An Efficient Clustering Algorithm for Market Basket Data Based on Small Large
Ratios
Ching-Huang Yun and Kun-Ta Chuang and Ming-Syan Chen
Department of Electrical Engineering
National Taiwan University
Taipei, Taiwan, ROC
E-mail: [email protected], [email protected], [email protected]
Abstract
In this papec we devise an eflcient algorithm for cluster- ing market-basket data items. In view of the nature of clus- tering market basket data, we devise in this paper a novel measurement, called the small-large (abbreviated as SL) ra- tio, and utilize this ratio toperform the clustering. With this
SL ratio measurement, we develop an eficient clustering algorithm for data items to minimize the SL ratio in each group. The proposed algorithm not only incurs an execution time that is sign@cantly smaller than that by prior work but
also leads to the clustering results of very good quuliv. Keywords -Data mining, clustering analysis, market- basket data, small-large ratios.
1
IntroductionMining of databases has attracted a growing amount of attention in database communities due to its wide applica- bility to improving marketing strategies [3][4]. Among oth- ers, data clustering is an important technique for exploratory data analysis [5][6]. In essence, clustering is meant to di- vide a set of data items into some proper groups in such a way that items in the same group are as similar to one another as possible. Market-basket data analysis has been well addressed in mining association rules for discovering the set of large items. Large items refer to frequently pur- chased items among all transactions and a transaction is rep- resented by a set of items purchased [2]. Different from the traditional data, the features of market basket data are known to be high dimensionality, sparsity, and with mas- sive outliers [7]. The authors in [8] proposed an algorithm for clustering market-basket data by utilizing the concept of large items to divide the transactions into clusters such that similar transactions are in the same cluster and dissimilar
B . C , U U . F . It B , O , I -
il
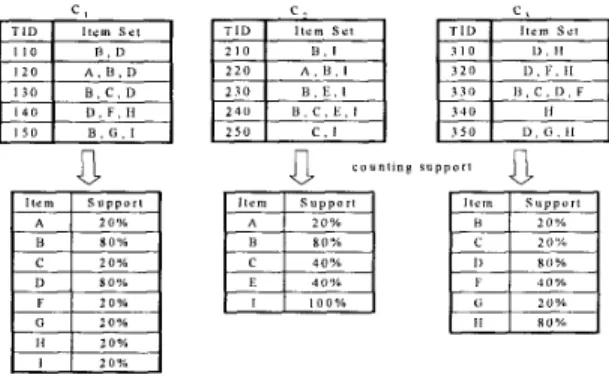
C. T l D I l e m S c f 2 1 0 1 3 . 1 2 2 0 A , K I 2 3 0 B , E . I 2411 U . C , E , I 2 s u c . 1 4 0 % 4 0 % I n n ","Figure 1. An example database for clustering
market-basket data.
transactions are in different clusters. This algorithm in [8] will be referred to as algorithm Basic in this paper, and will be used for comparison purposes. An example database for clustering market-basket data is shown in Figure 1.
In view ofthe nature ofclustering market basket data, we devise in this paper a novel measurement, called the small- large (abbreviated as SL) ratio, and utilize this ratio to per- form the clustering. The support of an item i in a cluster C, Supc(i), is defined as the percentage of transactions which contain this item i in cluster C. For the clustering U0 shown in Figure 1, the support Supc, ( A ) is 20% and Supc, ( B )
is 80%. An item in a cluster is called a large item if the sup- port of that item exceeds a pre-specified minimum support S (i.e., an item that appeared in a sufficient number of trans-
actions). On the other hand, an item in a group is called a small item if the support of that item is less than a pre- specified maximum ceiling E (i.e., an item that appeared in a limited number of transactions). To model the relation- ship between minimum support S and maximum ceiling E, the damping factor X is defined as the ratio of E to S, i.e.,
(Minimum Support S = 60%). (Maximal Ceiling E = 30x1) A, C, F, G , H, 1 B. C, G Intra(U,) = 7 Inter (U,) = 2 Cost (Uo) = 9 S1.R Threshold U = 3/2 .. -. . 350 I D , G , H I 1/2
2.1 Large Items and Small Items
The concept of large items is first introduced in mining association rules [2]. In [8], using large items as similar-
ity measure of a cluster is utilized in clustering transac- tions. Specifically, large items in cluster Cj are the items frequently purchased by the customers in cluster Cj. In other words, large items are popular items in a cluster and thus contribute to similarity in a cluster. While rendering the clustering of fine quality, it is noted that the execution efficiency of 1 he algorithm in [8] could be fkther improved
due to its relatively inefficient steps in the refinement phase. This could be partly due to the reason that the similarity measurement used in [8] does not take into consideration the existence of small items. To remedy this, a maximal ceiling E is proposed in this paper for identifying the items of rare occuirences. If an item whose support is below
Figure 2. The large, middle, and small items in clusters, and the corresponding SL ratios of transactions.
