Multi-Pass
Algorithm of
Motion
Estimation
in
Video
Encoding for Generic GPU
Yu-Cheng Lin, Pei-Lun Li, Chin-Hsiang Chang, Chi-Ling Wu, You-Ming Tsao, and Shao-Yi Chien Media IC and System Lab
Graduate Institute of Electronics Engineering and Department ofElectrical Engineering National Taiwan University
yucheng@media.ee.ntu.edu.tw
TABLE I
Abstract- The importance of video encoding has boomed
rapidly since video data communication was widely needed. In this paper, we propose a multi-pass algorithm to accelerate the
motion estimation (ME), the dominant part in video encoding, Tools Datapath Percentage(%)
with the graphics processing unit (GPU). By the multi-pass Operation (MIPS)
method to unroll and rearrange the multiple nested loops, the Motion Estimation 24,768.2 97.94 complex ME can be implemented on GPU. Besides, ME can Transform & Quant 432.527 1.710 be executed efficiently with the built-in parallel processing and Others 88.0320 0.348 texturefilter of GPU.Experimentalresults show that, byutilizing
the computing power of GPU, about two times and 14 times
speed-up can be achieved for integer-pel ME and MPEG-1/2 TABLE II
half-pel ME,respectively. INSTRUCTIONPROFILING RESULTS OFH.264ENCODER.
I. INTRODUCTION Tools Datapath Percentage(%)
Digital entertainment with multimediacontent, is definitely Operation (MIPS) one of the most
important applications
in thetwenty-first
Motion EstimationTransform &Quant 5,402.50152,897 94.663.345
century. Fancy multimedia content, especially video content, Others 3,225.30 1.997
usually accompanies huge volume of data. Consequently, video encoding and decoding play key roles tothemost
mul-timedia applications. Thanks to the development of modern
technologies, digital still cameras (DSC) and digital video programmed to make changes in the routinepipelines [3] [4].
recorders (DV) have become commonand popular consumer A GPU is no longer with fixed pipeline but is now more
electronicsproducts. Everyonecould be amultimedia content appropriately described as a SIMD parallel processor or a provider as long as he or she has a DSC or DV. High streamingprocessor [5].
resolution video equipments are occupying more and more Moreover, the performance of GPU evolves much faster market share in addition. In the 3G mobile era, there are than the famous Moore's law for theperformanceofCPU, that potentialmultimediacontentproviders everywhere.As aresult is, 2.4 times/year versus 2 times per 18 months [6] [7]. With of the abovereasons, videoencoding has becomeasimportant all theseadvantagesoverCPU,especiallySIMDoperationand
as video decoding has been. parallel processing, there is an active research area of using
Comparing the computation profile ofMPEG-4 in Table. GPU for nongraphics oriented operations, such as FFT [6]
I [1] and H.264 in Table. II [2], it is evident that motion and motioncompensation [7]. However, due to the instruction estimation is themostsignificantpartinvideo encoding. That limit of GPU andlarge inputdataamount, thecomplex motion is, improving the performance of motion estimation would
actually speedup the whole videoencoding. Thus the motion
estimation is chosen to be accelerated as the
starting
point
of Vertex ProgammableVertexreal-time video encoding.
On the other hand, more and morecommodityPC and game Polygon PolygonSetup,
consoles are commonly equipped with graphics processing Clig atrzto
units (GPUs). Graphics processors are designed to perform Fragment
Programmable
Per-1Memory,
a mass of operations on a crowd of vertices or pixels, and Tetr aaFtc,fl lednthey do this very efficiently because of their inherent multiple
parallel pipelines. In the recent years, graphics processors IImage
IZ-Buffer
fpl6 Blending, L have changedfromfixed pipelines to programmable pipelines.Figure 1 shows that the vertex and fragment shader could be Fig. 1. A programmable graphics pipeline [4].
______ Programmable MIMD CPU D_ata 'UProcessing(fp32)
6.4 GB/s 6.4 GB/s up to
or mere 8 GB/s
F_L_i_s_t_s__1 SIMD Rasterization SystemMemoy Noah.eri GeCGPU _ To Display
ProgrammableSIMD Memory up to 35GB/s
Processing(tp32) SouthBridge Video Memory
Daa DataPetch,tptBBleeding E
i__ta_
PredicatedWrite,fp16D Blending, Multiple Output O
Fig. 3. Theoverall system architecture of a PC [4]. Fig. 2. The GeForce 6 Seriesarchitecture for non-graphics applications [4].
