API 参考
文档版本 08
发布日期 2020-08-03
版权所有 © 华为技术有限公司 2021。 保留一切权利。
非经本公司书面许可,任何单位和个人不得擅自摘抄、复制本文档内容的部分或全部,并不得以任何形式传 播。
商标声明
和其他华为商标均为华为技术有限公司的商标。
本文档提及的其他所有商标或注册商标,由各自的所有人拥有。
注意
您购买的产品、服务或特性等应受华为公司商业合同和条款的约束,本文档中描述的全部或部分产品、服务或 特性可能不在您的购买或使用范围之内。除非合同另有约定,华为公司对本文档内容不做任何明示或暗示的声 明或保证。
由于产品版本升级或其他原因,本文档内容会不定期进行更新。除非另有约定,本文档仅作为使用指导,本文 档中的所有陈述、信息和建议不构成任何明示或暗示的担保。
华为技术有限公司
地址: 深圳市龙岗区坂田华为总部办公楼 邮编:518129
网址:
https://www.huawei.com
客户服务邮箱:
[email protected]
客户服务电话:4008302118目 录
1 使用前必读... 1
1.1 概述... 1
1.2 调用说明...1
1.3 终端节点...1
1.4 约束与限制... 1
1.5 基本概念...2
2 API 概览... 3
3 如何调用 API...4
3.1 申请服务...4
3.2 构造请求...4
3.3 认证鉴权...7
3.4 返回结果...9
4 API...10
4.1 自然语言处理基础服务接口说明...10
4.1.1 分词... 10
4.1.2 多粒度分词... 19
4.1.3 依存句法分析... 25
4.1.4 命名实体识别(基础版)... 30
4.1.5 命名实体识别(领域版)... 33
4.1.6 文本相似度(基础版)...39
4.1.7 文本相似度(高级版)...42
4.1.8 句向量... 45
4.1.9 实体链接... 48
4.1.10 关键词抽取... 52
4.1.11 事件抽取... 55
4.2 语言生成服务接口说明... 60
4.2.1 文本摘要(基础版)... 60
4.2.2 文本摘要(领域版)... 64
4.2.3 诗歌生成... 69
4.3 语言理解服务接口说明... 72
4.3.1 情感分析(基础版)... 72
4.3.2 情感分析(领域版)... 76
4.3.3 文本分类... 79
4.3.4 属性级情感分析...83
4.3.5 属性级情感分析(高级版)... 87
4.3.6 实体级情感分析...91
4.3.7 意图理解... 95
4.3.8 文档分类... 99
4.4 机器翻译服务接口说明...103
4.4.1 文本翻译... 103
4.4.2 语种识别... 107
4.4.3 文档翻译任务创建... 111
4.4.4 文档翻译状态查询... 114
5 数据结构... 117
5.1 公共请求参数... 117
5.2 公共响应参数... 117
6 附录... 119
6.1 状态码... 119
6.2 错误码... 119
6.3 获取项目 ID... 123
6.4 获取帐号 ID... 124
6.5 配置 OBS 访问权限...124
7 修订记录... 126
1 使用前必读
1.1 概述
欢迎使用自然语言处理(Natural Language Processing) ,服务主要包括自然语言处 理基础服务、语言生成服务、语言理解服务、机器翻译服务等功能。
在调用自然语言处理服务API之前,请确保已经充分了解自然语言处理服务相关概念,
详细信息请参见产品介绍。
1.2 调用说明
自然语言处理服务提供了REST(Representational State Transfer)风格API,支持您 通过HTTPS请求调用,调用方法请参见如何调用API。
1.3 终端节点
终端节点即调用API的请求地址,不同服务不同区域的终端节点不同,您可以从地区和
终端节点中查询所有服务的终端节点。
目前自然语言处理基础、语言生成、语言理解和机器翻译服务支持以下地区和终端节 点:
表1-1 自然语言处理基础、语言生成、语言理解和机器翻译服务
区域名称 区域 终端节点(Endpoint) 协议类
型 华北-北京四 cn-north-4 nlp-ext.cn-
north-4.myhuaweicloud.com HTTPS
1.4 约束与限制
更详细的限制请参见具体API的说明和产品介绍约束与限制。
1.5 基本概念
● 帐号
用户注册华为云时的帐号,帐号对其所拥有的资源及云服务具有完全的访问权 限,可以重置用户密码、分配用户权限等。由于帐号是付费主体,为了确保帐号 安全,建议您不要直接使用帐号进行日常管理工作,而是创建用户并使用他们进 行日常管理工作。
● 用户
由帐号在IAM中创建的用户,是云服务的使用人员,具有身份凭证(密码和访问 密钥)。
在我的凭证下,您可以查看帐号ID和用户ID。通常在调用API的鉴权过程中,您需 要用到帐号、用户和密码等信息。
● 区域(Region)
从地理位置和网络时延维度划分,同一个Region内共享弹性计算、块存储、对象 存储、VPC网络、弹性公网IP、镜像等公共服务。Region分为通用Region和专属 Region,通用Region指面向公共租户提供通用云服务的Region;专属Region指只 承载同一类业务或只面向特定租户提供业务服务的专用Region。
详情请参见区域和可用区。
● 可用区(AZ,Availability Zone)
一个AZ是一个或多个物理数据中心的集合,有独立的风火水电,AZ内逻辑上再将 计算、网络、存储等资源划分成多个集群。一个Region中的多个AZ间通过高速光 纤相连,以满足用户跨AZ构建高可用性系统的需求。
● 项目
华为云的区域默认对应一个项目,这个项目由系统预置,用来隔离物理区域间的 资源(计算资源、存储资源和网络资源),以默认项目为单位进行授权,用户可 以访问您帐号中该区域的所有资源。如果您希望进行更加精细的权限控制,可以 在区域默认的项目中创建子项目,并在子项目中购买资源,然后以子项目为单位 进行授权,使得用户仅能访问特定子项目中资源,使得资源的权限控制更加精 确。
图1-1 项目隔离模型
2 API 概览
自然语言处理提供了如下接口,方便用户对自然语言处理的使用。各类接口的说明如
表2-1所示。
表2-1 接口说明
接口类型 说明
自然语言处理基础接口 包含分词、多粒度分词、依存句法分析、命名实体识 别、文本相似度和句向量、实体链接、关键词抽取、事 件抽取接口等。
语言生成接口 包含文本摘要、诗歌生成接口。
语言理解接口 包含情感分析、文本分类、意图理解接口。
机器翻译接口 包含文本翻译、语种识别接口。
3 如何调用 API
3.1 申请服务
1. 进入自然语言处理NLP主页,单击“立即使用”。
进入自然语言处理控制台。
2. 在“总览”页面,选择需要使用的服务,在操作列单击“开通服务”。
3. 在弹出的对话框中单击“确定”。
服务开通成功后,开通状态显示“已开通”。
图3-1 开通服务
说明
● NLP服务开通后,暂不支持关闭。开通服务时,计费规则默认为“按需计费”,按需计 费时,不使用NLP服务,则不收费。如果您购买了套餐包,套餐包扣减规则请参见价格 计算器计费详情页。
● 如未开通服务,直接调用NLP API会提示ModelArts.4204报错。
3.2 构造请求
本节介绍REST API请求的组成,讲述如何调用API接口。
请求示例如下所示,一个请求主要由请求URL、请求方法、请求消息头和请求消息体 几部分组成,各个部分将在下文详细解释。
图3-2 请求示例图
请求 URI
请求URI由如下部分组成。
{URI-scheme} :// {Endpoint} / {resource-path} ? {query-string}
尽管请求URI包含在请求消息头中,但大多数语言或框架都要求您从请求消息中单独传 递它,所以在此单独强调。
● URI-scheme:表示用于传输请求的协议,当前所有API均采用HTTPS协议。
● Endpoint:指定承载REST服务端点的服务器域名或IP,不同服务不同区域的 Endpoint不同,您可以从地区和终端节点中获取。例如自然语言处理(NLP)服 务在“华北-北京四”区域的Endpoint为“nlp-ext.cn-
north-4.myhuaweicloud.com”。
● resource-path:资源路径,也即API访问路径。从具体API的URI模块获取,例如
“文本分类”API的resource-path为“/v1/{project_id}/nlu/classification”。其 中{project_id}为项目编号,请参考获取项目ID获取。
● query-string:查询参数,是可选部分,并不是每个API都有查询参数。查询参数 前面需要带一个“?”,形式为“参数名=参数取值”,例如“limit=10”,表示 查询不超过10条数据。当前NLP服务未使用该参数。
