國立臺灣大學電機資訊學院資訊工程學研究所 碩士論文
Department of Computer Science and Information Engineering College of Electrical Engineering and Computer Science
National Taiwan University Master Thesis
結合多辭典與常識網路的情緒分析系統
Sentiment Analysis Using Multi-dictionary and Commonsense Knowledgebase
吳蕙欣 Hui-Hsin Wu
指導教授:許永真 博士 Advisor: Jane Yung-jen Hsu, Ph.D.
中華民國 100 年 7 月
July, 2011
Acknowledgments
在完成碩士學業的同時, 也正式為十多年來的學生生涯畫下句點。 回顧這兩年 的研究所生活, 不論在知識上的成長或是面對困難所培養出的處事能力, 都使 我獲益良多。
感謝許永真教授及蔡宗翰教授對我的期許,指引我方向,並給予我指導與鼓 勵, 使我學會獨立思考,並能適時的發問、合作討論,得到最完美的成果。 並 且感謝口試委員鄭卜壬老師對本研究提供許多寶貴的建議, 使學生更了解未來研 究所需注意、改進的地方,並使論文內容更加完善。
感謝實驗室的夥伴們和iPlayr的組員們, 一同在研究的這條道路上相互扶持。
研究卡關了,大家一起想辦法,互相提供意見; 學習倦怠了,大家一起運動,互 相鼓勵; 期限快到了,大家一起熬夜,互相打氣。 這段日子如果沒有你們,我 想我會很孤單。
最後,感謝我最愛的家人作我的後盾, 因為有你們的支持,才讓我無後顧之 憂, 帶著無比的信心與動力面對我所遇到的任何問題, 也讓我有勇氣走過這段 求學歷程,在此獻上無限的感激。
i
Abstract
This thesis presents a new approach to language independent sentiment analysis that combines multi-dictionary and commonsense knowledgebase.
Sentiment analysis is the task of identifying positive and negative opinions, emo- tions, and evaluations. One major impediment to Non-English sentiment analysis research is the lack of a complete sentiment dictionary. In light of this, we collected nine kinds of sentiment dictionaries as sentiment concept seed, then through senti- ment spreading activation from common sense network (ConceptNet) to get more sentiment concepts. And got a sentiment dictionary named iSentiDictionary. iSenti- Dictionary contains 28,248 sentiment terms (9,701 words and 18,547 concepts), and assigned a sentiment score between -1 and 1 for each sentiment term.
Final, we used iSentiDictionary to mine sentiment from Chinese pop song dataset (iPop). Compared to use the translation of ANEW as sentiment dictionary, iSenti- Dictionary reduced the error distance from 0.7315 to 0.4568.
Keywords: lyric sentiment; sentiment analysis;opinion mining;commonsense knowledgebase;sentiment dictionary
ii
摘
摘 摘 要 要 要
本研究為基於多種情緒辭典與常識網路以協助分析歌詞文本之情緒。 此研究 可應用於以情緒為主的推薦系統或搜尋引擎等相關研究。 由於現今除了英語的情 緒詞語資源較豐富外,其餘語言則常因為情緒詞語資源的不完善, 不容易挖掘文 本情緒或是作更進一步的應用。 因此,提出一語言獨立的情緒詞語擴散方法來得 到較完善的情緒詞語辭典是本研究的重點。
目前情緒分析的應用,往往只基於一種情緒辭典,我們為了增加的情緒詞語資 料的完整性, 收集了九種不同類型的情緒辭典,並利用辭典間相互驗證的方法來 增加情緒詞語資料的正確性。
透過常識網路(ConceptNet)具有大量知識且概念與概念間互相連接的特性, 藉 由情緒擴散激發,將情緒詞語種子的情緒值擴散到相鄰的概念,傳遞到整個常識 網路, 得到擴散後的情緒辭典,我們稱之為iSentiDictionary。 其包含28,248個詞 語(9,701個單字與18,547的概念),且每個詞語皆分配一個情緒分數,介於-1和1之 間。
之後,我們利用所建構的iSentiDictionary預測歌詞文本情緒值,其情緒誤差距 離為0.4568, 比起利用翻譯ANEW情緒辭典的誤差距離0.7315,降低了0.2747。
關
關關鍵鍵鍵字字字:::歌詞情感;情感分析;意見挖掘;常識網路;情緒辭典
iii
Contents
Acknowledgments i
Abstract ii
List of Figures vii
List of Tables viii
Chapter 1 緒緒緒論論論 1
1.1 研究動機 . . . 1
1.2 問題定義 . . . 2
1.3 研究方法與架構 . . . 3
1.3.1 情緒擴散模組 . . . 3
1.3.2 情緒挖掘模組 . . . 4
1.4 論文結構 . . . 4
Chapter 2 情情情緒緒緒辭辭辭典典典介介介紹紹紹 6
iv
2.1 標記情緒值辭典 . . . 7
2.1.1 Affective Norms for English Words . . . 7
2.1.2 SenticNet . . . 8
2.1.3 SentiWordNet . . . 9
2.2 標記情緒極性辭典 . . . 10
2.2.1 知網-情感分析用詞語集 . . . 10
2.2.2 General Inquirer-Emotion . . . 12
2.2.3 WordNet-Affect . . . 13
2.2.4 National Taiwan University Sentiment Dictionary . . . 14
2.3 標記情緒詞語辭典 . . . 15
2.3.1 Never Ending Language Learner-Emotion . . . 15
2.3.2 WeFeelFine . . . 16
2.4 情緒辭典特性觀察 . . . 17
2.4.1 標記方法 . . . 17
2.4.2 標記內容 . . . 17
2.4.3 標記類型 . . . 19
Chapter 3 情情情緒緒緒擴擴擴散散散模模模組組組 20 3.1 情緒單元種子收集 . . . 22
3.1.1 翻譯情緒辭典 . . . 23
3.1.2 情緒辭典擴張 . . . 24
3.1.3 情緒辭典合併 . . . 26 v
3.2 情緒擴散激發 . . . 28
3.2.1 常識網路(Common Sense Network) . . . 28
3.2.2 基本的擴散激發 . . . 29
3.2.3 自我學習的擴散激發 . . . 31
Chapter 4 情情情緒緒緒分分分析析析模模模組組組 35 4.1 自然語言處理 . . . 35
4.1.1 Yahoo! 斷章取義 . . . 37
4.2 句子情緒挖掘 . . . 37
4.2.1 情緒單元挖掘 . . . 39
4.2.2 程度詞處理 . . . 39
4.2.3 否定詞處理 . . . 40
4.2.4 轉折詞處理 . . . 41
4.3 文本情緒挖掘 . . . 41
Chapter 5 實實實驗驗驗設設設計計計與與與結結結果果果 43 5.1 情緒擴散模組實驗設計與結果 . . . 43
5.2 情緒分析模組實驗設計與結果 . . . 47
Chapter 6 結結結論論論與與與未未未來來來展展展望望望 51 6.1 貢獻 . . . 52
6.2 未來展望 . . . 52
Bibliography 53
vi
List of Figures
1.1 系統架構圖 . . . 5
2.1 ANEW PA值分布圖 . . . 8
2.2 知網範例 . . . 11
2.3 各情緒辭典標記方法分類圖 . . . 17
2.4 各情緒辭典標記內容分類圖 . . . 18
