Mining Indirect Associations over Data Streams
Chun-Hao Chen
Dept. of Computer Science and Information Engineering Tamkang University
Taipei 251, Taiwan, R.O.C. chchen6814@gmail.com
Wen-Yang Lin, Yi-Ching Chen, and He-Yi Li
Dept. of Computer Science and Information EngineeringNational University of Kaohsiung Kaohsiung 811, Taiwan, R.O.C.
wylin@nuk.edu.tw
Abstract—Indirect association is a new type of infrequent pattern, which provides a new way for interpreting the value of infrequent patterns and can effectively reduce the number of uninteresting infrequent patterns. The concept of indirect association isto “indirectly”connecttwo rarely co-occurred items via a frequent itemset called mediator, and if appropriately utilized it can help to identify real interesting “infrequent itempairs” from databases. All of the literature on indirect association mining, to our best knowledge, is confined to the traditional, relatively static database environment; no research work has been conducted on mining indirect associations over data streams. In this paper, we propose an approach, namely MIA-LM (Mining Indirect Association over a Landmark Model) algorithm, for mining indirect associations over data streams. The proposed method can not only discover indirect associations over data streams efficiently, but also guarantee the error of derived itemsets not to exceed a user-specified parameter. Experiments on real web-click stream are also made to show the effectiveness and efficiency of the proposed approach.
Keywords—data stream mining, indirect association, indirect itempair, landmark window model.
I. INTRODUCTION
In recent years, due to the rapidly improvement of informatics techniques, a new continuous data collection approach, namely data stream, is applied widely to different applications, such as sensor networking, intrusion detection, traffic controlling, financial analysis and earthquake prediction [1, 2, 6]. As usual, pattern mining in data stream for researcher is the most interesting field as in the traditional data mining fields. Most data stream mining approaches are focus on discovering frequent patterns [7, 10, 12].
However, infrequent patterns have also been shown their high valuable merits if they have certain characteristics such as negative correlation [13, 14]. It is a tough challenge for discovering infrequent patterns that have negative correlations since the number of infrequent patterns is significantly larger than that of frequent patterns. Another problem is how to avoid generating useless patterns. Although lots of approaches have been proposed for discovering infrequent patterns [5, 13, 19], they still can not deal the problems well.
Indirect association, proposed by Tan and Kumar [15], is a new type of infrequent pattern, which provides a new way for interpreting the value of infrequent patterns and can effectively reduce the number of uninteresting infrequent patterns. The concept of indirect association is to indirectly connect two
rarely co-occurred items via a frequent itemset called “mediator”,and ifappropriately utilized itcan help toidentify realinteresting “infrequentitempairs”from databases. Many approaches have been proposed and applied on different fields, including e-commerce, text mining, bioinformatics, etc. [3, 8, 9, 16, 17, 18]. To our best knowledge, all of the literatures on indirect association mining are confined to the traditional, relatively static database environment.
In this paper, we propose an algorithm, namely MIA-LM (Mining Indirect Association over a Landmark Model), for mining indirect associations over data streams. We show that: (1) the support error of an itemset is smaller than the support error threshold ; that is, no false negative itemsets will be generated by using the proposed approach; (2) if the mediator dependence threshold tdis set smaller than (tf), all possible indirect association patterns can be derived by the proposed approach. Experiments on real web-click stream are also made to show the effectiveness and efficiency of the proposed approach.
II. PROBLEMDEFINITION
Definition 1 An indirect association{x, y} | Mmeans that
an itempair {x, y} is indirectly associated via a mediator M if it satisfies the following three conditions:
1. Itempair support condition: sup({x, y}) < ts;
2. Mediator support condition: sup({x}M)tfand sup({y}
M)tf;
3. Mediator dependence condition: dep({x}, M) td and
dep({y}, M)td,
where ts, tf and td are itempair support threshold, mediator
support threshold and mediator dependence threshold,
respectively. dep(R, S) is a measure of the dependence between itemsets R and S. The well-known dependence function IS
measure IS(R, S) (= P(R, S) / sqrt(P(R)P(S))) is used in this
paper.
