行政院國家科學委員會專題研究計畫 成果報告
在放大前送合作式通訊系統下之最佳功率配置及相關議題 之聯合考量
研究成果報告(精簡版)
計 畫 類 別 : 個別型
計 畫 編 號 : NSC 100-2221-E-011-071-
執 行 期 間 : 100 年 08 月 01 日至 101 年 07 月 31 日 執 行 單 位 : 國立臺灣科技大學電子工程系
計 畫 主 持 人 : 方文賢
計畫參與人員: 碩士班研究生-兼任助理人員:廖偉鈞 碩士班研究生-兼任助理人員:黃傑良 碩士班研究生-兼任助理人員:陳建甫
報 告 附 件 : 出席國際會議研究心得報告及發表論文
公 開 資 訊 : 本計畫可公開查詢
中 華 民 國 101 年 10 月 31 日
中 文 摘 要 : 合作式通訊系統能藉由使用者之間互相協助傳遞訊息至目的 端來形成一個分散式天線陣列,進而提供空間分集增益,是 現今一種相當有潛力的無線網路傳輸技術。在網路資源有限 的情況下,利用已知的通道訊息來適當的分配各式資源如中 繼端之功率、頻寬…等,將能有效提升合作式通訊系統的效 能。在本計畫中,我們考量多了在使用者在解碼前送合作式 通訊網路的下行傳輸環境中,同時考慮中繼端選擇與中繼端 功率分配以及使用者頻寬分配的最佳化問題,我們首先在忽 略掉某些限制的情況下,證明此問題為一個凸函數的最佳化 問題,進而推得系統的效能上限。同時我們提出一以混合式 基因演算法以解決此非線性最佳化問題,其演算法之染色體 部分,將中繼端選擇部分以整數字串基因來表示,而中繼端 功率分配與使用者頻寬分配部分皆由實數基因所組成,且整 數及實數基因皆有相對應的混合式交配及突變運算,以此求 取系統最佳解。另外我們也提出了兩階段式混合式基因演算 法以進一步降低計算複雜度。模擬結果顯示我們所提出的混 合式基因演算法及低複雜度混和式基因演算法之效能皆能夠 貼近系統上限,並相較於其他相關文獻之方法能有更優異的 效能。此外,低複雜度混合基因演算法亦能夠有效的降低計 算複雜度。
中文關鍵詞: 合作式通訊、資源分配、功率分配、中繼端選擇、頻寬分 配、凸函數的最佳化、基因演算法。
英 文 摘 要 : Cooperative networks, which can provide spatial diversity by relaying each other's messages to the destination, are an emerging transmission scheme in wireless communication systems [1], [2]. Two most widespread cooperative protocols include amplify-and- forward (AF) and decode-and-forward (DF) schemes. It is well known that the performance of a cooperative network can be improved by appropriately allocating the resource and miscellaneous approaches have been suggested for optimal relay selection, power
distribution, time/bandwidth allocation, etc. In this project we consider the issues of relay selection, bandwidth allocation, and power distribution as a whole, which have never been treated altogether in previous works. Our objective is to maximize the sum capacity of all users, where each user, for ease of communication overhead, is assisted by a single relay in the data retransmission process. We first
determine an upper bound for the optimization problem considered by ignoring some constraints. Thereafter, we propose a GA approach to resolve this highly nonlinear problem. GA has been well-known to be an effective optimization technique that emulates the crossover and mutation phases in the evolution of a chromosome to efficaciously search the optimal
solution. To suit the new problem, the GA employed in this paper possesses two distinctive features. First, each chromosome is comprised of not only an integer string for relay selection, but also
two real number strings for bandwidth allocation and power distribution to accommodate the joint
consideration. Second, new crossover and mutation operations are employed to accommodate these new chromosomes. In addition, to further alleviate the complexity, a low-complexity two-stage implementation is also addressed, which first uses a GA to determine the optimal relay subset, and followed by another GA to refine the bandwidth allocation and power
distribution among the users and the selected relays.
Conducted simulations show that both of the proposed GA and its low-complexity implementation can attain close performance as the upper bound and outperform some representative previous works. The low-
complexity version is especially appealing with reduced computations, yet negligible performance degradation.
