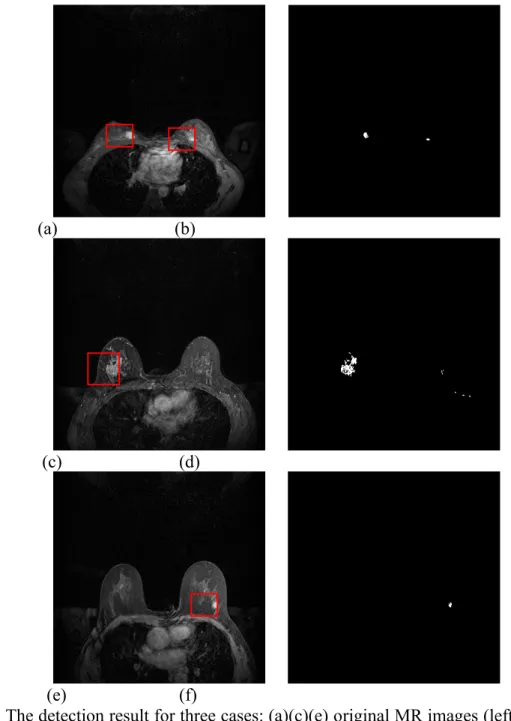
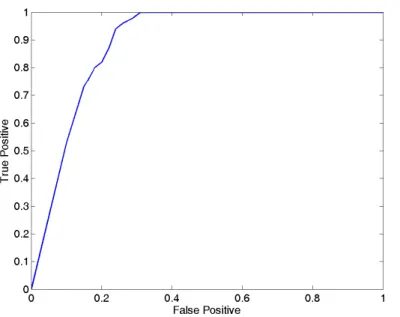
Suspicious Region Detection and Identification Based on Intra-/Inter-frame Analyses and Fuzzy Classifier for Breast
Magnetic Resonance Imaging
Guo-Shiang Lin
1, Sin-Kuo Daniel Chai
2, Wei-Cheng Yeh
3,Yi-Chang Lin
11*
First Name : Guo-Shiang Last Name : Lin
Affiliation : Associate Professor, Da-Yeh University
Phone : 886-4-8511888 ext. 2405 Fax : 886-4-5811350
Address : Dept. of Computer Science and Information Engineering, Da-Yeh University No.
168, University Rd., Dacun, Changhua County 51591, Taiwan E-mail: [email protected]
2
First Name : Sin-Kuo Last Name : Chai
Affiliation : Associate Professor, China Medical University Phone : 886-4-22053366 ext. 6312 Fax : 886-4- 22031108
Address : Dept. of Health Services Administration, China Medical University, Taiwan E-mail: [email protected]
3
First Name : Wei-Cheng Last Name : Yeh
Affiliation : Chief of Medical Imaging depart., Nantou Hospital Phone : 886-49-2231150
Address : Medical Imaging dept., Nantou Hospital, dept. of Health, Executive Yuan, Taiwan
E-mail: [email protected]
1
First Name : Yi-Chang Last Name : Lin
Affiliation : Master student, Da-Yeh University
Phone : 886-4-8511888 ext. 2405 Fax : 886-4-5811350
Address : Dept. of Computer Science and Information Engineering, Da-Yeh University No.
168, University Rd., Dacun, Changhua County 51591, Taiwan E-mail: [email protected]
Please send correspondence to Prof. Lin.
Email : [email protected]
ABSTRACT
Breast cancer is one of the leading causes of death from cancer in Taiwan. In this paper, we propose a feature-based scheme composed of preprocessing, feature extraction and a fuzzy classifier for suspicious region detection and identification. In the preprocessing stage, we first extract regions of interest and then coarsely determine suspicious regions via candidate screening. Some features are extracted based on intra-slice, texture, and inter-slice analysis techniques for suspicious region identification. Intra-slice analysis evaluates the intensity and size of suspicious regions. To find a precise region, we propose a region growing algorithm based on ellipse-based approximation. In texture analysis, some texture cues are extracted from spatial and wavelet domains and integrated as a combined texture feature by using a neural network. Inter-slice analysis is based on the continuity characteristic and consistency of a suspicious region’s size; the objective is to verify the static behavior of suspicious regions. Several MRI cases are utilized to evaluate the performance of the proposed scheme.
Experimental results demonstrate that our scheme can not only extract regions of interest but also identify tumors well from magnetic resonance images.
