科技部補助專題研究計畫成果報告
期末報告
應用關聯結構隨機邊界法探討我國勞工薪資低付與性別差異問
題
計 畫 類 別 : 個別型計畫 計 畫 編 號 : MOST 104-2410-H-004-012-執 行 期 間 : 104年08月01日至105年07月31日 執 行 單 位 : 國立政治大學金融系 計 畫 主 持 人 : 黃台心 計畫參與人員: 博士班研究生-兼任助理人員:胡聚男中 華 民 國 105 年 09 月 13 日
中 文 摘 要 : 當勞動市場上存在樣本選擇 (sample selection) 問題時, 本研究 嘗試建構聯立迴歸模型, 同時包含隨機工資與工時兩條邊界方程式, 藉以探討男女兩性勞工薪資低付程度課題。基於組合誤差項的存在, 必須使用關聯結構法推導出它們的聯合機率密度函數, 進而建構隨 機邊界關聯結構模型。整理民國94、96、98、100 與102等五年的台 灣「人力運用調查」資料, 進行迴歸實證分析。再按年齡、工作經 驗、教育程度、工作身分、婚姻狀態和工作地等6類, 分別比較男、 女性勞工的薪資效率並檢定6個假說。 實證結果發現考慮樣本選擇的平均薪資效率遠低於未考慮樣本選擇 者,工作身分、工作地等 2 類, 不論有無考慮樣本選擇, 相同性別 勞工薪資效率變動趨勢大致一致, 但其餘 4 類, 變動趨勢相左。考 慮樣本選擇的實證結果與以往文獻有相當差異, 可能是因為以往文 獻探討薪資效率時, 多未同時考慮樣本選擇問題, 即將無工作者樣 本完全排除, 導致迴歸分析結果僅適用於有工作者。 中 文 關 鍵 詞 : 樣本選擇、薪資低付、組合誤差項、關聯結構法、隨機邊界關聯結 構模型、薪資效率
英 文 摘 要 : This paper compiles the “Manpower Utilization Survey” data, conducted by Directorate General of Budget,
Accounting, and Statistics, Executive Yuan, ROC, to study the issue of wage underpayment. Under the case of sample selection, we apply the copula methods to derive the joint probability density function for composed errors in the equations of wage and hours of work. The likelihood function is able to take both workers, who have observed wages, and non-workers, who have no observed wages, into account. Non-workers are usually excluded by previous researchers, studying similar issues like ours, since they overlook the role of sample selection. We separately
estimate the male and female wage equations and evaluate the wage efficiency on the basis of six different
classifications.
The empirical results show that the trend of wage efficiency in the categories of working identity and working area are almost the same in each gender, whether correcting for the sample selection problem or not. However, in the remaining 4 categories, the sample selection bias appears to play an important role on the determination of wage efficiency. With the correction of the sample election bias, most of the findings differ from the past literatures that consider only workers with wage and salary.
英 文 關 鍵 詞 : sample selection; wage underpayment; composed errors;copula methods; stochastic frontier copula model;wage efficiency
考慮樣本選擇下分析兩性勞工薪資低付問題: 關聯結
構隨機邊界法之應用
Analyzing Gender Wage Underpayment with Sample
Selection: A Copula-based Stochastic Frontier Approach
黃台心
Tai-Hsin Huang
Department of Money and Banking National Cheng-Chi University
Taipei, Taiwan Email: [email protected]
劉洪禎
Hung-Chen Liu
Department of Money and Banking National Cheng-Chi University
Taipei, Taiwan
Email: [email protected]
胡聚男
Chu-Nan Hu
Department of Money and Banking National Chengchi University
Taipei, Taiwan
中文摘要
勞動市場若存在樣本選擇 (sample selection) 問題, 本研究嘗試建構聯立迴歸 模型, 同時包含隨機工資與工時兩條邊界方程式, 可探討男女兩性勞工薪資低付 程度課題。因存在組合誤差項, 必須使用關聯結構法推導出聯合機率密度函數, 進 而建構隨機邊界關聯結構模型。整理民國 94、96、98、100 與 102 等五年的台灣 「人力運用調查」資料, 進行迴歸分析。發現考慮樣本選擇的平均薪資效率遠低於 未考慮樣本選擇者,與以往文獻有相當差異, 可能原因為以往文獻探討薪資效率時, 未同時考慮樣本選擇問題, 將無工作者樣本完全排除, 導致迴歸分析結果僅適用 於有工作者。 關鍵字: 樣本選擇、薪資低付、組合誤差項、關聯結構法、隨機邊界關聯結構模 型、薪資效率 JEL 分類:C34; J31;ABSTRACT
This paper compiles the “Manpower Utilization Survey” data, conducted by Directorate General of Budget, Accounting, and Statistics, Executive Yuan, ROC, to study the issue of wage underpayment. Under the case of sample selection, we apply the copula methods to derive the joint probability density function for composed errors in the equations of wage and hours of work. The likelihood function is able to take both workers, who have observed wages, and non-workers, who have no observed wages, into account. Non-workers are usually excluded by previous researchers, studying similar issues like ours, since they overlook the role of sample selection. We separately estimate the male and female wage equations and evaluate the wage efficiency on the basis of six different classifications.
The empirical results show that the trend of wage efficiency in the categories of working identity and working area are almost the same in each gender, whether correcting for the sample selection problem or not. However, in the remaining 4 categories, the sample selection bias appears to play an important role on the determination of wage efficiency. With the correction of the sample election bias, most of the findings differ from the past literatures that consider only workers with wage and salary.
