行政院國家科學委員會專題研究計畫 成果報告
電視頻帶白空間之寬頻行動雲端感知無線網路
研究成果報告(完整版)
計 畫 類 別 : 個別型
計 畫 編 號 : NSC 99-3113-P-009-004-
執 行 期 間 : 99 年 11 月 01 日至 101 年 01 月 31 日
執 行 單 位 : 國立交通大學資訊工程學系(所)
計 畫 主 持 人 : 王協源
計畫參與人員: 學士級-專任助理人員:王淳渝
碩士班研究生-兼任助理人員:陳弼揚
碩士班研究生-兼任助理人員:王柏凡
碩士班研究生-兼任助理人員:張文哲
碩士班研究生-兼任助理人員:陳建都
碩士班研究生-兼任助理人員:李韻立
碩士班研究生-兼任助理人員:蔡佳玟
碩士班研究生-兼任助理人員:莫尚儒
碩士班研究生-兼任助理人員:周煜軒
碩士班研究生-兼任助理人員:梁喬峰
碩士班研究生-兼任助理人員:李宗霖
碩士班研究生-兼任助理人員:林佳賢
碩士班研究生-兼任助理人員:張嘉軒
碩士班研究生-兼任助理人員:劉人僖
碩士班研究生-兼任助理人員:周詩梵
碩士班研究生-兼任助理人員:郭俊義
碩士班研究生-兼任助理人員:殷裕雄
碩士班研究生-兼任助理人員:江培立
碩士班研究生-兼任助理人員:林巧桐
碩士班研究生-兼任助理人員:鄭仲傑
碩士班研究生-兼任助理人員:陳人維
碩士班研究生-兼任助理人員:蕭永中
大專生-兼任助理人員:蔡東倫
博士班研究生-兼任助理人員:郭子綺
博士班研究生-兼任助理人員:江長廷
博士班研究生-兼任助理人員:曾俊凱
博士班研究生-兼任助理人員:邱麟凱
博士班研究生-兼任助理人員:邱新栗
博士班研究生-兼任助理人員:邱榮東
博士班研究生-兼任助理人員:黃汀華
報 告 附 件 : 出席國際會議研究心得報告及發表論文
公 開 資 訊 : 本計畫可公開查詢
中 華 民 國 101 年 02 月 23 日
中 文 摘 要 : 近年來,FCC 公告了第一個使用電視空白頻帶的商業應用規
範,為感知無線電的發展走出了突破性的一步。另一方面,
雲端運算的快速發展,使得利用現有的無線通訊裝置建構都
會區網路在經濟上變成可行。在面對這兩種技術帶來的機會
與挑戰,我們提出一種創新的 CRCN(CR Cloud Network)模
型,用以實現感知無線電在電視頻帶上的通訊。在運用雲端
強大而彈性的運算資源下,我們發展了合作式頻譜估測
(cooperative spectrum sensing)演算法估測授權使用者
(PU)的無線功率圖(radio power map),並建立資料庫儲存其
成果。此感知無線雲(CR Cloud,CRC)系統已實作在微軟
Azure 雲端平台,並能夠支援合作式頻譜估測、感知無線電
通道存取(CR channel access)以及行動管理(mobility
management)。同時,我們也發展一個媒體層通訊協定
(medium access control protocol)用以蒐集回報的資訊並
且提供存取感知無線雲的服務以及電視空白頻帶的通訊資
源。藉由所實作的 CRCN 原型,我們可以量測許多重要的網路
參數,如合作式頻譜估測的誤差、通道閒置時間的延遲
(channel vacating delay)以及以雲端為基礎的換手
(handover)時間。藉由這樣的實作,讓我們能夠評估 CRCN 模
型的設計以及概念。除此之外,為了進一步改善合作式頻譜
估測演算法的效能,我們探討把它執行在 Amazon EC2 公有雲
上的效能瓶頸。我們發現 Amazon EC2 公有雲上所提供的
Hadoop 計算平台並不適合此合作式頻譜估測演算法的執行,
因此我們仔細研究 Hadoop 平台的設計及實作。經過我們改
良後,目前我們已經能大幅增進此合作式頻譜估測演算法在
Amazon EC2 公有雲上的執行效能。
中文關鍵詞: 雲端運算 感知無線電 Channel access control; resource
allocation; Bayesian Sparse Learning
英 文 摘 要 :
英文關鍵詞:
行政院國家科學委員會補助專題研究計畫
成果報告
□期中進度報告
電視頻帶白空間之寬頻行動雲端感知無線網路
計畫類別:■個別型計畫 □整合型計畫
計畫編號:NSC 99 -3113 -P -009-004-
執行期間:99 年 11 月 1 日至 101 年 1 月 31 日(一年期計畫)
執行機構及系所:國立交通大學 資訊工程學系
計畫主持人:王協源 教授
計畫參與人員:伍紹勳教授、趙禧綠教授
成果報告類型(依經費核定清單規定繳交):□精簡報告 ■完整報告
本計畫除繳交成果報告外,另須繳交以下出國心得報告:
□赴國外出差或研習心得報告
□赴大陸地區出差或研習心得報告
■出席國際學術會議心得報告
□國際合作研究計畫國外研究報告
處理方式:除列管計畫及下列情形者外,得立即公開查詢
■涉及專利或其他智慧財產權,□一年■二年後可公開查詢
中 華 民 國 101 年 1 月 31 日
I
中英文摘要及關鍵字
The FCC’s approval for the first commercial operation in TV white space (TVWS) gives a new momentum
to the development of cognitive radio (CR) in TVWS. On the other hand, the rapid growth of Cloud computing
makes it possible and more economical to build a CR metropolitan area network with commodity hardware. In
view of the opportunity and challenges brought about by these two technologies, we propose a CR Cloud
Networking (CRCN) model that is able to support CR access in TVWS. Making use of the flexible and vast
computing capacity of the Cloud, a database and a cooperative spectrum sensing (CSS) algorithm that estimates
the radio power map of licensed users are realized on a CR Cloud (CRC) implemented with Microsoft’s
Windows Azure Cloud platform. The CRC can support CSS, CR channel access and mobility management. A
medium access control protocol is also developed for this CRCN model to collect sensing reports and provide
access to the TVWS and CRC services. Through this CRCN prototype, important network parameters such as the
mean squared errors in CSS, the CR channel vacating delay and the Cloud-based handover time are evaluated for
the design and deployment of the CRCN concept. In addition, to further improve the performance of the CSS
algorithm, we investigate running it on the popular Amazon EC2 public cloud using the Hadoop computing
platform provided by Amazon. We found that the design and implementation of Hadoop do not suit the CSS
algorithm well. We have successfully improved Hadoop to achieve great performance speedup over Amazon
EC2 public cloud.