英文關鍵詞: cooperative network, resource allocation, power distribution, relay selection, bandwidth allocation, convex optimization, genetic algorithm, low-
complexity algorithm
行政院國家科學委員會專題研究計畫成果報告
在合作式通訊系統下之最佳功率配置及相關議題之聯合考量 Optimal Power Allocation and Related Issues in Relay Networks
計畫類別:■ 個別型計畫 □ 整合型計畫計畫編號:NSC 100-2221-E-011-071
執行期間:100 年 08 月 01 日至 101 年 07 月 31 日
計畫主持人:方文賢
計畫參與人員:廖瑋鈞、黃傑良、陳建甫
成果報告類型(依經費核定清單規定繳交):
■
精簡報告□
完整報告本成果報告包括以下應繳交之附件:
□赴國外出差或研習心得報告一份
□赴大陸地區出差或研習心得報告一份
■
出席國際學術會議心得報告及發表之論文各一份□國際合作研究計畫國外研究報告書一份
處理方式:除產學合作研究計畫、提升產業技術及人才培育研究計畫、
列管計畫及下列情形者外,得立即公開查詢
□涉及專利或其他智慧財產權,■一年 □二年後可公開查詢 執行單位:國立台灣科技大學電子工程系
中 華 民 國 101 年 10 月 30 日
一、 中文摘要
合作式通訊系統能藉由使用者之間互相協 助傳遞訊息至目的端來形成一個分散式天線陣 列,進而提供空間分集增益,是現今一種相當 有潛力的無線網路傳輸技術。在網路資源有限 的情況下,利用已知的通道訊息來適當的分配 各式資源如中繼端之功率、頻寬…等,將能有 效提升合作式通訊系統的效能。在本計畫中,
我們考量多了在使用者在解碼前送合作式通訊 網路的下行傳輸環境中,同時考慮中繼端選擇 與中繼端功率分配以及使用者頻寬分配的最佳 化問題,我們首先在忽略掉某些限制的情況 下,證明此問題為一個凸函數的最佳化問題,
進而推得系統的效能上限。同時我們提出一以 混合式基因演算法以解決此非線性最佳化問 題,其演算法之染色體部分,將中繼端選擇部 分以整數字串基因來表示,而中繼端功率分配 與使用者頻寬分配部分皆由實數基因所組成,
且整數及實數基因皆有相對應的混合式交配及 突變運算,以此求取系統最佳解。另外我們也 提出了兩階段式混合式基因演算法以進一步降 低計算複雜度。模擬結果顯示我們所提出的混 合式基因演算法及低複雜度混和式基因演算法 之效能皆能夠貼近系統上限,並相較於其他相 關文獻之方法能有更優異的效能。此外,低複 雜度混合基因演算法亦能夠有效的降低計算複 雜度。
Keywords:
合作式通訊、解碼前送之中繼網路、功率分配、中繼端選擇、頻寬分配。
計畫緣由與目的
Cooperative networks, which can provide spatial diversity by relaying each other’s messages to the destination, are an emerging transmission scheme in wireless communication systems [1], [2]. Two most widespread cooperative protocols include amplify-and-forward (AF) and decode-and-forward (DF) schemes. It is well known that the performance of a cooperative network can be improved by appropriately allocating the resource and miscellaneous approaches have been suggested for
optimal relay selection, power distribution, time/bandwidth allocation, etc. For instance, Zhao et
al. [3] addressed a relay selection scheme which
selected the best relay node to maximize the capacity in AF relay networks. Beres et al. [4] considered a relay selection scheme by using the relay with maximum channel gain. Pham et al. [5] considered a relay assignment to maximize the capacity by the mixed-integer linear programming technique in AF cooperative networks, and proposed a greedy algorithm to mitigate the computational load. Joshi and Boyd [6] considered a number of sensor/relay selection algorithms under various considerations. It has been observed that the system performance can be further enhanced if the relay selection is combined with the power allocation. For this, Zhao et al. [3]devised an optimal power distribution following the best relay selection to achieve even superior performance. Fang et al. [7] proposed an effective GA for joint relay selection and power distribution in AF cooperative networks where the source is assisted by either one or more relays. Chen et al. [8] addressed a distributed joint relay selection and power allocation scheme in wireless multi-hop cooperative networks.
Phan et al. [9] considered the joint power allocation and relay selection in AF cooperative networks where each source-destination pair is constrained to be assisted by a set of available relays. Kadloor et al. [10]
proposed a joint relay selection and power distribution scheme. To reduce the computational complexity, [10]
also proposed a relaxed convex solution to achieve the near-optimal solution. Uddin et al. [11] considered a joint relay assignment and power distribution problem for multicast cooperative networks, and proposed a Branch and Bound technique to solve the mixed Boolean-convex optimization problem.
Since bandwidth is yet another crucial resource concern, it is inappropriate to divide the bandwidth
equally to each user when the available bandwidth of the network is limited. In light of this, Krishnan et al.
[12] considered a bandwidth sharing and power minimization problem in cellular systems. Tous et al.
[13] proposed a particle swarm optimization to solve the joint power and bandwidth allocation for multi-user AF relay networks. Mari˙c et al. [14]
considered a power distribution and bandwidth allocation in Gaussian relay networks with one source-destination pair aided by multiple relays. Gong
et al. [15] investigated a joint bandwidth allocation
and power distribution problem with a fixed relay assignment in wireless multi-user DF relaying networks.To attain superior performance in multi-user DF relay networks, in this project we consider the issues of relay selection, bandwidth allocation, and power distribution as a whole, which have never been treated altogether in previous works. Our objective is to maximize the sum capacity of all users, where each user, for ease of communication overhead, is assisted by a single relay in the data retransmission process.
We first determine an upper bound for the optimization problem considered by ignoring some constraints. Thereafter, we propose a GA approach to resolve this highly nonlinear problem. GA has been well-known to be an effective optimization technique that emulates the crossover and mutation phases in the evolution of a chromosome to efficaciously search the optimal solution [16]. To suit the new problem, the GA employed in this paper possesses two distinctive features. First, each chromosome is comprised of not only an integer string for relay selection, but also two real number strings for bandwidth allocation and power distribution to accommodate the joint consideration. Second, new crossover and mutation operations are employed to accommodate these new chromosomes. In addition, to further alleviate the
complexity, a low-complexity two-stage imple- mentation is also addressed, which first uses a GA to determine the optimal relay subset, and followed by another GA to refine the bandwidth allocation and power distribution among the users and the selected relays. Conducted simulations show that both of the proposed GA and its low-complexity implementation can attain close performance as the upper bound and outperform some representative previous works. The low-complexity version is especially appealing with reduced computations, yet negligible performance degradation.