Key words: sample selection; wage underpayment; composed errors; copula method; wage efficiency;
目 錄
1. 前言………1
2. 文獻回顧………3
2.1 隨機邊界法分析薪資相關議題………3 2.2 薪資的性別差異………4 2.3 臺灣勞動市場之薪資差異與性別歧視………5 2.4 保留薪資(reservation wage) ………63. 研究方法………8
3.1 隨機薪資與工時邊界模型………8 3.2 關聯結構隨機薪資邊界模型………94. 變數定義與假說設定………13
4.1 資料來源與變數定義………13 4.2 假說設定………175. 實證分析………19
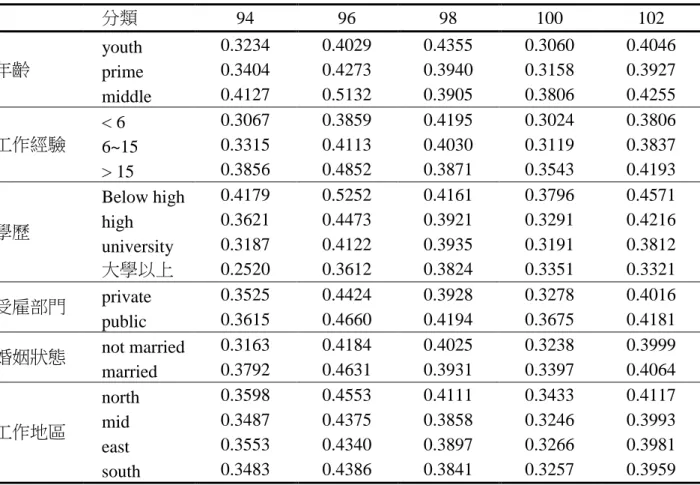
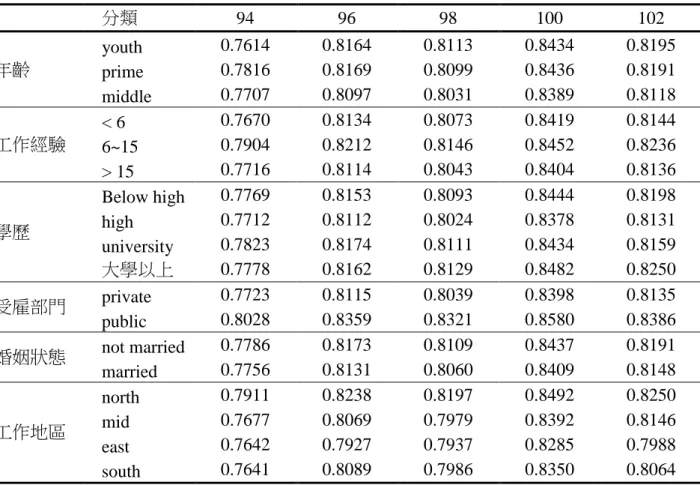
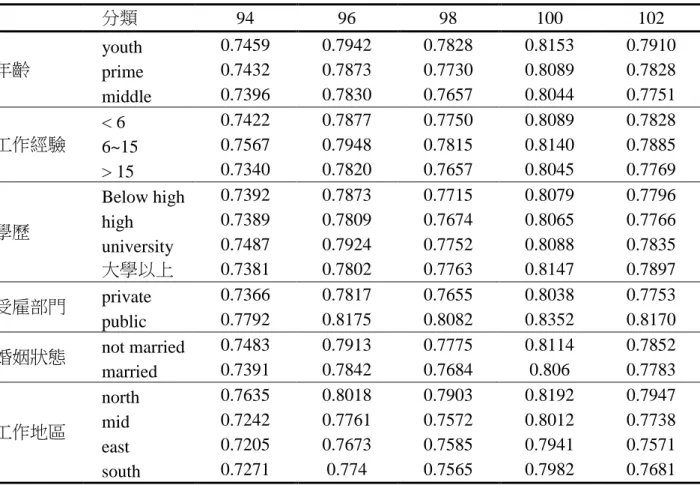
5.1 各年度薪資效率估計結果………24 5.2 各年度薪資效率估計結果………25 5.3 分群比較薪資效率………256. 結論………34
表目錄
表 1 男性樣本之敘述統計量………15 表 2 女性樣本之敘述統計量………16 表 3 女性樣本之迴歸係數 – 考慮樣本選擇………21 表 4 女性樣本之迴歸係數 – 考慮樣本選擇………22 表 5 男性邊際效果………23 表 6 女性邊際效果………23 表 7 各年度平均薪資效率 – 考慮樣本選擇………241. 前言
薪資在勞動經濟學中是主要研究的對象之一, 用來探討諸如勞動供給行為、生 產力變動、所得分配、薪資差異或歧視以及國民所得等議題。以國民所得為例, 我 國國內生產毛額 (GDP) 當中, 接近一半的比例是受雇人員報酬, 在 2000-2012 年 的比率介在 47%-50%之間, 是四大要素所得中比例最高者。 勞動經濟學的搜尋理論 (search theory) 指出, 勞工在尋找工作時所獲得的實 際薪資, 應介於本身所要求的最低保留薪資以及根據個人特質所能得到的最大潛 在薪資之間。因為尋找工作的機會成本隨時間而遞增, 而人的一生有限, 不可能每 個人都願意花很長的時間來尋找心目中最理想的工作, 故實際薪資總是會低於潛 在薪資, 也就是薪資容易被低付 (underpayment)。根據行政院主計總處的資料顯示, 我國自 2008 年後的平均薪資一直停滯不前; 經過物價指數平減後的實質平均薪資 更是從 2003 年出現倒退趨勢。依據 2013 年的資料, 名目每人月平均薪資與 2008 年相比只成長約 1,300 元; 實質每人月平均薪資反而減少了 592 元, 且此 6 年當中, 只有 2 年的實質平均薪資年增率為正。這段期間內, 勞工的實際與潛在薪資以及薪 資低付的程度各有何變化?是本文關心的問題之一。Hofler and Polachek (1985) 與 Hofler and Murphy (1992) 以勞動市場的資訊不 充分, 解釋實際薪資低於潛在薪資的原因, 並以隨機邊界法估計個人的薪資不效 率程度。Hofler and Murphy (1992) 論及若一國實際薪資水準低於最大潛在薪資 10%, 這種薪資不效率程度可使該國的 GDP 減少約 5%, 且此比例隨著薪資占 GDP 比例的上升而上升, 顯示勞動市場的不效率程度影響國民福祉十分深遠。
本文除了打算運用隨機邊界模型估計我國勞工的薪資低付程度外, 也將樣本 選擇 (sample selection) 問題一併納入, 以聯立迴歸模型同時估計工資與工時方程 式, 依據不同分類方式,深入探討男、女性勞工的薪資不效率議題。因為工資與工 時 方 程 式 均 包 含 組 合 誤 差 (composite errors), 必 須 借 助 關 聯 結 構 法 (copula methods) 推導誤差項的聯合機率密度函數,進而得到考慮樣本選擇的概似函數, 以利進行實證分析。 國內探討男女性薪資差異的文獻不在少數, 大多以 Oaxaca (1973) 的性別歧 視模型為主, 以隨機邊界法分析薪資差異者較少, 且大多探討特定行業內薪資不 效率的程度, 例如江錦淑 (2008) 以隨機邊界法估計銀行業薪資低付程度, 但未涉 及薪資差異的議題, 僅劉錦添與詹方冠 (1990) 論及工資的性別歧視程度,距今約 有 25 年, 臺灣的勞動結構已大幅轉變, 有必要再次針對現今勞動市場上之薪資低 付情況予以研究。總而言之, 本研究想要探討如下問題: 1. 實際薪資與潛在薪資的差距, 即薪資低付程度。 2. 薪資低付情況男性和女性有無差異? 薪資低付與薪資差異情況隨時間經過, 愈 趨嚴重抑或逐漸緩和? 3. 不同類別勞工薪資低付程度有無差異。 4. 不考慮樣本選擇問題, 對於實證分析結果是否產生重大影響? 這些議題具有重要應用價值, 可提供政府制定教育或勞動政策時的參考。本文 除第一節為前言外, 第二節回顧過去相關文獻, 第三節建立聯立迴歸模型, 利用關
聯結構法推導誤差項的聯合機率密度函數與概似函數, 第四節說明資料來源與設 定六個假說, 第五節進行實證分析, 利用隨機邊界關聯結構模型, 分別估計男性和 女性的工資與工時聯立迴歸方程式, 據以分析薪資低付和檢定前節設定的六個假 說, 最後一節是結論與建議。
2. 文獻回顧
2.1 隨機邊界法分析薪資相關議題
本小節主要回顧一些國外以隨機邊界法分析勞動市場上的保留薪資、潛在薪 資以及薪資不效率的文獻。
Hofler and Polachek (1985) 認為勞工在勞動市場上常因缺乏充分資訊, 實際得 到的薪資常會低於資訊充分下的的最大潛在薪資。未能達到潛在薪資的程度, 稱為 勞工在勞動市場上的 "無知 (ignorance)"。採用 Aigner, Lovell, and Schmidt (1977) 的隨機邊界法估計出市場的總無知 (market ignorance); 再以 Jondrow et al. (1982) 的方法, 估計出個別的無知 (specific ignorance)。實證結果與搜尋理論所提出的觀 點有高度的吻合, 即薪資低付 (無知) 的情況, 黑人比白人嚴重、鄉村比都市嚴重、 教育水準以及工作經驗低者較嚴重、風險趨避程度較高者較嚴重、找工作的機會 成本較高者較嚴重; 加入工會者可以大幅降低薪資低付的情況。Hofler and Murphy (1992) 進一步擴大前篇論文的假設, 依搜尋理論提出 6 個假設:不同的群體如壯年 男性、女性以及青少年勞工, 會受到不同的預算與居住限制, 故薪資被低付程度有 所不同;1 住在失業補助金較多的區域、教育程度較高者、住在都市者、財富較多 者以及任職期間較長者, 薪資被低付的程度較低。估計的結果, 假設 2 的失業補助 似乎完全不能降低薪資低付程度, 其餘五個假設皆達到統計顯著。 若在勞動市場上, 勞方知道資方最高願付價格, 而資方知道勞方的最低願受 價格, 則會透過動態過程得到一個唯一的均衡薪資。Polachek and Yoon (1987) 認為 在完全競爭市場中, 同質勞工的薪資之所以會偏離均衡, 來自於勞資雙方在市場 皆未能取得充分資訊。此文同時考慮勞資雙方對於彼此的資訊都不充分的情況,2
採用 1981 年 panel study of income dynamics 資料, 以最大概似估計法估計出勞方的 無知是 0.288, 而資方的無知是 0.400。表示勞方拿到的薪資少於資方最大願付金額 28.8%; 而資方付出的薪資多於勞方最低願受價格 40%。
Hofler and Murphy (1994) 根 據 美 國 1983 年 的 當 前 人 口 調 查 (current population survey, CPS) 資料, 僅選取有薪資者樣本, 採用隨機邊界法估計勞工的 保留薪資, 發現勞工的實際薪資平均高出保留薪資 25%, 男性的保留薪資高於女 性, 且與年齡、教育程度、都市化程度以及財富有直接的相關。Webb, Watson, and Hinks (2003) 採用 1991、1995 和 1999 年的英國家庭追蹤調查 (British household panel survey, BHPS) 資料庫, 以隨機邊界法估計英國金融業員工的保留薪資以及 薪資高付(wage overpayment) 的情形。發現 1990 年代的金融業員工平均薪資高出 保留薪資 30%, 年資較深的員工薪資高付的情形尤其顯著, 且在樣本期間內成長 了 14%。Lang (2005) 以隨機邊界法估計並比較 2000 年西德本國人以及移民的潛 在薪資, 發現移民薪資較低原因為較低的人力資本。不論本地勞工還是移入勞工, 皆可以領到各自潛在薪資的 84%, 顯示移入者的薪資不效率程度並不如預期的嚴 1 例如:壯年男性的失業通常是因為被資遣, 可以申請失業保險補助, 比起女性以及青少年的初入 職場, 有較雄厚的財務補助。導致女性與青少年迫於經濟壓力而接受被低付的薪資。
2 絕大多數相關文獻僅探討勞工薪資低付情況, Hofler and Murphy (1992) 曾提出解釋:資方通常會
避免過分壓榨薪資, 因為薪資若太低, 一來不易找到適合勞工, 職位的空缺期間可能會很長; 二 來就算找到勞工, 也不易久待其位。
重。
Polachek and Xiang (2005) 挑選 Luxembourg income study 資料中有完整變數 的 11 個國家,3
採隨機邊界法衡量薪資不效率的程度, 約落在 30%至 35%之間。其 中已婚者不效率程度低於鰥寡和離婚者, 男性低於女性, 教育程度較高及工作經 驗較多者較低。此外, 制度面因素也有顯著影響, 外籍勞工的移入會使薪資不效率 的程度提高。Adamchik and King (2007) 採用隨機邊界法衡量 2001 年波蘭的勞動 市場的資訊不完全程度, 並與 Polachek and Xiang (2005) 的估計結果比較, 發現 波蘭的薪資邊界與其他 OECD 的國家雖然相近, 但是薪資不效率程度卻最低。
2.2 薪資的性別差異
男女兩性的平均薪資存在差異, 去除人力資本差異後的部分, Oaxaca (1973) 將其歸諸於性別歧視。由於國外探討薪資差異的文獻眾多, 本小節只回顧其中採用 隨機邊界法者; 而探討我國勞動市場薪資差異之文獻相對較少, 故不論是否採用 隨機邊界法皆予討論,其中大多以行政院主計總處收集的「人力運用調查」資料 為分析對象。Robinson and Wunnava (1989) 指出 Oaxaca (1973) 性別歧視模型有一個重要 缺點:男女性的特質之間可能存在「無法觀察到的差異」, 因而無法被薪資方程式 掌握。過去的文獻必須假設「兩性間所有無法觀察到的特質都相同」; 這種假設可 能會高估女性的應有薪資。4
Robinson and Wunnava (1989) 將歧視定義為女性薪資 低於隨機邊界的程度, 故只需針對女性樣本進行研究。利用美國 1983 年 CPS 資料, 實證研究發現女性薪資平均低於隨機邊界 26%。易言之, 女性若沒有被歧視且市場 有效率, 薪水可以再多出約四分之一。自 1991 年蘇聯解體後, 勞動市場的薪資也 由中央統一管制, 轉變成廠商可自訂薪資。Ogloblin and Brock (2005) 比較性別、 地區生活成本 (local cost of living) 和工時等, 對於薪資低付程度以及潛在薪資的 影響。針對 2000-2002 年的合併資料進行估計, 發現不同性別的薪資低付程度有相 當的差異, 且低付程度因為市場的不效率而高於西方國家, 其中男性勞工約只領 到潛在薪資的 64.5%, 女性則是 72.9%。
Díaz and Sánchez (2011) 以 European community household panel 資料庫分析 1995-2001 年間, 英國、義大利、德國、法國以及西班牙等五國之薪資差異與性別 歧視間的關係。採用 Wang (2002) 之方法計算性別對於薪資不效率程度的邊際效 果, 發現性別變數顯著影響各國薪資不效率程度, 女性的實際與潛在薪資差距較 大; 其邊際效果五國間的差距也很大, 最高為英國的 33.7%, 最低為法國與西班牙 的 16%。5 反映出各國勞動市場的異質性、薪資不均程度以及女性工作型態的不同, 薪資的性別歧視存在於歐洲各國的結論, 與以往文獻一致。Díaz and Pérez (2013) 採用與前篇論文相同的資料與期間, 分析英國、義大利、德國以及西班牙等三國, 至少連續工作 7 年以上 40 歲以下的年輕勞工, 檢視婚姻狀態是否與薪資不效率程 3 包含美國、加拿大、英國、德國、瑞典、芬蘭、冰島、挪威、荷蘭、捷克以及唯一非 OECD 國 家的以色列。 4 例如: 男女性的薪資差異可能是因為女性工作意願低, 造成工作努力程度較低, 此時就算與男性 有相同的教育程度, 薪資水準仍會較低。此非歧視所造成, 但是傳統估計方法仍將其視為歧視。 5 以英國的邊際效果為例, 女性的效率薪資低於男性的 33.7%。
度有關。根據相關文獻, 已婚女性的薪資報酬低於未婚女性主要原因有二: 一是已 婚女性的勞動參與率較低、二是已婚女性為照顧家庭, 容易中斷其在勞動市場原本 的成就, 減少工時以及選擇低報酬的職業, 也降低在公司內部所能受到的培訓機 會, 這些因素皆對人力資本累積以及生產力有負面影響。但是此文發現, 年輕女性 即使在控制人力資本累積不中斷的情況下, 已婚者的薪資不效率程度仍高於未婚 狀態, 已婚年輕女性的勞動報酬之所以較低, 似乎不是因為中斷人力資本累積, 而 是因為歧視。
2.3 臺灣勞動市場之薪資差異與性別歧視
Gannicott (1986) 曾以 1982 年我國人力運用調查資料, 將男女性的工資差異拆 解成稟賦項 (endowment) 以及歧視項, 其中稟賦項可解釋 40.3% 的工資差異, 而 有 59.7% 無法解釋而歸諸於歧視項。 劉錦添與劉錦龍 (1987) 以 1984 年資料, 採特徵性工資模型 (hedonic wage model)估計男女性的薪資方程式, 發現臺灣男女性的薪資在同一職業中明顯存在 性別歧視, 其中最嚴重的是服務業, 而最輕微的是專業性人員。薛立敏 (1988) 以 同年度資料分析後指出, 在教育、年齡、經驗等條件相等的情況下, 男性的薪資高 出女性 14%-30%, 且愈需體力的職業, 薪資差異程度愈大; 而愈需專業技能的職業 則差異程度愈小, 與劉錦添與劉錦龍 (1987) 結論一致。王素彎與連文榮 (1989) 為求與前兩篇文獻比較, 也採相同年度資料並以 F 檢定估計性別歧視是否顯著存 在於臺灣勞動市場, 發現相同學歷的女性薪資受到相當的性別歧視。 林忠正 (1988) 為排除女性勞動參與中斷對薪資差異之影響, 採用 1984 年初 次進入勞動市場的樣本作為分析對象, 將薪資差異拆解成「可解釋的部分」、「職業 隔離」以及「同工不同酬」三個部分, 實證結果指出, 臺灣男女性勞工的職業隔離 程度雖然顯著, 但是男女薪資差異大部分源自同工不同酬的因素而非職業隔離; 並推論臺灣勞動市場存在性別歧視。劉鶯釧 (1989) 則認為女性受到歧視的成因眾 多, 不易精確衡量所有可能來源,6 故僅衡量純粹的工資歧視。同時採用直接迴歸與 逆向迴歸計量方法, 檢定同一個職業當中是否有違反同工同酬的現象。7 以 1987 年資料的實證結果來說, 多數行、職業中的同工不同酬的現象不若想像中的嚴重。 劉錦添與詹方冠 (1990) 採用 Robinson and Wunnava (1989) 之觀點與方法衡量臺 灣公私部門之性別歧視程度,8 並與 Oaxaca (1973) 及 Cotton (1988) 的方法作比 較, 得出私部門工資的性別歧視程度高於公部門。 高長 (1990) 修正樣本選擇偏誤後, 發現真實的女性工資歧視在平均工資較高 的職業中被高估; 而在平均工資較低的職業則被低估。他認為臺灣勞動市場性別的 工資差異主要原因不是職業隔離因素, 而是預期人力資本存量。因而推論性別工資 6 例如: 女性從事女性化且低薪的職業有可能是純粹出於自願, 但此「自願」也可能是受到曾被灌 輸的性別歧視刻板印象所致。 7 直接迴歸衡量「具有同等生產力的男女是否得到相同的工資水準」; 逆向迴歸則是檢定「具有相 同工資的男女是否具有相同生產力」。8 在 Robinson and Wunnava (1989) 的觀點中, 女性之實際薪資與隨機邊界薪資之差即為性別歧視
的程度, 但是劉錦添與詹方冠 (1990) 認為此一差距來自於性別歧視及勞動市場資訊不完全的程 度。
差異的主要原因, 出於個人自由意志選擇下的不同人力資本投資行為, 而非就業 不均等或工資報酬不公平。黃台心與熊一鳴 (1992) 以 1989 年的資料經樣本選擇 偏誤的修正後, 採用 Oaxaca (1973) 的計量方法推估兩性間的全職與兼職之工資 差異, 推論性別歧視存在於臺灣勞動市場。 邱曉培 (1997) 與劉佳苓 (1997) 參考林忠正 (1988) 的作法, 皆控制女性勞 動參與中斷之因素, 但是改以 1995 年的未婚樣本為分析對象。邱曉培 (1997) 採用 劉鶯釧 (1989) 之直接迴歸與逆向迴歸計量方法, 檢定臺灣勞動市場中的薪資差異 是否存在歧視, 實證結果顯示兩種計量方法皆確認女性在勞動參與未中斷的情形 下, 工資仍受到歧視; 劉佳苓 (1997) 也得到類似的結論。曾敏傑 (2001) 採 Oaxaca 薪資分解模型, 發現男女薪資差異在 1982、1992 及 2000 年間有縮小的趨 勢。陳建良與管中閔 (2006) 考慮樣本選擇問題, 採分量迴歸估計臺灣 2002 年工資 函數及性別歧視程度。發現男女性別歧視的程度在各個工資分量下均相當嚴重, 尤 其是低工資的女性。 徐美、陳明郎與方俊德 (2006) 使用 1978-2003 年資料, 擴充 Oaxaca 之薪資 分解模式, 探討台灣產業結構變遷和性別歧視變動對於男女薪資溢酬改變的影響。 發現男女薪資差異歸因於性別歧視的比例逐年縮小, 主因為產業結構由重體力性 轉變為重心智性以及女性就業者教育水平的快速提升。Bishop et al. (2007) 亦使用 相同的資料期間, 以 Oaxaca 原始模型以及隨機邊界法兩種方法, 分別檢視臺灣 男女薪資差異與性別歧視間的關係。根據 Oaxaca 模型得到的結果, 顯示性別歧視 的程度幾乎沒有變動, 不甚合理; 但是, 以隨機邊界法得到的結果, 顯示男女兩性 勞工的薪資效率皆逐漸提升, 但女性提升的速度高於男性, 受歧視的程度逐漸下 降。Bishop et al. (2007) 認為這個結果比起 Oaxaca 模型更貼近臺灣的實際情勢。
2.4 保留薪資 (reservation wage)
保留薪資即是勞工在勞動市場上願意接受的最低薪資水準, 保留薪資的提高 通常會使薪資低付程度下降。由於保留薪資與工作搜尋理論以及薪資低付程度皆 有關聯, 本小節僅回顧與性別有關的保留薪資文獻。 Gørgens (2002) 認為以往文獻討論搜尋理論時, 只著重在薪資而忽略其他非 薪資的變數, 可能導致錯誤的經濟推論與政策建議,9 故將工時因素納入模型, 以 保留效用策略 (reservation utility strategy) 取代保留薪資策略, 提出相對應的條件 保留薪資解釋搜尋理論。發現美國女性搜尋工作時,會同時考慮工時因素。例如 全職工作女性的條件保留薪資比起兼職工作女性高出 16–31%, 廠商給薪 (wage offer) 預期較高的女性, 從事兼職工作的保留薪資高於從事全職工作; 廠商給薪預 期較低的女性, 從事全職工作的保留薪資高於從事兼職工作; 提供失業補助可大 幅提高女性兼職工作的保留薪資, 但對全職工作的保留薪資只有輕微影響; 有丈 夫或子女者的保留薪資較高, 但幅度不大, 但若丈夫的薪水很高, 則該婦女的保留 薪資會顯著提升。 9 例如某個勞工面臨兩個工作機會: 甲工作月薪 40,000 元, 每天工作 12 小時; 乙工作月薪 39,999 元, 每天工作 8 小時。若只考慮薪資水準, 勞工會選甲工作, 惟若同時納入工時 (非薪資因素), 則 很有可能會選擇乙工作。Pannenberg (2010) 採 德 國 的 German socio-economic panel 縱 橫 資 料 , 以 2004–2006 年未受雇用者分析風險態度與保留薪資的關係, 發現未受僱用者超過半 數有風險趨避的情況, 且風險趨避與保留薪資有反向關係。此外, 若未受僱用者為 男性、未婚、受教育年數愈長、尋找全職工作、受到財務補助或財富較高者, 其保 留薪資較高。 Brown et al. (2011) 使用 1991–2008 年英國 BHPS 縱橫資料, 針對未被雇用及 自我雇用者, 以 Oaxaca (1973) 的方式拆解男性與女性的保留薪資差異, 發現有無 子女對於兩性保留薪資差異中可解釋的部分非常重要。此文作者們認為造成此現 象的原因可能與年齡有關, 無子女女性的平均年齡 40 歲, 大於有子女的女性平均 年齡 28 歲。較年長的女性可能因為過去的經驗、歧視或其他無法觀察的個人特質, 對勞動市場的期待較低, 較不適合進入勞動市場。
3. 研究方法
3.1 隨機薪資與工時邊界模型
根據 Hofler and Polachek (1985) 的模型, 第 i 勞工的對數隨機潛在薪資 (lnWip) 為 ln 0 p i W 1Xi 2 vi 2, (1) 其中, 𝛽0為截距項, 𝑋𝑖2 代表第 i 勞工的人力資本變數向量, 𝛽1 為對應之迴歸係數 向量, 𝑣𝑖2 是隨機干擾項且𝑣𝑖2~𝑁(0, 𝜎𝑣22), 𝜎𝑣22是未知常數; (1) 式中0 1Xi2稱為 確定邊界, 而0 1Xi2 vi2稱為隨機邊界。
Hofler and Polachek (1985) 認為勞工在勞動市場因為缺乏充分資訊, 搜尋工作 時, 實際得到的對數薪資水準 (lnWi) 通常會低於資訊充分下的的最大潛在薪資, 即 ln 𝑊𝑖 ≤ ln𝑊𝑖𝑝。 (2) 改寫 (2) 式為等式並將 (1) 式代入 ln 𝑊𝑖 = ln𝑊𝑖𝑝− 𝑢𝑖2 =0 1Xi2 vi2 ui2, (3) 式中ui2 0, 代表勞工實際領得之薪資未能達到最大潛在薪資的差距, 視為勞工在 勞動市場上的無知 (ignorance)。若其在勞動市場上的資訊愈充分, 則薪資愈有效率, 2 i u 愈接近 0, 也就是實際薪資愈靠近最大潛在薪資水準。 由於存在薪資無效率項ui2, (3) 式中出現組合誤差項i2 vi2 ui2, ui2是非負 隨機變數且與vi2統計獨立, 形成隨機薪資邊界模型。若不考慮樣本選擇問題, 可直 接採用最大概似法進行估計。其中ui2有多種設定, 例如半常態分配 (half normal distribution)、指數分配 (exponential distribution)、截斷常態分配 (truncated normal distribution) 以 及 伽 瑪 分 配 (gamma distribution) 。 本 文 假 設 其 為 半 常 態 分 配 𝑢𝑖2~𝑁+(0, 𝜎𝑢22),
10
依循 Aigner, Lovell, and Schmidt (1977), 令 𝜎2 = 𝜎𝑣22+ 𝜎𝑢22,
λ = 𝜎𝑢2/𝜎𝑣2, 若有 n 位勞工, 可得對數概似函數 ln𝐿(𝑾|𝜷, 𝜎, 𝜆) = −𝑛2ln(𝜋𝜎22)+ ∑𝑛𝑖=1lnΦ (−𝜀𝑖2λ 𝜎 ) − 1 2𝜎2∑𝑛𝑖=1𝜀𝑖22 = constant − n lnσ + ∑𝑛𝑖=1lnΦ (−𝜀𝑖2λ 𝜎 ) − 1 2𝜎2∑𝑛𝑖=1𝜀𝑖22, (4) 其 中 , 𝑾為n1薪 資 向 量 , 𝜷 為 迴 歸 係 數向 量 ; i2 vi2 ui2 lnWi 0 1Xi2 ,
是標準常態分配的累積分配函數 (cumulative distribution function, CDF)。運用 (4) 式可將 𝜷, 𝜎, 𝜆 等參數估計出來。再根據 Jondrow et al. (1982) 求算出每個樣本 10 2 i 的機率密度函數請參見 (20) 式。
的薪資不效率程度 𝑢𝑖2 的條件期望值, 代表薪資不效率的點估計量 𝑢̂ , 即 𝑖2
𝑢̂ = 𝐸(𝑢𝑖2 𝑖2 |𝜀𝑖2) = 𝜇𝑖∗+ 𝜎∗( 𝜙(−
𝜇𝑖∗
𝜎∗)
1−Φ(−𝜇𝑖∗𝜎∗)), (5)
其 中, 𝜙 是 標 準 常 態 分 配 的 機 率 密 度 函 數 (probability density function, PDF),
𝜎∗ = 𝜎𝑢2𝜎𝑣2/𝜎, 𝜇𝑖∗ = −𝜎𝑢22𝜀𝑖2/𝜎2。個別勞工的薪資效率可以 𝑇𝐸𝑖 = 𝑒− 𝑢̂𝑖2 估計。
𝑇𝐸𝑖 即是第 i 個勞工實際薪資占潛在薪資的比例, 故 0T Ei 1。此比例愈靠
近 1, 表示薪資愈有效率, 也就是此位勞工的實際薪資愈靠近最大潛在薪資, 該勞 工在市場上實際薪水被低付的程度較輕。但一般認為 Battese and Coelli (1988) 的 估計量有更好的統計性質: 𝑇𝐸𝑖 = 𝐸(𝑒−𝑢𝑖2 |𝜀𝑖2) = 1−Φ(𝜎∗−𝜇𝑖∗𝜎∗) 1−Φ(−𝜇𝑖∗ 𝜎∗) × 𝑒−𝜇𝑖∗+𝜎∗22, (6) 故本文之後提到的薪資效率程度也將以此為計算公式。
3.2 關聯結構隨機薪資邊界模型
由於樣本資料包含男性與女性勞工, 一般認為女性勞工常有樣本選擇性問題, 但男性勞工也有類似問題, 只是程度較輕微。採用 Heckman (1974) 模型但將隨機 邊界概念引入, 暫不考慮下標 i, 假設勞工取自然對數的保留工資方程式為 lnWR 0 1ln H 2X1v1, (7) 式中WR為保留薪資, 代表對數工時, X1是影響保留工資的解釋變數, 本文將 放入年齡及平方項、婚姻狀態、教育程度、戶籍地、婚姻狀態與年齡交乘項、教 育程度與年齡交乘項等變數, α = [𝛼0, 𝛼1, 𝛼2′]′ 為迴歸係數向量, 為隨機干擾項。 (3) 式中關於X2向量, 本文放入受教育年數及其平方項、潛在工作經驗及其 平方項、婚姻狀態、婚姻狀態與潛在工作經驗交乘項等變數, 0 1X2可視為勞工 的潛在對數工資。 若lnWR lnW , 則 = 0,11 表 示 此 勞 工 不 工 作 ; 反 之 , 工 時 會 調 整 至 , 代表此勞工選擇工作。12 即 ln H = 0 1 2 0 2 1 1 X X 2 2 1 1 v u v = 𝛿′𝑍1+ 𝑉1− 𝑈1, (8) 其中,Z1 0 1X2 0 2X1/1, V1
v2 v1
/1,U1 u2 /1。考慮樣本選 11 即將 H1 視為無工作者。 12 根據個體經濟學勞動供給模型,假設勞工的無異曲線是消費和休閒的函數,消費的價格標準化 為一,他會在無異曲線與預算線相切處,選擇最佳消費和休閒時數 (以及工時)。此時預算線的 斜率為市場工資率 (W),無異曲線的斜率可視為休閒的影子價格,也就是保留工資,故對於有 工作者,其均衡條件為 W= WR。唯有在邊角解 (corner solution) 發生時,WR W。Heckman(1974) 頁 681 亦有類似說明。 ln H 1 v ln H lnWR lnW
擇性問題的聯立迴歸模型表為 1 1 1 1 1 0 1 2 2 2 2 2 ln ln H Z V U Z W X v u Z 若 > 0 (9) lnW = lnH = 0 若 0, (10) 其中, 𝜀1 = 𝑉1− 𝑈1 , 𝛽′𝑍2 = 𝛽0+ 𝛽2′𝑋2, 𝜀2 = 𝑣2− 𝑢2。無工作者 (lnH < 0) 的對 數工時與工資皆為 0; 但有工作者lnH > 0, 其對數工時與工資皆可以觀察到。此處 雖然有ε1與 ε2 兩套組合誤差, 但只需估計σv1、σv2、σu2 等 3 個分配參數。針對 無工作者, 僅知其機率為 P rob ln
H 0
P rob
1 Z1
F
Z1
, ( 1 1 ) 其中, 是 的累積分配函數。有工作勞工 和 的聯合機率密度函數為 f( , ), 故包含有工作與無工作勞工的概似函數表為 L =
lnH0 f lnH, lnW
lnH0F
Z1
。 (12) 值得一提者, 為能估計或辨認 (identify) (9) 式中 ln𝑊 與 ln𝐻等兩條迴歸方 程式全部的迴歸係數, 解釋變數向量X1和X2至少須有一個以上變數不相同, 或 者1和2不相關。因為 , 而1亦含有v2和u2, 1和2必然相關, 故向量 1 X 和X2至少須有一個以上變數不相同, 才能將模型中全部係數估計出來。 相對於劉錦添與詹方冠 (1990) 僅考慮有工作者樣本, (12) 式在隨機邊界模型 下同時考慮有工作者及無工作者的所有樣本, 解決了樣本選擇性問題; 利用此概 似函數得到的迴歸係數估計值具有一致性與漸進常態等性質, 可用來推論有工作 與無工作者的勞動供給行為。反之, 若只使用有工作勞工樣本進行估計, 如 (4) 式, 迴歸係數估計值僅能用來分析有工作勞工的勞動供給行為。 (12) 式的概似函數屬於非線性模型, 不易估計。在沒有組合誤差的情況下要解 決樣本選擇的問題, 使係數估計量符合一致性, 常採用 Heckman (1976) 的兩階段 估計法, 第一階段先以全部樣本使用 Probit 模型估計個人工作與否的機率, 並算 出機率矯正因子--Mills 比率倒數 (inverse Mills ratio, IMR); 第二階段將求出的 IMR 項 當做一個新的解釋變數加入原先的薪資迴歸式, 僅用有薪者的樣本再次估 計。不過, 第二階段估的誤差項會有異質變異數問題, 導致迴歸係數的估計變異數 不具一致性。若1和2皆為組合誤差, 它們的期望值皆不為 0, 更讓兩階段估計法 缺乏良好統計性質。最大概似法應是較佳選擇, 可避免兩階段估計法的缺點, 但面 臨以下兩個問題: 1. 如何推導組合誤差 和 的聯合機率密度函數?進而得到聯合機率分配 f( , ); 2. 如何推導組合誤差的累積分配函數?第一個問題可根據 Lai and Huang (2013), 採用關聯結構法予以解決。假設 及 分別為 和 邊際累積分配函數, 它們的相關係數為 , 依照 Sklar (1959) 的理論, 及 的聯合累積分配函數表為 ln H ln H F 1 ln H ln W ln H ln W 2 v2 u2 1 2 ln H ln W 1( 1) F F2(2) 1 2 1 2
𝐹(𝜀1, 𝜀2) = 𝐶(𝐹1(𝜀1), 𝐹2(𝜀2); 𝜌), (13) 其中, 為 和 的關聯結構函數, 若 和 為連續函數, 則存在唯 一的關聯結構函數, 及 的聯合機率密度函數為 f
1, 2
c
F1
1 ,F2
2 ;
2
1 j j j f
, (14) 其中, c F
1
1 ,F2
2 ;
2C F
1
1 ,F2
2 ;
/ F1
1 F2
2 , 是關聯結構 密度函數 (copula density function), 而 為邊際機率密度函數。過去文獻已發 展出許多種 copula 函數, 例如 Student’s t copula、Archimedean copula、Gumble n-copula 和 Clayton n-copula 等。本文依循 Lai and Huang (2013) 採用 Gaussian copula 推導出 (13) 式的二變數聯合累積分配函數, 表為
1 1
1 1 2 2 2 1 1 2 2 1 1/ 2 ( ), ( ); ( ( )), ( ( )); 1 1 exp 2 2 C F F F F , (15) 其中, 為單變量標準常態累積分配函數的反函數, 為二元標準常態累 積分配函數, 隨機變數向量 1
1
1 1 2 2 F F 的相關係數矩陣為 1 1 2 1 , (16) 對應 (15) 式的 Gaussian copula 機率密度函數為 c
F1
1 ,F2
2 ;
1 2
1/ 2 1 1 exp 2 I , (17) 其中, 為 單位矩陣。將 (17) 式代入 (14) 式, 可得到組合誤差的聯合機率 密度函數 f 1, 2 11/ 2 exp
1 2 1 2 I
2 1 j j j f
。 (18) 在標準隨機邊界模型中, j vj uj, 已知 的機率密度函數為 (19) 其中, λ1 = 𝜎𝑢1/𝜎𝑣1, λ2 = 𝜎𝑢2/𝜎𝑣2 , 𝜎12 = 𝜎𝑢21+ 𝜎𝑣21, 𝜎22 = 𝜎𝑣22+ 𝜎𝑢22。(19) 式中包含
, 沒有封閉形式, 故無法經由積分直接推導出累積分配函數Fj
j , 導致 (12) 式的概似函數無法估計。此問題可採用模擬或是近似函數的方法得到組合誤差的 近似累積分配函數, 本文利用 Tsay et al. (2013) 發展的方法, 推導 的近似函 數, Tsay et al. (2013) 證明該近似累積分配函數的準確度極高, 誤差小於 5 10 。 暫不考慮下標 j,利用 (19) 式針對 積分可得下式 ( ) C F1( ) F2( ) F1( ) F2( ) 1 2 ( ) j j f 1 ( ) 2( ) 2 I 22 ( ) j j f 1, 2 . 2 ( ) j j j , j j j j j j f ( ) j j F F(Q)= Q f d
2 I Q , (20) 其中, 被定義為 I Q Q
a d
b d
, (21) 上式中 , 。Tsay et al. (2013) 針對 (21) 式推導出近似積 分 如下 , (22) 式中誤差函數 (error function) 定義如下 , (23) 符號函數 分別在 時等於 1, 0, -1,常數 與 , 可讓 盡可能靠近 。Tsay et al. (2013) 證明在 之下, 十分接近 , 可用來代替誤差函數, 進而求出 (22) 式中的 ,代入 (20) 式得到近似累積分配函數 Fapp
Q 2 Ia p p Q , (24) 以 代替 , 即可得到本模型中的概似函數 (12) 式, 本文將以此函數利 用最大概似法進行估計。 請留意, 本研究的組合誤差項與標準隨機邊界模型有所不同, 參考 (9) 式, 兩 個組合誤差項分別為1 V1U1=
v2 v1
/1u2 /1和2 v2 u2, 只有2與標準 隨機邊界模型相同, 1比較複雜, 必須另行推導Iapp
Q 和Fapp
Q , 從而得到1的 機率密度函數 f1
1 與累積分配函數F1
1 , 相關推導詳見附錄一。根據該附錄, 需重新定義λ1 = 𝜎𝑢2/√𝜎𝑢1+ 𝜎𝑢2和𝜎12 = (𝜎 𝑣21+ 𝜎𝑣22+ 𝜎𝑢22)/𝛼2, 至於λ2和𝜎22同 (19) 式。 I / 0 a b 1 / 0
app I Q 2 2 2 2 1 1 2 2 2 2 2 2 2 2 2 2 ( 1 1 ( )(1 ( )) 2 2 2 1 a 2 ( ) ( ) e x p ( ) 1 4 ) 4 ( ) 2 a p p b Q sig n Q e rf b c a c Q b a c sig n Q e rf b a c b a c b a c I Q ( ) erf
2 2 0 0 2 1 2 2 ( ) 2 ( ) 2 2 1 1 ex p ( ) ( ) z z t erf z e d t t d t z c z c z g z
sign Q Q , , 0 c1 1.09500814703333 2 0.75651138383854 c g z( ) erf z( ) 0 z g z( ) erf z( )
app I Q ( ) a p p F Q F Q( )4. 變數定義與假說設定
4.1 資料來源與變數定義
鑒於勞動供給行為短期間內不易有大幅度變化, 本研究採用行政院主計總處 民國 94、96、98、100、102 等 5 個年度的「人力運用調查」資料, 此調查的範 圍涵蓋居住於台灣之普通住戶與共同事業戶, 其戶內年滿十五歲以上, 自由從事 經濟活動之本國籍民間人口。 本研究針對年齡介在 15 歲至 65 歲的民間人口, 因考慮樣本選擇性問題, 必須同時將無工作者樣本納入, 但在學及準備升學者、身心障礙者以及傷病者, 雖 無工作, 但與樣本選擇性問題關聯度低, 故予以剔除。無工作在找工作者、已找工 作正在等待結果者、想工作而未找工作且隨時可以開始找工作者、料理家務者、 賦閒者等予以保留, 因為這些人在勞動市場上選擇不工作可能是來自市場薪資低 於其心中的保留薪資, 若剔除這些樣本可能導致偏誤的估計結果。另一方面, 有工 作者當中, 工作身分若為雇主、自營作業者及無酬家屬工作者, 其薪資與工時的性 質不同於一般受雇勞工, 也不列入樣本中。 應變數薪資與工時分別使用取過自然對數後的月薪資與月工時, 本文以民國 100 年為基期的消費者物價指數平減月薪資, 以利各年度比較。另外, 我們也觀察 到市場上存在有薪資卻無工時者, 這些樣本多是因傷病或例假所導致,13 故設算其 應有的工時後補回, 若該勞工受政府僱用, 令其每週工時為 40 小時; 若受私人僱 用則為 42 小時。 以下條列各變數的定義, 表 1 與表 2 列出迴歸方程式中各變數之樣本統計量。 1. 年齡 (age) 與其平方項 (age2): 年齡為連續變數, 但往後會分成小於或等於 25 歲的青年 (youth)、介在 26 到 44 歲的壯年 (prime) 以及大於 44 歲的中年 (middle) 等 3 群進行分析和比較。2. 教育程度: 分為高中職 (dedu1)、大學與專科 (dedu2)、碩博士 (dedu3), 而以國 中及以下為基準組。
3. 工作地: 按內政部統計處的內政統計通報的分類, 將工作場所分為北部 (north)、 中部 (mid)、東部 (east) 與南部 (south), 將金馬及境外地區的樣本剔除, 並以 南部為基準組。北部包含新北市、基隆市、臺北市、宜蘭縣、桃園縣、新竹市 和新竹縣; 中部包含苗栗縣、臺中市、彰化縣、南投縣和雲林縣; 東部包含臺 東縣與花蓮縣; 南部包含臺南市、高雄市、嘉義縣、屏東縣及澎湖縣。
4. 戶籍地: 同工作地的分類, 北部 (dlnorth)、中部 (dlmid) 與東部 (dleast), 仍以 南部為基準組。 5. 工作身分: 分為受私人雇用 (private) 與受政府雇用 (public) 等兩類。 6. 受教育年數 (edu) 與其平方項 (edu2): 本文依該勞工的教育程度推算, 分別為: 不識字、自修 = 0; 國小 = 6; 國中 = 9; 高中、職 = 12; 專科 = 14; 大學 = 16; 碩士 = 18; 博士 = 26。 13 在此的傷病者同時為有工作者, 與上述因傷病而無工作者的身分不同。
7. 潛在工作經驗 (expe) 與其平方項 (expe2): 也就是設算的工作年資, 因為本研 究的迴歸模型同時納入有工作和無工作者, 但問卷題目僅針對有工作者調查現 職工作經驗, 無工作者從缺, 故須使用設算的工作年資。依照勞動經濟學文獻, 設算工作年資等於 age – edu – 6 (若是男性再扣 1 年役期), 但是不識字與自修 者若以此公式設算工作年資, 易有高估問題, 故再減去 6 年。若設算工作年資 為負值, 我們以現職工作經驗替代設算工作經驗, 若也無現職工作經驗者則剔 除此樣本。 8. 婚姻狀態 (dmarr): 若為未婚 dmarr =1, 其他狀態 (已婚或結過婚後離婚或鰥 寡) 者 dmarr =0。 9. 教育程度與年齡的交乘項 (dedu1×age、dedu2×age、dedu3×age)。 10. 婚姻狀態與年齡的交乘項 (dmarr×age)。 11. 婚姻狀態與潛在工作經驗的交乘項 (dmarr×expe)。
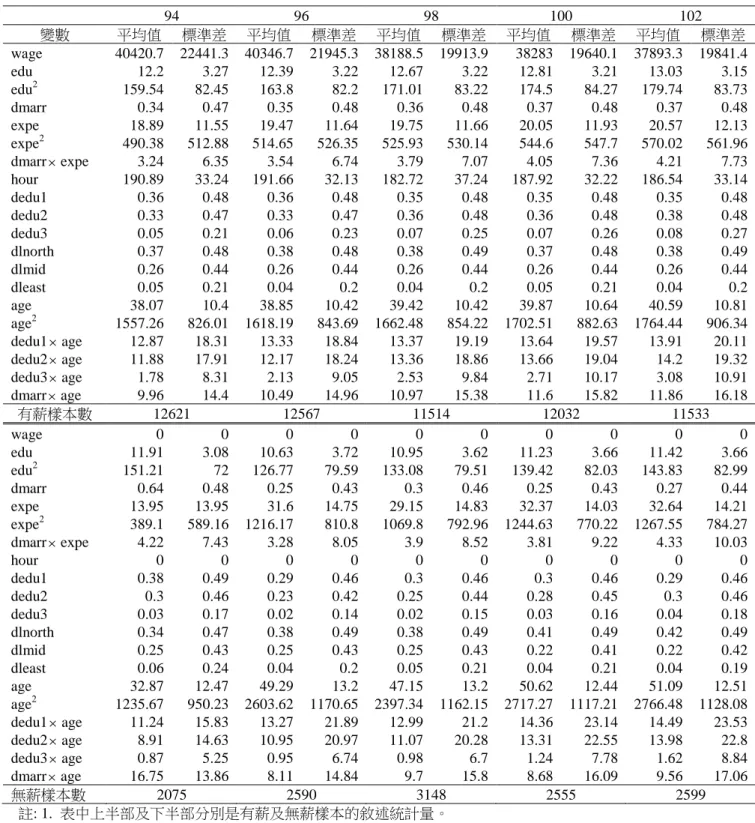
表 1 男性樣本之敘述統計量 94 96 98 100 102 變數 平均值 標準差 平均值 標準差 平均值 標準差 平均值 標準差 平均值 標準差 wage 40420.7 22441.3 40346.7 21945.3 38188.5 19913.9 38283 19640.1 37893.3 19841.4 edu 12.2 3.27 12.39 3.22 12.67 3.22 12.81 3.21 13.03 3.15 edu2 159.54 82.45 163.8 82.2 171.01 83.22 174.5 84.27 179.74 83.73 dmarr 0.34 0.47 0.35 0.48 0.36 0.48 0.37 0.48 0.37 0.48 expe 18.89 11.55 19.47 11.64 19.75 11.66 20.05 11.93 20.57 12.13 expe2 490.38 512.88 514.65 526.35 525.93 530.14 544.6 547.7 570.02 561.96 dmarrexpe 3.24 6.35 3.54 6.74 3.79 7.07 4.05 7.36 4.21 7.73 hour 190.89 33.24 191.66 32.13 182.72 37.24 187.92 32.22 186.54 33.14 dedu1 0.36 0.48 0.36 0.48 0.35 0.48 0.35 0.48 0.35 0.48 dedu2 0.33 0.47 0.33 0.47 0.36 0.48 0.36 0.48 0.38 0.48 dedu3 0.05 0.21 0.06 0.23 0.07 0.25 0.07 0.26 0.08 0.27 dlnorth 0.37 0.48 0.38 0.48 0.38 0.49 0.37 0.48 0.38 0.49 dlmid 0.26 0.44 0.26 0.44 0.26 0.44 0.26 0.44 0.26 0.44 dleast 0.05 0.21 0.04 0.2 0.04 0.2 0.05 0.21 0.04 0.2 age 38.07 10.4 38.85 10.42 39.42 10.42 39.87 10.64 40.59 10.81 age2 1557.26 826.01 1618.19 843.69 1662.48 854.22 1702.51 882.63 1764.44 906.34 dedu1age 12.87 18.31 13.33 18.84 13.37 19.19 13.64 19.57 13.91 20.11 dedu2age 11.88 17.91 12.17 18.24 13.36 18.86 13.66 19.04 14.2 19.32 dedu3age 1.78 8.31 2.13 9.05 2.53 9.84 2.71 10.17 3.08 10.91 dmarrage 9.96 14.4 10.49 14.96 10.97 15.38 11.6 15.82 11.86 16.18 有薪樣本數 12621 12567 11514 12032 11533 wage 0 0 0 0 0 0 0 0 0 0 edu 11.91 3.08 10.63 3.72 10.95 3.62 11.23 3.66 11.42 3.66 edu2 151.21 72 126.77 79.59 133.08 79.51 139.42 82.03 143.83 82.99 dmarr 0.64 0.48 0.25 0.43 0.3 0.46 0.25 0.43 0.27 0.44 expe 13.95 13.95 31.6 14.75 29.15 14.83 32.37 14.03 32.64 14.21 expe2 389.1 589.16 1216.17 810.8 1069.8 792.96 1244.63 770.22 1267.55 784.27 dmarrexpe 4.22 7.43 3.28 8.05 3.9 8.52 3.81 9.22 4.33 10.03 hour 0 0 0 0 0 0 0 0 0 0 dedu1 0.38 0.49 0.29 0.46 0.3 0.46 0.3 0.46 0.29 0.46 dedu2 0.3 0.46 0.23 0.42 0.25 0.44 0.28 0.45 0.3 0.46 dedu3 0.03 0.17 0.02 0.14 0.02 0.15 0.03 0.16 0.04 0.18 dlnorth 0.34 0.47 0.38 0.49 0.38 0.49 0.41 0.49 0.42 0.49 dlmid 0.25 0.43 0.25 0.43 0.25 0.43 0.22 0.41 0.22 0.42 dleast 0.06 0.24 0.04 0.2 0.05 0.21 0.04 0.21 0.04 0.19 age 32.87 12.47 49.29 13.2 47.15 13.2 50.62 12.44 51.09 12.51 age2 1235.67 950.23 2603.62 1170.65 2397.34 1162.15 2717.27 1117.21 2766.48 1128.08 dedu1age 11.24 15.83 13.27 21.89 12.99 21.2 14.36 23.14 14.49 23.53 dedu2age 8.91 14.63 10.95 20.97 11.07 20.28 13.31 22.55 13.98 22.8 dedu3age 0.87 5.25 0.95 6.74 0.98 6.7 1.24 7.78 1.62 8.84 dmarrage 16.75 13.86 8.11 14.84 9.7 15.8 8.68 16.09 9.56 17.06 無薪樣本數 2075 2590 3148 2555 2599 註: 1. 表中上半部及下半部分別是有薪及無薪樣本的敘述統計量。 2. wage 與 hour 為月薪資及月工時。 3. wage 已經過消費者物價指數平減。
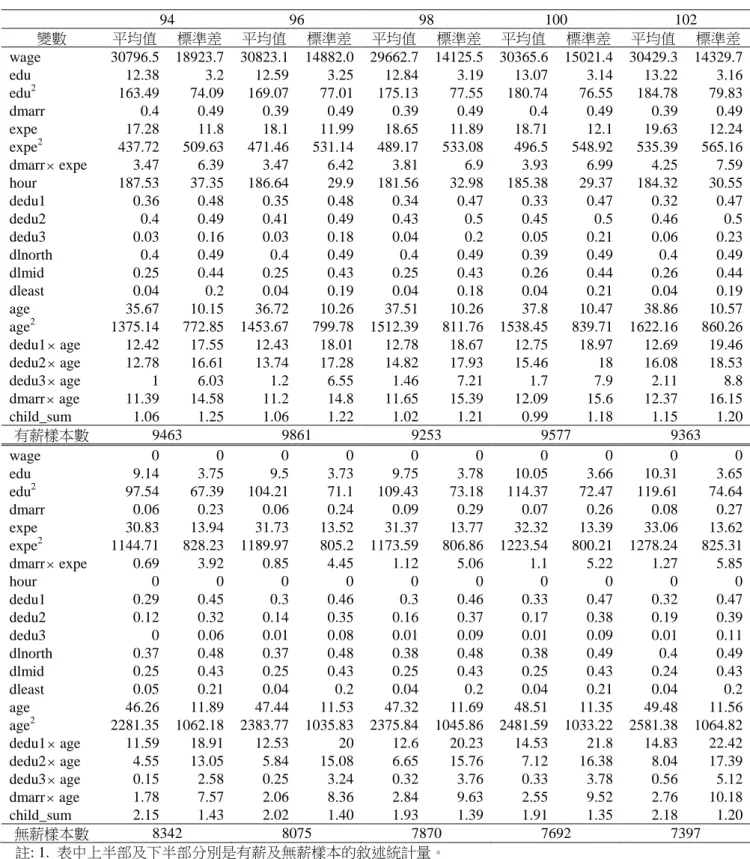
表 2 女性樣本之敘述統計量 94 96 98 100 102 變數 平均值 標準差 平均值 標準差 平均值 標準差 平均值 標準差 平均值 標準差 wage 30796.5 18923.7 30823.1 14882.0 29662.7 14125.5 30365.6 15021.4 30429.3 14329.7 edu 12.38 3.2 12.59 3.25 12.84 3.19 13.07 3.14 13.22 3.16 edu2 163.49 74.09 169.07 77.01 175.13 77.55 180.74 76.55 184.78 79.83 dmarr 0.4 0.49 0.39 0.49 0.39 0.49 0.4 0.49 0.39 0.49 expe 17.28 11.8 18.1 11.99 18.65 11.89 18.71 12.1 19.63 12.24 expe2 437.72 509.63 471.46 531.14 489.17 533.08 496.5 548.92 535.39 565.16 dmarrexpe 3.47 6.39 3.47 6.42 3.81 6.9 3.93 6.99 4.25 7.59 hour 187.53 37.35 186.64 29.9 181.56 32.98 185.38 29.37 184.32 30.55 dedu1 0.36 0.48 0.35 0.48 0.34 0.47 0.33 0.47 0.32 0.47 dedu2 0.4 0.49 0.41 0.49 0.43 0.5 0.45 0.5 0.46 0.5 dedu3 0.03 0.16 0.03 0.18 0.04 0.2 0.05 0.21 0.06 0.23 dlnorth 0.4 0.49 0.4 0.49 0.4 0.49 0.39 0.49 0.4 0.49 dlmid 0.25 0.44 0.25 0.43 0.25 0.43 0.26 0.44 0.26 0.44 dleast 0.04 0.2 0.04 0.19 0.04 0.18 0.04 0.21 0.04 0.19 age 35.67 10.15 36.72 10.26 37.51 10.26 37.8 10.47 38.86 10.57 age2 1375.14 772.85 1453.67 799.78 1512.39 811.76 1538.45 839.71 1622.16 860.26 dedu1age 12.42 17.55 12.43 18.01 12.78 18.67 12.75 18.97 12.69 19.46 dedu2age 12.78 16.61 13.74 17.28 14.82 17.93 15.46 18 16.08 18.53 dedu3age 1 6.03 1.2 6.55 1.46 7.21 1.7 7.9 2.11 8.8 dmarrage 11.39 14.58 11.2 14.8 11.65 15.39 12.09 15.6 12.37 16.15 child_sum 1.06 1.25 1.06 1.22 1.02 1.21 0.99 1.18 1.15 1.20 有薪樣本數 9463 9861 9253 9577 9363 wage 0 0 0 0 0 0 0 0 0 0 edu 9.14 3.75 9.5 3.73 9.75 3.78 10.05 3.66 10.31 3.65 edu2 97.54 67.39 104.21 71.1 109.43 73.18 114.37 72.47 119.61 74.64 dmarr 0.06 0.23 0.06 0.24 0.09 0.29 0.07 0.26 0.08 0.27 expe 30.83 13.94 31.73 13.52 31.37 13.77 32.32 13.39 33.06 13.62 expe2 1144.71 828.23 1189.97 805.2 1173.59 806.86 1223.54 800.21 1278.24 825.31 dmarrexpe 0.69 3.92 0.85 4.45 1.12 5.06 1.1 5.22 1.27 5.85 hour 0 0 0 0 0 0 0 0 0 0 dedu1 0.29 0.45 0.3 0.46 0.3 0.46 0.33 0.47 0.32 0.47 dedu2 0.12 0.32 0.14 0.35 0.16 0.37 0.17 0.38 0.19 0.39 dedu3 0 0.06 0.01 0.08 0.01 0.09 0.01 0.09 0.01 0.11 dlnorth 0.37 0.48 0.37 0.48 0.38 0.48 0.38 0.49 0.4 0.49 dlmid 0.25 0.43 0.25 0.43 0.25 0.43 0.25 0.43 0.24 0.43 dleast 0.05 0.21 0.04 0.2 0.04 0.2 0.04 0.21 0.04 0.2 age 46.26 11.89 47.44 11.53 47.32 11.69 48.51 11.35 49.48 11.56 age2 2281.35 1062.18 2383.77 1035.83 2375.84 1045.86 2481.59 1033.22 2581.38 1064.82 dedu1age 11.59 18.91 12.53 20 12.6 20.23 14.53 21.8 14.83 22.42 dedu2age 4.55 13.05 5.84 15.08 6.65 15.76 7.12 16.38 8.04 17.39 dedu3age 0.15 2.58 0.25 3.24 0.32 3.76 0.33 3.78 0.56 5.12 dmarrage 1.78 7.57 2.06 8.36 2.84 9.63 2.55 9.52 2.76 10.18 child_sum 2.15 1.43 2.02 1.40 1.93 1.39 1.91 1.35 2.18 1.20 無薪樣本數 8342 8075 7870 7692 7397 註: 1. 表中上半部及下半部分別是有薪及無薪樣本的敘述統計量。 2. wage 與 hour 為月薪資及月工時。 3. wage 已經過消費者物價指數平減。
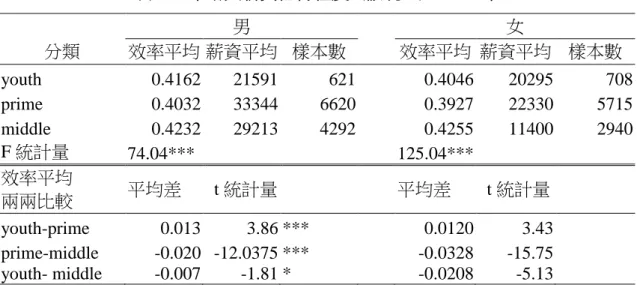
根據表 1 與表 2, 女性就業者的平均實質月薪資幾乎沒有成長, 94 年為 30796 元, 至 102 年略減為 30429 元, 同一時期男性就業者的平均實質薪資則是由 40420 元減少至 37893 元。不過男女性間的平均薪資差由 94 年的 9624 元縮小到 102 的 7464 元,性別間的薪資差異逐年在縮小, 縮小的主因來自男性薪資水準的下降。兩 性就業者的受教育年數皆逐漸增加, 而女性就業者的平均受教育年數皆超越男性 就業者。就業者中, 最高學歷是高中職的比率逐漸下降; 大學、專科生及碩、博士 的比例逐漸提高, 其中又以前者的提高幅度最大。就業者中未婚狀態的比例較低, 但是男性未婚者的比例又低於女性未婚者, 男性就業者未婚比例有逐漸提高的趨 勢。兩性就業者的平均潛在工作經驗及年齡均逐年提高, 工時在 98 年的金融海嘯 明顯下降, 可能是無薪假增加之故, 戶籍地的分布比例在此 5 個年度則無太大變 動。 值得注意者, 男性各年有工作者與無工作者人數各約有 12000 人與 2000 人, 女性各年有工作者與無工作者人數各約有 9000 人與 7300 人。女性樣本中無工作 者比例遠超過男性, 研究樣本中如果忽略無工作者, 易獲得有偏誤的結果, 其中女 性樣本偏誤情形較男性樣本嚴重。
4.2 假說設定
類似 Hofler and Murphy (1992) 與相關研究, 本研究提出以下 6 個假說, 檢 定造成本國勞動市場上薪資低付原因並與過去文獻比較。
假說 1、薪資低付程度會因年齡層不同而不同, 處於壯年時期 (26 到 44 歲) 的勞 工, 預期薪資低付程度較低。Hofler and Murphy (1992) 認為壯年勞工無工作原因, 通常為被資遣, 可以請領失業救濟金, 面臨經濟上的壓力較輕, 可以花較長的時間 尋找低付程度輕微的工作。青年勞工無工作狀態通常來自初次踏入職場, 無法請領 失業補助, 故面臨較大經濟壓力, 尋找工作時可能會壓低自身的保留薪資, 因此預 期青年的薪資無效率程度較高。
假說 2、薪資低付的程度與勞工的工作經驗有關, 預期工作經驗愈長, 薪資遭受低 付程度愈輕。Hofler and Murphy (1992) 認為隨現職工作期間愈長以及人力資本的 累積, 勞工薪資成長速度會大於邊際勞動產值, 進而降低薪資低付程度。由於無工 作者無法調查現職工作經驗,本文以潛在工作經驗代替現職工作經驗, 進行檢定。 假說 3、勞工的教育程度愈高, 薪資低付程度愈低。Hofler and Murphy (1992) 認 為教育程度愈高的人, 保留薪資也較高, 且願意付出較多心力搜尋工作。此外, 教 育程度較高者在搜尋工作時可能較有效率, 相關資訊比較充足, 故提出教育程度 會影響薪資低付程度的假說。 假說 4、工作身分會影響薪資低付程度, 預期在私部門工作的男性以及在公部門工 作的女性, 薪資低付程度較低; 根據劉錦添與詹方冠 (1990) 的結論, 女性在私部 門薪資被歧視的程度比較嚴重, 故推測女性在私部門的薪資效率較低, 男性則相 反。 假說 5、已婚男性的薪資低付程度低於未婚男性; 已婚女性的薪資低付程度高於未 婚女性。Díaz and Pérez (2013) 的實證研究,發現已婚女性的薪資低付程度高於未 婚女性, 但已婚與未婚男性的薪資低付程度孰高孰低, 尚無相關研究, 故提出本假 說進行檢定, 釐清此議題。
假說 6、工作地點影響薪資低付程度, 預期在北部工作的勞工薪資低付程度最低。 Hofler and Murphy (1992) 認為, 若在都市地區工作, 搜尋工作的機會成本比鄉村 地區小, 因此保留薪資會提高, 薪資低付程度會降低。北部地區因為都市化程度高, 預期薪資低付程度較輕微。
5. 實證分析
男女兩性的薪資結構因為性別差異或其他因素有所不同, 分開估計兩性的薪 資邊界方程式可能比較適當。本研究採用概似比檢定 (likelihood-ratio test) 探討兩 性的薪資邊界是否有結構性差異, 合併估計與分別估計薪資邊界方程式, 利用對 數概似函數值計算得到的概似比檢定統計量, 5 個年度分別等於 14946、6621.8、 4245.4、3000.2 和 5435.8, 自由度均為 26, 皆達到 1% 顯著水準, 確認兩性之薪資 邊界方程式存在結構性差異, 不應將兩性樣本合併估計。5.1 各年度迴歸係數估計結果
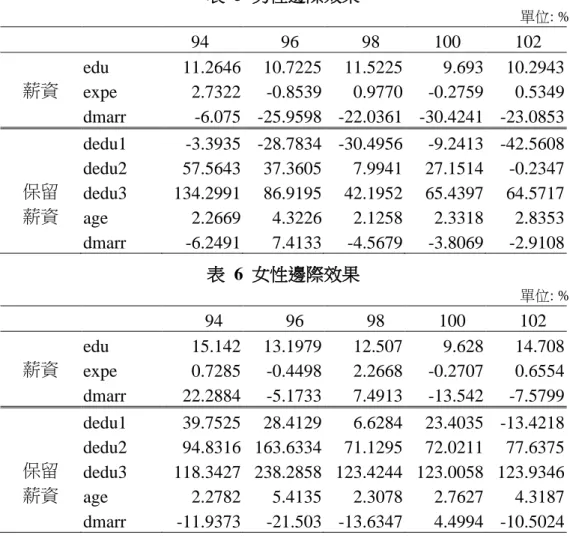
本文的對數薪資迴歸式挑選的變數係依據 Mincer (1974) 的薪資方程式並加 以擴充, 第 (3) 與 (7) 式分別設定如下: ln𝑊 = 𝛽0+ 𝛽1𝑒𝑑𝑢 + 𝛽2𝑒𝑑𝑢2+ 𝛽3𝑑𝑚𝑎𝑟𝑟 + 𝛽4𝑒𝑥𝑝 + 𝛽5𝑒𝑥𝑝2+ 𝛽6𝑑𝑚𝑎𝑟𝑟 × 𝑒𝑥𝑝 + 𝑣2− 𝑢2, ln𝑊𝑅 = 𝛼0+ 𝛼1𝑙𝑛𝐻 + 𝛼2𝑑𝑒𝑑𝑢1 + 𝛼3𝑑𝑒𝑑𝑢2 + 𝛼4𝑑𝑒𝑑𝑢3 + 𝛼5𝑑𝑙𝑛𝑜𝑟𝑡ℎ + 𝛼6𝑑𝑙𝑚𝑖𝑑 + 𝛼7𝑑𝑙𝑒𝑎𝑠𝑡 + 𝛼8𝑑𝑚𝑎𝑟𝑟 + 𝛼9𝑎𝑔𝑒 + 𝛼10𝑎𝑔𝑒2+ 𝛼 11𝑑𝑒𝑑𝑢1 × 𝑎𝑔𝑒 + 𝛼12𝑑𝑒𝑑𝑢2 × 𝑎𝑔𝑒 + 𝛼13𝑑𝑒𝑑𝑢3 × 𝑎𝑔𝑒 + 𝛼14𝑑𝑚𝑎𝑟𝑟 × 𝑎𝑔𝑒 + 𝑣1, 各變數定義請參見 4.1 節之說明, 由此不難導出 (8) 式ln𝐻的迴歸方程式, 組成 (9) 式並利用 (12) 式的概似函數進行迴歸分析。3.2 小節特別提到, 為能辨認 (9) 式 中ln𝑊與 ln𝐻等兩條迴歸方程式全部的迴歸係數, ln𝑊與ln𝑊𝑅的解釋變數至少須 有一個以上不相同。14 男性與女性樣本薪資與保留薪資方程式的迴歸係數估計結果, 分別列在表 3 與表 4, 其中上半部是薪資迴歸方程式的係數估計結果, 下半部則是保留薪資迴 歸方程式的係數估計結果。15 不考慮樣本選擇的狀況下, 只使用有工作者樣本的迴 歸係數估計結果, 放在附錄二, 以資比較。由於兩個表中有許多二次項與交乘項, 不易直接看出個別自變數對應變數的邊際效果, 本文另外算出這些自變數的邊際 效果, 並按男、女性分別整理至表 5 與 6, 表中上半部是各自變數對ln𝑊的邊際效 果, 下半部則是對ln𝑊𝑅的邊際效果, 單位為百分比。例如在 102 年, 給定其他條件 不變之下, 男性受教育年數增加 1 年, 薪資平均增加 10.29%。若變數為虛擬變數, 則邊際效果指高於基準組的百分比。16 例如在 98 年, 給定其他條件不變之下, 未 婚女性的薪資平均高出已婚女性 7.49%。以下綜合表 3 至表 6 的結果說明之。 值得一提者, (15) 式中 1
1 1 F 與 1
2 2 F 的相關係數1 2估計值皆為正且 顯著, 表示ln W 與ln H 具正相關, 符合預期, 也凸顯聯立迴歸模型的重要性。 14 因為本研究的迴歸方程式同時考慮有工作和無工作者, 造成一些有工作者才能觀察到的變數, 例如行、職業別變數和現職工作經驗等, 無法放入迴歸模型中, 大幅限縮可以放入的自變數個 數。 15 根據 (7) 式, 因為 lnH 的係數估計值 1 在表 3 和 4 中皆為正值, 表示保留工資與工時具同向關 係, 符合預期, 而附錄一的推導也要求1 0。16 其中 dmarr 為虛擬變數, 其偏導數與連續變數的偏導數經濟意義不同, 本文根據 Hill, Griffths,
and Lim (2012, 頁 272, 7.3.2 節 ) 的公式計算在其他條件相同下, 與基準組的平均薪資差距, 並將其定義為虛擬變數的「邊際效果」。
薪資迴歸式估計結果
• 受教育年數 (edu): 在 5 個樣本年度中, 男性的一次項係數在 94、96 與 98 年皆顯著為負, 二次 項則顯著為正; 女性除 100 與 102 年之外一次項皆顯著, 其中 94 年為負, 96 與 98 年為正, 二次項皆顯著為正。計算對 edu 的偏導數, 若一次項為負, 其 轉折點約介在 0.5–4 年之間, 表示不論男女, 在受完小學教育 (受教育年數為 6) 之前, 教育對薪資報酬的影響即開始有邊際報酬遞增的現象, 若一次項為正, 教育對薪資自始即有報酬遞增現象。表 5 與 6 顯示男性受教育的薪資報酬率約 為 10%, 女性大約為 12%。 • 潛在工作經驗 (expe): 男性除了 100 年之外一次項皆顯著, 但正負號各年不盡相同; 女性一次項皆 顯著, 各年正負號也有差異。男、女性平方項係數皆顯著, 各年正負亦不相同。 男性在 94、98、100 年為凹性 (concavity), 轉折點介在 15–42 年之間; 在 96 與 102 年為凸性 (convexity), 轉折點分別為 59 年與 -12 年。女性在 94、98 與 100 年為凹性, 轉折點介在 15–42 年之間; 在 96 與 102 年為凸性, 轉折點 分別為 32 年與 9 年。表示在同一年度, 男、女性的潛在工作經驗對薪資報酬 的影響方向相同。在 94、98 與 100 等三年的影響型態, 與人力資本文獻一致, 也就是潛在工作經驗增加, 提高薪資報酬, 但邊際影響遞減。 • 婚姻狀態 (dmarr): 不論男、女性, 所有年度的婚姻狀態一次項迴歸係數為負且皆顯著, 未婚者的 薪資水準較已婚者低; 本文另外放入婚姻狀態與潛在工作經驗的交乘項, 而男 女性所有年度交乘項的係數皆為正且顯著, 表示婚姻狀態與潛在工作經驗有顯 著的交互影響, 不論男或女性, 若保持未婚, 潛在工作經驗的增長有利於薪資 增加; 一旦結婚, 則潛在工作經驗的增加不利薪資提高。過往文獻認為已婚女 性可能因照顧家庭而中斷工作, 回到職場時必須重新累積經驗與人力資本, 故 薪資並不隨著潛在工作經驗的增加而增長, 本文發現不只女性, 男性也可能出 現類似情況。根據表 5, 男性在 5 個樣本年度中, 未婚者的平均薪資皆低於已 婚者, 94 年約低 6% , 往後年份約低 22%–30%。表 6 顯示女性未婚者在 94 及 98 年的平均薪資分別高出已婚者 22% 與 7%, 其他年份則約低 5% 到 13% 之間。以往的人力資本文獻大多發現男性較女性易有「婚姻溢酬」; 換言之, 已 婚男性的薪水較未婚男性高, 但已婚女性薪水則未必比未婚女性高。此處的發 現也與人力資本文獻的預測吻合。表 3 男性樣本之迴歸係數 – 考慮樣本選擇 94 96 98 100 102 0 10.442*** 11.2623*** 11.0092*** 10.5328*** 10.6151*** edu -0.0484*** -0.0325*** -0.0718*** 0.0462 0.0409 edu^2 0.0066*** 0.0056*** 0.0074*** 0.002*** 0.0024*** dmarr -0.3262*** -0.8427*** -0.5644* -0.5955*** -0.6338*** expe 0.0441*** -0.0224*** 0.015*** 0.0043** -0.0047*** expe^2 -0.0006*** 0.0001*** -0.0003*** -0.0003*** 0.0001*** dmarrexpe 0.0139*** 0.0278*** 0.016** 0.0116 0.0181*** 0 -55.4724*** -73.4383*** -45.5404*** -27.5328*** -53.2984*** lnH 12.1897*** 15.024*** 10.0843*** 6.7577*** 11.6661*** dedu1 -0.6331*** -0.6033*** -0.0952*** -0.1274 -0.5831*** dedu2 -0.2484*** -0.5947*** -0.5801*** -0.3198*** -0.6983*** dedu3 0.6868 0.4165 -0.5354* 0.0254 -0.5955* dlnorth 0.1000*** -0.1011*** -0.2085*** -0.1273*** -0.2138*** dlmid 0.0384 -0.0907*** 0.0996*** -0.0001 -0.1055** dleast -0.4609*** 0.3638*** -0.2769*** -0.0068 0.2323** dmarr 0.7844*** 1.7681*** 0.7416*** 0.6144*** 0.7981*** age 0.0583*** 0.1966*** 0.1472*** 0.1047*** 0.1045*** age^2 -0.0005*** -0.0019*** -0.0016*** -0.0010*** -0.0010*** dedu1age 0.0157*** 0.0081* -0.0053*** 0.0009 0.0039 dedu2age 0.0216*** 0.0249*** 0.0167*** 0.0148*** 0.0171*** dedu3age 0.0172* 0.0117 0.0243*** 0.0158*** 0.0306*** dmarrage -0.0223*** -0.0437*** -0.0200*** -0.0164*** -0.0204*** 1 2 0.6674*** 0.6597*** 0.7381*** 0.8754*** 0.7059*** 1 v 1.8073*** 2.2203*** 1.6421*** 1.1788*** 1.6984*** 2 v 0.2503*** 0.2276*** 0.2165*** 0.3312*** 0.2541*** 2 u 5.0164*** 5.8467*** 6.9278*** 6.0142*** 6.1013*** 樣本數 14696 15157 14662 14587 14132 Log-likelihood -27388.6 -28808.9 -30544.9 -28428.2 -27850.5 註:* 代表達到 10%顯著水準; ** 代表達到 5%顯著水準; ***代表達到 1%顯著水準。
表 4 女性樣本之迴歸係數 – 考慮樣本選擇 94 96 98 100 102 0 10.7303*** 10.4586*** 9.5751*** 10.6884*** 10.4924*** edu -0.0872*** 0.0038*** 0.0508*** 0.0236 -0.0067 edu^2 0.0096*** 0.0051*** 0.0029*** 0.0028*** 0.0058**** dmarr -0.1209*** -0.4506*** -0.1202* -0.2327*** -0.6137*** expe 0.0159*** -0.0185*** 0.0366*** 0.0137** -0.0168*** expe^2 -0.0005*** 0.0002*** -0.0005*** -0.0005*** 0.0003*** dmarrexpe 0.0186*** 0.0220*** 0.0103** 0.0047 0.0272*** 0 -25.8558*** -105.384*** -33.0937*** -19.216*** -71.505*** lnH 6.3614*** 21.5496*** 7.9352*** 5.0486*** 15.1296*** dedu1 0.7392*** -0.9823*** -0.0256 0.3467*** -0.7681*** dedu2 1.0361*** 0.6077** 0.0087 0.3804*** -0.1365*** dedu3 1.6665*** 1.3617* 1.2292*** 1.0566*** 1.1356** dlnorth 0.2680*** 0.1232*** 0.0640** 0.0601*** 0.0975*** dlmid 0.0392 0.0126 0.0153 0.0219 -0.0278 dleast -0.2639*** 0.2095 -0.0285 0.0477 0.1849 dmarr 0.0901 0.6677** 0.3228* 0.4205*** 1.0916*** age 0.1064*** 0.0774*** 0.0694*** 0.1137*** 0.0893*** age^2 -0.0011*** -0.0005*** -0.0007*** -0.0011*** -0.0006*** dedu1age -0.0096*** 0.0345*** 0.0025 -0.003 0.0163*** dedu2age -0.0025 0.0280*** 0.0187*** 0.0090*** 0.0235*** dedu3age -0.0135 0.0278 0.0001 0.0046 0.0027 dmarrage -0.0061* -0.0248*** -0.0125*** -0.0100*** -0.0309*** 1 2 0.9499*** 0.7713*** 0.9021*** 0.9691*** 0.8249*** 1 v 1.7183*** 3.1884*** 1.5063*** 1.3133*** 2.4431*** 2 v 0.443*** 0.2541*** 0.2637*** 0.3800*** 0.2321*** 2 u 13.6423*** 13.0499*** 13.1744*** 14.2024*** 12.5035*** 樣本數 17805 17936 17123 17269 16760 Log-likelihood -31639.2 -31016.5 -30555.1 -31050.8 -29460.4 註:* 代表達到 10%顯著水準; ** 代表達到 5%顯著水準; ***代表達到 1%顯著水準。