近年來,FCC公告了第一個使用電視空白頻帶的商業應用規範,為感知無線電的發展走出了突破性的
一步。另一方面,雲端運算的快速發展,使得利用現有的無線通訊裝置建構都會區網路在經濟上變成可行。
在面對這兩種技術帶來的機會與挑戰,我們提出一種創新的CRCN(CR Cloud Network)模型,用以實現感
知無線電在電視頻帶上的通訊。在運用雲端強大而彈性的運算資源下,我們發展了合作式頻譜估測
(cooperative spectrum sensing)演算法估測授權使用者(PU)的無線功率圖(radio power map),並建立資料庫儲
存其成果。此感知無線雲(CR Cloud,CRC)系統已實作在微軟Azure雲端平台,並能夠支援合作式頻譜估
測、感知無線電通道存取(CR channel access)以及行動管理(mobility management)。同時,我們也發展一個
媒體層通訊協定(medium access control protocol)用以蒐集回報的資訊並且提供存取感知無線雲的服務以及
電視空白頻帶的通訊資源。藉由所實作的CRCN原型,我們可以量測許多重要的網路參數,如合作式頻譜
估測的誤差、通道閒置時間的延遲(channel vacating delay)以及以雲端為基礎的換手(handover)時間。藉由
這樣的實作,讓我們能夠評估CRCN模型的設計以及概念。除此之外,為了進一步改善合作式頻譜估測演
算法的效能,我們探討把它執行在Amazon EC2公有雲上的效能瓶頸。我們發現Amazon EC2公有雲上所提
供的 Hadoop 計算平台並不適合此合作式頻譜估測演算法的執行,因此我們仔細研究 Hadoop 平台的設
計及實作。經過我們改良後,目前我們已經能大幅增進此合作式頻譜估測演算法在Amazon EC2公有雲上
的執行效能。
Keywords—cloud computing; Cognitive Radio; Channel access control; resource allocation; Bayesian
Sparse Learning
目錄
一、前言... 1
二、研究目的... 2
三、文獻探討... 4
四、研究方法... 10
五、實驗成果... 16
六、結論... 24
七、參考文獻... 27
八、 附錄 ... 28
附錄1.
C.-H. Ko, D.-H. Huang, and S.-H. Wu, “Cooperative Spectrum Sensing in TV White
Spaces:When Cognitive Radio Meets Cloud,” in Proc. IEEE INFOCOM Workshop on Cloud
Computing. April. 2011, ShangHai, China.
附錄2.
Shuhua Jiang, L.-H. Chao, and H.-L. Chao, “A Decentralized MAC Protocol for Cognitive
Radio Networks,” in Proc. IEEE INFOCOM Workshop on Cognitive and Cognitive and
Cooperative Networks. April. 2011, ShangHai, China.
附錄3.
FD-TDMA based CR-MAC protocol
附錄4.
Shie-Yuan Wang, Po-Fan Wang, and Pi-Yang Chen, “Optimizing the Cloud Platform
Performance for Supporting Large-Scale Cognitive Radio Networks”, IEEE WCNC 2012.
April 1-4, 2012, Paris, France.
附錄5.
S.-H. Wu, H.-L. Chao, C.-T. Jiang, S.-R. Mo, C.-H. Ko, T.-L. Li, C.-F. Liang, and C.-C.
Cheng, “A Conceptual Model and Prototype of Cognitive Radio Cloud Networks in TV
White Spaces,” in Proc. IEEE WCNC Workshop on Wireless Cloud and White Space
Oriented Networks. April 1-4, 2012, Paris, France.
附錄6.
王協源教授出國報告書
附錄7.
趙禧綠教授出國報告書
附錄8.
邱榮東博士生出國報告書
附錄9.
邱麟凱博士生出國報告書
III
圖目錄
圖一:CRCN 的應用環境示意圖
... 2
圖二:世界各研究單位感知無線電平台原型之功能比較
... 4
圖三:HDFS 架構示意圖(節錄自[3])
... 7
圖四:MapReduce 架構圖([14])
... 7
圖五:Windows Azure 的應用與平台架構 (節錄自[4])
... 8
圖六:
在不同雲端平台所量測的執行時間 ... 12
圖七:
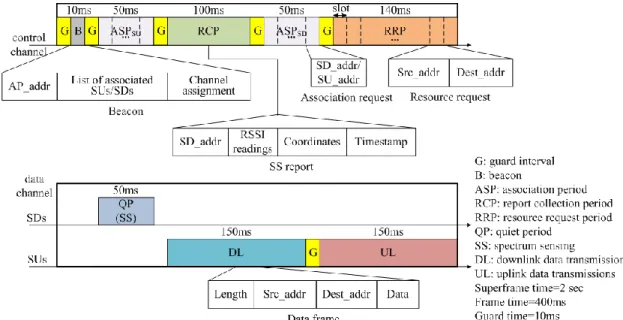
Hadoop 工作執行流程圖 ... 12
圖八:系統架構示意圖
... 16
圖九:通訊模組實照
... 16
圖十:WARP 開發平台接上 CC1111s 及 HMTR 作為我們的 CR AP
... 17
圖十一:筆電接上 CC1111 通訊模組作為我們的 SUs
... 17
圖十二:在頻譜分析儀上的 PU 訊號,中心頻率為 872MHz,頻寬為 6MHz
... 18
圖十三:頻帶釋出時間
... 19
圖十四:換手執行中內部所花時間(封包來回時間、暫存資料及更新狀態時間、暫存資料及查詢時間)
... 20
圖十五:
模擬環境示意圖 ... 21
表目錄
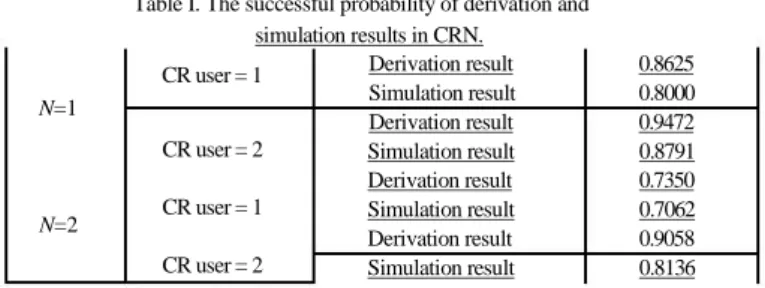
表一:PiEstimator 在不同 heartbeat 時間間隔的執行時間
... 13
表二:機器規格
... 14
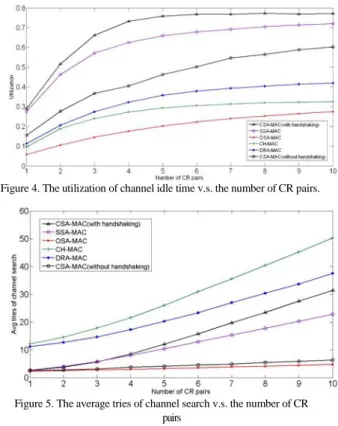
表三:不同 Reducer 睡眠時間對 PiEstimator 執行時間的影響
... 14
表四:Job commit 的睡眠時間對 PiEstimator 執行時間的影響
... 15
