A New Approach to Construct Membership
Functions and Generate Fuzzy Rules from Training Instances
Shyi-Ming Chen* and Fu-Ming Tsai**
*Department of Computer Science and Information Engineering National Taiwan University of Science and Technology
Taipei, Taiwan, R. 0. C.
**Department of Electronic Engineering National Taiwan University of Science and Technology
Taipei, Taiwan, R. 0. C.
A b s M - In recent years, many researchers focused on the research topic of constructing fuzzy classification systems to deal with the Iris data classification problem. One of the methods to construct furzy classification systems is to construct membership functions at first, and then to generate fuzzy rules. I n this paper, we present a new method to construct membership functions and generate fuzzy rules from training instances based on the correlation coefficient threshold value the boundary shift value
r. and the center shift value 6 to deal with the Iris data
classification pmblem, where < E 10, 11, FE 10, I ] and S E [0, 11. The proposed method can get a higher average classification accuracy rate and generates fewer fuzzy rules than the existing methods.
I. INTRODUCTION
To develop a fuzzy classification system, the most important task is to constlllct membership functions and to find a set of suitable funy rules. There are two approaches to obtain fuvy rules. One of them is given directly by domain experts; the other is obtained through a machine learning process based on training instances. In recent years, many methods have been proposed to generate fuzzy rules 60m training instances [ I]-[SI, [10]-[17], [19]-[25].
In this paper, we present a new method for consbucting membership functions and generating fuzzy rules h m training data to deal with the Ins data [9] classification problem. The proposed method conshucts the membership functions and generates fuzzy rules h m training instances based on the comelation coefficient threshold value 5 the boundary shift value E and the center shfi value 6, where (E [0, I], E E [0, 11 and 6 E [0, I]. The experimental results show that the proposed method can get a higher average classification accuracy rate and generates fewer fuzzy rules than the existing
methods,
The rest of this paper is organized as follows. In Section 11, we briefly review basic concepts of f u q sets. In Section 111, we present a new method to conshuct membership functions and generate fuzzy rules h m training instances. In Section W, we compare the experimental results of the proposed method with the existing methods. The conclusions are discussed in Section V.
11. BASIC CONCEPTS OF FUZZY SETS
In this section. we briefly review basic concepts of fuzzy sets [26].
Definition 2.1: Let U he the universe of discourse, U = {xirx2, ..., x,}.Afuzzy set A o f t h e universeofdiscourseu can be represented as follows:
A=PA(XI)IXI + P A ( ~ z ) / ~ I + ... PA(^&., (1)
where pA is the membership function of the fuzzy set A, pA: U-[0, I], pA(xi) denotes the grade of membership of xi belonging to the fuzzy set A, andpA(xi)€ [0, I].
Definition 2 . 2 Let U be the universe of discourse, where U is an infinite set. A fuzzy set A of the universe of discourse U can be represented as follows:
A = I p ( x ) l x , X E U , (2) where pA is the membership function of the fuzzy set A,
PA: U-[O, I], pA(x,) denotes the grade of membership of xl
belonging to the fuzzy set A, andpA(x,)E [0, 11.
Definition 2.3: Let A and B be two fuzzy sets defined in
0-7803-8353-2/04/$20.00 0 2004 IEEE 831
the universe of discourse U. The union between the fuzzy sets A and B, denoted as AUB, is defined as follows:
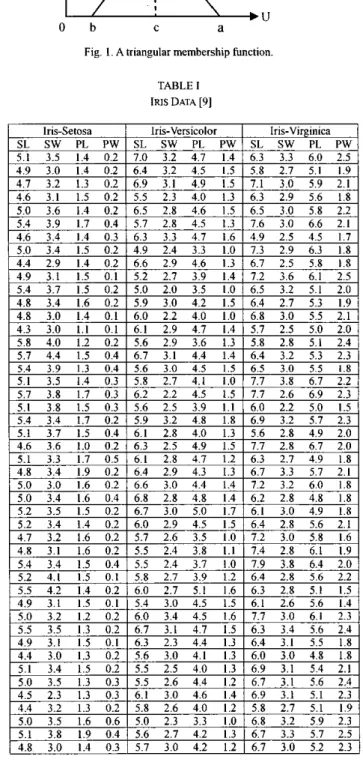
“h is called the left vertex of the triangular fuzzy set A;
a IS called the right vertex of the triangular fuzzy set A.
“ >1
.
1.0 _ _ _ _ _ _ _ _ _ _ _
U
TA,
PAUB(x) = “bA(x). pB(x))> t/
X EU, (3) where pA and p e are the membership functions of the fuzzy sets A and 9, respectively, pA: U-[O, I], and p ~ : U-[0, I].
Definition 2.4: Let A and B be two fuzzy sets defmed in the universe of discourse U. The intersection between the fuuy sets A and 9, denoted as AnB, is defmed as follows:
O b
Ca
Fig. I . Atriangular membership function
pAnB(x) = mink&), ~B(x)),
X EU, (4) where pA and pB are the membership functions of the fuzzy sets A and 9, respectively, pA: U-[0, I], andpB: U-[O, 11.
111. ANEW METHOD TO CONSTRUCT MEMBERSHIP FUNCTIONS AND GENERATE F U Z Y RULES FROM
” l N G INSTANCES
In this section, we present a new method to construct membership functions and generate fuzzy rules from training instances to deal with the Iris data [9] classification problem. The Iris data contains 150 instances having 4 input attributes, i.e., Sepal Length (SL), Sepal Width (SW), Petal Length (PL) and Petal Width (PW) as shown in Table 1. There are three species of flowers (i.e., Iris-Setosa, Iris-Versicolor and Iris-Virginica) in the Iris data. Table I1 shows the maximum attribute value and the minimum attribute value of the input attributes of the Iris data, respectively.
Assume that the ftb training instance a, has four input amibute values xi.ser4 L ~ ~ ~ u I , x,sCpd
Mdth, X~,FW~ ~ “ ~ 6 , x,.rcM
Wldthr
and one output attribute value yi shown as follows:
% =
((XiSepal Length, xisepal Wid& %,Pea Lengtb XiPetal W d dyih where
Lmgthdenotes the attribute value of the attribute “Sepal L e n g t h of the ith training instance;
mdtb denotes the attribute value of the attribute “Sepal Width of the ith training instance; denotes the attribute value of the attribute “Petal Length” of the ith training instance; x , ~ , , ~
Widthdenotes the attribute value of the attribute “Petal Width” of the ith training instance; y, denotes the species of flower of the ith training instance, where y i c (Iris-Setosa, Iris-Versicolor, Iris-Virginica} and 1 s i 2 150. The type of membership functions we used in this paper is the triangular membership function, as shown in Fig. 1, where the membership function of the triangular fuzzy set A can be represented by a triple (b, c, a), where “c” is called the center of the triangular fuzzy set A;
TABLE I
INS DATA [9]
5.1 3.8 1.6 0.2 5.3 3.7 1.5 0.2 5.0 3.3 1.4 0.2 4.6 3.2 1.4 0.2
5.7 2.9 4.2 1.3 6.3 2.5 5.0 1.9 1 r 1, the stronger the linear relationship between the 5.1 2.5 3.0 1 . 1 6.2 3.4 5.4 2.3 variables x and y; rxy = 0 implies no linear correlation
5.7 2.8 4.1 1.3 5.9 3.0 5.1 1.8 between the variables x and y . A positive value of the
6.2 2.9 4.3 1.3 6.5 3.0 5.2 2.0
Amibute Value
In the following, we review the defmition of the correlation coefficient from [IS]. Sometimes, we wish to obtain an indicator of the degree of strength of the linear relationship between two variables x and y. The correlation coefficient r can be used to measure the degree of strength of the linear relationship between two variables x andy. Assume that there are n instances, n l = (xl. yi), nz = (x2, y2), n3 = (x3. y3), .... n. = (x”, y”), where xi, xz, x3, .._, and x, are the values of the variables x;yl. yz,yi, . ._, andy.are the values ofthe variabley, then the correlation coefficient r between the variables x andy is defined as follows:
I = I
S I ?
= 1 ( y, - U )
9,=I
variables x andy.
(3) The closer the correlation coefficient rJy is to 0, the weaker the degree of strength of the linear relationship between the variables x andy.
Assume that the correlation coefficient threshold value, the boundary shift value, and the center shift value given hy the user are r, Eand 6, respectively, where C E [0, I], E € [0, I] and 6 E 10, I]. The correlation coefficient threshold value
6 is used to test which attributes can be used to deal with the classification; the boundary shift value E is used to shift the right vertex and the left vertex of a membership function; the center shift value 6 is used to shift the center vertex of a membership function, where E [0, 11, E € [0, I] and 6 E [0, I]. The proposed algorithm is now presented as follows:
Step 1: Assign an integer number to each. species of the training instances, where we assign the integer number “ I ” to the species “Iris-Setosa” of the training instances, assign the integer number “2” to the species “Iris-Versicolor” of the training instances, and assign the integer number “3” to the species “Iris-Virginica” of the training instances.