Definition 2 A transaction data stream TDS is any ordered
pair (T,), where a transaction T = tid, Itis a set of items It with identifier tid and ItI, where I = {i1, i2, …, im} is a set of items, and Δ isasequenceofpositive real time intervals.
In this paper, given a transaction data stream TDS and parameters, including an itempair support ts (0, 1), a mediator support tf (ts, 1), a mediator dependence td (0, 1) and a support error threshold (0, ts), we attempt to design
an algorithm for mining indirect associations over a transaction data stream with an acceptable error rate.
III. RELATEDWORK
A. Data Stream Mining
Since data stream is a continuous and unlimited incoming data along with time, different window models are used for collecting data for further analyzing. Suppose that we have a data stream D = (t1, t2,…,ti,…), where tidenotes the data arrived at time i. A window W represents the sequence of data arrived from time i to j, denoted as W[i, j] = (ti, ti+1,….,tj). In the literature, there are three different window models for data stream mining, i.e., landmark window, damped window and sliding window models [20]. The main advantage of the landmark window model is that it can exactly derive the patterns from incoming data because it holds the whole data completely. Many approaches have been proposed for different mining patterns over data streams, including frequent itemset [4, 7, 10, 12] and maximal frequent itemset [11].
The first work of mining frequent itemsets over data stream with landmark window model was proposed by Manku et al. [12]. They presented an algorithm, namely Lossy counting, for computing frequency counts exceeding a user-specified threshold over data streams. Although the derived frequent itemsets are approximate, the proposed algorithm guarantees that no false negative itemsets are generated. However, the performance of lossy counting is limited due to memory constraint.
In 2004, Li et al. proposed DSM-FI algorithm [10] for mining frequent itemsets. Similar to lossy counting, it divides data stream into blocks. In each time unit, a block is processed and read into memory. Because it is time-consuming for generating all subsets of itemsets, DSM-FI transforms a transaction into item-suffix transactions, which are then used to construct the corresponding item suffix trees for maintaining the itemsets and their counts. After processing all transactions in the block, itemsets are pruned if their counts are less than a predefined threshold. Those itemsets with support values larger than minimum support are then outputted when a user query request is issued. The DSM-FI algorithm guarantees that no false negative itemsets are generated and is superior to lossy
counting both on execution time and memory usage. B. Indirect Association Mining
In 2000, Tan et al. [15] proposed another concept for mining infrequent itemsets, namely indirect association, which provides a new way for interpreting the value of infrequent patterns and can effectively reduce the number of uninteresting infrequent patterns. Recently, indirect association has emerged as an important pattern because of its applications on different fields [3, 8, 9, 16, 17, 18]. Existing researches on indirect association mining can be divided into two categories, either focusing on proposing more efficient mining algorithms [3, 18] or extending the definition of indirect association for different applications [3, 8, 9].
The original indirect association mining approach proposed by Tan et al., called “INDIRECT”consists of two phases, frequent itemsets mining and indirect associations mining
phases. Any frequent itemsets mining approaches can be used in phase 1. The derived frequent itemsets are then used to generate indirect association patterns. However, it is time-consuming to generate all frequent itemsets before mining indirect association. Wan and An [18] proposed an approach, called HI-mine, for improving the efficiency of INDIRECT algorithm. The basic concept of HI-mine is to find all Indirect
Itempair Set (IIS) IIS = {a, b| sup({a})tfsup({b}) tf
sup({a, b}) < ts}. Each item of an itempaira, bin IIS is then used to find their Mediator Support Set (MSS), MSS(a) and
MSS(b). All possible mediators of itempair a, bcan be
generated by intersecting of MSS(a) and MSS(b). Chen et al. [3] also proposed an indirect association mining approach that was similar to HI-mine, namely MG-Growth. The differences between them are that the directed graph and bitmap are used in MG-Growth for constructing IIS. The corresponding mediator graphs of MSS are then generated for deriving indirect associations.
