國立臺灣大學電機資訊學院電子工程學研究所 碩士論文
Graduate Institute of Electronics Engineering College of Electrical Engineering and Computer Science
National Taiwan University Master Thesis
利用可滿足性求解法與克雷格內插法 之大尺度亞氏函式拆解
Large Scale Ashenhurst Decomposition via SAT Solving and Craig Interpolation
林炫伯 Hsuan-Po Lin
指導教授:江介宏 博士
Advisor: Jie-Hong Roland Jiang, Ph.D.
中華民國 98 年 6 月
June, 2009
Acknowledgements
I am grateful to many people who made this thesis possible. I would like to thank my advisor, Dr. Jie-Hong Roland Jiang, with his enthusiasm, his academic experiences, and his inspiration. Throughout the past two years, he provides en- couragements, useful advise, and lots of good ideas. I would have lost without him.
The members of ALCom Lab, I-Hsin Chen, Wei-Lun Hung, Sz-Cheng Huang, Chia-Chao Kan, Ruei-Rung Lee, Chih-Fan Lai, Meng-Yan Li, Jane-Chi Lin, and Fu-Rong Wu, have been my great memory in academic journey. We had a lot of inspiring discussions and joyful cooperations. I would also like to thank all of my friends who helped me get through difficult time and provided invaluable supports.
I cannot end this acknowledgement without thanking my parents and brother for their constant supports and encouragements no matter what happened. To them I dedicate this thesis.
Hsuan-Po Lin
National Taiwan University June 2009
利用可滿足性求解法與克雷格內插法之大尺度亞氏函式拆解
研究生:林炫伯 指導教授:江介宏博士
國立台灣大學電子工程學研究所
摘要
函式拆解著眼於將一個布林函式拆解成一系列較小的子函式。在本篇論文裡面,
我們著重在亞氏函式拆解,這是一種因為他的簡易性而有許多實際應用的常見函 式拆解法。我們將函式拆解問題包裝成可滿足性求解問題,更進一步的採用克雷 格內插法以及函式相依性計算來找出相對應的子函式。在我們採用可滿足性求解 法為核心的研究中,輸入變數分組的過程可以被自動的處理,並且嵌入我們的函 式拆解演算法中。我們也可以自然的將我們的演算法延伸,應用在允許共用輸入 變數與多輸出變數的函式拆解問題上,這些問題在以往採用二元決策圖為核心資 料結構的演算法中都很難被解決。實驗結果顯示,我們提出的演算法可以有效的 處理輸入變數達到三百個之多的函式。
關鍵字:布林函式、函式拆解、可滿足性求解法、克雷格內插法、函式相依性
Large Scale Ashenhurst Decomposition via SAT Solving and Craig Interpolation
1Student: Hsuan-Po Lin Advisor: Dr. Jie-Hong Roland Jiang
Graduate Institute of Electronics Engineering National Taiwan University
Abstract
Functional decomposition aims at decomposing a Boolean function into a set of smaller sub-functions. In this thesis, we focus on Ashenhurst decomposition, which has practical applications due to its simplicity. We formulate the decomposition problem as SAT solving, and further apply Craig interpolation and functional depen- dency computation to derive composite functions. In our pure SAT-based solution, variable partitioning can be automated and integrated into the decomposition pro- cedure. Also we can easily extend our method to non-disjoint and multiple-output decompositions which are hard to handle using BDD-based algorithms. Experi- mental results show the scalability of our proposed method, which can effectively decompose functions with up to 300 input variables.
Keywords: Boolean function, functional decomposition, SAT solving, Craig interpolation, functional dependency.
1The preliminary version of this thesis appears in [18].
Contents
Acknowledgements i
Chinese Abstract ii
Abstract iii
List of Figures viii
List of Tables ix
1 Introduction 1
1.1 Thesis Overview . . . 1
1.2 Related Work . . . 7
1.3 Our Contributions . . . 8
1.4 Thesis Organization . . . 10
2 Preliminaries 11 2.1 Functional Decomposition . . . 12
2.1.1 Decomposition Chart . . . 13
Contents
2.2 Functional Dependency . . . 15
2.3 Satisfiability and Interpolation . . . 16
2.3.1 Conjunctive Normal Form . . . 16
2.3.2 Circuit to CNF Conversion . . . 16
2.3.3 Propositional Satisfiability . . . 18
2.3.4 Refutation Proof . . . 19
2.3.5 Craig interpolation . . . 22
3 Main Algorithms 27 3.1 Single-Output Ashenhurst Decomposition . . . 27
3.1.1 Decomposition with Known Variable Partition . . . 28
3.1.2 Decomposition with Unknown Variable Partition . . . 37
3.2 Multiple-Output Ashenhurst Decomposition . . . 43
3.2.1 Shared Variable Partition . . . 45
3.3 Beyond Ashenhurst Decomposition . . . 46
3.4 Decomposition under Don’t-Cares . . . 47
3.5 Implementation Issues . . . 48
3.5.1 Minimal UNSAT Core Refinement . . . 48
3.5.2 Balanced Partition . . . 48
3.5.3 Elimination of Equality Constraint Clauses . . . 49
3.6 A Complete Example . . . 49
4 Experimental Results 54
Contents
4.1 Single- and Two-Output Ashenhurst Decomposition . . . 54
4.2 Quality of Variable Partition . . . 59
4.3 Fast Variable Partitioning . . . 61
4.4 n-Output Ashenhurst Decomposition . . . 67
4.5 Quality of Composite Functions . . . 68
5 Conclusions and Future Work 71
Bibliography 74
List of Figures
1.1 Ashenhurst decomposition . . . 6
2.1 The diagonal decomposition chart due to introduce of common variable 14 2.2 Circuit to CNF representation . . . 17 2.3 Refutation proof and the unsatisfiable core . . . 22 2.4 Craig interpolation . . . 23 2.5 Interpolant construction of an unsatisfiable formula ϕ = (¬c)(¬b +
a)(c + ¬a)(b) . . . 26
3.1 Circuit representation of Formulas (3.2) and (3.3) . . . 30 3.2 (a) Relation characterized by ψA(XG1, XG2, c) for some c ∈ [[XC]] (b)
Relation after cofactoring ψA(XG1 = a, XG2, c) with respect to some a ∈ [[XG1]] . . . 30 3.3 Example circuit used in the complete example . . . 50 3.4 The decomposition chart of the example circuit . . . 51 3.5 (a) Relation of the derived interpolant function, (b) Relation after
cofactor by (a1, b1) = (0, 0) . . . 52
List of Figures
3.6 (a) The base functions, (b) h function derived by functional dependency 53
4.1 Best variable partition found in 60 seconds – without minimal UNSAT core refinement . . . 58 4.2 Best variable partition found in 60 seconds – with minimal UNSAT
core refinement . . . 58 4.3 Variable partition qualities under four different efforts . . . 60 4.4 First-found valid partition – without minimal UNSAT core refinement 61 4.5 First-found valid partition – with minimal UNSAT core refinement . . 62 4.6 Comparison of disjointness between different partition efforts . . . 65 4.7 Comparison of disjointness between different partition efforts . . . 66 4.8 Disjointness versus total variables of the best found partition in 60
seconds with minimal UNSAT core operation . . . 66 4.9 Runtime of multi-output Ashenhurst decomposition . . . 68
List of Tables
4.1 Single-output Ashenhurst decomposition . . . 55
4.2 Two-output Ashenhurst decomposition . . . 56
4.3 Variable distribution in different partition efforts . . . 64
4.4 Circuit information of s9234 . . . 69
Chapter 1
Introduction
1.1 Thesis Overview
Functional decomposition [1, 7, 14, 22] plays an important role in the analysis and design digital systems. It refers to the process of breaking a complex function into parts, which are less complex than the original function and are relatively indepen- dent to each other. In addition the behavior of the original function can be recon- structed if we compose these parts together. In logic synthesis, a complex function is decomposed into a set of sub-functions, such that each sub-function is easier to analyze, to understand, and to further synthesize. Functional decomposition has long been recognized as a pivotal role in LUT-based FPGA synthesis. It also has various applications to the minimization of circuit communication complexity.