二、 研究方法及成果
Data Model
Consider a dual-hop, multi-user cooperative networks, which consists of a base station (BS), |R|
relay nodes, and |U| users. Denote the channel coefficients from BS to relay node r, relay node r to user , and BS to user
i i
ash sr
,h ri
, andh si
S i i
, respectively. In phase I, BS transmits the signal , intended for user
i
, to all relays, where is normalized asS
2 1
E S ⎡ ⎣ i ⎤ = ⎦
, in which E [・] denotes the expectation operation. Also, the average power used at BS isP s
in every transmission. The received signal at the relay node , , can thus be expressed asr u r
,
r s ri i r
u
=P h s
+v r
∈ (1)R
where is the additive white Gaussian noise with zero-mean and variance N0
. In phase II, assume that only one relay, say relay r, is employed to assist for data retransmission. Let be the power employed at the relay r to forward the signal from BS to user , then the signal received by user can be written asv r
P ri
i i
, i
i s si i ri ri ri r i
y
=P h s
+P ρ h u
+w
∈ (2)U
where
u r
is normalized asE u ⎡ ⎣ r 2 ⎤ = ⎦ 1
andρ ri
is an indicator function which uses 1 or 0 to denote whether the relay is selected to help useri
transmission or not, and is the additive white Gaussian noise with zero-mean and variance . Note that the second and the third terms of (2) denote the signals through the direct path (from BS to user) and the indirect path (through relay to user), respectively.r th
w i
N 0
Suppose that the total bandwidth of the spectrum of the signals is for the wireless relay networks, which is divided into many non-overlapping channels, say Hz is the bandwidth allocated to user
i
. Then, based on [10], the received signal-to-noise ratio(SNR) at the relay node y
W T
W i
r is given b
2 0 s
sr sr
i
P W N
of the direct-path signal from BS to user
i
and that of the signal from relay ode r to useri
can beSN h
. Likewise, the received SNRn as
R
=expressed
2
0 s
si h s i
i
P
=
W N
SNR
and2 0 ri
ri ri
i
SNR P h
=
W N
, respectively. Assume that the relay uses the same codebook as BS, so the source-destination channel capacitC
y can be expressed as [11]
(3) where
1 2
min( , )
C si
=C
( )
log 1
1
2i 2 sr
node channel capacity and
C
=W
+SNR
is the BS-relay( )
2
log 12
2
i
si ri
C
=W
+SNR
+SNR
is the maximum capacity at which BS can communicate to user
i
with the assistance of onemuch slower than the non-LoS component in the Rayleigh fading, so we can assume relay. The LoS components in the Rician fading channel attenuate
that
SNR sr > ( SNR si + SNR ri ) , ∀ ∈ r R i U , ∈
[10].Based on this assumption, the channel capac user can be re-written as [11]
ity of each
( )
log 1
2
2
i
si si ri
C SNR
+SNR
(4)ers under
=
W
+Proposed Algorithms
A. Problem Formulation and Upper Bound
Consider a multi-user DF cooperative network discussed above, where there are |U| users and |R|
relays. To follow our objective is to take the relay selection, bandwidth allocation, and power distribution as a whole to maximize the capacity of all us
the sum power constraint and the sum bandwidth constraint, which can be posted as [11],[15]:
{ },{ }
| |
1
max
ri i U W i i
α ∑ = C
(5a)| |
1
s.t. U ri 1, 0 ri 1
i
α α
=
, r R i U ,
= ≤ ≤
∑ ∈ ∈
(5b)| |
1
| |
U
i T
i
W U W W
=
= × =
∑
(5c) 0 , ,mi ri m n m n R i U
α
×α
= ≠ ∈ ∈ (5d) 2 ,2
i
W
≤W
≤W i U
∈ (5e) where2 2
log 1 2
i s r
i si ri ri
C W P h P h
0 0
2 ⎛ W N i W N i
α⎞
= ⎜ + + ⎟
ish
⎝ ⎠
user
i 's
channel capacity, in whicP s
is thetotal transmit power available at
P r
is the total power available at each relayW i
denotesBS, , and
t of each user, and
the bandwidth allocated to user
i
,W
is the initial bandwid hα ri
is the fraction of power used at relayr
for the retransmission of data to useri
.Note that the constraint (5b) denotes that the power employed at each to assist all of the users equals the total relaying power
P r
. The constraint (5c)implies that the sum of the bandwidth allocated to each user is equal to the total available bandwidth. The constraint (5d) enforces each user to select exactly one relay for assistance. Also, the constraint (5e) ensures that every user can get an essential bandwidth.
For the nonlinear optimization problem in (5a), a straightforward approach is to conduct an exhaustive search by testing all
R U
possible relay combinations, and then solve |R| water-fillingproblems corresponding to the bandwidth allocation and power distribution at each relay. This approach, however, is infeasible for a practical number of users and relays. Nevertheless, by ignoring (5d), we can get an upper bound to the above problem. More specifically, we can observe that
2
2 2
1 2
3 3
0 2ln 2
i i
ri
ri
C W
A A A A
α α
∂ −
∂ = ⎛ ⎞
+ +
⎜⎝
≤
⎟⎠
(6)
where
A 1
=W N i 0
,A 2
=P h s
|si
|2
, and| |
2 r ri
A 3
=P h
. Similarly,( )
2
2 1 2
2 2
1 2
( )
2ln 2 0
i
i i i
B B C
W W B
− +
∂ = ≤
+ (7)
W B
∂ +
where
2 1
0
| |
s si
B P h
=
N
and2 2
0 ri
|ri
B P h N
r
|α
= .
(6) implie at
C i
is concave inri
Eq.
s th
α
providedW i
is fixed, while (7) implies that
C i
is concave inW i
providedα ri
is fixed. Based on the property of joint concavity and convexity in [17, 18], we can then invoke the joint convex optimization with respect toW i
andα ri
to determine the bandwidth allocation anGA-
nd find the optimal
d power distribution among
power distribution
shown in Fig. 1. The genes in the relay selection part
d power distribution among the users and the selected relays.
To resolve the highly nonlinear optimization
problem addressed above, below we address a
based approach to simultaneously select the most appropriate relay subset a
bandwidth allocation an the users and the relays.
B. GA-Based Approach
The proposed GA divides each chromosome into three parts: the relay selection part, the bandwidth allocation part and the part, as
form an integer string,
R S
, whosei th
gene value,S
( )R i
, indicates the relay selected for useri
. Meanwhile, like the conventional real GA, those in treal number,
he power distribution part are formed by a sequence of
P R
, whosei th
gene value,P i R
( ), denotes the power allocated to useri
at the assisted . Likewise, the genes in the bandwidth part are also formed by a sequence of real number,W
, whosei th
gene value,W i
( ) , denotes the bandwidth allocated to useri
. To accommodate this chromosome structure, we also implement a mechanism that modifies the two key steps of the GA, namely, the crossover operation and the mutation operation. Next, we describe the steps of the proposed GA in which erelay
very solution is represented by a pacity in (5a) is taken as our
e. The
whereas, the bandwidth allocation part comprises of ich is randomly distributed in chromosome and the ca
fitness function.
Step 0:(Initialization)
The algorithm begins with creating
P
parent chromosomes, where P is the population sizrelay selection part comprises of |U| genes, each of which is randomly distributed in {1, . . . , |R|}.
The power distribution part comprises of |U| genes, each of which is randomly distributed in (0, 1);
|U| genes, each of wh
(0,
W T
).Step 1: (Evaluation)
In each generation, the fit s lues computed for each of the
P
chromosomes of the current population by substitutingS
nes va are
R
,P R
andW
by into the capacity in (5
normalize the power bandwidth
a). Meanwhile, we also and
, ( )
' ( ) ( )
( )
r
j i r
R R
P R j
j P
P i P i P
=
= ×
∑
and| |
( )
U
∑ W i
to ensure thati= 1
'( ) ( ) W T , ...,|
W i = W i × i
es
in a mating pool and parent chromosomes for the
in
ly picked c
1, = U |
,they satisfy the constraints (5b) and (5c), respectively.
Step 2: (Selection)
In order to preserve better chromosom (solutions) to yield better offsprings, we employ the truncated selection scheme [16] which only retains
T
parent chromosomes that have higher fitness values.We then reproduce them randomly select two following crossover step.
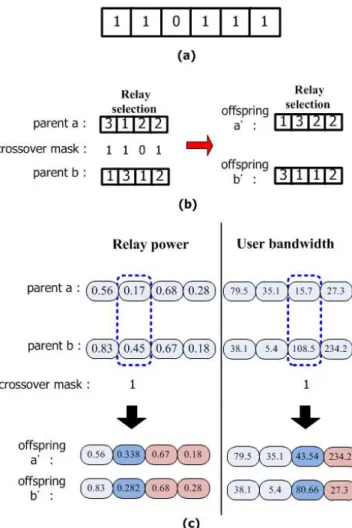
Step 3: (Crossover)
The new crossover step begins by constructing a (|U|+2)×1 crossover mask sequence which consists of 1’s and 0’s generated with equal probability [16].
The first |U| elements of the mask are for the relay selection part, while the remain 2 elements are for the power distribution and for the bandwidth allocation part. For the relay selection part, if the elements in the crossover mask are 1’s, the genes of the two parent chromosomes in the corresponding positions will be exchanged; whereas, if the elements are 0’s, they will remain unchanged. The crossover operations in the bandwidth allocation and the power distribution parts are based on the arithmetic crossover operation [19].
More specifically, for the parent chromosomes a and b, based on the arithmetic crossover operation, if the
correspond g element in the cross mask equals 1, the genes at the left side of the random ross point, say
j
, remain the saj j
' (1 ) b
me, those at the cross point will be regenerated as a
j
= −β
× + ×aβ
andj j j
b '= × + −
β
b (1β
) a× , whereβ
is randomly distributed in (0, 1), and those at the right side of the cross point will be exchanged. For example, assume that the crossover mask sequence is [1, 1, 0, 1, 1, 1]as given in Fig. 2 (a). The relay selection parts of the parent chromosomes a and b will produce theoffspring chromosomes a′
th the relay selection parts as shown in Fig. 2 (b). Also, if 0.6and b
′
wiβ
= and the cross point is 2, andβ
=0.3 and the cross point is 3 for the power distribution part and the bandwidth allocation part, respectively, the corresponding offspring a′
and b′
will have the powerdistribution part and the bandwidth allocation part as shown in Fig. 2 (c). Note that based on thiscrossover, the genes at the relay selection part will always lie in {1, . . . , |R|}, so the relay selectiont u
can be easily made. This crossover ntil the size of the populatio
operation will repea n
reaches
P
.Step 4: (Mutation)
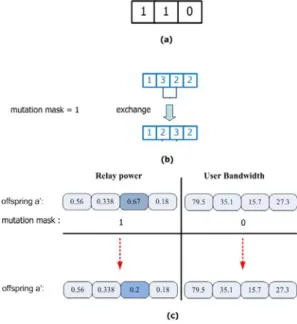
The new mutation operation is also divided into two operations: the integer mutation for the relay selection part, and the uniform mutation for the bandwidth allocation and the power distribution parts.
