國立臺灣大學理學院數學系(所) 博士論文
Department of Mathematics College of Science
National Taiwan University Doctoral Dissertation
廣義多參數概似模型之估計 On Estimation Methods in Generalized Multiparameter
Likelihood Model
陳律閎 Lu-Hung Chen
指導教授: 鄭明燕教授 Advisor: Prof. Cheng, Ming-Yen
中華民國 99 年 1 月
國 立 臺 灣 大 學 數 學 系( 所)
博 士 論 文
廣 義 多 參 數 概 似 模 型 之 估 計
陳
律
閎
撰
99
1
Abstract
Multiparameter likelihood models (MLMs) with multiple covariates have a wide range of applications; however, they encounter the “curse of dimension- ality” problem when the dimension of the covariates is large. We develop a generalized multiparameter likelihood model that copes with multiple covari- ates and adapts to dynamic structural changes well. It includes some popular models, such as the partially linear and varying-coefficients models, as special cases. We discuss the backfitting and profile likelihood procedures and present a simple, effective two-step method to estimate both the parametric and the nonparametric components when the model is fixed. All these estimators of the parametric component has the n−1/2 convergence rate, and the estimator of the nonparametric component enjoys an adaptivity property. We suggest a data-driven procedure for selecting the bandwidths, and propose an initial es- timator in backfitting and profile likelihood estimation of the parametric part to ensure stability of the approach in general settings. We further develop an automatic procedure to identify constant parameters in the underlying model.
We provide several simulation studies and an application to infant mortality data of China to demonstrate the performance of our proposed method.
中文摘要
能處理多個共變數(covariate)的多參數概似模型(Multiparameter Likelihood Models, MLMs)有非常廣泛的應用。然而,當共變數的維度很大時,我們會 遇到”維度的詛咒(curse of dimensionality)”的問題。我們將多參數概似模型 推廣成半參數模型,使之能處理較大的共變數維度同時能適應動態的結構變 化。我們的模型包含了許多特例,如部份線性模型(partially linear models)、
變係數模型(varying coefficients models)等。我們介紹兩種既有的方法以及提 出一個簡單而且有效的兩步驟估計法來估計此模型的參數化的部份以及非參 數的部份。這些估計方式在參數化的部份具有和一般參數化模型一樣的收斂 速度(n−1/2),非參數的部份則能估的和已知參數化的部份時一樣好(即具有 adaptivity property)。我們也提了一個自動帶寬選擇(bandwidth selection)法,
以及一個自動化的流程來決定哪些共變數應該被放在參數化的部份。我們做了 一些模擬研究,並且舉了一個中國嬰兒死亡率的資料來顯示我們估計方法的性 能。
致謝
首先感謝指導教授鄭明燕老師多年以來費心的指導與栽培,不管是學術上 知識的教導還是其對工作、研究的嚴謹與熱誠的身教言教,均給我莫大的影 響,讓我獲益良多。沒有鄭老師給我這麼好的題目以及過程中的指導,本研究 的進行及論文撰寫不可能如此順利的完成,在此謹致上由衷的謝忱。
另外要感謝曾勝滄老師、戴政老師、張淑惠老師以及丘政民老師首肯擔任 我的口試審查委員,給我論文撰寫以及實務研究方面之詳細指正,讓本論文不 致犯錯並更加完備。此外,感謝陳祝嵩老師慷慨提供計算資源,使論文得以如 期完成。
最後,謹將本論文獻給我的父母,感謝他們的養育之恩及對我永遠的支持、
鼓勵。
Contents
ABSTRACT i
中文摘要 ii
致謝 iii
1 Introduction 1
2 Motivating examples and model identifiability 7
3 Reviews of related models 11
4 Estimation procedures 16
4.1 Backfitting estimation . . . 16
4.2 Profile likelihood estimation . . . 18
4.3 Two-step estimation . . . 22
5 Bandwidth selection and identifying constant parameters 26 5.1 Model selection criteria . . . 27
5.1.1 Akaike Information Criterion (AIC) . . . 27
5.1.2 Bayesian Information Criterion (BIC) . . . 29
5.2 Bandwidth selection . . . 30
5.3 Identifying constant parameters . . . 32
6 Asymptotic properties 36
7 Simulation study and data analysis 40
7.1 Logistic Regression . . . 40 7.2 Weibull model . . . 48 7.3 Hazard Regression . . . 60