2.5 各情緒辭典標記類型分類圖 . . . 18
3.1 情緒擴散模組架構圖 . . . 21
3.2 ConceptNet常識網路 . . . 30
4.1 情緒擴散模組架構圖 . . . 36
5.1 情緒擴散模組實驗之覆蓋度結果 . . . 46
5.2 情緒擴散模組實驗之平均情緒極性正確率結果 . . . 46
5.3 情緒擴散模組實驗之平均誤差距離結果 . . . 47
5.4 中文歌詞範例 . . . 50
vii
List of Tables
2.1 知網資料統計表 . . . 12
2.2 知網-情感分析用詞語集(HowNet-VSA)資料統計表 . . . 12
3.1 情緒辭典的翻譯結果數量統計表 . . . 23
3.2 情緒贅詞擴張樣板 . . . 24
3.3 情緒程度詞擴張 . . . 25
3.4 情緒否定詞擴張 . . . 25
3.5 情緒辭典的擴張結果數量統計表 . . . 26
3.6 情緒單元種子收集結果統計表 . . . 28
4.1 中文情緒程度詞列表 . . . 40
4.2 中文否定詞語列表 . . . 41
4.3 中文轉折詞語列表 . . . 41
5.1 歌詞情緒預測之結果 . . . 50
viii
Chapter 1 緒
緒 緒論 論 論
本章首先介紹我們研究情緒分析系統的動機與期望目標,接著定義本研究的兩個 問題, 並分別提出解決研究與系統架構,最後簡介此論文的各章節結構。
1.1 研 研 研究 究 究動 動 動機 機 機
在以往的情緒研究[2]中發現,音樂是傳遞情緒的媒介, 可藉由歌曲的表現,傳 達不同的情感。 也因此,當使用者在不同情緒下,想聽的歌曲情緒類型也可能 隨之不同。 例如心情低落時,有些人會想聽悲傷的歌曲以發洩情緒, 心情平靜 時,希望襯著同樣輕快的歌曲,欣賞窗外的風景。 正因如此,許多基於情緒的 歌曲搜尋系統慢慢產生。 如Hsu[12]所提出的 iPlayr系統,一個提供基於情感及關 鍵字搜尋的音樂平台, 可經由對情感的描述或是概念,查詢音樂。 Allmusic 1和 Last.fm2 則是對歌曲標上情緒標籤,例如「happy」、「sad」, 讓使用者可以透
1http://www.allmusic.com/
2http://www.last.fm/
1
2 CHAPTER 1. 緒論
過查詢音樂情緒相關的標籤,得到所對應的歌曲。 而Musicovery3是一互動式的網 路電台, 其將情緒表現成二維的向量空間(Arousal-Valence),使用者透過點擊情 緒空間上的點, 指定情緒類別,以得到符合此情緒類別的推薦歌曲。
早期的歌曲情緒分析多著重於音頻的討論,因此Wu[23]進一步探討中文歌詞對 於歌曲情緒的影響, 發現對於歌曲的激動程度(Arousal)而言,音頻有較重的影響 力, 但在預測歌曲的正負向情緒(Valence)時,則是歌詞有較具影響力。 且在預 測歌曲情緒時,加入歌詞的預測系統會改善單純利用音頻預測的正確率。 綜合以 上結果,顯示歌曲情緒預測時,歌詞情緒分析對其是有幫助的。
對於分析歌詞情緒,常見方法是利用情緒辭典,找出具有情緒代表性的詞語,
再利用所存在的情緒詞語, 透過統計模型或是機器學習分類器,進一步預測其情 緒正負向[13][24]。 但是卻極少預測歌詞的「情緒數值」,其原因是中文缺乏具有 情緒數值的情緒辭典, 以往在解決此問題時,常利用翻譯技術,將具有情緒值的 英文情緒辭典翻譯成中文, 但我們發現,翻譯過後的中文情緒辭典對於歌詞的覆 蓋率並不高,導致歌詞的情緒常取決於少數的情緒詞語, 使得預測效果不如預 期。因此,我們的目標是探討若具有一完整的中文情緒辭典, 增加對歌詞語料庫 的覆蓋率,是否對中文歌曲情緒分析有所幫助。
1.2 問 問 問題 題 題定 定 定義 義 義
此篇論文中,我們將探討若具有一完整的中文情緒辭典,增加對歌詞語料庫的覆 蓋率, 是否對中文歌曲情緒分析有所幫助,以下基於此目標我們定義了兩個情緒 分析問題:
3http://musicovery.com/
1.3. 研究方法與架構 3
1. 從少量的已知情緒單元激發出更多的未知情緒單元: 在預測歌詞情緒值之 前,我們必須將現有的已知情緒單元激發出更多的未知情緒單元,以獲得足 夠的情緒單元覆蓋率。
2. 挖掘歌詞情緒值: 擴大情緒單元的覆蓋率後,如何善加利用此情緒辭典,
預測歌詞情緒值。
1.3 研 研 研究 究 究方 方 方法 法 法與 與 與架 架 架構 構 構
對於1.2所提出的第一個問題「從少量的已知情緒單元激發出更多的未知情緒單 元」, 我們提出情緒擴散模組來激發更多的情緒單元,對於第二個問題「挖掘歌 詞情緒值」, 我們提出情緒挖掘模組來預測歌詞情緒值,其架構圖可參考Figure 1.1, 以下我們分別描述情緒擴散模組與情緒挖掘模組的細部流程。
1.3.1 情 情 情緒 緒 緒擴 擴 擴散 散 散模 模 模組 組 組
我們提出了情緒擴散(Sentiment Spreading)的想法,以解決情緒詞語資源不完善 的問題。 情緒擴散的想法有以下兩種概念:
1. 收集現有的情緒辭典資源: 因為情緒詞語資源的不完整,不存在一情緒辭 典能包含所有的正確情緒詞語, 因此我們希望透過多種辭典間相互驗證的 方法,收集情緒單元種子。
2. 將情緒從常識網路中擴散: 有了少數情緒單元種子後,我們利用常識網路 具有大量知識且概念與概念間互相連接的特性, 將這些情緒單元種子,藉
4 CHAPTER 1. 緒論
由情緒擴散激發(Sentiment Spreading Activation), 將種子的情緒值擴散到 相鄰的概念,傳遞到整個常識網路,回收更多的情緒單元。
1.3.2 情 情 情緒 緒 緒挖 挖 挖掘 掘 掘模 模 模組 組 組
我們提出情緒挖掘模組來挖掘文本情感的問題。對於輸入的歌詞文本資料, 經由 自然語言處理(Natural Language Processing)將其斷句與斷詞,再拆解成兩個部分 分析其情感:
(1) 挖掘句子情感數值:利用情緒擴散模組所輸出的情緒單元辭典,和句子情感挖 掘規則來判斷句子的情緒值。
(1) 總整文本的情緒值:結合每一句子的情感數值和文本情感挖掘規則,計算完整 歌詞文本的情緒值。
1.4 論 論 論文 文 文結 結 結構 構 構
本論文的章節架構如下:Chapter 2 介紹九種常見的情緒辭典,並分析彼此間的 相關程度, Chapter 3 描述利用從多種情緒辭典中收集的情緒單元種子藉由常識 網路擴散情緒值, Chapter 4 則解釋挖掘文本情緒的演算法,Chpter 5 為我們實 作在英文和中文這兩種不同語言的實驗流程, 最後在Chapter 6 作總結與未來展 望。
1.4. 論文結構 5
Figure 1.1: 系統架構圖
Chapter 2 情
情 情緒 緒 緒辭 辭 辭典 典 典介 介 介紹 紹 紹
在這個章節中,我們介紹了此論文會使用到的九種常見情緒辭典,並將此九種辭 典分成以下三類: 2.1 標記情緒數值辭典:對於每個單詞標註一情緒數值 (Affec- tive Norms for English Words、SenticNet、SentiWordNet)。 2.2 標記情緒極性辭 典:對於每個單詞標註其為正向或是負向情緒 (HowNet-Vocabulary for Sentiment Analysis、General Inquirer-Emotion、 Wordnet-Affect、National Taiwan Univer- sity Sentiment Dictionary)。 2.3 無標記之情緒辭典:單純條列出每個情緒字 (Never Ending Language Learner-Emotion、WeFeelFine)。 且在最後一小節2.4依 三個不同角度討論我們所觀察到的情緒辭典特性。
6
2.1. 標記情緒值辭典 7
2.1 標 標 標記 記 記情 情 情緒 緒 緒值 值 值辭 辭 辭典 典 典
2.1.1 Affective Norms for English Words
Affective Norms for English Words (ANEW)[3] 提供一情緒英文單字的集合, 並 將每個單字標註一情緒數值。此情緒數值由心理系學生人工標記,且每一情 緒數值可細分成三個維度: 愉悅程度(Pleasure)、激動程度(Arousal)和支配程 度(Dominance),以下簡稱為PAD值。
ANEW情緒數值皆介於1到9之間,對於每個維度而言,數值大小代表程 度 高 低 。 如 愉 悅 程 度(Pleasure)所 標 記 的 情 緒 數 值 越 小 表 示 此 單 字 越 使 人 不 愉 快(Unpleasant), 數 值 越 大 表 示 此 單 字 越 使 人 愉 快(Pleasant); 激 動 程 度(Arousal)所標記的情緒數值越小表示此單字越使人平靜(Calm), 數值越大表示 此單字越使人興奮(Excited); 支配程度(Dominance)所標記的情緒數值大小表示 此單字強勢程度的高低。
ANEW實驗過程中,使用 Self-Assessment Manikin (SAM)情緒評估系統收集 標記結果。 SAM評估表上對於三個不同的維度,有各自的5個標記用假人來幫助 其標記, 例如標記愉悅程度的假人從第一個皺著眉頭、不開心到第五個表情微 笑、快樂; 標記激動程度的假人從第一個昏昏欲睡代表放鬆到第五個睜大眼睛代 表興奮; 標記支配程度的假人從第一個身材瘦小代表弱勢到第五個身材高大代表 強勢。
