國立臺灣大學管理學院資訊管理研究所 碩士論文
Graduate Institute of Information Management College of Management
National Taiwan University Master Thesis
結合臺灣健保資料庫與生物醫學文獻偵測藥物不良反應 Detecting Drug Safety Signals by Combining National Taiwan Health Insurance Research Database and Biomedical Literature
劉睿蕓
Jui-Yun Liu
指導教授:魏志平 教授 Advisor: Chih-Ping Wei, Ph.D.
中華民國 105 年 7 月
July 2016
口試委員會審定書
誌謝
兩年的碩士生涯如今也到了尾聲,能夠完成兩年學業與這份論文,最感謝的人 莫過於指導教授──魏志平老師。魏老師的教學態度十分嚴謹細心,邏輯清晰,於 研究上,老師會適時地幫助我們了解整體的研究架構與研究方法,讓我們不要迷失 方向,並清楚地指出我們未想到的盲點,引導我們深入地去分析研究資料與結果。
另外,老師時常會分享自己的過往生活趣事與人生經驗,並關心我們的日常生活與 學業,教導我們積極面對未來。也特別感謝三位口試委員:劉敦仁老師、盧信銘老 師及蕭斐元老師,在口試時給予許多寶貴的建議,讓本論文更臻完善。
接著,要感謝辛苦叮嚀與張羅我們大小事的虹鈞,讓我們能夠專心研究。感謝 一起奮鬥的好夥伴冠穎、張翔、子嫻與敏倫,不時地互相督促、互相鼓勵、互相幫 助,以後再一起出去吃喝玩樂!感謝竣貿與學弟妹們:雯伶、坤樸、彥勳、奕閔與 世祐的幫忙與協助,已經畢業的學長姐子勻、宇婷、筑雅與昱安的照顧,以及常常 鼓勵我、關心我的朋友們。最後,當然要感謝我的家人給予我的支持與鼓勵,長時 間包容我的怪脾氣與熬夜習慣,我愛你們。
劉睿蕓 謹識 于臺大資訊管理學研究所 西元二零一六年七月
中文摘要
因受限於受試者人數與觀察期長度,在藥物上市前的臨床實驗中很難發現所 有的藥物不良反應。因此,藥物主動監視(Pharmacovigilance)的目標在於提早偵 測出藥物安全信號,並最大限度地減少對病人的傷害。一個信號(signal)指的是 一個潛在的藥物不良反應,而這個藥物與不良反應(疾病)之間的關係是以前不曾 被得知的或未正式被記錄下來的。藥物不良反應自發報告系統(Spontaneous Reporting System)和電子健康記錄(Electronic Health Record)是用於偵測藥物安 全信號的兩個主要資料來源。由於 SRS 資料存在一些限制,有研究轉向使用電子 健康紀錄進行藥物上市後監控。近年來,開始有人使用多個資料來源偵測藥物不良 反應,如生物醫學文獻也可以用來輔助藥物上市後監控。
在本研究中,我們提出一個改良方法,藉由結合臺灣健保資料庫與 MEDLINE 資料庫,並利用排序學習法排序可疑的藥物安全信號,找出可能的藥物不良反應。
除了傳統基於失衡分析法的變數外,我們也納入了基於主題模型考量藥物和疾病 之間隱性關係的變數以及基於 ABC 模型的文獻變數。我們亦建立了三個額外的實 驗情境以評估本研究所提出的方法效能。主要結果顯示,本研究所提出的使用多個 變數和多種資料來源的方法能夠有效提升偵測藥物不良反應的準確度。
關鍵字:藥物主動監視、資料探勘、臺灣健保資料庫、生物醫學文獻
ABSTRACT
It is difficult to identify all the adverse drug reactions (ADRs) during premarketing clinical trials. As the result, the aims of Pharmacovigilance (PhV) are detecting signals early and minimizing harm to patients. A signal means a potential adverse drug event which is previously unknown or incompletely recorded. Spontaneous reporting system (SRS) and electronic health record (EHR) are two major data sources used for drug safety signal detection. Due to inherent limitations of using SRSs for signal detection, some research has focused on the use of EHR databases for PhV. In recent years, some researchers start to use multiple data sources to detect adverse drug events. For example, biomedical literature has been used to assist the detection of potentials ADRs.
In this study, we propose an improved method incorporating both Taiwan’s national health insurance research database and MEDLINE database to rank and detect signals on the basis of a learning to rank approach. In addition to multiple traditional disproportional analysis measures and LDA-based measures considering the implicit relations between drugs and diseases, literature-based measures under the idea of ABC model are also added.
We also design three additional experiments to evaluate our proposed method for drug safety signal detection. The major results show that our proposed method using multiple measures and multiple sources has better effectiveness for signal detection than using single measure and single source, except for one disease.
Keywords: Pharmacovigilance, Data mining, NHIRD, Biomedical literature
TABLE OF CONTENTS
口試委員會審定書 ... i
誌謝 ... ii
中文摘要 ... iii
ABSTRACT ... iv
TABLE OF CONTENTS ... v
LIST OF FIGURES ... vii
LIST OF TABLES ... ix
Chapter 1 Introduction ... 1
1.1 Background ... 1
1.2 Research Motivation and Objective... 3
Chapter 2 Literature Review ... 5
2.1 Spontaneous Reporting Systems (SRSs) ... 5
2.1.1 Definition and Examples of SRSs ... 5
2.1.2 Existing SRS-based Methods ... 6
2.2 Electronic Health Records (EHRs) ... 10
2.2.1 Definition and Examples of EHRs ... 10
2.2.2 Existing EHR-based Methods ... 10
2.2.3 Traits of EHRs ... 11
2.3 Biomedical Literature ... 12
2.3.1 Definition and Famous Database of Biomedical Literature ... 12
2.3.2 Existing Literature-based Methods ... 13
2.4 Research Gap ... 16
Chapter 3 Our Proposed Method ... 20
3.1 Data Preprocessing for Training ... 21
3.1.1 Patient Visits Generation ... 22
3.1.2 Drug-Appearing Diagnosis (DAD) Generation ... 24
3.1.3 Disease or Drug Grouping ... 25
3.1.4 Signal Labeling ... 25
3.1.5 Term Mapping ... 26
3.1.6 Concept Network Construction ... 27
3.2 Learning System ... 30
3.2.1 DAD-based Measure Calculation ... 30
3.2.2 Network-based Measure Calculation ... 33
3.2.3 Summary of All Measures ... 37
3.2.4 Ranking Model Building ... 38
3.3 Data Preprocessing for Testing ... 39
3.4 Detection System ... 40
3.4.1 DAD-based or Network-based Measure Calculation ... 40
3.4.2 Signal Ranking ... 40
Chapter 4 Evaluation and Results ... 42
4.1 Experimental Data ... 42
4.1.1 NHIRD ... 42
4.1.2 MEDLINE ... 46
4.1.3 Ontologies ... 46
4.1.4 Term Mapping ... 47
4.2 Evaluation Design ... 47
4.2.1 Evaluation Criteria ... 47
4.2.2 Evaluation Procedure ... 49
4.3 Comparative Experiment ... 49
4.4 Additional Experiments ... 53
4.4.1 Experiment 1: Effects of Different Training Sizes ... 53
4.4.2 Experiment 2: Effects of Different Window Sizes ... 56
4.4.3 Experiment 3: Feasibilities of Cross-Domain Training. ... 63
Chapter 5 Conclusion and Future Work... 68
References ... 70
LIST OF FIGURES
Figure 1. The basic concept of Swanson’s ABC model ... 13
Figure 2. The general framework of a LBD system ... 14
Figure 3. The framework of learning-to-rank (Liu, 2009)... 18
Figure 4. The overall process of our proposed method ... 20
Figure 5. The detailed process of the data preprocessing for training phase ... 22
Figure 6. Example of DAD generation proposed by Hsieh (2014) ... 24
Figure 7. The detailed process of the learning system ... 30
Figure 8. Example of link grouping by using MAX method... 35
Figure 9. Example of the calculation of Link 2 measures after link grouping ... 36
Figure 10. Example of the calculation of Link 1 measures after link grouping ... 36
Figure 11. The detailed process of the data preprocessing for testing phase... 39
Figure 12. The detailed process of the detection system ... 40
Figure 13. The arrangement of coders ... 43
Figure 14. The rule to solve the inconsistency problem ... 44
Figure 15. Comparative NDCG evaluation results of cancer ... 51
Figure 16. Comparative NDCG evaluation results of cardiovascular events ... 51
Figure 17. Comparative NDCG evaluation results of hepatotoxicity ... 52
Figure 18. Comparative NDCG evaluation results of acute renal failure ... 52
Figure 19. Effects of different training sizes (for cancer) ... 54
Figure 20. Effects of different training sizes (for cardiovascular events) ... 55
Figure 21. Effects of different training sizes (for hepatotoxicity) ... 55
Figure 22. Effects of different training sizes (for acute renal failure) ... 56
Figure 23. Effects of different control window sizes (for cancer) ... 58
Figure 24. Effects of different control window sizes (for cardiovascular events) ... 58
Figure 25. Effects of different control window sizes (for hepatotoxicity) ... 59
Figure 26. Effects of different control window sizes (for acute renal failure) ... 59
Figure 27. Effects of different observation window sizes (for cancer) ... 60
Figure 28. Effects of different observation window sizes (for cardiovascular events) ... 61
Figure 29. Effects of different observation window sizes (for hepatotoxicity) ... 61
Figure 30. Effects of different observation window sizes (for acute renal failure) ... 62
Figure 31. Illustration of mono-domain training ... 63
Figure 32. Illustration of cross-domain training ... 64 Figure 33. The NDCG results of cross-domain training (20%-80%) for cancer ... 65 Figure 34. The NDCG results of cross-domain training (20%-80%) for cardiovascular events ... 65 Figure 35. The NDCG results of cross-domain training (20%-80%) for hepatotoxicity 66 Figure 36. The NDCG results of cross-domain training (20%-80%) for acute renal failure
... 66
LIST OF TABLES
Table 1. A 2x2 contingency table for the association between a drug 𝑋 and an adverse
event 𝑌 ... 7
Table 2. Commonly disproportional analysis measures of frequentist methods ... 8
Table 3. The probabilities calculated in the LDA model ... 11
Table 4. The description of some link weighting methods ... 15
Table 5. The description of six claim data files in NHIRD ... 23
Table 6. The details of label types and their corresponding relevance scores ... 26