8 Analysis for infant mortality in China 63
9 Conclusion and Future Works 77
REFERENCES 79
A Proofs for Backfitting 83
B Proofs for Profile Likelihood Estimation 90
C Proofs for 2-Step Estimation 94
List of Figures
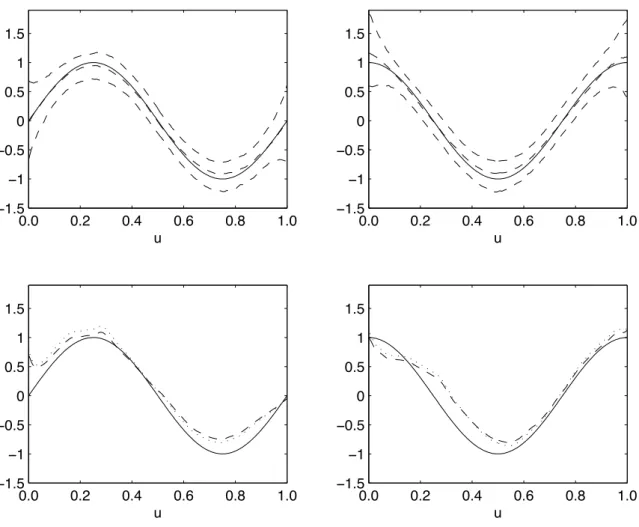
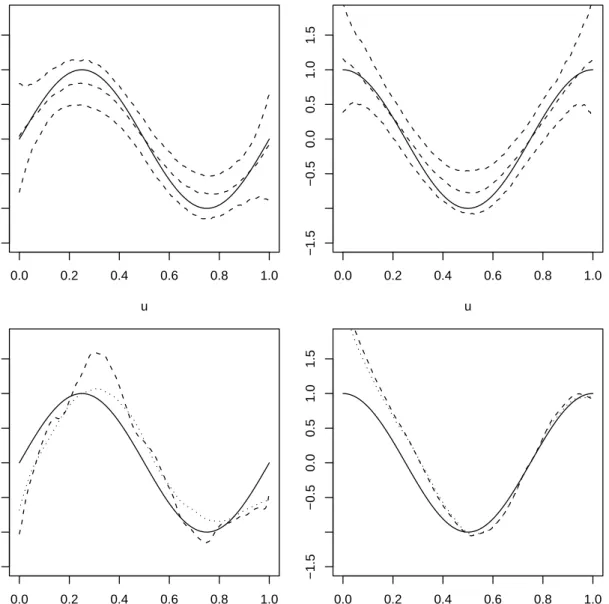
1 Functional parameters in logistic regression when the sample size is
1000 . . . 43
2 Functional parameters in logistic regression when the sample size is 500 . . . 44
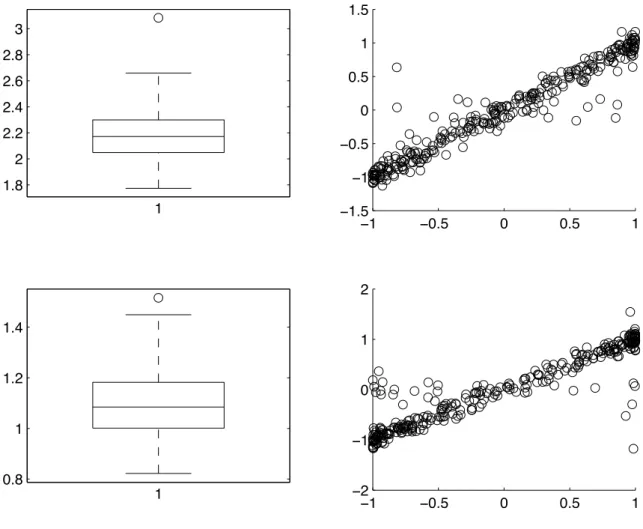
3 Parameter predictions in the logistic example when the sample size is 1000 . . . 46
4 Parameter predictions in the logistic example when the sample size is 500 . . . 47
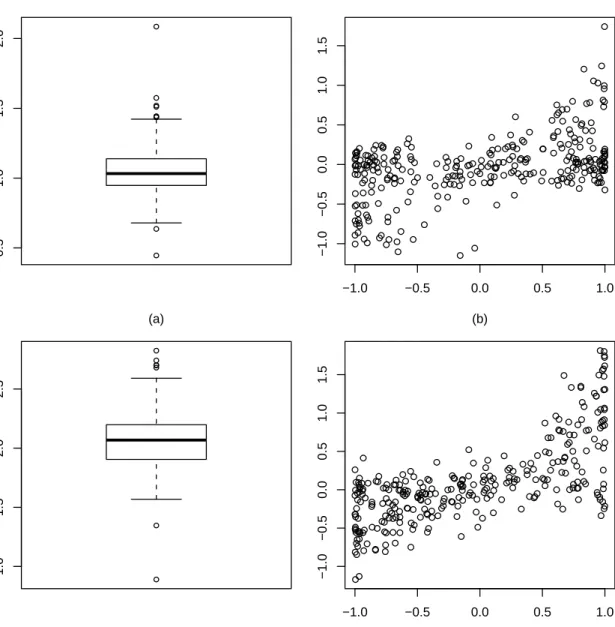
5 Parameter predictions in the logistic example by the AIC criterion when the sample size is 1000. . . 49
6 Parameter predictions in the logistic example by the AIC criterion when the sample size is 500. . . 50
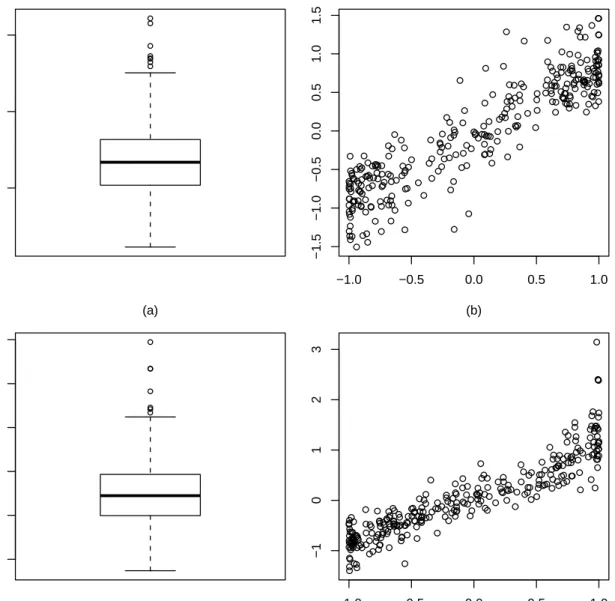
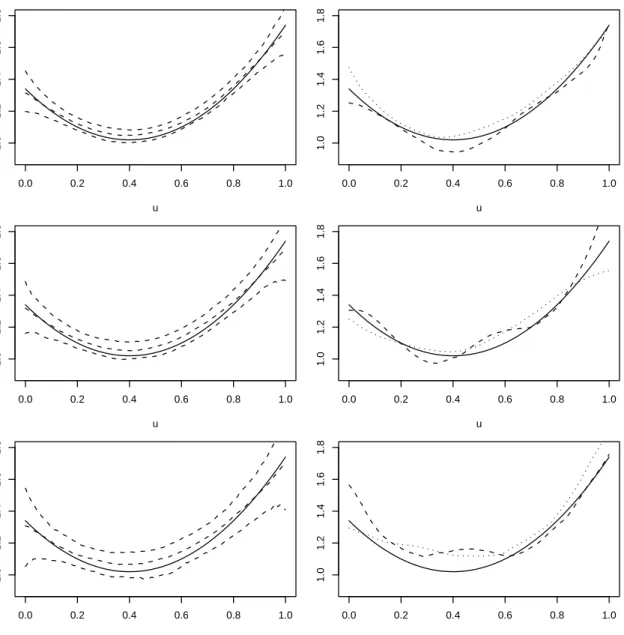
7 Estimates of the functional parameter in the Weibull example. . . 53
8 Parameter predictions in the Weibull example. . . 57
9 Parameter predictions in the Weibull example with the AIC criterion. 59 10 Impacts of covariates on infant mortality with modelM0 . . . 66
11 Impacts of covariates on infant mortality with modelM′0 . . . 67
12 Impacts of covariates on infant mortality . . . 70
13 Impacts of covariates on infant mortality with modelM′ . . . 73
List of Tables
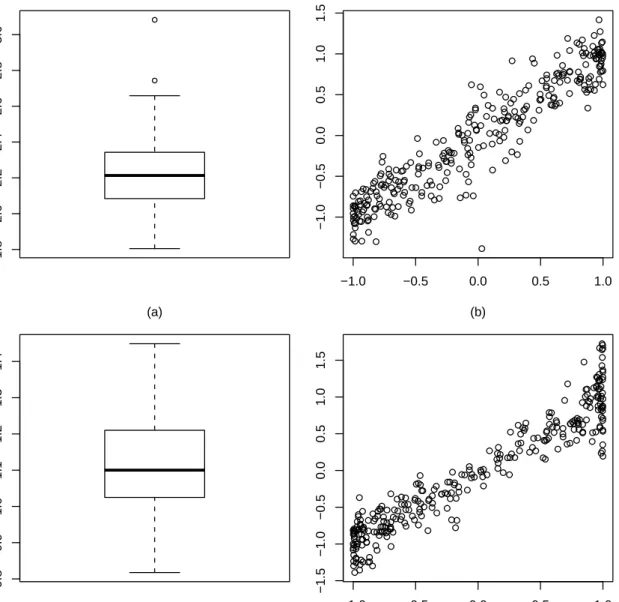
1 MIAEs of different estimation methods for logistic regression. . . 41 2 Performances of different estimation methods on the Weibull example
when the sample size is 1000. . . 54 3 Performances of different estimation methods on the Weibull example
when the sample size is 500. . . 54 4 Performances of different estimation methods on the Weibull example
when the sample size is 250. . . 55 5 Performances of model selection procedures of the Weibull example. . 58 6 Estimated impacts of the constant parameters with modelM and M′ 74 7 List of Covariates with Descriptive Statistics . . . 75
1 Introduction
Consider statistical modeling of the relationship between a response variable and some covariates. Maximum likelihood estimation is most powerful when the joint distribution of the response variable and covariates is specified by a parametric form.
But parametric approaches are at risk for model misspecification, which can result in seriously biased estimation, misinterpretation of data, and other problems. Non- parametric modeling is more flexible and allows data to present the unknown truth;
however, it often comes up against the “curse of dimensionality” problem — that is, model instability when the dimension of the covariates is large. Numerous hybrids of parametric and nonparametric models, generally called semiparametric models, have been proposed to achieve a good balance between flexibility and stability in model specification. We will review related models in Section 3.