例如,您需要在“华北-北京四”区域调用文本分类API,则需使用“华北-北京四”区 域的Endpoint(nlp-ext.cn-north-4.myhuaweicloud.com),并在文本分类的URI部分 找到resource-path(/v1/{project_id}/nlu/classification),拼接起来如下所示。
https://nlp-ext.cn-north-4.myhuaweicloud.com/v1/{project_id}/nlu/classification
图3-3 URI 示意图
说明
为查看方便,在每个具体API的URI部分,只给出resource-path部分,并将请求方法写在一起。
这是因为URI-scheme都是HTTPS,而Endpoint在同一个区域也相同,所以简洁起见将这两部分 省略。
请求方法
HTTP请求方法(也称为操作或动词),它告诉服务你正在请求什么类型的操作。
● GET:请求服务器返回指定资源。
● PUT:请求服务器更新指定资源。
● POST:请求服务器新增资源或执行特殊操作。
● DELETE:请求服务器删除指定资源,如删除对象等。
● HEAD:请求服务器资源头部。
● PATCH:请求服务器更新资源的部分内容。当资源不存在的时候,PATCH可能会 去创建一个新的资源。
在文本分类的URI部分,您可以看到其请求方法为“POST”,则其请求为:
POST https://nlp-ext.cn-north-4.myhuaweicloud.com/v1/{project_id}/nlu/classification
请求消息头
附加请求头字段,如指定的URI和HTTP方法所要求的字段。例如定义消息体类型的请 求头“Content-Type”,请求鉴权信息等。
如下公共消息头需要添加到请求中。
● Content-Type:消息体的类型(格式),必选,默认取值为“application/
json”,有其他取值时会在具体接口中专门说明。
● X-Auth-Token:用户Token,NLP服务使用Token方式认证,必须填充该字段。用 户Token请参考3.2 认证鉴权。
添加消息头后的请求如下所示。
POST https://nlp-ext.cn-north-4.myhuaweicloud.com/v1/{project_id}/nlu/classification Content-Type: application/json
x-auth-token: MIIaBgYJKoZIhvcNAQcC……
请求消息体
请求消息体通常以结构化格式发出,与请求消息头中Content-type对应,传递除请求 消息头之外的内容。若请求消息体中参数支持中文,则中文字符必须为UTF-8编码。每 个接口的请求消息体内容不同,也并不是每个接口都需要有请求消息体(或者说消息 体为空),GET、DELETE操作类型的接口就不需要消息体,消息体具体内容需要根据 具体接口而定。
对于文本分类接口,您可以从接口的请求部分看到所需的请求参数及参数说明。将消 息体加入后的请求如下所示。
POST https://nlp-ext.cn-north-4.myhuaweicloud.com/v1/{project_id}/nlu/classification Content-Type: application/json
x-auth-token: MIIaBgYJKoZIhvcNAQcC……
{
"content":"XXX去屑洗发水,全国包邮",
"domain":1 }
到这里为止这个请求需要的内容就具备齐全了,您可以使用curl、Postman或直接编 写代码等方式发送请求调用API。对于文本分类接口,您可以从响应消息部分看到返回 参数及参数说明。
3.3 认证鉴权
调用NLP服务接口目前支持Token认证进行认证鉴权。
Token 认证
Token在计算机系统中代表令牌(临时)的意思,拥有Token就代表拥有某种权限。
Token认证就是在调用API的时候将Token加到请求消息头,从而通过身份认证,获得 操作API的权限。
说明
● Token的有效期为24小时,需要使用一个Token鉴权时,可以先缓存起来,避免频繁调用。
● 如果您的华为云帐号已升级为华为帐号,将不支持获取帐号Token,建议您为自己创建一个 IAM用户,授予该用户必要的权限,获取IAM用户Token。
● 如果您是第三方系统用户,直接使用联邦认证的用户名和密码获取Token,系统会提示密码 错误。请先在华为云的登录页面,通过“忘记密码”功能,设置原华为云帐号密码。
● 如果您开启了登录保护并设置登录保护为MFA验证,请参考获取IAM用户Token(使用密码 +虚拟MFA)获取IAM用户Token。
● 如果需要获取具有Security Administrator权限的Token,请参见:如何获取Security Administrator权限的Token。
● 通过Postman获取用户Token示例请参见:如何通过Postman获取用户Token。
NLP服务所需Token获取可参考下文,如需了解更多获取Token方式,请参考获取用户
Token。
获取用户Token接口请求构造如下,您可以从接口的请求部分看到所需的请求参数及参 数说明。获取Token消息头只需填写“Content-Type”,将消息体加入后的请求如下所 示。
加粗的斜体字段需要根据实际值填写,其中
username
为用户名,domainname
为用 户所属的帐号名称,********
为用户登录密码。详细信息请参见Token消息体中username,domain name和project name分别指的是什么?章节。
获取Token的终端节点和
projectname
需与NLP服务终端节点保持一致。当访问华北- 北京四的终端节点(即nlp-ext.cn-north-4
.myhuaweicloud.com时),获取Token请 使用终端节点https://iam.cn-north-4
.myhuaweicloud.com,projectname
对应使用cn-north-4
。Token可通过调用获取用户Token接口获取,调用本服务API需要project级别的 Token,即调用获取用户Token接口时,请求body中auth.scope的取值需要选择 project,如下所示。
POST https://iam.cn-north-4.myhuaweicloud.com/v3/auth/tokens Content-Type: application/json
{ "auth": { "identity": { "methods": [
"password"
],
"password": { "user": {
"name": "username", "password": "********", "domain": {
"name": "domainname"
} } } }, "scope": { "project": {
"name": "projectname"
} } } }
如下图所示,返回的响应消息头中“x-subject-token”就是需要获取的用户Token。获 取Token之后,您就可以使用Token认证调用NLP服务API。
图3-4 获取用户 Token 响应消息头
您还可以通过这个视频教程了解如何使用Token认证:https://
bbs.huaweicloud.com/videos/101333 。
AK/SK 认证
如需使用AK/SK认证,建议使用自然语言处理SDK参考,或使用下文签名SDK。
说明
AK/SK签名认证方式仅支持消息体大小12M以内,12M以上的请求请使用Token认证。
AK/SK认证就是使用AK/SK对请求进行签名,在请求时将签名信息添加到消息头,从而 通过身份认证。
● AK(Access Key ID):访问密钥ID。与私有访问密钥关联的唯一标识符;访问密钥 ID和私有访问密钥一起使用,对请求进行加密签名。
● SK(Secret Access Key):与访问密钥ID结合使用的密钥,对请求进行加密签名,
可标识发送方,并防止请求被修改。
使用AK/SK认证时,您可以基于签名算法使用AK/SK对请求进行签名,也可以使用专门 的签名SDK对请求进行签名。详细的签名方法和SDK使用方法请参见API签名指南。
须知
签名SDK只提供签名功能,与服务提供的SDK不同,使用时请注意。
AK/SK获取方式请参考获取AK/SK。
3.4 返回结果
状态码
请求发送以后,您会收到响应,包含状态码、响应消息头和消息体。
状态码是一组从1xx到5xx的数字代码,状态码表示了请求响应的状态,完整的状态码 列表请参见状态码。
对于NLP服务接口,如果调用后返回状态码为“200”,则表示请求成功。
响应消息头
对应请求消息头,响应同样也有消息头,如“Content-type”,“x-request-id”,
NLP服务响应消息头无特殊用途,可用于定位问题使用。
响应消息体
响应消息体通常以结构化格式返回,与响应消息头中Content-type对应,传递除响应 消息头之外的内容。
对于文本分类接口,返回如下消息体,格式请具体参考文本分类响应消息部分。
{ "result": {
"content": "XXX去屑洗发水,全国包邮", "label": 0,
"confidence": 0.5190434 }
