新型数据管理系统研究进展与趋势
崔 斌
1, 高 军
1, 童咏昕
2, 许建秋
3, 张东祥
4, 邹 磊
51(北京大学 信息科学技术学院,北京 100871)
2(软件开发环境国家重点实验室(北京航空航天大学),北京 100083)
3(南京航空航天大学 计算机科学与技术学院,江苏 南京 211106)
4(电子科技大学 计算机科学与工程学院,四川 成都 611731)
5(北京大学 计算机科学技术研究所,北京 100871)
通信作者: 崔斌, E-mail: [email protected]
摘 要: 随着各类新型计算技术和新兴应用领域的浮现,传统数据库技术面临新的挑战,正在从适用常规应用的 单一处理方法逐步转为面向各类特殊应用的多种数据处理方式.分析并展望了新型数据管理系统的研究进展和趋 势,涵盖分布式数据库、图数据库、流数据库、时空数据库和众包数据库等多个领域.具体而言:分布式数据管理技 术是支持可扩展的海量数据处理的关键技术;以社交网络为代表的大规模图结构数据的处理需求带来了图数据库 技术的发展;流数据管理技术用来应对数据动态变化的管理需求;时空数据库主要用于支持移动对象管理;对多 源、异构而且劣质数据源的集成需求催生出新型的众包数据库技术.最后讨论了新型数据库管理系统的未来发展 趋势.
关键词: 分布式数据库;图数据库;流数据库;时空数据库;众包数据库 中图法分类号: TP311
中文引用格式: 崔斌,高军,童咏昕,许建秋,张东祥,邹磊.新型数据管理系统研究进展与趋势.软件学报,2019,30(1):164193.
http://www.jos.org.cn/1000-9825/5646.htm
英文引用格式: Cui B, Gao J, Tong YX, Xu JQ, Zhang DX, Zou L. Progress and trend in novel data management system. Ruan Jian Xue Bao/Journal of Software, 2019,30(1):164193 (in Chinese). http://www.jos.org.cn/1000-9825/5646.htm
Progress and Trend in Novel Data Management System
CUI Bin1, GAO Jun1, TONG Yong-Xin2, XU Jian-Qiu3, ZHANG Dong-Xiang4, ZOU Lei5
1(School of Electronics Engineering and Computer Science, Peking University, Beijing 100871, China)
2(State Key Laboratory of Software Development Environment (Beijing University of Aeronautics and Astronautics), Beijing 100083, China)
3(College of Computer Science and Technology, Nanjing University of Aeronautics and Astronautics, Nanjing 211106, China)
4(College of Computer Science and Engineering, University of Electronic Science and Technology of China, Chengdu 611731, China)
5(Institute of Computer Science and Technology, Peking University, Beijing 100871, China)
Abstract: With the emergence of novel computing techiniques and applications, the traditional database manamgement systems face challenges, and undergo significant shifts from the single data model processing to multiple data model processing. This paper presents a
基金项目: 国家自然科学基金(61832001, 61572040, 61822201, 61622201, 61602087)
Foundation item: National Natural Science Foundation of China (61832001, 61572040, 61822201, 61622201, 61602087) 本文由“软件学科发展回顾特刊”特约编辑梅宏教授、金芝教授、郝丹副教授推荐.
本文作者同等贡献,其中,张东祥主要负责第 2 节,邹磊主要负责第 3、第 4 节,许建秋主要负责第 5 节,童咏昕主要负责第 6 节 收稿时间: 2018-07-03; 修改时间: 2018-08-21; 采用时间: 2018-09-25; jos 在线出版时间: 2018-11-22
CNKI 网络优先出版: 2018-11-23 07:17:57, http://kns.cnki.net/kcms/detail/11.2560.TP.20181123.0717.002.html
comphrensive survey on the recent progress and future direction in the novel data management systems, including distributed databases, graph databases, streaming databases, spatial-temporal databases, and crowdsourcing databases. Specifically, the distributed techinqiues play a key role to improve the scabablity of large scale data processing. Graph data management techniques are driven by the big graph management requirement in applications like social network. Stream data management techiniques are also developed to process dynamic data. Spatial-temporal databases are mainly applied in the management of mobile objects. Last but not least, the processing of multiple sources, hetergonenous and low quality data motivates the advance of crowd-sourcing techniques. This study also surveys other hot research directions and foresees the future work.
Key words: distributed databases; graph databases; stream databases; spatial-temporal databases; crowd-sourcing databases
21 世纪以来,随着计算机技术,尤其是互联网和移动计算技术的发展,大量新型应用应运而生.这些应用不 仅对人类的日常生活、社会的组织结构以及生产关系形态和生产力发展水平产生了深刻的影响,也使得人们能 够获取的数据规模呈爆炸性增长.“大数据”这一词汇被发明出来,用以概括这种态势.
目前广泛认为大数据具有所谓的“4V”特征,即规模大(volume)、变化快(velocity)、种类杂(variety)和价值密 度低(value).为了有效地应对大数据的上述“4V”特征,各类新型数据管理系统也逐渐涌现出来.表 1 中我们列举 了部分典型的新型数据管理系统.
Table 1 Category of novel data management systems
表 1 新型数据管理系统分类系统类型 代表性系统 主要解决的问题
分布式数据管理系统 MongoDB,Redis,Cassandra,Spanner,Oceanbase 数据的规模大(volume) 流数据管理系统 STREAM,Aurora,TelegraphCQ,NiagaraCQ,Gigascope 数据的变化快(velocity) 图数据管理系统 Pregel,Giraph,PowerGraph,GraphChi,Xstream,Giraph+ 数据的种类杂(variety) 时空数据管理系统 SpatialHadoop,Simb,OceanRT,DITA,SECONDO 数据的种类杂(variety) 众包数据管理系统 CrowdDB,CDB,Deco,Qurk,DOCS,gMission 数据的价值密度低(value)
数据规模大在诸多数据处理场景中都有所体现.例如社交媒体应用中的用户关系数据,若用图数据模型进 行建模,其涉及的节点数可高达几亿.为了处理这类大规模的数据,一个朴素的想法是分而治之,即,将数据分布 式地存储在多台机器上分别处理.据此,人们提出了各类分布式数据管理系统.
数据变化快这一特征具体体现在数据实时到达、规模庞大、大小无法提前预知,并且数据一经处理,除非 进行存储,否则很难再次获取.在金融应用、网络监控、社交媒体等诸多行业领域,都会产生这类变化极快的数 据.为了解决这一问题,人们提出了流数据处理系统.
针对数据种类杂的特征,人们采取“各个击破”的手段,针对各类数据分别提出专门的数据管理系统,图数据 管理系统和时空数据管理系统是典型代表.图数据模型是一种具有高度概括性的数据模型,其典型应用包括社 交媒体数据的建模和知识图谱等.时空数据在人们的日常生活中也十分常见,例如各类地图应用在提供导航服 务时,都需要对大量的时空数据进行高效的处理.
大数据的价值密度通常较低,例如社交媒体中大量的图片数据在未经标注之前,并不具备显著的价值.众包 正是解决该问题的有效手段之一.众包通常是指“一种把过去由专职员工执行的工作任务通过公开的 Web 平台 以自愿的形式外包给非特定的解决方案提供者群体来完成的分布式问题求解模式”,是完成大规模的对计算机 较为困难而对人类相对容易的任务的有效手段,例如数据标注.为了有效地对众包过程中的数据和众包参与者 群体进行有效管理,人们提出了众包数据管理系统.
如表 1 所示,我们可以看到:人们已经提出了分布式数据管理系统、图数据管理系统、流数据管理系统、
时空数据管理系统和众包数据管理系统以应对大数据的“4V”特征带来的挑战,并设计了大量代表性数据管理 系统,在实际应用中已经取得了较好的效果.下面我们将针对不同系统类型分别阐述上述技术及相关系统的进 展,并展望后续发展趋势.本文最后对新型数据管理系统在数据模型、计算模型和体系结构等方面的挑战和机 遇进行了探讨.