In this article we suggest a semiparametric model for a population (X, U, Y ) in which U is a continuous variable and the conditional density function of Y given (X, U ) is specified by
f (
Y ; X, θ, xT1a1(U ), · · · , xTℓaℓ(U ) )
, (1.1)
where f is a known parametric density function, θ = (θ1,· · · , θq)T is an unknown constant vector, X = (X1,· · · , Xp)T with X1 ≡ 1, and xj is a pj-dimensional subvec- tor of X and aj(·) = (aj1(·), · · · , ajpj(·))T is an unknown function, j = 1,· · · , ℓ. Here 1 ≤ ℓ ≤ d, where d is as defined in (1.2). Model (1.1) is a hybrid of the standard
multiparameter likelihood model (MLM) that assumes that the conditional density function of Y given X follows the form
f (
Y ; a1(X), · · · , ad(X) )
, (1.2)
where f has d identifiable parameters and a1(X),· · · , ad(X) are unknown functions;
that is, Y depends on X through the d identifiable parameters in f being modeled as nonparametric functions of X. Aerts and Claeskens (1997) studied a locally lin- ear maximum likelihood estimator of MLMs when X is univariate, and Cheng and Peng (2007) proposed a variance reduction technique to improve the estimation.
The MLM provides a general framework for specifying statistical relationship be- tween response and covariates under a wide range of data configurations, including continuous, categorical, binary and count variables as the response and cases where the response is univariate or vector-valued. In addition, it can be easily adopted to cope with various statistical problems, such as mean regression, variance estima- tion, quantile regression, hazard regression, logistic regression, and longitudinal data analysis (for details, see, e.g., Aerts and Claeskens 1997; Loader 1999; Claeskens and Aerts 2000; Cheng and Peng 2007.)
With the availability of U , model (1.1) specifies ℓ of the d parameter functions in model (1.2) by some nonparametric or semiparametric form, and if d− ℓ > 0, then the other d− ℓ parameter functions in (1.2) are now modeled parametrically in (1.1), with θ comprising all of the constant parameters. Like MLM (1.2), (1.1) pro-
vides a unified approach to modeling a wide range of data settings and dealing with various inference problems. Nonetheless, (1.1) avoids the curse of dimensionality problem that (1.2) has when the dimension of X is large, and it allows paramet- ric, nonparametric or semiparametric modeling of the parameter functions in (1.2).
Furthermore, (1.1) broadens the application of MLMs, because it can cope with categorical covariates, which often arise in practice. Model (1.1) is a very general semiparametric model provided that there exists a continuous variable U and other covariates X. It reduces to a partially linear model (3.1) when ℓ = 1, x1 = X1 ≡ 1 and θ interacts with X through a linear function. When ℓ = 1, q = 0 and x1 = X, model (1.1) becomes the varying-coefficients model (3.2) of Hastie and Tibshirani (1993) with the same modifying variable U . Thus (1.1) inherits the stability, flexi- bility, and interpretability that varying-coefficients models enjoy. In addition, it is closely related the regression model II of Bickel, Klaassen, and Ritov and Wellner (1993, sec 4.3).