X =
f .
In addition, an item is called a middle item if it is neither large nor small. For the supports of the items shown in Figure I , if S == 60% and E = 30%, we can obtainthe large, middle, and small items shown in Figure 2. In
C2 = {210,220,230,240,250}, B and I are large items. In addition, C and E are middle items and A is a small item.
Clearly, the portions of large and small items represent the quality ofthe clustering. Explicitly, the ratio ofthe num- ber of small items to that of large items in a group is called small-large ratio of that group. Clearly, the smaller the SL ratio, the more similar the items in that group are. With this
S L ratio measurement, we develop an efficient clustering al- gorithm, algorithm SLR (standing for Small-Large Ratio), for data items to minimize the SL ratio in each group. It is shown by our experimental results that by utilizing the SL ratio, the proposed algorithm is able to cluster the data items very efficiently.
This paper is organized as follows. Preliminaries are given in Section 2. In Section 3, an algorithm, referred to as algorithm SLR (Small-Large Ratio), is devised for cluster- ing market-basket data. Experimental studies are conducted in Section 4. This paper concludes with Section 5 .
2
Preliminariesa specified maximal ceiling E , that item is called a small item. Hence, small items in a cluster contribute to dissimi- larity in a cluster. In this paper, the similarity measurement of transactions is derived from the ratio of the number of large items to that of small items. In the example shown in Figure 1, with the minimum support S = 60% and the max- imum ceiling E = 30%, we can obtain the large, middle,
and small items by counting their supports. In Cl, item B is large because its support value is 80% (appearing in TID 1 10, 120,130, and 150) which exceeds the minimum sup- port S . However, item A is small in C1 because its support is 20% which is less than the maximum ceiling E.
2.2 C o s t ]Function
We use La1 (Cj , S ) to denote the set of large items with respect to aictribute I in Cj, and S r n ~ ( C j , E ) to denote the set of small items with respect to attribute I in
Cj.
For a clustering U = {C,, ..., Ck}, the corresponding cost for attribute I has two components: the intra-cluster cost Intra1 ( U ) and the inter-cluster cost Inter1 ( U ) , which are described in detail below.
Intra-Cluster Cost: The intra-cluster item cost is meant to represent for intra-cluster item-dissimilarity and is mea- sured by the total number of small items, where a small item is an item whose support is less than the maximal ceiling E .
Explicitly, we have We investigate the problem of clustering market-basket
data, where the market-basket data is represented by a set of transactions. A database of transactions is denoted
by
D
= { t l , t 2 ,...,
t l L } , where each transaction ti is a Note that we did not use x&iISm~(Cj, as the intra- set of items { i l,
i2,.
. .,
ih}. For the example shown in cluster cost since the use of\
Smr (Cj,
E )I
may cause Figure 1, we are given a predetermined clustering U0=<
the algorithm to tend to put all records into a single or C1, C2, C3>,
where C1 = {110,120,130,140,150}, few clusters even though they are not similar. For exam-C2 = {210,220,230,240,250}, and C3 = ple, suppose that there are two clusters that are not sim-
(310,320,330,340,350). If large items remain
~ n t r a l ( ~ ) =
I
S m r ( C j ,E ) I .
large after the merging, merging these two clusters will reduce ISmr(Cj, E)I because each small item previ- ously counted twice is now counted only once. However,
required. The goal of this paper focuses on designing an efficient algorithm for the refinement phase.
this merging is incorrect because sharing of small items should not be considered as similarity. For the clustering U0 shown in Figure 2, the small items of C1 are {A, C, F, G, H, I ) . In addition, the small item of Cz is {A) and the
small items of C3 are {B, C, G). Thus, the intra-cluster cost Intra1 (Uo) is 7.
