使用List Decodable Codes之似磁碟陣列系統
40
0
0
全文
(2) 2 A Fault-Tolerant RAID-like System with List Decodable Codes Ming Yu Liu. Abstract With list decoding of error-correcting codes, we can correct errors beyond the traditional ”error-correction radius”. The advantage is that the transmitted message can suffer from more errors caused by the noise in the communication channel. But after we perform the list-decoding algorithm on the received word, we get a list of codewords, and still don’t know which is the correct one. Codes that have list-decoding algorithm are called listdecodable codes. In the thesis, we will use the list-decodable codes to build a RAID-like system with high fault tolerance, for example, more than half the system is faulty. That is, we can safeguard a document in the system, even when more than half the system are failure. We will also bring up some experimental results about our system. Keywords: Coding theory, List-decoding, Reed-Solomon codes, RAID, Fingerprint.
(3) Contents 1 Introduction. 9. 2 List-decodable codes. 13. 2.1. Reed-Solomon codes . . . . . . . . . . . . . . . . . . . . . . . 13. 2.2. Unique-decoding of Reed-Solomon codes . . . . . . . . . . . . 14. 2.3. List-decoding of Reed-Solomon codes . . . . . . . . . . . . . . 16. 2.4. Decoding of RS codes with erasures . . . . . . . . . . . . . . . 18. 2.5. An example . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19. 3 The RAID-like system. 23. 3.1. Background . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23. 3.2. The high fault-tolerant RAID-like system . . . . . . . . . . . . 24. 3.3. 3.2.1. The store function . . . . . . . . . . . . . . . . . . . . 25. 3.2.2. The retrieve function . . . . . . . . . . . . . . . . . . . 26. Choose a proper (N, K)q RS code . . . . . . . . . . . . . . . . 28. 4 Experimental results. 31. 4.1. The list size of the list-decoder . . . . . . . . . . . . . . . . . . 31. 4.2. The RAID-like system . . . . . . . . . . . . . . . . . . . . . . 33 4.2.1. The simulation environment . . . . . . . . . . . . . . . 33. 4.2.2. Simulation results . . . . . . . . . . . . . . . . . . . . . 35. 5 Conclusion. 37. 3.
(4) 4. CONTENTS.
(5) List of Figures 3.1. The RAID-like system . . . . . . . . . . . . . . . . . . . . . . 24. 3.2. The store function . . . . . . . . . . . . . . . . . . . . . . . . 25. 3.3. Get the candidate list for a document fragment . . . . . . . . 26. 3.4. The retrieve function . . . . . . . . . . . . . . . . . . . . . . . 27. 3.5. The efficient-retrieve function . . . . . . . . . . . . . . . . . . 28. 4.1. Snapshot 1 of the simulation environment . . . . . . . . . . . 33. 4.2. Snapshot 2 of the simulation environment . . . . . . . . . . . 34. 4.3. Unique-retrieve (left) and efficient-retrieve (right) with p = 0.3. 36. 4.4. Unique-retrieve (left) and efficient-retrieve (right) with p = 0.5. 36. 4.5. Unique-retrieve (left) and efficient-retrieve (right) with p = 0.7. 36. 5.
(6) 6. LIST OF FIGURES.
(7) List of Tables 2.1. + operation over GF (24 ) . . . . . . . . . . . . . . . . . . . . . 20. 2.2. · operation over GF (24 ) . . . . . . . . . . . . . . . . . . . . . 21. 3.1. Some (N, K) RS codes with 1/2 error-correcting rate . . . . . 29. 4.1. The list size of the list-decoder for the (16, 2)24 RS code . . . . 32. 4.2. The list size of the list-decoder for the (32, 4)25 RS code . . . . 32. 7.
(8) 8. LIST OF TABLES.
(9) Chapter 1 Introduction When we transmit a message in a communication channel, some errors caused by the noise in the channel may occur such that we receive a different message on the other side. To ensure that the receiver can recover the original message from the received information, some redundant information is required. Coding theory deals with such problem with efficiency in the time of encoding/decoding and the space of redundant information. In coding theory, the distance d(C) of a code C is the minimum Hamming distance over all pairs of non-identical codewords in C. It is the key factor in deciding the error-correcting capability of a code C since a conventional dec errors. Within this error-correcting bound, coder can correct up to b d(C)−1 2 c the decoder can find at most one codeword c ∈ C such that d(c, r) ≤ b d(C)−1 2 where d(c, r) is the distance between the codeword c and the received word r. So such decoding problem is called unique-decoding. Another notion called list-decoding, which was introduced independently by Elias[1] and Wozencraft[16] in the late 1950s, deals with the problem that the number of errors is beyond the traditional ”error-correction radius” (i.e. half the minimum distance). A list-decoder will output all of the possible codewords within a specified distance with the received word. Until now, the listdecoding algorithms for some error-correcting codes are invented and codes that have efficient list-decoding algorithms are called list-decodable codes. 9.
(10) 10. CHAPTER 1. INTRODUCTION The list decoding algorithm of Reed-Solomon codes was shown by Madhu. Sudan[13] in 1997.. It inspires the research in this area.. Then, the. list decoding algorithms for other well-known codes, such as Reed-Muller codes[10], Chinese remainder codes[6], algebraic-geometric codes[5], concatenated codes[4] and algebraic soft decoding[8] were invented. There was also a new combinatorial approach to list decoding resulting a linear time encodable and list-decodable codes by Venkatesan Guruswami and Piotr Indyk[7] in 2003. Same idea in coding theory can be applied to applications in data storage. Plank[11] gave a tutorial on how to use RS code to build a RAID-like System with unique-decoding. Teng et al. [14] used the extractor codes to build a EC-RAID system, which offers high fault tolerance, while there is no specific implementation. In this thesis, we show an architecture of RAID-like system by using the list-decodable codes. The RAID-like system can provide higher fault tolerance and reliability due to the nice property of list-decoding. We not only describe the full details about how to store and retrieve a document in our system, but also build a simulation environment in Java programming language so that we can demonstrate the reliability of the storage system with visualized testing. Our RAID-like simulation system through the web can be accessed via http://www.csie.nctu.edu.tw/∼myliu/java2/. Since a list-decoder can correct more errors than a traditional uniquedecoder, it usually takes more time. But if we have other useful information (e.g. erasures), we can reduce the decoding time. Similar information are found when we try to reconstruct the source document in our system. The information can be used not only to speedup the decoding time, but also to filter impossible decoding results. So the retrieve function provided by our system is more efficient than just using a list-decoder directly. As pointed by McEliece[9], we find similar results in our experiments that the list size is almost unique. Even so we have used the fingerprint to help the list decoding algorithm reconstruct the unique answer from the lists. Our.
