基於演化式計算的分散式最佳化模糊聚類演算法之研究(二) A Study on the Distributed Optimization Approach to Fuzzy Clustering
Algorithms Based on Evolutionary Computing (II)
計畫編號: NSC90-2213-E011-025
執行期限: 90 年 8 月 1 日至 91 年 7 月 31 日止
主持人: 范欽雄 國立台灣科技大學電機工程系 副教授
計畫參與人員: 韋至修 國立台灣科技大學電機工程系 博士班研究生
中文摘要
模糊 c 種平均值聚類(fuzzy c-means clustering) 是廣泛被使用的非監督式演算法,其主要的缺點是 無法確保找到全域性的最佳值(global optimum);
目前已經有許多研究者針對這個缺點提出改進的 方法,其中將演化式計算(evolutionary computing) 與模糊聚類演算法結合,是重要的解決方法之一。
但是這些現有的方法也有先天上的缺陷,例如:搜 尋區域(search space)過大與搜尋參數精確度不夠 的問題。有鑑於此,我們提出基於演化式計算的分 散式最佳化模糊聚類演算法,它能有效地切割原本 巨大的搜尋區域成為多個小搜尋區域,而且每個搜 尋區域是由一個獨立的演化環境所計算處理,因而 可以降低演化的計算量,相較於以前的方法,我們 的方法能快速且正確地收斂。本報告共提出三個演 算法:前兩個是循序式演算法,分別以聚類中心 (cluster center)與歸屬度(membership grade)當作搜 尋參數,此二者是把所有的演化環境全部建立在同 一台計算機,因而稱為循序式演算法。第三個是以 同步中央伺服器演算法(synchronous central server algorithm)為架構的分散式演算法,這種方法的概 念就是把所有的演化環境分散到由多台計算機所 組 成 的 分 散 式 計 算 環 境 (distributed computing environment)去平行處理;藉著這種平行計算法,
我們可以讓模糊聚類演算法擁有處理大量資料與 搜尋全域性最佳值的能力。
關鍵詞:演化式計算、基因演算法、模糊聚類、分 散式最佳化方法、中央伺服器演算法。
Abstract
Fuzzy c-means clustering is a widely known unsupervised clustering algorithm, but it cannot guarantee to find the global minimum. To improve this situation, we present a distributed optimization approach to fuzzy c-means clustering based on genetic algorithms. This approach incorporates genetic search strategies in the fuzzy clustering algorithm to explore the data space from a multiple-point concept. In the meantime, to reduce the size of the search space formed by coding parameters, our genetics-based fuzzy clustering algorithm with the distributed optimization approach
is first proposed to divide the huge search space into small ones. Each of them is manipulated by an independent evolution environment. Next, such a distributed optimization approach is implemented by three algorithms. The first and second are serial algorithms which establish all the evolution environments in one computer, and select cluster centers and membership grades as the coding parameters, respectively. The third algorithm is implemented on a distributed computing environment (DCE) by a synchronous central server algorithm, which distributes
n evolution
environments to n independent client computers. By means of the concept of parallelism in the DCE, we have for the first time endowed the enormous computation abilities to the fuzzy clustering for handling the large data set and speeding up the optimization processing.Keywords: evolutionary computing, genetic algorithm, fuzzy clustering, distributed optimization approach, central server algorithm.
1. INTRODUCTION
Clustering is understood to be the grouping of similar objects and separating of dissimilar ones, which is the basic tool for producing classification from initially unclassified data. In many years, clustering is an important technique in image processing, taxonomy, diagnostic, geology, business, sonar, and radar that all require accurate classification from the original data [1]. Before applying any clustering procedure, the most important matter to be considered is which mathematical properties of the data set, for example, distance, connectivity, or intensity should be used and in what ways should they be used in order to identify clusters. The conventional crisp clustering methods that have been achieved like k-means, maxmin-distance, isodata [2], split-and-merge [3], simulated annealing [4], [5], and moving method [6]
are all well documented in the literature.
The crisp clustering algorithms generate partitions such that each data point is assigned to exactly one cluster. Often, however, data points
belong to whichever cluster is vague in nature, so the application of the fuzzy set theory was proposed to incorporate the uncertainty of the final classification results. This opened the door of research in the area of fuzzy clustering based on objective functions by Ruspini [7]. Then Bezdek improved the work of Ruspini and proposed the famous fuzzy c-means [8].
