國立臺灣大學電機資訊學院資訊網路與多媒體研究所 碩士論文
Graduate Institute of Networking and Multimedia College of Electrical Engineering and Computer Science
National Taiwan University Master Thesis
基於辯論歷程之反論點生成
Counter-argument generation with debating history
林建甫 Jian-Fu Lin
指導教授:陳信希 博士 Advisor: Hsin-Hsi Chen, Ph.D.
中華民國 109 年 7 月
July, 2020
誌謝
謝謝我的指導教授陳信希教授這兩年來的指導、對我們的關心及照顧。
謝謝瀚萱學長即使接了教職仍繼續參與我們的討論、提供許多寶貴的意見。
謝謝又慈替實驗室打理大大小小的事物、陪我們聊天、吃飯和玩耍。謝謝重 吉學長、安孜學姊、聖倫學長、煥元學長、傳恩學長、廷宇學長、祐婷學 姊、敏桓學長、忠憲學長、宏國學長、奎伯學長、大祐學長、林聰學長、黃 晴學姊及怡婷學姊,在我剛加入實驗室的時候指導我許多事情、也很熱心回 答我的疑惑。謝謝士勛、Charles、家郡及國祐這兩年的陪伴、看著優秀的 你們總是能夠讓我提起許多動力,與你們討論時也總是能有許多收穫。謝謝 禹廷、法宣、泰德、怡廷、劍韜、庭瑋、山下夏輝,實驗室在你們的加入之 後又多了許多歡笑。謝謝實驗室的大家,這兩年來著實留下了許多美好的回 憶。
摘要
反論點生成是自然語言處理中非常具挑戰性的研究領域,它可能同時牽 涉到許多子問題,例如論點探勘、自然語言生成、自然語言理解甚至資訊檢 索。截至目前為止,關於反論點生成的研究只有探討單一來回情境下的生 成,也就是只給定一段含有多個論點的論述並生成反論點。然而,在現實的 辯論當中,一個結辯通常是透過一連串的來回討論而來,因此,一個生成反 論點的模型應該需要具備組織理解多個來回之辯論歷程的能力。
這篇論文有兩個主要的貢獻。首先,這是第一篇將辯論歷程引入反論點 生成的文章,接著,我們建立了一個大規模的資料集、用以訓練反論點的生 成模型。為了能更深入了解辯論歷程對於反論點生成的重要性,我們用數個 不同的模型來做實驗,實驗結果顯示當引入辯論歷程後,模型能夠生成更加 適切的反論點。
關鍵字: 自然語言生成、論點探勘、論點生成
Abstract
Counter-argument generation is one of the most challenging problems in natural language processing as it involves many sub-problems like argument mining (AM), natural language generation (NLG), language understanding, or even information retrieval (IR). To date, researches on counter-argument generation only address the scenario of single-turn debate, that is, they gener- ate counter-arguments according to one statement of someone’s viewpoints.
Nevertheless, in real-world debating, an argumentative conclusion usually comes along with multiple turns of discussion. Thus, an argument generation system should have the capability to model multi-turn discussion history.
This thesis has two main contributions. First, this research is the first one exploring the task of counter-argument generation with multi-turn debating history context. Second, we construct a large-scale dataset which contains around 800k counter-arguments for training the generator. To further investi- gate the importance of debating history, we experiment with different models.
The result shows that by incorporating the information of debating history, the model can generate more appropriate counter-arguments.
Keywords: Natural Language Generation, Argument Mining, Argument Gen- eration
Contents
誌謝 ii
摘要 iii
Abstract iv
1 Introduction 1
2 Background 4
2.1 Argument Mining . . . 4
2.2 Natural Language Generation . . . 5
2.2.1 Sequence to Sequence Neural Networks . . . 5
2.2.2 Beam Search . . . 7
2.3 Metrics . . . 8
2.3.1 BLEU . . . 8
2.3.2 ROUGE . . . 9
3 Related Works 11 3.1 Argument Generation . . . 11
3.2 Conversation History Modeling . . . 12
4 Corpus Construction 14
4.1 Data Collection . . . 14
4.2 Domain Specifying and Data Preprocessing . . . 15
4.3 External Evidence Retrieval . . . 17
4.3.1 External Evidence Collection and Indexing . . . 18
4.3.2 Query Formulation . . . 18
4.4 Keyphrases Extraction . . . 19
4.5 Sentence Style Labeling . . . 19
5 Method 21 5.1 Problem Formalization . . . 21
5.2 Input Encoding . . . 22
5.3 Content Selection . . . 23
5.4 Style Planing . . . 25
5.5 Argument Generation . . . 25
6 Experiments 28 6.1 Dataset Overview . . . 28
6.2 Experimental Setup . . . 30
6.2.1 Single-turn Model . . . 31
6.2.2 Multi-turn Model . . . 32
6.2.3 Multi-turn Model with Speaker Embedding . . . 33
7 Results 35 7.1 Automatic Evaluation . . . 35
7.1.1 Content Diversity . . . 36
7.2 Human Evaluation . . . 37 7.2.1 Annotation Setup . . . 38 7.2.2 Result . . . 39
8 Discussion 42
8.1 Effect of Speaker Embedding . . . 42 8.2 Sample Generated Arguments . . . 43
9 Conclusion 45
Bibliography 47
List of Figures
1.1 An example of counter-argument with debating history . . . 3
2.1 An example for Argument Mining . . . 5
6.1 Distribution of the length of discussion history . . . 29
6.2 Architecture of the single-turn counter-argument generation model . . . . 31
6.3 Architecture of the multi-turn counter-argument generation model . . . . 32
6.4 Architecture of the multi-turn model with speaker embedding . . . 33
7.1 Average number of distinct n-gram per argument . . . 37
7.2 Type-token ratio of different models . . . 38
7.3 Annotation guidance for human evaluation . . . 39
7.4 Example annotation interface of a single thread . . . 41
8.1 An example of generated counter-arguments . . . 44
List of Tables
4.1 Politic lexicon . . . 16
4.2 Regular expressions for sentence styles . . . 20
6.1 Statistics of dataset . . . 28
6.2 Comparison of source inputs and targets . . . 29
7.1 Automatic evaluation result . . . 36
7.2 Human evaluation result . . . 40
8.1 Evaluation of model with fixed speaker embeddings . . . 43
Chapter 1
Introduction
With a goal of helping human decision making, Argument Mining (AM) has drawn a lot of attention and made dramatic progress in recent years, especially in identifying and clas- sifying the argumentative components [17]. Consequently, researchers start to put effort into Argument Generation to further leverage AM techniques, alleviating the difficulty of organizing the argumentative contents.