(11) 11 system can be used to develop new list decoding techniques. With the object oriented nature of Java, users can design and test their new coding methods on our system. The organization of the rest of this thesis is as follows. Chapter 2 introduces the list-decodable codes we used. Chapter 3 shows an application in data storage with the list-decodable codes. Chapter 4 gives some experimental results on the codes and the system. At last, we make a conclusion in chapter 5..
(12) 12. CHAPTER 1. INTRODUCTION.
(13) Chapter 2 List-decodable codes In this thesis, we use the most widely used Reed-Solomon codes to be our listdecodable code. So we will give a detail introduction of the code, including unique-decoding, list-decoding and decoding with erasures.. 2.1. Reed-Solomon codes. Reed-Solomon code is one of the most practical and well-known errorcorrecting codes. They were introduced by Irving S. Reed and Gustave Solomon[12]. Until now, they have a wide range of applications in digital communication and data storage. We define the codes first. Definition 2.1.1 (Reed-Solomon codes) Let Σ = Fq be a finite field and α1 , . . . , αn be distinct elements of Fq . Given n, k and Fq such that k ≤ n ≤ q, we define the encoding function for Reed-Solomon codes as: C : Σk → Σn where on message m = h m0 , m1 , . . . , mk−1 i consider the polynomial p(X) = Pk−1 i i=0 mi X and C(m) = h p(α1 ), p(α2 ), . . . , p(αn ) i is the codeword. From the above definition, we know that a Reed-Solomon code is a mapping from a vector space of dimension k over a finite field Fq into a vector space of higher dimension n > k over the same field. The following theorem shows that it matches the singleton bound. 13.
(14) 14. CHAPTER 2. LIST-DECODABLE CODES. Theorem 2.1.2 Reed-Solomon code is a [n, k, n − (k − 1)]q -code. Proof. Let p1 and p2 be any two polynomials with both degree ≤ k − 1. Their codewords agree at the i-th coordinate iff (p1 − p2 )(αi ) = 0. Since the degree of (p1 − p2 ) is ≤ k − 1, it has at most k − 1 zeros. So the minimum distance d ≥ n − (k − 1). With the singleton bound, we have the minimum distance d = n − (k − 1).. 2.2. Unique-decoding of Reed-Solomon codes. The well-known decoding algorithm for Reed-Solomon codes is given by Berlekamp and Welch[15]. Before we describe the algorithm, we need to define the error-locating polynomial. Definition 2.2.1 (Error-locating polynomial) Let e, k be some parameters. Let α1 , . . . , αn and m1 , . . . , mn be such that there exists a polynomial p of degree ≤ k − 1 such that p(αi ) 6= mi for ≤ e values of i. E(x) is an error-locating polynomial for the above input if we have 1. E(αi ) = 0 if p(αi ) 6= mi . 2. deg(E) ≤ n − k, and E 6= 0. Note the given E, we know the location where these errors occur by finding the i’s for which E(αi ) = 0. Then we replace mi with ? for those i’s and run erasure decoding on the resulting vector of mi ’s. This works because there are at most n − k ≤ d − 1 i’s for which E(αi ) = 0. Now we define N (x) = E(x) · p(x). It is clear that (mi − p(αi ))E(αi ) = 0 for all i. Then, N (αi ) = E(αi )p(αi ) = mi E(αi ), for all i. The BW decoding algorithm is as follows..
(15) 2.2. UNIQUE-DECODING OF REED-SOLOMON CODES. 15. Berlekamp-Welch decoding algorithm Input: α1 , . . . , αn , m1 , . . . , mn where αi , mi ∈ Fq . k and e ≤ b(n − k)/2c Procedure: 1. Find polynomial N (x) and E(x) such that (a) N (αi ) = mi E(αi ) for all i. (b) deg(N ) ≤ e + k − 1 and N (x) 6= 0 (c) deg(E) ≤ e and E(x) 6= 0 2. Let p(x) = N (x)/E(x) Output: The coefficients of the polynomial p(x). Theorem 2.2.2 Let α1 , . . . , αn and m1 , . . . , mn be such that there exists a polynomial p of degree at most k − 1 such that p(αi ) 6= mi for e ≤ b(n − k)/2c values of i. Then we can find the polynomial p by the Berlekamp-Welch decoding algorithm efficiently. Proof. 1. The polynomials N (x) and E(x) exist. Q Define E(x) = i:p(αi )6=mi (x − αi ). If there are e errors, deg(E) = e ≤ b(n − k)/2c and E(x) is what we call error-locating polynomial for our input. Then define N (x) = E(x) · p(x). We saw earlier that for such N (x), N (αi ) = mi E(αi ) for all i. So the polynomials N (x) and E(x) both exist. 2. The polynomial p found by the BW decoding algorithm is unique. To prove the uniqueness of the polynomial p, we assume that there are two pairs (N, E) and (N 0 , E 0 ) which both satisfy the condition in step 1. If. N E. =. N0 , E0. we prove the uniqueness of the polynomial p.. Let’s consider two cases..
(16) 16. CHAPTER 2. LIST-DECODABLE CODES case 1: mi = 0: Then N (αi ) = N 0 (αi ) = 0, so case 2:. mi. 6=. 0:. Then N (αi )N 0 (αi ). N E. =. =. N0 E0. = 0.. mi E(αi )N 0 (αi ). =. N (αi )mi E 0 (αi ). Dividing through by mi , we get N 0 (αi )E(αi ) = N (αi )E 0 (αi ) for all i. Since N 0 · E and N · E 0 have degree ≤ 2e + k − 1, while n > 2e + k − 1, this implies that N 0 · E = N · E 0 as polynomial. So the polynomial p is unique. 3. The algorithm is efficient. In step 1, it is solving a homogeneous linear system of n equations e+k−1 X j=0. Nj αij. = mi. e X. Ej αij. j=0. in the unknowns N0 , . . . , Ne+k−1 , E0 , . . . , Ee−1 , and Ee = 1. There are 2 · e + k ≤ n unknowns and we have n equations. The straightforward way of solving the linear system works in time O(n3 ). In step 2, the division of the polynomials works in time O(n). So the BW decoding algorithm is efficient.. 2.3. List-decoding of Reed-Solomon codes. The first list-decoding algorithm for Reed-Solomon codes is invented by Madhu Sudan in 1997[13]. We describe the algorithm in this section.. Definition 2.3.1 (weighted degree) For weights wx , wy ∈ Z + , the (wx , wy )-weighted degree of a monomial qij xi y j is iwx + jwy . The (wx , wy )P P weighted degree of a polynomial Q(x, y) = i j qij xi y j is the maximum, over the monomials with non-zero coefficients, of the (wx , wy )-weighted degree of the monomial..