Keywords: suspicious region detection, fuzzy classifier, magnetic resonance imaging, MRI
I. INTRODUCTION
In Taiwan the mortality rate from breast cancer has increased markedly over the past two decades, and it is now the fourth leading cause of death from cancer. According to statistics published by the Department of Health [2], the death rate from female breast cancer increased from 3.9% in 1985 to 16% in 2011. In fact, breast cancer for women is one common cancer in many countries. Rangayyan et al. [5] observed that detecting breast cancer at an early stage will greatly improve the therapy and reduce mortality. However, detecting breast cancer at an early stage is extremely challenging. Currently, breast cancer is usually detected by mammography, ultrasonography, or magnetic resonance imaging (MRI) [17]. Mammography is an imaging tool that is widely used for early detection of breast cancer, and various computer-aided mammography methods have been developed [3],[6]-[8]. Ultrasonography is also a popular method for breast cancer diagnosis, but it is limited to detecting cystic lesions and advanced breast cancer [6].
In contrast to ultrasound and mammography, which have limitations in early breast cancer detection, MRI has demonstrated its greater capability and higher sensitivity for the task [17],[19]. This increased capacity is especially true for young women and for those with dense breasts. Some researchers have addressed the issue of detecting tumor regions for MR imaging [18],[28],[29],[30]. For instance, a segmentation method [18] based on dynamic programming and edge detection technique was proposed to segment the abnormal mass in breast MRI. However, it is often tough to clearly determine edges of abnormal masses, especially, dense breasts. In addition, due to dynamic programming and edge detection technique, the computational complexity is overly high to process all of breast MRI images.
A computer-aided diagnosis (CAD) system [28] was developed to explore breast MRI data.
However, a radiologist is needed to find the suspicious regions manually in this system [28].
Meinel et al. [29] proposed a lesion classification method for breast MRI. In the existing
method [29], a region growing algorithm where seeds are determined by an interactive thresholding is used to find out ROIs (region of interest) and some features are measured for each ROI. After feature extraction, a neural network is used to achieve lesion classification.
Nie et al. [30] proposed a diagnostic method for breast MRI. In the method [30], lesion segmentation is first performed by image subtraction and initial square ROIs should be placed manually to indicate suspicious areas. After segmentation, morphology and texture features are then measured and used with a neural network to achieve lesion classification.
However, since motion may exist between images, the segmentation by using image subtraction may result in some misclassified regions.
Even though some existing methods [18],[28],[29],[30] can be used for breast MRI, detecting tumor regions precisely is still a difficult problem, especially when the background is composed of organs, soft tissues and noise. Moreover, it is a very time consuming task for a physician to manually goes through all the slices and search for suspicious regions.
Physicians may miss suspicious regions. Hence, there is a need for a computer-aided diagnostic system based on MR imaging to reduce physicians’ workload in screening suspicious regions for tumor detection. This need motivated us to develop a suspicious region detection and identification scheme to achieve tumor detection for MR imaging.
ROI extraction has been used in many applications [20],[21],[22]. Since the size of a
MRI sequence is large, a ROI extraction algorithm was developed to raise the efficiency of
the proposed system. Because of the nature of tumors, it is difficult to detect them accurately
by using single-domain features. Intuitively, multiple features extracted from different
domains should be more useful in detecting suspicious regions. In addition, fuzzy logic is a
powerful tool to deal with imprecise and noisy data in real-world applications [14],[15],[26],
[27]. The main advantages of fuzzy rule-based systems are: 1) low memory
storage, 2) high inference speed and 3) high flexibility in adjusting fuzzy
rules [14],[15]. This means that a fuzzy system can be easily adjusted and expressed to model real-world problems, and it has better tolerance of imprecision. Based on this rationale, we have developed an efficient scheme that integrates different kinds of features and a fuzzy classifier with domain knowledge to detect suspicious regions simultaneously.
The remainder of this paper is organized as follows. In Section II, we introduce the proposed suspicious region detection scheme and discuss the first procedure. Section III describes the feature extraction process of the proposed detection system. In Section IV, we propose a fuzzy classifier for integrating different kinds of features. In Section V, we present the experiment results to demonstrate the efficacy of the proposed scheme. Section VI contains some concluding remarks.