}
当接口调用出错时,会返回错误码及错误信息说明,错误响应的Body体格式如下所 示。
{ "error_code": "NLP.0301",
"error_msg": "query param error content.at least one of Chinese, English, or number;"
}
其中,error_code表示错误码,error_msg表示错误描述信息。
4 API
4.1 自然语言处理基础服务接口说明
4.1.1 分词
功能介绍
对文本进行分词处理。
具体Endpoint请参见终端节点。
调用华为云NLP服务会产生费用,本API支持使用基础套餐包,购买时请在自然语言处
理价格计算器中查看基础套餐包和领域套餐包支持的API范围。
调试
您可以在API Explorer中调试该接口。
前提条件
在使用本API之前,需要您完成服务申请和认证鉴权,具体操作流程请参见申请服务和
认证鉴权章节。
说明
用户首次使用需要先申请开通。服务只需要开通一次即可,后面使用时无需再次申请。如未开通 服务,调用服务时会提示ModelArts.4204报错,请在调用服务前先进入控制台开通服务,并注 意开通服务区域与调用服务的区域保持一致。
URI
● URI格式
POST /v1/{project_id}/nlp-fundamental/segment
● 参数说明
表4-1 URI 参数说明
参数名 必选 说明
project_id 是 项目编号。获取方法,请参见获取项目ID。
请求消息
请求参数如表4-2所示。
表4-2 请求 Body 参数
参数名 参数类型 必选 说明
text String 是 待分词文本,长度为1~2000,文本编 码为UTF-8。
pos_switch Integer 否 是否开启词性标注功能,1为开启,0为 关闭,默认为关闭。
lang String 否 支持的文本语言类型,目前支持中文
(zh)和英文(en),默认为中文。
criterion String 否 支持的分词规范。
中文分词标准目前支持PKU(北大分词 标准)、CTB(宾州中文树库标准),
默认为PKU。
英文分词标准默认为Penn TreeBank
(宾州树库标准),不需要传入该参 数。
响应消息
响应参数如表4-3所示。
表4-3 响应参数
参数名 参数类型 说明
words Array of words 分词结果,请参见表4-4。
error_code String 调用失败时的错误码,具体参见错误
码。
调用成功时无此字段。
error_msg String 调用失败时的错误信息。
调用成功时无此字段。
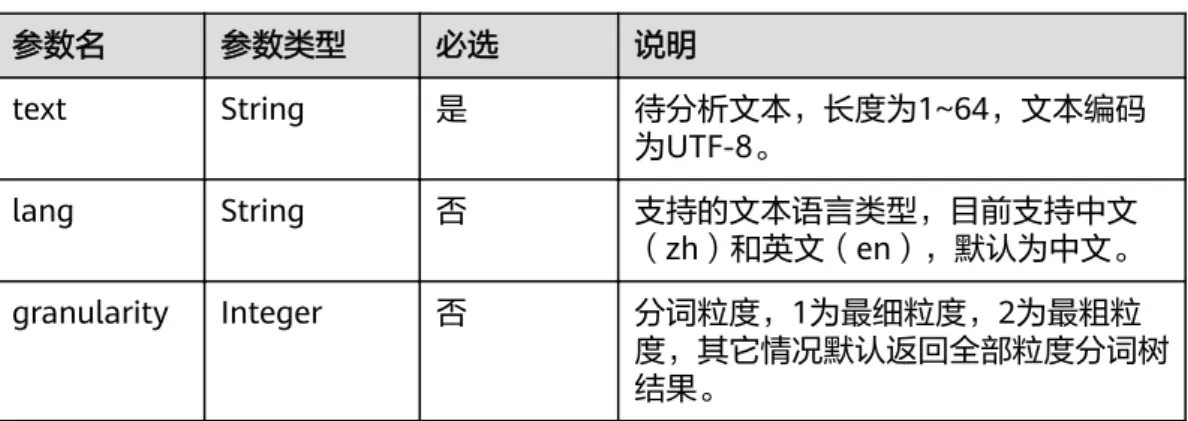
表4-4 Word 字段数据结构说明
参数名 参数类型 说明
content String 词汇文本。
pos String 词汇对应的词性。详细说明请参见表4-5、表
4-6、表 (Penn TreeBank) 词性说明。
表4-5 PKU 词性说明
一类词性 二类词性 三类词性
n:名词 nr:人名 ● nr1:汉语姓氏
● nr2:汉语名字
● nrj:日语人名
● nrf:音译人名
ns:地名 nsf:音译地名
nt:机构团体名 -
nz:其它专名 -
nl:名词性惯用语 -
ng:名词性语素 -
t:时间词 tg:时间词性语素 -
s:处所词 - -
f:方位词 - -
v:动词 vd:副动词 -
vn:名动词 -
vshi:动词“是” - vyou:动词“有” -
vf:趋向动词 -
vx:形式动词 -
vi:不及物动词(内动 词)
-
vl:动词性惯用语 -
vg:动词性语素 -
a:形容词 ad:副形词 -
an:名形词 -
一类词性 二类词性 三类词性 ag:形容词性语素 -
al:形容词性惯用语 -
b:区别词 bl:区别词性惯用语 -
z:状态词 - -
r:代词 rr:人称代词 -
rz:指示代词 ● rzt:时间指示代词
● rzs:处所指示代词
● rzv:谓词性指示代词 ry:疑问代词 ● ryt:时间疑问代词
● rys:处所疑问代词
● ryv:谓词性疑问代词
rg:代词性语素 -
m:数词 mq:数量词 -
mg:甲、乙、丙、丁、
戊、己、庚、辛、壬、癸 -
q:量词 qv:动量词 -
qt:时量词 -
d:副词 - -
p:介词 pba:介词“把” -
pbei:介词“被” -
c:连词 cc:并列连词 -
u:助词 uzhe:着 -
ule:了、喽 -
uguo:过 -
ude1:的、底 -
ude2:地 -
ude3:得 -
usuo:所 -
udeng:等、等等云云 - uyy:一样、一般似的、
般 -
一类词性 二类词性 三类词性
udh:的话 -
uls:来讲、来说而言、说
来 -
uzhi:之 -
ulian:连 (“连小学生都
会”) -
e:叹词 - -
y:语气词(delete yg) - -
o:拟声词 - -
h:前缀 - -
k:后缀 - -
x:字符串 xe:Email字符串 -
xs:微博会话分隔符 -
xm:表情符号 -
xu:网址URL -
w:标点符号 wkz:左括号,全角:
( 〔 [ { 《 【 〖 〈 半 角:( [ { <
-
wky:右括号,全
角:) 〕 ] }》 】 〗〉
半角: ) ] { >
-
wyz:左引号,全角:
“ ‘ 『 -
wyy:右引号,全角:”
’ 』 -
wj:句号,全角:。 - ww:问号,全角:? 半
角:? -
wt:叹号,全角:! 半
角:! -
wd:逗号,全角:, 半
角:, -
wf:分号,全角:; 半
角: ; -
wn:顿号,全角:、 -
一类词性 二类词性 三类词性 wm:冒号,全角:: 半
角: : -
ws:省略号,全角:……
… -
wp:破折号,全角:——
-- ——- 半角:--- ----
-
wb:百分号千分号,全 角:% ‰ 半角:% - wh:单位符号,全角:¥
$ > ° ℃ 半角:$ -
表4-6 CTB 词性说明
词性 名称 示例
AD 副词 不 也 就
AS 动态助词 了 著 过
BA 把字结构 将 把
CC 并列连接词 和 与
CD 限定数量词 一 两 三
CS 从属连接词 虽然 如果 若
DEC 补语或名词化 的 之
DEG 关联或所有格 的 之
DER 补语短语“得” 得
DEV 方式“地” 地
DT 限定词 这 各 全
ETC 等等 等 等等
FW 外来词 A E B
IJ 感叹词 唉呀 哈拉
JJ 名词修饰词 大 新 小
LB 长“被”结构 被 为 受
LC 方位词 中 上 时
M 量词 个 年 美元
词性 名称 示例
MSP 其他助词 所 而 来
NN 名词 经济 企业 人
NR 专有名词 中国 浙江
NT 时间名词 目前 去年
OD 数词 第一 第二 首
ON 拟声词 O
P 介词 在 对 以
PN 代词 他 我 自己
PU 标点符号 , 。
SB 短“被”结构 被 遭
SP 句末助词 了 的 吗
VA 谓词性形容词 大 多 好
VC 系动词 是 为 非
VE 主要动词“有” 有 没有 无
VV 动词 说 要 会
表4-7 Penn TreeBank 词性说明
词性 名称 示例
CC 并列连接词 and, but, or
CD 基数 one, two
DT 限定词 a, the
EX 存在型there there
FW 外文单词 mea, culpa
IN 介词/从属,连接词 of, in, by
JJ 形容词 yellow
JJR 形容词,比较级 bigger
JJS 形容词,最高级 wildest
LS 列表项标记 1, 2, One
MD 情态动词 can, could, might
词性 名称 示例
NN 名词,可数或不可数 llama
NNS 名词,复数 llamas
NNP 专有名词,单数 IBM
NNPS 专有名词,复数 Carolinas
PDT 前位限定词 all, both
POS 所有格结束词 's
PRP 人称代名词 I, me, you,
PRP$ 物主代词,所有格代名词 my, your, yours
RB 副词 quickly
RBR 副词,比较级 faster
RBS 副词,最高级 fastest
RP 小品词 up, off
SYM 符号(数学或科学) +, % ,&
TO to to
UH 感叹词 ah, oops
VB 动词,基本形态 eat
VBD 动词,过去式 ate
VBG 动词,动名词/现在分词 eating
VBN 动词,过去分词 eaten
VBP 动词,非第三人称单数现
在式 eat
VBZ 动词,第三人称单数现在
式
eats
WDT wh-限定词 which, that
WP wh-代词 what, who
WP$ 所有格wh-代词 whose
WRB wh-副词 how, where
PU 标点符号 , . :
示例
● 请求示例
Request Header:
Content-Type: application/json X-Auth-Token:
MIINRwYJKoZIhvcNAQcCoIINODCCDTQCAQExDTALBglghkgBZQMEAgEwgguVBgkqhkiG...
