i
國
立
交
通
大
學
資訊科學與工程研究所
碩
士
論
文
基於 AdaBoost.MH 之模糊化文件分類法
Document Classification based on Fuzzy AdaBoost.MH
研 究 生:方士元
指導教授:李嘉晃 教授
ii
基 於 AdaBoost.MH 之 模 糊 化 文 件 分 類 法
Document Classification based on Fuzzy AdaBoost.MH
研 究 生:方士元 Student:Shih-Yuan Fang
指導教授:李嘉晃 Advisor:Chia-Hoang Lee
國 立 交 通 大 學
資 訊 科 學 與 工 程 研 究 所
碩 士 論 文
A ThesisSubmitted to Institute of Computer Science and Engineering College of Computer Science
National Chiao Tung University in partial Fulfillment of the Requirements
for the Degree of Master
in
Computer Science
June 2011
Hsinchu, Taiwan, Republic of China
iv
基 於 AdaBoost.MH
之 模 糊 化 文 件 分 類 法
學生:方士元
指導教授:李嘉晃 教授
國立交通大學資訊學院 資訊科學與工程研究所碩士班
摘要
本論文中,我們提出了一個 Fuzzy AdaBoost.MH 演算法,而且將此 Fuzzy AdaBoost.MH 方法運用在文件分類上。Boosting 的主要觀念為利用許多 weak hypotheses,透過 Boosting 架構得到這些 weak hypothesis 權重,最後將這些 weak hypotheses 予以合併,形成一個高準確度的強分類法。我們使用 fuzzy rule 作為 weak hypothesis,利用 decision stump rule 為基礎的方法來當作我們判 別的依據,而每一個 fuzzy rule 則是以文件中的 term 為依據。在文件特徵表示 法中,每一個 n-gram term 常作為文件最基本的特徵;然而每一文件所包含的 n-gram 數目常會是一個巨大的數量,因此在系統的設計中,我們使用 term 出現 的頻率來當作 term 篩選的方法,並且將通過篩選的 term 放入我們的 rule pool 中。每一回合,Fuzzy AdaBoost.HM 從 rule pool 中挑選出最好的 fuzzy rule, 所有 fuzzy rule 的集合則是系統分類的依據。
同時,我們提出了一個 Fuzzy Number 的表示法,來表示每一條 fuzzy rule 的信心度。這些 fuzzy rule 的信心度訊息是我們做為推論分類結果的依據。當 訓練的過程結束之後,我們可以經由程度轉化的過程推論我們最後的模糊化分類 結果。本論文中也使用了三種文章集進行實驗,而在實驗的數據中,Fuzzy AdaBoost.MH 皆能有不錯的分類結果。
v
Document Classification
based on Fuzzy AdaBoost.MH
Student:Shih-Yuan Fang Advisor:Prof. Chia-Hoang Lee Institute of Computer Science and Engineering
College of Computer Science National Chiao Tung University
Abstract
In this paper, we propose a fuzzy AdaBoost.MH algorithm and apply fuzzy AdaBoost.MH to document classification domain. The main idea of boosting is to generate many, relatively weak hypotheses and to combine these weak hypotheses into a single highly accurate classifier. In rule design, we employ decision stump rule as the basic discriminative function and each rule is correspondent to a weak hypothesis. In system design, we employ term frequency as filtering criterion to construct a rule pool. On each round, the best fuzzy rule can be selected from the pool using AdaBoost framework.
Meanwhile, we propose a fuzzy number representation to represent each rule’s confidence. These fuzzy rules with confidence information are the bases of classification inference. When the training phase is completed, the final fuzzy classification result can be obtained from the inference result with a degree transformation process. The experimental results show that fuzzy AdaBoost.MH works very well in three data corpora.
vi
誌謝
首先,感謝指導教授李嘉晃老師對我的悉心指導,才能有今日的成果。老師 就像我的良師益友,時而嚴厲,時而慈祥,不論是研究討論或課堂授課時,所教 導我的專業知識和處世道理,都著實讓我獲益良多。這些過程與經驗,都將成為 我一生受用無窮的寶庫。接著要感謝三位辛苦的口詴委員,陳柏琳教授、張嘉惠 教授與張道行教授,謝謝教授們的建議,讓本論文的內容能夠更加完整。 同時,我亦感謝這兩年來陪伴在我身邊的實驗室同學們、學長以及學弟。尤 其是我的同學們,智愷、俊憲、而益,總是不斷的鼓勵我,對我的幫助更是多不 勝數。兩年的時間,雖然不是很長,但是曾經有過的歡笑淚水,這些回憶會一輩 子永存在我的心中。 最後,我要感謝我的爸爸、媽媽、姐姐,感謝你們對我的愛護和包容。謝謝 你們在背後默默的支持,使我能夠順利的完成碩士學位。 心中有太多的感謝不知道如何表達,在此僅以本篇論文表示我對你們最誠摯 的感謝,並祝福你們身體健康、萬事如意,謝謝。 方士元 謹誌 資訊科學與工程研究所 智慧型系統實驗室 中華民國一百年七月vii
目錄
中文摘要... iv 英文摘要... v 誌謝... vi 圖目錄... viii 表目錄... ix 第一章、緒論... 1 1.1 研究動機... 1 1.2 研究目的與方法... 2 1.3 論文架構... 4 第二章、相關研究... 5 2.1 模糊理論... 5 2.2 AdaBoost... 7 2.3 AdaBoost.MH... 102.4 SVM(Support Vector Machine)... 13
2.5 Naïve Bayes... 17
2.6 Fuzzy Rule Methods Comparison... 18
第三章、系統設計... 20 3.1 概念... 20 3.2 系統架構... 21 3.3 系統演算法... 23 3.4 系統概念... 34 3.5 Semi-Boosting... 42 第四章、實驗過程與結果討論... 44 4.1 實驗資料集... 44 4.2 實驗設計... 45 4.3 實驗結果... 50 4.4 實驗討論... 60 第五章、結論與未來展望... 62 5.1 研究總結... 62 5.2 未來展望... 62 參考文獻... 63
viii
圖目錄
圖 2-1.模糊集合 ... 6 圖 2-2.原始資料集的分布圖 ... 14 圖 2-3.經過 SVM 分類後的結果 ... 14 圖 2-4.將原始資料轉換至高維度中進行切割 ... 14 圖 2-5.超平面示意圖 ... 15圖 2-6.Boosting fuzzy rule 時間複雜度計算 ... 19
圖 3-1.Fuzzy Classification 系統流程架構圖 ... 22 圖 3-2.Logistic Function 演算法圖示 ... 27 圖 3-3.梯形面積生成 ... 29 圖 3-4.面積公式推導(1) ... 29 圖 3-5.面積公式推導(2) ... 29 圖 3-6. AdaBoost.HM 之 Hypothesis 分析 ... 34 圖 3-7.計算錯誤次數之實際結果 ... 36 圖 3-8.Logistic Function 之前置處理 ... 37 圖 3-9.Bad、Wast 之計算面積方法 ... 38
圖 3-10.舉例的 Testing Data 文章所計算出 POS、NEG 類別的總值 ... 39
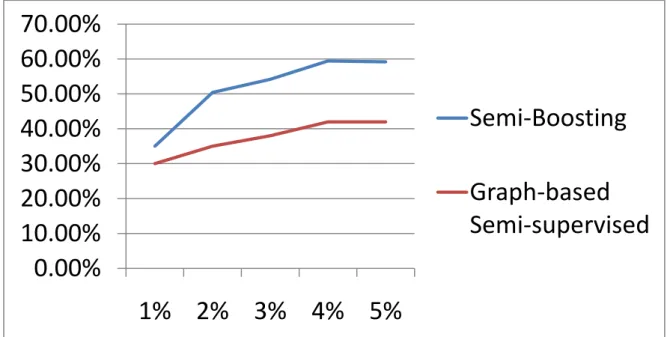
圖 3-11 正規化形成 Degree(Testing Data 1) ... 41 圖 3-12 正規化形成 Degree(Testing Data 2) ... 41 圖 3-13.Semi-Boosting 系統流程圖 ... 43 圖 4-1.F-Value 計算例圖(一) ... 46 圖 4-2.F-Value 計算例圖(二) ... 47 圖 4-3.F-Value 計算例圖(三) ... 48 圖 4-4.本系統 N-Gram Model 解說 ... 49 圖 4-5.Semi-Boosting 之 20-Newsgroups 成長圖表(一) ... 57 圖 4-6.Semi-Boosting 之 20-Newsgroups 成長圖表(二) ... 58 圖 4-7.Semi-Boosting 之 Reuters 成長圖表 ... 59
ix
表目錄
表 3-1.舉例的 Training Data 文章中,Hypotheses 出現的情況與其值 ... 35
表 3-2.舉例的 Testing Data 文章中,Hypotheses 出現的情況與其值 .... 37
表 4-1.Reuters-21578 文章集之各類別文章篇數 ... 45 表 4-2.電影影評文章集之實驗數據 ... 50 表 4-3.電影影評文章集實驗時間比較表[時:分:秒] ... 51 表 4-4.電影影評文章集之 F-Value ... 51 表 4-5.20-Newsgroups 之多種組合實驗數據 ... 52 表 4-6.20-Newsgroups 之多種組合實驗時間比較表[時:分:秒] ... 52 表 4-7.20-Newsgroups 之多種組合之 F-Value ... 53 表 4-8.Reuters 文章集之實驗數據 ... 53 表 4-9.Reuters 文章集實驗時間比較表[時:分:秒] ... 54 表 4-10.Reuters 文章集之 F-Value ... 54 表 4-11.20-Newsgroups 之小資料量多種組合實驗數據 ... 55 表 4-12.20-Newsgroups 之小資料量多種組合之 F-Value ... 55 表 4-13.Semi-Boosting 之 20-Newsgroups 實驗數據(一) ... 56 表 4-14.Semi-Boosting 之 20-Newsgroups 實驗數據(二) ... 57 表 4-15.Semi-Boosting 之 Reuters 文章集實驗數據 ... 58
1
第一章、緒論
1.1 研究動機
近年來,在這資訊蓬勃發展和思想自由發達的時代,伴隨著我們的是諸多的 文字和資訊,如何在如此龐大的文章中,快速且有效的對文章進行分析、分類, 是一個相當大的難題。近年來,越來越多研究使用機器學習方法來進行文件分析 或分類;在實際應用上,除了時間之外,如何提高文章分類的準確度,也都是值 得我們研究的議題。 由於時間上的累積,人們寫作的文章數量越來越龐大,以至於各種不同類別 的文章數量相當龐大,而且每天無時無刻都在增加當中。若是要將新的一篇文章 分析出是屬於哪一個類別,如果是由人工來進行分類,那麼,遇到龐大的資料量 或是類別時,將需要耗費相當多的時間;另外文章內容可能很冗長,或是用詞模 糊不清,此外每個人的看法與觀點也不一定相同,主觀的想法也會造成分類錯誤 的發生,進而演變成人力資源上的浪費。對於現代的社會,有很多種類的文章, 例如電影影評的文章,或是公司的問卷調查,都是需要在少量的時間下就必頇要 將所有的文章分類出來,因為電影公司或是有些電影網站需要知道某一部電影在 社會上一般人的觀後感;或著是對於公司的問卷,我們想要知道關於此次的問卷 內容經由填寫者填出來的結果是偏向正面評價或是負面評價。就以上的兩個簡單 的例子中,文件分類已經成為一樣重要的研究;所以本論文希望發展一套系統, 能夠同時兼顧高準確度以及加快機器分類的時間。 一般來說,使用模糊化的技術在文件分類上,能夠擁有較高的文件分類準確 度,也能夠提升原先分類法的準確度。而在資訊量較小的情況下,一般分類法往 往無法訓練出一個良好的分類模型,分類結果沒有辦法有滿意的結果;加入模糊 化技術之後,有機會可以提高更多的準確度。所以本論文加入模糊化技術,希望 能夠比傳統分類法有較好的分類結果。2
1.2 研究目的與方法
本論文希望能將各種不同類別的文章,有效率的分類到正確的類別中。本論 文考慮到各種不同領域以及類別的文章,在論文的實驗中,將會考慮在不同的文 章集下以及同一文章集但是不同排列組合下的情況,另外本研究會與其他分類法 作比較。 相對於傳統的監督式學習方法,Ensemble Learning[1]結合了多個不同權重 的分類器去解決各種不同的分類問題。Ensemble Learning 主要是用來改善分類 或是預測、效能的一個模型。而目前在所有以 Ensemble 為基礎的演算法中最有 名的為 AdaBoost[2]分類法,它的各種演算法的變化已經運用在各種不同的領域 中,也都具有不錯的成效[3][4][5][6][7]。 本論文方法部分是以 AdaBoost.MH[8]為基礎,結合模糊化的技術,形成一 個更準確且新穎的分類法。會使用 AdaBoost.MH 主要原因為,它可以對多類別以 及多標籤文章進行分類,加上訓練時間也較有些分類法來的快,除此之外,也具 有不錯的準確度,所以在時間以及準確度兩者皆要兼顧的考量上是個不錯的分類 法。而模糊化的技術自從 20 世紀開始,就一直是個讓許多研究者所研究的議題, 在傳統的自然語言處理上,往往會有許多的資訊是屬於不確定的、不準確的,但 是在二元的邏輯思維模式中,要解決這些問題,是有一定的困難和挑戰性,往往 到了最後只能以隨機的或是猜測的方式來對這些資訊進行處理。模糊理論用在分 類的方法上,是一種能夠更有效提高準確度的方法。模糊理論跟傳統的分類方法 中,在本質上有些的不同,模糊理論是屬於多元邏輯,代表說除了二元邏輯的非 真即假觀念,還多了有漸進的值,不再是只有 0 或 1 而已。結合 AdaBoost.MH 和模糊化的技術,擴大了模糊理論在自然語言領域的運用,是一個新穎的想法, 但是兩者方法的結合,是否有比原先 AdaBoost.MH 的準確度更高,又或著是在時 間上是否需要花費更多的時間,都是本論文中所需要研究的議題。本論文的目的 主要是要將模糊化的技術運用在分類的方法上,可以利用模糊化技術提升本來方3
法的效能之外;達到比傳統其他的方法在時間和準確度上都有更好的優勢。 本論文也嘗詴了將本系統演變為 Semi-Supervised 的形式,稱為
Semi-Boosting,只需要提供少量的 training data 給系統作學習,就能將大量 的文章資料進行分類。不同於傳統的 Semi-Supervised 分類法對於文章的分類只 進行一個循環,代表只有一次的 Training 以及一次的 Testing,本系統
Semi-Boosting 將會對所要分類的文章集進行多次的循環,經由多次的循環 Training 以及 Testing,能夠在準確度上有提高的機會。
實驗比較的部分,其他比較著名的機器學習的演算法,例如,Support Vector Machine(SVM)[9][10]、以及 Naïve Bayes[11],本論文也用了相同的文章集去 實作了這些方法當作我們比較的數據。文章集皆為英文,本論文使用了 Pang 的 電影影評文章集、20-Newsgroups、和 Reuters,其實驗的設計以及實驗的數據 在本論文中會詳細介紹。
4
1.3 論文架構
第一章:緒論,簡單的介紹論文研究的動機,以及探討研究的目的與方法。 第二章:相關研究,概述本論文中所使用的技術背景知識,以及其他關於分 類方法的研究和探討。 第三章:系統設計,將本研究之系統架構與演算法作一個詳細的介紹。 第四章:實驗過程與結果討論,包含實驗的設計以及其它分類法的比較數 據。 第五章:結論與未來展望,對本論文的研究作總結以及統整,並且提出結論 與未來本系統可以改善和研究的方向。5
第二章、相關研究
2.1 模糊理論
模糊邏輯,自從 Lotfi Zadeh[12][13]教授在 1965 年發表之後,就被廣泛 的使用在各種層面上,從控制理論到人工智慧等等。傳統的邏輯問題中,用所謂 的二元邏輯來解決問題,而在我們所生活的現實世界中,充滿著太多的不確定性 以及不明確性,無法單單使用 true 或 false 來解決所有的問題。在模糊邏輯的 技術上,對於二元邏輯無法解決的問題,可以有程度的概念,不用再拘泥於傳統 的思維。模糊邏輯的基礎是由許多的 if-then 結構所形成的,if 部份就是條件 的前提部分,可以辨別這個敘述句是否成立,而 then 則是這個敘述句成立時, 所要做出的結論或是回應。這些模糊法則一般是由專家經驗或經由訓練樣本所建 立,但是缺點就是這些模糊法則無法自動從資料中學習而得到,因此近年來有許 多結合模糊邏輯與機器學習的模型,希望可以同時具備模糊邏輯的彈性與機器學 習的自動學習能力。神經模糊系統(Neuro-fuzzy systems)融合了模糊邏輯和神 經網路,結合推論式模糊系統的彈性與神經網路的學習能力,在近二十年當中, 眾多的神經模糊系統被廣泛的使用在控制領域中[14][15]。 此外,在神經網路當中,越來越多的研究者採用演化式計算的演算法或是 AdaBoost 從資料中進行學習[16][17][18][19][20][21]。Scherer[21]建立了一 個 AdaBoost 結合神經模糊關係性的分類法。Del Jesus 等人[16]設計了演化式 計算的 boosting 演算法,他們將每一條的模糊規則視為一個 weak hypothesis, 而每一個模糊規則庫可以解釋為 weak hypothesis 以及權重的結合。基本上,他 們的分析結果符合 weak hypothesis 的設計原則,也就是說 weak hypothesis 可以是任何類型的分類器。Otero 與 Sanchez[20]與 Del Jesus 等人[16]的方法 類似,但是他們採用 Logitboost[22]演算法去解決模糊規則在分類上的問題。而在所謂的集合方面,包含了明確集合與模糊集合,在模糊邏輯的領域中, 我們所使用到的集合為模糊集合,明確集合簡單來說,就只是有或是沒有,例如
6
有一個明確集合{a,b,c},那這個集合有沒有包含 a?有沒有包含 e?前者的答案為 有,後者為沒有,這就是一個很簡單的明確集合的例子。而模糊系統中所使用到 的模糊集合,由圖 2-1 就代表了一個模糊集合的例子,它的論域 U 的範圍界在 2 到 3 之間,對應的歸屬度函數為 2 0.1x ,一般的情況下歸屬度(membership grade) 會界定在 0 和 1 之間,而 x 稱作元素。 圖2-1.模糊集合 模糊集合的基本運算,也可以分成五種,在此我們假設 A 和 B 為模糊集合, 論域為UX,其歸屬函數分別為 fA
x ,fB x ,且 x UX。 (1)補集(complement)
1
c A B BA f x f x (2)包含(containment)
A B A B f x f x (3)相等(equality)
A B A B f x f x (4)聯集(union)7
max
,
A B B B f x f x f x (5)交集(intersection)
min
,
A B B B f x f x f x2.2 AdaBoost
2.2.1 AdaBoost 演算法AdaBoost 演算法是由 Freund 和 Shapire 在 1995 年所發表[2],詳細演算 法如 Algorithm 2-1 所示;此演算法將( ), ( ),…, ( ),此 m 個 pair 當作演算法的輸入, , ,…, ,是已知 training sample,他們的 label 分別是 ,…, ,而 屬於{+1, -1},並且假設這 m 個點的權重一開始皆 是 。
Algorithm 2-1 AdaBoost Algorithm
Given: ( ), ( ),…, ( ),where , Initialize: .
for t=1,…,T do
Train weak learner using distribution
Get weak hypothesis with error
Choose α . Update: .
where is a normalization factor end for
8 H( =sign( α )
2.2.2 AdaBoost 演算法分析
首先已知 training sample 有 m 個點, , ,…, ,他們的 label 分別 是 ,…, ,而 屬於{+1, -1},並且假設這 m 個點的權重一開始皆是 。並且預設有 n 個基本分類器。 接下來我們會跑 T 個回合的迴圈,每一個迴圈主要目的是調整此 m 個點權重, 並挑選一個錯誤率最低的基本分類器。 以下為演算法的迴圈: { 1. 計算每一基本分類器的錯誤率,錯誤率計算 , 基本分類器, 第 t 回合第 i 點的錯誤率。 Ex:在第一回合,要決定初始基本分類器,我們會從已經預設好的基本分類 器集裡選擇一個最好一個基本分類器。選擇方法如下: 利用每一個基本分類器分別去測詴此 m 個點的分類結果,看預測出來的 結果有無跟 ,…, 的 label 是一樣的,如果沒有,增加此點的權重給 此分類器當作錯誤率,初始錯誤率計算 , 基本分類器。 並找出錯誤率最低的基本分類器當作我們的初始基本分類器 2. 找出錯誤率最低的基本分類器當作第 t 回合的基本分類器 。 3. 接下來要決定α 的值,目的在於在下一個回合中使整體的錯誤率會最低。 當α 時,整體的 error 會最低。 4. 一開始此 m 個點的權重都是一樣的,在每一回合中,我們要提升這回合中分 錯的點的權重,以及降低此回合被分對的點的權重,此舉的目的是讓下一回 合所挑選的基本分類器能夠將此回合被分錯的點分對:
9 (1)for i=1,…,m do Temp(i) = α α end for (2) = (3)for i=1,…,m do = α α end for 當此回合所挑出的基本分類器錯誤率 > 50%,則跳出此迴圈。 } 1~5:說明跑T 個回合的迴圈,並在每回合中更新training sample , ,…, 的權重 ,在下一回合中,利用更新過的權重選擇一個錯誤率最小基本分 類器,提升這回合分錯的點的權重,以及降低此回合被分對的點的權重,此舉的 目的是讓下一回合所挑選的基本分類器能夠將此回合被分錯的點分對。此舉的目 的是讓不同的基本分類器可以互相填補各自在分類方法上不足的地方,也就是結 合多個基本分類器,讓這些基本分類器變成一個比較強大的基本分類器。 所以最終的強分類器就是由一堆基本分類器的線性組合: H( =sign( α ) , 代表強分類器.
10
2.3 AdaBoost.MH
2.3.1 AdaBoost.MH 演算法
AdaBoost.MH 可以針對多群數目以及多標籤數目的文章集進行分類,其詳細 演算法如 Algorithm 2-2 所示。而 Schapire 與 Singer[4]在 2000 年所發表的 BoosTexter 系統為 AdaBoost.MH 的一個實作系統。 演算法中, 定義為所有的 Training Data 文章, 為所有類別的集合, 我們將 集合的大小設定為 k 。假設有一篇 training 的文章為 ( , )x Y , , x Y ,且 l ,可得知以下結果:
1 1 if l Y if l YY l
S為所有訓練的資料,包含了
x Y1, 1
,..., x Ym, m
,xi ,Yi 。每一 Round 所挑選出的 weak hypothesis ht: ,h x l 解釋為一個預測此文章
, x是 否有被分配到類別l,而h x lt
i, 可以解釋為此次預測的信心度。每一個 training 的項目 ( , )x Y 對應到k個二元的 label,就像是
x l Y l, ,
,for all l ,一樣。而 演算法中的Zt為一個正規化的變數,如方程式(2.1)所示:
1,
exp
,
m t t t i t i i lZ
D i l
Y l h x l
(2.1)每一 Round t 輸出的 hypothesis 形式如下所示。w為一個 term,wxi則 代表w出現在第 i 篇文章中,c 為一個數值,代表 weak hypothesis jl ht的輸出結 果; j 為 0 或是 1,各自代表了w出現在文章中或是不出現在文章中的兩種情況。
11
0 1,
l l C if w x t i C if w xh x l
Algorithm 2-2 AdaBoost.MH Algorithm Given:
x Y1, 1
,..., x Ym, m
where xi ,Yi Initialized: D i l1
, 1/
mk ,i1,...,m for t1,...,T doPass distribution Dt to weak learner. Get weak hypothesis ht: .
Choose Update: t 1
, t
, exp
t i
t
i,
t D i l Y l h x l D i l Z whereZtis a normalized factor end for
Output the final hypothesis:
1 , , T t t t f x l h x l
12 2.3.2 Weak hypothesis 每一篇文章xi在類別l的權重一開始皆是D i l1
, 1/
mk 。而X ,j,
0 : X x wx 為代表 term w沒有出現在文章中,X1
x w: x
為有出現。 先給予當下第 t Round 的Dt,以及 term w,使得Xj, j
0,1 ,且對每一 個類別l作相對應的計算。Wjl( jl W )可以稱為根據Dt在文章發生Xj的情況下且 文章是(不是)l這個類別所計算出來的權重。方程式(2.2)為計算 jl b W 之方法:
1,
m jl b t i j i iW
D i l
x
X
Y l
b
(2.2) 而Zt可以用 j b W 來表示,如方程式(2.3)。
:exp
i j t i j j i x XZ
D i
Y c
j cj j cj
jW e
W e
(2.3) 接著再對Zt對作微分,可以得出c 。jl c 可以被解釋為這個 feature 對於類jl 別l有多少的影響,c 為一個向量,其大小為總類別數目。jl c 的公式如方程式(2.4)jl 所示。1
ln
2
jl jl jlW
c
W
(2.4) 如果 jl W 或是Wjl很小甚至趨近於 0,從方程式(2.4)公式中則會得到很大的 jl c ,這樣將會發生許多問題。為了避免這樣的問題發生,設定了 1/ mk加入 到公式中,原先計算c 的公式變成如方程式(2.5)所示: jl1
ln
2
jl jl jlW
c
W
(2.5)13
每一 Round 所選出的 weak hypothesis 需要是計算出來最小的Zt。而將方 程式(2.4)代入到方程式(2.3)可得出方程式(2.6)。 0,1
2
jl jl t j lZ
W W
(2.6)每一 Round 我們所要選取的 term w就是Zt為最小的w,而每一 Round 將會 挑選最小的Zt來當作 weak hypothesis。假如一個 feature 對於每一個類別能夠 提供較大的區別性,這代表了系統可以根據這個 feature 的出現或是不出現在文 章中辨別這篇文章的類別。舉例來說,若是一個 feature 出現在正向的類別文章 中很多次,而在負向的類別文章出現次數很少,那麼計算出來的c 在預測正向jl 類別的值將會很高,反之在預測負向類別的值將會很低,若是總類別為 2 時,所 計算出來的cjl在兩個類別的值將會呈現對稱,例如 0.8 與-0.8。當 jl W 與 jl W 差 異最大時,將會得到最小化的Zt。
2.4 SVM(Support Vector Machine)
文章的分類問題中,越來越多研究者使用machine-learning的技術來解決這 方面的議題。Joachims[9]使用了Support Vector Machines(SVM)[10]來對文章 進行分類。SVM為目前表現較好的一種分類演算法,其概念為事先給予一群分類 好的資料集,如圖2-2所示,利用這些已知的資料訓練產生預測模型。爾後,若 有尚未分類的資料時,都可以直接使用該模型預測該資料的結果。簡而言之,我 們可以把模型想像成是一個黑箱,當任意資料通過模型後都會被對應至符合條件 的區域,且作出分類結果,如圖2-3所示。
14 圖2-2.原始資料集的分布圖 圖2-3.經過SVM分類後的結果 然而,有時候原始空間中的資料分布,並非線性可分割(Non-linearly Separable)。因此,我們必頇將資料映射至較高的維度中,才有機會以超平面將 資料分割開來,如下圖 2-4 所示,在原本二維空間中無法線性分割的資料,再將 資料點轉換至更高維度的三維空間後,可找到一超平面將資料點線性分割。 圖2-4.將原始資料轉換至高維度中進行切割 Feature Mapping : X Y Original Space X Y Z Hyperplane Feature Space
15 為達成上述的目的,我們將利用訓練資料來尋找空間中的超平面,透過該超 平面將資料順利的切開,如圖 2-5 所示的實線,並且期望該平面將兩側類別的距 離分開的越遠越好,讓該超平面可以達到最一般化的效果(Generalization), 否則容易使預測結果偏向某一類別,而過於迎合(Overfitting)訓練資料,造 成未來使用該模型預測測詴資料時,分類的結果不盡理想。下列為支援向量機的 各項基本定義。 訓練資料集: , Xi:第 i 個資料的特徵屬性,表示為 d 維度的向量。 Yi:第 i 個資料的類別,於此表示為兩種類別的其中一種,+1 或-1。 分隔的超平面表示式: ˙ w:代表為平面的法向量 (Normal Vector), 。 圖2-5.超平面示意圖 如圖 2-5 所示,假設 : ˙ 為一可將兩種類別資料分隔之超平 面,藉由適當的重新調整(Rescaling),我們可以定義兩個平行於 P 的輔助超 平面,並且這兩個輔助超平面會分別通過兩種類別距離 P 最近的所有資料點 Support Vectors
16 (Support Vectors),圖 2-5 中所示之虛線,其定義如下: ˙ (2.7) ˙ (2.8) 考量到分類器的一般化情況,支援向量機的目標為使得兩個輔助超平面的距 離越大越好,利用幾何學的原理,發現兩個輔助的超平面,方程式(2.7)和方程 式(2.8),中間的距離為 。因此,欲讓兩者間距有最大值,必頇使得 的 數值越小越好。 目前支援向量機的現成工具方面,LIBSVM[23]為目前最熱門及方便的支援向 量機工具軟體之一,本研究亦採用此軟體來做為實驗數據的比較方法之一。
17
2.5 Naïve Bayes
Naïve Bayes(NB)[11]分類法,是基於Bayes定理獨立性假設的一個簡易機率 分類法。在以下公式中,c為類別變數,T1,...,Tn為features變數,這些變數的交 集機率,就如方程式(2.9)所示:
1
1
Pr c T, ,...,Tn Pr c P T,...,T cn |
1
2 1
1 1
Pr c Pr T c| Pr T c T| , ...P T c Tn| , ,...,Tn
1
2
Pr c Pr T c| Pr T c| ...P T cn|
1 Pr Pr | n i i c T c
(2.9) 文章的分類當中,每一篇文章可以被表示成一個term的向量或是feature的 向量。基於NB的假設:當給定文章類別資訊,文章內的特徵會互相獨立。每一篇 文章d被分到類別c的機率的公式如方程式(2.10)所示:
1
1 Pr | Pr , Pr , ,..., Pr Pr | n n i i c d c d c T T c T c
(2.10) 如方程式(2.11)所示,當我們給定一個類別集C,和一篇文章d,文章d將 會被分類到最大機率的類別c中,其中Pr c 為一篇文章發生在類別
c的先前機 率,而Pr
T c 為term i |
Ti發生在類別c的文章中的機率。 *
arg max Pr | c C c c d
1 arg max Pr Pr | n i c C i c T c
(2.11)18
2.6 Fuzzy Rule Methods Comparison
建立 fuzzy rule 的方法有很多種,一般來說模糊法則是依據專家經驗或經 由訓練樣本所建立,每一個法則是以 If-Then 的形式來表達條件敘述語句。If 可以說是前提部分,是用來提供這個條件法則語句是否成立,Then 的部分則為 如果條件法則語句成立所執行的結果。模糊法則的數量可依據訓練樣本數來增加 或是減少,法則的數量越多,則越有更精確的結果。
AdaBoost[2]的方法建立 fuzzy rule,是一種以 Boosting 為基礎的方式產 生出 fuzzy rule,就像之前所提到的 Del Jesus 等人在[16]所發表的方法。雖 然這種方式可以產生出各種形式的 fuzzy rule,精確度相較之下也有較高的效 果,但是僅限制在當 input 數量較少或是種類較小的情況之下,當我們的 input 數量大或著是種類多的時候,這種 Boosting Fuzzy Rule 的方法就會耗費相當多 時間,進一步導致無法運算的可能性也提高,以下將會有更詳細的說明。
以下我們假設一個例子,在此小節的例子中,xi為此 fuzzy rule 的第 i 個 input, j
i
R 為第i 個 input 的所有有可能發生的情況, j1...N代表此 input i 有 可能的情況有N種,i1...n代表此 fuzzy rule 一共有n個 input,若都符合條 件的需求,則結果 為 0。
1 1 ... 0
j j
n n
if x is R and and x is R then
若此時我們假設N以及n都持續的增加。因為 Boosting Fuzzy Rule 的方法 是將所有種類的 fuzzy rule 全部都計算出來其結果,可以如圖 2-6 的結果知道, 時間複雜度將會相當高,若是處理大量文章集的情況,可能會耗時相當大的時間, 而在本系統中,假如 training 的 Round 數目為 500,只管 term 出現或是不出現 在文章中兩種情況,代表說我們的n500,N2則我們所需要運算的 fuzzy rule 種類為 500 2 種,也代表說在此種情況下一共有 500 2 條的 fuzzy rules,因為數量 太過於龐大,所以在該情況下完全無法做運算,所以我們可以說,Boosting Fuzzy Rule 的方法可行,但是必頇要在文章集的量較小或是 input 數目較少以及每一
19
個 input 的可能性不多的情況,若是要在大量的文章集情況,則不可行,代表無 法在各種變化多的形式下作處理,也無法適應多種不同的文章集。
圖2-6.Boosting fuzzy rule時間複雜度計算
本系統中所使用到的 fuzzy rule 是屬於可使用在多 input 的情況下,每一 條 fuzzy rule 只有一個 input,也就是 term,每一個 input 也只有兩種情況, 包含了出現以及不出現,代表說每一條 fuzzy rule n1,N2,而 fuzzy rule 的數目由 training 的 Round 數目來決定。所以本系統所有 fuzzy rule 需要計算 的次數為Training s Rounds' 2,其時間複雜度為
Training s Rounds'
。以下舉 兩個例子為本系統所使用的 fuzzy rule,可行性較高也可用在各種多變化的文 章集和情況。1
" " " " " l"
if bad is present in document then return c
0 " l"
else return c
1
" " " " " l"
if wast is present in document then return c
0 " l"
20
第三章、系統設計
3.1 概念
AdaBoost[2]為一種群體學習演算法,它允許其它的分類法當成其中的一個 弱分類器;例如決策樹、簡單的 decision rule、甚至於 SVM[9][10]。AdaBoost 扮演的角色是一個框架的角色,將這些弱分類器列為它框架的一部份,AdaBoost 可藉由調整訓練資料的權重,每一回合挑出最佳的弱分類法,最後找出一組弱分 類法集合和此集合裡每個弱分類法的權重,最後再予以合併,形成一強分類器。 Schapire 與 Singer 所發表的 AdaBoost.MH 是將 AdaBoost 做延伸,將原先 weak hypothesis 的 output 從+1,-1 延伸到實數 [8],並且加入了 Multi-Class、 Multi-Label 的處理能力,是一種相當實用的分類法。 模糊邏輯的技術在不同的領域都可以看到它的蹤跡,自從 Zadeh 教授的 "Fuzzy Sets"論文在 1965 年發表後[13],就帶動了這方面的研究風氣。由於現 實世界的許多問題都充滿著不確定性及不可預料,如果想要靠傳統的二元邏輯的 思考模式來解決所有的問題,是幾乎不可能的。本研究結合 Fuzzy 與 AdaBoost.MH, 提出一個分類的方法;本研究也針對傳統的模糊化技術在訓練模糊規則需時過長 的問題做了改善。 本論文使用 AdaBoost.MH[8] framework 設計出模糊化分類系統,而 AdaBoost.MH 能夠在每一回合挑選出最好的 weak hypothesis,且每一個 weak hypothesis 將會對應到一個 if-then rule,根據 if-then rule 所判斷出的結果, 取出相對應的 weak hypothesis 數值,本研究提出使用 fuzzy number 代表分類 的結果,詳細的流程將會在後面章節有更多的說明。Del Jesus 等人[16]提出一 個結合 fuzzy 與 AdaBoost 之方法,他們將每一個 fuzzy rule 視為一個 weak hypothesis,且 fuzzy rule base 能被解釋為 weak hypothesis 與權重的結合。 基本上,他們的分析結果符合 weak hypothesis 的設計原則,即 weak hypothesis 可以是任何類型的分類器。
21 本論文也將本系統的運作原理發展出 Semi-Supervised 的形式,稱為 Semi-Boosting,可用少量的 labeled 資料來進行文件分類,實驗結果有不錯之 成效,詳細的流程在後續章節中會詳細介紹。此新方法為本系統的延伸想法,其 演算法以及準確度在未來可望改善以及提升。除此之外在時間方面在未來也有改 善的空間和可能性。
3.2 系統架構
如圖 3-1 所示。本系統分成幾個步驟來完成:首先,在 Fuzzy rule base 架 構中,rule selector 會在每一回合從 rule pool 中選擇最好的 fuzzy rule 出 來,其目標是為了減少訓練的 error。而選擇的標準將會在之後的章節會有詳細 的介紹。當 rule base 準備好之後,系統將會從訓練資料中計算出每一個 rule 的訓練錯誤次數。之後將使用 logistic function 將這些錯誤轉換成 accuracy ratio value,其範圍在 0~1 之間。此外,本論文提出一個以面積為基礎的表示 法,藉此來表示每一個 rule 的信心度(fuzzy confidence value)。最後,本系 統的分類結果可以透過一個程度轉換(degree transformation)方法,得出文件 歸屬到各類別的程度。
22
23
3.3 系統演算法
本論文是延伸自 AdaBoost.MH,將每一個 weak hypothesis 以 fuzzy rule 表示,最後結果則是以 fuzzy number 來計算。Algorithm 3-1 為本系統之整體 演算法,包含了 AdaBoost.MH 以及本系統之主要演算法,而本系統主要的演算法 將在這節會有詳細的介紹。
Algorithm 3-1 Fuzzy AdaBoost.MH Algorithm Given:
x Y1, 1
,..., x Ym, m
where xi ,Yi Initialized: D i l1
, 1/
mk ,i1,...,m for t1,...,T doFind the weak hypothesis ht: that minimizes the error with respect to the Distribution Dt
Choose Update:
1 , exp , , t t i t i t t D i l Y l h x l D i l Z ,whereZtis a normalized factor end for
Given: h x l1
i, ,...,hT
x l and i, Yi where i1,...,m and Yi , for t1,...,T do
1 arg max , m t t i i l i Error h x l Y
end forInitialize: Maxmax E[ 1,...,ET], Minmin[E1,...,ET],
1 1 T t t Avg E T
1 / 10
24 for t1,...,T do
/ 10 t Avg E Max Min τ , 1 1 t b A a e τ end for for i1,...,z do
2 1 1 , , [1 (1 ) ] 2 T i t i t t S x l h x l A
end forInitialize: Smax Max S x l[ ( , ),..., ( , )]1 S x lz , Smin min[ ( , ),..., ( , )]S x l1 S x lz if
Smin 0
then for i1,...,z do
min ( , )i ( , )i 1 1 S x l S x l S end for end if 1 1 ( , ) z average i i S S x l Z k
for i1,...,z do 1 ( , ) 1 i Degree x l e τ ,
max min
( , ) / 10 i average S x l S S S τ end for25
接著將介紹本系統的四大主要演算法,分別為(1)Error Count Calculation (2)Accuracy Ratio Calculation (3)Fuzzy Confidence Calculation (4)Degree Transformation,以及本系統的延伸 Semi-Boosting。傳統的 machine learning 中,每一篇文章 x 將會被分類到單一的類別y 中。而在 multi-label 中, 每一篇文章 x 將有可能被分類到多個類別中Y 。
本系統的演算法中,定義 為所有 Training Data 的文章集合, 為所有 的 label 類別,其類別數量為| | k ,x 為第 i 篇 Training Data,i i1,...,m代 表 Training Data 文章數目為m,T 為 training 的 Round 數目,Yi為每一篇文 章xi 所被標記到的類別集合且Yi ;本系統可對 multi-label 的 dataset 進行處理,故集合中的類別數量未必為 1,而 Testing Data 的數目為z。而w為 一個 term,wxi則代表w出現在第 i 篇文章中,h x l 為第t
i, t Round 所挑選出 來的 weak hypothesis,其ht的值為根據 input document x 所計算出的數值,i l 為 label 類別,而 weak hypothesis 的值可以針對w是否出現於文章中來決定其 數值。
0 1,
l l C if w x t i C if w xh x l
jl c 為一個數值, j 為 0 或是 1,各自代表了w出現在文章中或是不出現在文 章中的兩種情況。Algorithm 3-2 中的 output 為Et(where t1,...,T ),代表第 t Round 的 Hypothesis 的 Error Count,而 Algorithm 3-3 中的 output 為At (t1,...,T )則為第 t Round 的 Hypothesis 的 Accuracy Ratio,S x l 為第
i, i 篇文 章在類別l所計算出來的面積值,Degree x l 是第
i, i 篇文章在類別l的 degree。 關於 AdaBoost.MH 的詳細定義可以參考本論文第二章的相關研究的部分,有更詳 細的解說以及介紹。26 3.3.1 Error Count Calculation
本小節所介紹的演算法中,方程式(3.1)為第t Round 的 weak hypothesis 在第 i 篇文章中,回傳最大值類別的 index,並且根據回傳類別的 index,到所有 類別集合 中取出相對應的 label 名稱,並且檢查第 i 篇 training 文章是否有 被分類到此類別,如果不符合,代表此規則為成立,回傳 1,則此 hypothesis 的 Error Count 加 1,其中 ・ 為一個 indicator function。最後 output 的是每 一個 hypothesis 的 Error Count。
1 arg max , m t t i i i Error h x l Y
(3.1) Ex:{pos neg Y, }, i {pos}
假設此例中wxi所以回傳c0l ( 0.1, 0.1),故arg maxh x lt
i, 的回傳 值為 2,代表 arg maxh x lt
i, 所取出來的 label 為 neg,因為negYi, 故條件成立,此Errort加 1。Algorithm 3-2 Error Count Calculation Algorithm
Given: h x l1
i, ,...,hT
x l and i, Yi where i1,...,m and Yi , for t1,...,T do
1 arg max , m t t i i i Error h x l Y
end for Output: E1,...,ET27 3.3.2 Accuracy Ratio Calculation
本小節所介紹的演算法,是根據方程式(3.1)的結果E1,...,ET來做後續的運 算;Max和Min分別為所有 hypothesis 中最大及最小 Error Count, Avg 為所有 Hypotheses 的 Error Count 之平均, , ,a b c 為三個參數。此演算法可將原本每一 個 Hypothesis 的 Error Count 轉變為 Accuracy Ratio。在方程式(3.2)中的分 母
Max Min
/10為代表算出最大與最小的距離,除以 10 個間隔,以計算出每 一個間隔的大小,在本系統是將設定值的範圍定於+5~-5 之間,代表分成 10 等 份。如圖 3-2 可以很清楚了解範圍大致上是在+6~-6 之間。分子AvgEt代表此 Hypothesis 與平均值的差距,若AvgEt越大代表此 Hypothesis 的錯誤次數越 小,則At越大,代表 Accuracy Ratio 越大。最後將方程式(3.2)代入到方程式(3.3) 中,就可以計算出每一個 hypothesis 的 Accuracy Ratio。
/ 10 t Avg E Max Min τ (3.2) 1 1 t b A a e τ (3.3) 圖3-2.Logistic Function演算法圖示28
Algorithm 3-3 Accuracy Ratio Calculation Algorithm Given: E1,...,ET
Initialize: Maxmax E[ 1,...,ET], Minmin[E1,...,ET],
1 1 T t t Avg E T
1 / 10
arounding off Max Min c , b for t1,...,T do
/ 10 t Avg E Max Min τ , 1 1 t b A a e τ end for Output: A1,...,AT3.3.3 Fuzzy Confidence Calculation
本小節所介紹的演算法為計算每一篇 Testing Data 文章在每一個類別l的面 積值,方程式(3.4)中所計算的S x l 為第
i, i 篇文章在類別l的面積值,這代表了 假設| | k ,則代表一共有k的類別,而每一篇文章也將會算出k個面積值。方 程式(3.4)為將每一 Round t 的 Hypothesis 的 confidence 當作三角形面積的底 寬度,而 Hypothesis 的 Accuracy Ratio 是由方程式(3.3)所計算出來,用來當 作三角形切線的高度,其經由 Accuracy Ratio 所切出來的面積為一個梯形,而 此梯形面積為此演算法所要計算之值。
2 1 1 , , [1 (1 ) ] 2 T i t i t t S x l h x l A
(3.4) Ex: 假設我們目前想要計算的面積為等號左邊的藍色梯形面積(圖 3-3),以
|h x l 當作三角形面積的底,但是由於我們需要知道此面積算出來為正還t i, | 是負,所以在本演算法中並沒有加上絕對值,保持原先的正負號。故我們可 以先計算出等號右邊藍色三角形的面積1
, 2h x l 。 t i29 圖3-3.梯形面積生成 接著算出白色小三角的面積,由圖 3-4 可知其步驟。最後將兩三角形相 減,就可得到最後藍色梯形面積值。如圖 3-5 為將圖 3-4 算出來的白色小三 角形,代入到圖 3-3 中,就可得到其結果。 圖3-4.面積公式推導(1) 圖3-5.面積公式推導(2)
30
經由方程式(3.4)計算出每一篇 Testing Data 在所有類別l中各自的面積值 之後,將其 output 給下一個 Algorithm 使用。
Algorithm 3-4 Fuzzy Confidence Calculation Algorithm Given: A1,...,AT,h x l1
i, ,...,hT
x l where i, i1,...,z for i1,...,z do
2 1 1 , , [1 (1 ) ] 2 T i t i t t S x l h x l A
end for Output: S x l where
i, i1,...,z 3.3.4 Degree Transformation 本小節的演算法是對所有 Testing Data 在所有類別l的面積值,進行正規化 處理,形成每一篇 Testing Data 皆會有一個在各類別l的 Degree。首先在方程 式(3.4)中計算出的所有S x l( , )i wherei1,...,z中找出最小值Smin與最大值Smax, 若是找出的最小值Smin小於 0,則執行方程式(3.5)對所有的S x l( , )i 加上所找出 的最小值Smin乘上-1 之後再加上 1,加 1 是使用 smoothing 技巧以避免有 0 的情 況發生,之後得到出新的S x l( , )i 。
min ( , )i ( , )i 1 1 S x l S x l S (3.5) 接著方程式(3.6)為算出所有S x l( , )i 的平均Saverage。 1 1 ( , ) z average i i S S x l Z k
(3.6) 最後再經由方程式(3.7)代入到方程式(3.8)去求出每一篇 Testing Data 在 各個類別中的 Degree,且範圍為 0~1,其演算法如 Algorithm 3-5 所示。其中31
arg max Degree x l( , )i 代表先找出此篇 Testing 文章 i 在各類別中最大 Degree 類 別l的 index,接著再到 中找出類別的名稱,並且回傳。
max min
( , ) / 10 i average S x l S S S τ (3.7) 1 ( , ) 1 i Degree x l e τ (3.8)Algorithm 3-5 Degree Transformation Algorithm Given:S x l( , )i where i1,...,z
Initialize: Smax Max S x l[ ( , ),..., ( , )]1 S x lz , Smin min[ ( , ),..., ( , )]S x l1 S x lz if
Smin 0
then for i1,...,z do
min ( , )i ( , )i 1 1 S x l S x l S end for end if 1 1 ( , ) z average i i S S x l Z k
for i1,...,z do 1 ( , ) 1 i Degree x l e τ ,
max min
( , ) / 10 i average S x l S S S τ end for32 3.3.5 Semi-Boosting
本小節為 Semi-Boosting 的演算法,在此我們設z為 Testing Data 的文章 數目,Yi為第 i 篇 Training Data 的類別。演算法中間的 if 條件式是為了要辨別 此篇 Testing Data 所被分類到的類別其信心度是否大於等於門檻值C,若條件 成立,則將此 Testing Data 加入到 Training Set 中,並且從 Testing Set 中刪 除此篇文章。而演算法最後的 if 條件式則是判斷剩餘的 Testing Set 中的文章 數目是否大於所設定的門檻值,如果條件成立,則會再繼續進行下一回合的 Semi-Boosting 演算法,直到不符合條件式的條件才會停止。
Algorithm 3-6 Semi-Boosting Algorithm
Given labeled example pairs
x Y1, 1
,..., x Ym, m
,unlabeled examples
x1,...,xZ
,where xi ,Yi ,a confidence threshold value Cand a stopping threshold value NRun AdaBoost.MH algorithm using labeled examples
x Y1, 1
,..., x Ym, m
for i1,...,z do xi.dataxi
1 1 . arg max , T i t i l K t label h x l
x
1 1 . max , T i t i l K t confidence h x l
x end for for i1,...,z do if xi.confidenceC thenRemove xi.data from unlabeled set
Insert
xi.data, .xilabel
into labeled set end if33 end for
if number of unlabeled examples N then
Run Semi-Boosting with new labeled examples and unlabeled examples else
Insert the rest of unlabeled examples with their labels into labeled set
34
3.4 系統概念
系統流程解說:
以下為詳細的系統概念例子,分別介紹各 Step 的詳細步驟。 Step 1: Hypothesis Value
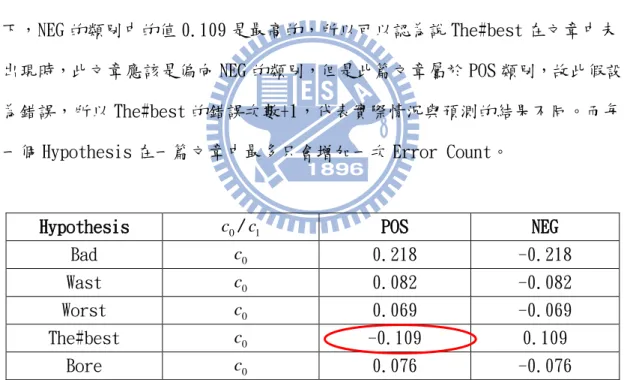
假設我們由 Adaboost.MH 跑出來的 Hypothesis 如圖 3-6 右方,Round 數為 5, 所以共有 5 個 Hypotheses。我們由第一個 Round 取出來的字 bad 來解釋,圖 3-6 左方表格的 POS、NEG 為要分類的兩個類別名稱,c0、c1分別代表 bad 這個字不
出現以及出現在文章中的情況,而 0.344、-0.344、0.218、-0.218 為經由 AdaBoost.MH 所計算出來的數值。例如表中-0.344 為文章中出現 bad 且同時被分 到 POS 這個類別得到的值,這也代表說 0.344 為文章中出現 bad 且同時被分到 NEG 這個類別得到的值。反之 0.218 為文章中未出現 bad 且同時被分到 POS 這個 類別得到的值,由此類推。
35 Step 2: Error Count Calculation
假設我們一篇為 POS 類別的 Training Data 在 5 個 Hypotheses 的預測後, 出現情況如表 3-1,其中c0代表此 Hypothesis 不出現在這篇文章當中,c1為此
篇文章有出現,POS、NEG 欄位為取出相對應c0或是c1的值。由於此篇 Training Data 文章是屬於 POS 的類別,所以可以假設說不管 Hypothesis 的出現情況是c0 還是c1,其 Hypothesis 的值在 POS 的類別中都會是最大的,因為這樣的結果代 表此 Hypothesis 偏向 POS 這個類別。以 bad 為例,在c0的情況下,POS 的類別 的值 0.218 是最高的,所以我們可以認為說 bad 不出現於文章中時,此文章應該 是偏向 POS 的類別,而此假設也符合此篇 Training Data 的類別 POS,所以預測 正確,Error Count 並未增加。由此類推,如同表 3-1 中 The#best,在c0的情況 下,NEG 的類別中的值 0.109 是最高的,所以可以認為說 The#best 在文章中未 出現時,此文章應該是偏向 NEG 的類別,但是此篇文章屬於 POS 類別,故此假設 為錯誤,所以 The#best 的錯誤次數+1,代表實際情況與預測的結果不同。而每 一個 Hypothesis 在一篇文章中最多只會增加一次 Error Count。
Hypothesis c0/c1 POS NEG
Bad c0 0.218 -0.218
Wast c0 0.082 -0.082
Worst c0 0.069 -0.069
The#best c0 -0.109 0.109
Bore c0 0.076 -0.076
表 3-1.舉例的 Training Data 文章中,Hypotheses 出現的情況與其值
此篇文章所計算出來每一個 Hypothesis 的錯誤次數為: Bad:0
Wast:0 Worst:0 The#best:1
36 Bore:0
圖 3-7.是在 Pang 的影評文章中算出來的實際例子,我們也以這個例子作為 後面的計算數值:
圖3-7.計算錯誤次數之實際結果
Step 3: Accuracy Ratio Calculation
首先在所有的 Hypotheses 中取出 MAX 以及 MIN 的 Error Count,並且計算 Average 的 Error Count,接著我們將每一個 Hypothesis 的錯誤次數,使用 Logistic Function 調整成正確的程度。其計算流程之前處理如圖 3-8。以下為 根據圖 3-7 所舉的例子。
將 Error Count 代入到公式中
37
圖3-8.Logistic Function之前置處理
Step 4: Fuzzy Confidence Calculation
如表 3-2 為 5 個 Hypotheses 的 Error Count 經由 Accuracy Ratio
Calculation 出來後的 Accuracy Ratio,以及在此篇 Testing Data 文章出現的 情況與其相對應的值。
Hypothesis Accuracy c0/c1 POS NEG
Bad 0.9 c1 -0.344 0.344
Wast 0.7 c0 0.082 -0.082 Worst 0.7 c0 0.069 -0.069
The#best 0.5 c0 -0.109 0.109
Bore 0.8 c0 0.076 -0.076
38
接著需要計算 POS 類別的面積值,如圖 3-9,以 bad 為例,以-0.344 為三角 形面積底部的中心座標,因為其絕對值為此 Hypothesis 在 POS 這個類別的信心 度,所以用絕對值來當作三角型底部的寬度,而三角形外框的高設為 1,但由於 bad 在 Training Data 中所算出來的正確率值(Accuracy Ratio)為 0.9,代表除 了信心度之外,實際上的正確程度為 0.9,並沒有百分之百的正確,因此將 0.9 設為高度,代表經由 Training Data 測詴之後影響了信心度的程度。最後計算高 度為 0.9 的梯形面積,由於 bad 在 POS 類別值為負,故計算出來的面積我們給他 標記為負號。使用面積法來當作 fuzzy number 符合 fuzzy number 的定義,包含 了(1)convex (2)normal fuzzy set 兩種的特性。
39 因此類推,每一篇 Testing 文章在每一個類別底下都會有一個總和的面積值, 我們將會取最大面積的類別當作此篇文章所預測的類別。如圖 3-10 所示,假設 我們一篇文章在 POS 以及 NEG 兩個類別算出來的面積值總和在圖 3-10 的最下方, 我們可以看到在 NEG 類別的面積大於在 POS 類別的面積,故我們可以知道這篇文 章將會被本系統分類到 NEG 的類別中。 圖3-10.舉例的Testing Data文章所計算出POS、NEG類別的總值 最後我們要將文章在不同的類別中具有 Degree 的概念,所以我們必頇對所 有的 Testing Data 進行正規化的處理。由 Degree Transformation 的演算法求 出每一篇 Testing Data 在各個類別中的 Degree。以下為計算 Degree 之步驟的 例子,詳細步驟如下:
40
EX:假設下表為 Testing Data 中的其中兩篇文章在 POS 以及 NEG 兩個類別底 下經由 Fuzzy Confidence Calculation 步驟所計算出來的面積值。
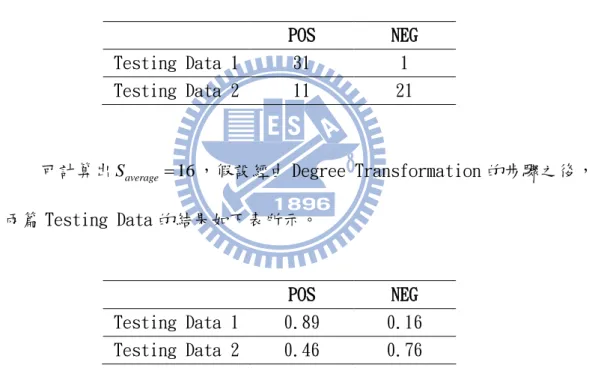
POS NEG Testing Data 1 15 -15 Testing Data 2 -5 5
假設此 Testing Data 中的Smax 15,Smin 15,接著將所有的值加上
1 Smin1,因為Smin 0,其所給的兩篇例子結果如下表。POS NEG Testing Data 1 31 1 Testing Data 2 11 21
可計算出Saverage16,假設經由 Degree Transformation 的步驟之後,
兩篇 Testing Data 的結果如下表所示。
POS NEG Testing Data 1 0.89 0.16 Testing Data 2 0.46 0.76
圖 3-11、3-12 分別為正規化形成 Degree 的結果的兩篇 Testing Data 1 和 Testing Data 2,可清楚呈現出兩篇 Testing Data 在兩種類別的 Degree,圖中 的例子為在兩種類別 POS 以及 NEG 下的 Degree 情形,可以很明顯的看出在圖 3-11 的文章偏向 POS 類別的程度比圖 3-12 的文章偏向 POS 類別的程度來的高,而且 圖 3-11 的文章偏向 POS 類別的程度比偏向 NEG 類別的程度高,所以可以知道圖 3-11(Testing Data 1)的文章將會被本系統分類到 POS 的類別中,而圖
41
圖3-11正規化形成Degree(Testing Data 1)
42
3.5 Semi-Boosting
本小節將介紹由本系統的 Supervised 演變出的新想法 Semi-Boosting,也 就是使用 Semi-Supervised 的方法對文章集進行處理。本系統 Semi-Boosting 目前只能對 Single-Label 進行處理,所以以下流程將以 Single-Label 的方式呈 現。本系統 Semi-Boosting 的詳細流程可由圖 3-13 來一一作解說。 (1)Training:假設我們現在使用 20%的 Training Data 來進行 Training,Training 的方 法一樣是使用本系統的 Training 方法,使用 AdaBoost.MH 進行這個步驟,並且 可以得到 Training 出來的 Hypotheses 進行下一個步驟。
(2)Testing:
第二步驟為使用 Hypotheses 對剩下的 80% Testing Data 進行預測的步驟, 並且可以得到每一篇 Testing Data 在每一個不同類別底下的預測信心值,此步 驟與原先本系統的 Test 步驟相同。
(3)Select:
圖 3-13 的下方有綠色以及紅色的點,分別代表 Testing Data 被分到 POS 以及 NEG 兩種類別的文章,綠色以及紅色的點中間有黑色直條線將其兩種類別區 隔開來,由此黑色直條線為基準線,越往左右兩邊的點代表差異性越大,也可以 說這些越外圍的點,我們可以很容易看得出來是屬於哪一個類別,代表文章趨向 那一個類別的程度越大。在圖 3-13 的下方綠色以及紅色的點中,以綠色的點為 例子,在所有綠色的點中,我們將其群中心的部分切一半,如 POS 類別中淺藍色 的直條線,淺藍色直條線的左方與右方各有 50%的綠色點,我們可以說在淺藍色 直條線左方的點,被分到 POS 類別有較大的信心度,而在淺藍色直條縣右方的點, 對於被分到 POS 類別的信心度並不足夠。 (4)Recall:
43
Training Data 中,剩下比較靠近中心的點則繼續放回 Testing Data 中,並且 準備進行下一回合的 Training,本系統是取各類別中 50%的 data 為實驗。
44
第四章、實驗過程與結果討論
4.1 實驗資料集
本論文使用了三種不同的文章集作為估計本系統的效能,分別為 Bo Pang1的 電影影評文章集、20 Newsgroups2 、Reuters-215783 ,以上三種文章集包含了 Multi-Class 以及 Multi-Label 的問題。使用三種不同的文章集,為了就是要評 估本系統在不同領域的文章集中是否皆有較好的準確度。本章節將使用本系統對 於以上三種文章集進行實驗,實驗方法步驟與實驗的結果將在以下章節作詳細解 說,最後也會對於實驗結果進行分析與討論。Movie Review Data
電影的影評文章集為從網路電影的資料庫中搜集出使用者對於電影評論的 文章,出自於 IMDB4 。此文章集包含了 2000 篇的電影影評文章,其中的 1000 篇 文章被標記為 POS,代表是屬於正向的影評文章,而另外的 1000 篇文章被標記 為 NEG,代表是屬於負向的影評文章。本論文所用 Bo Pang 的電影影評文章版本 為 polarity dataset v2.0。 20 Newsgroups 20 Newsgroups 是目前相當受歡迎用來評估分類方法的文章集,擁有 Single-Label 以及 Multi-Class 的特性,其文章集包含了 7 個大的主要類別, 以及 20 個的子類別,每一個子類別有 1000 篇文章,總共有 20000 篇文章,本論 文也將此 20 Newsgroups 文章集的標頭過濾掉,因為文章的標頭會有類別的資訊, 故本論文將其刪除掉。本論文的實驗數據,將對此文章集選出幾種組合來進行實 驗,包含了主要類別的分類以及子類別的分類,本論文所用的 20 Newsgroups 1 http://www.cs.cornell.edu/people/pabo/movie-review-data/ 2 http://people.csail.mit.edu/jrennie/20Newsgroups/ 3 http://www.daviddlewis.com/resources/testcollections/ 4 http://www.imdb.com/
45 版本為 20news-19997。 Reuters-21578 本文章集包含 21578 篇文章,一共擁有 123 個類別,是屬於 Multi-Class 且 Multi-Label 的文章集,由於類別數目眾多,故本論文取文章篇數前 10 大的 類別,來進行本論文的實驗,如表 4-1 為本論文實驗所取的類別之文章篇數, 9108 為所取的文章總數目。 acq 2131 corn 207 crude 510 earn 3753 grain 528 interest 389 money-fx 601 ship 276 trade 449 wheat 264 9108 表 4-1.Reuters-21578 文章集之各類別文章篇數
4.2 實驗設計
4.2.1 文章集的前置處理 各種文章集的內容繁雜,除了英文單字以及片語之外,包含許多數字和各種 標點符號。而每一個單字在詞性上也有很多種變化,不同的詞性也有可能有不同 的拼法。本論文將其文章集做統一的處理,包含以下兩個部分: (1)只保留英文字母 文章中包含許多的標點符號以及數字,為了不讓這些不必要的內文影響了分46 類的結果,故本論文將只會對文章集保留大小寫的英文字母 A 到 Z,這樣也同時 會減少取 feature 時的數目,降低取到不必要資訊的可能性。 (2)進行 Stemming 處理 英文中每一個單字的將會因為不同詞性而有可能有不同種的拼法,而造成分 類上的混亂,例如:play 和 plays,都是屬於同樣意思的單字,差別只在單複數 主詞。故本論文為了將其統一,而對於只剩下英文字母的文章集進行 stemming 的處理。 4.2.2 實驗方法與參數 (1)1.Accuracy 的評估方法: accuracy: 中分類正確的文章篇數 所有的 的文章篇數