Abstract—Mining association rules from a large business database, has been recognized as an important topic in the data mining community. A method that can help the analysis of associations is the use of classification ontology (taxonomy) and the setting of parameter constraints, such as minimum support. In real world applications, however, the classification ontology cannot be kept static while new transactions are continuously added into the original database, and the analysts may also need to set a different support constraint from the original one while formulating a new query in discovering real informative rules. Efficiently updating the discovered generalized association rules to reflect the change with classification ontology, support constraint and new added transactions is a crucial task. In this paper, we examine this problem and propose a novel algorithm, called IMA_HOSU, which can incrementally update the discovered generalized association rules when the classification ontology updates with a renewed minimum support. Empirical evaluations show that our algorithm is faster than applying the contemporary generalized associations mining algorithms to the whole updated database.
Index Terms—Association rules; Classification ontology; Incremental mining;
I. INTRODUCTION
ining association rules has been recognized as a very important topic in data mining [1][2]. An association rule is an expression of the form X Y, where X and Y are sets of items. Such a rule reveals that transactions in the database containing items in X tend to also contain items in Y, and the probability, measured as the fraction of transactions that contain X also contain Y, is called the confidence of the rule. The support of the rule is the fraction of the transactions that contain all items in both X and Y. The problem of mining association rules is to discover all association rules that satisfy support and confidence constraints.
In many applications, there are explicit or implicit classification ontology (taxonomy) over the items, so it may be more useful to find associations at different levels of the classification ontology than only at the primitive concept level
[8][15]. For example, consider the classification ontology of items in Fig. 1. It is likely that the association rule,
Systemax V HP LaserJet (sup 20%, conf100%), does not hold when the minimum support is set to 25%, but the following association rule may be valid,
Desktop PC HP LaserJet.
PDA HP LaserJet
Desktop PC PC
IBM TP MITAC Mio
Systemax V Sony VAIO
ACER N
ms25 % Fig. 1. Example of classification ontology.
Previous work on mining generalized association rules assumed that the classification ontology are static, ignoring the fact that the classification ontology may change as time passes while new transactions are continuously added into the original database. Further, the analysts may need to set a different support constraint from the original one while they put a query in discovering real informative rules. Under these circumstances, how to efficiently discover the generalized association rules under incremental transactions, a classification ontology update and a renewed minimum support becomes a critical task.
In this paper, we examine this problem and propose an algorithm called IMA_HOSU (Incremental Mining of generalized Association rules under Classification Ontology and Support constraint Update), which reuses frequent itemsets and is capable of effectively reducing the number of candidate sets and database rescanning, and so can update the generalized association rules efficiently. Empirical evaluations show that our algorithm is faster than applying the contemporary generalized association mining algorithms to the whole updated database.
As founded in [1], the work of association rules mining can be decomposed into two phases:
1) Frequent itemset generation: find all itemsets that sufficiently exceed the minimum support ms.
Incremental Mining of Generalized Association
Rules under Classification Ontology and Support
Constraint Update
Ming-Cheng Tseng
1, Wen-Yang Lin
2and Rong Jeng
31, 3
Institute of Information Engineering, I-Shou University, Kaohsiung 840, Taiwan
1
[email protected],
3[email protected]
2
Dept. of Comp. Sci. & Info. Eng., National University of Kaohsiung, Kaohsiung 811, Taiwan
2
[email protected]
2) Rule construction: from the frequent itemsets generate all association rules having confidence higher than the minimum confidence mc.
Since the second phase is straightforward and less expensive, we concentrate only on the first phase of finding all frequent itemsets.
The remaining of this paper is organized as follows. We discuss previous work in Section II, and describe the problem in Section III. In Section IV, we propose the IMA_HOSU algorithm and give an example in Section V. In Section VI, we evaluate the performance of the proposed IMA_HOSU algorithm. Finally, we conclude the work of this paper in Section VII.