(17) 2.3. LIST-DECODING OF REED-SOLOMON CODES. 17. Sudan-List-decoding algorithm for RS codes Input: n, k, t and {(α1 , m1 ), . . . , (αn , mn )} Procedure: p 1. Let d = k − 1, m = dd/2 − 1e and l = d (2(n + 1)/d)e − 1. 2. Find any bivariate polynomial Q(α, m) such that (a) Q(α, m) has (1, d)-weighted degree at most m + ld. (b) Q(αi , mi ) = 0 for all i. (c) Q 6= 0. 3. Factor Q into irreducible factors. Output: All the polynomials p such that (m − p(α)) is a factor of Q and p(αi ) = mi for at least t values of i. Theorem 2.3.2 Let F be a field and {α1 , m1 }, {α2 , m2 }, . . . , {αn , mn } be n distinct pairs where αi , mi ∈ F. Then we can find all polynomials p:F→F q 2(n+1) c e−b (k−1) of degree at most k−1, such that p(αi ) = mi for t ≥ (k−1)d 2 k−1 values of i by the above list-decoding algorithm efficiently. Proof. 1. The bivariate polynomial Q in step 2 exists. We show how to find Q directly, which implies the existence. Let P Pm+(l−j)d qkj αk mj . We want to find coefficients qkj Q(α, m) = lj=0 k=0 P Pm+(l−j)d qkj αik mji = 0 for all i. The satisfying the constraints lj=0 k=0 homogenous linear system has (m+1)(l+1)+d·l(l+1)/2 > n unknowns and n equations. Hence, a non-zero solution exists. q c and p is a polynomial such that e − b (k−1) 2. If t ≥ (k − 1)d 2(n+1) 2 k−1 p(αi ) = mi for at least t values of i, the polynomial p must be in the output list of the list-decoding algorithm..
(18) 18. CHAPTER 2. LIST-DECODABLE CODES It is equivalent to prove that (m − p(α)) divides Q(α, m). First, let P Pm+(l−j)d qkj αk mj and it f (α) = Q(α, p(α)). Since Q(α, m) = lj=0 k=0 has (1, d)-weighted degree at most m+ld, we have that k +jd ≤ m+ld. P Pm+(l−j)d qkj αk (f (α)j ) has degree at most k+jd. And our f (α) = lj=0 k=0 Thus, we know that f (α) has degree at most m + ld. Since p is a polynomial such that p(αi ) = mi for at least t values of i,qwe have f (αi ) = Q(αi , p(αi )) is zero for greater than t ≥ (k − c = d(l + 1) − b d2 c > m + ld points. But f (α) has e − b (k−1) 1)d 2(n+1) 2 k−1 degree at most m + ld, so f (α) = Q(α, p(α)) is identical zero, which means (m − p(α)) divides Q(α, m). The above is the first list decoding algorithm for RS codes. Actually, an. improve list-decoding algorithm for RS code has been invented in 1999 by p Guruswami and Sudan[5]. It can correct up to N − (K − 1)N for a (N, K) RS code. So more errors can be corrected with the GS-decoder. But since the polynomial Q during decoding has much higher degree than the original algorithm, resulting in taking much more time, we choose to implement Sudan’s list decoding algorithm. To be consistent with the implementation and the experimental results, we will use Sudan’s algorithm throughout this paper.. 2.4. Decoding of RS codes with erasures. Consider a (N, K) RS code, let C(M )RS = h m1 , m2 , . . . , mN i denote the codeword for some message M . If the codeword suffers e ≤ N − K erasures in the last e tuples, the receive word is h m1 , m2 , . . . , mN −e , ∗, . . . , ∗i. Then we can do error-correcting on the first N − e tuples by viewing the first N − e tuples as a new receive word h m1 , m2 , . . . , mN −e i corresponding to a (N − e, K) RS code. From theorem ??, we know that a (N − e, K) RS code can correct up to b(N − e − K)/2c errors with unique-decoding. And from theorem 2.3.2, a (N − e, K) RS code can correct up to (N − e) − q 2(N −e+1) c errors with list-decoding. So, we have that e − b (K−1) (K − 1)d 2 K−1.
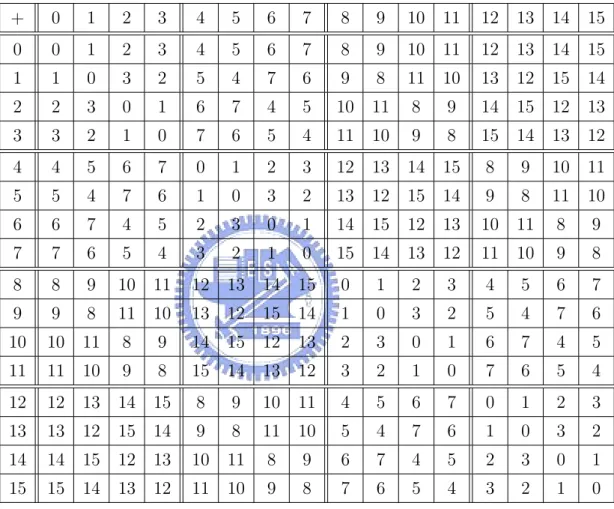
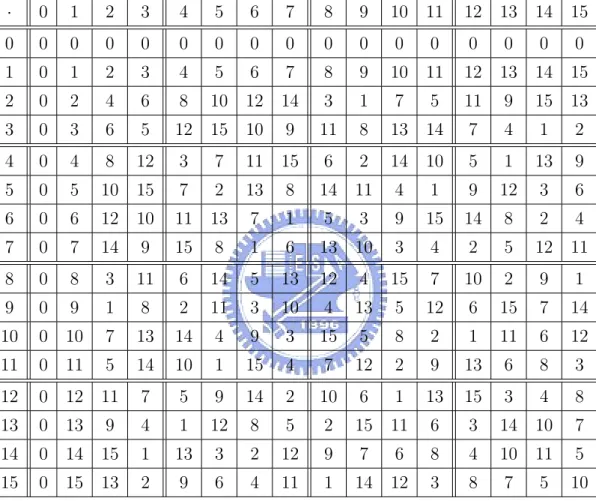
(19) 2.5. AN EXAMPLE. 19. a (N, K) RS code can be unique decoded from e ≤ N − K erasures and b(N − e − K)/2c errors by using the BW unique-decoding q algorithm or list −e+1) c e+b (K−1) decoded from e ≤ N −K erasures and (N −e)−(K −1)d 2(NK−1 2 errors by using Sudan’s list-decoding algorithm.. 2.5. An example. Now we show an example of how to do list-decoding of a RS code. As an example, let CRS be a [16, 2, 15]24 Reed-Solomon code. Then CRS : Σ2 → Σ16 where Σ is GF (24 ). We use ”0” to denote 00002 , ”1” to denote 00012 , ”2” to denote 00102 , ”3” to denote 00112 , . . ., ”14” to denote 11102 , ”15” to denote 11112 . Table 2.1 and 2.2 show the definition of operations + and · over GF (24 ). Consider the message m = h 6, 8 i and its corresponding polynomial is p(x) = 6 + 8x. Then CRS (m) = h p(1), p(2), p(3), . . . , p(13), p(14), p(15), p(0) i = h 14, 5, 13, 0, 8, 3, 11, 10, 2, 9, 1, 12, 4, 15, 7, 6 i From theorem 2.3.2, we know that the original message m must be in the output list of the list-decoding algorithm if there are at least 6 elements in CRS (m) not changed. It means that the number of errors can be up to 10, c= which is greater than the traditional ”error-correction radius” e = b D−1 2 c = 7. b 15−1 2 0 Let CRS (m) be the word that after CRS (m) occurs some errors.. CRS (m) h 14, 5, 13, 0, 8, 3, 11, 10, 2, 9, 1, 12, 4, 15, 7, 6 i 0 7→ CRS (m) h 14, 6, 13, 1, 9, 4, 11, 11, 2, 10, 1, 13, 5, 0, 7, 7 i. Then we need to find any non-zero bivariate polynomial Q with (1, 1)weighted degree at most 5 and it passes through (1, 14), (2, 6), (3, 13), (4, 1), (5, 9), (6, 4), (7, 11), (8, 11), (9, 2), (10, 10), (11, 1), (12, 13), (13, 5), (14, 0),.