Step 2: /* Calculate the correlation coefficient between each attribute and each species of the training instances, and then calculate the absolute value of the correlation coefficient. */
FOR each attribute A DO
calculate the correlation coefficient r’ between attribute A and the corresponding hteger of each species of the training instances;
(7)
(9)
The characters of the correlation coefficient r.v are described as follows:
(I) The value of correlation coefficient rrV is between -I and+I.
(2) The correlation coefficient rw can be used to indicate the degree of strength of the linear relationship between the variables x and y; the larger the value of
]FA’= SL THEN let rsL= I r’l;
IF A = SW THEN let rsw= I r’l;
let rpL= I r’l;
let rpw= I r’l IF A = PL THEN I F A = PW THEN END.
Step 3: /* Find useful attributes to deal with the classification. */
IF rsL is larger than the coefficient threshold value r,
where < E [0, I ] THEN the attribute SL is a useful attribute to deal with the classification;
IF rsw is larger than the coefficient threshold value 5.
where [0, I] THEN the attribute SW is a useful attribute to deal with the classification;
833
IF rPL is larger than the coefficient threshold value 6,
where C,E [0, I ] THEN the attribute PL is a useful attribute to deal with the classification;
IF rpw is larger than the coefficient threshold value C,, where <E [0, I] THEN the attribute PW is a useful attribute to deal with the classification.
Step 4: /* Find the maximum attribute value a of each attribute of each species of the training instances; find the minimum attribute value b of each attribute of each species of the training instances: find the average attribute value e of each attribute of each species of the training instances. */
FOR each species of the training instances DO FOR each useful amibute A obtained in Step 3 DO
find the maximum athibute value a of the amibute A of the w i g instances:
f i d the minimum attribute value b ofthe amibute A of the mining instances;.
fmd the average amibute value e of the attribute A of the hainiig instances
END END.
Step 5: /* Calculate the left vertex a’ and the right vertex b’
of each membership function of each attribute of each species. */
’FOR each species of the training instances DO FOR each useful attribute A obtained in Step 3 DO
fmd the number Nl of the W i g instances whose attribute value of the attribute A of each species is equal to the maximum attribute value a of the attribute A
fmd the number Nz of the hainimg instances whose attribute value of the attribute A of each species is equal to the minimum attribute value b of the attribute A;
let a’= a + NI x E, where
Eis the boundary shift value given hy the user and E € [0, I]:
let b’= b - Nz x E, where
Eis the boundary shift value given by the user and E € [O, I]
END END.
Step 6: /* Calculate the center vertex c’ of the membership function of each attribute. */
FOR each species of the training instances DO FOR each useful attribute A obtained in Step 3 DO
IF (NI is larger than N,) OR (N2 is larger than NI) THEN let the center vertex e’ of the membership function of the attribute A be equal to c + (N1 - Nz) x 6;
IF NI is equal to NI THEN let the center vertex e’ of the membership function of the attribute A be equal to e
END
END.
Step 7: /* Based on the right vertex a’, the left vertex b’, and the center vertex e’ obtained in Step 5 and Step 6, construct the membership function of each attribute of each species. */
FOR each species of the training instances DO FOR each useful attribute A obtained in Step 3 DO
construct the membership function (a’, E’, b’) of the attribute A
END END.
Step 8: /* For each species of the training instances, generate a fuzzy rule. */
Assume that the left vertex, the center vertex and the right vertex of the membership functions of attribute TI of the species S is (al, b,, cl); the left vertex, the center vertex and the right vertex of the membership functions of amibute T2 of the species S is (a2, b2, c2); the left vertex, the center vertex and the right vertex of the membership functions of amibute Tj of the species S is (aj, bj, cj); ... ; the left vertex, the center vertex, and the right vertex of the membership functions of attribute T, of the species S is (%, b,, c3, where S E {Iris-Setosa, Iris-Versicolor, Iris-Virginicaf , then generate the following fuzzy rule:
IF TI is (al, b,, cI) AND T2 is (a2, b2, c2) AND T; is (aj. b;, THEN the flower is S,
where S E {Iris-Setosa, Iris-Versicolor, Iris-Viinicaf . testing instance, shown as follows:
Step 1: FOR each generated fuzzy rule DO c;) AND . _ . AND T. is (a,,, b., c.)
