framework except that PROXCoCoA+ has shrinked step size, which is required to guarantee convergence. Therefore, we didn’t compare it with our method.
Chapter 2
Problem Setup
In this work, we consider the regularized Empirical Risk Minimization problem, which given a data set D ={(ϕn, yn)}Nn=1, estimates a model through
min
w∈Rd,ξ∈RpF (w, ξ) = R(w) +
∑N n=1
Ln(ξn)
s.t.ϕnw = ξn, n∈ [N]
(2.1)
where w∈ Rdis the model parameters to be estimated, ϕnis a p by d design matrix that encodes features of the n-th data sample,Ln(.) is a convex loss function that penalizes the difference between ground truth and prediction vector ξn ∈ Rp, and R(w) is a convex regularized function preventing overfitting.
The formulation (2.1) cover a large class of statistical learning problems ranging from classification [26], regression [19], ranking [10], and convex clustering [21]. For exam- ple, in classification problem, we have p =|Y | where Y consists the set of all labels, we can use logistic loss Ln(ξ) = log(∑
k∈Y exp(ξk)− ξyn) in logistic regression and hinge loss Ln(ξ) = maxk∈Y(1− δk,yn + ξk− ξyn) in support vector machine; in a (multi-task) regression problem, there are K real values for the target variable Y , we have p = K, and the square loss Ln(ξ) = 12||ξ − yn||22 is often used. There are various regularizers
R(w) used in different applications, which includes the L2-regularizer R(w) = λ2||w||2 in ridge regression and many classification problems, L1-regularizer R(w) = λ||w||1 in Lasso, nuclear norm R(w) = λ||w||∗ in matrix completion, and a family of structure group norms R(w) = λ||w||g [12]. These variety functions of R(w), Ln(ξ) differ in two properties – strongly convexity and smoothness – that dramatically affect the convergence behavior of the block minimization algorithm.
Definition 1 (Strongly Convexity). A function f (x) is strongly convex iff it is lower bounded by a simple quadratic function
f (y)≥ f(x) + ∇f(x)T(y− x) + m
2||x − y||2 (2.2)
for some constant m > 0 and∀x, y ∈ dom(f).
Definition 2 (Smoothness). A function f (x) is smoothness iff it is upper bounded by a simple quadratic function
f (y) ≤ f(x) + ∇f(x)T(y− x) + M
2 ||x − y||2 (2.3)
for some constant 0 ≤ M < ∞ and ∀x, y ∈ dom(f). For instance, the square loss and logistic loss are both smooth and strongly convex 1, while the hinge loss satisfies neither of them. Moreover, L2-norm is the only regularizer that is both strongly convex and smooth, other regularizer such as L1-norm, structured group norm, and nuclear norm have neither of these two properties. We will demonstrate the effects of these properties to Block Minimization algorithms.
Throughout this paper, we will assume that given a solver for the ERM problem (2.1) that works in the condition that the model and the data can fit in memory, we can easily integrate the solver into our framework, and the framework can efficiently solve (2.1)
1The logistic loss is strongly convex when its input ξ are within a bounded range, which is true as long as we have a non-zero regularizer R(w)
when data cannot fit into memory or model cannot fit into memory. We will also assume that either model or data can fit into memory when another one cannot in the limited memory condition. In the following sections, we will abbreviate the condition that data cannot fit in memory as large data condition, and the condition that model cannot fit into memory as large model condition.
Chapter 3
Primal and Dual Block Minimization
In this section, we will first extend the block minimization framework of [25] from linear L2-regularizer SVM to the general setting of regularized ERM problem (2.1) in the large data scenario. Then we will discuss the block minimization framework for regularized ERM problem in the condition that model cannnt fit in memory.
3.1 Data Size is Larger than The Memory Size
For the large data condition, we apply dual-BCD to ERM problem, the dual form of equa- tion (2.1) can be expressed as
min
µ∈Rd,αn∈RpR∗(−µ) +
∑N n=1
L∗n(αn)
s.t.