(20) 20. CHAPTER 2. LIST-DECODABLE CODES. +. 0. 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13 14. 15. 0. 0. 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13 14. 15. 1. 1. 0. 3. 2. 5. 4. 7. 6. 9. 8. 11. 10. 13. 12 15. 14. 2. 2. 3. 0. 1. 6. 7. 4. 5. 10. 11. 8. 9. 14. 15 12. 13. 3. 3. 2. 1. 0. 7. 6. 5. 4. 11. 10. 9. 8. 15. 14 13. 12. 4. 4. 5. 6. 7. 0. 1. 2. 3. 12. 13 14. 15. 8. 9. 10. 11. 5. 5. 4. 7. 6. 1. 0. 3. 2. 13. 12 15. 14. 9. 8. 11. 10. 6. 6. 7. 4. 5. 2. 3. 0. 1. 14. 15 12. 13. 10. 11. 8. 9. 7. 7. 6. 5. 4. 3. 2. 1. 0. 15. 14 13. 12. 11. 10. 9. 8. 8. 8. 9. 10. 11. 12. 13 14. 15. 0. 1. 2. 3. 4. 5. 6. 7. 9. 9. 8. 11. 10. 13. 12 15. 14. 1. 0. 3. 2. 5. 4. 7. 6. 10. 10. 11. 8. 9. 14. 15 12. 13. 2. 3. 0. 1. 6. 7. 4. 5. 11. 11. 10. 9. 8. 15. 14 13. 12. 3. 2. 1. 0. 7. 6. 5. 4. 12. 12. 13 14. 15. 8. 9. 10. 11. 4. 5. 6. 7. 0. 1. 2. 3. 13. 13. 12 15. 14. 9. 8. 11. 10. 5. 4. 7. 6. 1. 0. 3. 2. 14. 14. 15 12. 13. 10. 11. 8. 9. 6. 7. 4. 5. 2. 3. 0. 1. 15. 15. 14 13. 12. 11. 10. 9. 8. 7. 6. 5. 4. 3. 2. 1. 0. Table 2.1: + operation over GF (24 ).
(21) 2.5. AN EXAMPLE. 21. ·. 0. 1. 2. 3. 4. 5. 6. 7. 8. 9. 10 11. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 1. 2. 3. 4. 5. 6. 7. 8. 9. 10 11. 2. 0. 2. 4. 6. 8. 10. 12 14. 3. 1. 7. 5. 3. 0. 3. 6. 5. 12 15. 9. 11. 8. 4. 0. 4. 8. 12. 3. 7. 11 15. 6. 2. 5. 0. 5. 10 15. 7. 2. 13. 8. 14 11. 6. 0. 6. 12 10. 11 13. 7. 1. 5. 7. 0. 7. 14. 9. 15. 8. 1. 8. 0. 8. 3. 11. 6. 14. 9. 0. 9. 1. 8. 2. 10. 0 10. 7. 13. 11. 0 11. 5. 12. 0 12. 13. 0. 12 13 0. 0. 14 15 0. 0. 12 13. 14 15. 11. 9. 15 13. 13 14. 7. 4. 1. 2. 14 10. 5. 1. 13. 9. 4. 1. 9. 12. 3. 6. 3. 9. 15. 14. 8. 2. 4. 6. 13 10. 3. 4. 2. 5. 12 11. 5. 13. 12. 4. 15. 7. 10. 2. 9. 1. 11. 3. 10. 4. 13. 5. 12. 6. 15. 7. 14. 14. 4. 9. 3. 15. 5. 8. 2. 1. 11. 6. 12. 14. 10. 1. 15. 4. 7. 12. 2. 9. 13. 6. 8. 3. 11. 7. 5. 9. 14. 2. 10. 6. 1. 13. 15. 3. 4. 8. 0 13. 9. 4. 1. 12. 8. 5. 2. 15. 11. 6. 3. 14. 10. 7. 14. 0 14. 15. 1. 13. 3. 2. 12. 9. 7. 6. 8. 4. 10. 11. 5. 15. 0 15. 13. 2. 9. 6. 4. 11. 1. 14. 12. 3. 8. 7. 5. 10. 10. Table 2.2: · operation over GF (24 ).
(22) 22. CHAPTER 2. LIST-DECODABLE CODES. (15, 7) and (0, 7). Since the bivariate polynomial Q has 21 unknowns and we have 16 equations, the polynomial Q exists. After solving the homogenous linear system, we choose one of the non-zero solutions be our polynomial Q.. Q(x, y) = 4 + 2x + 4y + 6x2 + 12xy + 4y 2 + 10x3 + 4x2 y + 13xy 2 + y 3 + x4 +9x3 y + xy 3 + y 4 + 12x5 + 3x4 y + 13x3 y 2 + x2 y 3 + xy 4 + y 5 After factoring the polynomial Q into irreducible polynomials, we get. Q(x, y) = 4 + 2x + 4y + 6x2 + 12xy + 4y 2 + 10x3 + 4x2 y + 13xy 2 + y 3 + x4 +9x3 y + xy 3 + y 4 + 12x5 + 3x4 y + 13x3 y 2 + x2 y 3 + xy 4 + y 5 = (6 + 8x + y) · (7 + 8x + y) ·(4 + 4x + 5x2 + 8xy + x3 + 13x2 y + xy 2 + y 3 ) Both of the polynomials p 1 (x) = 6 + 8x and p 2 (x) = 7 + 8x satisfy the output constraints of the list-decoding algorithm. So we get two possible messages h 6, 8 i and h 7, 8 i. We can check them again. 0 CRS (m) = h 14, 6, 13, 1, 9, 4, 11, 11, 2, 10, 1, 13, 5, 0, 7, 7 i. CRS (h 7, 8 i) = h 15, 4, 12, 1, 9, 2, 10, 11, 3, 8, 0, 13, 5, 14, 6, 7 i and 0 (m) = h 14, 6, 13, 1, 9, 4, 11, 11, 2, 10, 1, 13, 5, 0, 7, 7 i CRS. CRS (h 6, 8 i) = h 14, 5, 13, 0, 8, 3, 11, 10, 2, 9, 1, 12, 4, 15, 7, 6 i 0 Both agree with CRS in 6 positions..
(23) Chapter 3 The RAID-like system From the previous chapter, we have shown that the error-correcting capability of Reed-Solomon codes can be more powerful with the list-decoding algorithm. In this chapter, we show an application in data storage with the list decoding.. 3.1. Background. A RAID-like system consists of individual storage devices and each of them works independently as shown in figure 3.1. Today, if we want to safeguard a document in a RAID-like system, the most trivial method is to replicate it, and to store the different copies in different storage devices. Suppose the RAID-like system has n devices, and each of them holds one copy. Then we can reconstruct the original document by doing majority vote on the copies collected from each device if no more than half of the system incur arbitrary failures, including alterations to the data. However, the method has a main drawback that the required storage space grows linearly with the number of storage devices. Rather than using the method of replication, those who are familiar with the coding theory may use an error-correcting code to encode the document. Suppose the size of the document is s and we use a [N, K, D]q Reed-Solomon 23.
(24) 24. CHAPTER 3. THE RAID-LIKE SYSTEM Storage devices Disk 1. Disk 2. Disk 3. Disk n. CPU. Figure 3.1: The RAID-like system code where q = 2s/K and N = n, the number of storage devices. The document can be viewed as a vector space of dimension K over a field F of size q. By the encoding function of the code, the vector space of dimension K maps into a vector space of dimension N over the same field and each device holds the data of one dimension. With the unique-decoding of Reed-Solomon codes, we can reconstruct the original document when up to b(D − 1)/2c = b(N − K)/2c storage devices incur arbitrary failures, including alterations to data stored in them. The above describes a traditional setting when using an error-correcting code with traditional unique-decoding to safeguard a document in a RAIDlike system. Since the distance D of a code is at most equal to the block length N , the fraction of the failure storage devices in the system is at most ≈ 1/2 when N → ∞. That is, the above method can never satisfy the failure model that the fraction of failure storage devices is more than 1/2, whatever the error-correcting codes we use. So it is a challenge to construct a RAID-like system with high fault tolerance that more than half of the storage devices incur arbitrary failures.. 3.2. The high fault-tolerant RAID-like system. The RAID-like system needs to provide two important functions: store and retrieve. The store function takes a document as the input, and transforms the document into several data pieces. On the other hand, the retrieve function takes several data pieces as the inputs, and tries to reconstruct the.
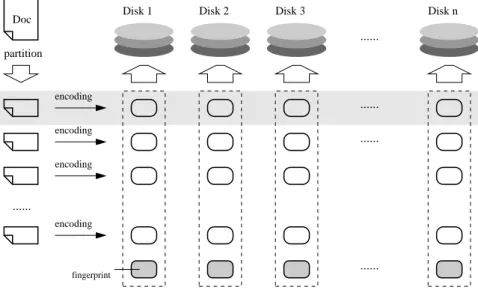
(25) 3.2. THE HIGH FAULT-TOLERANT RAID-LIKE SYSTEM. Disk 1. Doc. Disk 2. Disk 3. 25. Disk n. ...... partition. encoding. ....... encoding. ....... encoding. ...... encoding. ....... fingerprint. Figure 3.2: The store function original document based on the information in those pieces. In this chapter, we assume that there are n storage devices in the system, the size of the document is s bits and the number of faulty storage devices in the system is at most e where e ≥ n/2. We use ErrBoundU (e) to denote the error-correcting bound of unique-decoding with e erasures. ErrBoundL (e) denotes the error-correcting bound of list-decoding with e erasures.. 3.2.1. The store function. First, we need to choose a proper (N, K)q Reed-Solomon code where N = n and q is as small as possible such that the code can correct up to e errors. So the code can encode M = K ∗ log2 q bits. Then, we partition the document into s/M fragments and encode each fragment separately. After encoding, each fragment is transformed into n data pieces and we store them on the n storage devices separately. At last, each device holds s/M data pieces and an extra hash value of the original document as fingerprint. Figure 3.2 shows the store function..
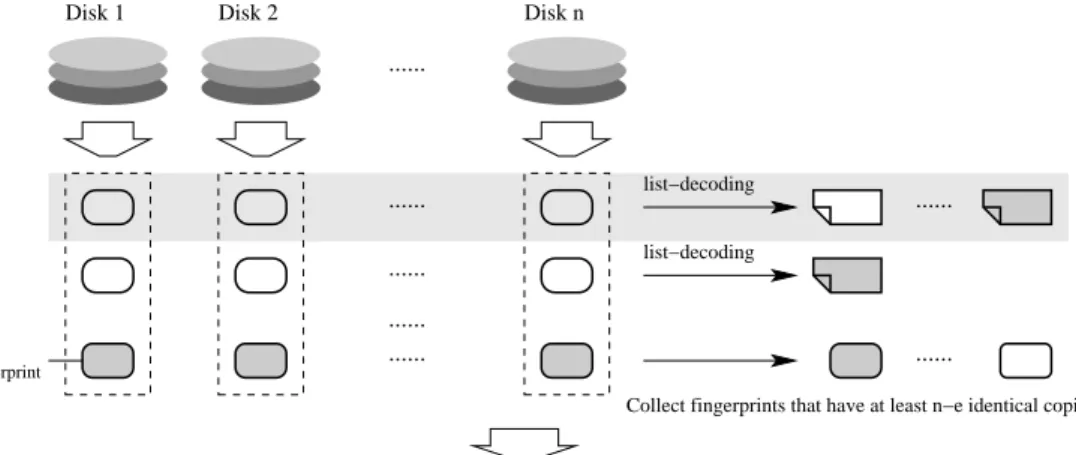
(26) 26. CHAPTER 3. THE RAID-LIKE SYSTEM. store encoding. retrieve ....... list−decoding. n data pieces. document fragment. ...... candidate list. Figure 3.3: Get the candidate list for a document fragment. 3.2.2. The retrieve function. The goal of the retrieve function is to reconstruct the original document. First, we can get a candidate list for each document fragment by performing the list-decoding algorithm on its corresponding data pieces. If there are at most e storage devices failure, every candidate list must contain the original corresponding document fragment. See figure 3.3. Now we show how to choose the correct one from the candidate list for all document fragments. Step 1. Let I be an empty set that is used to collect the indices of the failure storage devices. Step 2. For all candidate lists, do as follows: if the candidate list has only one message m, let C(m)RS denote the (N, K)q RS code of m and D0 , D1 , . . . , Dn−1 denote the corresponding data pieces of m. I = I ∪ {i : C(m)RS i 6= Di } where 0 ≤ i ≤ n − 1 Then, the set I has some indices of failure storage devices. Step 3. For all candidate lists of size which is greater than one, do as follows: If e − |I| ≤ ErrBoundU (|I|), we can use unique-decoding with erasures to get the correct document fragment. Otherwise, assume the candidate list has messages m1 , m2 , . . . , ml . Let C(m)RS denote the (N, K)q RS code of some message m and D0 , D1 , . . . , Dn−1 denote the corresponding data pieces of m. For the message mj where 1 ≤ j ≤ l, if | I ∪ {i : C(mj )RS i 6= Di } |> e where 0 ≤ i ≤ n − 1 we delete the message mj from the candidate list..
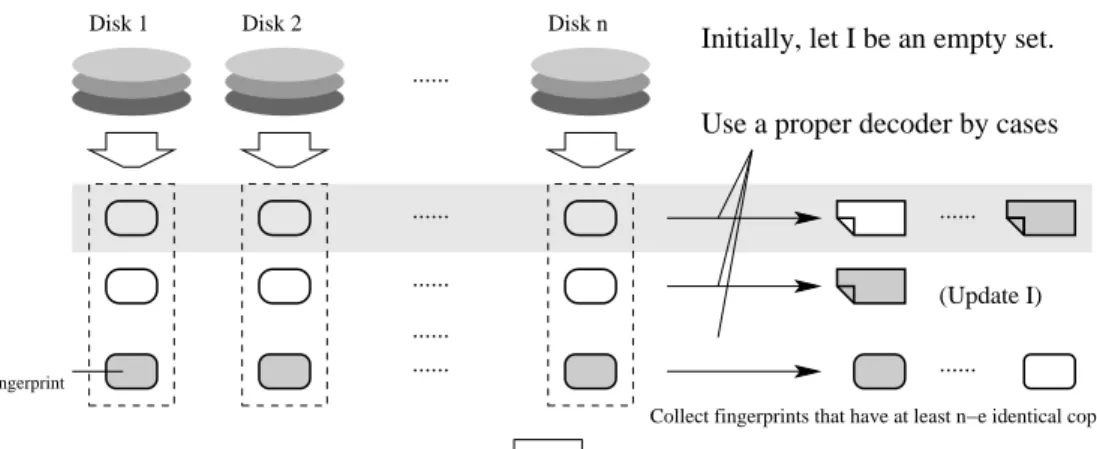
(27) 3.2. THE HIGH FAULT-TOLERANT RAID-LIKE SYSTEM. Disk 1. Disk 2. 27. Disk n. ....... list−decoding. ....... list−decoding. ...... ...... ....... fingerprint. ....... ...... Collect fingerprints that have at least n−e identical copies. Collect information about the indices of failure storage devices. Drop impossible data fragments for all candidate lists. List all. that match the fingerprints. Figure 3.4: The retrieve function Step 4. If the sizes of all candidate lists are one. Concatenate them and we get the original document. Otherwise, compare all combinations with the fingerprints that have at least n − e identical copies in the n storage devices to get all possible documents. We summarize all of the procedures in figure 3.4. Since the list-decoding algorithm takes more time, we can reorder some procedures in figure 3.4 to speed up the retrieve function. That is, every time we get the candidate list for some document fragment, we can update the set I, if the list size is one. Then, we can discard the indices in I as the positions of erasures. If e − |I| ≤ ErrBoundU (|I|), we use a uniquedecoder with erasures to decode the next document fragment. Otherwise, ErrboundU (|I|) < e − |I| ≤ ErrBoundL (|I|), we use a list-decoder with erasures. The more information about the erasures, the less time taken by the list-decoding algorithm. Figure 3.5 shows a speedup version of the retrieve.
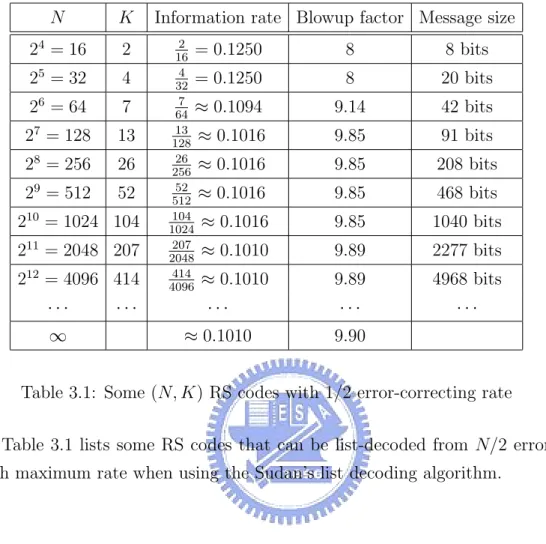
(28) 28. CHAPTER 3. THE RAID-LIKE SYSTEM. Disk 1. Disk 2. Disk n. Initially, let I be an empty set.. ....... Use a proper decoder by cases ....... ....... ....... (Update I). ...... ....... fingerprint. ...... Collect fingerprints that have at least n−e identical copies. Drop impossible data fragments for all candidate lists. List all. that match the fingerprints. Figure 3.5: The efficient-retrieve function function.. 3.3. Choose a proper (N, K)q RS code. In the store function, we need a proper (N, K)q RS code as the encoder. Here, we show how to choose a code with error-correcting rate 0.5. First, N is set to n, the number of storage devices in the system and q is set to 2dlg2 ne . From theorem 2.3.2, we knowq that an (N, K) RS code with +1) c errors. If e + b (K−1) list-decoding can correct up to N − (K − 1)d 2(N 2 K−1 we want our system to correctly retrieve the stored document with half of the system failed, that is, we need to choose K with some fixed N to satisfy r (K − 1) 2(N + 1) c ≤ N/2. e+b (K − 1)d 2 K −1 p It is clear that if K ≤ b5N + 7 − 2 2(N + 1)(3N + 4)c, then the above inequality holds..