II. PREVIOUSWORK
The problem of updating association rules incrementally was first addressed by Cheung et al. [4], whose work was later be extended to incorporate the situations of deletion and modification [6]. Since then, a number of techniques have been proposed to improve the efficiency of incremental mining algorithm [9][11][14][16]. But all of them were confined to mining associations among primitive items. The problem of mining association rules in the presence of classification ontology information was first introduced in [8] and [15], independently. Cheung et al. [5] were the first to consider the problem of maintaining generalized (multi-level) association rules. Another form of association rule model with multiple minimum supports was proposed in [10]. Their method allowed users to specify different minimum supports to different items and could find rules involving both frequent and rare items. However, their model considers no classification ontology at all, and hence fails to find generalized association rules. We then extended this problem model to that of incorporating the classification ontology of items [17]. In [7], Han and Fu explored the refinement of concept hierarchies for knowledge discovery in databases and proposed an approach for dynamic generation. In our previous paper [18], we proposed an approach for the maintenance of generalized association rules under transaction update and taxonomy revolution with a uniform support constraint.
III. PROBLEMSTATEMENT
A. Problem Description
Consider the situation when new transactions in db are added to DB and the classification ontology T is changed into a new one T*. Let ED* and ed* denote the extended version of the original database DB and incremental database db, respectively, by adding the generalized items in T* to each transaction. Further, let UE* be the updated extended database containing ED* and ed*, i.e., UE*ED* + ed*. The problem of updating the set of frequent itemsets in ED, LED, when new transactions db are added to DB, T is changed into T*, and the old minimum support (msold) is changed into the new one (msnew) is equivalent to finding the set of frequent itemsets in UE* with respect to msnew, denoted as LUE*.
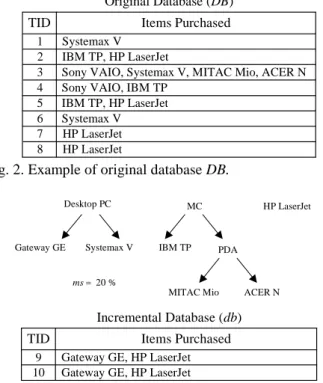
For illustration of our proposed approach, consider the original database in Fig. 2. The old item classification ontology is shown in Fig. 1, and the original minimum support is set to 25%. Suppose that primitive item “Sony VAIO” and generalized item “PC”are deleted from the “PC”group, and new primitive item “Gateway GE” isinserted into its top generalized item “MC”, where “MC”is a new one. Fig. 3 shows the new item classification ontology and an incremental database to be updated to the original database. The minimum support is changed from 25% to 20%.
Original Database (DB) 1 3 2 Systemax V IBM TP, HP LaserJet
TID Items Purchased
Sony VAIO, Systemax V, MITAC Mio, ACER N
5 4
IBM TP, HP LaserJet Sony VAIO, IBM TP
6 Systemax V 7
8 HP LaserJet HP LaserJet
Fig. 2. Example of original database DB.
HP LaserJet Desktop PC Systemax V Gateway GE MC IBM TP ACER N PDA MITAC Mio ms20 % Incremental Database (db) 9 10
Gateway GE, HP LaserJet Gateway GE, HP LaserJet
TID Items Purchased
Fig. 3. Example of incremental database db with new item classification ontology.
B. Situations for Classification Ontology Update
According to our observation [18], there are four basic types of item updates that will affect the structure of a classification ontology: item insertion, item deletion, item renaming and item reclassification.
Type 1: Item Insertion. The strategies to handle this type of
update operation are different, depending on whether an inserted item is primitive or generalized. When the new inserted item is primitive, we do not have to process it until an incremental database update containing that item indeed occurs. This is because the new item does not appear in the original database, neither in the discovered associations. However, if the new item is a generalization, then the insertion will affect the discovered associations since a new generalization often incurs some item reclassification.
Type 2: Item Deletion. Unlike the case of item insertion, the
deletion of a primitive item from the classification ontology would incur inconsistence problem. In other words, if there is no transaction update to delete the occurrence of that item, then the refined item classification will not conform to the updated database. To simplify the problem, we assume that outdated
items will not be of interest, and the update of the classification ontology is always consistent with the transaction update to the database. Additionally, the removal of a generalization may also lead to item reclassification. So we always have to deal with the situation caused by item deletion.
Type 3: Item Renaming. When items are renamed, we do
not have to process the database; we just replace the frequent itemsets with new names.
Type 4: Item Reclassification. This is the most profound
operation among the four types of classification ontology. Once an item, primitive or generalized, is reclassified into another category, all of its generalized items in the old and new classification ontology are affected.
IV. THEPROPOSEDMETHOD
A. Algorithm Basics
Let a k-itemset denote an itemset with k items. The basic process of our mining association rules under update of incremental transactions, classification ontology and support constraint follows the level-wise approach used by most Apriori-like algorithms.
A straightforward method for updating the discovered generalized frequent itemsets would be to run any of the algorithms for finding generalized frequent itemsets, such as Cumulate and Stratify [14], on the updated extended database UE* with the new support constraint. This simple way, however, does not utilize the discovered frequent itemsets and ignores the fact that scanning the whole updated database would be avoided. Instead, a better approach is to, among the set of discovered frequent itemsets LED, differentiate the itemsets that are unaffected with respect to the classification ontology change from the others, and then utilize them to avoid unnecessary computation in the course of incremental update. To this end, we first have to identify the unaffected items whose supports does not change with respect to the classification ontology, and then use them to identify the unaffected itemsets.
We introduce the following notation to facilitate the discussion: I, J denote the set of primitive items and the set of generalized items in T, respectively, and I*, J* represent the counterparts in T*.
Definition 1. An item in T is called an unaffected item if its
support does not change with respect to the classification ontology evolution.
Lemma 1. Consider a primitive item a in TT*. Then
1) countED*(a)countED(a) if aI I*, and 2) countED*(a)0 if a I*I,
where countED*(a) and countED(a) denote the support count of item a in ED* and ED, respectively.
Lemma 2. Consider a generalized item g in T*. Then
countED*(g)countED(g) if desT*(g)desT(g), where desT*(g) and desT(g) denote the sets of descendant primitive items of g in
T* and T, respectively.
In summary, Lemmas 1 and 2 state that an item is unaffected by the ontology update if it is a primitive item before and after the ontology evolution, or it is a generalized item whose
descendant set of primitive items remains the same.
Definition 2. An itemset A in ED* is called an unaffected
itemset if its support does not change with respect to the classification ontology evolution.
Lemma 3. Consider an itemset A in ED*. Then
1) countED*(A) countED(A) if A contains unaffected items only;
2) countUE*(A)0 if A contains at least one item a, for a I –
I*.
After clarifying how to identify the unaffected itemsets, we consider the situation when the old support threshold (msold) is change to the new one (msnew), and derive two lemmas as follows.
Lemma 4. An itemset is frequent in ED* with respect to
msnewif it is frequent in ED with respect to msoldand msnew
msold.
Lemma 5. An itemset is infrequent in ED* with respect to
msnewif it is infrequent in ED with respect to msoldand msnew
msold.
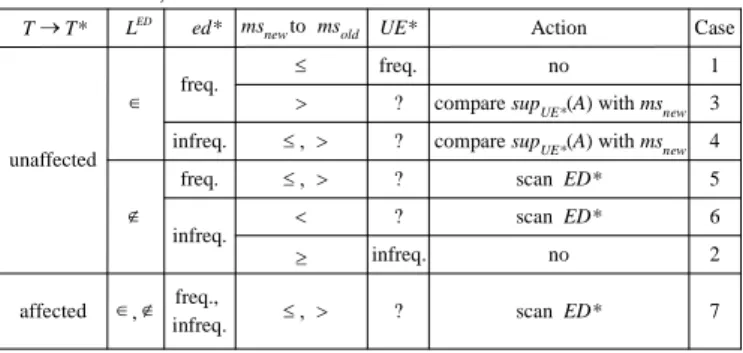
Now, we will further show how to utilize this information to alleviate the overhead in updating the supports of itemsets. Consider a candidate itemset A generated during the mining process. We observe that there are seven different cases for computing the support count of A in the whole updated database UE* with respect to msnew.
1) If A is an unaffected itemset and is frequent in ED and ed*, and msnewmsold, then it is also frequent in the extended updated database UE*.
2) If A is an unaffected itemset and is infrequent in ED and ed*, and msnewmsold, then it is also infrequent in UE*. 3) If A is an unaffected itemset and is frequent in ED and ed*,
and msnew> msold, then a simple calculation can determine whether A is frequent or not in UE*.
4) If A is an unaffected itemset and is frequent in ED but infrequent in ed*, then no matter msnewmsold or msnew>
msold, a simple calculation can determine whether A is frequent or not in UE*.
5) If A is an unaffected infrequent itemset in ED but is frequent in ed*, then it is an undetermined itemset in UE* no matter msnewmsoldor msnew> msold, i.e., it may be either frequent or infrequent.
6) If A is an unaffected infrequent itemset in ED and is infrequent in ed*, and msnew < msold, then it is an undetermined itemset in UE*.
7) If A is an affected frequent itemset and is frequent or infrequent in both ED and ed*, then no matter msnewmsold or msnew> msoldit is an undetermined itemset in UE*. These seven cases are summarized in Table 1. Note that only Cases 5, 6 and 7 require an additional scan of ED* to determine the support count of A in UE*. In Case 3, after scanning ed* and comparing the supports of A with msnew, even if A is frequent in
ed*, A may become infrequent in UE* under msnew> msold. In Case 4, after scanning ed* and comparing the supports of A with msnew, even if A is infrequent in ed* and no matter what msnewis,
A may become frequent in UE*. Therefore, only a simple comparison with msnewis required for the supports of A in Cases
3 and 4. In Case 5, after scanning ed* and comparing the supports of A with msnew, if A is frequent in ed*, no matter what
msnew is, A may become frequent in UE*. In Case 6, after scanning ed* and comparing the supports of A with msnew, even if A is infrequent in ed*, A may become frequent in UE* if msnew < msold. Then we need to rescan ED* to determine the support count of A for Cases 5 and 6. For Case 7, since A is an affected itemset, its support count could be changed in ED*. No matter what msnewis, we need to further scan ED* to decide whether it is frequent or not.
For Cases 1 to 4, there is no need to further scan ED* to determine the support count of an itemset A. Thus we have utilized the information of unaffected itemsets and discovered frequent itemsets to avoid such a database scan. Furthermore, the identification of itemsets satisfying Case 2 provides another opportunity for candidate pruning.
TABLE1.SEVEN CASES ARISING FROM THE INCREMENTAL DATABASE, MSAND CLASSIFICATION ONTOLOGY UPDATE.
unaffected affected ED L , ed* freq. infreq. UE* Action no
compare supUE*(A) with msnew Case scan ED* scan ED* no 7 T T* msnewto msold freq. infreq. ? ? ? ? ? freq., infreq. freq. infreq. scan ED* 2 6 5 4 1 3 compare supUE*(A) with msnew
B. Algorithm IMA_HOSU
Based on the aforementioned concepts, we propose an algorithm, called IMA_HOSU, to accomplish this task. The main process of IMA_HOSU algorithm is presented as follows. First, let candidate 1-itemsets C1be the set of items in the new item classification ontology T*, i.e., all items in T* are candidate 1-itemsets. Next, we identify the affected items. Then load the original frequent 1-itemsets ED
L
1 and divide C1 into three independent subsets: CX, CYand CZ, where CXconsists of unaffected k-itemsets inL
EDk , and CYis composed of unaffectedk-itemsets not in
L
EDk , and CZcontains affected k-itemsets. CXis used for Cases 1, 3 and 4, CYfor Cases 2, 5 and 6, and CZfor Case 7. Next, scan ed* to get the support count of itemsets in C1. For each 1-itemset in CX, accumulate its support count in ed* and ED*, and compare supports of those 1-itemsets satisfying Cases 3 and 4 with msnewand get frequent 1-itemsets for* 1
UE
L
.For the set CY, only frequent 1-itemsets in ed* or infrequent 1-itemsets in ed* with msnew < msold need to undergo a rescanning of ED* (corresponding to Cases 5 and 6); after getting the support count in ED*, accumulate the support count for each 1-itemset in ed* and ED*, and compare each 1-itemset’s support with msnewto get frequent 1-itemsets for
* 1
UE
L
. For CZ, scan ed* and ED*, compare the support of each 1-itemset with msnew, and get frequent 1-itemsets for* 1
UE
L
.After getting all frequent 1-itemsets in UE*, the algorithm continues to generate candidate k-itemsets Ck from
* 1
UE k
L
andprocesses the same procedure for generating
L
1UE* until no frequent k-itemsets UE*k
L is created. The IMA_HOSU algorithm is shown in Fig. 4.
Input: (1) DB: the original database; (2) db: the incremental database; (3)
msold: the old minimum support setting; (3) msnew: the new minimum support
setting; (4) T: the old item classification ontology; (5) T*: the new item classification ontology; (6) ED
L : the set of original frequent itemsets. Output: LUE*: the set of new frequent itemsets with respect to T*, ed* and
msnew.
Steps:
1. Identify all affected items;
2. k1;
3. repeat
4. if kthen generate C1from T*; 5. elseCkapriori-gen( * 1 UE k L);
6. Delete any candidate in Ckthat consists of an item and its ancestor;
7. Load original frequent k-itemsets ED k L ;
8. Divide Ckinto three subsets: CX, CYand CZ;
9. for each ACXdo /* Cases 1, 3 & 4 */
10. Assign countED*(A)countED(A);
11. Scan ed* to count counted*(A) for each itemset A in Ck;
12. ed*
k
L {A | ACkand suped*(A)msnew};
13. Delete any candidate A from CYif A ed*
k
L and msnewmsold; /*
Case 2 */
14. Scan ED* to count countED*(A) for each itemset A in CYand CZ; /*
Cases 5, 6 & 7 */
15. Calculate countUE*(A)countED*(A)counted*(A) for each itemset
A in Ck;
16. UE*
k
L {A | ACkand supUE*(A)msnew};
17. until UE* k L 18. * UE L Uk * UE k L ;
Fig. 4. Algorithm IMA_HOSU.
V. ANEXAMPLE FORIMA_HOSU ALGORITHM
Consider the example in Fig. 2 and 3. To simplify the illustration, we use item “A” to stand for “PC”, “B” for “Desktop PC”,“C”for“Sony VAIO”,“D”for“IBM TP”,“E” for“Systemax V”,“F”for“PDA”,“G”for“MITAC Mio”,“H” for“ACER N”,“I”for“HP LaserJet”, “J”for “MC”, and “K” for “Gateway GE” in the item classification ontology. The resulting figure is shown in Fig. 5.
First, let candidate 1-itemsets C1be the set of items in the new item classification ontology T, i.e., all items in T* are candidate 1-itemsets. Second, load the original frequent 1-itemsets ED
L
1 and divide C1into three subsets: CX, CYand CZ, where CX{D, E, I}, CY{F, G, H} and CZ{B, J, K}. Next, scan ed* for C1. Then delete any 1-itemset in CYif A* 1
ed
L
andmsnewmsoldand scan ED* for CYand CZ. Calculate the support count of each 1-itemset in C1. After comparing the supports of
each 1-itemset with msnew, the set of new frequent 1-itemsets
* 1
UE
L
is {B, D, E, I, J, K}.After generating
L
1UE*, we use UE1 *L to generate candidate 2-itemsets C2, obtaining C2{BD, BI, BJ, DE, DI, DK, EI, EJ, EK, IJ, IK, JK}. Next load the original frequent 2-itemsets ED
L
2and divide C2into three subsets: CX{DI}, CY{DE, EI} and
CZ {BD, BI, BJ, DK, EJ, EK, IJ, IK, JK}. Note that {DK}, {EK}, {IK} and {JK} are not scanned in ED* since they contain a new item “K”that does not exist in ED*; {BE}, {BK} and {DJ} are deleted due to the existence of item-ancestor relationship. Then scan ed* for C2and determine the frequent itemsets in ed*. Then delete any 2-itemset in CYif A
* 2
ed
L
and msnewmsold. Next scan ED* for CY and CZ. Calculate the support count for each 2-itemset in C2and generate* 2
UE
L
{DI,JI, KI}. Finally, we use
L
UE2 *to generate candidate 3-itemsets C3and apply the same procedure to generate* 3 UE L , obtaining an empty set. A E C I D B F H G I B E K H G J D F msold25 % msnew20 %
Original Extended Incremental Database (ed)
Updated Extended Incremental Database (ed*) 9 10 B TID Primitive Items Generalized Items K, I K, I 9 10 TID Primitive Items Generalized Items K, I K, I
Updated Extended Database (ED*) Original Extended Database (ED)
1 6 5 4 3 2 A, B A TID Primitive Items Generalized Items A, B, F A, B A E C, E, G, H E D, I C, D D, I A, B 7 8 I I 1 6 5 4 3 2 B J TID Primitive Items Generalized Items B, F, J J J E C, E, G, H E D, I C, D D, I B 7 8 I I B
Fig. 5. Example of incremental database and classification ontology.
VI. EXPERIMENTS
In order to examine the performance of IMA_HOSU, we conduct experiments to compare its performance with that of applying two leading generalized association mining algorithms, Cumulate and Stratify, to the whole updated database. Synthetic datasets generated by the IBM data generator [2] were used in the experiments. The parameter settings for synthetic data are shown in Table 2. We also adopted two different support counting strategies for the implementation of each algorithm: one with the horizontal counting [1][2][3][12] and the other with the vertical intersection counting [13][19]. For the
horizontal counting, the algorithms are denoted as Cumulate(H), Stratify(H) and IMA_HOSU(H) while for the vertical intersection counting, the algorithms are denoted as
Cumulate(V), Stratify(V) and IMA_HOSU(V). All
experiments were performed on an Intel Pentium-IV 2.80GHz with 2GB RAM, running on Windows 2000.
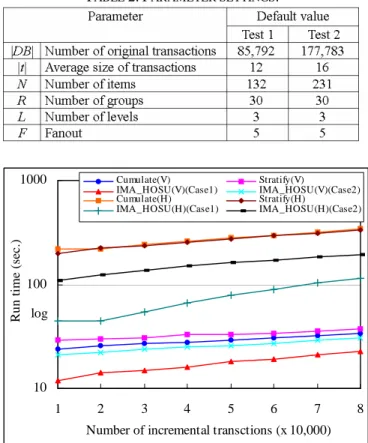
We then compare the three algorithms under varying transaction sizes. The new minimum support (msnew) was specified to 1%, and the percentage of affected items, i.e., the ratio of affected items to total items, was set to 1.4%. Besides, the comparison was performed under two different cases: 1) msnewmsold= 0.9%; and 2) msnewmsold= 1.1%. As the results shown in Fig. 6 and Fig. 7, the running times of all algorithms increase in proportional to the incremental size. Furthermore, IMA_HOSU(H) significantly outperforms Cumulate(H) and Stratify(H), and IMA_HOSU(V) beats Cumulate(V) and Stratify(V).
TABLE2. PARAMETER SETTINGS.
10 100 1000
1 2 3 4 5 6 7 8
Number of incremental transctions (x 10,000)
R u n ti m e (s ec .) Cumulate(V) Stratify(V) IMA_HOSU(V)(Case1) IMA_HOSU(V)(Case2) Cumulate(H) Stratify(H) IMA_HOSU(H)(Case1) IMA_HOSU(H)(Case2) log
Fig. 6. Performance with different incremental sizes for test 1.
VII. CONCLUSIONS
In this paper, we have investigated the problem of updating generalized association rules when new transactions are inserted into the database with the item classification ontology and support constraint update. We also have presented a novel algorithm, IMA_HOSU, for updating discovered generalized frequent itemsets. Empirical evaluation shows that the IMA_HOSU algorithm is more efficient than applying the contemporary generalized association mining algorithms to the
whole updated database. In the future, we will extend the problem of updating generalized multi-supported association rules under the classification ontology and support constraint update.
100 1000 10000
2 4 6 8 10 12 14 16
Number of incremental transctions (x 10,000)
R u n ti m e (s ec .) Cumulate(V) Stratify(V) IMA_HOSU(V)(Case1) IMA_HOSU(V)(Case2) Cumulate(H) Stratify(H) IMA_HOSU(H)(Case1) IMA_HOSU(H)(Case2) log
Fig.7. Performance with different incremental sizes for test 2.
ACKNOWLEDGMENT
This work was supported in part by the National Science Council of ROC under grant No. NSC 94-2213-E-390-006.
REFERENCES
[1] R. Agrawal, T. Imielinski and A. Swami, “Mining Association Rules between Sets of Items in Large Databases,” in Proc. 1993 ACM-SIGMOD Intl. Conf. Management of Data, 1993, pp. 207-216.
[2] R. Agrawal, and R. Srikant, “Fast Algorithms for Mining Association Rules,”in Proc. 20th Intl. Conf. Very Large Data Bases, 1994, pp. 487-499.
[3] S. Brin, R. Motwani, J.D. Ullman and S. Tsur, “Dynamic Itemset Counting and Implication Rules for Market Basket Data,”SIGMOD
Record, Vol. 26, 1997, pp..255-264.
[4] D.W. Cheung, J. Han, V.T. Ng, and C.Y. Wong, “Maintenance of Discovered Association Rules in Large Databases: An Incremental Update Technique,”in Proc. 1996 Int. Conf. Data Engineering, 1996, pp. 106-114.
[5] D.W. Cheung, V.T. Ng and B.W. Tam, “Maintenance of Discovered Knowledge: A case in Multi-level Association Rules,”in Proc. 1996 Int.
Conf. Knowledge Discovery and Data Mining, 1996, pp. 307-310.
[6] D.W. Cheung, S.D. Lee and B. Kao, “A General Incremental Technique for Maintaining Discovered Association Rules,”in Proc. DASFAA'97, 1997, pp. 185-194.
[7] J. Han and Y. Fu, “Dynamic Generation and Refinement of Concept Hierarchies for Knowledge Discovery in Databases,”in Proc. AAAI’94 Workshop on Knowledge Discovery in Databases, 1994, pp. 157-168.
[8] J. Han and Y. Fu, “Discovery of Multiple-level Association Rules from Large Databases,”in Proc. 21st Intl. Conf. Very Large Data Bases,
Zurich, Switzerland, 1995, pp. 420-431.
[9] T.P. Hong, C.Y. Wang and Y.H. Tao, “Incremental Data Mining Based on Two Support Thresholds,”in Proc. 4 Int. Conf. Knowledge-Based
Intelligent Engineering Systems and Allied Technologies, 2000, pp.
436-439.
[10] B. Liu, W. Hsu and Y. Ma, “Mining Association Rules with Multiple Minimum Supports,”in Proc. 5th Intl. Conf. Knowledge Discovery and
Data Mining, 1999, pp. 337-341.
[11] K.K. Ng and W. Lam, “Updating of Association Rules Dynamically,”in
Proc. 1999 Int. Symp. Database Applications in Non-Traditional Environments, 2000, pp. 84-91.
[12] J.S. Park, M.S. Chen and P.S. Yu, “An Effective Hash-based Algorithm for Mining Association Rules,”in Proc. 1995 ACM SIGMOD Intl. Conf.
on Management of Data, San Jose, CA, USA , 1995, pp. 175-186.
[13] A. Savasere, E. Omiecinski and S. Navathe, “An Efficient Algorithm for Mining Association Rules in Large Databases,”in Proc. 21st Intl. Conf.
Very Large Data Bases, 1995, pp. 432-444.
[14] N.L. Sarda and N.V. Srinivas, “An Adaptive Algorithm for Incremental Mining of Association Rules,”in Proc. 9th Int. Workshop on Database
and Expert Systems Applications, 1998, pp. 240-245.
[15] R. Srikant and R. Agrawal, “Mining Generalized Association Rules,”in
Proc. 21st Int. Conf. Very Large Data Bases, 1995, pp. 407-419.
[16] S. Thomas, S. Bodagala, K. lsabti and S. Ranka,“An Efficient Algorithm for the Incremental Updation of Association Rules in Large Databases,” in Proc. 3rd Int. Conf. Knowledge Discovery and Data Mining, 1997, pp. 263-266.
[17] M.C. Tseng and W.Y. Lin, “Maintenance of Generalized Association Rules with Multiple Minimum Supports,”Intelligent Data Analysis, Vol. 8, 2004, pp. 417-436.
[18] M.C. Tseng, W.Y. Lin and R. Jeng, “Maintenance of Generalized Association Rules under Transaction Update and Taxonomy Evolution,” in Proc. Intl. Conf. on Data Warehousing and Knowledge Discovery, 2005, pp. 336 -345.
[19] M.J. Zaki, “Scalable Algorithms for Association Mining,” IEEE
Transactions on Knowledge and Data Engineering, Vol. 12, No. 2, 2000,