The variance criterion, minimizing the sum of squared distances, is adopted as the objective function of fuzzy c-means; moreover, different types of distances have been invented to search for clusters of specific shapes. Fuzzy c-shell [9], [10] fixes the variance criterion of fuzzy c-means. The radius of the shell is included in the objective function to classify ring-shaped data sets.
Fuzzy c-means is a milestone algorithm in the area of fuzzy c-partition clustering. All of the following objective-functional-based fuzzy
c-partition algorithms incorporate the formulas (See
Eqs. (1b) and (1c) in Section 2) of fuzzy c-means as the prime mover in their algorithms. Those algorithms, in a sense, are the improved versions of fuzzy c-means, because all of them apply the derived formulas of fuzzy c-means to calculate the cluster centers or membership grades. For example, recently, evolution strategies and genetic algorithms have been attempted in order to make them useful in the adaptive and optimization processes. They are searching procedures based on the mechanics of natural selection and natural genetics [11], which exploit probabilistic rules to guide their searching processes instead of deterministic rules. Additionally, they consider many points in the search space simultaneously, not a single point, and therefore have less chance of converging to local optima. As these algorithms are capable of searching the global minimum, they are employed to fuzzy c-partition algorithms to overcome their local minimum deficiency [12]-[14]. Another technique frequently used to obtain the global minimum is simulated annealing, which is referred to simulate the process of heating up an object to a high temperature followed by a slow decrease in the temperature of the environment. Simulated annealing has also been applied to fuzzy c-partition algorithms to explore the global minimum of an objective function [15]-[17].Fuzzy c-means clustering is a widely known unsupervised clustering algorithm, but it cannot guarantee to find the global minimum. For this deficiency, many algorithms have been proposed; the incorporation of evolutionary algorithms is one of the important techniques adopted to surmount the problem of falling into local minima. However, the traditional combination of evolutionary algorithms and fuzzy clustering also has raised some problems.
The first is the search space is too large, and the second is the accuracy of search parameters is possibly not enough. Therefore, we propose a distributed optimization approach to fuzzy c-partition clustering based on genetic algorithms that divide the huge search space into many small ones. Compared
to traditional methods, our algorithm can converge quickly and correctly.
In this report, we have implemented the distributed optimization approach to genetics-based fuzzy c-partition clustering on a distributed computing environment (DCE) by a synchronous central server algorithm. With the concept of parallelism, the developed distributed computing environments have reached large computation abilities to handle the large data set and speed up the optimization processing.
2. FUZZY C-MEANS CLUSTERING
The definition of fuzzy c-means clustering can be stated below. Let
X = { x 1 , x 2 ,..., x n }
be any finite set.V
cn is the set of all realc × n
matrices, andc∈
[ n2, ] is an integer. The matrixcn
ik
V
u U ~ = [ ] ∈
is called a fuzzy c-partition if it satisfies the following conditions [18]:
(1)
u ik ∈ [ 0 , 1 ], 1 ≤ i ≤ c & 1 ≤ k ≤ n
; (2)∑ c i = 1 u ik = 1 , 1 ≤ k ≤ n
;(3)
0 < ∑ n k = 1 u ik < n , 1 ≤ i ≤ c
.M
fcdenotes the set of all matrices satisfying the
above conditions. One of the frequently used criteria to improve an initially randomly assigned partition is the so-called variance criterion. This criterion measures the dissimilarity between the points in a cluster by the Euclidean distance. Supposex
k denotes a point in a data set X of p dimensions, and the location of a cluster is represented by its cluster centerv
i= ( v
i1, v
i2,..., v
ip) ∈ ℜ
p, i =
1,2,...,c
. Letcp
v
cv v
v = (
1,
2,..., ) ∈ ℜ
be the vector of all cluster centers, where eachv
i in general does not correspond to the element of the data set X. Then the fuzzy c-means clustering amounts to solving the following optimization problem:, )
