A Scalable Complex Event Analytical System with
Incremental Episode Mining over Data Streams
Jerry C.C. Tseng, Jia-Yuan Gu
Department of Computer Science and Information Engineering, National Cheng Kung University, Tainan City, Taiwan (R.O.C.)
PF Wang, Ching-Yu Chen, Chu-Feng Li
Institute for Information Industry, Taipei City, Taiwan (R.O.C.)Vincent S. Tseng
*Department of Computer Science, National Chiao Tung University
Hsinchu City, Taiwan (R.O.C.) *Corresponding author: vtseng@cs.nctu.edu.tw
Abstract — Episode pattern mining is a very powerful technique to get high-valued information for people to solve real-life cross-disciplinary problems, such as for the analysis of manufacturing, stock markets, weather records and so on. As data grows, the mining process must be re-triggered again and again to obtain the most updated information. However, periodically re-mining the full dataset is not cost-effective, and thus a number of incremental mining approaches arise for the growing data. However, to our best knowledge, there exist few studies targeted on the problem of incremental episode mining. Moreover, streaming data of complex events is more and more popular because digital sensors always collect data around us in this big data age. Now the challenge is not only mining valuable episode patterns of incremental dataset, but also mining episode patterns over data streams of complex events. To address this research problem, we adopt the Lambda Architecture to design a scalable complex event analytical system that could be used to facilitate the incremental episode mining process over complex event sequences of data streams. Apache Spark and Apache Spark Streaming are applied as the development framework of the batch layer and the speed layer, respectively. To take both the efficiency and accuracy into consideration, we develop a series of modules and three algorithms, namely, batch episode mining, delta episode mining and pattern merging. Results from the experimental validation on a real dataset show that the proposed system carries high scalability and delivers excellent performance in terms of efficiency and accuracy.
Keywords— Data Stream, Incremental Mining, Episode Pattern Mining, Lambda Architecture
I. INTRODUCTION
Because of more and more streaming data is continuously collected, it raises the explosive requirements to gain useful information by analyzing those data streams. It’s very common that different sources of data that are collected simultaneously as multiple time series events, for such sequences we refer to complex event sequences[10]. Among data mining techniques, episode mining [1][2][8][9][11][15][16][17] is a very powerful tool that can be applied to discover useful patterns from the past events to foresee the possible events that will happen in the future, and there are many real-life cases around us using this technique to solve the problems, such as for the manufacturing or attack detection [21], high utility episodes [24], and stock market analysis [6]. As for the sustainability of life, those mining techniques can be applied in energy management, not only to cut down the electricity consumption but also to reduce the carbon emission [13].
Moreover, in many applications, people want to have not only the information of the episode patterns that learned from the historical data, they also hope to obtain the most updated information that learned from the growing data. To have the most updated result, another full mining for the cumulative whole data is the most intuitive and easiest way, but surely it’s not cost-effective, so there exist many incremental mining approaches trying to address this subject. Till now, it is a very hot topic on how to keep learning from the continuous complex data streams, and how to efficiently do the episode mining for the growing streaming data. To our study, most of the existing incremental mining researches focused on batch mining for association rules [3][20][25] or sequential patterns [12][22] for static incremental data, such like traditional transaction databases. There are very limited researches to address the incremental episode mining problems for the sequences containing simultaneous events that are often encountered in real-life applications.
The abovementioned situations motivate us to develop a system to address the incremental episode mining problems for complex event data streams. The first consideration we take into account is the trade-off between the efficiency and the accuracy. They are both crucial factors of an analytical system designed for incremental mining so that they need to be taken into account at the same time. The second consideration we need to take into account is the scalability of the system. Since now it’s the era of big data, we hope the system must be scalable for the practical use of huge data size. To meet these requirements, we adopt the
Lambda Architecture [26][27] as the system architecture, and use Apache Spark [28] and Apache Spark Streaming [29] as the
development framework of the batch layer and the speed layer respectively.
In this paper, we propose an analytical system named SICEM (Scalable Incremental Complex Event Mining), which consists of four major components, namely, preprocessing layer, batch layer,
speed layer, and merge layer. We develop a series of modules
within the four components, and design three algorithms, namely,
batch episode mining, delta episode mining, and pattern merging
accordingly. We use a real dataset from a smart sootblower system of a fired power plant to validate our system, and the excellent performance results prove the feasibility of the proposed system.
• We integrate some well-known approaches and ming algorithms to successfully deliver an analytical system for complex event data streams.
• We adopt Lambda Architecture to take both the latency and accuracy into consideration at the same time.