1.1. Thesis Overview
Functional decomposition can be classified as follows:
• The function to be decomposed can be a completely or an incompletely speci- fied function.
• The function to be decomposed can be a single- or multiple-output function.
• A decomposition is disjoint if the sub-functions do not share common input variables; otherwise, it is non-disjoint.
• A decomposition is called Ashenhurst decomposition or simple decomposition if the topology of the decomposition is f (X) = h(g(XG), XH), where X = XG ∪ XH and g is a single-output function; a decomposition is called bi- decomposition if the topology is f (X) = h(g1(XA), g2(XB)), where X = XA∪ XB and h is a two-input gate.
In this thesis, our method focuses on completely specified functions. In addition the proposed method deals with multiple-output and non-disjoint decompositions.
Furthermore, we pay our attention to Ashenhurst decomposition.
The functional decomposition problem was first formulated by Ashenhurst in 1959 [1]. He visualized the decomposition feasibility with a decomposition chart, which is a two-dimensional Karnaugh map with rows corresponding to variables in the free set and columns corresponding to variables in the bound set. The decompo- sition chart is used to determine whether a given function f can be simply disjointly
1.1. Thesis Overview
decomposed with respect to a set of given bound set variables. Ashenhurst reduced the chart by merging all identical columns, and he showed that there exists a simple disjoint decomposition if and only if there are at most two distinct columns in the reduced decomposition chart. The disadvantage of Ashenhurst’s method is that we have to construct every chart with respect to every variable partition we consider. If we consider all the variable partitions, a function with n variables would have O(2n) charts since every variable can be in either the bound set or free set.
Roth and Karp proposed a cover-based method [22], trying to reduce the memory requirement of Ashenhurst’s method. They used covers to represent the functions.
By cover manipulations, the minterms of bound set variables will be mapped into equivalence classes. These equivalence classes are in one-to-one correspondence with the distinct columns in Ashenhurst’s method. Nevertheless, the process time of the algorithm is still a problem except we restrict the size of the bound set variables to be up-bounded by some constant k. A typical value of k is 5 which is the common input size of a LUT.
Recent progress on function manipulation using BDDs makes the BDD data structure becomes a popular tool to handle the functional decomposition problem.
Lai, Pedram, and Vrudhula [15] proposed a fast BDD-based method to implement the Roth-Karp algorithm. They used BDDs to represent Boolean functions, and showed that every variable ordering in the BDD implies a variable partition of the decomposition of the function. They ordered all the bound set variables above
1.1. Thesis Overview
the cut, and ordering all the free set variables in and below the cut. Based on Lai’s method, Stanion and Sechen proposed a method [25] to enumerate all the possible cuts in the BDD in order to find a good decomposition. The enumeration can be achieved by constructing a characteristic function for the set of cuts, then using a branch-and-bound procedure in order to find a cut which produces the best decomposition.
Identifying the common sub-functions in decomposing a function set is an im- portant issue in multiple-output functional decomposition. The first approach to multiple-output functional decomposition was proposed by Karp [14]. However Karp’s multiple-output approach works only for two-output functions. In order to overcome the limitation of Karp’s method, researchers proposed several ways to handle the multiple-output decomposition problem. Wurth, Eckl, and Antreich pre- sented an algorithm [29] based on the concept of a preferable decomposition function, which is a decomposition function valid for a single output and with the potential to be shared by other output functions to handle multiple-output decomposition.
They showed that the construction of all preferable decomposition functions can be achieved by partitioning the minterms of bound set variables into some global classes, and this information can be used to identify the common preferable decom- position functions of a multiple-output function.
Sawada, Suyama, and Nagoya proposed a BDD-based algorithm [24] to deal with the issue of identifying common sub-functions. They proposed a effective Boolean
1.1. Thesis Overview
resubstitution technique based on support minimization to effectively identify the common LUTs from a large amount of candidates. However when the size of the support variables is large, the examination becomes time-consuming and sometimes fails due to memory explosion.
Most prior work on functional decomposition used BDD as the underlying data structure. BDD can be used to handle the functional decomposition problem with proper variable ordering, which the size of the BDD is under an acceptable threshold.
However in some cases, the BDD-based algorithm has several limitations:
• Firstly, there are memory explosion problems for BDD-based algorithms. BDD can be of large size in representing a Boolean function. In the worst case, BDD size is exponential to the number of variables. When special variable ordering rules need to be imposed on BDDs for functional decomposition, the memory size needed in BDD computation may not be improved by changing a suitable variable ordering. Therefore it is typical that a function under decomposition using BDD as the underlying data structure can have just a few variables.
• Secondly, variable partitioning needs to be specified a priori, and cannot be au- tomated as an integrated part of the decomposition process. Decomposability under different variable partitions need to be analyzed case by case. In order to enumerate different variable partitions effectively and keep the size of BDD reasonably small, the set of bound set variables cannot be large. Otherwise, the computation time will easily over the pre-specified threshold.
1.1. Thesis Overview
• Thirdly, for BDD-based approaches, non-disjoint decomposition cannot be handled easily. In practical, decomposability needs to be analyzed by cases exponential to the number of joint (or common) variables.
• Finally, even though multiple-output decomposition [30] can be converted to single-output decomposition [12], BDD sizes may grow largely in this conver- sion.
Figure 1.1: Ashenhurst decomposition
The above limitations motivate the need for new data structures and computa- tion methods for functional decomposition. This thesis shows that, when Ashen- hurst decomposition [1] is considered, these limitations can be overcome through satisfiability (SAT) based formulation. Ashenhurst decomposition is a special case of functional decomposition, where, as illustrated in Figure 1.1, a function f (X) is decomposed into two sub-functions h(XH, XC, xg) and g(XG, XC) with f (X) = h(XH, XC, g(XG, XC)). For general functional decomposition, the function g can be
1.2. Related Work
a functional vector (g1, . . . , gk) instead. It is the simplicity that makes Ashenhurst decomposition particularly attractive in practical applications.
The techniques we used in this thesis, in addition to SAT solving, include Craig interpolation [6] and functional dependency [16]. Specifically, the decomposability of function f is formulated as SAT solving, the derivation of function g is by Craig interpolation, and the derivation of function h is by functional dependency.
1.2 Related Work
Aside from the related prior work using BDD as underlying data structure, we com- pare some related work on functional decomposition and Boolean matching using SAT-based techniques. In bi-decomposition [17], a function f is decomposed into f (X) = h(g1(XA, XC), g2(XB, XC)) under variable partition X = {XA|XB|XC}, where function h is known as a priori and is fixed to be special function types, which can be two-input or, and, xor gates, etc.. The functions g1 and g2 are the unknowns to be computed. Compared with bi-decomposition, Ashenhurst decom- position f (X) = h(XH, XC, g(XG, XC)) focuses on both unknown functions h and g, where no any fixed type of gates are specified. The Ashenhurst decomposition problem needs be formulated and solved differently while the basic technique used in our thesis is similar to that in [17].
FPGA Boolean matching, see, e.g., [3], is a subject closely related to functional
1.3. Our Contributions
decomposition. In [19], Boolean matching was achieved with SAT solving, where quantified Boolean formulas were converted into CNF formulas. In order to eliminate the universal quantifiers, the CNF formulas will be duplicated exponential times related to the input variable sizes. The intrinsic exponential explosion in formula sizes limits the scalability of the approach. Typically, this method cannot handle functions with input variables greater than 10. To overcome this problem, a two- stage SAT-based Boolean matching algorithm [26] and an implicant-based method [4] were proposed to improve the limitation of methods mentioned in [19]. Different from the above algorithms mainly focus on completely specified functions, Wang and Chan proposed a SAT-based Boolean matching method [28] to handle functions with don’t-cares. On the other hand, our method may provide a partial solution to the Boolean matching problem, at least for some special PLB configurations similar to the topology of Ashenhurst decomposition.
1.3 Our Contributions
Compared with BDD-based methods, the proposed SAT-based algorithm is advan- tageous in the following aspects.
• Firstly, it does not suffer from the memory explosion problem and is scalable to large functions. Experimental results show that Boolean functions with more than 300 input variables can be decomposed effectively.
1.3. Our Contributions
• Secondly, it needs not be specified a priori when variable partitioning, and can be automated and derived on the fly during decomposition. Hence the size of the bound set variables XG needs not be small. Bound set variables XG can be as large as free set variables XH to obtain a more balanced variable partition.
• Thirdly, it works for non-disjoint decomposition naturally. The automated variable partition process in our method can indeed generate a non-disjoint variable partition. In practical, we wish the number of the common (non- disjoint) variables XC to be small, thus we further propose an UNSAT core refinement process to heuristically reduce the number of common variables as much as possible.
• Finally, it can be easily extended to multiple-output Ashenhurst decomposi- tion if we assume that all of the output functions fi share the same variable partition X = {XH|XG|XC}.
However when generalizing our method to functional decomposition beyond Ashenhurst’s special case, both SAT-based formula size and computation time of SAT solving grow. This is the limitation of our proposed method.
As interconnects become a dominating concern in modern nanometer IC designs, scalable decomposition methods play a pivotal role in circuit communication mini- mization. While functional decomposition breaks the original function into smaller
1.4. Thesis Organization
and relatively independent sub-functions, the communication complexity between these sub-functions are greatly reduced proportional to the number of interconnect- ing wires between these parts.
With the advantages of the proposed method, hierarchical logic decomposition could be made feasible in practice. In addition, our results may provide a new way on scalable Boolean matching for heterogeneous FPGAs as well as topologically constrained logic synthesis.
1.4 Thesis Organization
This thesis is organized as follows. Chapter 2 introduces essential preliminaries.
Our main algorithms are presented in Chapter 3, and evaluated with experimental results in Chapter 4. Finally, Chapter 5 concludes the thesis and outlines future work.
Chapter 2
Preliminaries
In this chapter, we provide the necessary and sufficient background needed in this thesis. As conventional notation, in this thesis, sets are denoted in upper-case letters, e.g., S; set elements are in lower-case letters, e.g., e ∈ S. The cardinality of S is denoted as |S|. A partition of a set S into Si ⊆ S for i = 1, . . . , k (with Si ∩ Sj = ∅, i 6= j, and S
iSi = S) is denoted as {S1|S2| . . . |Sk}. For a set X of Boolean variables, its set of valuations (or truth assignments) is denoted as [[X]], e.g., [[X]] = {(0, 0), (0, 1), (1, 0), (1, 1)} for X = {x1, x2}.
2.1. Functional Decomposition
2.1 Functional Decomposition
Definition 2.1 Given a completely specified Boolean function f , variable x is a support variable of f if fx 6= f¬x, where fx and f¬x are the positive and negative cofactors of f on x, respectively.
Definition 2.2 A set {f1(X), . . . , fm(X)} of completely specified Boolean functions is (jointly) decomposable with respect to some variable partition X = {XH|XG|XC} if every function fi, i = 1, . . . , m, can be written as
fi(X) = hi(XH, XC, g1(XG, XC), . . . , gk(XG, XC))
for some functions hi, g1, . . . , gk with k < |XG|. The decomposition is called disjoint if XC = ∅, and non-disjoint otherwise.
For m = 1, it is known as single-output decomposition, and for m > 1, multiple- output decomposition. Note that h1, . . . , hm share the same functions g1, . . . , gkif we are dealing with multiple-output decomposition problem. The so-called Ashenhurst decomposition [1] is for k = 1, which g function has only one output bit.