Counter-argument generation is one of the most challenging problems in natural lan- guage processing, which involves many subproblems, e.g., argument mining, natural lan- guage generation, language understanding, or even information retrieval. Given a state- ment of viewpoints and a sequence of discussion on the topic, the constructed model is to generate persuasive responses that refute the viewpoints in the statement. Based on the recent advancements in neural generative models of natural language, Hua et al. [3] pro- posed a model that generates a counter-argument with a given statement of viewpoints on a topic. Nevertheless, in real-world debating, an argumentative conclusion usually comes along with multiple turns of discussion. Thus, an argument generation system should have the capability to model multi-turn discussion history.
Modeling multi-turn utterance information is not an unexplored technique. In fact, many natural language processing tasks like the chit-chat system or goal-oriented system (e.g. hotel room reservation chatbot) implement this as a part of their system pipeline.
However, this type of tasks have relatively short context in a single utterance like a sen- tence or even only an option term and thus it is not that challenging to capture the multi-turn information in a series of utterance. In a scenario of debate, any utterance can have several paragraphs including many talking points.
The goal of this research is to address the task of counter-argument generation with discussion history. Because there is no existent dataset for such a problem, we constructed a large-scale dataset as the training resources for the counter-argument generator. A sam- ple thread from subreddit ChangeMyView (CMV) is shown in Figure 1.1. As the example shows that a thread starts with an original post containing the original poster’s viewpoints, followed by a length of debating history (2 utterances in this example). The counter- argument generator is trained to generate the target counter-argument which is also the last comment of the thread. It can also be noted in the example that the faulty viewpoints of the original poster appear in the debating history (Comment 2). Thus, if we neglect the debating history, there is no way we can precisely answer the point that the original poster states, not to mention convincing them.
As the following content, we first introduce the preliminary knowledge in Chapter 2, followed by the related works of this research in Chapter 3. As we constructed the dataset for training by ourselves, the details of each stage (e.g. counter-arguments collection, external passages retrieval) are in the Chapter 4. We formally introduce the model details in Chapter 5. The detailed experimental setup of this research and the resultant experiment outcomes are in Chapter 6 and Chapter 7, respectively. In Chapter 8, we further discuss
Original Post:
It is a fact that being addicted to drugs has more to do with your psychological weakness rather than any having “evil intent” or malice. I fail to understand in what way it is a crime when it is only an individual falling prey to their own mental weakness. In a case of drug addiction, a person needs therapy not a jail cell. There are two types of crime - One is when you try to harm others (murder, rape etc) and other is when you try to do something with is unfair to others (tax evasion, fraud). In a drug addiction, no one is getting hurt but yourself …
Comment 1 (User in CMV):
Well at least in the us it ‘s normally the crimes that go along with drug addiction rather than the addiction itself that is considered a crime. Often times people who are addicted to drugs commit crimes to feed the habit …
Comment 2 (Original Poster):
If a drug user commits a crime, he should be charged with the crime. However the mere intake of drugs should be medically treated.In fact if the government advertises rehab services/mental therapy to those in need who are suffering from addiction, they can voluntarily come and receive help over the counter.
Target Counter-argument:
Well do you realise that drug use is not a crime. Technically its drug possession and trafficking that are crimes.So if the drug addict is being arrested its most likely for that or an ancillary crime. Not the use of the drug itself.
DebatingHistory
Figure 1.1: An example of counter-argument with debating history.
the generated content of our model in different aspects. We conclude this research in Chapter 9.
Chapter 2
Background
This chapter provides the theoretical preliminary knowledge of this research. We will introduce Argument Mining (AM) and Natural Language Generation (NLG) first, which are both the fields closely related to Counter-argument generation, then the metrics we use to evaluate the output of the models.
2.1 Argument Mining
Different from general natural discourse, arguments always have goals to persuade par- ticular audiences of a particular stance on a topic [16]. Given a span of text, the tasks of AM aim to highlight the argumentative component, and classify them according to their functions (e.g. premise or claim) or their stance (e.g. supporting or opposing). Some works in AM also predict the relations between components. A claim can be defined as a span of text that states a conclusion toward a topic which usually also contains a stance.
On the other hand, a premise provides reasoning or evidence to support/attack a claim.
Figure 2.1 is an example on iDebate1discussing on a controversial topic about the fee
1http://idebate.org/
of university. The sentence ”The quality of education suffers ...” states a concern about cutting university fee which can be seen as a claim having opposite stance toward the topic.
The premise ”This leads to larger class sizes ...” further describes the reasons behind the claim, and thus have the same stance as the conclusion. It can be also noted that not only premises can support/attack another argument component, claims can also have relations with another component.
Topic: This House believes university education should be free
…The quality of education suffers when university education is free.
…
Without university fees, universities become dependent on the state for funding. This leads to larger class sizes and less spending per student.Yet with fees, the quality of universities increases.
Claim Premise
Support Attack
Figure 2.1: An example for Argument Mining.
2.2 Natural Language Generation
Natural Language Generation tasks aim to transform structured data into natural language text. With the recent evolution of neural network models, the natural language generation tasks like Machine Translation or Chit-chat system are also pushed to a new level [20].
2.2.1 Sequence to Sequence Neural Networks
A Sequence to Sequence (seq2seq) model can be seen as a function that map an input sequence to an output sequence. For a seq2seq model based on encoder-decoder archi- tecture, it can be noted that the lengths of the input sequence and the output sequence are arbitrary, that is, their lengths can be inconsistent. To achieve this, recurrent neural
network (RNN) used as the main component of seq2seq models.
More thoroughly, the sequence to sequence architecture in a model have two recur- rent neural network (RNN) units, encoder and decoder. Given a input sequence X = {x1, x2, ..., xm}, the encoder aims to maps it into a encoded representation Enc(X). On the other hand, the decoder is to generate the resultant sequence Y = {y1, y2, ..., yn} based on the encoded representation Enc(X). In our implementation, the first set of the decoder’s hidden states are initialized with the last encoder’s hidden states.
There are several types of RNN units like long short-term memory (LSTM) [2] or gated recurrent unit (GRU) [1]. In this work, we use LSTM as our encoder and decoder.
Given a sequence of input X = {x1, x2, ..., xm}, a cell of LSTM encoder is defined as follows:
ft= sigmoid(Wfxt+ Ufht−1+ bf) it= sigmoid(Wixt+ Uiht−1+ bi) ot= sigmoid(Woxt+ Uoht−1+ bo)
˜
ct= tanh(Wcxt+ Ucht−1+ bc) ct= ft◦ ct−1+ it◦ ˜ct
ht= ot◦ tanh(ct)
(2.1)
where c0 = 0 and h0 = 0 are initialized as 0. The subscript t in the equations represent the time step. f , i, o, and ˜ctare the activation vectors of forget gate, update gate, output gate, and cell input gate, respectively. W and U are trainable weight matrices which need to be learned during training, and b is the bias vector.
The hidden state htcan be seen as the summarization of the sub-sequence{x1, x2, ..., xt}.
Thus, for a sequence with a length of T, we take hT as its representation.
2.2.2 Beam Search
When generating the output sequences, it is not feasible to compute the probabilities over all possible sequences. Finding the global optimal sequence is computationally expensive.