Loop(rows of macro blocks (MBs)){ Loop(columns of MBs){
estimation algorithm, which is the most important in video Loop (rows of search range (SR))
encoding, has neverbeen implemented on GPU. Besides, the SAD computation;
time-consuming interpolation computing offractional motion SAD comparison;
estimation is another challenge for speed-up.
In the past, motion estimation has been implemented by
use of dedicated hardware of multiple parallel processing _}_l
elements (PEs) [8] [9] [10]. The graphicsprocessorsnowadays Fig. 4. The pseudocode of the classic integer-pel ME algorithm. also have similar parallel architecturebecause of the graphics
processing requirements. Furthermore, motion estimation is
block-wise and thus suitable for SIMD-like GPUprocessing. memory bandwidth.
In conventional approach, the powerful GPU is idle when no
graphics-relatedprocess is going on. Itis natural to leverage B.
implementation Envionment
GPU to off-load some of the CPU's tasks to achieve the We implemented the motion estimation (ME) algorithm on
maximum co-throughput of CPU and GPU. In this paper, a nVidia GeForce 6800 GT graphics card, which features wepropose an algorithm to map motion estimation (ME) on fully programmable vertex and fragment units, 32-bitfloating
generic commodity GPUtoaccelerate the video encoding. We point frame buffers and textures. The fragmentprocessor can expect to accelerate motion estimation with GPU and would sustain 12 floating-point operations per pixel per clock cycle
accomplish areal-time video encodingsystem hereafter. With [11]. Both the vertex and fragment shaders were programmed unrolling and rearranging loops of the motionestimation, the with OpenGL and the Cg computer language and runtime ME could be implemented on GPUin the limited instruction libraries of nVidia Corporation [12] [13]. TheME isinherently number with multi-pass technique.Second, the large input data an image-based algorithm. As such, we perform the ME by
would be bound as textures in graphics pipeline to reduce executing several fragment programs successively in a
SIMD-the memory access time. Finally, GPU has inherent built-in like fashion.
interpolation engine, which readily accelerates the fractional C. A Novel Motion Estimation Algorithm
interpolation process. The implementation detail would be . . . is ..
shown in the
following
section. Note that, nVidia GeForce Thetmotonestimat
algorith
isitsiclly
complx 6800, a famous GPU, is used as anexample
in this paper.nBesdes
the sum of absolutedlfference
(SAD)computatuon
Theorganizationofthispaperis shownbelow. The proposed
Bsd
thesump
of ab
effer
(sAD) coation
motionmotion stimatinestimation algorithmalgoithm is described in Sec. II.isdescribd in Sc. 11. Next,ext, iin
algorithm,
and SAD comparison,as shown inthere are fourFig.
4 [10].loopsIn ourIn theproposed
classic MEMESec.
III,
theexperimental
results will be shown.Finally,
ashort algorithm shown in Fig. 4[10].icneourdprops Me
cocuso is gie in Sec
algorithm
shownin
Fig.
5, the fourclassic
nested loops areconclusion is given in Sec. IV. unrolled and
rearranged.
Abstractly,
theoperations
on all theII. MOTION ESTIMATIONIMPLEMENTATION pixels could be thought as executed in parallel. Therefore, the inner loop of processing elements is unrolled and
ex-ecuted almost
simultaneously.
Theoriginal
four-tiered
loop When used for non-graphics applications, the nVidia aretransformed into a one-tiered loop and a two-tiered loop. GeForce 6 Series could be viewed as two programmable Thecomputation complexity is reduced and theparallelism is blocks that run serially: the vertex shader for MIMD pro- increased in this way. In fact, there are only 16 pipelines incessing and the fragment shader for SIMD processing, both GeForce6800. All the operations would be scheduled,folded, with support for fp32 operands and intermediate values [4]. and executed as concurrently as possible in the 16 pipelines.
