行政院國家科學委員會專題研究計畫 成果報告
綠豆 cDNA Library 的建構與澱粉合成酵素基因的選殖
計畫類別: 個別型計畫 計畫編號: NSC91-2313-B-039-002- 執行期間: 91 年 08 月 01 日至 92 年 07 月 31 日 執行單位: 中國醫藥大學營養學系 計畫主持人: 柯源悌 計畫參與人員: 柯源悌 石韻琦 報告類型: 精簡報告 處理方式: 本計畫可公開查詢中 華 民 國 92 年 10 月 31 日
九十一年度國科會專題計畫成果報告
計畫編號:NSC 91-2313-B-039-002
綠豆cDNA library 的建構與澱粉合成酵素基因的選殖
Construction of mung bean cDNA library and cloning of its starch synthase genes 執行期限:91 年 8 月 1 日至 92 年 7 月 31 日
主持人:柯源悌 中國醫藥大學 營養系 e-mail: [email protected] 中文摘要:
依據參與澱粉生合成的酵素群BE, SSS, GBSS
及SP 保守區間所設計的基因特異性引子組,對成
長中之台南五號綠豆 (Vigna radiata L. cv Tainan no. 5) 的 PolyA mRNA 進行反轉錄聚合酶鏈鎖反應 (RT-PCR)的 cDNA 選殖,只有 SBE F1 及 SBE R1
引子對,成功的量化出一段794 bp 的 cDNA。其內
部序列經過與GCG Database 比對,發現和
Phaseolus vulgaris 物種的 BE I (kbe1; accession no.
AB029548; 3,360 bp) 全長序列的重疊部分有 97% 的相似度,和 Ipomoea batatas (sweet potato) 的 SBE II (AB071286; 3,123 bp) 全長序列的重疊部分 有84%的相似度,經過 PileUp 並排後,所得綠豆 cDNA 序列為靠近中間部位,已將此 cDNA 片段選 殖到pGEM T-Eazy 載體中作為株系保存,命名為 pVrbeIp。為了得到全長序列,目前由所得的 SBE cDNA 片段內部序列已設計引子在單股 cDNA library 中進行 5’與 3’RACE,3’RACE 反應較平順, 獲得之1,200 bp 定序當中。 關鍵詞:綠豆、澱粉合成酉每、基因選殖、RT-PCR Abstract
Gene-specific primer pairs designed from cDNA conserved motifs of BE, SSS, GBSS and SP, a group of enzymes involved in starch biosynthesis, were used in RT-PCR cloning on the polyA mRNA of premature mung bean (Vigna radiata L. cv Tainan no. 5). Only SBE F1 and SBE R1 pairs were successfully amplify a partial-length of cDNA (794 bp) encoding starch branching enzyme (SBEI; 2.4.1.18). The internal
sequence of the amplicon was searched in the GCG database and found to have 97% similarity with
Phaseolus vulgaris BE I (kbe1; accession no.
AB029548; 3,360 bp) and 84% similarity with
Ipomoea batatas (sweet potato) SBE II (AB071286;
3,123 bp) within the overlapped regions and thus designated VrbeIp. Besides, it was also shown to be located in the central region of the postulated
full-length cDNA by PileUp alignment and was then cloned into pGEM T-Eazy vector, designated pVrbeIp for further use. In order to pursue a full-length clone, internal primers were designed from VrbeIp sequence to conduct RACE on the first strand cDNA library. 3’-RACE was performed more smoothly than
5’-RACE and a 1,200 bp fragment were generated and currently subjected to sequencing.
Keyword: Mung bean (Vigna radiata L.), Starch synthase, Gene cloning, RT-PCR
二 二二、、緣由與目的:、 綠豆是亞熱帶栽種的作物,其澱粉為世界上單 價最高的澱粉,是中國傳統食品製作冬粉不可或缺 的原料,在化學性質方面認為綠豆澱粉的直鏈澱粉 (amylose) 含量約為 32-35%,較一般澱粉的 15-30% 為高,且 amylose 與分支澱粉 (amylopectin) 的分 子構造特別,使冬粉具有久煮不爛的韌性,不能為 其他種類的澱粉所取代;對於合成澱粉的酵素群, 在植物醣類代謝的能量儲存方面不僅具生理上的 必要性,不同種類的澱粉合成酶對澱粉的結構扮演 關鍵性的角色,然而國內外的澱粉相關研究缺乏對 於綠豆澱粉合成酶 (starch synthases) 的探討。 基 於 許 多 物 種 對 澱 粉 生 合 成 酵 素 SS 、 GBSS、SBE 與 SP 在酵素活性方面了解,但將 大分子蛋白質完全定序是花費極高的工程及所
獲資訊有限之下,促使尋找其編碼基因變得相對 迫切,因為在諸多研究顯示即使同種或異種之異 構酶的抗體可相互作用與辨認彼此的蛋白質,或 中和彼此的活性,然而無法回答是否異構酶之間 在蛋白質的三度空間構形或一級胺基酸有絕對 的相似性,然而一旦在核酸層面獲得序列的資 訊,得以將編碼基因推衍出其胺基酸序列、與其 他基因並排作相似度比對、酵素親源的樹譜、結 構的預測等;其基因可利用基因工程技術操作, 轉接在不同的啟動子之後、放入不同宿主表現等 作多元化分子生物學上探討。本計畫目的是選殖 澱粉合成酵素之cDNA,試驗策略是由綠豆種子
先抽 total RNA,再將 total RNA 純化為 polyA
RNA,接著利用基因特異性引子進行 RT-PCR, 之後將 RT-PCR 得到的產物作 PCR 二次放大、 純化、定序,將序列進入資料庫搜尋比對是否為 目標產物,再利用 TA-cloning 方法將目標產物 殖入質體中,期間抽質體DNA 作定序,再次進 入資料庫比對確認無誤後作株系(clone)保存。所 得的 SBE cDNA 片段內部序列再設計引子對
cDNA library 進行 5’與 3’RACE,以獲得全長的 cDNA。
三
三三、、、材材材料料料與與與方方方法法法
材料:
農業改良場台南朴子分廠提供之未成熟台南五 號綠豆種子(Vigna radiata L. cv Tainan no. 5) 設計基因特異性引子-
利用GCG SeqWeb 的 Lookup 或 StringSearch
指令搜尋出相似物種序列,利用Motif Search 找出
序列的conserved motif,由 Reading Frame 得到分
別對 N,C-端之最遠端的二個 Motif。假設最遠端為
Motif A 及 Motif B,由 motif A 找 forward primer,
由motif B 找 reverse primer、將此二段序列分別跑
Primer Selection,將找到符合條件的 Primer 再跑 Blastn (確認其專一性),相似性愈少愈好,再和 α-amylose family conserved region 比 對 , 排 除 α-amylose family 的 Motif。
(1) .利用 GCG SeqWeb 自行設計引子 命名 序列 SBE-F1 TGGATATTGTTCACAGTCATGC SBE-R1 CTTGGGAAATCTATCCATTCAGGATGCC SBE-R2 GGAAATCTATCCATTCAGGATGCCC SSS-F1 CTTGACAAGGGTGAGGCAGTC SSS-F2 CCTTGACAAGGGTGAGGCAGTC SSS-R1 GCAGTTATTCGGTGGGAAACTGGAACA SSS-R2 GCAGTTATTCGGTGGGAAACTGGAACAC SSI-F1 GACTGGTGGATTAGGAGATGTTTGTGG SS1-R1 CTTAGGCCCCCCGTGCTATGAACAAT SP-F1 TGGATGGTGCTAATGTGGAAATCAG SP-R1 CAGGTAAAACAAGGGTGTTCCAGG (2) .由得到之 SBE cDNA 794 bp 片段內部序列設計 引子進行RACE 命名 序列 SBE-F2 AAGATGAGGACTGGAAAATGGGCG SBE-F3 TCACGGGGTTATCATTGGATGTGGG SBE-R3 CCGTCAAACTTGTATTCATCCAGCCACC SBE-R4 TATCGCCCATTTTCCAGTCC Total RNA 之抽取 先取20 ml 抽取緩衝液(100 mM Tris-HCl [pH 7.5]、100 mM LiCl、100 mM EDTA [pH 8.0]、1% SDS、100 mM β-mercaptoethanol)預熱至 65℃,加 入 20 ml 等體積之 phenol 作平衡 pH 備用。自-80℃ 冰箱取出4 g 綠豆種子,加入液態氮以研缽研磨呈 粉末狀後,加入上述之40 ml 混合溶液並研磨均 質。將均質樣品分裝至50 ml 離心管中,於 65℃水 浴槽中加熱5 分鐘,震盪混勻,再加入 1/2 體積 Chloroform:isoamylalcohol = 24:1,震盪萃取 1 分 鐘,於4℃以 15,000 rpm 離心 20 分鐘。取出上清 液,加入等體積Phenol:Chloroform:isoamylalcohol = 25:24:1,再震盪萃取 1 分鐘,於 4℃以 15,000 rpm 離心10 分鐘。取出上清液,再加入等體積 Chloroform:isoamylalcohol = 24:1,震盪萃取 1 分 鐘,於4℃以 15,000 rpm 離心 5 分鐘去除 phenol, 此步驟重複二次,取上清液,隨後加入等體積4 M LiCl,置於-70℃冰箱 1-2 小時幫助 RNA 沈澱。於 4℃ 以15,000 rpm 離心 30 分鐘,將沈澱物溶於 10 ml 之2 M LiCl,以 15,000 rpm 離心 10 分鐘。將沈澱
物加入5 ml 之 0.1% lauro-sarcrosyl,震盪溶解 RNA。取 2 ml 之離心管加入 1ml 之 100%酒精及 40 µl 醋酸溶液(3M、pH 4.3),將溶解之 RNA 分裝至 離心管中,置於-70℃冰箱過夜。於 4℃以 14,000 rpm 離心15 分鐘後,去除上清液,取 80%酒精清洗沈 澱物,於4℃以 14,000 rpm 離心 15 分鐘後真空乾 燥沈澱。RNA 沈澱物溶於 200 µl 之 0.1%
lauro-sarcrosyl,測 total RNA 濃度及 A260/A280比值,
儲存於-80℃。取 5 µl 跑 RNA 甲醛洋菜膠體電泳確 認。
PolyA mRNA 之分離
利用商品化PolyATtract○R
mRNA isolation systems (Promega, Cat. No.5200 )。藉由 biotinylated oligo(dT)在高鹽溶液下(20x SSC) (dT)端先會與 mRNA 3’端的 poly(A) tail 以氫鍵鍵結,接著 biotinylated oligo(dT)的 biotin 端會和 SA-PMPs (streptavidin-paramagnetic particles)結合成連結複合
物,再利用磁板會物理性吸住SA-PMPs 後,以低
鹽溶液(0.5x 及 0.1x SSC)洗去不吸附的物質,最後
以RNase-free 水將複合物上的 polyA RNA 溶離出
來。
取 0.1-1 mg total RNA 加 DEPC 水至總體積為 500 µl,65℃下反應 10 分鐘,加 3 µl oligo(dT) probe 及13 µl 20x SSC,混合均勻(勿用 vortex),置於室 溫 直 到 完 全 冷 卻 約 10 分 鐘 。 利 用 磁 板 抓 取 SA-PMPs 原理以 0.5 x SSC (300 µl/次) 清洗 SA-PMPs 三次。將準備好的樣品取至 SA-PMPs 中 混勻,室溫下反應 10 分鐘,過程中每 2-3 分鐘輕 輕混勻一次。以磁板吸附SA-PMPs 移除上清液(注 意不要吸到SA-PMP pellet)。以 0.1x SSC(300µl/次) 清洗SA-PMPs 四次,移除上清液。以 100 µl RNase
Free H20 溶離出 poly A RNA,再以 150 µl RNase
Free H20 溶 離 出 poly A RNA , 測 吸 光
A260/A280≧2.0。
RT-PCR
利用 SuperScript TM One-Step RT-PCR Systems
(Invitrogen Cat. No.10928-042)。於 0.2 ml 離心管中
依序加入25 µl 2X Reaction Mix、10 pg-1 µg polyA
RNA、10 µM 的 sense 及 antisense primer 各 1 µl 及 1 µl RT/Platinum Taq Mix,最後加水至 50 µl 混合均
勻。進行 RT-PCR 反應,反應條件為:(1) cDNA
synthesis and pre-denaturation:45 30 min℃ 、94 2 ℃ min;(2) PCR amplification:94℃ 15 s (Denature)、 60℃ 30 s (Anneal)、72℃ 2 min (Extend),重複 35 次;(3) Final extension:72℃ 10 min。取 5 µl 跑電 泳確認。
PCR
於 0.2 ml 離心管中依序加入 5 µl 10x PCR buffer、10 mM dNTP 各 1 µl、10 µM 的 sense 及 antisense primer 各 3 µl 及 0.4 µl FastStart Taq DNA Polymerase (Roche),混合均勻後再加入 Template DNA (>500 ng/reaction),最後加無菌水至總體積為 50 µl。進行 PCR 反應,條件為:(1) 95℃ 3 min;(2) 95℃ 30 s、60℃ 30 s、72℃ 1min,重複 35 次;(3)72℃ 10 min。 取 5 µl 跑電泳確認。 PCR 產物純化
使 用 PCR-MTM Clean Up System (Viogene Cat.
No.PF1001)
(1) 以 Modified TAE buffer (40 mM Tris-acetate、
pH8.0,0.1 mM Na-EDTA)製膠。取適量樣品跑膠
後,以UV 確認後,切下條紋 (<100 µl at 100mg) 放
入column,離心 5000 x g 10 分鐘,收集 Vial 中液
體,測吸光值。
(2) 取 10-100 µl PCR 產物和 0.5 ml Px buffer 混合均
勻 , 取 至 column (Millipore Ultrafree-DA, Cat.
No.4260)中(每次勿超過 0.7ml)離心 1,3000 rpm 60 秒,加入0.5 ml WF buffer,離心 1,3000 rpm 60 秒 後丟棄流出液。加入0.7 ml WS buffer,離心 1,3000 rpm 4 分鐘後,換新的 1.5 ml 離心管。加入 30 µl 的滅菌水,放置1-2 分鐘,離心 13000 rpm 2 分鐘, 此步驟重複二次,測吸光值。 T-A cloning 使用材料有:
pGEM-T Easy Vector Systems (Promega Cat.A1380)
Competent cells:DH5α 及 JM110
Gel extraction kit (Viogene Cat.GF1001) 抽 plasmid DNA kit (Viogene Cat.EG1001) LB 固 體 培 養 基 : LB Broth + Agar + ampicillin/IPTG/X-Gal LB 液體培養基:LB Broth+ampicillin(100 µg/ml) 限制酶:EcoRI 【方法】 (1) 純化:將 SBE 二次放大後的產物跑 1%電泳 分析確認後,切下約800 bp 的片段,利用 Gel
extraction kit (Viogene)將切下的膠片純化,再 次跑膠確認。
(2) Ligation:取 3µl 的樣品依序加入試劑後,加
滅菌水至總體機為 10 µl,室溫下培養 1 小時
後,4℃隔夜反應。
(3) Transformation:分別取 5 µl ligation reactions
加入50 µl 之 Competent cells (DH5α 及 JM110) 混合均勻後,置於冰浴中 20 分鐘後,42℃加 熱40-45 秒(heat shock),冰浴 2 分鐘。加入 950 µl LB 液體培養基,於 37℃、150 rpm 震盪培 養1.5 小時,取 1ml 塗抹於 LB/Amp/IPTG/X-Gal 固體培養基,37℃隔夜培養。
(4) 篩選 clone:將 plate 上之 positive clone 培養
於2 ml 的 LB 液體培養基中,37℃隔夜培養。
以小量抽取 plasmid DNA 套組(Viogene)得到
的質體 DNA,再以限制酶(EcoRI)作用,將接 入載體上之 DNA 切出,確認大小後,進行定 序。 (5) 菌液培養:將剩餘菌液取 20 µl 加 2ml LB 液 體培養基,於37℃、150 rpm 震盪隔夜培養。 取800 µl 加 200 µl 80% glycerol 保存於-80℃。 抽質體 DNA
使 用 抽 plasmid DNA kit (Viogene
Cat.EG1001),取 1.5 ml 菌液離心 2 分鐘,除去 上清液,加250 µl MX1 buffer 將 pellet 完全溶解 後,加250 µl MX2 buffer 混勻,室溫下反應 1-5 分鐘,加入350 µl MX3 buffer 混勻後,離心 5-10 分鐘。將上清液取至column 中,離心 60 秒丟棄 流出液,加0.5 ml WF buffer,離心 60 秒丟棄流 出液,再加0.7 ml WS buffer,離心 60 秒丟棄流 出液,空轉 3 分鐘。將 column 取至一新的離心 管中,加100 µl 的滅菌水,靜置 1-2 分鐘後,離 心2 分鐘。所有的離心轉速為 13,000-14,000 rpm。
RACE (Rapid Amplification of cDNA Ends)
使用 Smart TM RACE cDNA Amplification Kit
(Clontech Cat.K1811-1)
(一) First-Strand cDNA Synthesis:
(1) 取 50 ng-1 µg 的 polyA mRNA,分別進行
3’-及5’-RACE Ready cDNA 的合成。
(2) 3’-RACE-Ready cDNA
於 70℃加熱 2 分鐘後置於冰浴 2 分鐘,加入 Mix reaction (2 µl 5X first-strand buffer、1 µl 20 mM DTT 、 1 µl 10 mM dNTP Mix 、 1 µl PowerScript reverse transcriptase),總體積為 10 µl。離心混合均勻,42℃下反應 1.5 小時,以 100-250 µl Tricine-EDTA buffer 稀釋,於 72℃ 反應7 分鐘後。測吸光值,保存於-20℃。 (3) 5’-RACE-Ready cDNA 取 1-3 µl polyA mRN 加 1 µl 5’-CDS primer 及 Smart II A oligo,加滅菌水至 5 µl。於 70℃加 熱2 分鐘後置於冰浴 2 分鐘,加入 Mix reaction (2 µl 5X first-strand buffer、1 µl 20mM DTT、1 µl 10 mM dNTP Mix、1 µl PowerScript reverse transcriptase),總體積為 10 µl。離心混合均勻, 42℃下反應 1.5 小時,以 100-250 µl Tricine -EDTA buffer 稀釋,於 72℃反應 7 分鐘後。測 吸光值,保存於-20℃。
(二) 3’ RACE:利用自行設計之基因特異性
forward primer (SBEF1) 和 套 組 提 供 之 UPM (Universal Primer A Mix) 進行 RACE,再將第一
次量化之產物以TE buffer 稀釋 50-100 倍。由已
得到的 SBE cDNA 片段再往內設計 forward
primer (SBEF2 及 SBEF3)和套組提供之 NUP (Nested Universal Primer A),以稀釋過的產物為 template 再次進行 RACE,得到一段約 1200 bp 的片段,目前進行定序中。
reverse primer (SBER1) 和 套 組 提 供 之 UPM (Universal Primer A Mix) 進行 RACE,再將第一
次量化之產物以TE buffer 稀釋 50-100 倍。由已
得 到 的 SBE cDNA 片段再往內設計 reverse
primer (SBER3 及 SBER4) 和套組提供之 NUP (Nested Universal Primer A),以稀釋過的產物為 template 再次進行 RACE,目前尚未得到較確定 的片段。
四、、結果與討論: 、
Total RNA 之抽取:
由4 g 綠豆種子抽得之 total RNA 總量約 1.18 mg。
在RNA gel 上看出抽得之 total RNA 主要有二條明
顯的條紋分別為28 S 及 18 S,其中分子量較低的 條紋可能為已裂解之RNA,因此接著純化 polyA RNA 獲得 6 µg。 RT-PCR 產物經 PCR 二次放大 將polyA RNA 以四種酵素基因特異性引子進行 RT-PCR,只有 SBE-F1 與 SBE-R1 成功得到一條約 800 bp 的產物(結果未示),但因條紋不明顯,產量 不足以進行定序,因此,將800 bp 產物切出、純化 作為模板,以SBE-F1 與 SBE-R1 為引子進行二次 PCR 放大。結果得到三條明顯的條紋,其中分子量 最大的800 bp 條紋大小和原 RT-PCR 所得的 800 bp 產物相同,因此將其切下、純化、定序、隨後確認 為BEI 的部分序列、命名為 VrbeIp。 VrbeIp cDNA 序列比對 1401 1450 AB029548 tgtacacagt cattcatcaa ataatacatt ggatgggcta aacatgtttg SBE-SBEF TTT TTAGTGTCCT CGATTCTTTG AGATGGCTAG CATAGCTTTG Consensus ---T ---TC-- --A-T---T- -GATGG---- -A-A--TTTG
1451 1500 AB029548 atggaactga tggtcattac ttccatcctg ggtcacgagg ttatcattgg SBE-SBEF ATGGAACTGA TAGTCATTAC TTCCATCCTG GGTCACGGGG TTATCATTGG Consensus ATGGAACTGA T-GTCATTAC TTCCATCCTG GGTCACG-GG TTATCATTGG
1501 1550 AB029548 atgtgggatt ctcgcctttt caattatgga agctgggaag tattaaggta SBE-SBEF ATGTGGGATT CTCGTCTTTT CAATTATGGA AGCTGGGAAG TACTAAGGTA Consensus ATGTGGGATT CTCG-CTTTT CAATTATGGA AGCTGGGAAG TA-TAAGGTA
1551 1600 AB029548 tctactttca aatgcgagat ggtggctgga tgaatacaag tttgacggat SBE-SBEF TCTACTTTCA AATGCAAGAT GGTGGCTGGA TGAATACAAG TTTGACGGAT Consensus TCTACTTTCA AATGC-AGAT GGTGGCTGGA TGAATACAAG TTTGACGGAT
1601 1650 AB029548 ttcgatttga tggtgttaca tcaatgatgt acactcatca tggattgcag SBE-SBEF TTCGATTTGA TGGTGTTACA TCAATGATGT ACACTCATCA TGGGTTGCAG Consensus TTCGATTTGA TGGTGTTACA TCAATGATGT ACACTCATCA TGG-TTGCAG
1651 1700 AB029548 gtagcattca ctggaaatta cagtgagtac tttggtttgg caactgatgt SBE-SBEF GTAGCATTCA CTGGAAATTA CAGTGAGTAC TTTGGTATGG CAACTGATGT Consensus GTAGCATTCA CTGGAAATTA CAGTGAGTAC TTTGGT-TGG CAACTGATGT
1701 1750 AB029548 tgatgctgtg gtttacctga tgctggctaa tgatctcatt catggactct SBE-SBEF TGATGCTGTG GTTTACCTGA TGCTGGCTAA TGATCTCATT CATGGGCTCT Consensus TGATGCTGTG GTTTACCTGA TGCTGGCTAA TGATCTCATT CATGG-CTCT
1751 1800 AB029548 tccctgaggc agttaccatt ggtgaagatg tgagtggaat gccaacattc SBE-SBEF TCCCCGAGGC TGTTACCATT GGTGAAGATG TGAGTGGAAT GCCAACATTC Consensus TCCC-GAGGC -GTTACCATT GGTGAAGATG TGAGTGGAAT GCCAACATTC
1801 1850 AB029548 tgccttccta cacaagatgg tggggttggt tttgattatc gcctgcaaat SBE-SBEF TGCCTTCCTA CACAAGATGG TGGTGTTGGT TTTGATTATC GCCTGCAAAT Consensus TGCCTTCCTA CACAAGATGG TGG-GTTGGT TTTGATTATC GCCTGCAAAT
1851 1900 AB029548 ggccattgca gacaagtgga ttgagattct caagaagcaa gatgaggact SBE-SBEF GGCCATTGCA GACAAGTGGA TTGAGATTCT CAAGAAGCAA GATGAGGACT Consensus GGCCATTGCA GACAAGTGGA TTGAGATTCT CAAGAAGCAA GATGAGGACT
1901 1950 AB029548 ggaaaatggg tgatattgtg cacacactaa caaacagaag gtggctggaa SBE-SBEF GGAAAATGGG CGATATTGTC CACACACTAA CAAACAGAAG ATGGCTGGAA Consensus GGAAAATGGG -GATATTGT- CACACACTAA CAAACAGAAG -TGGCTGGAA
1951 2000 AB029548 aaatgtgtag cttatgctga gagtcatgac caggccttgg ttggtgacaa SBE-SBEF AAATGTGTAG CTTATGCTGA GAGTCATGAT CAGGCCTTGG TTGGTGACAA Consensus AAATGTGTAG CTTATGCTGA GAGTCATGA- CAGGCCTTGG TTGGTGACAA Fig. 1 綠豆的 Total RNA
Lane 1 是 DNA ladder marker; Lane 2 和 3 是同一批抽到之 total RNA,樣品量分別為 220 ng 與 370ng。
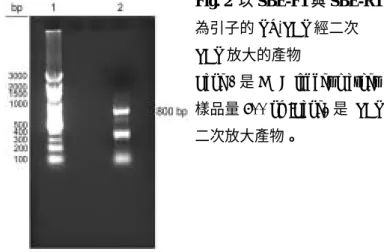
Fig. 2 以 SBE-F1 與 SBE-R1 為引子的RT-PCR 經二次 PCR 放大的產物
Lane 1 是 DNA ladder marker 樣品量600 ng ;Lane2 是 PCR 二次放大產物。
2001 2050 AB029548 gacaattgca ttttggttga tggacaagga tatgtatgac ttcatgtctt SBE-SBEF GACAATTGCA TTTTGGTTGA TGGACAAGGA TATGTATGAC TTCATGGCGT Consensus GACAATTGCA TTTTGGTTGA TGGACAAGGA TATGTATGAC TTCATG-C-T
2051 2100 AB029548 tagacaggcc agctacacct cgtatagatc gtggtatagc attacacaaa SBE-SBEF TAGACAGGCC ATCTACACCT CGTATAGATC GTGGTATAGC ATTACACAAA Consensus TAGACAGGCC A-CTACACCT CGTATAGATC GTGGTATAGC ATTACACAAA
2101 2150 AB029548 atgattaggc ttattaccat gggacttggt ggtgaaggat atttaaattt SBE-SBEF ATGATTAGGC TTATTACCAT GGGACTTGGT GGTGAAGGGT ATTTGAATTT Consensus ATGATTAGGC TTATTACCAT GGGACTTGGT GGTGAAGG-T ATTT-AATTT
2151 2200 AB029548 tatggggaat gagtttggtc atcctgagtg gattgatttc ccaaggggtg SBE-SBEF TATGGGGAAT GAGTTTGGCC TCCTTGATGG GAAGAATTCC CCAAGAAAAA Consensus TATGGGGAAT GAGTTTGG-C --C-TGA--G GA---ATT-C CCAAG---
Fig. 3 綠豆 VrbeIp 與 Phaseolus vulgaris 物種的 BE I (kbe1; accession no. AB029548; 3360 bp) cDNA 的並排序 列與相同核酸區域比對
得到之SBE 片段 (794 bp) 經 GCG Database 比對
和 Phaseolus vulgaris 物 種 的 BEI (kbe1; accession no. AB029548; 3,360 bp) 序 列 bp 1408-2201 之 間 有 97% 的 相 似 度 。 此 外 和
Ipomoea batatas (sweet potato) 的 SBE II
(AB071286; 3,123 bp) 全長序列的重疊部分有 84%的相似度(比對序列未示),因此確認找到綠
豆的BEI 部分序列、命名為 VrbeIp。
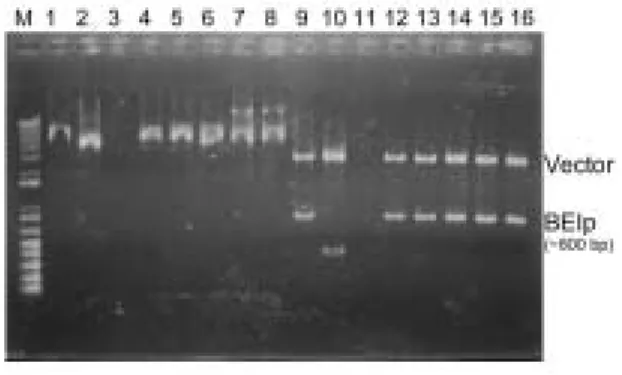
pVrbeIp 株系的保存
Fig. 4 轉形(transform)入宿主的 pVrbeIp 正株系確認 Lane M 是 marker;Lane 1-6 是 DH5α 1-6株係抽得之 intact
plasmid DNA;Lane 7,8 是 JM110 3-4株系抽得之intact plasmid
DNA;Lane 9-14 是 DH5α 1-6株係抽得之plasmid DNA 以限制
酶EcoRI 作用;Lane 15,16 是 JM110 3-4株係抽得之plasmid
DNA 以限制酶 EcoRI 作用。
以 T-A cloning 將 VrbeIp 保存於 pGEM-T Easy
vector 中轉形入 DH5α 與 JM110 得到 6 個與 2 個 white colonies。將這 8 個 clones 抽質體 DNA, 以
EcoRI 切, 由 Lane10 可知 DH5α 2 得到的片段較
小,非目標基因; Lane 3、11 可知 DH5α 3 是
False-positive clone;其餘 6 株皆是成功獲得的 pVrbeIp clones。
3’ RACE:
3’ RACE 產物獲得是先利用 forward primer (SBEF1)
和套組提供之UPM (Universal Primer A Mix) 對 1st
strand cDNA 進行 RACE 反應後,將第一次量化之
產物以TE buffer 稀釋 50-100 倍。再利用已得到的
VrbeIp cDNA 片 段 往 內 設 計 之 forward primer (SBEF3) 和 套 組 提 供 之 NUP (Nested Universal Primer A),以上述稀釋過的產物為 template 再次進
行 RACE,接著將第二次 RACE 量化之產物以 TE
buffer 稀釋 50-100 倍,以 SBE F2 和套組提供之 NUP
再次進行 RACE,結果得到三條紋,其中第一條
band 約 1,200 bp、第二條 band 約 800 bp。已將此
二band 切下、純化、目前正在定序中。
五、、計畫成果自評: 、
本計畫執行方向大致與原計畫相符合,但是沒
有建立綠豆的cDNA Library 於 phage vector 而是以
1st strand cDNA 保存於溶液當中伺機利用 PCR 作
選擇性的量化,也因為目前研究以RACE 技術獲得
Fig. 5 3’ RACE 產物
Lane1:marker; Lane2: 3’RACE 產物
full length cDNA 的研究報告很多,因而我們得以順
利的選殖出partial cDNA 的 clone, 可用作
hybridization probe。本計畫在補助一年期間內, 讓 本實驗室建立了分子生物實驗的基礎, 與指導目前 碩士班二年級研究生石韻琦共同完成, 目前正進入 狀況,因此希望未來可繼續獲得經費支助,得以進 行後續將澱粉生合成酵素當作功能性基因之具有 實用價值的探討。 六、、參考文獻: 、
1. Abel,G.J.W.; Springer,F.; Willmitzer,L.; Kossmann,J. Cloning and functional analysis of a cDNA encoding a novel 139 kDa starch synthase from potato (Solanum tuberosum L.). The Plant Journal 1996, 10, 981-991.
2. Baba,T.; Nishihara,M.; Mizuno,K.; Kawasaki,T.; Shimada,H.; Kobayashi,E.; Ohnishi,S.; Tanaka,K.; Arai,Y. Identification, cDNA cloning, and gene expression of soluble starch synthase in rice (Oryza sativa L.) immature seeds. Plant Physiology 1993, 103, 565-573. 3. Baga,M.; Nair,R.B.; Repellin,A.; Scoles,G.J.; Chibbar,R.N. Isolation of a cDNA encoding a granule-bound 152-kilodalton starch- branching enzyme in wheat. Plant Physiol 2000, 124, 253-263.
4. Clark,J.R.; Robertson,M.; Alnsworth,C.C. Nucleotide sequence of a wheat (Triticum asetivum) cDNA clone encoding the waxy protein. Plant Molecular Biology 1991, 16, 1109-1101.
5. Dry,I.; Smith,A.; Edwards,A.; Bhattacharyya,M.; Dunn,P.; Martin,C. Characterization of cDNAs encoding two isoforms of granule-bound starch synthase which show differential expression in developing storage organs of pea and potato. The Plant Journal 1992, 2, 193-202. 6. Fisher,D.K.; Kim,K.N.; Gao,M.; Boyer,C.D.; Guiltinan,M.J. A cDNA encoding starch branching enzyme I from maize endosperm. Plant Physiol 1995, 108, 1313-1314.
7. Gao,M.; Fisher,D.K.; Kim,K.N.; Shannon,J.C.; Guiltinan,M.J. Independent genetic control of maize starch-branching enzymes IIa and IIb. Isolation and characterization of a Sbe2a cDNA. Plant Physiol 1997, 114, 69-78.
8. Gao,M.; Chibbar,R.N. Isolation, characterization, and expression analysis of starch synthase IIa cDNA from wheat (Triticum aestivum L.). Genome 2000, 43, 768-775.
9. Harn,C.; Knight,M.; Ramakrishnan,A.; Guan,H.; Keeling,P.L.; Wasserman,B.P. Isolation and charaterization of the zSSIIa and zSSIIb starch synthase cDNA clones from maize endosperm. Plant Molecular Biology 1998, 37, 639-649.
10. Kossmann,J.; Abel,G.J.W.; Springer,F.; Lloyd,J.R.; Willmitzer,L. Cloning and functional analysis of a cDNA encoding a starch synthase from potato (solanum tuberosum L.) that is predominantly expressed in Ieaf tissue. Planta 1999, 208, 503-511.
11. Lycett.G.W.; Delauney,A.J.; Zhao,X.C.; Gatehouse,J.A.;
Croy,R.R.D.; Boulter,D. Two cDNA clones coding for the legumin protein of Pisum sativum L., sequence repeats. Plant Mol.Biol. 1984, 3, 91-96.
12. Nair,R.B.; Baga,M.; Scoles,G.J.; Kartha,K.K.; Chibbar,R.N. Isolation, characterization and expression analysis of a starch branching enzyme IIcDNA from wheat. Plant Science (Limerick) 1997, 122, 153-163.
13. Nakamura,Y.; Yamanouchi,H. Nucleotide sequence of a cDNA encoding starch-branching enzyme,or Q-enzyme I, from rice endosperm. Plant Physiol. 1992, 199, 1265-1266.
14. Poulsen,P.; Kreiberg,J.D. Starch branching enzyme cDNA from Solanum tuberosum. Plant Physiol 1993, 102, 1053-1054. 15. Rosa A.P.B.D.L; Estrella A.H; Utsumi S; Lopez O.P Molecular characterization, cloning and structural analysis of a cDNA encoding an amaranth globulin. Plant Physiol. 1996, 149, 527-532.
16. Salehuzzaman,S.N.I.M.; Jacobsen,E.; Visser,R.G.F. Cloning, partial sequencing and expression of a cDNA coding for branching enzyme in cassava. Plant Molecular Biology 1992, 20, 809-819.
17. Salehuzzaman,S.N.I.M.; Jacobsen,E.; Visser,R.G.F. Isolation and characterization of a cDNA encoding granule-bound starch synthase in cassava (Manihot esculenta Crantz) and its antisense expression in potato. Plant Molecular Biology 1993, 23, 947-962.