國立臺灣大學電機資訊學院資訊工程學系 碩士論文
Department of Computer Science and Information Engineering College of Electrical Engineering and Computer Science
National Taiwan University Master Thesis
適用於點對點中文語篇剖析的遞迴類神經網路統一架 構
A Unified RvNN Framework for End-to-End Chinese Discourse Parsing
林傳恩 Chuan-An Lin
指導教授:陳信希博士 Advisor: Hsin-Hsi Chen, Ph.D.
中華民國 107 年 7 月 July, 2018
誌謝
首先感謝我的指導教授陳信希老師,耐心的在研究方向上提供給我 許多建議,也給了我一個很好的研究環境讓我學習、研究。感謝瀚萱 學長,無論在討論研究方法和投稿時都給我許多幫助。感謝祐婷學姊 與重吉學長在 meeting 時給予的建議。感謝友善的同屆大神同學們:博 政大神、佳文大神、宗翰大神、子軒大神、瑋柔大神、斯文大神。感謝 實驗室的其他同學,自然語言處理實驗室越來越人丁興旺了。最後感 謝我家人的支持。
林傳恩 民國 107 年 7 月
摘要
中文語篇剖析有四項子任務,包含初級語篇單元分割、剖析樹建立、
主次關係識別、語篇關係辨識等。本文展示一個點對點中文語篇剖析 器,並提出一套統一架構,可以對輸入之中文篇章直接產生完整的中 文語篇剖析結果。我們的剖析器以遞迴類神經網路為基礎,同時對四 項子任務進行學習,在中文語篇樹庫(CDTB)資料集上,達到最先進 的效能。我們釋出了這個剖析器的原始碼與預先訓練完成的模型,立 即可用。據我們所知,這是第一個開放原始碼的中文剖析工具集,而 且這套獨立的工具集不須依賴外部資源(如句法剖析器),便於下游應 用的整合。
關鍵字: 自然語言處理、中文語篇剖析、遞迴類神經網路、篇章結構、
基本篇章單元
Abstract
This paper demonstrates an end-to-end Chinese discourse parser. We propose a unified framework based on recursive neural network (RvNN) to jointly model the subtasks including elementary discourse unit (EDU) seg- mentation, tree structure construction, center labeling, and sense labeling. Ex- perimental results show our parser achieves the state-of-the-art performance in the Chinese Discourse Treebank (CDTB) dataset. We release the source code with a pre-trained model for the NLP community. To the best of our knowledge, this is the first open source toolkit for Chinese discourse parsing.
The standalone toolkit can be integrated into subsequent applications without the need of external resources such as syntactic parser.
Keywords: Natural Language Processing, Chinese Discourse Parsing, Re- cursive Neural Network, Discourse Structure, Elementary Discourse Unit
Contents
誌謝 iii
摘要 v
Abstract vii
1 Introduction 1
1.1 Background . . . 1
1.1.1 Discourse parsing and its application . . . 1
1.1.2 Task Definition . . . 2
1.2 Motivation . . . 4
1.3 Goals . . . 5
1.4 Structure . . . 6
2 Related Work 7 2.1 English Discourse Corpora . . . 7
2.2 English Discourse Research . . . 8
2.3 Chinese Discourse Corpora . . . 8
2.4 Chinese Discourse Research . . . 9
2.5 Recurrent Neural Network . . . 9
2.6 Recursive Neural Network . . . 10
3 Datasets 13 3.1 Chinese Discourse Treebank . . . 13
3.2 Chinese Treebank . . . 18
4 Methods 20 4.1 System Overview . . . 20
4.2 Recursive Neural Network . . . 21
4.3 Text Segmentation . . . 22
4.4 Handling Binary Tree Structure . . . 23
4.5 Parser Training . . . 24
4.6 Parse Tree Construction . . . 25
4.7 Model Variation . . . 26
5 Experiments 30 5.1 Evaluation Matrix . . . 31
5.2 Gold EDU Experiment . . . 31
5.3 End-to-End Parsing Experiment . . . 33
5.4 Joint Parsing Experiment . . . 34
5.5 Analysis . . . 34
5.6 Case Analysis . . . 37
6 Conclusion and Future Work 41 6.1 Conclusion . . . 41
6.2 Future Work . . . 42
6.2.1 Enhance the sense classifier and center classifier . . . 42
6.2.2 Fit the parsing model to the multi-way tree structure . . . 42
6.2.3 Integrate syntactic information to build a syntactic-discourse jointly parsing model . . . 42
Bibliography 43
List of Figures
1.1 Sample paragraph (S1) consisting of seven EDUs (a), (b), (c), ..., (g). . . . 3
1.2 Discourse parse tree of (S1). . . 4
2.1 The basic RNN framework . . . 9
2.2 The basic single RNN unit . . . 10
2.3 The basic RvNN framework . . . 11
2.4 The basic single RvNN unit . . . 12
3.1 Sample syntactic tree in CTB. . . 19
4.1 Architecture of our discourse parser. . . 20
4.2 Tree-LSTM unit for discourse parsing. . . 21
4.3 Transforming between a multi-way tree and a binary tree for the discourse relation. . . 23
4.4 Transforming an EDU composed of multiple segments to a binary tree. . . 23
4.5 Training Instances Example . . . 24
4.6 The RvNN-CKY2+Seq-EDU model. . . 27
4.7 The RvNN-CKY2+bi-LSTM model. . . 27
4.8 The 2-Staged-RvNN-CKY2 model. . . 28
4.9 The training instances construction for the 2-Staged-RvNN-CKY2 model. 29 5.1 Example of the Parseval evaluation matrix. . . 32
5.2 Sample paragraph consisting of seven EDUs (a), (b), (c), ..., (g). . . 38
5.3 Partitions into four EDUs by our model of the EDU (a) in the sample paragraph . . . 38 5.4 The binary form of the gold discourse parsing tree of the sample paragraph 39 5.5 The binary predicted discourse parsing tree of the sample paragraph . . . 39 5.6 The original multi-way gold discourse parsing tree of the sample paragraph. 40 5.7 The predicted discourse parsing tree of the sample paragraph after binary-
to-multi-way transformation. . . 40
List of Tables
3.1 Statistics of CDTB. . . 13
3.2 Distribution of discourse relation senses in CDTB. . . 15
3.3 Distribution of discourse relation types in CDTB. . . 16
3.4 Distribution of discourse relation senses and types in CDTB. . . 16
3.5 Distribution of discourse relation senses and centers in CDTB. . . 17
3.6 Distribution of argument number in CDTB. . . 17
3.7 Distribution of punctuations in CDTB. . . 18
5.1 Training and testing data split . . . 31
5.2 System performances given the gold EDUs in F-score. . . 32
5.3 End-to-End system performances in F-score. . . 33
5.4 System performances in F-score. . . 34
5.5 Evaluation of the RvNN-CKY2 + Seq-EDU model on discourse tree node predicting before and after the multiway-to-binary transformation. . . 35
5.6 Distribution of relation sense predicting for all nodes. . . 36
5.7 Distribution of relation sense predicting for nodes whose span are cor- rectly identified. . . 36
5.8 Distribution of relation type and its recall score of sense predicting for all nodes. . . 36
5.9 Distribution of relation type and its recall score of sense predicting for nodes whose span are correctly identified. . . 37
Chapter 1 Introduction
Discourse structure appears in every articles. Parsing the discourse structure involves large-scale understanding of the text. In Chinese, discourse relations often appear in more implicit ways. With the help of neural network approach, we can learn to recognize the discourse structure and relations without the need of surface lexical and syntactic features.
In this thesis, we will discuss first how to construct discourse structure from Chinese raw text in paragraph level based on recursive neural network, we then try to recognize the discourse relations, finally develop an end-to-end Chinese discourse parsing system.
1.1 Background
1.1.1 Discourse parsing and its application
A discourse unit is a sequence of words, ranging from a single sequence, several sen- tences, even to the whole paragraph. As pointed out by Mann and Thompson [1988], no part in an article is completely isolated. Discourse parsing is aimed at identifying how the discourse units are related with each other, forming the hierarchical structure of an article.
There are many NLP applications have been shown benefited from the information ex- tracted by discourse parsing. Following are three examples:
summarization: Louis et al. [2010] explored how discourse structure and relations help text summarization, and concluded that the former information improves the performance more significantly.
information retrieval: In the work of Lioma et al. [2012], discourse paring is used to help model the article relevance.
text categorization: Ji and Smith [2017] conduct experiments on several tasks, including article sentiment classification, news categorization and other text categorization tasks.
The discourse information improve the performance in almost all tasks to a certain extent.
1.1.2 Task Definition
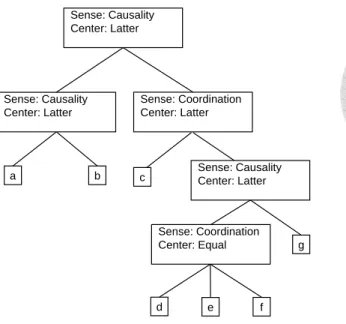
From a piece of text like a paragraph or an article to a discourse tree, there are a num- ber of subtasks to deal with, including elementary discourse unit (EDU) segmentation, tree structure construction, center labeling, and discourse relation recognition. We will intro- duce these subtasks with the example paragraph (S1) shown in Figure 1.1, which consists of three sentences and seven EDUs, numbered as (a), (b), (c) to (g). This example is extracted from CDTB. we will discuss this corpus in next chapter.
Given (S1) as the input paragraph, our goal is to generate a discourse parse tree of (S1) as illustrated in Figure 1.2.
Following the CDT scheme Li et al. [2014b], we define the discourse parsing task to involve four perspectives as follows:
EDU Segmentation: EDUs are special discourse units (DUs) acting as the leaf nodes of a discourse parse tree. According to most Chinese discourse corpora, the EDU is limited to clause, which is segmented by some punctuation marks and containing at least one predicate that expresses at least one proposition. Besides, an EDU should be related to other EDUs with some propositional function instead of acting as a part of other EDUs.
Discourse Structure Construction: The combination of successive DUs (including both EDUs and non-leaf DUs) generates new discourse units (DUs) in a higher level of the discourse tree. As shown in Figure 1.2, the EDUs (d), (e), and (f) are combined as a new DU, which is further combined with the other EDU (g), and so on. Finally, the hierarchal structure is constructed covering all EDUs in (S1).
Sense Labeling: In CDTB, four top types of discourse relation sense are defined, including Causality, Coordination, Transition, and Explanation. Taking the relation between (a) and (b) in (S1) as an example, (a) states the premise and (b) states the outcome, so a sense of causality is the sense of discourse relation is Causality.
(a) 浦東開發開放是一項振興上海,建設現代化經濟、貿易、金融中心的跨世 紀工程,(Pudong’s development and opening up is a century spanning undertaking for vigorously promoting Shanghai and constructing a modern economic, trade, and financial center.)
(b) 因此大量出現的是以前不曾遇到過的新情況、新問題。(Therefore, new situa- tions and new questions that have not been encountered before are emerging in great numbers.)
(c) 對此,浦東不是簡單的採取 “幹一段時間,等積累了經驗以後再制定法規 條例” 的做法,(In response to this, Pudong is not simply adopting an approach of
“work for a short time and then draw up laws and regulations only after experience has been accumulated.”)
(d) 而是借鑒發達國家和深圳等特區的經驗教訓,(Instead, Pudong is taking advan- tage of the lessons from experience of developed countries and special regions such as Shenzhen,)
(e) 並且聘請國內外有關專家學者,(by hiring appropriate domestic and foreign spe- cialists and scholars,)
(f) 並且積極、及時地制定和推出法規性文件,(actively and promptly formulating and issuing regulatory documents.)
(g) 使這些經濟活動一出現就被納入法制軌道。(So that these economic activities are incorporated into the sphere of influence of the legal system as soon as they appear.)
Figure 1.1: Sample paragraph (S1) consisting of seven EDUs (a), (b), (c), ..., (g).
Center Labeling: The centering from semantic discriminates the focus of the two DUs joined. A discourse relation is either mononuclear or multinuclear. A mononuclear relation, which is the join of two DUs, usually has a nucleus DU and a satellite DU. The nucleus DU reflects the intention focus of the discourse and is thus more salient in the dis- course structure, whereas the satellite DU presents supportive information for the nucleus.
For example, In the join of (a) and (b) in Figure 1.2, (b) act as a nucleus since it stands for the outcome statement in the discourse relation of the causality sense. Since the nucleus may be the front DU, the later DU, or even both DUs, there are three centering types for a mononuclear relation: Front, Latter, and Equal, respectively. The multinuclear relation only occurs with the discourse sense Coordination, where multiple DUs combined in par- allel, the centering relation comes out to be multinuclear like the join of (d), (e), and (f) in Figure 1.2.
a b c
d e f
g Sense: Coordination Center: Equal
Sense: Causality Center: Latter Sense: Coordination Center: Latter Sense: Causality
Center: Latter
Sense: Causality Center: Latter
Figure 1.2: Discourse parse tree of (S1).
Besides, connective is also an important aspect in the original CDT scheme. Connec- tives or discourse markers are a set of words or phrases suggest the sense of discourse relation. In (S1), the connectives 因此 (therefore) and 對此 (In response to this) denote the discourse relation in the sense of causality; the parallel connective 不是... 而是...(is not...but...) suggests the sense of coordination. Discourse relations are divided into two types according to the existence or not of connectives. Explicit relations have a con- nective and Implicit relations have not. In deed, the CDT scheme views connectives as the predicates of discourse relations. However, we skip connective recognizing during our discourse parsing process. One reason is that we expect the unified neural network framework could learn to recognize connectives implicitly, and the another reason is that connectives does not appear in most discourse relations in Chinese corpora. We will dis- cuss this issue in the next section.
1.2 Motivation
The performances of prior discourse parsing systems are limited due to several issues.
First of all, most system conduct a pipeline approach. Indeed, The subtasks in Chinese discourse parsing depend on each other. In a pipelined system, there may be a severe issue
of error propagation among elementary discourse unit (EDU) segmentation, connective recognition, parse tree construction, and relation labeling Kang et al. [2016].
Furthermore, there may be separate units to deal with discourse relations that has a connective (called explicit relation) and that doesn’t (called implicit relation) Kang et al.
[2016]. The intention is to make the best use of connective cue for the explicit rela- tions. Unfortunately, the properties of Chinese are quite different from that of English, resulting challenging issues to build a Chinese discourse parser. Firstly, in Chinese Dis- course Treebank (CDTB), the only Chinese discourse corpus with structure annotation at the paragraph levelLi et al. [2014b], 82% discourse relations have no explicit connective, comparing to 55% in Penn Discourse Treebank (PDTB), one of the largest English dis- course corpus Prasad et al. [2014]. This makes a difficulty for the approach to discourse relation recognition that heavily relies on the literal cues in the text. Secondly, the annota- tion scheme used in CDTB is much different from that of RST-DT. Therefore, the parser constructed for RST-DT cannot be directly adapted to the CDTB dataset.
The other issue is that prior Chinese discourse parser relies on linguistic features ex- tracted by external third party packages. For a toolkit targeting real-world applications, a standalone system is more robust and easy to deploy.
1.3 Goals
For the aforementioned reasons, in this work we propose an end-to-end Chinese dis- course parser that performs EDU segmentation, discourse tree construction, and discourse relation labeling in a unified framework based on RvNN Goller and Kuchler [1996].
RvNN learns to construct the structured output through merging children nodes to parent nodes in the bottom-up fashion. Within the RvNN paradigm, recurrent neural networks (RNNs) are employed to model the representations from word segments, discourse units, to the whole paragraph. With these approaches, we are able not to rely on external parser and pass the connective recognizing part to adapt to the characteristics of Chinese text. In the prediction stage, we use the CKY algorithm to deal with both local and global infor- mation during the construction of discourse parse tree, eliminating the gap between the
bottom-up approach and top-down annotation schemes.
The contributions of this work is three-fold. 1) We release a ready-to-use toolkit for end-to-end Chinese discourse parsing. To the best of our knowledge, this is the first pub- licly available toolkit for Chinese discourse parsing.1 2) We propose a unified framework based on RvNN for this task. Our model achieves the state-of-the-art performance. 3) Without the need for external resource like syntactic parser, our standalone end-to-end parser can be easily integrated into subsequent applications. The open source package can be even adapted to other languages.
1.4 Structure
The rest of this paper is organized as follows. Chapter 2 describes related works.
Chapter 3 introduces the datasets. We present our system in Chapter 4 and discuss the system performance in Chapter 5. Chapter 6 concludes the remarks.
1https://github.com/abccaba2000/discourse-parser
Chapter 2 Related Work
2.1 English Discourse Corpora
In this section, we will introduce the two commonly used English discourse corpus.
The first one is the Rhetorical Structure Theory Discourse Treebank (RST-DT) Carlson et al. [2001]. RST-DT is annotated from 385 Wall Street Journal (WSJ) articles, which is selected from the Penn TreebankMarcus et al. [1993]. RST-DT follows the Rhetorical Structure Theory (RST) Mann and Thompson [1988]. In the RST framework, the discourse structure can be represented as a tree, with EDUs being the leaf nodes, and each internal node annotated by a rhetorical relation.
The second corpus is the Penn Discourse Treebank (PDTB) Xue et al. [2005], which is annotated on 2,159 WSJ articles selected from the Penn Treebank. PDTB adapts a predicate-argument view, one relation has two DUs as arguments. The whole discourse structure is not limited to be a complete tree. We use Example 2.1.1 and Example 2.1.2 to illustrate this aspect. Each example shows a discourse relation annotated in PDTB, and both these two relations are of EntRel relation sense which means ”the only relation between the two arguments is that they describe different aspects of the same entity”, as described in Zhou and Xue [2012]. We can see that the second argument of the relation in Example 2.1.1 appears again as the first argument of the relation in Example 2.1.2. This phenomenon can not appear in a hierarchically annotated corpus such as CDTB.
Example 2.1.1. [Rolls-Royce Motor Cars Inc. said it expects its U.S. sales to remain steady at about 1,200 cars in 1990.]arg1[The luxury auto maker last year sold 1,214 cars in the U.S.]arg2
Example 2.1.2. [The luxury auto maker last year sold 1,214 cars in the U.S.]arg1[Howard Mosher, president and chief executive officer, said he anticipates growth for the luxury auto maker in Britain and Europe, and in Far Eastern markets.]arg2
Besides. PDTB annotate connectives and divide discourse relations to be explicit or implicit.
2.2 English Discourse Research
Since the release of RST-DT, the research on English discourse parsing has attracted attention in recent years Braud et al. [2017], Zhao and Huang [2017], Wang et al. [2017].
Li et al. [2014a] adopt RvNN from word level to the whole discourse, with a binary clas- sifier to deal with the probability of two discourse units merging into a bigger unit, and a classifier to label the relation. Bowman et al. [2016] propose a neural network-based shift-reduce model with handcrafted features to build the parse tree in RST-DT dataset.
Zhao and Huang [2017] integrates RST-DT and PDTB, develop a span-based constituency parser that jointly parses in both syntax and discourse levels
2.3 Chinese Discourse Corpora
There are fewer works on Chinese discourse corpus until recent years. The only corpus with the annotation of discourse structure at the paragraph level in Chinese is the Chinese Discourse Treebank (CDTB) dataset developed by Li et al. [2014b], which contains 500 Xinhua newswire documents from the Chinese Treebank Xue et al. [2005]. CDTB is the main training and testing data in our work. We will discuss this corpus in next chapter.
Zhou and Xue [2012] annotated another Chinese Discourse Treebank (CDTB-Zhou), which follows PDTB annotation scheme with some adaption to Chinese linguistic char- acteristics to annotate 890 articles of CDT. Again, this annotation scheme does not limit the discourse structure to be in hierarchical form. The paragraph in Figure 1.1 in Chapter 1 are annotated in both CDTB and CDTB-Zhou; however, in CDTB-zhou, the EDU (b)
is related to EDU (a) with a Causation relation while (b) is also related to (c)-(d)-(e)-(f) with a Conjunction relation.
2.4 Chinese Discourse Research
Prior work of Chinese discourse parsing focuses on inter-sentential parsing Huang and Chen [2012] and shallow parsing Xue et al. [2016a], Wang and Lan [2016], The CoNLL 2016 Shared Task deals with shallow parsing Xue et al. [2016b]. So far, there is quite less work on complete hierarchical Chinese discourse parsing at paragraph or article level.
Shih and Chen [2016]build an end-to-end parser focusing on explicit relations where a connective is presented. Kang et al. [2016] make the text propagate through different components: EDU detector, discourse relation recognizer, discourse parse tree generator, and attribution labeler, and the system is the current state-of-the-art. Both of the two are pipeline system with pure hand-crafted features.
2.5 Recurrent Neural Network
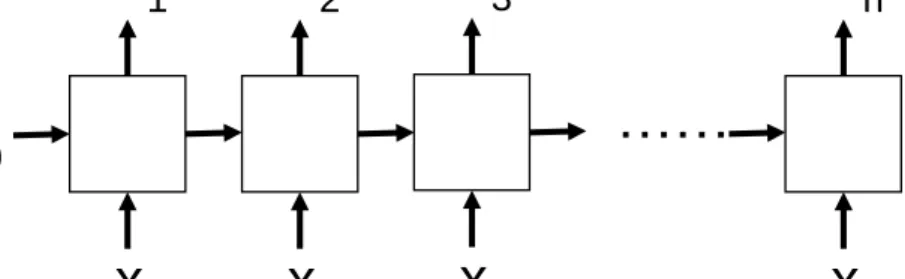
Recurrent Neural Network (RNN) is reportedly successful in learning the text repre- sentation, and we also integrate this component into our discourse parsing model. Figure
x
1h
0h
1x
2h
2x
3h
3x
nh
n…… h
i+1h
i+1x
ih
iFigure 2.1: The basic RNN framework
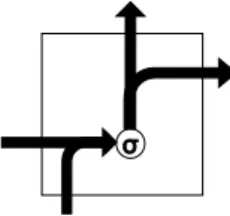
2.1 demonstrated the framework of a basic RNN. RNN connects its unit iteratively to learn the representation of a ordering sequence. (x1, x2, x3...xn) denotes the representations of the input sequence of RNN. For an input sentence, xi may be the vector representation
of the ith word or character. Commonly, RNN needs another input which is the h0 in Figure 2.1, h0 is another initialized h-dimensioned vector. (h1, h2, h3...hn) is the output representation sequence while each hi is also the input of the next RNN unit. Figure 2.2 shows the computation flow inside a basic RNN unit. The formula of the computation in a unit may be like as follow:
h⃗i = σ(W
⃗xi
⃗hi−1
+⃗b) (2.1)
where W is the weighting matrix, ⃗b is the bias vector, and σ is some activation function such as tanh(). Both W and ⃗b are parameters to be trained with some objective function.
There are many variation of neural network suitable for the discourse parsing task, and the
x1 h0
h1
x2 h2
x3 h3
xn hn
…… hi+1
hi+1
xi hi
Figure 2.2: The basic single RNN unit
Long Short-term Memory (LSTM) neural network Hochreiter and Schmidhuber [1997] is a variation of RNN that makes use of memory and forgetting mechanism to keep valuable information in the processing through the sequence.
2.6 Recursive Neural Network
Recursive Neural Network (RvNN) connects its unit hierarchically to process tree structured data. Many tasks have benefited from this recursive framework, including sen- tence parsing Bowman et al. [2016], and sentiment analysis Socher et al. [2013]. Also, RvNN has been successfully applied on English discourse parsing task Socher et al. [2013].
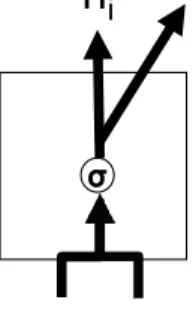
Figure 2.3 shows the framework of a basic RvNN. Each xi denotes the representation of
x
1h
2x
2x
3h
1x
ih
ix
i+1h
iFigure 2.3: The basic RvNN framework
each element of the tree-structured input. In the discourse parsing task, an xi can be the representation of the ith DU in the input paragraph. Each hi acts as the output of each RvNN unit and also the input to the next unit. 2.4 shows the computation flow inside a basic RvNN unit. The formula of the computation in a unit may be like as follow:
h⃗k = σ(W
⃗xior ⃗hi
⃗ xjor ⃗hj
+⃗b) (2.2)
Again, W is the weighting matrix, ⃗b is the bias vector, both of which can be adjusted during the training process. σ is the activation function.
The TreeLSTM Tai et al. [2015] takes both advantages from LSTM and RvNN, gener- alizing the LSTM unit to take the representations of two children node in the binary tree as input, and ouput the representation of the parent node. TreeLSTM has been proved effec- tive for predicting semantic relatedness of two sentences and sentiment classification Tai et al. [2015]. We will discuss the mechanism of TreeLSTM in Chapter 4 when introducing our model.
x
1h
2x
2x
3h
1x
ih
ix
i+1h
iFigure 2.4: The basic single RvNN unit
Chapter 3 Datasets
3.1 Chinese Discourse Treebank
As mentioned in Chapter 2, we use CDTB annotated by Li et al. [2014b] as our main dataset. Each paragraph is annotated with EDUs, connectives, discourse structures, rela- tion senses and centers informations in CDTB. We then gives the analysis of CDTB in this section.
Articles Paragraphs EDUs Relations
Number 500 2,342 10,609 7,308
Table 3.1: Statistics of CDTB.
Table 3.1 lists the amount of articles, paragraphs, EDUs and relations in CDTB. The 7, 308 relations are categorized into four main relation sense. We give the interpretation by Shih [2015] of each relation sense below. Following each interpretation, we also give examples which are also used for latter discussion.
Coordination: Coordination is used when the arguments are descriptions on different aspects of the same things that share common features.
Example 3.1.1. [去年實現進出口總值達一千零九十八點二億美元,(Last year, the total value of imports and exports reached US$1,092,200,000,)]arg1[占全國進出口總值 的比重由上年的百分之三十七提高到百分之三十九。(which increased from 37%
in the previous year to 39% in the proportion of the total import and export value of the country)]arg2
(sense: Coordination, center: Former, type: Implicit)
Example 3.1.2. [有關部門先送上這些法規性文件,(The relevant departments will send these regulatory documents first, )]arg1[然後有專門隊伍進行監督檢查。(and then have a special team to supervise and inspect.) ]arg2
(sense: Coordination, center: Latter, type: Explicit)
Causality: Causality is used when an event in an argument causes the event in another argument. It expresses the relationship between the cause and the effect.
Example 3.1.3. [浦東開發開放是一項振興上海,建設現代化經濟、貿易、金融 中心的跨世紀工程,(Pudong’s development and opening up is a century spanning un- dertaking for vigorously promoting Shanghai and constructing a modern economic, trade,
and financial center.)]arg1[因此大量出現的是以前不曾遇到過的新情況、新問題。
(Therefore, new situations and new questions that have not been encountered before are emerging in great numbers.)]arg2
(sense: Causality, center: Latter, type: Explicit)
Example 3.1.4. [上海浦東近年來頒佈實行了涉及經濟、貿易、建設、規劃、科技、文 教等領域的七十一件法規性文件,(In recent years, Shanghai Pudong has promulgated and implemented 71 legal documents covering economic, trade, construction, planning, science and technology, culture and education, etc.,) ]arg1[確保了浦東開發的有序進行。
(ensuring the orderly development of Pudong.)]arg2 (sense: Causality, center: Former, type: Implicit)
Transition: Transition is used when the arguments contrast with each other. It shows the difference between arguments.
Example 3.1.5. [數年前,北海還是北部灣一個默默無聞的小漁村,(A few years ago, Beihai was still a small fishing village in the Beibu Gulf.)]arg1[然而三五年時間北 海已建成了一個現代化都市的框架,街上客流如潮,樓房拔地而起。(However, in the past three or five years, the Beihai has built a framework of a modern city. The streets are full of passengers and buildings.)]arg2
(sense: Transition, center: Latter, type: Explicit)
Example 3.1.6. [科爾認為,俄羅斯軍隊最終全部撤離德國是“歐洲戰後歷史的終 結”。(Cole believes that the final withdrawal of the Russian army from Germany is ”the end of post-war history in Europe.“) ]arg1[他說,1941年6月22日德國進攻蘇 聯是不能忘記的。(He said that, the Germany’s attack on the Soviet Union on June 22 in 1941 could not be forgotten.)]arg2
(sense: Transition, center: Former, type: Implicit)
Explanation: Explanation expresses the same concept using different wordings. It is used for arguments that try to explain the same thing in different ways.
Example 3.1.7. [建 築 是 開 發 浦 東 的 一 項 主 要 經 濟 活 動,(Buildings are a major economic activity in the development of Pudong.)]arg1[百家建築公司、四千餘個建築 工地遍佈在這片熱土上。(Over the years, hundreds of construction companies and more than 4,000 construction sites have been scattered throughout the land.)]arg2
(sense: Explanation, center: Former, type: Implicit)
Example 3.1.8. [外 商 投 資 企 業 的 出 口 商 品 仍 以 輕 紡 產 品 為 主,(The export commodities of foreign-invested enterprises are still dominated by light textile products.)
]arg1[其中,出口額最大的商品是服裝,去年為七十六點八億美元。(Among them,
the largest export commodity is clothing, which was 7.68 billion US dollars last year.)]arg2 (sense: Explanation, center: Latter, type: Explicit)
Table 3.1 shows the relation sense distribution. We can see that the distribution of the four senses is quite unbalanced. While the Coordination sense appears in more than half of all relations, Transition has only the proportion of 2.9%. Avoiding bias may be an issue when predicting the relation sense.
Coordination Causality Transition Explanation
Number 4,148 1,331 212 1,617
Proportion 56.8% 18.2% 2.9% 22.1%
Table 3.2: Distribution of discourse relation senses in CDTB.
Table 3.1 gives the relation type distribution of CDTB. About three quarters of dis- course relations are of implicit type. It indicates the big challenge for Chinese discourse
relation sense and center classification since implicit relations have less lexical cues to the task.
Explicit Relations Implicit Relations
Number 1,814 5,494
Proportion 24.8% 75.2%
Table 3.3: Distribution of discourse relation types in CDTB.
To further look into the property of discourse relations in CDTB, we use Table 3.1 to inspect the join distribution of relation sense and relation type.
We can see that most of the Coordination and Explanation relations are of Implicit type. It might be because that in Chinese writing, two neiborghing statements can often be interpreted to be about the same aspect without lexical cues. As shown in Example 3.1.1, we can easily infer that both two DUs are discussing about the total value of imports and exports. In Example 3.1.7, the latter DU is obviously the elaboration of the former.
Conversely, some connectives such as ” 而且 (and)”, ” 還 (also)”,” 先... 然後 (first...and then)”,” 其中 (Among them)” which appear in these two relations can be omitted without changing the meaning. Example 3.1.2 and Example 3.1.8 can illustrate this aspect.
In contrast, Explicit relations act as the majority of Transition relations. It is much more difficut to delete a connective such as ” 但 是 (but)” or ” 然 而 (however)” in a Transition relation. Example 3.1.7 shows that we may take more efforts to recognize a Transition relation without such connective.
Coordination Causality Transition Explanation
Explicit 974 466 173 201
Implicit 3,174 865 39 1,416
Table 3.4: Distribution of discourse relation senses and types in CDTB.
Table 3.1 shows the join distribution of relation sense and relation type.
Most discourse relations of Coordination sense did not put semantic center on either arguments. Even when a Coordination relation is labeled with center Front or Latter, the central DU is not so obvious, as shown in Example 3.1.1 and Example 3.1.2.
While the latter statements are often more prominent in Transition relations, Explana- tion relations often forcus on the former statements which act as the main idea. Example
3.1.5 and 3.1.7 can illustrate this aspect. It is also worth noticing that in the Explanation relation of center Latter shown in Example 3.1.8, the connecive ” 其中 (among which)”
is used to emphasize the largest export commodity of foreign-invested enterprises.
Coordination Causality Transition Explanation
Front 283 416 11 1,398
Latter 184 875 191 197
Equal 3,681 40 10 22
Table 3.5: Distribution of discourse relation senses and centers in CDTB.
Table 3.1 lists the relation distribution of different argument number. Note that only the relations of Coordination sense and Equal Center are possible to have more than two arguments. According to the tabel more than 99% relations have no more than 4 arguments and about 91% relations are binary relations. Example 3.1.9 demonstrates a special case of a 8-argument relation. It lists a series of parallel DU to describe the production value improvement.
Argument Number 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
Relation Number 6653 454 135 40 15 6 1 1 0 0 1 0 1 0 1
Table 3.6: Distribution of argument number in CDTB.
Example 3.1.9. [據 廣 州 市 統 計 局 提 供 的 資 料, 去 年 廣 州 市 完 成 國 內 生 產 總 值 一 千 四 百 四 十 五 點 八 四 億 元;(According to the data provided by the Guangzhou Municipal Bureau of Statistics, last year Guangzhou completed a GDP of 144.448 billion yuan;)]arg1[完 成 工 業 增 加 值 五 百 七 十 三 點 四 八 億 元;(completed industrial added value of 573.384 billion yuan;)]arg2[農業增加值八十點七五億元;(agricultural added value of 80 A total of 750 million yuan;)]arg3[固定資產投資六百五十五點四五億元;(
fixed assets investment of 6.545 billion yuan;)]arg4[社會消費品零售總額六百四十四點 三二億元;(total retail sales of consumer goods reached 634.324 billion yuan;)]arg5[外貿 出口總值六十五點一三億美元;(total export value of 6.53 billion US dollars;)]arg6[實 際利用外資二十六億美元;(actual use Foreign investment was US$2.6 billion;)]arg7[零 售物價指數上漲百分之四點三。(the retail price index rose by 4.3%.)]arg8
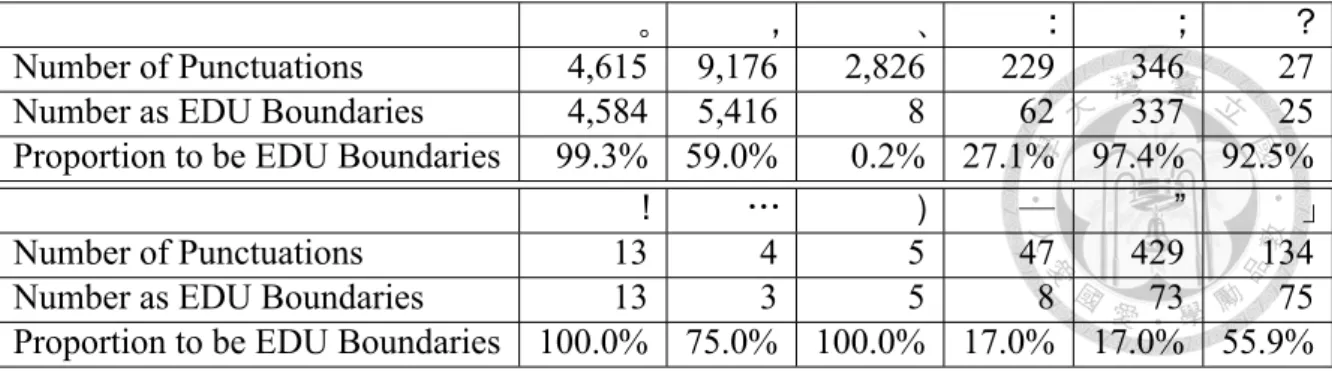
。 , 、 : ; ?
Number of Punctuations 4,615 9,176 2,826 229 346 27
Number as EDU Boundaries 4,584 5,416 8 62 337 25
Proportion to be EDU Boundaries 99.3% 59.0% 0.2% 27.1% 97.4% 92.5%
! … ) — ” 」
Number of Punctuations 13 4 5 47 429 134
Number as EDU Boundaries 13 3 5 8 73 75
Proportion to be EDU Boundaries 100.0% 75.0% 100.0% 17.0% 17.0% 55.9%
Table 3.7: Distribution of punctuations in CDTB.
Table 3.1 lists the number of punctuations in CDTB as well as the number of the punc- tuations being a EDU boundary. We can see from it that some punctuations are much more clear-cut for EDU boundary detection than others. For example, almost all ’。’s are EDU and almost all ’、’s are not. In contrast, ’,’s are very ambiguous when en- countering while they are the punctuations which appear most frequently. So, whether the punctuation encountered is a boundary of a EDU is the main challenge when doing EDU detection.
3.2 Chinese Treebank
In the last part of our experiment, we attempt to use the syntactic structure information of each sentence when training our model. Since the articles of CDTB is selected from CTB which is a much bigger Chinese corpus annotated with syntactic information, so we also use CTB to look for this desired information.
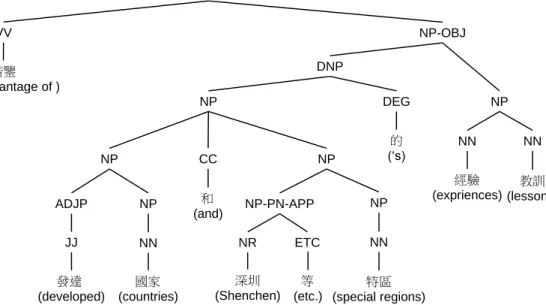
Figure 3.1 presents a part of syntactic parsing tree annotated in CTB as an example.
Similar to the case of discourse parsing, we can retrieve folowing informations from a Chinese syntactic parsing tree:
Word segmentation: A sequence of Chinese characters is first segmented into words, a Chinese word may consist of one to three characters in most cases. In Figure 3.1, the word ’ 借鑒 (take advantage of)’ consists of character ’ 借 (borrow)’ and ’ 鑒 (refer)’.
Words are the leaf nodes in a syntactic parsing tree.
POS tags: A word is labeled by its part of speech (POS) tag. In a syntactic parsing
tree, the POS tag is labeled on the direct parent node of its corresponding word. In Figure 3.1, the POS tag of ’ 借鑒 (take advantage of)’ is ’VV’ which is a subclass of verb. The POS tag of ’ 發達 (developed)’ is ’JJ’ which is a subclass of noun classifier.
Syntactic structure and grammatical labels: The tree structure we see in Figure 3.1 is the syntactic structre. Each nodes except the leaf nodes and the POS nodes are tagged with grammatical labels which represent the grammatical relations of the node.
For example, ’NP’ means a ’noun phrase’.
NN
發達 (developed)
國家 (countries)
和 (and)
深圳 (Shenchen)
等 (etc.)
特區 (special regions)
的 (‘s)
經驗 (expriences)
教訓 (lessons) VV
JJ NN
CC
NR ETC
借鑒 (take advantage of )
DEG
NN NN
ADJP NP NP-PN-APP NP
NP
NP NP
NP
DNP
NP-OBJ VP
Figure 3.1: Sample syntactic tree in CTB.
The syntactic information is useful for the discourse parsing task. However, to avoid the need of external syntactic parser, our model needs to learn to extract syntactic informa- tion itself. In Section 5.4 of Chapter 5, we describe our attemption to integrate syntactic structure information into our model.
Chapter 4 Methods
4.1 System Overview
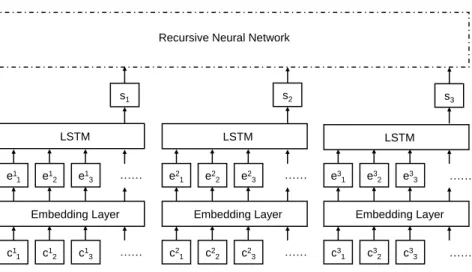
The architecture of our united framework for end-to-end Chinese discourse parsing is shown in Figure 4.1. For a given text, we first segment the text into m text segments w1, w2, w3, ..., wm by using punctuation marks as delimiter, where wi = (w1i, . . . , wni
j) forms the sequence of words in the ith text segment. The words are fed into an embed- ding layer, and wi is then represented as ei = (ei1, . . . , einj). Then, LSTM is trained to convert eiinto the segment representation si, and s1, s2, s3, ..., smserve as the input for the RvNN. Through the RvNN, segments are hierarchically joined to DUs in the bottom-up fashion. Finally a single discourse parse tree is constructed, and the sense and the center- ing relations of each join are labeled.
Segment level
Character level Segment/DU level
c11 c12 c13 ……
=Embedding Layer
=LSTM
c21 c22 c23 ……
=Embedding Layer
=LSTM
c31 c32 c33 ……
=Embedding Layer
=LSTM Recursive Neural Network
e11 e12 e13 …… e21 e22 e23 …… e31 e32 e33 ……
s1 s2 s3
Figure 4.1: Architecture of our discourse parser.
4.2 Recursive Neural Network
=Embedding Layer=LSTM
Recursive Neural Network
……
……
w11 e11
s1
e12 e13
w12 w13
=Embedding Layer
……
……
w21 e21
s2
e22 e23
w22 w23
=Embedding Layer
……
w31 e31
s3
e32 e33
w32 w33 ……
Tree-LSTM Unit Merge
Scorer
right input left input
to parent unit Sense
Classifier
Center Classifier
=LSTM =LSTM
Figure 4.2: Tree-LSTM unit for discourse parsing.
Figure 2.3 shows the unit in our RvNN based on the Tree-LSTM unit [Tai et al., 2015].
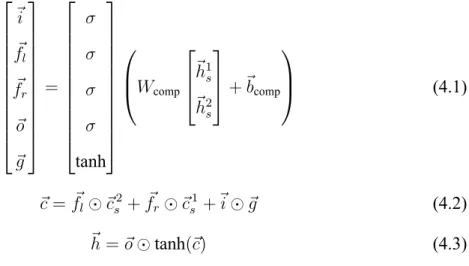
Given the left and the right inputs (i.e. two text segments or two DUs), the Tree-LSTM composition function produces a representation for the new tree node. The Tree-LSTM unit generalizes the LSTM unit to tree-based inputs. Similar to LSTM, Tree-LSTM makes use of intermediate states as a pair of an active state representation ⃗h and a memory rep- resentation ⃗c. We use the version similar to Bowman et al. [2016] as the formula:
⃗i f⃗l f⃗r
⃗o
⃗ g
=
σ σ σ σ tanh
Wcomp
⃗h1s
⃗h2s
+⃗bcomp
(4.1)
⃗c = ⃗fl⊙ ⃗cs2+ ⃗fr⊙ ⃗cs1+⃗i⊙ ⃗g (4.2)
⃗h = ⃗o ⊙ tanh(⃗c) (4.3)
where σ is the sigmoid activation function,⊙ is the element-wise product, and the pairs
⟨⃗h1s, ⃗cs1⟩ and ⟨⃗h2s, ⃗cs2⟩ are input from its two children tree nodes. The output of Tree-LSTM is the pair⟨⃗h,⃗c⟩. Note that the Tree-LSTM unit is designed for binary tree. In Section 4.4, we show how to handle the multinuclear, where more than two children nodes join, in this framework.
The representation ⃗h and ⃗c produced by Tree-LSTM is taken for four usages: merge scoring, sense labeling, center labeling, and as input for the upper Tree-LSTM unit. In the
prediction stage, the representation will be first sent into the merge scorer to measure the probabilities of the join of its two children tree nodes:
⃗
pm = softmax(Wm
⃗h
⃗c
+⃗bm) (4.4)
The output ⃗pm is a 2-dimensional vector, representing the probabilities of to merge and not to merge.
Similarly, the sense classifier and the center classifier compute the probability distri- bution ⃗psand ⃗pcas follows:
⃗
ps = softmax(Ws
⃗h
⃗c
+⃗bs) (4.5)
⃗
pc= softmax(Wc
⃗h
⃗c
+⃗bc) (4.6)
For sense labeling, ⃗ps consists of 6 values constituting the probabilities of six senses:
Causality, Coordination, Transition, Explanation, subEDU, and EDU. Our end-to-end parser constructs the discourse parse tree from the text segments, EDUs, and to non-leaf DUs in an united framework, so we need to use the last two categories to mark which condition the current node is under EDU level.
For center labeling, ⃗pc consists of 3 values constituting the probabilities of the three center categories including Front, Latter, and Equal. Center labeling is only performed at the DU level.
4.3 Text Segmentation
The raw text sent to our system is first divided to several segments by using specific punctuation marks as delimiter. The punctuation marks include full-stop (。), question mark ( ?), exclamation mark ( !), comma ( ,and 、), semicolon ( ;), colon (:), right
quotation mark ( ” and 」), ellipsis (…), and dash (──).
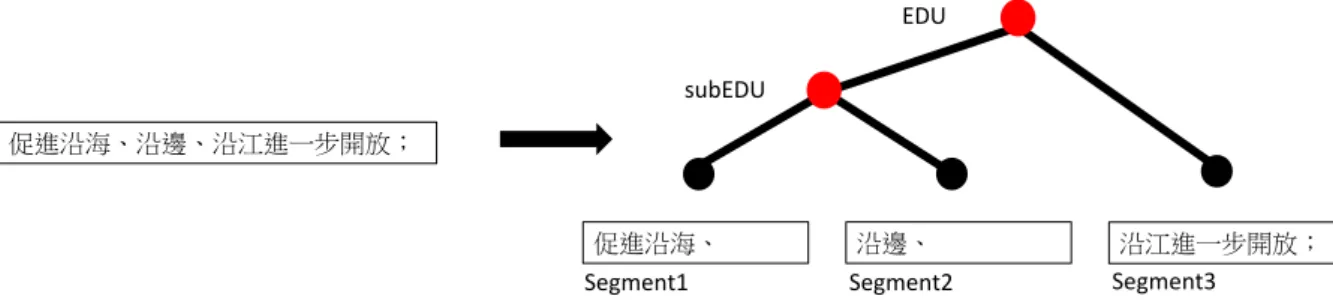
A segment forms an EDU by itself if it contains at least one predicate and expresses at least one proposition. Otherwise, multiple segments are merged to form an EDU. For example, the EDU (f) in Figure 1.1 consists of two segments “并且积极” (“and actively”) and “及时地制定和推出法规性文件” (“promptly formulating and issuing regulatory documents”).
4.4 Handling Binary Tree Structure
Binary-Multi-Way Transformation
Sense: Coordination Center: Equal
Sense: Coordination Center: Equal
Sense: Coordination Center: Equal
DU2
DU1 DU3 DU1 DU2 DU3
促進沿海、 沿邊、 沿江進一步開放;
Segment1 Segment2 Segment3 EDU
促進沿海、沿邊、沿江進一步開放;
Figure 4.3: Transforming between a multi-way tree and a binary tree for the discourse relation.
Binary-Multi-Way Transformation
Sense: Coordination Center: Equal
Sense: Coordination Center: Equal
Sense: Coordination Center: Equal
DU2
DU1 DU3 DU1 DU2 DU3
促進沿海、 沿邊、 沿江進一步開放;
Segment1 Segment2 Segment3
EDU
促進沿海、沿邊、沿江進一步開放;
subEDU
Figure 4.4: Transforming an EDU composed of multiple segments to a binary tree.
In the CDT scheme, the discourse parse tree is not limited to binary tree. As mentioned in Section 4.2, however, Tree-LSTM is modeled as binary tree. Therefore, we have repre- sent the discourse parse tree with the structure of binary tree. In the discourse parse tree, there are two cases where a tree node has more than two children. In the first case, the tree node is an internal DU with the sense type coordination, where its all subtrees are
parallel joined. As shown in Figure 4.3, we transform the tree node to two new nodes in the left-first merging scheme. In the second case, the tree node is an EDU that consists of more than two text segments as shown in Figure 4.4. Similarly, we merge the k segments into tree structure with k− 1 binary nodes in the left-first merging scheme. The highest node is labeled as EDU, and all the rest of the nodes are labeled as subEDU.
4.5 Parser Training
Positive/Negative instances
Positive instance Negative instance EDU
Figure 4.5: Training Instances Example
To train the RvNN, the positive instances are the tree nodes extracted from the dis- course parse trees in CDTB. Figure 4.5 illustrate a parsing tree constructed from five seg- ments(the black node). The black nodes, black lines, and the red nodes form the parsing tree itself. So, we can find four subtrees by considering one red node as the root. These four subtrees are the four positive instances we can derive from this parsing tree for train- ing. On the other hand, we select arbitrary two neighboring subtrees and merge them into a new tree. The new tree is regarded as a negative instance if it is inconsistent with the ground-truth. We can see from Figure 4.5 that there are four possible trees as negative instances with the blue nodes as the root. The losses of the merging scorer, the sense classifier, and the center classifier,Lm,Ls, andLc, respectively, are measured with cross- entropy. When training on negative instance, we don’t need to estimate the performance
of classification of sense and centering. In contrast, in the positive cases, we sum up the loss of the three and optimize them jointly. More formally, our loss functionL is defined as:
L =
Lm, if the instance is negative Lm+Ls+Lc, otherwise
(4.7)
We use stochastic gradient decent (SGD) with the learning rate of 0.1 for parameter opti- mization.
4.6 Parse Tree Construction
In the prediction stage, we construct the discourse parse tree based on the predictions made by Tree-LSTM. We modify the Cocke–Younger–Kasami (CKY) CKY algorithm Younger [1967] to maximize the probability of the whole parse tree. The CKY-like dy- namic programing algorithm simulates the recursive parsing procedure, considering local and global information jointly. In each step of the dynamic programming procedure, we consider several combinations of two neighboring trees L and R, merge them to a new tree N , and select two such N s with higher probability P r(N ) as candidates for future steps. Pr(N) is formulated as follows:
P r(N ) = P rM erge(L, R)× P r(L) × P r(R) (4.8)
The P rM erge(L, R) above is the output of the merge scorer in our model. Since we always stored the top two N s in each entry of the dynamic programming table, we mark our CKY-like algorithm as CKY2. See Algorithm 1 for details.
Algorithm 1 Discourse Parse Tree Construction with Dynamic Programming
1: P robs← table[][]
2: for level from 0 to n− 1 do ▷ The span range
3: for col from 0 to n− level do ▷ The start column
4: P robs[level][col]← 0
5: Candidates← list[]
6: for k from 1 to level do
7: Lef tT ree← GetTree(k − 1, col) ▷ Get the candidate tree for left span
8: RightT ree← GetTree(level − k, col + k)
9: N ewT ree, M ergeP rob← Merge(LeftT ree, RighT ree)
10: ▷ Apply RvNN unit
11: P rob← MergeP rob × P robs[k − 1][col] × P robs[level − k][col + k]
12: T ree, P rob← Candidates.MaxP rob()
13: ▷ Get the maximum probabilty and the tree
14: SaveTree(level,col,T ree) ▷ Save as the candidate tree
15: P robs[level][col]← P rob
4.7 Model Variation
Variations of our RvNN framework will also be tested for comparison. In the ver- sion shown in Figure 4.6, instead of running our CKY algorithm throughout the whole construction process from segment level, CKY is only adopt after EDU detection. For EDU detection, we process through the segment representations s1, s2, s3...snfrom left to right, judging based on the merge scorer whether to merge the next segment as a part of EDU or separate it to be the start of a new EDU. The intention is to fit how we construct our training instance, as mentioned in Section 4.5. We abbreviate our original model as RvNN-CKY2, and this modified version as RvNN-CKY2+Seq-EDU.
Considering each segment representation si output by the LSTM layer only contains informations of the segment itself. We attempt to add one bi-LSTM layer between the original LSTM and CKY part to integrate context information into each segment repre- sentation, as shown in Figure 4.7. In this version, s1, s2, s3...sn are first fed into the bi-LSTM, and the outputs f1, f2, f3...fnare then fed into the RvNN. We abbreviate this version of our model as RvNN-CKY2+bi-LSTM.
In a further attempt to integrate syntactic information into our model while still avoid the need of external syntactic parser, we generalize our model to not only construct dis-
Segment level
Character level Segment/DU level
c11 c12 c13 ……
=Embedding Layer
=LSTM
c21 c22 c23 ……
=Embedding Layer
=LSTM
c31 c32 c33 ……
=Embedding Layer
=LSTM
e11 e12 e13 …… e21 e22 e23 …… e31 e32 e33 ……
s1 s2 s3
DU level: CKY
segment level: left-to-right merge, detecting EDU boundaries RvNN
Figure 4.6: The RvNN-CKY2+Seq-EDU model.
Segment level
Character level Segment/DU level
c11 c12 c13 ……
=Embedding Layer
=LSTM
c21 c22 c23 ……
=Embedding Layer
=LSTM
c31 c32 c33 ……
=Embedding Layer
=LSTM
e11 e12 e13 …… e21 e22 e23 …… e31 e32 e33 ……
s1 s2 s3
RvNN(CKY)
bi-LSTM
f1 f2 f3
Figure 4.7: The RvNN-CKY2+bi-LSTM model.
course structure, but also to construct syntactic structure for each text segment automati- cally. This variation of our model is shown in Figure 4.8. Instead of feeding each character embedding eij for the ithsegment into a LSTM layer to get the segment embedding si, the model processes eijthrough another RvNN with CKY2 algorithm similar to the process of the original RvNN, resulting in a two-staged RvNN framework. We use the same training set in CDTB, and we can get the gold syntactic parsing for each articles from CTB which is the source corpus for CDTB. Note that we only use this external resource other than CDTB
during the training stage. After training, our model can construct the syntactic structure automatically. We abbreviate this version of our model as 2-Staged-RvNN-CKY2.
Segment level
Character level Segment/DU level
c11 c12 c13 ……
=Embedding Layer
=RvNN(CKY)
c21 c22 c23 ……
=Embedding Layer
=RvNN(CKY)
c31 c32 c33 ……
=Embedding Layer
=RvNN(CKY)
e11 e12 e13 …… e21 e22 e23 …… e31 e32 e33 ……
s1 s2 s3
RvNN(CKY)
Figure 4.8: The 2-Staged-RvNN-CKY2 model.
In this version of our model, the RvNN process from characters to the whole paragraph through a deep tree structure, as shown in Figure 4.9. We then adapt sampling mechanism to reduce the huge amount of training instances. We sample the character level training instances (the subtrees rooted in a red or blue node in the character level area in Figure 4.9) to the amount as same as the amount of instances above segment level. Also, we do not merge a node above segment level with a neighboring node of character level to construct an instance.
Ex:海关统计表明,
DU level
segment level
character level
Positive instance
Negative instance
Character
Positve/Negative instances
Figure 4.9: The training instances construction for the 2-Staged-RvNN-CKY2 model.