國
立
交
通
大
學
資訊工程學系
博
士
論
文
醫學影像資料庫之研究
A Study on Medical Image Database
研 究 生:鄭培成
指導教授:楊維邦 教授
錢炳全 教授
醫學影像資料庫之研究
A Study on Medical Image Database
研 究 生:鄭培成 Student:Pei-Cheng Cheng
指導教授:楊維邦 博士 Advisor:Dr. Wei-Pang Yang
錢炳全 博士
Dr. Been-Chian Chien
國 立 交 通 大 學
資 訊 工 程 學 系
博 士 論 文
A Dissertation Submitted to Department of Computer Science
College of Computer Science National Chiao Tung University in partial Fulfillment of the Requirements
for the Degree of Doctor of Philosophy
in
Computer Science December 2006
Hsinchu, Taiwan, Republic of China
醫學影像資料庫之研究
學生: 鄭培成 指導教授: 楊維邦 博士
錢炳全 博士
國立交通大學資訊科學與工程研究所 博士班
摘 要 隨著數位化科技以及網路通訊的快速發展,影像資料在醫療院所、數位典藏 以及網際網路上被大量的產生,日漸提高了影像檢索技術的需求。另一方面由於 網路的快速連結,跨越了國界,各種語言的資料都可以在網路上檢索。本論文主 要研究一個跨語言的醫學影像查詢系統,讓使用者可以使用熟悉的語言或是使用 影像內容來找尋相關的醫學影像。 本論文探討的兩個研究主題,為醫學影像內容查詢以及跨語言的資訊檢索。 在醫學影像內容查詢方面,我們提出了一些針對學影像內容特徵的表示法,相關 的相似度計算方法,以及新的接受使用者回饋的模式,在實驗結果中顯示所提出 的特徵表示法可以有效的提高準確率及查全率。在跨語言方面我們針對在翻譯時 所常遇到的岐義性的問題,提出了利用本體知識來改善的方法,實驗結果顯示我 們所提出解決岐義性問題的方法,可以有效提高查詢結果的準確率。 關鍵字: 醫學影像查詢; 跨語言查詢; 相關回饋查詢;A Study on Medical Image Database
Student: Pei–Cheng Cheng Advisors: Dr. Wei-Pang Yang Dr. Been-Chian Chien Institute of Computer Science and Engineering
National Chiao Tung University
ABSTRACT
The importance of digital image retrieval techniques increases in the emerging fields of medical imaging, picture archiving and communication systems. In this dissertation, a bilingual medical image database system is proposed for users to retrieve medical images. The principal objective is to provide users a medical image retrieval system to find similar diagnosis and to obtain useful information for treatment.
This dissertation relates to two areas – medical image retrieval and cross-language information retrieval. We proposed an effective representation for content-based medical image retrieval and an approach to address the translation ambiguity problem for cross-language image retrieval. Furthermore, a novel relevance feedback mechanism is proposed to improve the retrieval effectiveness by interacting with users.
誌 謝
論文能夠順利完成,首先要感謝我的指導教授楊維邦教授及錢炳全教授,多 年來悉心的教導以及鼓勵,使我不論在學業上以及待人處事方面,都能夠更進一 層的學習。兩位老師平時的循循善誘以及諄諄教誨都給予我適時的鼓舞作用,讓 我可以持續堅持下去,完成這本論文。 我也要特別感謝袁賢銘教授、孫春在教授、陳榮傑教授、唐傳義教授、項潔 教授、黃明祥教授以及曾定章教授對於本論文的不吝指教及給予本論文諸多寶貴 的意見。 還有感謝資料庫實驗室的伙伴們,讓我在實驗室裡獲得許多的協助以及關 心,使我能夠渡過這個漫長的等待,我畢業囉! 學弟 加油! 最後要感謝我的家人對於我百分之百的支持,長久以來對於我的關懷以及不 求回報的付出,是我努力不懈的原動力,非常感謝對我非常關心的父母,爸爸、 媽媽以及哥哥,謝謝你們!我想你們最想聽到的話就是"我畢業了"吧。TABLE OF CONTENTS
Chapter 1 Introduction... 1
1.1 The Rationale of Cross Medical Image Retrieval System ...2
1.2 Content Based Medical Image Retrieval ...5
1.3 Combine Text and Visual Feature for Medical Image Retrieval...6
1.4 Medical Image Retrieval with Relevance Feedback...7
1.5 Motivation & Objective ...8
1.6 Organization of This Dissertation ...10
Chapter 2 Content Based Medical Image Retrieval ... 12
2.1 Proposed Methods for Medical Image Comparison ...17
2.2 The Experiment and Result...27
Chapter 3 Combine Text and Visual Feature for Medical Image Retrieval ... 33
3.1 Previous Work for Cross-Language Document Retrieval...35
3.2 Combine Text and Visual Feature for Medical Image Database...41
3.3 Reduce the Cross-Language Translation Ambiguity ...45
Chapter 4 Medical Image Retrieval with Relevance Feedback ... 57
4.1 Previous Relevance Feedback Works ...58
4.2 Proposed Relevance Feedback Mechanism ...62
Chapter 5 Conclusions and Future Research ... 70
Bibliography ... 72
LIST OF FIGURES
Figure 1-1: The data model of our system ...3
Figure 1-2: an example case note from the medical case ...4
Figure 2-1: concept view of content based image retrieval system ...14
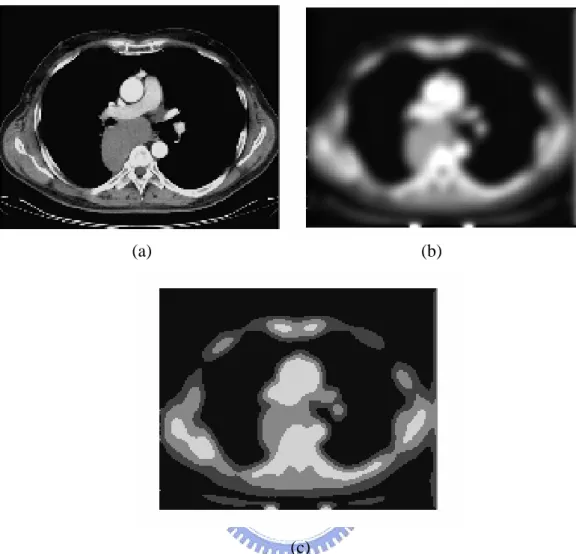
Figure 2-2: (a) original image with 256 levels; (b) new image after clustering with only 4 levels...22
Figure 2-3: (a) original image; (b) image after smoothing; (c) image after clustering into four classes. ...23
Figure 2-4: An example medical case note and associated images ...28
Figure 2-5: Precision Vs. Recall graphs without and with feedback. ...29
Figure 2-6: Result of an example query ‘Pelvic’ ...30
Figure 2-7: Result of example query ‘lung’...30
Figure 2-8: Result of example query ‘hand’ ...31
Figure 3-1: Example from the Casimage collection ...41
Figure 3-2: The data model of medical image retrieval system...42
Figure 3-3: Text based multilingual query translation flowchart...42
Figure 3-4: The cross medical image system architecture...45
Figure 3-5: Proposed system flowchart ...46
Figure 3-6: An example of ontology. ...48
Figure 3-7: semantic relationship map...49
Figure 3-8: The precision v.s. recall...54
Figure 4-1: Graphic User Interface for the Proposed CBIR System. ...66
LIST OF TABLES
Table 2-1: Results reported at imageCLEF2004……… 29
Table 3-1: The query result of visual feature only……….. 51
Table 3-2: The result of mixed retrieval runs………. 51
Table 3-3: The mean average precision……….. 55
Chapter 1
Introduction
Image capture capabilities are evolving so rapidly, extreme amount of images are produced daily. The importance of digital image retrieval techniques increases in the emerging fields of publication on the internet, variety trademarks, and the medical imaging (Geneva radiology department generate 20,000 images per day), etc. An image is worth thousand of words especially in medical application. It is a hard work to retrieve an image from thousand of images by browsing one bye one. Retrieving large amount of images rely on annotation is expensive and time consume. On the other hand, human has subjective viewpoint, image that annotate by different people may be described into different annotation.
Content Based Image Retrieval (CBIR) is a new technology to assist image finding. CBIR retrieve image by itself without annotation. CBIR allow user to query image database by image example, partial region of image, sketch contour, or dominate color, etc. IBM in 1995 have developed the QBIC[20] system which lets user make queries of large image databases based on visual image content properties such as color percentages, color layout, and textures occurring in the images. User can match colors, textures and their positions without describing them in words. Content based image retrieval offer an alternate method for user to retrieve desired images. CBIR is a very convenient and economic approach for image retrieval system because it is an automatic method to analyze images.
Imaging systems and image archives have often been described as an important economic and clinical factor in the hospital environment [22]. Several methods from
computer vision and image processing have already been proposed for the use in medicine [51]. Medical images have often been used for retrieval systems, and the medical domain is often cited as one of the principal application domains for content-based access technologies [6] [32] [48] [64] in terms of potential impact. Images by their nature are language independent, but often they are accompanied by texts semantically related to the image (e.g. textual captions or metadata). Images can then be retrieved using primitive features based on pixels with form the contents of an image (e.g. using a visual exemplar), abstracted features expressed through text or a combination of both. The language used to express the associated texts or textual queries should not affect retrieval, i.e. an image with a caption written in English should be searchable in languages other than English.
In this dissertation, we study on a cross medical image retrieval system to assist
clinical student learning or patient to understand his condition. In this chapter the rationale of cross medical image retrieval system is introduced. The status of medical image retrieval is also reviewed. The main results of this dissertation are stated in the last of each chapter.
1.1 The Rationale of Cross Medical Image Retrieval System
The use of CBIR systems is becoming an important factor in medical imaging research. In this dissertation we study CBIR systems and determine how associated cross-language text can be used in combination with CBIR to improve retrieval and ranking in particular medical domain. The goal is to find images that are similar with respect to modality (CT, radiograph, MRI...), with respect to the anatomic region shown (lung, liver, head ...) and sometimes with respect to the radiological protocol (such as a contrast agent.).
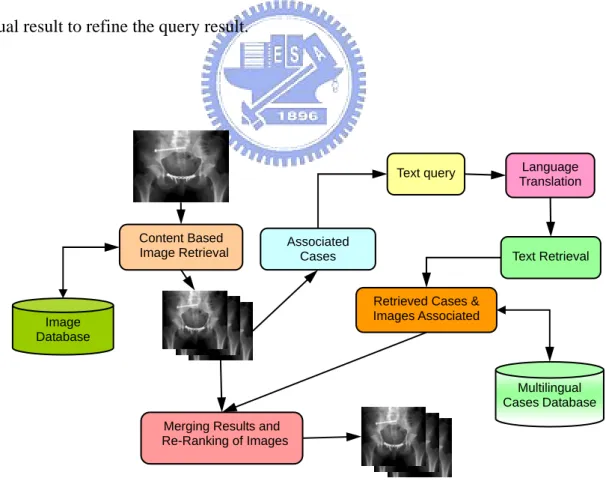
The medical image retrieval systems allow user can use image example to retrieve related documents or use native language to query another language documents or images. Figure 1-1 is the data model of cross medical image retrieval system. When user issues query by image example first, visual feature was used to find visual similar images. The images are associated with case notes; a written description of a previous diagnosis for an illness the image identifies (e.g. Figure 1-2). Case notes consist of several fields including: a diagnosis, a free textual description, clinical presentation, keywords and title. Case notes are mixed language written in either English or French. We can use the associated notes to improve the query result. Extracting the possible keyword from the visual similar result as query words used to execute text query. In the last phase, we can combine the text and visual result to refine the query result.
Content Based Image Retrieval
Image Database
Merging Results and Re-Ranking of Images
Multilingual Cases Database
Text Retrieval
Retrieved Cases & Images Associated Text query Associated Cases Language Translation
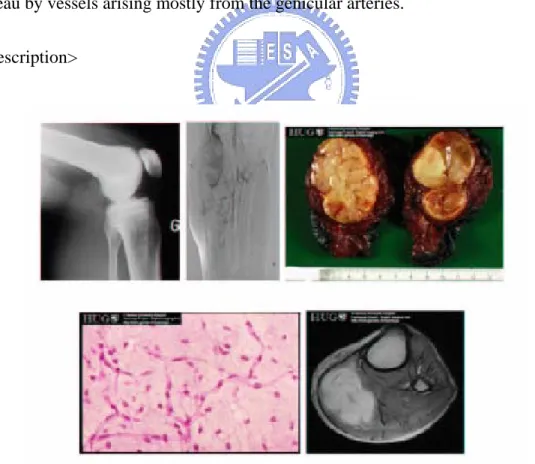
An example case and images
<Description>
X ray: Mass effect within the soft tissues of the proximal part of the left calf, difficult to outline, seen only as it displaces the fat planes. There are no calcifications. The adjacent bone is normal.
MRI: Oval mass within the medial gastrocnemius muscle, very well delineated, slightly lobulated (axial cuts). Its structure is heterogeneous. On T1, it is slightly hyperintense compared to the adjacent muscle (red arrow). It is isointense to fat on proton density images (DP), very hyperintense on T2 and IR with some hypointense areas in its centre. After injection of contrast medium, there is marked enhancement except for the central area, which remains hypointense.
Arteriography: there is hypervascularity of the soft tissues outside the medial tibial plateau by vessels arising mostly from the genicular arteries.
…..
</Description>
1.2 Content Based Medical Image Retrieval
In the past years, content-based image retrieval has been one of the most hot research areas in the field of computer vision. The commercial QBIC [20] system is definitely the most well known system. Another commercial system for image and video retrieval is Virage [2][25] that have well known commercial customers such as CNN. In the academia, some systems including Candid [32], Photobook [50], and Netra [37] use simple color and texture characteristics to describe image content. The Blobword system [5][9] exploits higher-level information, such as segmented objects of images, for queries. A system that is available free of charge is the GNU Image Finding Tool (GIFT) [67]. Some systems are available as demonstration version on the Web such as Viper, WIPE or Compass.
Content based image retrieval system contains two main phases: first phase is feature representation, the system extract the features from image automatic. The feature selection dependent on the application, good representation will be the first condition to obtain better performance. The second phase is similar metric designing, the similar metric must correspondent to the representation of images.
The general application of image retrieval to broad image databases has experienced limited success, principally due to the difficulty of quantifying image similarity for unconstrained image classes (e.g., all images on the Internet). We expect that medical imaging will be an ideal application of CBIR, because of the more-limited definition of image classes, and because the meaning and interpretation of medical images is better understood and characterized. In this thesis, we design several image feature representation methods and similar metric for medical images content based retrieval. In Chapter 2, the experiment result shows that proposed
method is out performance than previous work.
1.3 Combine Text and Visual Feature for Medical Image
Retrieval
Although content based approach can find similar images automatically, content based method use image features to retrieve image sometimes the query result is unexpected by user because the result rely on image features automatic produced by system. Image feature is unlike keyword which is easy reasonable by user.
Content based image retrieval still has some problem need to be solved. Two of the common problems are sensory gap and semantic gap. The loss between the actual structure and the representation in a digital image is called sensory gap. The another problem is semantic gap, Even systems using segments and local features such as Blobworld [9] are still far away from identifying objects reliably. How can we use limited feature domain to represent real world infinite possible objects. No system offers interpretation of images or even medium level concepts as they can easily be captured with text. This loss of information from an image to a representation by features is called the semantic gap. The more a retrieval application is specialized for a certain, limited domain, the smaller the gap can be shortened. Content based queries are often combined with text and keyword predicate to get powerful retrieval methods for image and multimedia databases. In the experiment result show that combines the text and visual feature will get better performance.
The rapid growth in size of the World Wide Web (WWW) and the increasing speed of internet cause the world become globalization. People can get information
from various countries on the internet. Thus, multilingual information retrieval problem becomes a hot research field.
Cross-language retrieval is the retrieval of any type of object (texts, images, products, etc.) composed or indexed in one language (the target language) with a query formulated in another language (the source language). There may be any number of source languages and any number of target languages.
In many collections (e.g. historic or stock photographic archives, medical databases and art/history collections), images are often accompanied by some kind of text (e.g. metadata or captions) semantically related to the image. Retrieval can then be performed using primitive features based on pixels which form an image’s content (CBIR); using abstracted textual features assigned to the image, or a combination of both. The language used to express the associated texts or metadata should not affect the success of retrieval, i.e. an image with English captions should be searchable in languages other than English.
In Chapter 3, retrieving medical image with multilingual annotation is studied. While translating query language to another language will cause the ambiguous problem, we proposed an ontology-based approach to overcoming the problem of translation ambiguity. The experimental results show that the proposed approach can effectively remove the irrelevant results and improve the precision.
1.4 Medical Image Retrieval with Relevance Feedback
Many researches show that relevance feedback method really improves the performance of content based approach results. Users often have subjective viewpoint. Some user may want to find similar color images and others may want to find similar
shape images. Furthermore, the color definition of similar red for each person is different. The system initially hard to know the user’s biased like and the system can’t designed for specify users without profile of users. Relevance feedback learn user’s preference reflect to the system. System according to the user offered example (positive examples or negative examples) to reformulate the query. The relevance feedback mechanism improves the precision of result respect for user.
In Chapter 4, we propose a new relevance feedback mechanism to fast trace the user’s interesting. Previous works use positive and negative example to reformulate the query example. In this thesis, an ordering query examples model was proposed, user can further express the prefer images in an order. Based on the ordering information, we can refine the result more fast and precise.
1.5 Motivation & Objective
Content based image retrieval method is a good and only choice to retrieval images while images do not have explanatory notes. The increasing reliance of modern medicine on diagnostic techniques such as radiology, histopathology, and computerized tomography has led to the explosion in the number and importance of medical images now stored by most hospitals. While the prime requirement for medical imaging systems is to be able to display images relating to a named patient, there is increasing interest in the use of CBIR techniques to aid diagnosis by identifying similar past cases.
In the world, people confront with variety disease and accident. In different country, the similar cases of illness may occur. The rare diseases especially need reference similar past cases to aid diagnosis. There is a problem need to be conquered that the diagnosis cases was annotated in different language. In this thesis,
we also study the cross-language information retrieval method to add the robust of medical image systems and offer user can query in native language. We try to combine the keyword and image to improve the precision of the medical image systems. The images illustrate the fact without keyword, thus the cross language problem is not exist. The similar images (found by CBIR) may offer a connection to link the similar diagnosis cases which were annotated in different language. The similar content of images may be annotated by different languages, but they all describe the same things. In the world there exist many usefully diagnosis cases, but the diagnosis are described in different languages. Based on the medical image, we may offer a cross language environment for user to query similar past cases which are written bye different languages.
In previous related work, user only can mark the result image which is relevant or not. The relevance feedback mechanism relies on the positive examples or negative examples to refine the query formulation. In this dissertation we design a novel relevance feedback model to receive more information from user. User can set a prefer order of similar images of result. According to the rank images set by user, the systems is more easy to tune the weight of each image features. We expect this reformulation mechanism can fast close to the user’s interesting than previous feedback mechanism.
In this study we research what technologies can be used in the application of medical image retrieval. In the limited domain some technologies may need modify to suit the specify application. We proposed a wavelet based signature for images combine and modify previous methods to analysis the coefficient of wavelet. The representation we designed consider the human’s perceptual cooperate with low level image features have better performance than previous works.
In this dissertation contain two main research topics. One is medical image retrieval problem and the other is about bilingual language information retrieval. In the medical image retrieval issue, we modify exist content based techniques used in general propose images to suit medical images retrieval. We also develop several new representations of medical images from human’s conceptual and the correspondent metrics of new representation was designed. In the cross language information retrieval problem, we propose an ontology method to solve the translation ambiguity problem. The occurrence probability of transformed words in the same class will help to solve the translation ambiguity problem.
In the previous related works, user can refine the results by relevant feedback mechanism. User can mark images as relevant or not from result for retrieval system. The system according to user’s interesting that is positive examples tunes the weight of related features to improve the result. In the experiment result of previous related work show that positive example will improve the results. Previous works only allow user to mark relevant or not, the system need several times to refine the results. In is dissertation we design a new mechanism allow user to offer more information for system to fast close to his interesting. Proposed feedback mechanism allows user to rank the results by similarity. According to the ranking of selected images we can get the information for weighting the image features.
1.6 Organization of This Dissertation
The remainder of this thesis is organized as follows. In Chapter 2, we review previous related visual medical image researches and proposed an efficient representation correspond to user’s viewpoint and similar matching metric. In Chapter 3, we combine text and visual feature to improve the accuracy of query
result and propose an ontology method to conquer the ambiguity problem of cross language retrieval. In Chapter 4, relevance feedback methods were surveyed and a novel feedback mechanism is proposed. Last, the conclusion and further works is described in Chapter 5.
Chapter 2
Content Based Medical Image Retrieval
The number of digitally produced medical images is rising strongly. In the radiology department of the University Hospital of Geneva alone, the number of images produced per day in 2002 was 12,000, and it is still rising. The management and the access to these large image repositories are increasing the need for tools that effectively filter and efficiently search through large amounts of visual data. Most access to these systems is based on the patient identification or study characteristics (modality, study description) [35] as it is also defined in the DICOM standard [52].
Imaging systems and image archives have often been described as an important economic and clinical factor in the hospital environment [22]. Several methods from computer vision and image processing have already been proposed for the use in medicine [51]. Medical images have often been used for retrieval systems, and the medical domain is often cited as one of the principal application domains for content-based access technologies [6] [32] [48] [64] in terms of potential impact.
Two exceptions seem to be the Assert system on the classification of high resolution CTs of the lung [1] [63] and the Image Retrieval in Medical Applications (IRMA) system for the classification of images into anatomical areas, modalities and view points [33]. Assert system allow the physician to circles one or more Pathology Bearing Regions (PBR) in the query image. The system then retrieves the n most visually similar images from the database using an index comprised of a combination of localized features of the PBRs and of the global image. The database consists of High Resolution Computed Tomography of the lung. CBIR is particularly needed for this domain because the current state of the art in diagnosis,
for those cases not immediately recognizable, is to consult a published atlas of lung pathologies. Assert system saves the radiologist from the laborious task of paging through the atlas looking for an image that matches the pathology of their current patient.
Image Retrieval in Medical Applications (IRMA) is a cooperative project of the Department of Diagnostic Radiology, the Department of Medical Informatics, Division of Medical Image Processing and the Chair of Computer Science VI at the Aachen University of Technology. Aim of the project is the development and implementation of high-level methods for content-based image retrieval with prototypical application to medico-diagnostic tasks on a radiological image archive.
They want to perform semantic and formalized queries on the medical image database which includes intra- and inter-individual variance and diseases. Example tasks are the staging of a patient's therapy or the retrieval of images with similar diagnostic findings in large electronic archives. Formal content-based queries also take into account the technical conditions of the examination and the image acquisition modalities.
The system ought to classify and register radiological images in a general way without restriction to a certain diagnostic problem or question. Methods of pattern recognition and structural analysis are used to describe the image content in a feature based, formal and generalized way. The formalized and normalized description of the images is then used as a mean to compare images in the archive which allows a fast and reliable retrieval.
In addition to the queries on an existing electronic archive, the automatic classification and indexing allows a simple insertion of conventional radiographs into the system. Automated classification of radiographs based on global features with respect to imaging modality, direction, body region examined and biological
system under investigation.
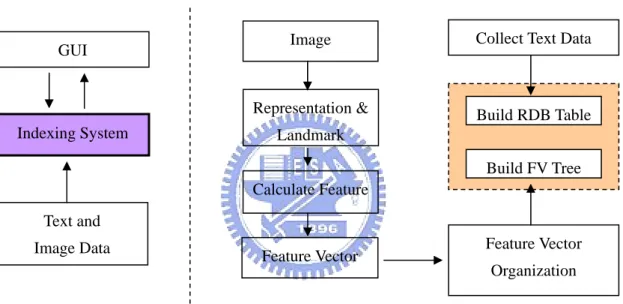
Identification of image features that are relevant for medical diagnosis these features are derived from a-priori classified and registered images. The resulting system must retrieve images similar to a query image with respect to a selected set of features. These features can, for example, be based on the visual similarity of certain image structures. Figure 2-1 is a concept view of content based image retrieval system. Indexing System Text and Image Data GUI Image Representation & Landmark Calculate Feature Feature Vector Build RDB Table Build FV Tree Feature Vector Organization Collect Text Data
Figure 2-1: A concept view of content based image retrieval system
Content-based retrieval has also been proposed several times from the medical community for the inclusion into various applications [7] [69], often without any implementation. Still for a real medical application of content-based retrieval methods and the integration of these tools into medical practice a very close cooperation between the two fields is necessary for a longer period of time and not simply an exchange of data or a list of the necessary functionality.
Most existing content-based image retrieval (CBIR) systems rely on computing a global signature for each image based on color, texture and shape information [65].
However, medical image usually consists of gray level variations in highly localized regions in the image. Thus, the content-based image retrieval method in color based can’t apply to medical images directly. In the gray level images, the contrast of gray level is more important than illuminate in human’s viewpoint. In this dissertation, we consider the human’s conceptual and we design a wavelet-based image representation method. Wavelets have proven their efficiency in image retrieval, for their capability in capturing texture and shape information [1] [42] [49]. Making use of wavelet sub-band decomposition, relevant information about the structure of data can be computed, which can serve as a low dimensional feature vector. A wavelet-based medical image retrieval system, which is mainly based on textural information, has shown satisfactory results in retrieving HRCT lung images [31].
One of the most significant problems in content-based image retrieval results from the lack of a common test-bed for researchers. Although many published articles report on content-based retrieval results using color photographs, there has been little effort in establishing a benchmark set of images and queries. It is very important that image databases are made available free of charge for the comparison and verification of algorithms. Only such reference databases allow comparing systems and to have a reference for the evaluation that is done based on the same images. ImageCLEF1 [12] offers numerous medical images for evaluation and has many benefits in advancing the technology and utilization of content-based image retrieval systems.
Compared to text retrieval little is known about how to search for images, although it has been an extremely active domain in the fields of computer vision and information retrieval [41][56][64][69]. Benchmarks such as ImageCLEF [12] allow evaluating algorithms compared to other systems and deliver insights into the
1
techniques that perform well. They offered a default CBIR system that is GIFT2. This software tool is open source and can be used by other participants of ImageCLEF. The feature sets that are used by GIFT are:
−Local color features at different scales by partitioning the images successively into four equally sized regions (four times) and taking the mode color of each region as a descriptor;
−Global color features in the form of a color histogram, compared by a simple histogram intersection;
−Local texture features by partitioning the image and applying Gabor filters in various scales and directions, quantized into 10 strengths;
−Global texture features represented as a simple histogram of responses of the local Gabor filters in various directions and scales.
In this dissertation we want to study a medical image retrieval system that contains variety of type images for clinical student to learning or patient to understand his condition. The image contains variety of type image, thus we consider global and local image features expect to describe variety of type images. We based on the wavelet coefficient to extract dominate gray value and texture information. For efficient retrieving we design several new representations of features. The following is our proposed feature representation methods.
2.1 Proposed Methods for Medical Image Comparison
In color images, users are usually attracted by the change of colors more than the positions of objects. Thus, we use color histogram as the feature of color images to retrieve similar color images. Color histogram is suitable to compare images in many applications. Color histogram is computationally efficient, and generally insensitive to small changes in the camera position.
Color histogram has some drawbacks. Color histogram provides less spatial information; it merely describes which colors are present in an image, and in what quantities. Because gray images encompass few colors (usually 256 gray levels), directly using color histogram in gray images will get bad retrieval results. For gray images, we must emphasize spatial relationship analysis; furthermore, object and contrast analysis is important for medical images; therefore, three kinds of features that can indicate the spatial, coherence, and shape characteristics, gray-spatial
histogram, coherence moment, and gray correlogram, are employed as the features
of gray images.
In the following we describe the four kinds of features, one for color images and three for gray images, used in this paper.
2.1.1 Color Image Features
Color histogram [68] is a basic method and has good performance for presenting image content. The color histogram method gathers statistics about the proportion of each color as the signature of an image. Let C be a set of colors, (c1, c2…cm) ∈ C that can occur in an image. Let I be an image that consists of pixels p(x, y)3. The
3
color histogram H(I) of image I is a vector (h1, h2, …, hi,…, hm), in which each bucket hi counts the ratio of pixels of color ci in I. Suppose that p is the color level of a pixel. Then the histogram of I for color ci is defined as Eq. (1):
} { Pr ) ( i I p c I p c hi = ∈ ∈ (1)
In other words, corresponds to the probability of any pixel in I being of the color c
) (I
hc
i
i. For comparing the similarity of two images I and I’, the distance between the histograms of I and I’ can be calculated using a standard method (such as the L1
distance or L2 distance). Then, the image in the image database most similar to a
query image I is the one having the smallest histogram distance with I.
Any two colors have a degree of similarity. Color histogram is hard to express the similar characteristic between neighbor bins. Each pixel does not only assign a single color. We set an interval range δ to extend the color of each pixel. Then the histogram of image I is redefined as the Eq. (2):
m c p p I h m j i j j ci
∑
= ∩ + − = 1 ] 2 , 2 [ ) ( δ δ δ (2)Where pj is a pixel of image, and m is the total number of pixels.
The colors of an image are represented in HSV (Hue, Saturation, Value) space, which is closer to human perception than spaces such as RGB (Red, Green, Blue) or CMY (Cyan, Magenta, Yellow). In implementation, we quantize HSV space into 18 hues, 2 saturations and, 4 values, with additional 4 levels of gray values; as a result, there are a total of 148 bins.
Using the modified color histogram, the similarity of two color images q and d is defined as Eq. (3):
∑
∑
= = = ∩ = n i i n i i i q h d h q h 1 1 ) ( )) ( ), ( min( | H(q) | H(d) H(q) H(d)) (q), SIMcolor(H (3)2.1.2 Gray Image Features
Gray images are different from color images in human’s perception. Gray images have fewer colors than color images, only 256 gray levels in each gray image. Human’s visual perception is influenced by the contrast of an image. The contrast of an image from the viewpoint of human is relative rather than absolute. To emphasize the contrast of an image and handle images with less illuminative influence, we normalize the value of pixels before quantization. In this paper we propose a relative normalization method. First, we cluster the whole image into four clusters by the K-means cluster method [26]. We sort the four clusters ascendant according to their mean values. We shift the mean of the first cluster to value 50 and the fourth cluster to value 200; then each pixel in a cluster is multiplied by a relative weight to normalize. Let mc1 is the mean value of cluster 1 and mc4 is the mean value of
cluster 4. The normalization formula of pixel p(x, y) is defined as Eq. (4).
) ( 200 )) 50 ( ) , ( ( ) , ( 1 4 1 c c c normal p x y m m m y x p − × − − = (4)
After normalization, we resize each image into 128*128 pixels, and use one level wavelet with Haar wavelet function [66] to generate the low frequency and high frequency sub-images. Wavelets are mathematical functions that decompose signals into different frequency components, and then analyze each component with a resolution matching its scale. The main advantage of wavelets over Fourier analysis is that they allow better resolution in space and frequency [23]. Consequently, the wavelet transform (WT) is more efficient in analyzing periodic
signals, such as images, especially if they contain impulsive sharp changes. The continuous WT of a function f(x) using a wavelet functions basis is defined as
∫
= f x x dx j
i
F(, ) ( )ψi,j( ) (5) The basis of wavelet function is obtained by shifting and scaling a single mother wavelet functionψ( x): 0 ; ) ( 1 ) ( , > − = dx i i j x i x j i ψ ψ (6)
Where i is the scale factor and j is the shift value. The mother wavelet should satisfy the zero average condition. The Discrete WT is obtained by taking i=2n and b∈Z. The analyzed signal can be a 2-D image. The 2-D analysis is performed as a product of two 1-D basis functions
) 2 ( ) 1 ( ) 2 , 1 ( 1,1 2, 2 2 , 2 ; 1 , 1j i j x x i j x i j x i ψ ψ ψ = ⋅ (7)
This yields a decomposition of the image into 4 subbands called the approximation (the low frequency components in 1 subband) and the details (the high frequency components in 3 subbands). From the whole set of approximation and details coefficients, it is possible to reconstruct the original image again. The decomposition process can be iterated with successive approximations being decomposed in turn.
Process an image using the low pass filter will obtain an image that is more consistent than the original one; on the contrary, processing an image using the high pass filter will obtain an image that has high variation. The high-frequency part keeps the contour of the image. After wavelet translation, there are four sub-bands denoted by Low_Low (LL), Low_Height (LH), Height_Low (HL), Height_Height (HH). High-frequency pixels may be important in medical images for doctor
diagnoses. By performing the OR operation for LH, HL, and HH bands, we get the contour of a medical image.
2.1.3 Gray-Spatial Histogram
In a gray image the spatial relationship is very important especially in medical images. Medical images always contain particular anatomic regions (lung, liver, head, and so on); therefore, similar images have similar spatial structures. We add spatial information into the histogram so we call this representation as gray-spatial histogram in order to distinguish from color histogram. We use the LL band for gray-spatial histogram and coherence analysis. To get the gray-spatial histogram, we divide the LL band image into nine areas. The gray values are quantized into 16 levels for computational efficiency.
The gray-spatial feature estimates the probability of each gray level that appears in a particular area. The probability equation is defined in Eq. (2), where δ is set to 10. The gray-spatial histogram of an image has a total of 144 bins.
2.1.4. Coherence Moment
One of the problems to design an image representation is the semantic gap. The state-of-the-art technology still cannot reliably identify objects. The coherence moment feature attempts to describe the features from the human’s viewpoint in order to reduce the semantic gap.
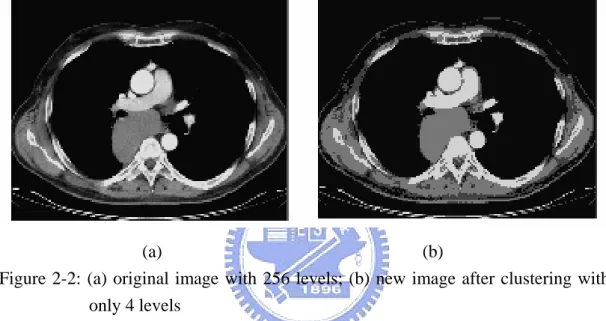
We cluster an image into four classes by the K-means algorithm. Figure 2-2 is an example. Figure 2-2 (a) is the original image and Figure 2-2 (b) is four-level gray image. We almost can not visually find the difference between the two images. After
clustering an image into four classes, we calculate the number of pixels (COHκ), mean value of gray value (COHμ) and standard variance of gray value (COHρ) in
each class. For each class, we group connected pixels in eight directions as an object. If an object is bigger than 5% of the whole image, we denote it as a big object; otherwise it is a small object. We count how many big objects (COHο) and small objects (COHν) in each class, and use COHο and COHν as parts of image features.
(a) (b)
Figure 2-2: (a) original image with 256 levels; (b) new image after clustering with only 4 levels
We intend to detect the reciprocal among neighbor pixels and eliminate the effect of noise; we apply smoothing method to the original image. If two images are similar, they will also be similar after smoothing. If their spatial distributions are quite different, they may have different result after smoothing. After smoothing, we cluster an image into four classes and calculate the number of big objects (COHτ) and small objects (COHω). Figure 2-3 is an example. Each pixel will be influenced
by its neighboring pixels. Two close objects of the same class may be merged into one object. Then, we can analyze the variation between the two images before and after smoothing. The coherence moment of each class is a seven-feature vector, (COHκ, COHμ, COHρ, COHο, COHν, COHτ, COHω). The coherence moment of an
classes.
(a) (b)
(c)
Figure 2-3 (a) original image; (b) image after smoothing; (c) image after clustering into four classes.
2.1.5 Gray Correlogram
The contour of a medical image contains rich information. Diseases can be easily detected in the high frequency domain. But, in this task we are going to find similar medical images, not to detect the affected part. A broken bone in the contour may be different from the healthy one. Thus we choose a representation that can estimate the partial similarity of two images and can be easy to calculate their global similarity.
We analyze the high frequency part by our modified correlogram algorithm. The definition of the correlogram [28][47] is as Eq. (8). Let D denote a set of fixed distances {d1, d2, d3,…, dn}. The correlogram of an image I is defined as the
probability of a color pair (ci, cj) at a distance d.
} | | { Pr ) ( 2 1 2 , , 2 1 d p p c p I j I p c p d c c i j i = ∈ ∈ ∈ − = γ (8)
For computational efficiency, the autocorrelogram is defined as Eq. (9) } | | { Pr ) ( 2 1 2 , 2 1 d p p c p I i I p c p d c i i = ∈ ∈ ∈ − = λ (9)
The contrast of a gray image dominates human’s perception. If two images have different gray levels they still may be visually similar. Thus the correlogram method cannot be used directly.
Our modified correlogram algorithm works as follows. First we sort the pixels of the high frequency part decadently. Then we order the results of the preceding sorting by the ascendant distances of pixels to the center of the image. The distance of a pixel to the image center is measured by the L2 distance. After sorting by gray value and distance to the image center, we select the top 20 percent of pixels and the gray values higher than a threshold to estimate the autocorrelogram histogram. We set the threshold zero in this task. Any two pixels have a distance, and we estimate the probability that the distance falls within an interval. The distance intervals we set are {[0,2], (2,4], (4,6], (6,8], (8,12], (12,16], (16,26], (26,36], (36,46], (46,56], (56,66],(66,76] (76,100]}. The high frequent part comprises 64*64 pixels, thus the maximum distance will be smaller than 100. The first n pixels will have n*(n+1)/2 numbers of distances. We calculate the probability of each interval to form the correlogram vector similarity metric
2.1.6 Gabor Texture Features
Gabor filter is widely adopted to extract texture features from images for image retrieval [37], and has been shown to be very efficient. Gabor filters are a group of wavelets, with each wavelet capturing energy at a specific frequency and a specific direction. Expanding a signal using this basis provides a localized frequency description, therefore capturing local features/energy of the signal. Texture features can then be extracted from this group of energy distributions. The scale (frequency) and orientation tunable property of Gabor filter makes it especially useful for texture analysis.
The Gabor wavelet transformation Wmn of Image I(x, y) derived from Gabor
filters according to [37] is defined in Eq. (10)
. ) , ( ) , ( ) , (x y =
∫
I x y g∗ x−x1 y−y1 dx1dy1 Wmn mn (10)The mean μmn and standard deviation σmn of the magnitude |Wmn| are used for the
feature vector, as shown in Eq. (11).
. ) | ) , ( (| , | ) , ( | ) ,
(x y =
∫∫
Wmn x y dxdy andδmn=∫∫
Wmn x y −umn 2dxdymn
μ (11)
This image feature is constructed by μmn and σmn of different scales and orientations. Our experiment uses four (S=4) as the scale and six (K=6) as the orientation to construct a 48 feature vectorsf , as shown in Eq. (12).
]. , ,..., , , , [u00 δ00 u01 δ01 u35 δ35 f = (12)
2.1.7 Similarity Metric
While an image has features to represent it, we need a metric to measure the similarity between two feature vectors (and consequently, the similarity between
two images). The similarity metric of color histogram is defined as Eq. (3) and that of gray-spatial histogram is defined as Eq. (13):
∑
∑
= = = ∩ = n i i n i i i q h d h q h 1 1 al gray_spati ) ( )) ( ), ( min( | H(q) | H(d) H(q) H(d)) (H(q), SIM (13)The similarity metric of the coherence moment is defined as Eq. (14)
|) ) ( ) ( | 2 | | | ) ( ) ( | | | | | | | | (| )) ( ), ( ( 2 / 1 2 / 1 2 / 1 2 / 1 4 1 i i i i i i i i i i i i i i d q d q d v q v d o q o classes i d q d q d q coh COH COH COH COH COH COH COH COH COH COH COH COH COH COH d COH q COH DIS ω ω τ τ ρ ρ μ μ κ κ − + × − + − + − + − × − + − =
∑
= (14)The correlogram metric is defined as Eq. (15):
∑
∑
= = + − = n i i i n i i i d h q h d h q h 1 1 hf | ) ( ) ( | | ) ( ) ( | H(d)) (H(q), DIS (15)The similarity of two images Q and D is measured by Eq. (16): SIMimage(Q, D) = W1×SIMcolor(H(Q),H(D) +
W2×SIMgray-spatial(H(Q),H(D) +
W3×1/(1+DIScoh(COH(Q),COH(D))) + W4×
1/(1+DIShf(COH(Q),COH(D))),
(16)
where Wi is the weight of feature i. In this task the database contains color and gray
images. When the user queries an image by example, we first determine whether the example is color or gray. We calculate the color histogram, if the four bins of gray values occupy more than 80% of the whole image, we decide the query image is gray; otherwise it is color. If the input is a color image, then we set W1=10, W2=0.1,
2.2 The Experiment and Result
We use the ImageCLEF 2004 evaluation to evaluate the performance of our system. The dataset for the medical retrieval task is called CasImage and consists of 8,725 anonymised medical images, e.g. scans, and X–rays from the University Hospitals of Geneva. The majority of images are associated with case notes, a written description of a previous diagnosis for an illness the image identifies. Case notes are written in XML and consist of several fields including: a diagnosis, free-text description, clinical presentation, keywords and title. The task is multilingual because case notes are mixed language written in either English or French (approx. 80%).
An example case notes field for description and corresponding images is shown in Figure 2-4. Not all case notes have entries for each field and the text itself reflects real clinical data in that it contains mixed–case text, spelling errors, erroneous French accents and un–grammatical sentences as well as some entirely empty case notes. In the dataset there are 2,078 cases to be exploited during retrieval (e.g. for query expansion). Around 1,500 of the 8,725 images in the collection are not attached to case notes and 207 case notes are empty. The case notes may be used to refine images which are visually similar to ensure they match modality and anatomic region.
The process of evaluation and the format of results employ the trec_eval tool. There are 26 queries. The corresponding answer images of every query were judged as either relevant or partially relevant by at least 2 assessors.
Figure 2-4: An example of medical case note and associated images
In this task, we have two experiments. The first run, VIS, uses the visual features of the query image to query the database. The second run, VWF, is the result where the user manually selects the relevant images as positive examples. In the results summary, the mean average precision of the first run VIS of our system is 0.3788. The mean average precision of run2 (VWF) is 0.4474 (refer to appendix). Figure 2-5 shows the precision and recall graphs.
The results show that the image features we propose can represent the medical image content well. The medical image’s background is very similar. Relevance feedback can extract the dominant features; thus it can improve the performance strongly. This result is better than that of the GIFT system (MAP=0.3791), used as the baseline for medical imageCLEF 2004 [12]. It is also even better than the best work in visual method (MAP=0.4214) [12]. For convenience, we have tabulated them in table 2-1 where ‘1’,’2’,’3’ indicate the top 3 result of the medical imageCLEF 2004 published in [12], respectively.
In this paper we consider that the contrast of a grayscale image dominates human perception. We use a relative normalization method to reduce the impact of illumination. Figure 2-6 is the result of an example query returned by our system. It can be observed from Figure 2-6: that F_10/9719.jpg and F_17/16870.jpg are darker than the query image (def_queries/1.jpg), but our system still can find them out. Figure 2-7 and Figure 2-8 are some of the query results of our system.
Rank 1 2 3 Ours
MAP 0.4214 0.4189 0.3824 0.4474 Table 2-1 Results reported at imageCLEF2004
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Recall Precision VIS VWF
Figure 2-5: Precision vs. Recall graphs without and with feedback. VIS is the result without relevance feedback. VWF is the result with manual feedback
Figure 2-6: Result of an example query ‘Pelvic’
Figure 2-8: Result of example query ‘hand’
The first run has accuracy above 50% in the first 20 images. The really similar images may have similar features in some aspect. The misjudged images are always less consistent. So we try to refine the initial result by the automatic feed back mechanism. We cluster the first 20 images into six classes. If the class contains diverse images, the center of the class will become farther, and consequently more different, from the query image. Thus we can improve the result by our feedback method.
In this section we propose several image features to represent medical images. Although the color histogram of content-based image retrieval methods has good performance in general-purpose color images, unlike general-purpose color images the X-ray images only contain gray level pixels. Thus, we concentrate on the contrast representation of images.
representation is immune to defective illumination. A total of 322 features are used. It is very efficient in computation.
An image represents thousands of words. An image can be viewed from various aspects; furthermore, different people may have different interpretations of the same image. This means that many parameters need to be tuned. In the future, we will try to learn the user behavior and tune those parameters by learning methods.
Chapter 3
Combine Text and Visual Feature for Medical
Image Retrieval
Images by their very nature are language independent, but often they are accompanied by texts semantically related to the image (e.g. textual captions or metadata). Images can then be retrieved using primitive features based on pixels with form the contents of an image (e.g. using a visual exemplar), abstracted features expressed through text or a combination of both. The language used to express the associated texts or textual queries should not affect retrieval, i.e. an image with a caption written in English should be searchable in languages other than English.
There is an increasing amount of full text material in various languages available through the Internet and other information suppliers. The world of globalization is increasing, many countries have been unified. The European project to unify European countries is a very important example in order to eliminate broader for the cooperation, global and large market, real international and free business. The high-developed technologies in network infrastructure and Internet set the platform of the cooperation and globalization. Indeed, the business should be global and worldwide oriented. Thus, the issues of the multilinguality arise in order to overcome the remaining technical barriers that still separate countries and cultures.
There are 6,700 languages spoken in 228 countries and English is used as the native language only 6 % of the World population, but English is the dominant language of the collections, resources and services in the Internet. Actually, the
English language is widely used on the Internet. About 60 % of the world online population is represented by English and 30% by European languages [44]. Approximately 147 M people are connected to the Internet (US and Canada about 87 M, Europe 33.25 M, Asia/Pacific 22 M, and Africa 800,000). However, the size of Web sites and Internet users from other countries (non-English countries) is increasing progressively, so that the multilingual problem becomes more and more important.
Recently, a lot of digital libraries will be set up containing large collections of information in a large number of languages. However, it is impractical to submit a query in each language in order to retrieve these multilingual documents. Therefore, a multilingual retrieval environment is essential for benefiting from worldwide information resources. Most research and development activities are focused on only one language. But, this is not the objective of the digital libraries and Internet philosophy. Both technologies aim at establishing a global digital library containing all information resources from different areas, different countries and in different languages.
The access to those materials should be possible for the worldwide community and never be restricted because of non-understanding languages. Thus, the EU funded some projects addressing the multilingual issues. For instance, in the ESPRIT project EMIR (European Multilingual Information Retrieval) a commercial information retrieval system SPIRIT has been developed which supports French, English, German, Dutch and Russian. UNESCO launched some projects in order to democratize and globalize the access to the world cultural patrimony, such as Memory of the World. Recently, UNESCO has started the MEDLIB4 project which aims at creating a virtual library for the Mediterranean region.
Cross-language Information retrieval allows user query document in another language. In 1996, ACM SIGIR Workshop for Multilingual Information Retrieval names it as Cross-Language Information Retrieval. Many international conferences focus on Cross-Language information retrieval issues, like as ACL Annual Meeting,ACM SIGIR99 (SIGIR00), etc. The organizations TREC, CLEF, and NTCIR are three major Cross-Language Evaluations to evaluate Cross-language technologies.
3.1 Previous Work for Cross-Language Document Retrieval
The approach of cross-language information retrieval allows a user to formulate a query in one language and to retrieve documents in others. The controlled vocabulary is the first and the traditional technique widely used in libraries and documentation centers. Documents are indexed manually using fixed terms which are also used for queries. These terms can be also indexed in multiple languages and maintained in a so-called thesaurus.
Using dictionary-based technique queries will be translated into a language in which a document may be found. The corpus-based technique analyzes large collections of existing texts and automatically extracts the information needed on which the translation will be based. However, this technique tends to require the integration of linguistic constraints, because the use of only statistical techniques by extracting information can introduce errors and thus achieve bad performance [24]. Latent Semantic Indexing (LSI) is a new approach and a new experiment in multilingual information retrieval which allows a user to retrieve documents by concept and meaning and not only by pattern matching. In following, we will review those three approaches.
3.1.1 Dictionary-Based Approach
The size of public domain and commercial dictionaries in multiple languages on the Internet is increasing steadily. As an example we cite a few of them: Collins COBUILD English Language Dictionary and its series in major European languages, Leo Online Dictionary, Oxford Advanced Learner's Dictionary of Current English, and Webster’s New Collegiate Dictionary.
Electronic monolingual and bilingual dictionaries build a solid platform for developing multilingual applications. Using dictionary-based technique queries will be translated into a language in which a document may be found. However, this technique sometimes achieves unsatisfactory results because of ambiguities. Many words do not have only one translation and the alternate translations have very different meanings. Moreover, the scope of a dictionary is limited. It lacks in particular a technical and topical terminology which is very crucial for a correct translation. Nevertheless, this technique can be used for implementing simple dictionary-based application or can be combined with other approaches to overcome the above mentioned drawbacks.
Using electronic dictionary-based approach for query translation has achieved an effectiveness of 40-60% in comparison with monolingual retrieval [4] [29]. In [27] a multilingual search engine, called TITAN, has been developed. Based on a bilingual dictionary it allows to translate queries from Japanese to English and English to Japanese. TITAN helps Japanese users to search in the Web using their own language. However, this system suffers again from polysemy.
3.1.2 Corpus-based Technique
The corpus-based technique seems to be promising. It analyzes large collections of existing texts (corpora) and automatically extracts the information needed on which the translation will be based. Corpora are collections of information in electronic form to support e.g. spelling and grammar checkers, and hyphenation routines (lexicographer, word extractor or parser, glossary tools).
These corpora are used by researchers to evaluate the performance of their solutions, such TREC collections for cross-language retrieval. A few examples of mono, bi- and multilingual corpora are Brown Corpus, Hansard and United Nation documents respectively. The Hansard Corpus5 contains parallel texts in English and Canadian French collected during six years by the Canadian Parliament. The Brown Corpus consists of more than one million words of American English. It was published 1961 and it is now available at the ICAME6 (International Computer Archive of Modern English). Interested readers are referred to the survey about electronic corpora and related resources in [17].
In the United States, the WordNet Project at Princeton has created a large network of word senses in English related by semantic relations such as synonymy, part-whole, and is-a relation [19] and [39]. Similar work has been launched in Europe, called EuroWordNet [21]. These semantic taxonomies in EuroWordNet, have been developed for Dutch, Italian and Spanish and are planned to be extended to other European languages. Related activities have been launched in Europe, such as ACQUILEX7 (Acquisition of Lexical Knowledge for Natural Language Processing Systems), ESPRIT MULTILEX 8 (Multi-Functional Standardized Lexicon for 5 http://morph.ldc.upenn.edu/ldc/news/release/hansard.html 6 http://www.hd.uib.no/icame.html 7 http://www.cl.cam.ac.uk/Research/NL/acquilex 8 http://www.twente.research.ec.org/esp-syn/text/5304.html
European Community Languages).
The main problems associated with dictionary-based CLIR are (1) untranslatable search keys due to the limitations of general dictionaries, (2) the processing of inflected words, (3) phrase identification and translation, and (4) lexical ambiguity in source and target languages. The category of untranslatable keys involves new compound words, special terms, and cross-lingual spelling variants, i.e., equivalent words in different languages which differ slightly in spelling, particularly proper names and loanwords. In this dissertation translation ambiguity refers to the increase of irrelevant word senses in translation due to lexical ambiguity in the source and target languages.
The collection may contain parallel and/or comparable corpora. A parallel corpus is a collection which may contain documents and their translations. A comparable corpus is a document collection in which documents are aligned based on the similarity between the topics which they address. Document alignment deals with documents that cover similar stories, events, etc. For instance, the newspapers are often describing political, social, economical events and other stories in different languages. Some news agencies spend a long time in translating such international articles, for example, from English to their local languages (e.g. Spanish, Arabic). These high-quality parallel corpora can be used as efficient input for evaluating cross-language techniques.
Sheridan and Ballerini developed an automatic thesaurus construction based on a collection of comparable multilingual documents [62]. Using the information retrieval system Spider this approach has been tested on comparable news articles in German and Italian (SDA News collection) addressing same topics at the same time. Sheridan and Ballerini reported that queries in German against Italian documents
achieve about 32% of the best Spider performance on Italian retrieval, using relevance feedback. Other experiments on English, French and German have been presented in [72]. The document alignment in this work was based on indicators, such as proper nouns, numbers, dates, etc. There is also alignment based on term similarity as in latent semantic analysis. This allows mapping text between those documents in different languages.
3.1.3 Indexing by Latent Semantic Analysis
In previous approaches the ambiguity of terms and their dependency leads to poor results. Latent Semantic Indexing (LSI) is a new approach and a new experiment in multilingual information retrieval which allows a user to retrieve documents by concept and meaning and not only by pattern matching. If the query words have not been matched, this does not mean that no document is relevant. In contrast, there are many relevant documents which, however, do not contain the query term word by word. This is the problem of synonymy. The linguist will express for example his request differently as computer scientist. The documents do not contain all possible terms that all users will submit. Using thesauri to overcome this issue remains ineffective, since expanding query to unsuitable terms decreases the precision drastically.
The latent semantic indexing analysis is based on singular-value decomposition [16]. Considering the term-document matrix terms and documents that are very close will be ordered according to their degree of “semantic” neighborhood. The result of LSI analysis is a reduced model that describes the similarity between term-term, document-document, and term-document relationship. The similarity between objects can be computed as cosine between their representing vectors.
The results of the LSI approach have been compared with those of a term matching method (SMART). Two standard document collections MED and CISI (1033 medical documents and 30 queries, 1460 information science abstracts and 35 queries) have been used. It has been showed that LSI yields better results than term matching.
Davis and Dunning [14] have applied LSI to cross-language text retrieval. Their experiments on the TREC collection achieved approximately 75 % of the average precision in comparison to the monolingual system on the same material [15]. The collection contains about 173,000 Spanish newswire articles. 25 queries have been translated from Spanish to English manually. Their results reported in TREC-5 showed that the use of only dictionary-based query expansion yields approx. 50 % of the average precision in comparison to results of the multilingual system. This degradation can be explained by the ambiguity of term translation using dictionaries.
This technique has been used by Oard [45] as the basis for multilingual filtering experiments, and encouraging results have been achieved. The representation of documents by LSI is “economical” through eliminating redundancy. It reduces the dimensionality of document representation (or modeling), and the polysemy as well. However, updating (adding new terms and documents) in representation matrices is time-consuming.
3.2 Combine Text and Visual Feature for Medical Image
Database
In this proposed we want to design a cross-language medical image retrieval system. The data for the experiment were taken from a medical case database called casImage [55]. This database contains almost 9000 images from more than 2000 medical cases. Images contain annotation in XML format but these annotations are very rudimentary and are not at all controlled with respect to quality or fields that have to be filled in. About 10% of the records do not contain any annotation. A majority of the documents are in French (70%), with around 20% being in English.
Figure 3-1 shows a few example images from the database. These images are among others the query topic for the performance evaluation. Figure 3-2 is the data model of the medical image retrieval system. The database contains multilingual patient diagnosis documents. User can use native language to retrieve other language patient cases. Our proposed system allows user can use keyword or medical image example to query medical image cases.
Content Based
Image
Merging results and re-ranking of images
Multilingual Text retrieval
Retrieved cases & Images associated
Text query
Associated
Language
Figure 3-2: The data model of medical image retrieval system
In the ImageCLEFmed collections of annotations are in English, French and German. The overall multilingual search process is shown in Fig. 3-3. Given an initial query Q, the system performs the cross-language retrieval, and returns a set of relevant documents to user. We use the representation expressing a query as a vector in the vector space model [59]. The Textual Vector Representation is defined as following. Let W (|W| = n) be the set of significant keywords in the corpus. For a document D, its textual vector representation (i.e., DT) is defined as Eq. (17),
Other language query Word translation Query expansion Ambiguous analysis Dictionary Wordnet Co-occurrence relationships Query Q
Figure 3-3: Text based multilingual query translation flowchart > =< ( ),..., ( ) 1 T t T t T w D w D D n (17)