Note that, for |XG| = 1, there is no successful decomposition because of the violation of the criterion k < |XG|. On the other hand, the decomposition trivially holds if XC ∪ XG or XC ∪ XH equals X. The corresponding variable partition is called trivial. This paper is concerned about decomposition under non-trivial variable partition. Moreover, we focus on Ashenhurst decomposition.
2.1. Functional Decomposition
The decomposability of a set {f1, . . . , fm} of functions under the variable par- tition X = {XH|XG|XC} can be analyzed through the so-called decomposition chart, consisting of a set of matrices, one for each member of [[XC]]. The rows and columns of a matrix are indexed by {1, . . . , m} × [[XH]] and [[XG]], respectively.
For i ∈ {1, . . . , m}, a ∈ [[XH]], b ∈ [[XG]], and c ∈ [[XC]], the entry with row index (i, a) and column index b of the matrix of c is of value fi(XH = a, XG= b, XC = c).
Proposition 2.1 [1,7,14] A set {f1, . . . , fm} of Boolean functions is decomposable as
fi(X) = hi(XH, XC, g1(XG, XC), . . . , gk(XG, XC))
for i = 1, . . . , m under variable partition X = {XH|XG|XC} if and only if, for every c ∈ [[XC]], the corresponding matrix of c has at most 2k column patterns (i.e., at most 2k different kinds of column vectors).
2.1.1 Decomposition Chart
Given a variable partition X = {X1|X2}, we want to check if a decomposition f = h(g(X1), X2) exists. To do this, we build a table called decomposition chart.
Decomposition chart is a table rearrange from the K-map of a given function f . The table has 2|X1|columns correspond to input vectors of X1 and 2|X2| rows correspond to input vectors of X2. Each entry in the decomposition chart represents a function value whose input value is a combination of the index of corresponding rows and columns. Moreover, if we allow some variables can be common in both the row and
2.1. Functional Decomposition
column, the resulting decomposition chart will be formed by some sub-chart in a diagonal way.
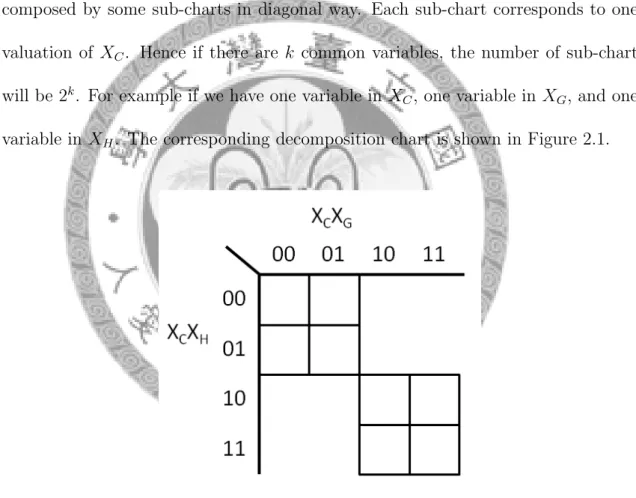
In our Ashenhurst decomposition, the corresponding decomposition chart of the given function f uses input variables of g as its column index variable, and input variables of h as its row index variables. The whole decomposition chart of f is composed by some sub-charts in diagonal way. Each sub-chart corresponds to one valuation of XC. Hence if there are k common variables, the number of sub-chart will be 2k. For example if we have one variable in XC, one variable in XG, and one variable in XH. The corresponding decomposition chart is shown in Figure 2.1.
Figure 2.1: The diagonal decomposition chart due to introduce of common variable
2.2. Functional Dependency
2.2 Functional Dependency
Definition 2.3 Given a Boolean function f : Bm → B and a vector of Boolean functions G = (g1(X), . . . , gn(X)) with gi : Bm → B for i = 1, . . . , n, over the same set of variable vector X = (x1, . . . , xm), we say that f functionally depends on G if there exists a Boolean function h : Bn → B, called the dependency function, such that f (X) = h(g1(X), . . . , gn(X)). We call functions f , G, and h the target function, base functions, and dependency function, respectively.
Note that functions f and G are over the same domain in the definition; h needs not depend on all of the functions in G.
The necessary and sufficient condition of the existence of the dependency function h is given as follows.
Proposition 2.2 [11] Given a target function f and base functions G, let h0 = {a ∈ Bn : a = G(b) and f (b) = 0, b ∈ Bm} and h1 = {a ∈ Bn : a = G(b) and f (b) = 1, b ∈ Bm}. Then h is a feasible dependency function if and only if {h0 ∩ h1} is empty. In this case, h0, h1, and Bn\{h0∪ h1} are the off-set, on-set, and don’t-care set of h, respectively.
By Proposition 2.2, one can not only determine the existence of a dependency func- tion, but also deduce a feasible one. A SAT-based formulation of functional depen- dency was given in [16]. It forms an important ingredient in part of our computation.
2.3. Satisfiability and Interpolation
2.3 Satisfiability and Interpolation
2.3.1 Conjunctive Normal Form
A formula is said to be in Conjunctive Normal Form (CNF) if it is a conjunction of clauses. Each clause is a disjunction of one or more literals, where a literal is the occurrence of a variable x or its complement ¬x. Without loss of generality, we shall assume that there are no any equivalent or complementary literals in one clause. For example, the formula (x + ¬y)(¬x + y) is a CNF representation of the equality function for variable x and y. The formula has 2 clauses, and each clause has 2 literals.
The CNF is similar to Product of Sum (POS) representation in the circuit theory.
It is one of the major contributing factor for the recent success of the Boolean Satisfiability (SAT) problem. The CNF representation of a SAT problem provides a data structure for efficient implementation of various techniques used in most popular SAT solvers.
2.3.2 Circuit to CNF Conversion
The CNF formula of a combinational circuit can be constructed in linear time by introducing some intermediate variables. The CNF formula of a combinational cir- cuit is the conjunction of the CNF formulas for each gate output, where the CNF
2.3. Satisfiability and Interpolation
formula for each gate denotes the valid input and output assignments of the gate.
The detail information for converting a circuit to CNF representation can be found in [27].
ϕ = (a + ¬c)(b + ¬c)(¬a + ¬b + c) (c + ¬e)(d + ¬e)(¬c + ¬d + e)
(a) Consistent assignment
ϕ0 = (a + ¬c)(b + ¬c)(¬a + ¬b + c) (c + ¬e)(d + ¬e)(¬c + ¬d + e)(¬e)
(b) With property e = 0
Figure 2.2: Circuit to CNF representation
Figure 2.2 shows an example of a simple circuit with the corresponding CNF formula indicating the truth assignment and the CNF formula with some given properties. As can be seen, the CNF formula can be divided into two parts, each part is a set of clauses for one particular gate. Two gates share the same interme-
2.3. Satisfiability and Interpolation
diate variable c. So the CNF representation of the circuit is the conjunction of the sets of clauses for each particular gate. Hence, given a combinational circuit it is straightforward to construct the CNF formula for the circuit as well as the CNF formula for proving a given property of a the circuit.
2.3.3 Propositional Satisfiability
In the beginning of this subsection, we firstly define some terminologies of proposi- tional satisfiability problem in the scope of modern SAT solvers. Let V = {v1, . . . , vk} be a finite set of Boolean variables, where each vi ∈ B = {0, 1}. A SAT instance is a set of Boolean formulas in CNF. A assignment over V gives each variable vi ∈ V a Boolean value either True(1) or False(0). A SAT instance is said to be satisfiable is there exists an assignment over V such that the CNF formula is evaluated as True.
More specifically, each clause of the CNF formula is evaluated as True. Otherwise, it is unsatisfiable. A SAT problem is a decision problem asked the given SAT instance is satisfiable or not. A SAT solver is designed to answer the SAT problem.
SAT was the first known NP-complete problem, as proved by Stephen Cook in 1971 [5]. The problem remains NP-complete even if the SAT instance is written in conjunctive normal form with 3 variables per clause, yielding the 3SAT problem.
Most of the popular modern SAT solvers use David-Putnam-Logemann-Loveland (DPLL) [8, 9] procedure as the basic algorithm to solve the SAT problem. DPLL is tested to solve large propositional satisfiable problem efficiently.
2.3. Satisfiability and Interpolation
The basic idea of DPLL procedure in solving a SAT problem is to branch on variables V until a conflict arises or a satisfying assignment is derived. Once a conflict arises, DPLL chooses another branch to keep testing the satisfiability. If the variable value on a certain branch results in a satisfying assignment over the SAT problem, the DPLL procedure stops the rest branching step immediately, then returns the answer satisfiable as well as the satisfying assignment. Otherwise, DPLL procedure needs to test all the branches to report the unsatisfiability. In this thesis, we use MiniSat [10] developed by Niklas E´en and Niklas S¨orensson as the underlying SAT solver in the experiments.
2.3.4 Refutation Proof
Some of the modern SAT solvers generate a refutation proof to demonstrate the unsatisfiability of a SAT instance. Refutation proof is a series of resolution steps show the unsatisfiable SAT instance will eventually imply an empty clause. Each step in these series of steps called resolution. The detailed definition of resolution and other terminology are shown in this subsection.
Definition 2.4 Let (v ∨ c1) and (¬v ∨ c2) are two clauses. Where v is a Boolean variable, v and ¬v are literals, c1 and c2 are disjunction of other literals different from v and ¬v. The resolution of these two clauses on variable v is a new clause (c1∨ c2). The variable v here is called a pivot variable, and (c1∨ c2) is resolvent. The resolvent exists when only one pivot variable exists. In other word, the resolvent
2.3. Satisfiability and Interpolation
can not be a tautological clause.
For example, clauses (a ∨ ¬b) and (¬a ∨ b) on variable a has no resolvent since clause (¬b ∨ b) is tautological. Also, resolution on variable v over two given clauses is similar to existential quantification on variable v. That is, ∃v.(v ∨ c1) ∧ (¬v ∨ c2) = (c1∨ c2).
Proposition 2.3 The conjunction of (v ∨ c1) and (¬v ∨ c2) implies its resolvent (c1∨ c2).
(v ∨ c1) ∧ (¬v ∨ c2) ⇒ (c1∨ c2)
Theorem 2.1 For an unsatisfiable SAT instance, there exists a resolution refutation steps leads to an empty clause.
Proof. Since every unsatisfiable SAT instance must imply a contradiction that is an empty clause. Hence, theorem 2.1 can be proved directly by Proposition 2.3.
There must exists some resolution steps leads to an empty clause. 2
Often, only a subset of clauses of an unsatisfiable SAT instance participate in the resolution steps, which lead to an empty clause. This subset of clauses of a unsatisfi- able SAT instance is called unsatisfiable core, the detailed definition of unsatisfiable core will be described later.
Definition 2.5 A refutation proof of an unsatisfiable formula ϕ is a directed acyclic graph (Vϕ, Eϕ). Where Vϕ is a set of clauses, and the SAT instance of formula ϕ is
2.3. Satisfiability and Interpolation
a clause set C, such that
• for each vertex k ∈ Vϕ, either
– k ∈ C, and k is a root, or
– k has exactly two predecessors, k1 and k2, and k is the resolvent of k1 and k2, and
• there exists an empty clause be the unique leaf of (Vϕ, Eϕ).
Theorem 2.2 If there is a refutation proof of unsatisfiability for clause set C, C must be unsatisfiable.
Definition 2.6 For an unsatisfiable SAT instance of formula ϕ, the unsatisfiable core of the formula is the subset of clauses whose conjunction is still unsatisfiable.
The unsatisfiable core is called minimal if all the subsets of it are satisfiable. The unsatisfiable core is called minimum if it contains the smallest number of the original clauses to be still unsatisfiable.
The intuition behind the unsatisfiable core is that, these subset of the original clauses are sufficient causing whole CNF formula to be constant F alse. The as- signment of variables not in the unsatisfiable core will not effect the unsatisfiability of the formula. Note that the unsatisfiable core of a unsatisfiable formula is not unique, there are one or many different unsatisfiable cores of a particular unsatis- fiable formula. In the point of view of a resolution refutation proof, the simplest
2.3. Satisfiability and Interpolation
unsatisfiable core is the subset of root clauses that has a path to the unique empty leaf clause.
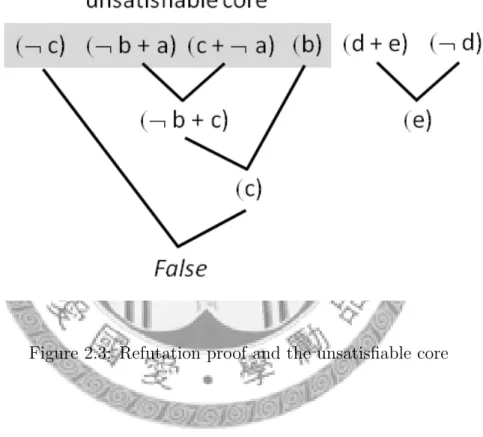
Figure 2.3 illustrates the resolution refutation proof, and one of the simplest unsatisfiable core of the unsatisfiable formula ϕ = (¬c)(¬b+a)(c+¬a)(b)(d+e)(¬d).