II. PREPROCESSING
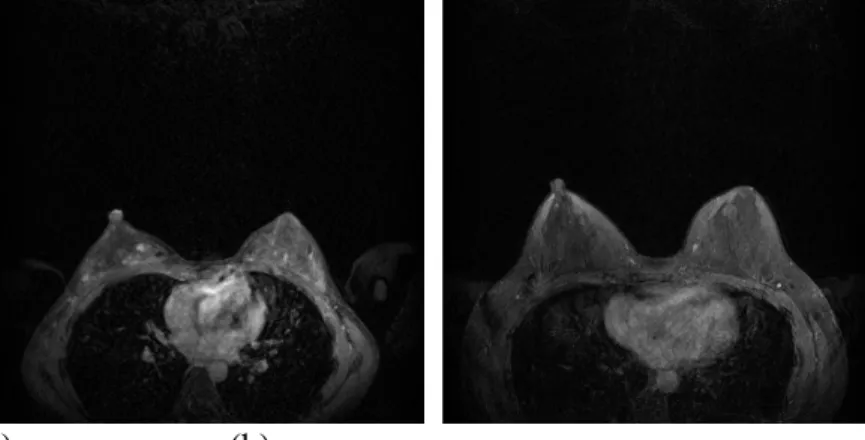
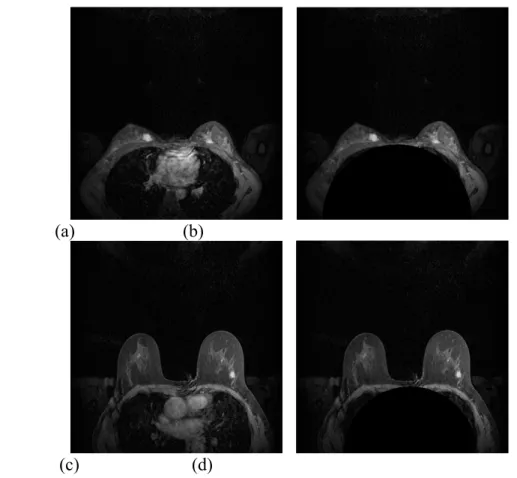
In [29] and [30], semi-automatic ROI detection was used to identify suspicious areas. To design a highly efficient mechanism for automatically detecting tumors in breast MR images, we should first analyze the characteristics of tumor regions. Figure 1 shows two MRI slices coming from different cases. As shown in the figure, each slice in a breast MRI is composed of organs, soft tissues, and noise. In addition, pixels with large values are located in the thoracic cavity as well as the breast. Although high intensity pixels are often associated with tumor regions, it is difficult to localize suspicious regions precisely by using only the information about pixel intensity. Therefore, we devise ROI extraction and candidate screening methods to detect suspicious candidate regions coarsely in a pre-processing stage.
Dissimilar to [29] and [30], we first perform automatic ROI extraction by removing the non-
interesting regions (non-ROIs) in the pre-processing stage. From the ROI region, we screen
some suspicious candidates and measure their characteristics as features. Then, using a fuzzy
classifier and the features, we can detect and localize suspicious regions. Figure 2 shows the
(a) (b)
Fig. 1. Examples of MRI slices for two cases: (a) Slice 53 of case 1; (b) Slice 74 of case 2
Fig. 2. Block diagram of our proposed suspicious detection and identification scheme
2.1 ROI extraction
In Fig. 1, the pixel values of some areas in the thoracic cavity are similar to those of
tumors; hence, detecting tumors correctly may be more difficult. According to physicians, it
is not possible for tumors to exist in the thoracic cavity. It is expected that removing some
parts of the thoracic cavity, especially organs and soft tissues, can reduce the difficulty of
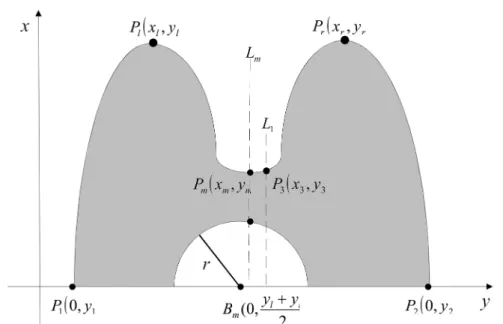
detecting tumors. Figure 3 shows that a breast MRI slice is composed of a gray region (i.e.,
an ROI) and a semicircular region (i.e., a non-ROI). As shown in Figs. 1 and 3, the
semicircular region contains some organs and soft tissues. Therefore, we remove a part of the
thoracic cavity (i.e., non-ROI) to find the gray region (ROI) for further analysis.
Fig. 3. An illustration of ROI extraction in an MRI slice
As shown in Figs. 1 and 3, the semicircular region (i.e., non-ROI) can be localized according to two peak points (i.e., P
land P
r) in the x direction. Therefore, to localize and remove the semicircular region, the steps of ROI extraction in each MR image are described as follows:
R1. Normalize an MRI slice via
, , , 1,2,...,12 8
max
, , ,
,
t t y x I
t y x t I
y x
I
N, (1)
where I x , y , t and I
N x , y , t denote, respectively, the (x,y)-th original pixel value and the normalized pixel value in the t-th slice of an MRI sequence I; t is the slice number in the test MRI sequence; and max is an operator used to find the maximum input value.