Inter-Cluster Cost: The inter-cluster item cost is to rep- resent inter-cluster item-similarity and is measured by the duplication of large items in different clusters, where a large item is an item whose support exceeds the minimum support
S.
Explicitly, we haveI n t e r r ( U ) =
E~=,IL~~(c,,s)I
-1
LU~(C,,S)J Note that this measurement will inhibit the generation of similar clusters. For the clustering U0 shown in Figure 2, the large items of C1 are { B, D}. In addition, the large items of Cz are { B, I} and the large items of Cs are { D, H}. Asaresult,E;=,ILUI(C,,S)I
= 6 and1
L n l ( C , , S ) / = 4. Hence, the inter-cluster cost Interr(U0) = 2.Total Cost: Both the intra-cluster item-dissimilarity cost
and the inter-cluster item-similarity cost should be consid- ered as the total cost incurred. Without loss of generality, a weight w is specified for the relative importance of these two terms. The definition of item cost C o s t ~ ( U o ) with re- spect to attribute I is:
Cost1 ( U o ) = w
*
intra^ (Uo)+
I d e r r ( Uo).
If the weight zu>
1, I?1t?Xr(Uo) is more important than I,nterZ(Uo), and vice versa. In our model, we let w =1. Thus, for the clustering U0 shown in Figure 2, the CostI(U0) is 7
+
2 = 9.3
AlgorithmSLR
for Clustering Market- Basket DataIn this section, we devise algorithm SLR (Small-Large Ratio) which essentially utilizes the measurement of the small-large ratio (SL ratio) for clustering market-basket data. For a transaction t with one attribute I , ILl(t)l rep- resents the number of the large items in t and ISz(t)
I
repre- sents the number of the small items in t. The SL ratio o f t with attribute I in cluster Ci is defined as:For the clustering shown in Figure 1, -
= { 110,120,130,140,150}, Cz -
c1
{ 210,220,230,240,250}, and C3 -
{310,320,330,340,350}. Figure 2 shows that the minimum support S = 60% and the maximal ceiling E = 30%. For TID 120, we have two large items {B, D} and one small item { A } . Thus, the SL ratio of TID 120 is SLR1tem(C1, 120) = = 0.5. Similarly, the SL ratio of TID 240 is SLR1t,,,(Cz, 240) =
$
= 1, because TID240 has 2 large items { B, I} and 2 small items { C, E}. As
mentioned before, although algorithm Basic utilizes the large items for similarity measurement, algorithm Basic is exhaustive in the decision procedure of moving a transac- tion t to cluster Cj in current clustering U = { CI, . .
. ,
ck}
. For each transaction t , algorithm Basic must compute all costs of new clusterings when t is put into another cluster. In contrast, by utilizing the concept of small-large ratios, algorithm SLR can efficiently determine the next cluster-
for each transaction in an iteration, where an iteration is
2‘3 Objective Of Market-Basket Data a refinement procedure from one clustering to the next The objective ofclustering market-basket data is “We are
given a database of transactions, a minimum support, and a maximum ceiling. Then, we would like to determine a
clustering U such that the total cost is minimized’. The procedure of clustering algorithm we shall present includes two phases, namely, the allocation phase and the refinement phase. In the allocation phase, the database is scanned once and each transaction is allocated to a cluster based on the purpose of minimizing the cost. The method of allocation phase is straightforward and the approach taken in [8] will suffice. In the refinement phase, each transaction will be evaluated for its status to minimize the total cost. Explicitly, a transaction is moved from one cluster to another cluster if that movement will reduce the total cost of clustering. The refinement phase repeats unti! no further movement is
clustering.