• The proposed system is developed using Apach Spark and
Apache Spark Streaming to have the scalability for the
massive quantity of data.
• The proposed system is validated using a real dataset and delivers excellent performance in terms of efficiency and accuracy.
The rest of the paper is organized as follows. We review the related works in Section II, and introduce the design of the proposed system in Section III. The experimental validation and results are presented in Section IV. The conclusion is conducted in Section V, and some future works are introduced in this section as well.
II. RELATED WORKS
In [15], Mannia et al. introduced us the definitions of a complex event sequence and a episode. A complex event sequence is a sequence of events, where each event has an associated time of occurrence. Given a set of event types E, an
event is a pair (A, t) where A ∈ E is an event type and t is an integer, the occurrence time of the event. A complex event sequence S on E is a triple (s, Ts, Te), where s = <(A1, t1), (A2,
t2), …, (An, tn)> is an ordered sequence of events such that Ai ∈ E
for all i = 1, …, n, and ti ≤ tj for all 1 ≤ i ≤ j ≤ n. Furthermore, Ts
and Te are the starting time and the ending time of S respectively,
and Ts ≤ ti ≤ Te for all i = 1, …, n. The size of a complex event
sequence is equal to the number of time points in complex event sequence, and it is defined as Te = Ts + 1. Given two sequences s
and s’, s’ is a subsequence of s, if s’ can be obtained by removing some events in s. An episode f is an ordered tuple of simultaneous event set with the form <SE1, SE2, …, SEk>, SEi
appears before SEj for all i, j (1 ≤ i < j ≤ k).
As shown in Fig. 1, episodes are categorized into three types [16] according to the relationship among them: a). serial episodes, only consider the serial relationship between the events, any event in the episode exists an order between each other event; b).
parallel episodes, only consider the parallel relationship between
the events, there are no constraints on the relative order between any two events; c). composite episodes, it’s the mixture of serial and parallel episode. There are two ways to count the support of an episode: a). the number of sliding windows [15]; and b). the number of minimal occurrences [11][17]. We can generate rules from the frequent episodes, and then make use of the rules to help people make decisions.
Fig. 1. Different types of episdoe
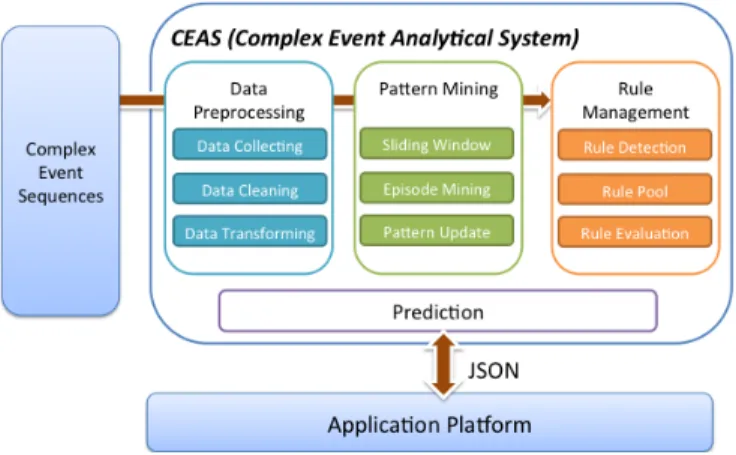
Fig. 2. System framework of CEAS
Cheung et al. proposed algorithm FUP in [3] and then extended FUP to FUP2 in [4]. FUP and FUP2 are both
well-known incremental mining algorithms based on the Apriori properties to update the association rules when new transcation records are inserted into or some records are removed from the database. In [1], Ayan proposed an algorithm UWEP with the concept of negative borders to enhance the efficiency of FUP-based algorithms. The above algorithms are not good to be applied in such a streaming environment, because of the following problems, namely, a). the occurrence of a potentially huge set of candidate itemsets; b). the need of multiple scans of database.
Pattern mining of data streams have become increasingly popular over the recent past. Manku and Motwani [14] proposed a lossy counting algorithm for approximate frequency counting over streams, with no assumptions on the stream. In [18], Patnaik et al. presented a streaming algorithm for mining frequent episodes over a window of recent events in the stream. These algorithms can work well for a single data stream, but it is not good to apply them for the complex event sequence analytic process, so somehow they are limited to be the solution for many real-world problems.