∑N n=1
ϕTnαn= µ
(3.1)
where R∗(−µ) is the convex conjugate of R(w) and L∗n(αn) is the convex conjugate of Ln(ξn). The convex conjugate is defined as follow
Definition 3 (Convex Conjugate). Given a convex function f : χ→ R∪{∞}, the convex
conjugate f∗ : χ→ R ∪ {∞} is defined as
f∗(y) := sup
x∈χ⟨x, y⟩ − f(x) (3.2)
where⟨·, ·⟩ denotes the inner product in a Euclidean vector space χ.
The block minimization framework of [25] basically performs a dual-BCD over (3.1) by dividing the whole data set D into K blocks DB1, ..., DBK, and optimize a block of dual variables (αBk, µ) at a time, where DBk ={(ϕn, yn)}n∈Bk and αBk ={αn|n ∈ Bk}.
In [25], the dual problem (3.1) is derived explicitly and solved in the dual function in order to perform the algorithm. However, for many sparsity-inducing regularizer such as L1-norm and nuclear norm, it is more efficient and convenient to solve in primal function [6, 27]. Therefore, here we express the dual problem implicitly as
G(α) = min
w,ξ L(α, w, ξ)
= min
w,ξ R(w) +
∑N n=1
Ln(ξn) +
∑N n=1
αTn(ϕnw− ξn)
(3.3)
whereL(α, w, ξ) is the Lagrangian function of equation (2.1). Then we maximize (3.3) w.r.t a block of dual variables αBkwith other dual variables{αBj = αtB
j}j̸=kfixed, where t denotes the iteration of the BCD algorithm. By strong duality,
maxαBk
{
minw,ξ L(α, w, ξ) }
= min
w,ξ
{
maxαBk L(α, w, ξ) }
= min
w,ξ FBk(w, ξ) (3.4)
we can form a primal sub-problem for each block. The maximization of dual variables αBk in (3.4) enforces the primal equalities ϕnw = ξn, n∈ Bk, resulting the block mini-
mization primal problem
min
w∈Rd,ξ∈RpFBk(w, ξ) = R(w) +
∑N n=1
Ln(ξn) + µtB
k
Tw
s.t.ϕnw = ξn, n∈ Bk
(3.5)
where µtB
k =∑
n /∈BkϕTnαtndenotes the information of other blocks that affects the value of global function (2.1). Note that in (3.5), variables{ξn}n /∈Bk have been dropped since they are not relevant to the dual variables in this block αBk. Therefore, given the d dimen- sional vector µtB
k, we can solve (3.5) without the data of other blocks{(ϕn, yn)}n /∈Bk. In the algorithm, we maintain a d dimensional vector µt =∑N
n=1ϕTnαtnand obtain µtB
k by
µtB
k = µt− ∑
n∈Bk
ϕTnαtn (3.6)
to solve each block subproblem (3.5). A convenient property for the subproblem (3.5) is that it has the same form of the original problem (2.1) except for one additional linear augmented term µtBkTw. Given a solver of (2.1), we can easily adapt the solver to solve (3.5) by adding an augmented term for the gradient
∇wFBk(w, ξ) =∇wF (w, ξ) + µtB
k
of the solver, where FBk(·) denotes the subproblem function and F (·) denotes the original function. Note that the augmented term µtB
k is constant and separable w.r.t. coordinate, so it takes little overhead to the solver. After obtaining the solution (w∗, ξ∗B
k) from (3.5), we can compute the corresponding dual variables αBk according to the KKT condition and maintain µ by
αt+1n =∇ξnLn(ξ∗n), n∈ Bk (3.7)
µt+1n = µtBk + ∑
n∈Bk
ϕTnαt+1n (3.8)
The procedure is summarized in Algorithm 1, which consumes O(d +|DBk| + p|Bk|) memory capacity. The factor d comes from the storage of the vector µt, wt, factor|DBk| comes from the storage of data block, and the factor p|Bk| comes from the storage of αBk. Note that this algorithm requires the same space complexity as that require in the original algorithm proposed for linear SVM [25], where p = 1 for the binary classification problem.
