A Decision Tree Based Quasi-Identifier Perturbation Technique for Preserving Privacy in Data Mining
Bi-Ru Dai
Department of Computer Science and Information Engineering
National Taiwan University of Science and Technology, Taipei, Taiwan, ROC
Abstract-Classificationis an important issue in data mining, and decision tree is one of the most popular techniques for classification analysis. Some data sources contain private personal information that people are unwilling to reveal. The disclosure of person-specific data is possible to endanger thousands of people, and therefore the dataset should be protected before it is released for mining. However, techniques to hide private information usually modify the original dataset without considering influences on the prediction accuracy of a classification model. In this paper, we propose an algorithm to protect personal privacy for classification model based on decision tree. Our goal is to hide all person-specific information with minimized data perturbation. Furthermore, the prediction capability of the decision tree classifier can be maintained. As demonstrated in the experiments, the proposed algorithm can successfully hide private information with fewer disturbances of the classifier.
Keywords-classijication; preserving privacy; decision tree;
quasi-identijier
I. INTRODUCTION
In recent years, large amounts of data are collected from various applications and can be used for different data mining purposes [1]. For example, many business organizations collect data for analyzing consumer behavior and improving business strategies, and many medical organizations collect medical records for treatment and medical purpose.
It is noted that many organizations collect data containing confidential personal information, which is usually denoted by the quasi-identifier [5, 6, 18]. A quasi-identifier is a subset of attributes that can identify a unique tuple in the dataset. For example, suppose that there is a dataset with attributes age, income, sex and occupation. A tuple is a quasi-identifier if the combination of attribute values of this tuple is unique among all tuples. In other words, this tuple can uniquely identify a person. If a malicious user obtains a quasi-identifier from the dataset, he can use the quasi-identifier to identify a unique person and take malicious action on that person. For example, the medical data is usually mined for better medical care, but patients are not willing to reveal their private information.
Therefore, the dataset should be disturbed before it is released for mining. Consequently, the preservation of sensitive
Yang-Tze Lin
Department of Computer Science and Information Engineering
National Taiwan University of Science and Technology, Taipei, Taiwan, ROC
personal information starts to attract lots of research attention and becomes a promising issue in data mining.
Classification is a technique that can be used to extract models to predict classes for future data. The decision tree is one of the most popular classification methods. A decision tree is a class label appraiser that recursively partitions the training set into several subsets until each partition entirely or dominantly consists of examples with the same class [2]. In this paper, we focus on hiding the personal information while the prediction capability of a decision tree can be maintained.
Note that removing names and other unique identifiers is not enough to protect confidentiality of personal records. Malicious analyzers still can infer a unique person from the combination of attribute values.
K-anonymity is a major technique that can solve the problem about quasi-identifier effectively [6, 12]. However, this technique has the side effect that the predictive capability of a decision tree is severely degraded. In the process of hiding quasi-identifier by K-anonymity, the structure and characteristics of the decision tree, such as entropy or information gain, are not taken into consideration.
Consequently, although the private information is successfully protected, the modified dataset is not applicable because of the terrible prediction power.
Some privacy preservation mining techniques were designed for datasets having only numerical (or categorical) non-class attributes [3, 4]. However, natural datasets are more likely to contain several types of attributes in real life. In this paper, we consider both numerical and categorical non-class attributes as sensitive and confidential ones. Besides, we devise the clustering method to select tuples from the quasi-identifier set, and the Efficient Protection with Less Perturbation (EPLP) algorithm to perturb unique characteristic from tuples. The proposed algorithm tries to minimize the perturbation of dataset, and maintains predictive capability of the decision tree.
As demonstrated in experimental results, algorithm EPLP can hide sensitive personal information with fewer disturbances of the dataset. Therefore, the predictive power of the decision tree is mostly maintained.
The rest of this paper is organized as follows. In the next section, the related work is reviewed. Section 3 gives problem defmitions of decision tree and quasi-identifier. The proposed
9781-4244-2865-6/09/$25.00©2009 IEEE
algorithms are presented in section 4.In section 5 we present some experiment results to demonstrate advantages of our technique. Finally, we discuss future work and conclude the paper.
II. RELATED WORK
In this section, we review some existing techniques about protecting individual privacy when mining with the decision tree model, and we discuss some of their limitations which make them unsuitable for our purpose.
There are many researches that apply diverse perturbation techniques to protect privacy. In [5, 6, 12], the tuples with privacy-related attributes are hidden so that at leastkreleased records have the same values of these sensitive attributes combination and these techniques are called k-anonymity. As a result, no privacy-related information can be easily inferred, and the quality of dataset be considered.
Islam and Brankovic [13, 14] apply various probability distributions to add noises in class and attributes. This paper emphasizes on the similarity of produced decision trees between the original dataset and the perturbed one. Though the original decision tree is similar to the perturbed one, and the structure of decision tree is maintained, this method does not ensure the predictive capability and classification result of the perturbed tree.
In 2004 Islam and Brankovic [15] consider that attributes of tuples can be divided into confidential and non-confidential attributes. Hence this framework perturbs both confidential and non-confidential attributes by adding noise. In addition, this paper can add noise to class attribute by Random Perturbation Technique. In the following year, Islam and Brankovic [16]
purpose a novel approach towards clustering of categorical values that can perturb data and maintain the patterns in the dataset at the same time.
Some of these techniques horizontally partition all transactions into several parties in [7, 8], and some other techniques apply vertical partitioning to dataset in [9, 10]. In the horizontally partitioned database, each party of the database contains some records with whole attributes. In a vertically partitioned database, each party has all records with part of all attributes. In both cases, normally, all parties know the complete structure of the database. It means that they know all of the attribute names and their possible values. On the other hand, some of these techniques achieve the purpose of privacy preserving through homomorphic encryption in a horizontally or vertically partitioned database [11].
In 2007 Xiao-dan and Dian-min [17] perturbed each value of attribute in the database through Additive Data Perturbation, Multiplicative Data Perturbation and Rotation Data Perturbation respectively. Besides, this paper provided a comprehensive survey on prior studies to fmd out the current status of privacy preserving data mining development by data distortion.
The above-mentioned techniques can either hide thequasi- identifier or maintain the structure of decision tree, but are not able to deal with both issues at the same time. All these above
studies supply momentous notion to predictive accuracy of a classifier. This motivates us to take into consideration the predictive accuracy of a classifier and the data quality when the dataset is perturbed for protecting confidential personal information.
III. PROBLEM STATEMENT
In this section, we introduce the quasi-identifier problem, and discuss the issue that perturbing the quasi-identifier will influence the prediction capability of a decision tree.
STATEMENT 1(Quasi-identifier)
Let n be the total number of tuples in the datasetD, and each tuple has K attributes. Assume that there are m quasi- identifiers in datasetD,wherem;;;n. Tupleiis a quasi-identifier if it is unique inD.
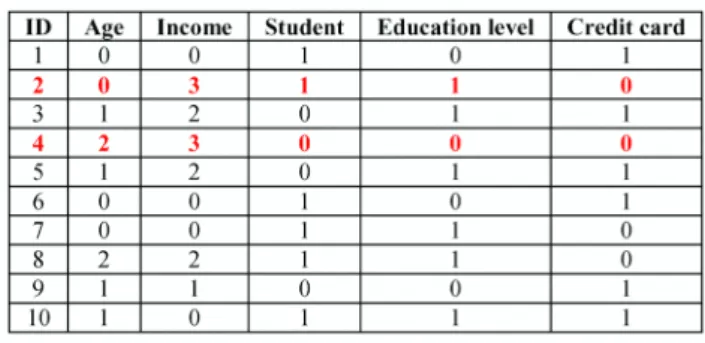
As shown in the example in Table I, the credit card approval dataset has ten tuples, and each tuple contains four non-class attributes, "Age", "Income", "Student", and
"Education level"; "Credit card" denotes the class label.
Suppose that numerical attributes are divided into several levels as shown in the table. The attribute value combination of tuple2 is "0, 3, 1, 1", which is unique in the dataset. Thus, tuple2 is a quasi-identifier. Similarly, tuple4 is also a quasi- identifier. If this attribute combination is unique and contains private information, then the quasi-identifiers can be used to link to a person. The privacy of that person will be revealed.
STATEMENT 2 (Successful hiding)
Assume that tuplei is aquasi-identifier in datasetD. After the perturbation, tuplei is said to be hidden successfully if
1) the attribute value combination of tuple; is the same as other tuples in datasetD,or
2) tuple; does not belong to the original quasi-identifier set.
Aquasi-identifier is successfully protected if at least one of the above conditions is satisfied. For example, if the attribute value combination of tuple2 is modified to "0, 0, 1, 0" or "0, 0, 0, 0", then tuple2 is hidden successfully.
TABLEI. THE ORIGINAL CREDIT CARD APPROVAL DATASET WHERE TUPLE2 AND TUPLE4 AREQUASI-IDENTIFIERS.
ID A2e Income Student Education level Credit card
1 0 0 1 0 1
2 0 3 1 1 0
3 1 2 0 1 1
4 2 3 0 0 0
5 1 2 0 1 1
6 0 0 1 0 1
7 0 0 1 1 0
8 2 2 1 1 0
9 1 1 0 0 1
10 1 0 1 1 1
A. Preliminary Process
Clustering is usually a useful technique to improve experimental results of data mining tasks. For example, Islam and Brankovic cluster categorical attributes by decision tree, and fmd out the target to be modified [16]. They focus on the modification that does not significantly destroy the classification structure. However, the prediction accuracy is not taken into consideration.
STATEMENT3(Perturbation of the decision tree)
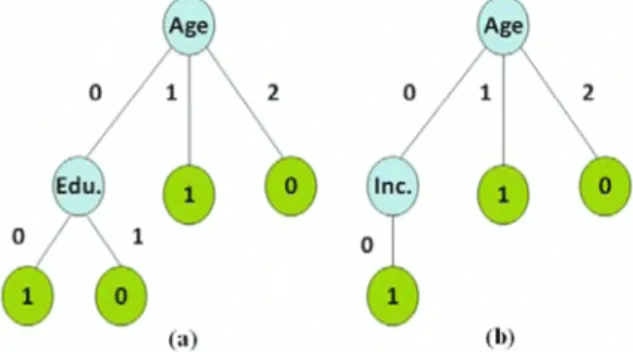
When we modify an attribute value without considering the computational process of entropy or each attribute value, the structure of a decision tree will be perturbed. For instance, assume that tuple} to tuple6 represent the training dataset, and tuple7 to tuples represent the test dataset. The original decision tree and the perturbed decision tree are shown in Figure 1.
After perturbation, the attribute combination of tuple2 is "0, 0, 1, 0", and tuple7 is tested in the perturbation tree. The prediction result of tuple7 is "1", which is different from the
prediction result of obtained by the original decision tree.
I
oat.sou....,1-
RemowIO ...omd.t...' ..Discretiz~tionof nuttH!'rical attribute
Clujt~rcombinationof
~
Updlted~et lIttribute~Ivalu~...- Disturbtomblnatlon of attribute value Restoreof
numerical attribute
f
Pseudo source
ID A2e Income Student Education level Credit card
1 1 1 0 0 0
2 1 1 1 1 0
3 0 1 0 1 0
4 1 0 1 0 0
5 3 1 0 1 1
6 3 1 0 1 1
7 2 2 1 1 1
8 3 2 1 1 1
9 2 1 1 1 1
10 0 1 0 0 1
11 1 0 0 0 1
TABLEII. THIS DATASET CONTAINS NINE QUASI-IDENTIFIERS, WHICH ARE MARKED BY RED COLOR. THERE ARE FOUR TUPLES IN LABEL0AND
SEVEN TUPLES IN LABEL1.
Figure 2. A decision tree basedquasi-identifierperturbation technique for protecting personal-related sensitive information.
In our framework, by clustering quasi-identifiers, the influence on the classification structure can be reduced, and the prediction of decision tree can be mostly kept. Our method is called similar attribute combination around the unique tuple (SACUT) in this paper.
Suppose that ti and ~are two unique tuples, ti, tzED, i=Fj.
The parameter P represents the allowed number of different attribute values between two unique tuples. If the number of different attribute values betweentiand~is not larger thanP,~
is regarded as similar to ti and ~is called a similar tuple of tie These attribute values do not include the class attribute. The range of parameter P is 1 to K. The common pattern points out different attributes and marks them as "?", the others are represented by original attribute values.
As shown in Table II, tuple} differs from tuple2 by two attribute values; therefore, tuple2 is a similar tuple of tuple} and will be in the same group of the cluster table if P is two. On the contrary, the number of different attribute values between tuple3 and tuple4 is more than two; therefore, they are not similar tuples. Furthermore tuple} and tuple6 are not similar tuples because their class labels are different.
2
(b)
o
2
(a)
o
Edu.
o 1
Figure1. (a) A decision tree built on the original credit card approval dataset.
(b) A decision tree obtained from the perturbed dataset.
In this paper, we consider the quasi-identifier and the decision tree problem at the same time. The main technique to perturb quasi-identifiers and maintain the predictive accuracy of a decision tree will be explained in the next section.
IV. THE FRAMEWORK
We primarily assume that the dataset is required to be released for various purposes such as research, marketing, health care, and fmance. Ideally, the whole dataset should be released without any access restriction so that users can apply various data mining techniques. However, the disclosure of confidential individual values with sufficient certainty is indeed a breach of privacy. Note that deletion of identifiers such as name, customer ID, or credit card number is not sufficient to prevent such disclosure. In this paper, we design the Efficient Protection with Less Perturbation (EPLP) algorithm to perturb quasi-identifiers, and furthermore the perturbation count is a small amount.
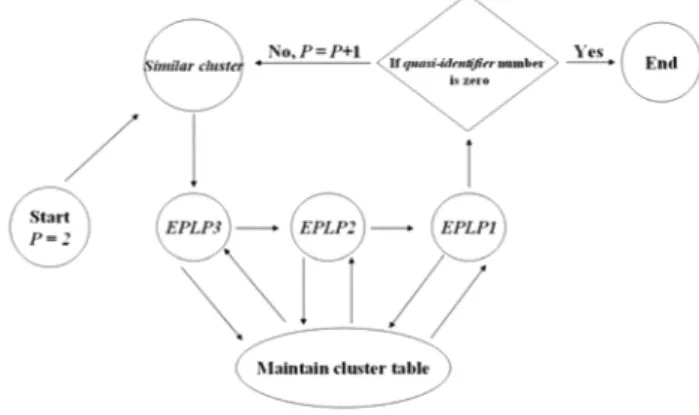
According to the framework in Figure 2, at fITst, person- identifiers are deleted from the data source. Then, numerical attributes are discretized and a cluster table is created. Next, the EPLP algorithm uses the cluster table to disturb quasi- identifiers. Finally, numerical attributes will be restored. The produced pseudo source, which is the dataset after perturbation, can be used to construct the predictive model.
The clustering algorithm to create the cluster table is presented in subsection A. Subsection B gives defmitions of some terminology, and the details and advantages of the proposed EPLP algorithm are provided.
Figure 3. (a) The example of two tuples which differ by 2 attribute values. (b) The example of two tuples which differ by 4 attribute values. Blue circle represent the unique tuple ti,and red circle represent the similar tuple of ti•
swaptup/e Tuple,
,1,0, Target tuple
][odijiable tuple sM'ap tuple
Target tuple Tuple,
,1,0,
3.1.0'/
Jlodifiable tuple
B. The Efficient Protection with Less Perturbation (EPLP) Algorithm
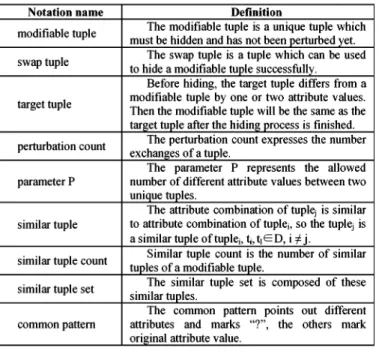
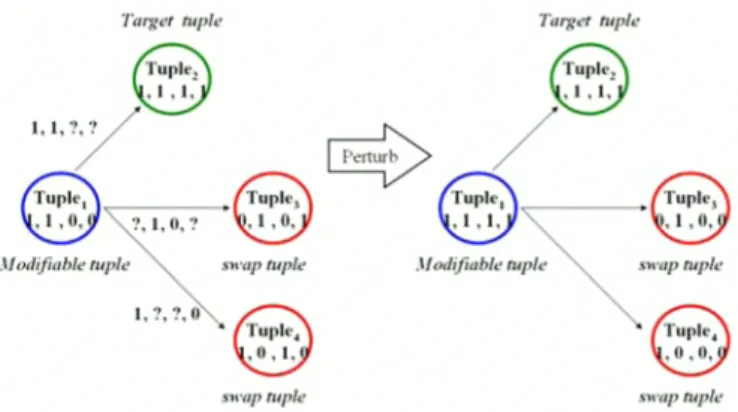
Before presenting the main algorithm, we briefly introduce some terminology, including modifiable tuple, swap tuple, target tuple, perturbation count, similar tuple count, and similar tuple set. The cluster table stores patterns and the similar tuple count of every unique tuple. The modifiable tuple is a unique tuple which must be hidden and has not been perturbed yet. The swap tuple is a tuple which can be used to hide a modifiable tuple successfully. Before hiding, the target tuple differs from a modifiable tuple by one or two attribute values. Then the modifiable tuple will be the same as the target tuple after the hiding process is fmished. The perturbation count expresses the number exchanges of a tuple. Note that the swap tuple and the target tuple are the similar tuples of modifiable tuple. As shown in Table II and Figure 5, because tuples differs from tuple7 by one attribute value, the attribute values of tuples can be changed to the same as tuple7 by swapping a value with tuple9, so, tuple7 is the target tuple of tuples, and tuple9 is the swap tuple oftuples.
Figure 5. The relation between modifiable tuple, swap tuple and target tuple.
The modifiable tuple exchanges the second attribute value with the swap tuple, and the modifiable tuple is to the same as the target tuple after exchanging.
Blue circles represent modifiable tuples, red circles represent swap tuples of modifiable tuple,and green circles represent target tuples of modifiable tuple.
Finally, we utilize the result of algorithm SACUT to construct a cluster table. We will use the cluster table to reduce the influence on a decision tree while the dataset is perturbed to protect sensitive information.
(b) Tuple)
0,1,0,1 1,0, ?
(a) 1,1,?, ?
According to the example in Table II, tuple} = "1, 1, 0, 0", and tuple2="I, 1, 1, I". Because tuple} and tuple2 differ by two attribute values, which are Student and Education level, the common pattern of tuple} and tuple2 is "1, 1, ?, ?", as shown in Figure 3. (a).
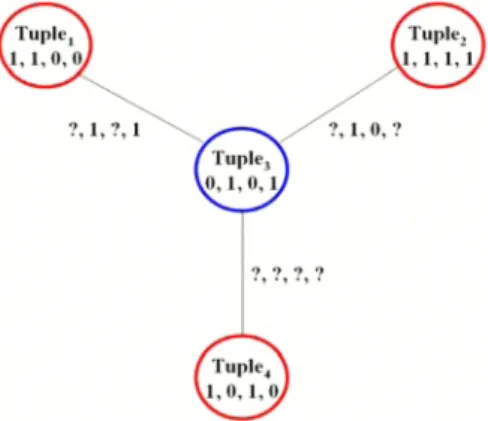
Consider an extreme case that there are n quasi-identifiers in datasetD,and these attribute values of n tuples are different from one another. Even parameterPis set toK-l,any tuple can not be the similar tuple of the other tuple. Hence, by setting P to K, two arbitrary tuples can be regarded as similar tuples. For example, tuple3 = "0, 1, 0, I", tuple4 ="1, 0, 1, 0", and the attribute values of these two tuples are totally different. Both of the attribute number K and the parameter P are four. The common pattern of tuple3 and tuple4 is"?, ?, ?, ?",and tuple4 is the similar tuple oftuple3, as shown in Figure 3. (b).
Note that given parameterP,patterns oftiwill include all patterns that obtained from setting smaller values ofP. As shown in Figure4,assume P is equal to four, we can fmd out the tuple4 is a similar tuple oftuple3, and the common pattern is
"?, ?, ?, ?", .In addition, another two tuples, tuple} and tuple2, are also similar tuples oftuple3. Therefore,"?,1,?, I" and "?, 1, 0,?"are also common patterns oftuple3.
Figure 4. Three patterns can be obtained for tuple3 when P is equal to the attribute numberK,where,K=4.
Similar tuple count is the number of similar tuples of a modifiable tuple. The similar tuple set is composed of these similar tuples. Every similar tuple count is calculated from the corresponding modifiable tuple. As shown in Table II, assume that P is two, we can observe that tuple}} is the only similar tuple of tuplelO, the similar tuple count of tuplelO is one, and tuplelO has one common pattern "?, ?, 0, 0". If a modifiable tuple has no similar tuple in particular P, the similar tuple count is zero. Because it is impossible for fmding the swap tuple and the target tuple with a modifiable tuple whose similar tuple count is zero, this modifiable tuple can not be hidden by current value of P. On the contrary, the similar tuple count of modifiable tuple is very high, swap tuples or target tuples can be found easily. Then this modifiable tuple will be hidden in the hiding process.
The Efficient Protection with Less Perturbation (EPLP) algorithm includes three kinds of methods, which will be explained in the following subsections. At last subsection, we will combine these three methods to achieve hiding quasi-
AlgoritluuEPLPl
identifiers and maintaining the prediction accuracy. In our design, each unique tuple is modified twice at most. The reason is that if a unique tuple is perturbed many times, the structure of decision tree is usually severely influenced. Therefore, we try to design a method that can hide more number of tuples at the same time. In other words, the number of perturbation steps is minimized.
swap tuple swap tuple 1,1,0,?
~'Jodifiable tuple
Figure 7. Algorithm EPLP1 exchanges an attribute value of the modifiable tuple with the swap tuple. Blue circles represent modifiable tuples, red circles
represent swap tuples of modifiable tuple.
We hope that the attribute values of each unique tuple are exchanged twice at most in this method. As shown in Figure 6, suppose that the similar tuple count of tiis the highest. If tihas the swap tuple lj, we denote ti as the modifiable tuple.
According to STATEMENT 2, the perturbation result is correct if tuple tiand ljare no longer unique tuples among Q. Finally, the algorithm EPLP1 exchanges attribute value of ti with attribute value oflj, and update the dataset D and the cluster table T. Algorithm EPLP1 will try to perturb each modifiable tuple until no more tuples can be perturbed by the current value of P. Then, the procedure of algorithm SACUT is executed again, and P is increased by one.
As shown in Table II and Figure 7, suppose that the similar tuple count of tuplelO is the highest one. TuplelO is the modifiable tuple, and it has two similar tuples that are tuple9 and tuplell. Tuplell which is regarded as a swap tuple is chosen randomly from the similar tuple set. After exchanging the age value of tuplelo with that of tuple11, Tuplelo becomes "3, 1, 0, 0" and tuplel1 becomes "2, 0, 0, 0". TuplelO and tuplel1 do not belong to the original quasi-identifiers set anymore. Therefore, they are successfully perturbed. The result is marked by red color in Table IV.
Although this method can guarantee that all quasi- identifiers can be perturbed by increasing the value of P, it probably changes the structure of a decision tree. Therefore, we next devise a method to reduce this influence.
THE SUMMARIZATION OF NOTATION USED IN THIS PAPER.
TABLEIII.
C. Algorithm EPLP1
Now we present the fITst method, named EPLP1. This method can hide two tuples at the same time. The main idea is as follows. The similar tuple set of every modifiable tuple can be found via similar cluster. The swap tuple is chosen randomly from the similar tuple set, where the perturbation count of this swap tuple must be small than two. We observe the common pattern, and fmd one different attribute randomly.
Finally, the modifiable tuple and the swap tuple exchange this attribute value with each other.
Notation name Definition
modifiable tuple The modifiable tuple is a unique tuple which must be hidden and has not been perturbed yet.
swap tuple The swap tuple is a tuple which can be used to hide a modifiable tuple successfully.
Before hiding, the target tuple differs from a target tuple modifiable tuple by one or two attribute values.
Then the modifiable tuple will be the same as the target tuple after the hiding process is finished.
perturbation count The perturbation count expresses the number exchanges of a tuple.
The parameter P represents the allowed parameterP number of different attribute values between two
unique tuples.
The attribute combination of tuplej is similar similar tuple to attribute combination of tuplei, so the tuplej is
a similar tuple oftuplei, ti, tiED, i#j.
similar tuple count Similar tuple count is the number of similar tuples of a modifiable tuple.
similar tuple set The similar tuple set is composed of these similar tuples.
The common pattern points out different common pattern attributes and marks "?", the others mark
original attribute value.
Input: the set of modifiable tupleQ, the cluster table T Output: the datasetD
for each tuple tiofQand this similar tuple COUllt of tuple tiis highest do find R=the similar tuple set
for(R =1= 0) do
randomly choose one tuple as swap tuple t}, t}ER if pelturbation result is coned then
exchange the value oftiandt}
updatetiandt}to D and T delete tifromQ end if
end for end for returnD
T ABLEIV. PERTURB ATTRIBUTE COMBINATIONS BY ALGORITHMEPLP.
RED: THE PERTURBATION RESULT OFEPLP1.BLUE: THE PERTURBATION RESULT OFEPLP2.GREEN: THE PERTURBATION RESULT OFEPLP3.
ID A2e Income Student Education level Credit card
1 1 1 1 1 0
2 1 1 1 1 0
3 0 1 0 0 0
4 1 0 0 0 0
5 3 1 0 1 1
6 3 1 0 1 1
7 2 2 1 1 1
8 2 2 1 1 1
9 3 1 1 1 1
10 3 1 0 0 1
11 2 0 0 0 1
Figure 6. Algorithm EPLP1
Targl!t tupll!
D. Algorithm EPLP2
This method, named EPLP2, is able to maintain the predictive accuracy by perturbing more tuples simultaneously.
In this method, thetarget tuple must differ by two attribute values with modifiable tuple. According to the attribute combination of the modifiable tuple, we fmd out the target tuple. We observe two different attributes between modifiable tuple and target tuple, and we can obtain swap tuples from the similar tuple set by these attribute values of target tuple. These two different attributes have one attribute value that is the same as the attribute value ofswap tuples in similar tuple set, the other attribute value equal to the attribute value of the other swap tuples in similar tuple set. Finally, we choose two swap tuples randomly. After exchanging the attribute values between themodifiable tuple and two swap tuples, the modifiable tuple will become the same as thetarget tuple.
Note that if the modifiable tuple or the target tuple are perturbed again after hiding, the hiding result will be destroyed, that is to say, the modifiable tuple is no longer equal to the target tuple. According to above-mentioned mentioned, the modifiable tuple and the target tuple can be perturbed at most once, but both of two swap tuples can be perturbed at most twice.
AlgoritluuEPLP~
Inpul: the~doflIIodifil1bh"fliP/I."Q.rI~duster lableT Output; tbe datasetD
Cor each tuplettofQandtlm~similarmp!ecolllItofluplc:'ti~ hl~hesl dOl
fUlelR.:;;:; the similar '"ple$('1110mT
fOf(R if:. NULL)do
randomly choose one tuple as'(I'~~I r"p/~I) •UleIJdifferslly two attribute \'alues with11,
~;'JER.
find Ihe:tua StrapIlIpl...ftit;.md11by twodiffe:rcnlall..iblltc~betwcenIIIod{!iabl"fIIP/."and
Icl1'gt"lll/plt'.li :l= '4 '* 1/.:I1;.,/ER if perlmhahonre~,mlt I~cOlTed •
exchangethe value ofI,. IJ:andII
update '.,Ii;andIItoDamiT delete:t.t10111Q
endif endfOf
end for return!>.'
Figure 8. AlgorithmEPLP2
As shown in Figure 8, suppose that thesimilar tuple count of ti is highest, and ti has the two swap tuples tk and tz, we denoteti as the modifiable tuple. We will fmd the target tuple;
that similar the attribute value of the modifiable tuple tie According to STATEMENT 2, the perturbation result is correct if the attribute values ofti are the same as that of; in dataset D, and tuples tk and tz are no longer unique tuples among Q.
Finally, the algorithmEPLP2 exchanges attribute value ti with attribute value oftkand tz, and then update the dataset D and the cluster table T. Algorithm EPLP2 will try to perturb each modifiable tuple until no more tuples can be perturbed by the current value ofP. Then, algorithm EPLP1 will be activated.
As shown in Table II and Figure 9, suppose that thesimilar tuple count of tuple} is highest. Tuple} is the modifiable tuple, and it has threesimilar tuples that are tuple2, tuple3, and tuple4.
We choose tuple2 as atarget tuple randomly from similar tuple
set. Then we can use tuple3 and tuple4 to perturb tuple}. The attribute value of tuple} and tuple2 are the same after the perturbation process. Note that tuple2, tuple3, and tuple4 are also perturbed during the hiding of tuple}. The result is expressed in blue rows of Table IV.
TQrg~ttuple
~ ~
~ ~
1,1.,/ $ /
Tuple,I~ ~ ~ Tuple.
,1,0, ?,.,O,? \t9 ~ ~ ,1,0,
Jlodijiahle tuple swap tuple J/odifiable tuple swap tuple
1,1,1.0 ~ ~
~ ~
SK'ap tuple t...ap tuple
Figure 9. AlgorithmEPLP2exchanges two attribute values of themodifiable tuplewith attribute values f twoswap tuples,and themodifiable tupleis to the
same as hetarget tupleafter exchanging. Blue circles representmodifiable tuples,red circles representswap tuplesofmodifiable tuple,and green circles
representtarget tuples.
AlgorithmEPLP2 can increase the number of tuples that can be perturbed in each step, and thus can maintain the structure of decision tree, and this Algorithm can balance the flexibility of perturbation and correct prediction result than algorithm EPLP1. However, the attribute value of modifiable tuple will be exchanged twice, and theperturbation countofit is two. We hope that the attribute value of all tuples can be exchanged once in each perturbation process to achieve better prediction ability. Because of this reason, we further educe the perturbation count of the modifiable tuple to obtain a better result by the third version of algorithm EPLP which is introduced in the following subsection.
E. Algorithm EPLP3
Though algorithm EPLP2 can maintain the predictive accuracy, the attribute values of modifiable tuple must be exchanged twice. In this section we extend algorithmEPLP2 to algorithm EPLP3 which is able to hide three tuples in one process, and the attribute value of modifiable tuple is exchanged only once.
In this method, thetarget tuple must differ by one attribute value with the modifiable tuple. After fmding out the target tuple from the similar tuple set, we observe the different attribute value between the modifiable tuple and the target tuple. By using this attribute value of the target tuple, swap tuples which also have the same attribute value can be obtained.
Finally, we choose one swap tuple randomly. After exchanging this attribute value betweenmodifiable tuple and swap tuple, themodifiable tuple will become the same as the target tuple.
As shown in Table II and Figure 5, suppose that tuples is the modifiable tuple, tuple9 is the swap tuple, and tuple7 is the target tuple. After this perturbation process, the attribute values of tuples are equal to that of tuple7. Note that tuple9 is also perturbed in this process. Therefore, three tuples are perturbed in one perturbation process. The result is expressed in green
rows of Table IV. Algorithm EPLP3 will try to perturb each modifiable tuple until no more tuples can be perturbed by the current value ofP. Then, algorithm EPLP2 will be activated.
The process of algorithm EPLP3 is similar to algorithm EPLP2, but it needs only one swap tuple. Because the target tuple must differs by one attribute value with the modifiable tuple, algorithm EPLP3 can hide three tuples at the same time by o~e swap tuple, and the the attribute value of modifiable tuple IS only exchanged once in algorithm EPLP3.
The predictive result of algorithm EPLP3 is better than EPLP1 and EPLP2, but the number of tuples which can be
pe~rbed by algorithm EPLP3 is fewer tuple in the same settmg of parameterP. At last subsection, we will summarize the advantages of these three algorithms in detail and exploit the advantages of them to obtain a best solution.
F. The Integrated EPLP Algorithm
In the fmal part of this section, we summarize the features of three versions of the EPLP algorithm and devise an integrated algorithm to combine advantages of these methods.
!his .integra~ed algo~ithm can guarantee that all quasi-
lden~ifi~rs will be hidden, and maintain the accuracy of prediction model. As shown in Figure 10, algorithm EPLPl ca? guarantee all quasi-identifiers to be perturbed by the a?Justment of parameter P. Although algorithm EPLP1 can hide all quasi-identifiers, it will destroy the structure of the decision tree more seriously than other two methods.
Algorithm EPLP2 can maintain a better structure of the decision tree than algorithm EPLP1, but it has to choose two sw.ap tuples. In additio?,t~eattribute value of modifiable tuple wIll ?e exchanged twice m each process of perturbation by algorithm EPLP2. Therefore, we design algorithm EPLP3 to further improve algorithm EPLP2. We hope that attribute value of~ach ~pleis exchanged only in one process of perturbation.
This notion can reduce the influence on the prediction accuracy.
llide quasi-identifier EPLPJ
EPLP1
EPLP3 IVI.lintain predictionaccul"3c)"
Figure 10. Depiction of the trade-off between hidingquasi-identifierand maintaining prediction accuracy.
As shown in Figure 11, at fITst the parameter P is set to be two. Note that the step is redundant when parameter P is one.
For example, assume that there are some unique tuples in a dataset, the modifiable tuple= "0, 0, 0, 0", and the swap tuple =
"0, 0, 0,. 1". The modifiable tuple and the swap tuple differ by one. attribute value. When the algorithm EPLP exchanges the attribute value of the modifiable tuple and the swap tuple, it
excha~gesthe fourth attribute value of two tuples. This hiding result IS that the modifiable tuple = "0, 0, 0, 1", and the swap tuple= "0, 0, 0, 0". These two tuples are still unique tuples for the d~taset,and therefore this hiding result does not have any meanmg.
Figure 11. The integrated EPLP algorithm
We use cluster table to save the cost of hiding procedure.
At fITst, the cluster table is created by similar cluster. If a
u~ique tuple is perturbed by algorithm EPLP, the patterns of thiS tuple will be changed. We do not update the cluster tableT by algorithmSACUT each time, but delete perturbed patterns in cluster table T. It reduces the time for executing similar cluster.
Hence, we will get better efficiency in this framework.
According to Figure 10, algorithm EPLP3 has the best ability to maintain prediction accuracy; therefore the order of theseme~hodsis EPLP3, EPLP2, and EPLP1. When algorithm EPLP3 IS unable to perturb any quasi-identifier, algorithm EPLP2 will be activated. Similarly, algorithm EPLP1 is executed after algorithm EPLP2 can no longer perturb any quasi-identifier. Algorithm EPLP is not able perturb rest of quasi-identifiers in this iteration, we have to increase value of parameter P. Increasing P will also increase the number of
sim~lartuples for all quasi-identifiers. When P equals to the attribute number K, two arbitrary unique tuples are similar tuples which can be used to perturb by algorithm EPLP.
Consequently, we achieve the purpose of hiding all quasi- identifiers.
V. EXPERIMENTAL RESULTS
In this section we present results of our experiments. Our algorithm is compared with LINAPT [15] algorithm. We select real dat~ sets which ~re usually used by the data mining
comm~nltyand are aval!abl.e from the VCI Machine Learning RepOSitory at http://archlve.lcs.ucLedu/ml/. A Core Duo E6300 1.86GHz PC with 1GM RAM was used to conduct our experiment. The algorithm was implemented in C/C++. We use ID3 decision tree [2] to create all decision tree in this study.
We perform the experiments in two phases. In the fITst phase, we apply the integrated EPLP algorithm on Adult and Pima (two real datasets) in order to observe the prediction accuracy of perturbed dataset. The Adult dataset has 32561 tuples, 14 attributes. The Adult dataset is divided into twp parts, 20% are regarded as the training data and 80% are regarded as the test data. On the other hand, the Pima has 768 tuples, 8
numerical attributes. The training data and test data has data size of 80% and 20% respectively. The experimental results will demonstrate the correlation between the prediction accuracy and percentage of hiding. Second, we compare the modification count of both methods. This experiment shows that our method successfully hide quasi-identifiers by fewer number of modifications. In other words, algorithmEPLP can protect private information with fewer disturbances of the dataset.
1200 ~---'-'.- --- ----. --- ----,--- --- --- --.--- --- ---.---, leX))
200
O~-~--L....I...I--L....I...I~-L-I~...a....&~
20% 40% Em' SO% 99% ]00%
O.lK O.2K DJK OAK 0.5K 0.511\
Number of quasi·idtmifiers
7000 .---~
Figure 14. Number of quasi-identifier vs. mofification count. The result is based on dataset Pima.
lK 2K 31\. 3.71\. ~K 5K
N"lll~lofC.lu"'iHdent1fit'I~
-=~ 5000 r-,
~ ~ooo
.~-= 30CXl
!2000
1000 6000 ]00
90
Cll 80 <>- ----0 ....
i:). 70
~ 60
=
~~ 50
:: 40
g
'J 30
-=~
It 10 10
0
Figure 12. Percentage of hiding vs. prediction accuracy. The result ofquasi- identifierhiding is based on dataset Pima.
Figure 15. Number of quasi-identifier vs. modification count. The result is based on dataset Adult.
VI. CONCLUSION
In this paper we devise a framework to protect individual privacy of sensitive information based on perturbing quasi- identifiers within the decision tree. In the past years, most algorithms that had been proposed were only focus on privacy or the prediction accuracy of prediction model. Our goal is to hide all person-specific information with minimized data perturbation while maintain the prediction accuracy. As demonstrated in the experiments, the proposed algorithm can successfully hide private information with fewer disturbances of the classifier.
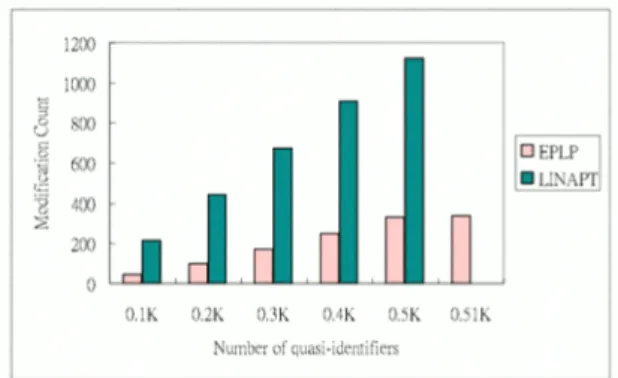
The second experiment shows the correlation between the modification count and the number of quasi-identifiers. In Adult dataset, we set the number of quasi-identifiers form 1000 to 5000. And in Pima dataset, the number of quasi-identifiers increases 100 at each time.
We can observe that the modification count increases with respect to the number of quasi-identifiers. As shown in Figure 14 and Figure 15, when the number of quasi-identifiers grows linearly, the modification count of the integrated EPLP algorithm will grow slowly. In addition, scalability of the integratedEPLP algorithm outperforms LINAPT. Note that the integrated EPLP algorithm can completely hide all quasi- identifier while LINAPT can not. As validated in these experiments, the integrated EPLP algorithm is able to hide confidential information and maintain the prediction accuracy of decision tree with less modification of the original dataset.
100%
o'---_~ _ _ _ 1_ _- L - _ - - - J
0%
roo
Pel(fld~orlu.du~
Figure 13. Percentage of hiding vs. prediction accuracy. The result ofquasi- identifierhiding is based on dataset Adult.
eo
t· ~
=~ ro
I
4Q '~ 10
As shows the Figure 12 and Figure 13, the lines scratch the relationship between the percentage of hiding and the prediction accuracy. The prediction results of the perturbed decision tree are compared with the original decision tree. We can observe that the prediction results of the integratedEPLP algorithm are more similar to the classification results of the original decision tree. In other words, this experiment demonstrates that the integrated EPLP algorithm outperforms LINAPT on maintaining the prediction results of the classification model.
VII. REFERENCES
[1] M.-S. Chen,1. Han, P.S. Yu, "Data mining: An overview from a database perspective," InIEEE Transactions on Knowledge and Data Engineering,8 (6), 1996, pp. 866-883.
[2] l.R."Quinlan, Induction of decision trees". Machine Learning 1, 1986, 81-106.
[3] C. C. Aggarwal. "On k-anonymity and the curse of dimensionality," in VLDB '05: Proceedings of the 31st international conference on Very large data bases, pages 901-909. VLDB Endowment, 2005.
[4] D. Agrawal and C. C. Aggarwal. "On the design and quantification of privacy preserving data mining algorithms". InPODS '01: Proceedings of the twentieth ACM SIGMOD-SIGACT-SIGART symposium on Principles of database systems,pages 247-255, New York, NY, USA, 2001. ACM Press.
[5] 1. Li, R. C.-W. Wong, Ada W.-C Fu and 1. Pei, "Achieving k- Anonymity by Clustering in Attribute Hierarchical Structures", in proceedings of the Data Warehousing and Knowledge Discovery, 2006, 405-416.
[6] 1. Byun, A. Kamra, E. Bertino, N. Li, "Efficient k-Anonymization using clustering techniques". In: Kotagiri, R., Radha Krishna, P., Mohania, M., Nantajeewarawat, E. (eds.) DASFAA 2007. LNCS, vol. 4443,2007, pp.
188-200. Springer, Heidelberg.
[7] W. Du and Z. Zhan, "Building Decision Tree Classifier on Private Data", In CRPITS' 14: Proceedings of the IEEE international conference on Privacy, security and data mining, pages 1-8, Darlinghurst, Australia, Australia, 2002. Australian Computer Society, Inc.
[8] V. Yan Fu Tan, S.-K. Ng, "Privacy-preserving sharing of horizontally- distributed private data for constructing accurate classifiers," Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics) 4890 LNCS, pp. 116-137.
[9] 1. Vaidya and C. Clifton. "Privacy-Preserving Decision Trees over Vertically Partitioned Data," in Data and Application Security (DBSec), pages 139-152,2005.
[10] M.-1. Xiao, L.-S. Huang, Y.-L. Luo, and H. Shen, "Privacy Preserving ID3 Algorithm over Horizontally Partitioned Data," in Parallel and Distributed Computing, Applications and Technologies, pages 239-243, 2005.651.
[11] 1. Zhan, "Using homomorphic encryption for privacy-preserving collaborative decision tree classification," in Proceedings of the 2007 IEEE Symposium on Computational Intelligence and Data Mining, CIDM 2007, art. no. 4221360, pp. 637-645.
[12] B.C.M. Fung, K. Wang, P.S. Yu, "Anonymizing classification data for privacy preservation," in IEEE Transactions on Knowledge and Data Engineering,19 (5), 2007,pp. 711-725.
[13] M. Z. Islam, and L. Brankovic," Noise Addition for Protecting Privacy in Data Mining," inProceedings of The 6th Engineering Mathematics and Applications Conference (EMAC2003),Sydney, 85-90.
[14] M.Z.Islam, P.M.Barnaghi and L. Brankovic, "Measuring Data Quality:
Predictive Accuracy vs. Similarity of Decision Trees," in Proceedings ofthe 6e" Intenational Conference on Computer & Information Technology (ICCIT 2003), 2003, Dhaka, Bangladesh, Vol. 2,457-462.
[15] M.Z.Islam and L. Brankovic, "A Framework for Privacy Preserving Classification in Data Mining," in Proceedings of Australasian Workshop on Data Mining and Web Intelligence (DMWI 2004), Dunedin, New Zealand, CRPIT, 32, 1. Hogan, P. Montague, M. Purvis and C. Steketee, Eds., Australasian Compuiter Science Communications, 163-168.
[16] Md.Z. Islam, L. Brankovic, "DETECTIVE: A decision tree based categorical value clustering and perturbation technique for preserving privacy in data mining," in2005 3rd IEEE International Conference on Industrial Informatics, INDIN2005,art. no. 1560461, pp. 701-708.
[17] X.-D. Wu, D.-M. Yue, F.-L. Liu, Y.-F. Wang, C.-H. Chu, "Privacy preserving data mining algorithms by data distortion," inProceedings of 2006 International Conference on Management Science and Engineering, ICMSE'06 (l3th),art. no. 4104898, 2007, pp. 223-228.
[18] B.C.M. Fung, K. Wang, P.S. Yu, "Anonymizing classification data for privacy preservation". inIEEE Transactions on Knowledge and Data Engineering,19 (5), 2007, pp. 711-725.