As to extending the definition of indirect association, Kazienko et al. applied indirect association on web pages recommendation system [8, 9]. Chen et al. [3] proposed an approach for mining indirect association of items by adding time feature of goods. Since each item has its lifespan, the relationships of new coming items can thus easily be discovered.
IV. THEPROPOSEDAPPROACH
In this section, we describe the proposed approach, namely
MIA-LM (Mining Indirect Association over a Landmark
Model). The strategy used by MIA-LM is maintaining the set of
frequent itemsets and candidate infrequent itempairs, from which generate the qualified indirect associations as user query is launched. To this end, MIA-LM adopts data structures modified from DSM-FI [10] and HI-mine [18] algorithms, including:
1. ISFI-forest: An ISFI-forest consists of a dynamic FI-list (Frequent Item list) and a set of dynamic IS-trees
(Item-Suffix tree).
2. FI-list: The information of each item is stored in FI-list, including item-id, item-count, block-id and head-link. The item-id records the identifier of inserted item, the
item-count records the number of occurrence of certain
item in transactions, the block-id is the identifier of which block when this item is inserted, and the
head-link points to the root node of the corresponding IS-tree.
3. IS-tree: An IS-tree consists of a dynamic header_table and a prefix tree structure. The header_table of an
IS-tree is composed of item-id, item-count, block-id, and head-link. The item-id records the identifier of inserted
item, the item-count is the number of occurrence of certain item in transactions, the block-id is the identifier of which block when this item is inserted, and the
head-link points to the first node with the same item in the
corresponding prefix tree. Each node of the prefix tree is composed of item-id, item-count, block-id, and
node-link. The first three components are the same as
header_table, and the fourth component is a pointer which points to the next node with the same item.
4. candidateIIS-list: If the support of a 2-itemset (itempair) is less than itempair support ts, no matter its subsets are frequent or not, it is stored in candidateIIS-list. Two attributes, item-id and item-count, of each itempair are recorded in candidateIIS-list.
A. Algorithm Description
The MIA-LM algorithm is described in Fig. 1. Four user-specified parameters must be given, including ts, tf, td, and . The MIA-LM algorithm first divides TDS into blocks that are denoted as {B1, B2, ..., Bn}. Each block Biconsists of a set of transactions represented as Bi{T1, T2, ..., Tk}, where k is set to 1/as suggested by [12]. Moreover, the total number of transactions N seen so far in the transaction data stream TDS is defined as N|B1||B2|... |Bl|, ln. The other four phases of the proposed algorithm (Lines 4~8) are Transaction
projection, Candidate IIS updating, Pruning ISFI-forest and Indirect Association Mining.
Algorithm Name: MIA-LM(TDS, ts, tf, td,)
Input: Transaction data stream TDS, an itempair support threshold
ts, a mediator support threshold tf, a mediator dependence
threshold tdand a support error threshold.
Output: Indirect Association Patterns P. Step:
1: Determine the size of block by using1/;
2: Divide TDS into blocks; each block contains 1/ transactions;
3: for each Bido
4: TrasactionProjection(Bi, i);
5: UpdateIIS(ISFI-forest, candidateIIS-list, ts, N);
6: PruneISFI-forest(ISFI-forest, i); 7: if user query request = ture
8: IndirectAssociationMining(ISFI-forest, candidateIIS-list, tf, td, ts, N);
9: endfor
Figure 1. The MIA-LM algorithm.
In the transaction projection phase, each transaction is loaded from the current block and projected to a set of item-suffix transactions. That is, a transaction T = {x1, x2, ..., xm} is projected to m items-suffix transactions that are t1= {x1, x2,…,
xm}, t2= {x2, x3,…,xm}, …, tm-1= {xm-1, xm} and tm= {xm}. These item-suffix transactions are then inserted into the corresponding IS-tree and FI-list according to the first item of each item-suffix transaction.
The main task of candidate IIS updating phase is to maintain the candidate Indirect Itempair Set (candidate IIS), which is used for deriving indirect associations in the last phase. Each 2-itemset in ISFI-forest whose count is less than ts*N is first put into candidateIIS-list. If a 2-itemset already exists in
candidateIIS-list, then update its count. Due to deleting existing
2-itemsets in candidateIIS-list in this phase may lead to false positive indirect itempairs, MIA-LM postpones the deletion till the fourth phase.
Memory usage is very important in a data stream mining environment. The purpose of pruning ISFI-forest phase is to prune itemsets whose counts are less than a specific threshold
k(currentblockid X.block_id + 1). The currentblockid and X.block_id denote the current block and the block where
itemset X is inserted. Since we choose the block size k to be the inverse of support error threshold , the threshold equals to (currentblockidX.block_id + 1). If the count of an itemset is less than this threshold, that itemset will have low probability to appear in subsequent blocks, and should be considered as infrequent itemset. In this case, the itemset is pruned to save the memory space.
In the indirect association mining phase, the proposed approach generates the indirect association patterns and response patterns to user by usingISFI-forest and candidateIIS
as HI-mine did. For each itempair {x, y} in candidateIIS, it first uses ISFI-forest to generate its corresponding frequent itemsets. If the mediator dependences of frequent itemsets are larger than the mediator dependence threshold td, they are put into mediator support set, denoted as MSS(x) and MSS(y). If an itemset Z appears both in MSS(x) and MSS(y), then an indirect association{x, y} | Zis generated.
B. An Example
Assume that we have a transaction data stream and the support error threshold is set at= 20%. The transaction data stream is divided into blocks, each of which contains five (= 1/0.2) transactions. The first two blocks are shown in Fig. 2.
... Block3 Time TID1 A,B,D TID2 B,C,D TID3 C,D TID4 B,D,E TID5 B,D Block1 Block2 TID6 A,C TID7 A,D,E TID8 B,C TID9 C,D,E TID10 A,D,E
Figure 2. The first two blocks of transaction data stream.
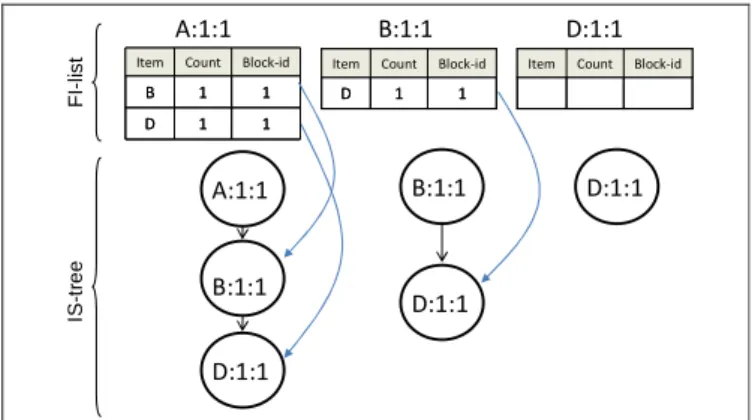
The first transaction TID1 = {A, B, D} in Block1 is projected to three item-suffix transactions, including {A, B, D}, {B, D} and {D}. These item-suffix transactions are inserted into the corresponding IS-tree and FI-list according to the first item of each item-suffix transaction. The updated ISFI-forest is shown in Fig. 3. B:1:1 D:1:1 Block-id Count Item B 1 1 D 1 1 Block-id Count Item B 1 1 D 1 1 A:1:1 D:1:1 B:1:1 D:1:1 A:1:1 B:1:1 D:1:1 1 1 D Block-id Count Item 1 1 D Block-id Count
Item ItemItem CountCount Block-idBlock-id
F I-lis t IS -t re e
Figure 3. The updated ISFI-forest after inserting TID1.