Request Body:
{
"text":"今天天气真好", "pos_switch":1, "lang":"zh", "criterion":"PKU"
}
● Python3语言请求代码示例
# -*- coding: utf-8 -*-
# 此demo仅供测试使用,建议使用sdk。需提前安装requests,执行pip install requests import requests
import json def nlp_demo():
url = 'https://{endpoint}/v1/{project_id}/nlp-fundamental/segment' # endpoint和project_id需替换 token = '用户对应region的token'
header = {
'Content-Type': 'application/json', 'X-Auth-Token': token
} body = {
'text': '今天天气真好', 'pos_switch': 1, 'lang': 'zh', 'criterion': 'PKU' }
resp = requests.post(url, data=json.dumps(body), headers=header) print(resp.text)
if __name__ == '__main__':
nlp_demo()
● Java语言请求代码示例
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.net.HttpURLConnection;
import java.net.URL;
/** * 此demo仅供测试使用,建议使用sdk */public class NLPDemo {
public void nlpDemo() { try {
//endpoint和projectId需要替换成实际信息。
URL url = new URL("https://{endpoint}/v1/{project_id}/nlp-fundamental/segment");
String token = "对应region的token";
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("POST");
connection.setDoInput(true);
connection.setDoOutput(true);
connection.addRequestProperty("Content-Type", "application/json");
connection.addRequestProperty("X-Auth-Token", token);
//输入参数
String text = "订单记录怎么删除";
String body = "{\"text\":\"" + text + "\",\"pos_switch\":1 ,\"lang\":\"zh\",\"criterion\":\"PKU\"}";
OutputStreamWriter osw = new OutputStreamWriter(connection.getOutputStream(),
"UTF-8");
osw.append(body);
osw.flush();
InputStream is = connection.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is, "UTF-8"));
while (br.ready()) {
System.out.println(br.readLine());
}
} catch (Exception e) { e.printStackTrace();
} }
public static void main(String[] args) { NLPDemo nlpDemo = new NLPDemo();
nlpDemo.nlpDemo();
} }
说明
“endpoint”、“project_id”、“token”等请求参数获取方式可参考快速入门,参数详情请见 构造请求。
● 响应示例
– 成功响应示例
{ "words": [ {
"content": "今天", "pos": "t"
}, {
"content": "天气",, "pos": "n"
}, {
"content": "真", "pos": "d"
}, {
"content": "好", "pos": "a"
} ] }
– 失败响应示例
{ "error_code": "NLP.0301",
"error_msg": "The length of text should be in the range of 1-512"
}
状态码
状态码请参见状态码。
错误码
错误码请参见错误码。
4.1.2 多粒度分词
功能介绍
给定一个句子输入,输出不同粒度的所有单词的层次结构。
以“华为技术有限公司的总部”为例,多粒度分词得到的层次结构如下图所示。其中 白色圆形节点为字符单元,蓝色圆角矩阵节点为词汇单元。
图4-1 多粒度分词
本API免费调用,调用限制为2次/秒。
调试
您可以在API Explorer中调试该接口。
前提条件
在使用本API之前,需要您完成服务申请和认证鉴权,具体操作流程请参见申请服务和
认证鉴权章节。
说明
用户首次使用需要先申请开通。服务只需要开通一次即可,后面使用时无需再次申请。如未开通 服务,调用服务时会提示ModelArts.4204报错,请在调用服务前先进入控制台开通服务,并注 意开通服务区域与调用服务的区域保持一致。
URI
● URI格式
POST /v1/{project_id}/nlp-fundamental/multi-grained-segment
● 参数说明
表4-8 URI 参数说明
参数名 必选 说明
project_id 是 项目编号。获取方法,请参见获取项目ID。
请求消息
请求参数如表 请求参数所示。
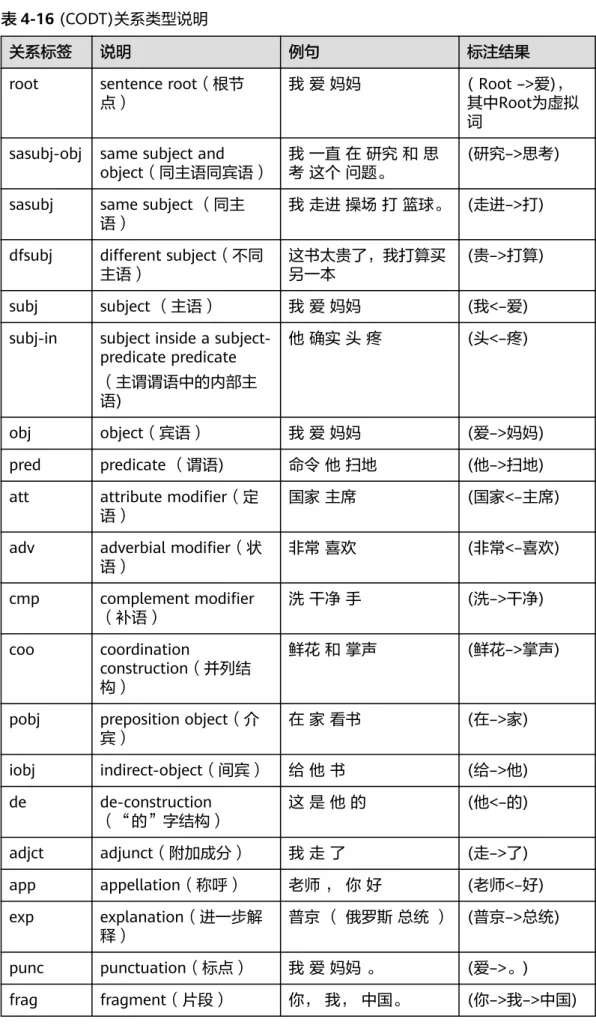
表4-9 请求参数
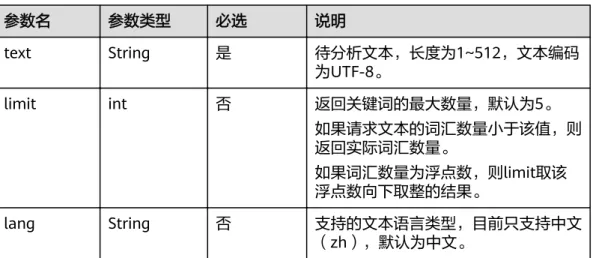
参数名 参数类型 必选 说明
text String 是 待分析文本,长度为1~64,文本编码 为UTF-8。
lang String 否 支持的文本语言类型,目前支持中文
(zh)和英文(en),默认为中文。
granularity Integer 否 分词粒度,1为最细粒度,2为最粗粒 度,其它情况默认返回全部粒度分词树 结果。
响应消息
响应参数如表4-10所示。
表4-10 响应参数
参数名 参数类型 说明
result Array of node objects
或 Array of strings 分词结果。默认返回全部粒度分词树结 果,如果选择了分词粒度,则返回对应 粒度的词汇列表结果。
表4-11 node 字段数据结构说明
参数名 参数类型 说明
content String 该节点对应的文本内容,并基于文本的 unicode编码,做归一化处理。
例如:中文标点","会映射到英文标点“,”。
type String 节点类型,包括 WORD-词汇类型,CHAR-字 符类型。
sub_contents Array of node
objects 子节点列表。
示例
● 请求示例1
POST https://{endpoint}/v1/{project_id}/nlp-fundamental/multi-grained-segment Request Header:
Content-Type: application/json X-Auth-Token:
MIINRwYJKoZIhvcNAQcCoIINODCCDTQCAQExDTALBglghkgBZQMEAgEwgguVBgkqhkiG...