1 分布式数据库
1.1 引 言
在大数据时代下,移动互联网、智能设备以及物联网技术的发展,使得全球数据量呈现爆发式增长,远远超 出传统的单机版数据库的处理能力.近几年,分布式数据库一直是工业界和学术界的研究重点.分布式数据库应 该具备强一致性、高可用性、可扩展性、易运维、容错容灾以及满足ACID 属性的高并发事务处理能力.但在 实际设计中,一方面受限于 CAP 理论[1],即,在必须支持分区容错性(partition tolerance)的前提下,系统实现只能 侧重一致性(consistency)和可用性(availability)的一个方面而无法同时满足;另一方面,支持 ACID 事务属性及高 并发事务处理一直是分布式关系数据库的难点.针对这些挑战,现有的解决策略大致可分成 3 类:(1) 将现有商 业关系数据库(如 Oracle、SQLServer、MySQL、PostgreSQL)在分布式集群或者云平台上进行小规模扩展和部 署;(2) 放弃关系数据库模型和 ACID 的事务特性,选择灵活的 schema-free 数据模型及高可用性和最终一致性 的NoSQL 数据库;(3) 融合关系数据库和 NoSQL 优势的新型数据库(NewSQL).
1.2 主要研究问题
主流的分布式数据库基本上围绕数据强一致性、系统高可用性和ACID 事务支持等核心问题展开研究工 作,这些性质与系统的扩展性和性能密切相关,甚至相互制约,往往需要根据具体的应用需求进行取舍.
数据强一致性:银行交易系统等金融领域往往有数据强一致性和零丢失的需求.当更新操作完成之后, 任何多个后续进程或线程的访问都要求返回最近更新值.如果在这个分布式系统中没有数据副本,那 么系统必然满足数据强一致性要求,原因是只有独本数据,才不会出现数据不一致的问题.但是分布式 数据库系统的设计需要保存多个副本来提高可用性和容错性,以避免宕机时数据还没有复制,导致提 供的数据不够准确.如何低成本地保证数据的强一致性,是分布式数据库系统的一个重要难题;
系统高可用性:在分布式数据库中,系统的高可用性和数据强一致性往往不可兼得.当存在不超过 1 台 机器发生故障的时候,要求至少能读到一份有效的数据,往往需要牺牲数据的强一致性来保证系统的 高可用性.相当一部分 NoSQL 数据库采用这个思路来支持互联网场景下的大规模用户并发访问请求, 它们通过实现最终一致性来确保高可用性和分区容忍性,弱化了数据的强一致要求.为了解决数据不 一致问题,不同的分布式数据库设计各自的冲突机制.另外,有效的容错容灾机制也是保障系统高可用 性的坚实后盾;
ACID 事务支持:ACID 指的是事务层面的原子性(atomicity)、一致性(consistency)、隔离性(isolation) 和持久性(durability).如何有效地支持 ACID 事务属性,一直是分布式数据库的难点,涉及到很多复杂的 操作和逻辑,会严重影响系统的性能,很多 NoSQL 数据库都是放弃支持事务 ACID 属性来换取性能的 提升.近年来,新型数据库(NewSQL)的出现给分布式数据库的发展带来新的方向,它的目标是提供与 NoSQL 相同的可扩展性和性能,同时支持事务的 ACID 属性.这种融合一致性和可用性的 NewSQL 已 经成为分布式数据库的研究热点.
1.3 国内外研究现状
1.3.1 基于分布式集群或云平台的关系数据库
MySQL 集群是一种常见的开源分布式数据库,它基于无共享的(shared-nothing)数据存储模式,采用读写分 离的主从模式(master-slave)来实现高可用性.该设计方法也被主流的云平台关系数据库采纳和应用,包括亚马 逊的Amazon RDS(Amazon relational database service)[2]、谷歌的Google Cloud SQL[3]、微软的Azure SQL Database[4]以及国内的阿里云RDS[5]、腾讯CDB(cloud DataBase)[6]和网易的蜂巢RDS[7].与传统数据库相比,这 些云数据库往往同时支持MySQL、SQL Server 及 PostgreSQL 等数据库引擎,具有低成本、易运维、可伸缩、
高可用等优势,并提供容灾、备份、恢复、监控、迁移等数据库运维全套解决方案.
基于分布式集群或云平台关系数据库的主要缺陷是很难低成本地保持数据的一致性,每次将数据写到
master 节点后,都要及时同步 slave 节点,所以往往牺牲性能来保障强一致性.另外,如果 master 节点宕机,会直接 导致业务不可写,也会影响整个系统的高可用性.为解决这一问题,MySQL 集群自带的数据同步策略从最初的 异步复制进化为MySQL 5.7 版本的半同步复制,但效果依旧有限.各大企业也纷纷设计 MySQL 补丁来保证数据 一致.Amazon Aurora 将事务引擎和存储引擎分离,redo 日志从事务引擎中剥离,归并到存储引擎中,属于典型的 shared disk 架构,通过存储层共享来解决一致性问题.Galera Cluster 采用多主架构(multi-master)来实现真正的多 点读写,即集群中每个节点都可读写,无需读写分离.集群不同节点之间数据同步是基于 Galera replication 中间 件,避免了 MySQL 集群主从节点之间的复制延迟.
国内的云关系数据库也对数据一致性的提升做出了原创性贡献.阿里巴巴的 AliSQL 利用了分布式一致性 协议(Raft)[8]以保障多节点状态切换的可靠性和原子性.为了保证多节点之间的 binlog 的强一致性,腾讯的 PhxSQL 使用分布式一致性协议 Paxos 实现 master 管理.同时,用 BinlogSvr 来支持 MySQL 的异步复制协议以 支撑微信后台的账号系统、企业微信及QQ 邮箱等.网易 RDS 则是采用虚拟同步复制技术,确保所有主机的更 新事务在提交前都首先在从机上落盘,保证主从切换后数据完全一致.在节点上使用了并行复制技术,大幅度提 高了从机回放主机事务的速度,复制延迟消失,保证了在秒级完成主从切换.
1.3.2 NoSQL 数据库
由于事务处理过程对 ACID 属性的严格要求,云关系数据库的可扩展性相对有限.为提升系统存储和处理 海量数据的能力,NoSQL 从底层数据模型进行考虑,放弃关系模型,也不保证支持 ACID 事务处理.它采用 schema-free 的数据模型,可以根据不同应用需求衍生出多种类型的分布式数据库.按照存储模型来分类,可将 NoSQL 数 据 库 分 为 列 式 存 储 ( 如 HBase[9]和 Cassandra[10]) 、 键 值 存 储 ( 如 Redis[11]、MemcacheDB[12]、 DynamoDB[13]、SimpleDB[14])和文档存储(如 MongoDB[15]和CouchDB[16]).
一个分布式系统最多同时满足一致性(consistency,简称 C)、可用性(availability,简称 A)和分区容错性 (partition tolerance,简称 P)中的两项,可根据相应的设计目的进行选择.对 NoSQL 而言,分区容错性是不能牺牲 的,因此只能在一致性和可用性上加以取舍.如果在这个分布式系统中数据没有副本,那么系统必然满足强一致 性条件,因为只有独本数据,不会出现数据不一致的问题,此时 C 和 P 都具备.但是,如果某些服务器宕机,那必然 会导致某些数据是不能访问的,那 A 就不符合了;反之,如果在这个分布式系统中数据是有副本的,那么如果某 些服务器宕机,系统还是可以提供服务的,即符合 A,但是很难保证数据的一致性.因为宕机时可能有些数据还没 有复制到副本中,那么提供的数据就不准确了.一般情况下,对于一致性要求比较高的业务在访问延迟时间方面 就会降低要求,适合选择 CP 模式;对于访问延时有高要求的业务在数据一致性方面会降低要求,适合选择 AP 模式.
CP 模式
CP 模式要求分区容忍性,同时对数据一致性要求较高,即,能够保证所有用户看到相同的数据.当网络通信 出现问题时,暂时隔离开的子系统可继续运行(分区容忍性),但是不保证某些节点故障时,所有请求都能被响应.
如果主节点宕机,可能需要选举新的主节点,同步节点间数据以及进行数据回滚等操作,这会使系统的可用性降 低.常见的 CP 模式系统有 BigTable[17]、HBase[9]、Redis[11]、MongoDB[15]和MemcacheDB[12].