因為ANEW為純人工建置而成,從1999年發表以來,經常被用於情緒分析或 是情緒挖掘[13] [9]。 ANEW 總共收集了1034個英文單字,其PA值分布如Figure 2.1, 若取P值 = 5視為中性情緒標準,則其中有584個正向英文單字,450個負向 英文單字。
8 CHAPTER 2. 情緒辭典介紹
Figure 2.1: ANEW PA值分布圖
2.1.2 SenticNet
SenticNet[6]是一個供意見挖掘與情感分析的語意資源。 不同於傳統意見挖掘 方法,單純依靠部分情感文字 (例如正向情感文字:「好」、「幸運的」、
「優越」,負向情感文字:「不良」、「骯髒」、「貧窮」) 來分析文本的情 感或是意見。SenticNet覺得有些情感的表達很含蓄, 隱藏在文本內容或是所 談論的領域中,而這樣的含蓄情感表達方法,只分析字面情感文字是無效的。
因此,SenticNet利用新技術-Sentic Computing[5], 藉由常識推理(Common sense reasoning)更進一步的了解、認識並處理人類情感。
SenticNet從漏斗情緒模組(The Hourglass of Emotions)拿取情緒關鍵字與相對
2.1. 標記情緒值辭典 9
應的情緒值, 放入AffectiveSpace[4]計算兩兩概念的情感相似度,進一步將情感 數值擴散。 AffectiveSpace為結合常識網路(ConceptNet)和 2.2.3介紹的WordNet- Affect 所建構出的n維向量空間,每個概念都表示成一n維向量, 兩兩概念間的情 感相似度亦可利用此兩個概念所代表的向量相似度計算出來。
SenticNet總共擁有5,732個擁有介於-1和1之間的情緒值的概念集合。 若將情緒 值等於零視為中性情緒,則SenticNet包含3,372的正向情緒概念與2,360個負向情 緒概念。
2.1.3 SentiWordNet
SentiWordNet[10][1]同2.1.2 介紹的SenticNet都是一個意見挖掘與情感分析的詞語 資源。 不同的地方是,SenticNet結合字義和常識網路,計算出每個概念的語意情 緒值, 而SentiWordNet則基於WordNet(2.0版本),分配每個同義詞組(Synsets)一 個包含積極性(Positivity)、 消極性(Negativity)和客觀性(Objectivity)的三維情緒 值組。
SentiWordNet假設每個同義詞組對不同的情感相關屬性會有不同的情感程 度。 因此對於WordNet中的每個同義詞組s給予三個情感數值分數:Obj(s)、
Pos(s)和Neg(s), 各 別 代 表 客 觀 、 積 極 和 消 極 程 度 。 每 個 維 度 的 數 值 介 於0.0到1.0之間, 且每個同義詞組的三維度數值總合為1.0。這意味著,這三維度 中,必至少有一維度具有非零數值。 例如 Pos([estimable]) = 0.75,Neg([estimable])
= 0.25, 這裡estimable的意思為「值得尊重且重視的」。
因為SentiWordNet對於WordNet中的每個同義詞組都賦予一個三維度的情 感數值分數, 因此SentiWordNet的數量龐大,包含147,157個英文詞語,但其
10 CHAPTER 2. 情緒辭典介紹
中112,793個詞語的Obj分數都為1.0 (代表Pos和Neg分數都為零),22,376個詞語 的Obj分數皆大於Pos和Neg分數, 剩餘11,988個詞語才具有高度情緒分數。 對 於完全客觀性(Obj分數為1.0)或高度客觀性(Obj分數高於Pos和Neg分數)的同義詞 組, 我們無法確認是因為本身帶有任何的情感或是因為此同義詞組在不同上下 文帶有不同的情感, 因此我們之後的論文內容排除這些同義詞組,只討論剩餘 的11,988個高度情緒詞組。
2.2 標 標 標記 記 記情 情 情緒 緒 緒極 極 極性 性 性辭 辭 辭典 典 典
2.2.1 知 知 知網 網 網-情 情 情感 感 感分 分 分析 析 析用 用 用詞 詞 詞語 語 語集 集 集
董振東先生於1988年創建知網(HowNet)1。 他認為知識是一個系統,是一個包含 著各種概念與概念之間的關係,以及概念的屬性與屬性之間的關係的系統。 知網 便在這樣的想法下產生:以漢語和英語的詞語所表達的概念為描述對象, 詳盡地 描述出概念與概念之間以及概念所具有的屬性之間的關係為基本內容的常識知識 庫。
知網作為一個知識系統,比起將字義分類歸入同義詞集(例如WordNet)的建 構樹作法, 更希望能表示成一個網路,著力於反映出概念的共通性與個別性,
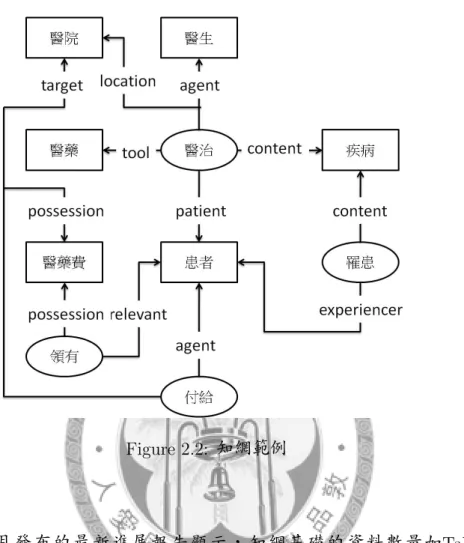
以Figure 2.2為例:對於「醫生」和「患者」, 「人」是他們的共通性而各自的 個別性則為「具有醫治的能力」和「具有患病的經驗」。 對於「富翁」和「窮 人」,「美女」和「醜八怪」而言,「人」也是他們的共通性, 而各自的個別性 為:「貧」、「富」與「美」、「醜」等不同的屬性值。 知網除了以上描述的概 念語意屬性外,對於語義知識,也利用例如:同義或是反義的關係表示出來。
1http://www.keenage.com/
2.2. 標記情緒極性辭典 11
Figure 2.2: 知網範例
從2010年4月發布的最新進展報告顯示,知網基礎的資料數量如Table2.1。
且在2007年10月,知網發表了「情感分析用詞語集」(Vocabulary for Sentiment Analysis), 簡稱HowNet-VSA,其中包含了中文與英文的正面情感詞語(例如:
愛、讚賞、快樂、感同身受)、 負面情感詞語(例如:哀傷、半信半疑、鄙視、後 悔)、正面評價詞語(例如:不可或缺、才高八斗、動聽)、 負面評價詞語(例如:
醜、苦、華而不實、荒涼)、程度級別詞語(例如:很、超級、極)、 主張詞語(例 如:知道、自覺、聽到)。各類型的資料數量如Table2.2。
我們收集其中具有情感標記的正面情感詞語、負面情感詞語、正面評價詞語、
正面評價詞語, 共包含8,747英文詞語和8,746中文詞語。
12 CHAPTER 2. 情緒辭典介紹
數量 中文詞語 100,168 英文詞語 96,370 中文語義 114,985 英文語義 121,042 概念定義 29,868 Table 2.1: 知網資料統計表
英文數量 中文數量 正面情感詞語 769 833 負面情感詞語 1,011 1,254 正面評價詞語 3,594 3,730 負面評價詞語 3,563 3,116 程度級別詞語 170 230
主張詞語 35 38
Table 2.2: 知網-情感分析用詞語集(HowNet-VSA)資料統計表
2.2.2 General Inquirer-Emotion
Stone等人在1966年所發展出來的General Inquirer (GI)[20] 可算是最早的文本內容 分析(Content analysis)方法。
為了內容分析,GI從以下2種不同來源收集每個單字的標籤,以便了解每個單 字用於哪些領域或是屬於哪種類別:
1. The Harbsrd IV-4 psychosocial dictionary: 此本辭典包含以下十四個不同領 域的標籤類別,Osgood三語意層面(正向-負向、強度-弱度、主動-被動)、
快樂或痛苦、描述仔細或是輕描淡寫、社會學標籤(例如:學術類或是經 濟學類)、人類關係中所扮演的角色、 歸屬(例如:男人、女人、動物)、位 置、物件、通訊、動機相關(例如:需要、目標)、改變、 認知取向(例如:
2.2. 標記情緒極性辭典 13
想法、原因)、代詞(例如:你、我、他)、否定與感嘆詞(例如:否、不。)
2. The Lasswell value dictionary: 此 本 辭 典 包 含 八 個 基 本 價 值 類 別 : 財 富(Wealth)、權力(Power)、尊重(Respect)、正直(Rectitude)、 技能(Skill)、
啟蒙(Enlightenment)、情緒(Affection)、福利(Wellbeing), 每個類別又可細 分多個不同程度的標籤,例如:assist屬於「Power Gain」、 divorce屬於
「Affect Loss」、cubism屬於「Skill Aesthetic」。
結合以上兩種來源,GI收集了11,787個英文單字(同字不同義則視為不同的 單字)與182種標籤, 而我們將標有「Positive Outlook」與「Negative Outlook」
標 籤 的 英 文 單 字 當 作GI-Emotion辭 典 , 其 中 包 含1,654個 正 向 情 緒 英 文 單 字 與2,028個負向情緒英文單字。
2.2.3 WordNet-Affect
Strapparava和Valitutti於2004年提出一個表示情感知識的語言資源WordNetAffect[21],
WordNet-Affect取材於WordNet, 通過選擇與過濾同義詞集(Synsets)來表示情感 概念。