Request Body:
{
"text": "华为技术有限公司的总部", "lang":"zh",
"granularity":2 }
● Python3语言请求代码示例
# -*- coding: utf-8 -*-
# 此demo仅供测试使用,建议使用sdk。需提前安装requests,执行pip install requests import requests
import json def nlp_demo():
url = 'https://{endpoint}/v1/{project_id}/nlp-fundamental/multi-grained-segment' # endpoint和 project_id需替换
token = '用户对应region的token' header = {
'Content-Type': 'application/json', 'X-Auth-Token': token
} body = {
'text': '华为技术有限公司的总部', 'granularity': 1
}
resp = requests.post(url, data=json.dumps(body), headers=header) print(resp.text)
if __name__ == '__main__':
nlp_demo()
● Java语言请求代码示例
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.net.HttpURLConnection;
import java.net.URL;
/** * 此demo仅供测试使用,建议使用sdk */public class NLPDemo {
public void nlpDemo() { try {
//endpoint和projectId需要替换成实际信息。
URL url = new URL("https://{endpoint}/v1/{project_id}/nlp-fundamental/multi-grained- segment");
String token = "对应region的token";
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("POST");
connection.setDoInput(true);
connection.setDoOutput(true);
connection.addRequestProperty("Content-Type", "application/json");
connection.addRequestProperty("X-Auth-Token", token);
//输入参数
String text = "华为技术有限公司的总部";
String body = "{\"text\":\"" + text + "\",\"granularity\":1}";
OutputStreamWriter osw = new OutputStreamWriter(connection.getOutputStream(),
"UTF-8");
osw.append(body);
osw.flush();
InputStream is = connection.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is, "UTF-8"));
while (br.ready()) {
System.out.println(br.readLine());
}
} catch (Exception e) { e.printStackTrace();
}
}
public static void main(String[] args) { NLPDemo nlpDemo = new NLPDemo();
nlpDemo.nlpDemo();
} }
说明
“endpoint”、“project_id”、“token”等请求参数获取方式可参考快速入门,参数详情请见 构造请求。
● 响应示例1 成功响应示例
{ "result": [
"华为技术有限公司", "的",
"总部"
]}
● 请求示例2
POST https://{endpoint}/v1/{project_id}/nlp-fundamental/multi-grained-segment Request Header:
Content-Type: application/json X-Auth-Token:
MIINRwYJKoZIhvcNAQcCoIINODCCDTQCAQExDTALBglghkgBZQMEAgEwgguVBgkqhkiG...
Request Body:
{ "text": "华为技术有限公司的总部", "lang":"zh"
}
● 响应示例2
– 成功响应示例
{ "result": [ {
"content": "华为技术有限公司", "sub_contents": [
{
"content": "华为", "sub_contents": [ {
"content": "华", "type": "CHAR"
}, {
"content": "为", "type": "CHAR"
} ],
"type": "WORD"
}, {
"content": "技术", "sub_contents": [ {
"content": "技", "type": "CHAR"
}, {
"content": "术", "type": "CHAR"
}
],
"type": "WORD"
}, {
"content": "有限公司", "sub_contents": [ {
"content": "有限", "sub_contents": [ {
"content": "有", "type": "CHAR"
}, {
"content": "限", "type": "CHAR"
} ],
"type": "WORD"
}, {
"content": "公司", "sub_contents": [ {
"content": "公", "type": "CHAR"
}, {
"content": "司", "type": "CHAR"
} ],
"type": "WORD"
} ],
"type": "WORD"
} ],
"type": "WORD"
}, {
"content": "的", "sub_contents": [ {
"content": "的", "type": "CHAR"
} ],
"type": "WORD"
}, {
"content": "总部", "sub_contents": [ {
"content": "总", "type": "CHAR"
}, {
"content": "部", "type": "CHAR"
} ],
"type": "WORD"
} ]}
– 失败响应示例
{ "error_code": "NLP.0301",
"error_msg": "the length of the text must between 1-64"
}
状态码
状态码请参见状态码。
错误码
错误码请参见错误码。
4.1.3 依存句法分析
功能介绍
识别句子中词汇与词汇之间的相互依存关系。
本API免费调用,调用限制为2次/秒。
调试
您可以在API Explorer中调试该接口。
前提条件
在使用本API之前,需要您完成服务申请和认证鉴权,具体操作流程请参见申请服务和
认证鉴权章节。
说明
用户首次使用需要先申请开通。服务只需要开通一次即可,后面使用时无需再次申请。如未开通 服务,调用服务时会提示ModelArts.4204报错,请在调用服务前先进入控制台开通服务,并注 意开通服务区域与调用服务的区域保持一致。
URI
● URI格式
POST /v1/{project_id}/nlp-fundamental/dependency-parser
● 参数说明
表4-12 URI 参数说明
参数名 必选 说明
project_id 是 项目编号。获取方法,请参见获取项目ID。
请求消息
请求参数如表 请求参数所示。
表4-13 请求参数
参数名 参数类型 必选 说明
text String 是 待分析文本,长度为1~32,文本编码 为UTF-8。
lang String 否 支持的文本语言类型,目前只支持中文
(zh),默认为中文。
响应消息
响应参数如表 响应参数所示。
表4-14 响应参数
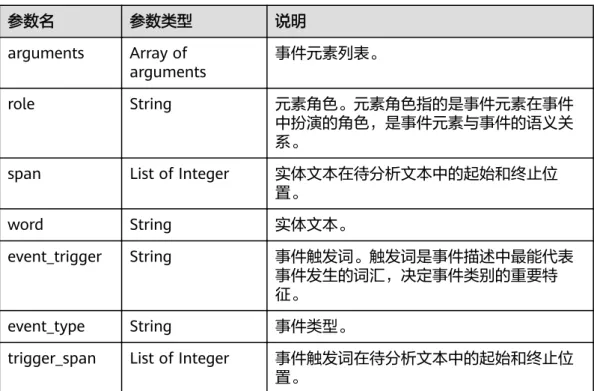
参数名 参数类型 说明
words Array of words
objects 依存句法分析结果。
请参见表 words数据结构说明。
error_code String 调用失败时的错误码,具体参见6.2 错误
码。
调用成功时无此字段。
error_msg String 调用失败时的错误信息。
调用成功时无此字段。
表4-15 words 数据结构说明
参数名 参数类型 说明
id Integer 词汇id,从1开始计数。
word String 词汇内容。
pos String 词性,请参见表4-6。
head_word_id String 头结点id。如果是根节点,默认为0。
dependency_la
bel String 词与头节点的依存关系,使用汉语开放依存 句法树库(CODT)依存关系标签集合。
详细说明请参见表 (CODT)关系类型说明。
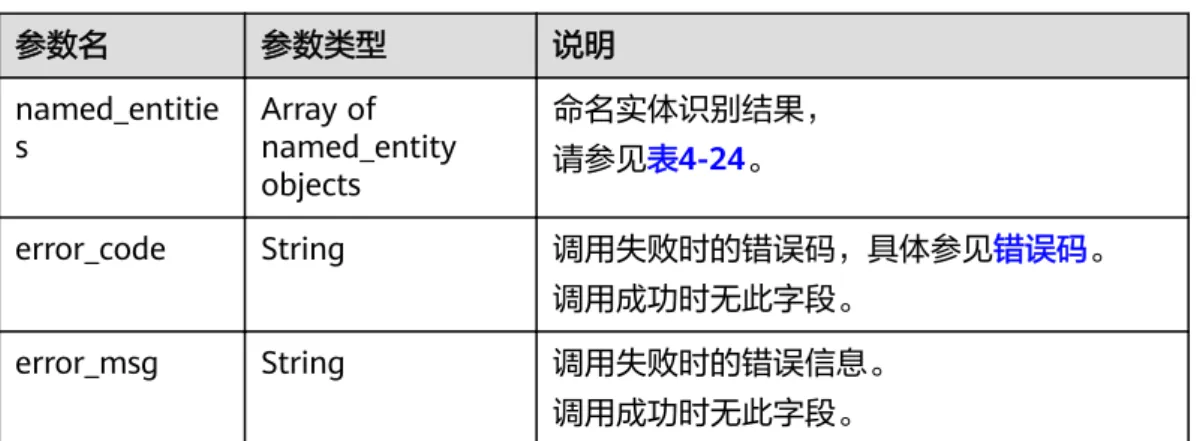
表4-16 (CODT)关系类型说明
关系标签 说明 例句 标注结果
root sentence root(根节 点)
我 爱 妈妈 ( Root –>爱),
其中Root为虚拟 词
sasubj-obj same subject and
object(同主语同宾语) 我 一直 在 研究 和 思
考 这个 问题。 (研究–>思考) sasubj same subject (同主
语)
我 走进 操场 打 篮球。 (走进–>打)
