Using Support Vector Machine for Integrating Catalogs
8
0
0
全文
(2) Source Catalog N. The goal is finding the. Support vector machine. corresponding category in M for each document The support vector machine is a new machine. in N.. technique used for classifier. Vapnik introduced. 1.2 Related Work. SVM in his work on structural risk minimization [3]. The general SVM solve the primal problem. Naïve Bayes Classifier. as (1), which is given training vectors xi ∈ R , n. Bayesian decision theory is a fundamental statistical approach to the problem of text categorization. This approach is based on quantifying. the. tradeoffs. between. i = 1…l, in two classes, and a vector. y ∈ R l such that y i ∈ {1,−1} [3].. various. costs that accompany such decisions.. l 1 min ω T ω + C ∑ ξ i (1) ω ,b ,ξ 2 i =1. According to Bayes formula (5), we can convert. y i (ω T φ ( xi ) + b) ≥ 1 − ξ i , ξ i ≥ 0, i = 1,..., l.. classification decisions using probability and the. the posteriori probability P(C|x) from prior probability P(C). Our training process is in turn. In a simplest form, there are binary. to estimate the proper parameters of our model,. examples in a two-dimension plane. A linear. such as P(x) and P(x|C).. SVM is a line, two-dimension hyper plane separate s set of positive examples from a set. P (Ci | x) =. P( x | Ci ) P(Ci ) P ( x). (5). of negative examples with maximum margin as Figure 1. In general case, find a decision function as a hyper plane separating training. In a simple case with two categories and only. data and maximize the margin. It is possible. one feature, it’s rather instinct that we have. that a separable hyper plane in the space does. better chance to make the right decision if we. not exist. In such case, we define a parameter. always choose the category with the larger. C, which is the penalty imposed on training. conditional probability P (Ci | x ) .. examples that fall on the wrong side of the decision boundary. In the linearly separable. In recent research [1], Naïve Bayes classification. case, this problem can be expressed as an. is well applied in the integration catalogs. optimization problem in Eq. 2 [5].. problem. Using Naïve Bayes classification, we can incorporate the similarity information present in source catalogs easily. The challenge is applying better classification technologies to this problem..
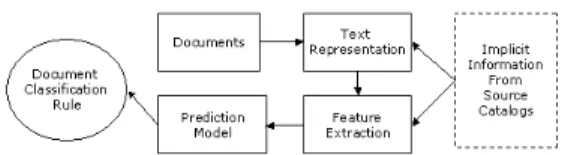
(3) broader sense, it can be seen to estimate a Figure 1: A diagram of Linear SVM. 1 || ω || 2 subject to 2 y i (ω ⋅ xi − b) ≥ 1, i = 1,..., l . (2) Minimize. membership function, which takes a document di as it input and maps this Input into a set of class cj. In other words, this membership function tries to determine the. k-Nearest Neighbor. binary relationship vector { ai1, ai2, … , aim } for. K-nearest neighbor (kNN) classification is an. each document di according to its own document. instance-based learning algorithm [13] that has. features (may be extracted from content or other. shown to be very effective in text classification.. structural information) where m is the total. It assumes all instances correspond to points in. number of predefined categories and aij are. the n-dimensional space ℜ . The similarity (or. values from { 0, 1 }. A value of 1 for aij is. distance) between instances is defined in terms. interpreted as document di belongs to category cj,. of the standard Euclidean distance. More. while 0 means document di doesn’t belong to. precisely, let an arbitrary instance x be described. category cj. The method described above is used. by the feature vector. common in this problem.. n. <a1(x), a2(x), … an(x)> where ar(x) denotes the value of the rth attribute of instance x. Then the distance between two instances xi and xj is defined to be d(xi,xj), where. d ( xi , x j ) ≡. Figure 2: A Overview of Integrating Catalogs. ∑ (a ( x ) − a ( x )) n. r =1. 2. r. i. r. j. kNN is a learning method based on similarity.. We can solve this problem by the following steps [13]: (1) Text Representation, (2) Feature Extraction, (3) Construct prediction model, (4) Document classification rules. In this problem,. Because the specific characteristics of kNN, it. we pay more attention to step (2) and (3), then. performs well than other learning method in text. we could apply some research about text. categorization problem except SVM. In recent. classification in recent to this problem as Fig. 2.. research, kNN is still a well-used method in text. 2 TEXT CLASSIFICATION USING SUPPORT VECTOR MACHINE. categorization, because its well performance and easily implementation. The major problem of kNN is insufficient of training data. When. A support vector machine (SVM). training data is not enough, kNN performs. algorithm has been shown in previous work. incredible worse than the same method with. to be both fast and effective for text. enough training data.. classification problems [6, 7, 10].. Text Categorization Text categorization (or classification) is the. In text and language processing domain, the problem are usually based on vector space. task of automatically assigning predefined. model. In vector space model, we represent a. categories to natural language texts. In its. text document as a numerical vector..
(4) Typically, the document vector is very high. a vector with highly dimension and the. dimensional, at least the thousands for large. dataset is usually unbalanced. The original. collections. The SVM is for new machine. SVM could not handle this problem. The. technique alone this line.. SVM parameter C and p must to be determined [2]. C is the penalty for examples,. 2.1 Multi-class Classification. which fall on the wrong side. p is the decision threshold. We can tune p to control. Support vector machines were originally. classification precision and recall.. designed for binary classification. There are many on-going researches for extending the. Feature Selection. original design for multi-class classification.. Before compute TF•IDF, we select the. We choose “one-against-one” [11] approach. terms which could discriminate documents as. for multi-class SVM. This method was shown. feature. About feature selection, we focused. that the method is more suitable for practical. on Chinese text in this paper. Chinese. use than other methods [12]. This method. documents are becoming widely available in. constructs C. n 2. classifiers where each one is. trained on data from two classes. Then, we have a decision function: l. arg max m =1,..., k (∑ (C im Ai − α im ) K ( xi , x ) + bm ), m = 1,..., k i =1. the Internet. By the growing up importance of Chinese in the Internet, we discuss the different process approach in feature selection. We have some special problem for Chinese text as follow: (1) For Chinese text (and others like Japanese and Korean), there are no. (3). 2.2 Using SVM for Text Classification. space characters to delimit words. (2) For large amount of Chinese words, we should. The document dataset are all text data.. implement a hashing function for the. Even if we change this dataset to numerical. character index and the posting retrieval. expression by a vector of TF•IDF (Term. speed can be very fast. (3) Not exist a general. Frequency * Inverse Document Frequency).. Chinese dictionary contained enough. TF•IDF is the standard choice for kernel. important words for information retrieval,. function in text mining or information. like proper nouns. We use Bigram-based. retrieval community as follow: [4].. indexing, which is a completely data-driven. φi =. TFi log( IDFi ). Where. κ. κ. (4). is normalization constant. ensuring that || φ || 2 = 1 . The function. technique. It does not have the out-of-vocabulary problem.. 3 SVM FOR CATALOGS. INTEGRATING. K ( x, z ) =< φ ( x) ⋅ φ ( z ) > is clearly a valid kernel, since it is the inner product in an explicitly constructed feature space. Using this kernel function, the document is. We discuss the basic method in [1] first. Then we illustrate how to apply SVM for this problem..
(5) 3.1 On Integrating Catalogs. value, and let n(Ci) represent the number of documents in category Ci. Then we can. The goal is using the information from. estimate for P(t| Ci) is n(Ci ,t)/ n(Ci). For. source catalogs to classify the products in. avoiding divided by zero and zero probability,. source catalogs S to master catalogs M. Using. we apply Lidstone’s law to the equation.. the implicit information of S, the. Finally, we can estimate for P(t| Ci) by Eq. 9.. straightforward idea is that using conditional probability to define this relation. By this way, we discuss the traditional method, which is called Naïve Bayes classifier in this section.. P(t | Ci ) =. n(C i , t ) + λ , λ ≥ 0 (9) n(Ci ) + λ | V |. Where |V| is the number of vocabulary. (i.e., feature) According to the equation above, we can. Using Naïve Bayes Classifier Given a document d, the Naïve Bayes. integrate catalogs from S to M straightly. First,. classifier estimates the posterior probability. for each category C in M, we can evaluate. of category Ci .. P(Ci) and P(t| Ci) by Eq. 8 and Eq. 9. P(C i | d ) =. respectively. Second, for each document d in. P (C i ) P ( d | C i ) (5) P(d ). S, we can evaluate P(Ci|d) by Eq. 5 using the. P(d) is the same for all categories, so that. result computed in first step. Finally, we. we can ignore this term of Eq. 5. To estimate. assign d to the category with the highest value. the term P(d| Ci), we assume that all the. for P(Ci|d).. words in d are independent of each other. The probability of the document d is the product. 3.2 Using Catalogs. SVM. for. Integrating. of the multiplication of the probability of all terms t in d.. The major problem of Naïve Bayes. P(d | C i ) = P(t1 | C i ) ⋅ P(t 2 | Ci ),...,⋅P(t k | C i ) = ∏ P(t | Ci ) t∈d. (6) If the document consists of both text and. classification is that (1) the classification is dominated by large category, and (2) the classifier is bias by a few special examples. (3). features, we can assume the independence. In practice, Naïve Bayes classifier predictive. between the text and the features to compute. performance is not as strong as in the training. Eq. 7.. cases. This phenomenon is described as over. P (d | C i ) = P (d text | C i ) ⋅ P (d attr | C i ) (7). fitting. Consequently, Naïve Bayes classifier usually has less performance than SVM in. P(Ci) is estimated by Eq. 8.. text classification community [6]. But in the. P(Ci) =(Number of documents in category. problem of integrating catalogs, it is easily to. Ci )/(Total number of documents in the. use the implicit information of source catalog. dataset) (8). by conditional probability.. To estimate P(t| Ci), we compute the. If the information of source catalog is. number of documents which occurs term t. useful for classification, we can assume that a. and in category Ci. Let n(Ci ,t) represent the. category Ci in S could be mapping to several.
(6) category in M. To emphasize this information. the kernel function will be the same as standard. in numerical vector data, we control the. classifier without information of source catalog. weight β of the centroid of all examples in. when β=0.. this category of S. Increasing β, result in more effect from S for classification to M. More separate example let SVM finding the hyper plane with maximize margin easily. We illustrate the idea as a new kernel function as Eq. 10. In this equation, we control the distribution of examples to present the. Figure 4: The kernel function for. information of source catalogs.. φ ' (d ) = β ⋅ φ (d ) + (1 − β ). 1 ∑ φ (d ) | C | d∈C∈s. (10) 1.. 2. 3.. integrating catalogs. 4 EXPERIENMENTAL RESULTS For our experienment, we use a large. For each category Ci in master catalog S,. collection of classified documents from. determine the weight βi of the relation. books.com.tw [8] and bookzone.com.tw by. between Ci and M. Commonwealth Publishing Company [9].. Compute the new representation of d in. These datasets are both classified book. S.. descriptions from their popular electronic. Classification d by SVM trained by all. commerce web sites.. documents in M. Figure 3: SVM Integrating Catalog Algorithm This kernel function is a term reweighing scheme. The function emphasizes the important. 4.1 Catalogs Description Dataset. Categories. Docs. Books.com.tw. 24. 2,374. Bookzone. 20. 917. term of the source category. In the view of the. Table 1: Dataset Characteristics:. vector space, the function aggregates the vector. Books.com.tw and Commonwealth. to the centroid. Increasing β indicate that we believe the information of source catalog is useful to classify in master catalog more. It is possible that the source catalog is orthogonal to master catalog. In other words, the information of source catalog is completing. Publishing Company These two datasets are Chinese catalogs. In our experienment, we use Bigram-based indexing for feature selection and a hashing function for indexing and retrieval. In these two catalogs, all documents. irrelevant for classification in master catalog.. contain the information of author, publisher,. For example, if the categorization in source. the printed date, printed location, ISBN. catalog is by region and the categorization in. number, price, content, and a short essay for. master catalog is by season. We could treat these. introduction to the book. The size of each. two catalogs orthogonal. Under this situation,. document is about 60~80K bytes with.
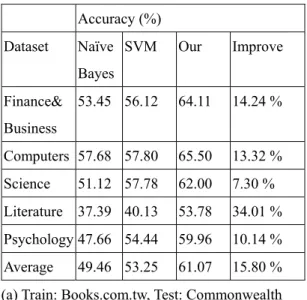
(7) 500~600 Chinese words. The major difference of these two catalogs is their size. Books.com.tw is a general book. show that our method can make a meaningful improvement of classification accuracy. We tune β as 0.3 to reach a state-of-the-art. stores on Internet, but Bookzone just only. performance of our method. These two. sales their own books. Books.com.tw declare. catalogs are similar enough for using the. that there is 120,000 books in their database.. information of source catalog.. Almost all books in bookzone could be. In Table 2, we compare the accuracy of. founded at Book.com.tw. So we collect a part. traditional learning method. Our. of this database. We collect 2,374 documents. experienment also shows that SVM could. from Books.com.tw and collect 917. performs well than Naïve Bayes classifier. We. documents from bookzone (Table 1). The. never used implicit classification information.. book distribution of Bookzone is very. The “improve” column shows the percent. unbalanced (2/3 books in category Finance,. improvement from only using training. Science, Psychology, and Literal) and a few. examples to adding the information of. books. This is unfavorable for Naïve Bayes. classification. Our experiments show that if. classifier.. using this information well, we can have a. 4.2 Experienment. large improvement of classification accuracy. Accuracy (%). The purpose of the experienment was to. Dataset. see how much we could increase accuracy by. Naïve SVM. Our. Improve. 53.45 56.12. 64.11. 14.24 %. Bayes. using SVM and such kernel function. For. Finance&. comparison, we also compute using SVM and. Business. Naïve Bayesian classifier without any. Computers 57.68 57.80. 65.50. 13.32 %. information with source catalog.. Science. 51.12 57.78. 62.00. 7.30 %. Literature 37.39 40.13. 53.78. 34.01 %. different classification strategies: Naïve. Psychology 47.66 54.44. 59.96. 10.14 %. Bayes classifier and SVM. We can find that. Average. 61.07. 15.80 %. even if we just only classify without any. (a) Train: Books.com.tw, Test: Commonwealth. Table 2 shows the average accuracy of the. information with source catalogs, the performance of SVM is still better than Naïve. Accuracy (%) Dataset. Our. Improve. 42.77 49.74. 53.12. 6.80 %. Computers 45.60 48.25. 55.54. 15.11 %. Science. 41.14 44.60. 47.72. 6.99 %. Literature 30.99 37.21. 42.21. 12.44 %. Psychology 40.05 40.11. 43.35. 8.08 %. Average. 43.39. 10.08 %. Bayes classifier. To measure the performance of integrating catalogs, we compare the accuracy of these classification strategies to our method with the information of source catalogs. If the information of source catalogs is not orthogonal to master catalogs, we can use the information as far as possible. The results. 49.46 53.25. Naïve SVM Bayes. Finance& Business. 40.11 43.98.
(8) (b) Train: Commonwealth, Test: Books.com.tw. 2000.. Table 2: Experienment Classification Accuracy [6]. Yiming Yang, A re-examination of Text. 5 CONCLUSIONS. Categorization Methods, In Proceedings of the 22nd International Conference on Research and Development in Information. By the results above, we believe that SVM is. Retrieval (SIGIR ‘99), 1999.. very useful to the problem of integration catalogs with text documents. Traditionally,. [7]. James Tin-Yau Kwok, Automated Text. SVM is a classification tool. In this paper, we. Classification Using Support Vector. using SVM with a novel kernel function to suit. Machine, International Conference on. this problem. The experienment here serves as a. Neural Information Processing(ICNIP ’98),. promising start for the use SVM for this problem.. 1998.. We can also improve the performance by. [8]. incorporation of another kernel function and proved it, or combining structural information of text document, requires future work.. 6 REFERENCES. Book.com.tw Company, http://www.book.com.tw. [9]. Bookzone by Commonwealth Publishing Company, http://www.bookzone.com.tw. [10] Thorsten Joachims, Text Categorization with Support Vector Machines: Learning. [1]. Rakesh Agrawal, Ramakrishnan Srikant,. with Many Relevent Features. In European. On Integrating Catalogs, In proceedings of. Conference on Machine Learning. th. [2]. [3]. [4]. The 10 International World Wide Web. (ECML ’98), pages 137-142, Berlin, 1998,. Conference, Hong Kong, 2001.. Springer.. Chih-Chung Chang and Chih-Jen Lin,. [11] Knerr, S., Personnaz, L., & Dreyfus G.,. LIBSVM: a library for support vector. Single-layer Learning Revisited: a. machines, 2001.. stepwise procedure for building and. Vladimir N. Vapnik, The Nature of. training a neural netwrk, In J. Fogelman. Statistical Learning Theory,. (Ed.), Neurocomputing: Algorithms,. Springer-Verlag, 1995.. architecture and applications.. Nello Christianini and John Shawe-Taylor,. Springer-Verlag,1990.. An Introduction to Support Vector Machines and other Kernel-Based. Comparison of Methods for Multi-class. Learning Methods, Cambridge University. Support Vector Machines, 2001.. Press, 2000. [5]. [12] Chih-Wei Hsu and Chih-Jen Lin, A. Susan Dumais and Hao Chen,. [13] Sholom M. Weiss, Chidanand Apte, Fred J. Damerau, David E. Johnson, Frank J. Oles,. Hierarchical Classification of Web Content,. Thilo Goetz, and Thomas Hampp,. In proceedings of the 23rd International. Maximizing Text-Mining Performance, In. Conference on Research and Development. IEEE Transactions on Intelligent Systems,. in Information Retrieval (SIGIR ‘00),. (Vol. 14, No. 4), pp. 63-69, 1999..
(9)
數據
相關文件
It is well known that second-order cone programming can be regarded as a special case of positive semidefinite programming by using the arrow matrix.. This paper further studies
◦ Lack of fit of the data regarding the posterior predictive distribution can be measured by the tail-area probability, or p-value of the test quantity. ◦ It is commonly computed
support vector machine, ε-insensitive loss function, ε-smooth support vector regression, smoothing Newton algorithm..
Official Statistics --- Reproduction of these data is allowed provided the source is quoted.. Further information can be obtained from the Documentation and Information Centre
“Transductive Inference for Text Classification Using Support Vector Machines”, Proceedings of ICML-99, 16 th International Conference on Machine Learning, pp.200-209. Coppin
For the data sets used in this thesis we find that F-score performs well when the number of features is large, and for small data the two methods using the gradient of the
Microphone and 600 ohm line conduits shall be mechanically and electrically connected to receptacle boxes and electrically grounded to the audio system ground point.. Lines in
* All rights reserved, Tei-Wei Kuo, National Taiwan University, 2005..