Moreover, with a decoder built base on RNN, the length of a output sequence is usually unpredictable.
A common solution to ease the computational resource is to use Beam Search. Beam search is a breadth-first search algorithm keeps only k most promising sub-sequences at time step t, where k is also called beam width. Algorithm 1 shows how beam search process implemented in detail. Given the maximum of sequence length T , beam search generates one token for each time step t, and simultaneously keeps a list of k most promis- ing sequences. The hyper-parameter k can be used to trade-off between computational resource and the quality of generated content.
Algorithm 1 Beam Search
1: x← hidden representation from encoder
2: k← beam width
3: V ← vocabulary
4: q← priority queue q.insert(0, {})
5: for t = 1...T do
6: q′ ← priority queue with capacity k
7: for z inV do
8: for l, s in q do
9: P ← l + logP (zt= z|x, s)
10: Seq← {s, z}
11: q′.insert(P , Seq)
12: q← q′
13: return q.max()
2.3 Metrics
To evaluation the quality of the generated counter-argument from different models, we conduct bilingual evaluation understudy (BLEU [13]) and recall-oriented understudy for gisting evaluation (ROUGE [10]). Both of them are commonly used to evaluate the quality of machine translation models. Moreover, besides the automatic evaluation, we also hire human annotators for human evaluation, which is introduced in Chapter 7.
2.3.1 BLEU
The quality of a given generated output is considered to be its correspondence to human- written output, that is, the target counter-argument in this research. As a metric, BLEU is similar to another metric, Precision, but with modified counting mechanism called mod- ified n-gram precision.
Formally, given a candidate sentence generated by machine and a reference sentence written by human, there is a number called Count Clip. CountClipis derived as follow:
1. Get the maximum number CountCand of times that a candidate n-gram occurs in any single reference.
2. For each reference, compute the number of times a candidate n-gram occurs CountRef. If there are several reference for one candidate, there will be multiple counts for a candidate n-gram (i.e. CountRef 1, CountRef 2...).
3. Get the maximum reference count CountRef M ax for each candidate n-gram.
4. CountClipof a n-gram is the minimum of CountRef M ax and CountCand.
Next, we compute modified n-gram precision pn by dividing the sum of CountClip
and the total number of distinct candidate n-grams.
pn=
∑
C∈{Candidates}
∑
t∈CCountClip(t)
∑
C∈{Candidates}
∑
t∈CCount(t) (2.2)
BLEU score also introduces a penalty named Brevity Penalty (BP ) to penalize short candidate sequences. BP is calculated as shown below:
Brevity Penalty =
1, If c > r e(1−r/c), If c≤ r
(2.3)
where c and r are the lengths of a candidate and a reference, respectively. After cal- culating Brevity Penalty and the Count Clip, we can derive BLEU score:
BLEU = BP × exp ( N
∑
n=1
wnlog(pn) )
(2.4)
where wnis the weight of n-gram, and usually we set it as 1/N .
2.3.2 ROUGE
Different from BLEU score, which is precision-oriented metric, ROUGE is a recall-oriented metric. Calculation of ROUGE for n-gram ROU GEnis relatively simple in comparison of BLEU.
ROU GEn =
∑
C∈{References}
∑
t∈CCountM atched(t)
∑
C∈{References}
∑
t∈CCount(t) (2.5)
In this work, we conduct its variation ROUGE-L, which is a metric similar with F score that consider both recall and precision, also counts the longest common sub-sequence (LCS) between candidate and reference. Given machine-generated sequence X and human-
written sequence Y , ROU GELis defined as below:
RLCS = LCS(X, Y )
m (2.6)
PLCS = LCS(X, Y )
n (2.7)
ROU GEL = (1 + β2)× RLCSPLCS
RLCS+ β2PLCS (2.8)
where m and n are the length of the reference sequence and candidate sequence, re- spectively. β is the tunable parameter for trading off between precision and recall. In this work, we set it as 1.
Chapter 3
Related Works
3.1 Argument Generation
Earlier works like (Benoit et al. ,1997 [6]) and (Reed et al. ,1996 [16]) aim to create a rule-based system, designing different strategies, selecting the content for generation, and reordering the selected content. Rakshit et al. (2017 [15]) proposed a initial prototype of retrieve-based argument generation system which retrieves appropriate counter-arguments based on their similarity algorithm. However, retrieve-based models are limited by the re- trieval pool. That is, the models can only select the content from the predefined candidates and do not have ability to generate novel responses. Le et al. (2018 [7]) explore not only retrieve-based approach, but also generative approach. They found that though the gen- erative model can generate responses that are not seen in the dataset, the retrieve-based models still have their superiority of generating high-quality responses.
The most relevant work to this research would be (Hua et al. ,2019 [3]). Different from the previously mentioned works which are mainly done on chit-chat system, their model needs to deal with much longer input with usually a few paragraphs. Given a statement
on a controversial topic, their proposed model is to generate a counter-argument. Their approach also introduces external resource containing factual information and reasoning to enrich the generated responses.
3.2 Conversation History Modeling
On the other hand, our research also in line with the works leveraging the information of conversation history. Recently, neural models built upon the sequence to sequence architecture [22] are widely used in chit-chat or goal-oriented generation tasks. Among these tasks, some of them not only encode the given human response of current time step, but also attend the conversation history to generate a response. Lu et al. (2019 [12]) encode the dialog context with bi-directional GRU [1] and further match the encoded context with the candidate responses to do the responses selection task. Su et al. (2019 [21]) unfold the dialog context and concatenate it with the target utterance, the resultant input is then fed to a transformer based model. The task is to rewrite the target utterance, recovering the omitted parts in the utterance. They also add position embedding, which is the same as one used in normal transformer architectures [23], and additional turn embedding to indicate which turn each token belongs to. Iulian et al. (2016 [19]) encode the context information with their proposed architecture named hierarchical recurrent encoder-decoder (HRED), which enable the models to embed a complex distribution over sequences of sentences within a compact parameter space.
Our proposed model unfold comments in a debating history and concatenate it with the statement of original post. To get the representation for sentence planing, style pre- diction, and the final response realization, the unfolded inputs are encoded with 2-layer bi-directional LSTM. Previously mentioned tasks involving multi-turn utterance model-
ing usually has a fixed speaker for each utterance, e.g. human and machine talk in turn in QA task. However, in a scenario of online debate, the comments in a debating history are not always in turn. Thus we add a speaker embedding to out proposed model, attending the speakers along the whole input.
Chapter 4
Corpus Construction
4.1 Data Collection
The corpus is constructed and collected from a subcommunity of Reddit, Change My View (/r/ChangeMyView). The community aims to make open discussions on many controver- sial topics. For each thread, the poster states his viewpoint on a certain topic, which can be a stance, opinion, or attitude. The viewpoints they hold may be flawed, and the goal of the community is to point out the weaknesses in the statements of original posters’
viewpoints, trying to change their stance on the discussed topic.