R2. Smooth the normalized image with a 33 average filter.
The smoothing operation reduces the impact of noise in the remainder of the procedure.
R3. Binarize the smoothed normalized image by thresholding; then label and select the
largest object.
In the thresholding step, the average value of each smoothed normalized image is taken as the threshold. Based on Figs. 1 and 3, it is assumed that the largest object contains the breast. Figure 4 shows two examples after binarization and labeling. The figure shows that the largest object did contain the breast part after thresholding and labeling. However, the organs and soft tissues in the thoracic cavity are also included.
To resolve the problem the proposed scheme removes the semicircular region to achieve ROI extraction.
(a) (b)
Fig. 4. Two examples after binarization and labeling
R4. Find P
1, P
2, and P
3for the largest object.
In this step, we first vertically project the largest object to find the leftmost and rightmost points, P
1and P
2, of the projected region on the horizontal axis, respectively. Based on P
1and P
2shown in Fig. 3, we can draw a vertical line L
1passing through the point 0 , y
1 y
2 2 . Then, we can identify the intersection point P
3of the vertical line L
cand the chosen object’s contour. The y-coordinate of P
3is
1 2 / 2
3
y y
y .
R5. Search peaks P
land P
ron the left and right of P
3, respectively, and find the point P
mwhose x-coordinate is the minimum between P
land P
r.
To find the peaks P
land P
r, we follow the contour of the chosen object from P
3in both directions searching for the points with the largest x-coordinate on the left and right sides of P
3. After obtaining P
land P
r, the point P
mcan be found by searching for the point with the smallest x-coordinate between P
land P
ralong the contour of the chosen object.
R6. Draw the vertical line L
mpassing through the point P
m, and derive the radius r is
x
m k
m , where x
mis the x-coordinate of P
mand k
mis a constant. Then, the semicircular region whose radius is r and its center is at B
mcan be identified.
R7. Remove the semicircular region to obtain the ROI for further candidate screening.
2.2 Candidate screening
When searching for suspicious candidates, we consider two phenomena. First, we look for pixels with unusual pixel values because, according to [29] and physicians, the values of a tumor region are often higher than those of the surrounding regions. Second, a tumor region is small in the early stages, a useful cue that can be used to enhance the capability of detecting tumors at an early stage. Based on these two phenomena, we can coarsely screen suspicious candidate regions from ROI areas. The steps of suspicious candidate screening are as follows.
S1. Morphological opening
Because the intensity of tumor regions is usually high, morphological opening [1] is used here to separate the background from the foreground, which contains the candidate tumor regions. The foreground part can be obtained by
t t t S
R
I I
I , (2)
where stands for the morphological opening operator [1], I t denotes the t-th
original image, I
R t represents the resulting version after morphological opening and
subtraction, and S is the structure element in the morphological operator.
S2. Adaptive thresholding
It is expected that the range of pixel values as well as I
R t may not be similar in different MR images. Then adaptive thresholding can be used to select suspicious region candidates according to the following formula:
otherwise , max ,
, if 0 , 1
, I x y t T
1T
2t
t y x I
C C R
B
, (3)
where I
R x , y , t denotes the (x,y)-th pixel value in the t-th slice of the resulting version after morphological opening and subtraction; I
B t represents the result of adaptive thresholding in the t-th slice; T
1Cis a predefined threshold; and T
2C t denotes the threshold used to select several percentages of pixels with high values after morphological opening of the t-th slice. Based on Eq. (2), Eq. (3), and the definition of
t
T
2C, the thresholding is adaptive.
S3. Connected component labeling
After adaptive thresholding, the chosen regions in the ROI are labeled. Actually, some labeled objects may only contain other tissues, such as blood vessels. To reduce the impact of such tissues on suspicious region detection, connected regions whose sizes satisfy a given constraint (e.g., smaller than T
1A(900)) are identified for the following shape refinement step.
2.3 Ellipse-based approximation with shape refinement
Although suspicious candidates can be obtained after morphological opening,
thresholding, and labeling, their regions may not be detected correctly. To analyze each
suspicious candidate accurately in the feature extraction phase, the shape of the candidate
must be refined. In addition, according to physicians, the shape of an early-stage tumor in an
MRI looks like an ellipse. Therefore, we adopt an ellipse-based approximation with shape refinement to represent each tumor candidate.
The ellipse-based approximation method was developed to find correct tumor regions and measure their properties, such as the center of mass (COM) and the best-fit ellipse [1]. To refine the shape of each suspicious candidate, we propose a region growing algorithm for each labeled candidate L
i. For each labeled candidate L
i, the steps of the algorithm are described as follows.