Algorithm 1 Dual Block Minimization
Require: Split dataD into blocks B1, B2, ...BK.
1: Initial µ0 = 0.
2: for t=0,1,... do
3: Draw k uniformly from [K].
4: LoadDBk and αtBk into memory.
5: Compute µtB
k from (3.6).
6: Solve (3.5) to obtain (w∗, ξ∗B
k).
7: Compute αt+1B
k from (3.7).
8: Maintain µt+1by (3.8)
9: Save αt+1B
k out of memory.
3.2 Model Size is Larger than The Memory Size
For the large model condition, we perform primal-BCD to ERM problem (2.1). We first split model w into K blocks wB1, ...wBK, and optimize a block of primal variables wBk at a time, where wBk ={wi|i ∈ Bk} indicate the parameters in this block. We derive the subproblem from LagrangianL(α, w, ξ) by minimizing a block of primal variables wBk
maxα
{ min
wBk,ξL(α, w, ξ) }
= max
α GBk(α) (3.9)
with parameters in other blocks {
wBj = wtB
j
}
j̸=k fixed, again t is the iteration of the primal-BCD algorithm. The minimization of primal variables wBk in (3.9) enforces the dual equality ∑N
n=1ϕTn,iαn = µi, i ∈ Bk, which resulting in the block minimization
problem
min
µBk∈Rd/K,αn∈RpR∗(−µBk) +
∑N n=1
L∗n(αn)− δtn,Bk
Tαn
s.t.
∑N n=1
ϕTn,B
kαn = µB
k
(3.10)
where ϕn,B
k = {
ϕn,i|i ∈ Bk
} denotes the feature of the n-th data which have the same
dimension of the parameters in this block Bk, µn,B
k = {
µn,i|i ∈ Bk
}, and δtn,B
k =
{ϕn,iwti}
i /∈Bk. Note that in (3.10), variables{R(wi)}i /∈Bk have been dropped since they have no effect to the block subproblem. Given the p dimensional vector δn,Bk for each sample, we can solve (3.10) without the parameters outside the block Bk. Same as the dual-BCD algorithm, we maintain p dimensional vector δn= ϕnwtand obtain δn,Bk by
δtn,B
k = δtn− ϕn,BkwtB
k (3.11)
to solve the block subproblem (3.10). After obtaining solution (α∗) from (3.10), we are able to derive the corresponding optimal primal variable wBk for (3.9) according to the KKT condition and maintain δnby
wt+1B
k =
( N
∑
n=1
ϕn,Bk
)−1∑N
n=1
∇αnL∗n(α∗n) (3.12)
δt+1n = δtn,B
k+ ϕn,Bkwt+1B
k (3.13)
Note that we can modify the original solver for (3.1) easily by adding an augmented term to the original gradient
∇αG(α) =˜ ∇αG(α)− δtBk
where ˜G(·) denotes the subproblem (3.10) and G(·) denotes the original problem (3.1).
3.2.1 Solve Block SubProblem in Primal
We also can form a primal subproblem for the above primal-BCD algorithm, for the con- venient of solving with many sparsity-inducing regularizer such as L1-norm and nuclear norm. By strong duality, the subproblem (3.9) can be express as
maxα
{
wminBk,ξL(α, w, ξ) }
= min
wBk,ξ
{
maxα L(α, w, ξ)}
= min
wBk,ξFBk(w, ξ) (3.14)
The maximization of dual variables α enforces the primal equation ϕnw = ξ, resulting a subproblem
wminBk,ξFBk(w, ξ) = min
wBk,ξR(wBk) +
∑N n=1
Ln(ξn)
s.t.ϕn,B
kwBk = ξn− δn,Bk, n∈ [N]
(3.15)
which can directly output wt+1B
k without computing α∗.
The overall procedure for primal-BCD is summarized in Algorithm 2, which requires O(|Bk| + D + p × n) space complexity. The factor |Bk| comes from the storage of model block wBk, the factorD comes from the storage of data, and the factor p × n comes from the storage of αn, δtn.
Algorithm 2 Primal Block Minimization
Require: Split model w into blocks B1, B2, ...BK.