3.1 Description
of
AlgorithmSLR
Figure 3 shows the main program of algorithm SLR, which includes two phases: the allocation phase and the re- finement phase. Similarly to algorithm Basic [8], in the al-
location phase, each transaction t is read in sequence. Each transaction t can be assigned to an existing cluster or a new cluster will be created to accommodate t for minimizing the total cost of clustering. For each transaction, the initially allocated cluster identifier is written back to the file. How- ever, different from algorithm Basic, algorithm SLR com- pares the SL ratios with the pre-specified SLR threshold cr
some transactions might not be suitable in the current clus- ters. Hence, we define an excess transaction as a transac- tion whose SL ratio exceeds the SLR threshold a. In each iteration of the refinement phase, algorithm SLR first com- putes the support values of items for identifying the large items and the small itenis in each cluster. Then, algorithm SLR searches every cluster to move excess transactions the
excess pool, where all excess transactions are collected to- gether. After collecting all excess transactions, we compute the intermediate support values of items for identifying the large items and the small items in each cluster again. Fur- thermore, empty clusters are removed. In addition, we read each transaction t, from the excess pool. In line 8 to line 14 of the refinement phase shown in Figure 3, we shall find for each transaction the best cluster that is the cluster where that transaction has the minimal SL ratio after all clusters are considered. If that ratio is smaller than the SLR thresh- old, we then move that transaction from the excess pool to the best cluster found. However, if there is no appropriate cluster found for that transaction t,, t , will remain in the excess pool. If there is no movement in an iteration after all transactions are scanned in the excess pool, the refine- ment phase terminates. Otherwise, the iteration continues until there is no further movement identified. After the re- finement phase completes, there could be some transactions still in the excess pool that are not thrown into any appro- priate cluster. These transactions will be deemed outliers in the final clustering result. In addition, it is worth mentioning that algorithm SLR is able to support the incremental clus- tering in such a way that those transactions added dynam- ically can be viewed as new members in the excess pool. Then, algorithm SLR will allocate them into the appropri- ate clusters based on their SL ratios in existing clusters. By treating the incremental transactions as new members in the excess pool, algorithm SLR can be applied to clustering the incremental data efficiently.
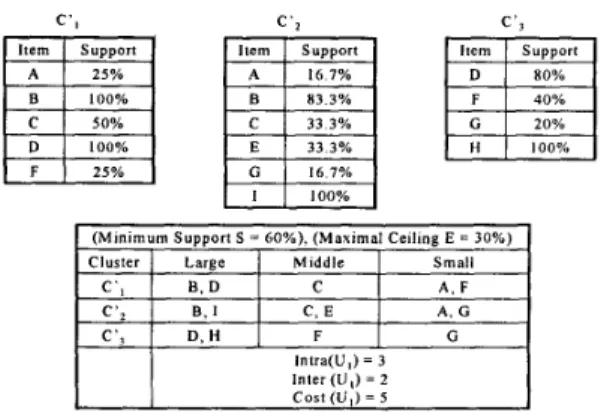
3.2 Illustrative Example of SLR
Suppose the clustering U0
=<
C1, C,, C3>
shown in Figure 1 is the clustering resulted by the allocation phase. The cost of U0 examined by the similarity measurement is shown Figure 2. In this experiment, the minimum sup- port S = 60%, the maximal ceiling E = 30%, and the SLRthreshold a =
$.
In the refinement phase shown in Figure 4, algorithm SLR computes the SL ratio for each transac- tion and reclusters the transactions whose SL ratios exceed a. Figure 5 is the final clustering U1=<
Ci, C $ , CA>
obtained by applying algorithm SLR to the clustering U0.First, algorithm SLR scans the database and counts the sup- ports of items shown in Figure 1. In C1, the support of item A is 20% and the support of item B is 80%. Then, algorithm SLR identifies the large and small items shown
Figure 3. The overview of algorithm SLR.
in Figure 2. In C1, item A is a small item and item B is a large item. For the transactions in each cluster, algorithm SLR compuies their SL ratios in that cluster. In C1, the large items are {B, D} and the small items are {A, C, F, G, H, I}. For transaction TID 120, item {A} is a small item and items {B, D) are large items. Thus, the SL ra-
tio of TID 12!0 is SLR1tC,,(C1,120) = which is smaller than a. However, for transaction TID 140, items { F, H} are small items and item { D} is the only large one. The SL ra- tio of TID 140 is S L R I ~ ~ , , ( C ~ , 140) = +, larger than a . After the SL ratios of all transactions are determined, algo- rithm SLR shall identify the excess transactions and move them into the excess pool. Three transactions, i.e., TIDs 140, 150, and 330, are identified as the excess transactions as shown in Figure 2. After collecting all excess transac- tions, we compute the intermediate support values of items for identifying the large items and the small items in each cluster again. The intermediate clustering of U0 is shown in
Figure 4. For each transaction in the excess pool, algorithm SLR will compute its SL ratios associated with all clusters, except the cluster that transaction comes from. Note that an item that is not shown in the cluster C, can be viewed as a small item because its support will be one when the corresponding transaction is added into C,. For transaction TID 140 moved from C1, SLRlt,,(C2,140) = = CO with three small items {D, F, H} in C2. On the other hand, SLRrtem(C3,140) = with one small item {F} and two large items { D, H} in C3. For transaction TID 140,
C ' , C ' , C', Item A B c E G 330 E C . V,F
L'
Support 1 6 7 % 83.3% 33 3% 3 3 3% 1 6 7 % B C P I C I a o IFigure 4. Using small-large ratio to recluster
the transactions by algorithm SLR.
the smallest SL ratio is SLRrtem(C3, 140) = which is smaller than cx =
4.
Thus, transaction TID 140 is reclus- tered to C,. Figure 4 shows that algorithm SLR utilizes the SL ratios to recluster transactions to the most appropriate clusters. The resulting clustering is U1=<
Ci, Ci, CA >.In the new clustering, algorithm SLR will compute the sup- port values of items for all clusters. Figure 5 shows the supports of the items in C ; , C4,and Ci. Algorithm SLR proceeds until no more transaction is reclustered. The clus- tering
U1
is also the final clustering for this example and the final cost Custr(U1) = 5, which is smaller than the initial cost Costr(Uo) = 9.4
Experimental ResultsTo assess the performance of algorithm SLR and algo- rithm Basic, we conducted several experiments for cluster- ing various data. We comparatively analyze the quality and performance between algorithm SLR and algorithm Basic in the refinement phase.
4.1 Data Generation
We take the real data sets of the United States Congres- sional Votes records in 1984 [I] for performance evalua- tion. The file of 1984 United States congressional votes contains 435 records, each of which includes 16 binary at- tributes corresponding to every congressman's vote on 16 key issues, e.g., the problem of the immigration, the duty of export, and the educational spending, and so on. There are
168 records for Republicans and 267 for Democrats. We
Fl
100% 2 5 %I I 100%
100%
(Minimum Support S = 60%), (Maximal Ceiling E = 30%) Middle Small C, E A. G I r 3 . I n~ I F I c. I Intra(U,) = 3 Inter ( U , ) = 2 c o s t (U,) = 5
Figure 5. The clustering Ul
=<
Ci,Ci,
C;>
obtained by algorithm SLR.
set the minimum support to 60%, which is the same as the minimum support setting in [8] for comparison purposes.
To provide more insight into this study, we use a well- known market-basket synthetic data in [2], as the synthetic data for performance evaluation. This code will generate volumes of transaction data over a large range of data char- acteristics. These transactions mimic the transactions in the real world retailing environment. The size of the transaction
is picked from a Poisson distribution with mean /TI, which is set to 5 in our Experiments. In addition, the average size ofthe maximal potentially large item sets, denoted by 111, is set to 2. The number of maximal potential large item sets, denoted by (LI, is set to 2000. The number of items, denoted by
IN(,
is set to 1000 as default.4.2 Performance Study
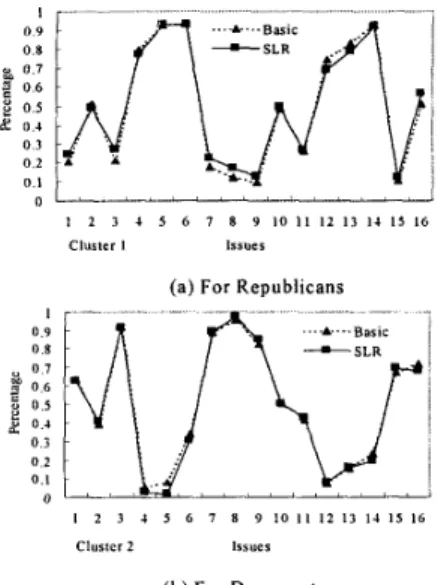
In the experiment for the real data, S = 0.6 and cy = 2.5,
and X varies from 0.4 to 1, where X is the damping factor. Figure 6 shows the results of two clusters, cluster 1 for Re- publicans and cluster 2 for Democrats. It shows that these two results are similar to each other in the percentages of the issues in cluster 1 and cluster 2. Recall that an iteration is a refinement procedure from one clustering to the next clustering. Figure 7 shows the comparison of the execution time between algorithm SLR and algorithm Basic in each it- eration. It can be seen that although algorithm SLR has one more iteration than algorithm Basic, the execution time of algorithm SLR is much shorter than that of algorithm Basic in every iteration.
We next use the synthetic data mentioned above in the following experiments. It is shown by Figure 8 that as the database size increases, the execution time of algorithm Basic increases rapidly whereas that of algorithm SLR in-
.... . . .. .. .. .. .. . . . ... . . .. ... . .. ... . . p 0.5 d! 0.4 0.1 I 2 3 1 5 6 7 8 9 1 0 1 l 1 1 1 3 1 1 1 5 1 6 Cluster I I S S U C l
(a) For Republicans
1 0.9 0 8 0 7 9 0 6 5 0 5 &j 0.4 0 3 0 2 0.1 0 I 2 3 J 5 6 7 8 9 1 0 1 1 1 2 1 3 I J 1 5 1 6 Clur1cr 2 ISSUE-l (b) For Democrats
Figure 6. The percentage of the issues in clus-
ter 1 and cluster 2.
creases linearly, indicating the good scale-up feature of al- gorithm SLR.
5
Conclusion
In view of the nature of clustering for market basket data,
we
devisedin
thispaper a
novel measurement, called thesmall-large ratio. We have developed an efficient clustering algorithm for data items to minimize the SL ratio in each group. The proposed algorithm is able to cluster the data items very efficiently. This algorithm not only incurs an
I 2 3 4
lterawn
Figure 7. Execution time of algorithm SLR and
algorithm Basic in each iteration.
3mm
Figure 8. Execution time of algorithm SLR and
algorithm Basic as the number of transac-
tions
ID1
varies.execution time that is significantly smaller than that by prior work but also leads to the clustering results of very good quality.
Acknowledgments
The authcas were supported in part by the Ministry of
Education Project No. 89-E-FA06-2-4-7 and the National Science Council, Project No. NSC 89-221 8-E-002-028 and NSC 89-22 1!3-E-002-028, Taiwan, Republic of China.
References
[l] UCI Machine Learning Repository.
http: ://www. ics. uci. eddmleardMLRepository html.
[2] R. Agranal and R. Srikant. Fast Algorithms for Mining As-
sociation Rules in Large Databases. Proceedings ofthe 20th International Conference on Very Large Data Bases, pages
478-499, September 1994.
[3] A. G. Buchner and M. Mulvenna. Discovery Internet Market- ing Intelligence through Online Analytical Web Usage Min- ing. ACM SIGMOD Record, 27(4):54-61, Dec. 1998. [4] M.-S. Chen, J. Han, and P. S . Yu. Data Mining: An Overview
from a Database Perspective. IEEE Transactions on Knowl- edge and Data Engineering, 8(6):866-833, 1996.
[ 5 ] A. K. Jain, M. N. Murty, and P. J. Flynn. Data Clustering: a Review. ,4CMCornputingSurveys, 31(3):264-323, Sep. 1999. [6] D. A. Keim and A. Hinneburg. Clustering Techniques for the Large Data Sets
-
LFrom the Past to the Future. Tutorial notes for ACM SIGKDD 1999 international conference on Knowl- edge discovery and data mining, pages 141-181, Aug. 1999.[7] A. Strehl and J. Ghosh. A Scalable Approach to Balanced, High-dimensional Clustering of Market-baskets. Proceed- ings of the 7th International Conference on High Performance Computing, December 2000.
[8] K. Wang, C. Xu, and B. Liu. Clustering Transactions Using
Large Items. ACM CIKM International Conference on Infor- mation and Knowledge Management, pages 483490, Nov.