(G1) Compute the average intensity I
Li t of L
iand its COM as follows:
1 , 1
) , ( )
,
(
i
i l xy L
i c L
y l x i
c
y
y L L x
x , (4)
where ( x
c, y
c) denotes the coordinate of COM of an object, L
lidenotes the i-th candidate in the l-th iteration, and L
lirepresents the area of L
li.
(G2) Measure D x , y , t and x , y , t as follows:
} 2 , 1 {
2 2
2 , 1 ,
i
f f
L
i
i
y y
x a x
t y
x , (5)
x , y , t x , y , t I x , y , t I t
2D
neighbor
Li, (6)
where I
neighbor x , y , t is the pixel value of the neighboring pixel based on 8-
connectivity in the t-th slice; and x ,
fiy
fi (i=1,2) denotes the coordinates of the foci of an ellipse. The coordinates of the foci can be derived based the COM and the eccentricity of the ellipse. In [1], the semi-major axis a
Lin Eq. (5) is defined as
8 1
min 3 4 max 1
4
I a
LI
, (7)
and
Li
y x
c
c
x x
y y I
) , (
2
min
( ) cos ( ) sin , (8)
Li
y x
c
c
x x
y y I
) , (
2
max
( ) sin ( ) cos , (9)
where sin and cos represent sine and cosine functions, respectively, and theta
denotes the angle between the major axis and the x-axis (i.e., the horizontal axis).
According to Eqs. (6) and (7), the value of D x , y , t is small because a pixel is near the focal points of an ellipse and the pixel’s value is close to I t
Li
. This means the neighboring pixel with small D x , y , t is similar to the pixels in the current candidate
(G3) Include neighboring pixels as their D x , y , t values are less than T (500).
D(G4) Check whether the candidate overlaps the other candidates. If this situation exists,
merge the overlapping candidates, re-label all candidates, and return to Step (G1).
(G5) Check whether there are any neighboring pixels to be processed by calculating
1
li liD
i
L L
L . If L
Diis less than T (15), repeat Steps (G1) to Step (G4);
Lotherwise, stop.
III. FEATURE EXTRACTION
After pre-processing, we coarsely detect the suspicious regions in each slice; however, some
non-tumor regions may be misclassified as suspicious regions. For a suspicious detection and
identification scheme to be effective, the number misclassified regions should be reduced as
much as possible. It is expected that further analysis are necessary to confirm the status of
each suspicious candidate and thereby improve the performance of the proposed scheme.
According to physicians, there is no optimal representation of a tumor, so features extracted from different perspectives are useful for tumor detection. In addition, although the components of an MRI are complex, generally the characteristics of a tumor region are high intensity, small size, and complex texture, and there is continuity between the MRI slices.
Therefore, we extract these characteristics as features to reduce the number of possible errors.
As we need to analyze the continuity of each suspicious candidate, we apply 3D labeling to identify suspicious candidate objects before feature extraction. We elaborate on the types of analysis used for feature extraction in the following subsections. Note that the analyses are only applied to the selected candidate objects.
3.1 Intra-slice analysis
As the intensity value of a tumor region is a basic and effective characteristic for tumor detection [29], we measure the average intensity of a suspicious candidate as a feature. The average intensity of a suspicious candidate O
ican be calculated as
Oi
i i i
i
N
t x,y O
N O i
O
O
I x y t
O I N
1
, 1 ,
1 , (10)
where I and
ONiI
Oirepresent the normalized and average intensities of the i-th object O
irespectively; and N
Oiis the number of slices in which the i-th object O
ioccurs. It is
expected that the higher the value I
Oi, the greater possibility that the object is a tumor.
However, as blood vessels may also be classified because they often exhibit high intensity, it is necessary to discover more features to improve the performance of tumor detection.