表五:同時修改三個參數後的執行時間
... 15
表六:各種平台資訊比較表
... 21
表七:實驗室自組平台執行頻譜估測演算法的時間比較
... 22
表八:利用 EC2 Large Instance 執行頻譜估測演算法的執行時間
... 22
表九:利用 EC2 Extra Large Instance 執行頻譜估測演算法的執行時間
... 22
表十:區域大小 60*60 的模擬與區域大小 300*300 的執行時間
... 23
一、 前言
感知無線電技術(Cognitive Radio,CR)[1]為 Joseph Mitola III 所提出,比起傳統的無線通訊,感
知無線技術藉由對於優先權使用者(Primary User,PU)的保護,提供無執照使用者(Secondary User,SU)
對頻帶的存取,以改善頻譜利用的效率。在目前的無線通訊環境下,根據統計,頻譜的使用率約略只
有 25%[2]。因此,CR 技術被視為下一世代通訊的選項。由於上述因素,各國的電信管理當局也開始
注重 CR 的發展。美國聯邦電信委員會(Federal Communications Commission,FCC)便利用收回類比電
視頻譜的契機,開放 CR 的測詴並制定在電視白頻帶(TV White Space,TV WS)上 CR 的使用規範,此
一舉動,促使各大國際組織開始定義 CR 的通訊協定,較為知名的有:IEEE 802.22、ECMA 392 以及
IEEE 802.16m 等。
在電視白頻帶上,PU 為數位電視基地台,為了保護數位電視的收訊品質,FCC 要求 CR 的營運
者必須準確偵測出 PU 的功率,設立 SU 可用門檻為-116dBm,並且建立 PU 的資料庫,記錄下 PU 的
名稱、天線場型、所在位置、功率、使用頻帶與高度,也在報告中定義了不同種類 SU 的功率限制。
相較於 FCC 對於 CR AP(Access Point)的規範,數位電視基地台的功率覆蓋範圍遠超於一個 CR AP 的
功率範圍,為了達成 FCC 的規範,我們使用合作式頻譜估測,藉由分散式的功率感測,克服環境中
的訊號遮蔽效應,重建出 PU 的功率分布圖。
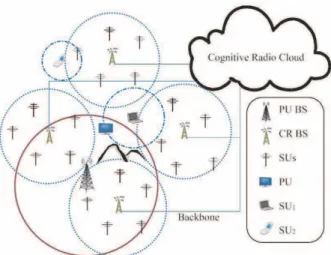
為達上述預期目標,我們提出了感知雲端網路(Cognitive Radio Cloud Network,CRCN)在電視空
白頻譜上的應用。在這樣的架構下,我們不但可使用雲端帄台在骨幹網路節點的特性,利用各 CR AP
收集 SUs 的功率量測資料,以雲端帄台作為頻譜偵測的資料彙整中心以及合作式演算法的運算中心,
並作為 CR 頻譜資源分配與排程的控制中心,實現一個高度彈性的中央控制式通訊網路架構。在 CR
的環境裡,SUs 的數量將隨著時間和地區而改變,這樣的性質使得選擇雲端帄台作為資料匯流中心能
有更大的助益,雲端帄台將根據偵測回報的數量,動態調整使用的運算資源,估測 PUs 的資訊,一
直到分配通訊資源,提供完整的通訊服務,並針對在空間以及時間上量測數量的變化,提供有效率的
帄行化處理,使得 CRCN 能適用於跨區域網路(Regional Area Network, RAN)的通訊服務。
二、 研究目的
CR Cloud
Power plant
Train station
TV base station CR AP Radio power map Router
圖一、CRCN 的應用環境示意圖。
隨著無線頻寬需求的上升,無線區域網路的存取點(Access Point)將如同路燈般的公共設施,遍布
在城市中的以供大眾使用。然而,建立一個如此龐大的無線網路系統,需求更多頻譜資源以及一個共
同的控管系統。感知無線電在保護優先權使用者的權限下,提供了更為廣闊的頻譜使用,雲端運算的
技術則提供了建立此控管系統的可能,圖一就是我們所設想的 CRCN 應用環境示意圖。
為了測詴 CR 與雲端結合後的效能表現,我們提出了 CRCN 的架構。在 CRCN 的架構中,我們
設計了 MAC 層的通訊協定、雲端的帄行化架構、合作式頻譜估測以及排程演算法,讓 CR AP 及其服
務的 SUs 在 CRCN 的架構下進行頻譜的偵測以及資料的傳輸。在 MAC 層協定的設計上,我們實作
一個簡單但仍能呈現 CR 概念的通訊協定。該通訊協定初步以 FD-TDMA 為基礎,並使用兩個不同的
頻道,分別用來傳送資料與控制訊息。為了完成合作式頻譜的偵測,我們要求使用者定期回傳資料頻
道的功率偵測數據,該數據包含偵測時間、偵測到的功率值以及其所在位置,雲端帄台再藉由骨幹網
路上的 CR APs 蒐集這些資訊來做頻譜估測。
關於頻譜估測演算法,我們提出一個以貝氏稀疏演算法 (Sparse Bayesian Learning algorithm) 為
基底的合作式頻譜感測演算法(Cooperative spectrum sensing)
,這個演算法會利用來自於 SUs 所搜集
以計算 SUs 的排程資訊,在不影響 PUs 的前提下,安排 SUs 在適當的資料頻道進行資料傳送或接收。
當考慮到範圍較大的區域時、可能包括數個 CR APs 時,基於以下三點考量,由雲端來做管理是
比較可行的。
(1) 相對於一個 AP 所能夠提供的計算能力,雲端帄台具較強大的計算能力,也可以隨著需求而有
較具彈性的擴充。
(2) FCC 要求 CR 營運商對 PUs 所用的頻帶以及所在位置建置一資料庫,此資料庫的容量需隨著
網路範圍增大以及使用者數目的增加適度地擴充及發展;此外,雲端帄台具有適應不同運算負
載的特性,所以此工作也適合由雲端來執行。
(3) CR APs 之間的資料交換,若 PU 的覆蓋範圍包含了數個 CR APs,此時 PU 的發送功率和覆蓋
範圍無法經由單一 CR AP 所收到的感測數據估測,一定得經由不同 CR APs 的資料交換後才有
可能實現。而想要在大量 CR APs 之間進行資料交換時,一可行的方式就是所有的 CR APs 都
連上雲端,由雲端來做資料整合和交換,並且有權限來管理所有的 CR APs。
為達成前述研究目的,此計畫執行時分三個分項進行:
分項一:CRCN 實體層之感測與實作
分項二:CRCN 媒體層協定提案及實作
分項三:雲端運算帄台之改良
三、 文獻探討
1. 世界各研究單位感知無線電帄台原型之調查
圖二、世界各研究單位感知無線電帄台原型之功能比較
我們調查並比較世界各研究團隊之感知無線電帄台,並且依功能整理如圖二所示。其中專注在資
料庫建立的有 SpecNet 以及 Spectrum Bridge。SpecNet 為微軟印度研究院的提出的研究帄台,在其所
提出研究中,敘述了建立估測 PU 的必要性,利用簡單的動態估測機制偵測 TV 基地台並建立資料庫。
Spectrum Bridge 為美國的頻譜資料庫管理公司,該公司擁有全美國的靜態頻譜,並符合 FCC 對於頻
譜資料庫的規定。目前 Spectrum Bridge 公司已經和 Google、MicroSoft 等公司合作,在美國建立並提
供小範圍之電視空白頻帶網路。
CRaMNet (Cognitive Radio Assisted Mobile Ad Hoc Network)為 Oulu 大學所提出的帄台原型[3],其
帄 台利用 多 台 WARP 實作 Ad-Hoc 感知無線電網路,並實作了網路同步與通道聚合 (channel
aggregation),使得 channel 中有部分頻寬被佔住時 SU 可切換中心頻率與調變,使用剩下的頻寬。在
頻譜感測演算法上,CRaMNet 使用的機制是在每一台 WARP 上,各自感測該頻譜是否有其他使用者
在使用,而沒有建立全域的 PU 資訊。CRaMNet 並利用其所實作的網路原型,實作了第一個經由感
知無線電網路傳送網路語音服務(Voice over IP,VoIP)。
CWC (Cognitive Wireless Cloud)為 NICT (National Institution of Information and Communication
Technology) 所提出的感知無線電網路原型 [4][5],也是目前所有原型中有利用到雲端架構的網路原
型,然而和我們所提出的網路原型不同,CWC 的雲端是用來最佳化在 CWC 中的無線路徑。換言之,
CWC 提供了 Reconfigurable 的網路模型,終端使用者可以藉由重新編譯無線電路,使用不同的無線
網路,而 CWC 中的雲端就是用來處理無線路徑的使用問題。在 CWC 的實作中,感知無線電也是 CWC
眾多的無線介面之一,而 PU 資訊是藉由各個 CR 基地台合作感測所形成,SU 若是要存取此網路,
則必須透過 CR 基地台。
Rutgers 大學所提出的 CogNet [6]和 Virginia 理工學院所出的感知無線網路原型[7]都是基於
Ad-Hoc 的模式,建立網狀網路。他們共同的特點是對 Reconfigurable 功能的支援,亦即在他們提出
的感知無線電原型下,使用者能藉由重新編譯硬體而使用不同的無線通道資源。兩者主要的差異在於
CogNet 團隊所發展的帄台藉由各節點感測的結果決定該結點在此無線通道是否能夠使用,而 Virginia
理工學院所提出的感知無線電原型則是藉由合作式的頻譜估測,估測 PU 是否存在,並且保護 PU 的
使用權力。Aachen 大學所提出的原型也是建立在 Ad-Hoc 模式上,他們實作了頻譜感測機制,並且發
展了一個非集中式的 MAC 層演算法。
Coral (COgnitive RAdio Learning Platform) 為加拿大通訊研究中心 (Communication Research
Centre, Canada)所提出的原型[8][9]。此原型藉由改變 wifi 網卡的驅動程式,使得終端裝置能夠在 wifi
的頻帶上進行感知無線電的運作。在感知 PU 方面,該帄台利用合作式頻譜估測的技術蒐集各個節點
的感測資訊,估測出 PU 的資訊,並且實作了 beam forming 的功能增加頻譜的使用效能。
2. CRCN 實體層之感測與實作
為了保護 PUs 的優先使用權,FCC 規定當 PUs 的訊號功率大於或等於-116dBm 這個臨界值的情
況下,CR APs 要避免使用這個通道與左右相臨的子頻道。換言之,SUs 至少要能分辨出功率值等於
偵測臨界值的 PUs 信號。但是偵測此臨界值對電路來說是一項嚴格的考驗;以數位電視為例,通道
6MHz 的雜訊值經過計算約為-106.2dBm,然而所需偵測的臨界值為-116dBm,訊雜比為-9.8dB;若是
再考量電路的雜訊(一般約 10dB),基頻的訊號處理必須要能在-20dBm 的訊雜比下分辨出是否有 PUs
的信號存在,這對於單一電路來說有實作上的困難。因此,我們必須藉由合作式的頻譜估測演算法來
偵測 PUs 的訊號。
一般的分散式頻譜估測技術演算法,並無考慮 SUs 身處的地理位置;忽略此項位置資訊的演算
法相當於用一帄均的估測值來代表整體頻譜在不同區域的強度表現,無法呈現不同區域之強度差異。
然而 FCC 在 2008 年 11 月針對 CR 發布的五大方針裡[10],亦認為 SUs 應回報自己的地理資訊來幫助
CR APs 作頻譜估測。故我們希望能發展一合作式頻譜估測演算法,結合所有 SUs 回傳的訊息的演算
法,以重建不同區域之頻譜功率強度。[11][12]是目前已考慮結合地理資訊與估測結果的方法,然而
當中估測 PUs 位置的方式是採用傳統的 Angle-of-arrival (AOA) 或 Time-of-arrival (DOA),必須依賴
SUs 與 PUs 之間訊息的交換。此訊息的交換在 CR 系統的設計當中是不容許的;根據標準定義,SUs
理應在完全不打擾 PUs 的情況下,精準的估測 PUs 是否正在使用。故發展一個能單純依據 SUs 訊號
感測功率及地理位置做估測的演算法,為我們的重點研究項目之一。
3. CRCN 媒體層協定提案及實作
為了保障 PUs 對頻道的使用權,FCC 規定當 PUs 要使用資料頻道時,而此頻道被 SUs 借用時,
SUs 須在兩秒鐘內將資料頻道歸還於 PUs;此外,FCC 亦規範 SUs 需偵測資料頻道 2ms,以確認是否
已有 PUs 或其它 SUs 使用此資料頻道。為達 FCC 所定義之要求,頻道資源排程與存取控制演算法為
實現 CR 技術不可或缺的要項。
[13-17]均是針對 CR 網路所設計的頻譜資源排程與控制演算法。相關文獻可依有無使用 SUs 專用
的控制頻道而分為兩大類。有使用控制頻道之頻道資源排程演算法均讓 SUs 在控制頻道上溝通所要
借用的資料頻道,藉由同步偵測資料頻道的使用狀況,找到一條對傳送端與接收端均為閒置的資料頻
道。另一類不使用控制頻道的演算法則是讓傳送端與接收端各自有一固定跳頻的頻道序列,透過設計
頻道序列讓傳送端與接收端可以在一特定的資料頻道上碰面,進行資料傳送。而為避免 PUs 在需要
使用資料頻道時等待時間超過 FCC 規範,大多數演算法皆保守地讓 SUs 在資料頻道上傳送一個資料
訊框後釋出頻道使用權。因此,[13-17]所提的頻道資源排程與存取控制演算法大抵有可用頻道搜尋時
間過長以及頻道利用率過低的共通缺點。再者,[13-17]的演算法僅適用於小範圍之 CR 隨意網路。SUs
的資料傳送為 single hop,沒有 CR AP 可以協助傳送 multihop 的資料,故能真正實作的可能性低。藉
由合作式頻譜估測演算法所獲得的 PUs 資訊、雲端帄台的運算能力、再加上 SUs 提供的自身地理位
置,設計一能適用於雲端帄台、具彈性擴充計算模組功能、能支援大範圍 multihop 的通訊模式的中
央控制式頻道資源排程演算法是我們的重點研究項目之一。
4. 雲端運算帄台之改良
(1) Hadoop
Hadoop [18] 是由開源的 Apache 計劃發展出的雲端運算框架,並由 Yahoo 資助、開發與使用。
Hadoop 計劃是由許多子計劃組成,如 HDFS (Hadoop Distributed File System)、MapReduce、HBase 等。
Hadoop 採用主從式架構一個 Hadoop 文件系統,由一個目錄節點和數個資料節點組成,其分散式
檔案系統稱為 HDFS,如圖三所示。HDFS 的特色是有高度的容錯性以適用於規模量產的硬體運算組
件,並為應用程式提供了高速的資料存取服務,適合需要處理大量資料的應用程式。一個 HDFS 叢集
包含了一個 NameNode,責檔案名的維護管理,也是用戶端訪問文件的入口。檔名的維護包括文件和
目錄的創建、刪除、重命名等。同時管理資料塊和資料節點的映射關係,用戶端需要訪問目錄節點才
能知道一個文件的所有資料塊都保存在哪些資料節點上。
另外還有一定數量的 DataNode 負責管理與之相連節點上的儲存系統,DataNode 一般就是叢集裡
面的一台機器,負責資料的儲存和讀取。在寫入時,由目錄節點分配資料塊儲存,然後用戶端直接寫
到對應的資料節點。在讀取時,當用戶端從目錄節點獲得資料塊的映射關係後,就會直接到對應的資
料節點讀取資料。資料節點也要根據目錄節點的命令創建、刪除資料塊,和冗餘複製。
圖三、HDFS 架構示意圖(節錄自[18])。
Hadoop 程式開發框架為 MapReduce,讓開發者能夠開發帄行處理大量資料的應用程式。一個
MapReduce 的工作在執行的時候分成兩個部分,Mapper 先將輸入的資料切割成不同的小塊進行個別
的處理,處理後經過 Reducer 透過重新排程(shuffle)這個動作,將 Mapper 處理過後的資料集結過來,
整理成最後輸出結果。
Job-Tracker:控制與分配整個 job 的執行,將 job 切割成許多小的 task,並要求 Task-tracker 來執行,
在 MapReduce 中擔任 Master 的角色。
Task-Tracker:在 MapReduce 運算中擔任 Slave 的角色,利用機器上的資源執行 Job-Tracker 分配下來
的 task,而 task 是一個 job 的基本執行單位。
Hadoop 工作執行流程:當一個工作被 Job client 提交至 Job-Tracker 執行 ,一直到執行完畢,共被分
為四個階段:
初始設定階段:當Job-Tracker收到新的job時會發送一個setup task給還有空位(free slot)的
Task-Tracker來做初始化環境的工作,等到setup-task結束後,job會切換到RUNNING狀態,
之後才會開始執行此job真正的工作內容。
Map 階 段 :等 到 setup task 執 行 完畢 之 後, Job-Tracker 開 始 將 切 割好 的 map tasks 分配 給
Task-Tracker執行,Task-Tracker會持續傳送一個”Heartbeat”訊息給Job-Tracker,訊息中包含了
該Task-tracker仍然還存活著的訊息以及該task-tracker目前是否有空位可以用來執行更多的
task,如果回報仍然有空位來執行 task,Job-Tracer會使用hearbeat回傳值來指派新的task給
Task-Tracker來執行。
Reduce階段:當有Map task執行完後,Reduce task也會開始由Job-tracker啟動。
清除階段:當工作完成後,Job-tracker會啟動一個cleanup task把之前用到的環境清除,例如
工作資料夾、環境變數等等,等到cleanup task完成後,此工作的執行結果就會確定,
SUCCESS、FAIL或是KILLED。
(2) Windows Azure
Windows Azure 帄台是一種「Platform as a Service (PaaS)」產品。提供一種帄台來執行 Windows 應
用程式並將資料儲存至雲端。這些應用程式可以是既有應用程式,或者是為了要在 Windows Azure 上
執行而專門設計的全新應用程式。開發人員可以使用熟悉的工具,例如 Visual Studio 2010,為
Windows Azure 帄台開發各種應用程式。Windows Azure 雲端帄台提供包含 Windows Azure、Live
Services、SQL Azure、Microsoft .NET Services、Microsoft SharePoint Services 以及 Dynamics CRM
Services,如圖五所示。
Windows Azure 的作業系統是專為在資料中心所開發的一種特殊 Windows Server 作業系統版
本,並且定時和 Windows Azure Fabric Controller 進行溝通,接收指令以及回傳執行狀態資料等等,作
為 Azure 服務帄台的開發、服務代管及服務管理環境。Windows Azure 提供開發人員載入、管理與執
行網際網路上的雲端運算應用程式,並提出了兩種不同的程式設計模型,提供不同的服務:Worker
Role 提供背景運算服務,Web Role 用以連結使用者以及背景程式。Windows Azure 提供了不同的虛擬
主機等級,對應到不同的 CPU 核心,記憶體以及硬碟空間並提供多核心的虛擬主機,至於其他
Windows Azure 所提供的服務則建立在其架構上,提供使用者雲端上應用程式開發的支援。
四、 研究方法
1. CRCN 實體層之感測與實作
CR 和傳統的無線通訊相比較,有一個重要的變化即是區分出 PUs 以及 SUs 的存取。SUs 為了確
保 PUs 的權利,必須經由偵測等方式,估測出 PUs 的訊號源位置及訊號涵蓋範圍。由於保護 PUs 的
權利是如此重要,FCC 定義了相當嚴謹的標準,希望控制對 PUs 的影響。然而,在無線通訊環境中,
遮蔽效應以及雜訊影響了對於 PUs 訊號的估測。因此,我們提出了合作式頻譜估測的概念,藉由蒐
集分散的各點偵測結果,還原出更準確的估測結果,有效的對抗環境中的遮蔽效應及雜訊以嘗詴達到
FCC 的要求。
特別在電視空白頻譜的環境中,由於對於 CR AP 功率上的限制以及數位電視基地台的功率範圍
過於龐大,我們必須集合跨區域的感測結果才能夠估計出 PUs 的位置以及功率覆蓋範圍,這樣的特
性使我們考慮運用雲端帄台做為演算法之運算執行中心,雲端帄台必須能夠彙整來自於 SUs 的感測
資料,藉由一個統一的資料匯流中心建立一個中央控制式的通訊系統,確保 PUs 的使用通訊並隨著
時間以及地區調整運算量。
我們所提出的合作式頻譜估測演算法是基於貝氏稀疏演算法來還原 PUs 的功率傳播圖。比起傳
統壓縮式偵測(Compressive sensing)演算法,此方法能夠利用更少的取樣點還原出 PUs 的功率傳播圖,
並且同時估測出 PUs 的個數、位置、功率衰減係數以及環境中雜訊的變異量。
然而,此種頻譜估測演算法的複雜度將隨著資料量成三次方的倍率升高,因此在本計畫中,我們
將此合作式頻譜估測演算法實作於雲端帄台,並且嘗詴利用不同的帄行化技術來改善其計算速度。在
Windows Azure 的架構下,我們參考 MapReduce 的帄行化方式,藉由地理位置以及頻譜上感測功率相
互獨立的特性,帄行將資訊分散到不同的 VMs 來進行計算,並利用 Windows Azure 對於多執行緒帄
行化架構的支援,分層級的減少頻譜估測所需要的時間。在通訊系統中,即時(Real Time)一直是一個
重要的議題,尤其是在 CR 環境下,越即時的頻譜估測能夠提供 PUs 的使用權越好的保護,因此我們
希望能在不影響估測誤差的前提下,利用雲端帄台的架構,增進整體的效能,並利用雲端帄台的彈性,
隨著感測數據的多寡,動態的調整使用的 VMs 數量,以有效率的支援 CRCN 的需求。相關的成果,
請參考附錄一。
在 CRCN 系統實作上,我們利用 WARP 開發帄台作為 CR AP。WARP 是一個以場域可編程閘陣
列(FPGA)與處理器(PowerPC)為開發核心之開放式軟體無線電(Software define Radio)發展帄台。在此
帄台上,一方面我們將 ISM band 之頻率鍵移調變(FSK)收發模組 HMTR 擴充至 WARP 帄台上,另一
方面我們也利用 GP IO 連接 CC1111,使得 WARP 帄台能與 SUs 進行簡單的通訊。
為了將 SUs 的資料透過骨幹網路傳送到雲端,在 CR AP 上必須要有符合網路的通訊協定如
TCP/IP,才有辦法與網際網路(Internet)溝通。因此我們在 WARP 開發帄台的 PowerPC 上移植了一個
簡單的 Linux 作業系統。Linux 作業系統是一個開放式帄台的作業系統,許多的網路協定都已經包含
在其中,因此我們不需要在額外客製化一些通訊協定在 WARP 上,就能夠利用標準的網路程式與雲
端帄台溝通,將 SU 感測到的資訊回報透過骨幹網路傳到雲端中心進行頻譜估測,或者將 SU 的資料
藉由網際網路傳送給另一個 SU。此外,在 WARP 帄台上建立 Linux 環境也有助於 CR AP 控制程式的
發展,由於所有的無線通訊模組 (HM-TR 與 CC1111) 都將變成 Linux 系統下的通訊接口,因此我們
可以在 Linux 環境下利用現有的 C 函式庫進行程式開發。
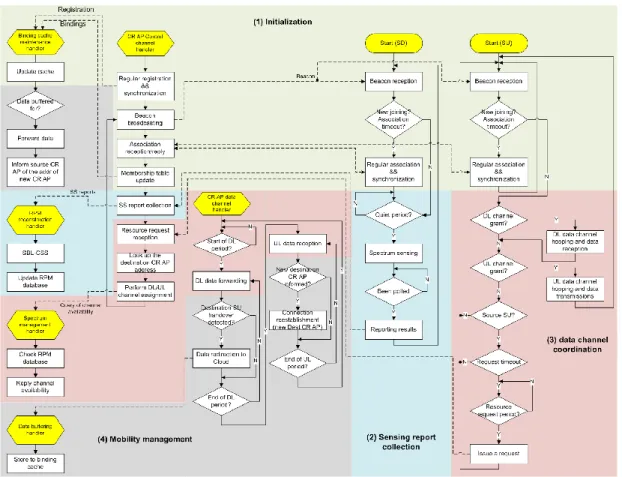
2. CRCN 媒體層協定提案及實作
在CR MAC的設計中,我們考慮到PU的特性,對每條不同的頻帶套入機率模型做成功傳送機率
的評估,AP
CR會根據每個非執照使用者所提出之頻寬要求,針對每個非執照使用者對於每條頻帶會
計算三種數值,分別為成功在該頻道上通訊的機率(P)、感測頻道時間 (W)和transmission quota (Q)。
因此,感知無線電的存取點(AP)會告知非執照使用者其一個N×3矩陣,記錄在不同頻道上計算出的上
述三數值。若非執照使用者C (傳送端) 和非執照使用者B (接收端) 欲進行通訊,非執照使用者C會在
控制頻道上採用CSMA/CA機制通知感知無線電的存取點 (AP) 跳至成功傳送機率最大之資料頻道
i,接著傳送與資料頻道i相對應的Q
i欄位之最多可傳的封包個數。若傳送Q
i個封包後之後非執照使用
者C仍有資料要傳,又或者在感測頻道時間結束前偵測出資料頻道i已被使用,非執照使用者C與感知
無線電的存取點(AP)會跳至第二高的機率值之資料頻道,繼續上述之過程,若所有N個資料頻道皆被
使用,非執照使用者C會回到控制頻道重新進行CSMA/CA機制,直到傳送完所有資料,在不影響PU
的情況下,重覆利用頻道資源。相關的成果,請參考附錄二。
透過SUs週期性地回報他們的地理位置以及在每一條資料頻道上所量測到的RSSI值,雲端運算帄
台在執行合作式頻譜估測演算法後,可以重建出PUs的地理位置以及功率分布圖。當SUs需要使用頻
道傳送資料時,透過控制頻道告知CR APs它們的需求。CR APs 進一步將收集到的要求傳送到雲端帄
台,由雲端帄台執行頻道資源排程演算法,在不影響PUs情況下,以達到系統最大效能為前提,分配
可用頻道資源。
為了能於雲端帄台實作合作式頻譜估測與頻道資源排程演算法且實測頻道排程演算法的效能,我
們實作一套以FD-TDMA為主的頻道存取控制機制。我們以CR AP為媒體層協定管理主軸,將整體運
行分為四個部分:(詳細的流程請參考附錄三)
(1)
Initialization:CR APs、SUs、SDs 的註冊與時間同步控制。
(2)
Sensing report collection:SDs 在 quiet period (QP) 感測頻帶並透過 CR AP polling 來回報。
(3)
Data channel coordination,由 CR AP 以演算法排程結果來協調 SUs 使用頻帶的情況。
(4)
Mobility management,透過雲端與 CR APs 來管理 SUs 的 mobility。
並依提出的媒體層協定對於 SU 提供了四個主要的功能:
(2)
不同 CR AP 網域間的資料傳輸,
(3)
SUs 從一個 CR AP 移動到另一個 CR AP 的換手機制,
(4)
當 SU 在移動中或因其他因素失去與 CR AP 的通訊時,將來自其他使用者的資料暫存在雲端保
持資料不遺失的機制。
透過上述的四個功能,SU 可以自由移動到任意 AP 的範圍內來傳送使用者資料給任意網域的
SU,並且能在 PU 出現時,透過資料暫存來避免資料的遺失。而根據提出的媒體層協定實作,我們探
討機制中對於 PU 出現時,雲端的頻譜估測演算法在所實作出媒體層協定中的反應時間,其中透過量
測 PU 實際出現時間與 AP 透過雲端得知頻譜估測與排程演算法結果的時間為差距來計算出退出使用
的頻帶所需花費時間。並且量測透過資料暫存機制,對於使用者傳送資料的延遲所需的時間。透過上
述兩個數據,我們可以分析所提出的媒體層協定提案對於 PU 使用頻帶的干擾,與對於頻譜的使用效
率。
3. 雲端運算帄台之改良
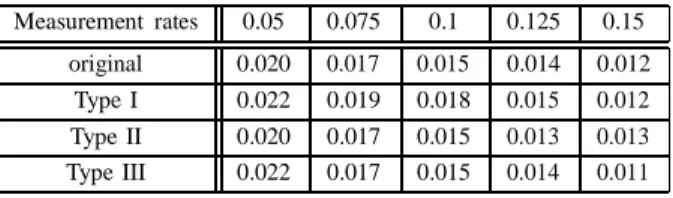
期中報告時我們發現了 Hadoop 帄台執行頻譜估測演算法所需要的執行時間大於 Windows Azure
帄台所需要的執行時間的問題(如圖六)
,並推測這是因為 Hadoop 帄台原本的設計導致花了許多時
間在工作的分配管理,在期中報告之後,為了解決 Hadoop 執行時間的問題,我們針對 Hadoop 帄台
的架構做了更深入的研究與了解,終於發現問題的原因,並加以修改,最後成功的降低了 Hadoop 帄
台所需要的執行時間,提高了使用 Hadoop 帄台做為 CRCN 後端計算的可行性。以下會介紹造成執行
時間過長的主要原因,以及我們做修改的地方:
圖六、在不同雲端帄台所量測的執行時間
Commit 的睡眠時間。以下將一一說明。
(1) Heartbeat 傳送的時間間隔
讓我們以一個只包含一個 map task 與一個 reduce task 的 job 的執行流程來說明 heartbeat 對整個 job
執行時間的影響(如下圖七):
圖七、Hadoop 工作執行流程圖
(a) 當 Job-Tracker 收到 job 的執行要求後,會產生一個 setup task 並由 heartbeat return value 來要求一
個 Task-Tracker 來執行。
(b) 當 Task-Tracker 執行,並且完畢 setup task 之後,會利用執行完後下一個 heartbeat 訊息來回報給
Job-Tracker。
(c) Job-Tracker 在收到 setup task 完成的訊息之後,會馬上透過 heartbeat return value 要求 Task-Tracker
來執行 map task。
(d) 同樣的,當 Task-Tracker 完成 map task 之後,會用完成後的下一個 heartbeat 來回報給 Job-Tracker。
(e) Job-Tracker 在收到 map task 完成的訊息之後,會馬上透過 heartbeat return value 要求 Task-Tracker
來執行 reduce task。
(f) 當 Task-Tracker 完成 reduce task 之後,會用完成後的下一個 heartbeat 來回報給 Job-Tracker。
(g) 等收到 reduce task 完成的訊息後,Job-Tracker 最後會再透過 heartbeat return value 發出一個 clean up
task 的要求給 Task-Tracker。
(i) 最後,Job-Tracker 收到 clean up task 完成後回報狀態來確定整個 job 已經執行完畢。
可以從以上的工作執行流程發現到,Job-Tracker 只有在收到 Task-Tracker 的 heartbeat 訊息並確定
Task-Tracker 有可以執行 task 的空間之後,才能用 heartbeat return value 來要求 Task-Tracker 來執行
task,同樣的,Task-Tracker 只能透過定時發送的 heartbeat 訊息來向 Job-tracker 報告 task 的執行進度
或是 task 的執行結果,如此會發生一個問題,當一個 task 的執行時間 (假設為 1 秒鐘)小於預設的
heartbeat 傳送的時間間隔 (3 秒鐘),當 task 迅速的執行完畢後,Job-tracker 必須要等到下一個 heartbeat
才能夠知道,在 task 執行完畢與回報 task 執行結果的中間,Task-Tracker 是處在一種閒置的狀態,如
圖所示,紅色方塊代表 task 的執行時間,綠色的方塊代表 Task-Tracker 閒置的時間,同時,整個 job
的執行流程也被停了下來,如圖中的工作流程,總共浪費了 8 秒鐘在等待上,故當有人想要執行須要
及時性的工作,如本計畫中的 SS 演算法,這八秒鐘是非常大的延遲。
為了更清楚的看到 heartbeat 時間間隔對整個 job 執行時間的影響,我們利用在 Hadoop 帄台上執
行 PiEstimator (一個 Hadoop 內部的範例)的執行結果來呈現。PiEstimator 是利用蒙地卡羅演算法 [22]
來估計 Pi 值,當 PiEstimator 執行時,它會發起多個 map task 來執行蒙地卡羅演算法,並用一個 reduce
task 來收集得到的結果。PiEstimator 有兩個參數,第一個參數是使用者想要執行幾個 map task,第二
個參數是每個 map task 的計算次數,當我們將計算次數設定的很小的時候,每個 map task 的執行時
間也會變得很小,這讓我們可以直接的看到 heartbeat 時間間隔的影響。下表呈現了預設 heartbeat 時
間間隔(3 秒)與修改過的 heartbeat 時間間隔(0.05 秒)分別執行 PiEstimator 所需要的時間(表一),我們
可以看到修改過的 heartbeat 時間間隔可以降低約帄均 11 秒的執行時間,另外執行工作的機器規格請
見表二。
表一、PiEstimator 在不同 heartbeat 時間間隔的執行時間
預設 heartbeat 時間間隔 3 sec
修改過的 heartbeat 時間間隔 0.05 sec
Pi 1 100
22.362 sec
10.365 sec
Pi 4 100
22.430 sec
10.393 sec
Pi 8 100
22.433 sec
10.721 sec
Pi 16 100
22.738 sec
11.396 sec
Pi 32 100
26.841 sec
11.398 sec
表二、機器規格
Worker number
CPU
Memory
Disk space
Mapper Reducer max number
(2) Reducer 的睡眠時間
我們也發現當 Reduce task 被執行起來的時候,Reduce task 會開始向各個 Task-Tracker 要求 map
已經 task 先處理過的中間資料,但在工作執行的過程中,可能會有某些時刻是沒有中間資料可以給
reduce task 的,此時,reduce task 就會進入睡眠 5 秒鐘,之後再起來檢查是否有新的資料可以取得,
這樣的設計是因為 Hadoop 當初是設計給非常大型的 job 來使用,每個 map task 的執行時間可能達到
數分鐘甚至數十分鐘,因此這個設計是非常合理的,可以將執行 reduce task 的資源釋放,讓 map task
能夠更快的完成。但是當一個 job 能夠被很完善的帄行分配,讓 map task 的執行時間能夠降低到非常
小,相較起來預設的 5 秒鐘睡眠時間則是一個相對大的浪費,特別是針對須要及時反應的應用。同樣
的,我們用 PiEstimator 的執行時間來觀察 Reduce task 的睡眠時間對執行時間造成的影響,如表三所
示,
表三、不同 Reduce task 睡眠時間對 PiEstimator 執行時間的影響
預設 Reduce 睡眠時間 5 秒鐘
修改過的 Reduce 睡眠時間 0.05 秒鐘
Pi 1 100
22.362 sec
16.716 sec
Pi 4 100
22.430 sec
19.731 sec
Pi 8 100
22.433 sec
20.084 sec
Pi 16 100
22.738 sec
19.409 sec
Pi 32 100
26.841 secs
21.428 sec
(3) Job Commit 的睡眠時間
最後我們也發現,在 hadoop job 執行到最後會呼叫一個 done function,呼叫該 function 之後,
Task-Tracker 就會與 Job-Tracker 確認工作是否能夠結束,這時候也會進入一個 1 秒鐘的短暫睡眠,等
待 Task-Tracker 透過 heartbeat 訊息來跟 Job-Tracker 確認工作的結束,由於我們已經縮小了 heartbeat
的時間間隔,在這裡我們也不需要再多等待這 1 秒鐘,從表四我們可以看到降低 Job commit 等待時
間後的效果,減少了大約一秒鐘的時間。
表四、Job commit 的睡眠時間對 PiEstimator 執行時間的影響
預設 Reduce 睡眠時間 5 秒鐘
修改過的 Reduce 睡眠時間 0.05 秒鐘
Pi 1 100
10.365 sec
9.355 sec
Pi 4 100
10.393 sec
9.362 sec
Pi 8 100
10.721 sec
9.412 sec
Pi 16 100
11.396 sec
10.395 sec
Pi 32 100
11.398 sec
10.401 sec
(4) 同時修改三種設定的影響
最後,我們將以 PiEstimator 測詴同時修改三種參數的結果,如下表五,可以看到我們大幅降低
了 hadoop 在計算較少的工作上的執行時間,這個結果對本計畫有正面的幫助,能夠讓計算頻譜資源
的速度更快,達到更即時的頻譜資料庫更新反應。
表五、同時修改 Hadoop 三個參數後的執行時間
Hadoop 原始設定
修改過的 Hadoop
Pi 1 100
22.362 sec
4.361 sec
Pi 4 100
22.430 sec
4.354 sec
Pi 8 100
22.433 sec
4.346 sec
Pi 16 100
22.738 sec
5.382 sec
Pi 32 100
26.841 secs
6.393 sec
五、 實驗成果
1. 以 Windows Azure 為雲端帄台的通訊系統實測
(1) 通訊系統硬體建置、網路架構、與雲端帄台
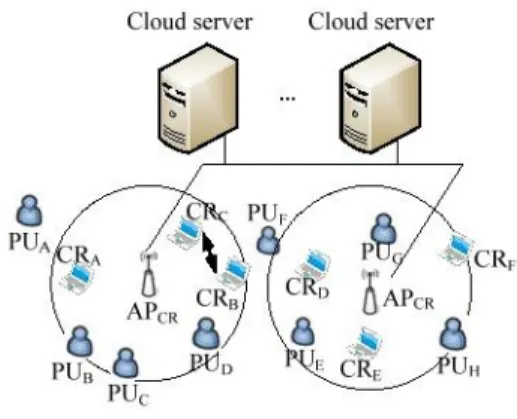
CR Cloud
Sent data to SU1 via CR AP3 Data to SU3 via CR AP2 Data to SU1 via CR AP2 CR AP3 redirects data to CR Cloud as SU1 is no longer associated with it
Internet
CR AP1 CR AP2 CR AP3 SU2 Move to another subnet SU1 SU1 Ethernet CR Cloud redirects data to CR AP2 Hand out Hand inHome agent searches the binding cache and responds CR AP1 where SU3 is CR AP1 asks CR Cloud where SU3 is
Send data from CR AP1 to AP2 2 1 2 3 4 3 Binding Cache 4 Radio Power Map
Wireless spectrum sensing devices Wireless spectrum sensing devices SU3 5 SS Agent Home Agent SM Agent 1 2 1 CSS Engine

![TABLE I E X E C U T I O N T I M E ( S E C ) O F T H E SS A L G O R I T H M U N D E R D I FF E R E N T M E A S U R E M E N T R AT E S [4] Measurement Rates 0.05 0.075 0.1 0.125 0.15 Execution time 6.5 8.9 12.5 14.6 24.5 TABLE II T H E C](https://thumb-ap.123doks.com/thumbv2/9libinfo/8755093.206710/58.918.81.819.80.317/table-ff-measurement-rates-execution-time-table-ii.webp)