BigTable 是一个 GFS[18]之上的索引层,采用两级的 B+树索引结构.GFS 保证至少写入一次成功的记录并由 BigTable 记录索引.为了保证 BigTable 的强一致性,同一时刻同一份数据只能被一台机器服务,且 BigTable 中的 Tablet Server 没有对每个 Tablet 备份.HBase 是 Apache Hadoop 中的一个子项目,属于 BigTable 的开源版本,是满 足强一致性的分布式数据库,主要用来存储非结构化和半结构化的松散数据.HBase 利用 Hadoop HDFS[19]作为 其文件存储系统,借助 MapReduce[20]计算模型来处理海量数据,并使用 Zookeeper 作为分布式协同服务.HBase 使用了事务机制中常见的一致性实现方式WAL(write-ahead logging)[21].
Redis 集群通常是主备,主节点负责写入和读取,而 slave 节点只是用来备份.当主节点失败时,slave 节点有机 会被提升为主节点.MongoDB 采用类似于 Redis 的主从集群方式,主节点作为单点写操作服务,然后同步到 slave 节点,可以通过设置 autoresync 发现 slave 节点的数据不是最新,则自动地从主服务器请求同步数据.MongoDB
使用基于Raft 协议选主策略,一旦主节点发生故障,整个 MongoDB 会进行交流,然后选择一个合适的 slave 节点 快速实现故障恢复.
MemcacheDB 是一个新浪网基于 Memcached 开发的分布式 Key-Value 存储持久化开源项目,它使用 BerkeleyDB[22]作为存储引擎,通过为 Memcached 增加 Berkeley DB 的持久化存储机制和异步主辅复制机制,使 Memcached 具备了事务恢复能力、持久化能力和分布式复制能力,非常适合超高性能读写速度和持久化保存的 应用场景.
AP 模式
AP 模式主要以实现最终一致性来确保可用性和分区容忍性,但却弱化了对数据的一致要求,大部分 NoSQL 系统都属于 AP 模式范畴.
Amazon Dynamo[13]是一个分布式键值存储系统,它采用去中心化、松散耦合方式,由数百个服务组成面向 服务架构,不支持复杂的查询.Dynamo 利用一致性哈希来完成数据分区,给系统中的每个节点随机分配一个 token,这些 token 构成一个哈希环.执行数据存放操作时,首先计算 key 的哈希值,然后存放到顺时针方向第 1 个 大于等于该哈希值的 token 节点上.这种算法的优点是:节点的增删只会影响哈希环中相邻的节点,对其他节点 没有影响.
Cassandra[10]由Facebook 开发并于 2008 年开源,系统架构与 Dynamo 一致,均为基于 DHT(分布式哈希表) 的完全P2P 架构,具有高度可扩展性和高度可用性,没有单点故障.Cassandra 使用由 Dynamo 引入的架构特性来 支持BigTable 数据模型,并采用 MemTable 和 SSTable 方式进行存储.在 Cassandra 写入数据之前,需要先记录日 志(CommitLog),再将数据开始写入 ColumnFamily 对应的 MemTable 中.
Amazon SimpleDB[14]是一个可大规模伸缩、用Erlang 编写的高可用数据存储,类似于 Amazon S3,但两者 的一致性有很大的区别.Amazon S3[23]一致性模型为弱一致性,只支持最基本的 Put/Get/Delete 操作,且每个操作 之间是互相独立的.SimpleDB 除了支持 Get/Put/Delete,还需要支持强一致读以及基于条件更新或者删除的乐观 锁机制.Amazon S3 直接使用“Last Write Wins”的方式解决冲突,因为集群内部机器时钟不一致的概率很低.另 外,发生同一条记录被多个客户端更新且同时发生机器故障等异常情况的概率也很低.SimpleDB 需要支持一些 条件更新或者删除,从而支持乐观锁机制以实现最终一致性.
Apache CouchDB[16]是一个面向文档数据管理的开源数据库,使用 JSON 存储半结构化的数据,查询语言为 JavaScript 并封装 MapReduce 和 HTTP 作为 API,适合 CMS、电话本、地址本等的应用.其最显著的特性是支持 多主复制,没有锁机制,通过使用 MVCC(多版本并发性控制)[24]实现最终一致性.Tokyo Cabinet[25]的开发者是日 本人Mikio Hirabayashi,主要被用在日本最大的 SNS 网站 mixi.jp 上,也曾是键值数据库领域的热点.其他的高可 用性NoSQL 数据库还有 Voldemort[26]、Riak[27]等(见表 2).
Table 2 Comparison of representative NoSQL systems
表 2 代表性 NoSQL 数据库比较MongoDB HBase Cassandra Redis
数据模型 Document Column Column Key-Value
存储模型 普通存储 HDFS 普通存储 内存
数据一致性 最终一致性保证 强一致性保证 最终一致性保证 无一致性保证
数据压缩 支持 支持 支持 不支持
事务支持 不支持 不支持 不支持 不支持
1.3.3 NewSQL 数据库
近年来,以 Spanner[28]为代表的新型数据库(NewSQL)的出现,给数据存储和分析带来了 SQL、NoSQL 之外 的新思路.NewSQL 指的是提供与 NoSQL 相同的可扩展性和性能,并同时能支持满足 ACID 特性的事务.这保留 了NOSQL 的高可扩展和高性能,且支持关系模型.融合一致性和可用性的 NewSQL 可能是未来大数据存储新 的发展方向.
Spanner 是第一个将数据分布到全球规模的系统,并且在外部支持一致的分布式事务,设计目标是横跨全球
上百个数据中心,覆盖百万台服务器.不同于 BigTable 版本控制的键值存储模型,Spanner 演化为时间上的多维 数据库.旧版本数据根据可配置的垃圾回收政策处理,应用可以读取具有旧时间戳的数据.Spanner 显著的特点 是外部一致读写和在某一时间戳的全度跨数据库一致读取.对于最典型的读写事务,Spanner 使用常见的两阶段 锁策略(2PL)来控制并发,并实现了一个所谓的外部一致性.F1[29]是Google 公司提出的建立在 Spanner 基础上的 用于广告业务的存储系统.F1 实现了丰富的关系型数据库的特点,包括严格遵从的 schema、强力的并行 SQL 查询引擎、通用事务、变更与通知的追踪和索引.其存储被动态分区,数据中心间的一致性复制能够处理数据 中心崩溃引起的数据丢失.Google F1 提供了一种可能性:OLTP 与 OLAP 融合的可能性,这是在其他数据库中从 未没有实现过的.
国内数据库在NewSQL 领域的代表性系统包括阿里巴巴的 OceanBase[30]和腾讯的DCDB[31].OceanBase 是 支持海量数据的高性能分布式数据库系统,实现了数千亿条记录和数百 PB 数据的跨行跨表事务.数据多副本通 过 Paxos 协议同步事务日志,多数派成功事务才能提交.缺省情况下,读、写操作都在主副本进行,保证强一致.
存储采用读写分离架构,没有主从结构,集群节点全对等,每个节点都具备计算和存储能力,无单点瓶颈.腾讯 DCDB 又名 TDSQL,是一种兼容 MySQL 协议和语法且支持自动水平拆分的高性能分布式数据库,即:业务显示 为完整的逻辑表,数据却均匀地拆分到多个分片中.每个分片默认采用主备架构,提供灾备、恢复、监控、不停 机扩容等全套解决方案,适用于 TB 或 PB 级的海量数据场景.这几年,TDSQL 不断进步,研发了很多新特性,诸如 多级分区、热点更新、隐含主键、分布式事务等,不仅有力地支撑了事务型数据库应用,而且在体系结构上也 朝Spanner 架构上迈进,是一个名副其实的 NewSQL 系统.
TiDB[32]作为NewSQL 开源社区的代表,是 PingCAP 公司基于 Google Spanner/F1 论文实现的开源分布式 NewSQL 数据库,能够实现分布式事务以及跨数据中心数据强一致性保证.TiDB 最底层用 Raft 来同步数据.每次 写入都要写入多数副本,才能对外返回成功,即使丢掉少数副本,也能保证系统中还有最新的数据.TiDB 的事务 模型采用乐观锁,只有在真正提交时才会做冲突检测,如果有冲突,则需要重试.由于分布式事务要做两阶段提 交,并且底层还需要做 Raft 复制,一个非常大的事务会使得提交过程非常慢,并且会卡住下面的 Raft 复制流程, 所以在设计上,TiDB 和 Spanner 对事务的大小进行了限制.
1.4 总结与展望
本节从CAP 理论出发,对分布式数据库的数据一致性、系统可用性和 ACID 事务属性进行了综述,并针对 国内外数据库的发展状况,介绍了现有商业关系数据库如何在云平台上进行扩展和部署,NoSQL 数据库如何支 持schema-free 数据模型、高可用性和最终一致性,以及新型数据库(NewSQL)如何提供与 NoSQL 相同的可扩 展性和性能,同时能够支持满足 ACID 特性的事务.
在大数据环境下,NoSQL 分布式数据库与传统分布式数据库的最终目标都是对用户提供完善的数据存储 和查询功能,并且在运营上能够实现可伸缩和高可用等特性,并提供容灾、备份、恢复、监控等功能.两者最大 的区别在于传统分布式数据库追求数据强一致性,并且需要提供 ACID 事务支持,导致其在峰值性能、伸缩性、
容错性、可扩展性等方面的表现不尽如人意,很难满足海量数据的柔性管理需求.NoSQL 则是以牺牲支持 ACID 为代价,换取更好的可扩展性和可用性.NewSQL 是一种相对较新的形式,旨在将 SQL 的 ACID 保证与 NoSQL 的可扩展性和高性能相结合.
未来几年,融合关系数据库和 NoSQL 优势的 NewSQL 将继续在分布式数据库领域大放光彩,并成为一个重 要的研究热点.以 OceanBase 和 DCDB 为代表的国内 NewSQL 系统也将在海量复杂业务的推动下持续发展和 优化,并作为国家大数据发展战略提供有力支撑.这也意味着,我国有可能在下一波数据库技术潮流当中占领先 机,进入第一梯队.
2 图数据库
2.1 引 言
近年来,随着社交网络与语义网的发展,基于互联网的图数据规模越来越大.截止到 2017 年底,微信已经有 了将近 10 亿的活跃用户,这些用户相互关联与通信,仅在 2016 年春节期间,用户之间就互相分发了 32 亿个红 包[33].在语义网的 Linked Open Data 项目中,已有超过 1 184 个 RDF 图数据集,合计超过 800 亿条边[34].针对这些 规模巨大的图数据,设计与实现高效的图数据管理系统成为一个很重要的研究热点.
现阶段,工业界和学术界已经设计并实现了不少大规模图数据管理系统.按照对图数据管理的抽象程度,可 以将其分成如下两类.
低层次抽象的提供编程接口的图数据管理系统:这类系统会针对图数据管理中的基本操作设计并实 现相应的编程接口,用户利用这些编程接口来实现相应的管理功能;
高层次抽象的提供描述性查询语言的图数据管理系统:这类系统设计图数据管理描述性查询语言,用 户将相应的管理需求用描述性查询语言表达,系统解析这些描述性查询语句并生成相应的查询计划 以进行执行处理.
表3 中,我们列举了本文即将介绍的图数据管理系统以及它们的分类.
Table 3 Category of graph data management systems
表 3 图数据管理系统分类系统类型 代表性系统 编程模型 描述性查询语言
低层次抽象的 提供编程接口的 图数据管理系统
Pregel,Giraph,PowerGraph,GraphLab,Quegel,PAGE 点计算
Trinity 基于内存云的键值对
GraphX 图并行计算/数据并行计算
高层次抽象的提供 描述性查询语言的 图数据管理系统
Neo4j Cypher
EmptyHeaded 自定义查询语言
gStore SPARQL
2.2 主要研究问题
针对大规模图数据处理,主要有以下几个常见问题.
图搜索:给定一个图,从一个点出发沿着边搜索其他所有节点.常见的图搜素方法有宽度优先、深度优 先和最短路径等.图搜索是图计算问题的基础,用于衡量图计算的 Benchmark Graph500[35]就是以宽度 优先搜索性能作为评测机器的图计算能力的标准;
基于图的社区发现:社区发现是社交网络分析中一个重要的任务,用于分析网络图中的密集子图.这对 于理解社交网络中的用户行为和朋友推荐等都具有非常重要的应用价值,典型的社区发现算法有 K-core[36]、K-truss[37]以及 K-clique[38];
图节点的重要性和相关性分析:计算图中某个节点的重要程度,例如在网页链接图中分析网页的重要 程度,代表性工作是 Pagerank[39];衡量图上两个节点的相关性,例如社交网络中两个人之间的关系,代表 工作包括SimRank[40]和Random Walk[41]等;
图匹配查询:给定数据图和查询图,图匹配查询找出所有在数据图上与查询图同构的子图,这个问题常 用于描述针对图结构的查询.图匹配查询的应用包括化学分子库中的分子拓扑结构查询[42]、在一个社 交网络图中的特定社交结构查询[43]等.面向 RDF 知识图谱数据的 SPARQL 查询语言就是基于子图匹 配的查询语义[44,45].
2.3 国内外研究现状
2.3.1 低层次抽象的提供编程接口的图数据管理系统
提供低层次抽象编程接口的图数据管理系统包括 Pregel[46]及其衍生[4751]、Trinity[52]、GraphX[53]等;系统
会将常见的图运算中的基本操作抽象成编程接口.虽然这类系统屏蔽了包括图数据的内部数据结构表示、分布 式环境下的通信处理等底层系统问题,但是由于是低层次抽象的编程接口,用户还需要将具体的图计算任务转 换成系统提供的低层次抽象编程接口逻辑.
这类系统中典型的是“点计算模型”,即允许用户定义每个点的计算任务.最早的系统是谷歌提出的一种分 布式图数据管理系统Pregel[46],该系统基于 BSP 分布式计算模型[54]进行设计,图数据的每个点为基本计算核心, 机器之间通过消息传递来实现同步.Pregel 将图运算用一系列的超级计算步(superstep)来描述,在运算每一次超 级计算步时,每一个顶点都能接收来自上一次超级计算步的信息,然后将这些信息传送给下一个顶点,并在此过 程中修改其自身的状态信息(例如以该顶点为起点的出边状态信息)或改变整个图的拓扑结构.Pregel 系统将不 同机器的通信进行了封装,用户需要通过编程来描述点计算函数进而实现自身的需求.
Pregel 的基于 BSP 的点计算模型得到了工业界以及学术界的广泛关注与认可.很多人在 Pregel 上开发了效 率更高的系统,包括 Giraph[47]、PowerGraph[48]、GraphLab[49]、Quegel[50]、PAGE[51]等.
除了基于“点计算”的图计算系统,Trinity[52]是微软研发的一个基于内存的分布式图数据管理系统.Trinity 认为:随着时代的发展,一方面内存越来越大且越来越便宜;另一方面,图数据上的基本操作非常复杂,将数据存 储在外存会导致操作不便,所以利用内存进行图数据管理才是更好的选择.因为单机内存规模总是有限的,所以 Trinity 使用了内存云的技术,也就是将多台机器的内存封装起来,使得用户能够同时使用多台机器的内存,而且 无需知道底层细节.Trinity 的基本数据结构是键值对,可以通过邻接表的形式存储与管理数据图,用户通过编程 调用内存中的邻接表来实现自身需求.
GraphX[53]将图计算任务分成两种:图并行计算任务(graph-parallel computation)和数据并行计算任务(data- parallel computation).所谓图并行计算任务,主要是指基于 BSP 点计算模型来实现的迭代计算任务,如 PageRank;
所谓数据并行计算任务,主要是指图上代数运算,如构建一个图、合并两个图、跨越多个图等等.GraphX 的作者 认为:现有的图计算系统(如 Pregel[46]、GraphLab[49])通过限定编程框架的形式来提高图并行计算任务的执行效 率,但是这些系统并不适合数据并行计算任务.基于上述观察,GraphX 在分布式计算平台 Spark[55]的基础上构建 了GraphX,以同时处理图并行计算任务和数据并行计算任务.GraphX 以图为第 1 类组成对象,以属性图为数据 模型.所谓属性图,就是每个点和每条边都可以关联一个属性值表.GraphX 定义了很多图上的操作.既包括一些 图并行计算任务,如 Pregel 等,也包括一些数据并行计算任务,如 map、filter 等.