As shown in Fig. 2, in our previous work [23], we proposed an analytical system named CEAS (Complex Event Analytical System) and designed a algorithm named EM-CES (Episode Mining over Complex Event Sequence) for the episode pattern mining over complex event sequences. In CEAS, we adopted SAX [5] as the symbolic transformation and extended the episode mining algorithms of WINEPI [15] and MINEPI [16] to be integrated as an analytical system for the multivariate complex event sequence. CEAS can help people to facilitate the episode pattern mining process for complex event sequence, but we did not considerate the need of incremental mining for the growing dataset, or for the non-stop data streams. The another shortcoming of CESA is that it was not designed to be scalable with enough capacity for huge dataset or data streams.
Because we hope to develop a scalable system, we notice that Nathan Marz came up with the term Lambda Architecture [26] for a generic data processing architecture. Fig. 3 shows the high-level perspective of Lambda Architecture, and three components are included, namely, batch layer, speed layer and serving layer.
Fig. 3. High-level perspective of Lambda Architecture (LA)
Lambda Architecture is an architecture that is designed to
handle massive data by taking advantage of both batch-processing and streaming-batch-processing methods. This architecture attempts to balance latency, throughput, and fault-tolerance by using batch processing to provide comprehensive and accurate views of batch data, while simultaneously using real-time stream processing to provide views of online data.
III. THE PROPOSED SYSTEM
Fig. 4 shows the high-level overview of our proposed system
SICEM (Scalable Incremental Complex Event Mining). The
input data here is the complex evet sequences, and most of them are continuous streaming data from various kinds of data sources, e.g., digital sensors or intelligent meters. The raw data streams need to be properly pre-processed before dispatching to batch and speed layer process. Batch layer has a mechanism of periodically re-computing, kind of a re-mining for all data, to keep the accurancy of the mining result.
Between the two full-mining time point, the stream processing and incremental computing of the speed layer can help speed up the mining efficiency. The merge layer is responsible for consolidating the results of batch views and incremental views to have the most updated episode patterns with good accuracy. The final merged results of episode patterns or rules are presented in the JSON format [30] to be accessed by other applications.
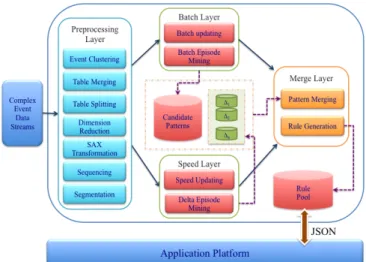
Fig. 4. High-level overview of SICEM
Fig. 5. System framework of SICEM
A. Modules
Fig. 5 is the system framework of SICEM and shows that there are twelve modules in our proposed system, namely, seven modules in the preprocessing layer, two modules in the batch layer, two modules in the speed layer, and two modules in the merge layer. Following is the descriptions of these modules.
1) Modules in Data Preprocessing Layer
a) Event clustering: According to the user-specified event
groups, recoding the event attributes. The input of this module includes a table with categorical event attributes, and the user-specified event groups. The output is the re-coded table.
b) Table merging: To merge the input tables and sort the
records in the time ascending order. The input of this module includes several tables with the same attributes, including a time stamp attribute. And the output is the merged table sorted by its time stamp.
c) Table splitting: To split the table into several sub tables
by the event attributes. Since that in our aimed applications, events in different groups are irrelative, the records related to different event groups should be separated. The input of this module includes a table with event attributes, and the output includes several tables, each represents an event group.
d) Dimension reducing: To reduce the dimension of the
table. Same with Table splitting, some attributes which are considered irrelative to the event groups, will be removed from the table for a specified event group. The input of this module is a table which represents an event group, and the attribute sets that will be kept for the event group. The output is the reduced table.
e) SAX transformation: To discretize the numeric
variables into categorical variables by SAX [5]. It first computes the values of average and variance for each numeric variable, then divide the range of the variable into several blocks with the same probability, based on the characteristics of normal distribution. The input of this module is a table with numeric variables, output is the transformed table. The parameters for
each numeric variable include a number N, which is the number of output symbols after the transformation, and a valid range, out of which the values will be not considered and will be transformed into another predefined symbols, e.g., outliers.
f) Sequencing: To transform the table into sequence form.
Each record of the input table will be transformed into an itemset. The input of this module is a table with time stamp, and the output is the transformed complex event sequence.
g) Segmentation: To set segmentation flags into the
complex event sequence for episode mining in batch and speed layers. User gives a criteria for the segmentation, for example, in 15 minutes after a specified event occurs. Then the segmentation symbols will be inserted into the input long sequence. The input of this module is a complex event sequence, and the output is the sequence inserted with segmentation symbols.
2) Modules in Batch Layer
a) Batch updating: To fetch data stored in speed layer into
batch layer, and reset the storage of speed layer. It makes sure that whenever the batch layer works, the newest data are included in Batch episode mining. The input of this module is the storage of speed layer, and merge them into the batch layer storage as the output.
b) Batch episode mining: To mine the episode patterns in
batches. The algorithm will be introduced in 3.3. The input of this module is the complex event sequence with segmentation symbols, stored in the batch layer storage. The output is the episode patterns with their supports. The parameter of this module is a user-specified minimum support.
3) Modules in Speed Layer
a) Speed updating: To fetch the new coming data from the
data stream and stored them in speed layer storage for Delta
episode mining. The storage will be reset whenever the Batch updating requests the data stored in speed layer. The input of
this module is preprocessed data stream and an initial state based on the criteria defined in Segmentation module, and merge them into the speed layer storage as the output.
b) Delta episode mining: To mine the delta episode
patterns in micro batches. The algorithm will be introduced in next section as well. The input of this module is the complex event sequence with segmentation symbols, stored in the speed layer storage, and the patterns found by Batch episode mining. The output is the delta patterns with their supports. The parameter of this module is a user-specified minimum support.
4) Modules in Merge Layer
a) Pattern merging: To merge the episode patterns from Batch episode mining and Delta episode mining and find the
patterns for the whole. The algorithm will be introduced in 3.3. The input of this module is the patterns with their supports from batch layer and speed layer, and the output is the merged patterns.
b) Rule generation: To generate rules from the merged
patterns. The default rule generation logic is to split a k-pattern (k itemsets in the pattern) into a (k-1)-prefix pattern and a 1-postfix pattern, for example, a pattern <A B C> will generate a
{ "RULES": [ { "LHS": ["(A)", "(B)"], "RHS": ["(C)"], "sup": 0.50, "conf": 0.80 }, { "LHS": ["(B,C)", "(A,B,E)", "(D)"], "RHS": ["(A,D,E)"], "sup": 0.33, "conf": 0.75 }, … ] }
Fig. 6. Sample rules in JSON format
rule <A B> → <C>. Then compute the confidence of the rule by the ratio of the supports of the k-pattern and the (k-1)-prefix pattern. Rules with low confidence, i.e., the confidence is less than a user-specified minimum confidence, will be discarded. The input of this module is the merged patterns, and the output is the generated rule set in JSON format, for further applications. An example of the output is shown in Fig. 6. RULES are a set of element. Each rule is composed by four parts: LHS, RHS, sup and conf, where LHS and RHS represent the segments of the rule, with the support and confidence. For example, the first rule in Fig. 6 is <A B> → <C>, whose support is 0.50 and confidence is 0.80.
B. Algorithms
The algorithms of our proposed system comprises three parts, namely, Batch episode mining (in batch layer), Delta episode
mining (in speed layer) and Pattern merging (in merge layer). In
the Batch episode mining, the patterns of the whole data will be found. Since the overhead of that each time the batch layer works is high, the speed layer should be fast to meet the response time requirement of the users for real-time queries. Thus, Delta
episode mining finds the delta patterns from the new coming data
in the speed layer. Since the delta patterns cannot represent the behaviors of the total data, we have to merge the patterns from batch layer and speed layer to find the approximate pattern set of the patterns of the total data.
For the Batch episode mining, we use a PrefixSpan [19] approach with MapReduce [7]. The reason why we choose this approach is that, the previous works about episode mining are not suitable for our application, which is described in Section IV. Both sliding-window-based [15] and minimum-occurrence-based [11][17] approaches cannot only consider the events appear around the “key event,” which is highlight by Segmentation module. Before the mining process, the Batch updating module will fetch the data from speed layer storage. That means, the whole data at this point will be all collected in the batch layer storage. Then the speed layer storage will be reset to collect the new coming data. In Batch episode mining, first we compute the support of each 1-item episode by a pair of Map and Reduce functions, note that the count refers to the number of segments with different segmentation symbols and are the supersequence of the counting 1-item episode. The 1-episodes whose support are
less than the user-specified minimum support are discarded as unpromising episodes. Then we choose one of the promising episode as prefix and generate its projected complex event sequence, that is, discard the items located in segments without the prefix, or appeared before the prefix. Then we can take the projected complex event sequence as input to repeat the counting step by Map/Reduce functions recursively and find the episode patterns with the assigned prefix. After taking all the 1-item episode pattern as prefixes, all the episode patterns will be found.
For the Delta episode mining, we have a similar mining process with Batch episode mining. First, the speed layer storage, which collect the new coming data, i.e., the data never be mined by Batch episode mining, will be reset to initial state (empty or a partial segment) based on the criteria defined in Segmentation module. Whenever the new data comes from the preprocessed data stream, they will be fetched by Speed updating module and be appended to the speed layer storage for Delta episode mining. In Delta episode mining, a PrefixSpan-based approach with MapReduce for mining the delta patterns is used. Basically the main flow of the algorithm is similar to Batch episode mining, but whenever it finds an episode whose support is less than the user-specified minimum support, it has to check that if the episode is an episode pattern in Batch episode mining. If yes, the episode is still considered as a promising pattern. After the Delta
episode mining is done, the delta episode patterns are found. The
pseudo code of DeltaEpisodeMining is shown in Fig. 7. DeltaEpisodeMining(S, min_sup, pref)
Input: Complex event sequence with segmentation symbols S, Minimum support threshold min_sup, Prefix episode pref
Output: Frequent episode patterns P 1 2 3 4 5 6 SegmentRDD ← S.map(SegmentSpilit)
//SegmentSplit() is a map function to split the input sequence by segmentation symbols
itemFlatRDD ← SegmentRDD.flatMap(ItemFlat)
//ItemFlat() is a flatMap function to flat items in segments and remove repetitions
itemPairRDD ← itemFlatRDD.mapToPair(toPair)
//toPair() is a mapToPair function to make items as (item, count) pairs
CountRDD ← itemPairRDD.reduceByKey(Counting)
//Counting() is a reduceByKey function to compute the support counts of items
PromisingRDD ← CountRDD.filter(isPromising)
//isPromising() is a filter function to remove non-promising items foreach 1-episode e1 in PromisingRDD
7 8 9 10 12 newPref ←pref.append(e1) P ← P ∪ {newpref} ProjSegments ← SegmentRDD.map(SegProject)
//SegProject() is a map function to remove non-promising items and the items appeared before the new prefix
ProjComplexSeq ← ProjSements.flatMap(SegFlat)
//SegFlat() is a flatMap function to flat segments into a complex event sequence with segmentation symbols
DeltaEpisodeMining(ProjComplexSeq, min_sup, newPref)
13 end for
Fig. 7. Pseudo Code of DeltaEpisodeMining
Once the Delta episode mining is done, the Pattern merging will be activated. It quickly matches the patterns found in Batch
episode mining and Delta episode mining. If a pattern appears in
both Batch and Delta episode mining, its support can be easily computed by a weighted average. The weights of the supports from batch and delta are decided by the data size of the storage of batch layer and speed layer. If the pattern appears only in Delta
episode mining, the support of the pattern in Batch episode mining will be considered as 0 to compute the weighted average,
since that in most cases, the data size and weight of support in batch layer is larger, and it is costly and not necessary to gather the missing information of the supports in batch episode mining. The error made by this assumption is minor when the data size of batch layer storage is much larger than the data size of speed layer storage. There is no episode patterns can appear in Batch
episode mining in batch layer but not in Delta episode mining in
speed layer, since patterns appeared in the batch layer are considered as promising patterns in the speed layer, even if their support in Delta episode mining is low. After the matching, the patterns with re-computed supports will be compared with the user-specified minimum support again, to find the final patterns in Pattern merging.
IV. EXPERIMENTAL EVALUATION
In this section, we evaluate the performance of a real-world case, a fossil-fuel power station data. The scenario is that the station heats the water and pushes the turbines by steam to generate electric power. The heat energy will be lost if the conduction equipment cannot perfectly transfer the energy from the boiling water to the steam. Some events, for example, ash cleanups and cool system activities, will impact the efficiency. Our aim is to find the episode pattern of events which are strongly related to the energy conversion performance.
A. Dataset
The dataset consists of two parts, the first part is sensor data, collected by a fossil-fuel power station during three months and the frequency of data collection is one record per minute. The total number of records is almost 130 thousands, and each record consists of 384 sensor attributes and a time stamp. Except for the recording time, all the other attributes are of numeric data type. The another part of dataset is event data, including about 53 thousands ash cleanup events recorded with the start and end time of the event, the duration time, and the activated cleaner. It’s a typical case of multivariate complex event sequence, and we hope to mine the useful episode patterns for the sensors and ash cleanup events.
The samples of data appearance are shown in Fig. 8 and Fig. 9. The first column in Fig. 8 is the time stamp, and the frequency is one record per minute. The remaining columns are sensors’ measurements, which are mainly temperatures. The columns in Fig. 9 are the trigger ID (who triggers the event), start time, end time and the duration in seconds. The dataset is split into two partitions, and we take the data of the first two months as the base for batch mining and the data of the third month as the incoming streaming data.
Fig. 8. The appearance of experimental dataset (sensor data)
Fig. 9. The appearance of experimental dataset (event data)
In the data preprocessing layer, the event data shown in Fig. 9 will be processed by Event clustering module. The attribute sb_id will be replaced by event_group with four values, DS, FS, RH, and PS. For example, sb_id {14L, 15L, 14R, 15R} will be recoded into PS, since they have the same relative sensor group. The sensor data shown in Fig. 8. will be processed by Table
merging, to merge the tables in different time durations; Table splitting, to split the table into four sub tables, DS, FS, RH and
PS; Reducing, to remove irrelative sensors by each group; an additional preprocessing here is to compute the difference to the previous record, by minus the value of each sensor with the previous record; SAX transformation, to discretize the numeric sensor data into categorical data with 9 levels; Sequencing, to transform the table into complex event sequence; and
Segmentation, to insert segmentation symbol into the complex
event sequence with the criteria, in 15 minutes after the ash cleanup event occurred. After preprocessing, the complex event sequence will be used to mine episode patterns by Batch episode
mining and Delta episode mining, corresponding to the
description in the previous paragraph.
TABLE I. EXPERIMENTAL ENVIRONMENT
Roles HW Spec.
Qty’s CPU Main Memory
master 1 @3.5GHz, 1600 MHz Intel i7-2600 32GB slaves 6 @2.7GHz, 1600 MHz Intel Celeron G1620 8GB
B. Experimental Environment
The experimental environment is constructed using Ubuntu 12.04.5 LTS, and Cloudera CDH 5.3.8 is utilized to facilitate the cluster management job. The hardware information of the cluster environment is shown in Table. I. The programming language of the system development is Java with SE runtime environment of build 1.7.0.
C. Experimental Results
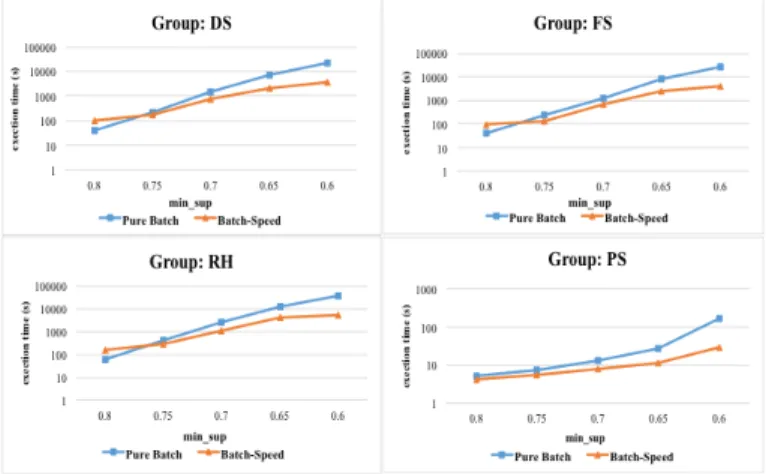
For each event group {DS, FS, RH, PS}, we compare our proposed system with the baseline method, which use batch layer only, by execution time with different minimum support thresholds. The compared methods first executes with the first two months data, and once for each day as new coming data for the remained month. The baseline method totally execute batch layer processing about 30 times, and our proposed method totally execute batch layer processing 1 time and speed layer processing about 30 times. Fig. 10 show the results of the execution time in event group DS, FS, RH, PS, separately.
In Fig. 10, we can find that the patterns in group DS and FS are quite similar, since the sensor sets of DS and FS are partially overlapping. When the minimum support threshold is set to 0.8, the proposed method, which is denoted as ‘Batch- Speed’, is slower than the baseline method, which is denoted as ‘Pure Batch’. That is because the number of patterns is very small and the basic overhead of speed layer processing based on
SparkStreaming will be relatively significant. When the
minimum support becomes lower, the advantage of speed layer processing will be more significant. Besides, in the case of
min_sup = 0.8, the patterns are almost short patterns (in which
there are only 2 or less events). Since in real cases, the rules generated from short patterns are hard to use, the min_sup should be set to 0.7 or less. Fig. 10 shows the result of RH group, with the same trend as the result in DS and FS but a little bit higher in scale. Fig. 10 also shows the result of PS group, which is quite different to the previous groups. Both the data size and number of patterns in the PS group dataset is quite smaller than the previous groups. In most of the cases, our proposed system outperforms the baseline about 1 order when the minimum support is set as 0.6.
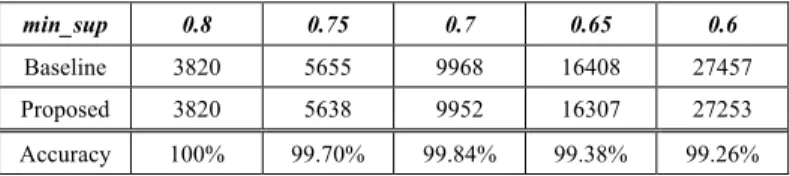
TABLE II. ACCURACY COMPARSION
min_sup 0.8 0.75 0.7 0.65 0.6
Baseline 3820 5655 9968 16408 27457
Proposed 3820 5638 9952 16307 27253
Accuracy 100% 99.70% 99.84% 99.38% 99.26%
Also, to validate the accuracy of our proposed system, we compare the patterns with those the baseline method found. The result is shown in TABLE II. Since that the baseline method always read the whole data at any moment, the patterns it found are right and sound. According to the properties of our proposed
Delta episode mining and Pattern merging, the supports of the
patterns after merging must be no greater than the supports they should be. So there will be only false negative patterns in our proposed system. In Table II, we first show that the number of patterns (sum by the four event groups) found by the baseline method and our proposed system, under the settings of different
min_sups, from 0.8 to 0.6. Then we compute the accuracy as the
ratio of the two and show it below. In the table we can see that, our proposed system performs well with the accuracy over 99% in all of the test cases. That means, the patterns we found are almost the same with the re-mining method.
V. CONCLUSTION AND FUTURE WORKS
In this paper, we propose an analytical system named SICEM (Scalable Incremental Complex Event Mining) for complex event incremental mining with episode mining over data streams. We develop a series of modules and three algorithms within the four major components, namely, preprocessing layer, batch layer,
speed layer and merge layer in this lambda-based architecture.
We successfully applied and extended several well-known data mining techniques to make them work well for the incremntal episode mining of complex events analysis. From the results of experimental evaluation, it proves that the proposed system can take both the efficiency and accuracy into account. The incremental batch-speed mode has better performance in execution time than the pure batch mode, and they have almost the same episode patterns of high accuracy performance. Besdies, we adopt the Lambda Architecture and take use of Apache Spark and Apache Spark Streaming as the development framework. This architecture makes the proposed system have a good scalability to process the huge complex event data streams.
There exist lots of enhancements that we could explore in the future: 1). We plan to develop a module to have better control for the process flow of the complex event sequences of data streams; 2). We plan to design an interface for users to make use of this system more easily; 3). We will try to build a sizeable cluster of more nodes for experiments; 4). We hope to find more real datasets of real-life applications to validate the system.
ACKNOWLEDGMENT
This study is conducted under the “Complex Event Processing Decision-Making Analysis Platform - Smart Sootblower System of Fired Power Plant” of the Institute for Information Industry which is subsidized by the Ministry of Economic Affairs of the Republic of China.
REFERENCES
[1] Necip Fazil Ayan, Abdullah Uz Tansel, M. Erol Arkun, “An Efficient Algorithm to Update Large Itemsets with Early Pruning,” KDD 1999: 287-291.
[2] G. Casas-Garriga, “Discovering Unbounded Episodes in Sequential Data,” Knowledge Discovery in Databases: PKDD, Vol. 2838, pp. 83–94, 2003. [3] D. Cheung, J. Han, V. Ng, and C. Y. Wong. Large Databases, “An
Incremental Updating Technique,” in Proceedings of the 12th International Conference on Data Engineering, pp 106—114, 1996.
[4] D. Cheung, S. D. Lee, and B. Kao, “A General Incremental Technique for Updating Discovered Association Rules,” in Proceedings of the Fifth International Conference On Database Systems for Advanced Applications, pp. 185—194, 1997.
[5] J. Lin, E. Keogh, S. Lonardi and B. Chiu, “A Symbolic Representation of Time Series, with Implications for Streaming Algorithms,” in Proceedings of ACM SIGMOD Workshop on Research Issues in Data Mining and Knowledge Discovery, pp. 2-11, 2003
[6] Y. Lin, C. Huang and Vincent S. Tseng, “A Novel Mining Methodology for Stock Investment,” Journal of Information Science and Engineering Vol. 30, pp. 571-585, 2014.