dfsubj different subject(不同
主语) 这书太贵了,我打算买
另一本 (贵–>打算) subj subject (主语) 我 爱 妈妈 (我<–爱) subj-in subject inside a subject-
predicate predicate
(主谓谓语中的内部主 语)
他 确实 头 疼 (头<–疼)
obj object(宾语) 我 爱 妈妈 (爱–>妈妈) pred predicate (谓语) 命令 他 扫地 (他–>扫地) att attribute modifier(定
语) 国家 主席 (国家<–主席)
adv adverbial modifier(状
语) 非常 喜欢 (非常<–喜欢)
cmp complement modifier
(补语) 洗 干净 手 (洗–>干净)
coo coordination
construction(并列结 构)
鲜花 和 掌声 (鲜花–>掌声)
pobj preposition object(介 宾)
在 家 看书 (在–>家)
iobj indirect-object(间宾) 给 他 书 (给–>他) de de-construction
(“的”字结构)
这 是 他 的 (他<–的)
adjct adjunct(附加成分) 我 走 了 (走–>了) app appellation(称呼) 老师 , 你 好 (老师<–好) exp explanation(进一步解
释)
普京 ( 俄罗斯 总统 ) (普京–>总统)
punc punctuation(标点) 我 爱 妈妈 。 (爱–>。) frag fragment(片段) 你, 我, 中国。 (你–>我–>中国)
关系标签 说明 例句 标注结果 repet repetition(重复) 你 吃 , 吃 饭 了 吗 ? (吃–>吃)
示例
● 请求示例
POST https://{endpoint}/v1/{project_id}/nlp-fundamental/dependency-parser Request Header:
Content-Type: application/json X-Auth-Token:
MIIFbwYJKoZIhvcNAQcCoIIFYDCCBVwCAQExDTALBglghkgBZQMEAgEwggNBgkqhkiG9...
Request Body: { "text":"张三买电脑", "lang":"zh"
}
● Python3语言请求代码示例
# -*- coding: utf-8 -*-
# 此demo仅供测试使用,建议使用sdk。需提前安装requests,执行pip install requests import requests
import json def nlp_demo():
url = 'https://{endpoint}/v1/{project_id}/nlp-fundamental/dependency-parser' # endpoint和 project_id需替换
token = '用户对应region的token' header = {
'Content-Type': 'application/json', 'X-Auth-Token': token
} body = {
'text': '张三买电脑', 'lang': 'zh' }
resp = requests.post(url, data=json.dumps(body), headers=header) print(resp.text)
if __name__ == '__main__':
nlp_demo()
● Java语言请求代码示例
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.net.HttpURLConnection;
import java.net.URL;
/** * 此demo仅供测试使用,建议使用sdk */public class NLPDemo {
public void nlpDemo() { try {
//endpoint和projectId需要替换成实际信息。
URL url = new URL("https://{endpoint}/v1/{project_id}/nlp-fundamental/dependency-parser");
String token = "对应region的token";
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("POST");
connection.setDoInput(true);
connection.setDoOutput(true);
connection.addRequestProperty("Content-Type", "application/json");
connection.addRequestProperty("X-Auth-Token", token);
//输入参数
String text = "订单记录怎么删除";
String body = "{\"text\":\"" + text + "\",\"lang\":\"zh\"}";
OutputStreamWriter osw = new OutputStreamWriter(connection.getOutputStream(),
"UTF-8");
osw.append(body);
osw.flush();
InputStream is = connection.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is, "UTF-8"));
while (br.ready()) {
System.out.println(br.readLine());
}
} catch (Exception e) { e.printStackTrace();
} }
public static void main(String[] args) { NLPDemo nlpDemo = new NLPDemo();
nlpDemo.nlpDemo();
} }
● 响应示例
{ "words": [ { "id": 1, "word": "张三", "pos": "NR", "head_word_id": 2, "dependency_label": "subj"
}, { "id": 2, "word": "买", "pos": "VV", "head_word_id": 0, "dependency_label": "root"
}, { "id": 3, "word": "电脑", "pos": "NN", "head_word_id": 2, "dependency_label": "obj"
} ] }
– 失败响应示例
{ "error_code": "NLP.0301",
"error_message": "Missing parameters:text"
}
状态码
状态码请参见状态码。
错误码
错误码请参见错误码。
4.1.4 命名实体识别(基础版)
功能介绍
对文本进行命名实体识别分析,目前支持人名、地名、时间、组织机构类实体的识 别。
具体Endpoint请参见终端节点。
调用华为云NLP服务会产生费用,本API支持使用基础套餐包,购买时请在自然语言处
理价格计算器中查看基础套餐包和领域套餐包支持的API范围。
调试
您可以在API Explorer中调试该接口。
前提条件
在使用本API之前,需要您完成服务申请和认证鉴权,具体操作流程请参见申请服务和
认证鉴权章节。
说明
用户首次使用需要先申请开通。服务只需要开通一次即可,后面使用时无需再次申请。如未开通 服务,调用服务时会提示ModelArts.4204报错,请在调用服务前先进入控制台开通服务,并注 意开通服务区域与调用服务的区域保持一致。
URI
● URI格式
POST /v1/{project_id}/nlp-fundamental/ner
● 参数说明
表4-17 URI 参数说明
参数名 必选 说明
project_id 是 项目编号。获取方法,请参见获取项目ID。
请求消息
请求参数如表4-18所示。
表4-18 请求参数
参数名 参数类型 必选 说明
text String 是 待分析文本,中文长度为1~512,英文 和西班牙文长度为1~2000,文本编码 为UTF-8。
参数名 参数类型 必选 说明
lang String 否 支持的文本语言类型,目前支持中文
(zh),英文(en),和西班牙文
(es),默认为中文。
响应消息
响应参数如表4-19所示。
表4-19 响应参数
参数名 参数类型 说明
named_entitie
s Array of named_entity objects
命名实体识别结果。
请参见表4-20。
error_code String 调用失败时的错误码,具体参见错误码。
调用成功时无此字段。
error_msg String 调用失败时的错误信息。
调用成功时无此字段。
表4-20 named_entity 数据结构说明
参数名 参数类型 说明
word String 实体文本。
tag String 实体类型,枚举类型。
● 中文支持人名“nr”,地名“ns”,机构 名“nt”,时间“t”。
● 英文支持人名“per”,地名“loc”,机 构名“org”,时间“t”。
● 西班牙文支持人名“per”,地名
“loc”,机构名“org”,时间“t”。
offset Integer 实体文本在待分析文本中的起始位置。
len Integer 实体文本长度。
示例
● 请求示例
POST https://{endpoint}/v1/{project_id}/nlp-fundamental/ner Request Header:
Content-Type: application/json X-Auth-Token:
MIINRwYJKoZIhvcNAQcCoIINODCCDTQCAQExDTALBglghkgBZQMEAgEwgguVBgkqhkiG...
Request Body:
{
"text":"昨天程序员李小明来到北京参加开发者大赛,在比赛中表现优异,赢得了第一名。", "lang":"zh"
}
● Python3语言请求代码示例
# -*- coding: utf-8 -*-
# 此demo仅供测试使用,建议使用sdk。需提前安装requests,执行pip install requests import requests
import json def nlp_demo():
url = 'https://{endpoint}/v1/{project_id}/nlp-fundamental/ner' # endpoint和project_id需替换 token = '用户对应region的token'
header = {
'Content-Type': 'application/json', 'X-Auth-Token': token
} body = {
'text': '昨天程序员李小明来到北京参加开发者大赛,在比赛中表现优异,赢得了第一名。', 'lang': 'zh'
}
resp = requests.post(url, data=json.dumps(body), headers=header) print(resp.text)
if __name__ == '__main__':
nlp_demo()
● Java语言请求代码示例
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.net.HttpURLConnection;
import java.net.URL;
/** * 此demo仅供测试使用,建议使用sdk */public class NLPDemo {
public void nlpDemo() { try {
//endpoint和projectId需要替换成实际信息。
URL url = new URL("https://{endpoint}/v1/{project_id}/nlp-fundamental/ner");
String token = "对应region的token";
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("POST");
connection.setDoInput(true);
connection.setDoOutput(true);
connection.addRequestProperty("Content-Type", "application/json");
connection.addRequestProperty("X-Auth-Token", token);
//输入参数
String text = "昨天程序员李小明来到北京参加开发者大赛,在比赛中表现优异,赢得了第一名。";
String body = "{\"text\":\"" + text + "\",\"lang\":\"zh\"}";
OutputStreamWriter osw = new OutputStreamWriter(connection.getOutputStream(),
"UTF-8");
osw.append(body);
osw.flush();
InputStream is = connection.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is, "UTF-8"));
while (br.ready()) {
System.out.println(br.readLine());
}
} catch (Exception e) { e.printStackTrace();
} }
public static void main(String[] args) { NLPDemo nlpDemo = new NLPDemo();
nlpDemo.nlpDemo();
} }
● 响应示例
– 成功响应示例
{ "named_entities": [ {
"word": "昨天", "tag": "t", "offset": 0, "len": 2 }, {
"word": "李小明", "tag": "nr", "offset": 5, "len": 3 }, {
"word": "北京", "tag": "ns", "offset": 10, "len": 2 } ] }
– 失败响应示例
{ "error_code": "NLP.0301",
"error_msg": "The length of text should be in the range of 1-2000."
}
状态码
状态码请参见状态码。
错误码
错误码请参见错误码。
4.1.5 命名实体识别(领域版)
功能介绍
对文本进行命名实体识别分析,目前支持通用、商务和娱乐领域。
● 通用领域:支持人名、地名、组织机构、时间点、日期、百分比、货币额度、序 数词、计量规格词、民族、职业、邮箱、国家、节日的实体的识别。
● 商务领域:支持公司名、品牌名、职业、职位、邮箱、手机号码、电话号码、IP 地址、身份证号、网址、专业的实体的识别。
● 娱乐领域:支持电影名、动漫、书名、互联网、歌名、产品名、电视剧名、电视 节目名的实体的识别。
具体Endpoint请参见终端节点。
调用华为云NLP服务会产生费用,本API支持使用领域套餐包,购买时请在自然语言处
理价格计算器中查看基础套餐包和领域套餐包支持的API范围。
调试
您可以在API Explorer中调试该接口。
前提条件
在使用本API之前,需要您完成服务申请和认证鉴权,具体操作流程请参见申请服务和
认证鉴权章节。
说明
用户首次使用需要先申请开通。服务只需要开通一次即可,后面使用时无需再次申请。如未开通 服务,调用服务时会提示ModelArts.4204报错,请在调用服务前先进入控制台开通服务,并注 意开通服务区域与调用服务的区域保持一致。
URI
● URI格式
POST /v1/{project_id}/nlp-fundamental/ner/domain
● 参数说明
表4-21 URI 参数说明
参数名 必选 说明
project_id 是 项目编号。获取方法,请参见获取项目ID。
请求消息
请求参数如表4-22所示。
表4-22 请求参数
参数名 参数类型 必选 说明
text String 是 待分析文本,长度为1~512,文本编码 为UTF-8。
lang String 否 支持的文本语言类型,目前只支持中文
(zh),默认为中文。
domain String 否 支持的领域类型,目前支持通用
(general)领域、商务(business)
领域、娱乐(entertainment)领域,
默认为general。
响应消息
响应参数如表4-23所示。
表4-23 响应参数
参数名 参数类型 说明
named_entitie
s Array of named_entity objects
命名实体识别结果,
请参见表4-24。
error_code String 调用失败时的错误码,具体参见错误码。
调用成功时无此字段。
error_msg String 调用失败时的错误信息。
调用成功时无此字段。
表4-24 named_entity 数据结构说明
参数名 参数类型 说明
word String 实体文本。
tag String 实体类型,枚举类型。
● 通用领域:支持人名nr,地名ns,机构名 nt,时间点tpt,日期day,百分比pct,货 币额度mny,序数词ord,计量规格词 qtt,民族race,职业job,邮箱email,国 家coun,节日fest。
● 商务领域:支持公司名com、品牌名 bra、职业job、职位post、邮箱email、手 机号码cell、电话号码tele、IP地址ip、身 份证号id、网址web。
● 娱乐领域:支持电影名mov、动漫 anime、书名book、互联网int、歌名 song、产品名pro、电视剧名dra、电视节 目名tv。
offset Integer 实体文本在待分析文本中的起始位置。
len Integer 实体文本长度。
示例 1
● 请求示例
POST https://{endpoint}/v1/{project_id}/nlp-fundamental/ner/domain Request Header:
Content-Type: application/json X-Auth-Token:
MIINRwYJKoZIhvcNAQcCoIINODCCDTQCAQExDTALBglghkgBZQMEAgEwgguVBgkqhkiG...
Request Body:
{
"text":"昨天程序员李小明来到北京参加开发者大赛,在比赛中表现优异,赢得了第一名。", "lang":"zh",
"domain":"general"
}
● Python3语言请求代码示例
# -*- coding: utf-8 -*-
# 此demo仅供测试使用,建议使用sdk。需提前安装requests,执行pip install requests import requests
import json def nlp_demo():
url = 'https://{endpoint}/v1/{project_id}/nlp-fundamental/ner/domain' # endpoint和project_id需替 换 token = '用户对应region的token'
header = {
'Content-Type': 'application/json', 'X-Auth-Token': token
} body = {
'text': '昨天程序员李小明来到北京参加开发者大赛,在比赛中表现优异,赢得了第一名。', 'lang': 'zh'
}
resp = requests.post(url, data=json.dumps(body), headers=header) print(resp.text)
if __name__ == '__main__':
nlp_demo()
● Java语言请求代码示例
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.net.HttpURLConnection;
import java.net.URL;
/** * 此demo仅供测试使用,建议使用sdk */public class NLPDemo {
public void nlpDemo() { try {
//endpoint和projectId需要替换成实际信息。
URL url = new URL("https://{endpoint}/v1/{project_id}/nlp-fundamental/ner/domain");
String token = "对应region的token";
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("POST");
connection.setDoInput(true);
connection.setDoOutput(true);
connection.addRequestProperty("Content-Type", "application/json");
connection.addRequestProperty("X-Auth-Token", token);
//输入参数
String text = "昨天程序员李小明来到北京参加开发者大赛,在比赛中表现优异,赢得了第一名。";
String body = "{\"text\":\"" + text + "\",\"lang\":\"zh\",\"domain\":\"general\"}";
OutputStreamWriter osw = new OutputStreamWriter(connection.getOutputStream(),
"UTF-8");
osw.append(body);
osw.flush();
InputStream is = connection.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is, "UTF-8"));
while (br.ready()) {
System.out.println(br.readLine());
}
} catch (Exception e) { e.printStackTrace();
} }
public static void main(String[] args) {
NLPDemo nlpDemo = new NLPDemo();
nlpDemo.nlpDemo();
} }
● 响应示例
– 成功响应示例
{ "named_entities": [ {
"len": 2, "offset": 0, "tag": "day", "word": "昨天"
}, {
"len": 3, "offset": 2, "tag": "job", "word": "程序员"
}, {
"len": 3, "offset": 5, "tag": "nr", "word": "李小明"
}, {
"len": 2, "offset": 10, "tag": "ns", "word": "北京"
}, {
"len": 2, "offset": 32, "tag": "ord", "word": "第一"
} ] }
– 失败响应示例
{ "error_code": "NLP.0301",
"error_msg": "The length of text should be in the range of 1-512."
}
示例 2
● 请求示例
POST https://{endpoint}/v1/{project_id}/nlp-fundamental/ner/domain Request Header:
Content-Type: application/json X-Auth-Token:
MIINRwYJKoZIhvcNAQcCoIINODCCDTQCAQExDTALBglghkgBZQMEAgEwgguVBgkqhkiG...
Request Body:
{
"text":"程序员小明是华为的员工,邮箱是[email protected],电话12345678。", "lang":"zh",
"domain":"business"
}
● 响应示例
– 成功响应示例
{ "named_entities": [
{
"len": 3, "offset": 0, "tag": "job", "word": "程序员"
}, {
"len": 2, "offset": 6, "tag": "com", "word": "华为"
}, {
"len": 15, "offset": 15, "tag": "email",
"word": "[email protected]"
}, {
"len": 8, "offset": 33, "tag": "tele", "word": "12345678"
} ] }
– 失败响应示例
{ "error_code": "NLP.0301",
"error_msg": "The length of text should be in the range of 1-512."
}
示例 3
● 请求示例
POST https://{endpoint}/v1/{project_id}/nlp-fundamental/ner/domain Request Header:
Content-Type: application/json X-Auth-Token:
MIINRwYJKoZIhvcNAQcCoIINODCCDTQCAQExDTALBglghkgBZQMEAgEwgguVBgkqhkiG...
Request Body:
{
"text":"我早上看了动画《海贼王》,下午学唱《童年》,晚上在安徽卫视看《甄嬛传》。", "lang":"zh",
"domain":"entertainment"
}
● 响应示例
– 成功响应示例
{ "named_entities": [ {
"len": 3, "offset": 8, "tag": "anime", "word": "海贼王"
}, {
"len": 2, "offset": 18, "tag": "song", "word": "童年"
}, {
"len": 4, "offset": 25,
"tag": "pro", "word": "安徽卫视"
}, {
"len": 3, "offset": 31, "tag": "dra", "word": "甄嬛传"
} ] }
– 失败响应示例
{ "error_code": "NLP.0301",
"error_msg": "The length of text should be in the range of 1-512."
}
状态码
状态码请参见状态码。
错误码
错误码请参见错误码。
4.1.6 文本相似度(基础版)
功能介绍
对文本对进行相似度计算。
具体Endpoint请参见终端节点。
调用华为云NLP服务会产生费用,本API支持使用基础套餐包,购买时请在自然语言处
理价格计算器中查看基础套餐包和领域套餐包支持的API范围。
调试
您可以在API Explorer中调试该接口。
前提条件
在使用本API之前,需要您完成服务申请和认证鉴权,具体操作流程请参见申请服务和
认证鉴权章节。
说明
用户首次使用需要先申请开通。服务只需要开通一次即可,后面使用时无需再次申请。如未开通 服务,调用服务时会提示ModelArts.4204报错,请在调用服务前先进入控制台开通服务,并注 意开通服务区域与调用服务的区域保持一致。
URI
● URI格式
POST /v1/{project_id}/nlp-fundamental/text-similarity
● 参数说明
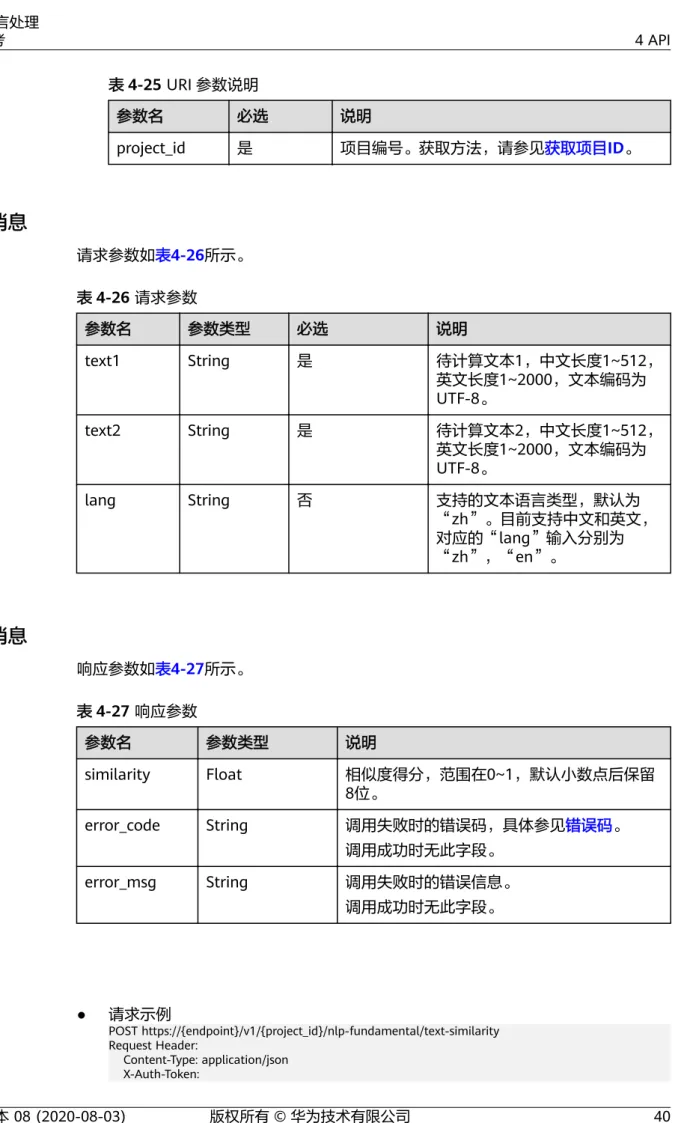
表4-25 URI 参数说明
参数名 必选 说明
project_id 是 项目编号。获取方法,请参见获取项目ID。
请求消息
请求参数如表4-26所示。
表4-26 请求参数
参数名 参数类型 必选 说明
text1 String 是 待计算文本1,中文长度1~512,
英文长度1~2000,文本编码为 UTF-8。
text2 String 是 待计算文本2,中文长度1~512,
英文长度1~2000,文本编码为 UTF-8。
lang String 否 支持的文本语言类型,默认为
“zh”。目前支持中文和英文,
对应的“lang”输入分别为
“zh”,“en”。
响应消息
响应参数如表4-27所示。
表4-27 响应参数
参数名 参数类型 说明
similarity Float 相似度得分,范围在0~1,默认小数点后保留 8位。
error_code String 调用失败时的错误码,具体参见错误码。
调用成功时无此字段。
error_msg String 调用失败时的错误信息。
调用成功时无此字段。
示例
● 请求示例
POST https://{endpoint}/v1/{project_id}/nlp-fundamental/text-similarity Request Header:
Content-Type: application/json X-Auth-Token: