行政院國家科學委員會補助專題研究計畫成果報告
以預測法改善可逆式資訊隱藏技術之研究
計畫編號:NSC 99-2221-E-153-003
執行期限:99年08月01日至100年07月31日
主 持 人:楊政興 教授([email protected]) 國立屏東教育大學資訊科學研究所 計畫參與人員:孔芃勝、邱志仁、鄭達懿、劉俊緯 國立屏東教育大學資訊科學研究所摘要
資訊隱藏是達到多媒體安全的重要技 術之一。近來越來越多研究人員致力於可 逆式資訊隱藏的研究,可逆式資訊隱藏可 以在取出嵌入的機密訊息後完整地回復原 始多媒體。在本計畫中,我們提出一個邊 緣吻合的方法來改進灰階影像上的直方圖 可逆式資訊隱藏技術。直方圖是利用所有 的像素和他們的預測值之間的差值來建 立。實驗結果顯示我們的方法能夠提供良 好的嵌入容量並且不會造成明顯失真。在 第一層資料隱藏下,我們的方法保持影像 的 PSNR 值大於 48 dB,而且有最佳的藏 量。此外,在多層式資料隱藏下,我們提 出旋轉策略來更進一步地增進影像品質。 實驗結果顯示在多層式資料隱藏下,我們 的方法較佳於其他已存在的方法。 關鍵詞:資訊隱藏,可逆式資訊隱藏,邊 緣吻合,預測值,直方圖Information hiding is one of important methods to achieve multi-media security. Recently, many researchers have paid attention to the reversible data hiding scheme, which can completely recover the original multi-media after the embedded data are extracted. In this project, a side-match approach is proposed to improve histogram-based reversible
created by exploiting all difference values between pixels and their predictive values. Experimental results show that our method is capable of providing
a great embedding capacity without making
noticeable distortion. In the one-level hiding, our method remains image qualities larger than 48 dB and has the best capacity. Besides, in the multilevel hiding, a rotation strategy is proposed to improve image qualities further. Experimental results show that our method performs better than other existed methods in the multilevel hiding cases.
Keywords: Information hiding, reversible
data hiding, side match, prediction,
在 2006 年,Ni 等人提出了可逆式資 訊隱藏技術,他們的方法利用原始影像建 立直方圖以嵌入機密訊息。在直方圖裡, 他們找出多個峰點及零點配對,其中峰點 是原始影像中出現較多次的像素值,零點 則是原始影像中沒有出現的像素值。若只 用一對峰點與零點來嵌入機密訊息,他們 的演算法如下: 1. 建立原始影像的直方圖 H(x),其中 x [0, 255]。 2. 直方圖中找到峰點 p 和零點 z,其中 p, z[0, 255]。 3. 將峰點與零點之間的數值位移: (a)若 p>z,則區間[z + 1, p – 1] 的數值皆向左位移一個位置。 (b)若 p<z,則區間[p + 1, z – 1] 的數值皆向右位移一個位置。 4. 由左而右,由上而下掃描全影像,當 遇見像素值 p 則藏入一個位元: (a)若藏 0,像素值保持為 p。 (b) 若藏 1,當 p<z 或 p>z,像素值 改變為p+1 或 p-1。 5. 輸出偽裝影像、峰點p 和零點 z。 (二) Lin 等人的方法 在 2008 年,Lin 等人提出了誤差影 像的方法來改善直方圖式可逆資訊隱藏技 術 [4]。他們使用原始影像的左右行誤差 來產生誤差影像並建立直方圖。對於一張 大小為 P × Q 的影像 H,其誤差影像大小 為 P × (Q –1)。為避免過度的失真,他們 將原始影像分割為 4 × 4 不重疊的區塊, 因此每一個區塊均會產生 4 × 3 的誤差影 像。假設 Hi, j是影像 H 在位置(i,j)的像 素值,Di,j是誤差影像 D 在位置(i,j)的 差值。其演算法如下: 1. 利用以下算式產生誤差影像。 1 , , ,j ij ij i H H D 2. 利用誤差影像建立直方圖並找出峰點 p。 3. 若 Di, j>p,則將 Di, j的值加 1。 4. 當誤差影像差值 Di, j等於p 時,則藏 入一個位元: (a) 藏 0 時,其 Di, j的值不變。 (b) 藏 1 時,其 Di, j的值加 1。 5. 利用原始影像與改變後的誤差影像來 建構出偽裝影像 S。假設 Si, j是偽裝 影像的像素值,則可從下列算式獲得 otherwise D H H H if H S i i i i i i ; ; 0 , 0 , 1 , 0 , 0 , 0 , , otherwise H H H if D H S i i i i i i ; ; 1 , 1 , 0 , 0 , 0 , 1 , , otherwise D S H H if D S S j i j i j i j i j i j i j i ; ; 1 , 1 , , 1 , 1 , 1 , , 6. 輸出偽裝影像與峰點p。
叁
、我們提出的資訊隱藏方法
(一)嵌入方法 在本節中我們提出一個新的基於直方 圖法的可逆式資訊隱藏技術,我們利用邊 緣吻合預測策略來增加直方圖式可逆式資 訊隱藏技術的嵌入容量,並且維持好的影 像品質。圖 1 為邊緣吻合預測的主要概 念。我們的預測方法是運用像素 Hi, j的鄰近像素 Hi, j-1, Hi-1, j-1, Hi-1, j以及 Hi-1, j+1來
預測 Hi, j。
Hi-1, j-1 Hi-1, j Hi-1, j+1
Hi, j-1 Hi, j
圖 1 邊緣吻合預測的主要概念 假設一個為 512 × 512 的原始灰階
圖 4 位移後之預測差值與直方圖 接著,我們嵌入機密訊息。預測差 值相等於 P1 或 P2時被用來嵌入機密訊 息 。 假 設 機 密 訊 息 I =101001101000110(2)。經過嵌入 I 之後, 預測差值與直方圖如圖 5 所示。最後預測 差值轉換為像素值,比如 H′0, 0 = D′0,0 + 128 = –3 + 128 = 125, H′0, 1= D′0, 1+ H0, 0= –2 + 126 = 124, 125 2 125 126 0 2 1 , 0 0 , 0 ' 0 , 1 ' 0 , 1 D H H H 127 4 124 125 126 125 2 4 2 , 0 1 , 0 0 , 0 0 , 1 1 , 1 ' 1 , 1 ' D H H H H H 等等。嵌入結果如圖 6。 –3 –2 –1 2 1 0 2 0 2 –2 3 2 1 3 –1 –2 –1 0 2 0 3 1 –2 –3 0 0 2 4 6 -3 -2 -1 0 1 2 3 圖 5 嵌入後之預測差值與直方圖 125 124 124 126 126 125 127 125 126 123 128 127 126 127 124 124 124 125 127 125 127 126 123 122 124 圖 6 偽裝影像 (二) 取出與回復 在取出與回復的過程,機密訊息被 取出並且回復原始影像的像素值。其演算 法如下: 輸入:偽裝影像H′、兩組峰點與零點 輸出:原始影像、機密訊息 1. 重複步驟 2 至 4 由左而右、由上 而下處理每個偽裝影像的像素。 2. 由偽裝影像H′建立預測差值 D′i,j。 3. 利用(P1, Z1)和(P2, Z2)取出機密訊息及 回復預測差值: (a) 若 D′i, j與 P1或 P2相等,訊息 0 被取出並且回復預測值 Di, j = D′i,j。 (b) 若 D′i, j與 P1+1 或 P2-1 相等,訊 息 1 被取出並且回復預測值 Di, j = D′i,j–1 或 Di, j= D′i, j+1。 (c) 若 D′i, j[P1 + 2, Z1],回復預測 差值 Di, j= D′i, j–1。 (d) 若 If D′i, j[Z2, P2–2],回復預 測差值 Di, j= D′i, j+ 1。 4. 轉換預測差值 Di, j為原始像素 Hi, j。 5. 輸出原始影像及機密訊息。 (三)邊緣吻合之方向策略 邊 緣 吻 合 策 略 可 以 從 不 同 方 向 執 行。如圖 7 所示,用邊緣吻合策略預測 Hi, j可以從不同方向,並有各式各樣的選 擇,比如從左上角{Hi, j–1, Hi–1, j–1, Hi–1, j, Hi–1, j+1}, {Hi, j–1, Hi–1, j–1, Hi–1, j}, {Hi, j–1, Hi-1, j}及{Hi, j–1}是預測像素 Hi ,j的一些可能的
選擇。同樣地,從右上角{Hi, j+1, Hi-1, j+1,
Hi-1, j, Hi-1, j-1}, {Hi, j+1, Hi-1, j+1, Hi-1, j}, {Hi, j+1, Hi-1, j}及{Hi, j+1}也是預測像素 Hi ,j的一
些可能的選擇。在我們的實驗裡,我們從 右上角使用{Hi, j+1, Hi-1, j}來預測 Hi, j。
Hi-1, j-1 Hi-1, j Hi-1, j+1
Hi, j-1 Hi, j Hi, j+1
Hi+1, j-1 Hi+1, j Hi+1, j+1
(c) 圖 9 旋轉策略的例子:(a)第一層由左至右 的預測方向來嵌入。(b)第二層由左至右的 預測方向來嵌入。(c)第二層改成由右至左 的預測方向來嵌入。 (五)上溢位與下溢位的解決方案 用我們的方法嵌入機密訊息之後,每 個像素改變量為±1。因此若嵌入前的像 素值等於 0 與 255 將會變成-1 與 256,產 生上溢位與下溢位問題。為了解決此問 題,我們利用前置處理方法[8]。當原始 影像的像素值等於 0 或 255 時,它們事先 改變為 1 或 254。然後對每個像素值 1, 用一個標誌位元的 0 與 1 去區別此像素的 原先值是 0 或 1。同樣地,用一個標誌位 元紀錄像素值 254。因此,每個像素值 1 或 254,若是由 0 或 255 改變而成的,標 誌位元設為 1;若不是則標誌位元設為 0。
肆
、實驗結果
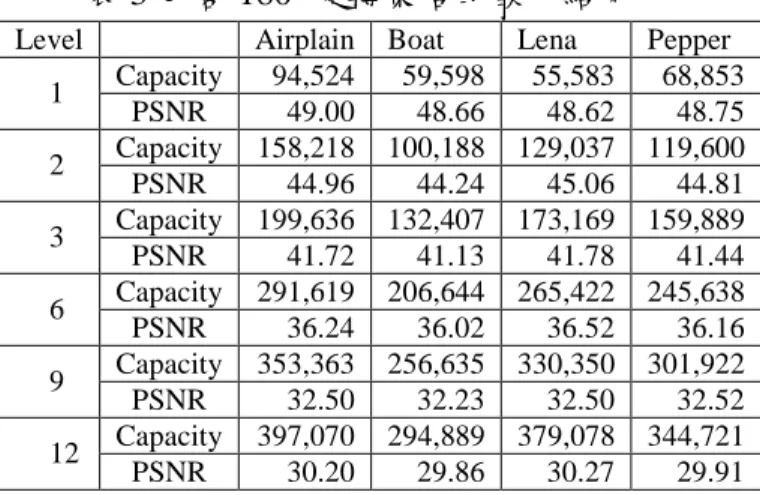
在此節中,我們展示我們方法的效 果。在我們的實驗裡使用了隨機數字當作 機密訊息,512 × 512 灰階影像作為掩護 影像。表 1 顯示與 Ni 等人[1]、Lin 等人 [4]、Li 等人[7]的方法與我們的方法之比 較,其中我們的方法只嵌入一個層次。我 們的方法的平均藏量為 Ni 等人方法的七 倍之多,而且影像品質相似。與 Lin 等人 及 Li 等人的方法比較,我們的藏量分別 高出 15%及 13%。表 2 與表 3 顯示運用 旋轉 180o 與多層次嵌入的結果。結果顯 示旋轉策略可以增進藏量,使更多的機密 訊息嵌入影像中。表 4 顯示前置處理溢位 的方法,大多數的影像所需的標誌位元數 量並不多。表 5 比較我們的方法與 Lin 等 人[4]、Hsiao 等人[8]、Lin 等人[3]的方 法,在 PSNR 值接近 30 dB 時的嵌入量, 其中 Hsiao 等人的方法是基於差異擴張技 術,我們的方法包含旋轉策略,且藏量扣 除了前置處理所需的標誌位元數量,並且 將藏了幾個層次顯示在括號裡。表 5 顯示 我們的方法平均藏量相較於 Lin 等人[4]、 Hsiao 等人[8]、Lin 等人[3]的方法分別高 出 11%、27%及 16%。 表 1 我們的方法與 Ni 等人、Lin 等人、Li 等人的方法之比較 Images Ni et al.’s method [1] Lin et al.’s method [4] Li et al.’s method [7] Our scheme Airplane 17,415 69,941 79,363 94,524 Boat 11,109 56,713 49,681 59,598 Lena 5,760 65,349 60,785 73,686 Peppers 5,737 64,632 62,206 68,836 Average 10,005 64,159 63,009 74,161 PSNR 48.30 48.67 48.41 48.70 表 2 不包含 180o旋轉策略的嵌入結果表 3 包含 180o旋轉策略的嵌入結果
Level Airplain Boat Lena Pepper Capacity 94,524 59,598 55,583 68,853 1 PSNR 49.00 48.66 48.62 48.75 Capacity 158,218 100,188 129,037 119,600 2 PSNR 44.96 44.24 45.06 44.81 Capacity 199,636 132,407 173,169 159,889 3 PSNR 41.72 41.13 41.78 41.44 Capacity 291,619 206,644 265,422 245,638 6 PSNR 36.24 36.02 36.52 36.16 Capacity 353,363 256,635 330,350 301,922 9 PSNR 32.50 32.23 32.50 32.52 Capacity 397,070 294,889 379,078 344,721 12 PSNR 30.20 29.86 30.27 29.91 表 4 前置處理在每個層次所需的標誌位元 數量
Level Airplane Boat Lena Peppers
1 0 0 0 17 2 0 0 0 46 3 0 0 0 139 4 0 0 0 229 5 0 0 0 341 6 0 0 0 567 7 0 1 0 867 8 0 1 0 1185 9 0 1 0 1572 10 0 2 0 1753 11 0 2 0 2164 12 0 3 0 2254 13 0 12 0 2453 14 0 15 0 2835 表 5 多層藏入後的比較 Images Lin et al. ‘s method [4] Hsiao et al. ‘s method [8] Lin et al. ‘s method [3] Our scheme Airplane 362,847 286,488 367,392 409,755 (13) Boat 314,196 266,724 307,937 283,031 (11) Lena 346,568 303,700 309,166 393,246 (13) Peppers 342,175 303,736 356,450 344,721 (12) Average 319,173 259,809 300,698 357,688 PSNR 30.19 30.00 30.26 30.00
伍
、結論
在本研究中,我們提出一個邊緣吻合 預測的方法來實作直方圖式無損的資訊隱 藏。我們的方法比 Li 等人的方法更能精 準的預測像素值,以產生較高的峰值,並 且預測差值的數量與原始影像像素的數量 相當。在每一個嵌入層,差值數量都比 Lin 等人[4]的方法還要多。此外,我們提 出影像旋轉策略來提高多層嵌入後的影像 品質,實驗結果顯示我們的方法較其它已 經存在的單層與多層的資訊隱藏方法來得 好。參考文獻
[1] Z. Ni, Y.Q. Shi, N. Ansari, and W. Su, "Reversible data hiding," IEEE Transaction on Circuits and Systems for Video Technology, Vol. 16, No. 3,
2006, pp. 354-362.
[2] P. Tsai, Y.C. Hu, and H.L. Yeh,
"Reversible image hiding scheme using predictive coding and histogram shifting," Signal Processing, Vol. 89, Issue 6, 2009, pp. 1129-1143.
[3] C.C. Lin and N.L. Hsueh, "A lossless data hiding scheme based on three-pixel block differences," Pattern Recognition, Vol. 41, No. 4, 2008, pp.
1415-1425.
[4] C.C. Lin, W.L. Tai, and C.C. Chang, "Multilevel reversible data hiding based on histogram modification of
difference images," Pattern
Recognition, Vol. 41, No. 12, 2008, pp.
3582-3591.
Skodras, and M. Xenos, "Reversible
image watermarking based on
histogram modification", 11th Panhellenic Conference on Informatics with international participation, Vol. B, 2007, pp.
93-104.
[6] S. Yousefi, H. Rabiee, E. Yousefi, and M. Ghanbari, "Reversible date hiding using histogram sorting and integer wavelet transform," In Proceedings of
IEEE DEST, 2007, pp. 487-490.
[7] Y.C. Li, C.M. Yeh, and C.C. Chang, "Data hiding based on the similarity
between neighboring pixels with
reversibility", Digital Signal Processing, 2009.
[8] J.Y. Hsiao, K.F. Chan, and J.M.
Chang, "Block-based reversible data embedding," Signal Processing, Vol. 89, No. 4, 2009, pp. 556-569.
[9] H.W. Tseng and C.P. Hsieh,
"Prediction-based reversible data hiding," Information Sciences, Vol. 179, No. 14, June 2009, pp. 2460-2469.
[10] D.M. Thodi and J.J. Rodriguez,
"Expansion embedding techniques for reversible watermarking," IEEE Transactions on Image Processing,
Vol. 16, No. 3, 2007, pp. 723-730. [11] H.J. Kim, V. Sachnev, Y.Q. Shi, J.
Nam, and H.G. Choo, "A novel difference expansion transform for reversible data embedding," IEEE Transactions on Information Forensics and Security, Vol. 3, No. 3,
2008, pp. 456-465.
"Lossless data hiding in the spatial domain for high quality image,"
IEICE Transactions on Fundamentals,
Vol. E90-A, No. 4, 2007, pp. 771-777. [13] J. Tian, "Reversible data embedding
using a difference expansion," IEEE
Transactions on Circuits and System for Video Technology, Vol. 13, No. 8,
計畫成果自評
本計畫之執行,依照原先計畫所設 定的目標,研究以預測法來改善可逆式資 訊隱藏技術,以及資訊隱藏技術的相關研 究,並且獲得良好的研究成果。上述成果 報告為我們研究成果的一部分。下面為該 計畫所發表的相關論文: (一)期刊論文:1. H.M. Sun, C.Y. Weng, C.F. Lee, and
C.H. Yang, “Anti-forensics with Steganographic Data Embedding in Digital Images,” IEEE Journal on Selected Areas in Communications, accepted on April 2011. (SCI, EI) 2. C.H. Yang, W.J. Wang, C.T. Huang,
and S.J. Wang “Reversible Steganography Based on Side Match and Hit Pattern for VQ-Compressed Images,”Information Sciences, Vol. 181, No. 11, pp. 2218-2230, June 2011. (SCI, EI)
3. C.H. Yang, S.C. Wu, S.C. Huang,
and Y.K. Lin, “Huffman-code
Strategies to Improve
MFCVQ-based Reversible Data Hiding for VQ Indexes,” Journal of Systems and Software, Vol. 84, No. 3, pp. 388-396, April 2011. (SCI, EI) 4. C.H. Yang, C.Y. Weng, H.K. Tso,
and S.J. Wang, “A Data Hiding Scheme Using the Varieties of Pixel-value Differencing in Multimedia Images,” Journal of Systems and
Software, Vol. 84, No. 4, pp. 669-678, April 2011. (SCI, EI)
(二)研討會論文: 1. 楊政興, 劉俊偉, 陳宜詠, “以交錯式 預測改進區塊的直方圖式可逆資訊 隱藏技術,”in 第二十一屆資訊安全 會議, 虎尾科技大學, May 26-27, 2011.
2. Hung-Min Sun, Chi-Yao Weng,
Cheng-Hsing Yang, and Shiuh-Jeng
Wang, “An EMD-oriented Hiding
Scheme for Reversibe Data
Embedding in Images,” in International Conference on Data Engineering and Internet Technology (DEIT 2011), Bali Dynasty Resort, Bali, Indonesia, March 15-17, 2011. 3. Cheng-Hsing Yang, Fu-Hau Hsu,
Min-Hao Wu, and Shiuh-Jeng Wang, “Improving Histogram-based
Reversible Data Hiding by
Tictactoemidlet Predictions,” presented in The Fourth International
Conference on Genetic and
Evolutionary Computing (ICGEC
2010), Shenzhen, China, December 13-15, 2010.
4. Cheng-Hsing Yang, Sheng-Chang
Wu, and Peng-Sheng Kong,
“Encoding Strategies to Improve
MFCVQ-based Reversible Data
國科會補助專題研究計畫項下出席國際學術會議心得報告
日期: 2010 年 12 月 31 日一、 參加會議經過
1. 行程說明
該會議為期三日,於會議初日前一天先抵達澳門後轉搭陸運至深圳,並於會議結束隔 日回程。The Fourth International Conference on Genetic and Evolutionary Computing (ICGEC) 是一個針對新方向的遺傳與進化電腦計算的國際會議,其中討論的議題包括網路通訊協 定、控制系統、智慧型運算及資訊安全。領域非常的多元,大致議題如下:
1. Genetic, Evolutionary and Intelligence Computing Particle Swarm Optimization
Intelligence and Evolutionary Computation Intelligent Information and Technique Planning, Analysis and Reasoning
Genetic, Evolutionary and Intelligence Computation Language Processing, Classification, Mining
Genetic Algorithm
計畫編號
NSC99-2221-E-153-003
計畫名稱
以預測法改善可逆式資訊隱藏技術之研究
出國人員
姓名
中文:楊政興 英文:Cheng-Hsing Yang服務機構
及職稱
國立屏東教育大學資訊科學系/ 教授會議時間
2010 年 12 月 13 日至 2010 年 12 月 15 日會議地點
深圳(Shenzhen), 中國(China) Hall of Harbin Institute of Technology of Shenzhen Graduate School會議名稱
(中文)
(英文)The Fourth International Conference on Genetic and Evolutionary Computing, Steganography and Watermarking
發表論文
題目
(中文)
2
Optimization
Intelligence Control Robotization
2. Genetic, Evolutionary and Intelligence Application Network Application, Protocol and Security
Control System
Ubiquitous and Pervasive Network
Information System and Network Management Systems and Algorithms for Telematics and Network Steganography and Watermarking
Video and Image Processing Signal, Biology and Medical
Network Control and Application Intelligence Service
此會議 ICGEC 2010 於 12 月 13-15 日在中國深圳的哈爾濱工業科技大學研究生院舉 辦,共計有 210 篇論文在本次會議中發表,同時間有 3 個議場同時進行,並且邀請國內外 知名學者進行主題演講。
2. 會議參加過程
此次會議,我們報告的論文題目為 “Encoding Strategies to Improve MFCVQ-based
Reversible Data Hiding Scheme”,主要內容是改善快速相關向量量化(MFCVQ)上的可逆式 資訊隱藏技術,運用該區塊即將進行嵌入訊息過程中,尋找適合的鄰近區塊進行編碼,並 且使用霍夫曼編碼概念和以 0 為中心的分類方式,加強 VQ 索引表的壓縮效率,如此不僅 有效的增加嵌入訊息,更提高了壓縮率。我們的報告被安排在第二天上午的議程。在第一 天的議程中,該會議舉行開幕儀式並邀請一位台灣學者進行專題演講,緊接著每個時段皆 有三個會議同時進行,會議內主題包括有網路通訊、控制系統等方面的論文。
第二天會議中,Steganography and Watermarking 議場內共發表 10 篇論文,其中有關
於資訊隱藏的論文,除了我所報告的論文之外,還有 “A fragile watermarking scheme for
VQ Index Tables”、 “A Data Hiding Method Using Secret Data Division and Pixel Value Differencing”、 “Data Hiding Scheme with High Embedding Capacity and Good Visual Quality
Based on Edge Detection”、 “Side-match Prediction Scheme in Data Hiding”、 “Improving
Histogram-based Reversible Data Hiding By Tictactoemidlet Predictions”、 “Energy-Proportion
Audio Watermarking Scheme in the Wavelet Domain”、 “Text Categorization by MILO Tree
Traversals”等論文。
Encoding Strategies to Improve MFCVQ-based Reversible Data Hiding Scheme
Cheng-Hsing Yang
Department of Computer Science National Pingtung University of
Education Pingtung 900, Taiwan [email protected]
Sheng-Chang Wu
Department of Computer Science National Pingtung University of
Education Pingtung 900, Taiwan [email protected]
Peng-Sheng Kong
Department of Computer Science National Pingtung University of
Education Pingtung 900, Taiwan [email protected]
Abstract—To solve the security problem of multi-media, data
hiding is one of important technologies. Lossless data hiding is a special type of data hiding technologies with the characteristic of completely recovering the cover media after the embedded data are extracted. Recently, many reversible data hiding methods have been proposed for VQ-compressed images. Lu et al. proposed a VQ reversible data hiding method based on the MFCVQ concept. In this paper, we propose a new MFCVQ-based scheme. A new classification and the Huffman-code concept are used in our scheme. The experimental results show that our method not only increases the embedding capacity but also reduces the compression ratio.
Keywords- Lossless data hiding, Reversible data hiding, VQ,
MFCVQ.
I. Introduction
With the fast development of computers and networks, the Internet has become the most popular way of information transmission. Therefore, various forms of digital information are sending over the Internet every day, such as digital images, audio, video, etc. The Internet is an open platform for information transmission, so the security problems, such as theft and tampering, are serious. In order to deceive the attacker, many researchers have focused on developing steganographic approaches which hide secret data into cover media. Traditional data hiding technologies embed secret data into cover media with damage. One disadvantage of these methods is that the cover media are still destructive after the secret data are extracted. In a reversible data hiding method, the cover media can be completely recovered after the embedded data are extracted. Recently, some reversible data hiding methods have been proposed for VQ-compressed images [1-7]. In 2009, a VQ-based reversible data hiding scheme was proposed by Yang and Lin [5]. Their method divides the codebook into clusters to embed secret data. In 2009, Lu et al. proposed a VQ reversible data hiding method based on the modified fast correlation VQ (MFCVQ) concept [6]. In 2010, a SMVQ-based reversible data hiding scheme was proposed by Chen and Chang [7]. Their method uses an adaptive index to hide more bits in one index code. The volume of the embedded result is usually smaller than that of the original compressed image plus the hidden data.
The goals of this kind of methods are larger embedding capacities and better compression rates.