1: Initial δ0 = 0.
2: for t=0,1,... do
3: Draw k uniformly from [K].
4: Load wBk into memory.
5: Compute δtB
k from (3.11).
6: Solve (3.10) to obtain (α∗) and compute wt+1B
k from (3.12)
7: (or solve (3.15) to obtain wt+1B
k )
8: Maintain δt+1by (3.13)
9: Save wt+1B
k out of memory.
Chapter 4
Augmented Block Minimization
Although the Block Minimization Algorithm 1 and 2 can be applied to the general regu- larized ERM problem (2.1), it is not guaranteed that the sequence{αt}∞t=1 and{wt}∞t=1 generated by Algorithm 1 and Algorithm 2 respectively converge to global optimum of (2.1). In fact, the global convergence of Algorithm 1 and Algorithm 2 only happens for some special function. One sufficient condition for the global convergence of a Block- Coordinate Descent algorithm is that the terms in objective function that are not separable w.r.t. blocks have to be smooth(Definition 2).
First, we examine the dual objective function (3.1), which contains two terms R∗(−∑N
n=1ϕTnαn)+
∑N
n=1L∗n(αn), where the second term is separable w.r.t. samples{αn}Nn=1, thus it is sep- arable w.r.t. blocks{αBk}Kk=1. However, the first term couples dual variables in all the blocks and it is not separable w.r.t. blocks. Therefore, if R∗(·) is smooth, Algorithm 1 will converge to global optimum. The following theorem suggests that it will happen only when R(w) is strongly convex.
Theorem 4.0.1 (Strong/Smooth Duality). Assume f (·) is closed and convex. Then f(·) is smooth with parameter M if and only if its convex conjugate f∗(·) is strongly convex with parameter m = M1
The proof of above theorem can be found in [11]. According to theorem 4.0.1, the
dual-BCD Algorithm 1 will guarantee to have global convergence only when the regu- larizer is L2-norm R(w) = 12||w||2. Unfortunately, most of regularizers is not strongly convex, thus the dual-BCD algorithm failed to converge to global minimum in most of the regularizers and many applications.
Then we consider the primal-BCD algorithm, the primal objective function (2.1) consist of two terms R(w) +∑N
n=1Ln(ϕnw). The first term is separable w.r.t. coordinate for L1-norm and L2-norm, hence it is separable w.r.t. blocks. There are many more choice of regularizers such as group lasso, sparse group lasso, and nuclear norm that are block separable. For the second term, although the logistic loss and square loss is smooth, there is a popular loss function called hinge loss Ln(ξ) = maxk∈Y(1− δk,y+ ξk− ξyn) which appears in the SVM model that is non-smooth. Therefore, Algorithm 2 is not globally convergent for SVM.
In this section, we propose a solution to this problem for both dual and primal BCD. We apply Proximal Point method to the subproblem, generating the smoothness for the non- smooth and non-separable term. As a result, both dual and primal BCD algorithm has fast global convergence.
4.1 Algorithm
The Proximal Point Method (or equivalently, Dual Augmented Lagrangian method) mod- ifies the original problem by introducing a sequence of Proximal Maps
w˜t+1 = arg min
w
F (w) + 1
2ηt||w − ˜wt||2 (4.1)
to iterative achieve optimum, where F (w) denotes the ERM problem (2.1). We will first demonstrate how to modify the dual-BCD algorithm, and then apply the same technique to primal-BCD algorithm.
4.1.1 Dual Augmented Block Minimization
In this section, we extend the algorithm in section 3.1. We perform dual-BCD algorithm on the proximal problem (4.1) instead of solving the original subproblem (3.5). As we show in the analysis section, the dual problem of (4.1) is globally convergent since the non- separable terms for the dual variables αBk are smooth. Given the current iterate model
˜
wt, the Dual Augmented Block Minimization optimize one block of the dual variables αBk of proximal point problem (4.1) at a time, with other variables fixed
{
αBj = α(t,s)B
j
}
j̸=k, where t denotes the number of iteration of proximal point method, and s denotes the num- ber of iteration of inner dual-BCD method. By strong duality,
maxαBk
{ min
w,ξ
L(α, w, ξ)˜ }
= min
w,ξ
{ maxαBk
L(α, w, ξ)˜ }
(4.2)
where ˜L(·) is the Lagrangian of (4.1)
L(α, w, ξ) = F (w, ξ) +˜
∑N n=1
αTn(ϕnw− ξn) + 1
2ηt||w − ˜wt||2 (4.3)
Once again, we maximization w.r.t. αBk enforces the primal equalities for this block ϕnw = ξn, n∈ Bkand form a primal subproblem
min
w∈Rd,ξ∈RpR(w) +
∑N n=1
Ln(ξn) + µ(t,s)B
k
Tw + 1
2ηt||w − ˜wt||2 s.t.ϕnw = ξn, n∈ Bk
(4.4)
where µ(t,s)B
k =∑
n /∈BkϕTnα(t,s)n . Note that (4.4) is almost the same as (3.5) except the ad- ditional proximal point term. We follow the same procedure to maintain the d dimensional vector µ(t,s)=∑N
n=1ϕTnα(t,s)n and obtain
µ(t,s)B
k = µ(t,s)− ∑
n∈Bk
ϕTnα(t,s)n (4.5)
to be able to solve the block subproblem (4.4). After obtaining the solution (w∗, ξ∗Bk) from (4.4), we derive dual variables αBk as
α(t,s+1)n =∇ξnLn(ξ∗n), n∈ Bk (4.6)
and maintain µ as
µ(t,s+1)n = µ(t,s)B
k + ∑
n∈Bk
ϕTnα(t,s+1)n (4.7)
The block subproblem (4.4) is similar to the original ERM problem (2.1) with additional simple quadratic augmented function which is separable w.e.t. coordinate. Given a solver of (2.1) working in sufficient memory condition, we can easily modify it to
∇wF˜Bk(w, ξ) =∇wF (w, ξ) + µ(t,s)B
k +w− ˜wt ηt
∇2wF˜Bk(w, ξ) =∇2wF (w, ξ) + I ηt
where ˜FBk(·) denotes the proximal point block subproblem, F (·) denotes the original objective function. The inner Block Minimization procedure is performed until every value of subproblem (4.4) reaches ϵin from the optimum. Then the outer proximal point method update ˜wt+1= w∗(α(t,s)) is performed, where w∗(α(t,s)) is the solution of (4.4) for the latest inner iteration s, and the corresponding dual variables is α(t,s). The overall procedure is summarize in Algorithm 3.
4.1.2 Primal Augmented Block Minimization
In this section, we show how to apply the Proximal Point Method to the primal-BCD algorithm, extending the algorithm in section 3.2. We introduce a sequence of Proximal Maps in the dual problem
˜
αt+1= arg min
α
G(α) + 1
2ηt||α − ˜αt||2 (4.8)
Algorithm 3 Dual-Aug. Block Minimization Require: Split dataD into blocks B1, B2, ...BK.
1: Initial µ0 = 0, ˜w0 = 0.
2: for t=0,1,... do
3: for s=0,1,...S do
4: Draw k uniformly from [K].
5: LoadDBk and α(t,s)B
k into memory.
6: Compute µ(t,s)B
k from (4.5).
7: Solve (4.4) to obtain (w∗, ξ∗B
k).
8: Compute α(t,s+1)B
k from (4.6).
9: Maintain µ(t,s+1)by (4.7)
10: Save α(t,s+1)B
k out of memory.
11: w˜t+1 = w∗(α(t,S+1))
where G(α) denotes the dual of ERM problem (3.1). We perform primal-BCD on the dual proximal problem (4.8) instead of the original ERM problem (2.1). The algorithm will converge to global optimum since the non-smooth loss Ln(·) which is not block separable will become smooth by adding the proximal term ||α − ˜αt||2. Given the current dual iterate variables ˜αt, which t is the number of outer iteration, the Primal Augmented Block Minimization algorithm optimizes the primal variables wBkin one block Bkat a time, and other primal variables
{
wBj = w(t,s)B
j
}
j̸=k are fixed, where s denotes the number of inner BCD iteration.
maxα
{
wminBk,ξ
L(α, w, ξ)˜ }
= max
α GBk(α) (4.9)
where ˜L(α, w, ξ) is the Lagrangian of (4.8)
L(α, w, ξ) = F (w, ξ) +˜
∑N n=1
αTn(ϕnw− ξn)− 1
2ηt||α − ˜αt||2 (4.10)
Note that there is a minus sign in front of the proximal term in (4.10), since we maximize the Lagrangian w.r.t. dual variables instead of minimizing in the problem (4.8). The maximization of (4.9) enforce the equality∑N
n=1ϕTn,iαn = µi, i∈ Bk, leading to a block
minimization subproblem
min
µBk∈Rd/K,αn∈RpR∗(−µBk) +
∑N n=1
L∗n(αn)− δ(t,s)n,BkTαn+ 1
2ηt||α − ˜αt||2 s.t.
∑N n=1
ϕTn,Bkαn= µBk
(4.11)
where δ(t,s)n,B
k = {
ϕn,iw(t,s)i }
i /∈Bk
. Note that (4.11) is the primal-BCD subproblem (3.10) with an augmented proximal point term. We have the some procedure to maintain δ(t,s)n = ϕnw(t,s)and to update δ(t,s)n,B
k by
δ(t,s)n,B
k = δ(t,s)n − ϕn,Bkw(t,s)B
k (4.12)
in order to solve the subproblem (4.11). After we obtain the solution α∗ from (4.11), we can update primal variables wBk as
w(t,s+1)B
k =
( N
∑
n=1
ϕn,Bk
)−1∑N
n=1
∇αnL∗n(α∗n) (4.13)
and maintain δnas
δ(t,s+1)n = δ(t,s+1)n,B
k + ϕn,B
kw(t,s+1)B
k (4.14)
Note that we can modify the original solver for (3.1) easily by adding an augmented term to the original gradient
∇αG(α) =˜ ∇αG(α)− δ(t,s)Bk +α− αt ηt
∇2αG(α) =˜ ∇2αG(α) + I ηt
where ˜G(·) denotes the subproblem (4.11) and G(·) denotes the original problem (3.1).
Solve Subproblem in Primal
Once again, we can solve the above subproblem (4.11) in the primal form for the conve- nient of solving sparsity-inducing regularizer, by strong duality, the subproblem (4.9) can first optimize dual variables
maxα
{ min
wBk,ξL(α, w, ξ) }
= min
wBk,ξ
{
maxα L(α, w, ξ)}
(4.15)
Resulting a primal subproblem
wminBk,ξR(wBk) +
∑N n=1
Ln(ξn) + ηt
2
∑N n=1
||(ϕn,BkwBk + δn,Bk − ξn)−α˜tn
ηt ||2 (4.16)
and we can directly obtain w(t,s)B
k without compute α∗.
The inner Block Minimization procedure stop when every subproblem (4.11) (or (4.16)) reaches ϵin tolerance. After that, a update of the outer proximal point method ˜αt+1 = α∗(w(t,s))is performed, where α∗(w(t,s)) is the solution of (4.11)(or (4.16)) for the latest primal variables w(t,s). The procedure is summarized in Algorithm 4.
Algorithm 4 Primal-Aug. Block Minimization Require: Split dataD into blocks B1, B2, ...BK.
1: Initial δ0 = 0, ˜α0 = 0.
2: for t=0,1,... do
3: fors=0,1,...S do
4: Draw k uniformly from [K].
5: Load w(t,s)B
k into memory.
6: Compute δ(t,s)B
k from (4.12).
7: Solve (4.11) to obtain (α∗).
8: (Or solve (4.16) to obtain w(t,s+1)B
k )
9: Compute w(t,s+1)B
k from (4.13).
10: Maintain µ(t,s+1)by (4.14)
11: Save w(t,s+1)B
k out of memory.
12: α˜t+1= α∗(w(t,S+1))