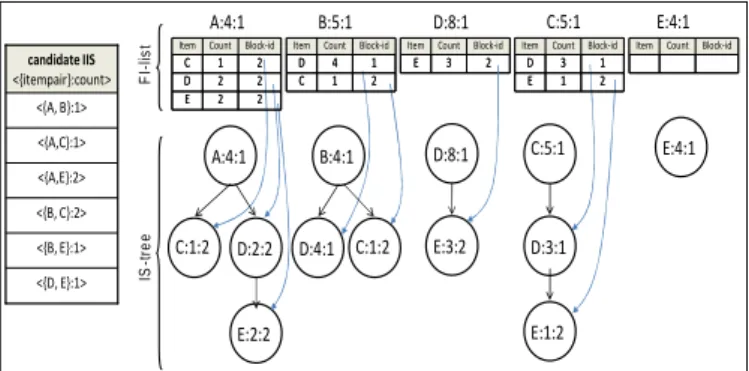
In candidate IIS updating phase, after processing transactions in current block, the proposed algorithm is then derived candidate indirect itempair set (candidate IIS) from the ISFI-forest. Take IS-tree of item A as an example, two 2-itemsets with their counts can be generated as <{A,B}:1> and
<{A,D}:1>. Assume the itempair support tsis set at 0.25, and since the number of transactions N processed from now on is five, the threshold of an itempair should be kept or removed is 1.25 (=0.25*5). Because the counts of these two 2-itemsets are smaller than 1.25, they are then put into candidate IIS. In the same way, other possible candidate indirect itempairs of items B, C, D and E can also be generated.
In the ISFI-forest pruning phase, the itemsets except 1-itemsets are pruned from ISFI-forest if their counts are less than (currentblockidx.block-id + 1). Take IS-tree of item A as an example. Two 2-itemsets with their counts and block id can be generated as {A, B}:1:1and {A, D}:1:1. Since
currentblockid1, an itemset will be pruned if its count is less
than 1 (1 –1 + 1). In this example, itemsets {A, B} and {A, D} are pruned from the IS-tree of item A. By repeating transaction projection, candidate IIS updating and ISFI-forest pruning phases, the Block2 can also be processed, and the
candidate IIS and the ISFI-forest are shown in Fig. 4.
A:4:1 D:4:1 B:5:1 D:8:1 C:5:1 A:4:1 B:4:1 D:8:1 C:5:1 D:3:1 E:4:1 E:4:1 C:1:2 D:2:2 E:2:2 E:3:2 C:1:2 E:1:2 2 1 C 2 2 D Block-id Count Item E 2 2 2 1 C 2 2 D Block-id Count Item E 2 2 1 4 D 2 1 C Block-id Count Item 1 4 D 2 1 C Block-id Count Item <{A,C}:1> candidate IIS <{itempair}:count> <{A, B}:1> <{A,E}:2> <{B, C}:2> <{B,E}:1> <{D, E}:1> <{A,C}:1> candidate IIS <{itempair}:count> <{A, B}:1> <{A,E}:2> <{B, C}:2> <{B,E}:1> <{D, E}:1> 2 3 E Block-id Count Item 2 3 E Block-id Count Item 1 3 D 2 1 E Block-id Count Item 1 3 D 2 1 E Block-id Count
Item ItemItem CountCount Block-idBlock-id
F I-lis t IS -t re e
Figure 4. The candidate IIS and ISFI-forest after processing Block1 and
Block2.
Assume that the user has a query request after processing Block2, the indirect association generating function is then used for deriving indirect associations by checking each itempair in candidate IIS with the ISFI-forest. Take itempair {B, E}:1in candidate IIS as an example, it first finds the mediator support sets of item B and E, i.e., MSS(B) and
MSS(E). Suppose tfand td are set at 0.3 and 0.5, respectively. From the IS-tree of item B, two candidate itemsetsBDand BCcan be generated. Since the count of itemset BDis large than 3 (=N*tf= 10*0.3), and the value of IS(B, D) is 0.632 ( 0.4[(0.5*0.8)1/2]) which also large than 0.5. Thus, itemDis put into MSS(B). In the same way, we can derive MSS(E) that contains itemD. Thus, from MSS(B) and MSS(E), we obtain an indirect associationB, E{D}, which is then outputted for user reference.