First, for each chromosome, we create a 3 × 1 mutation mask sequence comprising of 1’s and 0’s generated according to the mutation probability p
m
[16]. In the relay selection part of the chromosome, if the first element of the mutation mask is 1, two gene values which are randomly selected by the mating point will be exchanged; whereas, if this element is 0, the corresponding genes remain the same. For the genes in the power distribution and the bandwidth
allocation parts, if the corresponding element in the
, if it is 1, then a rando mut poin
beco
mutation mask is 0, then all of the genes will remain the same;
whereas mly selected ation
t, say
i
, of the offspring will meLB i
+(UB i
−LB i
)β i
, whereLB i
andUB i
denote the lower bound and upper bound of thei th
gene values, respectively, and _i
is randomly distributed in (0, 1), and the other genes remain the same. For example, consider the mutation mask sequence as shown in Fig. 3 (a). Since the first elemen tquence c espondin to the power distribution part is equal
mu
of the m tion mask sequence is 1, two randomly selected genes in the relay selection part, say the 2
nd
and the 3rd
genes, will be exchanged, resulting in {1, 2, 3, 2}. Meanwhile, as shown in Fig. 3 (c), since the element in the mutation mask se orr g to 1 with the nt being as 3,uta
tation poi
β 3
=0.2 ,LB 3
=0,3
1UB
= , so only the 3rd
gene value is changed and the other genes remain the same, resulting in {0.56, 0.338, 0.2, 0.18}. Likewise, since the element in the mutation mask sequence corresponding to the bandwidth allocation part is equal to 0, all of the genese
numbe
remain the same as its parent, {79.5, 35.1, 15.7, 27.3}.
Step 5: (Repeat/End)
Th algorithm repeats Steps 1 to 4 until the number of the generations meets the prescribed
r
G
, after which the chromosome with the maximum fitness value is chosen. The gene valueS
( )R i
in the relay selection part of this chromosome is selected as the relay for ui
; whereas, the gene values in the power distribution part,P i R
( ), and the bandwidth allocationser
part, optimal
ed to
tring for l number strings for
the
( )
W i
, denote the relaying power and the optimal bandwidth allocat useri
, respectively.C. Low-Complexity Two-Stage Implementation
Note that when there are lots of relays and users,GA needs a large number of population size,
P
, and/or a generation,G
, to converge. To mitigate the computational overhead, in this subsection, we consider a two-stage approach, which first uses a GA to determine the optimal relay subset, and then employs another GA to refine the bandwidth allocation and the power distribution among the users and the selected relays. As the above, each chromosome is also comprised of an integer srelay selection and two rea
bandwidth allocation and power distribution.
First stage: (Relay selection)
The algorithm begins with creating
P 1
parent chromosomes, whereP 1
is the population size in first stage. The relay selection part,R S
, comprises of|U| genes, each of which is randomly distributed d the bandwidth allocation parts comprise of |U|
in {1, . . . , |R|}. Both of the power distribution an
genes and the gene values are set as
R
( )P r P i
=U
and ( )W T
, 1,...,| |= =
W i i U
U
, respectively,throughout the evolution process.
The evolution process, which includes selection, crossover, and mutation steps, is similar as those in Sec 3.2, but only deals with the relay selection part.
The above steps are then repeated until the number of generations meets a prescribed num say
G 1
, after which the chromosome with the maximum fitness value is chose . The gene valueS
( )ber,
n
R i
in the relaymployed in
tio
selection part of this chromosome is selected as the relay for user
i
, and is e the second stage.Second stage: (Refined Power distribu n and bandwidth allocation)
The algorithm begins with creating
P 2
parent chromosomes, whereP 2
is the population size in the second stage. The gene values in the relay selection part are based on those determined in the first stageand remain the same throughout the evolution process in this stage. The power distribution part comprises of
|U| genes, each of which is randomly distributed in (0, 1); whereas, the bandwidth allocation part also
ca
es
i chromosom ote
g to low computational overhead. More e overall complexity required is reduced
e
j
ro
.
