應用自我組織圖於社會網路文字訊息之情感分析
56
0
0
全文
(2) 應用自我組織圖於社會網路文字訊息之情感分析. 指導教授:楊新章 博士 國立高雄大學資訊管理學系. 學生:吳俊諺 國立高雄大學資訊管理學系碩士班. 摘要. 隨著網際網路的發展和普及,以文本形式出現的訊息量也急遽地增長,對於 其上資料分析的需求量也隨之增加。透過情感分析可以從大量的文字內容中發掘 出具價值的知識,可得到可觀的商業、政治、經濟、情報、國安等利益,為企業 或個人提供意見或喜好資訊,以支援決策者進行最佳化決策。然而社會網路的文 字訊息不同於一般文字文件之特性,在進行文本探勘時便具有其差異性與困難度, 故如何在社會網路的環境下,發展一套有效能的概念探勘之方法是不可或缺的。 本研究將採用類神經網路中文件分群之方法,即自我組織圖,將不同的訊息 與情感概念加以分群,最後利用相似度分析來協助我們找尋訊息與概念間之關聯。 針對所發掘之關聯結果,本研究開發適合社會網路文字訊息之探勘技術,以偵測 出訊息之情感概念。. 關鍵字:情感分析、文本探勘、自我組織圖 I.
(3) Sentiment Analysis of Text Messages in Social Networks Based on Self-Organizing Maps. Advisor: Dr. Hsin-Chang Yang Department of Information Management National University of Kaohsiung Student: Chun-Yen Wu Institute of Information Management National University of Kaohsiung. ABSTRACT With explosive growth of the Internet, the amount of information in text form is growing rapidly and the demand for data analysis is also increasing. We can perform sentiment analysis on a large set of text messages to discover valuable knowledge and obtain enormous benefits in national security, business, politics, economics, , etc, However, text messages from the social networks are rather different from those of traditional text documents. Therefore, it is difficult but essential to develop an effective method of sentiment exploration in social networks. In this study we use a neural network method for document clustering, namely the self-organizing maps. We first applied self-organizing maps to cluster similar messages and sentiment keywords. We then developed an association discovery process to find the associations between the messages and sentiment keywords. The sentiment of a message is then determined according to such associations. We performed experiments on Twitter messages and obtained promising results. Keywords: Text Mining, Sentiment Analysis, Self-Organizing Map. II.
(4) 目錄 摘要 ........................................................................................................................... I ABSTRACT .............................................................................................................. II 圖目錄 ......................................................................................................................V 表目錄 .................................................................................................................... VI 一 緒論........................................................................................................... 1 1.1 1.2 1.3 1.4 二. 研究背景 ........................................................................................... 1 研究動機 ........................................................................................... 3 研究目的 ........................................................................................... 4 研究架構 ........................................................................................... 4. 文獻探討 ................................................................................................... 5 2.1 情感分析 ........................................................................................... 5 2.1.1 語料庫為本方法 ........................................................................ 6 2.1.2 詞典為本方法 ............................................................................ 7 2.2 概念偵測 ........................................................................................... 8 2.2.1 k-means ...................................................................................... 8 2.2.2 K-NN ......................................................................................... 9 2.2.3 類神經網路分群 ........................................................................ 9 研究方法 .................................................................................................. 11. 三 3.1 3.2. 文字訊息擷取.................................................................................. 12 文件前置處理.................................................................................. 12 3.2.1 斷詞 ......................................................................................... 12 3.2.2 字詞處理.................................................................................. 13 3.2.3 訊息文件向量化 ...................................................................... 14. 文件分群 ......................................................................................... 15 3.3.1 自我組織圖(SOM)訓練 ........................................................... 15 3.3.2 標記(labeling) .......................................................................... 19 3.4 關鍵字分群 ..................................................................................... 20 3.3. 3.4.1 關鍵字向量化 .......................................................................... 20 3.4.2 關鍵字之自我組織圖訓練....................................................... 21 3.5 情感分析 ......................................................................................... 22 3.5.1 意見探勘.................................................................................. 22 3.5.2 關聯發掘.................................................................................. 23 四. 實驗結果 ................................................................................................. 26 4.1 實驗步驟 .................................................................................................. 26 4.1.1 前置處理 ....................................................................................... 26 4.1.2 分群與標記 ................................................................................... 28 III.
(5) 五. 4.1.3 情感偵測 ....................................................................................... 32 4.2 實驗評估 .................................................................................................. 39 結論與分析 ............................................................................................. 43. 六. 5.1 結論........................................................................................................... 43 5.2 未來研究發展與建議................................................................................ 44 參考文獻 ................................................................................................. 45. IV.
(6) 圖目錄 圖 3-1. 研究架構圖 ................................................................................................ 11. 圖 3-2 圖 3-3 圖 3-4 圖 3-5. 向量空間模型 ........................................................................................... 14 二元向量空間模型 ................................................................................... 15 自我組織圖架構 ....................................................................................... 16 a.鄰近區域 ................................................................................................ 17. 圖 3-5 圖 3-6 圖 3-7 圖 3-8. b.鄰近區域縮小示意圖 ............................................................................ 18 SOM 訓練步驟 ......................................................................................... 19 神經元權重示意圖 ................................................................................... 21 關鍵字之向量模型 ................................................................................... 21. 圖 3-9 圖 3-10 圖 4-1 圖 4-2 圖 4-3. 關鍵字群組之極性示意圖........................................................................ 23 特徵圖關聯示意圖 ................................................................................... 24 正規化後之文件 ....................................................................................... 27 關鍵字選取之結果 ................................................................................... 27 二元文件向量圖 ....................................................................................... 28. 圖 4-4 圖 4-5 圖 4-6 圖 4-7. 關鍵字數大於二之意見分數圖 ................................................................ 33 關鍵字數大於三之意見分數圖 ................................................................ 33 關鍵字數大於四之意見分數圖 ................................................................ 34 相似度示意圖 ........................................................................................... 35. 圖 4-8. 訊息文件標記系統介面 ........................................................................... 39. V.
(7) 表目錄. 表 4-1 表 4-2 表 4-3. 文件群集圖- Neurone26 .......................................................................... 29 自我組織圖統計資料-文件分群 .......................................................... 31 自我組織圖統計資料-關鍵字分群....................................................... 31. 表 4-4 表 4-5 表 4-6 表 4-7 表 4-8. 字彙集 V2 之關聯對照表 ........................................................................ 36 字彙集 V3 之關聯對照表 ........................................................................ 37 字彙集 V4 之關聯對照表 ........................................................................ 38 情感偵測結果 ......................................................................................... 40 情感偵測結果_無中立文件 .................................................................... 41. 表 4-9. 情感偵測結果_過濾關鍵字後 ................................................................ 42. VI.
(8) 一 緒論 1.1 研究背景 社會網路(social network)服務與網站近年來蓬勃發展,網路上的所有行為皆 可用「互動、分享、關係」作為詮釋,造就了新型態資料整合與分享模式,並讓 網路世界和現實生活之間的界限越來越模糊。宏觀而言對於資訊科技、人際關係、 社會發展、乃至國家經濟等層面皆造成巨大影響;另從微觀的角度觀之,開啟了 人際關係間新的交流模式。人們花費越來越多的時間在使用網路上,人際間之通 訊頻率相較於以往之媒介,增加數以倍計,而社群網路的使用時間在 2011 年首 度超越搜尋引擎。據美國著名的市場研究公司 com.score 發表的 2011 年度社群網 路報告[1],指出目前全球網路使用者的行為,每五分鐘就有一分鐘是在瀏覽社 會網路,而每十位網友中,就有一位造訪過 twitter,網站用戶量也比去年同期增 長 59%。據 Nielsen 公司 2011 年第三季之統計[2]指出,美國人每月花在 Facebook 網站的時間為 Yahoo!的三倍,Google 的四倍,如此足以證明社會網路儼然成為 被普遍接受的社交管道。 社會網路所提供的服務也具多元化,常見的有訊息發布、首頁建立、部落格、 個人檔案維護、影音上傳、應用軟體(apps)等。雖然一般印象中使用者常花費大 量的時間於遊戲或應用軟體的使用上,但據實際使用者的使用統計[3]指出, Facebook 的使用者約花 27%的時間於觀看訊息與網頁、21%的時間用於觀看/維 護個人檔案、17%花在觀看/上傳影音上、而花在應用程式地時間僅占 10%。以 Facebook 網站而言,藉由朋友關係的建立,使用者可以將訊息透過分享傳播予 朋友及其追隨者;反之,使用者也能隨時得知朋友之近況分享且給予回應,在發 布與回應之中,訊息的傳遞以滾雪球的方式如病毒般向四周擴散而去,因此個人 或企業用戶將會越來越倚重訊息發佈管道以獲得最大的個人與商業效益。 由上述之統計資料顯示,社會網路之使用者主要活動集中於內容的發表及分 享。常見的社會網路中 使用者的活動主要集中於內容的分享,如文字(Facebook、 1.
(9) Twitter 等)、影像(Flickr、Picasa 等)、影片(Youtube 等)等。然而,其中最大內容 量的當屬文字訊息。如何從如此大量的文字內容中發掘具價值之知識,已成為現 今之熱門研究課題。 由於社會網路服務的使用者與資料日益增加,對於資料分析的需求量也隨之 增長,此類訊息多半屬於非結構化的資訊(unstructured)被儲存著,因此挖掘其中 有用的訊息即是相當重要的研究議題。目前社會網路分析與探勘(social networks analysis mining)相關研究如雨後春筍般相繼被提出與研究,大量解析網路中非結 構化的資訊,將其轉化作為可利用之市場行銷、人際互動分析等應用。傳統以來 分析社會網路主要有兩種方式,其一為基於圖論(graph theory)之連結分析(link analysis)方法為主,主要是藉由結點之特性與結點間之連結關係來發掘一社會網 路中重要的個體、群體、乃至人際關係;其二為內容分析方法(content analysis), 藉由分析社會網路中各結點內與結點間之內容來發掘隱含其中之知識。 從文字中發掘隱含知識之技術屬於文本探勘(text mining)的範疇。其中最主 要的核心技術之一在於發掘文件中之概念與其關聯,利用發掘出之概念,可作為 其類別,進而達成文件分類。 在社會網路之文字訊息具有下列特性: I.. 訊息長度極端化:在社會網路中所發布的文字訊息大多屬於個人心情 的抒發、現況的描述、或是針對新聞的引用與評論等。然而,這些訊 息的建立多為即時性與隨性式,故長度大多不長,甚至包含一、兩個 字。另一方面,使用者也常引用新聞報導、部落格文章、產品評測等 長度頗長的訊息。. II. 訊息內容抽象化:社會網路中之文字訊息經常包含一些較不具體的內 容且文句較無結構,甚至只包含表情符號而不具任何一般文字。然而 對於社會網路文字訊息而言,此類訊息反而有重大的涵義,主要是因 為這類訊息中隱含著大量的情感價值。. 2.
(10) III. 訊息量巨大化:社會網路訊息由於大多為心情抒發與訊息分享,因此 所產生之訊息量極為巨大且即時,並且容易因特定事件突然爆炸性的 增加。如 2011 年 3 月日本大地震發生時,Twitter 的訊息發佈量達到七 億三千六百萬則,較前日均量超出 20%。 由於社會網路之文字訊息具有許多不同於一般文字文件之特性,固在進行文 本探勘時便具有其差異性與困難度。因此必須發展適合社會網路之文字訊息之前 置處理與探勘程序。針對社會網路之文本探勘應用頗為廣泛,在本論文中將針對 情感分析進行應用之開發: 本研究之焦點為自動化之情感分析(Sentiment analysis)或意見探勘(Opinion mining),情感分析主要為分析一訊息之情感狀態,如作者當下抒發之情感或作 者欲引發之情感,另外也包含作者對於某一訊息之評價與判定。通常我們針對訊 息予以好、壞、或中立等評價,或賦予一訊息”快樂”、”悲傷”等情緒判斷。. 1.2 研究動機 社會網路中文字訊息之分享扮演極其重要的角色,顯而易見其間必定隱含著 可觀的商業、政治、經濟、情報、國安、醫療等利益。其間所隱含之情感或意見 若能被成功的發掘,則可應用於多種領域。如若能從這些文字訊息中,發掘使用 者對商品或品牌之偏好,則可對其發送可能為其所喜好之商品促銷訊息,擴大行 銷成果。若能從文字訊息發掘使用者之政治傾向,便可對其進行適當之政治宣傳。 醫療上,若能偵測使用者之心理狀態異常,則可給予適當之醫療意見,甚至若判 斷其可能對自身或他人產生危害時,亦可發送訊息於社福或相關警察單位採取防 範措施。在國安應用上,若能偵測出恐怖組織及其網路,則可對其可能發生之恐 怖行為予以制止與防護。上述各例只是一小部分社會網路文字訊息情感偵測之可 能應用,若能針對所需核心技術提出可行之解決方法,其應用層面將更為廣泛與 深入。然而由於社會網路訊息之特性,在其間進行情感分析便相對困難,如何發 展一適用於社會網路訊息之方法便成為現今重要之研究課題。 3.
(11) 1.3 研究目的 本研究的目的,主要針對於社會網路之短文訊息開發一情感分析方法,冀希 能為社會網路訊息情感分析應用提供一可行之解決方案。依此目的,本研究將發 展下列社會網路之文字訊息情感分析機制: 1.. 處理:針對社會網路訊息進行清理與精煉。本研究將針對社會網路訊息 保留其重要的語意甚至是情感概念,且進行文字處理程序之開發。本研 究之文字處理程序要進行的步驟包含取樣、斷詞、關鍵字比對與選取、 文件向量化等。. 2.. 情感分析:針對所蒐集到的社會網路之文字訊息進行探勘與分析。本研 究將利用分群法群聚類似文件之特性以偵測社會網路文本中所隱含的 概念。此類概念為社會網路中所重視之訊息情感傾向。. 1.4 研究架構 本論文共分五個章節。第一章為緒論,說明本論文之研究背景、動機與目的。 第二章則針對情感分析與概念偵測進行探討。第三章詳細說明本論文之研究方法、 架構。第四章為實驗結果,包含實驗資料前置處理、文件的分群與標記流程、與 情感偵測,並根據前一節所提及實驗設計,進行實驗結果呈現與評估分析。最後 第五章為結論與分析,針對研究成果進行討論。. 4.
(12) 二 文獻探討 此章節主要針對本研究之相關主題,即情感分析與概念偵測。在此首先介紹 情感分析領域中相關之研究,包含淬取情感關鍵字之方法;由於本研究中利用分 群演算法協助找尋文件間之關聯性,因此,在此針對分群演算法之相關文獻稍作 介紹。. 2.1 情感分析 情感分析又稱為意見挖掘,簡而言之,是針對帶有情感色彩的文件進行分析、 處理、歸納的過程。有別於傳統上基於主題的偵測,主題往往是由一個單獨且明 確的關鍵字所組成,而情感則是需要以一種微妙的的方式予以表達。情感分析最 初的研究源自於針對帶有情感色彩之形容詞的分析[13],如,”漂亮”是帶有褒義 色彩的詞彙,而”骯髒”則是帶有貶義色彩的詞彙。情感分析的基本工作之一,即 是抽取情感評論文中帶有意義的訊息單元,將無結構化的情感文件轉化為機器容 易識別和處理的結構化文本,進而分類為正向、負向、與中立等極性。此領域較 早的研究出現在 Tueney[14]與 Pang[15]等人之著作,Tueney 利用文件與正、負極 性之關鍵字彙間的相似程度,再經由分類演算法進行文件分類之動作,在 410 篇四種包含 4 種領域的評論,平均接近 74%的效能。 除了基本的極性等級外,隨後也出現多尺度之作法,如 Pang 等人[16]將電影 評分類為不同星級,然而上述的類別都僅侷限於不連續區分,而 Thelwall 等人[17] 則將等級擴充為一連續情感區間,用以評論社會網路之短文句情感。為了將蒐集 到的文件轉化為機器易處理之結構化文件,關鍵在於挖掘出足以代表文件特性之 特徵字句,如 Dey 等人[18]則使用字句間之文法關係來發掘文句間具有意見性的 特徵。若要從文中淬取出具有情感訊息之概念關鍵字,一般分為基於語料庫 (corpus-based)與基於詞典(thesaurus-based)兩種方法[33],以下就分別針對兩種方 法之相關文獻做詳盡的介紹。. 5.
(13) 2.1.1. 語料庫為本方法. 基於語料庫的方法中,關鍵字的識別與掘取主要是利用大量語料庫的統計特 性,藉由觀察一些法則與規律挖掘語料庫中的概念詞彙並判斷出其極性。由其連 接詞所連接的兩個形容詞的極性往往存在一定的關聯,如 and 所連接的形容詞極 性相同,而 but 所連接的形容詞極性相反。基於此種現象,Hatzivassiloglou 和 Mckeown[19]利用上述連接詞的特性且使用回歸模型來約束正、負極性之預測, 最後利用分群演算法依照所約束之形容詞限制來進行分群,並將形容詞予以正、 負向標記,也就是從華爾街日報(Wall Street Journal)中挖掘出大量的形容詞詞性 的評價關鍵字彙。隨後,Wiebe 等人[20]也使用一種相似度分佈關鍵字分群方法 在大量的語料庫中進行形容詞詞性的關鍵字挖掘,藉由情感關鍵字之間的分佈相 似性來提升關鍵字的詞義特徵(如極性),以利於後續分群之應用。 然而將情感關鍵字侷限於形容詞之詞性,則會忽略了其他詞性之情感關鍵字, 為了避免此種情形的限制,Riloff 等人[21]制訂了一些分類流程用以歸納出具有 主觀意識之種子情感關鍵字,藉由不斷的迭代分類方法去識別出更多之情感關鍵 字。隨後,Turney 和 Littman[22]提出從語意關聯中找出語意之極性,利用 point mutual information 與 Latent Semantic Analysis 去計算出某特定詞彙與正、負極性 之距離,其極性導向之公式如下: (2.1). 其中 Pword 為正向極性之字集合、Nword 為負向極性之字集合、A(word1, word2) 為 word1 與 word2 之關聯程度,即可識別某特定詞彙之極性為何,此種方法適應 各種詞性之情感關鍵字的識別。 基於語料庫的方法最大的優點在於簡單易行,缺點則在於可以利用的情感語 料庫有限,同時情感關鍵字在語料庫中的分佈等現象並不容易作歸納。. 6.
(14) 2.1.2. 詞典為本方法. 基於詞典的方法中,情感關鍵字淬取與判別主要是使用詞典中詞語之間的詞 義聯繫來發掘情感關鍵字,這裡的詞典一般是指使用 WordNet 或 HowNet 等。較 直觀的作法為使用詞典將手動選取的種子情感關鍵字進行擴展來獲取大量的情 感關鍵字[23,24],也是說利用一種子關鍵字之同義詞與反義詞來進行情感標記。 此種方法簡單容易,但是需依賴於種子情感關鍵字的數量與質量,並且容易由於 一些關鍵字的多義性而引發誤導。 為了避免多義性所導致的雜訊太多,一部分的學者使用詞典中詞語的註釋信 息來完成情感關鍵字的識別與極性判斷[25][26][27]。除此之外,Kamps 等人[28] 沿用了 Osgood’s[29]所提出距離公式 EVA 去計算出某特定關鍵字彙與正向極 性”good”和負向極性”bad”的相對距離,其公式如下: (2.2) 其中 d(word1, word2)為 word1 與 word2 之關聯距離,此種方法非常依賴詞典的完 備性,因此無法適用於詞典資源較為缺少的語言。 針對某些詞典資源較少的語言,Mihalcea 等人[30]提出將詞典資源豐富的語 言翻譯至資源缺乏的語言中,如將英文的情感詞典翻譯成中文,提供給中文情感 分析應用,但最後的實驗顯示,大多數的情感詞彙再翻義的過程之中變更了它的 極性。這也印證了 Wiebe 等人[31]所提出的”詞義與極性之間有一定的相關性, 但是相同的詞義並不一訂有相同的極性”。 基於詞典的方法最大的優點在於獲得情感關鍵字的規模相當可觀;但由於很 多的詞存在一詞多義現象,所以也容易造成了詞典往往含有較多的歧異字。. 7.
(15) 2.2 概念偵測 概念偵測亦稱為主題偵測(topic identification),比較常用之作法為利用文件 間共同出現(co-occurrence)的資訊來進行偵測,Landauer 等人[4]提出使用 Latent Semantic Analysis 方法,藉由大量的語料庫找出字詞與文件間的關聯,找出權重 較高之字詞作為主題之概念。然而,使用此類方法則被限制於時間與數量,即需 要大量的語料庫進行訓練作業,且所偵測之概念只適合用於當下搜集的資料。 鑒於時間的限制,另一種基於大量資料的方法為使用文件分類[5]或分群[6]。 文件分類需要大量的人力與時間去作蒐集與訓練用且為文件進行分類,其次,當 分類器訓練完成後,若加入新的主題之文件時,必須再重新訓練;分群則無此問 題,它會自動的依據文件之間的相似性進行分群,並找出各個群組的中心點 (centroid),藉由不斷的調整每個文件與群心之最佳距離來優化其效能,故較自動 化且具可調整性。然而,Karypis 等人[7]則認為分群演算法之優劣關鍵在於參數 的選取是不正確的,或是挑選到的群組之特徵是不足夠的。由於一般分群結果之 校能有限,Scott 等人[8]提出使用自然語言處理(natural language processing)技術 來決定文字之語意,可以用以改善分群之校能。 然而,在情感分析領域中,Pang 等人[15]首先使用了機器學習的概念,利用 Naïve Bayes、Max Entropy、SVM 等分類器,在電影評論之中自動的分類情感。 Mullen 等人[35]提出針對詞彙與片語給予不同之權重值,再經由 SVM 分類正、 負向之極性。Davidiv 等人[34]則提出 50 個標籤和 15 個表情符號作為分類依據, 進行 kNN-like 分類,避免了大量勞力之手動標注。 目前以存在許多資料分群方法,如常用之 k-means、K-NN 等,以下就分別 針對這兩種方法及本研究所用之自我組織圖以相關文獻作介紹。 2.2.1. k-means. k-means 分群主要是以 k 為輸入參數,再隨機散佈 k 個點做為群集中心,而 每群內每點離群心皆是最近之距離,而後再重新計算群心,直到群集收斂且群心 8.
(16) 不再變動為止,且使得群內之相向度高,而不同群之相似度低。然而,k-means 分群校能主要以群數和與群心之距離有很大的關聯。Arora[9]等人認為應該減少 其最接近的每一點到中心的最大距離,且每點距離群心之距離總和應該盡量縮減, 以利增加分群之校能。 k-means 分群的優勢在於簡單有效率能快速收斂且得到結果,時間複雜度相 對較低;但卻容易受極端值影響導致群心偏移、分群之效能優劣也取決於群聚是 否為球型分佈與初始群心之選擇。 2.2.2. K-NN. k-nearest neighbors,即第 K 位最為接近的鄰居,主要是以向量空間的方式來 表示各篇文件的特性,將測試資料與所有訓練資料逐一比對,並算出測試資料和 訓練資料之間的歐基里德距離,接著找出大於門檻值之 K 筆資料,最後再依據 這 K 筆訓練資料分派其所屬類別。根據 Yang 和 Liu[10]之實驗顯示再進行類別的 分類時,相較於其他分類器擁有較佳的效能。 K-NN 分類的優點在於訓練資料量少時,其分類校能較佳;反之,當訓練資 料量大或文件特徵向量之維度過高時,若無做適當的前置處理,如切割資料等, 則容易因為分類時須大量的相似度計算,導致分類效率不佳。 2.2.3. 類神經網路分群. 類神經網路是一種模仿神經系統運作方式的資訊處理模型,其結構由大量的 神經元以大量的神經鍵互相連接,藉由每個神經元來接受外界或其他神經元的輸 入,經由簡單的運算後,再輸出結果到外界或其他神經元。如同人類從經驗中學 習一般,網路則是藉由訓練資料來調整的變數,透過不同之參數設定,進行訓練 以產生較佳之分析與預測。若提供的訓練資料越多,其輸出精準率則越高。 本研究所採用的是由 Kohonen[11]於 1982 年提出的自我組織圖作為文件分 群之基礎演算法。自我組織圖(Self-Organizing Maps)是一種屬於類神經網路之非 監督式分群演算法,其概念來源為人類大腦網路或生物網路在處理資訊時, 處理 相同資訊的神經元會聚集在一起的特性。SOM 有一個很重要的優點為,將 N 維 9.
(17) (N-dimension)的資料映射(mapping)到 2 維(2-dimension)的空間上,並且維持資料 中的拓撲(topology),提供簡易的距離概念視覺化呈現文件之群聚地圖,以便進 行資料之分析與檢索。 雖然自我組織圖有視覺化的功能,但卻無法自動偵測出各群集之間的界線, 因此 Rauber[12]等人提出 LabelSOM 的方法讓使用者從特徵中了解群集之結構, 且自動標記出特徵的屬性。LabelSOM 是希望能夠在形成各種群集後根據不同的 特徵來描述該群集,而非在形成群集前先用特徵來制定類別。因此 LabelSOM 可 以找出具代表性的特徵屬性,將分群後的群集標記出主要的特徵屬性。藉由上述 方法,我們可以找出文件間的關聯與群組標籤。. 10.
(18) 三 研究方法 在進行完相關研究的探討分析後,本研究將利用社會網路之文字訊息的探勘 方式來找出訊息中所隱含的情緒,以利於社會網路應用的開發。運用網路平台之 情緒訊息來挖掘出深層知識,將可擴展目前的社會網路應用至另一階段,創造新 的商機。本研究架構之流程如圖 3-1 所示,以下將詳述主要之研究步驟及方法。. Twitter. 文字訊息擷取 訊息情感/意見 文字訊息. 前置處理. 訊息文件向量. 文件/關鍵字關聯. 文件分群. 關鍵字向量. 文件分群. 文件群組. 關聯發掘. 關鍵字群組. 圖 3-1 研究架構圖. 11.
(19) 在本章中,首先會介紹如何將英文文件做適當的前置處理,並採用著名之向 量空間模型(vector space model, VSM)來做文件向量轉換,接著先後針對訊息與情 緒關鍵字進行分群 SOM 訓練並產生特徵圖,而後運用一挖掘關聯之演算法,最 後可獲得情緒群組與關鍵字群組之關聯性以便進行訊息之情感檢索的工作。. 3.1 文字訊息擷取 本研究以社會網路推特(Twitter)做為研究資料來源, 並從中擷取兩種訊息, 即側寫檔(profile)資訊與文字訊息。側寫檔資訊主要用於提供訊息之屬性,如發 文者、發文時間、發文地點等,也可用於發送者之社交網路關係。文字訊息則作 為主要探勘來源,並將資料淬取後保留符合研究所需之相關資料格式。本研究將 建立一實驗資料庫。資料庫包含一萬筆文字訊息,用於開發過程之實驗與結果展 示。. 3.2 文件前置處理 資料前置處理(data preprocessing)是在文件內容中淬取重要的特徵集合來替 代原始文件,而後透過特徵(feature)辨識的方法,將自然語言文件標示適當的主 題類別;若缺少此項步驟,則因包含過多無效文件,而導致分類效果不佳之結果。 本研究將針對社會網路之文字訊息發展適合的前置處理方法,目的在於將原始的 文件轉換為一文件向量以供後續分群訓練使用。此轉換之過程包含下列步驟: 3.2.1. 斷詞. 文件本身是由許多文字與詞彙組合而成,在自然語言(natural language)當中, 許多描述式的詞彙對文件本身的涵義並無太大的影響;如果文件無經過適當的處 理,變無法將文件導入分類、分群演算法中加以應用,且如程序處理的不合宜, 將導致分類、分群的效果不佳。為實現分類、分群之工作,需透過斷詞與斷句的 程序,將文件拆解成文字、詞彙或關鍵字的集合,並剔除對文章涵義較薄弱的文 字,如無意義的文字與符號,再利用剩餘的詞彙作為文章的特徵進行文件類別之. 12.
(20) 辨識。文章的特徵淬取就是文件經由斷詞的步驟將文件拆解成關鍵字集合,且剔 除無意義的符號與文字。 此步驟主要將原始文件中以字元為基礎之表示法轉換為以字詞(word)為基 礎之表示法。拉丁語系之文件(如英文),字詞和字詞之間通常存在著分隔符號(如 標點符號或空白字元),因此,斷詞較為容易。本研究只針對單一語言訊息進行 斷詞處理,在此目標語言為英文,因市面上已存在許多可利用之斷詞程式,這部 分將採取公開原始碼程式進行。 3.2.2. 字詞處理. 經過上述斷詞程序後,文件可以其所包含之字詞集合所表示,然而這些字詞 的重要性權重並非相等,有些字詞與該文件之涵義並無顯著之相關性,部分字詞 甚至不具意涵;另一方面,過多的字詞也將導致分類、分群之演算法效果不彰, 故必須選擇從文件之中挑選較具代表性的字詞作為文件的特徵、以簡化文件之表 達與後續之處理,經過篩選過後之字詞,我們也稱之為關鍵字(keyword)。 傳統上,英文關鍵字之選擇包含幾個主要的步驟:停用字的去除(stopword elimination)、關鍵字選取等。首先停用字去除方面,一般在處理文字文件時為了 降低關鍵字數量常會將一些不具太多涵義又經常出現的常用字做去除的動作,例 如冠詞、介系詞與連接詞等。然而在情緒表達時有些常用字卻包含重要訊息,例 如”不”代表否定、”嗎”代表疑問等,將其去除會影響訊息情緒之判斷,故將其保 留。本研究將採用標準之 Brown corpus 之停用字集來剔除文件中非隱含情緒之 停用詞。 本研究在建構字彙集(vocabulary)時,並不會將文件中所有的字詞進行蒐集。 主要是因為本研究將仰賴關鍵字之情感極性作為分析之基礎,然而一般而言我們 無法直接判定字詞之情感極性(polarity),必須另行定義與判別。文件中的訊息極 性通常可由一些不同情緒涵義之字詞所構成,而這些隱含情緒極性的字詞常不侷 限於某些特定詞性。故本研究將採用 Hu and Liu[13]等人所提出之全詞性情感詞. 13.
(21) 彙集來進行詞彙比對,並選擇比對成功之字詞作為關鍵字。利用上述關鍵字詞彙 集,可以簡化英文文件之表達,並避免無效關鍵字的干擾,提高字彙集的精確度。 由於社會網路之訊息長度過於簡短,甚至有些文件只包含一個情感關鍵字, 因此為了分群訓練的效果,本研究將採用關鍵字字數大於 2 以上之文件,且同時 考慮關鍵字字數大於 3 及大於 4 的文件進行訓練。. 3.2.3. 訊息文件向量化. 將文件簡化為關鍵字集合後,我們必須將其轉化為一向量以供後續程序使用 本研究將採用由 Salton[32]等人提出之向量空間模型(vector space model)進行轉 換。向量空間模型為目前被引用次數最為頻繁且受大部分研究者所接受之方式, VSM 是由關鍵字與文件組合而成的「關鍵字-文件」矩陣(term-document matrix), 可利於機器方便閱讀並加速系統之執行效能。利用查詢語句之向量與「關鍵字- 文件」矩陣運算檢索出像似度高的文件。圖 3-2 為一具有 j 份文件與 i 個關鍵字 之「關鍵字-文件」矩陣。其中 wij 為關鍵字 i 在 j 文件中的權重值。. 圖 3-2 向量空間模型. Salton 等人所提出之文件向量概念,以關鍵字出現的頻率(term frequency, TF) 來衡量該關鍵字於文件中之重要性,並以權重來表達,其計算方式如下: (3.1) wij:代表關鍵字 i 在文件 j 中的權重值 tfij:代表關鍵字 i 在文件 j 中出現之次數. 14.
(22) 本研究中並未採用 Salton 等人所使用的 tf 及 idf(inverse document frequency) 之權重作法,而使用較單純、只考慮關鍵字之共現(co-occurrence)模型之二元權 重(binary weighting)方法。其做法先將每份文件之關鍵字以聯集方式集合成字彙 集 V,再將每份文件之關鍵字依序與 V 作比對。若關鍵字出現於該 V 中,則該文 件向量中相對應的元素給予值 1;反之,若未出現於文件中,則給予值 0,如下 圖 3-3 之所示。如此我們可以將文件 dj 轉換為一向量 di。. 圖 3-3 二元向量空間模型. 3.3 文件分群 本步驟之目的在於找出文件間之關聯以提供後續分析使用。而為了讓相似的 文件群集在一起且文件中的知識分佈情況以視覺化的方式呈現給使用者。因此本 研究將選擇自我組織圖(self-organizing map)作為分群之方法,原因為其具有頗佳 的分群效能,能將高維度資料間之拓樸關係呈現於二維之平面上,且使得每一個 相鄰的群組具有某種程度的相關性。這點有利於我們去發掘資料間之關聯。 3.3.1 自我組織圖(SOM)訓練 自我組織圖演算法由 Kohonen [11]在 1982 所提出,為一種非監督式學習網 路模式。其以特徵映射的方式,將任意維度的特徵向量,映射至低維的的特徵映 射圖上,如一維向量方式或二維矩陣方式排列形成之拓樸映射圖,並依據目前的 輸入向量在神經元間彼此相互競爭,優勝者則為優勝神經元,其可獲得調整鏈結 權重向量的機會,而最後再輸出層的神經元會依據輸入向量的特徵以有意義的拓 樸結構展現在輸出空間中。此拓樸結構可以反映出輸入向量的特徵且顯示出文件 彼此間的關聯情形。 15.
(23) 自我組織圖的網路架構主要由輸入層、輸出層兩個部分組成,如圖 3-4 所示。 輸入層為網路的輸入變數,為一向量值。輸出曾代表著訓練後分群結果,每一神 經元代表一個群組,神經元間之排列可以式一維、二維甚至多維,但通常以 N×N 個神經元所形成的二維矩形較為常用。輸入層之神經元與輸出層所有神經元間均 有鏈結關係,其強度以權值向量表示,當網路訓練完後,其輸出神經原相鄰近者 會具有相似的權值向量。. 輸出層 (神經元陣列,代表分群). 輸入層 (資料向量,代表輸入變數) 圖 3-4 自我組織圖架構. 自我組織圖主要概念為模仿人類大腦結構,即大腦中具有相似性質的腦細胞 會聚集在一起的特性,將一群未知或未經標記的資料,透過 SOM 演算法,尋找 出彼此間相似的特性,再將這些具有某種相似特性的資料聚集成一類。而自我組 織圖具有以下特性: I.. 維度縮減(dimensionality reduction) 自我組織圖是模擬人類大腦特徵映射之特性,可將任意維度之輸入向量, 以低維度之輸出神經元陣列對映資料間的分佈關係,常以一維或二維的拓 樸網路來表示,如此可易於了解文見間之群集關係。. II.. 拓樸維持(topology preservation) 16.
(24) 由於自我組織圖可以將高維度資料彼此間所具有的關係映射於低維度的特 徵空間中,使低維度之網路拓樸仍具有高維度資料間之關係與群集關係, 以利於資料之視覺化。 以下為自我組織圖的基本名詞與兩層結構之介紹: I.. 輸入層:此層為網路的資料輸入來源,通常為訓練資料之特徵向量,其神經 元的數目依據輸入向量的維度而定。. II.. 輸出層:此層為網路的輸出變數,即訓練範例的分群結果,通常為 N×N 個 神經元形成的矩形。. III. 網路鏈結:輸入層中每個神經元透過此鏈結與輸出層中的神經元連結,每一 鏈結皆依其權重來表達神經元之間的關聯。 IV. 學習速率α(t):影響神經元突觸權重之調整速度,一般介於數值 0 到 1 之間, 並隨著訓練週期或時間的增加而逐漸降低。 V.. 鄰近中心:優勝神經元,即輸入層中的輸入向量與輸出層中距離最短的神經 元。以該神經元為中心,在鄰近半徑區域內的神經元之所有神經元之鏈結權 重均會進行調整。. VI. 鄰近半徑:決定鄰近區域之大小,一開始可取較大的半徑值,隨著訓練週期 或時間的增加,逐漸縮小此鄰近半徑,鄰近區域也隨之變小。如圖 3-5 所示。. 鄰近區域 鄰近中心(優勝神經元) 鄰近半徑. 圖 3-5 a.鄰近區域 17.
(25) 第n次 第 n+1 次 第 n+2 次. 圖 3-5 b.鄰近區域縮小示意圖. 自我組織圖演算法的主要目標就是以這種映射方式,將輸入向量映射到特徵 圖上。其學習過程步驟如下: . Step1:設定網路參數 設定訓練所需的參數,如輸入層神經元數、輸出層神經元數、輸入文件向量 筆數、學習速率α(t)、學習次數 T,並以亂數設定鏈結權重向量 wi。. . Step2:自訓練文件向量中隨機挑選一文件向量 dj 行訓練。. . Step3:計算 dj 與所有神經元鏈結權重向量 wi 間之歐基里德距離,挑選最小 的神經元 c,該神經元即為優勝神經元,其滿足下列公式, (3.2) 其中 wi 為第 i 個神經元的權重向量,M 為輸出神經元總數。. . Step4:更新鏈結權重的向量。 鏈結權重向量調整的法則是將優勝神經元 c 與其鄰近區域內的神經元皆進 行調整,更新鏈結權重向量如下: (3.3). 18.
(26) 其中 Nc 為優勝神經元 c 之鄰近區域內的神經元集合,此鄰近區域將隨著訓 練週期的增加而遞減,α(t)為訓練時間為 t 時的學習速率參數。 . Step5:重複 Step2~ Step4 直到所有的文件向量都經過一次訓練。. . Step6:停止檢查條件。 令 t=t+1,假如 t 達到了預先設定的總學習次數 T 時,則訓練完成;否則就 減少學習速率α(t),並縮減鄰近區域的範圍,回到 Step2 繼續執行訓練。. 訓練完成後,每一神經元即代表一資料(文件)群集,且藉由一標記(labeling)過 程,我們可以得知屬於該群集之文件為何。下圖 3-6 為 SOM 演算法之訓練步驟。. 圖 3-6 SOM 訓練步驟. 3.3.2 標記(labeling) 經過自我組織圖的訓練後,我們將針對神經元進行標記過程,並產生文件群 集圖(document cluster map, DCM)。所謂的標記處理即將先前文件於訓練完成之. 19.
(27) 自我組織圖之優勝神經元標示出來,以便知道哪些文件與文件之間的相似度是高 的。文件群集圖之標記方法如下: 在 DCM 中,概念上每一個神經元即代表一些文件的集合,且標記於此神經 元內的文件具有高度字詞同時出現(co-occurrence)的特性,因此被標記在同一個 神經元或鄰近神經元上的文件彼此間有一定程度的相似程度。 產生 DCM 所使用的方法為計算文件向量與各神經元鏈結權重向量的距離。 我們將第 j 筆文件向量 dj 與所有神經元的鏈結向量進行比較,假設第 j 筆文件向 量與第 i 個神經元的鏈結權重向量的距離最小,則將此文件向量標記至此神經元 上。 最後將所有文件向量之標記神經元記錄下來,即是文件群集圖。透過這個過 程,我們可以將相似度高的文件標示於同一或鄰近神經元上,如此則可以獲得文 件之群集,也就是達成分群的目的,並獲得文件間之關聯。 同樣的,經關鍵字標記後,每一神經元皆會被某些關鍵字所標記,這些被標 記在同一神經元的關鍵字便構成一關鍵字群集,再將所有文件向量之標記神經元 記錄下來,即是關鍵字群集圖(keyword cluster map, KCM)。在 KCM 中每一神經 元內所包含的是一些字詞的群集,且這些字詞為其對應之文件中的常用字詞,因 此這些字詞在其被標記的神經元之鏈結權重向量中占有一定程度的權重值。. 3.4 關鍵字分群 此步驟的目的在於找出關鍵字間的相似度,以提供後續文件與關鍵字間的關 聯分析。而為了使相似的關鍵字群集在一起,本研究一樣選擇自我組織圖作為分 群之演算法。 3.4.1 關鍵字向量化 本研究的文件向量是以二元向量來表示,因此經 SOM 訓練後的鏈結權重向 量理論上最好的情況應該是 0 或 1,權重 0 代表關鍵字對於此神經元完全不重要; 反之,權重 1 則表示關鍵字對此神經元具有很大的重要性。但事實上並不會出現 20.
(28) 極端的 0 或 1,因為在訓練的過程之中每一個神經元均會受到鄰近神經元之修正。 如下圖所示:. 圖 3-7 神經元權重示意圖. 每個關鍵字 kj 於每個神經元 ii 之中都有一個專屬於自己的權重值,代表著其 字詞於神經元中的重要程度,如下圖 3-8 關鍵字之向量模型所示。我們每個關鍵 字 kj 於所有神經元之權重記錄下來,便可得到關鍵字 kj 之關鍵字向量 kj,供後續 關鍵字 分群 所用。 如圖 3-8 中, k1 關鍵字 之關鍵 字向 量即為 k1 = (0.25, 0.64,…,0.41)。. 圖 3-8 關鍵字之向量模型. 3.4.2 關鍵字之自我組織圖訓練 經關鍵字之向量化處理後所得到的關鍵字向量,再輸入自我組織圖進行分群 訓練,最後使用上述的標記(labeling)過程將各關鍵字標示於訓練後之自我組織圖 上。在此所謂標示即是計算此關鍵字與所有神經元鏈結權重向量的距離,找出權 重距離最小的神經元後,則將此關鍵字標記至此神經元上。透過這個過程,我們 21.
(29) 可以將相關的關鍵字標示於同一神經元上,如此則能夠聚集相似度高的關鍵字於 一群,被分群在同一神經元上之關鍵字應具有相同主題,而這些關鍵字又會具有 許多共用的文件神經元,也就是完成分群的目的,而透過標示的過程,也能逐漸 的收斂相似度高的關鍵字於同一鄰近區域。. 3.5 情感分析 此步驟最大目的在於針對文字訊息分析其所隱含之意見,而後進一步分析使 用者之情緒狀態。情感/意見分析模式可分為兩種,其一為訊息進行極性(polarity) 分析,例如判斷此訊息所隱含之意見為”贊成”、”中立”或”反對”等尺規不同之極 性,屬於極性分析者,在此概稱為意見探勘。另一種為非極性分析,即判斷訊息 為某一狀態,而此種屬於非尺規的區分,例如”喜”、”怒”、”哀”、”樂”等。本研 究將針對尺規等級進行研究,利用關鍵字分群後獲得的特徵圖進行意見探勘,歸 納出所有神經元之極性,再利用文件與意見分數探勘後之結果做關聯連結,取得 文件神經元所對應至極性神經元,當一文件群組屬於某一極性之概念時,即可被 歸類至該概念群組,意即我們可以用這些極性來代表文件群組之語意。 3.5.1 意見分數 在此我們想要針對一關鍵字群組所表達之意見等即給予評定,自”最讚同” 至”最反對”間予以評等。作法為賦予一關鍵字一意見分數,若其為 1 則代表”讚 同”-1 則代表”反對”。舉例而言,”贊成(approve)”、”開心(happy)”之分數為 1;” 不贊成(disapproval)”分數為-1 等。探勘方法為採用投票法來進行,令 So(ki)為關 鍵字 ki 之意見分數、Ki 為關鍵字群組。則關鍵字群組 Ki 之意見分數為其概念之 意見分數總和: (3.4) 由於我們在式(3.4)中已將意見分數與以正規化,故 S(Ki)之值將落於+1 與-1 之間, 代表不同之同意程度。 22.
(30) 由於我們逐一將每一關鍵字群組予以評分,賦予它一個群組各自擁有的專 屬極性分數,最後依據此分數之性質,給予各群組之情感極性。如下圖 3-9 所示:. 圖 3-9 關鍵字群組之極性示意圖. 3.5.2 關聯發掘 此步驟主要是發掘出文件群組所隱含的情感極性,利用完成文件向量與關 鍵字向量的訓練後,會得到兩張特徵圖,其一為文件分群圖,其二為關鍵字分群 圖。這些特徵圖可以呈現文件間或關鍵字間之關聯,然而文件群組與關鍵字群組 間的關聯卻難直接獲得,其原因是此特徵圖間並不存在直接的對應關係,以下我 們將發展一方法來發掘此二特徵圖間之關聯,如下圖 3-10 所示:. 23.
(31) 圖 3-10 特徵圖關聯示意圖. 要找出不同特徵圖之間的關聯,首先我們必須將一文件分群圖之神經元對 應至另一關鍵字分群圖之某一神經元上。假設 Pk 為關鍵字群組 Ki 內之關鍵字向 量,Pd 為文件群組 Dj 內之文件向量,其中 Nc(Dj)為群組 Dj 之鄰近群組所構成之 集合,則關鍵字群組 Ki 與文件群組 Dj 間之相似度是 S(Ki,Dj):. (3.5). 在此舉一例說明。對某一文件群組 Dj 而言,當 S( ,. )是所有 S(. ,. ),. 1<=i<=n 中最大時,其所對應的關鍵字群組為 Ki。其步驟為先計算文件群組 Dj 與所有關鍵字群組間的相似度,相似度為文件向量與關鍵字向量進行內積計算, 再除以每個關鍵字群組之關鍵字字數進行正規化處理,最後找出其中最大的相似 度之群組對應至該文件群組。舉例來說,當關鍵字字數共有 10 個,而 K1 神經元 上 的 關 鍵 字 有 {K1 、 K2 、 K4 、 K6} , 則 此 關鍵 字 向 量 , 即 式 (3.5) 之 Pk , 為 {1,1,0,1,0,1,0,0,0,0}。若文件神經元 Dj 的文件向量,亦即式(3.5)中之 Pd ,為 {0.2,0.0,0.4,0.4,0.71,0.51,0.0,0.0,0.52,0.64},為了找出關鍵字向量 Pk 的最相似的文 件向量,我們將進行兩向量之內積相似度計算,其值為{0.2+0.0+0.4+0.51},再 除以關鍵字向量之長度 4,作正規化處理,則 Dj 與 K1 的相似度為 0.2775,接著 依 序 計 算 4 個 鄰 居 文 件 神 經 元 Dj-10 、 Dj-1 、 Dj+1 、 Dj+10 , 分 別 為 {0.3,0.41,0.5,0.0,0.0,0.62,0.1,0.0,0.0,0.41}、{0.1,0.21,0.0,0.0,0.34,0.0, 0.14,0.1,0.16,0.0}、{0.0,0.13,0.14,0.8,0.3,0.41,0.0,0.0,0.0,0.0}、{0.0,0.46,0.85, 0.13,0.31,0.71,0.0,0.0,0.6,0.14},利用上述之相似度計算公式,依序計算其與 周遭 4 個鄰居之相似度後,其值分別為 0.33、0.08、0.34、0.33,接著將 5 個神 經元之相似度進行加總後,再除以 Nc(Dj)集合之長度,即文件群組 Dj 之鄰近群 24.
(32) 組的集合的長度,其集合長度為 5,進行正規化處理,讓其值範圍受限於 0~1 之 間。 決定了各文件群組之對應關鍵字群組後,可以用以下方式來偵測訊息之情 感。一新進文件 dI 先依第二節所述進行前置處理並轉換為一文件向量 dI。此輸 入文件向量再與文件分群圖中之所有神經元比較以找出最近的文件分群 CI。若 CI 對應至某一關鍵字分群 KI,則文件 dI 會被視為擁有此對應關鍵字群組 KI 之情 感傾向與權重值。. 25.
(33) 四 實驗結果 4.1 實驗步驟 本研究所使用之實驗資料集來源為由高雄應用科技大學李俊宏教授所整理 而成之 Twitter 之文字訊息,其內容為 Twitter 自 2012 年 01 月至 2012 年 03 月中 所收集之訊息,總共約一億筆網路文字訊息。而為了達到較好的效果,我們捨棄 了包含關鍵字數過少(少於 2 個字)之訊息。本研究共蒐集其中之一萬筆訊息,並 將蒐集到的資料以隨機的方式分為訓練資料集與測試資料集,本研究參考前人研 究經驗,將訓練集與測試集以 7:3 比例隨機混合挑選,各包含 7000 與 3000 份 文件。再利用第三章所述之方法將其轉換為文件向量,隨後再進行自我組織圖的 分群訓練,建立文件之分群圖。再利用文件分群圖建立關鍵字向量後,進行第二 次的自我組織圖訓練且建立關鍵字分群圖。最後透過關聯挖掘來計算出文件群組 之相對應之關鍵字群組來進行本研究所提之情感傾向之偵測,並且進行評估。 4.1.1 前置處理 本研究前置處理的步驟包含文件正規化與無效文件篩選,此步驟目的在於 將無效字元去除以得到文本文件,並剔除無效文件以提升分群訓練之品質。本研 究去除訊息中各種型式之多媒體物件,並擷取出其中之有效文字部分構成文本文 件。本研究亦會捨棄非英文語系之無效文件,只保留英文語系之文本文件,以降 低後續情感關鍵字比對效果不佳之可能性。圖 4-1 為正規化後之文件之範例。. 26.
(34) 圖 4-1 正規化後之文件. 在處理完文件之篩選後,將進行關鍵字之選取。由於文件中包含許多無意 義的贅字、或是一些不包含太多語意的字詞,因此需要作關鍵字的選擇。為了保 留最具情感語意的字作為關鍵字,本研究將採用 Hu and Liu[13]等人提出之全詞 性情感詞彙集來進行詞彙比對,並選擇比對成功之字詞作為關鍵字。圖 4-2 為關 鍵字選取後之結果,在每個關鍵字後面的數字為此字詞於文件中出現的次數。. 圖 4-2 關鍵字選取之結果. 經過關鍵字選取流程後,本研究將分別依其出現次數,建立不同之文件集。 27.
(35) 其中文件集 V2 包含出現次數大於 2 之關鍵字,共包含 1847 個關鍵字;文件集 V3 包含出現次數大於 3 之關鍵字,共包含 1614 個關鍵字;文件集 V4 包含出現次 數大於 4 之關鍵字,共包含 855 個關鍵字。 完成前述步驟後,我們將文件進行向量化。首先我們依上述方式建立字彙 集,再使用 3.2.3 節之方法將文件轉換為二元文件向量。圖 4-3 為二元文件向量 圖。. 圖 4-3 二元文件向量圖. 4.1.2 分群與標記 在完成前置處理後,我們接著使用 SOM 對訊息文件向量與關鍵字向量先後 進行訓練。訓練後將進行一標記過程,將文件與關鍵字標記於自我組織圖之優勝 神經元上,進而針對上述兩種不同特性之向量各得到一張分群特徵圖,分別為文 件群集圖與關鍵字群集圖,圖中每一神經元即代表著一個分群,由於 SOM 分群 28.
(36) 主要依據文件與每個神經元去計算距離,且將文件標記於最近之神經元之上,因 此,被標記在同一神經元上的文件,其相似度很高,故我們可以得到文件之分群 結果。 本研究的文件分群訓練其輸入為隨機挑選中屬於訓練資料集之文件,再根 據前述所提及之依照關鍵字字數條件過濾,所得共 840、3850、7000 份文件。經 由文件分群訓練後,可從每份文件於文件分群圖上的映射位置,表示出其文件間 之相似程度,而文件所屬的神經元之距離越接近,即表示他們的關係越緊密。這 是因為擁有相似主題之文件,其使用的文字亦會有相似的語言特徵,即有很大的 機會採用相同之詞彙,故他們會擁有相似的特徵向量,在進行映射至文件分群圖 時,會被映射至相同或相鄰之神經元上面。表 4-1 為關鍵字字數大於 4 之群集圖, 以神經元編號 26 為例:在表中我們能發現被分在同一群的訊息皆有相近的情感 傾向,而情感類似的群組也會被聚集在一起。 表 4-1. 文件群集圖- Neurone26. Neurone16: 1.. Idiots, idiots, you are all idiots, why would you cry when your master dies? Why would you not rejoice at the remot .... 2.. " Ride for him , cry for him , die for him , sit right in front of the judge right hand up straight lie for him". 3.. You gotta chill in these lonely streets. One day im gonna kill all those muthafuckas that made me cry.. 4.. I just want to scream fuck you in your face and then cry to you about home much ilu. 29.
(37) Neurone25:. Neurone26:. Neurone27:. 1.. 1.. 1.. 2.. You got to admire james. Whenever someone calls me. pease for helping out the. ugly, I get super sad and hug. support a good charity event. rays the only problem is the. them, because I know how. Sam cycling or crawling im. only race he is going to win. tough life is for the visually. there lol ;0). is to the .... impaired.. Another uncomfortable. 2.. 2.. 4.. Unfortunately, 97% of. I think Lennox Mall misses. twitter users will not RT this. tidbit: "electable" candidates. me!!! But right now. for support cancer. But the. who do win tend to screw. Wal-mart needs me..... my. 3% who do are the ones. GOP over on important. fridge is lookin super sad!!. willing to. issues. 3.. im allways willing to. 3.. happy born day to the man. I will make it fair for. that made me so ambitious. everyone.3 lucky fans will. today! never steers me in the. win an autographed photo. wrong direction & always. when reaches 5k.This way. willing to support. love ya. e .... pops!. Good. One less excuse to use if we fail to win this game. Neurone.36: 1.. Aw lol. if you are anything like her after she watched it every noise scared her aha bless her!. 2.. is now lying down in a darkened room after the trauma of hovering. Bless. 3.. Having a very powerful conversation with Darryl Coley.> wow God Bless him appreciate that man he is a musical genius. 4.. My vacuum cleaner is making a distinctly TARDIS-esque noise. While kinda cool, it is somewhat disconcerting.. 30.
(38) 表 4-2 為文件自我組織圖之統計資料。本研究嘗試不同之參數範圍,自我 組織圖神經元數量為 100,學習速率為 0.1、0.4、0.7,最大訓練週期由 200 至 700。 此表為字彙集 V2、V3、V4 之文件集的文件分群之最佳結果。. 表 4-2 參數. 自我組織圖統計資料-文件分群 文件集(V2) 文件集(V3) 文件集(V4). 自我組織圖大小 神經元突觸數量 學習速率初始值. 10×10 1847 0.7. 10×10 1614 0.7. 10×10 855 0.7. 最大訓練週期. 400. 600. 700. 在完成文件分群後,我們會得到一組神經元之鏈結權重向量。我們將利用 此鏈結權重向量來構成關鍵字分群訓練的輸入向量。經由關鍵字分群訓練後,可 從每個關鍵字於關鍵字分群圖上的映射位置,表示出其與其他關鍵字間之相似程 度。兩個關鍵字所屬的神經元之距離越接近,即表示它們的關係越緊密。而這些 隸屬於相同主題下的關鍵字,其皆使用相似的神經元作為特徵值,故他們會擁有 相似的特徵向量,故在進行映射至關鍵字分群圖時,會被映射至相同或相鄰之神 經元上面。表 4-3 為關鍵字自我組織圖之統計資料。本研究嘗試不同之參數範圍, 自我組織圖神經元數量為 100,學習速率為 0.1、0.4、0.7,最大訓練週期由 200 至 700。此表為字彙集 V2、V3、V4 之文件集的關鍵字分群之最佳結果。. 表 4-3 參數. 自我組織圖統計資料-關鍵字分群 文件集(V2) 文件集(V3) 文件集(V4). 自我組織圖大小 神經元突觸數量. 10×10 100. 10×10 100. 10×10 100. 學習速率初始值 最大訓練週期. 0.7 600. 0.7 500. 0.7 500. 31.
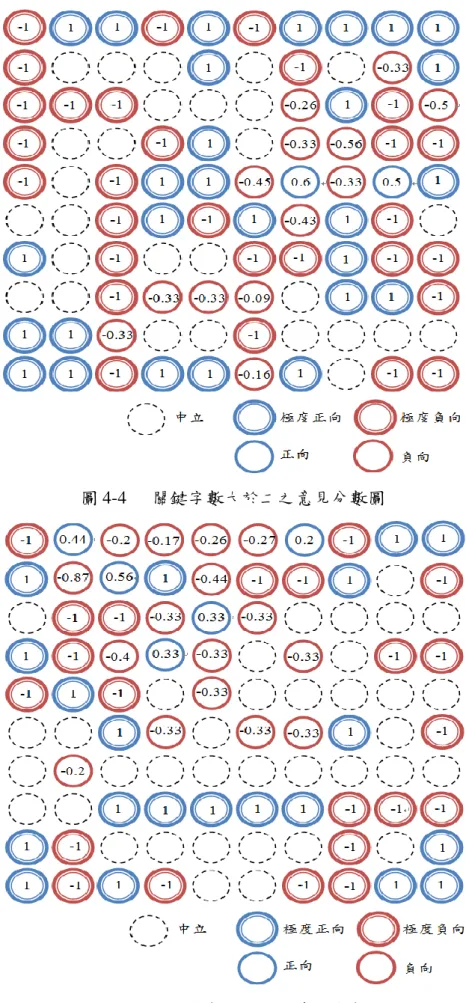
(39) 4.1.3 情感偵測 得到文件與關鍵字之分群結果後,便可針對關鍵字群組進行意見的探勘, 最後再依文件群組與關鍵字群組之間存在的關聯,來進行訊息的情感偵測,分述 如下。 4.1.3.1 意見分數 此步驟的目的在於針對每一個關鍵字群組進行意見評分,發掘出關鍵字群 組中之情感極性及分數,作為該分群之意見傾向。由於關鍵字分群圖上的每個群 集,是由所有關鍵字以不重複的方式予以標記上,因此被標記在同一個神經元之 上的關鍵字,所採用的特徵值彼此間的相似度極高,且這些關鍵字往往能反映出 群組之特徵主題。故本研究透過情感詞彙集中針對每個詞彙皆賦予一意見分數, 去探勘出屬於群組的情感極性及分數。本研究意見分數計算方式如前文式(3.4) 所示。圖 4-4、4-5、4-6 分別為關鍵字字數大於二、三、四之意見探勘結果。圖 中藍色表示正向、紅色表示負向、黑色虛線表示中立,即無情感傾向,而情感強 烈則以雙圈表示。圓圈中的數值則為依式(4.1)所計算之分數。由此結果顯示相鄰 之群組通常亦具有相似之意見極性。. 32.
(40) 圖 4-4. 關鍵字數大於二之意見分數圖. 圖 4-5. 關鍵字數大於三之意見分數圖 33.
(41) 圖 4-6. 關鍵字數大於四之意見分數圖. 4.1.3.2 關聯挖掘 關聯挖掘的目的在於找出文件組與關鍵字群組之間存在的關聯。亦即,我 們須將某一文件群組依照對應至某一最相似之關鍵字群組。然而這些不同特徵圖 之間並不存在直接的對應關係或關聯。本研究將先計算所有關鍵字群組與某一文 件群組間的相似度,再找出其中具有最大相似度之關鍵字群組對應至該文件群組。 本研究計算相似度之公式如前文式(3.5)所示。以下圖 4-7 為例,為了計算文件群 組 D5 與關鍵字群組 K1 間的相似度,我們必須將文件群組 D2、D4、D6、D8 一併 納入考慮,也就是分別計算相似度與正規化過程,再將個別相似度進行加總,再 作正規化處理,最後得到之數值即為文件群組 D5 與關鍵字群組 K1 間的相似度。. 34.
(42) 圖 4-7. 相似度示意圖. 經由前述之關聯發掘過程後,文件群組與關鍵字群組之關聯對照表如下表 4-4~4-6 所示。例如表 4-4 中文件群組編號(欄位 Docs_no)0 對應至關鍵字群組 編號(欄位 KW_no)90,且其相似度分數 1(Score),其他依此類推。表 4-4、 4-5、4-6 分別為字彙集 V2、V3、V4 之文件集於之關聯發掘結果。. 35.
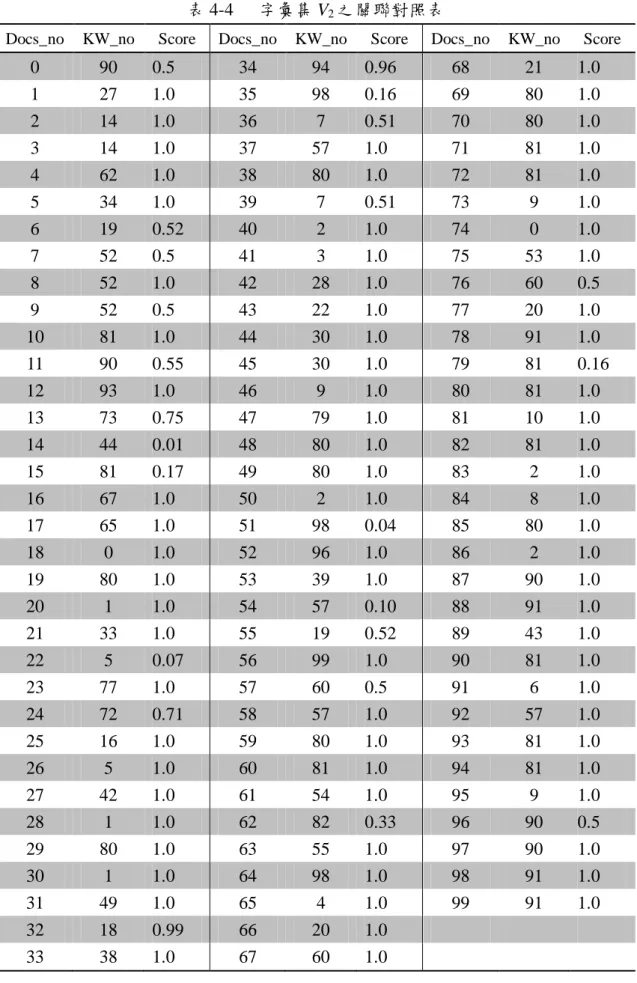
(43) 表 4-4 Docs_no. KW_no. 0 1 2 3 4. 90 27 14 14 62. 5 6 7 8. Score. 字彙集 V2 之關聯對照表. Docs_no. KW_no. 0.5 1.0 1.0 1.0 1.0. 34 35 36 37 38. 94 98 7 57 80. 34 19 52 52. 1.0 0.52 0.5 1.0. 39 40 41 42. 9 10 11. 52 81 90. 0.5 1.0 0.55. 12 13. 93 73. 14 15 16 17. Docs_no. KW_no. 0.96 0.16 0.51 1.0 1.0. 68 69 70 71 72. 21 80 80 81 81. 1.0 1.0 1.0 1.0 1.0. 7 2 3 28. 0.51 1.0 1.0 1.0. 73 74 75 76. 9 0 53 60. 1.0 1.0 1.0 0.5. 43 44 45. 22 30 30. 1.0 1.0 1.0. 77 78 79. 20 91 81. 1.0 1.0 0.16. 1.0 0.75. 46 47. 9 79. 1.0 1.0. 80 81. 81 10. 1.0 1.0. 44 81 67 65. 0.01 0.17 1.0 1.0. 48 49 50 51. 80 80 2 98. 1.0 1.0 1.0 0.04. 82 83 84 85. 81 2 8 80. 1.0 1.0 1.0 1.0. 18 19 20 21 22. 0 80 1 33 5. 1.0 1.0 1.0 1.0 0.07. 52 53 54 55 56. 96 39 57 19 99. 1.0 1.0 0.10 0.52 1.0. 86 87 88 89 90. 2 90 91 43 81. 1.0 1.0 1.0 1.0 1.0. 23 24 25 26. 77 72 16 5. 1.0 0.71 1.0 1.0. 57 58 59 60. 60 57 80 81. 0.5 1.0 1.0 1.0. 91 92 93 94. 6 57 81 81. 1.0 1.0 1.0 1.0. 27 28 29 30 31. 42 1 80 1 49. 1.0 1.0 1.0 1.0 1.0. 61 62 63 64 65. 54 82 55 98 4. 1.0 0.33 1.0 1.0 1.0. 95 96 97 98 99. 9 90 90 91 91. 1.0 0.5 1.0 1.0 1.0. 32 33. 18 38. 0.99 1.0. 66 67. 20 60. 1.0 1.0. 36. Score. Score.
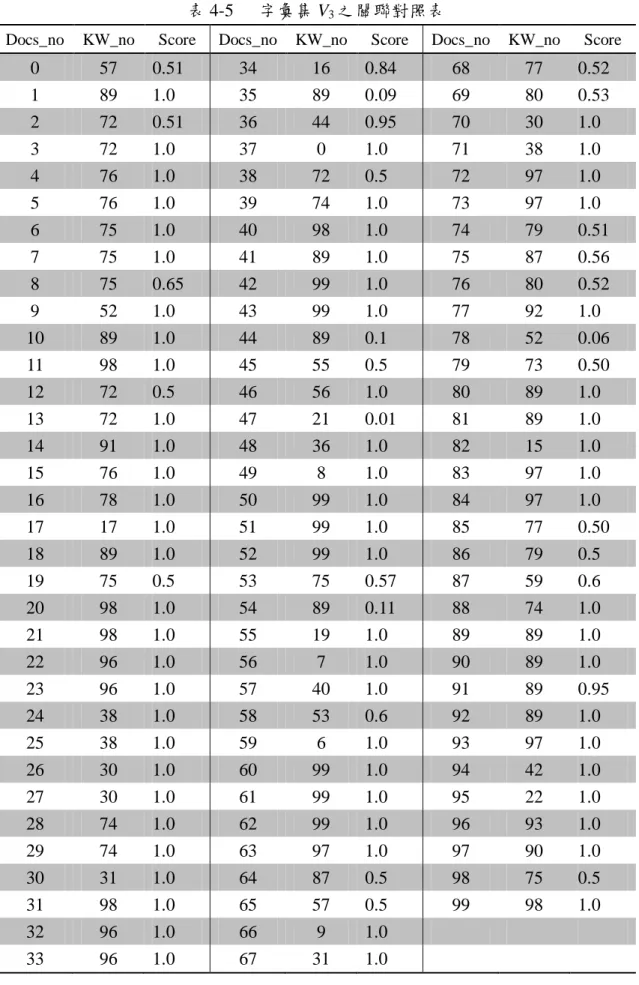
(44) 表 4-5 Docs_no. KW_no. 0 1 2 3 4. 57 89 72 72 76. 5 6 7 8. Score. 字彙集 V3 之關聯對照表. Docs_no. KW_no. 0.51 1.0 0.51 1.0 1.0. 34 35 36 37 38. 16 89 44 0 72. 76 75 75 75. 1.0 1.0 1.0 0.65. 39 40 41 42. 9 10 11. 52 89 98. 1.0 1.0 1.0. 12 13. 72 72. 14 15 16 17. Docs_no. KW_no. 0.84 0.09 0.95 1.0 0.5. 68 69 70 71 72. 77 80 30 38 97. 0.52 0.53 1.0 1.0 1.0. 74 98 89 99. 1.0 1.0 1.0 1.0. 73 74 75 76. 97 79 87 80. 1.0 0.51 0.56 0.52. 43 44 45. 99 89 55. 1.0 0.1 0.5. 77 78 79. 92 52 73. 1.0 0.06 0.50. 0.5 1.0. 46 47. 56 21. 1.0 0.01. 80 81. 89 89. 1.0 1.0. 91 76 78 17. 1.0 1.0 1.0 1.0. 48 49 50 51. 36 8 99 99. 1.0 1.0 1.0 1.0. 82 83 84 85. 15 97 97 77. 1.0 1.0 1.0 0.50. 18 19 20 21 22. 89 75 98 98 96. 1.0 0.5 1.0 1.0 1.0. 52 53 54 55 56. 99 75 89 19 7. 1.0 0.57 0.11 1.0 1.0. 86 87 88 89 90. 79 59 74 89 89. 0.5 0.6 1.0 1.0 1.0. 23 24 25 26. 96 38 38 30. 1.0 1.0 1.0 1.0. 57 58 59 60. 40 53 6 99. 1.0 0.6 1.0 1.0. 91 92 93 94. 89 89 97 42. 0.95 1.0 1.0 1.0. 27 28 29 30 31. 30 74 74 31 98. 1.0 1.0 1.0 1.0 1.0. 61 62 63 64 65. 99 99 97 87 57. 1.0 1.0 1.0 0.5 0.5. 95 96 97 98 99. 22 93 90 75 98. 1.0 1.0 1.0 0.5 1.0. 32 33. 96 96. 1.0 1.0. 66 67. 9 31. 1.0 1.0. 37. Score. Score.
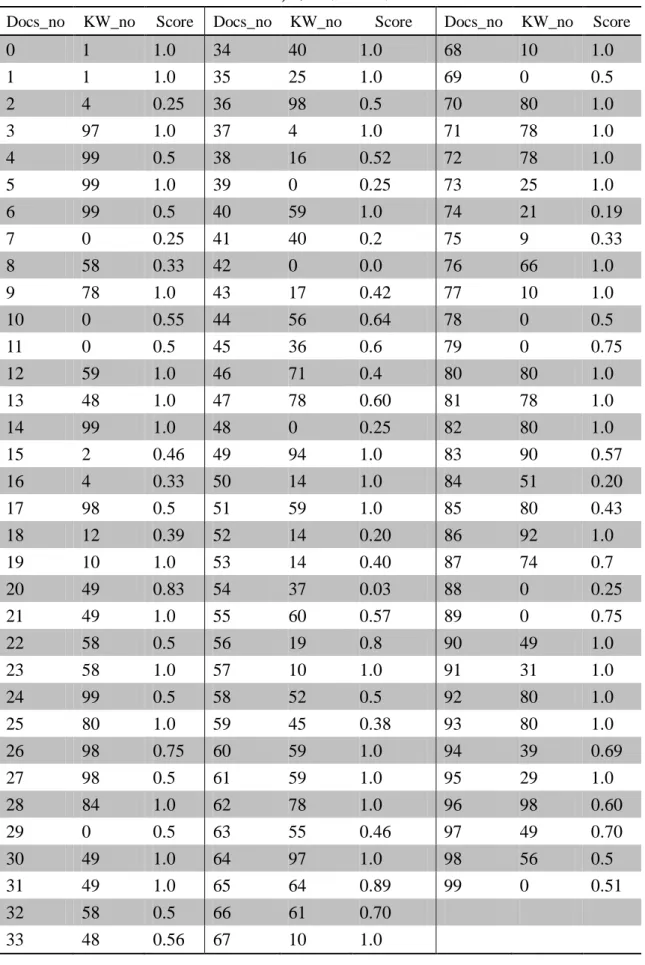
(45) 表 4-6. 字彙集 V4 之關聯對照表. Docs_no. KW_no. Score. Docs_no. KW_no. 0 1 2 3 4. 1 1 4 97 99. 1.0 1.0 0.25 1.0 0.5. 34 35 36 37 38. 40 25 98 4 16. 5 6 7 8. 99 99 0 58. 1.0 0.5 0.25 0.33. 39 40 41 42. 9 10 11. 78 0 0. 1.0 0.55 0.5. 12 13. 59 48. 14 15 16 17. Docs_no. KW_no. Score. 1.0 1.0 0.5 1.0 0.52. 68 69 70 71 72. 10 0 80 78 78. 1.0 0.5 1.0 1.0 1.0. 0 59 40 0. 0.25 1.0 0.2 0.0. 73 74 75 76. 25 21 9 66. 1.0 0.19 0.33 1.0. 43 44 45. 17 56 36. 0.42 0.64 0.6. 77 78 79. 10 0 0. 1.0 0.5 0.75. 1.0 1.0. 46 47. 71 78. 0.4 0.60. 80 81. 80 78. 1.0 1.0. 99 2 4 98. 1.0 0.46 0.33 0.5. 48 49 50 51. 0 94 14 59. 0.25 1.0 1.0 1.0. 82 83 84 85. 80 90 51 80. 1.0 0.57 0.20 0.43. 18 19 20 21 22. 12 10 49 49 58. 0.39 1.0 0.83 1.0 0.5. 52 53 54 55 56. 14 14 37 60 19. 0.20 0.40 0.03 0.57 0.8. 86 87 88 89 90. 92 74 0 0 49. 1.0 0.7 0.25 0.75 1.0. 23 24 25 26. 58 99 80 98. 1.0 0.5 1.0 0.75. 57 58 59 60. 10 52 45 59. 1.0 0.5 0.38 1.0. 91 92 93 94. 31 80 80 39. 1.0 1.0 1.0 0.69. 27 28 29 30 31. 98 84 0 49 49. 0.5 1.0 0.5 1.0 1.0. 61 62 63 64 65. 59 78 55 97 64. 1.0 1.0 0.46 1.0 0.89. 95 96 97 98 99. 29 98 49 56 0. 1.0 0.60 0.70 0.5 0.51. 32 33. 58 48. 0.5 0.56. 66 67. 61 10. 0.70 1.0. 38. Score.
(46) 4.2 實驗評估 任何的評估機制都需要建構在一個合理且公平的評估程序底下,並採用合 宜的評估準則以及效能評分(Performance Scoring)。由於本研究採用 Twitter 內 之訊息作為實驗資料,訊息本身並不存在既有的情感類別標記,且訊息本身之情 感傾向容易因個人的主觀意識產生差異,導致不同的人對於相同的訊息文件容易 產生不同的情感意識。鑒於此,我們在針對訊息之情感類別之標記上採用人工識 別進行投票來判定之。在標記的過程中,首先我們先將每則訊息依照情感的正負 向強弱進行李克特”五點”量表的區分,即將情感分為強烈正向、正向、中立、負 向、強烈負向五種量度。然後將同一則訊息分給 3 位標註者進行情感標記,最後 再以投票法進行此訊息的情感類別選取。例如 3 位標注者若剛好挑中一正向、一 負向、一中立的話,則將此訊息標記為中立訊息。我們總共收集了 10000 份文件, 其中正向文件為 4799 份文件、負向文件為 4529 份文件、中立文件為 672 份文件。 圖 4-8 為本研究所建立之訊息文件標記系統介面。. 圖 4-8. 訊息文件標記系統介面. 在效能評估方面,本研究將採用準確度(accuracy)作為評估偵測效能的指標。 在此準確度之定義為成功偵測數量之比率。在本研究中,準確度代表在文件群組 39.
(47) 中所擁有之文件符合正確情感傾向的文件數比率。以本實驗為例,在使用字彙集 V2 的測試文件數量為 3000 筆,而成功偵測數量為 1820 筆,準確率為 1820/3000 =61%,即顯示出訊息情感之偵測能力。表 4-7 為情感偵測結果。 表 4-7. 情感偵測結果. 描述. 值/結果. 文件集. V2. V3. V4. 測試文件數量. 3000. 1650. 360. 成功偵測數量. 1820. 1038. 217. 準確率. 61%. 63%. 60%. 導致訊息的分類效能較低的原因,可能有以下幾種因素: 1.. 中立文件之情感傾向識別度不佳。. 2.. 文件分群之神經元內文件情感相似度低。. 3.. 文件與關鍵字分群之關聯度不高。. 在第一個因素中,主要是因為中立的文件本身情感傾向不明確或訊息個人 的主觀程度太高導致人工標記者無法精準識別。因此本研究決定過濾掉標記為中 立之文件後再進行評估流程。以 V2 為例,原測試資料集共 3000 筆文件,扣除 196 筆中立文件,最後總計 2804 筆文件,其中正向文件 1474 筆、負向文件 1330 筆。以過濾後之資料集進行實驗,成功偵測數量為 1820 筆,準確率為 1820/2804 =0.65%,即顯示出訊息情感之偵測能力的確有所提升。表 4-10 為過濾中立文件 後之情感偵測結果。. 40.
(48) 表 4-8. 情感偵測結果_無中立文件. 描述. 值/結果. 文件集. V2. V3. V4. 測試文件數量. 2804. 1517. 348. 成功偵測數量. 1820. 1038. 217. 準確率. 65%. 68%. 62%. 從上表 4-8 中的實驗結果來看,主要是由於中立之文件本身情感傾向的鑑 別度不佳,雖然過濾中立文件後之測試文件數量下降,但成功偵測數量卻不減少, 亦即中立文件在整體資料集中會有雜訊(noise)般的效果產生,故影響整體準 確率。因此,在不考慮情感意向不明確之文件後,準確率皆提升約 3%左右。 在第二個因素中,主要的原因在隸屬於同一群組內的文件本身情感傾向並 不相近,即關鍵字本身對於情感分群的效果不佳。此類型關鍵字在社會網路訊息 之中,時常同時出現在正向與負向的訊息之中,故其並無強烈且明顯的情感傾向, 亦即此類關鍵字用於分類之效能較差,且會進而導致第三個因素產生。 在第三個因素中,主要是由於文件群組與關鍵字群組間的關聯錯誤,即文 件群組的情感傾向與關鍵字群組的情感傾向不一致,導致原本該是正向(負向) 的文件卻經由關聯的挖掘對應至負向(正向)的情感。主要的原因是由於網路訊 息中有一些常用的關鍵字常常被使用在反向的訊息之中,且多當作語助詞與誇飾 用語使用,如 fucking、damn 等。 在上述兩種因素中,我們探究其主因在於某些關鍵字本身對於情感傾向的 特徵並不明顯,此類型關鍵字容易導致文件在分群時,神經元內的文件情感傾向 不相近,與找尋文件群組與關鍵字群組的關聯時,連結正確率下降。由於此類型 關鍵字時常出現於正向文件與負件文件之間,即表示其本身所隱含之情感傾向極 為薄弱,因此本研究針對上述鑑別度不佳之關鍵字進行過濾動作。以過濾後實驗 為例,在使用 V2 的測試文件數量為 2970 筆,而成功偵測數量為 1936 筆,準確 41.
(49) 率為 1936/2970=65%,即顯示出訊息情感之偵測能力有所提升。表 4-9 為過濾 關鍵字後之情感偵測結果。. 表 4-9. 情感偵測結果_過濾關鍵字後. 描述. 值/結果. 資料特性 文件集. 原始資料. 無中立文件. V2. V3. V4. V2. V3. V4. 測試文件數量. 2970. 1647. 360. 2777. 1514. 348. 成功偵測數量. 1936. 1090. 238. 1980. 1086. 246. 準確率. 65%. 66%. 66%. 71%. 72%. 71%. 從上表中實驗結果來看,不論是原始的資料或無中立文件的資料,在略為 降低測試文件的數量後,還能夠提升成功偵測數量。也就是說,在過濾一些鑑別 度不佳的關鍵字後,能夠更精準的進行文件分群,群組內的文件情感傾向相似度 也提高,或是文件群組與關鍵字群組的對應上也更加的準確,而在整體的準確度 上平均有 4~5%的提升。. 42.
(50) 五 結論與分析 5.1 結論 社會網路在近年來的發展與趨勢成長, 提供的服務也越加多元化,對於隱 藏於其中資料的分析需求量也隨之成長,因此,如何有效的從訊息之中發掘出有 用之知識為一迫切解決之課題。故本研究希望運用文本探勘之技術,在社會網路 訊息的使用者與訊息量急遽增多的情況下,來協助我們進行情感分析,以降低在 情感分析時對於人力的需求。 情感分析主要是針對附有情感色彩的文件進行分析、處理、歸納的過程,藉 由抽取文章中帶有義意的字詞或訊息單元,將不具結構化的情感文件轉換成為機 器容易識別的結構化文本,也就說利用概念偵測技術去挖掘出隱含於其中之重要 意見與情感的表達。 本研究藉由社會網路 Twitter 的文字訊息來進行文件與內部關鍵字之群集分 析,並去發掘出兩群集間之關聯,進行社會網路訊息之情感偵測。情感偵測是指 偵測出訊息的情感傾向。透過訊息中的情感關鍵字,我們可以依照文件與各群組 之間的相似度計算,偵測出它隸屬於哪一文件群組,再去對應至相關的情感關鍵 字群組,進而得到此訊息的情感傾向。透過上述之研究架構,則能夠將為尚未標 記情感傾向之訊息,偵測出發文者在當文當下所欲表達的情感。 本研究的目的在於針對社會網路訊息的特性,長度極端化、內容極度抽象、 訊息量大、去發展適合社會網路之文字訊息的前置處理與探勘程序,來協助進行 社會網路訊息的情感分析,利用自動化的情感傾向偵測,大量降低使用人工識別 的需求量。 在訊息的前置處理上,由於社會網路訊息的特性較一般傳統文本不同,因此 在字詞地處理上,我們只保留情感意識較為強烈之字詞來代表此訊息之情感,故 此我們選用一情感詞彙詞集來進行文本的意義表達,由於情感詞集的品質高度相. 43.
(51) 關於本研究的結果,在實驗中我們也剔除一些情感意識較為薄弱之情感關鍵字詞, 來增加機器在判斷時的準確度。 在探勘程序上,本研究主要利用訊息與關鍵字之間的相似度來進行分群,也 就是將相似的訊息歸納於同一群組內,同一關鍵字也依照本身特性群集在一起, 最後依照訊息與關鍵字兩類型群組之相似性計算,找出彼此間最為相近之群組對 應,且在這兩群組之間拉上一條連結作為關連對應。. 5.2 未來研究發展與建議 本研究採用 Twitter 的文字訊息作為實驗資料,然而該文本集中的文件深受 140 字的限制,因此字數大多為簡短訊息,這現象在進行自我組織圖之訓練時, 會導致神經元對於某些特徵值的訓練不足,進而導致偵測的準確率降低。除此之 外,本研究的準確度也受限於情感關鍵字的品質與訊息本身的情感意識明顯與否。 在第一個因素中,本研究使用情感關鍵字做為文件之關鍵字,因此當關鍵字本身 無法凸顯出其文件的情感傾向時,將導致文件分群效果不佳及關聯情感對應錯誤。 第二因素為本實驗利用人工分類進行情感標注作業進行驗證作業,因此一旦面臨 訊息的情感傾向不太明顯時,將導致標記錯誤或無法識別的情況出現,因此那些 訊息本身所隱含的真實情感,則無法真正挖掘出來,進而導致準確度下降。 在未來可繼續的方向上,就訊息方面可以針對社會網路訊息之特性發展一情 感詞彙集,來進行更加精準的訊息群集分析與關聯挖掘。另外,由於本研究只針 對英文語言進行分析,然而情感分析之研究是沒有語系的限制,若是發展多國語 言文件的偵測方法,更可以針對不同國家和語系進行更深入的研究。除了訊息之 外,更可加入更多探討的因素,如長期追蹤特定使用者、或特定地點的訊息內容, 如此一來將有更深入的情感探討可供研究,也將更具有變化性與多元性。. 44.
數據
Outline
相關文件
Al atoms are larger than N atoms because as you trace the path between N and Al on the periodic table, you move down a column (atomic size increases) and then to the left across
You are given the wavelength and total energy of a light pulse and asked to find the number of photons it
好了既然 Z[x] 中的 ideal 不一定是 principle ideal 那麼我們就不能學 Proposition 7.2.11 的方法得到 Z[x] 中的 irreducible element 就是 prime element 了..
Allan (Eds.), Proceedings of the 38th Conference of the International Group for the Psychology of Mathematics Education and the 36th Conference of the North American Chapter
volume suppressed mass: (TeV) 2 /M P ∼ 10 −4 eV → mm range can be experimentally tested for any number of extra dimensions - Light U(1) gauge bosons: no derivative couplings. =>
For pedagogical purposes, let us start consideration from a simple one-dimensional (1D) system, where electrons are confined to a chain parallel to the x axis. As it is well known
The observed small neutrino masses strongly suggest the presence of super heavy Majorana neutrinos N. Out-of-thermal equilibrium processes may be easily realized around the
incapable to extract any quantities from QCD, nor to tackle the most interesting physics, namely, the spontaneously chiral symmetry breaking and the color confinement..