(29) 3.3. CHOOSE A PROPER (N, K)Q RS CODE. N. K. 24 = 16. 2. 25 = 32. 4. 26 = 64. 7. 27 = 128. 13. 8. 2 = 256. 26. 29 = 512. 52. 210 = 1024 104 211 = 2048 207 12. 2. = 4096 414 ··· ∞. ···. 29. Information rate Blowup factor Message size 2 = 0.1250 16 4 = 0.1250 32 7 ≈ 0.1094 64 13 ≈ 0.1016 128 26 ≈ 0.1016 256 52 ≈ 0.1016 512 104 ≈ 0.1016 1024 207 ≈ 0.1010 2048 414 ≈ 0.1010 4096. 8. 8 bits. 8. 20 bits. 9.14. 42 bits. 9.85. 91 bits. 9.85. 208 bits. 9.85. 468 bits. 9.85. 1040 bits. 9.89. 2277 bits. 9.89. 4968 bits. ···. ···. ···. ≈ 0.1010. 9.90. Table 3.1: Some (N, K) RS codes with 1/2 error-correcting rate Table 3.1 lists some RS codes that can be list-decoded from N/2 errors with maximum rate when using the Sudan’s list decoding algorithm..
(30) 30. CHAPTER 3. THE RAID-LIKE SYSTEM.
(31) Chapter 4 Experimental results In the previous chapter, we have described the design of our RAID-like system. To study the reliability of the storage system, we show some experimental results in this chapter.. 4.1. The list size of the list-decoder. The list size of the list-decoding algorithm for RS codes plays an important role in the design of our RAID-like system. The previous work[9] on this topic by R. J. McEliece shows that list-decoder almost always returns a list of size one. In this section, we show this by experimental results. We may choose a (N, K)q RS code and assume it can correct up to e errors with the list-decoding algorithm. In each experiment, we will choose randomly a message and encode the message with the chosen RS code. After encoding, we get a codeword and randomly replace the values of e0 positions for the codeword where (N − K + 1) − e ≤ e0 ≤ e. Finally, we decode the codeword by the list-decoding algorithm and collect the outputs into the set L. For all e0 , we do the experiment t times. Table 4.1 shows the experimental results for the (16, 2)24 RS code which can correct up e = 10 errors with the list-decoding algorithm. Table 4.2 is for the (32, 4)25 code with e = 18. 31.
(32) 32. CHAPTER 4. EXPERIMENTAL RESULTS. t = 100, 000 for each e0 e0 : # of errors. #{|L| > 1}. The fraction of |L| > 1. 10. 2389. 0.02389. 9. 1408. 0.01408. 8. 720. 0.00720. 7. 340. 0.00340. 6. 99. 0.00099. 5. 24. 0.00024. Table 4.1: The list size of the list-decoder for the (16, 2)24 RS code t = 1, 000, 000 for each e0 e0 : # of errors #{|L| > 1}. The fraction of |L| > 1. 18. 0. 0. 17. 0. 0. 16. 0. 0. 15. 0. 0. 14. 0. 0. 13. 0. 0. 12. 0. 0. 11. 0. 0. Table 4.2: The list size of the list-decoder for the (32, 4)25 RS code.
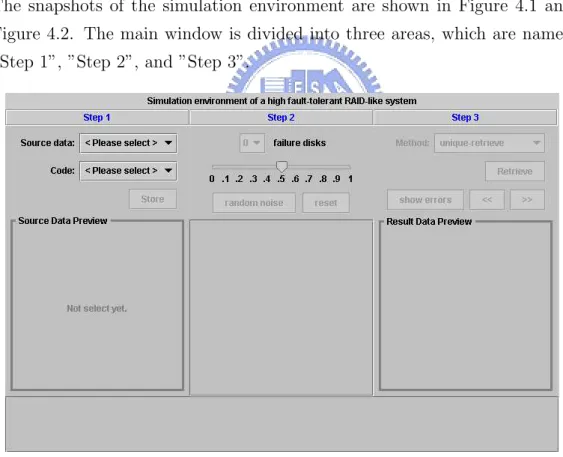
(33) 4.2. THE RAID-LIKE SYSTEM. 33. The results in Table 4.2 may seems unusual. It shows that the output list of the list-decoder is size one with very high probability. It indicates that in most cases the list-decoder behaves just like a conventional decoder(uniquedecoding algorithm).. 4.2. The RAID-like system. Before we show the experimental results of the system, we introduce its simulation environment first.. 4.2.1. The simulation environment. The snapshots of the simulation environment are shown in Figure 4.1 and Figure 4.2. The main window is divided into three areas, which are named ”Step 1”, ”Step 2”, and ”Step 3”.. Figure 4.1: Snapshot 1 of the simulation environment ”Step 1” Area:.
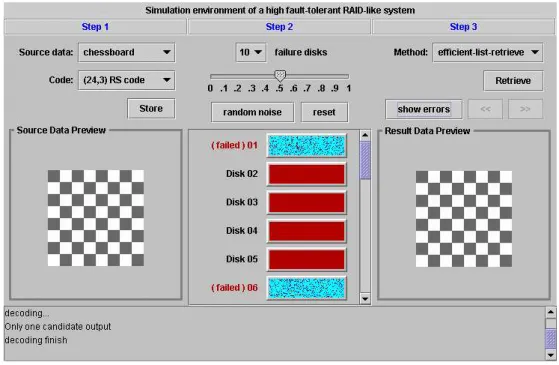
(34) 34. CHAPTER 4. EXPERIMENTAL RESULTS. Figure 4.2: Snapshot 2 of the simulation environment In this area, users can select a source data (document) and a code as the encoder. Once both of them are selected, users can press the button named ”Store” to perform the store function. In order to easily compare the original document in ”Step 1” area with the retrieved document in ”Step 3” area, we use images as the sources. Once select an image, users can preview the image on the bottom of this area. ”Step 2” Area: Once press the ”Store” button in ”Step 1” area, all disks of the system will store the encoded data. Then, we can use the button named ”random noise” to add random errors to the disks. The ”reset” button is used to reset all disks to a state of error free. Before pressing the ”random noise” button, users can decide the number of failure disks and an error probability. Now suppose the number of failure disks is e, and the error probability is p. After pressing the ”random noise” button, it will randomly select e disks as failure disks and the error probability for each data piece and each fingerprint on these failure disks will be p..
(35) 4.2. THE RAID-LIKE SYSTEM. 35. ”Step 3” Area: In this area, users can select a retrieving method to retrieve the document from the encoded data stored in those disks. Once select the retrieving method, users can press the button named ”Retrieve” to perform the retrieve function and the result will be shown on the bottom of this area. If users just want to see where the errors occur, then press the button named ”show errors”. If we have more than one outputs, the button named ” ” and ” ” can be used to switch between them. Here we provide two retrieving method. The first retrieving method is called unique-retrieve. It uses the unique-decoding algorithm as the decoder and its error-correction bound is half of the minimum distance of the code. Another retrieving method is called efficient-retrieve. It uses the listdecoding algorithm as the decoder and hence it has higher error-correction capability.. 4.2.2. Simulation results. We use the Lena (or Lenna) picture, which is one of the most widely used images for data compression, to be our source data (document) and the (16, 2)24 RS code, which can correct up to 10 errors, to be our encoder. The number of failure disks is set to 10. Figure 4.3 shows the result when the error probability p is set to 0.3. Figure 4.4 is the result when p = 0.5. Figure 4.5 is the result when p = 0.7. The (16, 2)24 RS code can correct up to 7 errors with unique-decoding and 10 errors with list-decoding. So once the encoded data pieces for some document fragment has more than 7 errors, the unique-retrieve method cannot reconstruct the original fragment and some parts of the retrieved picture will be corrupted. But for the efficient-retrieve method, it can correctly retrieve the original picture under this setting..
(36) 36. CHAPTER 4. EXPERIMENTAL RESULTS. Figure 4.3: Unique-retrieve (left) and efficient-retrieve (right) with p = 0.3.. Figure 4.4: Unique-retrieve (left) and efficient-retrieve (right) with p = 0.5.. Figure 4.5: Unique-retrieve (left) and efficient-retrieve (right) with p = 0.7..
(37) Chapter 5 Conclusion In the thesis, we have shown how to use one of the list-decodable codes, Reed-Solomon codes with list-decoding to build a RAID-like system with high fault tolerance. Moreover, the system can offer traditional error-correcting capability if we replace a unique-decoder with the list-decoder. Then we can save much time in decoding if there are only few disks failure. Since list-decoding of RS codes can be viewed as bivariate interpolation and factorization problem[2, 3], the retrieve function in this system may be too slow if the size of the document is too large. To overcome this problem, we can use other list-decodable codes (e.g. expander codes) that have low complexity in time to replace RS codes although we may need more disk space to store the encoded data.. 37.
(38) 38. CHAPTER 5. CONCLUSION.
(39) Bibliography [1] P. Elias, “List decoding for noisy channels,” Institute of Radio Engineers, 94-104, 1957. [2] J. von zur Gathen and E. Kaltofen, “Polynomial time factorization of multivariate polynomials over finite fields,” Math. Comput, 45:251–261, 1985. [3] Shuhong Gao and Alan G.B. Lauder, “Hensel lifting and bivariate polynomial factorisation over finite fields,” Mathematics of Computation, Volume 71, Issue 240, October 2002. [4] V. Guruswami and M. Sudan, “List decoding algorithms for certain concatenated codes,” Proceedings of the 32nd annual ACM symposium on Theory of computing, 181–190, May 2000. [5] V. Guruswami and M. Sudan, “Improved Decoding of Reed-Solomon Codes and Algebraic Geometry Codes,” IEEE Transactions on Information Theory, vol. 45, no. 6, pp. 1757-1767, September 1999. [6] V. Guruswami, A. Sahai and M. Sudan, “Soft-Decision Decoding of Chinese Remainder Codes,” Proceedings of the 41st Annual Symposium on Foundations of Computer Science, 2000. [7] V. Guruswami and P. Indyk, “Linear Time Encodable and List Decodable Codes,” STOC, 2003. 39.
(40) 40. BIBLIOGRAPHY. [8] R. Koetter and A. Vardy, “Algebraic soft-decision decoding of ReedSolomon codes,” IEEE Transactions on Information Theory, August 31 2001 [9] R. J. McEliece, “On the average list size for the Guruswami-Sudan Decoder,” International Symposium on Communication Theory and Applications, July 2003. [10] R. Pellikaan and Xin-Wen Wu, “List decoding of q-ary Reed-Muller codes,” IEEE Transactions on Information Theory, April 2004. [11] J. S. Plank, “A Tutorial on Reed-Solomon Coding for Fault-Tolerance in RAID-like Systems,” Software, Practice and Experience, 27(9):995-1012, September 1997. [12] Irving S. Reed and Gustave Solomon, “Polynomial Codes over Certain Finite Fields,” Journal of the Society for Industrial and Applied Mathematics, 1960. [13] Madhu Sudan, “Decoding of Reed-Solomon codes beyond the errorcorrection bound,” Journal of Complexity, 13(1):180–193, 1997. [14] C.-Y. Teng, R.-J. Chen, M.-Y. Liu and S.-C. Tsai, “Extractor Codes with Applications,” NCS 2003. [15] L. R. Welch and E. R. Berlekamp, “Error correction for algebraic block codes,” US patent, Number 4, 633, 470, 1986. [16] J. M. Wozencraft, “List decoding,” Quarterly Progress Report, Research Laboratory of Electronics, MIT, 48:90-95, 470, 1958..
(41)
數據

+7

相關文件
In this paper, we propose a practical numerical method based on the LSM and the truncated SVD to reconstruct the support of the inhomogeneity in the acoustic equation with
2.28 With the full implementation of the all-graduate teaching force policy, all teachers, including those in the basic rank, could have opportunities to take
Reading Task 6: Genre Structure and Language Features. • Now let’s look at how language features (e.g. sentence patterns) are connected to the structure
Let us suppose that the source information is in the form of strings of length k, over the input alphabet I of size r and that the r-ary block code C consist of codewords of
If we want to test the strong connectivity of a digraph, our randomized algorithm for testing digraphs with an H-free k-induced subgraph can help us determine which tester should
• involves teaching how to connect the sounds with letters or groups of letters (e.g., the sound /k/ can be represented by c, k, ck or ch spellings) and teaching students to
• We will look at ways to exploit the text using different e-learning tools and multimodal features to ‘Level Up’ our learners’ literacy skills.. • Level 1 –
• Copy a value from the right-hand side (value or expression) to the space indicated by the variable in the left-hand side.. • You cannot write codes like 1 = x because 1 cannot
