國立高雄大學統計研究所
碩士論文
An Interactive Web Application of Data Science with R
using Shiny
運用
R Shiny 建立互動式資料科學平台
研究生:李政葦 撰
指導教授:黃士峰 博士
致謝辭
時光飛逝,轉眼間兩年的研究所生涯即將邁入尾聲,心中滿是不捨,感謝讓我 在這兩年有所蛻變的一切。此篇論文的完成承蒙許多人的支持以及鼓勵,首先感謝 我的指導教授 黃士峰老師,兩年來悉心指導,無論是在學術上的提攜、生活上的 照顧,總是毫無保留的關懷。黃老師親切關懷和悉心指導,從論文課題的選擇到項 目的最終完成,黃老師都始終給予我細心的指導和不懈的支持,讓我能從中學習到 對於研究的執著與態度。其次,感謝 張志鴻教授與 劉青松教授在百忙之中抽空來 擔任我的口試委員,仔細閱讀我的論文並於口試時給予寶貴意見與指正,讓此篇碩 士論文更臻於完善,在此表示深摯的謝忱。另外,感謝所上所有老師的教導,在我 研究路上給予的寶貴經驗分享,著實令我受益良多。 在求學期間內,研究所同學們彼此的情誼是最值得回憶的歷程。感謝助教 吳 蘭屏小姐無微不至的照顧與總是不斷關心我的近況,感謝同研究室的悅誠、益誠、 筱雅在研究上互相激勵與共同成長,感謝暐詒平時生活上的互相關心,感謝奕婷的 互相勉勵與提醒,感謝星達、炳男、書豪、建中、婷穎在研究之餘一起聊天所帶來 的樂趣,感謝宇瀚經常的散撥歡笑,感謝孟瑾課程中的幫助。很高興在我的人生旅 途當中遇見你們,我會永遠珍惜這個緣分。最後,感謝默默支持與關心我的家人, 讓我在求學過程當中無後顧之憂,忙碌之餘總是為我加油打氣。 需要感謝的人不計其數,心中的謝意也是溢於言表,在此,謹以上述文字,對 所有幫助過我的人,獻上由衷的感激及真摯的祝福。 李政葦 撰 國立高雄大學統計學研究所 中華民國一百零八年七月An Interactive Web Application of Data Science with R
using Shiny
by
Lee, Cheng Wei
Advisor
Huang, Shih Feng
Institute of Statistics
National University of Kaohsiung
Kaohsiung, Taiwan 811 R.O.C.
目錄
摘要 ... xiii ABSTRACT ... xiv 第一章 前言 ………1 第二章 文獻回顧 ... 3 2.1 Orange Software 介紹 ... 3 2.1.1 Orange Software 特色介紹 ... 3 2.2 Orange Software 示例 ... 5 2.3 方法比較 ... 6 第三章 方法及工具 ... 7 3.1 Shiny 套件... 7 3.2 ShinyDashboard 套件 ... 8 第四章 視覺化介紹 ... 11 4.1 校務資料 ... 11 4.1.1 100 學年度畢業滿 5 年學生問卷回收... 11 4.1.2 102 學年度畢業滿 3 年學生問卷回收... 11 4.1.3 大學部歷年成績表 ... 12 4.1.4 108 年學測試場分配表 ... 12 4.1.5 108 學年度大學個人申請入學各校系通過第一階段篩選名單 .... 12 4.2 輸出圖表介紹 ... 13 4.2.1 單變量變數 ... 13 4.2.1.1 單變量類別型變數 ... 13 4.2.1.2 單變量連續型變數... 17 4.2.3 多變數... 22 4.3 其他常用圖形 ... 25 第五章 資料科學平台 ... 315.3 方法介紹 ... 38 5.3.1 迴歸分析 ... 38 5.3.1.1 線性迴歸模型 ... 39 5.3.1.2 羅吉斯迴歸模型 ... 41 5.3.1.3 對數線性模型 ... 43 5.3.2 機器學習方法 ... 45 5.3.2.1 決策樹 ... 45 5.3.2.2 Random Forest 隨機森林 ... 47 5.3.2.3 單純貝氏分類器 ... 48 5.3.2.4 Adaboost ... 50 5.3.2.5 支持向量機 ... 52 5.3.3 時間序列模型 ... 53 第六章 畢業生流向調查平台 ... 56 6.1 問題探討 ... 56 6.2 問題回答 ... 56 6.2.1 就業地區(例如:南部或北部)與就業類別對薪資是否有影響 ... 56 6.2.2 那一些系所之畢業生薪資較高? ... 61 6.2.3 學生時期應該陪養的能力? ... 64 6.2.4 在學修課成績對薪資是否有影響?... 68 6.3 互動式視覺化介面... 71 第七章 招生問題視覺化界面 ... 74 7.1 學校招生問題分析... 74 7.2 視覺化介面呈現 ... 75 Chapter 8 總結 ... 77 參考文獻 ………...79 附錄1. ………. ... 80 附錄2. ………. ... 81 附錄3. ………. ... 87
圖目錄
圖2.1 Orange 軟體選單 ... 4 圖2.2 Orange 軟體操作示例 ... 5 圖2.3 Orange 軟體配適決策樹模型及繪出圖形 ... 5 圖3.1 ShinyDashboard 主體架構 ... 8 圖3.2 ShinyDashboard 標題 ... 8 圖3.3 ShinyDashboard 標題訊息 ... 9 圖3.4 ShinyDashboard 標題通知 ... 9 圖3.5 ShinyDashboard 標題任務 ... 9 圖3.6 ShinyDashboard 互動式側欄 ... 10 圖3.7 ShinyDashboard 主面板 ... 10 圖4.1 100 學年度畢業滿 5 年學生問卷回收 ... 11 圖4.2 102 學年度畢業滿 3 年學生問卷回收 ... 11 圖4.3 98-104 學年度大學畢歷年成績表... 12 圖4.4 108 年學測試場分配表 ... 12 圖4.5 108 學年度大學個人申請入學招生各校系通過第一階段篩選名單 ... 13 圖4.6 圓餅圖 ... 14 圖4.7 互動式圓餅圖 ... 15 圖4.8 長條圖 ... 16 圖4.9 橫向長條圖... 16 圖4.10 連續型變數圓餅圖 ... 17 圖4.11 盒鬚圖 ... .18 圖4.12 散佈圖 ... 19 圖4.13 雙變數盒鬚圖 ... 20 圖4.14 折線圖 ... 21圖4.17 熱圖 ... 24 圖4.18 互動式熱圖 ... 24 圖4.19 簡單線性迴歸圖形示例 ... 25 圖4.20 殘差圖 ... 26 圖4.21 分位圖 ... 27 圖4.22 Scale-Location Plot ... 28
圖4.23 Residuals vs. Leverage Plot ... 29
圖4.24 決策樹範例圖形 ... 30 圖4.25 互動式地圖範例 ... 30 圖5.1 上傳資料介面 ... 31 圖5.2 介面顯示資料複製成功 ... 33 圖5.3 資料下載畫面 ... 33 圖5.4 隱藏欄位選單畫面 ... 34 圖5.5 使用範例資料進行資料視覺化 ... 35 圖5.6 互動式地圖呈現 ... 35 圖5.7 敘述統計量表格 ... 36 圖5.8 使用範例資料繪製相關係數圖 ... 37 圖5.9 各變數之相關係數及 p-value ... 37 圖5.10 互動式熱圖 ... 38 圖5.11 互動式資料集表格 ... 39 圖5.12 線性迴歸介紹範例(一) ... 39 圖5.13 線性迴歸介紹範例(二) ... 40 圖5.14 線性迴歸模型配適結果 ... 40 圖5.15 羅吉斯迴歸模型配適結果... 41 圖5.16 多元羅吉斯迴歸模型配適... 43 圖5.17 對數線性模型及其結果視覺化 ... 43 圖5.18 決策樹介紹頁面 ... 45 圖5.19 CART 樹模型配適結果 ... 46 圖5.20 隨機森林介紹頁面 ... 47
圖5. 21 隨機森林模型配適頁面 ... 47 圖5. 22 單純貝氏分類器頁面 ... 49 圖5. 23 單純貝氏分類器模型配適結果頁面 ... 49 圖5. 24 Adaboost 介紹頁面 ... 50 圖5. 25 Adaboost 模型配適結果頁面 ... 51 圖5. 26 Adaboost 誤差下降曲線 ... 51 圖5. 27 支持向量機介紹頁面 ... 52 圖5. 28 支持向量機模型配適結果頁面 ... 53 圖5. 29 支持向量迴歸配適結果頁面 ... 53 圖5. 30 ARMA 模型(一) ... 54 圖5. 31 ARMA 模型(二) ... 54 圖5. 32 GARCH 模型(一) ... 55 圖5. 32 GARCH 模型(二) ... 55 圖6.1 畢業 5 年畢業生北部地區工作型態 ... 57 圖6.2 畢業 5 年畢業生中部地區工作型態 ... 58 圖6.3 畢業 5 年畢業生南部地區工作型態 ... 58 圖6.4 畢業 3 年畢業生北部地區工作型態 ... 59 圖6.5 畢業 3 年畢業生中部地區工作型態 ... 60 圖6.6 畢業 3 年畢業生南部地區工作型態 ... 60 圖6.7 畢業 5 年畢業生五大學院薪資盒鬚圖 ... 62 圖6.8 畢業 3 年畢業生五大學院薪資盒鬚圖 ... 63 圖6.9 階層式分群法分群結果 ... 65 圖6.10 分群結果各群能力培養(一) ... 66 圖6.11 分群結果各群能力培養(二) ... 66 圖6.12 畢業 5 年學生分群結果各群薪資盒鬚圖 ... 68 圖6.13 畢業 3 年學生分群結果各群薪資盒鬚圖 ... 69 圖6.14 畢業生流向調查介面之資料呈現(一) ... 71
圖6.17 畢業生流向調查介面各系所薪資 ... 72 圖6.18 畢業生流向調查介面各地區薪資 ... 73 圖6.19 畢業生流向調查介面各地區檢定結果 ... 73 圖7.1 三角比值圖... 75 圖7.2 招生視覺化介面(一) ... 75 圖7.3 招生視覺化介面(二) ... 76 圖7.4 招生視覺化介面(三) ... 75
表目錄
表2.1 方法比較 ... 6 表4.1 圓餅圖程式碼 ... 14 表4.2 互動式圓餅圖程式碼 ... 15 表4.3 長條圖程式碼. ... 16 表4.4 橫向長條圖程式碼 ... 17 表4.5 連續型圓餅圖程式碼. ... 18 表4.6 盒鬚圖程式碼 ... 18 表4.7 散佈圖程式碼 ... 19 表4.8 雙變數盒鬚圖程式碼 ... 20 表4.9 折線圖程式碼. ... 21 表4.10 密度圖程式碼 ... 22 表4.11 相關係數圖程式碼. ... 23 表4.12 熱圖程式碼 ... 24 表4.13 互動式熱圖程式碼. ... 24 表4.14 殘差圖程式碼 ... 26 表4.15 分位圖程式碼. ... 27 表4.16 Scale-Location Plot程式碼. ... 28表4.17 Residuals vs. Leverage Plot程式碼. ... 29
表4.18 互動式地圖範例程式碼 ... 30 表5.1 上傳資料介面程式碼 ... 32 表5.2 資料視覺化介面程式碼 ... 35 表5.3 敘述統計量表格程式碼 ... 36 表5.4 相關係數圖程式碼 ... 37 表5.5 互動式熱圖程式碼 ... 38
表5.8 對數線性模型程式碼 ... 44 表5.9 CART 樹模型程式碼 ... 46 表5.10 隨機森林模型程式碼 ... 48 表5.11 單純貝式分類器模型程式碼 ... 50 表5.12 Adaboost 模型程式碼 ... 52 表5.13 支持向量機模型程式碼 ... 53 表6.1 畢業五年問卷調查各地區人數及薪資中位數 ... 57 表6.2 畢業三年問卷調查各地區人數及薪資中位數 ... 59 表6.3 畢業五年檢定結果. ... 61 表6.4 畢業三年檢定結果 ... 61 表6.5 畢業五年問卷調查各學院人數及薪資中位數. ... 61 表6.6 畢業三年問卷調查各學院人數及薪資中位數 ... 62 表6.7 畢業五年各學院薪資檢定結果 ... 63 表6.8 畢業三年各學院薪資檢定結果 ... 64 表6.9 能力指標勾選範例. ... 64 表6.10 畢業五年能力指標分群結果 ... 67 表6.11 畢業五年能力指標各群薪資檢定結果... 67 表6.12 畢業五年成績分群結果 ... 68 表6.13 畢業三年成績分群結果. ... 69 表6.14 畢業五年畢業生各組薪資中位數檢定結果 ... 70 表6.15 畢業三年畢業生各組薪資中位數檢定結果. ... 70
運用
R Shiny 建立互動式資料科學平台
指導教授:黃士峰 博士 國立高雄大學 統計研究所 學生:李政葦 國立高雄大學 統計研究所摘要
本研究應用 R 程式語言中的 Shiny 套件建立一個應用於數據科學上的互動式 介面,主題包括:時間序列、資料探勘、機器學習、迴歸分析等。由於Shiny 套件 為動態且互動式的應用程序,允許使用者更改設置並馬上查看結果變化,因此可節 省大量運行及修改程式的時間。此外,本互動式介面對於統計方法介紹和進一步理 解亦非常有幫助,使用者能透過互動式方法進行數據的描述並使用 R 程式語言完 成所有的操作,有助於提升數據科學在教學與學習方面的成效。 關鍵字:互動式介面、數據科學、視覺化ABSTRACT
An Interactive Web Application of Data Science with R using Shiny
Advisor: Professor Shih-Feng Huang Institute of Statistics
National University of Kaohsiung
Student: Cheng-Wei Lee Institute of Statistics National University of Kaohsiung
Abstract
This study uses the Shiny package in the R programming language to create an interactive web application for data science including time series, data mining, machine learning, regression analysis, etc. Since the Shiny package is a dynamic and interactive application that allows users to change settings and check results right away, it saves users a lot of time from rerunning and modifying programs. In addition, this interactive web application is very helpful for the introduction and further understanding of statistical methods. Users can describe the data through interactive methods and use R programming language to complete all operations, which is helpful for improving the effectiveness of data science in teaching and learning.
第一章 前言
資料視覺化在現今重視資料科學的社會中是非常重要的。有效的視覺化可以 幫助使用者分析、推理資料中的證據,使複雜的資料更容易理解和使用。根據 Friedman(2008)“Main goal of data visualization is to communicate information clearly and effectively through graphical means.”我們可以透過資料視覺化有效的傳遞我們 在資料中發現的訊息。更有一些研究表示,視覺化及互動式教學的結合應用,有助 於學生更有效地學習。所以在這項研究中我們所做的是使用 R 語言中的“Shiny” 套件及其擴充套件“ShinyDashboard”來構建互動式網頁應用程序。“Shiny”是 一個可以直接從 R 語言中建構動態交互式網頁應用程序的套件。“Shiny”的優點 是用戶不需要使用網頁語言編程(如 HTML、JavaScript…等等),用戶只需幾行 R 語言中的程式代碼就可以建構出網頁應用程序。而另一個優點是當用戶修改輸入 時,輸出會立即發生變化無需重新加載瀏覽器。 那麼為何要互動式呢?互動式網頁應用程序有四個好處。首先是“使用者選 項”,使用者可以自行上傳資料或選擇變數來繪製或訓練模型。其次是“不需要重 寫程式”,在以往的 R 語言中,我們每要更改變數繪圖,就需要重新寫一次程式, 而在這個網頁應用程序中不需要重寫程式,僅需勾選變數就可以得到更改變數後 的結果。第三是“節省運行時間”,在以往的 R 語言中,我們每要更改變數繪圖, 就需要重新及重新運行一次程式,而在這個網頁應用程序中使用者只需要選擇他 們需要的變數而不需重新運行程式。最後一個是“及時查看結果”,更改變數後使 用者可以立即獲得圖表或表格等結果。 本 論 文 主 要 呈 現 使 用 R 語 言 中 的 “ Shiny ” 套 件 及 其 擴 充 套 件 “ShinyDashboard”建構三個介面,分別為“資料科學平台”、“畢業生流向調查 平台”及“招生問題視覺化界面”。“資料科學平台”為提供使用者運用迴歸模 型、機器學習及時間序列模型…等常用的資料科學方法,將使用者上傳的資料配適 模型、視覺化呈現及方法介紹,並馬上得到結果。“畢業生流向調查平台”為將國 立高雄大學學務處提供的畢業生流向調查問卷進行資料分析,針對各系所畢業生 之薪資、各地區畢業生薪資中位數及畢業生認為在校應該培養的能力等問題,將分
假設檢定並得到結果,有助於使用者快速瞭解問卷資料及分析的方法與過程。“招 生問題視覺化界面”為學校希望了解招收的學生是否偏向某一區域,我們使用網 路爬蟲取得大考中心公布的「108 學年度大學個人申請入學招生第一階段篩選結 果」,透過計算比值顯示各校招生區域比例,並透過互動式地圖呈現各校、各系通 過第一階段學生來自的地區及准考證號碼,幫助各校、各系了解招生地區問題,例 如:選擇高雄大學應用數學系,得到北部比值 0.548、中部比值 0.863、南部比值 2.345,表示高雄大學應用數學系通過第一階段學生多為來自南部地區且比全國南 部考生比例多了 2.345 倍。 本論文第二章為文獻回顧,第三章將介紹“ShinyDashboard”主要架構及每個 部份可以呈現的內容,第四章將介紹我們在應用程序中使用過的視覺化圖形並附 上程式碼提供讀者使用。第五章為“資料科學平台”,我們說明使用於應用程序方 法及功能並附上程式碼提供讀者使用,第六章將介紹“畢業生流向調查平台”,我 們先說明各系所畢業生之薪資、各地區畢業生薪資中位數及畢業生認為在校應該 培養的能力等問題的分析方法及結果並在最後一節呈現視覺化介面的結果介紹。 第七章為“招生問題視覺化界面”,我們將說明學生是否偏向某一區域的比值計 算方式並呈現視覺化介面的結果介紹。
第二章 文獻回顧
在本章中,我們將回顧一些互動式界面。首先,參考過去已經完成此類互動式 界面的成果,我們將對Orange 軟體做一個簡單的介紹。2.1 Orange Software 介紹
Orange 是一個開源軟體,包括數據挖掘、資料視覺化及機器學習。它具有視 覺化的前端介面,可用於探索數據分析和交互式數據視覺化,甚至可以鏈接Python 軟體。 Orange 使用了被稱為“widget”的小組件,其範圍包含資料視覺化,資料子集 選擇及資料預處理、模型建立和預測建立模型的評估。每個步驟透過組合“widget” 來實現數據分析的過程。在此界面中,通過鏈接Orange 中提供的小部件來創建數 據分析過程並透過互動式介面實現視覺化分析流程。 2.1.1 Orange Software 特色介紹 Orange 軟體將小部件分為五類,“資料”、“視覺化”、“模型配適”、“模 型評估”和“非監督式學習”如圖2.1 所示。第一部分“資料”為資料預處理的部 分:包括資料輸入,資料過濾,資料抽樣,資料插補,特徵操作和特徵選擇。第二 部分“視覺化”包含箱形圖(Box Plot)、長條圖(Bar graph)、散佈圖(Scatter plot)、決 策樹圖形(Decision Tree plot)、熱圖(Heat map)及一些多變量視覺化圖形,如 Mosaic plot 及 Sieve diagram。第三部分“模型配適”為使用上述做完資料預處理的資料配 適模型,此分類中的方法皆為監督式學習,包含一些機器學習方法及一些迴歸分析 方法。監督式機器學習方法包括隨機森林(Random Forest)、支持向量機(Support Vector Machine) 、 Boosting… 等 等 。 迴 歸 分 析 方 法 包 括 線 性 迴 歸 分 析 (Linear Regression analysis),羅吉斯迴歸分析(Logistic Regression analysis)…等等。第四部 分“模型評估”提供了一些模型預測的計算結果,包括交叉驗1234 證、混淆矩陣 及預測方法的評分…等等。最後一部分“非監督式學習”包含一些非監督學習演 算 法 多 用 於 分 類 , 例 如 k- 平 均 演 算 法 (K-means Algorithm) 、 階 層 式 分 群 法(Correspondence analysis)。
2.2 Orange Software 示例
在這一部分中,我們將使用Orange Software 來做一個數據分析的例子。圖 2.2 顯示如何使用Orange Software 的互動式界面實現視覺化編程。 圖2.2 Orange 軟體操作示例 此範例中,橘色部分為“資料”分類中的資料匯入及資料預處理,粉紅色部分 為“模型配適”,淺藍色部分為“模型評估”,藍色部分為“非監督式學習”,透 過線段連接將各個圓形小部件連接就可做出要做的分析,例如圖2.3 右下角紅色部 分,將資料與決策樹及決策樹視覺化連線,就可配適出決策樹模型及繪出決策樹的 圖形。2.3 方法比較
在此將比較我們的應用程序與Orange Software 及 Microsoft Excel 的差異,從 下表可得知,我們的網頁應用程序相較於Orange Software 及 Microsoft Excel 方面 少了資料處理的部分,而在統計方法與模型建立的部分與Orange Software 所提供 的方法僅缺少類神經網路即一些非監督式學習的方法,這個部分為Microsoft Excel 無法提供的功能。而在時間序列模型上,Orange Software 較少提供建立時間序列 模型及預測的功能如:ARIMA 模型及 GARCH 模型。最後在視覺化圖形建立的部 分,我們的應用程序提供了互動式的圖形及互動式地圖,使用者可以在移動游標後 看到一些統計量甚至是針對圖形局部放大縮小,這是 Microsoft Excel 無法提供的 功能。而在地圖方面,Orange Software 及 Microsoft Excel 都有辦法繪製地圖,但無 法如我們的應用程序做到可以點開地圖上的座標點進而得到更詳細資料及任意放 大縮小的互動方式。
Orange Excel application My Web Data upload YES YES YES Data processing YES YES NO Data visualization YES YES YES
Decision Tree YES NO YES Random Forest YES NO YES Support Vector Machine YES NO YES Linear Regression YES YES YES Logistic Regression YES NO YES Naïve Bayes YES NO YES Adaboost YES NO YES Neural Network YES NO NO Model Evaluate YES NO YES Time Series Model NO YES YES
PCA YES NO YES
Interactive Map NO NO YES Clustering YES NO NO
第三章 方法及工具
在本章中,我們將介紹我們製作此網頁應用程序使用的工具。我們在 R 語言 中使用了名為“Shiny”和“ShinyDashboard”的套件來構建這個互動式網頁應用 程序。我們將在下面介紹“Shiny”和“ShinyDashboard”這兩個套件的特色及使 用方法。3.1 Shiny 套件
“Shiny”是 R-Studio 在 2012 年發布的一個套件,它利用網頁應用程序和 R 語言的計算能力在短時間內呈現分析結果,並與網路上的使用者進行互動。“Shiny” 的目標是讓不了解網頁語言的 R 語言使用者在網站上展示他們的分析結果,並在 最短的時間內與其他使用者互動。開發人員通過Shiny 套件可以編寫一個只需要使 用R 語言的網頁,不需要使用 HTML 或 JavaScript 等網頁語言,自從“Shiny”發 布以來,它在使用R 語言的社群內受到很大的歡迎。 “Shiny”支援 HTML 的一些輸入格式,包括文本字段、選單、下拉選單和勾 選方格,透過這些選單來達到與使用者互動的目的。“Shiny”主要的輸出內容包 含三大部分:文字輸出、表格輸出及圖像輸出。文字輸出多為結果摘要或總結,例 如:模型配適摘要、檢定結果總結等。表格輸出多為資料檢視及結果檢視,例如: 原始資料表格、混淆矩陣等。圖像輸出則多為視覺化的結果呈現,例如:ROC 曲 線、決策樹圖形、AdaBoost中的誤差降低視覺化圖形…等等。 最基本的Shiny 項目由兩部分組成: 1. ui.R:網頁應用程序的前端代碼,是構成網頁應用程序格式配置、頁面呈現的 部分。 2. server.R:網頁應用程序的後端代碼,是網頁應用程序中分析、計算及繪圖的主 要部分,並將輸出結果傳遞給前端。 “Shiny”最大的優點是開發人員僅需要使用 R 語言而不需要使用 HTML 或 JavaScript 等網頁語言就可以開發出一個網頁應用程序並在網路上呈現及並與其他 使用者共享。且“Shiny”也具有動態顯示結果的功能,當使用者輸入參數(Input)當使用者在控制面板中輸入或更改參數時,瀏覽器會將參數傳遞給計算部分,也就 是開發人員的server.R,R 語言會將 server.R 所產生的結果(Output)再回傳給 ui.R 前端輸出,進而呈現分析結果,而輸出對象可以是文字、圖像或是表格。
3.2 ShinyDashboard 套件
“ShinyDashboard”是“Shiny”的一個擴展套件,是以 BI 框架來建構“Shiny” 應用程序。“ShinyDashboard”由三部分組成:標題欄,側欄和主面板,如圖 3.1 所示。 圖3.1 ShinyDashboard主體架構 標題欄為圖3.1 的藍色部分可以顯示標題,左上角輸出標題如圖 3.2 在標題顯 示“My Dashboard”,右上方則可顯示類似社群軟體中的“訊息”如圖3.3、 “通知”如圖3.4 及“任務”如圖 3.5。 圖3.2 ShinyDashboard 標題圖3.3 ShinyDashboard 標題訊息
圖3.4 ShinyDashboard 標題通知
圖3.5 ShinyDashboard 標題任務
側欄則為圖3.1 的左側黑色部分,可以列出應用程序的分頁及一些互動式按鈕, 例如:字串輸入、日期選擇、勾選方格…等等。圖 3.6 為在介面的側欄加入數字
圖3.6 ShinyDashboard 互動式側欄 主面板為圖3.1 的右側灰色部分,呈現介面主要內容,可以放置互動式圖像 輸出、表格輸出、字串結果輸出、動畫…等等。圖 3.7 為介面的主面板輸出互動 式地圖的範例展示。 圖3.7 ShinyDashboard 主面板 透過以上3 個部分的程式編寫,就能輸出由“ShinyDashboard”套件建構的網 頁應用程序。
第四章 視覺化介紹
在本章中,我們將介紹我們在應用程序中呈現的視覺化圖表。首先,我們將介 紹我們在此應用程序中使用的幾個數據,並使用這些數據進行下方範例呈現。4.1 校務資料
4.1.1 100 學年度畢業滿 5 年學生問卷回收 資料源自於國立高雄大學學務處,總共包含927 筆問卷資料,部份格式如圖 4.1 所列。問卷資料中包含就業流向及學習回饋二大部份共 12 題,每題共有 11 到 30 種不等的選項,填答者可單選或是複選。 圖4.1 100學年度畢業滿5 年學生問卷回收 4.1.2 102 學年度畢業滿 3 年學生問卷回收 資料源自於國立高雄大學學務處,總共包含992 筆問卷資料,部份格式如圖 4.2 所列。問卷資料中包含就業流向、就業條件及學習回饋三大部份共 14 題,每題 共有5 到 30 種不等的選項,填答者可單選或是複選。4.1.3 大學部歷年成績表 資料源自於國立高雄大學教務處,紀錄 98 學年度到 104 學年度之高雄大學學 生每門課程成績,總共包含549983 筆學生成績資料,部份格式如圖 4.3 所列。資 料變數包含識別碼、學號、修課學年、修課學期、課程學分數、修課成績、必修判 別碼、必選修…等。 圖4.3 98-104學年度大學畢歷年成績表 4.1.4 108 年學測試場分配表 資料源自於中華民國大考中心網站,紀錄 108 年學測試場分配地區及對應准 考證號碼,總共包含116 筆考區資料,部份格式如圖 4.4 所列。資料變數包含分區 名稱、分區地點、准考證號碼(起)、准考證號碼(迄)、經度、緯度。 圖4.4 108 年學測試場分配表
4.1.5
108 學年度大學個人申請入學各校系通過第一階段篩選名單 資料源自於中華民國大學甄選入學委員會,紀錄各校系 108 學年度通過大學 個人申請入學招生第一階段篩選之名單,總共包含183835 筆考生准考證資料,部 份格式如圖4.5 所列。透過網路爬蟲擷取考生准考證資料及結合上小節「108 年學 測試場分配表」將考生准考證代碼對應到指定考區,資料變數包含學校、系所、系 所代碼、准考證號碼、考區、地址、經度及緯度。圖4.5 108 學年度大學個人申請入學招生各校系通過第一階段篩選名單
4.2 輸出圖表介紹
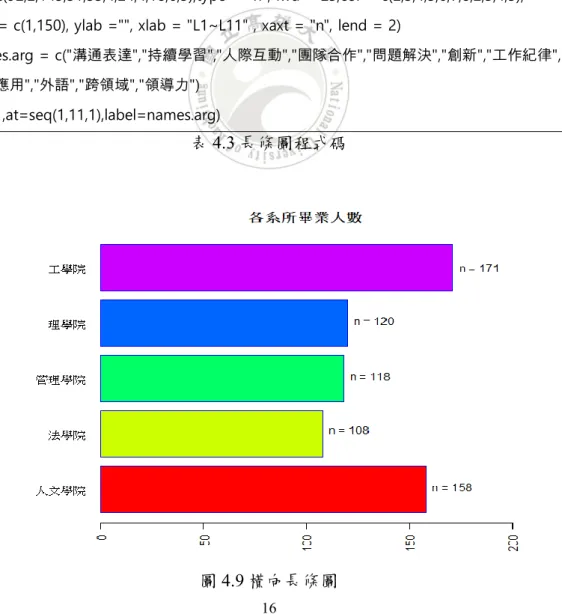
在這一部分中,我們將展示在使用上述資料進行資料視覺化的結果。我們將所 有圖表分為四個部分:單變量變數、雙變量變數、多變量變數及其他圖表分別進行 介紹。 4.2.1 單變量變數 單變量變數表示使用者想了解或分析特定變量為單一變數,此類圖形通常是 敘述性統計,包括:平均值,標準差,次數和百分比。 我們可以將單變量變數分 為類別型變數和連續型變數。 4.2.1.1 單變量類別型變數 當您要分析的變數是單變量類別型變數時,我們通常使用繪製此變數的次數。 我們經常使用的圖形是:餅圖,條形圖和折線圖。 圓餅圖:圓餅圖是一個圓形統計圖表,分為幾個扇形區域來描述類別型變數的 數量及頻率。在圓餅圖中,扇形區域的圓心角比例是其代表的數字的比例。圖 4.6 為使用 100 學年度畢業滿 5 年學生問卷統計各院學生人數繪出的圓餅圖; 圖4.7 為使用 100 學年度畢業滿 5 年學生就業類別取向的互動式圓餅圖。圖 4.6 圓餅圖
type = c("人文學院","管理學院","法學院","理學院","工學院") nums = c(51,83,116,77,92)
df = data.frame(type = type, nums = nums)
label_value = paste('(', round(df$nums/sum(df$nums) * 100, 1), '%)', sep = '') label = paste(df$type, label_value, sep = '')
p = ggplot(data = df, mapping = aes(x = "人數", y = nums, fill = type))+geom_bar(stat = 'identity', position = 'stack',width = 18,col=heat.colors(length(5)))
p + coord_polar(theta = 'y') + labs(x = '', y = '', title = '') + theme(axis.text = element_blank())+theme(axis.ticks = element_blank()) + theme(legend.position
="none")+geom_text(aes(y=df$nums/5+c(-8,cumsum(df$nums)[-length(df$nums)]), x = sum(df$nums)/60, label = label))
圖4.7 互動式圓餅圖 ui: loadEChartsLibrary(), tags$div(id="chartQ7", style="width:50%;height:400px;") server: datpieQ7 <- reactive({ y7 <- as.numeric(input$selectQ7) d7 <- c(“非常符合”, 28),rep(“符合”,44),rep(“尚可”,35),rep(“不符合”, 8),rep(“非常不符合”, 7)) d7}) observeEvent(datpieQ7(),{
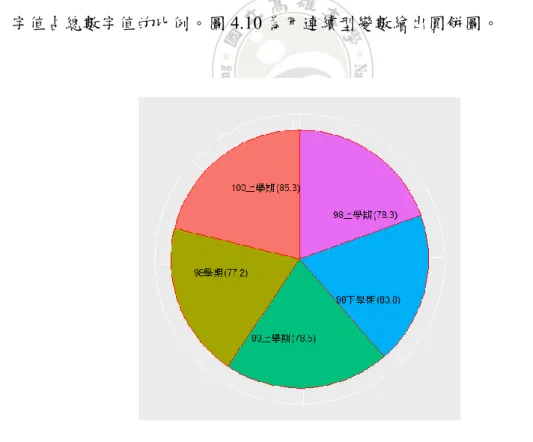
renderPieChart(div_id = "chartQ7",data = as.vector(unlist(datpieQ7()))) }) 表4.2 互動式圓餅圖程式碼 長條圖:長條圖是一個統計圖表,矩形的高度為對應值,用於比較單變數的兩 個變數或多個值變數,通常用於較小的數據集分析。長條圖也可以水平排列或 以多維排列。圖4.8 為使用 100 學年度畢業滿 5 年學生問卷學生人數繪出能力 選項長條圖;圖49 為使用 100 學年度畢業滿 5 年學生人數橫向長條圖。
圖4.8 長條圖
plot(c(92,2,145,31,33,4,24,4,18,6,3),type = "h", lwd = 25,col = c(2,3,4,5,6,7,8,2,3,4,5), ylim = c(1,150), ylab ="", xlab = "L1~L11" , xaxt = "n", lend = 2)
names.arg = c("溝通表達","持續學習","人際互動","團隊合作","問題解決","創新","工作紀律"," 資訊應用","外語","跨領域","領導力")
axis(1,at=seq(1,11,1),label=names.arg)
表4.3 長條圖程式碼
par(mar=c(3,8,3,3))
ex1 = c(158,108,118,120,171) ex1 = as.matrix(ex1)
barplot(ex1, main="各系所畢業人數",col=rainbow(5), beside =T,
ylab = NULL, xlab ="",border="blue", horiz = T ,las=2, xlim = c(0,200), space = c(0.2,0.2,0.2,0.2,0.2), names.arg=c("人文學院","法學院","管理學院","理學院","工學院")) text( ex1+13, c(0.75,2,3.15,4.35,5.5), paste("n = ",ex1,sep="") , cex = 1)
表4.4 橫向長條圖程式碼 4.2.1.2 單變量連續型變數 當使用者要分析的單變量變數是連續型時,例如平均值,中位數,標準差或百 分比,我們可以使用幾個圖形,包括:圓餅圖和盒鬚圖。 圓餅圖:圓餅圖是一個圓形統計圖表,分為幾個扇形區域來描述類別型變數的 數量及頻率。在連續行變數的圓餅圖中,每個扇形區域的圓心角比例代表其數 字值占總數字值的比例。圖4.10 為用連續型變數繪出圓餅圖。 圖4.10 連續型變數圓餅圖
library(ggplot2)
type = c("98 上學期","98 下學期","99 上學期","98 學期","100 上學期") nums = c(78.3,83,78.5,77.2,85.3)
df = data.frame(type = type, nums = nums) label_value = paste('(', df$nums, ')', sep = '') label = paste(df$type, label_value, sep = '')
p = ggplot(data = df, mapping = aes(x = "人數", y = nums, fill = type)) +geom_bar(stat='identity',position='stack',width=20,col=heat.colors(length(5))) p + coord_polar(theta = 'y') + labs(x = '', y = '', title = '') + theme(axis.text =
element_blank())+theme(axis.ticks = element_blank()) + theme(legend.position = "none") + geom_text(aes(y=df$nums/1.5+c(10,cumsum(df$nums)[-length(df$nums)]), x =
sum(df$nums)/120, label = label))
表4.5 連續型圓餅圖程式碼
盒鬚圖:是一個顯示變數分散的統計圖表。盒鬚圖是非參數的,不做任何統計
分佈的假設,異常值會被繪製為單一點。圖4.11 為用單一變數盒鬚圖。
圖4.11盒鬚圖 ex3 <- as.data.frame( rnorm(100,0,1))
boxplot(ex3)
表4.6盒鬚圖程式碼
雙變量表示兩個變數之間可能存在相關性。我們可以通過散佈圖,折線圖,盒 鬚圖和密度圖繪製雙變量圖形。 散佈圖:散佈圖是一種非數學方法,用於查看測量值與可能的原因因子之間的 關係。數據必須成對(X,Y)。 通常縱軸表示現象測量值 Y,橫軸表示可能 的原因因子X,優點為易於溝通且易於理解。 圖4.12 散佈圖 library(plotly)
trace_1 <- rnorm(100, mean = 0) trace_2 <- rnorm(100, mean = -5) x <- c(1:100)
data <- data.frame(x, trace_0, trace_1, trace_2)
p <- plot_ly(data, x = ~x, y = ~trace_1, name = 'A', type = 'scatter', mode = 'markers') %>%
add_trace(y = ~trace_2, name = 'B', mode = 'markers') p
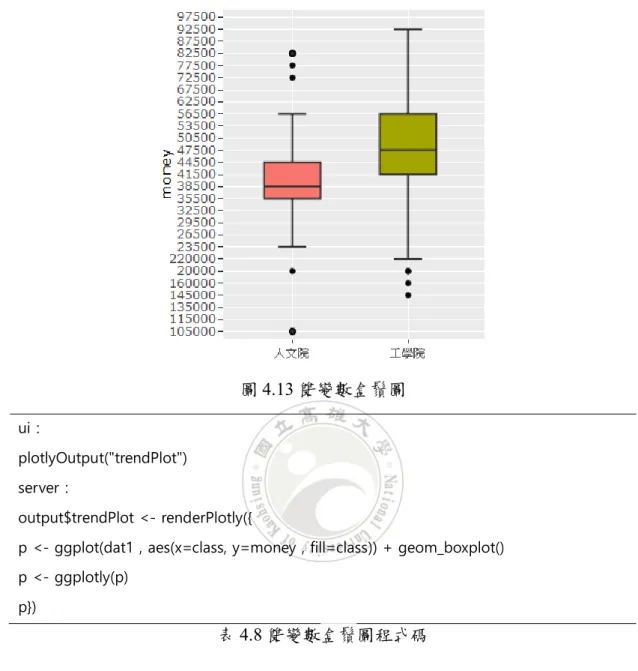
分布狀態。 圖4.13 雙變數盒鬚圖 ui: plotlyOutput("trendPlot") server: output$trendPlot <- renderPlotly({
p <- ggplot(dat1 , aes(x=class, y=money , fill=class)) + geom_boxplot() p <- ggplotly(p)
p})
折線圖:折線圖是數據點通過直線連接的圖表,通常用於在一段時間內視覺化 資料的趨勢。在折線圖中,類別型變數(如日期)沿水平軸平均排列,變數數值 沿垂直軸分佈。 圖4.14 折線圖 library(plotly) x <- c(1:30)
random_y <- rnorm(30, mean = 0) data <- data.frame(x, random_y)
p <- plot_ly(data, x = ~x, y = ~random_y, type = 'scatter', mode = 'lines') p
表4.9 折線圖程式碼
密度圖:密度圖是連續間隔或時間內數據分佈的視覺化。此圖表是直方圖的變 型,使用kernel 轉化的值繪製,通過轉化後可以實現更平滑的分佈密度圖的峰 值顯示該區間內值的集中位置。
圖4.15 密度圖 d <- density(mtcars$mpg)
plot(d, main=" Density Plot") polygon(d, col="green", border=2)
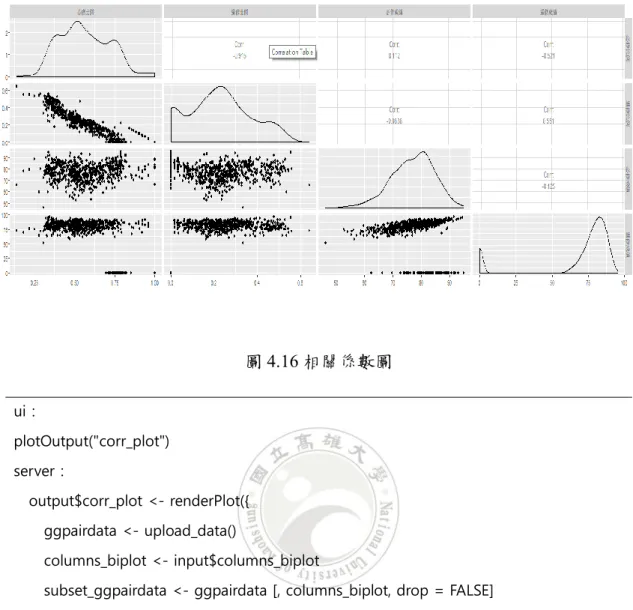
表4.10 密度圖程式碼 4.2.3 多變數 多個變數意味著我們同時對許多變量感興趣,因此我們創建了允許同時比較 不同變量的圖形。 相關係數圖:在這個相關係數圖中,我們繪製了每個變數之間的密度圖及散佈 圖,並且計算了相關矩陣,主要用於同時研究多個變量之間的相關性。圖表右 上方為輸出每個變數與其他變數之間的相關係數,有助於使用者更了解數據。 下圖示例為使用四個變數繪製出的相關係數圖。
圖4.16 相關係數圖 ui: plotOutput("corr_plot") server: output$corr_plot <- renderPlot({ ggpairdata <- upload_data() columns_biplot <- input$columns_biplot
subset_ggpairdata <- ggpairdata [, columns_biplot, drop = FALSE] ggpairs(subset_ggpairdata) })
表4.11 相關係數圖程式碼
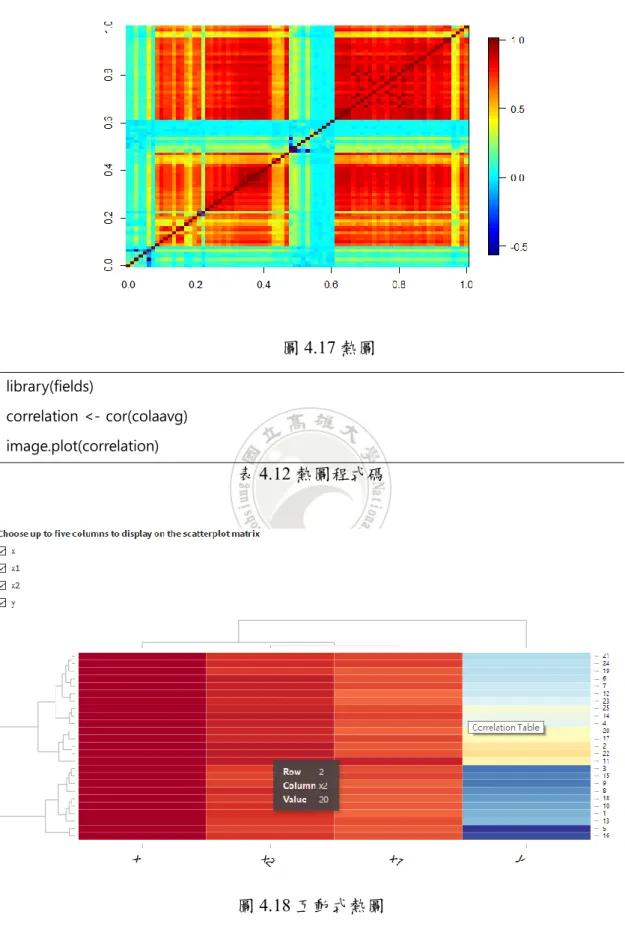
熱圖: 熱圖是資料數值的圖形表示,將資料矩陣中的各種值以顏色表示。可以 透過顏色的差異或顏色的深淺來觀察數據的特徵。
圖4.17 熱圖 library(fields) correlation <- cor(colaavg) image.plot(correlation) 表4.12 熱圖程式碼 圖4.18 互動式熱圖 ui:
d3heatmapOutput("heatmap", width = "100%", height="400px") server:
output$heatmap <- renderD3heatmap({ the_data <- upload_data()
columns_heatplot = input$columns_heatplot
the_data_subset_heat = the_data[, columns_heatplot, drop = FALSE] d3heatmap(the_data_subset_heat) }) 表4.13 互動式熱圖程式碼
4.3 其他常用圖形
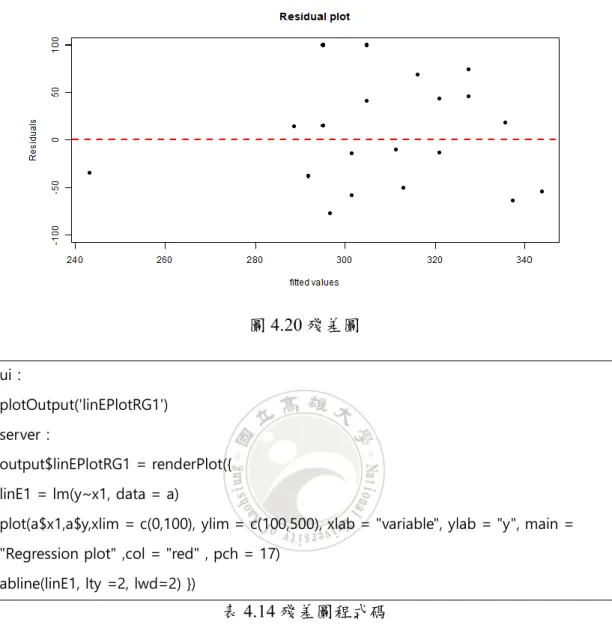
在本節中,我們將介紹一些常用於數據科學或資料視覺化的圖形。這些圖形有 些時常用於統計方法中檢測模型結果,另一些圖形是根據機器學習中的算法原理 所繪出。 迴歸圖:迴歸圖是結合散佈圖和折線圖的圖形,我們可以在二維平面上繪製自 變數及應變數的散點圖及其迴歸線。圖 4.19 為一個使用單變數配適簡單線性 迴歸的示例。 圖4.19 簡單線性迴歸示例 圖4.20 為一簡單殘差圖範例。 圖4.20 殘差圖 ui: plotOutput('linEPlotRG1') server: output$linEPlotRG1 = renderPlot({ linE1 = lm(y~x1, data = a)
plot(a$x1,a$y,xlim = c(0,100), ylim = c(100,500), xlab = "variable", ylab = "y", main = "Regression plot" ,col = "red" , pch = 17)
abline(linE1, lty =2, lwd=2) }) 表4.14 殘差圖程式碼 分位圖:分位圖(QQ 圖)是一種通過比較兩個機率分布的分位數對這兩個機率 分布進行比較的機率圖方法。選定分位數的對應機率區間集合,在此機率區間 上,點對應於第一個分佈的一個分位數 x 和第二個分佈在和 x 相同機率區間 上相同的分位數,畫出的是一條含參數的曲線,參數為機率區間的分割數。該 圖主要呈現殘差值是否為常態分佈,殘差值如果沿著斜直線及代表為常態分 佈。
圖4.21 分位圖 ui:
plotOutput("linPlot") server:
observeEvent(input$goButton_lin , {
output$linPlot<- renderPlot({par(mfrow = c(2, 2), oma = c(0, 0, 2, 0)) plot(fitModellin(),sub.caption="Diagnostic Plots")}) })
表4.15 分位圖程式碼
Scale-Location Plot:它也被稱為Spread-Location Plot。此圖顯示殘差是否沿預 測變量的範圍均勻分佈,是用來檢查相等方差(同方差性)假設的圖形。
圖4.22 Scale-Location Plot ui:
plotOutput("linPlot") server:
observeEvent(input$goButton_lin , {
output$linPlot<- renderPlot({par(mfrow = c(2, 2), oma = c(0, 0, 2, 0)) plot(fitModellin(),sub.caption="Diagnostic Plots")}) })
表4.16 Scale-Location Plot程式碼
Residuals vs. Leverage Plot:Residuals vs. Leverage 圖可幫助您識別模型上有影 響力的數據點。異常值可能具有影響力,但有些並不一定具有影響力,且模型 中正常範圍內的某些點可能非常有影響力。
圖4.23 Residuals vs. Leverage Plot ui:
plotOutput("linPlot") server:
observeEvent(input$goButton_lin , {
output$linPlot<- renderPlot({par(mfrow = c(2, 2), oma = c(0, 0, 2, 0)) plot(fitModellin(),sub.caption="Diagnostic Plots")}) })
表4.17 Residuals vs. Leverage Plot程式碼
決策樹圖:決策樹是一種過程較為直覺、執行效率也相當高的監督式機器學習 模型,常用於分類及迴歸資料類型的預測。決策樹的特點是每個決策階段(也 就是決策樹的每個節點)都相當的明確,視覺化後有助於使用者理解與解釋決 策樹模型。
圖4.24 決策樹範例圖形 地圖:在 R 語言中我們可以使用資料中的經緯度,在地圖上繪製出一些標示 及上色,有助於我們了解資料與地域之間的關係。圖4.25 為使用 108 學年度 大考中心學測學生資料,繪製出臺灣大學 108 年通過第一階段初試學生在北 部、中部、南部所佔的人數 圖4.25 互動式地圖範例 point.df = data.frame(lat = a2()$lat, long = a2()$lon) leaflet(point.df) %>% addTiles() %>% addMarkers( clusterOptions = markerClusterOptions())
第五章
資料科學平台
在本章中,將展示實際應用“ShinyDashboard”及上一章節的資料視覺化技巧 建立資料科學網頁應用程序。網頁應用程序分為四部分,“上傳資料”,“資料視 覺化”,“方法介紹”,“模型訓練”,以下將針對各個部分進行介紹。5.1 上傳資料
在上傳資料這部分,使用者上傳他們需要分析的資料後,他們上傳的資料隨即 顯示在網頁應用程序上,使用者可以選擇他們的資料是否具有欄位名稱,並可以在 橘色方塊部分選擇他們的資料的分隔型示,例如:包括逗號、分號及空白…等等, 而上傳的資料大小最大為5MB 的 CSV 檔案。 圖5.1 上傳資料介面 ui: dataTableOutput(outputId = "data") server: upload_data <- reactive({the_data = read.csv( inFile$datapath, header = input$header, sep = input$sep, quote = input$quote, stringsAsFactors=FALSE) return(the_data) }) observeEvent(input$file1,{inFile<<-upload_data() })
output$data = renderDataTable(upload_data(), filter = c("top") , extensions = c('Buttons','FixedColumns','FixedHeader'), options = list(dom = 'Blfrtip',
buttons = c('copy', 'csv', 'excel', 'pdf', 'print' , 'colvis'), scrollX = TRUE, fixedColumns = TRUE,
pageLength = nrow(a), fixedHeader = TRUE) ) 表5.1 上傳資料介面程式碼 選擇完是否具有欄位名稱及資料分隔型態後,資料經以表格方式呈現在網頁 應用程序得主頁面中,此時表格上方會出現 6 個選項“Copy”、“CSV”、 “EXCEL”、“PDF”、“Print”、“Column Visibility”可供使用者進行互動式動 作。“Copy”表示複製資料,點選後會顯示對話框「複製成功到剪貼簿」(如圖 5.2), “CSV”表示將資料儲存成以逗號分隔的資料型態,按下後會如同在一般網頁的 下載按鍵一樣顯示出使用者需要儲存路徑(如圖 5.3),“EXCEL”代表將資料儲存 成常使用的EXCEL 檔案,按下後也會如同“CSV”按鍵一樣顯示出使用者需要儲 存路徑(如圖 5.3),“PDF”代表將資料儲存成常使用的 PDF 檔案,按下後也會如 同上述兩步驟顯示出使用者需要儲存路徑(如圖 5.3),最後一個按鍵“Column Visibility”則表示使用者可以選擇想看到的欄位,按下後會跳出資料所有的欄位選 項(如圖 5.4),使用者即可點選不需要看到的欄位。
圖5.2 介面顯示資料複製成功
圖5.4 隱藏欄位選單畫面
5.2 資料視覺化
在第二部份“資料視覺化”中,我們對使用者上傳的資料進行視覺化,使用者 可以選擇他們需要的變數繪製盒鬚圖(Box plot)、直方圖(Histogram)、密度圖(Density plot)和長條圖(Bar graph)。除了使用者上傳的資料外,此應用程序還提供兩個分類 及迴歸分析常使用的範例資料集(iris 資料集及 mtcars 資料集)提供給使用者使用, 圖5.5 為使用 iris 資料的 sepal.length 變數與 species 變數繪製出的範例圖型。而當 資料內有經緯度資料時,只要將經度及緯度的變數欄位名稱改為“Longitude”及 “Latitude”,在下方的地圖呈現就會自行將互動式地圖繪製於介面上。圖5.5 使用範例資料進行資料視覺化 圖5.6 互動式地圖呈現 ui: plotOutput("plot1") server: output$plot1 = renderPlot({ plot.object = ggplot_dat() if(is.null(plot.object)) return()
if(input$show.points==TRUE){
plot1<-plot1+ geom_point(color='black',alpha=0.5, position = 'jitter')} plot1<-plot1+labs(fill= input$group, x= "", y= input$variable )+.theme print(plot1)}) 表5.2 資料視覺化介面程式碼 在資料視覺化的下一個介面中,我們先計算出使用者上傳的數據的敘述統計 量,包括各個變數的樣本數、平均數、標準差…等等,並輸出成表格形式提供使用 者查看,圖5.6 為使用畢業三年大學生成績資料之敘述統計量表格。 圖5.7 敘述統計量表格 ui: tableOutput(“summary”) server: output$summary = renderTable({ the_data <- upload_data() psych::describe(the_data) }) 表5.3 敘述統計量表格程式碼 本頁下方部分包括相關係數圖及相關係數摘要。使用者可以選擇變數,相關係 數圖形將會立即顯示。各變數的相關係數及檢定統計量也會以表格形式顯示在頁 面最下方。
圖5.8 使用範例資料繪製相關係數圖 ui:
plotOutput("corr_plot") server:
output$corr_plot = renderPlot({ ggpairdata = upload_data() columns_biplot = input$columns_biplot
subset_ggpairdata = ggpairdata[, columns_biplot, drop = FALSE] ggpairs(subset_ggpairdata) })
在相關係數圖下方,我們提供互動式熱圖讓使用者可以選擇變數,熱圖也可依 照使用者的需求在局部地區放大及縮小。
圖5.10 互動式熱圖 ui:
d3heatmapOutput("heatmap", width = "100%", height="400px") server:
output$heatmap = renderD3heatmap({ the_data = upload_data()
columns_heatplot = input$columns_heatplot
the_data_subset_heat = the_data[, columns_heatplot, drop = FALSE] d3heatmap(the_data_subset_heat) }) 表5.5 互動式熱圖程式碼
5.3 方法介紹
在第三部份“方法介紹”中,我們提供了數據科學常使用的幾種主要方法,包 括時間序列,資料探勘,機器學習,迴歸分析等。應用程序中簡要介紹了方法原理 和範例。我們將本應用程序使用的所有方法分為三大部分,“迴歸分析”、“機器 學習”及“時間序列方法”,並提供方法簡述、簡要推導以及每種方法的範例。5.3.1 迴歸分析
在迴歸分析部分,我們將介紹幾種在此應用程序中使用的迴歸分析方法,包含簡單線性迴歸分析、羅吉斯迴歸模型及對數線性迴歸模型。 5.3.1.1 線性迴歸模型 在簡單線性迴歸模型頁面中,我們使用一個簡單的資料集並以表格形式呈現 於頁面右上方(如圖 5.10),並針對此資料集的各個變數繪製出散佈圖(如圖 5.11), 我們將迴歸分析時常使用的變異數分析表格的公式及每個參數的簡要推導以及模 型的結果輸出(如圖 5.12),最後呈現模型診斷圖:殘差分析圖、Normal-QQ 圖、 Scale-Location 圖及 Residuals vs Leverage 圖(如圖 5.12)。
圖5.11 互動式資料集表格
圖5.13 線性迴歸介紹範例(二) 在簡單介紹線性迴歸模型後,我們在下一頁提供使用者使用線性迴歸模型配適使 用者上傳的資料集,在使用者選擇反應變數及解釋變數後,就能得到配適結果的 ANOVA 表格及模型結果診斷圖形(如圖 5.12)。 圖5.14 線性迴歸模型配適結果 ui: 1. verbatimTextOutput("other_val_show_lin") 2. plotOutput("linPlot") server: 1. observeEvent(input$goButton_lin, {
output$other_val_show_lin<-renderPrint({ input$other_var_select_lin input$ind_var_select_lin f<-upload_data() form<-sprintf("%s~%s", input$ind_var_select_lin,paste0(input$other_var_select_lin,collapse="+")) linreg <-lm(as.formula(form),data=f) print( anova(linreg)) }) }) 2. observeEvent(input$goButton_lin , { output$linPlot<- renderPlot({ par(mfrow = c(2, 2), oma = c(0, 0, 2, 0)) plot(fitModellin(),sub.caption="Diagnostic Plots") }) }) 表5.6 線性迴歸模型程式碼 5.3.1.2 羅吉斯迴歸模型 迴歸分析方法的第二部分是羅吉斯迴歸模型,也稱為對數機率迴歸模型。羅吉 斯迴歸是一種邏輯模型(Logit 模型,也被翻譯為評估模型、分類評估模型)。它是 離散型方法模型之一,屬於多變量分析的範疇。我們簡要介紹羅吉斯迴歸,並讓使 用者使用上傳的資料配適羅吉斯迴歸模型。 圖 5.14 顯示了配適羅吉斯迴歸模型的 結果,包含變異數分析及殘差。
ui: 1. verbatimTextOutput("other_val_show_log") 2. plotOutput("logPlot") server: 1. observeEvent(input$goButton_log, { output$other_val_show_log=renderPrint({ input$other_var_select_log input$ind_var_select_log f<-upload_data() library(caret) form = sprintf("%s~%s",input$ind_var_select_log, paste0(input$other_var_select_log,collapse="+")) logreg = glm(as.formula(form),family=binomial(),data=f) print( summary(logreg)) }) }) 2. observeEvent(input$goButton_log, { output$logPlot<-renderPlot({ par(mfrow = c(2, 2), oma = c(0, 0, 2, 0)) plot(fitModellog(),sub.caption="Diagnostic Plots") }) }) 表5.7 羅吉斯迴歸模型程式碼 羅吉斯迴歸模型的反應變數只能使用二分類變數,也就是是否或是有無。在此, 我們還為用戶提供多項羅吉斯迴歸模型以配適他們的模型,使用者可以使用多類 變數來配適他們的模型。圖5.15 顯示使用者配適多項羅吉斯迴歸模型的結果。
圖5.16 多元羅吉斯迴歸模型配適 5.3.1.3 對數線性模型 迴歸分析方法的第二部分是對數線性模型。我們簡要介紹對數線性模型,並讓 使用者使用上傳的資料配適對數線性模型。圖 5.16 顯示了配適對數線性模型及其 結果的視覺化。 圖5.17 對數線性模型及其結果的視覺化 ui: 1. verbatimTextOutput("other_val_show_ loglin") 2. plotOutput("loglinPlot")
input$other_var_select_loglin input$ind_var_select_loglin f<-upload_data() library(caret) form=sprintf("%s~%s",input$ind_var_select_loglin, paste0(input$other_var_select_loglin,collapse="+")) logreg <-loglm(as.formula(form),data=f) print( summary(logreg)) }) 2. output$loglinPlot<-renderPlot({ input$other_var_select_loglin input$ind_var_select_loglin f = upload_data() form=sprintf("%s~%s",input$ind_var_select_loglin, paste0(input$other_var_select_loglin,collapse="+")) loglinreg <-loglm(as.formula(form),data=f) mosaicplot(as.formula(form), shade=TRUE,data=f) }) 表5.8 對數線性模型程式碼
5.3.2 機器學習方法
在這一部分中,我們將介紹在這個網頁應用程序中使用的幾種機器學習方法, 包括一些樹模型,集合方法等。 5.3.2.1 決策樹 決策樹是一種預測模型,決策樹中每個分叉路徑表示一個可能的結果,每個葉 節點對應於從根節點到葉節點的路徑所表示的對象的值。數據挖掘中的決策樹是 一種常用技術在經過視覺化後有助於使用者了解決策樹配適模型的結果,可用於 分析數據也可用於預測。圖 5.17 顯示裝袋集成學習的介紹,及我們在介面中繪製 決策樹範例。 圖5.18 決策樹介紹頁面 進行完決策樹的基本介紹後,我們在下一部分中提供了使用者幾種使用採用 不同演算法的決策樹,例如:CART(Classification And Decision Tree)、C4.5 樹及 C5.0 樹。將分為三個頁面供使用者進行模型配適及視覺化,圖 5.18 為使用 CART 頁面配適之結果。圖5.19 CART 樹模型配適結果 ui: 1. verbatimTextOutput("other_val_show_DCTree ") 2. plotOutput("DCTreePlot") server: 1. observeEvent(input$goButton_DCT, { output$other_val_show_DCTree<-renderPrint({ input$other_var_select_DCT input$ind_var_select_DCT f =upload_data() library(rpart) form=sprintf("%s~%s",input$ind_var_select_DCT, paste0(input$other_var_select_DCT,collapse="+")) DCTree = rpart(as.formula(form),data=f,method="class") print( DCTree) }) }) 2. library(rpart.plot) observeEvent(input$goButton_DCT, { output$DCTreePlot<-renderPlot({
prp(fitDCTree(), faclen=0, fallen.leaves=F, shadow.col="gray", extra=2) }) }) 表5.9 CART 樹模型程式碼
5.3.2.2 Random Forest 隨機森林 隨機森林是一種結合隨機節點優化和裝袋集成學習使用 CART 過程構建森林 的方法。因此,在這一部分,我們首先介紹裝袋集成學習,隨後介紹隨機森林及其 優點,最後讓使用者使用上傳的資料配適隨機森林模型。下圖顯示隨機森林的示意 圖及優點,最後則是使用者使用配適隨機森林模型的準確率與誤差曲線。 圖5.20 隨機森林介紹頁面
ui: 1. verbatimTextOutput("other_val_show_ RMF") 2. plotOutput("RMFPlot") server: 1. library(randomForest) output$other_val_show_RMF<-renderPrint({ input$other_var_select_RMF input$ind_var_select_RMF f<-upload_data() form = sprintf("%s~%s",input$ind_var_select_RMF, paste0(input$other_var_select_RMF,collapse="+"))
RMF =randomForest(as.formula(form),data=f, ntree=100, nodesize=7,) print(RMF) }) 2. output$RMFPlot<-renderPlot({ input$other_var_select_RMF input$ind_var_select_RMF f<-upload_data() form = sprintf("%s~%s",input$ind_var_select_RMF, paste0(input$other_var_select_RMF,collapse="+")) RMF <-randomForest(as.formula(form),data=f,ntree=100,nodesize=7) plot(RMF) }) 表5.10 隨機森林模型程式碼 5.3.2.3 單純貝氏分類器 在機器學習中,單純貝氏分類器是一種簡單的機率分類器,它根據貝氏定理應 用特徵之間的獨立假設。在這一部分中,我們介紹單純貝氏分類器,並向用戶展示 簡單的公式推導。圖5.21 顯示了單純貝氏分類器及其簡單公式推導的結果和結果。
圖5.22 單純貝氏分類器頁面
圖5.23 單純貝氏分類器模型配適結果頁面
ui:
verbatimTextOutput("other_val_show_ nbc") server:
input$ind_var_select_nbc f = upload_data() form <- sprintf("%s~%s",input$ind_var_select_nbc, paste0(input$other_var_select_nbc,collapse="+")) NBclassfier <-naiveBayes(as.formula(form),data=f) print(NBclassfier) }) 表5.11 單純貝式分類器模型程式碼 5.3.2.4 Adaboost
Adaboost(Adaptive Boosting,簡稱 Adaboost)是集成學習中的一種方法,是 Yoav Freund 和 Robert Schapire 提出的機器學習方法。Adaboost 的基本概念是將不 同權重分配給多個分類器,並通過加權多數投票對其進行分類,並改善前一步分類 器分類錯誤的樣本的權重。每次訓練新分類器時,它將集中於錯誤分類的訓練樣本。 在這一部分中,我們將讓使用者了解Adaboost 的原理,並使用一個簡單的範例向 用戶展示adaboost 改進每次迭代錯誤的過程。圖 5.23 中間的混淆矩陣表格顯示了 adaboost 中每次迭代改進錯誤的地方。 圖5.24 Adaboost 介紹頁面
在Adaboost 的下一頁中,我們讓使用者使用上傳的資料配適 Adaboost 模型, 他們可以選擇他們想要在模型中進行多少次迭代並繪製了誤差線圖,讓使用者知 道在多少次迭代後誤差將達到最小。 圖5.25 Adaboost 模型配適結果頁面 圖5.26 Adaboost 誤差下降曲線 ui: 1. verbatimTextOutput("other_val_show_ ADA") 2. plotOutput("ADAPlot") server: 1. library("ada") output$other_val_show_ADA<-renderPrint({ input$other_var_select_ADA input$ind_var_select_ADA f = upload_data() form <- sprintf("%s~%s",input$ind_var_select_ADA, paste0(input$other_var_select_ADA,collapse="+"))
print(Adaboost) }) 2. output$ADAPlot<-renderPlot({ input$other_var_select_ADA input$ind_var_select_ADA f = upload_data() form <- sprintf("%s~%s",input$ind_var_select_ADA, paste0(input$other_var_select_ADA,collapse="+")) Adaboost <-ada(as.formula(form),data=f,loss="exponential", type=c("real"),iter=100) plot(Adaboost) }) 表5.12 Adaboost 模型程式碼 5.3.2.5 支持向量機 支持向量機(簡稱SVM)是機器學習中常見的分類器,由 Vladimir N.Vapnik 和Alexey Ya Chervonenkis 於 1963 年所提出。它是一種通過調整參數來解決優化 問題的分類方法。支持向量機的基本概念是找到一個分隔不同類型數據的超平面, 這個超平面稱為分離超平面。分隔數據的兩個邊界稱為支持超平面,它們之間的距 離稱為邊界。我們將介紹它的原理及提供一個互動式支持向量機的例子,再更改支 持向量機的參數或是對資料進行調整時,可以馬上見到分離超平面的改變。 圖5.27 支持向量機介紹頁面
在讓使用者了解支持向量機之後,我們提供支持向量機和支持向量迴歸模型, 讓使用者使用上傳的資料配適模型。下圖顯示配適支持向量機及配適支持向量迴 歸的結果。 圖5.28 支持向量機模型配適結果頁面 圖5.29 支持向量迴歸配適結果頁面 ui: verbatimTextOutput("other_val_show_ svm") server: output$other_val_show_svm<-renderPrint({ input$other_var_select_svm input$ind_var_select_svm f = upload_data() form <- sprintf("%s~%s",input$ind_var_select_svm, paste0(input$other_var_select_svm,collapse="+")) svm <-svm(as.formula(form),data=f) print(svm) }) 表5.13 支持向量機模型程式碼
5.3.3 時間序列模型
應用程序的左側選擇arima 模型的參數。我們展示了 arima 模型,ACF 圖和 PACF 圖的摘要,幫助用戶進行模型檢測。下圖顯示了Arima 模型的結果。
圖5.30 ARMA 模型(一)
下一部分我們以Garch 模型為例,數據與在 ARMA 模型中使用相同。 我們還 展示了GARCH 模型,ACF 圖的總結,圖 5.29 顯示了 GARCH 模型的結果。
圖5.32 GARCH 模型(一)
第六章 畢業生流向調查平台
在本章節中,我們使用校務資料中的畢業生流向調查資料(畢業三年、五年)及 在校生及大學部歷年成績表(98-104 學年度)三份資料進行校務資料分析研究,探討 在拿到這些資料後,讓人感興趣的問題與視覺化介面的呈現。6.1 問題探討
畢業生流向調查為學校希望了解畢業生現況的問卷調查,內容包括畢業生的 工作行業、工作地點、薪資及調查畢業生在校時期所學是否與工作相符…等項目。 我們將上述兩筆資料結合,希望探討一些問題如下: 1. 就業地區(例如:南部或北部)與就業類別對薪資是否有影響? 2. 那一些系所之畢業生薪資較高? 3. 學生時期應該陪養的能力? 4. 在學修課成績對薪資是否有影響? 希望透過上述兩筆資料,對以上四個問題作出回答。6.2 問題回答
在本部份我們將針對上一小節提出的問題進行回答。6.2.1 就業地區(例如:南部或北部)與就業類別對薪資是否有影響
在本部分將針對就業地區與就業類別對薪資是否有影響,在畢業生流向調查 問卷中,第六題為詢問畢業校友的工作地點,我們將就業地區依序分為北部、中部 及南部。北部地區包含基隆市、臺北市、新北市、桃園市、新竹縣、新竹市及苗栗 縣,中部地區包含臺中市、南投市、彰化市、雲林縣、嘉義縣、嘉義市,南部地區 包含臺南市、高雄市、屏東縣,而東部地及外島地區因為在本次問卷中人數過少不 做討論。將畢業三年問卷及畢業五年問卷依照上述方式分類後,可以得到表格如下: 畢業五年問卷調查: 地區 人數 薪資中位數 北部 294 47500 中部 98 41500 南部 422 44500 表6.1 畢業五年問卷調查各地區人數及薪資中位數 而畢業五年畢業生北部、中部、南部工作興致如下圖所示。 圖6.1 畢業 5 年畢業生北部地區工作型態
圖6.2 畢業 5 年畢業生中部地區工作型態
畢業三年問卷調查: 地區 人數 薪資中位數 北部 181 41500 中部 69 35500 南部 152 38500 表6.2 畢業三年問卷調查各地區人數及薪資中位數 而畢業三年畢業生北部、中部、南部工作興致如下圖所示。 圖6.4 畢業 3 年畢業生北部地區工作型態
圖6.5 畢業 3 年畢業生中部地區工作型態
圖6.6 畢業 3 年畢業生南部地區工作型態
最後,我們比較各地區薪資中位數之差異,使用無母數分析中的雙樣本中位數 差異檢定,分別對畢業三年級畢業五年各地區作檢定,得到結果如表6.3,畢業五 年之畢業生在北部工作的薪資中位數顯著的比中部及南部的畢業生高,南部工作
的畢業生薪資中位數顯著的比中部的畢業生高;畢業三年之畢業生在北部工作的 薪資中位數顯著的比中部及南部的畢業生高,而中部及南部之畢業生薪資中位數 無顯著差異。 畢業五年: 樣本中位數差異檢定 P-value 北 vs 南 0.003612 南 vs 中 0.02153 表6.3 畢業五年檢定結果 畢業三年: 樣本中位數差異檢定 P-value 北 vs 南 0.001164 南 vs 中 0.09584 表6.4 畢業三年檢定結果
6.2.2 那一些系所之畢業生薪資較高?
在本節中我們將針對畢業五年及畢業三年各學院之畢業生的薪資進行討論, 將畢業生依照學號分為五大學院:人文學院、法學院、管理學院、理學院及工學院, 畢業五年及畢業三年各學院之人數、薪資中位數如下表: 畢業五年: 系所 人數 薪資中位數 人文院 158 38500 法院 108 41500 管院 118 40000 理院 120 49000 工院 171 47500 表6.5 畢業五年問卷調查各學院人數及薪資中位數圖6.7 畢業 5 年畢業生五大學院薪資盒鬚圖 畢業三年: 系所 人數 薪資中位數 人文院 51 32500 法院 83 41500 管院 116 38500 理院 77 38500 工院 92 44500 表6.6 畢業三年問卷調查各學院人數及薪資中位數
圖6.8 畢業 3 年畢業生五大學院薪資盒鬚圖 最後,我們比較畢業五年及畢業三年各學院薪資中位數之差異,使用無母數分 析中的雙樣本中位數差異檢定,分別對各學院作檢定,得到結果如下表,由表6.7 可得知,畢業五年工學院及理學院畢業生的薪資中位數兩者無顯著性差異但顯著 的比其他三個學院之畢業生高,法學院畢業生的薪資中位數顯著的比其人文學院 之畢業生高;畢業三年工學院畢業生的薪資中位數顯著的比其他四所學院畢業生 高,而人文學院畢業生薪資中位數顯著的比其他四所學院低,法學院、管理學及院 學院薪資無顯著差異。 畢業五年檢定結果: 人文院 法院 管院 理院 工院 人文院 0.015 0.300 4.396e-05 1.824e-05 法院 0.129 0.01519 0.02 管院 0.0003513 0.0002 理院 0.6263 工院
畢業三年檢定結果: 人文院 法院 管院 理院 工院 人文院 0.00036 0.00034 0.0003188 1.977e-08 法院 0.5856 0.985 0.03951 管院 0.589 0.002419 理院 0.03631 工院 表6.8 畢業三年各學院薪資檢定結果
6.2.3 學生時期應該陪養的能力?
在本部分將針對學生時期應該陪養的能力進行回答,在畢業生流向調查問卷 第十一題為「根據您畢業後到現在的經驗,您認為學校對您那些能力的培養最有 幫助?」,我們將畢業生對此題的答案作為依據,進而回答學生時期應該陪養的能 力。 在十一題中,可以勾選的答案分別為「溝通表達能力」、「持續學習能力」、「人 際互動能力」、「團隊合作能力」、「問題解決能力」、「創新能力」、「工作紀律、責任 感及時間管理能力」、「資訊科技應用能力」、「外語能力」、「跨領域整合能力」及「領 導能力」等十一項能力,我們將畢業生有勾選記為「1」,沒有勾選記為「0」得到 以下資料格式如表6.9,L1 到 L11 分別對應上數十一項能力。 L1 L2 L3 L4 L5 L6 L7 L8 L9 L10 L11 0 0 0 0 0 0 1 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 1 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 表6.9 能力指標勾選範例 對上表資料形式我們透過階層式分群法(Hierarchical Clustering)將資料進行分 類,階層式分群法為一種非監督式學習的分群方法,透過計算資料間的距離對資料 進行分群,而我們的資料皆為類別行變數,因此使用「漢明距離」作為計算距離的方法。漢明距離是計算兩個等長字串之間對應位置的不同字元的個數,常用於計算 類 別 行 變 數 的 距 離 。 例 如 上 述 資 料 第 一 筆 為 「 00000010000 」、 第 二 筆 為 「00100000000」,第三個字元與第七個字元不同,故此二字串漢明距離為2。 透過上述方法將資料進行分類會將資料分為 7 群,階層式分群法分群結果如 下圖。透過下圖可知道各群之畢業生認為學生應該培養的能力。圖 6.10 顯示,第 一群畢業生多認為「溝通表達能力」與「人際互動能力」較為重要;第二群畢業生 多認為「持續學習能力」較為重要;第三群畢業生多認為「溝通表達能力」較為重 要;第四群畢業生多認為「問題解決能力」較為重要;圖 6.11 顯示,第五群畢業 生多認為「團隊合作能力」較為重要;第六群畢業生多認為「跨領域整合能力」較 為重要;第五群畢業生多認為「資訊應用能力」較為重要。 圖6.9 階層式分群法分群結果
圖6.10 分群結果各群能力培養(一)
我們將分為 7 群後,將各組學生在校表現及薪資表現計算出並得到表 6.10, 將各群學生之畢業後薪資中位數作為比較基準並使用無母數分析中的雙樣本中位 數差異檢定,分別對各群的薪資中位數作檢定後得到檢定統計量並列出下表6.11, 第五組、第六組及第七組因為分類後樣本數與前四組相差過大,因此在此不做討論。 由表 6.11 可得知,第一組畢業生認為「溝通表達能力」與「人際互動能力」較為 重要者,薪資中位數較第三組及第四組顯著的高,而第一組畢業生與第二組畢業生 薪資中位數無顯著的差異,因此「溝通表達能力」、「人際互動能力」與「持續學習 能力」在為學生時期應該陪養的能力。 分組 人數 薪資 平均 薪資標 準差 必修 成績 選修 成績 必修 比例 選修 比例 第一組 196 54262 19378 81.37 83.42 0.418 0.427 第二組 126 51079 20217 78.95 80.59 0.424 0.386 第三組 131 49385 20044 77.86 80.27 0.387 0.423 第四組 175 50245 22055 80.33 82.43 0.434 0.386 第五組 47 52904 20874 79.03 79.98 0.435 0.350 第六組 32 53718 19866 79.75 82.48 0.459 0.368 第七組 33 54318 25586 78.60 79.61 0.405 0.346 表6.10 畢業五年能力指標分群結果 第一組 第二組 第三組 第四組 第一組 0.1421 0.025 0.025 第二組 0.58 0.385 第三組 0.83 第四組 表6.11 畢業五年能力指標各群薪資檢定結果