3.2 Inter-slice analysis A. Object continuity
In addition to intra-slice analysis, we perform inter-slice analysis to improve the
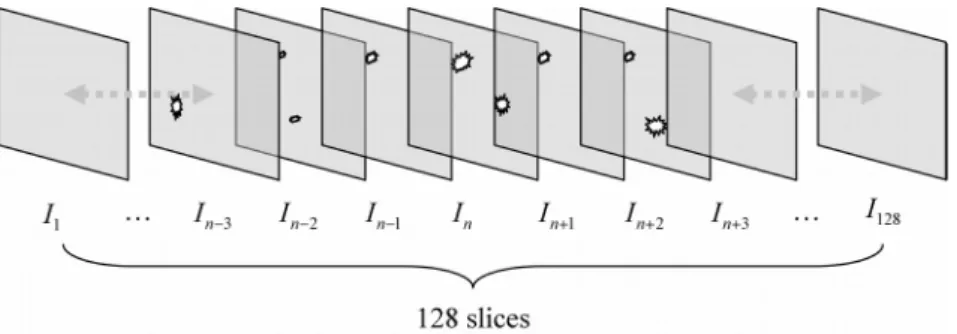
accuracy of suspicious region identification. Figure 5 illustrates the continuity of a tumor
with several slices. Generally, the position of a tumor region does not change significantly in a sequence of MRI slices. It is expected that recognized tumor regions in two adjacent slices should overlap and their COMs should be closed. Based on this assumption, a continuity test (CT) is performed on each candidate and its output is then exploited as a feature. To perform the continuity test, we measure the COM and the overlapped area between the recognized suspicious regions of two adjacent slices by checking whether
otherwise
1 ,
min 1 1
1 ,
if 0
1
Oi i
i i
i i
d i
O i
t T O t O
t O t t O
O t O T t
O t O t dist
C
i,
(11)
where is the logical AND operator; is the intersection operator; min is an operator for finding the minimum value of the input; O
i t and O
i t 1 denote the i-th suspicious regions in the t-th slice and the (t-1)-slice respectively; T and
dT are thresholds; and
O
O t , O t 1 x t x t 1
2 y t y t 1
2dist
i i c c c cis the Euclidean distance of the
COM between the t-th and (t-1) slices. Here, the values of T and
dT are 5 and 0.8
Orespectively. For each suspicious candidate O
i, a continuity test (CT) is performed on all MRI slices in a sequence.
Fig. 5. An illustration of continuity in inter-slice analysis
Actually, the size and pixel value of a tumor may change over several adjacent slices. It
is possible that a tumor may not be detected in one slice after per-processing, which means that the tumor may be divided into two small candidates. As a result, the continuity property of one of the small tumor candidates should be reduced and may make the proposed detector invalid. To solve the problem, we utilize the CT results in the two previous slices and the two subsequent slices to determine whether the CT result for the current slice is true or not. The rule is as follows: if the CT results in the two previous slices and the two subsequent slices are all true, the CT result of the current slice is also set as true, and the adjacent objects are grouped as a new object.
After adjusting the CT results, the continuity C
Oi,1of a suspicious candidate can be expressed as
Oii i
N t
O
O
C t
C
1 1
,
. (12) In fact, C
Oi,1measures the number of slices in which the candidate object is present.
According to physicians, if C
Oi,1is large, the probability that the candidate object is a tumor is high.
B. Consistency of object size
As small blood vessels may occur in several adjacent images, they may be misclassified as a tumor. However, a blood vessel does not usually follow a straight line in several adjacent slices. We characterize this phenomenon as a feature in order to reduce the impact of blood vessels on suspicious region identification. The feature, denoted as C
Oi,2,
analyzes the number of suspicious candidate objects that are larger than a threshold T
2A(9) in several adjacent images. It is defined as
Oii i
N t
A i
O
O
U O t T
C N
1
2 2
,
1 1 . (13)
where U denotes the unit step function ( U x 1 for x 0 , and U x 0 for x 0 ).
According to Eq. (13), the value of C
Oi,2should be small if the suspicious candidate O
iis a blood vessel; and the value should be high if the O
iis located in a tumor.
3.3 Texture analysis
Texture has been generally utilized to detect and classify diseases as well as to segment suspicious regions in X-ray, ultrasound, MRI images [29],[30]. Similar to [29] and [30], texture information is also measured as features in the proposed scheme. The main reason is texture information in a tumor region differs from that in normal areas. Note that we only examine the pixels output during pre-processing. To extract texture information, we analyze each suspicious pixel and its neighboring pixels in a block. However, based on the extracted texture information, it is difficult to distinguish tumors from normal tissues when the block size is too small or large. In our experiments, we found that the best block size is 3232 pixels. Moreover, because texture cues can be measured in multiple domains, we compute the texture cues of each block in the spatial and wavelet domains. Therefore, in each MR image, a block of 3232 pixels centered at each pixel in the output of the pre-processing step is chosen as a candidate block for extracting texture features from multiple domains. Then, a neural network is used to fuse the texture cues into a single texture feature for tumor detection.
A. Spatial domain
In the spatial domain, we utilize three kinds of texture cues. First, we calculate the mean, standard deviation, and energy of the pixel values in each candidate block directly.
Second, as Law’s masks are popular for texture analysis, we also adopt them to extract
texture values. Following [11], we select two basic one-dimensional masks, R5 and W5, to
generate two two-dimensional masks, R5W5 and R5W5 respectively. Then, based on Law’s
mask, the TEM (texture energy measure) of each slice can be derived by the following
equations:
55 5
5
1
( , , ) , , R5W 5 ( , )
TEM
i j
t j i,y x t
y x I t
y
x , (14)
55 5
5
2
( , , ) , , W5R5 ( , )
TEM
i j
t j i,y x t
y x I t
y
x , (15)
x,y , t TEM x,y , t TEM x,y , t
TEM
1
2. (16) After computing the TEMs based on Eqs. (14)-(16), the mean and standard deviation of the TEMs for each suspicious candidate are calculated as texture cues by
ii O
O yxt i
T
x,y t
f O
,1
1
1 TEM ,
, (17)
ii O
O yxt
T i
T
tx,y f
f O
,1 2 1
2
TEM ,
1
1 . (18)
Finally, as the co-occurrence matrix, which characterizes the spatial distribution of intensity values in an image, is a popular and robust statistical tool for extracting texture information from images [3],[11],[12], we also extract some texture cues from a gray-level co-occurrence matrix. An element at location (i,j) of the matrix signifies the joint probability density of the occurrence of intensity values i and j in a specified orientation and a specified distance d from each other. Thus, for different and d values, different matrices are generated. The steps for extracting texture cues from a co-occurrence matrix are as follows.
(1) Quantize the pixel values in the candidate block into N
plevels.
(2) Compute the co-occurrence matrix p
d,as
10 1 0
, , ,
, , ,
P P
N i
N j
d d d
j i M
j i j M
i p
, (19)
Mx N y
d
d
i j I x y i I x y j
M
1 1 ,
,
,
, , , , (20)
where
d, m , n is the impulse function whose output is 1 only when m=0 and n=0. The two parameters, d and , represent, respectively, the distance and orientation between two pixels for generating the co-occurrence matrix. The relations between the (x,y)-th pixel and the ( x , y )-th pixel can be expressed as
cos d x
x and y y d sin . In this work, for each candidate block, we computed two matrices corresponding to two different directions ( =0° and 90°), one distance (d=1 pixel), and N
p=64.
(3) Calculate the following features from the obtained co-occurrence matrix:
(i) contrast: f
N i j p
d i j
i N
j
T P 1 P ,
,
0 1 0
2
3
, (21)
(ii) energy:
10 1 0
2 ,
4 P P
,
N i
N j
d
T
p i j
f
, (22)
(iii) homegeneity:
10 1 0
,
5
1
,
P P
N i
N j T d
j i
j i
f p
. (23)
B. Wavelet domain
The wavelet transform is a powerful tool that is used to analyze image content in many applications, such as image/video retrieval and image segmentation. After the l levels of 2D discrete wavelets decomposition [11],[31],[32],[35], there are 3l detail subbands (LL, LH, HL). In fact, these detail subbands contain texture information. Therefore, we analyze each candidate block and extract some texture cues from the wavelet domain. After 2D wavelet decomposition, the energies of three subbands (LL, LH, and HL) in each candidate block are computed as features. The steps for feature extraction in the wavelet domain are as follows.
(1) Transform the current block to obtain three subbands by using the Haar wavelet transform.
(2) Calculate the energy of the subbands (i.e., LH, HL, and HH) as texture features via
i j
b T
b
W i j
f
2, , (24)
where W
b i , j represents the wavelet coefficient in the b-th subband; and b denote the LH, HL, and HH bands respectively.
C. Texture cue fusion
As these texture cues are extracted from different domains and their ranges are different, we merge them to form a combined texture feature. Specifically, after extracting 14 texture cues, we utilize a supervised multi-layer feedforward neural network [39] to combine them. The neural network has three layers: input, hidden, and output. A linear transfer function is used for the input layer and logistic sigmoid transfer functions are used for the hidden and output layers. There are 14, 9, and 1 neurons in the input, hidden, and output layers, respectively.
In the training phase, we collect a large number of blocks classified by physicians into a training set. To train the neural network, the back-propagation and Levenberg-Marquardt algorithms are used [39]. To prevent over-training, we adopt the Q-fold cross-validation method [10]. That is, the training set is randomly divided into Q disjoint sets of equal size
Q
N
s/ , where N
sis the total number of samples. The (Q-1) sets selected arbitrarily from
the Q disjoint sets are exploited to train the neural network and the remaining set is used to
estimate the generalization error. The neural network is then trained Q times, each time with
a different set as the validation set. After training, because texture cues measured from spatial
and wavelet domains are the input of the neural network, the output of the neural network can
be exploited as a combined texture feature. Because a logistic sigmoid transfer function is
adopted in the output layer, the output range of the neural network is from zero to one. The
higher the output of the neural network is, the higher probability that a tumor exists will be.
Due to the main advantages of fuzzy rule-based systems mentioned in Section I, a fuzzy classification system was devised based on human knowledge and mathematical models. In terms of practicability, a trained fuzzy system can be exploited easily in real applications. Moreover, a fuzzy technique is often used to combine some features from different sources [15],[26],[27]. Therefore, based on the results of intra-slice, inter-slice, and texture analyses in the feature extraction phase, we can obtain four features for each suspicious candidate object to distinguish between tumors and non-tumors. For each suspicious candidate object, the four features are: (i) the average intensity f
1of the pixel
values (i.e., I
Oi); (ii) the object’s continuity f
2(i.e., C
Oi,1); (iii) the combined texture information f
3(i.e., the output of the neural network); and (iv) the consistency f
4of the
object’s size (i.e., C
Oi,2). We integrate the above four features as the input for a fuzzy classifier to develop a tumor detector.
There are many types of fuzzifier, defuzzifier, and fuzzy inference engines [14] from which various systems can be built. Similar to the approaches in [14] and [15], we construct a fuzzy system comprised of a product inference engine, a singleton fuzzifier, and a center- average defuzzifier. The steps for constructing the above fuzzy system are detailed in [15].
Following [14] and [15], the output of the fuzzy system proposed this work is derived by
Ri f R
i f
N j
j f N i N j
j f N i j
v c
v
1 1
1 1
, (25)
where f
i (i=1, …,4) and v R are the input and output of the fuzzy system, R respectively; v
cjis the center value of the output fuzzy set in the j-th rule (j=1,2,…, N
R);
N
Ris the number of fuzzy rules; and (i=1, …,
fjiN
f) is the membership value of f
i.
There is no standard procedure for devising the membership functions. As each feature
f
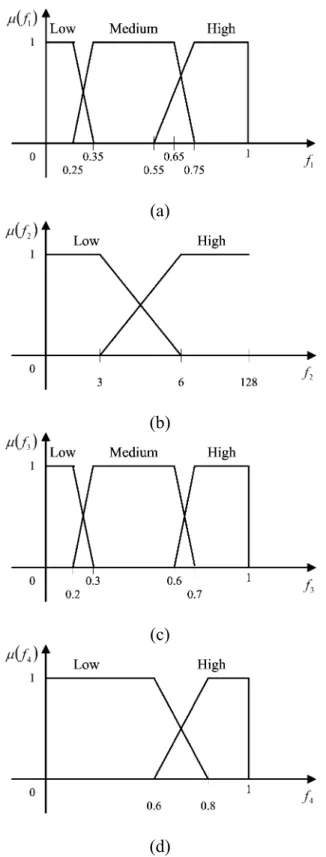
ihas a different impact on tumor detection, one way to obtain the corresponding member function is through heuristics. It is suggested that, to improve the performance of a fuzzy system, the fuzzy membership functions should be trained and adjusted by a large amount of training data. Based on this rationale, we conducted extensive experiments and propose four membership functions that correspond to the four features shown in Fig. 6, where “low”,
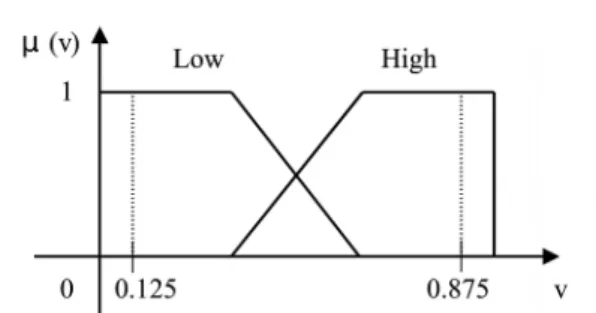
“medium”, and “high” are linguistic variables. The same design rationale applies to the membership functions of the output of the fuzzy system, as shown in Fig. 7.
The fuzzy rule base consists of a set of fuzzy if-then rules. Based on the four features, the above observation, and our experience, we define 36 rules in the fuzzy rule base. We do not list the rules because of space limitations. In Eq. (25), feature fusion is performed to process the membership values of all the features and obtain an output value. Then, based on the proposed membership functions of the input features and the output, a final decision can be made by using the following guidelines. The smaller the value of
v(v=L), the higher the probability that the current candidate is a healthy region. The larger value of
v(v=H), the greater the probability that the current candidate contains a tumor. To summarize, the decision rule is as follows:
Non-tumor, if
vv
H
max
L,
= “Low”;
Tumor, if
vv
H
max
L,