國
立
交
通
大
學
資訊科學與工程研究所
碩
士
論
文
濾波反投影演算法之 FPGA 硬體平台實現
FPGA Implementation for Filtered Back Projection
Algorithm
研 究 生:張騰介
指導教授:荊宇泰 博士
濾波反投影演算法之 FPGA 硬體平台實現
FPGA Implementation for Filtered Back Projection Algorithm
研 究 生:張騰介 Student:Teng-Chieh Chang
指導教授:荊宇泰 Advisor:Yu-Tai Ching
國 立 交 通 大 學
資 訊 科 學 與 工 程 研 究 所
碩 士 論 文
A ThesisSubmitted to Institute of Computer Science and Engineering College of Computer Science
National Chiao Tung University in partial Fulfillment of the Requirements
for the Degree of Master
in
Computer Science September 2005
Hsinchu, Taiwan, Republic of China
濾波反投影演算法之 FPGA 硬體平台
實現
學生:張騰介 指導教授:荊宇泰博士
國立交通大學資訊科學與工程研究所
摘 要
電腦斷層掃瞄自發明以來到現在,技術已經非常成熟,除了應用在醫療診斷 外,也應用在其他領域。但是由於價格昂貴,體積龐大不易搬動,難以在其他領 域堆廣。我們利用現今硬體製程進步,IC 技術發達之利,希望能設計一顆便宜 的系統單晶片來執行影像重建的工作。我們使用濾波反投影演算法作為影像重組 的理論基礎,並且使用 Xilinx 公司出產的 ML310 Development Board 作為我們實 作的平台。實作出來的系統單晶片雛形在重建影像上效率符合預期,重建出來的 影像也有良好的效果。FPGA Implementation for Filtered
Back Projection Algorithm
Student:Teng-Chieh Chang Advisor:Dr. Yu-Tai Ching
Department of Computer and Information Science
National Chiao Tung Universal
Abstract
Since Computer Tomography (CT) scanner was invented, many
advances have been made in scanner technology as well as in the
algorithm used for CT reconstruction. Today CT scanners are used in
diagnostic medicine and other applications. But the CT scanner is
expensive and too heavy to take it along, so CT is not popular except
diagnostic medicine. Now the hardware and IC design progress rapidly,
so we hope to design a cheap SoC for reconstructing image. The Filtered
Back Projection Algorithm is the base theory of our design and we
implement it on ML310 Development Board of Xilinx company.
Experimental results show that the efficiency of SoC model of the
Filtered Back Projection Algorithm reach our anticipation and the quality
of reconstructed image is feasible.
誌謝
在這裡首先我要感謝我的指導老師,荊宇泰教授,在這兩年中給
予我自由學習的機會,也指導我研究的方向,更重要的是信任我的研
究與學習。再來要感謝志陽、富祺、冠杰、書豪、方正、滄智學長們
對我的關懷,尤其謝謝冠杰學長帶我接觸佛學的精神,讓我多些生活
的體悟。謝謝滄智學長給我許多學習上的建議並與我ㄧ起努力共同渡
過論文難產期。也謝謝這兩年來陪我ㄧ路走過來的同學,孟誌、樹偉、
杰翰及雅榆。謝謝你們與我ㄧ起上課、一起熬夜寫程式、一起吃飯、
一起休閒,在學習或生活上共同扶持。謝謝學弟們與我共同討論學
習,尤其是秉章,對於研究的熱情讓我也學習不少。
最後感謝我的父母,我的家人以及我的小姑。沒有你們的支持我
無法考上交大資科所,沒有你們的鼓勵畢業的路也許更長。謝謝你們
我的父母我的家人我的同學及朋友們,願將喜悅與你們分享。
目錄
中文摘要...i 英文摘照...ii 誌謝...iv 目錄...v 第一章 緒論...1 1.1 研究背景...1 1.2 論文架構...2 第二章 影像重組理論...4 2.1 影像重建演算法...52.1.1 Fourier Slice Theorem ...6
2.1.2 濾波反投影演算法...9 2.1.3 濾波反投影演算法實作...12 第三章 系統單晶片設計與發展平台...17 3.1 系統單晶片設計...17 3.1.1 軟硬體共同設計...18 3.2 嵌入式系統 SoC 發展平台...19 第四章 FBP 演算法嵌入式系統 ...23 4.1 嵌入式系統軟體實作...24 4.1.1 FBP 演算法分析與實作 ...24 4.2 嵌入式系統硬體實作...25 4.2.1 嵌入式系統硬體架構...25 4.2.2 建立 FBP 週邊元件 ...28 第五章 FBP 元件實作 ...34 5.1 IP 介紹及 fbp_locate 模組實作 ...35
5.1.1 Single-Port Blcok Memory IP ...35
5.1.2 Fast Fourier Transform v3.1 IP...38
5.1.3 fbp_locate VHDL 程式模組實作...44 5.2 user_logic VHDL 程式模組...46 5.2.1 user_logic 模組實作...46 5.2.2 軟體與硬體溝通介面...49 第六章 實驗與討論...52 6.1 系統驗證與實驗結果...52 6.2 結果討論與未來展望...54
圖目錄
圖 2-1 兩種投影方式示意圖。(a)平行投影,(b)扇形投影 ...4 圖 2-2 平行投影與投影資料關係圖 ...5 圖 2-3 傅立葉切片理論建立起投影資料與物體截面圖頻率域中射線的關係 ...8 圖 2-4 待測物體截面圖二維傅立葉頻率域 ...8 圖 2-5 這圖顯示從投影資料中得到的頻率域情形。(a)是理想狀況,(b)是經過傅 立葉切片理論後...9 圖 2-6 背投影過程示意圖 ...12 圖 2-7 (a)是sinogram影像的示意圖,(b)是 256x256 pixels灰階的範例圖,(c)是(b) 的sinogram...13 圖 2-8 FBP演算法程式流程 ...14 圖 2-9 頻率域中的濾波函數 ...16 圖 3-1 嵌入式系統SoC設計流程圖 ...18 圖 3-2 典型軟硬體設計流程 ...19圖 3-3 Xilinx公司的ML310 Development Board...20
圖 3-4 以PowerPC 405 為核心的嵌入式系統架構 ...21 圖 4-1 EDK設計流程概觀 ...23 圖 4-2 基礎嵌入式系統架構圖 ...26 圖 4-3 FBP演算法嵌入式系統架構圖 ...28 圖 4-4 IPIF是IP模組與PLB bus之間的介面...29 圖 4-5 FBP元件與PLB bus間的模組示意圖 ...33 圖 4-6 使用者建立週邊元件並加入系統的過程 ...33 圖 5-1 FBP元件內的模組階層 ...34
圖 5-2 Core Schematic Symbol ...36
圖 5-3 No-Read-on-Write Mode Waveform ...37
圖 5-4 Core Schematic Symbol ...39
圖 5-5 IP開始輸入資料的波形圖...43
圖 5-6 IP輸出資料的波形圖...43
圖 5-7 Core Schematic Symbol ...44
圖 5-8 fbp_locate模組中的有限狀態機示意圖 ...45
圖 5-9 Core Schematic Symbol ...46
圖 5-10 user_logic模組的有限狀態機示意圖...47
圖 5-11 user_logic模組功能方塊圖...48
圖 6-1 (a)是原始影像,(b)是圖(a)的sinogram影像,共投影 128 次,每次投影偵測 128 筆資料。...54
第一章 緒論
1 第一章 緒論
我們常說「眼見為憑(To see is to believe.)」。從我們身體感官系統所直接感 受到的訊息是最為直接,最容易讓我們信賴,視覺是最佳實例。映入眼簾的不只 是一張圖片或影像而已,隨著時間演進,我們大腦可以從圖片或影像的動態變 遷,串接成連續的資訊,讓我們了解身體外在的環境,其生動與變化遠遠勝過語 言或文字描述。所以在影像處理 這門學問中有句名言:「一張圖片勝過千言萬語 (A picture is more than a thousand words.)」。
在醫學診斷方面也是如此,回想我們生病上醫院看病時的過程,若用工程觀 點來分析醫師對我們的診斷治療過程,那醫師對病情資料的蒐集是首要的步驟。 而為了顯現人體內部的病變,並且希望能夠以非侵入方式透視人體內部結構時, 往往就需要仰賴透視人體的利器——電腦斷層掃描。
1.1 研究背景
電腦斷層掃描(Computer Tomography,CT)在一九七二年由 Godfrey Newbold Hounsfield 發明問市以來,在醫學臨床診斷上一直扮演著舉足輕重的角色,雖然 X光有輻射危險之虞,但是此系統可以讓醫護人員以非侵入方式,透視人體各部 分器官的形態變化,對於病變的診斷有很大助益,突破傳統解剖等醫療技術。 這項劃時代重大發明讓 Hounsfield 與建立電腦斷層掃描系統的線積分基礎 的物理學家 Alan Cormack,共同分享一九七九年諾貝爾獎。不過其中有關線積 分數學理論基礎,在一九一七年就被奧地利數學家 Johann Radon 推演過,因此
電腦斷層掃描技術中的物質密度函數沿著直線的線積分也被稱之為雷登轉換 (Radon Transform)。以雷登轉換為基礎,利用傅立葉理論在頻率空間尋求影像重 組的解決方法。而電腦斷層掃描中一般重建影像是利用最基本的反向投影法 (Back Projection)配合影像重建濾波器(Filter)重組影像,稱為濾波反投影(Filtered Back Projection,FBP)是一種快速有效的影像重建演算法。 隨著時代的進步,電腦斷層掃描的發展相當的成熟且應用領域越來越廣,除 了醫學外,也應用在天文學及一些非破壞性的偵測上例如機場,港口等因為安全 因素對來往的旅客或是貨物進行偵測,或是應用在生物、農業上對動植物生長作 觀察。然而,醫用的電腦斷層掃描儀器由於體積龐大不易搬運,再加上掃描方式 不適當、造價昂貴等因素因此無法有效的普及化。 但是隨著半導體技術的快速發展及電路設計軟體的進步,目前的積體電路 (Integrated Circuit,IC)設計主流⎯系統單晶片(System on Chip,SoC),可以整合 多個完整功能的電路,將構成整個系統的模組完整的放入晶片中,而不需要多顆 晶片就能擁有完整的系統功能。這樣可以大大的減低以晶片做核心的儀器生產成 本,也可以縮小儀器體積。
在此論文中,我們以 Xilinx 公司的 ML310 Development Board 為發展平台搭 配 Xilinx 公司的 Embedded Development Kit 軟體設計一個可以重建 128x128 pixels 灰階影像的嵌入式系統 SoC 晶片雛形。希望藉由 SoC 上成本及體積的優 勢,使電腦斷層掃描系統能變成攜帶容易,能掃描任意物體,且造價低廉的非醫 用電腦斷層掃描系統,使得這項非破壞性檢驗技術能更廣泛地應用在各層面。
1.2 論文架構
動機與目的。第二章介紹影像重建理論與我們使用的演算法⎯濾波反投影演算 法。第三章介紹系統單晶片設計與發展平台。第四章與第五章介紹我們實作濾波 反投影演算法嵌入式系統 SoC 雛型的過程。第六章討論我們的實作成果與未來 可以改進的地方。
第二章 影像重組理論
2 第二章 影像重組理論
電腦斷層掃描(Computer Tomography,CT)利用 x-ray、超音波或是放射線同 位素等對待測物體進行不同角度的投影(Projection),接著在投影的反面利用一連 串的探測器對透射出的 x-ray 等能量進行衰減量的偵測。這些資料我們稱為投影 資料(Projection Data)。透過一些影像重建演算法,我們可以利用這些不同投影角 度得到的投影資料重建出待測物體的截面圖。
對物體進行投影而收集投影資料的方式約有兩種,(1)平行投影(parallel projection)、(2)扇形投影(fan beam projection)。示意圖如下
(a) (b)
圖 2-1 兩種投影方式示意圖。(a)平行投影,(b)扇形投影
而下面我們要介紹的演算法是以平行投影為基礎的影像重建演算法。首先,我們 會先介紹電腦斷層攝影的基本概念,最後將介紹實際使用的演算法,濾波反投影 (filtered back projection,FBP)演算法。
2.1 影像重建演算法
影像重建演算法的主要問題在於如何利用投影資料來尋找物體截面圖上各 個點的線性衰減係數。例如我們以 x-ray 對生物組織進行投影,則我們可以在投 影面的另一邊偵測到 x-ray 的衰減量。在這裡我們考慮物體的每個點有不同的 x-ray 衰減係數(物質密度不同),而每個偵測器得到的衰減量,就是對應的 x-ray 射線透射物體時直線經過的點的衰減係數總和(類比物質密度總和),相當於是 x-ray 射線經過物體的那條路徑的線性積分(line integral)。如下圖所示圖 2-2 平行投影與投影資料關係圖 由上圖可知我們以二維函數 f
(
x,y)
來描述物體,加上( )
θ,t 參數,我們以線性積 分Pθ( )
t 來描述(
θ,t)
參數對應的 x-ray 射線對物體作投影而得到衰減係數總和。( )
=∫
( )( )
t f x y ds t P , , θ θ (2.1) 使用 delta function(2.2)
( )
⎩ ⎨ ⎧ = ≠ = 0 , 1 0 , 0 n n n δ 公式(2.1)可以改寫如下 (2.3)( )
t f( ) (
x y x y t)
dxdy P =∫ ∫
∞ + − ∞ − ∞ ∞ − δ θ θ θ , cos sin 公式(2.3)就是函數 的雷登轉換(Radon Transform)。集合所有同一個角度θ 的 值就成為角度θ的投影資料。(
x y f ,)
( )
t Pθ 後面將介紹到的濾波反投影演算法是利用傅立葉理論(Fourier Theory)與投 影資料來達到前述問題的封閉解(closed form solution)繼而重組出截面圖。連結傅 立葉轉換(Fourier Transform)到待測物體的截面圖之間的 基礎理論就是傅立葉切 片理論(Fourier Slice Theorem)。2.1.1 Fourier Slice Theorem
連 結 傅 立 葉 理 論 到 投 影 資 料 與 待 測 物 體 截 面 圖 之 間 的 基 礎 理 論 是 由 Bracewell[4]、Ramachandran和Lakshminaraynana[2],[3]發展,接下來的證明則是 由Kak和Slaney[1]推導的結果。二維傅立葉轉換定義如下: (2.4)
( )
( )
( ) dxdy e y x f v u F∫ ∫
∞ j ux vy ∞ − ∞ ∞ − + − = 2π , ,其中 u,v 是cycles unitlength。
接著我們定義角度為θ的投影資料及其傅立葉轉換 (2.5)
( )
P( )
te dt Sθ ω θ −j2πωt ∞ ∞ −∫
=其中ω是radians unitlength。
為了導出 Fourier Slice Theorem,我們需要定義新的座標系統
( )
t,s ,(
座標是原有的座標系統
)
s t,
(2.6) ⎥ ⎦ ⎤ ⎢ ⎣ ⎡ ⎥ ⎦ ⎤ ⎢ ⎣ ⎡ − = ⎥ ⎦ ⎤ ⎢ ⎣ ⎡ y x s t θ θ θ θ cos sin sin cos 參考圖 2-2,圖中的投影資料Pθ
( )
t 是相對於( )
x,y 座標從 0 度以逆時針旋轉θ角對 物體進行投影而得到的資料。若我們考慮新的座標系統( )
t,s ,則 是相對於 座標系統以( )
t Pθ(
t,s)
θ =0角度對物體進行投影得到的資料。此時在(
座標系統 中,考慮公式)
s t,( )
t f( ) (
x y x y t)
dxdy P =∫ ∫
∞ + − ∞ − ∞ ∞ − δ θ θ θ , cos sin (2.3) 及θ =0,沿著常數 t 定義出來的投影可以寫成 (2.7)( )
t f( )
t sds P∫
∞ ∞ − = , θ 將(2.7)代入(2.5)中我們可以得到 (2.8)( )
f( )
t s ds e dt Sθ ω ∞ , −j2πωt ∞ − ∞ ∞ −∫ ∫
⎢⎣⎡ ⎥⎦⎤ = 將整理公式(2.8),以公式(2.6)將( )
t,s 座標系統轉回( )
x,y 座標系統,則我們可以 得到下列公式 (2.9)( )
∫ ∫
∞( )
( ) ∞ − ∞ ∞ − + − = f x y e dxdy Sθ ω , j2πωxcosθ ysinθ 公式(2.9)的右手邊就是 2 維傅立葉轉換的定義,因此( )
F( )
u v Sθ ω = , (2.10) 從公式(2.10)可知道,在θ角度對待測物體截面圖作投影得到的投影資料,經過一 維傅立葉轉換後相當於待測物體截面圖的二維傅立葉頻率域(frequency domain) 中的一條通過低頻中心點的射線。下圖可以清楚的表示公式(2.10)的意義圖 2-3 傅立葉切片理論建立起投影資料與物體截面圖頻率域中射線的關係 有了上述結果,我們可以在θ1,θ2,…,θk角度對物體作投影,得到投影資料後 經過一維傅立葉轉換對應到截面圖的二維傅立葉頻率域中。如下圖所示: 圖 2-4 待測物體截面圖二維傅立葉頻率域 假設我們可以作無限個不同角度的投影,那我們得到的資料經過一維傅立葉轉換 後,可以填滿截面圖的頻率域,接著我們只要再作反傅立葉轉換(inverse Fourier Transform)就可以得到我們所希望的截面圖。 可是實際上,我們只能得到有限個不同投影角度的投影資料,且由 圖 2-4可知,從投影資料經過一維傅立葉轉換對應到頻率域中的資料點是中心點(低
頻)密集,外圍(高頻)離中心點越遠越稀疏,因此頻率域沒有對應到的資料點就需 要從已知資料點作內插法來當成預設資料。可是這其中會有相當大的誤差,尤其 是 越 高 頻 的 地 方 誤 差 越 大 , 造 成 重 建 回 來 的 截 面 圖 會 有 影 像 剝 蝕 (image degradation)的情形。因此上面提到的是電腦斷層掃描重建影像概念上的模式,實 作上我們得用不同的方式來完成。
2.1.2 濾波反投影演算法
這 邊 我 們 要 使 用 來 完 成 影 像 重 建 的 演 算 法 是 濾 波 反 投 影 (Filtered Back Projection,FBP(1))演算法。這演算法也是由 Fourier Slice Theorem 衍生而來,是 藉由公式原理的改寫來達成不同的運算實作。這邊我們先了解濾波反投影演算法 的想法。 由前一小節我們可以知道角度θ的投影資料作一維傅立葉轉換可對應到物體 截面圖二維傅立葉頻率域中的一條射線,這相當於截面圖二維傅立葉頻率域乘於 一個簡單的濾波器(filter)而得到如下圖(b)所示的情形。 (a) (b) (c) 圖 2-5 這圖顯示從投影資料中得到的頻率域情形。(a)是理想狀況,(b)是經過傅立葉切片理論後 得到的狀況,(c)是(b)圖經過濾波器加權後到的狀況,(c)圖中的資料狀況近似於(a) 但是對影像重建而言,我們希望得到的是投影資料的一維傅立葉轉換可以跟 上圖(a)的派外型射線是相當的,這樣我們集合幾個這樣的射線就可以重建出高 品質的影像。對於這想法,採用最接近的方式就是將投影資料的一維傅立葉轉換 ⎯Sθ( )
ω ,乘以濾波器⎯圖 2-5(a)中的楔形物的寬度。假設在 180°內共執行K次 不同角度的投影,則在頻率ω下,楔形物的寬度是2πω K。Sθ( )
ω 在經過2πω K 的加權後,我們可以得到圖 2-5(c)的圖形,這跟圖 2-5(a)來比較,具有相近的”質量”。在足夠的投影次數下,集合圖 2-5(c)的射線,可以重建出接近圖 2-5(a) 所重建的影像。而濾波反投影演算法,聞其名可以知道,演算法是分為濾波 (filtering)部分:Sθ
( )
ω 在頻率域乘以濾波器作加權。及反投影(backprojection)部 分:將加權後的Sθ( )
ω 值重組回影像。底下我們要推導濾波反投影演算法的數學 公式。 我們同樣以二維函數 f(
x,y)
來描述待測物體, f( )
x,y 的反傅立葉轉換(inverse Fourier Transform)定義如下:
(2.11)
( )
∫ ∫
∞( )
( ) ∞ − ∞ ∞ − + = F u ve dudv y x f , , j2π ux vy將頻率域的標準座標系統轉成極座標系統(polar coordinate system),如下
θ ω θ ωcos , = sin = v u (2.12) 微分細節如下 θ ω ωd d dudv = (2.13) 公式(2.11)可以改寫如下 (2.14)
( )
∫ ∫
∞(
)
( + ) = 2π ω θ πω θ θω ω θ 0 0 sin cos 2 , ,y F e d d x f j x y 我們將積分(integral)分為 0°到 180°及 180°到 360°兩部分,則 (2.15)( )
(
)
( )(
)
[ ]∫ ∫
∫ ∫
∞ + + + ∞ + + + = π πω θ π θ π π πω θ θ θ ω ω π θ ω θ ω ω θ ω 0 0 ) sin( ) cos( 2 0 0 sin cos 2 , , , d d e F d d e F y x f y x j y x j 利用傅立葉原理(
ω,θ +π)
=F(
−ω,θ)
F (2.16) 可以簡化公式(2.15)如下( )
π(
ω θ)
ω πω ω θ d d e F y x f =∫ ∫
⎢⎣⎡ ∞ j t ⎥⎦⎤ ∞ − 0 2 , , (2.17)其中 t =xcosθ +ysinθ (2.18) 將公式(2.17)中括號的二維傅立葉轉換F
(
ω,θ)
以投影資料的一維傅立葉轉換( )
ω θ S 來代替,我們得到( )
π( )
ω ω πω ω θ θ e d d S y x f =∫ ∫
⎢⎣⎡ ∞ j t ⎥⎦⎤ ∞ − 0 2 , (2.19) 整理公式(2.19)中的積分式子 (2.20)( )
x y πQθ(
x θ y θ)
dθ f =∫
+ 0 cos sin , 其中( )
( )
ω ω πω ω θ θ t S e d Q∫
∞ j t ∞ − = 2 (2.21) 其中公式(2.21)描述一個濾波的動作。在頻率域中使用ω 當濾波器對Sθ( )
ω 進行 加權,所以公式(2.21)稱為濾波投影(filtered projection)。而公式(2.20)則對每個 進行背投影(back projection)的動作。對於重建影像上的每個點(
,在角 度θ下可以找到對應的值( )
t Qθ x,y)
θ θ sin cos y x t= + 。如 圖 2-6,由θi 角可以找到對應的Q( )
t ,在 i θ Qθi( )
t 距離投影資料中心點tj置,可以找到LM直線上 所有(
x,y)
點累加的衰減係數總和Q( )
tj i θ 值,Qθi( )
tj 值可以平均分布到LM直線上 的所有(
點。假設在 180°內對物體的投影有K次,則對重建影像的點( )
而 言,每個點可以累加K次對應的)
y x, x,y( )
tj Qθ i 值,計算出每個點的線性衰減係數,而重 建出影像。公式(2.20)及(2.21)就是從投影資料到整個影像重建完成的計算過程。 底下我們將介紹在個人電腦上如何以軟體實作此演算法。 備註 1:後面的章節中,濾波反投影演算法將以 FBP 演算法來簡稱。圖 2-6 背投影過程示意圖
2.1.3 濾波反投影演算法實作
FBP 演算法由前一小節可以知道,共分為濾波投影及備投影兩部分。根據 Filtered Projection f( )
x y =∫
πQθ(
x θ +y θ)
dθ 0 cos sin , (2.20) Back Projection Qθ( )
t∫
Sθ( )
ω ωej πωtdω ∞ ∞ − = 2 (2.21) 兩程式,假設 0°到 180°之間對待測物體共作 K 次不同角度的投影,所以演算法 簡單的流程如下: I. 濾波投影 取得θi的投影資料Pθi( )
t ,i 從 0 到K−1,執行下列工作共 K 次。 i. 將Pθ( )
t 作傅立葉轉換到頻率域,成為Sθ( )
ω 。 ii. 對Sθ( )
ω 乘與濾波器ω 在頻率域作加權。iii. 將加權後的Sθ
( )
ω 值作反傅立葉轉換回空間域(space domain),成為 。( )
t Qθi. 從點
(
x,y)
及角度θi算出tj =xcosθi + ysinθi,i 從 0 到K −1,共 K 次。 ii. 累加每個Qθi( )
t 中,位置 tj上得到的Qθi( )
tj 值,共累加 K 次,得到 點原本的線性衰減係數。( )
x,y 在實作上,電腦斷層掃描取得的投影資料會排列成一張影像,我們稱為 sinogram。sinogram的排列,是按照 0°到 180°依序將投影資料以一列一列的方式 擺列成一張影像,其中若平行投影光束有 256 束,則每列就有 256 筆偵測器得到 的偵測資料。sinogram示意圖如圖 2-7(a)所示: 0° 90° 180°Ray beam width Projection Data
(a)
(b) (c)
圖 2-7 (a)是 sinogram 影像的示意圖,(b)是 256x256 pixels 灰階的範例圖,(c)是(b)的 sinogram 影像。
的小正方形。而圖 2-7(c)就是對圖 2-7(b)進行 256 次投影,每次投影偵測到 256 筆偵測資料而得到的sinogram影像,因此sinogram影像也是 256x256 pixels大小, 在此我們重建影像要求得的pixel點衰減係數就是pixel的灰階值。 我們參考前面的提到的 FBP 演算法流程,先在個人電腦上以 C Language 實 作此演算法,以驗證 FBP 演算法的正確性。根據演算法流程,FBP 演算法程式 設計流程圖如下所示: Input
sinogram image Filter Backproject
Output reconstructed image 圖 2-8 FBP 演算法程式流程 所以程式上的內容主要也是分成四個部分,以底下的 pseudo code 程式來表 示我們軟體的實作內容: 表 2-1 FBP 演算法的 pseudo code #define angle=128; /* 旋轉 128 個角度 */
#define rays=128; /* rays beam 與 image 的 raw pixel 個數一樣 */ const int x_max = rays;
const int y_max = rays;
const int x_cen = x_max/2; /* x_cen 表示 sinogram 影像 x 軸的中心位置 */ const int y_cen = y_max/2; /* y_cen 表示 sinogram 影像 y 軸的中心位置 */ double sonogram[angles][ rays]; /* 儲存原始 sinogram 影像的陣列 */
double filtered_rel[angles][rays]; /* 儲存完成 filter 後的 singogra 影像的陣列 */ double reconstructed[rays][ rays]; /* 儲存重建完成影像的陣列 */
main() begin
/******從 sinogram 影像中讀取投影資料******************/ read sinogram image to sinogram[angles][rays];
/******底下是filtered projection的pseudo code **************/ /* 作 1D FFT 及 IFFT 之前要作 2 冪次方的 ZERO Padding */
int logn = int(ceil(log10(rays)/log10(2))+1); int fftsize = int(pow(2,logn));
/* 定義FFT及IFFT中存實部,虛部的array */ double *rel = new double [fftsize+1];
double *img = new double [fftsize+1]; /* 定義 window值 */
double *window = new double [fftsize+1]; for(i=1; i<fftsize/2; i++)
window[i+1] = window[fftsize-i+1] = i; window[0] = window[1] = 1;
window[fftsize/2+1] = fftsize/2;
for( a=0 ; a<angle ; a++ ) loop
memset(rel,0,sizeof(double)*(fftsize+1)); memset(img,0,sizeof(double)*(fftsize+1)); memcpy(rel, sinogram[a],sizeof(double)*rays); FFT(rel, img); /* 做完 FFT 後與 windows 相乘 */ for(i=1;i<fftsize+1;i++) loop rel[i]*=(window[i]/(double)fftsize*2); img[i]*=(window[i]/(double)fftsize*2); end loop; IFFT(rel, img); memcpy(filtered_rel[a],rel,sizeof(double)*rays); end loop;
/******底下是back projection的pseudo code **************/ /* the mid-point是投影光束的中心位置 */
int midpoint = rays/2; for(y=0; y<y_max; y++) loop
for(x=0; x<x_max; x++) loop double sum = 0;
for(int i=0; i<angles; i++) loop
theta = i*PI/angles;
t =cos(theta)*((x-x_cen)/(double)(x_cen)) +sin(theta)*((y-y_cen)/(double)(y_cen));
/* mid_bin表示當角度為theta時,重建影像(x,y)pixel對應於Qθ(t)的位置*/
mid_bin = (t* mid_point)+ mid_point;
/* mid-bin可能在Qθ(t)的整數位置low-bin跟high-bin之間,所以要求 mid-bin在low-bin與high-bin之間的位置比例,方便以後作內插法 */ lb = (int)mid_bin; hb = lb + (mid_bin>lb? 1:0); frac = mid_bin - lb; /* mid_bin可以能在low_bin跟high_bin中間,所以作gray level要作內插法 計算 */
sum += (1-frac)*filtered_rel[i][lb] + frac*filtered_rel[i][hb];
end loop;
reconstructed [y][x] = sum;
end loop;
end loop;
/******將重建好的截面圖pixel灰階值寫回重建影像中******************/ write reconstructed[rays][ rays] to reconstructed imgae;
end;
上面的pseudo code內容是針對 128x128 大小的sinogram影像(0°到 180°共 128 個投 影角度,每次投影偵測有 128 筆偵測資料)可以重建出截面圖為 128x128 pixels大 小的的灰階影像。pseudo code中,在濾波投影(filtered projection)過程時,傅立葉 轉換我們以快速傅立葉轉換(Fast Fourier Transform,FFT)來完成,且執行快速傅 立葉轉換前,取樣資料需先執行Zero Padding擴大成 2 的冪次方。而在頻率域中 需 使 用 的 濾 波 器 ω 函 數 , 則 如 圖 2-9 所 示 , 將 投 影 資 料 的 一 維 傅 立 葉 值 ⎯Sθ
( )
ω ,乘與一個權重,低頻中心點權重值低,越往高頻則權重越高。第三章 系統單晶片設計與發展平台
3 系統單晶片設計與發展平台
系統單晶片(System on Chip,SoC)解決方案被譽為半導體業最重要的發展之 一,目前,從數位手機和數位電視等消費類電子產品到高階通訊 LAN/WAN 設 備中,這一元件隨處可見。過去,為了建立此類嵌入式系統,設計工程師不得不 在處理器、邏輯單元和記憶體等三種硬體中進行選擇,而現在這些元件已合併為 單一的 SoC 解決方案。3.1 系統單晶片設計
硬體製程技術提高,晶片中可容納的電晶體數量不斷提昇。在考慮晶片功 耗,面積及成本上,我們會希望將多個功能完整的電路整合成一顆積體電路,就 是系統單晶片(SoC)。可整合到系統單晶片的電路包括中央處理器,記憶體,溝 通介面,應用電路,數位訊號處理器(Digital Signal Processor,DSP)等。系統單 晶片最直接的想法,就是將構成系統的所有電路模組完整的放入單晶片中,所以 此類的系統單晶片也具有處理器,記憶體及應用電路,可以發展嵌入式系統的功 能。嵌入式系統SoC可採用現場可程式閘陣列(Field Programmable Gate Array , FPGA)或專用積體電路(Application Specific Integrated Circuit,ASIC)實現。傳統 設計的方法,如圖 3-1(a)所示,在設計的早期就將軟硬體明顯分離獨立設計,最 後階段才將軟硬體整合。由於軟體設計者不熟悉硬體的架構,硬體設計者不了解 軟體設計的方法,若合成發生問題,常常都無法確定是軟硬設計上何種錯誤,導
致修改上的困難度提高,延遲了產品上市的時間。再者,隨著晶片容量增大,功 能需求增加,嵌入式系統的複雜度也相對地提高,這種傳統設計方法,在最後邏 輯合成時除了時間的延遲外,也會浪費人力和成本在系統整合上。 (a) 傳統設計流程 (b)軟硬體共同設計流程 圖 3-1 嵌入式系統 SoC 設計流程圖 然而,晶片設計的生產力在這幾十年來是有目共睹,但是與晶片容量的成 長,卻是有著越來越大的落差。因此,一個新的設計方法論就因應的誕生-軟硬 體共同設計(Software/Hardware Co-design)。這是一個以系統觀點出發的方法論, 強調軟硬體設計時的一致性與整合性,如 圖 3-1(b),對於軟體發展的驗證 (Verification)更加容易,且硬體設計的錯誤也能提早發現,降低設計所需的時間 與成本,大大縮短系統設計的時間,因應市場的即時性。
3.1.1 軟硬體共同設計
一般而言,典型的軟硬體共同設計流程,可以用圖 3-2 典型軟硬體設計流 程來表示。圖 3-2 典型軟硬體設計流程 軟硬體共同設計的目的,是為了軟體與硬體的協同描述、驗證與合成提供一 個整合的環境,以圖 3-2 典型軟硬體設計流程可知,首先需對你所設計的系統 作規格與功能上的分析,決定有哪些功能,需要哪些硬體元件及控制流程為何 等。再來利用一套合適的演算法,將軟硬體部分切割,並設計一個介面供軟硬體 溝通之用。最後便是將軟硬體與溝通的介面三個部份實作出來,並加以整合,做 軟硬體共同的驗證(Verification)與測試(Testing),再依設計成本、系統效能或低 功率(Low power)等不同方向考量,若需要改進再重做軟硬體切割,直到最佳的 效果。 在這邊我們的 FBP 演算法將採用現場可程式閘陣列(FPGA)來實現,設計流 程也將採用上述的軟硬體共同設計的方式來完成我們的 FBP 演算法嵌入式系統 的實作。
3.2 嵌入式系統 SoC 發展平台
在我們的實作中採用的是Xilinx公司生產的嵌入式系統發展平台⎯ML310 Development Board,如 圖 3-3所示:圖 3-3 Xilinx 公司的 ML310 Development Board
平台的核心是一顆 Virtex-Ⅱ pro FPGA(Field Programmable Gate Array),型號 是 XC2VP30。這顆 FPGA 共有 30,816 Logic Cells(1)提供邏輯合成的電路資源, 且具有 2 顆內建的 PowerPC 405 處理器,可以當作嵌入式系統的核心處理器。此 外,FPGA 內尚有內建的 18x18 bits 的乘法器 136 顆及 136 塊 18Kbits 的 Block RAM 提供現成的電路元件。
除了 FPGA 外,發展平台提供一個嵌入式系統相當完整的發展環境,除了電 源與一些 I/O 介面,並利用匯流排將核心模組與邏輯模組整合在一起。平台上重 要的邏輯模組像是 DDR Memory,System ACE CF Controller,CompactFlash Slot, IDE Drive Connectors,PCI Slots 等。
平 台 上 主 要 的 匯 流 排 是 Process Local Bus(PLB) 與 On-chip Peripheral Bus(OPB),PLB bus 與 OPB bus 是 IBM CoreConnect 的標準匯流排,其中 PLB bus 是高速匯流排,而 OPB bus 是低速匯流排,兩個匯流排中間有個 Bridge 作連接, 形成整個嵌入式系統的骨幹。
圖 3-4 以 PowerPC 405 為核心的嵌入式系統架構
我們配合 ML310 平台使用的發展工具是 Embedded Development Kit(EDK) 及 Integrated Software Enviroment(ISE)。EDK 提供以 PowerPC 405 為核心的嵌入 式系統設計者豐富的設計工具及多樣的嵌入式系統週邊設備,如 Memory Controller、UART(Uni-versal Asynchronous Receiver/Transmitter)、GPIO(General Purpose Input/Output)等。EDK 發展工具主要包括下面幾部分:
z 嵌入式系統核心及週邊元件的硬體 IP(Intellectual Property)。 z 嵌入式系統軟體所需要的驅動程式(Drivers),函式庫(Libraries)。 z 具有整合軟硬體研發環境的 Xilinx Platform Studio(XPS)。
其中 Xilinx Platform Studio 中有幾個重要的發展工具,在我們的 FBP 演算法嵌入 式系統實作中將使用到,所以下面簡單介紹這些工具:
z The Base System Builder(BSB) wizard:這是一個軟體工具可以幫助使用者快 速的建立特定平台上可以執行的基礎嵌入式系統。在執行完 BSB wizard 後,會產生兩個重要的檔案,一個是硬體規格檔(Microprocessor Hardware Specification , MHS) , 另 一 個 是 軟 體 規 格 檔 (Microprocessor Software
Specification,MSS)。MHS 檔案定義系統的架構及使用到的週邊元件及核心 處理器。也定義了系統中週邊與核心元件間匯流排的連接關係,週邊元件在 系統中的位置地圖(address map)及各個週邊元件的參數設定。MSS 檔案則是 定義週邊元件的驅動程式,系統的標準輸入輸出設備,系統中斷處理常式及 相關的軟體設定。
z The Platform Generator Tool(PlatGen):輸入 MHS 檔案,建立系統的 netlist 檔案,並支援檔案下載到 FPGA 時所需的相關檔案,及新增週邊元件到系統 中的相關工作。在執行 PlatGen 工具時,ISE 將自動被呼叫去完成整個硬體 平台的邏輯合成,電路佈局到產生 netlist 檔案。
z The Library Generator Tool(LibGen):輸入 MSS 檔案,建立並個人化週邊元 件驅動程式、函式庫、系統中斷處理常式及檔案系統。
z The Bitstream Initializer tool:在 FPGA 中對處理器將存取的指令記憶體區塊 進行初始化設定,而指令記憶體區塊則存在 Block RAM 中。這個工具將讀 入 MHS 檔案,並且呼叫 ISE 的 Data2MEM 工具來初始化 FPGA 中使用到的 Block RAM。
z Create/Import Peripheral Wizard:幫助使用者建立自己的週邊元件並且加入嵌 入式系統中。
ISE 是套 IC 設計的整合軟體環境,包含多個軟體套件,可以執行完整的設 計流程。從硬體描述語言(Hardware Description Language)程式的編寫(如 VHDL 及 Verilog),設計的輸入,邏輯模擬,邏輯合成,電路佈局,產生 netlist 檔案, 產生可以載入 FPGA 配置電路的 BitStream 檔等工作。而 EDK 軟體中,有牽涉 到 IC 設計流程的工作則是呼叫 ISE 來完成這些工作。
第四章 FBP 演算法嵌入式系統
4 第四章 FBP 演算法嵌入式系統
我們的目標是將FBP演算法在ML310 Development Board的架構下實作成嵌 入式系統SoC。配合ML310 平台,我們使用EDK發展工具來完成我們的實作。而 EDK軟體上的設計流程如圖 4-1所示,是軟硬體共同設計的方式。 圖 4-1 EDK 設計流程概觀 由上面的流程圖可以知道,我們完全可以採用 Standard Embedded SW Development Flow,以 C Language 來完成 FBP 演算法所有功能,再與 ML310 Development Board 上的基本嵌入式系統元件如 PowerPC 405、PLB bus 及 DDR SDRAM 等硬體元件整合好,單純以 PowerPC 405 處理器執行所有運算,這樣就 是一個完整的 FBP 演算法嵌入式系統了。可是這樣並不符合我們的需求,首先 PowerPC 405 處理器並不支援硬體的 float point 運算,而是以軟體模擬的方式來 完成,加上 PowerPC 405 處理器的運算頻率並不高,這將使的 FBP 演算法運算 的時間拉長。再且,FBP 演算法中有許多運算式是固定的且重複執行次數可預 期,相當適合實作成硬體來加速整個演算法的運算。因此我們要先分析 FBP 演算法,分析出哪些地方採用硬體實作比較好,哪 些地方用軟體撰寫比較恰當。ML310 board 是一塊完整的嵌入式系統發展平台, 因此我們可以依據我們的需求選擇需要使用的模組。並將 FBP 演算法中要以硬 體加速的部分在 FPGA 中實作成硬體並加入嵌入式系統架構中。
4.1 嵌入式系統軟體實作
4.1.1 FBP 演算法分析與實作
假設 0°到 180°之間對待測物體共作K次不同角度的投影,則由表 2-1 FBP演 算法的pseudo code中,我們可以知道,程式主要分為Filtered Projection和Back Projection兩部分。Filtered Projection的計算集中在K次的FFT、Sθ( )
ω 乘與ω 作加 權及IFFT運算。而Back Projection過程中需作一個三層for-loop的數學運算,以表 2-1 FBP演算法的pseudo code內容為前提,我們要重建 128x128 的灰階影像,則 三層for-loop最內層的數學運算我們要執行 128*128*K次,這是相當大量的數學 運算。 由於我們在個人電腦上已完成 FBP 演算法的軟體實作,所以我們暫時先在 嵌入式軟體上完成 FBP 演算法。因為我們的實作平台 ML310 Development Board 不支援硬體的 float point 運算,所以程式的撰寫過程中我們以 fix point 的方式來 處理帶有小數的資料,以加速 FBP 程式運算的速度。由於處理的資料是 sinogram 影像中 pixel 的灰階值,資料寬度是 8 bits。因此我們以 fix point 的方式處理資料 的方法是將資料放大 1024(210)倍。一方面是資料放大 1024 倍相當可以保存小數 點以下三位的資料,不至於在數學運算過程中流失過多的資訊,使的重建回來的 影像失真。取 2 的冪次方倍數,則是考慮以硬體實作 FBP 演算法中的數學運算
時可以使用位元移動的方式來作乘除法的動作,避免使用過多的乘除法器增加電 路佈局的複雜度及所耗費的 FPGA 電路資源。
參照 圖 2-8的FBP程式流程圖,其中關於Input sonogram image及Output reconstructed image的部分,我們利用ML310 Development Board的CompactFlash Slot上的 512MB CompactFlash SanDisk作為sinogram影像及完成重建後影像的儲 存設備。
由於我們的 FBP 程式要讀取 SanDisk 上的 sinogram 影像及回存重建的影 像,因此我們需要可以讀寫 SanDisk 的函式庫。Xilinx 公司所提供的函式庫名稱 為 xilfatfs,我們只要在 EDK 的 Software Platform Settings 設定選項中勾選此函式 庫,並在 FBP 程式中包含 xsysace.h 及 sysace_stdio.h 兩個標頭檔,即可順利讀寫 SanDisk。
完成FBP程式後經過圖 4-1中的Standard Embedded SW Development Flow過 程可以得到一個附檔名為.elf的執行檔。附檔名為.elf的執行檔將與後面提到的系 統硬體平台設定檔system.bit合併使用。
4.2 嵌入式系統硬體實作
4.2.1 嵌入式系統硬體架構
完成 FBP 程式後,我們要建立嵌入式系統的硬體架構。ML310 Development Board 是完整的嵌入式系統發展平台,因此具有多種硬體設備。在這我們的重點 在於 FBP 演算法的運算,因此我們只要基本的嵌入式系統成員,如下所使示 z Processor:PowerPC 405 Corez Bus System:Processor Local Bus 及 On-Chip Peripheral Bus z Memory:DDR SDRAM 及 FPGA 內的 Block RAM
z I/O Device:RS232_Uart 及 SysAce_CompactFlash
其中RS232_Uart可以讓我們透過terminal程式經由serial port與系統溝通。 SysAce_CompactFlash 則 讓 我 們 可 以 透 過 System ACE CF Controller 控 制 CompactFlash card,以達到讀寫的目的。系統的建立,我們可以透過3.2節中提到 的EDK軟體中的功能,BSB wizard。透過此wizard從硬體選單中勾選我們需要的 硬體成員,由EDK軟體幫我們建立基本的系統。其中細部設定上,RS232_Uart 及SysAce_CompactFlash本身是比較慢的週邊設備,因此與OPB Bus連接,DDR SDRAM是高速的設備,因此與PLB Bus連接。 建立好的系統硬體架構圖如下: PLB Bus OPB Bus PPC 405 Core PLB2OPB Bridge SysACE_ CompactFlash RS232 _Uart DDR_ SDRAM 圖 4-2 基礎嵌入式系統架構圖
經過圖 4-1中Standard FPGA HW Development Flow流程後會產生系統硬體
平台設定檔 合併可以 產生系統設定檔 此 中可以配置電路安裝 整個 演算法嵌入式系統。但前面我們提到,此架構完全由 處理 system.bit。將4.1.1節中,完成的FBP程式執行檔與system.bit download.bit。將 Bitstream檔下載至FPGA FBP PowerPC 405
器擔任FBP程式的所有運算。由於不支援硬體的float point運算且PowerPC 405 本 身的運算頻率算不上快。因此我們將對FBP程式中運算負擔較重的地方實作成硬 體,使用硬體來加速。 由演算法分析中我們可以知道 FBP 程式中,時間耗費最大,運算量最高的 兩個 jection 過程中的 FFT 轉換、頻率域中的加權運算及 IFFT 轉換。 方的運算。我們將設計一個名 jection過程中從FFT開始到IFFT完成之間的所有數學運算。參考表 2-1 作傅立葉轉換成 Sθ(ω) */ g); θ |ω|作加權運算 */
i=1 ftsize+1 loop
ble)fftsize*2);
ω ω|作反傅立葉轉換成 Qθ(t) */
地方是: z Filtered Pro
z Back Projection 過程中的 3 層 for-loop 運算。 因此我們希望以硬體加速的方式來完成上面兩個地 為 FBP 的週邊元件,此週邊元件是一個 IP 將在 FPGA 中合成此電路。此 FBP 元 件有下列兩個功能 功能一: Filtered Pro FBP演算法的pseudo code,內容如下: 表 4-1 /* Pθ(t) FFT(rel, im S (ω)與濾波器 /*
for( ;i<f ;i++) rel[i]*=(window[i]/(dou img[i]*=(window[i]/(double)fftsize*2); end loop; /* 將 Sθ( ) | IFFT(rel, img); 功能二:
Back Projection過程中 3 層for-loop內的數學運算。參考表 2-1 FBP演算法的 pseudo code,內容如下:
表 4-2 /* 值可以求出第i次投影的投影角度θ(theta) */ theta = i*PI/angles; -y_ /(double)(y_cen)); 度為theta時,重建影像(x,y)pixel對應於Qθ(t)的位置*/ in在low_bin與 插法 */ 經由i t =cos(theta)*((x-x_cen)/(double)(x_cen))+sin(theta)*((y cen) /* mid_bin表示當角
mid_bin = (t* mid_point)+ mid_point;
/* mid_bin可能在Qθ(t)的整數位置low_bin跟high_bin之間,所以要求mid_b high_bin之間的位置比例,方便以後作內 lb = (int)mid_bin; /* lb表示low_bin */ hb = lb + (mid_bin>lb? 1:0); /* hb表示high_bin */ frac = mid_bin - lb; 由於我們希望 FBP 的運算頻率越快越好,因此我們將週邊元件 FBP IP 與高 速的
4.2.2 建立 FBP 週邊元件
ral Wizard 幫我們建立自己的週邊元件, 在這 PLB bus 作連接。因此新的系統硬體架構圖如下: PLB OPB Bus Bus 圖 4-3 FBP 演算法嵌入式系統架構圖 PLB2OPB Bridge PPC 405 Core SysACE_ CompactFlash DDR_ SDRAM RS232 _Uart FBPEDK 軟體提供 Create/Import Periphe
Peripheral wizard 建立 FBP 元件。FBP 元件的硬體描述,目前 EDK 軟體只支援 VHDL 模組,我們將最上層電路的 VHDL 模組,取名為 fbp。接下來我們選擇將 FBP 元件連接上 PLB Bus。之後我們要決定 FBP 元件與 PLB bus 之間的溝通方 式。EDK 提供 IP Interface(IPIF)框架,它可以提供使用者建立的 IP 模組與 on-chip buses 之間的溝通介面服務。由於連接的 Bus 是 PLB bus,因此我們使用的是 PLB IPIF。PLB IPIF 有兩個主要的介面,對 PLB bus 的介面及對 IP 模組的介面。
如下圖所示: 圖 4-4 IPIF 是 IP 模組與 PLB bus 之間的介面 IPIF Module IP Module IPIF Interfaces PLB bus
IPIF 提供的溝通介面服務,決定使用者的元件與 Bus 間資料的溝通方式。IPIF
d Module Information register(RST/MIR)
ogic Interrupt Support ort
upport
formation register(RST/MIR)及 User Logic 有下列幾項:
z S/W Reset an
z Burst and Cacheline Transaction Support z DMA
z FIFO z User L
z User Logic S/W Register Supp z User Logic Master Support z User Logic Address Range S
其中我們選用 S/W Reset and Module In
服務,會為了 FBP 元件定義一個唯寫的位址,當有特定的字元從軟體寫入此位 址時將會單獨的將此元件重新啟動。另外會定義一個唯讀的暫存器儲存 FBP 元 件的識別資訊。User Logic S/W Register Support 服務使 IPIF 模組在 fbp 模組內定 義出軟體可以定址的暫存器。透過這些暫存器,我們可以從軟體將資料寫入暫存 器供 FBP 元件作運算,也可以從暫存器取回計算完成的資料。在這我們定義了 32 個 64bits 的暫存器供我們使用。
IPIF 對使用者 IP 模組的介面稱為 IP Interconnect(IPIC),它是 IPIF 與使用者 IP 模
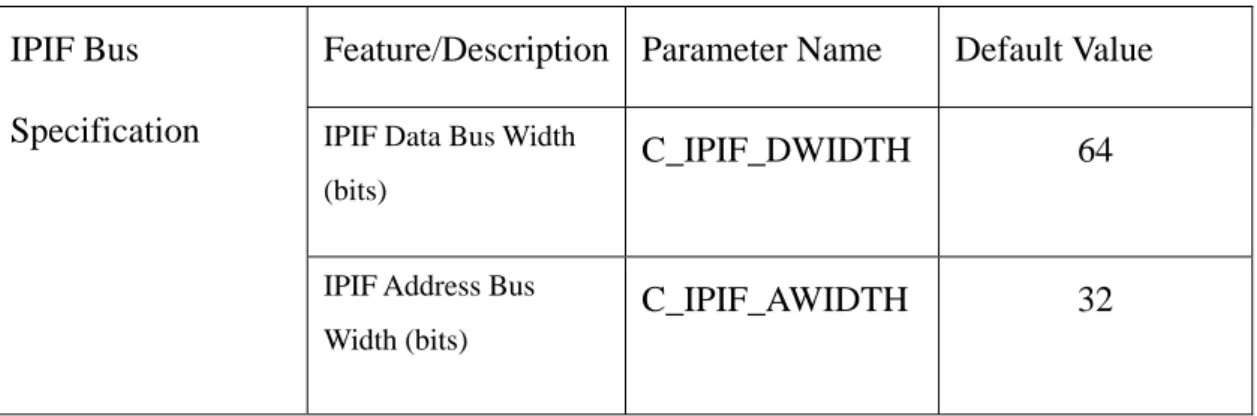
I/O Description
組連接的訊號集合。我們的 fbp 模組需要透過 IPIC 定義的訊號與 IPIF 連接 才能夠與 PLB bus 作溝通。IPIC 定義的訊號集內容隨著我們選用 IPIF 介面服務 的不同而有所不同,我們使用到的 IPIC 訊號定義如下:
表 4-3 PLB IPIF I/O Signals
Signal Name
Bus2IP_Clk O IPIC clock provided to IP. This PLB_CLk
Bus2IP_Reset O Active high reset for use by the User IP.
Bus2IP_Data(0:C_IPIF_DWIDTH-1) O Write data bus to the User IP. Write data is
accepted by the IP during a write operation by assertion of the IP2Bus_WrAck signal and the rising edge of the Bus2IP_Clk.
Bus2IP_BE(0:(C_IPIF_DWIDTH/8)-1) O ested read or
write operation with the User IP. Bit 0 Byte enable qualifiers for the requ
corresponds to Byte lane 0, Bit 1 to Byte lane 1, and so on.
Bus2IP_RdCE(0: see note 1) O Active high chip enable bus. Chip enables are
assigned per the User’s entries in the C_ARD_NUM_CE_ARRAY. These chip enables are asserted only during active read transaction requests with the target address space and in conjunction with the corresponding sub-address within the space.
Bus2IP_WrCE(0: see note 1) O ip enables are
assigned per the User’s entries in the Active high chip enable bus. Ch
C_ARD_NUM_CE_ARRAY. These chip enables are asserted only during active write transaction requests with the target address space and in conjunction with the corresponding sub-address within the space.
Bus2IP_RdReq O
is asserted for 1 Active high signal indicating the initiation of a read operation with the IP. It
Bus2IP_Clk during single data beat transaction and remains high to completion on burst write operations.
Bus2IP_WrReq O
with the IP. It is asserted for 1 Active high signal indicating the initiation of a write operation
Bus2IP_Clk during single data beat transaction and remains high to completion on burst write operations.
IP2Bus_Data(0:C_IPIF_DWIDTH-1) I
th the assertion of IP2Bus_RdAck Input Read Data bus from the User IP. Data is qualified wi
signal and the rising edge of the Bus2IP_Clk.
IP2Bus_Retry I
is Active high signal indicating the User IP is requesting a retry of an active operation. Th signal is currently unused by the PLB IPIF.
IP2Bus_Error I
sted Active high signal indicating the User IP has encountered an error with the reque operation. This signal is asserted in conjunction with IP2Bus_RdAck or the IP2Bus_WrAck.
IP2Bus_ToutSup I
the Active high signal requesting suppression of the data phase time-out function in the IPIF for active read or write operation.
IP2Bus_RdAck I
alid at the rising Active high read data qualifier. Read data on the IP2Bus_Data Bus is deemed v
edge of Bus2IP_Clk and the assertion of the IP2Bus_RdAck signal by the User IP.
IP2Bus_WrAck I
ed by the User IP at the rising edge of the Bus2IP_Clk and IP2Bus_WrAck asserted high by the User IP.
Active high write data qualifier. Write data on the IP2Bus_Data Bus is deemed accept
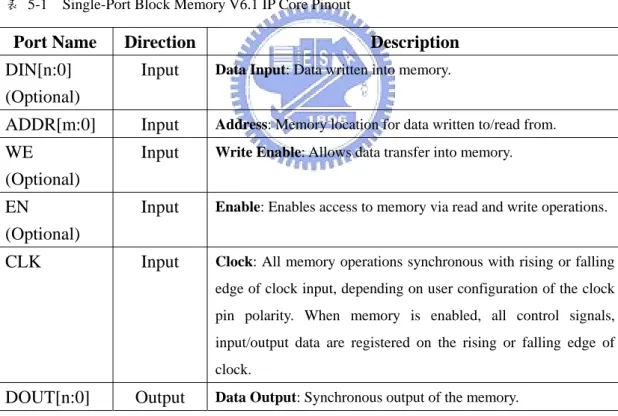
表 4-4 PLB IPIF Design Parameters
Feature/Description Parameter Name Default Value
IPIF Data Bus Width (bits)
C_IPIF_DWIDTH 64 IPIF Bus
pecification
IPIF Address Bus
S
Width (bits)
C_IPIF_AWIDTH 32
note1:在 IPIF 提供的 r Logic S/W Register Support 服務中,我們定義了 32 個 暫存器。而 Bus2IP_RdCE rCE 用來指定要讀寫的暫存器位置,所以 這兩個 signal 的寬度 s。 z /W z 的硬體元件功能:FBP 程式要實作成硬體的部份將在這實作完 p.vhd 及 示意圖如下。 Use 及 Bus2IP_W 皆是 32bit
在 Create Peripheral wizard 建立好 FBP 元件後,此元件會有三個部分。 z Bus 介面:定義與 PLB Bus 之間的訊號埠集。包括 IPIF 對 PLB Bus 的介面
及 IPIC。
IP Interface(IPIF)元件的使用:在這我們選用 RST/MIR 與 User Logic S Register Support,此時 EDK 軟體會建立可以讀取暫存器的介面。
使用者定義 成。
建 立 好 FBP 元 件 後 , 會 產 生 兩 個 重 要 的 檔 案 , 一 個 是 fb
fbp.vhd user_logic.vhd plb_ipif.vhd addr decode slave attach MIR/ Reset IPIC PLB Bus 圖 4-5 FBP 元件與 PLB bus 間的模組示意圖
建立好 FBP 元件後,我們執行 Import Peripheral Wizard 將 FBP 加入系統中。 FBP 元件是以 PLB Slave 的模式與 PLB Bus 連接。執行完 Import Peripheral Wizard 後,EDK 軟體會將 FBP 元件的資訊記錄在 MHS 檔案中。這樣我們就完成了 FBP 演算法嵌入式系統的架構。接下來我們將在 user_logic.vhd 檔案中的 user_logic VHDL 模組內完成 fbp 程式中欲實作成硬體的部分。 建立 FBP 元件並加入系統中的整個流程如下所示: User Logic plb_ipif user_logic.vhd plb_core.vhd plb_ipif User Logic fbp.vhd ppc_405 plb_v34 opb_v20 fbp system.mhs 圖 4-6 使用者建立週邊元件並加入系統的過程
第五章 FBP 元件實作
5 第五章 FBP 元件實作
從上一章節我們可以知道,我們要在user_logic VHDL模組內中完成4.2.1節 提到的FBP元件功能一及功能二的VHDL程式撰寫。在實作的過程中,我們將使 用到Xilinx公司提供的兩個IP,一個是Single-Port Block Memory v6.1 IP,另一個 是Fast Fourier Transform v3.1 IP。另外我們為了FBP IP功能二另外建立了一個名 為fbp_locate的VHDL 程式模組,在user_logic模組內對剛剛提到的兩個IP及 fbp_locate模組作元件宣告(Component Declaration)後使用。因此FBP元件的模組 階層如下: fbp user_logic fbp_locate Single-Port Blcok Memory IP Fast Fourier Transform IP 圖 5-1 FBP 元件內的模組階層
底下我們依序介紹 Single-Port Blcok Memory IP、Fast Fourier Transform IP 及 我們自己建立的
節。
5.1 IP 介紹及 fbp_locate 模組實作
Xilinx 公司提供的嵌入式系統發展環境除了平台像是我們使用的 ML310 Development Board,及搭配的軟體如 EDK 及 ISE 之外。Xilinx 也針對 IC 設計者 經常使用的特殊功能或是計算,實作成 IP 供使用者使用。這樣使用者可以節省 設計開發的時間,也可以使得設計更為模組化。模組化的好處將使得電路設計的 維護性增高,在模組電路的設計與驗證的過程中,可以比較容易找到設計錯誤的 地方。
5.1.1 Single-Port Blcok Memory IP
ML310 Board中的FPGA有 136 塊 18Kbits的Block Memory。由於Block Memory是on-chip memory,因此在存取速度上會比off-chip memory要快。我們在 設計FBP元件時要完成4.2.1節提到的兩個功能,其中FBP元件功能一需要一次讀 進sinogram 影像中某一列的所有pixel 灰階值。因此我們需要在我們的設計中增 加一個記憶體空間來儲存這些讀入的資料。Signal-Port Block Memory V6.1 IP可 以幫我們使用FPGA中的Block Memory規劃出一塊可以供我們使用的記憶體空 間。
此 Single-Port Block Memory V6.1 IP 的重要特色如下: z 支援 Read-Only Memory 及 Random-Access Memory 的功能
z 根據選擇的硬體架構,記憶體大小的設定範圍由 2 到 2M words 之間。 z 可以針對 memory 的儲存內容作初始化。
z 記 憶 體 寫 入 的 模 式 有 Read-after-Write , Read-before-Write 及 No-Read-on-Write 三種模式。
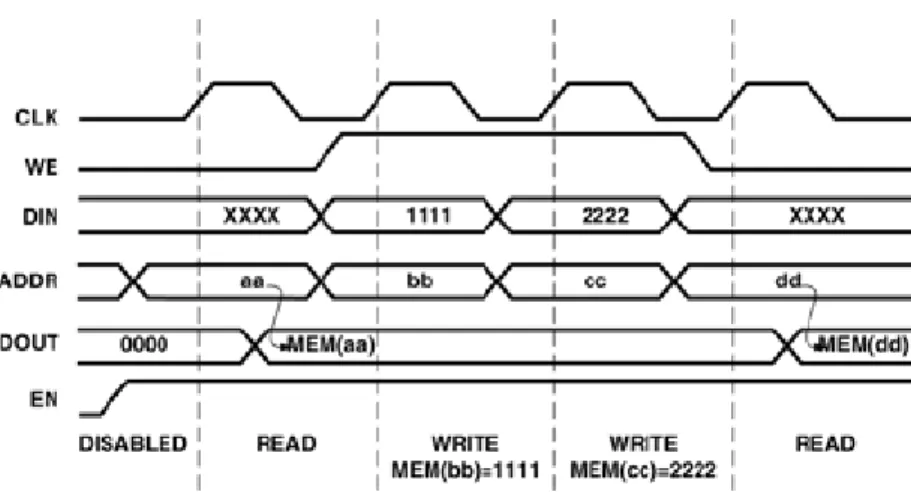
底下是 Signal-Port Block Memory V6.1 IP 的線路符號代碼,其中黑色的部分 代表在我們的設計中有使用到的訊號,灰色則是沒有選用到的訊號: ADDR[m:0] DIN[n:0] WE DOUT[n:0] EN RFD SINIT RDY ND CLK
圖 5-2 Core Schematic Symbol
下列的訊號定義表僅列出我們使用到的訊號定義:
表 5-1 Single-Port Block Memory V6.1 IP Core Pinout
Port Name Direction Description
DIN[n:0] (Optional)
Input Data Input: Data written into memory.
ADDR[m:0] Input Address: Memory location for data written to/read from.
WE (Optional)
Input Write Enable: Allows data transfer into memory.
EN
(Optional)
Input Enable: Enables access to memory via read and write operations.
CLK Input Clock: All memory operations synchronous with rising or falling
edge of clock input, depending on user configuration of the clock pin polarity. When memory is enabled, all control signals, input/output data are registered on the rising or falling edge of clock.
DOUT[n:0] Output Data Output: Synchronous output of the memory.
Single-Port Block Memory V6.1 IP 的功能介紹如下:
當 Block Memory 的致能訊號 EN 是 1 時,所有記憶體的動作將發生在時脈訊號 CLK 的上升緣(Rising Edge)或是下降緣(Falling Edge)變化時。當致能訊號 EN 為 0 時,則記憶體的設定及輸出訊號 DOUT 將不變。讀出的動作在致能訊號 EN 為
1 時,輸出訊號 DOUT 將輸出位置訊號 ADDR 所指定的記憶體位置內的值。當 寫入訊號 WE 為 1 時,在輸入訊號 DIN 的值將存在位置訊號 ADDR 所指定的記 憶體位置。而剛剛提到寫入的模式有三種,Read-after-Write,Read-before-Write 及 No-Read-on-Write。這是輸出訊號的行為在記憶體為寫入的狀態時,有三種不 同的輸出模式。分別敘述如下: z Read-after-Write 是指在同一個時脈中,在輸入訊號 DIN 中的值除了存到指 定的記憶體位置外也直接傳到輸出訊號 DOUT 中當成輸出。 z Read-before-Write 則是同一個時脈中,位置訊號 ADDR 所指定的記憶體位置 內的值將傳送到輸出訊號 DOUT 中當成輸出。 z No-Read-on-Write 是指記憶體在寫入的狀態時,輸出訊號 DOUT 維持原狀不 作改變。
在我們的設計中,Single-Port Block Memory V6.1 IP 的設定上我們選擇 No-Read-on-Write 的模式。記憶體的讀寫動作設定為發生在脈訊號 CLK 的上升 緣。而因為 FFT 及 IFFT 的過程中有 Zero Padding 的動作,所以記憶體大小,我 們設定為 256 words(128*2),每個 word 是 32bits,且 word 的初始值設定為 0。 至於 SINIT、ND、RFD 及 RDY 訊號,我們並不需要因此設定上選擇不用,以簡 化設計。我們參考到的時序圖如下:
5.1.2 Fast Fourier Transform v3.1 IP
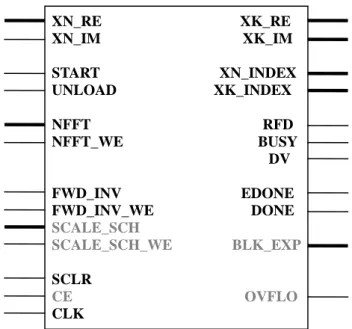
4.2.1節中提到的FBP元件功能一,包含FFT運算及IFFT運算。Xilinx公司也 有提供FFT及IFFT的IP可以供我們使用,我們不需從頭設計FFT及IFFT的電路。 Xilinx公司提供的Fast Fourier Transform v3.1 IP的重要特色如下:
z 此 IP 可以在執行狀態中設定為 FFT 或 IFFT 運算。 z FFT 及 IFFT 可以支援的取樣點數目大小是 N=2m ,m= 3 到 16。 z 每一筆輸入資料的精確度 bx可以是 8、12、16、20、24 位元寬度。 z FFT 運算過程中使用到的 phase factor 精確度 bw可以是 8、12、16、20、24 位元寬度。 z 計算過程中計算的形式有:
-Unscaled (full-precision) fixed point -Scaled fixed point
-Block floating point
z 在 butterfly 運算過程中產生的數值可以使用 Rounding 或是 Truncation 的方 式進位到最後一位。
z IP 的硬體架構有三種選擇: -Pipelined, Streaming I/O -Radix-4, Burst I/O
-Radix2, Minimum Resource
底下是 Fast Fourier Transform v3.1 IP 的線路符號代碼,黑色的部分表示我們 有使用到的訊號,灰色則代表在我們的設計中沒有選用這些訊號:
XN_RE XK_RE XN_IM XK_IM START XN_INDEX UNLOAD XK_INDEX NFFT RFD NFFT_WE BUSY DV FWD_INV EDONE FWD_INV_WE DONE SCALE_SCH SCALE_SCH_WE BLK_EXP SCLR CE OVFLO CLK
圖 5-4 Core Schematic Symbol
下列的訊號定義表僅列出我們使用到的訊號定義:
表 5-2 Fast Fourier Transform v3.1 IP Core Pinout
Port Name Port Width Direction Description
XN_RE bxn Input Input data bus: Real component
( bxn=8,12,16,20,24 )
XN_IM bxn Input Input data bus: Imaginary component
( bxn=8,12,16,20,24 )
START 1 Input FFT start signal(Active High): START is asserted to begin the data loading and transform calculation (for the Burst I/O architecture). For continuous data processing, START will begin data loading, which processing directly to transform calculation and the data unloading.
UNLOAD 1 Input Result unloading (Active High): For the Burst I/O architecture, UNLOAD will start the unloading of the results in normal order. The UNLOAD port is not necessary for the Pipelined, Streaming I/O architecture.
NFFT 5 Input Point size of the transform: NFFT can be the size of the transform or any smaller point size. For example, a 1024-point FFT
can compute point size 1024, 512, 256, and so on. The value of NFFT is log2 (point
size). This port is optional for Pipelined, Streaming I/O architecture.
NFFT_WE 1 Input Write enable for NFFT (Active High): Asserting NFFT_WE will automatically cause the FFT core to stop all processes and to initialize the state of the core. This port is optional for Pipelined, Streaming I/O architecture.
FWD_INV 1 Input Control signal that indicates if a forward FFT or an inverse FFT is performed. When FWD_INV=1, a forward transform is computed. If FWD_INV=0, an inverse transform is performed.
FWD_INV_WE 1 Input Write enable for FWD_INV (Active High).
SCLR 1 Input Master reset (Active High): Optional port.
CLK 1 Input Clock
XK_RE[(B-1):0] bxk Output Output data bus: Real component.
XK_IM[(B-1):0] bxk Output Output data bus: Imaginary component.
XN_INDEX Log2(point size) Output Index of input data.
XK_INDEX Log2(point size) Output Index of output data.
RFD 1 Output Ready for data (Active High): RFD is High during the load operation.
BUSY 1 Output Core activity indicator (Active High): This signal will go High while the core is computing the transform.
DV 1 Output Data valid (Active High): This signal is High when valid data is presented at the output.
EDONE 1 Output Early done strobe (Active High): EDONE goes High one clock cycle immediately prior to DONE going active.
DONE 1 Output FFT complete strobe (Active High): DONE will transition High for one clock cycle at the end of the transform calculation.
Xilinx 公司提供的這個 IP,可以設定為執行 FFT 或是 IFFT 運算。此 FFT 是一個 計算離散傅立葉轉換 (Discrete Fourier Transform,DFT)高效率的演算法。但是注 意的是 FFT 使用的函式是 DFT (5.1)
( )
( )
0 1 1 0 / 2 = − =∑
− = − N k e n x k X N n N jnk K π而 Fast Fourier Transform v3.1 IP 執行 IFFT 運算使用的函式是
(5.2)
( )
( )
0 1 1 0 / 2 = − =∑
− = N n e k X n x N k N jnk K π而不是和函式(5.1)對應的IDFT(inverse Discrete Fourier Transform)
( )
1( )
0 1 1 0 / 2 = − =∑
− = N n e k X N n x N k N jnk K π (5.3) 換句話說,如果作 128 筆取樣值的 FFT 轉換接著作 IFFT 轉換後,得到的資料將 比原取樣值大 128 倍,這是我們使用此 IP 要注意的地方。 此 IP 的內部架構有三種形式可以供我們選擇,說明如下:z Pipelined, Streaming I/O:此架構可以連續性的處理資料,也就是讀入資料, 做轉換及資料的輸出可以同時執行。此架構下執行 FFT 或是 IFFT 運算所需 的時間最少,但是此架構下 IP 要合成硬體所需要的硬體資源也是最多的。 此架構使用的傅立葉演算法為 Radix-2 butterfly。
z Radix-4, Burst I/O:此架構下執行 FFT 或是 IFFT 運算有兩個階段,一個是 資料的輸入輸出,另一個是資料的轉換運算過程。此架構下所需要的硬體資 源會比 Pipelined, Streaming I/O 架構要少,但運算的時間會增加。內部使用 的傅立葉演算法為 Radix-4 butterfly。
z Radix2, Minimum Resource:此架構跟 Radix-4, Burst I/O 架構一樣有資料的 輸入輸出及轉換運算過程兩個階段,但是因為內部的傅立葉演算法為 Radix-2 butterfly。因此整個運算的時間最長,但所需要的硬體資源也最少。 另外,執行 FFT 或是 IFFT 運算時,在 radix-4 或是 radix-2 butterfly 轉換過程中,
數值可能會增大,因此考慮可能發生位元溢位的狀況下。運算的過程中數值的計 算有三種形式:
z Unscaled (full-precision) fixed point:整個計算過程,不針對數值作任何比率 的縮小,此情形在數值位元寬度不足時可能發生溢位狀況。
z Scaled fixed point:在作 FFT 或是 IFFT 會有多個 radix-4 或是 radix-2 butterfly 轉換過程,每個過程都作比率的縮小,縮小的倍數可能是 1、2、4、8,代 表的是將數值作位元右移操作。每個過程要縮小的倍數定義在 SCALE_SCH 訊號中。
z Block floating point:此計算形式是指完成 FFT 或是 IFFT 運算後,由 IP 自 動決定要縮小幾倍,而縮小的倍數會儲存在 BLK_EXP 訊號中。
同樣的上述的三種數值計算形式也會影響到此 IP 合成硬體所需要的資源。 在我們的設計中,FBP 軟體將需要將取樣值經由暫存器傳給 FBP IP 中再由 Fast Fourier Transform v3.1 IP 執行 FFT 運算,因此 Pipelined, Streaming I/O 架構 無法跟我們的設計配合,因此我們選擇 Radix-4, Burst I/O 架構,使得資料的輸出 入跟資料作傅立葉轉換分成兩階段。另外,我們處理的資料是 pixel 的灰階值, 範圍是 0~255,只要 8bits 就可以表達。但是之前我們提到要使用 fix point 的方 式來處理 float point 的資料,因此將會乘上 2 冪次方倍數來保留運算中產生的小 數位的資訊,再加上考慮計算過程中可能發生的溢位問題,因此在輸入資料的位 元寬度及 phase factor 我們設定為 24 位元寬度。資料輸出則由 IP 自動設定為 33 位 元 寬 度 。 為 保 留 計 算 中 數 值 所 代 表 的 資 訊 完 整 性 , 我 們 選 擇 Unscaled (full-precision) fixed point 計算形式,避免縮小倍數的同時而失去部分資訊。至於 我們要執行多少取樣數的 FFT 及 IFFT 運算呢?前面我們提到原本的 128 pixels 的灰階值在執行 FFT 運算前要先作 Zero Padding 的動作,因次我們將取樣數設 為 256 筆。這樣我們就完成 Fast Fourier Transform v3.1 IP 的參數設定。
底下是我們參考到的時序圖:
圖 5-5 IP 開始輸入資料的波形圖
圖 5-6 IP 輸出資料的波形圖
其中要注意的是當 start 訊號拉成 1 時,從下一個 clock 開始的第四個 clock 才能輸入資料到 Fast Fourier Transform v3.1 IP 中。當 dv 訊號為 1 時,則開始輸
出傅立葉轉換後的資料。
5.1.3 fbp_locate VHDL 程式模組實作
我們建立fbp_locate模組來完成4.2.1節提到的FBP IP功能二的實作,而FBP 元件功能一則寫在user_logic.vhd檔案中的user_logic模組中。FBP元件功能二的工 作內容是輸入三階for-loop的索引值y、x及i,其中y及x代表的是重建影像上某個 pixel的座標索引( )
x,y ,而i則表示sinogram影像上的列索引值,也就是斷層掃描 從 0°到 180°共K次的投影中的第i次投影,經由i值可以算出投影的角度θ(theta)。 fbp_locate模組收到此三個索引值後經過計算,可以得到兩個數字,lbin及frac, 而frac則是mid-bin在lbin及hbin的位置比例值(參考表 4-2)。線路符號代碼如下: y_index x_index index lbin frac go ok rst clk圖 5-7 Core Schematic Symbol
訊號定義如下表所示:
表 5-3 fbp_locate module Core Pinout
Port Name Type Direction Description
y_index integer Input 表示重建影像的y軸座標值。(參考表 4-2) x_index integer Input 表示重建影像的x軸座標值。(參考表 4-2) index integer Input 表示sinogram影像的列索引值。(參考表 4-2)