2.3.2 高层次抽象的提供描述性语言的图数据管理系统
所谓高层次抽象的提供描述性查询语言的图数据管理系统包括Neo4J[56]、EmptyHeaded[57,58]、gStore[44,45,59]
等.这些系统为了方便用户对图数据的使用,在构建图数据管理系统的基础上,设计或者采用了一些描述性查询 管理语言.用户可以将自身的需求表达成描述性语句,然后系统将这些任务语句解析成执行计划,最后由系统按 照执行计划进行处理进而得到计算结果.因为这类系统用描述性查询语言作为用户和系统的交互中介,所以这 类系统具有较好的用户友好性.
Neo4J[56]是一个由美国Neo Technology 公司开发的基于 Java 平台的开源图数据管理系统,具有如下 4 个特 点:支持满足 ACID 特性的事务操作、很好的可用性、很高的可扩展性、支持高效率遍历查询.Neo4J 的描述性 查询语言是 Cypher[60],适合于开发者和在数据库上进行查询的数据专业操作人员.针对实际中各种应用需求, Cyper 定义不同的方法来描述与表达.Cyper 的许多关键字受 SQL 的启发,如 like 和 order by,它是一个申明式的 语言,焦点在如何从图中找回(what to retrieve),而不是怎么去做.在不公布实现细节的前提下,用户关心如何查 询优化.
EmptyHeaded[57,58]是由斯坦福大学开发的图数据管理系统,这个系统首先将图上的计算任务转化成边的连 接操作,然后利用现有关系数据库关于多路连接的最新研究成果[61]找出最优的多路连接查询执行计划.在查询 执行阶段,EmptyHeaded 利用 SIMD 技术来提高查询执行效率.EmptyHeaded 提出了自己的描述性查询语言,主 要整合了联合查询、聚集操作和迭代运算,支持常见的子图匹配、PageRank 计算、最短路径计算等.
着语义网的发展,越来越多的数据被表示成 RDF(resource description framework,即资源描述框架)[62]形式
发布到网络上.在 RDF 模型下,网络资源及其关系也可以被表示成一个图,方便用户利用图技术进行数据表示与 管 理. 针 对 RDF 数 据 , 已 经 有 推 荐 的 描 述 性 结 构 化 查 询 语 言 SPARQL(simple protocol and RDF query language)[63],可以实现大规模 RDF 的数据管理.
针对RDF 知识图谱的数据管理,可以采用基于关系数据库的方法,也可以采用图计算的策略.利用 RDF 知 识图谱的图结构特性来管理数据,代表性系统有基于图的 RDF 知识图谱数据管理系统 gStore[44,45,59]和支持自 然语言问句的RDF 知识图谱检索系统 gAnswer[64].
2.4 总结与展望
本文分类阐述了两类图数据管理方法,对图数据计算任务进行了不同程度的抽象,进而提出了不同的交互 方式.研究人员也提出了一些新的研究问题,包括在异构计算环境下的图数据管理问题,例如,如何利用新型高 性能计算芯片FPGA 进行图数据处理.异构计算环境下的图数据计算问题是一个开放性研究课题,同时,在传感 器、社交网络等环境下的图数据管理问题具有多源且实时更新的特点,面对多源的流式图数据管理也是图数据 管理所面临的新的挑战.
3 流数据管理
3.1 引 言
智能手机的普及和移动互联网的发展极大地加速了数据的生成过程,令数据呈现出爆炸式的增长,并给大 数据的实时管理带来了前所未见的难题和挑战.例如,微信的月活跃用户已超过了 10 亿,用户之间的交互则会 带来更大规模的数据,包括语音、视频、图片以及相关的文本等.数据的规模和复杂性还在高速增长,如社交网 络每天以亿级别的发文[65]、轨道交通应用形成的大规模定位与轨迹信息以及网络通信中的数据传播等.为了处 理实时增长的大规模复杂数据,流数据的管理和相关系统的研究一直是学术界和工业界的热点问题,包括早期 的关系型数据为主的数据流管理系统、近期在工业界普遍使用的流式计算系统以及目前广泛关注的对图数据 流管理系统的探索.
3.2 主要研究问题
流数据有众多不同的定义,但统一起来可以用随时间不断增长的数据模型来概括.除了基本的数据查询统 计等操作外,主要有 3 方面的研究问题——流数据采样、持续性数据查询和流数据并行计算.
流数据采样.基于有限的存储来管理无限的动态数据是流数据管理中的基本挑战之一,应对这一挑战 的最经典的思路则在于流数据上的高效采样.将高速更新的流数据采样到有明确规模边界的有限存 储中,通过对采样数据的计算和挖掘来反映流数据所蕴含的重要信息.一方面,需要研究不同流数据场 景下采样策略的选取,进而能够利用有限的资源尽可能地反映原流数据的特征信息;另一方面,需要结 合计算需求,精准分析采样数据上的计算与挖掘结果相对于精确解的近似程度,控制计算结果的偏移 范围;
持续性数据查询.流数据模型所对应的最核心的现实场景是实时监控.对不断生成的现实数据进行高 效的计算挖掘,能够及时获取现实世界中的重要信息.例如银行对实时的交易数据进行监控,及时规避 欺诈风险和追踪洗钱等违法行为.因此,给定基于结构特征、统计特征的数据查询模式,实时地监控流 数据中匹配的目标,一直都是研究的热点.一方面,需要保存已计算的中间结果来减少重复性的计算,另 一方面,又需要避免中间结果维护带来过高的额外开销;
流数据并行计算.应对流数据高速生成的一个重要策略就是利用数据和计算的独立性进行并行处理, 提高系统吞吐量.系统日志数据、银行流水数据以及大量的移动应用产生的用户数据等在其初期的归 整处理上都可以利用数据独立性进行流水线式的并行处理.在更复杂的数据计算和分析过程中,针对 计算独立性和流场景的一致性要求,设计锁机制来实现计算分析的并行化.
3.3 国内外研究现状
本节将通过流数据管理研究的 3 个不同阶段分别阐述流数据管理系统目前的研究脉络:首先,简单了解早 期以关系型数据为主的数据流管理系统(DSMS);然后,详细介绍近期针对大规模复杂数据的流式计算系统;最 后讨论目前兴起的对图数据流管理系统的探索.
3.3.1 数据流管理系统
数据流管理系统(DSMS)是指管理持续性数据流的计算机软件.不同于传统的数据库管理系统(DBMS),数 据流管理系统支持持续性查询,每个查询从注册开始有效直至撤销结束,不仅仅执行一次.在有效期间内,随着 数据流的不断更新,持续性查询的结果也会更新.传统的数据库管理系统一般假定有足够的外存用来持久化数 据,并且可以进行随机访问.而数据流管理系统中主要强调用有限的内存来处理无限的数据流,并且只能顺序访 问,这也是数据流管理最独特的特征以及最大的挑战.
目前,数据流管理系统并没有统一的系统框架,但在查询语言上,绝大多数都采用类似于传统数据库管理系 统中SQL 的声明式语言来表达查询,包括持续性查询语言(continuous query language,简称 CQL)[66]、流SQL[67]
等.流查询语言也会支持窗口表达.在图示化的查询语言中,每个细分的查询由一个“查询盒”表达,各个细分查询 的关联与组合通过“查询盒”[68]间的箭头连线表达.这个结构可以理解为流计算框架(诸如 Storm 等)中数据处理 与传输架构的前身.