Here we propose a simple, effective, and fast two-step procedure to estimate both the constant and functional parameters in (1.1). The implementation of this model involve none of the iteration usually required by conventional approaches, such as profile likelihood and backfitting. Furthermore, we develop an Akiake Information Criterion (AIC) data-driven procedure to select the bandwidths required in the two-step estimation. The use of an AIC criterion (and modified versions) to select smoothing parameters in nonparametric regression and local likelihood modeling has
been extensively discussed and implemented (see, e.g. Hurvich, Simonoff, and Tsai 1998; Loader 1999; Schucany. For local likelihood estimation, Aerts and Claeskens (1997) considered cross-validation and plug-in bandwidths, and Fan, Farmen and Gijbels (1998) suggested a bandwidth selector based on an approximation to the integrated mean squared error. The backfitting and profile likelihood approaches can be applied to estimate the constant parameters, too. We propose a new initial estimator to ensure stability of the backfitting and profile likelihood approaches regardless of in which types of model features (e.g., location, scale, and shape) the constant parameter play roles. In general, neither profile likelihood nor the two-step estimator of the constant parameters is consistently superior to the other (see the asymptotic results and discussion in Sec. 6 and simulation results reported in Sec.
7). Nevertheless, the major strength of the two-step estimation is its simple and fast implementation and numerical stability, with no iteration required.
In practice, the real challenge is that we are often given a collection of signifi- cant covariates but do not know which of the parameter functions are constant and which are functional in (1.1); that is, we are not sure about the specification of θ and x1,· · · , xℓ. In an attempt to solve this fundamental identification problem, we suggest a stepwise procedure based on a version of the Bayes information criterion (BIC) accounted for our model. Identification of constant parameters and band- width selection interact with each other. We propose selecting the bandwidths first and then keeping them fixed throughout the procedure for identifying the constant
parameters. This approach indeed resolves a complex problem in an effective, fast, and stable fashion and is confirmed to have these properties by a simulation study and a real data analysis. We are not aware of any existing methods for identifying constant parameters or covariates in the parametric component of a semiparamet- ric model, although there is an abundant literature on a different issue of variable selection for parametric models, nonparametric models, and parametric or nonpara- metric components in semiparametric models. For example, Irizarry (2001) derived weighted versions of the AIC and BIC and posterior probability model selection criteria for one-parameter local likelihood models. Fan and Li (2002) used profile likelihood techniques in their nonconcave penalized likelihood approach to selecting variables in the parametric part of Cox’s proportional hazards model. Fan and Li (2004) incorporated profiling ideas in their construction of penalized least squares for variable selection in the parametric component of a semiparametric model for longi- tudinal data analysis. Bunea (2004) constructed a penalized least squares criterion for variable selection in the linear part of a partially linear model. For a generalized varying-coefficient partially linear model, Li and Liang (2008) used a nonconcave penalized likelihood to select significant variables in the parametric component and a generalized likelihood ratio test to select significant variables in the nonparametric component, assuming that the two sets of covariates in the parametric and nonpara- metric components are separated in advance.
In section 2 we provide some motivating examples for model (1.1) and discuss
the identifiability issue. We review the two classical estimation procedures: back- fitting and profile likelihood estimation, and then present our two-step estimation procedure for both the constant and functional parameters and a new initial es- timator for profile likelihood estimation of the constant parameters in Section 4, and address bandwidth selection and identification of the constant parameters are addressed in Section 5. We investigate the asymptotic properties of the backfit- ting, profile likelihood, and two-step estimators in Section 6. In section 7 we present three simulated examples and an analysis of a motivating example concerning infant mortality in Section 8. We defer proofs of the theoretical results to Appendixes.
2 Motivating examples and model identifiability
In applications, some of the unknown functional parameters in the MLM (1.2) may simply be unknown constants. Under such circumstances, we would pay a price in efficiency if the unknown constants were still treated as unknown functions. An example of this is an analysis of 103 annual maximum temperatures (Cheng and Peng, 2007) in which Y|X is modeled by an extreme value distribution, where X is year. The estimates of the shape and scale parameter curves are flat except in the boundary regions, which is reasonable because the two parameters are unlikely to change much within 100 years. To accommodate such situations, (1.2) needs to be restricted to the following semiparametric model:
f (
Y ; X, θ, a1(X), · · · , aℓ(X) )
, (2.1)
where 1 ≤ ℓ < d and θ is a q-dimensional unknown parameter. Here ℓ out of the d parameter functions in (1.2) remain unknown functions of X, and the other d− ℓ parameter functions are formulated by certain parametric forms, for example, unknown constants, with θ comprising all of the constant parameters. The model studied by Severini and Wong (1992) is a special case of (2.1) with d = 2, ℓ = 1, and q = 1. These authors studied profile likelihood estimation of θ, along with consistent estimators of a least favorable curve.
When the dimension of X is large, neither (1.2) nor (2.1) would work, because the curse of dimensionality problem. Claeskens and Aerts (2000) suggested alle-
viating this problem by restricting a1(·), · · · , ad(·) in (1.2) to additive models and estimating them using a backfitting algorithm. Alternatively, a restriction of (2.1),
f (
Y ; X, θ, XTβ1, · · · , XTβℓ )
, (2.2)
where β1,· · · , βℓ are unknown constant vectors, would cope with the curse of dimen- sionality problem. But (2.2) actually implies a constant impact of X on Y , which is somewhat implausible in practice. For example, in the analysis of infant mortality in China detailed later, the impact of type of region of residence on mortality would not be a constant along the time U , because China has changed greatly since 1950, and the difference between rural and urban regions has changed. The impact must vary with U and the pattern of the change is of interest. Although we can modify (2.2) to some other parametric models involved with U to capture the trend, for example,
f (
Y ; X, θ, XTβ1P1(U ), · · · , XTβℓPℓ(U ) )
,
where Pj(U ) is some polynomial of U , j = 1,· · · , ℓ. However, determining the correct forms of Pj(·) to catch the dynamic changes is difficult. To capture the dynamic pattern of the changes in the impact more accurately, we extend (2.2) to
f (
Y ; X, θ, XTa1(U ), · · · , XTaℓ(U ) )
, (2.3)
where θ is an unknown constant vector, and aj(·) = (aj1(·), · · · , ajp(·))T is a vector of unspecified smooth functions, j = 1,· · · , ℓ. In (2.3), a1(·), · · · , aℓ(·) must share
the same dimension p, and all of the aij(·)’s are assumed to be functional. This model assumption may be unnecessary in some situations. The analysis of infant mortality in China is an example; the impact of ethnic group or type of feeding on infant mortality can be formulated as an unknown constant parameter. To remove such unnecessary restrictions and make the model more versatile, we generalize (2.3) to (1.1) with all the aij(·)’s in (2.3) that are constant absorbed by θ in (1.1).
When a1(·), · · · , aℓ(·) are all constant, model (2.3) reduces to model (2.2), and I(γ) defined in Theorem 3 becomes ˜I, where ˜I is I(γ) with aj(U ) replaced by βj. Condition (S7) in Appendix C ensures that the smallest eigenvalue of ˜I is greater than the positive number λ0 in condition (S7). If (Xi, Yi), i = 1,· · · , n, is a sample from model (2.2) then, under condition (S7), the Fisher information matrix is
∑n i=1
diag(Iq, Iℓ⊗ Xi) ˜Iidiag(Iq, Iℓ⊗ XTi) > λ0
∑n i=1
diag(Iq, Iℓ⊗ Xi)diag(Iq, Iℓ⊗ XTi)
≈ nλ0diag(Iq, Iℓ⊗ E(XXT)) > 0,
where ˜Ii is ˜I with X replaced by Xi. Here Ik denotes a size k identity matrix, and for any matrixes A and B, diag(A, B) denotes the matrix
( A 0
0 B )
.
The condition (S7) ensures that the Fisher information matrix of the parametric model (2.2) is positive-definite; that is, model (2.2) is identifiable. Furthermore, for any given value of U , the local version of model (2.3) is model (2.2); thus, under
condition (7), model (2.3) is identifiable for any given value of U , and so model (2.3) is identifiable. In addition, model (1.1) specifies some of the aij(·)’s in model (2.3) as constant and thus is identifiable. Based on the foregoing arguments, we have the following lemma.
Lemma 1. Under condition (S7) in Appendix C, both models (1.1) and (2.3) are identifiable.
3 Reviews of related models
Many semiparametric models have been proposed and developed. Most of them focus on the regression case or the extension of generalized linear models. For ex- ample, Engle, Granger, Rice, and Weiss (1986) proposed a partially linear regression model of the form:
Y = XTβ + g(U) + ϵ (3.1)
where X = (X1,· · · , Xp)T and U = (U1,· · · , Ud)T are vectors of covariates, β = (β1,· · · , βp)T is a vector of unknown parameters, g(·) is a unknown smooth function from Rd to R, and ϵ is independent of (X, U) with mean zero and finite variance E(ϵ2) = σ2. They applied this model to analyze the relationship between temper- ature and electricity usage. In their paper, β and g(·) are estimated by smoothing spline:
(β, ˆˆ g )
= arg min
β,g
1 n
∑n i=1
(Yi − XTi β− g(Ui))2
+ λ
∫
g′′(u)2du,
where λ is a smoothing parameter and can be automatically determined by cross- validation. Cai, Fan, Jiang, and Zhou (2007) used partially linear hazard regression to analyze multivariate survival data. They assumed that the marginal hazard function follows
λij(t) = Yij(t)λ0j(t) exp[
βTXij(t) + g (Uij(t))] ,
where Yij(t) = 1(Xij > t) is an at-risk indicator process, λ0j(t) is an unspecified baseline hazard function, and g(·) is an unspecified smooth function. The coefficients
of the parametric part β is estimated by profile partial likelihood approach, and the nonparametric part g(·) is estimated by local partial likelihood approach. For more details and applications about the partially linear model can be found in H¨ardle et al. (2000).
Hastie and Tibshirani (1993) proposed the varying coefficients model of the form:
Y = XTa(U ) + ϵ, (3.2)
where X = (X1,· · · , Xp)T, a(U ) = (a1(U ),· · · , ap(U ))T are unspecified smooth functions. They proposed a smoothing spline approach to estimate aj(·), that is, find aj(·), j = 1, · · · , p, to minimize
∑n i=1
{ yi−
∑p j=1
xijaj(ui) }2
+
∑p j=1
λj
∫
a′′j(u)2du
where λj > 0, j = 1, · · · , p are predefined smoothing parameters. Fan and Zhang (1998) proposed to estimate aj(·) by local linear smoothing. Suppose that aj(·) has a continuous second order derivative. For each given u0, we approximate aj(u) locally by a linear function aj(u0)≈ aj+ bj(u− u0), j = 1,· · · , p. Let (ˆa1, ˆb1,· · · , ˆap, ˆbp) be minimizer of
∑n i=1
{ yi−
∑p j=1
(aj − bj(Ui− u0)) xij }2
Kh(Ui− u),
where Kh(t) = K(t/h)/h, K(t) is a kernel function and h is bandwidth; then the local linear estimator of aj(u) is taken to be ˆaj, j = 1,· · · , p. The bandwidth h can
be automatically selected by cross-validation. Similar ideas can be found in Hoover et al. (1998). They applied the varying coefficients model to longitudinal data: let
Yij = Xij1a1(tij) +· · · + Xijpap(tij) + ϵi(tij)
for i = 1,· · · , n and j = 1, · · · , ni, where n denotes the number of subjects, ni denotes the number of measurements for the i-th subject, a1(t),· · · , ap(t) are un- known smooth functions which are estimated by smoothing spline or local polyno- mial smoothing with smoothing parameter selected by cross-validation, and ϵi(t) are uncorrelated stochastic processes.
Cai et al. (2000) proposed the generalized varying coefficient models that fol- lows:
g(m(U, X)) = XTa(U ),
where g is a link function and m(U, X) = E(Y|U, X). They applied a local max- imum likelihood estimation proposed by Fan et al. (1998) to estimate a(·). Let f (y; m(U, X)) denote the log conditional density function of Y given (U, XT). For any given u, let (ˆaT, ˆbT) be the maximizer of the local likelihood function
L(a, b) =
∑n i=1
f (
yi; g−1 [XTi {
a + b(Ui− u0) }])
Kh(Ui− u),
where a = (a1,· · · , ap)T and b = (b1,· · · , bp)T. The bandwidth h can be selected by minimizing the cross-validation criteria:
CV = −
∑n i=1
f {
yi; g−1 (
XTi aˆ\i(Ui) )}
,
where ˆa\i(Ui) is the estimated value of a(Ui) with the i-th observation deleted.
In practice, some of the components of a(·) in model (3.2) can be constant (or other parametric forms) while other components have unknown interactions with U . With out loss of generality, we can write the model as
Y = ZT1a1(U ) + ZT2a2+ ϵ (3.3)
where (ZT1, ZT2)T = X. This leads to a semiparametric model model known as semivarying coefficients model. Zhang et al. (2002) proposed a two step estimation procedure: they first treat a2as functionals of U and appeal to local linear smoothing to get the initial estimator of a2(Ui), namely, ˜a2(Ui). Then, they average ˜a2(Ui) over i = 1,· · · , n to get the final estimator of a2 and show that their estimator of a2 has n−1/2 convergence rate when the bandwidth for the initial estimator ˜a2(Ui) in the first step is taken to be of order O(n−1/4). Fan and Huang (2005) proposed a profile least-square technique to estimate a2. Their idea is that for any given a2, model (3.3) can be written as
Y = Z˜ T1a1(U ) + ϵ
which is a standard varying coefficients model, where ˜Y = Y − ZT2a2. Then the estimator of a1(U ) can be obtained by local linear smoothing, which can be written as ˜a1(U ) = S ˜Y , where S is the smoothing matrix. Substituting ˜a1(U ) for a1(U ) in model (3.3) we have
(I− S)Y = (I − S)ZT2a2+ ϵ,
and the least square estimator of a2 becomes
aˆ2 ={
ZT2(I− S)T(I− S)Z2
}T
ZT2(I− S)T(I− S)Y. (3.4)
Hence we can start from an initial guess of a2 which is not far from its true value, and estimate ˆa2 iteratively, as shown in Section 4.2. Fan and Huang (2005) showed that the asymptotic variance of their estimator reaches the lower bound for semi- parametric models.
4 Estimation procedures
Suppose that we have a sample (Xi, Ui, Yi), i = 1, · · · , n, from (X, U, Y ), which obeys model (1.1). Let xi,j be the pj-dimensional subvector of Xi that corresponds to xj, j = 1, · · · , ℓ, i = 1, · · · , n. We discuss existing backfitting and profile likelihood approaches, and introduce our two-step procedures for estimating both the constant and functional parameters in Sections 4.1, 4.2, and 4.3.
4.1 Backfitting estimation
The idea of backfitting is on iteration. If θ is given, model (1.1) reduces to a nonparametric model and the functional parameters can be estimated by regular local likelihood approach as follows. For any fixed u, by Taylor’s expansion, we have, for each j,
aj(Ui)≈ aj(u) + ˙aj(u)(Ui− u)
when Ui is in a neighborhood of u, where ˙aj(u) = daj(u)/du. This leas to the following local log-likelihood function:
∑n i=1
Kh1(Ui−u) log f(
Yi; Xi, θ, xTi,1{a1+ b1(Ui− u)} , · · · , xTi,ℓ{aℓ+ bℓ(Ui− u)}) , (4.1) where Kh1(·) = K(·/h1)/h1, K(·) is a kernel function, and h1 > 0 is a band- width. Note that we assume θ in (4.1) is known. Maximizing (4.1) with respect to(
aT1, bT1,· · · , aTℓ, bTℓ)T
we get the maximizer(
aˆ1(u)T, ˆb1(u)T,· · · , ˆaℓ(u)T, ˆbℓ(u)T)T
.
The estimator of a(u) is taken to be ˆa(u) = (
ˆa1(u)T, · · · , ˆaℓ(u)T)T
. On the other hand, when a1(·) , ..., al(·) are given, model (1.1) becomes the parametric model model (2.1) and the constant parameters can be estimated by maximum likelihood approach. Hence the backfitting algorithm start from an initial guess of θ, plug-in this guess to replace θ in 4.1 and update estimates of aj(·), j = 1, · · · , l, and then update estimates of θ iteratively until the estimates of θ converges. We state the details as follows.
(a) Initialize θ by a proper guess ˆθ(0)BF. Set k = 1.
(b) Estimate aj(·) by maximizing (4.1) with θ being replaced by ˆθ(kBF−1) with respect to(
aT1, bT1,· · · , aTℓ, bTl )T
we get the maximizer (
aˆ(k)1 T, ˆb(k)
T
1 ,· · · , ˆa(k)ℓ T, ˆb(k)
T
ℓ
)T
. The estimator of aj(·) in this step is taken to be ˆa(k)j (·), j = 1, · · · , l.
(c) Estimate θ by maximizing
f (
Y ; X, θ, xT1aˆ(k)1 (U ), · · · , xTℓˆa(k)ℓ (U ) )
, (4.2)
with respect to θ we get the maximizer ˆθ(k)BF. The estimator of θ is taken to be ˆθ(k)BF. If ˆθ(k)BF − ˆθ(kBF−1) is smaller than a pre-defined tolerance, we say that ˆθ(k)BF converges and the estimation procedure is completed. Denotes the final estimates ˆθBF = ˆθ(k)BF. Otherwise, change k to k + 1 and go to (b). In backfitting, (4.2) is maximized by solving
d dθ
∑n i=1
log f(
Yi; Xi, θ, xT1aˆ(k)1 (Ui) ,· · · , xTℓaˆ(k)ℓ (Ui) )
= 0
or by minimizing
d dθ
∑n i=1
log f(
Yi; Xi, θ, xT1aˆ(k)1 (Ui) ,· · · , xTℓaˆ(k)ℓ (Ui)) to avoid singularity.
It can be shown by Theorem 1 that ˆθBF has n−1/2 convergence rate under some regularity conditions if the bandwidth in (4.1) satisfies h1 ∝ n−1/4 (that is, ˆaj needs to be undersmoothed). However, there are some disadvantages for backfitting.
First, the bandwidth is difficult to choose automatically, especially when the initial guess of ˆθ(0)BF is far from the true value of θ. Under this circumstance, the variations of ˆaj may be dominated by the variations due to ˆθBF, which is unknown for us.
Second, the estimation requires iterations and is computation intensive. Third, if the initialization ˆθ(0)BF is far from the true value of θ, backfiiting procedure usually requires more iterations, or even fails to converge. Finally, if the design of U is sparse, estimation of ˆaj may fail, and thus ˆθBF may diverge.
4.2 Profile likelihood estimation
A profile likelihood estimator for θ maximizes, with respect to θ, a profiled log- likelihood
∑n i=1
log f(
Yi; Xi, θ, xTi,1˜a1θ(Ui),· · · , xTi,ℓa˜ℓ,θ(Ui) )
,
where, for any given θ, ˜aθ(·) =(
a˜1,θ(·)T,· · · , ˜aℓ,θ(·)T )T
is an estimator for a(·). In practice, we need to find the minimizer of
∂Ln
∂θ
(θ, ˜aθ)
+ ∂Ln
∂a
(θ, ˜aθ) ∂
∂θ˜aθ
(4.3)
by iteration, where Ln is the conditional log-likelihood function
Ln( θ, a)
=
∑n i=1
log f(
Yi; Xi, θ, xTi,1a1(Ui), · · · , xTi,ℓaℓ(Ui))
, (4.4)
where a(·) = (
a1(·)T,· · · , aℓ(·)T)T
. We describe the details of profile likelihood estimation as follows.
(a) Initialize θ by a proper guess ˜θ(0)P R. Set k = 1.
(b) Maximizing
∑n i=1
Kh1(Ui− u) log f(
Yi; Xi, ˜θ(kP R−1), xTi,1{a1+ b1(Ui− u)} , · · · , xTi,ℓ{aℓ+ bℓ(Ui− u)}) , (4.5)
with respect to(
aT1, bT1,· · · , aTℓ, bTℓ)T
we get the maximizer(
a˜(k)T1 , ˜b(k)1 T,· · · , ˜a(k)ℓ T, ˜b(k)ℓ T)T
. The estimator of aj,θ(·) is taken to be ˜a(k)j (·), j = 1, · · · , ℓ.
(c) Estimate θ by minimizing ∂Ln
∂θ (
θ, ˜a(k) θ
)
+∂Ln
∂a
(θ, ˜aθ) ∂
∂θa˜(k)θ
(4.6)
with respect to θ we get the maximizer ˜θ(k)P R. The elements of ∂
∂θ˜a(k)
θ can be estimated by assuming that ajθ is a polynomial of θi, i = 1, ..., q, j = 1, ..., ℓ.
The estimator of θ in this step is taken to be ˜θ(k)P R. If ˜θ(k)P R− ˜θ(kP R−1) is smaller than a pre-defined tolerance, we say that ˆθ(k)P R converges and the estimation procedure is completed. Denote the final estimates ˜θP R = ˜θ(k)P R. Otherwise, change k to k + 1 and go to (b).
Let ν∗ = a′θ
0(·) = ∂∂θaθ(·)
θ=θ0
be an l× q matrix. If ν∗ satisfies
E0 (∂L
∂θ (θ0, a0) + ∂L
∂a (θ0, a0) ν∗ )T (
∂L
∂a (θ0, a0) ν )
= 0
for all ν ∈ Λ, where
L( θ, a)
= log f(
Y ; X, θ, xT1a1(U ),· · · , xTℓaℓ(U )) ,
∂L
∂a(θ0, a0) is a 1×l vector and denotes the partial derivative of L (θ, z) with respect to z evaluated at the true values (θ0, a0), Λ denotes the space of a, and E0 is the expectation taken under the true parameters θ0 and a0, then aθ(·) are called the least favorable curves. If the least favorable curves exist and with some regularity conditions, it can be shown in Theorem 2 that ˜θP R has n−1/2 convergence rate if the bandwidth h used in (4.5) satisfies h∝ n−1/5.
When the specified semiparametric model is generally like (1.1), in which θ may involve shape or scale parameters in f , stability of the iteration relies heavily on the proper choice of the initial estimate. Under semiparametric models for the regression mean, Fan and Huang (2005) and Lam and Fan (2008) used difference- based methods to obtain a reliable initial estimate. But, difference-based methods
may not work for model (1.1), because some of the elements in θ can be other than mean parameters. We propose a new initial estimate for the backfitting and and profile likelihood procedures as follows.
First, we derive some rough estimates of aj(Ui), i = 1,· · · , n, j = 1, · · · , ℓ. Con- sider a model obtained by replacing θ in (1.1) with a0(U ), a q-dimensional unknown function of U . This model is now a fully nonparametric model and the functional parameters can be estimated by regular local likelihood approach as follows. For any given u, let (
¯a0(u)T, ¯b0(u)T, ¯a1(u)T, ¯b1(u)T,· · · , ¯aℓ(u)T, ¯bℓ(u)T )T
be the maximizer, with respect to(
aT0, bT0, aT1, bT1,· · · , aTℓ, bTℓ)T
, of the local log-likelihood function
∑n i=1
Kh1(Ui−u) log f(
Yi; Xi, a0+b0(Ui−u), xTi,1
{a1+b1(Ui−u)}
,· · · , xTi,ℓ
{aℓ+bℓ(Ui−u)}) .
Here h1 can be taken as the bandwidth ˆh1 in Section 5.2, because it is selected for local likelihood estimation by assuming model (5.2). Letting u = Ui in the foregoing procedure, we have ¯aj(Ui), j = 1,· · · , ℓ, i = 1, · · · , n. Then our initial estimate ¯θ is the maximizer of
∑n i=1
log f(
Yi; Xi, θ, xTi,1a¯1(Ui),· · · , xTi,ℓ¯aℓ(Ui) )
.
During the iteration in finding the minimizer of (4.6), ˜aθ(·) is taken to be the estimator that solves (4.5) with h1 replaced by ˆh1. With this choice of bandwidth, the least favorable curve is well approximated, by the nature of model (5.2). On convergence of the iteration, we obtain the profile likelihood estimator for θ. Then
we can estimate a(·) and select the bandwidth in the same manner as described later in Sections 4.3 and 5.2 with ˆθ replaced by the profile likelihood estimator for θ.
Unlike backfitting, the profile likelihood estimation does not need to under- smooth the estimates of functional parameters. However, the profile likelihood es- timation requires the least favorable curve assumption and more assumptions of
∂
∂θaθ(·) to attain √
n consistency, which is not always satisfied for all models. For example, as mentioned in Fan and Wong (2000), if Y is from N (µ (·) , σ2), then the profile likelihood estimator of σ2 is not consistent. This restricts the application of profile likelihood estimation. Furthermore, the profile likelihood approach also suffers some drawbacks as backfitting does. First, the bandwidth h used in (4.5) is difficult to select automatically, especially when the initialization ˆθ(0)P R is far from the true value of θ. In fact, the iteration may not converge under this situation even the bandwidth is correctly specified. Second, the profile likelihood approach requires more computation on estimating ∂θ∂aθ(·) so is even more computationally intensive. Finally, the iteration may also diverge when the design of U is sparse.