Figure 2.3: Refutation proof and the unsatisfiable core
2.3.5 Craig interpolation
Theorem 2.3 (Craig Interpolation Theorem) [6]
Given two Boolean formulas ϕA and ϕB, with ϕA ∧ ϕB unsatisfiable, then there exists a Boolean formula ψA satisfy the 3 properties that
2.3. Satisfiability and Interpolation
• ψA referring only to the common variables of ϕA and ϕB
• ϕA⇒ ψA
• ψA∧ ϕB is unsatisfiable.
The Boolean formula ψA is referred to as the interpolant of ϕA with respect to ϕB. Some modern SAT solvers, e.g., MiniSat [10], are capable of constructing an interpolant from an unsatisfiable SAT instance. Figure 2.4 illustrates the solution space of ϕA, ϕB and the interpolant ψA. Note that the smallest interpolant is ϕA itself and the largest interpolant is ¬ϕB.
Figure 2.4: Craig interpolation
There are many researches [20, 21] show that we can build an interpolant from the resolution refutation proof of an unsatisfiable SAT instance in linear time to the
2.3. Satisfiability and Interpolation
proof size itself. In this thesis, we use the method described in [20] as our underlying way to get an interpolant.
Suppose we are given a pair of clause sets (A, B) derived from the formula ϕ and a refutation proof of unsatisfiability (Vϕ, Eϕ) of A ∪ B. For the clause sets (A, B), a variable is said to be global if it appears in both A and B, and local to A if it appears only in A. Other variables are considered irrelevant in the interpolant construction procedure. Similarly, a literal is global or local depending on the variable it contains.
Moreover, given any clause c, we use g(c) to denote the disjunction of the global literals in c.
The linear time algorithm for interpolant construction mentioned in [20] is in the following rules.
• Let f (c) be a boolean formula for all vertices c ∈ Vϕ
• if c is a root, then
– if c ∈ A then f (c) = g(c)
– if c ∈ B then f (c) is the constant T rue
• if c is the intermediate vertex, let c1 and c2 be the predecessors of c, and v be their pivot variable.
– if v is local to A, then f (c) = f (c1) ∨ f (c1) – else, f (c) = f (c1) ∧ f (c1)
2.3. Satisfiability and Interpolation
Since every unsatisfiable SAT instance implies the constant F alse, so the last step of the resolution refutation proof resolve a constant F alse. Hence, f (F alse) is a boolean function constructed from the above rules. Also, it is the interpolant of the unsatisfiable clause sets A ∪ B and the corresponding refutation proof (Vϕ, Eϕ).
Figure 2.5 illustrates the resolution refutation proof and detailed construction step of an unsatisfiable formula ϕ = (¬c)(¬b + a)(c + ¬a)(b).
Note that the interpolant construction can be done in O(N + L) through the topology of the refutation proof, where N is the number of vertices in Vϕ and L is the total literal number in the resolution refutation proof (Vϕ, Eϕ). We need the complexity of L since each time a resolvent is going to be generated, we have to scan all of the literals in the predecessor clauses to find the pivot variable.
2.3. Satisfiability and Interpolation
A = (¬b + a)(c + ¬a) B = (b)(¬c)
local = a global = b, c
Figure 2.5: Interpolant construction of an unsatisfiable formula ϕ = (¬c)(¬b+a)(c+
¬a)(b)
Chapter 3
Main Algorithms
We show that Ashenhurst decomposition of a set of Boolean functions {f1, . . . , fm}, or in some cases we called it m-output Ashenhurst decomposition, can be achieved by SAT solving, Craig interpolation, and functional dependency. Whenever a non- trivial decomposition exists, we derive functions hi and g automatically for fi(X) = hi(XH, XC, g(XG, XC)) under the corresponding variable partition X = {XH|XG|XC}.
3.1 Single-Output Ashenhurst Decomposition
We first consider single-output Ashenhurst decomposition for a Boolean function f (X) = h(XH, XC, g(XG, XC)).
3.1. Single-Output Ashenhurst Decomposition
3.1.1 Decomposition with Known Variable Partition
Proposition 2.1 in the context of Ashenhurst decomposition of a single function can be formulated as satisfiability solving as follows.
Proposition 3.1 A completely specified Boolean function f (X) can be expressed as h(XH, XC, g(XG, XC)) for some functions g and h if and only if the Boolean formula
(f (XH1, XG1, XC) 6≡ f (XH1, XG2, XC)) ∧ (f (XH2, XG2, XC) 6≡ f (XH2, XG3, XC)) ∧
(f (XH3, XG3, XC) 6≡ f (XH3, XG1, XC)) (3.1)
is unsatisfiable, where a superscript i in Yi denotes the ith copy of the instantiation of variables Y .
Observe that Formula (3.1) is satisfiable if and only if there exists more than two distinct column patterns in some matrix of the decomposition chart. Hence the unsatisfiability means there are at most two different kind of column patterns in every matrix of the decomposition chart. Since the g function has only one output bit, so the unsatisfiability of Formula (3.1) is exactly the existence condition of Ashenhurst decomposition.
The intuition why we only allowed at most two different kind of column patterns in a matrix can be realized using the decomposition chart. Function g can be
3.1. Single-Output Ashenhurst Decomposition
treated as a mapping from a input assignment a ∈ [[XG, XC]] to the Boolean value 0 or 1. Since every column index of a matrix in the decomposition chart is exactly a input assignment a ∈ [[XG, XC]], if there are more than two different kind of column patterns, it cannot be mapped using binary value 0 and 1.
Note that, unlike BDD-based counterparts, the above SAT-based formulation of Ashenhurst decomposition naturally extends to non-disjoint decomposition. It is because the unsatisfiability checking of Formula (3.1) essentially tries to assert that under every valuation of variables XC the corresponding matrix of the decomposition chart has at most two column patterns. In contrast, BDD-based methods have to check the decomposability under every valuation of XC separately.
Now we have known that the decomposability of function f can be checked through SAT solving of Formula (3.1), the derivations of functions g and h can be realized through Craig interpolation and functional dependency, respectively, as shown below.
To derive function g, we partition Formula (3.1) into two sub-formulas
ϕA = f (XH1, XG1, XC) 6≡ f (XH1, XG2, XC), and (3.2) ϕB = (f (XH2, XG2, XC) 6≡ f (XH2, XG3, XC)) ∧
(f (XH3, XG3, XC) 6≡ f (XH3, XG1, XC)). (3.3)
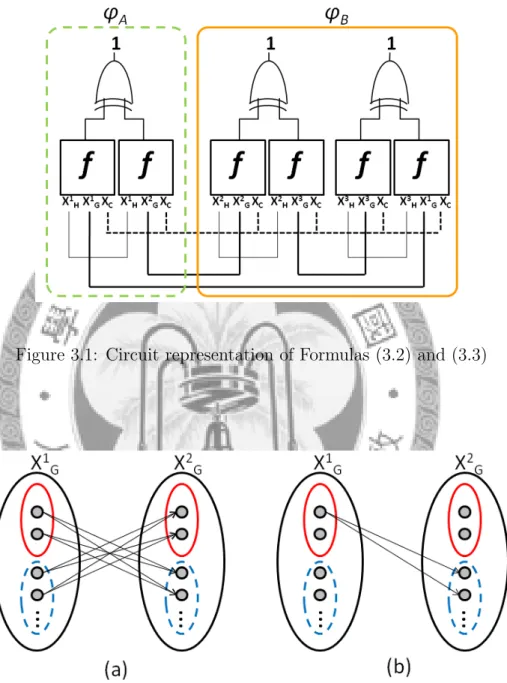
Figure 3.1 shows the corresponding circuit representation of Formulas (3.2) and (3.3). The circuit representation can be converted into a CNF formula in linear
3.1. Single-Output Ashenhurst Decomposition
time [27], and thus can be checked for satisfiability.
Figure 3.1: Circuit representation of Formulas (3.2) and (3.3)
Figure 3.2: (a) Relation characterized by ψA(XG1, XG2, c) for some c ∈ [[XC]] (b) Relation after cofactoring ψA(XG1 = a, XG2, c) with respect to some a ∈ [[XG1]]
Lemma 3.1 For function f (X) decomposable under Ashenhurst decomposition
3.1. Single-Output Ashenhurst Decomposition
with variable partition X = {XH|XG|XC}, the interpolant ψA with respect to ϕA of Formula (3.2) and ϕB of Formula (3.3) corresponds to a characteristic function such that,
1. for ϕA satisfiable under some c ∈ [[XC]], there exist b1 ∈ [[XG1]] and b2 ∈ [[XG2]]
such that ψA(b1, b2, c) = 1 if and only if the column patterns indexed by b1
and b2 in the matrix of c of the decomposition chart of f are different;
2. for ϕA unsatisfiable under some c ∈ [[XC]], there is only one column pattern in the matrix of c of the decomposition chart of f ;
3. for ϕA unsatisfiable under all c ∈ [[XC]], or in other word, unsatisfiable ϕA, variables XG are not the support variables of f and thus {XH|XG|XC} is a trivial variable partition for f .
Proof. For f decomposable, ϕA∧ ϕB is unsatisfiable by Proposition 3.1. Moreover from Theorem 2.3, we know the interpolant ψA of the unsatisfiability proof is a function that refers only to the common variables, XG1 ∪ XG2 ∪ XC, of ϕA and ϕB.
We analyze what the characteristic function ψA means for ϕA satisfiable under some c ∈ [[XC]]. Let ai ∈ [[XHi ]], bi ∈ [[XGi ]], for i = 1, 2, 3, in the following discussion.
Let Rc⊆ [[XG1]] × [[XG2]] be the relation that ψA(XG1, XG2, XC = c) characterizes. On the one hand, since ϕA ⇒ ψA, we know that ψA is an over-approximation of the solution space of ϕAprojected to the common variables XG1 ∪ XG2 ∪ XC. So Rc must
3.1. Single-Output Ashenhurst Decomposition
contain the set
{(b1, b2) | f (a1, b1, c) 6= f (a1, b2, c) for some a1}.
That is, a pair (b1, b2) must be in Rc if the columns indexed by b1 and b2 of the matrix of c in the decomposition chart of f are of different patterns.
On the other hand, since ψA∧ ϕB is unsatisfiable, the solution space of ψA is disjoint from that of ϕB projected to the common variables. Suppose that val- uations a2, a3, b1, b2, b3 satisfy ϕB under c, that is, f (a2, b2, c) 6= f (a2, b3, c) and f (a3, b3, c) 6= f (a3, b1, c). Then the columns indexed by b2 and b3 of the matrix of c in the decomposition chart of f are of different column patterns, and the column indexed by b3 and b1 has the same property. Since we know that f is decomposable under Ashenhurst decomposition, that means there are at most two different kind of column patterns for every matrix under c. So the columns indexed by b1 and b2
of the matrix of c must be the same column pattern. For ψA∧ ϕB unsatisfiable, it represents that (b1, b2) cannot be in Rc if the columns indexed by b1 and b2 are of the same pattern. We can now conclude that the interpolant ψA(XG1, XG2, c) charac- terize all different kind of column patterns indexed by (b1, b2), where b1 ∈ [[XG1]] and b2 ∈ [[XG2]] for some matrix of c.
Figure 3.2(a) illustrates the relation that ψA(XG1, XG2, c) characterizes for some c ∈ [[XC]]. The left and right sets of gray dots denote the elements of [[XG1]] and [[XG2]], respectively. For function f to be decomposable, there are at most two equivalence classes for the elements of [[XGi]] for i = 1, 2. In Figure 3.2(a), the two clusters
3.1. Single-Output Ashenhurst Decomposition
of elements in [[XGi]] signify two equivalence classes of column patterns indexed by [[XGi ]]. An edge (b1, b2) between b1 ∈ [[XG1]] and b2 ∈ [[XG2]] represents that b1 is not in the same equivalence class as b2, they have different kind of column patterns. In this case, ψA(b1, b2, c) = 1. Since all of the different column pattern pairs (b1, b2) in the matrix of c will be characterized by the interpolant ψA(XG1, XG2, c). So every element in one equivalence class of [[XG1]] is connected to every element in the other equivalence class of [[XG2]] as Figure 3.2(a) shows.
According to the above analysis, we conclude that, for ϕA satisfiable under c ∈ [[XC]], relation Rc characterizes exactly the set of index pairs (b1, b2) whose corresponding column patterns are different.
For ϕA unsatisfiable under some c ∈ [[XC]], it represents that there are no any different kind of column patterns in the matrix of c, so that there is only one column pattern in the matrix of c of the decomposition chart of f . Hence, under XC = c, the valuation of f is independent of the truth assignments of XG. No matter what different truth assignment of XG is, the value of f under the same truth assignment of XH is of the same. (In this case, ψA under XC = c can be an arbitrary function due to the solution space of ϕAis empty.) If ϕAis unsatisfiable under every c ∈ [[XC]], then the valuation of function f does not depend on XG, that is, XG are not the support variables of f .
Since the analysis holds for every c ∈ [[XC]], the lemma follows. 2
3.1. Single-Output Ashenhurst Decomposition
Next, we show how to derive function g from the interpolant ψA.
Lemma 3.2 For an arbitrary a ∈ [[XG1]], the cofactored interpolant ψA(XG1 = a, XG2, XC) is a legal implementation of function g(XG2, XC).
Proof. By Lemma 3.1, the interpolant ψA(XG1, XG2, XC) characterizes all different column pattern pairs in every matrix who has exactly two different kind of column patterns. Let γa(XG2, XC) = ψA(XG1 = a, XG2, XC) for some arbitrary a ∈ [[XG1]].
Then, under every such valuation c ∈ [[XC]], γa(XG2, c) characterizes the set of indices whose corresponding column patterns are different from the column pattern indexed by a. In other word, γa(XG2, c) characteristic either of the two equivalence classes of column patterns in the matrix of c.
Taking Figure 3.2(b) as an example, assume that a is the topmost element in [[XG1]]. After cofactoring, all the edges in Figure 3.2(a) will disappear except for the edges connecting a with the elements in the other equivalence class of [[XG2]].
On the other hand, for c ∈ [[XC]] whose corresponding matrix contains only one kind of column pattern. Since we know that XC = c is a don’t-care condition for function g, and thus γa(XG2, c) can be arbitrary.
From the above analysis, we can conclude that γa(XG2, XC) characterizes either the onset or the offset of function g(XG2, XC). So γa(XG2, XC) can be treated as the function g(XG2, XC) or negation of the function g(XG2, XC). After renaming XG2 to
XG, we get the desired g(XG, XC). 2
3.1. Single-Output Ashenhurst Decomposition
So far we have successfully derived function g by interpolation and cofactor operation. Next we need to compute function h. The problem can be formulated as computing functional dependency as follows. Let f (X) be our target function; let function g(XG, XC) we just derived and identity functions ıx(x) = x, one for each variable x ∈ XH∪ XC, be our base functions. So the computed dependency function is exactly our desired h. Since functional dependency can be formulated using SAT solving and interpolation [16], it well fits in our SAT-based computation framework.
Remark: For disjoint decomposition, i.e., XC = ∅. Rather than using functional dependency, we can derive the function h in a simple way.
Given two functions f (X) and g(XG) with variable partition X = {XH|XG}, our goal is to find a function h(XH, xg) such that f (X) = h(XH, g(XG)), where xg is the output variable of function g(XG). Let a, b ∈ [[XG]] with g(a) = 0 and g(b) = 1.
Then by Shannon expansion
h(XH, xg) = (¬xg∧ h¬xg(XH)) ∨ (xg∧ hxg(XH)),
where h¬xg(XH) = f (XH, XG = a) and hxg(XH) = f (XH, XG = b). The derivation of the offset and onset minterms of g is easy because we can pick an arbitrary minterm c in [[XG]] and see if g(c) equals 0 or 1. We then perform SAT solving on either g(XG) or ¬g(XG) depending on the value g(c) to derive another necessary minterm.
3.1. Single-Output Ashenhurst Decomposition
The above derivation of function h, however, does not scale well for decompo- sition with large |XC| because we may need to compute h(XH, XC = c, xg), one for every valuation c ∈ [[XC]]. There are 2|XC| cases to analyze. So when common variables exist, functional dependency may be a better way to compute function h.
The correctness of the so-derived Ashenhurst decomposition follows from Lemma 3.2 and Proposition 2.1, as the following theorem states.
Theorem 3.1 Given a function f decomposable under Ashenhurst decomposition with variable partition X = {XH|XG|XC}, then f (X) = h(XH, XC, g(XG, XC)) for functions g and h obtained by the above derivation.
Algorithm 1 Derive g and h with a given variable partition Input: f and a given variable partition X = {XH|XG|XC} Output: g and h
1: F ⇐ CircuitInstantiation(f, XH, XG, XC)
2: (ϕA, ϕB) ⇐ CircuitP artition(F )
3: P (XG1, XG2, XC) ⇐ Interpolation(ϕA, ϕB)
4: g(XG, XC) ⇐ Cof actor(P, a ∈ [[XG1]])
5: h ⇐ F unctionalDependency(f, g)
6: return (g, h)
Algorithm 1 summarizes the algorithms we used to derive the function g and h. Line 1-2 duplicate the original function f into 6 copies, and then partition it into two part, just as Figure 3.1 shows. Line 3-4 utilize interpolation technique to
3.1. Single-Output Ashenhurst Decomposition
derived a relation contain the information of pairs of distinct column patterns. Then using cofactor to get the g function we want. In line 5, we formulate the problem as computing functional dependency to get the h function.
3.1.2 Decomposition with Unknown Variable Partition
The construction in the previous subsection assumes that a variable partition X = {XH|XG|XC} is given. In this subsection, we will show how to automate the variable partition process within the decomposition process of function f . A similar approach was used in [17] for bi-decomposition of Boolean functions.
We introduce two control variables αxi and βxi for each variable xi ∈ X. In addition we instantiate the original input variables X into six copies X1, X2, X3, X4, X5, and X6. Let
ϕA = (f (X1) 6≡ f (X2)) ∧^
i
((x1i ≡ x2i) ∨ βxi) and (3.4) ϕB = (f (X3) 6≡ f (X4)) ∧ (f (X5) 6≡ f (X6)) ∧
^
i
(((x2i ≡ x3i) ∧ (x4i ≡ x5i) ∧ (x6i ≡ x1i)) ∨ αxi) ∧
^
i
(((x3i ≡ x4i) ∧ (x5i ≡ x6i)) ∨ βxi), (3.5)
where xji ∈ Xj for j = 1, . . . , 6 are the instantiated versions of xi ∈ X. Why αxi
and βxi are called control variables is because each of the control variable can enable of disable the corresponding clause. For example, a clause (a + b) associates with a control variable α results in a new clause (a + b + α). When α = 1, the clause






![Figure 3.2(a) illustrates the relation that ψ A (X G 1 , X G 2 , c) characterizes for some c ∈ [[X C ]]](https://thumb-ap.123doks.com/thumbv2/9libinfo/9607851.633535/42.892.159.796.430.803/figure-illustrates-relation-ψ-x-g-x-characterizes.webp)