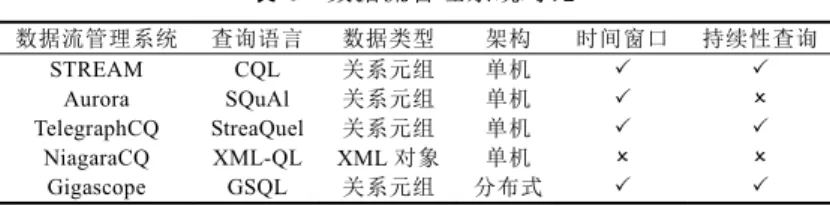
目前,主要的数据流管理系统有 STREAM[69]、Aurora[68]、TelegraphCQ[70]、NiagaraCQ[71]以及Gigascope[72]
等.STREAM 是斯坦福大学研发的基于关系模型的多功能数据流管理系统,它聚焦在数据流计算时的内存管理 以及近似查询.Aurora 是一个以工作流为导向的数据流管理系统,用户可以通过“查询盒”来定义查询计划,每个
“查询盒”含有基础的操作命令,“查询盒”之间的数据流指向决定了各个步骤结果的传输框架.TelegraphCQ 是一 个由伯克利大学开发的自适应数据流管理系统,用于支持不同场景的数据流应用.NiagaraCQ 是针对动态 Web 内容进行持续性 XML-QL 查询的数据流管理引擎(XML-QL 是 XML 查询语言的一种扩展,用来支持大 XML 文档上的数据抽取,能够跨多个不同的 DTD 解释 XML 数据以及集成多个不同源的 XML 数据).它对 XML 数据 的抽取、查询与监控分别由3 个主要组件来支撑:搜索引擎、查询引擎以及触发管理.Gigascope 是面向网络数 据流监控的分布式数据流管理系统,可以用来支撑网络流量分析、入侵检测、路由配置分析等,也能够进行网 络搜索、性能监控等.
表 4 给出了数据流管理系统的对比情况.这些系统的核心初衷在于对静态数据管理系统的流模型扩展,因 此,这些系统在查询语义和执行计算的数据处理逻辑方面与传统的数据管理模型有很大的重叠,可以认为是在 传统数据管理系统的语义和架构上的扩展,以支撑数据流场景的持续性查询.目前,大规模高速生成的数据结构 复杂,基于关系模型的数据流管理系统难以应对这种大数据场景.
Table 4 Comparisons of data stream flow management systems
表 4 数据流管理系统对比数据流管理系统 查询语言 数据类型 架构 时间窗口 持续性查询
STREAM CQL 关系元组 单机
Aurora SQuAl 关系元组 单机
TelegraphCQ StreaQuel 关系元组 单机
NiagaraCQ XML-QL XML 对象 单机
Gigascope GSQL 关系元组 分布式
3.3.2 流计算框架
流计算系统是目前学术界和工业界广泛使用的进行大规模数据处理的计算系统.目前,主流的流计算框架 主要有5 个:Storm[73,74]、Spark Stream[75]、Samza[76,77]、Flink[78,79]以及Kafka Stream[80].流计算框架具有两个重 要概念:交付保证(delivery guarantee)[81]、流处理类型中的实时处理流和微批量处理流.
交付保证是系统在处理新来的数据项时提供相应层次的处理保障,分为 3 种:第 1 种是“至少 1 次”,也就是
说,即便出现系统宕机等错误,也仍然能够保证新来的每个数据项被处理 1 次,可能会出现多次重复处理;第 2 种 是“最多 1 次”,也就是说,新来的数据最多会被处理 1 次,在宕机等错误情况发生时,有可能数据会被丢弃而导致 没有被处理;第 3 种则是“恰好 1 次”,也就是要求最严格的交付保证,确保无论发生什么情况,新来的数据项有且 仅有1 次处理.
流处理类型[82]的实时处理流是指每个新来的数据项都会被立即处理而无需等待后续的数据项,代表流框 架有Storm、Samza、Flink 以及 Kafka Stream;微批量处理流是指数据项并不是到达之后立即处理,而是等待一 段很短的时间使其聚成一定单位大小的单个小批量数据后再处理,对应的流框架有 Spark Stream 以及 Storm- Trident(Storm 的一个扩展,一个以实时计算为目标的基于 Storm 的高度抽象.它在提供处理大吞吐量数据能力 (每秒百万次消息)的同时,也提供了低延时分布式查询和有状态流式处理的能力).
Storm 是一个 Twitter 开源流系统,也是最早出现的开源流式计算框架.在初始化时,需要用户定义一个实时 计算框架,其结构是一个有向图.图中的点是集群中的计算节点,而边则对应整体计算逻辑中数据的传输,这个 图框架也被称为拓扑.在一个拓扑中,传输的数据单元是一系列不可修改的键值对(tuple),键值对从 spout(消息 源)点中输出形成流数据并传输到 bolts(消息处理者)点中进行计算,进而产生出新的输出流.bolt 输出流也可以 传输给其他bolts 节点,形成流水线式的计算处理流.Storm 也有不足之处,它并不支持状态管理以及窗口、聚集 等操作,支持的交付保证为“至少一次”而不是高要求的“恰好一次”.Storm 的容错机制是 Ack 机制,通信过程中 需要的额外开销可能会影响流计算的吞吐量.
Spark Stream(又称为 Structured Stream)其实是 Spark[83,84]核心API 的一个扩展,其对流式处理的支持其实 是将流数据分割成离散的多个小批量的RDD 数据(RDD 是 Spark 的数据单元),然后再进行处理.这些小批量的 数据被称为DStream(D 为 Discretized,即离散化的意思).Spark Stream 采用的是 Lambda[85,86]架构,即同时运行批 量处理和实时流处理的架构,其中,批量处理用来确保计算的正确性,而实时流处理则是为提高吞吐量.当实时 流处理计算结果与批量处理的计算结果不一致时,则会校正错误,因为有批处理的存在,所以自然而然就实现了 容错机制. Spark Stream 支持的是“恰好一次”的交付保证,而且与 Storm 一样,Spark Stream 并没有状态管理.
Samza 系统处理的流数据单元是类型相同或相近的消息,这些消息在产生之后是不可修改的.新产生的消 息将被追加到流中,而流中的消息也不断地被读取.每条消息可以有相应的键值,这些键值可以被用来对流中的 所有消息进行分割.Samza 的工作过程是按需计算转换(或过滤)一组输入流中的消息数据,并将计算结果以消息 数据的形式附加到输出流中.因此,运行工作负载可能包含多个工作组,工作组之间可能有流数据的依赖关系, 进而将整体计算抽象成一个数据流图框架.Samza 的一大特色在于对状态管理的良好支持,可以用来支撑流数 据的连接操作,其状态管理的引擎主要是 RocksDB[87]和Kafka Log.
Flink 与 Storm 相似,其整个数据处理过程被称为 Stream Dataflow,既定的数据流动框架类似于 Storm 的拓 扑.Flink 提取数据流的操作 Source Operator、数据转换(map,aggregate)的操作 Transformation Operator 以及数 据流输出的操作Sink Operator 与 Storm 架构中 Spout 与 Bolts 之间、Bolts 和 Bolts 之间的数据流是高度对应 的,区别在于容错机制:Flink 的容错机制是 Checkpoint,通过异步实现并不会打断数据流,因此 Checkpoint 的开启 与关闭对吞吐量的影响很小;Storm 采用的是 Ack 机制,开销大而且对吞吐量的影响明显.另外,Flink 提供的 API 相对 Storm 更高级.Storm 的优势主要是具有比较成熟的社区支撑和经过较长期迭代之后的稳定性.目前,Flink 成熟度较低,仍有部分功能需加以完善,如在线的动态资源调整等.Flink 提供的交付保证是“恰好一次”,优于 Storm 的“至少一次”.Flink 广泛受到大公司的亲睐,包括 Uber 和阿里巴巴,其中,阿里巴巴开发了基于 Flink 的流 计算系统Blink,并应用在电商流数据计算中.
Kafka Stream 是 Apache Kafka[80,88]中的一个轻量级流式处理类库,用来支撑 Kafka 中存储数据的流式计算 与分析.利用这个类库计算的结果既可以写回 Kafka,也可以作为数据源向外输出.目前的流式计算系统基本都 支持以Kafka Stream 的输出作为数据源,如 Storm 的 Kafka Spout.Kafka Stream 作为一个 Java 类库而非系统,是 流计算的重要工具之一.它可以非常方便地嵌入任意 Java 应用中,也可以任意方式打包和部署,除了 Kafka 之外, 并没有任何外部依赖.与流计算系统相比,使用 Kafka 所受到的逻辑限制较少,开发者能够更好地控制和使用
Kafka Stream 上的应用.Kafka Stream 提供的是“恰好一次”的交付保证,并且能够利用 RocksDB 进行状态管理.
目前,大公司在 Kafka Stream 上的实践较少,相关技术有待进一步成熟.
这些流系统最主要的相似性是针对数据独立性设计分布式并行计算策略,即:针对流式的输入,利用集群进 行协作计算,而整体的数据依赖框架一般是一个有向无环图.集群的整体协作更像是流水线的协作,计算框架中 的数据依赖所形成的数据流动方向基本上是单一既定的.除了数据处理的先后关系外,这些流系统对不同工作 组之间的数据独立性往往要求更高,可实现较好的并行效果.
已有针对这些流系统的基准比较(benchmarking)[89],然而系统的参数各不相同,同一系统在不同参数下的 性能也会大相径庭,所以 benchmarking 的结果可信度不足(见表 5).目前,从流系统支持的功能上来看,Flink 的功 能是最完备的,有状态管理、高吞吐量和低延迟、支持最严格的“恰好一次”交付保证、可调控内存使用等,并且 不会出现容错机制影响吞吐量的情况(如 Storm).虽然 Flink 的社区积累较少,相关 API 不够成熟,但在 Uber、阿 里巴巴等公司的使用和推广之下,目前逐渐成为广受欢迎、功能强大的流计算框架.
Table 5 Comparison of stream computing systems
表 5 流计算系统对比流计算系统 架构 交付保证 流处理类型 状态管理 吞吐量 延迟 成熟度
Storm 分布式 至少一次 实时 低 很低 高
Spark Stream 分布式 恰好一次 微批量 高 中等 高
Samza 分布式 至少一次 实时/微批量 高 低 中等
Flink 分布式 恰好一次 实时 高 低 低
Kafka Stream 分布式 恰好一次 实时/微批量 高 低 中等
3.4 图数据流管理系统的探索
目前的流数据除了规模大和增长快之外,还有结构复杂的特点,而图模型能够以简易的形式表达出丰富的 语义,因此,图模型与流数据模型融合而成的图数据流模型应运而生[90].图数据流的多种定义可以用无限增长的 边序列来概括(孤立点的现实意义有限),对应的研究问题除了传统的图计算问题之外,还有针对时间先后信息 定义的研究问题,如满足时序约束的路径、子图查询等[91].常见的时序约束有时间先后、时间间隔.例如,阿里巴 巴通过网购交易数据中的环形子图的实时监控来追踪通过网购进行恶意信用卡套现的行为[92].如图 1 所示:一 个信用卡恶意的套现模式中,套现者向商户发起信用卡虚假购买,银行将真实的资金支付给商户之后,商户通过 中间人将资金回流到套现者储蓄卡中,实现恶意套现.整个流程中,参与的对象和资金的流向构成了图的结构, 而每个行为环节有其明确的时间先后关系.因此,针对图数据流的管理能够解决很多现实中的重要问题.
Fig.1 Malicious cash arbitrage model of credit card[92]
图1 信用卡恶意套现模式[92]
在图数据流的管理方法上,核心的思路仍是在于利用已计算出来的结果来加速当前的计算,并且需要将中 间结果维护上的时间和空间代价控制在可接受的范围内[93].以流数据上的子图匹配为例,如果采用静态算法构 建复杂的索引的思路来加速查询,则需要针对复杂的索引设计高速更新的算法.然而往往对查询的加速容易增 加更新的代价,在无索引的极端情况下,针对子图的匹配需要完全重算;而在另一种极端情况下,即构建复杂的
索引时,往往需要高额的更新时间甚至整个索引重构.因此,图数据流下的计算首要考虑的是计算结果的维护与 计算加速的权衡.此外,在图数据流的高速更新场景下,多线程的并发计算仍然具有重要的意义.然而,图数据中 不同部分的关联程度较高,如单条边的删除能够导致大量路径特征的改变等,因此,在图数据流下进行并行算法 设计和并发访问控制等具有严峻的挑战.
基于目前已有的图数据管理的探索,可以总结出图数据流管理系统所需要解决的三大重要问题.
第 1 个是对图数据流中数据的基本操作的支撑,包括边序列的存储、增删改查以及已获取图数据的基 本访问操作,如节点度数、邻居等;
其次是针对图数据流上的更复杂的挖掘和查询支撑,包括边流行为分析、路径计算以及更复杂的子图 结构匹配等.对于复杂查询和挖掘的支撑,所设计的索引一方面需要考虑对计算的加速保证,另一方面 需要考虑在高速更新场景下对索引的更新维护代价;
第 3 个问题则是事务管理和并发、并行调度等机制的设计,旨在提高系统的吞吐量和缩短响应时间.
3.5 总结与展望
已有的数据流管理系统主要是在传统的数据流管理模型和架构上作了持续性查询的简单扩展,两者在语 义和计算逻辑方面有相似之处,大部分数据流管理系统来自高校科研团队,而且这些数据流管理系统已经难以 处理大规模复杂数据流的查询和计算.主流的流计算框架采用分布式的计算方式,利用数据独立性的特点进行 并行计算,与传统的数据管理模型有很大区别.对数据的格式要求不高,能够处理大规模的多种复杂数据流,有 大量的社区支持以及大规模企业的实践与推广,大部分是来自开源社区而鲜有是学术界的科研团队开发的.目 前,对大规模生成的复杂数据的计算处理基本上依赖于流计算框架.由于对数据的独立性要求较高,流计算框架 不适于处理数据之间有高度关联关系的模型,因此,目前针对图数据流管理系统的研究受到了学术界和工业界 的高度关注.
4 时空数据库
4.1 引 言
时空数据库是管理空间、时态以及移动对象数据的数据库系统,与传统的关系型数据相比,时空数据具有 多维度、多类型、动态变化、更新快等特点,关系型数据库不能很好地处理此类数据,需要新的有效数据管理 方法.近年来,时空数据库在地理信息系统、城市交通管理及分析、计算机图形图像、金融、医疗、基于位置 服务等领域有着广泛的应用.根据时空数据特点,时空数据库大致包括以下 3 种.
空间数据库:主要处理点、线、区域等二维数据,数据库系统需提供相应的数据类型以支持数据表示、
存储、常见拓扑运算操作和高效查询处理,同时需要与传统的关系数据库系统融合以扩展数据库系统 处理能力,支持不同类型数据的查询处理;
时态数据库:管理数据的时间属性,包括有效时间(valid time)、事务时间(transaction time)等.时间可以为 时间点或者时间区间:如果是时间区间,数据库管理系统将以开始和结束时间两个属性或一个区间属 性进行存储.不同的应用场景下,时间属性会有相应的特点(例如周期性);
移动对象数据库:管理位置随时间连续变化的空间对象,主要有移动点和移动区域:前者仅是位置随时 间变化,后者还包括形状和面积的变化.移动对象具有数据量大、位置更新频繁、运算操作复杂等特点.
近年来,随着定位设备的不断普及,例如智能手机,采集这类数据越来越容易.同时,与地图兴趣点(例如 酒店、餐馆等)相结合,使得移动对象具有语义信息,带来各种新的应用,例如基于位置服务、最优路径 规划等.
4.2 主要研究问题
数据模型和查询语言
数据模型包含数据类型和运算操作两个方面.时空数据类型包含多个,有些为定长记录存储(例如点、区间),
有些为变长记录存储(例如区域、移动点).运算操作定义时空拓扑运算(例如相交 intersect、重合 overlap),包含 语法和语义两个层面:前者描述输入输出参数类型,后者定义抽象层含义.时态和移动对象数据库均处理具有时 间因素的对象,数据类型和运算操作都涉及随时间变化的数值,增加了复杂性,主要体现在如何表示数值的动态 变化以及拓扑运算定义和求解方法上.移动对象除了要考虑自身的时空属性外,还需要结合对象所在的受限制 空间环境,例如道路网、室内空间等,因为位置表示与此相关.此外,不确定性时空数据也是研究内容之一,包括数 据模型和查询语言.时空数据类型可作为关系属性嵌套在关系模式下,从而对查询语言 SQL 扩展(运算操作、谓 词),以得到时空数据查询语言,支持形式化查询描述.