In this paper, we propose a new VQ reversible data hiding scheme based on MFCVQ by improving Luetal.’s method [6]. Our method has better compression rates and larger capacities than that of Lu et al.’s method. The remainder of this paper is as follows. In Section II, VQ, MFCVQ, and Lu et al.'s reversible data hiding method are introduced. Section III describes the details of our proposed scheme. Experiments are shown in Section IV. Finally, our conclusions are given in Section V.
II. Related Works
In this section, we introduce two related works: VQ and Lu et al.’s reversible data hiding method [6].
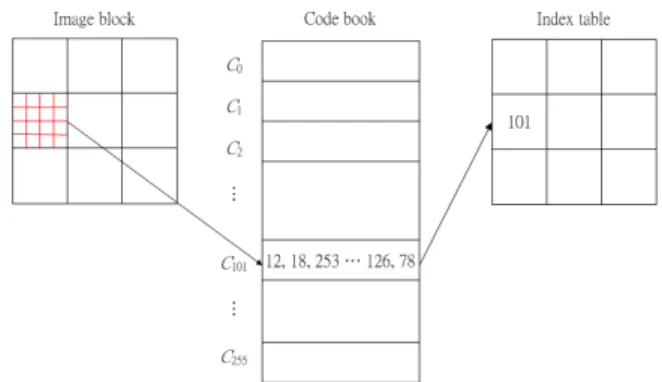
A. Vector quantization
Fig. 1 depicts the VQ encoding operation, where the codebook size and vector dimension are set to 256 and 16, respectively. The inputted image is divided into 4 × 4 non-overlapping blocks. For each block, the VQ encoder finds out the codeword with the minimum Euclidean distance to the block. For example, a codeword with index 101 is selected in Fig. 1. The value 101 is exported as the compressed code for the input block.
6
B. Lu etal.’s VQ reversible data hiding method
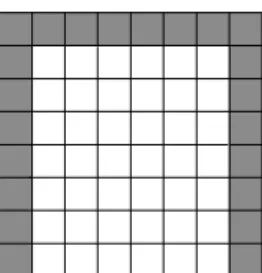
In 2009, Lu et al. used the MFCVQ concept to propose a VQ reversible data hiding method [6]. Their method can completely recover the original VQ-compressed image after embedded data are extracted. As shown in Fig. 2, the gray areas are seed blocks and are encoded by VQ. Each of the other blocks is encoded by its four adjacent blocks as shown in Fig. 3, where icuris the index of the current block and il, ilu,
iu, and iru are the indexes of the four adjacent blocks. The
2-bit position codes of il, ilu, iu, and iru are ‘00’,‘01’,‘10’,
and ‘11’,respectively. Before the data hiding algorithm is executed, codewords are sorted according their component sums. For all indexes not in the seed areas, the data hiding algorithm processes these indexes in order of left-to-right and top-to-down as follows:
Step 1: Calculate the average imof indexes il, ilu, iu, and
iru. Calculate the absolute difference values
between imand each of the indexes il, ilu, iu, and
iru.
Step 2: If at least two of the absolute difference values are different, a secret bit is embedded as follows:
Let dmin1be the smallest absolute difference
value and the corresponding index be imin1.
Let dmin2 be the second smallest absolute
difference value and the corresponding index be imin2.
If the to-be-embedded bit w = 0, the index
icuris encoded by imin1.
If the to-be-embedded bit w = 1, the index
icuris encoded by imin2.
Else
From the four adjacent indexes, let iclo be
the index with the minimum absolute difference value to index icur.
The index icuris encoded by iclo.
Let the index icur be encoded by one of its adjacent
indexes, says imin, and d = icur–imin. The encoding forms are
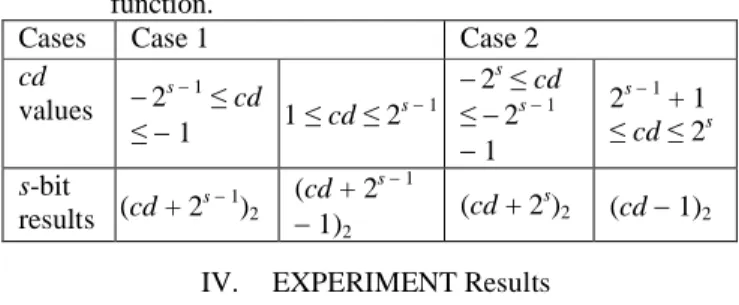
shown in Table I. The s is a pre-determined size to represent value d as a binary form. The integer s ranges from 1 to Ceil(log2N), where Ceil(x) denotes the least integer not less to x. The d values are divided into the following four cases:
Case 1: When 0 ≤d ≤ 2s1, the binary codestream is Position code || 11 || (d)2, where || denotes the concatenation operation, and (d)2 is the binary representation of d with size s.
Case 2: If (2s1) ≤d < 0, the binary codestream is
Position code || 10 || (d)2.
Case 3: If d > 2s1, the binary codestream is Position
code || 01 || (d)'2, where (d)'2 is the binary representation of d with size Ceil(log2N).
Case 4: If d < (2s1), the binary codestream is
Position code || 00 || (d)'2.
Figure 2. The areas of seed blocks shown by gray color.
Figure 3. Index relations of Lu etal.’s method
Table I. The encoding forms of Lu etal.’s method. Case 1 0 ≤d ≤ 2s 1 Case 2 (2s1) ≤ d < 0 Case 3 d > 2s 1 Case 4 d <(2s 1) Position code || 11 || (d)2 Position code || 10 || (d)2 Position code || 01|| (d)'2 Position code || 00 || (d)'2 III. Our Proposed Methods
In this section, we propose a new method to improve the MFCVQ-based reversible data hiding scheme. Some new encoding strategies are used in our method. For any current index to be processed, Fig. 4 shows the current index icurand
its adjacent indexes il, ilu, iu, and iru, where adjacent indexes il,
ilu, iu, and iruare renamed as i0, i1, i2, and i3according their 2-bit positions, respectively. If icuris located in the rightmost
column of the index table, i3is assigned to the position of i3'. We use the ring concept to calculate the difference between two indexes. For index i and index j, the difference d is calculated as follows: d = ij. Given the difference d, the circular difference cd is defined as:
otherwise. , 2 if , 2 2 if , 2 1 1 d d d d d cd L L L L i1 position = (01)2 i2 position = (10)2 i3 position = (11)2 i3' i0 position = (00)2 icur
Figure 5. The 0-isolated classification of all circular difference values.
For example, given two indexes 1 and 2L2, we have d = 1(2L2) = 2L+ 3 and cd = 1(2L2) + 2L= 3. Note that cd values fall into the range [2L1, 2L1–1]. We classify
the range of circular difference cd by a 0-isolated classification. Fig. 5 shows our classified results, where the codebook size is N = 2Land s is a parameter less to L. The range [2L1, 2L11] is classified into four cases: Case 0
contains only value 0; Case 1 contains ranges [2s1,1] and
[1, 2s1]; Case 2 contains ranges [2s,2s11] and [2s1+ 1, 2s]; Case 3 contains ranges [2L1,2s1] and [2s+ 1, 2L1 1]. We use the Huffman-code strategy to encode all cases. For a current index icurand one of its adjacent indexes,
say ip, let cd be the circular difference between icur and ip.
Index icuris encoded by the following strategy: if cd belongs
to Cases 0, 1, or 2, index icuris encoded by ip; if cd belongs
to Case 4, index icuris encoded by itself, i.e., 111 || icur, where
111 is the Huffman code of Case 4 and the symbol “||”is the string concatenation operator. When index icuris encoded by
its adjacent index ip, the function adjacent-code shown in
Table II is called. The form of the function adjacent-code(p,
cd) is case code || position || match(cd), where p is the 2-bit
number representing the position of index ip, case is a
Huffman code representing the case which cd belongs to , and the function match(cd) matches value cd to a s-bit value. Table III shows the match function for Cases 1 and 2.
Our embedding algorithm is as follows.
Step 1: For each index icur which is not in the seed area, mark its adjacent indices as i0, i1, i2, and i3. Step 2: Compute the circular differences between index
icur and its adjacent indexes and name them as cd0, cd1, cd2, and cd3.
Step 3: Let D = {cdi| cdibelongs to Cases 0, 1, or 2},
and suppose w is the current bits to be embedded. Case 3.1 |D| = 4
Let w be 2 bits. Let cd be the circular difference between icurand
iw. Output adjacent-code(w, cd).
Case 3.2 |D| = 3
Let p0, p1, and p2 be the three positions in increasing order such that cdp0, cdp1, cdp2 D.
If w = 0, let cd be the circular difference between icur and ip0 and
output adjacent-code(p0, cd). If w = 10, let cd be the circular difference between icur and ip1 and
output adjacent-code(p1, cd). If w = 11, let cd be the circular difference between icur and ip2 and
output adjacent-code(p2, cd). Case 3.3 |D| = 2
Let p0and p1be the two positions in increasing order such that cdp0, cdp1
D.
If w = 0, let cd be the circular difference between icur and ip0 and
output adjacent-code(p0, cd). If w = 1, let cd be the circular difference between icur and ip1 and
output adjacent-code(p1, cd). Case 3.4 |D| = 1
Let p be the position such that cdp
D.
If w = 0, let cd be the circular difference between icur and ip and
output adjacent-code(p, cd). If w = 1, no secret data is embedded and output 111 || icur.
Case 3.5 |D| = 0
No secret data is embedded and
output 111 || icur.
Step 4: Repeat Steps 1 ~ 3 to encode the remained indexes in the raster-scan order until all the indices except for the indices in the seed area are encoded.
Table II. The codestreams of adjacent-code(p, cd) for different cases.
Cases Case 0 Case 1 Case 2
Ranges cd = 0 2s1≤cd ≤1 or 1 ≤cd ≤2s 1 2s≤cd ≤2s1 1 or 2s1+ 1 ≤cd ≤2s Codes 0 || p 10 || p || match(cd) 110 || p || match(cd)
Table III. The matched results of cd values by the match function.
Cases Case 1 Case 2
cd values 2 s1≤cd ≤1 1 ≤cd ≤2s1 2s≤cd ≤2s1 1 2s1+ 1 ≤cd ≤2s s-bit results (cd + 2s1)2 (cd + 2s1 1)2 (cd + 2s)2 (cd1)2 IV. EXPERIMENT Results
8 (a) (b)
Figure 6. Two test images: (a) Baboon (b) Lena.
Tables IV and V show the comparisons between Lu et al.'s method and our method. In any case, our approach not only has a larger capacity but also has a better compression rate than that of Lu et al.’s method.On average, our approach increases 80% and 40% capacities for codebook sizes 256 and 512, respectively. Moreover, our approach reduces 31% and 28% compression rates for codebook sizes 256 and 512, respectively.
V. Conclusions
In this paper, a new MFCVQ-based reversible data hiding scheme is proposed to increase the embedding capacity and reduce the compression ratio for gray-level images. Compared to Lu et al.’s method, our method can effectively reduce the bit rate and improve the capacity. In our method, a larger s value will have a larger embedding capacity. Our approach can regulate s values to choose high capacities or low compression rates.
Table IV. Comparisons between Lu et al.'s [6] method and our method for codebook size 256.
Methods Images s Capacity Rate Our Method 24446 0.560 Lu etal.’s Baboon 5 15662 0.631 Our Method 27552 0.448 Lu etal.’s Boat 5 14758 0.609 Our Method 28291 0.486 Lu etal.’s Goldhill 5 15104 0.600 Our Method 24781 0.436 Lu etal.’s Lena 4 14954 0.569 Our Method 25447 0.414 Lu etal.’s Peppers 4 14784 0.563 Our Method 26010 0.376 Lu etal.’s Airplane 4 13588 0.589 Our Method 26088 0.453 Lu etal.’s Average 14808 0.594
Table V. Comparisons between Lu et al.'s method [6] and our method for codebook size 512.
Methods Images s Capacity Rate Our Method 17264 0.613 Lu etal.’s Baboon 5 15829 0.684 Our Method 24474 0.500 Lu etal.’s Boat 5 15537 0.664 Our Method 23426 0.533 Lu etal.’s Goldhill 5 15395 0.662 Our Method 20658 0.506 Lu etal.’s Lena 4 15319 0.635 Our Method 20658 0.478 Lu etal.’s Peppers 4 15590 0.626 Our Method 23177 0.429 Lu etal.’s Airplane 4 14631 0.649 Our Method 21610 0.510 Lu etal.’s Average 15384 0.653 ACKNOWLEDGEMENT
This research was supported by the National Science Council of the Republic of China under the Grants NSC 99-2221-E-153-003.
References
[1] C.C. Chang, C.Y. Lin, Reversible steganographic method using SMVQ approach based on declustering, Information Sciences, vol.177, no.8, pp. 1796–1805, 2007.
[2] C.C. Chang, T.C. Lu, Reversible index-domain information hiding scheme based on side-match vector quantization, Journal of Systems and Software, vol. 79, no. 8, pp. 1120–1129, 2006.
[3] C.C. Chang, W.C. Wu, Y.C. Hu, Lossless recovery of a VQ index table with embedded secret data, Journal of Visual Communication and Image Representation, vol. 18, no. 3, pp. 207–216, 2007. [4] J. X. Wang and Z. M. Lu, “A path optional lossless data hiding
scheme based on VQ joint neighboring coding,”Information Sciences, vol. 179, pp. 3332-3348, 2009.
[5] C. H. Yang and Y. C. Lin, “Reversible datahiding ofa VQ index table based on referred counts,”J. Vis. Commun. Image R., vol. 20, pp. 399-407, 2009.
[6] Z. M. Lu, J. X. Wang, and B. B. Liu, “An improved losslessdata hiding scheme based on image VQ-index residual value coding,”The
Journal of Systems and Software, vol. 82, pp. 1016-1024, 2009.
[7] C.C. Chen and C.C. Chang, “High capacity SMVQ-based hiding scheme using adaptive index,” Signal Processing, vol. 90, pp. 2141–2149, 2010.
[8] Y. Linde, A. Buzo, and R.M. Gray, “An algorithm for vector quantizerdesign,”IEEE Transactions on Communications, vol. 28,
The Fourth International Conference on
Genetic and Evolutionary Computing
December 13-15, 2010, Shenzhen, China http://bit.kuas.edu.tw/~icgec10
Dear Prof./Dr./Ms./Mr. Cheng-Hsing Yang,
Thank you for your submission to the Fourth International Conference on Genetic and Evolutionary Computing (ICGEC-2010), to be held on December 13-15, 2010, in Shenzhen, China. We are pleased to inform you that your paper
ID No.: ICGEC-2010-IS21-01
Title: Encoding Strategies to Improve MFCVQ-based Reversible Data Hiding Scheme Author(s): Cheng-Hsing Yang, Sheng-Chang Wu, and Peng-Sheng Kong
has been accepted for presentation in ICGEC-2010. Your paper will be published in the conference proceeding with the Conference Publishing Services of the IEEE Computer Society. Please do take the comments and suggestions of the reviewers into account in the revision to further improve the quality of your paper. Please refer to http://bit.kuas.edu.tw/~icgec10 for further information regarding the conference registration and to the online Author Guide at http://bit.kuas.edu.tw/~icgec10 for detailed procedures in the preparation of your camera-ready copy and copyright release form. Both deadlines are September 10, 2010.
We are looking forward to meeting you in Shenzhen. Further information on ICGEC-2010 can be obtained from the conference web sites: http://bit.kuas.edu.tw/~icgec10
Sincerely Yours,
Jeng-Shyang Pan, Conference Chair
Shenzhen Graduate School, Harbin Institute of Technology, China


![Table IV. Comparisons between Lu et al.'s [6] method and our method for codebook size 256.](https://thumb-ap.123doks.com/thumbv2/9libinfo/9012168.298026/20.892.461.813.239.513/table-iv-comparisons-lu-method-method-codebook-size.webp)