[7] Jeffrey Dean, Sanjay Ghemawat, “MapReduce: Simplified Data Processing on Large Clusters,” in Proceedings of Sixth Symposium on Operating System Design and Implementation OSDI, pp. 137-150, 2004
[8] K. Huang and C. Chang, “Efficient Mining of Frequent Episodes from Complex Sequences,” Information Systems, Vol. 33, pp. 96-114, 2008. [9] S. Laxman, P. S. Sastry and K. P. Unnikrishnan, “A Fast Algorithm for
Finding Frequent Episodes in Event Streams”, in Proceedings of ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 410-419, 2007.
[10] Y. Lin, P. Jiang and Vincent S. Tseng, “Efficient Mining of Frequent Target Episodes from Complex Event Sequences,” in Proceedings of International Computer Symposium, 2014.
[11] X. Ma, H. Pang and K. L. Tan, “Finding Constrained Frequent Episodes using Minimal Occurrences,” in Proceedings of IEEE International Conference on Data Mining, pp. 471-474, 2004.
[12] Bhawna Mallick, Deepak Garg, P. S. Grover, “Incremental mining of sequential patterns: Progress and challenges,” Intell. Data Anal. 17(3), pp. 507-530, 2013
[13] R. Mallik and H. Kargupta, “A Sustainable Approach for Demand Prediction in Smart Grids using a Distributed Local Asynchronous Algorithm,” in Proceedings of CIDU Conference of Intelligent Data Understanding, pp. 01-15, 2011.
[14] G. S. Manku and R. Motwani, “Approximate frequency counts over data streams,” in Proc. of the 28th Intl. Conf on Very Large Data Bases (VLDB), pp. 346–357, 2002.
[15] H. Mannila, H. Toivonen and A. I. Verkamo, “Discovering Frequent Episodes in Sequences,” in Proceedings of ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 210-215, 1995. [16] H. Mannila, H. Toivonen and A. I. Verkamo, “Discovering Frequent Episodes in Sequences,” Data Mining and Knowledge Discovery, Vol. 1, Issue 3, pp. 259-289, 1997.
[17] H. Mannila and H. Toivonen, “Discovering Generalized Episodes using Minimal Occurrences,” in Proceedings of ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 146-151, 1996. [18] D. Patnaik, S. Laxman, B. Chandramouli, N. Ramakrishnan, “Efficient Episode Mining of Dynamic Event Streams”, in Proceedings of the IEEE International Conference on Data Mining (ICDM), pp. 605-614, 2012. [19] J. Pei, J. Han, B. Mortazavi-Asl, H. Pinto, Q. Chen, U. Dayal and M. Hsu,
“PrefixSpan: Mining Sequential Patterns Efficiently by Prefix-projected Pattern Growth,” in Proceedings of International Conference on Data Engineering, pp. 215-226, 2001.
[20] Siddharth Shah, N. C. Chauhan, S. D. Bhanderi, “Incremental Mining of Association Rules: A Survey ,“ International Journal of Computer Science and Information Technologies, Vol. 3(3), pp. 4071-4074, 2012
[21] M.-Y. Su, “Discovery and Prevention of Attack Episodes by Frequent Episodes Mining and Finite State Machines,” Journal of Network and Computer Applications, Vol. 33, No. 2, pp. 156–167, 2010.
[22] Vincent S. Tseng and Chao-Hui Lee, "Effective Temporal Data Classification by Integrating Sequential Pattern Mining and Probabilistic Induction," Expert Systems with Applications (ESWA), Vol. 36, Issue 5, pp. 9524-9532, July, 2009.
[23] Jerry C. C. Tseng, Jia-Yuan Gu, Ping-Feng Wang, Ching-Yu Chen, Vincent S. Tseng, “A Novel Complex-Events Analytical System Using Episode Pattern Mining Techniques,” in Proceedings of IScIDE, pp. 487-498, 2015.
[24] C.-W. Wu, Y.-F. Lin, P.S. Yu and Vincent S. Tseng, “Mining High Utility Episodes in Complex Event Sequences.” in Proceedings of ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 536-544, 2013.
[25] Zequn Zhou, C. I. Ezeife, “A Low-Scan Incremental Association Rule Maintenance Method Based on the Apriori Property,” Canadian Conference on AI 2001: 26-35. [26] http://lambda-architecture.net/ [27] http://en.wikipedia.org/wiki/Lambda_architecture [28] http://spark.apache.org/ [29] http://spark.apache.org/streaming/ [30] https://en.wikipedia.org/wiki/JSON