V. THEORETICALANALYSES
A. Maximal Estimated Support Error of Itemsets
An important characteristic of stream data is that only one pass of database scan is allowed. The proposed algorithm thus has to sacrifice the correctness of mining results to overcome this limitation. Let the true support of an itemset X, called
Tsup(X), be the fraction of transactions so far containing X, and
the estimated support of an itemset X, called Esup(X), is the fraction of transactions containing X accumulated by the
proposed algorithm. First we will show that the difference between Esup(X) and Tsup(X) is smaller than the support error threshold,if the block size is k set to 1/.
Theorem 1:0Tsup(X)Esup(X)
Proof: Let X.block_id be the identifier of the block when itemset X is inserted in current IS-tree. Then the difference between estimated count of itemset X, Ecount(X), and true count of itemset X, Tcount(X), is smaller than*(X.block_id 1)*k. Thus, we have
Tcount(X)Ecount(X) *(X.block_id 1)*k (1) Let curr_block be the current block. The difference between Esup(X) and Tsup(X) can be derived by using inequality (1) divides by current transaction size
k curr_block id block X X Esup X Tsup * 1) ( ) 1 _ . ( ) ( ) ( (2)
From inequality (2), we know that the minimum and maximum values of X.block_id are 1 and curr_block, respectively. It follows that the difference between Esup(X) and
Tsup(X) is smaller than the error threshold when the block
size is set to1/(= k).
B. Estimated Dependence Condition Analysis
Recall that an indirect association is an itempair {x, y} indirectly associated via a mediator M, denoted as{x, y} | M, if it satisfies the three conditions. One of the three conditions is mediator dependence condition, which is used to guarantee the high dependence of the item x and mediator M. We will show that if the mediator dependence threshold is set smaller than a specific value, then all possible indirect association patterns can be generated. Theorem 2: 1 ) ( ) ( ) , ( M Esup X Esup M X Esup tf
Proof: According to Theorem 1, we can easily derive the intervals of estimated support of itemset X, mediator M and itemset (XM) are Tsup(X)Esup(X) Tsup(X), Tsup(M) Esup(M) Tsup(M) and Tsup(XM) Esup(XM) Tsup(XM), respectively. By using these three intervals, the
range of estimated mediator dependence can be derived as follows: ) ) ( )( ) ( ( ) , ( ) ( ) ( ) , ( ) ( ) ( ) , ( M Tsup X Tsup M X Tsup M Esup X Esup M X Esup M Tsup X Tsup M X Tsup (3)
If the itemset X and mediator M can form an indirect association, according to Definition 1, it is easily to know that the true support of itemset X, mediator M and itemset (XM) are, at least, larger than mediator support threshold tf and the maximal value of IS measure is 1. Besides, since we try to find a possible lower bound of estimated mediator dependence, the maximum value of Tsup(X)Tsup(M) can be set to 1. We
conclude that if the mediator dependence threshold td is set smaller than (tf ), then all possible indirect association patterns will be generated by using the proposed approach.
VI. EXPERIMENTALRESULTS
In this section, experiments on a real web-click dataset were made to show the effectiveness and efficiency of the proposed
MIA-LM algorithm. The dataset contains 294 attributes (items)
and 32711 instances (transactions). More details of the dataset
can be obtained from
“http://kdd.ics.uci.edu/databases/msweb/msweb.html”. We enlarged the dataset to 327,110 transactions by duplicating the original dataset. All experiments were implemented in Java and made on a HP ProLiant DL380 G6 with Intel Xeon E5530 2.40GHz and 6GB RAM. The comparison of the proposed approach (MIA-LM) and the traditional approach (INDIRECT) [15] with respect to execution time and memory usage were first made to show the performance of the proposed algorithm. The results are shown in Fig. 5 and 6. 12 11 8 8 7 8 8 8 7 261 114 77 57 45 31 25 22 19 0 50 100 150 200 250 300 0 0.001 0.002 0.003 0.004 0.005 0.006 0.007 0.008 0.009 tf = ts E xe cu ti o n T im e (s ec ) MIA-LM INDIRECT
Figure 5. Performance comparison of MIA-LM (= 0.00006, td= 0.1) and
INDIRECT. 8 7 7 7 7 7 6 6 6 11 10 10 9 9 9 9 9 8 0 2 4 6 8 10 12 0.001 0.002 0.003 0.004 0.005 0.006 0.007 0.008 0.009 tf M em or y U sa ge (M B ) MIA-LM INDIRECT
Figure 6. Memory usage comparison of MIA-LM (= 0.00006, td= 0.1) and
INDIRECT.
From Fig. 5, we can observe that although the execution times of both approaches are decreasing along with the increasing of mediator support (tf), MIA-LM is superior to
INDIRECT, especially when the mediator support is small (e.g. tf= 0.001). From Fig. 6, we can also observe that the memory usage of MIA-LM is less than INDIRECT. These experimental
results show that MIA-LM is suitable for mining indirect association patterns over data streams.
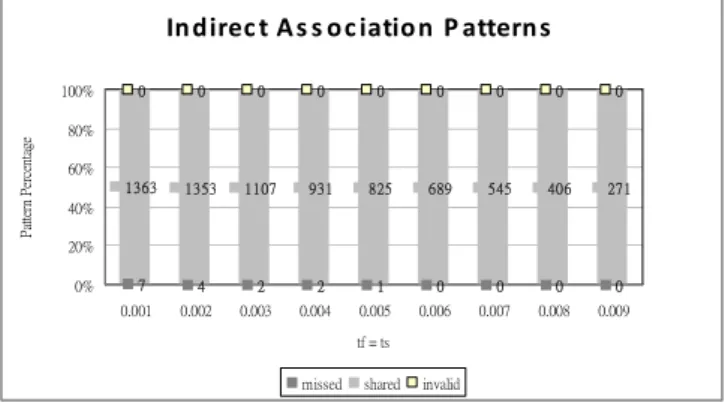
The experiments were then conducted to evaluate the quality of the indirect associations by comparing the results obtained by MIA-LM and INDIRECT, which is shown in Fig. 7, where “Shared”means the percentage of patterns discovered by both approaches, “Missed” represents the percentage of patterns missed by MIA-LM, and “Invalid” depicts the percentage of invalid patterns generated by MIA-LM.
Indirec t As s oc iation P atterns
7 4 2 2 1 0 0 0 0 1363 1353 1107 931 825 689 545 406 271 0 0 0 0 0 0 0 0 0 0% 20% 40% 60% 80% 100% 0.001 0.002 0.003 0.004 0.005 0.006 0.007 0.008 0.009 tf = ts P at te rn P er ce nt ag e
missed shared invalid
Figure 7. Comparison results of derived indirect association patterns by
using MIA-LM (= 0.00006, td= 0.1) and INDIRECT.
We can observe that no invalid indirect association patterns are generated by MIA-LM when comparing with INDIRECT. Since the frequent itemsets are maintained by using the data structure ISFI-forest, a little bit counting errors are raised. Some missing indirect associations are thus expected. Most of patterns generated by MIA-LM are the same as INDIRECT. These experimental results show the effectiveness of the proposed approach.
VII. CONCLUSIONS
In this paper, we have proposed an algorithm, namely
MIA-LM, for mining indirect associations over data streams. To the
best of our knowledge, the proposed MIA-LM algorithm is the first work for mining indirect associations over data streams. We also have shown that two important characteristics of
MIA-LM: (1) the support error of an itemset is smaller than the
support error threshold;and (2) if the mediator dependence threshold is set smaller than a specific value (= tf-), then all possible indirect association patterns can be generated by
MIA-LM. Experiments were also conducted on a real web-click
stream to show that efficiency and effectiveness of the proposed approach. In the future, we will continue our work on indirect associations mining over data streams, including improving the proposed algorithm and extending it to different window models.
ACKNOWLEDGMENT
This work is partially supported by National Science Council of Taiwan under grant No. NSC97-2221-E-390-016-MY2.
REFERENCES
[2] B. Babcock, S. Babu, M. Datar, R. Motwani, and J. Widom, “Models and Issues in Data Stream Systems,”Proc. 21st ACM Symposium on Principles of Database Systems, pp. 1-16, ACM, New York, 2002.
[3] L. Chen, S.S. Bhowmick, and J. Li, “Mining Temporal Indirect
Associations,” Proc. 10th Pacific-Asia Conference on Knowledge Discovery and Data Mining, pp. 425-434, Springer, Heidelberg, 2006.
[4] J.H. Chang and W.S. Lee, “Finding Recent Frequent Itemsets
Adaptively over Online Data Streams,” Proc. 9th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 487-492, ACM, New York, 2003.
[5] C. Cornelis, P. Yan, X. Zhang, and G. Chen, “Mining Positive and
Negative Association Rules from Large Databases,” Proc. IEEE International Conference on Cybernetics and Intelligent Systems, pp. 1-6, 2006.
[6] M.M. Gaber, A. Zaslavsky, and S. Krishnaswamy, “Towards an
Adaptive Approach for Mining Data Streams in Resource Constrained
Environments,” Proc. 6th International Conference on Data
Warehousing and Knowledge Discovery, pp. 189-198, Springer, Heidelberg, 2004.
[7] R. Jin and G. Agrawal, “An Algorithm for In-Core Frequent Itemset
Mining on Streaming Data,”Proc. 5th International Conference on Data Mining, pp. 210-217, 2005.
[8] P. Kazienko, “IDRAM—Mining of indirect association rules,”Proc.
International Conference on Intelligent Information Processing and Web Mining, pp. 77-86, 2005.
[9] P. Kazienko and K. Kuzminska, “The Influence of Indirect Association
Rules on Recommendation Ranking Lists,”Proc. 5th International Conference on Intelligent Systems Design and Applications, pp. 482-487 2005.
[10] H.F. Li, S.Y. Lee, and M.K. Shan, “An Efficient Algorithm for Mining
Frequent Itemsets over the Entire History of Data Streams,”Proc. 1st International Workshop on Knowledge Discovery in Data Streams, pp. 20-24, 2004.
[11] H.F. Li, S.Y. Lee, and M.K. Shan, “Mining Maximal Frequent Itemsets
in Data Streams,”Proc. 2004 International Computer Symposium, 2004.
[12] G.S. Manku and R. Motwani, “Approximate Frequency Counts over
Data Streams,”Proc. 28th International Conference on Very Large Data Bases, pp. 346-357, 2002.
[13] A. Savasere, E. Omiecinski, and S.B. Navathe, “Mining for Strong
Negative Associations in a Large Database of Customer Transactions,” Proc. 4th International Conference on Data Engineering, pp. 494-502, 1998.
[14] W.G. Teng, M.J. Hsieh, and M.S. Chen, “On the Mining of Substitution
Rules for Statistically Dependent Items,”Proc. IEEE 2nd International Conference on Data Mining, pp. 442-449, 2002.
[15] P.N. Tan, V. Kumar, J. Srivastava, “Indirect Association: Mining Higher
Order Fependencies in Data,”Proc. 4th European Conference Principles of Data Mining and Knowledge Discovery, pp. 632-637, 2000.
[16] P.N. Tan and V. Kumar, “Mining Indirect Associations in Web Data,”
Proc. 3rd International Workshop on Mining Web Log Data Across All Customers Touch Points, pp.145-166, 2001.
[17] V.S. Tseng, Y.C. Liu, and J.W. Shin, “Mining Gene Expression Data
with Indirect Association Rules,”Proc. National Computer Symposium, 2007.
[18] Q. Wan and A. An, “An Efficient Approach to Mining Indirect
Associations,”Journal of Intelligent Information System, vol. 27, no. 2, pp. 135-158, 2006.
[19] X. Wu, C. Zhang, and S. Zhang, “Efficient Mining of Both Positive and
Negative Association Rules,”ACM Transaction on Information Systems, vol. 22, no. 3, pp. 381-405, 2004.
[20] Y. Zhu and E. Shasha, “StatStream: Statistical Monitoring of Thousands
of Data Streams in Real Time,”Proc. 28th International Conference on Very Large Data Bases, pp. 358-369, 2002.