4.1
HotSpot Cache: Joint
Tern
tial LoeaIiUy
Exploitation
for
I-Cach
uetion
Chia-Lin Yang
Chien-Hao Lee
Department of Computer Science and
National Taiwan University
Taipei
106,Taiwan
yangc
Q csie.ntu.edu. tw
r910170csie.ntu.edu.tw
Department of Computer Science and
National Taiwan University
Taipei
106,Taiwan
Information Engineering
Information Engineering
ABSTRACT
such as cellular phones and personal digital assistants. ForPower consumption is an important design issue of current embedded systems. It has been shown that the instruction cache accounts for a sienificant nortion of the nower dissi-
a multimedia-enabled embedded system, reducing power re- quirement while meeting the performance demand is the most
I
pation of the whole chip. Several studies propose t o add a cache (LO cache) that is very small relative t o the con- ventional L1 cache on chip for power optimization since a smaller cache has lower load capacitance. However, energy savings often come at the cost of performance degradation. In this paper, we propose a novel instruction cache axchi- tecture, the HotSpot cache, t h a t achieves energy savings without sacrificing performance. The HotSpot cache identi- fies frequently accessed instructions dynamically and stores them in the LO cache. Other instructions are placed only in the L1 cache. A steering mechanism is employed t o di- rect a n instruction to its allocated cache in the instruction fetch stage. The simulation results show t h a t the HotSpot cache can achieve 52% instruction cache energy reduction on the average for a set of multimedia applications without performance degradation.
Categories and Subject Descriptors
B.3.2 [ M e m o r y Structures]: Design Styles - Cache Mem- ories
General Terms
Performance, Design, Experimentation
Keywords
Instruction Cache, Embedded Systems, Low Power Design
1.
INTRODUCTION
There has been a n increasing demand for running multi- media applications on battery-operated embedded systems
L1 Cache
1
L1 Cache1
,b,
F i g u r e 1: ( a ) Filter cache (b) HotSpot c a c h e It has been reported that the instruction cache consumes a significant portion of the total processor power. For ex- ample, 27% of processor power is dissipated in the L1 iu- struction cache in StrongARM 110 [13]. Cache partitioning
is commonly used t o reduce the dynamic energy dissipa-
tion of caches since a smaller cache has a lower load ca- pacitance. Block buffering [14] proposes to buffer the last accessed cache line. If the d a t a in t h e same cache line is accessed a n the ncxt request, only t h e buffer needs t o be accessed.
A
two-phase cache access scheme can be used to avoid performance degradation [7]. T h e Filter cache [9] adds a bigger buffer (i.e., the LO cache) to cache recently accessed cache blocks as shown in Figure l ( a ) . On each access, the LO cache is first zcessed. T h e L1 cache is only accessed when a n LO miss occurs. This approach can achieve more energy reduction compared with the block buffering mechanism, however, it could cause significant performance degradation if a n aodication's workina set cannot be caDtured in the..
Ismall LO cache. Studies show that the performance degra- dation could be more than 20%. In this paper, we propose a novel instruction cache architecture, the HotSpot cache as shown in Figure l(b). Unlike the Filter cache where the
LO
and L1 cache are accessed sequentially, a dynamic steering mechanism is employed to direct a request to &her the LO or the ~1 cache, ~h~ ~1 cache is augmented with a block buffer. The design goal is to achieve cnergy savings compa- rable t o the Filter cache without sacrificing performance.
Permission CO make digital or hard copies of all or of this work for
personal or ~ l a s s r ~ o r n use is granted withaul fee provided that copies are
not made or distributed for p.mfit or commercial advantage and that copies
I& this notice and the full Citation on the first page.'To copy otherwise. to republish. to past on sewers or to redistribute to lists. requires prior specific permission and/or a fee.
ISLJ'ED'O4, August 9-1 1,2004, Newpon Beach, California, USA. Copyright 2004 ACM 1-581 13-929-2/04/0008
...
$5.M).T h e energy advantage of the Filter cache comes from refer- ences that hit in the LO cache. The LO cache hits are results of temporal locality of frequently accessed basic blocks (i.e., hot basic blocks) and spatial locality within a cache line. Therefore, in the proposed HotSpot cache scheme, hot basic blocks are identified dynamically and stored in the LO cache, while others are placed only in the L1 cache. The L1 cache is augmented with a block buffer to exploit the spatial locd- ity of non-hot basic blocks for additional energy savings. To prevent performance degradation, we limit the size of basic blocks allocated t o the LO cache, and a steering mechanism is employed to direct an instruction to its allocated cache in the instruction fetch stage.
One key factor t h a t determines the energy efficiency of the proposed HotSpot cache is the LO cache utilization. It has been shown that program execution is often composed of distinct phases which contain different sets of hot basic blocks [12]. Multimedia applications also present the sim- ilar program behavior. Figure 2 plots frequently accessed branches running a jpeg encoder. Each data point r e p r c sents a branch that is executed at least 1000 times per Sam- ple duration (10,000 branches). We can see t h a t the jpeg encoder execution is composed of 3 phases and each phase contains different hot basic blocks. To fully utilize the LO
"ol.D1ll a,,mt1/ I>rnODO ~ ll2DDOQ 1 1 , D m Y o : I2loOnO **am00 4 1 4 m o 1 1 1 ~ 0 0 0 50 100 150 so0 23s PO0 IxI.yII.. Ynl, F i g u r e 2: EYequently accessed b r a n c h d i s t r i b u t i o n of jpeg encoder
cache, one should identify hot basic blocks in each program phase instead of the entire program lifetime. Bellas et al. [Z] propose a static approach, L-Cache, that selects basic blocks to be mapped to the LO cache based on profile information from the entire program execution. This approach may un- derutilize the LO cachc in program phases where identified hot basic blocks are not active. Therefore, we design a run- time mechanism that dynamically detects phase change and selects active hot basic blocks early in each program phase. To make such a hardware-based technique useful for low en- ergy, we build the detection mechanism around t h e Branch Target Buffer. The simulation results show that for applica- tions with multiple phases, the HotSpot cache can achieve up t o 2x higher LO cache utilization than the L-Cache. With- out the cost of performance degradation, the HotSpot cache achieves equal or more energy savings than the Filter cache for all applications tested in the paper. The energy reduc- tion provided by the HotSpot cache is 52% on the average. T h e rest of the paper is organized as follows. Section 2 discusses related work. Section 3 presents the HotSpot cache mechanism. Section 4 describes our experimental method-
ology and Section 5 shows the results. Section 6 concludes this paper.
2. RELATED WORK
Several studies have proposed to use a smaller cache for re- ducing the energy dissipation of instruction cache[l4][1][ll]. The Filter cache 191 adds a smaller cache between the procec sor and L1 cache to store recently accessed cache blocks. As mentioned in the previous section, energy reduction is oftcn achieved at the cost of longer average memory access time. Tang et al. 1151 use a next address prediction scheme which dynamically predicts where the next instruction exists (LO or L1) to reduce the performance impact of the conventional filter cache design. Bellas et al. [2] propose a profile-guided
compiler to map frequently accessed instructions to the LO cache. Later, they suggest to dynamically manage the LO cache utilizing the branch predictor and the confidence cs- timation mechanism [lG]. Basic blocks associated with high confidence branches are selected for placement in the LO cache. Their scheme depends on the prediction accuracy of the underlying branch predictor. In this paper, we provide a more accurate approach for hot basic block selection. There are other studies proposing to dynamically detect frequently accessed instructions as well, but they have different opti- mization objectives from this work. Merten et al. [12] focus on runtime optimization, and Hu e t al. [6] target at reducing I-cache leakage consumption.
3. HOTSPOT CACHE ARCHITECTURE
3.1
Main Idea
Promoted Besic Blocks >= LO Size
Profiling Ldonitoring
G 3
Phase ChangeF i g u r e 3: H o t - b l o c k s e l e c t i o n and phase d e t e c t i o n The proposed system is composed of two stages as shown in Figure 3. In the profiling stage, the system gathers access frequencies of executed branches and determines which basic blocks should be promoted t o the LO cachc. The promoting policy is straightforward: a basic block is promoted to the LO cache once the corresponding branch reaches a predefined threshold (candidate threshold). To prevent performance degradation from excessive LO cache misses, we limit the size of promoted basic blocks. Once the LO cache is filled up, we stop profiling and enter t h e monitoring stage.
During the monitoring stage, the system tracks branch execution t o ensure that hot branches should account for at least half of the total branches executed. If they are less than half, it indicates that either the program enters a new phase or true hot basic blocks have not yet been correctly identified. The system should go back to the profiling stage to detect new sets of hot blocks.
Merten et al. [12] also use a branch counting mechanism for run-time hot basic block detection. However, our scheme
has essentially different design considerations from theirs. The objective of the work done by Merten et al. [12] is t o perform run-time optimizations on identified basic blocks. Since run-time optimizations incur time overhead, they are more conservative in declaring a hot branch. Branches with access frequencies greater than the candidate threshold are observed for a period of time before they are declared as hot branches. In contrast, we promote a basic block to the LO cache as soon as its access frequency reaches t h e candidate threshold. We adopt the cager promotion policy because we want to utilize the LO cache as often as possible. Pro- moting spurious hot basic blocks t o the LO cache does not incur much overhead as long as true hot basic blocks can he identified eventually. This is ensured by the monitoring scheme described above. Another design issue particular to this study is false phase change. Since we limit t h e size of ha- sic blocks promoted to the LO cache, if hot basic blocks have large static footprints, the hot branch execution percentage could be lower than 50% even though hot basic blocks have been correctly identified. If this situation occurs, the system would switch between the profiling and monitoring stages constantly. The false phase change phenomenon could PO-
tentially degrade the effectiveness of the proposed scheme if the LO cache can not be utilized during the profiling stage. In the next section, we detail the implementations t o rcalize the proposed scheme and our solution for the false phase change problem.
3.2
Implementations
Figure 4: Block diagram of HotSpot cache To achieve energy saving, the mechanism should not in- cur significant hardware overhead. Therefore, we design the hot spot and phase detection mechanisms around the Branch Target Buffer (BTB), which is commonly used in a modern microprocessor t o resolve branch target addresses in the instruction fetch stage. The block diagram of the prc- posed scheme is illustrated in Figure 4. Each entry of the B T B is augmented with a valid bit, a n execution counter, a hot-block flag, and a prcv-hot flag. The valid bit indi- cates whether the corresponding branch is a predicted taken branch or a predicted non-taken branch. In the conventional B T B design, a branch is removed from the BTB once it is
predicted non-taken. In our design, a branch is still kept in t h e BTB even it is predicted non-taken such t h a t we do no lose the access frequency of the target basic block. There- fore, a valid bit is set t o zero (one) for a predicted non-taken branch (predicted taken branch). The associated execution counter is updated when a branch is resolved. We only keep
track of the access froquency of a taken-branch. When the execution counter reaches its maximum value (i.e., candidate threshold), a potential hot block is detected. Therefore, the hot-block flag is set and t h e corresponding basic block of this branch is promoted t o the LO cache.
An up/down counter called the monitor counter (8 bits) is used t o track the hot branch execution percentage. The monitor counter is initially set to 128. I t decrements by one when a hot branch is executed and increments by one when a non-hot branch is executed. When the counter overflows, hot-block flags are cleared and execution counters are reset. The system goes back to the profiling stage to detect new sets of hot basic blocks since identified hot branches are not active for a period of time. As mentioned before, if a pro- gram exhibits the false phase change behavior, the system would stay in the profiling stage most of time. Therefore, it is important to allow the LO cache t o be accessed during the profiling stage. We koep t h e hot branch information of the last phase in the prev-hot flag column until the system sta- bilizes (i.e., entering the monitoring stage). On each access, if either one of the hot-block and prev-hot flags is set, the access is directed t o the LO cache. Once the system enters the monitoring stage, all prev-hot flags are cleared.
The last component in the proposed mechanism is the mode controller which controls whether the LO or L1 cache should be accessed during the instruction fetch (IF) stage. There are three fetch modes:
o LO mode: Fetch a n instruction from the LO cache
o L1 mode: Fetch an instruction from the L1 cache
o Promoting mode: Fetch a n instruction from the L1 cache and copy it t o the LO cache.
Table 1 summaries transition events for each fetch mode. If an instruction hits in the B T B and the associated valid bit is 1, the LO mode is set if either the hot-block or prev-hot flag is 1. If both the hot-block and prev-hot flags arc zeros and the execution counter equals to the candidate threshold, the Promoting mode is set and t h e hot-block flag is set to one. If none of the above two cases is true, the L1 mode is set. For a BTB miss or a BTB hit with the associated valid bit equal to zero, we do not change the fetch mode. The rationale is as follows. In this scenario, an instruction could be (1) a non-branch instruction, ( 2 ) a predicted non-taken branch
or (3) a mis-predicted taken branch. The first case should not incur mode transition. As for the second scenario, we found that the access frequency of a non-taken branch is usually close to that of the last taken branch. Therefore, we do not keep track of the access frequency of a non-taken branch and simply let a non-taken branch inherit the fetch mode of the last taken branch. As for the third scenario, it
is hard to predict the status of a mis-predicted branch (hot or non-hot), therefore, we do not change the fetch mode.
The last event causing mode transition is an LO cache miss. Whenever a fetch misses in the LO cache, the L1 mode is activated. This is based on the observation that if an instruction misses in the LO cache, it is very likely that the remaining instructions in the same basic block also miss in the LO cache. Therefore, we should fetch instructions from the L1 cache directly t o avoid increasing the L1 cache access latency. Note t h a t we switch the fetch mode t o the L1 mode instead of Promoting for performance consideration. An
T a b l e 1: F e t c h mode t r a n s i t i o n e v e n t s
voice, image and video). study are summarized in Table 3.
The applications tested in the
5.
EXPERIMENTAL RESULTS
In this section, we evaluate if the HotSpot cache success- fully achieves the optimization goal: achieving energy sav- Table 2 : C a c h e energy c o n s u m p t i o n per access
~~
ings comparable t o the Filter cache without performance degradation. We first show that the overhead incurred from accessing various counters is negligible. We then compare the LO cache utilization of the HotSpot cache with t h a t of the static amroach
-
L-cache 121. Finallv. we comuare theLame /Mad
i
~ ~ 3 o -Mpeg2 encoder/decoder
I
Video..
L ." .
energy and performance of the HotSpot cache with those of the Filter cache.
5.1 Overhead Analysis
T a b l e 3: B e n c h m a r k s u m m a r i e s The main overhead imposed by the proposed scheme is from accessinc the execution counter (4 bits) associated with each BTB enGy and the monitor counter (8hits). We model LO cache miss indicates that the corresponding hot basic
block is very likely conflicting with other hot basic blocks, a counter as a register in Wattch The energy per ac- Therefore, to minimize the
Lo
cache miss rate, once a cache cess is roughly 0.18pJ and 0.34pJ for 4-bit and 8 - m regis- ters, respectively. Our siniulation results indicate t h a t for the benchmarks tested in this paper, there are 0.02/0.13 bit transition per cycle on the averaae for the executionlmonitor line is replaced from the LO cache, we do not bring it intothe LO cache again to eliminate conflicts among promoted
L - L L.-..:- L 1 - A . -
L L V L U_LL " L V C h D
counters. Note- that the frequency of bit transitions of the
4.
EXPERIMENTAL METHODOLOGY
We use the Wattch toolset 131 developed at Princeton Uni- versity to conduct our experiments. Wattch generates both the performance and energy data through execution-driven simulation. We modified Wattch t o simulate the HotSpot cache. Our baseline machine is ii single-issue in-order pro-
cessor. The processor contains a 512B, direct-mapped LO instruction cache and a 16KB direct-mapped L1 instruc- tion cache. The line size of both the LO and L1 cache is 32 bytes. The BTB has 64 sets and the associativity is 4. We implemented a 2-level branch predictor with a total of 2048 entries. All the caches are single-ported. We evaluate energy consumption assuming 0.35nm process technology. Table 2 shows the energy consumption per access for var- ious instruction cache components examined in this paper. Only the dynamic energy consumption is considered in this study. Note that the HotSpot cache is orthogonal t o other techniques for reducing the instruction leakage power, such as t h e Drowsy cache 141. The candidate threshold value is set to 16. We performed analysis on several threshold val- ues (8 t o 1024) and found that 16 works well for all the applications tested in this paper.
Since we focus on the multimedia applications in this p*
per, we use applications in the Mediabench
[lo]
and Mibench [5] to evaluate our scheme. But. the proposed scheme can also be applied to other classes of applications. We choose 6 sets of encoder/decoder for different media types (data,monitor counter is larger than the execution counter be- cause a n application stays in the monitoring stagc much longer than the profiling stage. On the average, the en- ergy consumed from counter accesses is 0.048 pJ per cycle.
It
is roughly 5 orders of magnitude lower than the energy consumed per I-cache access (1.9nJ). Therefore, the counter overhead is negligible.5.2 LO Cache Utilization
One key factor that determines the effectiveness of the HotSpot cache is the LO cache utilization. We claim t h a t the
LO
cache utilization of the HotSpot cache should be higher than that of the static approach-
L-cache 121 since phase in- formation is considered. We use the percentage of dynamic instructions accessing the LO cache as the metric t o quantify the LO cache utilization. To obtain theLO
cache utilization for the L-cache, we sort basic blocks according to their access frequencies and add the frequencies of most frequently exe- cuted basic blocks until their accumulated code size reaches the size of the LO Cache. This can be considered as the op- timal LO cache utilization achievable by a static mechanism similar t o the Lcache since it assumes no conflicts among frequently executed basic blocks.Two program attributes determine how well the HotSpot cache utilizes the LO cache compared with the L-cache. The first one is whether promoted cache blocks conflict from one another in the LO cache. Recall t h a t replaced LO cache lines are not brought into the LO cache again. This is a trade-
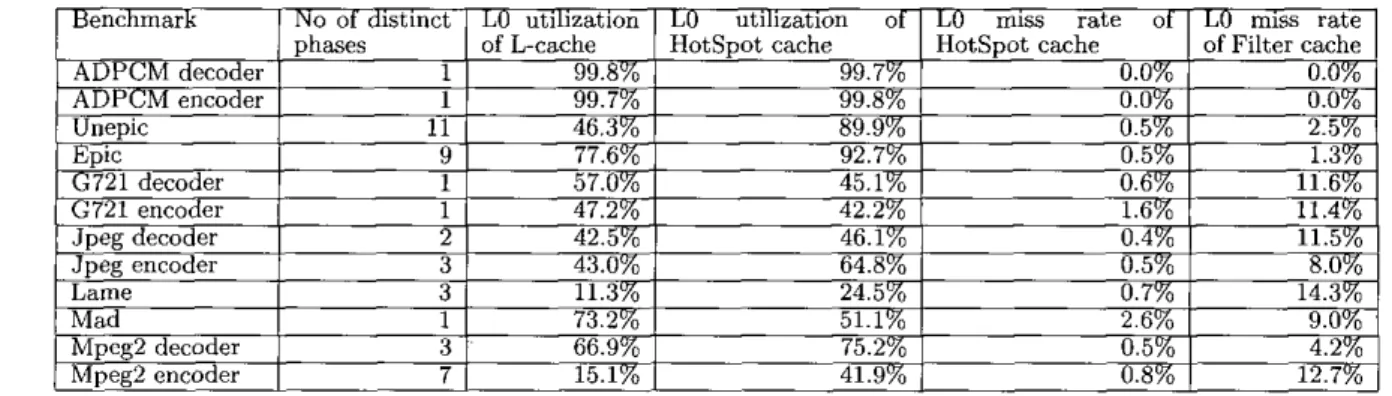
off between energy savings and performance. T h e second factor is the number of distinct phases in a program. The proposed scheme should have a more significant advantage over the L-cache for applications with more phases. From the results shown in Table 4, we can see t h a t for applica- tions with more distinct phases', such as unepic. epic, jpeg encoder, lame, and mpegl decoder/encoder, the HotSpot cache achieves significantly higher LO cache utilization than the L-cache. Adpcm encoder/decoder have very small code sizes, therefore, both the HotSpot cache and L-Cache c a p ture the whole program in the LO cache. Mad and g721 encoder/decoder are three applications where t h e HotSpot cache achieves lower LO utilization than the L-cache. All three applications have only one phase during program exe- cution. Mad has significantly lower LO utilization than the
LO
cache due to severe conflicts among hot basic blocks in the LO cache.We need to point out that the higher LO cache utilization achieved in the HotSpot cache does not come at the expense of performance degradation. In Table 4, we list the LO cache miss rates of both the HotSpot and Filter cache mechanism. We can see that except for mad, the LO cache miss rates for
all benchmarks are below or close t o 1% while the miss rate of the Filter cache is up t o 14%. Mad has severe interferences among promoted hot basic blocks. However, since we do not bring replaced hot basic blocks into the LO cache as described in Section 3.2, conflicts among hot basic blocks do not incur excessive LO cache misses. In the next section, we will show that performance degradation caused by
LO
misses i n mad is negligible.
5.3
Performance and Energy-Saving of the
HotSpot Cache
In this section, we compare the energy savings and perfor- mance of the HotSpot cache with the Filter cache. Figure 5 shows the energy consumption normalized to the base con- figuration (without the LO cache) for the Filter cache, hlock buffering, HotSpot cache, and HotSpot cache without block buffering. We can see that block buffering provides com- parable energy reduction (30% t o 40%) for all benchmarks. This indicates that the spatial locality within a cache line exists for all applications tested. The Filter cache achieves 'To determine the number of distinct phases, we performed t h e same branch behavior analysis of jpeg encoder as shown in Figure 2.
F i g u r e 5 : N o r m a l i z e d e n e r g y c o n s u m p t i o n of F i l t e r c a c h e , b l o c k buffering, HotSpot c a c h e and HotSpot c a c h e w i t h o u t b l o c k b u f f e r i n g
Table 4: LO c a c h e utilization: HotSpot c a c h e V.S. L-cache
more energy reduction compared with block buffering for most applications, however, the advantage diminishes for applications with high LO miss rates. For lame, the hlock buffering mechanism even consumes less energy than the Filter cache. The HotSpot cache is most energy efficient for all benchmarks. For applications that the Filter cache can capture almost the entire working sets (e.g.. adpcm en- coderJdecoder and epic/unepic), the HotSpot cache success- fully promotes the whole working set t o the LO cache thereby achieving equal amount of energy reduction as the Filter cache. For applications with large working sets (e.g., g721 encoderJdecoder, jpeg encoderJdecoder, lame and mpeg2 encoder), the HotSpot cache reduces more energy c o n s u m p tion than the Filter cache because of the additional energy savings from block buffering. To show the importance of ex- ploiting the spatial locality of instructions allocated t o the
L1
cache, we also measure t h e energy consumption of the HotSpot cache without block buffering. From Figure 5, we can see that the additional energy savings provided by block buffering (HotSpot cache vs. HotSpot cache without block buffering) are significant for applications with low LO cache utilization.To show that the HotSpot cache reduces energy reduc- tion without sacrificing performance, the execution time of the Filter and HotSpot cache normalized t o the base con-
Figure 6: N o r m a l i z e d delay of HotSpot c a c h e and Filter c a c h e
figuration (without the LO cache) is shown in Figure 6. We can sec that the normalized execution time of the HotSpot cache is close to 1 for all benchmarks while the Filter cache causes up t o 15% of performance degradation (e.g., g721 encoder/decoder).
6.
CONCLUSIONS
In this paper, we propose an architectural approach to dy- namically select basic blocks for placement in the LO cache. We design a profiling and phase detection nrechanism that can successfully identify frequently accessed basic blocks in each program phase at runtime. Only basic blocks declared as hot blocks are stored in the LO cache. The L1 cache is augmented with a block huffer for exploiting spatial locality within a cache line for energy savings. A mode controller is employed to determine which cachc (LO or L1) should
h e accessed during the instruction fetch stage. The simula- tion results show that the proposed mechanism can achieve more energy savings than the Filter cache. The energy con- sumption of the instruction cache is reduced by 52% on the average for a set of multimedia applications without perfor- mance degradation.
7. ACKNOWLEDGEMENTS
This work is supported in part by research grants from ROC National Science Council (NSC-92-2213-E-002-014, NSC- 93-2220-E-002.013) and Microsoft.
8.
REFERENCES
[l] R. S. Bajwa, M. H. H. Kojima, D. Gorny. K. Nitta,
A. Shridhar, K. Seki, and K. Sasaki. Instruction buffering t o reduce power in processors for signal processing. IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 5(4), December 1997. [2] N.
E.
Bellas, I. N. Hajj, C. D. Polychronopoulos, andG. Stamoulis. Architectural and compiler techniques for energy reduction in high-performance
microprocessors. IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 8(3), June 2000. [3]
D.
Brooks, V. Tiwari, and M. Martonosi. Wattch Aframework for architectural-level power analysis and optimizations. In Proceedings of the 27th International Symposium on Computer Architecture (ISCA). Vancouver, British Columbia, June 2000
[4] K . Flautner, N. S. Kim, S. Martin, D. Blaauw, and T. Mudge. Drowsy caches: Simple techniques for reducing leakage power. In Proceedings of the 27th International Symposium on Computer Architecture (ISCA), 2002.
[5] M. R. Guthaus, J. S. Ringenberg, D. Emst, T . M. Austin, T. Mudge, and
R.
B. Brown. Mibench: A free, commercially representative embedded benchmark suite. IEEE 4th Annual Workshop on WorkloadCharactenzation, December 2001.
[6] J . S. Hu, A. Nadgir,
N.
Vijaykrishnan, M. J. Irwin, and M. Kandemir. Exploiting program hotspots and code sequentiality for instruction cache leakage management. In Proc. of the International Symposium on Low Power Electronics and Design (ISLPED'03j, Seoul, Korea, August 2003.[7] M. B. Kamble and K. Ghose. Analytical energy dissipation models for low power caches. In Proc. of the International Symposium on Low Power Electronics and Design, 1997.
[8] S. Kaxiras, Z. Hu, and M. Martonosi. Cache decay: Exploiting generational behavior t o reduce cache leakage power. In Proceedings of the 28th International Symposium on Computer Architecture (ISCAj, Goteborg, Sweden, June 2001.
[9]
J.
Kin, 14. Gupta, andW.
H. MangioneSimith. The filter cache: An energy efficient memory structure. In Proceedings of 30th Annual International Symposium on Microarchitecture, December 1997.Media-bench: A tool for evaluating and synthesizing multimedia and communications systems. In Proceedings of the 30th Annual International
Symposium on MicroArchitecure, Decernbcr 1997. [ll] L.
H.
Lee, W. Moyer, and J. Arends. Instruction fetchenergy reduction using loop caches for embedded applications with small tight loops. In Proceedings of
International Symposium on Low Power Design, pages 63-68, August 1999.
Gyllenhaal, and W. W. Hwu. A hardware-driven profiling scheme for identifying program hot spots t o support runtime optimization. In Proceedings of International Symposium Computer Architecture, pages 136-147, May 1999.
[13]
J.
Montanaro and et al. A 160-mhz, 32-b, 0.5-w cmos risc microprocessor. IEEE Journal of Solid State Circuits, 31(11):1703-1714, November 1996. [14] C:L. Su and A. Despain. Cache design tradeoffs forpower and performance optimization: A case study. In Proceedings of International Symposium on Low Power Deszgn, April 1995.
[15] W. Tang, R. Gupta, and A. Nicolau. Design of a predictive filter cache for energy savings in high performance processor architectures. In International
Conference on Computer Design(lCCD), Austin, [lo] C. Lee, M. Potkonjak; and
W.
H. Mangione-Smith.[12] M. C. Mcrten, A. R. Trick, C.
N.
George, J . C.Texas, USA, 2001.
[16] N. E. Bellas and I. N. Hajj and C. D.
Polychronopoulos. Using Dynamic Cache Management Techniques to Reduce Energy in General Purpose Processors. IEEE Transactions on Very Large Scale