( minimize )
~ ; (
1 1
∑ ∑ − 2
= = =
c i
n
k k i G
m ik
m U v u x v
z
(1a)where
v u x
nu i c
k m ik n
k k
m ik
i ( ) ( ) , 1,2,...,
1
1
∑ =
= ∑
=
= , (1b)
1 , 1
1
) 1 ( 1
2 )
1 ( 1
2
∑
−
= −
=
− − c j
m
j G k m
i G k ik
v v x
x
u
n k
c
i =
1,2,..., &=
1,2,..., , (1c)and
x
k− v
iG2= ( x
k− v
i)
TG ( x
k− v
i)
. (1d)Here
v
i, the cluster center, is the mean of thex
k m-weighted by their degrees of membership. In the context of fuzzy clustering, a pointx
k with a high degree of membership has a higher influence onv
i than those with low degrees of membership. This tendency is strengthened by the weight m, which is a real number greater than 1. As to G, it is a symmetric and positive-definite matrix with the dimension ofp×p. The fuzzy system described by the optimization
of~ ; )
( U v
z m
can not be solved analytically.Nevertheless, fuzzy c-means adopts an iterative procedure which can approximate the minimum of the objective function
~ ; )
( U v
z m
. This procedure is listed as follows [18]:Step 1. Choose
c∈
[ n2, ],m ∈
(1,∞
), and the symmetric and positive-definite matrix G with p×p. InitializeU ~ ( 0 ) ∈ M fc
, and set iterative index
s = 0
.Step 2. Calculate the fuzzy cluster centers
v
i( s) by substituting~
(s)U
into Eq. (1b).Step 3. Calculate the new membership matrix
) 1
~
(s+U
by substitutingv
i( s) into Eq. (1c) if) ( s i
k
v
x ≠
. Else set
≠
= =
+
. for 0
for
)
11 (
, j i
i u j s k j
Step 4. Calculate the distance
~ ( s 1 ) ~ ( s )
U
U −
=
∆ +
.If
∆ > ε
, sets = s + 1
and go to Step 2. Ifε
≤
∆
, then stop.3. THE IMPLEMENTATION OF THE DISTRIBUTED OPTIMIZATION APPROACH
Presented in Subsections 3.1 and 3.2 are two new fuzzy clustering algorithms based on genetic algorithms with the distributed optimization approach, where cluster centers and membership grades are chosen as coding parameters, respectively.
These algorithms implemented by a synchronous central server algorithm are given in Subsection 3.3.
3.1 Algorithm of the Distributed Optimization Approach of Serving Cluster Centers as Coding Parameters
The following depicts the algorithm of the distributed optimization approach of serving cluster centers as coding parameters.
Step 1. Select the values of cluster number ],
, 2
c∈
[ n fuzzier weightm ∈
(1,∞
), and coding length b. Then set generation index= 0 s
.Step 2. Compute the range
B
l( kl
n l k
n k
k
x x
,,..., 2 , , 1 ,..., 2 ,
1
min
max
==
−
=
) of the l-th featureof the data set, for
l =
1,2,...,p
, and applyb-bit uniform coding to encode the range B
l. This also implies that the cluster centersv
i,l, fori =
1,2,...,c
, are located in the rangeB l
. Step 3. The chromosomes are formed by concatenating the codedv
i,l , forc
i =
1,2,..., . For each feature l, randomly generate the number ofmaxpop
chromosomes as the first generation, so long as eachv
i,l (i =
1,2,...,c
) is located in its range. As the number of features is p (l =
1,2,...,p
), we are able to set up p independent evolution environments, which can be performed in parallel.Step 4. Run the
p independent evolution
environments by means of reproduction, crossover, and mutation to create the next generation. Meanwhile, set generation index1.
s
s = +
For each of the evolution environments, new maxpop chromosomes are generated, and the best popsize chromosomes are retained as the seeds for the next generation. The fitness function adopted in the l-th evolution environment is) (
lml
v
g
. Since the optimization problem is to search the global minimum, a smaller value ofg
ml( v
l)
is taken to have a higher fitness value in the algorithm.Step 5. Select the chromosome with the largest fitness value to compute the new
u
i,k's by means of Eq. (1c). The corresponding cluster centers which constitute the selected best chromosome are denoted by[ ]
. ) ..., , , ,...,
,..., , , ,..., , (
, ,
2 , 1 2 ,
2 , 2 2 , 1 1 , 1 , 2 1 , 1 ,
best p c p p c
c l best
i best
v v
v v
v v v v v v v
=
=
Step 6. Compute termination criterion
) ( ) 1
( s
best s
best v
v −
=
∆ +
. If∆ > ε
, go to Step 4.If
∆ ≤ ε
, then stop.3.2 Algorithm of the Distributed Optimization Approach of Serving Membership Grades as Coding Parameters
What follows states the algorithm of the distributed optimization approach of serving membership grades as coding parameters.
Step 1. Select the values of cluster number ],
, 2
c∈
[ n fuzzier weightm ∈
(1,∞
), and coding length b. Then set generation index= 0 s
.Step 2. The range of the membership grades of point
k is located in [0, 1], for k =
1,2,...,n
. Useb-bit uniform coding to encode the range [0,
1].Step 3. The chromosomes are formed by concatenating the coded
u i , k
, forc
i =
1,2,..., . For each data point k, randomly generate the number ofmaxpop
chromosomes as the first generation, so long as eachu i , k
(i =
1,2,...,c
) is located in the range [0, 1]. As the number of data points isn ( k =
1,2,...,n
), we are able to set up n independent evolution environments, which can be performed in parallel.Step 4. Run the
n independent evolution
environments by means of reproduction, crossover, and mutation to create the next generation. Meanwhile, set generation index1.
s
s = +
For each of the evolution environments, new maxpop chromosomes are generated, and the best popsize chromosomes are retained as the seeds for the next generation. The fitness function adopted in the k-th evolution environment is) ( k
mk U
g
. Since the optimization problem is to search the global minimum, a smaller value ofg mk ( U k )
is taken to have a higher fitness value in the algorithm.Step 5. Select the chromosome with the largest fitness value to compute the new
v
i' s
by means of Eq. (1b). The corresponding membership grades which constitute the selected best chromosome are denoted by[ ]
. ) ,..., , ,...,
,..., , , ,..., , (
, , 2 , 1 2 ,
2 , 2 2 , 1 1 , 1 , 2 1 , 1 ,
best n c p p c
c k best
i best
u u u u
u u u u u u u
=
=
Step 6. Compute termination criterion
) ( ) 1
( s
best s
best u
u −
=
∆ +
. If∆ > ε
, go to Step 4.If
∆ ≤ ε
, then stop.3.3. The Distributed Optimization Approach Implemented by a Synchronous Central Server Algorithm
Nowadays, parallelism appears as an inevitable technique to reach large computation abilities.
Usually, a distributed system is defined as a collection of autonomous computers linked by a
network, with software designed to produce an integrated computing facility [19]. Distributed system software enables computers to coordinate their activities and to share the resources of the system hardware, software, and data. For example, if a collection of processes shares a resource or collection of resources managed by a server, then mutual exclusion is often required to prevent interference and ensure consistency when accessing the resources. Therefore, the coordination problem is known as one of the key considerations for the success of distributed system software. On the basis of genetic algorithms, our new distributed approach to fuzzy clustering is very suitable to be implemented on a parallel machine or a distributed computing environment. In this report, our approach is realized using a synchronous central server algorithm, which is a very simple way to achieve coordination. The
“synchronous” here indicates that a causal ordering has intervened in the central server algorithm.
Figure 1 shows the architecture of the synchronous central server algorithm. In this algorithm, the n clients correspond to the n independent evolution environments. For instance, the evolution environment of data point
x
k is clientk. After client k runs a genetic algorithm to obtain
better membership gradesu
ik' s
forx
k, it will send a request token to the server for updatingu
ik' s
and calculating new cluster centersv
i' s
. Before the server issues a reply token, client k will go into a waiting state. The server maintains twoc × n
arrays,) ( ) ( A and u B
u
, of the membership grades. The first one,u ( A ) = ( u 11 ( A ) , u 21 ( A ) ,..., u c ( 1 A ) , u 12 ( A ) , u ( 22 A ) ,..., u c ( 2 A ) ,...,
), ,..., , ( 2 ) ( )
) ( 1
A cn A n A
n u u
u
is for storing the new membership grades received from each of the clients in the current loop, and the second one,, , ,..., ,..., , , ,..., ,
( 11 ( ) 21 ( ) ( 1 ) 12 ( ) 22 ( ) ( 2 ) 1 ( ) 2 ( )
)
( B
n B n B c B B B c B B
B = u u u u u u u u
u )
..., u cn ( B )
, is for storing the old membership grades of the last loop. Each element of the arrays u(A) and u(B) is set to zero initially. Another important design of our server, we should point out, is that multiple threads are utilized to benefit its performance.Generally speaking, if a server has more than one thread, it needs to make its operations become atomic in order to keep its data items consistent [20]. This means that the effect of performing any single operation is free from interference due to concurrent operations being performed in other threads. To ensure that the effect of each operation is atomic, the server must guarantee that no other thread can access the same data items until the first thread has finished.
This can be easily achieved by use of mutual exclusion mechanism such as critical section, mutex, or semaphore.
Observing the synchronous central server algorithm depicted below, first, the “procedure 1: on initialization” of the server will set up a queue,
ReceiverQueue (a structure array with length n), for
storing the requests from the clients, and, second, the procedure 1 of the server will create a thread 2 as well, for handling the requests from the clients. The thread 2 has only one procedure, “procedure 7: on receiving,” whose function is to put the requests in the queue and increase the counter. For the synchronous server algorithm, procedure 7 should be an atomic operation, because when the subroutine 2 of thread 1 tries to decrease the shared data itemCounterR (queue counter), a request semaphore from
the clients, which tries to increase the CounterR may be received at this time. Therefore, an atomic operation is needed to relieve this situation.
v i
x n
x 2
x 1
1 2 n
ReceiverQueue Request token for updating u
ik′s and calculating v
i′s
Reply token with new v
i′s
x k
Request token for updating
u
i2′s and
calculating
s
i ' v
… Server
Figure 1.
The architecture of the synchronous central server algorithm.
When the server finds that there are queued requests which have not been processed (
CounterR − ProcssedCl ients ≠ 0
), the server will fetch a request (which is presented as the form of) ,..., ,
( u
1ku
2ku
ckrequest
) queued in the array,ReceiverQueue[ProcessedClients]. Then it copies
) ,..., ,
( u
1(kA)u
(2Ak)u
ck(A) to( u
1(kB), u
2(Bk),..., u
ck(B))
, updates)
,..., ,
( u
1(kA)u
(2Ak)u
ck(A) with the fetched( u
1k, u
2k,...,
ck
)
u
, and increases the ProcessedClients by one.After all the n clients’ requests are received and processed, Eq. (1b) is utilized to compute the new cluster centers. Next, compute the distance
) ( )
( A B
u u −
=
∆
, and test whether the termination criterion is satisfied or not. If so, the server sends a reply token to all the n clients with the flag,Terminate, set to TRUE. The flag is employed to
signal the clients to stop their programs. Then the server will terminate itself as well. If the criterion is not satisfied, the server also sends a reply token, which includes the information of the computed news
i '
v
and the Terminate flag set to FALSE. Next the server will back to a waiting state which is ready to process the newly arrival requests. The most important issue of the server is that a causal ordering is defined on it. That is the event of sending the reply tokens must happen behind all the n events of receiving the requests from the n clients. The synchronization is attained by means of the defined causal ordering [21]. When a client receives the reply token, it will end the waiting state and check if theTerminate flag is set to TRUE. If it is the case, the
client will terminate itself. Otherwise, it replaces theold
v i ' s
by the newv i ' s
attached in the reply token, runs a genetic algorithm to obtain the news
ik '
u
, and sends a request with the appended news
ik '
u
to the server again. Then the client backs to a waiting state.4. EXPERIMENTAL RESULTS AND DISCUSSIONS
To demonstrate the validity of our approach, two examples are given in the following simulation.
These examples are the well-known butterfly and Anderson’s Iris data sets, which are usually applied to test clustering algorithms. All the coefficients used throughout the two examples are listed below.
Weight: m = 1 or 2; population size survived in each generation: popsize = 70; maximum population size in each generation: maxpop = 200; mutation probability: pm = 0.1; crossover probability:
p
c = 1.0; Lagrange multiplier: r = 20gavg; norm matrix: G= identity matrix I.
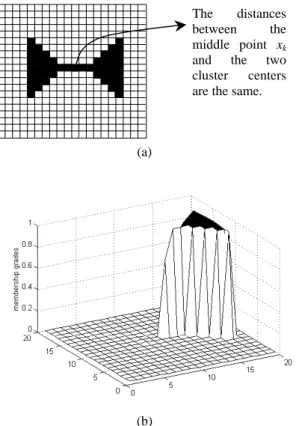
Example 1. The butterfly data set shown in Fig. 2 is composed of 53 data points and ready to be classified into two clusters with m = 1 and m = 2, respectively.
(b)
The distances between the middle point x
kand the two cluster centers are the same.
(a)
Figure 2.
(a) The original data set; (b) & (c) the membership grades of the data points in Clusters 1 and 2, respectively, for m = 1 ; (d) &
(e) the membership grades of the data points in Clusters 1 and 2, respectively, for m = 2 ; (f) &
(g) number of mis-classified points versus loops,
for m = 2 and m = 3 , respectively.
(c)
(e) (d)
0 2 4 6 8 10 12
loops (f) 25
20
15
10
5
0
mis -classified points
0 2 4 6 8 10 12
loops (g) 25
20
15
10
5
0
mis -classified points
Figure 2.
(Continued).
Example 2. Iris data set has been tested in many papers to illustrate various unsupervised clustering and supervised classification purposes [22]. The data set contains three species of iris, setosa, versicolor, and virginica, with 50 objects per species. There are four features measured on each object, so this is a four-dimensional data set with 150 objects to be classified into three clusters. One cluster is linearly separable from the data set, while the other two clusters have overlapping area, which are not linearly separable. The visualization of membership grades is not possible for the four dimensional data set, so, in Fig. 3, only the number of mis-classified objects and the energy of objective function
~ ; )
( U v
z m
versus iterations are shown. From Fig. 3(a), we can see that the mis-classified points descend to 13 instead of zero finally. This is due to the lack of information in the overlapping area. In this situation, maybe the fifth or even more features should be extracted to classify the data set, if possible. Moreover, the 13 mis-classified objects are gathered in Clusters 2 and 3. The 50 objects in Cluster 1 are all correctly classified.100 90 80 70 60 50 40 30 20 10
0 5 10 15 20 25 30 35 40 45 iterations
(a)
mis -classified points
Figure 3.
(a) Number of mis-classified objects versus iterations of Iris data set; (b) energy of objective function ~ ; )
( U v
z m versus iterations.
350 300 250 200 150 100 energy of objective finction 50
0 5 10 15 20 25 30 35 40 45 iterations
(b)
Figure 3. (Continued).
5. CONCLUSIONS
We have successfully presented a distributed optimization approach to fuzzy c-partition clustering based on genetic algorithms. Compared to traditional methods, our algorithm can converge quickly and correctly. It is known that fuzzy c-means is an iterative algorithm, and its theory is set upon differentiating the objective function with respect to both
v i
andu ik .
Hence, the minimization result of fuzzy c-means has chance to fall into a local minimum. Yet what we expect is a global minimum.Therefore, genetic algorithms have been incorporated into fuzzy c-means to solve the problem of falling into a local minimum. However, the traditional combination of genetic algorithms and fuzzy clustering has some problems also. The first is the search space is too large, and the second is the accuracy of the search parameters is possibly not enough. These motivated us to analyze the definition of fuzzy c-partition clustering and utilize the nature of the iterative method. As a result, a novel distributed optimization approach to fuzzy c-partition clustering based on genetic algorithms is proposed to divide the huge search space into many small ones.
When choosing cluster centers as the coding parameters, the original objective function with a huge search space has been transformed into p new objective functions with smaller search spaces. For a
b-bit coding, the original search space is
2c × p × b
; however, after our transformation, the new search space becomes p⋅2c×b. The enormous reduction of the search space will cause the probability of finding the global minimum to be largely increased. When choosing membership grades as the coding parameters, the original objective function with a huge search space has been transformed into the summation of n new objective functions with smaller search spaces. For a b-bit coding, the original search space is 2c × n × b
; however, after our transformation, the new search space is changed ton ⋅2 c × b
. Such huge reduction of the search space will also cause the probability of finding the global minimum to be largely increased.Our new distributed optimization approach to fuzzy clustering based on genetic algorithms is very suitable to be implemented on a parallel machine or a distributed computing environment, so we select the architecture of the synchronous central server algorithm to target our approach on it.
6. REFERENCES
[1] M. S. Yang, “On fuzzy clustering,” in Proc. of
the 1st Nat. Symp. on Fuzzy Set Theory &
Appl., Hsinchu, Taiwan, 1993, pp. 133-142.
[2] J. T. Tou and R. C. Gonzalez, Pattern
Recognition Principles, Reading, MA:
Addison-Wesley, 1974, chap. 3, pp. 97-104.
[3] D. Chaudhuri, B. B. Chaudhuri, and C. A.
Murthy, “A new split-and-merge clustering technique,” Pattern Recognition Letters, vol.
13, pp. 399-409, 1992.
[4] S. Z. Selim and K. Alsultan, “A simulated annealing algorithm for the clustering problem,” Pattern Recognition, vol. 24, no. 10, pp. 1003-1008, 1991.
[5] D. E. Brown and C. L. Huntley, “A practical application of simulated annealing to clustering,” Pattern Recognition, vol. 25, no.
4, pp. 401-412, 1992.
[6] Q. Zhang and R. D. Boyle, “A new clustering algorithm with multiple runs of iterative procedures,” Pattern Recognition, vol. 24, no.
9, pp. 835-848, 1991.
[7] E. H. Ruspini, “A new approach to clustering,” Inform. & Control, vol. 15, pp.
22-32, 1969.
[8] J. C. Bezdek, Pattern Recognition with Fuzzy
Objective Function Algorithms, New York:
Plenum Press, 1981, chap. 3, pp. 65-80.
[9] R. N. Dave, “Generalized fuzzy c-shells clustering and detection of circular and elliptical boundaries,” Pattern Recognition, vol. 25, no. 7, pp. 713-721, 1992.
[10] R. Krishnapuram, O. Nasraoui, and H. Frigui,
“The fuzzy c spherical shells algorithm: a new approach,” IEEE Trans. Neural Net., vol. 3, no. 5, pp. 663-670, 1992.
[11] D. E. Goldberg, Genetic Algorithms in Search,
Optimization, and Machine Learning,
Reading, MA: Addison-Wesley, 1989, chap. 3, pp. 59-86.[12] G. P. Babu and M. N. Murty, “Clustering with evolution strategies,” Pattern Recognition, vol.
27, no. 2, pp. 321-329, 1994.
[13] T. V. Le, “Evolutionary fuzzy clustering,” in
Proc. of IEEE Int. Conf. on Evolutionary Comput., Perth, Western Australia, 1995, pp.
753-758.
[14] F. Klawonn and A. keller, “Fuzzy clustering with evolutionary algorithm,” Int. Jour. of
Intelligent Systems, vol. 13, pp. 975-991,
1998.[15] K. S. Al-Sultan and S. Z. Selim, “A global algorithm for the fuzzy clustering problem,”
Pattern Recognition, vol. 26, no. 9, pp.
1357-1361, 1993.
[16] S. Chitroub, A. Houacine and B. Sansal,
“Robust optimal fuzzy clustering algorithm applicable to multispectral and polarimetric synthetic aperture radar images,” in Proc. of
the SPIE on Image and Signal Processing for Remote Sensing V, Florence, Italy, Sept., 1999,
vol. 3871, pp. 325-336.[17] S. Miyamoto and S. Katoh, “Crisp and fuzzy methods of optimal clustering on networks of objects,” in Proc. of the 1998 Second Int. Conf.
on Knowledge-Based Intelligent Electronic Systems, Adelaide, Australia, April, 1998, pp.
8-14.
[18] H. J. Zimmermann, Fuzzy Set Theory and Its
Applications, 2nd Ed., Boston, MA: Kluwer
Academic, 1991, chap. 11, pp. 220-236.[19] G. Coulouris, J. Dollimore, and Tim Kindberg,
Distributed Systems Concepts and Design,
2nd Ed., Reading, MA: Addison-Wesley, 1994, chap. 1, pp. 1-26, chap. 10, pp. 297-309, and chap. 12, pp. 354-366.[20] E. Melin, B. Raffin, X. Rebeuf, and B. Virot, A structured synchronization and communication model fitting irregular data accesses, Jour. Parallel and Distributed
Computing, vol. 50, no. 1-2, pp. 3-27, 1998.
[21] R. C. Gonzalez and R. E. Woods, Digital
Image Processing, 3rd Ed., Reading, MA:
Addison-Wesley, 1992, chap. 2, pp. 45-47.
[22] M. Nadler and E. P. Smith, Pattern
Recognition engineering, New York, NY:
John Wiley & Sons, Inc., 1993, chap. 7, pp.
340-345.