Table 7. Example of term mapping considering hierarchical structure ... 27
Table 8. Irrelevant publication types ... 28
Table 9. The MeSH subcategories selected by Chen (2013) ... 28
Table 10. Summary of the number of relations retrieved from ontology databases ... 29
Table 11. Example of a contingency table for {ATC1ICD3} ... 31
Table 12. The probabilities calculated from the LDA model in our study ... 32
Table 13. The summary table of LDA-based measures in our study ... 33
Table 14. Link weighting methods and corresponding concept networks in our study .. 34
Table 15. The description and formula of each target term ranking method ... 35
Table 16. Summary of all measures adopted in our proposed method ... 37
Table 17. Disease types and their corresponding ICD-9-CM codes ... 43
Table 18. Summary of different label types in four disease types ... 44
Table 19. Summary of different label types in four disease types after considering the year of literature... 45
Table 20. Summary of different label types in four disease types after considering the year of literature and the emerged year of drugs. ... 46
Table 21. Summary of the comparative experimental results ... 53
Table 22. The number of pairs in different control window sizes ... 57
Table 23. The number of pairs in different observation window sizes ... 60
Table 24. Summary of the results of the experiment 3 ... 67
Chapter 1 Introduction
1.1 Background
The drug approval process defined by the U.S. Food and Drug Administration (FDA) has three phases of clinical trials to ensure drugs are safe and effective. The purpose of the first phase is to find what the drug side effects most frequently occur, and the second phase is to obtain preliminary data on whether the drug works in people who have a certain disease or condition. After testing the two phases, the third phase would extend the scale of trials, such as different populations, different dosages or different concomitant medications (FDA, 2015).
However, there are some limitations on these clinical trials. First, the number of human subjects in the clinical trials is too limited to represent as all patients in the world.
Second, the length of observation period is not enough to cover the much longer periods in the real world. In consequence of the limited number of human subjects and the deficiency of observation period, it is difficult to identify all the adverse drug reactions (ADRs), especially the rare or long-latency ones, during the premarketing clinical trials (Almenoff et al., 2007; Harpaz et al., 2012; Hsieh, 2014; Henriksson et al., 2015).
Therefore, it is important to persistently monitor and evaluate the safety of drugs after marketing.
Pharmacovigilance (PhV), also known as post-marketing drug safety surveillance,
is defined by WHO as “the science and activities relating to the detection, assessment,
understanding and prevention of adverse effects or any other medicine-related problem.”
The aims of pharmacovigilance are to detect signals regarding possible adverse reactions early and to minimize harm to patients. A “signal” can refer to reported information on a possible causal relationship between an adverse event (AE) and a drug (or more drugs), the relationship being previously unknown or incompletely documented (WHO, 2002). It can alert healthcare professionals that the relationship among the drug-AE pair is worthy to explore further (Bate & Evans, 2009; Hauben & Aronson, 2009; Sakaeda et al., 2013).
Currently, there are several data sources used for signal detection, such as spontaneous report systems (SRSs), electronic health records (EHRs), and biomedical literature.
Since pharmacovigilance predominantly relies on the analysis of spontaneous reports in the early stage, many signal detection methods have been developed on the basis of spontaneous report systems (SRSs). Disproportionality analysis (DPA) is the most widely adopted approach for signal detection. According to different measures used in the DPA approach, it can be divided into two types: frequentist methods and Bayesian methods (Almenoff et al., 2007; Coloma et al., 2013). Nevertheless, well-recognized limitations exist in SRSs due to their intrinsic nature. In order to complement some of the deficiencies in SRS, some research presently has focused on the expanded secondary use of electronic health records (EHRs). Previous research using the biomedical literature as
data source is mostly for drug repurposing; by contrast, using literature for predicting adverse events is in the minority. However, biomedical literature has been used to assist the detection of potential ADRs in recent years (Avillach et al., 2013; Deftereos et al., 2011; Harpaz et al., 2014; Shetty & Dalal, 2011; Shang et al., 2014).
1.2 Research Motivation and Objective
Since adverse drug reactions may cause serious problems such as death, it is important to early identify ADRs by persistently monitoring on post-approval drugs.
SRSs and EHRs have been proven to be promising data sources for pharmacovigilance.
SRS is the most popular data source currently for signal detection, and several useful disproportionality analysis measures have been developed. However, there are some limitations caused by the intrinsic nature of SRSs. Thus, some researchers move the analysis methods using in SRSs to EHRs because of their large sample size, quality and completeness. Although most previous studies rely on a single source, either SRS or EHR, some researchers start to use multiple information sources to detect adverse drug events (Harpaz et al., 2013; Shang, 2014; Xu & Wang, 2014).
In this study, we propose an improved system incorporating both EHRs and biomedical literature to detect drug safety signals. In addition to different traditional DPA measures, the proposed method will combine one type of the ranking variables described by Hsieh (2014): drug-disease association measures, which can consider the implicit
relations between drugs and diseases for reducing the importance of non-drug-AE pairs (non-signals). Also, the literature-based measures are added as the third type of our ranking variables to improve the effectiveness of the method. Since different measures are suitable for different situations and the importance of different data sources for signal detection cannot be known, a pairwise learning to rank approach, which is a supervised learning method, will be used for combining multiple measures from different data sources to predict and rank signals. Besides, we will use National Health Insurance Research Database (NHIRD) in Taiwan covering the duration from 2000 to 2009 and MEDLINE database until 2010 as our data sources for signal detection. Three ontology databases will be also used for increasing the reliability of concept network built from literature.
The remainder of this thesis is organized as follows. In the next chapter, we review the data sources related to this study and their existing drug safety signal detection methods. Chapter 3 describes our proposed method, and then Chapter 4 will discuss the design of evaluation and the experimental results. Finally, Chapter 5 concludes this study, and gives some suggestions for future work.
Chapter 2 Literature Review
In this chapter, we first review two kinds of databases commonly used for pharmacovigilance and their existing drug safety detection methods. In addition to these databases, some researchers use biomedical literature to predict plausible adverse drug events and assist the detection of ADRs. Therefore, we will also review previous works related to this data source.
2.1 Spontaneous Reporting Systems (SRSs) 2.1.1 Definition and Examples of SRSs
In the wake of the thalidomide tragedy in the late 1960s, SRSs have been developed for post-marketing drug surveillance by many countries (Almenoff et al., 2007; Coloma et al., 2013). A spontaneous reporting system is a database to collect and save the spontaneous reports of suspected adverse events through voluntary reporters, who may be healthcare professionals, manufacturers, or even patients. Each report contains main information about patient demographics, suspected drugs, and adverse events occurring.
Besides, other information is optionally provided by reporters, such as concomitant use of medications, comorbidity, drug therapy dates and the date of the event occurring (Harpaz, Chase & Friedman, 2010).
There are some well-known SRSs used for post-marketing surveillance: the United States FDA’s Adverse Event Reporting System (FAERS), the World Health
Organization’s (WHO) VigiBase, and the European Medicines Evaluation Agency’s
(EMEA) EudraVigilance.
2.1.2 Existing SRS-based Methods
Traditional methods of detecting adverse drug events in SRSs relied on manual case reviews by pharmacological/clinical experts. However, due to the increasing size and complexity of data from SRSs, quantitative approaches that are generally designed to identify statistically significant associations between drugs and AEs have been proposed (Harpaz, Chase & Friedman, 2010).
Disproportionality analysis (DPA) is the approach most frequently used for signal detection on SRSs. The purpose of DPA is to measure the strength of drug-AE pairs (or associations) and then to find out the significant pairs (or associations) occurring at higher than expected frequencies (Bate & Evans, 2009; Coloma et al., 2013). Common DPA
measures include the relative reporting ratio (RRR), the proportional reporting ratios (PRR, used in EMEA’s EudraVigilance), the reporting odd ratio (ROR), the information
component (IC) calculated by Bayesian confidence propagation neural network (BCPNN, used in WHO’s VigiBase), and the empirical Bayes geometric mean (EBGM) computed
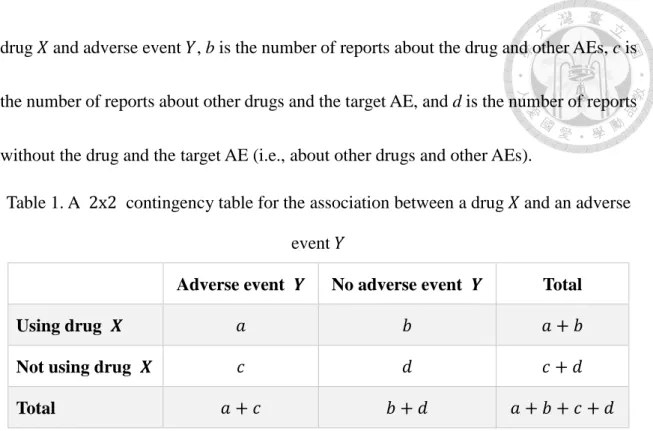
in multi-item gamma poisson shrinker (MGPS, used in the FDA’s AERS). For each drug- AE association, a two-by-two contingency table can be constructed by calculating the number of reports. In Table 1, a is the observed number of reports mentioning both
drug 𝑋 and adverse event 𝑌, b is the number of reports about the drug and other AEs, c is
the number of reports about other drugs and the target AE, and d is the number of reports
without the drug and the target AE (i.e., about other drugs and other AEs).
Table 1. A 2x2 contingency table for the association between a drug 𝑋 and an adverse event 𝑌
Adverse event 𝒀 No adverse event 𝒀 Total
Using drug 𝑿 𝑎 𝑏 𝑎 + 𝑏
Not using drug 𝑿 𝑐 𝑑 𝑐 + 𝑑
Total 𝑎 + 𝑐 𝑏 + 𝑑 𝑎 + 𝑏 + 𝑐 + 𝑑
Based on the 2-by-2 contingency table, these DPA measures can be calculated by comparing the observed frequency of drug-AE associations with the baseline expected frequency (Almenoff et al., 2007; Bate & Evans, 2009; Coloma et al., 2013; Hauben &
Bate, 2009; Harpaz et al., 2012). The expected frequency can be computed under an assumption that the drug and the adverse event occur independently (i.e. no association between the drug and the AE). The higher the observed frequency (i.e. count of observed reports) exceeds the expected frequency, the larger the value of these measures. If one of the drug-AE pairs has the significantly larger value than the others, it can be worthy of further investigation.
Furthermore, these measures can be classified into two types: frequentist methods and Bayesian methods (Harpaz et al., 2012; Sakaeda et al., 2013). Table 2 lists the
detailed information about measures of frequentist methods. Bayesian methods account for the uncertainty in the disproportionality measures when the counts are small (i.e.
sampling variation) by “shrinking” the measure toward the baseline case of no association (Almenoff et al., 2007; Harpaz et al., 2012). As the result of this shrinkage, spurious associations that have insufficient data to support them can be reduced. The BCPNN measure, one of the Bayesian methods, is based on estimation of the IC in a Bayesian confidence propagation neural network. Since the real probabilities of 𝑃(𝑑𝑟𝑢𝑔), 𝑃(𝐴𝐸) and 𝑃(𝐴𝐸|𝑑𝑟𝑢𝑔) are unknown, the expected values of each probability are calculated
in a beta distribution as BCPNN (Hsieh, 2014).
Table 2. Commonly disproportional analysis measures of frequentist methods DPA measure Mathematical definition Probabilistic interpretation
RRR 𝑎(𝑎 + 𝑏 + 𝑐 + 𝑑)
(𝑎 + 𝑐)(𝑏 + 𝑑)
𝑃(𝐴𝐸|𝑑𝑟𝑢𝑔) 𝑃(𝐴𝐸)𝑃(𝑑𝑟𝑢𝑔)
PRR 𝑎(𝑐 + 𝑑)
𝑐(𝑎 + 𝑏)
𝑃(𝐴𝐸|𝑑𝑟𝑢𝑔) 𝑃(𝐴𝐸|~𝑑𝑟𝑢𝑔)
ROR 𝑎𝑑
𝑐𝑏
𝑃(𝑑𝑟𝑢𝑔|𝐴𝐸)/𝑃(~𝑑𝑟𝑢𝑔|𝐴𝐸) 𝑃(𝑑𝑟𝑢𝑔|~𝐴𝐸)/𝑃(~𝑑𝑟𝑢𝑔|~𝐴𝐸)
IC log2𝑎(𝑎 + 𝑏 + 𝑐 + 𝑑)
(𝑎 + 𝑐)(𝑏 + 𝑑) log2 𝑃(𝐴𝐸|𝑑𝑟𝑢𝑔)
𝑃(𝐴𝐸)𝑃(𝑑𝑟𝑢𝑔)
2.1.3 Traits of SRSs
Since the spontaneous reporting is dependent on voluntary reporters, there are some inherent limitations of using SRSs for signal detection, such as underreporting, overreporting, duplicate reports, missing or incomplete data on reports, misattribution of
causality in drug-event combinations and no enough data for denominator (Bate & Evans, 2009; Harpaz et al., 2012).
The major problem in SRSs by the passive nature is underreporting for only about 10% of serious adverse events are reported (Hazell & Shakir, 2006). On the other hand, the patterns of reporting can change over time and then cause overreporting (Bate &
Evans, 2009). For example, the influence of media attention on a drug can lead to increase the proportion of the reports about the events which may occur with the drug, and thus causing too many spurious data. In addition, because adverse events can be reported by different individuals, a case about drug-related AE may be reported by health professionals and patients cured by them. This may make duplication of reporting happened. Besides, the reporter can be a patient with no sufficient domain knowledge, so the data in SRSs may be missing or incomplete. The personal view of reporters can also give rise to the misattribution of causality in drug-AE associations. Finally, due to the lack of information about the total number of patients taking the drugs or having the disease, the denominator is difficult to know (Hsieh, 2014). Thus, the significant associations selected by using SRSs data may be not really important in the real world.
Although SRSs have the problems mentioned above, they are still the most popular databases for pharmacovigilance. Recently, some researchers also have studied to explore the use of EHRs in order to develop more active surveillance system.
2.2 Electronic Health Records (EHRs) 2.2.1 Definition and Examples of EHRs
Unlike spontaneous reports in SRSs, electronic health records (EHRs) contain more complete information such as a patient’s medical history, treatments, conditions, and
potential risk factors (Harpaz et al., 2012). These records have various types of data, which can be categorized into structured and unstructured (Henriksson et al., 2015).
Besides, EHR databases are either medical records databases or administrative/claims
databases (Coloma et al., 2013). Medical records databases have records maintained for the patients’ clinical care, while administrative/claims databases have transactions
primarily to achieve administrative purpose (Hsieh, 2014).
There are several projects aiming to build surveillance systems based on EHR data, such as Observational Medical Outcomes Partnership (OMOP) in the US and the Exploring and Understanding Adverse Drug Reactions (EU-ADR) project in Europe.
2.2.2 Existing EHR-based Methods
Since EHRs have been not designed for capturing adverse drug reactions, there are no direct and clear connections between drugs and AEs. Therefore, some existing EHR- based signal detection methods are dependent on the use of time frames (i.e., temporal information) to extract possible drug-disease pairs. These time frames are also known as surveillance windows or time windows (Harpaz et al., 2012). According to Hsieh (2014),
there are two kinds of time windows used for extracting plausible drug-disease pairs (i.e.
the associations between the use of drugs and the occurrence of AEs): the observation (or surveillance) window and the control window. After such extraction, the measures of DPA approach commonly employed by existing SRS-based methods can be extended to the EHR-based signal detection (Choi et al., 2011). That is, the drug-disease pairs which are extracted from EHRs can be ranked by using one of the disproportional analysis measures.
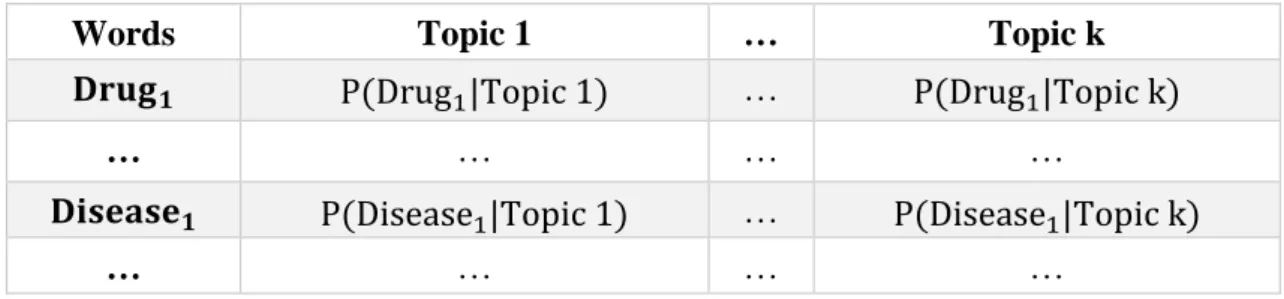
Furthermore, the LDA-based measures are proposed by Hsieh (2014) to reduce the importance of non-drug-AE pairs, since drug-disease pairs generated from EHRs by using time frames would contain a number of non-drug-AE pairs such as drugs’ indication.
These measures are mainly based on the probabilities over all topics of each drug or
disease calculated in the LDA model (see Table 3).
Table 3. The probabilities calculated in the LDA model
Words Topic 1 … Topic k
𝐃𝐫𝐮𝐠𝟏 P(Drug1|Topic 1) … P(Drug1|Topic k)
… … … …
𝐃𝐢𝐬𝐞𝐚𝐬𝐞𝟏 P(Disease1|Topic 1) … P(Disease1|Topic k)
… … … …
2.2.3 Traits of EHRs
In contrast to SRSs, the data in EHRs can only be recorded by healthcare professionals routinely rather than voluntarily. Therefore, post-marketing surveillance system using EHR-based signal detection methods can be more active. The underreporting or overreporting problem can be also solved by using the EHR data.
Moreover, a large number of the patients’ medical records in EHRs provide more precise denominator information. This can make the signal detection more accurate and earlier.
In addition, these records in EHRs offer the opportunity for longitudinal monitoring from routine clinical care recorded over long periods of time. Large EHR databases have the potential benefit of identifying AEs that have a long latency between exposure and clinical manifestations (Almenoff et al., 2007; Coloma et al., 2013; Harpaz et al., 2012;
Hsieh, 2014).
Consequently, the use of EHRs can be regarded as a promising alternative and complementary data source for pharmacovigilance. In this study, we will use the NHIRD, the national health insurance claims database in Taiwan, as the main data source for drug safety signal detection.
2.3 Biomedical Literature
2.3.1 Definition and Famous Database of Biomedical Literature
Biomedical literature is a growing information source which has enabled healthcare professionals to access potential ADEs in recent years (Harpaz et al., 2014). One famous literature database is MEDLINE, constructed by the U.S. National Library of Medicine (NLM), which is a publicly available biomedical literature database. MEDLINE is a leading source of scientific information. It has abundant biomedical articles covering the fields of medicine, dentistry, nursing and health care system. Each article is annotated
with Medical Subject Headings (MeSH) terms manually by NLM indexers.
2.3.2 Existing Literature-based Methods
Under the idea of the ABC model proposed by Swanson (1986), literature-based discovery (LBD) can process published biomedical literature to uncover implicit relationships among biomedical concepts. As Figure 1 shows, if concept A is related to concept B and concept B is related to concept C, Swanson’s ABC model suggests that concept A is highly possible to relate to concept C. If concept A represents a drug and C represents a disease, the relationship can be either repurposing chance or potential ADR.
Figure 1. The basic concept of Swanson’s ABC model
According to Yetisgen-Yildiz and Pratt (2009) and Chen (2013), the general framework of LBD systems (see Figure 2) designed with an open discovery consists of three main phases: term extraction and selection, link extraction and filtering, and target term ranking.
Figure 2. The general framework of a LBD system
The first step, term extraction and selection, is to process literature to biomedical concepts (or terms) and to select the terms related to specific semantic meanings. Previous studies extract biomedical concepts from MEDLINE literature by either using MeSH terms (Avillach et al., 2013; Chen, 2013; Shetty and Dalal, 2011; Yetisgen-Yildiz and Pratt, 2006) or processing free-text in titles and abstracts (Weeber et al., 2001; Xu and Wang, 2014). Chen (2013) selected terms with specific semantic groups by using MeSH subcategories that are related to drugs, genes, proteins and diseases for drug repositioning.
The next step, link extraction and filtering, is to extract relations between two different concepts. A common method to establish relationship between biomedical concepts from literature is co-occurrence analysis (Swanson and Smalheiser, 1997; Weeber et al., 2001).
After retrieving these relations, each link between concepts is assigned a weight by using link weight methods, such as TF-IDF, association rules, Z-score and Normalized MEDLINE Similarity (NMS). Yetisgen-Yildiz and Pratt (2009) showed that association
rules achieve a better performance than TF-IDF and Z-score. Chen (2013) adapted Normalized Google Distance (NGD) to MEDLINE as Normalized MEDLINE Distance
(NMD), and defined Normalized MEDLINE Similarity (NMS) as the difference of 1 and NMD. The formulas of association rules and NMS are presented in Table 4 where 𝐷𝐴 is the number of articles containing concept 𝐴, 𝐷𝐵 is the number of articles containing concept 𝐵, and 𝑀 denotes the total number of articles in MEDLINE.
Table 4. The description of some link weighting methods Link weight method Formula
Association rules 𝑠𝑢𝑝𝑝(𝐴, 𝐵) = |𝐷𝐴∩ 𝐷𝐵| 𝑐𝑜𝑛𝑓𝑖𝑑𝑒𝑛𝑐𝑒(𝐴, 𝐵) =|𝐷𝐴∩ 𝐷𝐵|
|𝐷𝐴| Normalized
MEDLINE Similarity 𝑁𝑀𝐷(𝐴, 𝐵) =max{log|𝐷𝐴|, log|𝐷𝐵|} − log|𝐷𝐴∩ 𝐷𝐵| log 𝑀 − min{log|𝐷𝐴|, log|𝐷𝐵|}
𝑁𝑀𝐷 = 1 𝑖𝑓 𝑁𝑀𝐷 > 1 𝑁𝑀𝑆(𝐴, 𝐵) = 1 − 𝑁𝑀𝐷(𝐴, 𝐵)
Besides, thresholds are often set to limit the number of links, to filter out the relations that seldom occur together, and to find more interesting relations. In the final step, target term ranking, the LBD system will rank the target terms related to the given starting term
through target-term ranking methods, such as average minimum weight (AMW), link term count (LTC), summation of minimum weight (Sum_MW), and summation of average weight (Sum_AW) in previous studies (Chen, 2013; Yetisgen-Yildiz and Pratt, 2006). Therefore, there is a ranking list of target terms related to the starting term.
In addition to integration of biomedical literature, we will incorporate three ontology databases to reduce the noisy information which the relationship is known and validated in ontologies but its ranking score is small, and to increase the credibility of the concept
network built from biomedical literature (Chen, 2013). We will calculate the weights of links by adopting Chen’s Extended Normalized MEDLINE Similarity (Extended NMS):
𝑆𝑖𝑚(𝐴, 𝐵) = {𝑁𝑀𝑆(𝐴, 𝐵), 𝑖𝑓 (𝐴, 𝐵) ∈ 𝐿𝑖𝑡𝑒𝑟𝑎𝑡𝑢𝑟𝑒 ∧ ∉ 𝑂𝑛𝑡𝑜𝑙𝑜𝑔𝑦 1 , 𝑖𝑓 (𝐴, 𝐵) ∈ 𝑂𝑛𝑡𝑜𝑙𝑜𝑔𝑦
2.4 Research Gap
The voluntary nature of SRSs constrains the surveillance ability of SRS-based signal detection methods. As a result, some research has started to use EHRs, which collect the real cases routinely by healthcare institutes. The measures of DPA approach commonly employed by existing SRS-based methods can be extended to EHR-based signal detection.
However, it can be generally realized that different measures are suitable for different situations. Therefore, multiple measures are combined to detect signals using a learning to rank method proposed by Hsieh (2014).
In recent years, some researchers adopted multiple information sources to detect adverse drug events. Harpaz et al. (2013) proposed that the EHR data can improve the performance of signal detection based on FAERS through remaining the signals that appear in both FAERS and EHR. Xu & Wang (2014) showed that the performance of
signal detection using FAERS are improved by boosting the signals that can be also extracted from MEDLINE. The boosting method they used is the square function, so that the scores of pairs which appear in both data sources will be squared as new ranking scores. Shang (2014) also showed that signal detected from EHR data can be improved by integrating knowledge from the literature and reranking the detecting signals from EHRs.
These above methods regarded the secondary data source as a higher importance source to prove drug-AE associations, and gave them implicitly higher weight. However, we cannot really know the importance of each information source for signal detection.
Taking the above problems into consideration, we will use a pairwise learning to rank approach to combine multiple measures from different data sources to predict and rank signals.
Learning to rank approaches can be divided into two processes, as Figure 3 shows.
The first is the learning process, which attempts to learn a ranking model with training data. In the beginning of the learning process, a number of queries (𝑞𝑖; 𝑖 = 1, … , 𝑛) are provided as the training data. Each query consists of documents (𝑥𝑗(𝑖); 𝑗 = 1, … , 𝑚) associated with the query and a perfect ranking list (𝑦(𝑖)) about the relevance between the documents and the query. Next, the learning system builds a ranking model (ℎ) on the
basis of the training data. Another process is the ranking process, which attempts to apply
the ranking model on test data. In this process, a new query consisting of relevant documents is given as test data. Then, the ranking model is applied to assign a relevance score or label to each document in the query. Therefore, the ranking system can return a ranking list with the scores in the descending order as the response to the query (Hsieh, 2014; Liu, 2009; Li, 2011).
Figure 3. The framework of learning-to-rank (Liu, 2009)
Moreover, learning to rank approaches can be classified into three types: pointwise, pairwise and listwise. The pointwise approach uses documents with relevance scores as training data. Then, the model learned from this approach can predict the relevance degree for each single document in a set of query-related documents. However, since the relative order between documents cannot be naturally considered in the learning process of the pointwise approach, the other two approaches have been proposed. In the pairwise
rank to the other are taken as training data. The pairwise model can predict the preference (usually +1 or -1) between each pair of documents. Unlike the two approaches, the listwise approach uses the entire group of documents associated with the same query as training data. The listwise model can predict a ranking list of the query-related documents.
In this study, queries can be one disease or one drug of interest and the query-related documents can be disease-anchored drug-disease pairs or drug-anchored drug-disease pairs. For the training purpose, the rank of drug-disease pairs whether drug-anchored or disease-anchored should be labeled by pharmaceutical professionals. Unfortunately, the labeling process takes a lot of time and effort, so the number of queries may be too small to employ the listwise approach which require a large number of queries. Therefore, we will build a model to rank drug-disease pairs (i.e. signals) by adopting the pairwise learning to rank approach.
Chapter 3 Our Proposed Method
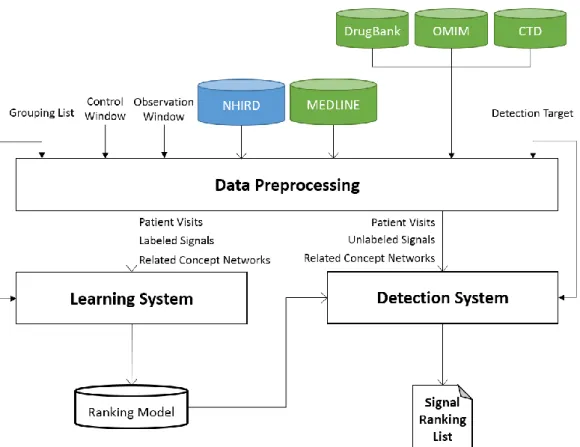
Our objective is to integrate MEDLINE database to assist the detection of potential adverse drug reactions from the NHIRD. As Figure 4 shows, our proposed method consists of three phases: data preprocessing, learning system, and detection system.
Figure 4. The overall process of our proposed method
In the one part of data processing phase, we first extract the drug-disease pairs from the NHIRD database. The sizes of two different time windows are predefined to perform some tasks for every patient visit. Subsequently, we generate drug-disease pairs corresponding to a given grouping list or a specific detection target. The signals generated by a grouping list are labeled by experts, and then we use a proportion of these labeled
signals as our training dataset. By contrast, the signals generated by a specific detection target need not be labeled, and these unlabeled signals can be our candidate signals in the detection system. In the other part of this phase, concept networks are constructed by using the relations retrieved from MEDLINE and three ontology databases. There are two types of concept networks after construction: Literature-based Concept Network and Comprehensive Concept Network. Therefore, through mapping ATC and ICD codes to MeSH terms, we can retrieve the concept networks related to each drug among the drug- disease pairs.
In the learning phase, the labeled signals, which are labeled from the drug-anchored or disease-anchored drug-disease pairs, are used as training dataset. Next, the learning system can learn a signal ranking model with these labeled signals. Finally, in the detection phase, the detection system generates all potential drug-disease pairs as testing data by giving a detection target. Then, the ranking model built by the learning system can rank these signals and return a ranking list. In the following, we will describe the detailed process of each phase in our method.
3.1 Data Preprocessing for Training
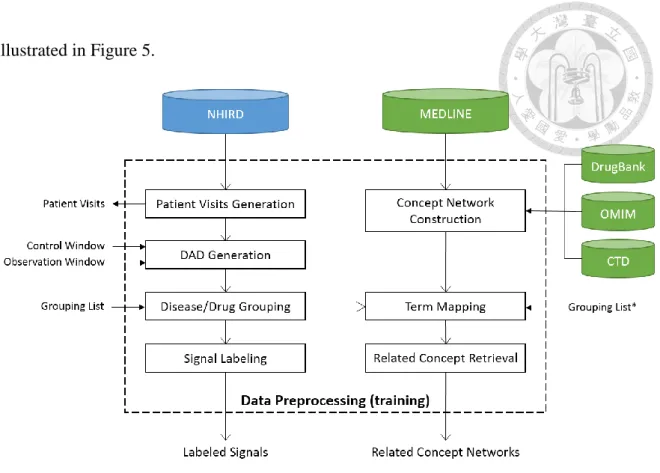
Since we attempt to combine more than two data sources in our method, there are two separate parts to preprocess the different data into labeled signals, patient visits, and related concept networks. The detailed process of data preprocessing for training is
illustrated in Figure 5.
Figure 5. The detailed process of the data preprocessing for training phase
For NHIRD data, we will create a file named “Patient Visits” from the original data and then generate drug-appearing diagnoses (DADs) from the Patient Visits using time windows. Moreover, the signals can be generated from DADs with a given grouping list, and then labeled by experts. For MEDLINE data, we will construct two types of concept networks: Literature-based Concept Network and Comprehensive Concept Network.
Furthermore, we will retrieve related concept networks through mapping lists.
3.1.1 Patient Visits Generation
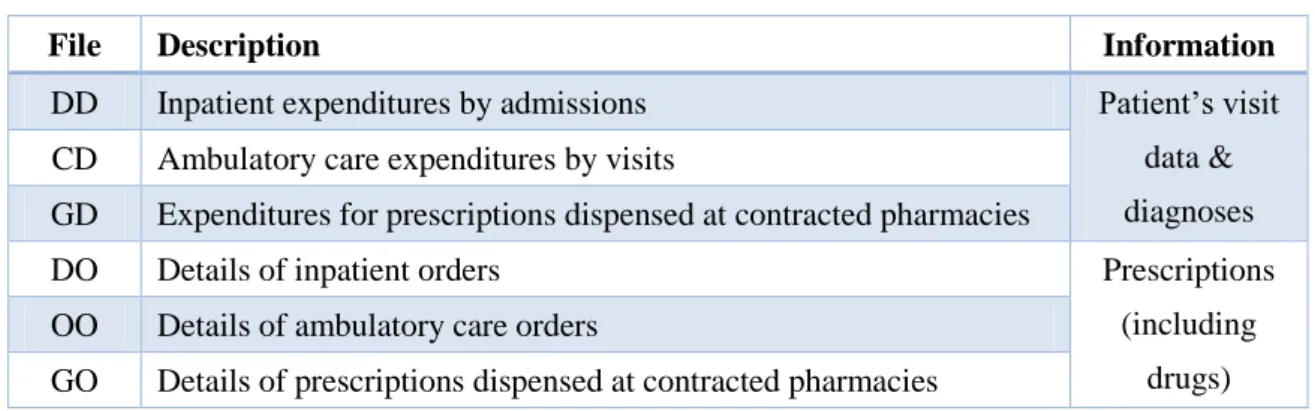
In this study, we only use the claim data files including DD, CD, GD, GO, OO and DO in NHIRD (see Table 5). Then, we will follow the linking procedure described in
Hsieh (2014) to process these six data files into a file called “Patient visits,” which store the information about every patient visit such as patient id, visit time, diagnoses, and drugs prescribed. The visits of one patient on a timeline are listed by chronological order.
Table 5. The description of six claim data files in NHIRD
File Description Information
DD Inpatient expenditures by admissions Patient’s visit data &
diagnoses CD Ambulatory care expenditures by visits
GD Expenditures for prescriptions dispensed at contracted pharmacies
DO Details of inpatient orders Prescriptions
(including drugs) OO Details of ambulatory care orders
GO Details of prescriptions dispensed at contracted pharmacies
Drugs are encoded in National Health Insurance Scheme (NHIS) Medicines List, which classifies the drugs in NHIRD by their generic name, the amount of dosage, and the ways to take medicines for easy price. One drug may be recorded as different codes due to its different component, different manufacturers, different dosage and different ways to take the medicine. Because of this problem, it is difficult to find true associations between drugs and diseases. Therefore, we map NHIS Medicines List to the corresponding Anatomical Therapeutic Chemical (ATC) codes. The ATC classification system is used internationally for the classification of drugs according to the organ on which they act, their therapeutic, and chemical properties. As the result, there are 1,168 ATC codes mapped from 19,686 NHIS codes. Since NHIRD uses International Classification of Diseases (ICD-9-CM) to code diagnoses in each claim, we just follow
this scheme to code diagnoses in our dataset. After this phase, we will have all patient visits, where the drugs are encoded in ATC and diseases are encoded in ICD.
3.1.2 Drug-Appearing Diagnosis (DAD) Generation
We will follow Hsieh’s drug-appearing diagnosis (DAD) generation by using the control window (𝑇c) and observation window (𝑇o) for each patient visit on a timeline. For example, DAD(Visit𝑖)={ATC1, ATC2; ICD4} can be generated in Figure 6. First, for a
patient visit Visit𝑖, we can obtain the current diagnoses as ICD1 and ICD2. By using the observation window, the post diagnoses have ICD2, ICD3 and ICD4. Also, the preexisting diagnoses before Visit𝑖 have ICD1 and ICD3 by using the control window.
Second, we obtain the appearing diagnosis ICD4 by removing the diagnoses in post diagnoses which are also in the preexisting and current diagnoses. Therefore, we will extract all the possible DADs for each patient visit.
Figure 6. Example of DAD generation proposed by Hsieh (2014)
3.1.3 Disease or Drug Grouping
Grouping list, which contains a disease or drug group of interest and the
corresponding ICD or ATC codes, is predefined in this step. If a specific disease group as our training query, DADs will group into disease-anchored DADs through converting the ICD codes in the DADs to the predefined disease group. Then, disease-anchored drug- disease pairs will be extracted from these disease-anchored DADs. Likewise, if a specific drug group as our training query, DADs will group into drug-anchored DADs through converting the ATC codes in the DADs to the predefined drug group. Then, drug- anchored drug-disease pairs will be extracted from these drug-anchored DADs. Therefore, the disease-anchored or drug-anchored drug-disease pairs are used for training purpose.
For example, a disease group of interest in the predefined grouping list is acute renal failure and it has ICD codes of 584 and 586. After this step, we will group DADs into disease-anchored DADs related to acute renal failure, map the “584” and “586” to acute renal failure, and then extract disease-anchored drug-disease pairs.
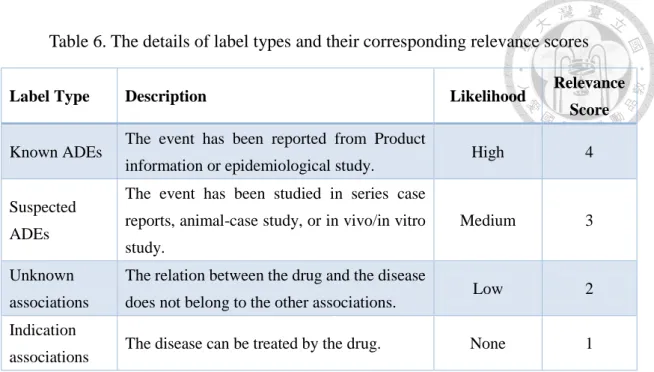
3.1.4 Signal Labeling
Experts label the disease-anchored or drug-anchored drug-disease pairs with label types defined in Table 6. These drug-disease pairs that are ranked by the likelihood of occurring ADEs with relevance scores will be used as our training data.
Table 6. The details of label types and their corresponding relevance scores
Label Type Description Likelihood Relevance
Score
Known ADEs The event has been reported from Product
information or epidemiological study. High 4
Suspected ADEs
The event has been studied in series case reports, animal-case study, or in vivo/in vitro study.
Medium 3
Unknown associations
The relation between the drug and the disease
does not belong to the other associations. Low 2 Indication
associations The disease can be treated by the drug. None 1
3.1.5 Term Mapping
The purpose of term mapping is to retrieve mapping lists between different codes with the same meaning from different data sources. We map ATC and ICD codes in disease-anchored (or drug-anchored) drug-disease pairs to the corresponding MeSH terms by using the latest version of Unified Medical Language System (UMLS), which provides a mapping structure among many biomedical thesauri, such as MeSH, RxNorm, ICD-9-CM and ICD-10, for a period of time. Besides, the version 2013AB of the UMLS integrate ATC for the first time.
However, it is possible that each ATC or ICD general code cannot be mapped directly to one MeSH term through UMLS. Considering that ATC and ICD9CM have a hierarchical structure, we will substitute the combination of the MeSH terms from all specific code for the general code. For example, ICD code of 146 has specific ICD codes
from 146.0 to 146.9. Suppose that 146 cannot map to any MeSH term by using UMLS, however, 146.0 has a corresponding MeSH term “Tonsillar Neoplasms” and the other
specific ICD codes also map to nothing. Then, as Table 7 shows, we will assign “Tonsillar Neoplasms” to 146.
Table 7. Example of term mapping considering hierarchical structure ICD MeSH term
146 X
146.0 Tonsillar Neoplasms
… X
146.9 X
146 Tonsillar Neoplasms
As the result of term mapping, we will get two mapping lists: ATC-MeSH list and ICD-MeSH list. Therefore, we can retrieve the concept networks related to the drugs among the drug-disease pairs extracted from NHIRD through these mapping lists later.
3.1.6 Concept Network Construction
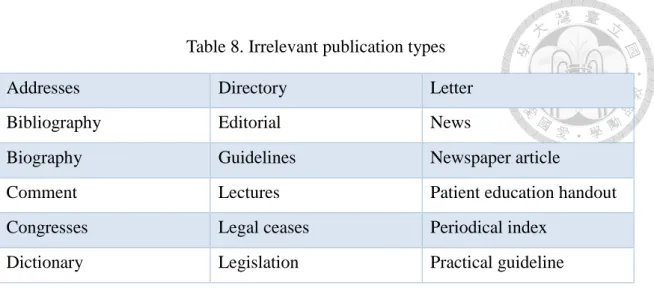
We follow the procedure of concept network construction based on Swanson’s ABC
model proposed by Chen (2013). First, we extract MeSH terms from MEDLINE 2011 baseline, which contains 19,680,423 biomedical articles until 2010, and then remove the articles with irrelevant publication types which suggested by Yetisgen-Yildiz and Pratt (2009) as shown in Table 8. As the result, our literature database consists of 18,712,338 biomedical articles.
Table 8. Irrelevant publication types
Addresses Directory Letter
Bibliography Editorial News
Biography Guidelines Newspaper article
Comment Lectures Patient education handout
Congresses Legal ceases Periodical index
Dictionary Legislation Practical guideline
Next, we extract the relations by Chen’s semantic subcategory filtering. Some MeSH subcategories in Table 9 are selected to limit terms within specific semantic groups related to relationships between drugs and diseases. Therefore, we retrieve 2,623,222 relations between 12,278 MeSH terms from the articles.
Table 9. The MeSH subcategories selected by Chen (2013) Semantic Group Corresponding MeSH Subcategories
Drugs D01-D05, D09, D10, D20, D26, D27
Genes, Proteins, and Enzymes D06, D08, D12, D13, D23
Pathological Effects G03-G16
Diseases C01-C23
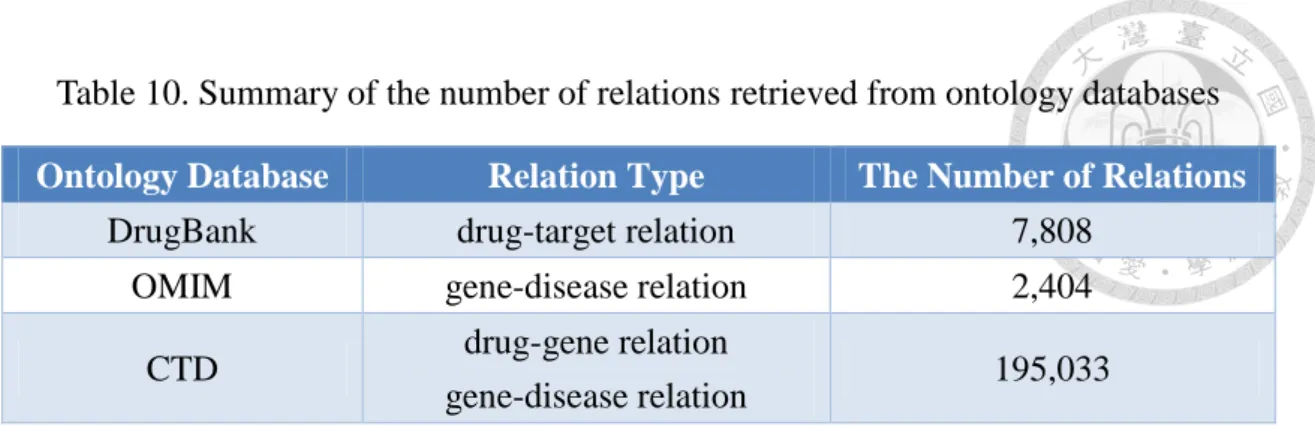
As we mentioned previously, the ontologies are also incorporated to reduce possibly noisy relations extracted from the literature. There are three ontology databases used in this study: DrugBank, Online Mendelian Inheritance in Man (OMIM), and Comparative Toxicogenomics Database (CTD). After translating terms from different coding systems to MeSH terms suggested by Chen (2013), Table 10 summarizes the number of relations and their relation types retrieved from different ontology databases.
Table 10. Summary of the number of relations retrieved from ontology databases Ontology Database Relation Type The Number of Relations
DrugBank drug-target relation 7,808
OMIM gene-disease relation 2,404
CTD drug-gene relation
gene-disease relation 195,033
There are two types of concept networks after construction: Literature-based Concept Network and Comprehensive Concept Network. Literature-based Concept Network is defined as a concept network only using literature database, while Comprehensive Concept Network is defined as a concept network using both literature and ontology databases.
3.1.7 Related Concept Retrieval
For each drug, which is called as starting term, in the disease-anchored (or drug- anchored) drug-disease pairs, we retrieve all the related concept networks from the literature-based or comprehensive concept network built previously. First, we retrieve all the concepts related to the drug, and call them as linking terms. Second, we extract the diseases in the disease-anchored (or drug-anchored) drug-disease pairs that have a link to one of these linking terms but not directly link to the drug, and define them as target terms.
All of the above steps, we use the mapping lists from the Term Mapping step to retrieve what we need with the corresponding MeSH terms in the concept networks.
3.2 Learning System
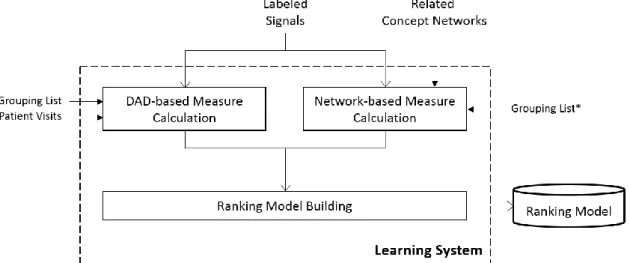
In the learning phase, the labeled signals, which are labeled from the disease- anchored or drug-anchored drug-disease pairs, are used as training dataset. Next, we calculate DAD-based and network-based measures by using Patient visits and related concept networks for the training dataset. Finally, the learning system can build a signal ranking model with these labeled signals by using Ranking SVM, a pairwise learning to rank method. The detailed process of the learning system is illustrated in Figure 7.
Figure 7. The detailed process of the learning system
3.2.1 DAD-based Measure Calculation
There are two types of measures calculated on the basis of DADs in our study:
traditional disproportionality analysis measures and LDA-based measures.
Traditional disproportionality analysis measures
Traditional DPA measures commonly employed by existing SRS-based methods can
be extended to the EHR-based signal detection, such as RRR, PRR, ROR and BCPNN, which have described in Section 2.1.2. These DPA measures for each drug-disease pair are based on a 2x2 contingency table like Table 1, which is constructed by calculating the number of DADs in our study. For instance, if there are three DADs: {ATC1, ATC2;
ICD3}, {ATC3; ICD2}, {ATC1, ATC4; ICD3}, and we extract a drug-disease association which is {ATC1ICD3} from the DADs, a contingency table can be constructed as shown in Table 11.
Table 11. Example of a contingency table for {ATC1ICD3}
ICD3 No ICD3 Total
ATC1 2 0 2
No ATC1 0 1 1
Total 2 1 3
LDA-based measures
The aims of LDA-based measures are to find the implicit relations between drugs and diseases, and to reduce the importance of non-drug-AE pairs. We adopt drug-disease association measures proposed by Hsieh (2014) as our LDA-based measures. The basic concept of LDA is that documents are represented as random mixtures over latent topics, where each topic is characterized by a distribution over words (Blei, Ng, & Jordan, 2003).
In our study, a patient visit can be as a document, and drugs or diseases can be as words in documents. Thus, the drugs and diseases that often occur together would have
large probability to be distributed in the same topics. In the LDA model, drugs will be represented by ATC codes, whereas diseases will be represented by ICD codes. As we described in Section 2.2.2, these measures are mainly based on the probabilities over all topics of each word calculated in the LDA model (see Table 12).
Table 12. The probabilities calculated from the LDA model in our study
Words Topic 1 … Topic k
𝐀𝐓𝐂𝟏 P(ATC1|Topic 1) … P(ATC1|Topic k)
… … … …
𝐈𝐂𝐃𝟏 P(ICD1|Topic 1) … P(ICD1|Topic k)
… … … …
After obtaining the probabilities like Table 12, we calculate the relatedness of the drug and the disease for each drug-disease pair by using cosine similarity method and the
formula is:
𝑐𝑜𝑠𝑖𝑛𝑒 𝑠𝑖𝑚𝑖𝑙𝑎𝑟𝑖𝑡𝑦 = 𝐴 ∙ 𝐵
|𝐴||𝐵|= ∑𝑛𝑖=1𝐴𝑖× 𝐵𝑖
√∑𝑛𝑖=1𝐴𝑖√∑𝑛𝑖=1𝐵𝑖
where 𝐴 is the probability vector of a drug over 𝑛 topics and 𝐵 is the probability vector of a disease over 𝑛 topics. However, since a disease group typically consists of many ICDs, we choose the maximum of cosine similarities related to the disease group as the overall similarity between the group and many drugs. For example, a disease group has corresponding ICD codes of ICD1, ICD2 and ICD3. There are three drug-disease pairs related to a drug coded ATC1 and their similarities are: sim(ATC1, ICD1)=0.8, sim(ATC1, ICD2)=0.6, and sim(ATC1, ICD3)=0.2. Thus, we will choose sim(ATC1,
ICD1)=0.8 as the overall similarity between the drug and the disease group.
Therefore, “Patient visits” are used to derive the LDA model. First, we will set the
time window as 0 day to extract some relations possibly related to drug indications.
Second, the time window will be extended to 30 days so that we may capture the additional relations such as disease progression within 30 days. Besides, we use JGibbLDA package to find the implicit relations between drugs and diseases, and set the hyperparameters 𝛼 and 𝛽 to 0.1 and 0.01 and the number of topics is 50. The summary table of LDA-based measures in our study is shown in Table 13.
Table 13. The summary table of LDA-based measures in our study
LDA-based measures
LDA – topic=50, window=0 LDA – topic=50, window=30
3.2.2 Network-based Measure Calculation
We call the measures calculated on the basis of related concept networks in our study as literature-based measures. There are two link weighting methods we used to calculate the weights of the links between two concepts: association rule and Extended Normalized MEDLILE Similarity (Extended NMS) (Chen, 2013). The formulas of these link weighting methods are described previously (see Table 4). Each weighting method will be used on different types of concept networks. Table 14 shows the link weighting methods that are used for the two types of concept networks.
Table 14. Link weighting methods and corresponding concept networks in our study Concept Network Information source used Link weighting method Literature-based Concept
Network
Literature Only Association Rule Comprehensive Concept
Network
Literature and Ontology Extended Normalized MEDLINE Similarity (Extended NMS)
In the related concept networks from data preprocessing, there may be two kinds of links between the drug and the disease in a drug-disease pair. We define a link that connects the drug and the disease directly (i.e., not through an intermediate node) as a direct link, while a link that connects the drug and the disease through some an intermediate node (i.e., linking node) is regarded as an indirect link. Noted that the links between a drug and a disease may have both direct links and indirect links. Therefore, a drug-disease pair will be assigned with two kinds of literature-based measures: Link 2 measures for indirect links and Link 1 measures for direct links.
However, since a disease group may have more than one disease concepts, we should group links by using the MAX method according to the grouping list. The MAX method is to choose the maximum of these link weights between a drug (or an intermediate) and the disease concepts in the same disease group as the overall link weight between the drug (or intermediate) and the disease group. As Figure 8 shows, a disease query “Cancer” has two MeSH terms C1 and C2 in drug A-related concept network. We use the maximum of two link weights between B1 and C1 and C2 (i.e., B1-C1) to represent the overall link
weight of B1-Cancer. Similarly, the maximum of two link weights between B2 and C1 and C2 (i.e., B2-C1) represents the overall link weight of B2-Cancer. Because B3-Cancer has only one link B3-C2, the overall link weight directly uses the link weight of B3-C2.
Figure 8. Example of link grouping by using MAX method
After grouping, we will use the ranking scores calculated from four target term ranking methods based on grouping weights of indirect links as our Link 2 measures for the drug-disease pair. The target term ranking methods we used are described in Table 15.
Table 15. The description and formula of each target term ranking method Method Description and Formula
Sum_MW
The summation of the minimum weight of every links between starting term A and target term C.
𝑆𝑢𝑚𝑀𝑊(𝐴, 𝐶) = ∑ min {𝑊𝑡(𝐴, 𝐵), 𝑊𝑡(𝐵, 𝐶)}
𝐵∈𝑁(𝐴)∩𝑁(𝐶)
Sum_AW
The summation of the average weight of every links between starting term A and target term C.
𝑆𝑢𝑚𝐴𝑊(𝐴, 𝐶) = ∑ 1
2[𝑊𝑡(𝐴, 𝐵) + 𝑊𝑡(𝐵, 𝐶)]
𝐵∈𝑁(𝐴)∩𝑁(𝐶)
LTC The count of linking terms between starting term A and target term C.
𝐿𝑇𝐶(𝐴, 𝐶) = 𝐵 𝐵 ∈ 𝑁(𝐴) ∩ 𝑁(𝐶)
AMW
The average of minimum weight of links between starting term A and target term C.
𝐴𝑀𝑊(𝐴, 𝐶) =1
𝐵 ∑ min {𝑊𝑡(𝐴, 𝐵), 𝑊𝑡(𝐵, 𝐶)}
𝐵∈𝑁(𝐴)∩𝑁(𝐶)
These target term ranking methods can rank the target terms based on the link weights between the drug and the intermediates as well as the overall link weights between the intermediates and the disease group. Figure 9 shows that how to calculate the ranking scores by LTC and AMW as the Link 2 measures for the A-Cancer pair.
Figure 9. Example of the calculation of Link 2 measures after link grouping Also, as Figure 10 shows, we define the overall weights of the direct links between the drug and the disease group as our Link 1 measures for the drug-disease pair.
Figure 10. Example of the calculation of Link 1 measures after link grouping
3.2.3 Summary of All Measures
Table 16 summarizes three types of measures adopted in our proposed method.
Based on different data sources, it also can be classified into DAD-based measures and concept network-based measures.
Table 16. Summary of all measures adopted in our proposed method
DAD-based Measures
Disproportional analysis (DPA) Measures
RRR
4 PRR
ROR BCPNN
LDA-based Measures
LDA – topic=50, window=0
2 LDA – topic=50, window=30
Concept Network- based Measures
Literature- based Measures
Link 2 (indirect)
Literature#AR#LTC
8 Literature#AR#AMW
Literature#AR#SumMW Literature#AR#SumAW
Literature + Ontology#NMS#LTC Literature + Ontology#NMS#AMW Literature + Ontology#NMS#SumMW Literature + Ontology#NMS#SumAW Link 1
(direct)
Literature#AR
2 Literature + Ontology#NMS
Total 16
3.2.4 Ranking Model Building
As mentioned previously, we use the labeled signals coded by experts as the training dataset. In our study, we adopt RankingSVM, a pairwise learning to rank approach proposed by Herbrich et al. (1999), to build a signal ranking model. The objective function of RankingSVM is to minimize the loss and optimize the weight vector for ranking model:
𝑚𝑖𝑛1
2‖𝑤‖2 + 𝐶 ∑ 𝜉𝑖
𝑁
𝑖=1
𝑠. 𝑡. 𝑧𝑖(𝑤𝑇, 𝑥𝑖(1)− 𝑥𝑖(2)) ≥ 1 − 𝜉𝑖 𝜉𝑖 ≥ 0
𝑖 = 1, … , 𝑁
where 𝑥𝑖(1) and 𝑥𝑖(2) are the feature vectors of one drug-disease pair and another pair, 𝜉𝑖 measures the degree of misclassification, and 𝑁 is the number of training queries. In our study, we use SVM-light package (Joachims, 1999) to build a signal ranking model.
3.3 Data Preprocessing for Testing
Similar to the data preprocessing for the training phase, there are two separate parts to preprocess the different data into unlabeled signals, patient visits, and related concept networks. The main differences between data preprocessing for training data and testing data are detection target and no signal labeling step. In this phase, unlabeled signals (i.e.
candidate signals) are generated as testing data by a given detection target. A detection target, similar to a grouping list, contains a disease or drug group of interest and the
corresponding ICD or ATC codes for testing purpose. Besides, the two types of concept networks constructed in data preprocessing for training phase is same for this phase. Thus, we can also retrieve related concept networks through mapping lists related to detection target. The detailed process of data preprocessing for testing is illustrated in Figure 11.
Figure 11. The detailed process of the data preprocessing for testing phase
3.4 Detection System
In the detection phase, the ranking model built from the learning system can rank candidate signals generated by giving a detection target and return a ranking list. The detailed process of the detection system is illustrated in Figure 12.
Figure 12. The detailed process of the detection system
3.4.1 DAD-based or Network-based Measure Calculation
Similar to the DAD- and the network-based measure calculation step in the learning system, this step also calculates all the measures described in Section 3.2.1 on the basis of DADs and Section 3.2.2 on the basis of related concept network for each unlabeled signals. Besides, we extract the drug-disease pair as candidate signals by setting
additional DPA measures threshold to remove insignificant pairs: the minimum number of incidences is 10 (𝑎 ≥ 10) and the value of ROR is larger than 1.5 (𝑅𝑂𝑅 ≥ 1.5).
3.4.2 Signal Ranking
In the final step, we apply the ranking model built from the learning system to rank
candidate signals. How RankingSVM determines the rank scores of signals by the ranking
model is using the scoring function:
𝑓(𝑥) = ⟨𝑤̂, 𝑥⟩
As the result, we can order these candidate signals by their rank score, and retrieve the signal ranking list.