4.3 Two-step estimation
Our two-step approach first produces an estimator for the constant vector θ, then plugs this estimator into the local likelihood function to estimate the functions aj(·), j = 1, · · · , ℓ.
The estimation procedure for θ consists of two stages. First, we treat θ as
an unknown function of U and appeal to the local likelihood approach to get a preliminary estimator ˜θ(Ui) for θ(Ui) for each Ui, i = 1,· · · , n. Then we average
˜θ(Ui) over i = 1,· · · , n to get the final estimator for θ. The procedure is as follows.
Consider the model that specifies the conditional density of Y given X and U as:
f (
Y ; X, θ(U ), xT1a1(U ), · · · , xTℓaℓ(U ) )
. (4.7)
For any fixed u, by Taylor’s expansion, we have, for each j,
aj(Ui)≈ aj(u) + ˙aj(u)(Ui− u).
when Ui is in a neighborhood of u, where ˙aj(u) = daj(u)/du. This leads to the following local log-likelihood function:
∑n i=1
Kh(Ui− u) log f(
Yi; Xi, θ, xTi,1{
a1+ b1(Ui− u)}
, · · · , xTi,ℓ
{aℓ+ bℓ(Ui− u)}) , (4.8) where Kh(·) = K(·/h)/h, K(·) is a kernel function, and h > 0 is a bandwidth.
Maximizing (4.8) with respect to (
θT, aT1, bT1,· · · , aTℓ, bTℓ)T
we get the maximizer (θ(u)˜ T, ˜a1(u)T, ˜b1(u)T,· · · , ˜aℓ(u)T, ˜bℓ(u)T
)T
. In the foregoing local likelihood esti- mation, θ is fitted by a local constant vector, because θ is constant under model (1.1) and fitting it by a local constant vector stabilizes the procedure. For i = 1,· · · , n, let u = Ui; we get an initial estimator ˜θ(Ui) of θ. The final estimator of θ is taken to be
θ = nˆ −1
∑n i=1
θ(U˜ i). (4.9)
For ˆθ to achieve the n−1/2 convergence rate, we need to choose a relatively small bandwidth h so that the biases of ˜θ(·) and ˜aj(·), j = 1, · · · , ℓ, are dominated by n−1/2. This ensures that estimating the constant and the functional parts simulta- neously in the first step does not create extra bias for θ. Then, averaging over ˜θ(Ui), i = 1,· · · , n, as in (4.9) brings the variance from the order (nh)−1 in nonparametric estimation back to the order n−1 in parametric estimation. Later, we show that ˆθ is root-n consistent when h is chosen properly. Like any other maximum local likelihood estimation procedure, the bandwidth h cannot be chosen too small, or otherwise one runs into problems with singularity of the design matrix. From an asymptotic standpoint, condition (S5) keeps the bandwidth h from being too small;
thus, conditions (S5) and (S7) guarantee that the estimators ˜θ(U1),· · · , ˜θ(Un) exist.
Furthermore, the method of Cheng and Wu (2008) can be used to modify the local likelihood function (4.8) to overcome the singularity problem caused by a small h or sparsity in the design points Ui’s. This approach also can be applied to (4.10) when estimating the function a(u).
With ˆθ, we can estimate a(u) using the maximum local likelihood approach.
Note that the estimator ˜a(u) =(
˜a1(u)T,· · · , ˜aℓ(u)T)T
that we obtained before is too noisy and is not appropriate for this purpose, because the bandwidth h is intention- ally chosen to be small to get a good estimator of θ. Thus we use another, larger bandwidth to estimate a(u). We replace θ in (4.8) by ˆθ to get a local log-likelihood
function for a(u),
∑n i=1
Kh1(Ui− u) log f(
Yi; Xi, ˆθ, xTi,1{
a1+ b1(Ui− u)}
, · · · , xTi,ℓ
{aℓ+ bℓ(Ui− u)}) , (4.10) where h1 > 0 is a bandwidth different from h. We could use a kernel other than K at this step, but this does not matter much. Maximizing (4.10) with respect to (aT1, bT1, · · · , aTℓ, bTℓ)T
, we get the maximizer(
aˆ1(u)T, ˆb1(u)T, · · · , ˆaℓ(u)T, ˆbℓ(u)T)T
. Our estimator of a(u) is taken to be ˆa(u) = (
ˆa1(u)T,· · · , ˆaℓ(u)T)T
. Because the con- vergence rate of ˆθ is n−1/2 (see Sec. 6), ˆa(u) would work as well as when θ is known and is used in the local log-likelihood (4.10); that is, ˆa(u) has the adaptivity property.
In some cases, local likelihood estimation of the varying coefficients aj(·), j = 1,· · · , ℓ, may require a different amount of smoothing (see, e.g., Claeskens and Aerts 2000). Backfitting ideas can be implemented to achieve this goal, as follows: (a) Use ˆa(·) as the initial estimate; (b) for each j, substitute all of the local linear coefficient functions except the jth and h1 in (4.10) by the previous estimates and use the bandwidth for smoothing the jth functional parameter, and then maximize the resulted local likelihood to find an estimate of aj(·); and (c) iterate step (b) until convergence. Convergence usually is attained quickly in this case.
5 Bandwidth selection and identifying constant parameters
In reality, we do not know which of the parameters are constant and which are functional in model (1.1). This is essentially a model selection problem. The problem can be formulated in the form of successive tests of null hypotheses against multiple alternative hypotheses, and actually only one of the alternative hypotheses is the one we are looking for. Thus even if we construct a test statistics, choosing an appropriate threshold is challenging. To avoid this troublesome issue, information- criteria-based model selection procedures are often used.
There are many model selection criteria under parametric assumptions, includ- ing cross-validation (Stone 1974), the AIC (Akaike 1970), the BIC (Schwarz 1978), and nonconcave penalized likelihood (Fan and Li 2001). Of these various criteria, the AIC and BIC are likely the most commonly used in practice, because of their easy implementation. We use the concepts of the AIC and BIC to select the bandwidths h1 and h in the estimation procedures and to identify the constant parameters in model (1.1).