In the following, we present a method to classify a
Calculate the membership grades of the testing instance that belongs to the membership functions of the linguistic terms appearing in the antecedent portion of the generated fuzzy rule;
Find the minimum value N of the membership grades of the testing instance belonging to the membership functions of the linguistic terms appearing in the antecedent portion of the generated fuzzy rule;
IF the inference result of the generated fuzzy THEN the degree of possibility that the testing instance belongs to the species L is N, where L E {Iris-Setosa, Iris-Versicolor, Iris-Viinica} and N E [O, 11
rule is the flower of the species L
END.
Step 2: Choose the rule which has the largest inference
degree of possibility. If the inference result of the chosen
96.273%
rule belongs to the flower of the species L, then the testing instance is classified into the species L, where L E (Iris-Setosa, Iris-Versicolor, Iris-Viinica}.
IV. EXPERIMENTAL RESULTS
Based on the proposed method, we have used Visual Basic Version 6.0 to implement a program on a Pentium 4 PC to deal with the Iris data classification problem, where the correlation coefficient threshold value <, the boundary shift value
Eand the center shift value 6 given by the user in Case 1 and Case 2 are 0.86, 113 and 0.025, respectively (i.e., 5 = 0.86,
E=1/3 and 6 = 0.025), and the correlation coefficient threshold value 5, the boundary shift value
Eand the center shift value 6 given by the user in Case 3 are 0.86,
1/3 and 0, respectively (i.e., 6 = 0.86,
E=I/? and S = 0):
Case 1: The system randomly chooses 75 instances from the Iris data as the training data set and lets the remaining 75 instances he the testing data set. After executing the program 200 runs, the average classification accuracy rate is 96.273% and the average number of generated fuzzy rules is 3.
Case 2: The system randomly chooses 120 instances from the Iris data as the training data set and lets the remaining 30 instances be the testing data set. After executing the program 200 runs, the average classification accuracy rate is 97.166% and the average number of generated fuzzy rules is 3.
Case 3: The system chooses I50 instances of the Iris data as the training data set and lets the same 150 instances be the testing data set. After executing the program 200 runs, the average classification accuracy rate is 97.333% and the average number of generated fuzzy rules is 3.
In Table 111, we make a comparison of the average classification accuracy rate and the average number of generated fuzzy rules for different methods. From Table 111, we can see that the proposed method can get a higher average classification accuracy rate than the existing methods. Furthermore, We also can see the proposed method generates fewer fuzzy rules than the existing methods.
TABLE 111
A COMPARISON
OFDIFFERENT METHODS
Hone-and-Lee's Method 1101
3
96.600%
96.820%
96.670%
97.333%
97.333%
(Training Data set: 75 Ins".
Testine Dam set: 75 Instances:
13
3
NIA*
NIA'
3 (Training Data Set: 75 Instances.
~
. .
(Training Data Set: 75 Instances, Executine. 200 Runs
)r h g wta set: 75 I ~ ~ c ~ s :
I Testing Dam Set: 75 Instances;
6.21 95,570%
Executing 200 Runs
)Wu-andChcn's Method 1241 (Training Data Sa: 75 Instm&;
Testing Dam set: 75 Instances;
Executing 200 Runs ) Tsa-andChen's Method [22]
(Training Data Set: 75 Instances.
resting Dam set: 75 Instances:
Executing 200 Runs
)The Propored Method (Training
~ a t a set: 75 htstances, resring Dacl Set: 75 Jmtanca Executing 2W Runs; Conelation Coefficient Threshold Value i
=0.86:
Boundq Shifl Value
E=In:
Center ShiflValue6=0.025) Castro's Method 121 (Training Data Set: 120 Instances, Testing Data Set: 30 Instances; 7 Labels:
Executing 10 Runs)
The Proposed Method (Tramkg Data Set: 30 Instances: Executing 200 Runs; Conelation Coefficient Threshold Value i
=0.86:
Bounday Shill Value
E4 1 3 : Center ShiflValue6=0.025) Hong-andChenS Method [ I l l (Training am
set:150
I ~ g n c e s ,rpsting m, s e ISO in~gncff) Hong-andChen's Methcd [I21 (Training Data Set 1% Instmcer.
Testing h t a Set: 150
Insgnces)The Propored Method (Training Dam set: 150
InstancesTesting
Data
set: 1%
Instances;Correlation Coeficient Threshold Value < = 0.86; Boundary Shill Value
E=I/;; Center Shifl Value 6
=
0)
~ a t a