The architecture is shown in Fig. 2. As shown in Fig. 3, the Thus we could still think of each pixel of fragment shader as
memory bandwidthbetween the GPU and the video memory a PB performed in parallel. We refer to the PB-like pixel as
is about five times as fast as that between the GPU and the PB and the pixel of the texture as pixel here. It is highly
system memory. The texture unit could be used as a random- recommended to include as many instructions as possible access datafetchunit to make use of the astonishing 35 GB/sec in [3]. However, the total instruction amount of full-search
Pass 1: MBO Loop(candidates per processing element){
Loop(processing elements){
SAD computation; OO0O
OI
*SSSSAD comparison; olcoo--- MBO ||
ooioo
32x32 PEs
Pass 2:
Loop(rows of a MB){ 512x512PEs
Loop(columns of a MB){ (512/16)x(512/16)x32x32
Loop(processing elements){ candidates pass 1 pass2
SAD comparison;
Fig. 7. The illustration of theproposedMEalgorithm.
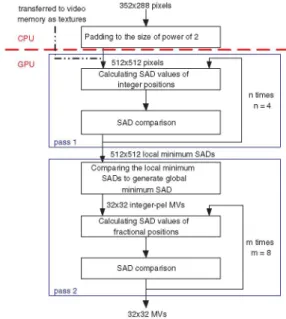
Fig. 5. The pseudo code of the proposed integer-pel ME algorithm. candidates in the search range of every MB in a frame into consideration, the formula for the number of candidates per transferred to video 352x288pixels PB is shownbelow:
memory as textures
I
WT
HT1
CPU
~~~~~~~~~~x
l
Paddingtothe size of power of 2CPU
n 'VT BiTS,,,xSRrowxSRcoiX11Ro
xx (1)MB
MBcol
MBrow
Wpi
Hlp
GPU 512x512pixels
CalculatingSADvaluesof Take WT = HT = 512,
MBrow
=MBcol
= 16, SRrowI integerpositions l l I
integer positions ntimes ISRCOI = [-16, +15] = 32,
Wpi
Hp1
= 512 as then=
n=4 illustration of Fig. 7. The result is n = 4, which means that
SADcomparison every
four candidates
are grouped and mapped to a PEin thepass 1 corresponding MB. We use texture coordinates to perfectly
V51x51lclal minimIIIumISADs
Comparingthe local minimum allot four differential candidates so that every candidate is SADs togenerate global taken into account. This is the only loop in the first pass
minimumSAD
32x32integer-pelMVs 7 besides the two loops of SAD computation. EachPEcompares
CalculatingSAD values of the sum of absolute difference (SAD) of the four candidates
fractionalpositions m times and writes the motion vector with the smallest SAD value to
m=8 thetexture
by using
the render-to-texture extensions.Notethat,SADcomparison in Fig. 7, only fourPEs areshown for a MB inthe firstpass,
pass 2 instead of 256 PEs inthis
example
case, forsimplification.
32x32MVs
2)
The Second Pass:Generating
Global Minimum SADs32x32MAVs
Fig. 6. The block diagram of the proposed MEalgorithm. As Well As Integer-Pel MVs and Generating Fractional-Pel MVs: The remained computation amount for the integer-pel
ME is much smaller in pass 2. Thus each MB only needs to
block matching motion estimation is much more than the be
processed by
a PE. The formula follows:instruction limit of GeForce 6800 GT. Therefore, amulti-pass
WT
HT
MEalgorithm on GPU is proposed. We perform theproposed Quad sizeof pass 2 x (2)
ME algorithm by executing two fragment programs in two In the second pass, each
PB
compares the remained localpasses. We draw quadrilaterals to invoke fragment programs minimum SAD values computed from the first ass in each
for every PB. Figure 6 shows the block diagram Of the threeppMB transferred via the texture, to find the smallest global
passes weproposedtoimplementtheME onGPU.Wetake the minimum. ' SAD values and the corresponding motion' vector.
sequence in CIF format
(352x288)
forillustration convenience The number of local minimum SADscompared
perPB
is asinFig. 7. The hollowcirclepoints representcandidates inthe follows:
search range while the other opaque circle points represent WT HT
PEs.
Wp
xHp
X ( WT XH3)
1) The FirstPass: Generating LocalMinimum SADs: The
MBci
MB
(whole video frames are first transferred from system memory In the above example as in Fig. 7, the quadrilateral size of to video memory as textures to make use of the largememory pass 2 would be 32x32, and 256 local minimum SAD values bandwidth in the following operations. The size of the texture would be compared to find a integer-pel motion vector. Then must be power of two. Thus we prepare a padded reference the fractional-pel MB is computed if needed. The
fractional-frame as well as a padded current frame. Both of the frames pel motion estimation is similar to the integer-pel motion equal to WT X HT. Next, a quadrilateral whichequalsto
Wp1
x estimation. After integer-pel MB is completed, this pass takesHp1
is drawn, which can be viewed as W xHp1
PBs.
We the integer-pel MVs and both the reference and current frames take MBrow xMBCo1
pixels as a macroblock (MB) and let as inputs to find the smallest SADs and the corresponding MVs the search range (SR) equal to SRrow xSRCoi.
Taking all the in the neighboring fractional search candidate positions. TheTABLE III TABLE IV
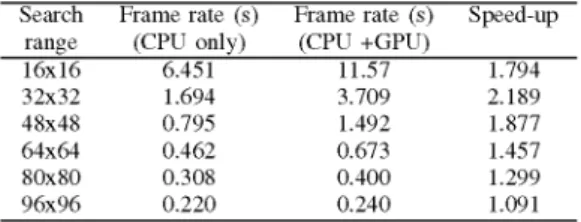
THE COMPARISONOFINTEGER-PEL ME BETWEEN CPUANDGPU THECOMPARISONOFHALF-PEL ME BETWEENCPUANDGPU
Search Frame rate (s) Frame rate (s) Speed-up Search Frame rate (s) Frame rate (s) Speed-up
range (CPU only) (CPU +GPU) range (CPU only) (CPU +GPU)
16x16 6.451 11.57 1.794 16x16 0.805 7.275 9.037 32X32 1.694 3.709 2.189 32X32 0.217 3.091 14.24 48x48 0.795 1.492 1.877 48x48 0.102 1.374 13.47 64x64 0.462 0.673 1.457 64x64 0.06 0.65 10.83 80X80 0.308 0.400 1.299 80X80 0.04 0.393 9.825 96x96 0.220 0.240 1.091 96x96 0.028 0.236 8.429
fragment processor uses the texture unit to fetch data from run on GPU about two times as fast as run on CPU in memory,optionally filtering the data before returning it to the 32x32 search range. Our proposed algorithm outperforms the fragment processor [4]. Thus the built-in texture filter is used classic software-based motion estimation computation because
to do the bilinear interpolation for the fractional candidates. offully utilizingGPU'sparallel computationpower. As we are
3) Future Optimization: From the resources' point of view, composing this paper, a nVidia GeForce 7800 GT GPU with the integer-pel ME must be divided into two passes due to 256 MB videomemory has been on sale on the market. The the instruction limit of GPU and the large data amount of performance degradation problem may be solved using the video encoding. As the instruction capacity grows, the two more powerful GPU.
passes ofinteger-pelMEmay be combinedto one pass. More Ourfuture work is to further investigate the power of GPU passes might be needed if quarter-pel ME is included. For and think thoroughly howtopartition the workloads in video optimization consideration, all the loops of the two passes encoding between CPU and GPU. The whole software-based could be unrolled and distributed averagely to achieve the video encoding architecture needto be accomplished as well.
maximum performance. Combined with the video decoding system [7], this work
would develop a complete real-time video codec system in
III. EXPERIMENTAL RESULTS the near future.
Weperformed extensivetests on aPC withanIntel Pentium
IV 3.00 GHz CPU, 1024MB memory, and a nVidia GeForce REFERENCES
6800 GT GPU with 128 MB video memory. Video sequence [1] H.-C.Chang, L.-G.Chen, M.-Y Hsu, and Y-C. Chang, "Performance Stefan in CIF (352x288) format with 30 fps with the archi- analysis and architecture evaluation of mpeg-4 video codec system,"
in Proc. IEEEInternational Symposiumon Circuits andSystems,May tecture in Fig. 7 iS used as an example to measureprocessing 2000, pp. 449-452.
time. [2] S.-Y Chien, Y-W. Huang, C.-Y Chen, H. H. Chen, and L.-G. Chen,
We compare the motion estimation speed achieved using
4"Hardware
communicationarchitecture design of videosystems,"IEEECommun.Mag., vol. 43, no. 8, pp. 122-compression for multimedia CPU only against that achieved with GPU acceleration. Six 131,Aug. 2005.different searchranges aretested forinteger-pel and fractional- [3] C. J. Thompson, S. Hahn, and M. Oskin, "Using modern graphics pel motion estimation. The experimental results are shown in architectures for general-purposein Proc. IEEE/ACM International Symposium on Microarchitecture,computing: a framework andanalysis," Table III for integer-pel ME and Table IV for half-pel ME of Nov.2002, pp. 306-317.
MPEG- 1/2.Full searchalgorithm is employed, and there is no [4] M.Pharr, Ed.,GPU Gems 2. AddisonWesley, 2005.
quality degradation in PSNR for MEonGPU. It isinteresting [5] B.B.Khailany,Towles, A. Chang, and S. Rixner, "Imagine: media processing withW.Dally,U. Kapasi, P.Mattson, J.Namkoong,J.Owens,
to observe that the speed-up of 32x32 search range reaches streams," IEEE Micro, vol. 21, no. 2, pp. 35-46, Mar. 2001.
the local maximum. That is, about two times and 14 times [6] K. Moreland and E.Angel, "Simulation andcomputation: The FFTon
of speed-up can be achievedrespectively for integer-pel and aGraphics
GPU,"
in Proc. ACMhardware, July 2003, pp. 112-119.SIGGRAPH/EUROGRAPHICS conference on half-pelME. The bilinearinterpolationis readily accomplished [7] G. Shen, G.-P. Gao, S. Li, H.-Y. Shum, and Y-Q. Zhang, "Accelerate with the help of the built-in texture filter. Thus the speed-up video decoding with generic GPU," IEEE Trans. Circuits Syst. Video ofthehalf-pelME ismuch more significantthanthe speed-up [8] Technol.,K.-M.Yang,vol. 15, no. 5, pp. 685-693,M.-T. Sun,and L.Wu,"AMayfamily2005.of VLSIdesignsfor theof the integer-pel ME. However, as the search range exceeds motion compensation block-matchingalgorithm," IEEE Trans. Circuits 32x32,thespeed-updeclines. Themostpossiblereasonis that Syst.,vol. 36,no. 10, pp. 1317-1325,Oct. 1989.
the speed-up mightdepend greatly on the memory bandwidth [9] VLSI treeY.-S. Jehng, L.-G. Chen, and T.-D. Chiueh, "An efficient and simplearchitecture for motion estimation algorithms," IEEE Trans.
requirement. The larger computation amount and memory SignalProcessing, vol. 41, no. 2, pp. 889-900, Feb. 1993.
bandwidth requirement always accompany the bigger search [10] H. Yeo andY.H. Hu, "A novel modular systolic array architecture for rnewhich might be the cause of performance degradation.range,~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~full-search block matching motion estimation," IEEE Trans. CircuitsSyst. Video Technol., vol. 5, no. 5, pp. 407-416, Oct. 1995.
[11] J.Montrym and H. Moreton, "The GeForce 6800," IEEE Micro, vol. 25, no. 2, pp. 41-51, Mar. 2005.
IV. CONCLUSION AND FUTURE WORK [12] R. Fernando and M. J. Kilgard, The Cg Tutorial. Addison Wesley, In thi paperwehaedemostratd thatGPUcn acceerate 2003.
Inti aer ehv dmntae ta P anaclrt [13] (2004) The GPGPU website. [Online].Available:
![Figure 1 shows that the vertex and fragment shader could be Fig. 1. A programmable graphics pipeline [4].](https://thumb-ap.123doks.com/thumbv2/9libinfo/8854489.243339/1.892.500.811.609.682/figure-shows-vertex-fragment-shader-programmable-graphics-pipeline.webp)
![Fig. 2. The GeForce 6 Series architecture for non-graphics applications [4].](https://thumb-ap.123doks.com/thumbv2/9libinfo/8854489.243339/2.892.160.363.153.309/fig-geforce-series-architecture-non-graphics-applications.webp)