r urc
comprises of |U| genes, each of which is randomly distributed in (0,W
T
).The evolution, including the selection, crossover, and mutation steps, are similar as those in Sec 3.2, but only deal with the power distribution part and the bandwidth allo tion part. The above steps will repeat until the number of generations meets a pr cribed number, say
G 2
, after which the chromosome with the maximum fitness value is chosen. Thei th
gene values in the power distribution part and the bandwidth alloca on part of the t e den the optimal relaying power and the optimal bandwidth allocated to useri
, respectively.Note that although the aforementioned implementation comprises of two stages, only parts of the chromosomes involve in the evolution process. As such, it in general requires a smaller population size and/or fewer number of generations to converge,
leadin er
specifically, th
from Ο ×(
P G
) toO P
(1
×G 1
+ ×P 2 G 2
).Simulations
Some simulations are conducted in this section to assess the proposed algorithm. Consider the multi-user DF cooperative network addressed in Sec. 2, where the total number of relays, |R|, is 4 and th total number of users is |U|. We take the COST-231 model as recommended by the IEEE 802.16 working group into consideration [20]. All the users are located within the circle cellular networks area, centered at the BS, in radius 1 kilometer. The relays are placed at (200 ± √2, 200 ± √2). All the user’s positions are randomly distributed inside the cell. The channels from BS to users and f m relays to users are mostly
used below the rooftop, so such non-line-of-sight (NLOS) propagation fading channels can be modeled as Rayleigh random variables with zero-mean and unit-variance The channel model parameters are described in Table I of [10]. W denotes the initial bandwidth fo each user, the transmitted so e power
P s
equals 100mWatt, the total power at each relay equalsP r
, and the noise power density isN 0
. 1000 Monte Carlo trials are conducted for each trial.h
capacity addressed in Sec. 3.1,
P
r
=a
of th , inc
out the when
Four algorithms are carried out for comparison, including the joint power distribution and bandwidt allocation [15] with channel gain relay selection [4]
(PA+BA with RS), joint relay selection and power distribution [11] with equal bandwidth allocation (RS+PA with EBA) , the proposed GA and its two-stage implementation. For reference, the upper bound of the
implemented via TOMLAB in [21], is also furnished for comparison.
We first evaluate the convergence behavior of the proposed GA approach, where W = 200kHz, |U|=10, 100mWatt, and N
0
= −174dBm/Hz. The overall system capacity versus the number of generations,G
, for the proposed GA is as shown in Fig. 4. As expected, the capacity of GA improves sG
, or thee population reases. We can notice that the capacity remains ab sam
size
P ≥
P
,e
100
or whenG ≥ 80
. Therefore, in the following simulations, we useP = 100
and80
G =
. As for the two-stage implementation, the overall capacity versus the number of generations ingeneratio he secon
and the c remains
the first stage,
P 1
, is as shown in Fig. 5 (a), from which we can note that whenP 1
≥100 and1
5G
≥ , the capacity remains about the same.Likewise, the overall capacity versus the number of ns in t d stage,
P 2
, is as shown in Fig. 5 (b), from which we can note that when2
100P
≥G 2
≥40, apacity aboutthe sam Therefore, in the following simulations,
d
nd
ssues sidera hole.
are
,
d its
four
re appealing by exhibiting very mance degradation with even less
lo
th
the complexity, a
y of the proposed GA approach along with mentation in finding an optimal e.
we use
P 1
=100 andG 1
=5, andP 2
=100 and2
40G
= .b
First, we compare the capacity versus
P r
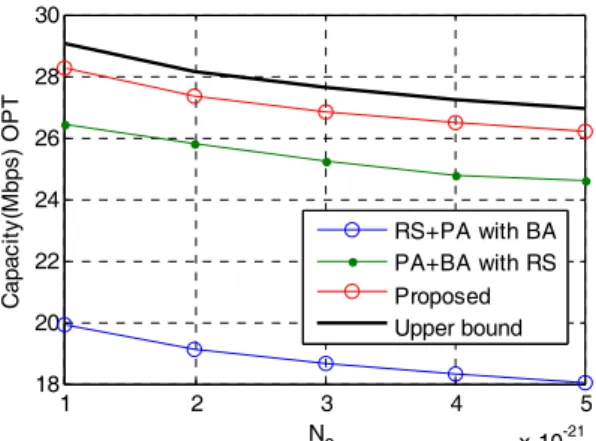
, as shown in Fig. 6, where W = 200kHz, |U|=10 andN 0
= −174dBm/Hz. We can observe from Fig. 6 that the performance of all algorithms improves asP r
increases. The algorithm (RS+PA with EBA) yields the worst performance as it does not consider the bandwidth allocation issue. The algorithm (PA+BA with RS) provides better performance by jointly determining the power and bandwidth allocation. The proposed GA outperforms the other two algorithms by simultaneously taking the relay selection, power distribution and bandwidth allocation into consideration, and its performance is close to the upper oundee i
. Also, the two-stage
into con
implementation
co
tion as a w yields about the same performance as the proposed GA.
Next, we compare the capacity versus W, as shown in Fig. 7, where |U|=10,
P r
=100mWatt, anN 0
= −174dBm/Hz. We can observe from Fig. 7 that the performance of all algorithms improves asW
increases. The performance of the algorithm (RS+PA with EBA) is the most inferior, as it only nsiders the issues of relay selection and power distribution.The performance of the proposed GA and its two-stage implementation is again superior to the other two algorithms and is close to the upper bou
We also compare the capacity versus
N 0
, as shown in Fig. 8, whereW
= 200kHz, |U|=10, andP r
=100mWatt. We can find from Fig. 8 that the performance of all algorithms deteriorates as the variance increases. The performance of the proposed GA is again superior to the other two algorithms by taking these thrThe two-stage implementation is very close the proposed GA.
Finally, we comp the capacity versus |U|, as shown in Fig. 9, where
W
= 200kHz,P r
=100mWatt andN 0
= −174dBm/Hz. We can note from Fig. 8 that the capacity increases as |U|increases, and that the proposed GA approach an two-stage implementation again outperforms the other two algorithms and is close to the upper bound.
To assess the computational overhead, we compare the complexity of the aforementioned algorithms of the CPU time required. For this, we compare these algorithms versus |U| based on the CPU time required, as shown in Fig. 10, where the computer employed is with Intel Core i7-2600 CPU
@3.40GHz and the system RAM is 4GB. We can observe from Fig. 10 that the CPU time of these four algorithms increases with the increase of |U| and that the CPU time of the proposed GA is more than the other two algorithms when there are only few users.
However, when the number of users increases, the complexity of the proposed GA prevails as the numbers of
P
andG
employed are less sensitive to the increase of |U|. Also, the two-stage implementation is monegligible perfor computational load.
計畫結果自評
In this project, we have deve ped an upper bound as well as an GA for simultaneously selecting the relay subset, and determining e bandwidth and power allocation in DF relay networks. Such a joint consideration entails a new structure of chromosomes along with new crossover and mutation operations. To further alleviate
two-stage implementation is also addressed. The results of simulations demonstrate
the efficac two-stage imple solution.
三、 參考文獻
[1] A. Sendonaris, E. Erkip, and B. Aazhang, “User cooperation diversity-part I: System description”
and “User coope
cooperative networks,” in Proc. IEEE Globecom, article ID 5425752, pp. 1-5, 2009.
ration diversity-part II:
rnell, “Cooperative
0,
ng
Beres and R. Adve, “Selection cooperation in
pp. 2387-2394, Jun, 2012.
7,
forward relay networks,” in
7-661,
nt allocation
ence
n and T. L. Ngoc,
“Joint power allocation and relay selection in
erative cellular networks,”
on for multicast
ring for relaying in cellular
E International
trategies in Gaussian
networks with and
004.
orem, Nov. 2, 2004, [Online] Available:
ic [10] S. Kadloor and R. Adve, “Relay selection and power allocation in coop
Implementation aspects and performance analysis,”IEEE
Trans. Commun., vol. 51, no. 11, pp.
1927-1948, Nov. 2003.
[2] J. Laneman, D. Tse, and G. Wo
IEEE Trans. Wireless Commun. vol. 9, no. 5, pp.
1676-1685, May 2010.
[11] M. F. Uddin, C. Assi, and A. Ghrayeb, “Joint relay assignment and power allocati
diversity in wireless networks: Efficient protocols and outage behavior,” IEEE Trans. Inform. Theory, vol. 5
cooperative networks,” IEEE Commun. Letters. vol.
16, no. 3, pp. 368-371, Mar. 2012.
[12] N. Krishnan, R. D. Yates, N. B. Mandayam, and J.
S. Panchal, “Bandwidth sha no. 12, pp. 3062-3080, Dec. 2004.
[3] Y. Zhao, R. Adve, and T. J. Lim, “Improvi amplify-and-forward relay networks: Optimal power allocation versus selection,” IEEE Trans. Wireless
Commun., vol. 6, no. 8, pp. 3114-3123, Aug. 2007.
[4] E.
systems,” IEEE Trans. Wireless Commun. vol. 11, no.
1, pp. 117-129, Jan. 2012.
[13] H. A. Tous and I. Barhumi, “Joint power and bandwidth allocation for multiuser amplify and forward cooperative communications using particle swarm optimization,” in Proc. IEE
multi-source cooperative networks,” IEEE Trans.
Wireless Commun., vol. 7, no. 1, pp. 118-127, Jan.
2008.
[5] T. T. Pham, H. H. Nguyen, and H. D. Tuan, “Relay
Workshop on Signal Proce. Adv. in Wireless Commun.
(SPAWC), pp. 55-59, 2012.
assignment for max-min capacity in cooperative wireless networks,” IEEE Trans on Vehicular
Technology, vol. 61, no. 5,
[14] I. Mari ˙ c and R. D. Yates, “Bandwidth and power allocation for cooperative s
relay networks,” IEEE Trans. Inform. Theory, vol. 56, no. 4, pp. 1880-1889, Apr. 2010.
[15] X. Gong, S. A. Vorobyov, and C. Tellambura,
“Joint bandwidth and power allocation with admission control in wireless multi-user
[6] S. Joshi and S. Boyd, “Sensor selection via convex optimization,” IEEE Trans. Signal Process., vol. 5 no. 2, pp. 451-462, 2009.
[7] W.-H. Fang, Y.-T. Chen, and H.-S. Chen, “A genetic approach for joint relay selection and power allocation in amplify-and-
without relaying,” IEEE Trans. Signal Process. vol. 59, no. 4, pp. 1801-1813, Apr. 2011.
Proc. IEEE International Conf. Intelligent Computing and Intelligent Systems, vol. 2, pp. 65
[16] J. H. Holland, Genetic Algorithms. Scientific American, vol. 267, pp. 66-92, 1992.
Guangzhou, China, 2011.
[8] D. Chen, H. Ji, and X. Li, “An energy-efficie
[17] S. Boyd and L. Vandenberghe. Convex
Optimization. Cambridge University Press, 2
distributed relay selection and power [18] C. J. Watrous, Lecture 14: The Lieb. concavity optimization scheme over wireless cooperative
The
networks,” in Proc. IEEE International Confer www.cs.uwaterloo.ca/~watrous/lecture-notes/701/14.p df
[19] T. Yalcinoz and H. Altun, “Power econom
on Communications, pp. 1-5, 2011.
[9] K. T. Phan, D. H. N. Nguye
p. 59-60, 2001.
ay/docs/80216j-06_013r3.pdf AB Optimization Environment, [Online]
Available: tomopt.com 四、圖表
dispatch using a hybrid genetic algorithm,” IEEE
power engineering review, vol. 21, p
[20] “Multi-hop relay system evaluation methodology,” [Online] Available:
http://ieee802.org/16/rel [21] TOML
Figure 1: Structure of the chromosome of the proposed GA, where |U|=4 and |R|=3.
Figure 2: Crossover operations: (a) crossover mask sequence, (b) relay selection part, (c) power distribution and bandwidth allocation parts,
where
β
=0.6 and the cross point is 2, andβ
=0.3 and the cross point is 3 for the power distribution part and the bandwidth allocation part, respectively.20 40 16
16.5 17 17.5 18 18.5
(a) Number of Generations(G
C apa ci ty (M bp s)
P 1 =200 P 1 =100 P 1 =50
20 40 60 80 20
22 24 26
(a) Number of Generations(G
C apa ci ty (M bp s)
P 2 =200 P 2 =150 P 2 =100
Figure 5: Two-stage implementation: (a) the capacity versus the number of generations in the first stage (G
1
), (b) the capacity versus the number of generations in the second stage (G2
)Figure 3: Mutation operations: (a) mutation mask sequence, (b) relay selection part, (c) power distribution and bandwidth allocation parts, where
β 3
=0.2 , ,, and the mutation point equals 3 for the power distribution part.
3
0LB
=3
1UB
=0.5 1 1.5 2
18 20 22 24 26 28 30 32
Total Relay Power (mW)
C apa ci ty (M bps ) opt m inl p+ B W
RS+PA withEBA PA+BA with RS Proposed Upper bound
20 40 60 80 100
10 15 20 25 30
Number of generations(G)
C apac ity (M bps )
P=200 P=100 P=50
Figure 6: The capacity versus total relay power (
P r
)100 200 300 400 500
0 10 20 30 40 50 60 70
W (kHz)
C ap ac ity (M bps )
RS+PA with EBA PA+BA with RS Proposed Upper bound
Figure 4: The capacity versus the number of generations (G)
Figure 7: The capacity versus the initial bandwidth of each user (
W
)1 2 3 4 5 x 10
-2118
20 22 24 26 28 30
N 0
C apac ity (M bps ) O P T
RS+PA with BA PA+BA with RS Proposed Upper bound
Figure 8: The capacity versus the variance of the white noise (
N 0
)2 4 6 8 10
0 5 10 15 20 25 30
Number of users C ap ac ity (M bps ) op t m inl p+ B W RS+PA with EBA
PA+BA with RS Proposed Upper bound
Figure 9: The capacity versus total number of users (|U|)
2 3 4 5 6 7 8 9 10
0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2
Number of users
CP Ut im e (* 10
3se c) RS+PA with EBA PA+BA with RS Proposed
Proposed(low-complexity)
Figure 10: The CPU time versus the total number of users (|U|)
計畫成果自評
國科會補助專題研究計畫成果報告自評表
就研究內容與原計畫相符程度、達成預期目標情況、研究成果之學術或應 價值(簡要敘述成果所代表之意義、價值、影響或進一步發展之可能性)、 否適合在學術期刊發表或申請專利、主要發現或其他有關價值等,作一綜 評估。
1. 請就研究內容與原計畫相符程度、達成預期目標情況作一綜合評估
達成目標□ 未達成目標(請說明,以 100 字為限)
□ 實驗失敗
□ 因故實驗中斷
□ 其他原因 說明:
2. 研究成果在學術期刊發表或申請專利等情形:
論文:■已發表 □未發表之文稿□撰寫中 □無 專利:□已獲得 □申請中 ■無
技轉:□已技轉 □洽談中 ■無 其他:(以 100 字為限)
3. 請依學術成就、技術創新、社會影響等方面,評估研究成果之學 術或應用價值(簡要敘述成果所代表之意義、價值、影響或進一步發 展之可能性)(以 500 字為限)
合作式通訊為下一世代無線通訊系統之一重要規格。在本計畫中,我們考 慮多使用者於合作式解碼前送網路系統中,結合中繼端選擇機制與中繼端功率分 配以及使用者頻寬分配,如何在有限的中繼端功率及可利用之頻寬資源下,將此 下行傳輸之通道容量最大化。我們首先在忽略掉某些限制的情況下,證明此問題 為一個凸函數的最佳化問題,進而推得系統的效能上限。同時針對該非線性的最 佳化問題,我們提出了一個混合式基因演算法來求解此聯合機制之問題,為提高 該基因演算法的收斂性,我們亦提出了低複雜度的混合式基因演算法,模擬結果 中顯示了本計畫所發展的兩種演算法與先前文獻中的方法比較,除了效能表現上 更優異且更貼近系統效能上界之外,並能夠有效的降低運算複雜度。該些新發展 的演算法不僅有學術上的創新性,同時因其複雜度較低,更有利於其實際應用,
因此其有實際應用價值。下一步我們將進一步考慮其他資源的綜合考量,也預期 所發展的演算法也會擁有較現今其它方法更優越的性能。
整 個 計 畫 的 執 行 , 已 經 大 致 完 成 。 其 先 期 成 果 已 發 表 於 2012 IEEE International Symposium on Intelligent Signal Processing and Communication Systems (ISPACS). 後續的成果已投稿至 IET-Networks,其他相關結果亦在推廣 及整理中。