WordNet可以說是文字的百科全書,包含了將近20萬個英文字義及其語意關 係,且使用同義詞集來表示詞彙間的概念, 也就是說在詞的型式和意義之間建立 起映射關係。不管在自然語言處理,或是搜尋引擎等研究中,都常見WordNet的 身影。
WordNet-Affect在WordNet中選擇某些同義詞集代表情感概念,不破壞原 本的WordNet架構, 只是再被選擇的同義詞集額外加上一個或多個情感標 籤(a-labels), 例 如 :EMOTION、MOOD、 COGNITIVE STATE、PHYSICAL
14 CHAPTER 2. 情緒辭典介紹
STATE。為了達到此目的, WordNet-Affect第一步先定義出「核心」情感,再來 利用WordNet中所存在的“關係”將核心情感擴散出去, 回收更多的情感概念。
WordNet-Affect總共包含了2,874種同義詞集和4,787個英文單字。 而我們拿 取情感標籤為「EMOTION」的1,587個英文單字當作WordNet-Affect情緒辭典,
其中492個英文單字被標記為正向情緒(Positive-emotion), 895個英文單字被標 記成負向情緒(Negative-emotion), 22個英文單字被標記成正向情緒(Neutral- emotion), 141個英文單字被標記成模糊情緒(Ambiguous-emotion), 剩餘37個英 文單字擁有兩個以上的情感標記。例如:dreamy被標記為正向情緒和中性情緒。
2.2.4 National Taiwan University Sentiment Dictionary
National Taiwan University Sentiment Dictionary (NTUSD)[15] 為一中文情緒辭 典,其來源來自於以下兩個情緒辭典:(1) 2.2.2所介紹過的GI (2) Chinese Network Sentiment Dictionary(CNSD):包含431正向中文情緒單詞, 1,948個負向中文情 緒單詞。
收集過程先將GI所包含的2,333個英文正向情緒單字和5,830個英文負向情緒單 字翻譯成中文, 合併CNSD的中文情緒單詞當作中文種子情緒單詞,再利用同義 詞詞林(tong2yi4ci2ci2lin2)[18] 與中研院中英雙語知識本體詞網(Academia Sinica Bilingual Ontological Wordnet) 2將每個情緒單詞作同義詞擴張。 NTUSD最後總 共收集了2,812個正面情緒中文單詞和8,276個負面情緒中文單詞。
2 http://bow.sinica.edu.tw/
2.3. 標記情緒詞語辭典 15
2.3 標 標 標記 記 記情 情 情緒 緒 緒詞 詞 詞語 語 語辭 辭 辭典 典 典
2.3.1 Never Ending Language Learner-Emotion
卡內基梅隆大學(Carnegie Mellon University)Carlson等研究人員[7] 開發出一個 永遠不會停止學習的人工智慧語言學習系統-Never Ending Language Learner,簡 稱NELL。 它的基本設計想法就是每天在Web上爬行,經由「閱讀」網頁上的文 字從中挖掘出事實。 從2010年1月建立以來運行至今已收集了673,098個事實。
NELL有兩個目標,第一個是能夠「閱讀」網頁並「學習」事實, 也就 是 說 希 望 從 數 以 百 萬 計 非 結 構 化 的 網 頁 資 料 中 提 取 出 結 構 化 的 資 訊 。 例 如:playsInstrument(George Harrison, guitar)。 第二個目標是企圖提高其閱讀與 學習能力,每一天都能比前一天從網頁提取出更多且更準確的事實。
為了達到以上的目標,NELL第一步先定義了一個初始本體(Ontology)資料 庫, 其中包含數以百計的類別,例如:person、sportsTeam、fruit、emotion,
和類別間的關係,例如:playsInstrument(musician,instrument)。 並在每一類別 和關係中,預先設定了10到15個例子。 類別例子如:person(walter gropius)、關係 例子如:playsInstrument(bob dylan, guitar)。
有了上述的初始資料,NELL從數量龐大的網頁中,利用每個類別與關係的挖 掘模型(Pattern), 例如Emotion類別的挖掘模型其中之一為:activists expressed
,來找尋新事實。 並利用半監督式學習(Semi-Supervised Learning)從先前收集到 的事實資料庫, 計算新事實的支持率,以選擇是否加入資料庫。當資料庫數量越 來越龐大後, 半監督式學習的條件也越來越嚴謹,使得新加入的事實也越來越準 確。
16 CHAPTER 2. 情緒辭典介紹
我們拿取NELL運行至今所挖掘出的情緒(Emotion)類別當作NELL-Emotion辭 典,其中共包含3109個英文概念。
2.3.2 WeFeelFine
Kamvar和Harris[14]在2005年8月發表了一挖掘全球人類情感的網站- WeFeelFine3。 此系統每隔幾分鐘就從全球新發表的部落格文章中,找尋出現「I feel」或是「I am feeling」的短語, 並將此完整句子記錄下來,再比對句子中是否出現預先定 義的情緒單字庫, 例如:sad、happy,來代表此句話所表達的情緒。至今已收集 了約上百萬個人類情感, 每天也穩定增加15,000到20,000個新情感句子。
因為部落格有一定的標準結構,所以在紀錄每一句情感句子時,可以一併拿取 此句子的屬性: 作者年齡、作者性別、發表的時間、作者的所在地、所在地的天 氣、附加照片。 WeFeelFine便利用這些屬性作更進一步有趣的人類情感分析,例 如:歐洲人比美國人更容易感到悲傷嗎? 雨天是否會影響人類的感覺?20多歲的 女性紐約人最容易具有何種情感? 在情人節當天,普遍人類的情感為何?世界上 哪裡是最幸福的城市?等等。 並利用六種不同的視覺化模式來展現所收集到的情 感資料:(1) Madness、(2) Murmurs、 (3) Montage、(4) Mobs、(5) Metrics、(6) Mounds 。
在第一段有提到WeFeelFine利用句子中出現「I feel」或是「I am feeling」來 代表此為一情感句子, 再利用預先定義好的情緒單字庫來確定此情感句子所表 達的情緒。 此情緒單字庫為人工條列出的2,179個英文情緒單字,我們將它視 為WeFeelFine辭典。
3 http://www.wefeelfine.org/index.html
2.4. 情緒辭典特性觀察 17
Figure 2.3: 各情緒辭典標記方法分類圖
2.4 情 情 情緒 緒 緒辭 辭 辭典 典 典特 特 特性 性 性觀 觀 觀察 察 察
我們依照其標記方法、標記內容與標記類型分別討論從多種情緒辭典中所觀察到 的特性。
2.4.1 標 標 標記 記 記方 方 方法 法 法
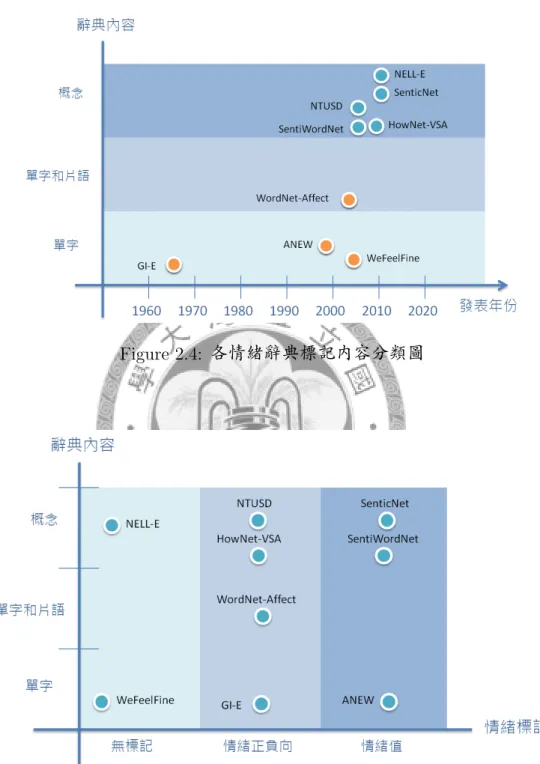
我們將各情緒辭典的發表年份和其所使用的建構方法畫製成Fig 2.3。 從圖中我們 可以發現,在早期的情緒辭典常使用手動標記,後來延伸成依照同義詞進行情緒 擴散, 近年的情緒辭典,則著重在利用語意進行情緒擴散。
2.4.2 標 標 標記 記 記內 內 內容 容 容
我們將各情緒辭典的發表年份和其所標記的容畫製成Fig 2.4。從圖中我們可以發
18 CHAPTER 2. 情緒辭典介紹
Figure 2.4: 各情緒辭典標記內容分類圖
Figure 2.5: 各情緒辭典標記類型分類圖
2.4. 情緒辭典特性觀察 19
現, 在早期的情緒辭典的收集單元為單字或是片語,2005之後,傾向於收集概 念。其原因可能為對於一詞語, 其語意所表達的情緒往往更顯著於其字義所表達 的情緒。 例如:我今天撿到一百塊,分開來看各個單字似乎沒有明顯的情緒表 達, 但看整個概念,卻發現其隱藏著高興的情緒。
2.4.3 標 標 標記 記 記類 類 類型 型 型
我們將情緒辭典依其標記類型分成三類,標記情緒值辭典、標記情緒極性辭典與 無標記之情緒辭典, 如Fig 2.5所示。標記情緒值辭典對於辭典中的每個單元,都 給予一個情緒分數, 標記情緒極性辭典則是將其單元標上正負向,最後無標記之 情緒辭典則是只條列出情緒單元,無其他的情緒標記。
Chapter 3 情
情 情緒 緒 緒擴 擴 擴散 散 散模 模 模組 組 組
對於中文情緒分析,因為大多數的情緒辭典皆為英文,如ANEW、SenticNet、GI- Emotion...等。 人們經常使用翻譯技術嘗試建立一中文情緒辭典。然而,文化差 異往往會導致不準確的翻譯結果, 我們希望經由不同情緒辭典間的相互驗證與中 文常識網路來解決此問題,以得到較貼近中文文化的情趣辭典。 除此之外,現存 的中文情緒辭典,如HowNet-VSA與NTUSD,只有標記每一詞語的正負極性,並 不存在其情緒數值, 我們希望經由不同的情緒辭典間不同的標記內容,如情緒極 性和情緒數值,獲得一擁有完整情緒數值的中文情緒辭典, 以便在分析情緒時,
能有更詳細的資源。
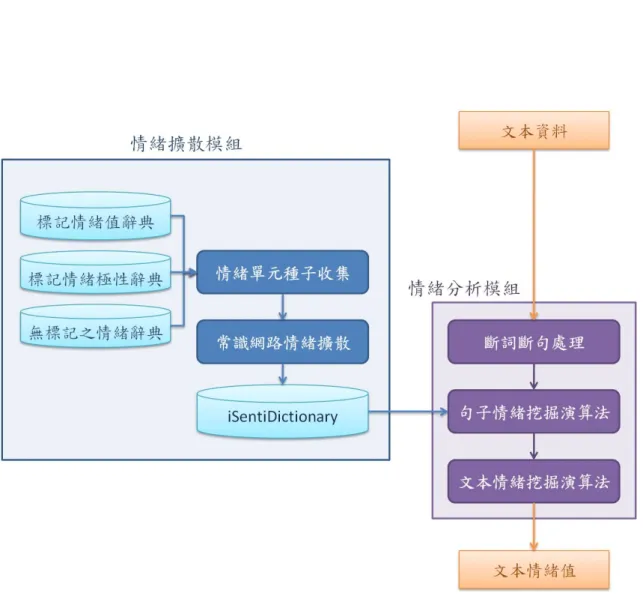
因此在這個章節中,我們提出了情緒擴散模組來收集更多的情緒單元集合成一 中文情緒辭典,以解決情緒辭典不完整的問題。 此情緒擴散模組分為兩個部分,
可參考Figure 3.1。 第一部分為3.1所介紹收集情緒單元種子,我們收集了九部情 緒辭典, 並利用不同辭典間的重複驗證,抽取4種不同的情緒單元種子, 標記情 緒數值(S-Value)、標記情緒正負向(S-Polarity)、標記模糊情緒(S-Ambiguity)以及
20
21
情緒不明(S-Unknown)。 第二部份為3.2所介紹的情緒擴散激發,利用第一部分所 收集的情緒單元種子, 經由常識網路中,具有大量概念且概念與概念間存在關係 的特性,將情緒擴散到每個概念節點, 其情緒擴散方法不僅考慮詞義,更考慮概 念間由關係所表達的隱藏情感, 最後得到一不僅考慮其詞彙意義更結合語意的情 緒辭典,我們稱之為iSentiDictionary。
Figure 3.1: 情緒擴散模組架構圖
22 CHAPTER 3. 情緒擴散模組
3.1 情 情 情緒 緒 緒單 單 單元 元 元種 種 種子 子 子收 收 收集 集 集
為了利用情緒擴散方法得到更多的情緒單元,我們必須先有一情緒單元種子集 合。 因此我們收集了在Chpater 2所介紹的九種常見情緒辭典, 第一步將英文情 緒辭典翻譯成中文, 第二步擴張情緒辭典增加兩兩辭典間的覆蓋度,以用來判斷 不同辭典間,對於同一詞語的標記是否一致, 最後合併所有存在於情緒辭典中的 詞語情緒標記,並選擇至少存在於兩種情緒辭典的詞語為情緒單元種子。 而因為 辭典間的標記內容不一致,有些標記情緒數值,有些標記情緒極性, 所以每個情 緒單元種子所收集到的情緒標記也不盡相同,因此我們將情緒單元種子分成以下 四種類型:
1. 標記情緒數值(S-Value):標有情緒數值的情緒單元種子,情緒數值介 於-1到1之間, 大於0代表為正向情緒,小於0為負向情緒,等於0為中性情 緒。
2. 標記情緒正負向(S-Polarity): 標記為正向或是負向但是卻沒有收集到情緒 數值的情緒單元種子。
3. 標記模糊情緒(S-Ambiguity):同時被標記為正向和負向情緒的情緒單元種 子。 對於某個標記情緒極性的情緒辭典,有可能將某一詞語同時標記為正 向和負向情緒, 對於多種情緒辭典,亦有可能發生其中一種辭典將此詞語 標記為正向,但另一種辭典卻將其標記為負向。 因此我們將此類型的情緒 種子視為模糊情緒,可能在不同的語意表達下會有不同的正負向情緒。
4. 標記未知情緒(S-Unknown):只知道此詞語為情緒詞語, 但卻無法從辭典中 得到其情緒標記的情緒種子。
3.1. 情緒單元種子收集 23
3.1.1 翻 翻 翻譯 譯 譯情 情 情緒 緒 緒辭 辭 辭典 典 典
我們收集到的情緒辭典中,除了HowNet-VSA和NTUSD外,皆為英文情緒辭 典, 因此在收集情緒種子時,第一步驟先將其翻譯。我們使用Google Trans- late和Yahoo Dictionary當作翻譯工具。 給定一個英文單字,Google Translate會 輸出一個翻譯結果, 而Yahoo Dictionary則會輸出所有可能的翻譯詞組。 我們設 計一個方法,結合這兩種翻譯工具, 使翻譯結果不僅具有Google Translate的高 精準度,也具有Yahoo Dictionary的高覆蓋度特性。
給定一個英文詞語e,假設Google Translate 輸出結果為g1, 而Yahoo Dictio- nary 則輸出一翻譯詞組集合 {y1, y2, y3, ..., yi, ..., yn}。 假設Yahoo Dictionary的 其中一個翻譯詞組yi包含g1時, 我們選擇yi為e的翻譯結果。 以翻譯「admired」
為例,Google Translate的翻譯結果為「欽佩」, Yahoo Dictionary的查詢結果 為「{欽佩、欣賞}、{稱讚, 誇獎}、{對...不勝佩服}」, 因此我們拿取出現「欽 佩」的{欽佩、欣賞}翻譯詞組當作翻譯結果。 Table 3.1列出每一情緒辭典的翻譯 結果數量。
情緒辭典 單字數量 情緒辭典 概念數量 ANEW 2,582 SenticNet 6,911 GI-Emotion 6,812 SentiWordNet 10,796 WordNetAffect 1,928 HowNet-VSA 8,761
WeFeelFine 4,734 NTUSD 10,371 NELL-Emotion 1,594 Table 3.1: 情緒辭典的翻譯結果數量統計表
24 CHAPTER 3. 情緒擴散模組
3.1.2 情 情 情緒 緒 緒辭 辭 辭典 典 典擴 擴 擴張 張 張
我們希望每個詞語能有盡量多的辭典標記,以便我們在合併辭典時能更準確判斷 情緒標記。 但我們發現每個翻譯過的詞語平均只有1.5479個辭典標記, 為了增加 其辭典標記,我們利用贅詞、情緒程度詞與否定詞來擴張辭典的詞語數量。
贅 贅
贅詞詞詞擴擴擴張張張
對於內容型態為概念的情緒辭典中,我們發現存在很多「情緒贅詞」, 這裡的 情緒贅詞定義為將其過濾掉仍不影響其情緒的詞語。而我們將其情緒標記擴散到 過濾墜詞後的單詞, 以擴張辭典的資料量。例如:ANEW中有一詞語為「大膽 的」,其中「的」為墜詞, 將其拿掉後的「大膽」其情緒值不變,因此「大膽 的」將會將其情緒標記擴散到「大膽」, 並在ANEW中新增「大膽」這筆資料,
並複製「大膽的」的情緒值。
Table 3.2條列出我們從辭典中所觀察到的情緒贅詞擴張樣板。
擴張樣板 擴張子詞語 覺得 {1} {1}
感覺 {1} {1}
感到 {1} {1}
使 {1} {1}
{1}的感覺 {1}
{1} 的
Table 3.2: 情緒贅詞擴張樣板
程 程
程度度度詞詞詞擴擴擴張張張
程度詞為修飾形容詞或是副詞強弱度的詞語,例如:「很」。如果將程度詞過濾
3.1. 情緒單元種子收集 25
掉,則情緒極性並不會改變, 例如:「很喜歡」和「喜歡」的情緒極性相同。因 此我們將過濾掉程度詞的詞語一併加入原本的辭典中, 並複製其情緒極性標記,
但對於情緒數值,我們考量到程度詞彙增強或減弱其情緒,所以情緒數值並不擴 張。 Table 3.3條列出我們從HowNet-VSA收集程度詞, 經由比對辭典中詞語所選 擇出來的情緒擴張程度詞。
一些 非常 極度 極其
萬分 很 太 有點
更 更加 超 超級
相當 相當多的 相當大的 特別 Table 3.3: 情緒程度詞擴張
否 否
否定定定詞詞詞擴擴擴張張張
由於否定詞句有情緒反轉之詞義,因此我們除了考慮同向的情緒擴張外,亦處理 反向的情緒擴張。 例如:「不公平」標記為負向情緒,則可以推論「公平」為正 向情緒。Table 3.4 條列出我們從辭典中觀察所達到的情緒否定詞。
不 不可 不可以 不能 不能夠 不得 不行 不准 不許 不必 沒有 沒
Table 3.4: 情緒否定詞擴張
辭 辭
辭典典典擴擴擴張張張結結結果果果
執行情緒辭典擴張後,每個翻譯過的詞語平均有1.8861個辭典標記, Table 3.5顯 示擴張後的辭典數量, 我們可發現每個情緒辭典內容數量皆上升。
26 CHAPTER 3. 情緒擴散模組
情緒辭典 單字數量 情緒辭典 概念數量
(擴張前/擴張後) (擴張前/擴張後) ANEW 2,582/3,691 SenticNet 6,911/8,923 GI-Emotion 6,812/9,678 SentiWordNet 10,796/13,741 WordNetAffect 1,928/3,040 HowNet-VSA 8,761/11,424
WeFeelFine 4,734/7,566 NTUSD 10,371/11,973 NELL-Emotion 1,594/2,376 Table 3.5: 情緒辭典的擴張結果數量統計表
3.1.3 情 情 情緒 緒 緒辭 辭 辭典 典 典合 合 合併 併 併
過程中我們共收集了在Chpater 2所介紹的九種常見情緒辭典, 依照其標記內容 將其分為三類,在合併辭典的詞語前, 我們先整理其標記內容為所需的模式,細 節如下:
1. 標記情緒數值辭典
(a) ANEW:原本情緒數值介於1到9之間,我們將其情緒數值對應到-1和1之 間。
(b) SenticNet:原本情緒數值介於-1到1之間,無作任何修改。
(c) SentiWordNet:包 含 三 維 情 緒 分 數[Pos,Neg,Obj], 且Pos+Neg+Obj = 1。 我們將其Pos分數減掉Neg分數代表情緒數值。
2. 標記情緒極性辭典
(a) HowNet-VSA:包含正向情緒、正向評價、負向情緒或是負向評價的標 籤, 同一詞語不一定只具有單一標籤。 因此我們將標記正向情緒或正 向評價但不標記負向情緒或負向評價的詞語極性視為正向情緒, 標記
3.1. 情緒單元種子收集 27
負向情緒或負向評價但不標記正向情緒或正向評價的詞語極性視為負 向情緒,剩餘為模糊情緒。
(b) GI-E:包含正向情緒或負向情緒的標籤,同一詞語不一定只具有單一標 籤。 我們將其中同時被標記正向和負向情緒的詞語視為模糊情緒極 性,其餘則同原本的標記情緒標籤。
(c) WordNet-Affect:包正向、負向、中性或模糊情緒的標籤, 同一詞語不 一定只具有單一標籤。 我們將重複標記為正向和負向情緒的詞語和標 記中性或模糊情緒的詞語都視為模糊情緒, 其餘詞語則依照GI-E所標 記的情緒標籤決定正負向。
(d) NTUSD:包含標記正向和負向情緒的標籤,同一詞語不一定只具有單 一標籤。 我們將其中同時標記正向和負向標籤的詞語視為模糊情緒極 性, 其餘詞語則依照NTUSD所標記的情緒標籤決定正負向。
3. 無標記之情緒辭典
(a) NELL-E:無任何情緒極性標記,無須更改。
(b) WeFeelFine:無任何情緒極性標記,無須更改。
我們從翻譯詞語集合中挑選至少存在於2個辭典中的詞語當作情緒單元種子。
合併不同辭典間的情緒標記時,我們先去計算被辭典標記為正向、負向和模糊情 緒的個數, 來決定每個情緒單元種子的情緒標籤。 若正向、負向和模糊情緒的 個數皆為0,則此情緒單元種子為未知情緒; 若正向情緒個數較多,則此情緒單 元種子為正向情緒; 若負向情緒個數較多,則此情緒單元種子為負向情緒; 若 正負向情緒個數一樣多或是模糊情緒個數最多,則此情緒單元種子為模糊情緒。
28 CHAPTER 3. 情緒擴散模組
決定情緒單元種子的情緒標籤後,再去考慮此種子是否被標記具有此情緒標籤的 情緒數值, 若有,則取其平均當此種子的情緒數值。
合併後,我們將有被標記上情緒數值的情緒單元種子歸於S-Value集合, 被標 記上正向情緒或負向情緒但不擁有情緒數值的情緒單元種子歸於S-Polarity集合,
被標記為模糊情緒的情緒單元種子歸於S-Ambiguity集合, 最後,未知情緒的種 子情緒單元種子歸於S-Unknown集合。 Table 3.6為合併辭典後,所收集到的情緒 單元種子各類型數量統計表。
S-Value S-Polarity S-Ambiguity S-Unknown Total 情緒單元種子 6,464 1,951 2,641 11 11,076
Table 3.6: 情緒單元種子收集結果統計表
3.2 情 情 情緒 緒 緒擴 擴 擴散 散 散激 激 激發 發 發
情緒的表達不只是因為詞語的字義,有時也會隱藏在語意或是上下文中。而常識 網路每個節點代表為一個概念, 概念與概念間存在不同的關係,我們將概念間 的「關係」視為情緒傳遞的橋梁,將其情緒傳遞出去, 例如中文常識網路中存 在「紅色 代表 熱情。」這句常識,如果知道「熱情」的情緒, 便可傳遞到「紅 色」中,這是單純使用詞義擴張所不能得到的隱藏情感資訊。
3.2.1 常 常 常識 識 識網 網 網路 路 路(Common Sense Network)
當人與人溝通時,常依靠共享龐大的背景常識知識,來了解對方。而常識知識可 解釋成被眾人所接受、 無須解釋的意見觀念,意即「尋常見識」,或是指普通社
3.2. 情緒擴散激發 29
會上一個智力正常的人應有的知識, 也即「平常知識」。但對於電腦而言,並不 具有這方面的共享知識,使得在運用人工智慧技術或是設計人機介面時, 常常面 臨許多困難。
為了讓電腦能更了解人類的思考模式,我們需要提供有用的知識讓它學習,
例如對事物之間的基本關係或是大眾都明白的道理。 因此 Open Mind Common Sense(OMCS) Project 1 [19]從1999年開始從網路上的自願者收集常識,十年來更 擴大收集不同領域或是不同語言的常識。 而其中英文常識已超過100萬個句子。
2009年開始,Kuo等人[16] 也致力於收集繁體中文常識。 利用PPT上的虛擬寵 物,透過寵物與使用者間的常識問答,收集常識。並設立批改考卷與回報問題機 智, 預防收集壞常識。至今已收集356,277筆常識,是OMCS中第二大語言。
為了讓電腦可簡單的存取OMCS常識知識,ConceptNet[11] 將常識知識表示成 一個語意網如Figure3.2, 每個節點代表一個「概念」(Concept),如Figure3.2中 的「cook」、 「oven」和「cake」,而節點間相連的線則表示為此兩概念間存 在某一種「關係」(Relation),如 Figure3.2中的「UsedFor」關係,代表「oven UsedFor cook」。
3.2.2 基 基 基本 本 本的 的 的擴 擴 擴散 散 散激 激 激發 發 發
Liu等人[17]於2003年提出以文字與生活常識為基礎的情緒分析系統, 並設計出一 個根據郵件中的每一句話,都賦予一個相對應的表情符號來表達其文字情緒的電 子郵件介面, 除了可增進使用者間傳遞訊息的趣味性外,更能進一步了解文字所 隱含的情緒。
1http://csc.media.mit.edu/node
30 CHAPTER 3. 情緒擴散模組
Figure 3.2: ConceptNet常識網路
在這研究上,第一次提出了使用真實世界的生活常識,也就是3.2.1所提到 的OMCS, 來作為情緒判斷的基礎。將ConceptNet中的各個關係連結,視為概念 與概念間的情緒橋梁,也就是說, 對於兩個之間存在關係的概念,其情緒可以傳 遞,以「Car accidents can be scary」這句常識為例, 因為概念「Car accidents」
和「scary」之間存在「can be」的關係, 若我們已經知道「Car accidents」的 情緒,便可將其情緒傳遞給「scary」。 這就是最原始的情緒擴散(Sentiment Spreading Activation)想法。
在此研究中,Liu等人收集了擁有6維情緒屬性([happy, sad, angry, fear, disgust, surprise]) 的情緒詞視為擴散種子,也就是說這些種子在ConceptNet具有初始 傳遞情緒的能力, 可經由連結的關係將情緒傳遞到鄰近的概念, 但是經過 的傳遞路徑越長,情緒所能激發的程度就會以d係數降低。 以下面三句存在 於ConceptNet中的常識句子為例, 假設happy和surprising為情緒種子,其各自的
3.2. 情緒擴散激發 31
情緒數值為[1,0,0,0,0,1]和[0,0,0,0,0,1],而d = 0.5:
1. Something exciting is both happy and surprising:
第一層情緒擴散,happy和surprising將情緒傳遞給exciting, 使得surprising具 有情緒值[1,0,0,0,0,1]。
2. Rollercoasters are exciting:
第二層情緒擴散,exciting將被傳遞的情緒數值擴散到Rollercoasters, 又擴 散遞減參數d為0.5,所以使得Rollercoasters具有情緒值[0.5,0,0,0,0.5]。
3. Rollercoasters are typically found at amusement parks:
第 三 層 情 緒 擴 散 ,Rollercoasters將 被 傳 遞 的 情 緒 數 值 擴 散 到amusement parks, 又 擴 散 遞 減 參 數d為0.5, 所 以 使 得amusement parks具 有 情 緒 值 [0.25,0,0,0,0.25]。
3.2.3 自 自 自我 我 我學 學 學習 習 習的 的 的擴 擴 擴散 散 散激 激 激發 發 發
自我學習(Self-Learning)為一種半監督式學習法。同字面上的解釋, 半監督式學 習法介於監督式學習法和非監督式學習法之間, 意即利用為大量為標記過的資料 結合一些已經將標記過的資料來做訓練的模型以解決資料數量少集分散的問題。
自我學習演算法可說是最早引進利用未標記過的資料這個概念的分類應 用。 訓練一開始時只利用少量標記過的資料,接著利用當下所定義的決策函 數(Decision function) 從未標記的資料中找出符合的點,加進原本標記過的訓練集 中,重新訓練並找出新的決策函數。 直到在未標記的資料中無法再找到可標示的 資料或是整個情形超過一些閥值(Threshold)。
32 CHAPTER 3. 情緒擴散模組
自我學習演算法有名的例子為Yarowsky [25]在1995年所提出的分辨語意歧異度 方法, 對於具有多種字義的單字,如何在文章中判斷其屬於哪個意思, 例如如 何決定plant在一篇文章中是植物還是工廠的意思。其利用的方法是從少量的標記 資料中, 找尋plant為植物意思時,前後所搭配的詞語,利用此特徵道為標記過的 文章中去找有同樣特徵的句子, 再收進訓練集裡,慢慢擴充訓練集的數量。 實 驗結果證明,這個方法訓練出來的模型跟只利用標記過資料及監督式學習法的效 果比起來, 確實將效能提昇並且少了很多人工標記的動作。
我 們 收 集 到 的 情 緒 單 元 種 子 , 有 四 種 不 同 的 類 型(S-Value, S-Polarity, S- Ambiguity 和 S-Unknown), 我們希望從情緒單元種子中學習一些資訊, 來幫助 基本情緒擴散激發方法, 我們研究過後發現,基本情緒擴散激發方法存在兩個問 題:
1. 錯誤情緒值也會被傳遞出去: 只限定傳遞出去的層數與遞減參數d, 卻沒有 考量到此概念是否不具有傳遞情緒之能力, 也就是說,如果此概念的情緒 值已經錯誤, 再將其情緒值傳遞出去可能造成更多的錯誤情緒產生。
2. 情緒數值失調: 對於多個情緒種子同時擴散情緒到一個概念時, 基本情緒激 活擴散計算其平均值作為最終的情緒數值。 但是這種計算方法會導致許多 概念具有接近零的情緒數值。
因此我們利用所收集到的情緒單元種子,幫助解決上述的兩個問題:
1. 判斷正確的擴散種子: 我們假設只有「情緒概念」有能力擴散情緒值, 此
「情緒概念」是指所有存在於情緒單元種子四種集合的概念。 較特別的 是,S-Polarity中的概念我們會先比對其接收到的情緒數值是否和辭典標記 的正負向相同, 如果相同,再將此概念的情緒傳遞出去,若不相同,我們
3.2. 情緒擴散激發 33
則不讓其有擴散情緒的能力, 以避免錯誤情緒持續擴散下去。
以下面四句常識為例,假設「快樂」的情緒數值為0.8,「幸福」存在 於S-Polarity且標記為正向情緒, 「睡不著」存在於S-Polarity且標記為負向 情緒, 「跳舞」存在於S-Ambiguity和「形容詞」不屬於情緒單元種子。
(a) 快樂 是一種 幸福。
「快樂」擴散情緒數值0.8到「幸福」,又因為「幸福」存在於S- Polarity且標記為正向情緒, 故「幸福」具有擴散情緒值的能力,能繼 續將情緒值擴散到鄰近概念。
(b) 快樂 的時候,你會 睡不著。
「快樂」擴散情緒數值0.8到「睡不著」,但因為「睡不著」存在 於S-Polarity且標記為負向情緒, 與接收到的情緒數值極性不符合,
故「睡不著」不具有擴散情緒值的能力,不能將情緒值擴散到鄰近概 念。
(c) 快樂 的時候會想要 跳舞。
「 快 樂 」 擴 散 情 緒 數 值0.8到 「 跳 舞 」 , 因 為 「 跳 舞 」 存 在 於S- Ambiguity, 故「跳舞」具有擴散情緒值的能力,能將情緒值繼續 擴散到鄰近概念。
(d) 快樂 是一種 形容詞。
「快樂」擴散情緒數值0.8到「形容詞」,因為「形容詞」不存在 於S-Ambiguity, 故「形容詞」不具有擴散情緒值的能力,不能將情緒 值擴散到鄰近概念。
2. 先決定情緒標籤再決定情緒數值: 利用S-Polarity與S-Valuse中的情緒種子計
34 CHAPTER 3. 情緒擴散模組
算其鄰居概念的種類後發現, 對於正向的情緒種子,其平均正向情緒的鄰 居個數約為負向情緒的鄰居個數的5倍; 對於負向的情緒種子,其平均負向 情緒的鄰居個數約為正向情緒的鄰居個數的4倍。 因此我們假設正向情緒概 念的鄰居大多也為正向情緒,同樣地,負向情緒概念的鄰居大多也為負向情 緒。
基於此種假設,對於多個情緒種子同時擴散情緒到某一概念時, 我們先去 計算其正負向情緒種子的個數來決定此概念須接收哪一種極性的情緒擴散。
若多為正向情緒的擴散,我們取正向情緒數值的平均為此概念所接收的情緒 數值, 反之,我們取負向情緒數值的平均為此概念所接收的情緒數值。
總結整個自我學習情緒擴散激發流程為,將從情緒辭典中所收集到的S- Value當作初始情緒擴散激發種子, 每作完一層的情緒擴散激發,便利用結 合S-Polarity、S-Ambiguity與S-Unknown中的種子, 判斷每個接收擴散情緒的概 念是否具有擴散情緒的能力,若具有情緒擴散的能力, 則將此概念加入下一層的 情緒擴散激發種子中,若有增加新的情緒擴散激發種子, 則繼續下一層情緒擴散 激發,若找不到新的情緒擴散激發種子,則結束自我學習。
Chapter 4 情
情 情緒 緒 緒分 分 分析 析 析模 模 模組 組 組
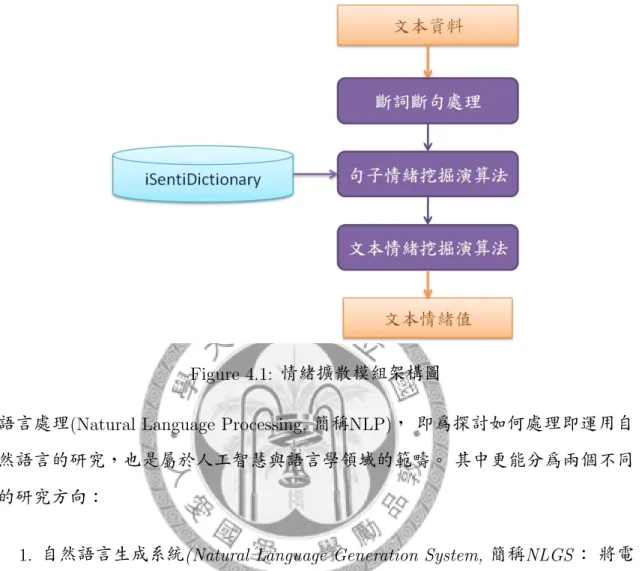
此章節介紹如何應用Chapter 3所得到的情緒辭典-iSentiDictionary 作文本情緒分 析。 情緒分析模組架構圖如Figure 4.1, 一開始我們將輸入的文本資料,經由自 然語言處理方式,將其斷詞且斷句, 再經由句子情緒挖掘演算法,逐一找出每一 句的情緒值,最後依照各上下文句子間的情緒值, 分析出完整的文本情緒值。
4.1會介紹自然語言處理與Yahoo斷章取義, 4.2會詳細說明我們所利用的句子情緒 挖掘演算法, 最後4.3則解釋如何將文本出的每一句情緒值傑合成整篇文本資料的 情緒值。
4.1 自 自 自然 然 然語 語 語言 言 言處 處 處理 理 理
自然語言通常是指一種自然地隨著地區文化演化的語言,又可解釋成用於日常溝 通的人類語言,如英文、中文或是日文。 相對於人造語言,如程式設計語言和數 學符號,自然語言因為已經進化經過長久演變, 難已表示成明確的規則。而自然
35
36 CHAPTER 4. 情緒分析模組
Figure 4.1: 情緒擴散模組架構圖
語言處理(Natural Language Processing, 簡稱NLP), 即為探討如何處理即運用自 然語言的研究,也是屬於人工智慧與語言學領域的範疇。 其中更能分為兩個不同 的研究方向:
1. 自然語言生成系統(Natural Language Generation System, 簡稱NLGS: 將電 腦所看得懂的數據語言,轉化成人類所理解的自然語言,以便傳達數據資訊 工人類理解。
2. 自然語言理解系統(Natural Language Understanding System, 簡稱NLUS:
和NLGS相反的,NLUS旨在將自然語言轉化為電腦程序容易理解與處理的 形式,通常需要經由標準化的處理, 如剖析樹(Parse Tree)架構,和關於外 在世界的廣泛知識以及運用操作這些知識的能力。 以便讓電腦易於處理自 然語言。
4.2. 句子情緒挖掘 37
為 了 解 決 以 上 兩 個 大 問 題 , 在 自 然 語 言 處 理 研 究 中 又 存 在 著 許 多 分 支 以處理各種不同的語言問題, 例如對於單句方面,有詞性標註(Tagging)、
句法分析(Parsing)、中文斷詞(Segmentation)等不同的研究。 而要更進一步分 析文本內容,則有文本分類(Document Categorization)、 訊息檢索(Information Retrieval)、自動摘要(Automatic Summarization)等不同的應用。
而我們為了分析文本情緒,起先要能了解文字結構,因此對於中文文本資料,
我們利用Yahoo! 斷章取義API將其斷詞。以下為詳細其介紹。
4.1.1 Yahoo! 斷 斷 斷章 章 章取 取 取義 義 義
對於中文文本而言,其斷詞不像英文直接利用空格作區隔那麼簡單,因為每個中 文單詞有可能為1個字、2個字或是更多。 因此我們利用中文斷詞工具的幫忙來了 解每一中文句子的架構,這裡我們使用Yahoo! 斷章取義。
Yahoo! 斷章取義1 [8] 提供使用者一個進行自動化文字語意分析與處理的介 面,此介面除了方便開發者應用於各種網路服務外, 更可提供學術界進行相關研 究。其API提供兩個方法,第一為斷詞語詞性標註,第二為文章關鍵字擷取。 並 提供兩種輸出格式供選擇:XML與JSON。
4.2 句 句 句子 子 子情 情 情緒 緒 緒挖 挖 挖掘 掘 掘
計算每一句子的情緒之前,我們先定義一些參數:
p:某一句子。
t:句子中所出現的情緒單元。
1http://tw.developer.yahoo.com/cas/
38 CHAPTER 4. 情緒分析模組
T :所有t的集合。
V (t):情緒單元t的情緒值,範圍介於-1到1之間。
W (t):情緒單元t的權重值。
並利用以下四個步驟來偵測句子 p中所存在的情緒單元 t並判斷其情緒值 V (t)與設定每一情緒單元的權重值 w:
1. 情緒單元挖掘:找出句子中所有的情緒單元 t,並設定其權重值w為初始權 重值。
2. 程度詞處理:偵測每一情緒單元t前後是否出現情緒程度詞,以加成情緒單 元的情緒值V (t)為r倍。
3. 否定詞處理:偵測每一情緒單元t前是否出現否定詞,以反轉情緒單元的情 緒情緒值。
4. 轉折詞處理:偵測句子中是否出現語氣轉折之詞語,以決定哪個情緒單 元t為情緒重心表示詞語, 並加重其情緒單元的權重值w。
計算完句子中所存在的情緒單元的情緒值與權重值後, 我們定義S(T )為T 中 每一情緒單元t的情緒值V (t)乘以其權重值W (t)的平均值, Sp(T )為T 中每一正向 情緒單元t的情緒值V (t)乘以其權重值W (t)的平均值, Sn(T )為T 中每一負向情緒 單元t的情緒值V (t)乘以其權重值W (t)的平均值。 公式如 4.1到4.3。
而對於每一句子的情緒值S(p),為了不讓每一句子的情緒值都接近0, 我們先 利用S(T )判斷其正負值,若S(T )大於0,則將Sp(T )視為S(p), 若S(T )小於0,則 取Sn(T )當作S(p),若S(T )等於0,則S(p)亦等於0。 詳細公式如 4.4 。
4.2. 句子情緒挖掘 39
S(T ) =
∑count
i=1 V (ti)× W (ti)
∑count
i=1 W (ti) , ti ∈ T (4.1)
Sp(T ) =
∑count
i=1 V (ti)× W (ti)
∑count
i=1 W (ti) , ti ∈ T andV (ti) > 0 (4.2)
Sn(T ) =
∑count
i=1 V (ti)× W (ti)
∑count
i=1 W (ti) , ti ∈ T andV (ti) < 0 (4.3)
S(p) =
Sp(T ), if S(T ) > 0 Sn(T ), if S(T ) < 0 0, otherwise.
(4.4)
4.2.1 情 情 情緒 緒 緒單 單 單元 元 元挖 挖 挖掘 掘 掘
iSentiDictionary為Chapter 3所介紹的情緒擴散模組所產生的情緒單元集合, 我們 先去偵測句子中是否出現都情緒單元,每一情緒單元不一定為一單詞,亦有可能 為概念。 將句子中的情緒單元挑選出來後,便考慮剩餘的詞語是否影響情緒單元 的情緒值,以做修改。
4.2.2 程 程 程度 度 度詞 詞 詞處 處 處理 理 理
程度詞是用來修飾形容詞和副詞的詞語,其強弱程度會影響所修飾的情緒單元的 情緒值。 在下面的例子中:「我非常高興。」,「非常」為修飾「高興」的程度 值, 又因為「非常」具有增強程度的效用,所以所得的情緒值也會以某程度增 強。
40 CHAPTER 4. 情緒分析模組
中文情緒程度前置修飾詞 增強權重值倍數
極度、極其、非常、極為、絕對、滔天、 1.5 十分、完完全全、萬般、萬分、無比、最為、
超級
很、多麼、份外、格外、好不、何等、相當、 1.3 相當多的、太、超、頗為、更為
更加、特別、越加 1.1
或多或少、一些、稍、稍微、稍許、稍為 0.8 略微、略為、一點、有點、有些、輕度 0.6
中文情緒程度後置修飾詞 增強權重值倍數
不得了、不可開交 1.5
之極、之至 1.3
Table 4.1: 中文情緒程度詞列表
我們從知網的情緒用語詞集,收集情緒程度修飾詞,並以人工過濾常見的程度 詞, 再參考知網對其標註的強度程度賦予每個程度其一程度增強權重值, 共44個 中文程度修飾詞如Table 4.1。
4.2.3 否 否 否定 定 定詞 詞 詞處 處 處理 理 理
否定詞具有轉換詞意之用途,會導致之後出現的情緒單元的情緒值反轉。 因此我 們經由語句分析獲得句子中含有否定詞後,便將其之後出現的情緒單元取為相反 情緒值。 例如以下句子:「生病會讓你 不舒服。」經由情緒單完挖掘後,得到
「舒服」為一正向情緒詞, 但因為其前端連接了「不」這個否定詞,因此我們將
「不舒服」的情緒值表示為「舒服」的反向情緒極性。
中文否定詞語我們拿取Wang[22]從知網中,擷取具有特徵「neg|否」的詞, 另 外擷取少數由中文詞類分析技術報告中所列舉的37個否定詞,如Table 4.2。
4.3. 文本情緒挖掘 41
中文否定詞語
不、不可、不可以、不能、不能夠、不得、不行、不准、絕不、
不許、不必、不用、不需、不須、弗、無庸、甭、無須、無法、
免、大可不必、無需、犯不著、不、不再、不會、物、絕非、
毋、別、決不、沒、並非、從不、從未、毫不、毫無 Table 4.2: 中文否定詞語列表
中文轉折詞語
終、終於、終究、終歸、居然、但是、但、
幸虧、幸好、幸而、幸、所幸的是、還好、
竟、竟然、可是、好在、硬是、不過 Table 4.3: 中文轉折詞語列表
4.2.4 轉 轉 轉折 折 折詞 詞 詞處 處 處理 理 理
轉折與器具有否定前面所代表的情緒,通常帶有轉折詞語的那一句話,其情緒值 比重較重,也就是說, 較為能帶代表整句話的情緒值。因此對於存在於轉折詞語 的句子, 我們會將加強轉折後出現的情緒單元的權重值。 例如「聚會很熱鬧,
但是我很孤單。」,會加重「孤單」的情緒權重值,已加強轉折詞之後的情緒表 達。
中文轉折詞語亦拿取Wang[22]經由人工擷取出的個否定詞, 如Table 4.3。
4.3 文 文 文本 本 本情 情 情緒 緒 緒挖 挖 挖掘 掘 掘
計算每一文本d的情緒之前,我們先定義一些參數:
d:某一文本。
p:文本中所出現的句子。
42 CHAPTER 4. 情緒分析模組
P :所有p的集合。
V (p):句子p的情緒值,範圍介於-1到1之間。
W (p):句子p的權重值。
計 算 完 句 子 的 緒 值 與 權 重 值 後 , 我 們 定 義S(P )為P 中 每 一 句 子p的 情 緒 值V (p)乘以其權重值W (p)的平均值, Sp(P )為P 中每一正向情緒句子p的情緒 值V (p)乘以其權重值W (p)的平均值, Sn(P )為P 中每一負向情緒句子p的情緒 值V (p)乘以其權重值W (p)的平均值。 公式如 4.5到4.7。
而對於每一文本的情緒值S(d),為了不讓每一文本的情緒值都接近0, 我們先 利用S(P )判斷其正負值,若S(P )大於0,則將Sp(P )視為S(d), 若S(P )小於0,則 取Sn(P )當作S(d),若S(P )等於0,則S(d)亦等於0。 詳細公式如 4.8 。
S(P ) =
∑count
i=1 V (pi)× W (pi)
∑count
i=1 W (pi) , pi ∈ P (4.5)
Sp(P ) =
∑count
i=1 V (pi)× W (pi)
∑count
i=1 W (pi) , pi ∈ P andV (pi) > 0 (4.6)
Sn(P ) =
∑count
i=1 V (pi)× W (pi)
∑count
i=1 W (pi) , pi ∈ P andV (pi) < 0 (4.7)
S(d) =
Sp(P ), if S(P ) > 0 Sn(P ), if S(P ) < 0 0, otherwise.
(4.8)
Chapter 5 實
實 實驗 驗 驗設 設 設計 計 計與 與 與結 結 結果 果 果
此章為本論文系統架構各元件的實驗設計和實驗結果,其中包含了情緒擴散模組 與情緒分析模組。
5.1 情 情 情緒 緒 緒擴 擴 擴散 散 散模 模 模組 組 組實 實 實驗 驗 驗設 設 設計 計 計與 與 與結 結 結果 果 果
我們的最終目標是建立一個中文情緒辭典,辭典中的每個詞語都附有一個情緒 值。 基礎的情緒擴散(Base SSA)方法中,利用收集而來的單一種類情緒種子,
經由常識網路間概念與概念互相連接的特性,將情緒傳遞到鄰近的概念, 以得 到更多附有情緒數值的概念集合。 而我們提出自我學習情緒擴散(Self-Learning SSA)方法, 希望從不同種類的情緒種子中,預先學習有效的資訊,使得情緒擴 散能激發更準確的情緒傳遞。 因此我們從現有的九種情緒辭典收集四種不同種 類的情緒種子, S-Value、S-Polarity、S-Ambiguity 和 S-Unknown, 將S-Value視 為初始情緒擴散的種子, 每擴散一回合後便利用S-Polarity、S-Ambiguity 和S-
43