索引结构
根据不同时空数据的特点设计访问结构,以支持快速查询处理,常见的空间和时态索引有 R-tree、K-d Tree、
Interval-tree 等.不同的索引结构有相应的运算操作,包括创建、插入、删除、更新及查询.其中,R-tree 是最为广 泛使用的结构,为提高查询效率,需对数据排序(例如 z-order),目的是将相似数据存储在邻近结构里,以减少搜索 的I/O 代价.同时,基于该结构的预测模型可以估计查询的 I/O 代价,为进一步优化提供分析的依据.根据时间因 素,移动对象索引可分为两类:(i) 历史数据索引,管理移动对象从开始到结束的所有位置和时间;(ii) 当前数据 及预测索引,管理移动对象当前位置和速度并进行预测,提供有效的位置更新策略及数据缓存方法.由于移动对 象的位置、时空分布、查询等频繁发生变化,主存索引及并行技术往往比外存索引更具优势,自动调优技术对 索引的参数动态调整以使性能最优.时空数据索引可以融入语义描述,从而拓展时空数据管理能力,以支持具有 语义的时空查询.
查询处理及优化
选择查询和最近邻查询是空间和移动对象数据库最常见的两类查询:前者返回在空间/时空查询窗口内的 对象,后者返回距离查询目标最近的对象.当查询目标是移动对象时,其最近邻对象也动态地发生变化,称为连 续最近邻查询;当返回结果的最近邻是查询目标对象时,称为反向最近邻查询.相似性查询定义评价函数,用于 计算对象之间的相似度,返回与查询目标最相近的对象;连接查询用于返回两个数据集中所有符合查询谓词条 件(例如相交、重合)的实体对,例如找出所有长江和黄河途经的城市.与选择查询、最近邻查询相比,连接查询的 复杂性更高,相关优化技术有数据划分、索引创建、排序等.时空数据查询还包括聚类查询、模式匹配、距离 查询等.将关键字或语义描述与位置相结合,可进行具有语义的 ranking 或 top-k 查询,返回对象不仅符合时空约 束,而且满足关键字条件,增加了用户对时空对象的全面理解.
时空数据管理系统
在定义了抽象模型的基础上,需要有系统实现模型包括数据结构和算法、逻辑设计及实现,同时需要将时 空数据模型和关系模型有效融合,从而扩展数据库处理能力.由于时空数据管理系统涉及多种索引结构和查询 算法(例如,基于 R-tree 的深度优先和宽度优先),因此需对数据库系统的功能、性能及可扩展性等进行全面测试 和评估,发现系统性能瓶颈从而进行优化.这主要通过基准测试完成,一般包括数据集(真实和模拟)、查询集、索 引结构及参数设置等,为模拟各种时空数据分布,需要相应的数据产生器及可视化工具.
除上述研究问题外,时空数据库管理还涉及时空数据仓库、时空图数据、时空数据流、基于位置服务(最 优路径规划和交通预测)、轨迹数据压缩、时空数据挖掘和分析等方面.
4.3 国内外研究现状
4.3.1 空间数据库依据不同的环境,空间数据库的研究包括自由空间和受限空间(例如道路网、有障碍空间),主要区别在于距 离函数,受限空间的距离计算依赖于最短路径求解,比自由空间要复杂.相关查询有范围查询、最近邻(反向最近 邻)、Skyline 查询、动态道路网下最短路径查询和路径规划等,索引技术和搜索策略在查询中起到了关键性作 用[94].查询过程一般包括过滤和提炼两个阶段:过滤阶段借助于索引和估计值找到一组备选对象,提炼阶段对每 个备选对象进行准确值求解.空间数据库查询还包括最大范围求和、容量受限分配等.在基于位置服务的应用 中,隐私保护是一个重要的研究内容,已有的工作包括基于位置隐私的攻击及保护方法,如模糊表示、匿名等.
近10 年来,空间关键字查询(spatial keyword search)得到了广泛和深入的研究[95],通过将空间位置与文本相 结合,用户可以查询同时符合空间和语义条件约束的对象,常见查询有 Top-k、k-NN 等.由于传统的空间数据索 引不支持文本数据管理,一般将空间索引与文本索引或位图技术相结合构成混合索引结构,支持同时对空间和 文本数据的查询,以缩小搜索范围.
4.3.2 时态数据库
在过去的20 年里,时态数据管理一直是数据库的活跃领域之一,研究内容包括数据模型、查询语言、索引 结构及高效查询算法,各种查询语言也被提出以支持时态数据查询的形式化描述.Enderle 等人基于常见的时态 数据索引之一——Interval-tree 设计了相应的外存结构以及在关系数据库系统中的实现方法,可以有效支持相 交查询和连接查询[96];Top-k 查询用于返回与查询点(区间)相交且权重最大的 k 个对象.Dignös 等人将时态数据 运算操作、转换原则及查询优化方法集成到关系数据库系统内核中(PostgreSQL),以扩展其处理能力[97],商用数 据库Oracle 提供了数据类型 PERIOD 及相关谓词和函数.
近几年,时态数据库的研究主要集中在高效处理各种连接查询(例如 overlap join,merge join)、聚类查询 (aggregation)以及数据划分和排列方法(partition/splitter,align).同时,硬件技术(例如多核 CPU)的发展也有助于 提高查询效率.不确定性时态数据将时态数据和不确定性相结合,也有不少相关研究工作,包括数据表示及建 模、不确定性时态数据查询等;时态数据集成是根据用户指定优先规则对多源时态数据加以融合.
4.3.3 移动对象数据库
早期的移动对象数据库研究主要集中在数据模型、索引和查询处理等[98],代表性索引结构有 TB-Tree、
SETI、TPR-tree、STRIPES 等[99],这些结构的差异主要体现在时空数据的管理方法(例如插入原则、时空优先 权)上,常见的移动对象查询有范围查询、(连续)最近邻、相似性轨迹、连接查询等.针对大规模移动对象位置 的实时更新,有学者提出了有效的更新策略及监控方法,也有学者对不确定性移动对象进行了研究[100].近年来, 面向特定应用的移动对象查询得到了广泛的关注,例如轨迹模式匹配、异常现象分析、基于轨迹的用户行为推 荐、轨迹压缩等.由于大规模移动对象数据获取已相对容易,对历史数据分析其结果可为应用提供支撑,例如最 优路径推荐、最优出行方式及路线规划、交通流量预测等.除了支持时空查询,系统也需要对用户的位置信息 进行有效保护,针对这一问题,有学者开展了基于位置隐私保护的研究.
人的运动除了在自由空间下,更多的时候是在受限空间下,例如道路网[101]、有障碍空间[102]和室内环境.不 同环境的主要区别在于移动对象位置表示和距离函数:自由空间的位置通过坐标表示,距离函数基于欧式距离;
而受限空间下的位置依赖于底层空间环境,距离函数与最短路径相关,求解过程相对复杂.例如,道路网环境下 采用Map-matching 技术,将 GPS 位置(经纬度)映射到道路网从而得到道路网移动对象;在室内环境,移动对象位 置获取一般依靠RFID、WiFi 等技术,位置表示则采用基于符号的表示方法.上述工作均是针对单个空间环境下 的移动对象,也有学者将多个环境的不同位置表示方法相融合,形成统一的位置表示方法,支持人的完整运动轨 迹表示以及不同运动方式的移动对象数据管理,例如步行公交车步行室内.
在大数据背景下,新应用要求数据包含更多的信息以全面理解用户行为,移动对象数据也从传统的时空数 据拓展到具有语义信息和行为描述[103,104].语义轨迹是将 GPS 数据和时空场景相结合,例如兴趣点或用户行为, 给移动对象赋予相关描述(可通过数据挖掘算法得出并以标签形式存储),丰富移动对象表示.基于语义轨迹的 常见查询有模式挖掘和匹配[103]、时空语义关键字查询、top-k 查询以及移动用户行为分析(规律性地访问某些 位置、规避和会合等).基于硬件的技术也被用于大规模轨迹数据查询和分析,例如基于主存的轨迹存储和查询 方法、分布式/并行轨迹数据处理平台(基于 Spark 和 Hadoop)、基于 GPU 的交互式时空数据查询等,轨迹数据 可视化技术也有相关研究.
4.3.4 时空数据管理系统
时空数据管理系统的设计主要有两种思路:一种是对传统关系数据库管理系统的内核修改或扩展以支持 时空数据管理,包括数据类型、访问方法、查询语言等;另一种则通过在应用层和传统数据库管理系统层之间 构建一层结构,用于时空数据和传统数据的相互转换,即,在应用层以时空数据处理而在系统存储层还是以传统