We collected 48,179 threads from Reddit, ranging from November 2016 to February 2020. To construct structured data for our model, we enumerate all possible discussion paths and retain paths that end with a comment awarded a Delta1 (∆) or having a posi- tive score (more upvotes than downvotes). Furthermore, with the observation that para- graphs within a single comment tend to have coherent arguments, we broke down target comments into paragraphs and each paragraph retained as a target counter-argument to
1In CMV, people can award others who successfully convince them a Delta (∆). There is also a ranked list called deltaboard, highlighting the users who have many ∆s.
the original post (OP) and corresponding discussion history. The resultant corpus has 4,632,314 samples.
4.2 Domain Specifying and Data Preprocessing
The collected dataset has threads discussing topics from diverse domains and these do- mains have unbalanced numbers of argumentative contents. Thus we decided to focus our research on topics within the domain of politics due to its argument richness. Threads discussing the political topic are also the majority of CMV.
Nevertheless, there is no topic tag available on CMV. We then built a model to classify the collected data. First, we downloaded a dump of English Wikipedia abstracts from DBpedia2. The dump contains 4,415,993 English abstracts and the average length of these abstracts is 523, with a similar scale of lengths of the collected original posts. We then pre-classified these abstracts with a hand-crafted politic lexicon introduced from Hua et al. [4]. The lexicon contains two types of words, political words, and non-political words.
Political words are words that often appear in political articles and threads. On the other hand, if an article contains any of the non-political words in the lexicon, it can be inferred that the article is not political-related. The contents of the lexicon are listed in Table 4.1.
In the pre-classification stage, we labeled abstracts having political words but none of any non-political word as positive samples, and vice versa. As a result, 411,958 abstracts are labeled as political articles, and 1,346,109 abstracts are labeled as non-political arti- cles. We took unigram TF-IDF as the features to train a logistic regression classifier. In detail, the top 50,000 frequent words are chosen as the vocabulary. And all the articles are lowercased and English stopwords are also excluded. To adapt the classifier to work on
2http://dbpedia.org/page/
Political Non-political
politics political science media
policy congress automobiles sports
rights election football fashion
president trump entertainment movie
clinton immigration movies music
democracy democrats musics art
democratic republican arts television constitution liberal religion philosophy government legalization morality dating surveillance amnesty eugenics marriage antisemitism terrorism parenthood history
war taxation organic handicaps
liberalism libertarianism disease marxism conservatism
anarchism autocracy fascism voting
Table 4.1: Politic lexicon for domain classification.
CMV posts, we conducted iterative bootstrapping. The detailed procedure is illustrated in Algorithm 2.
For each iteration, a logistic regression model is trained with given training samples and predicts the domain of each given CMV post with a probability. We will then pick a threshold manually that all the posts predicted with probabilities higher than the threshold are politic-related. Posts higher than the picked threshold will be added to the positive training samples for the next iteration. In this research, we do the bootstrapping for 3 iterations and there are 19,653 threads classified as politic-related.
To reduce the noise in data, we clean all machine-generated contents3 in the original posts, and further filtered the resultant dataset. Only samples meet all the following criteria are included:
• The length of the target counter-argument is larger than 20 tokens
• The length of the original post is larger than 100 tokens
3CMV randomly insert an introduction to CMV community at the end of the original posts.
Algorithm 2 Bootstrapping procedure for adapting domain classifier to CMV posts.
1: P os← abstracts containing politic words and no non-politic word
2: N eg ← abstracts containing non-politic words and no politic word
3: P osts← CMV posts
4: P oliticP osts← ∅
5: pos, neg, posts← TFIDFTransformer(P os, Neg, P osts)
6: while pos is not yet converged do
7: P redictions← DomainClassifier(pos, neg, posts)
8: threshold← threshold with high confidence based on P redictions
9: N ewP ositive← Filter(posts, threshold, P redictions)
10: pos← pos ∪ NewP ositive
11: P oliticP osts← P oliticP osts ∪ NewP ositive
12: posts← posts \ NewP ositive
13:
14: return P oliticP osts
• The lengths of all comments in discussion history are larger than 20 tokens
• No deleted comment in discussion history
• No toxic word4in the original post
• No any of Reddit-related words5 in the title
4.3 External Evidence Retrieval
To enrich the generated text with factual information, we collected a large-scale news dataset from an external source and set up an information retrieval system for us to query.
In this section, we first introduce what we collected and how we indexed them, followed by query construction.
4We filtered the toxic words with offense lexicon cooked by Google’s What do you like project.
5Reddit-related words include upvote, downvote, reddit, subreddit, karma, and delta.
4.3.1 External Evidence Collection and Indexing
We used Common Crawl to collected news of the New York Times as its high-quality content and diverse points of view. The HTML files dumped from Common Crawl are parsed with a New York Times parser, extracting the bodies of the news. The extracted news were first deduplicated and those fewer than 50 words were removed.
After cleaning the collected news, all the news were then broken into passages. A passage is constructed out of three sequential sentences if the consequent passage has a length longer than 50 words. Otherwise, the following sentences will be included in the passage. The resultant retrieval pool has 9,949,635 passages out of 465,870 news articles dating from September 1895 to December 2019. We used Elastic Search to index the passages. The passages are preserved in one single shard for the integrity of the retrieval results.
4.3.2 Query Formulation
For each original post, we construct one query per sentence of the statement. If the given sentence has more than 5 content words and more than 3 distinct words, it will be retained as a query. For each query, the corresponding relevant passages are retrieved with BM25.
We collected the top 3 passages per query to speed up the retrieval process. All the re- trieved passages for an original post were first deduplicated and the top 10 passages were recorded and re-ranked based on their BM25 scores. For training and validation data, we constructed queries with target counter-arguments rather than original post statements.
4.4 Keyphrases Extraction
In this section, we describe how the keyphrases extracted and the construction of the keyphrase selection labels. For each passage retrieved for the original posts, we used Stanford CoreNLP to parse the discourse structures. All the noun phrase (NP) and verb phrase (VP) were collected as keyphrase candidates. When adding a new keyphrase into the keyphrase bank, we also computed its similarity with each of the existed keyphrases, ensuring the content diversity of the keyphrase banks. In detail, if the candidate keyphrase has over a half overlap in content words with any of already existed keyphrases, it will be discarded. Up to 30 keyphrases were retained in a keyphrase bank of each original post.
To construct target labels for content selection decoder, target counter-arguments were split into sentences. Each of the sentences has a list of binary labels denoting the existence of all the keyphrases in selection candidates. The keyphrase selection labels will be used to train the content selection decoder of our models.
4.5 Sentence Style Labeling
To realize sentence-style control, we classified all the sentences of all the target counter- arguments into 3 classes, i.e. Claim, Premise, and Filler. A sentence labeled as Claim usually contains conclusions or stance of the speaker toward the given topic (e.g. ”I doubt transgender people are going to have a statistically higher prevalence of various psycho- logical problems.”). On the other hand, a Premise contains reasoning or evidence used to support or attack a claim [11] (e.g. ”If we push the idea that suicide is cowardly, either suicidal people won’t seek help out of shame, people won’t talk about suicide or it will encourage some suicidal people more because they would remove cowards.”). The third
style of sentences is Filler, sentences labeled as Filler tend to have a functional purpose of persuading, like ”let’s flip that logic around though.”.
We apply a set of regular expressions extended by Hua et al. [5] from Levy et al. [8], obtaining the sentence function labels for training. The complete regular expressions are listed in Table 4.2. If the given sentence doesn’t meet any of the expressions of either claim or premise, it will be labeled as filler.
Style Regular Expression
Claim
i (don’t)? (believe|agree|concede|suspect|doubt|see|feel|understand)
(any|anyone|anybody|every|everyone|everybody|most|few|no|no one|nobody|
it|we|you|they|there|all) \w{0,10} (could|should|might|need|must) (it|this|that) (make|makes) (no|zero)? sense
(chance|likelihood|possibility|probability) .* (slim|zero|negligible)
(be|seem) (necessary|unnecessary|justified|immoral|right|wrong|reasonable|
meaningless|jeopardized|inefficient|efficient|beneficial|important|justifiable|
unfair|harmful|moral|costly|stupid|flawed|unacceptable|impossible|foolish|
irrational|unconstitutional)
(in my opinion|imo|my view|i be try to say|have nothing to do with|tldr) Premise (help|improve|reduce|deter|increase|decrease|promote)
(for example|for instance|e.g.)
Table 4.2: Regular expressions for sentence styles.
Chapter 5
Method
5.1 Problem Formalization
We denote each training sample as (O, H, K −→ A), where O is an original post. A is a tar- get counter-argument that has high-quality argumentative contents. H ={h1, h2, ..., hn} represents the discussion history containing the comments between original post and the target counter-argument. hiis the i-th response in the discussion history. K ={k1, k2, ..., kn} contains a set of keyphrases to be selected for argument generation. Each keyphrase can be composed of a few tokens. An (O, H) pair can be duplicated in the dataset as we bro- ken the target counter-arguments into paragraphs. The goal of the addressed problem is to learn a generator which can properly understand the statement of the original post and the discussion history, and generate an appropriate counter-argument Y ={y1, y2, ..., yn} which is a sequence of words.
Our models are built upon sequence-to-sequence (seq2seq) architecture [22], with multiple training targets [5] (i.e. sentence style prediction, content selection, and content realization).
5.2 Input Encoding
We unfold all the tokens in (O, H) into (w1, w2, ..., wm), where m is the total number of tokens in the original post and the whole discussion history. A special tag <SEP > is inserted in between original post and the first utterance of the discussion history, as well as, any two utterances. There are two types of token embeddings as our encoder’s input (i.e.
word embeddings and speaker embeddings). For word embeddings, we use pre-trained GloVe 300 dimensions word embeddings [14]. As for speaker embedding, there are two types of speakers. For each token wi, the corresponding speaker si is denoted as:
speaker(wi) =
1, If wi is written by the original poster
2, If wi is written by the people other than original poster 0, Otherwise (special tags)
We derive encoded representation het for t-th token in unfolded input as described in Section 2.2.1. For each token wt, the input embedding to the encoder is the sum of its word embedding and its speaker embedding:
het = (−−→
Enc(I(wt)),←−−
Enc(I(wt))) (5.1)
I(wt) = W E(wt) + SE(wt) (5.2)
Each speaker embedding vector has 300 dimensions as GloVe [14] word embeddings do. Representations of the speaker embeddings are learned along with the model training
process, whereas we fixed the GloVe word embeddings here. We encode each keyphrase kiin a given keyphrase bank by summing up the embeddings of all the tokens:
Enc(ki) = ∑
w∈ki
W E(w) (5.3)
We use bi-directional LSTM to encode the unfolded inputs. The concatenation of the representations from two directions is the encoded vector we use to represent the whole input:
Enc(X) = (−−→
Enc(X),←−−
Enc(X)) (5.4)
5.3 Content Selection
For each sentence, a set of keyphrases will be selected by content planner from the given keyphrase bank M . We use a bi-directional LSTM based keyphrase reader to encode the keyphrases in the keyphrase bank:
hk = Keyphrase_Reader(M, Enc(ki)) (5.5)
The decision for sentence i are denoted as a selection vector vi, where each dimension vi,j ∈ {0, 1} represents whether the j-th keyphrase is selected as the content of sentence i.
There are two functional keyphrases (i.e. <Start> and <End>) included in the keyphrase bank M . Starting with selecting the functional tag <Start>, the content planner recur- rently decide the content for the following sentences until reaching the <End> tag.
To avoid talking a single concept repeatedly, Hua et al. [5] proposed a method to keep track of the selection history of the keyphrases. A keyphrase history vector qt is derived
as follow:
qt= (
∑t i=0
vi)T × E (5.6)
E = (h1, h2, ..., h|M|)T (5.7)
whereE is a matrix of keyphrase representations. The content selection vector vi+1is then calculated with an attention mechanism:
P (vi+1,j = 1|v1:i) = sigmoid(wvTsi+ qiWchj) (5.8)
where wvT and Wcare trainable parameters. siis a sentence representation calculated with a sentence-level LSTM with the summation of encoded representations of the selected keyphrases:
si = Sentence_Encoder(si−1, mi) (5.9)
mi =
∑|M|
j=1
vi,jhj (5.10)
As one of the training objectives, the loss of content selection is a binary cross-entropy loss that derived as:
Lsel=− ∑
(x,y)∈D
∑I i=1
∑|M|
j=1
log(P (vi,j∗ )) (5.11)
where D is the whole training set and the v∗is the ground-truth selection.
5.4 Style Planing
Given the embedding sum of the selected keyphrases miand sentence-level representation of i-th sentence si, the style planner is to predict the sentence style (i.e. Claim, Premise, or Filler) based on these information. Formally, the sentence style distribution for i-th sentence ˆti is derived as follow:
tˆi = sof tmax(wTs(tanh(Ws(mi, si)))) (5.12)
where (mi, si) is the concatenation of miand si. The trainable parameters wsand Ws learn how to decide appropriate style with the selected content. With the resultant style prediction ˆti, we pick the style having the highest probability as the final selection of the styles. The style distribution ˆtiis then one-hot encoded to tiwhich has each dimension to be{0, 1}. The one-hot encoded vector ti is the input of the counter-argument generator.
We calculate the loss of sentence style prediction with the predicted style distribution ˆtiand the ground-truth style t∗i:
Lstyle =− ∑
(x,y)∈D
∑I i=1
t∗ilog(ˆti) (5.13)
5.5 Argument Generation
To generate responses, we implemented a LSTM-based decoder g to get the hidden state zt for each token to be generated at time step t. The content-planning decoder’s hidden state si for i-th sentence is incorporated in the calculation of zt. i is the index of the sentence
which t-th token belongs to:
zt = g(zt−1, tanh(Wwssi, Wwwyt−1)) (5.14)
In word prediction, we take the hidden state zt, style prediction ti, and two context vec- tors (ckt and cet) as the inputs of the prediction function. The context vectors are calculated with attention mechanism over the unfold input statement (original post and discussion history) and over the keyphrase bank separately.
ckt =
∑|M|
i=1
αikhi
αki = sof tmax(ztWwkhi)
(5.15)
cet =
∑L i=1
αeihei
αei = sof tmax(ztWwehei)
(5.16)
where|M| and L are the size of keyphrase bank and the total length of the unfolded input, respectively. The predicted word ytfor time step t is then determined as follow:
P (yt|y1:t−1) = sof tmax(tanh(Wo(zt, cet, ckt, ti))) (5.17)
We also implement a copying mechanism from See et al. [18] to replace the unknown tag <U N K> by copying the content from source input.
The loss of word generation is also calculated with cross-entropy:
Lgen=− ∑
(x,y)∈D
∑T t=1
log(P (yt∗|x; θ)) (5.18)
The summary loss is aggregated from losses of content selection, sentence style pre- diction, and word generation as we train the model in multiple task setting.
L = Lgen+ βLsel+ γLstyle (5.19)
where β and γ are tunable hyper-parameters In this work we set both of them as 1 for the simplicity.
Chapter 6
Experiments
6.1 Dataset Overview
In splitting the constructed dataset, we hold 8,568 threads as training data, 1,101 threads as validation data, and 1,096 for testing. It is guaranteed that there is no overlap between any two subsets. That is, at testing stage, the original posts and its discussion histories are never seen in training. A simple statistics of the numbers of samples in different subsets is listed in Table 6.1.
Train Dev Test
#Counter-Args 625,717 85,505 81,458
#Threads 8,568 1,101 1,096
Table 6.1: Statistics of dataset. The value of Counter-Args is the number of samples that has a unique (original post, discussion history) pair.
We also compare the differences between the source input and the target ground truth.
The statistical numbers of different properties are listed in Table 6.2. Each value in the table is a average number. It can be noted that the numbers of the keyphrase in keyphrase bank have a gap between inputs and targets. It is because that we made queries out of target counter-arguments in training, and out of original post in testing, making our models to
0 2 4 6 8 0
0.05 0.1 0.15 0.2 0.25 0.3 0.35 0.4
Length of discussion history
Proportion to all samples
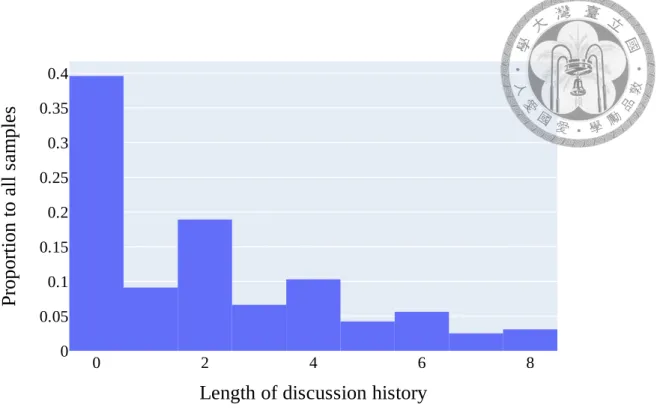
Figure 6.1: The distribution of the length of discussion history.
learn how to leverage the information of the given passages and keyphrases.
#Tokens #Sentences #KP(bank) #KP(selected)
Input 251.5 9.9 37.9 N/A
Target 60.9 6.7 19.3 4.0
Table 6.2: Comparison of source inputs and targets.
With the multi-turn discussion setting of this research, we plot the distribution of dif- ferent discussion history lengths in Fig 6.1. As shown in the bar chart, there are less samples having odd numbers of comments in discussion history. This implies that in the CMV community, people tend to leave comment and reply to each others in turn. The average length of the discussion history is 2.05.
6.2 Experimental Setup
In this section, we introduce the models’ experimental details of this research. There are three models in our experiment for comparison. One is a model incorporating the passage information which is also the model proposed by Hua et al. [5], another is the model with the discussion history encoded as input, and the other is the model with token-level speaker embeddings. These models share similar architectures which is based on seq2seq as we discussed in Chapter 5.
As for the encoder used to encode inputs’ token embeddings, we use two-layer bi- directional LSTM with 512 hidden dimensions with a dropout layer having 0.2 dropout rate between these two layers. The keyphrase reader is a bi-directional LSTM with 300 hidden dimensions used to generate context-aware keyphrase representations. We im- plement both sentence planner decoder and counter-argument generator with two-layer LSTM with 512 hidden dimensions.
In the training stage, we choose AdaGrad as our optimizer, and set the learning rate and the initial accumulator as 0.15 and 0.1, respectively. The gradient norms are clipped with a limitation of 2.0. We limit the lengths of the whole input statement (original post and the retrieved passages/discussion history) with 500 tokens, and the lengths of the un- folded retrieved passages and discussion history are also truncated with a maximum of 200 tokens. We train these three models with mini-batch size set as 32, and the best mod- els are chosen according to the BLEU-2 scores of the validation set. The whole training process takes approximately 35 hours on NVIDIA Titan RTX GPU card.
Original Post:
Self defense is one of the most important things that …
Retrieved Passages Input
Word Embedding Layer Input Encoder
News Passages Query
Keyphrase Bank:
public life, your faith, any official way, the intelligence, communities sheer incredulity,
… Content Selection + Style Planning
Counter-argument Generator Generated Counter-argument:
I don‘t think that’s true. It‘s not a “right”, it’s a political issue.
If you don‘t want to talk about …
Extract keyphrase
Figure 6.2: The architecture of the single-turn counter-argument generation model.
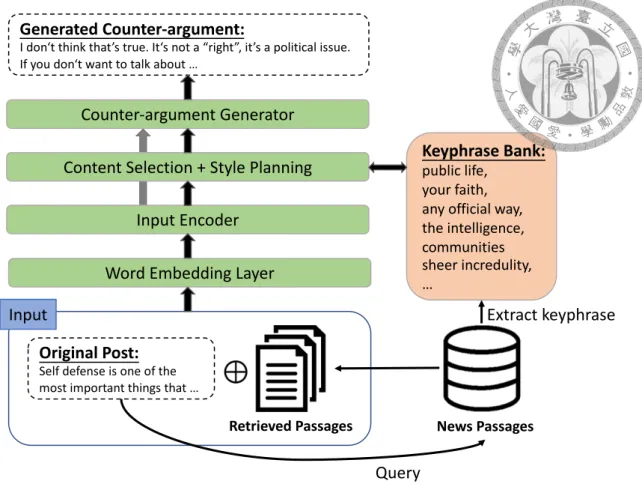
6.2.1 Single-turn Model
As discussed in Chapter 4, we make multiple queries for a single input statement. Thus, there are multiple retrieval results in a sample. We re-rank them based on the BM25 score of each passage. Following this order, the input statements are extended with the ordered lists of retrieved passages. Given a original post O having words{o1, o2, ..., on}, and the passages retrieved with the original post, where each passage Pkhas words{pk1, pk2, ..., pkn
k}, an unfolded input will look like
{o1, o2, ..., on, <SEP >, p11, ..., p1n1, <SEP >, p21, ..., p2n2, ..., <SEP >, pK1 , ..., pKnK}
K denotes the number of the passages retrieved from original post. Also, a <SEP > tag is inserted in between any two components. The overview architecture of single-turn model is illustrated in Figure 6.2.
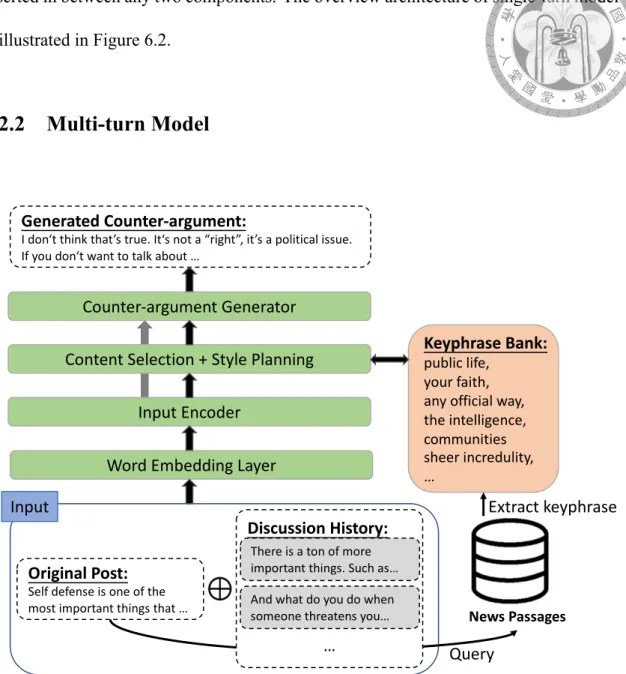
6.2.2 Multi-turn Model
Original Post:
Self defense is one of the most important things that …
Input
Word Embedding Layer Input Encoder
News Passages Query
Keyphrase Bank:
public life, your faith, any official way, the intelligence, communities sheer incredulity,
… Content Selection + Style Planning
Counter-argument Generator Generated Counter-argument:
I don‘t think that’s true. It‘s not a “right”, it’s a political issue.
If you don‘t want to talk about …
Extract keyphrase Discussion History:
There is a ton of more important things. Such as…
And what do you do when someone threatens you…
…
Figure 6.3: The architecture of the multi-turn counter-argument generation model.
Instead of encoding the retrieved passages as what Hua et al. [5] did, we incorporate the discussion history together with the original post. Due to there is already an order along the discussion history, we do not need to re-rank the comments in discussion history.
Given a original post O ={o1, o2, ..., on} and its corresponding discussion history where each comment Ck = {ck1, ck2, ..., ckn
k}, we unfold the comments and extend the original
post with a similar way as what we deal with retrieved passages. The input statement fed into the encoder is denoted as
{o1, o2, ..., on, <SEP >, c11, ..., c1n1, <SEP >, c21, ..., c2n2, ..., <SEP >, cK1 , ..., cKn
K}
As the illustration shows in Figure 6.3 the model does not leverage the content of the retrieved passages directly.
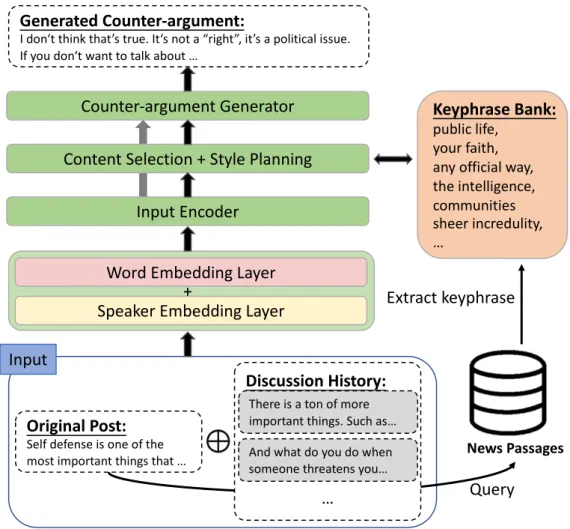
6.2.3 Multi-turn Model with Speaker Embedding
Original Post:
Self defense is one of the most important things that …
Input
Input Encoder
News Passages Query Keyphrase Bank:
public life, your faith, any official way, the intelligence, communities sheer incredulity,
… Content Selection + Style Planning
Counter-argument Generator Generated Counter-argument:
I don‘t think that’s true. It‘s not a “right”, it’s a political issue.
If you don‘t want to talk about …
Extract keyphrase
Discussion History:
There is a ton of more important things. Such as…
And what do you do when someone threatens you…
… Word Embedding Layer
Speaker Embedding Layer+
Figure 6.4: The architecture of the multi-turn model with speaker embedding.
The input statements for the multi-turn model with speaker embedding are constructed
with the same manner as multi-turn model. To make the model aware of the speaker for each token, we add a speaker embedding layer with the word embedding layer as illustrated in Figure 6.4. For a given word in the input statement, its token representation is constructed by summing up the corresponding word and speaker embeddings. This model also leverages the information of the discussion history and each token can be written by either the original poster or someone other than the original poster. Thus, there are three possible speaker embeddings (i.e. original poster, others, or special tokens) as we discussed in Chapter 5.
Chapter 7
Results
7.1 Automatic Evaluation
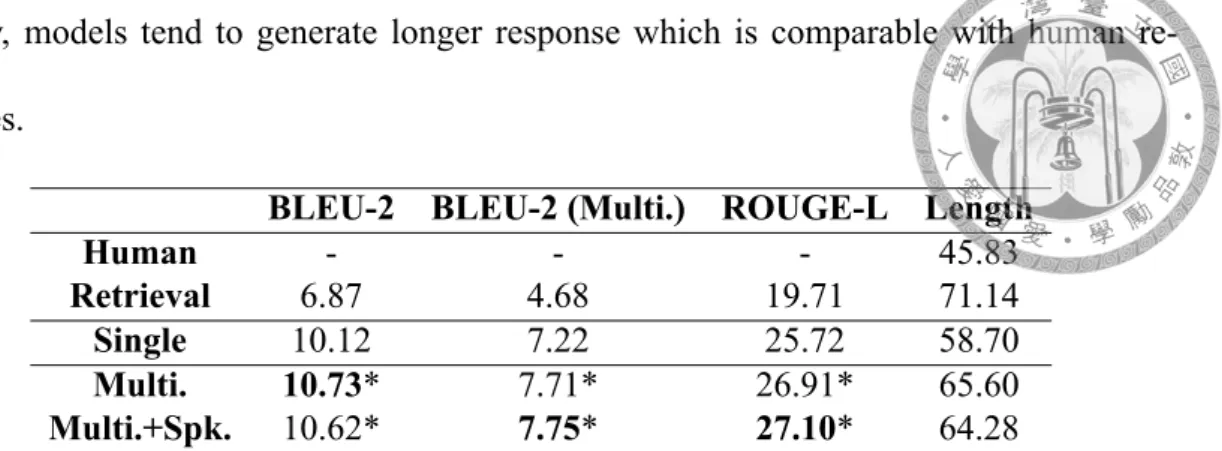
We conduct bilingual evaluation understudy (BLEU [13]) and recall-oriented understudy for gisting evaluation (ROUGE [10]) to evaluate the precision and recall of different mod- els in terms of target counter-arguments. The result of BLEU-2 and ROUGE-L are re- ported in Table 7.1. Because not all the samples in dataset have discussion history as shown in Figure 6.1, we also report the BLEU scores on only samples having discus- sion history (i.e. Multi.) to investigate the models’ ability on leveraging information of comments in between.
The models incorporating the information of discussion history have statistically sig- nificantly better performance on both BLEU and ROUGE than the model incorporating the retrieved passages. As for investigating the help of adding the speaker embedding, we found that although the model perform worse on overall BLEU score, it achieves better result when ignoring the samples having no discussion history. It implies that speaker embedding does have potential for helping models generate more appropriate counter-
argument by attending the speaker. Also, we found that by incorporating the discussion history, models tend to generate longer response which is comparable with human re- sponses.
BLEU-2 BLEU-2 (Multi.) ROUGE-L Length
Human - - - 45.83
Retrieval 6.87 4.68 19.71 71.14
Single 10.12 7.22 25.72 58.70
Multi. 10.73* 7.71* 26.91* 65.60
Multi.+Spk. 10.62* 7.75* 27.10* 64.28
Table 7.1: Automatic evaluation result. *: statistically significantly (randomization ap- proximation test, p < 0.005) better than the baseline model (i.e. Single).
7.1.1 Content Diversity
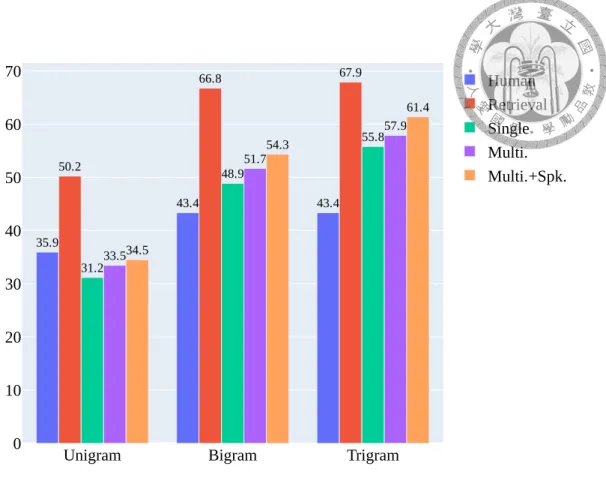
To further understand the quality of generated content, we investigated the lexical diversity of the generated responses. We can infer that a response has more distinct n-grams would also have higher content diversity [9]. We illustrate the numbers of distinct unigrams, bigrams, and trigrams for different models in Figure 7.1. As the figure shows, model- generated arguments have lower unigram diversity, but achieve higher on both bigram and trigram compared to the human arguments. On the other hand, the retrieved passages have the highest content diversity over all the other competitors. It conforms with the fact that the news written by trained journalists tend to have higher quality (e.g. lexical diversity).
In terms of the effect of incorporating discussion history on content diversity, we found that the models leveraging discussion history information (i.e. Multi. and Multi.+Spk.) tend to have higher diversity than the single-turn model. The speaker embedding also increases the diversity of the generated counter-arguments.
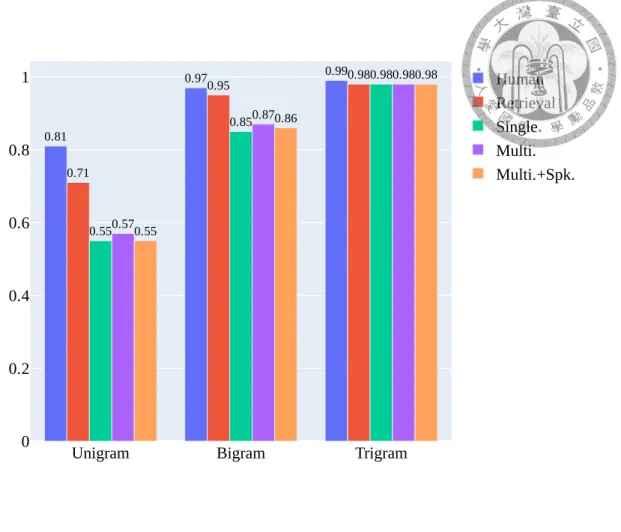
Next, we illustrate the average type-token ratio (TTR) of the counter-arguments in
35.9
43.4 43.4
50.2
66.8 67.9
31.2
48.9
55.8
33.5
51.7
57.9
34.5
54.3
61.4
Unigram Bigram Trigram
0 10 20 30 40 50 60
70 Human
Retrieval Single Multi.
Multi.+Spk.
Figure 7.1: Average number of distinct n-gram per argument.
Figure 7.2. As the figure shows, the models that generate longer counter-arguments (i.e.
Multi. and Multi.+Spk.) can still maintain comparable TTRs.
7.2 Human Evaluation
To understand humans’ subjective view on human/model written counter-arguments, we used Amazon Mechanical Turk (M Turk) to conduct human evaluation. In this section, we first talk about the annotation setup details for our human evaluation, including the guidance and the annotation interface we present to the annotators. Then we discuss our findings according to the result of the human evaluation.
0.81
0.97 0.99
0.71
0.95 0.98
0.55
0.85
0.98
0.57
0.87
0.98
0.55
0.86
0.98
Unigram Bigram Trigram
0 0.2 0.4 0.6 0.8
1 Human
Retrieval Single Multi.
Multi.+Spk.
Figure 7.2: Type-token ratio of different models.
7.2.1 Annotation Setup
We randomly picked 43 threads in the test set for the human annotation. Given a thread, the statement of the original poster and the corresponding comments in the discussion history are shown and there are 15 Likert scales to be rated (3 aspects per argument). Also, the order of the candidate responses to be annotated in each thread are shuffled to avoid the annotators’ bias. We hired three English native speakers to do the annotation job. Each annotator was asked to read the annotation guidance as shown in Figure 7.3, and then do the following annotations for all the threads. There are three aspects to be rated for each candidate: