N a tio n a l U niversity of Kao hsi un g
國立高雄大學電機工程系
碩士論文
以基因表達程式規劃實現影像式循跡系統之迴
歸分析–以輪型機器人驗證
Track Model Regression Using Genetic Expression
Programming for Visual-based Path-Following of
Mobile Robots
研究生:黃冠文撰
指導教授:吳志宏
N a tio n al U niversity of Kao hsi un g
以基因表達程式規劃實現影像式循跡系統之迴
歸分析–以輪型機器人驗證
指導教授: 吳志宏博士 學生:黃冠文 國立高雄大學電機工程系摘要
在智慧型機器人應用中,循跡 (path-following) 是指驅動具移動能力的機器人 跟隨特定「軌道」進行移動。軌道需使用感測器感知其分布、走向,再藉由控制 器計算驅動參數,這個過程往往需要經過多層繁瑣的計算。本研究提出一種新穎 的控制方法於影像式循跡系統的控制,將影像式循跡系統視為一個迴歸問題,影 像中的軌跡能被視為迴歸模型的輸入,機器人的控制訊號能被視為迴歸模型的 輸出。利用這些輸入、輸出資料分析系統的迴歸模型,簡化繁瑣的計算步驟,以 單一數學模型取代傳統循跡系統。在本論文中,以攝影機作為感測訊號來源,從 影像中擷取軌道的特徵點作為迴歸模型的輸入。再應用基因表達程式規劃 (gene expression programming) 技術,以演化方式對影像特徵點與驅動控制參數進行分 析,找出兩者間的迴歸關係式,實現即時影像式循跡系統。本論文將研究方法整 合至配有一台彩色攝影機的二輪型機器人上,並於真實環境下驗證其循跡效果。 實驗結果發現,少量的特徵點能取代高資訊量的軌道影像,使 GEP 能快速收斂, 迴歸模型也能有效地描述影像特徵點與驅動參數間的關係。 關鍵字:輪型機器人、影像式感測器、循跡、基因表達程式規劃、迴歸分析。N a tio n al U niversity of Kao hsi un g
Track Model Regression Using Genetic Expression
Programming for Visual-based Path-Following of
Mobile Robots
Advisor: Dr. Chih-Hung Wu Student: Guan-Wen HuangDepartment of Electrical Engineering, National University of Kaohsiung
ABSTRACT
Path-following is an essential and important task in the applications of autonomous robots. Visual-based control is an emerging method due to its convenience and flexibility. However, the control flow is level-wise transforming from visual signals of tracks to the activation of the hardware actuators, with complicated calculations and inevitably error accumulation. This study presents a new method for the control of visual-based path-following of mobile robots. The control flow of visual-based path-path-following is rephrased as a regression problem which takes the visual positions of tracks as the input and produces direct control signals as output. To deal with the complex regression problem in this study, the technique of gene expression programming (GEP) is employed for discovering feasi-ble control models. For any tracking paths, a control model can be obtained by collecting visual positions of tracks and the corresponding control signals by GEP. With the regres-sion models, the control of path-following can be done with simpler control rules and less processing time. Our proposed method is implemented and integrated with a two-wheeled service robot carrying a simple CCD camera and is validated for visual path-following in real environments. The experimental results show that the proposed method is able to produce simple and precise control rules and improves the robot’s performance for path-following .
Keywords: Mobile robots, Visual sensors, Path-following, Gene expression program-ming, Regression
N a tio n al U niversity of Kao hsi un g
致謝
本論文得以順利完成,乃受惠於諸多貴人之協助。第一位要感謝就是我 的指導教授吳志宏老師,從大學入學到碩士畢業的六年間,從做實驗、參加比 賽、辦營隊、撰寫計畫報告、出國報告研討會至碩士論文,老師都從旁提點、教 導了我不少事情。與六年前相比,在為人處事、做事態度、心態調節、研究報告 技巧、專案整合開發等方面,都有了不少成長,感謝老師對我的諄諄教誨,謝 謝。另外也感謝賴智錦教授、潘欣泰教授、歐陽振森教授於實驗、論文報告、專 案合作上的指導與建議,並擔任我的口試委員,使本論文得以更加完善。 感謝瓊輝學長、小駱學長在實驗室活動上的協助,以及實驗報告撰寫的相關 指導。感謝已經畢業的宜陞學長、俐雯學姊、右棟學長、立偉學長、錦源學長、 建榮學長、婉伊學姊,讓還是當時還是大學生的我快速融入實驗室的環境,也帶 我參加了許多有趣的活動。謝謝旻良學長帶我一頭栽進程式設計、機器人的世界, 讓我有機會從這個領域入門,了解軟硬體整合的方法。謝謝冬瓜學長研究、做 事、帶活動上的幫助,在畢業後也仍時常教導我身為一位研究生須注意的細節。 謝謝阿鐵、偉洲、育賢、孟瑋,感謝你們在這兩年與我在實驗室奮鬥的種種時光, 這些經歷勢必會成為我未來的助力。柏威、張簡多虧你們協助實驗室事務的處理, 讓我得以有時間完成這本論文。麒柏、奕辰、旻慧、耀葆、正齡謝謝你們在比賽 上的幫助,讓實驗室的機器人技術能慢慢地進步。感謝實驗室這六年來曾跟我相 處過的學長、姊、弟、妹,謝謝你們所教會我的所有事。 最後,要感謝我的父母,這幾年來無怨無悔地付出,讓我沒有經濟及精神上 的負擔,並時常關心我的生活狀況。默默支持我完成學業。也謝謝哥哥、姐姐在 大學畢業後就立刻就業,讓爸媽的負擔減輕。也請原諒我無法時常回家陪你們, 謝謝你們。 黃冠文謹誌於國立高雄大學電機工程學系計算機組 中華民國一零五年九月N a tio n al U niversity of Kao hsi un g
目錄
中文摘要 . . . i 英文摘要 . . . ii 致謝 . . . iii 目錄 . . . iv 圖目錄 . . . vi 表目錄 . . . viii 1 緒論 . . . 1 1.1 研究背景 . . . 1 1.2 研究動機與目的 . . . 2 1.2.1 研究動機 . . . 2 1.2.2 研究目的 . . . 4 1.2.3 研究限制 . . . 5 1.3 研究流程 . . . 5 1.4 論文架構 . . . 6 2 文獻探討 . . . 7 2.1 軌跡影像擷取 . . . 7 2.2 GA 與 GP . . . 8 2.3 GEP . . . 9 2.3.1 GEP 介紹 . . . 9 2.3.2 GEP 參數設定 . . . 13 2.3.3 GEP 相關應用 . . . 16 3 問題定義與分析 . . . 17 3.1 影像系統 . . . 17 3.2 軌跡擷取 . . . 18 3.3 特徵擷取 . . . 20 3.4 機器人移動控制 . . . 22 3.5 以 GEP 建立影像式循跡迴歸系統 . . . 24N a tio n al U niversity of Kao hsi un g 3.5.1 訓練資料集 . . . 24 3.5.2 適應函數 . . . 25 4 實驗與結果分析 . . . 26 4.1 機器人機構與硬體架構 . . . 26 4.1.1 機器人機構 . . . 26 4.1.2 硬體架構 . . . 28 4.2 實驗環境 . . . 28 4.3 實驗架構與流程 . . . 30 4.4 實驗 A–染色體的長度 lc調整 . . . 31 4.5 實驗 B–演化機率調整 . . . 37 4.6 實驗 C–運算子集合 OP 調整 . . . . 39 4.7 實驗 D–不同迴歸方法間的比較 . . . 40 4.8 實驗 E–實機測試 . . . 44 4.9 實驗小結 . . . 49 5 結論與未來展望 . . . 50 5.1 結論 . . . 50 5.2 未來展望 . . . 51 參考文獻 . . . 52
N a tio n al U niversity of Kao hsi un g
圖目錄
1.1 循跡系統處理流程 . . . 2 1.2 以迴歸模型取代傳統控制方法 . . . 3 1.3 研究流程 . . . 6 2.1 GA 染色體及演化流程 . . . 8 2.2 GP 的樹狀結構 . . . 9 2.3 GEP 染色體 . . . 11 2.4 突變 . . . 11 2.5 轉換 . . . 12 2.6 重組 . . . 12 2.7 基因表達程式演化流程圖 . . . 14 2.8 不同 lc的染色體 . . . 14 2.9 不同 Sop的染色體 . . . 15 3.1 可視範圍示意圖 . . . 17 3.2 攝影機影像 . . . 18 3.3 軌跡擷取流程 . . . 18 3.4 開放運算流程 . . . 19 3.5 循跡線影像過濾 . . . 20 3.6 特徵擷取流程 . . . 21 3.7 影像座標系統 . . . 21 3.8 掃描線 Ci . . . 21 3.9 循跡線影像與掃描線取交集 . . . 21 3.10 特徵標定 . . . 22 3.11 二輪機器人圓周運動 . . . 23 3.12 迴歸模型 . . . 24 4.1 實體機器人 . . . 26N a tio n al U niversity of Kao hsi un g 4.3 馬達驅動參數與機器人速度關係 . . . 27 4.4 馬達驅動參數與機器人速度關係 . . . 28 4.5 實驗場地 . . . 29 4.6 測試路線 . . . 29 4.7 實驗流程圖 . . . 30 4.8 lc為 13 之適應值隨迭代變化圖 . . . 34 4.9 lc為 17 之適應值隨迭代變化圖 . . . 34 4.10 lc 為 21 之適應值隨迭代變化圖 . . . 35 4.11 lc 為 25 之適應值隨迭代變化圖 . . . 35 4.12 lc 為 29 之適應值隨迭代變化圖 . . . 35 4.13 lc 為 33 之適應值隨迭代變化圖 . . . 36 4.14 lc 為 37 之適應值隨迭代變化圖 . . . 36 4.15 紅外線模組安裝示意圖 . . . 45 4.16 平行程度 µm 的模組編號設定 . . . 45 4.17 置中程度 µp 的模組編號設定 . . . 45
N a tio n al U niversity of Kao hsi un g
表目錄
4.1 攝影機規格 . . . 27 4.2 符號對照表 . . . 30 4.3 染色體長度 lc . . . 32 4.4 運算子集合種類 . . . 32 4.5 GEP 參數設定 . . . 32 4.6 不同染色體長度下之適應值 fL . . . 33 4.7 不同染色體長度下之適應值 fR . . . 33 4.8 適應值 fω與標準差的平均 . . . 34 4.9 GEP 參數設定 . . . 37 4.10 不同演化率訓練結果 . . . 38 4.11 GEP 參數 . . . 39 4.12 不同運算子集合 OP 的測試結果 . . . . 40 4.13 GEP 參數 . . . 41 4.14 各種迴歸方法產出模型誤差與適應值之比較 . . . 41 4.15 以測試資料驗證各模型之比較 . . . 41 4.16 10 次訓練結果的誤差與適應值之標準差 . . . 42 4.17 10 次測試資料驗證各模型之標準差 . . . 42 4.18 各方法迴歸模型使用運算子數量 . . . 43 4.19 各方法迴歸模型平均使用運算子數量 . . . 44 4.20 各方法迴歸模型不同次數的計算時間 . . . 44 4.21 模組編號與 µm 值對應關係 . . . 46 4.22 實機測試結果–逆時針繞行 . . . 47 4.23 實機測試結果–順時針繞行 . . . 48N a tio n al U niversity of Kao hsi un g
第 1 章
緒論
1.1
研究背景
智慧型機器人是一種能感知外在環境訊息,透過自我決策機制做出應對策 略,執行任務的機械裝置。智慧型機器人通常要在未知的環境下巡航,並獨立完 成指定的任務。為了獲得周遭環境的資訊,機器人通常需裝備各式各樣的感測器, 如:紅外線感測器、超音波測距儀、陀螺儀... 等。在智慧型機器人任務中,循 跡 (path-following) 是指驅動具移動能力的機器人跟隨特定「軌道」進行移動。穩 定的循跡系統能確保機器人在無人看管的情況,仍可獨立跟隨規劃的軌道移動。 應用此技術的場合很多,如:倉儲搬運路線 [1, 2]、自動化工廠焊接作業 [3]、船 艦導航 [4]、車輛自動駕駛 [5]... 等。因此,建立一套穩定的循跡系統是相當重要 的。 循跡機器人根據目的不同,會使用不同的感測器、控制器、驅動平台。不論 使用何種循跡的技術,循跡系統的運作流程皆可大致分為 5 個步驟,偵測軌道、 誤差量計算、移動方向計算、移動速度計算、驅動參數計算。透過感測器偵測軌 道,計算應修正的誤差量,使用控制器如:PID 控制器 [6, 7]、模糊控制器 (fuzzy control)[8],計算機器人的移動方向、速度,最後再轉換成出驅動參數,其流程如 圖1.1所示。例如:Cai[9] 以模糊邏輯控制球型機器人按照固定路徑移動,使球型 機器人能平滑地移動。Fernando[10] 藉由衛星影像,控制農藥噴灑機器人按照路 線行進。Yussof[7] 結合紅外線感測器與 PID 控制器,控制輪型平台進行高速循跡 任務。上述控制技術所用的感測器、控制方法,均存在各自的缺點。如:紅外線 感測器受限於其感測方式,只能針對單一點進行偵測,即使同時使用多組感測 器,模組與模組之間的空隙仍會存在感測死角。衛星影像與工廠常用的磁軌感應N a tio n al U niversity of Kao hsi un g 圖 1.1: 循跡系統處理流程 式循線,則是受限於場地限制與成本考量。使用 PID 控制器需針對微分、積分、 放大三個子控制器進行調節,三個控制器互相影響使得調節不易。模糊控制則須 先建立一套合理的規則庫,再將數值經過模糊化、模糊邏輯推導、解模糊化等流 程求解,通常需藉由專家經驗才能設計出一組好的模糊控制器。 近幾年由於裝置成本低、感測資訊量高、用途廣泛,影像式感測器逐漸成為 機器人感測器的主流 [11, 12, 13]。相較於紅外線感測器,影像式感測器拍攝的影 像矩陣間不存在空隙,且感測距離可近可遠較無限制。相較於衛星影像與磁感應, 影像式感測器容易安裝移動平台,且造價相對低廉。對於軌道特徵的擷取方式也 比較多元,以一張彩色影像而言,就有邊緣偵測、形狀偵測、顏色偵測等方法可 對軌道進行偵測與擷取。如:Wang[14] 在車輛上裝置一彩色攝影機,藉由車道線 與柏油路的邊緣捕捉車道線影像,保持車輛沿著車道線間行駛。由於影像具有龐 大的資訊量,從中能擷取的特徵種類豐富,若能在機器人上安裝影像式感測器並 用於循線,必能提高循線任務的穩定度。
1.2
研究動機與目的
1.2.1
研究動機
影像資訊的處理通常需經過好幾層繁瑣的計算過程,因此影像式循跡系統可 視為一個複合函數,如圖1.2所示。複合函數能藉由複數的方程式組合以描述系統 行為,建立機器人的循線功能,如前面提到的模糊控制、PID 控制。但當系統行 為過於複雜時,通常需要大量的方程式才能組合出系統的複合函數,甚至也有可N a tio n al U niversity of Kao hsi un g 圖 1.2: 以迴歸模型取代傳統控制方法 能不存在可以描述系統的數學模型。 若我們只在乎系統的輸入、輸出的對應關係,則可將循跡系統視為一個迴歸 問題,迴歸分析可以分成兩種,白盒子 (white box) 與黑盒子 (black box)。
• 黑盒子:不需要知道盒子內容,只需要知道給予何種輸入即可,適用於以多 種模組快速建立一大型系統的情況。 • 白盒子:能清楚剖析盒子內容,並了解系統輸入與輸出的關聯。適用於分析 系統,並且容易移植到不同系統平台。 本研究對影像式循跡系統進行迴歸分析,並實裝於機器人上使用,觀察不同數學 模型對於循跡的效果並進行微調,期望可以了解影像式循線系統的數學特性,因 此將採用白盒子迴歸模型。進行迴歸分析時,自變數與應變數如果是一對一的情 況,通常可以用簡單線性迴歸 (simple linear regression) 快速得到效果不錯的結果。 但在影像式循跡問題中,軌跡特徵通常是一個有許多元素的集合,即自變數與 應變數是多對一的情況,此時則須使用複迴歸分析 (multiple regression analysis) 處 理。隨著自變數的增加,迴歸模型的建立會更加複雜。若系統具有非線性特性, 還得視情況選用適合的非線性迴歸分析,例如:指數迴歸 (exponential regression)、 對數迴歸 (logarithmic regression)、雙曲線迴歸 (hyperbolic regression)、冪函數曲線 迴歸 (power regression)... 等。不同的非線性迴歸具有各自的特性,而影像式循跡 系統因應不同的路線,可能同時需要多種不同種類的非線性模型才能建立一組好 的迴歸模型。
N a tio n al U niversity of Kao hsi un g 近年來關於最佳化問題的處理,有許多關於機器學習 (machine learning) 演算 法的討論,並且都有著不錯的成效。白盒子式機器學習的迴歸分析,早期較知名 的方法為基因程式規劃 (gene programming ,以下簡稱 GP)。GP 是由基因演算法 (gene algorithm ,以下簡稱 GA) 變化而來,GP 以樹狀結構表達數學公式,以「適 者生存,不適者淘汰。」的概念進行演化,不斷修正數學公式直到找到問題的最佳 解,但 GP 因其資料結構的設計,使其具有較大的時間複雜度。因此基因表達程 式規劃 (gene expression programming ,以下簡稱 GEP) 在後來被提出,GEP 則是 一種兼具 GA 與 GP 特性的演化式機器學習演算法。GEP 以固定長度的陣列呈現 長度不定、內容相異的數學公式,並同樣以「適者生存,不適者淘汰。」的概念進 行演化,藉此產生符合問題的最佳解答。與傳統複迴歸相比,GEP 能同時選用不 同的線性、非線性運算子組合數學模型,並具備搜尋多個解答空間的能力,隨著 迭代的次數增加,慢慢逼近問題的最佳解,藉此提高迴歸分析的效率與精確性。
1.2.2
研究目的
本研究擬採用 GEP 對影像式循跡系統進行迴歸分析,並將分析結果應用於真 實的循跡機器人進行測試,明確希望達成的目標如下: • 以單顆攝影機蒐集真實環境的影像,從中分離出軌道影像。 • 從軌道影像分析出有效的軌跡特徵,並與驅動參數組成訓練資料集。 • 以 GEP 對訓練資料集進行迴歸分析,建構循跡機器人系統的迴歸模型,減 少傳統方法之人力、物力的花費。 • 以迴歸模型取代繁瑣的傳統循跡機器人系統,以簡化系統計算複雜度,並安 裝於機器人平台進行實際測試。N a tio n al U niversity of Kao hsi un g
1.2.3
研究限制
本研究所謂的「軌道」是指一條具有特殊顏色、樣式或其他特定物理性質之 連續不中斷的路線,通常為直線或夾角大於 90 度的曲線,夾角小於 90 度的路徑 則不在本研究範圍內。「軌道」不同於火車鐵軌 [15] 經由物理接觸拘束車輛沿著 軌道行駛,而需藉由感測器如:紅外線感測器 [6, 7]、電磁感測器、攝影機... 等 感知其分布、走向,藉此讓軌道保持在機器人中心下方,使機器人前進方向與軌 道沿伸的方向一致。另外,「軌道」不一定為實體軌道,例如 GPS[16] 導航規劃之 路線,是根據衛星資訊建立的虛擬路線。1.3
研究流程
本研究流程如下,主要分為相關文獻收集與探討、建立實體機器人、訓練資 料蒐集、機器學習設計、實驗與結果分析等部分。 • 相關文獻收集與探討:包含相關的研究背景知識,參考循跡機器人、GEP 等 相關文獻。 • 建立實體機器人:組裝移動平台並調整攝影機位置與視角,以利影像資料蒐 集,及影像式循跡之實測。 • 訓練資料蒐集:於真實環境蒐集軌道的影像資料,從中擷取合適的系統輸 入、輸出作為訓練資料。 • 機器學習設計:從相關文獻參考 GEP 使用方法,並撰寫 GEP 相關程式。 • 實驗與結果分析:依實驗結果分析,探討此機器學習方法之效果與應用,並 建議未來研究方向。N a tio n al U niversity of Kao hsi un g 圖 1.3: 研究流程
1.4
論文架構
本論文之架構分為五章節,其簡述如下: • 第一章『緒論』,說明本研究背景與動機。 • 第二章『文獻探討』,簡述演化式迴歸分析的參考文獻。 • 第三章『問題定義與分析』,對研究問題進行定義,並分析處理該問題的方 法。 • 第四章『實驗與結果分析』,設計相關實驗,實驗不同影像特徵、演化參數、 演化運算子種類對循跡系統迴歸分析的影響。 • 第五章『結論與未來展望』,總結本研究遇到的問題及方法,並提出未來可 以研究及更深入的方向與構想。N a tio n al U niversity of Kao hsi un g
第 2 章
文獻探討
2.1
軌跡影像擷取
由於影像式感測器具有感測範圍廣的特性,因此用於循跡時,勢必會接收到 其他干擾物或雜訊的影響,因此必須先將影像中的軌道分離出來。分離軌道影像 可分為兩個步驟:軌跡影像過濾、雜訊去除。 • 軌跡影像過濾:循跡任務中的軌道通常具有特定顏色或著樣式,根據軌道 的特性,使用如:顏色過濾 [17, 18]、邊緣偵測 [19]、局部二值模式 (Local binary patterns,以下簡稱 LBP)[20]... 等方法過濾出軌道的位置。 • 雜訊去除:過濾後的軌道影像通常會有雜訊,成因有很多種,如:影像感測 器本身的瑕疵、過濾方法的參數不佳、影像中有性質與軌道相似的干擾物... 等。此時通常會以過濾器去除影像雜訊,如:中值濾波器、高斯濾波器、卡 爾曼濾波器 (Kalman filter)[21],或著其他影像處理方法提高過濾效果,如: 感興趣區域 (region of interest,以下簡稱 ROI)[22]、形態學運算... 等。 藉由上述技術擷取軌跡影像的實例如:Lin[23] 根據車載攝影機的視角,以 ROI 將 車道線可能出現的影像區塊擷取出來,針對影像區塊進行邊緣偵測,藉此分離出 車道線的軌跡影像。Lim[24] 將地面影像分割出來,以邊緣偵測分離軌跡,並且使 用卡爾曼濾波器對連續的軌跡影像進行誤差修正,提到軌跡影像過濾的穩定度。 Chen[25] 使用 3 條水平線掃描軌跡影像,根據掃描寬度判斷影像中軌跡的分布。N a tio n al U niversity of Kao hsi un g (a) 染色體編碼 Initialize Population Fitness Evaluation Mutation Crossover Selection Solution Termination Conditions No Yes (b) GA 流程圖 圖 2.1: GA 染色體及演化流程
2.2
GA 與 GP
GA[26] 是一種搜尋問題最佳解的機器學習演算法,其核心精神源自於達 爾文進化論中的「適者生存,不適者淘汰。」,藉由模擬生物個體的基因序列及 遺傳特性,在某一特定環境對所有個體進行演化,最後找出最適應這個環境的 個體。在 GA 的概念中,會將處理的問題視為一個環境。針對不同的環境,需 設計不同編碼代表不同的個體基因序列,個體基因序列同時也稱作是染色體 (chromosome),如圖2.1所示。以大量的染色體作為一族群,當作問題的可行解 (candidate solutions),並根據問題設計一適應函數 (fitness function),評估每一條染 色體對環境的適應程度。為了擴張可行解的搜尋空間,提高找到最佳解的可能 性。基因演算法利用多種基本的演化運作機制對染色體編碼進行修改,包括選 擇 (selection)、交配 (crossover)、突變 (mutation),以產生新一群不同編碼的染色 體。在合理的時間範圍及條件內求得近似最佳解的染色體,其基本步驟如圖2.1所 示。近年來,GA 被多方面用於電腦科學 [27]、醫學、數學、經濟學、機器人學N a tio n al U niversity of Kao hsi un g 圖 2.2: GP 的樹狀結構 [28]... 等領域,協助處理有關搜尋最佳解的問題。並與其他演算法做結合,如: 模糊理論、增強式學習、類神經網路,衍生出多種進階的機器學習演算法。 GP[29] 是以 GA 為基礎,目的是為了處理讓電腦自行設計程式的問題。只需 要讓電腦知道程式的輸入、輸出,而不必告訴電腦如何撰寫程式。GP 的核心精神 與 GA 相同,以「適者生存,不適者淘汰。」的理念為主,並採用相同概念的演化 策略。而 GP 使用樹狀結構的染色體代表一組程式或數學模型,如圖2.2所示。透 化演化式學習,調整樹狀結構染色體的內容,透過適應函數篩選良好的個體,直 到達成預先訂定的中止條件為止。
2.3
GEP
2.3.1
GEP 介紹
GEP[30] 是 Ferreira 在 2001 年提出的一種新式演化式程式設計方法。GEP 結 合 GA 及 GP 之概念,以陣列形式的染色體取代樹狀結構,來呈現數學模型架 構。使用 GEP 進行模型分析時,能得到較 GP 低的時間複雜度。這是由於 GP 進 行染色體演化時,使用鏈結串列儲存樹狀染色體結構,節點搜尋的時間複雜度為 O(n)。而 GEP 使用陣列型態來儲存樹狀結構染色體,節點搜尋的時間複雜度為 O(1)。對於使用大量交配、突變計算的演化式演算法而言,有非常大的效能提
N a tio n al U niversity of Kao hsi un g
昇。GEP 的染色體分別由頭部 (head) 與尾部 (tail) 組成,頭部部分可以包含終端節 點 (terminal node) 與函數節點 (function node),而尾部只能是終端節點。函數節點
可以是 +、−、×、÷、AND、OR、sin、cos ... 等運算子,或著是自行定義的
數學函式。終端節點通常為常數、係數或著真實資料的值。頭部長度由使用者自 行設定,尾部長度則根據式2.1決定。
t = h(nmax− 1) + 1 (2.1)
t為尾巴長度,h 為頭長度,nmax 為此染色體中所有運算子的最大運算元數量
(maximum arity)。依照下列步驟能將 GEP 的染色體從陣列型態還原成樹狀結構:
Step-1: 設定層數計數器 l = 1。 Step-2: 從頭部染色體取出第一個節點作為樹的根結點。 Step-3: l = l + 1。 Step-4: 觀察 l− 1 層是否存在任何函數節點,若否則跳至 Step-9。 Step-5: 從頭部染色體依序取出節點,直到補足 l− 1 層函數節點所需的節點個數, 或著頭部染色體的節點被取完為止。 Step-6: 檢查頭部染色體的節點是否被取完,若否則跳至 Step-3。 Step-7: l = l + 1。 Step-8: 從尾部染色體依序取出節點,直到補足 l− 1 層函數節點所需的節點個數。 Step-9: 流程結束。 以圖2.3為例,最大運算元數量為 2,頭的長度為 5,尾巴的長度為 6,長度關係可 表示為 6 = 5(2− 1) + 1。依照流程可將染色體還原成圖2.3中的樹狀結構。
N a tio n al U niversity of Kao hsi un g (a) GEP 染色體陣列 (b) GEP 樹狀結構還原過程 圖 2.3: GEP 染色體 圖 2.4: 突變 GEP 的 染 色 體 演 化 方 式 主 要 有 三 種,突 變、 轉 換 (transposition) 與 重 組 (recombination),其功能如下: • 突變:隨機選擇染色體陣列中任意位置,若選擇位置處於染色體頭部,將陣 列元素值以隨機產生之運算元、運算子取代;若選擇位置處於染色體尾部, 將陣列元素值以隨機產生之運算子取代。運作方法如圖2.4所示。 • 轉換:隨機選染色體陣列中任意片段,複製此片段並插到染色體頭部任意位
N a tio n al U niversity of Kao hsi un g 圖 2.5: 轉換 圖 2.6: 重組 置。運作方法如圖2.5所示。 • 重組:選擇族群中任兩條染色體,任意挑選染色體陣列中任意位置當作重組 點,從重組點切斷染色體,並將切斷的染色體重新組合成新的染色體。運作 方法如圖2.6所示。 GEP 中 的 適 性 值 (fitness) 為 演 化 式 計 算 中 評 估 迴 歸 模 型 誤 差 之 指 標,常 見的指標有:均方差指標 (mean squared error ,以下簡稱 MSE)、平均絕對誤差
N a tio n al U niversity of Kao hsi un g
error ,以下簡稱 MAPE) 指標與決定係數 (coefficient of determination ,以下簡稱
R-square)[31]。如公式(2.2)-(2.4),其中 yi、y、yi′ 分別表示實際值、實際值平均與 模型推估值,n 表示資料筆數。MSE、MAE 為實際值與模型推估值的誤差值。 MAPE 的範圍為 0 到 100,為實際值與模型推估值的誤差程度。 MSE : 1 n n ∑ i=1 (yi− yi′) 2 (2.2) MAE : 1 n n ∑ i=1 |yi − y′ i| (2.3) MAPE : 100 n n ∑ i=1 |yi− y′i yi | (2.4) 每個世代演化完成後,計算出族群內各染色體之適性值,從中挑選出優秀的染色 體當作下個世代,持續演化直到達成終止條件為止。終止條件由使用者根據問題 設計,使用者可依照問題之誤差容許範圍設定終止條件。若終止條件較嚴謹,演 化次數相對較多,學習時間越久,故可依造問題之誤差容許範圍定義出最適合之 終止條件。GEP 的詳細演化流程如圖2.7,演化步驟如下: Step-1: 隨機產生族群數為 k 之條染色體,t1, . . . , tk。 Step-2: 計算族群內 ti之適性值,1 ≤ i ≤ k。 Step-3: 判斷終止條件是否達成,符合即結束演化,否則繼續 Step 4。 Step-4: 保留較好的染色體做突變,轉換,重組等動作後跳至 Step 2。
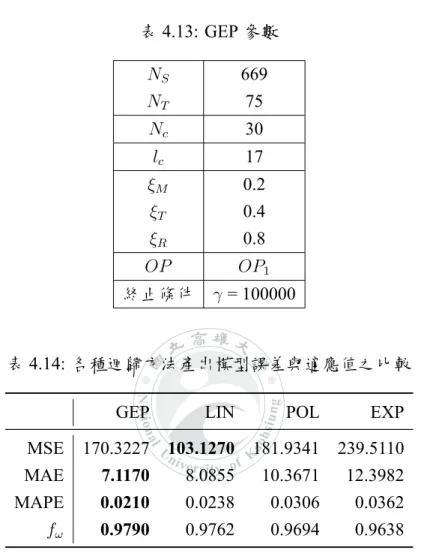
2.3.2
GEP 參數設定
GEP 模型轉換出的數學公式的長度與複雜度,與染色體長度及運算子種類 相關。理論上,染色體的長度 lc越大,越能表達公式長度越長的數學式,其數 學模型的描述能更加詳細,如圖2.8所示。其中 Sop為訓練時使用的運算子集合, n(Sop)表示運算子種類的個數,舉例來說,假設 GEP 能使用的運算子有 +、−、N a tio n al U niversity of Kao hsi un g ಖЗచҹǻ ࢂ ߃ۈϯ٠ബࢉՅᡏ ่״ ࣁΠжྗഢཥޑำԄ ᕷ ़ ߄ၲࢉՅᡏ ց ՉࢤำԄ ຑ܄ॶ ߥ੮ന٫ำԄ ᒧำԄ ፄᇙำԄ ँᡂ ᙯඤ ख़ಔ 圖 2.7: 基因表達程式演化流程圖 圖 2.8: 不同 lc的染色體 ×、÷,則 Sop = {+, −, ×, ÷},而 n(Sop) = 4。當 n(Sop)的值越大,數學模型能 呈現更多非線性、曲折的特性,如圖2.9所示。但實際上,若是染色體長度過長, 會造成單次迭代的訓練時間加長。而運算子種類 n(S )過大時,解答的搜尋空
N a tio n al U niversity of Kao hsi un g 圖 2.9: 不同 Sop的染色體 間也會被過度放大,可能會增加對建立模型無幫助的運算子種類,演化找到最 佳解的可能性也會跟著降低。舉例來說,當要建立線性數學模型 y = ax + b 時,
Sop = {+, −, ×, ÷} 比起 Sop = {+, −, ×, ÷ log, exp, sin, cos, tan},搜尋的範圍更
小,更容易找到最佳解。 另一控制 GEP 演化效果的參數為演化機率,對應三種演化方法:突變、轉 換、重組,同時也存在三組演化機率,分別為突變率 (ξM)、轉換率 (ξT)、重組率 (ξR)。當演化機率提高時,有助於加速演化的速度,但過高時會導致模型無法收 斂。反之,當演化機率降低時,演化速度較慢,且容易陷入區域最佳解,但較能 穩定減少迴歸模型的誤差。個別來講,突變是隨機修改染色體內容,打亂族群內 染色體過於相似的情況。突變率越高,每次迭代之間的迴歸模型誤差值越大。轉 換、重組則是產生跟父代染色體相似的子代染色體,穩定地使整個染色體族群往 最佳解的區域變化。轉換、重組率越高,理論上族群內的染色體會越相像。
N a tio n al U niversity of Kao hsi un g
2.3.3
GEP 相關應用
GEP 的相關研究與應用諸多,Gustafson[32] 改良交配的運作方法,以尋找 更精準的迴歸公式。Costa[33] 則發明了一個嶄新的選擇方法,(µ + λ− GP )。 Chou[34] 應用基因規劃的符號式迴歸引擎於全球定位系統的座標軸轉換,證實演 化式計算有能力解答實際的迴歸問題。Mwaura[35] 以多重基因序的染色體,產 生出循牆機器人的控制器。Zhong 等人 [36] 應用 GEP 預測蛋白質的存活情況。 Zhou[37] 使用 GEP 於處理分類問題。Ashutosh[38] 結合 GEP 與人臉影像,成功預 測受測者年齡。迴歸方法有很多種,本研究探討的是可以直接將問題描述成可視 公式的白盒子的模式。傳統可以達成此類要求的迴歸技術,例如線性迴歸 (linear regression ,以下簡稱 LIN)、多項式迴歸 (polynomial regression ,以下簡稱 POL) 等,常因為過份簡化問題而效果有限。為了高效率解決複雜的複迴歸問題,因此 本論文採用演化式基因表達程式規劃的技術進行循跡機器人模型建立。N a tio n al U niversity of Kao hsi un g
第 3 章
問題定義與分析
本研究所探討的循跡機器人系統之迴歸模型建立,可分為四個階段加以定 義:第一階段將討論影像系統,第二階段為軌道擷取,第三階段為特徵點擷取, 第四階段說明機器人移動控制,第五階段則討論如何以 GEP 建立影像式循跡迴歸 系統。3.1
影像系統
攝影機於機器人上的裝置位置與角度跟拍攝影像範圍遠近有關,由於單一攝 影機無法同時兼顧遠近的視角,因此需要調整攝影機角度、高度至適合的偵測範 圍。機器人進行循跡時,應時時刻刻保持機身中心處於軌道的正上方,因此攝影 機應放置於機器人中央且靠前方處,以確保軌道影像完整不被遮蔽。本研究中攝 影機的感測角度為 θc,攝影機裝置於機器人上的高度為 hc,攝影機俯角為 ϕc。攝 影機最遠可視距離為 df,最近可視距離為 dn,如圖3.1所示。df、dn能藉由幾何 關係與 θc、hc、ϕc的數值計算得到,其關係式如式(3.1)、式(3.2)所示。 df = hc· cot(ϕc− θc 2) (3.1) dn = hc· cot(ϕc+ θc 2) (3.2) 圖 3.1: 可視範圍示意圖N a tio n al U niversity of Kao hsi un g 圖 3.2: 攝影機影像 圖 3.3: 軌跡擷取流程 從機載攝影機擷取的影像如圖3.2所示,由於攝影鏡頭的光學成像原理,影像中的 軌道的粗細不一。在影像中由下往上,軌道會越來越細,對應到實際環境則軌道 離機器人距離越來越遠。過細的軌道不適合用於影像循跡系統中,因此 df 的值不 可以過大。
3.2
軌跡擷取
本研究使用的攝影機之解析度為 W × H,拍攝之影像為彩色影像。若直接使 用原始影像作為系統輸入,單張影像計算至少有 W × H × 3 byte 的大小,因此需 事先進行前置處理,去除跟軌道無關的部分。再從純粹的軌道影像,擷取出足以 代表軌道的特徵值。本實驗擬以以下流程進行影像特徵擷取,包括:軌跡擷取、 軌跡影像特徵,其流程如圖3.3所示。循跡線影像過濾分為兩階段,依序是影像二 值化與雜訊處理。 • 影像二值化: 影像二值化是將影像中不屬於軌道的顏色濾除掉,只留下軌道 的影像部分。過濾的方式是在 RGB 色彩空間中,設定軌道於 R(紅)、G(綠)、B(藍) 的範圍,分別為 Rmin、Rmax、Gmin、Gmax、Bmin、Bmax,當影像任
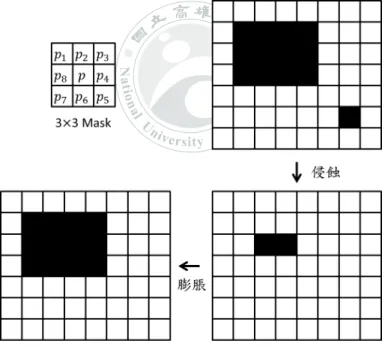
一點 p(x, y) 的 R 值 (R(p))、G 值 (G(p))、B 值 (B(p)) 都在軌道的範圍內,則 將 p(x, y) 的布林值 Bool(p) 設為 1,否則設為 0。其關係式如公式3.3所示。 • 雜訊處理: 雜訊處理的方法乃利用開放運算對二值化影像進行處理,開放運
N a tio n al U niversity of Kao hsi un g 算的步驟是先對影像進行侵蝕運算再進行膨脹運算,藉此處理影像中的斑 點、胡椒鹽形狀的雜訊。假設開放運算的遮罩大小為 M × M,其中 M 為奇 數。將此遮罩在欲處理之影像上滑動,遮罩中心點位置為 p(x, y),遮罩內的 其餘點為 p1、p2、...、pM2−1。舉例來說,假設使用 3× 3 大小的遮罩進行開 放運算,則影像處理的過程如圖3.4所示。依序完成影像二值化與雜訊處理 後,就獲得乾淨的軌道影像,如圖3.5所示。
Bool(p) = 1, Rmin ≤ R(p) ≤ Rmax, Gmin ≤ G(p) ≤ Gmax, Bmin ≤ B(p) ≤ Bmax
Bool(p) = 0,其餘狀況
(3.3)
N a tio n al U niversity of Kao hsi un g 圖 3.5: 循跡線影像過濾
3.3
特徵擷取
二值化後的影像能視為二維陣列,其大小為 W × H,其中陣列內容為 1 的 部分為軌跡的位置。若將所有軌跡的位置座標 pt(xt, yt)直接當作迴歸模型的輸 入,其資料維度會高達上千維度,將造成計算上的負擔。因此,需要進行取樣 (sampling),減少不必要的維度。在本研究中,擬採用水平掃描的方式進行取樣, 其步驟為:座標系統訂定、掃描線數量設定、取交集、特徵標定。 • 影像座標系統訂定: 使用直角座標描述影像,以便水平掃描線進行取樣。以 影像左上角 OI 為原點,水平方向為 x 軸,向右值越大,垂直方向為 y 軸, 向下值越大,便於二維陣列資料之轉換,如圖3.7所示。 • 掃描線數量設定: 以 Nl 條等距的線 Ci 掃描影像,如圖3.8所示。掃描線 Ci 為多點掃描點 cij 的集合,其關係式如式(3.4)所示,其中 i 代表掃描線編號, j 代表掃描線 Ci上每個掃描點的編號。 • 取交集: 取掃描線 Ci 與軌道的交集,作為粗略的軌道特徵,如圖3.9所示。 • 特徵標定: 沿著水平方向各別對每個交集區塊取中點,以此中點作為交集區 塊的特徵點,進一步簡化影像特徵的資訊量,如圖3.10所示。N a tio n al U niversity of Kao hsi un g 圖 3.6: 特徵擷取流程 圖 3.7: 影像座標系統 圖 3.8: 掃描線 Ci (a) 掃描直線 (b) 交集 (c) 掃描曲線 (d) 交集 圖 3.9: 循跡線影像與掃描線取交集
N a tio n al U niversity of Kao hsi un g 圖 3.10: 特徵標定 理想上,每一條掃描線 Ci 會各別對應一個特徵點 fi(x, y),因此共存在 Nl個特徵 點,以一個集合 F 表示一張影像中所有特徵點則如式(3.5)所示。 Ci ={cij|i = 1, 2, ..., Nl, j = 0, 1, ..., WI− 1} (3.4) F ={fi|i = 1, 2, ..., Nl, i∈ N} (3.5)
3.4
機器人移動控制
二輪機器人的控制方式,是藉由驅動機器人左右兩側的馬達進行移動。馬達 藉由驅動參數 ψL、ψR控制,左邊馬達驅動參數為 ψL,右邊馬達驅動參數為 ψR。 為確保馬達操作在額定功率內,其數值限制於安全範圍內,如式3.6所示。 ψmin < ψL< ψmax ψmin < ψR< ψmax (3.6) 直流馬達能夠順時針或逆時針轉動,ψmax 對應機器人輪子以最高轉速前進的參 數,ψmin 對應機器人輪子以最高轉速後退的參數,兩者的均值 ψ0 則對應使輪子 停止的參數。設定完驅動參數後,可經由轉換公式3.7計算真實環境下的輪子移動 速度 V ,其中,Vmax為控制參數等於 ψmax時的輪子移動速度。 V (ψ) = ψ− ψ0 ψmax− ψ0 × Vmax (3.7) 若要控制二輪機器人進行直走、轉彎,只需洽當地調整 ψL、ψR即可,但若想更N a tio n al U niversity of Kao hsi un g 圖 3.11: 二輪機器人圓周運動 以點 PO為圓心,若想以角速度 ω 做半徑 dr的圓周轉動,則左輪速度應為 VL,右 輪速度應為 VR,圖3.11為二輪機器人圓周運動的俯視圖。其中,PL為機器人左輪 的位置,PR為機器人右輪的位置,PM 為 PL及 PR 的中點,機器人寬 dL。由於 機器人是剛體,因此機器人轉動時,PL與 PR都同時以角速度 ω 轉動。並滿足如 式3.8的關係式。 VL= (dr− dL2 )× ω VR= (dr+dL2 )× ω (3.8) 由於使用左、右輪的數值控制二輪型機器人轉彎弧度較不直觀,因此將式3.8調 整,如式3.9所示。其中,Vf 代表機器人中心的移動速率,值越大移動的速率越 快。Vd代表機器人兩輪的速度差,值越大轉彎的幅度越大。 Vf = VR+VL2 = ω· dr Vd= VR− VL = ω· dL (3.9)
N a tio n al U niversity of Kao hsi un g (a) 左輪迴歸模型 (b) 右輪迴歸模型 圖 3.12: 迴歸模型
3.5
以 GEP 建立影像式循跡迴歸系統
3.5.1
訓練資料集
循跡系統的輸入與輸出,分別為攝影機影像與控制參數 ψ。但先前曾提到單 張影像資訊量過大,不適合直接作為訓練資料的輸入,因此本研究中以攝影機影 像的特徵集合 F 作為訓練資料的輸入。訓練資料的輸入、輸出、組成如下所列: • Input: F = {fi|i = 1, 2, ..., Nl}。 • Output: ψL、ψR。 • Training Set: {⟨F, ψL⟩j,⟨F, ψR⟩j|j = 1, 2, ..., NS}。 NS 為訓練資料集的元素個數,等同於訓練影像的張數。由於單個數學模型只有 ·)、N a tio n al U niversity of Kao hsi un g PR(·) 作為 ψL、ψR的迴歸函式如圖3.12所示。PL(·) 的訓練資料為 ⟨F, ψL⟩,PR(·) 的訓練資料為⟨F, ψR⟩。在訓練資料的蒐集方面,本研究建立了一人為操控的控制 系統,讓操作員透過攝影機畫面操縱機器人往合理的方向移動,以人工的方式收 集訓練用的資料。
3.5.2
適應函數
本研究擬以 MAPE 為參考,設計迴歸模型PL(·)、PR(·) 的適應函數值 fL、fR, 用來判斷迴歸模型的優劣,如式3.10所示。其中,ϵ 為 MAPE 值,代表迴歸模型 輸出與目標值的誤差程度百分比,i 代表訓練資料編號。而適應值則代表迴歸模型 輸出的正確程度百分比,值越高代表迴歸模型的輸出越接近訓練資料。 ϵL= NS1 ∑NSi=1|PL(Fi)−ψL,i
ψL,i | ϵR= NS1 ∑NS i=1| PR(Fi)−ψR,i ψR,i | fL= 1− ϵL fR= 1− ϵR (3.10)
N a tio n al U niversity of Kao hsi un g
第 4 章
實驗與結果分析
4.1
機器人機構與硬體架構
4.1.1
機器人機構
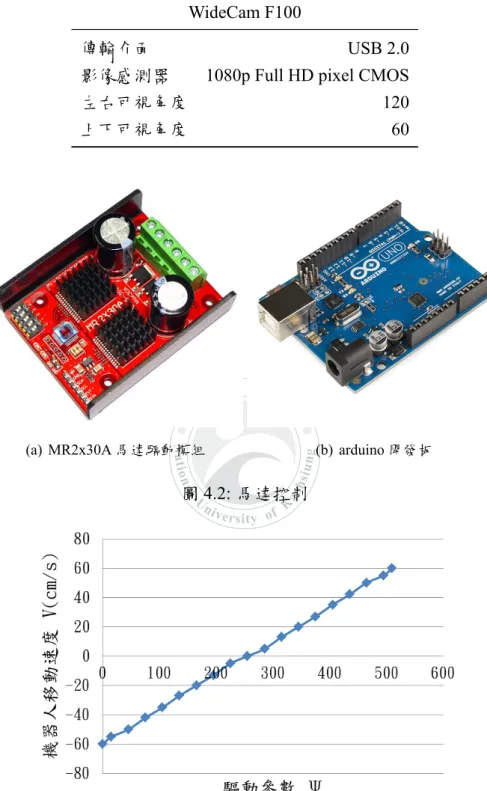
本研究使用二輪型機動型機器人做為測試平台,機體部分由鋁架、馬達、 輪子、壓克力組合而成,機器人整體長 30 公分、寬 30 公分、高 25 公分,重 6 公斤。前方配備一台彩色攝影機用以感測環境,如圖4.1所示。本研究機器人 之計算平台使用 Intel Core i5-4200U 處理器、DDR3 記憶體 4G,作業系統使用 Windows7。前方使用之彩色攝影機為 Genius 科技之 F100 廣角攝影機,並以俯角 ϕc25 度、高度 hc13 公分裝置於機器人前方,攝影機詳細規格詳見表4.1。馬達使 用祥儀科技出產之 IG-38PGM 馬達,減速比為 1:100。輪子材質使用硬質橡皮, 直徑 12.5 公分。馬達控制使用利基科技之 MR2x30A 馬達驅動模組,並以 Arduino UNO 開發板發送控制訊號,如圖4.2所示。馬達驅動參數 ψL、ψR 與機器人速度 vR、vR的關係如圖4.3所示,驅動參數上限 ψmax 為 510,下限 ψmin 為 0。電源供 應以兩顆鋰電池供應,分別為計算平台電源 19v 及馬達電源 12v。 圖 4.1: 實體機器人N a tio n al U niversity of Kao hsi un g 表 4.1: 攝影機規格 WideCam F100 傳輸介面 USB 2.0
影像感測器 1080p Full HD pixel CMOS
左右可視角度 120
上下可視角度 60
(a) MR2x30A 馬達驅動模組 (b) arduino 開發板
圖 4.2: 馬達控制
N a tio n al U niversity of Kao hsi un g
4.1.2
硬體架構
本研究機器人之硬體架構如圖4.4所示,可簡易分成計算層及驅動層。 • 計算層:包含計算平台、彩色攝影機。以計算平台為主要核心,連接彩色攝 影機接收影像訊號,並計算控制參數 ψ。• 驅動層:包含 Arduino UNO 開發板、MR2x30A 馬達驅動模組、兩組直流馬 達。以 Arduino UNO 開發板解析來自計算平台的控制字串,轉換成控制訊 號後發送給馬達驅動模組,再驅動兩組直流馬達。 圖 4.4: 馬達驅動參數與機器人速度關係
4.2
實驗環境
本實驗以黑色不反光地磚作為實驗場地,軌道使用寬 1.8 公分的白色膠帶黏 貼於黑色地磚上,並以白色保麗龍牆壁將四周圍起,以減少外在環境之干擾,如 圖4.5所示。實驗場地共分為六種場景,分別為直線、90 度轉彎、ㄇ字型路線、連 續 45 度轉彎、彎曲路線、複合型場地。如圖4.6所示。N a tio n al U niversity of Kao hsi un g 圖 4.5: 實驗場地 (a) 直線 (b) 90 度轉彎 (c) ㄇ字型路線 (d) 連續 45 度轉彎 (e) 彎曲路線 (f) 複合型場地 圖 4.6: 測試路線
N a tio n al U niversity of Kao hsi un g 圖 4.7: 實驗流程圖
4.3
實驗架構與流程
本實驗分為下列兩部分,包括離線訓練階段及實測階段。在離線訓練階段, 會依序針對 GEP 的每一項演算參數進行調整,包括染色體長度、演化率、演化 運算子種類,以獲得好的演化結果。並與其他白盒子式的迴歸方法進行比較,分 析 GEP 相較於傳統迴歸分析方法的誤差與穩定度。在實測階段,則將迴歸模型安 裝於機器人,比較不同種類迴歸的方法於真實環境下的效果。實驗流程如圖4.7所 示,依序共分為實驗 A、實驗 B、實驗 C、實驗 D、實驗 E。為簡化表格內容,部 分實驗參數以符號表示,如表4.2所示。 表 4.2: 符號對照表 訓練資料筆數 NS 突變率 ξM 測試資料筆數 NT 轉換率 ξT 族群數 Nc 重組率 ξR 染色體長度 lc 適應值 f 運算子集合 OP 誤差值 ϵ 迭代次數 γ 標準差 σN a tio n al U niversity of Kao hsi un g
4.4
實驗 A–染色體的長度 l
c調整
實驗 A 主要目的為測得適合的染色體長度 lc,lc共分為 13、17、21、25、29、 33、37 七種,其各自的頭、尾長度如表4.3所示。由於 GEP 為機率性的演算法, 因此本研究對不同長度的 lc值各進行 10 次的訓練,並分析此 10 次訓練的適應值 的均值與標準差,藉此得到可信度較高的結果。實驗 A 最終會挑選出高均值、低 標準差的 lc作為下階段的固定參數。 表4.5為此次實驗參數,使用 669 筆訓練資料及 75 筆測試資料,該資料集為 機器人於圖4.6的 6 種測試場地,分別沿路線以順時針、逆時針行走繞行一次所 獲得。每次迭代的族群數量 Nc為 30。使用所有種類的運算子進行演化,詳細的 運算子種類如表4.4所示。演化率皆設為高機率,降低陷入區域最佳解的可能性。 終止條件為 200000 次迭代停止訓練,表4.6、表4.7分別為迴歸模型PL(·)、PR(·) 的訓練結果,fLi、fRi 為個別 n 次訓練結果的適應值,fL、fR 分別為 fLi、fRi 的平均,如式(4.1)、式(4.2)所示。σL、σR分別為 fLi、fRi 的標準差,如式(4.3)所 示。表4.8為適應值 fL、fR 的平均 fω 與標準差 σL、σR 的平均 σω,如式(4.4)、 式(4.5)所示。 fL= 1 n n ∑ i=1 fLi (4.1) fR= 1 n n ∑ i=1 fRi (4.2) σ = v u u t 1 n n ∑ i=1 (fi− f) 2 (4.3) fω = fL+ fR 2 (4.4) σω = σL+ σR 2 (4.5) 其中 n = 10,從表4.8中能觀察到 lc為 13 時,其適應值 fω 最高,但同時其標準 差 σω也是最大的,可以推斷在 7 種 lc長度中,lc為 13 的收斂情況相對不穩定的。N a tio n al U niversity of Kao hsi un g 而 lc為 17 時,適應值 fω 雖然只有第二高,但標準差 σω 最小,收斂情況較其他 參數穩定。因此,若希望每次收斂的適應值高且穩定,則 lc為 17 是較好的選擇。 下階段的實驗 B 中,染色體長度 lc會固定為 17。另外觀察不同 lc的適應值隨迭代 次數的變化,大多數適應值幾乎在 100000 代後,就趨近於收斂狀態,如圖4.8至 圖4.14所示。因此,後續實驗將調整終止條件為 γ = 100000,以縮短訓練時間。 表 4.3: 染色體長度 lc lc 13 17 21 25 29 33 37 head 6 8 10 12 14 16 18 tail 7 9 11 13 15 17 19 表 4.4: 運算子集合種類
Sop1 Sop2 Sop3
x+y abs(x) 1/x exp(x) sin(x)
x-y (-x) 1-x pow(10,x) cos(x)
x*y min(x,y) x2 ln(x) tan(x)
x/y max(x,y) x3 log(x) csc(x)
floor(x) avg(x,y) sqrt(x) sec(x)
ceil(x) mod(x,y) x(1/3) cot(x)
表 4.5: GEP 參數設定 NS 669 NT 75 Nc 30 lc 13,17,21,25,29,33,37 ξM 0.4 ξT 0.8 ξR 0.8 OP OP1∪ OP2∪ OP3 終止條件 γ = 200000
N a tio n al U niversity of Kao hsi un g 表 4.6: 不同染色體長度下之適應值 fL lc 13 17 21 25 29 33 37 1 0.9768 0.9753 0.9765 0.9609 0.9779 0.9726 0.9779 2 0.9757 0.9718 0.9746 0.9755 0.9700 0.9690 0.9644 3 0.9666 0.9701 0.9761 0.9686 0.9750 0.9705 0.9697 4 0.9678 0.9760 0.9775 0.9720 0.9705 0.9671 0.9663 5 0.9673 0.9763 0.9676 0.9765 0.9732 0.9792 0.9609 6 0.9763 0.9677 0.9797 0.9753 0.9679 0.9702 0.9688 7 0.9759 0.9753 0.9730 0.9745 0.9690 0.9746 0.9768 8 0.9763 0.9759 0.9699 0.9661 0.9655 0.9764 0.9763 9 0.9753 0.9678 0.9677 0.9681 0.9661 0.9669 0.9651 10 0.9760 0.9770 0.9797 0.9700 0.9674 0.9698 0.9757 fL 0.9734 0.9733 0.9742 0.9708 0.9703 0.9716 0.9702 σL 0.0041 0.0035 0.0043 0.0047 0.0038 0.0038 0.0058 表 4.7: 不同染色體長度下之適應值 fR lc 13 17 21 25 29 33 37 1 0.9667 0.9722 0.9703 0.9676 0.9656 0.9580 0.9663 2 0.9576 0.9649 0.9671 0.9642 0.9667 0.9749 0.9553 3 0.9662 0.9743 0.9738 0.9749 0.9722 0.9721 0.9731 4 0.9639 0.9641 0.9702 0.9650 0.9641 0.9639 0.9757 5 0.9741 0.9641 0.9721 0.9699 0.9686 0.9771 0.9640 6 0.9555 0.9684 0.9534 0.9668 0.9602 0.9647 0.9654 7 0.9741 0.9662 0.9561 0.9677 0.9640 0.9644 0.9685 8 0.9754 0.9723 0.9572 0.9635 0.9707 0.9641 0.9641 9 0.9742 0.9648 0.9698 0.9674 0.9655 0.9718 0.9730 10 0.9751 0.9650 0.9641 0.9738 0.9651 0.9659 0.9646 fR 0.9683 0.9676 0.9654 0.9681 0.9663 0.9677 0.9670 σR 0.0071 0.0037 0.0070 0.0036 0.0033 0.0057 0.0056
N a tio n al U niversity of Kao hsi un g 表 4.8: 適應值 fω 與標準差的平均 lc 13 17 21 25 29 33 37 fω 0.9708 0.9705 0.9698 0.9694 0.9683 0.9697 0.9686 σω 0.0056 0.0036 0.0056 0.0042 0.0036 0.0047 0.0057 (a) PL的 10 次訓練結果 (b) PR的 10 次訓練結果 圖 4.8: lc 為 13 之適應值隨迭代變化圖 (a) PL的 10 次訓練結果 (b) PR的 10 次訓練結果 圖 4.9: lc 為 17 之適應值隨迭代變化圖
N a tio n al U niversity of Kao hsi un g (a) PL的 10 次訓練結果 (b) PR的 10 次訓練結果 圖 4.10: lc 為 21 之適應值隨迭代變化圖 (a) PL的 10 次訓練結果 (b) PR的 10 次訓練結果 圖 4.11: lc 為 25 之適應值隨迭代變化圖 (a) PL的 10 次訓練結果 (b) PR的 10 次訓練結果 圖 4.12: lc 為 29 之適應值隨迭代變化圖
N a tio n al U niversity of Kao hsi un g (a) PL的 10 次訓練結果 (b) PR的 10 次訓練結果 圖 4.13: lc 為 33 之適應值隨迭代變化圖 (a) PL的 10 次訓練結果 (b) PR的 10 次訓練結果 圖 4.14: lc 為 37 之適應值隨迭代變化圖
N a tio n al U niversity of Kao hsi un g
4.5
實驗 B–演化機率調整
在實驗 A 中,我們得到收斂狀態較穩定的染色體長度 lc,以及合適的演化終 止條件。而實驗 B 主要目的為測得適合的轉換率 (ξT)、重組率 (ξR)、突變率 (ξM), 期望在固定的迭代次數內,尋得適應值最高的迴歸模型。機率調整的範圍固定為 0.2、0.4、0.8 三種數值,分別代表低機率、中機率、高機率,實驗中演化率的組 合共有 27 種。每種組合均會訓練 10 次,並取其適應值最高者與其他參數的訓練 結果進行比較。經由該次實驗結果,會挑選出 fω 第 1 高的 ξT、ξR、ξM 作為下階 段的固定參數。表4.9為此次實驗參數,使用的訓練資料、族群數量、運算子種類 同實驗 A。終止條件為 100000 次迭代停止訓練。 實驗結果如表4.10所示,當演化率 ξM、ξT、ξR 為 0.2、0.4、0.8 時,fω 有最 高值。而與其他適應值相近的訓練結果比較,其迭代次數 γavg 相對較小。在下階 段的實驗中,演化率 ξM、ξT、ξR將會固定為 0.2、0.4、0.8。 表 4.9: GEP 參數設定 NS 669 NT 75 Nc 30 lc 17 ξM 0.2, 0.4, 0.8 ξT 0.2, 0.4, 0.8 ξR 0.2, 0.4, 0.8 OP OP1∪ OP2∪ OP3 終止條件 γ = 100000N a tio n al U niversity of Kao hsi un g 表 4.10: 不同演化率訓練結果 ξM ξT ξR fL fR γL γR fω γω 0.2 0.2 0.2 0.9753 0.9792 95354 99605 0.9773 97479.5 0.2 0.2 0.4 0.9795 0.9771 36294 71579 0.9783 53936.5 0.2 0.2 0.8 0.9799 0.9759 85029 95354 0.9779 90191.5 0.2 0.4 0.2 0.9812 0.9791 71987 52874 0.9801 62430.5 0.2 0.4 0.4 0.9800 0.9780 17566 56318 0.9790 36942 0.2 0.4 0.8 0.9812 0.9792 63990 25257 0.9802 44623.5 0.2 0.8 0.2 0.9800 0.9765 94467 84065 0.9783 89266 0.2 0.8 0.4 0.9763 0.9753 64191 99453 0.9758 81822 0.2 0.8 0.8 0.9810 0.9792 80404 97381 0.9801 88892.5 0.4 0.2 0.2 0.9770 0.9737 62417 92484 0.9754 77450.5 0.4 0.2 0.4 0.9802 0.9745 98448 63267 0.9773 80857.5 0.4 0.2 0.8 0.9768 0.9776 74964 54752 0.9772 64858 0.4 0.4 0.2 0.9764 0.9774 70028 80878 0.9769 75453 0.4 0.4 0.4 0.9810 0.9739 67290 97934 0.9774 82612 0.4 0.4 0.8 0.9799 0.9791 92012 94049 0.9795 93030.5 0.4 0.8 0.2 0.9764 0.9723 98038 38065 0.9743 68051.5 0.4 0.8 0.4 0.9771 0.9753 66697 87561 0.9762 77129 0.4 0.8 0.8 0.9764 0.9713 93967 90131 0.9739 92049 0.8 0.2 0.2 0.9760 0.9717 93468 71230 0.9738 82349 0.8 0.2 0.4 0.9791 0.9721 49321 98630 0.9756 73975.5 0.8 0.2 0.8 0.9754 0.9669 97655 50783 0.9711 74219 0.8 0.4 0.2 0.9760 0.9710 46534 99612 0.9735 73073 0.8 0.4 0.4 0.9753 0.9714 80289 70796 0.9734 75542.5 0.8 0.4 0.8 0.9739 0.9693 76142 21429 0.9716 48785.5 0.8 0.8 0.2 0.9760 0.9721 66791 75347 0.9741 71069 0.8 0.8 0.4 0.9735 0.9700 59591 30905 0.9718 45248 0.8 0.8 0.8 0.9676 0.9648 57862 88325 0.9662 73093.5
N a tio n al U niversity of Kao hsi un g
4.6
實驗 C–運算子集合 OP 調整
實驗 C 主要目的為比較不同運算子集合 OP 的訓練效果,使用 OP 為 OP1、OP2、OP3 的組合,OP1、OP2、OP3 的運算子集合種類如表4.4所示。其中 OP1
的線性運算子,不論問題複雜度高低幾乎都會使用,因此 OP 使用如下四種組合: • OP1
• OP1∪ OP2
• OP1∪ OP3
• OP1∪ OP2∪ OP3
與先前實驗相同,每種參數組合均會訓練 10 次,並取 10 次訓練的平均適應值 與其他參數的訓練結果進行比較。表4.11為此次實驗參數,使用的訓練資料、族 群數量、染色體長度同實驗 B。表4.12為不同運算子集合 OP 的測試結果。由 表4.12可以觀察到,當使用的運算子種類越多時,平均收斂迭代數越高,適應值 fω 越低。觀察四種運算子組合訓練出的迴歸模型,能發現染色體幾乎都由 OP1 的運算子組成。可以推測影像式循跡系統是一種不需要複雜非線性運算的系統, 表 4.11: GEP 參數 NS 669 NT 75 Nc 30 lc 17 ξM 0.2 ξT 0.4 ξR 0.8 OP OP1, OP2, OP3 終止條件 γ = 100000
N a tio n al U niversity of Kao hsi un g 表 4.12: 不同運算子集合 OP 的測試結果
OP OP1 OP1 ∪ OP2 OP1∪ OP3 OP1 ∪ OP2∪ OP3
fL 0.9762 0.9735 0.9758 0.9743 fR 0.9729 0.9682 0.9693 0.9668 γL 59548.6 66254.2 76278.1 79567.9 γR 71835.3 72758.1 76947.8 80400.7 fω 0.9746 0.9709 0.9725 0.9706 γω 65691.95 69506.15 76612.95 79984.3 當使用 OP1 進行分析時,能有最高的適應值與最少的迭代次數。因此僅使用 OP1 的運算子進行訓練效果會較佳。
4.7
實驗 D–不同迴歸方法間的比較
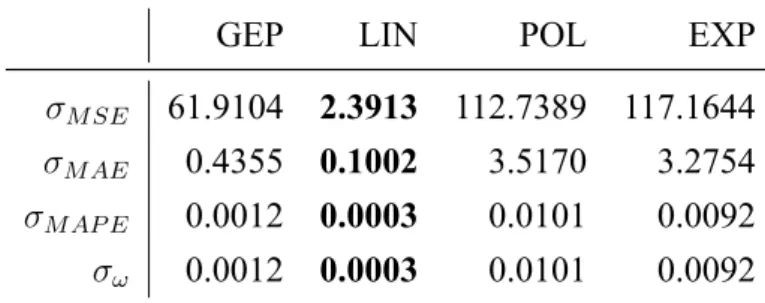
根據實驗 A、實驗 B、實驗 C 的實驗結果,本研究整理出適合訓練影像式循 跡系統的 GEP 參數。而實驗 D 主要目的為比較不同迴歸方法間的效果,實驗中將 比較線性迴歸、多項式迴歸、指數型迴歸 (exponential regression ,以下簡稱 EXP) 與 GEP 所建立的迴歸模型,分析 GEP 與傳統迴歸方法間的差異。表4.13為此次實驗參數,GEP 與 3 種迴歸方法均使用與實驗 A、實驗 B、實 驗 C 相同的訓練資料,並使用 10 次交叉驗證 (10-fold cross validation) 進行實驗, 提高實驗的可信度。表4.14為各迴歸模型的各項誤差指標與適應值,表4.15則為測 試資料代入迴歸模型的結果。其中,LIN 的 MSE 值最小,GEP 次之。而 MAE、 MAPE 值,則是 GEP 最小,LIN 次之。從這幾項指標特性判斷,推測是 GEP 建 立的模型在大部分情況較貼近目標值,但少數模型預測值偏離目標值過多導致。 表4.16為 10 次訓練結果的標準差,表4.17為訓練資料代入迴歸模型的標準差。從 中可以觀察到 LIN 建立的迴歸模型最穩定,GEP 因為是機率演算法,因此穩定度 較 LIN 差,而 POL 與 EXP 的穩定度則遜於 GEP。由上述現象可推測了影像式循
N a tio n al U niversity of Kao hsi un g 跡系統是一種線性系統。雖然 GEP 在穩定度上不如 LIN,但其最高適應值 fω 優 於 LIN。因此藉由基因演化的性質,GEP 可以找到比 LIN 更好的迴歸模型描述影 像式循跡系統。 表 4.13: GEP 參數 NS 669 NT 75 Nc 30 lc 17 ξM 0.2 ξT 0.4 ξR 0.8 OP OP1 終止條件 γ = 100000 表 4.14: 各種迴歸方法產出模型誤差與適應值之比較
GEP LIN POL EXP
MSE 170.3227 103.1270 181.9341 239.5110
MAE 7.1170 8.0855 10.3671 12.3982
MAPE 0.0210 0.0238 0.0306 0.0362
fω 0.9790 0.9762 0.9694 0.9638
表 4.15: 以測試資料驗證各模型之比較
GEP LIN POL EXP
MSE 122.8848 108.4696 189.3757 245.0444
MAE 7.0163 8.2804 10.5383 12.5713
MAPE 0.0208 0.0244 0.0311 0.0366
N a tio n al U niversity of Kao hsi un g 表 4.16: 10 次訓練結果的誤差與適應值之標準差
GEP LIN POL EXP
σM SE 61.9104 2.3913 112.7389 117.1644
σM AE 0.4355 0.1002 3.5170 3.2754
σM AP E 0.0012 0.0003 0.0101 0.0092
σω 0.0012 0.0003 0.0101 0.0092
表 4.17: 10 次測試資料驗證各模型之標準差
GEP LIN POL EXP
σM SE 37.9350 21.6912 142.6709 116.6275 σM AE 0.7772 0.6726 4.0697 3.2848 σM AP E 0.0023 0.0020 0.0118 0.0094 σω 0.0023 0.0020 0.0118 0.0094 各方法產生的最佳迴歸模型如下列所示,表4.18為各方法使用的運算子數量, 表4.20為各方法的計算時間,單位為秒。可以發現 GEP 的運算子數量與計算時間 遠小於其他方法。
• GEP(PL):(f7(y)+((Max(Min(f5(y),f4(x)),(0.6418*f6(x)))+ceil(((9.1155+f6(y))/ 2.0)))/2.0))/2.0
• GEP(PR):ceil(((f7(y)+((f7(y)+Min((f6(y)-f4(x)),(f4(y)/2.898)))/2.0))/2.0)) • LIN(PL):504.6605 + 0.0021 * f1(x)- 0.0163 * f1(y)- 0.0058 * f2(x)+ 0.0496 *
f2(y)+ 0.0348 * f3(x)- 0.022 * f3(y)+ 0.0458 * f4(x)- 0.032 * f4(y)+ 0.0308 * f5(x)- 0.007 * f5(y)+ 0.3195 * f6(x)- 0.5009 * f6(y)- 0.2631 * f7(x)
• LIN(PR):156.9651 + 0.0101 * f1(x)- 0.0139 * f1(y)- 0.0022 * f2(x)+ 0.0469 * f2(y)- 0.0085 * f3(x)+ 0.0244 * f3(y)- 0.0568 * f4(x)+ 0.0508 * f4(y)- 0.0191 * f5(x)+ 0.0376 * f5(y)- 0.2675 * f6(x)+ 0.4479 * f6(y)+ 0.2277 * f7(x)
N a tio n al U niversity of Kao hsi un g • POL(PL):-1369536872493.1 - 0.0324 * f1(x)+ 4E-05 * f12(x) - 444758022083.887 * f1(y)+ 2234964935.0949 * f12(y) + 0.0944 * f2(x)- 0.0001 * f22(x) - 1269913902544.05 * f2(y)+ 5313447290.9791 * f22(y) + 0.0347 * f3(x)- 5E-05 * f32(x) + 0.2209 * f4(x)- 0.0002 * f42(x) + 351581328230.088 * f4(y)- 1102135825.1732 * f42(y) + 0.2061 * f5(x)- 0.0003 * f52(x) - 0.0626 * f6(x)+ 0.0003 * f62(x) + 0.0048 * f7 (x)-0.0001 * f2 7(x) • POL(PR):2855168594735.66 - 0.013 * f1(x)+ 4E-05 * f12(x) + 1744427181919.39 * f1(y)- 8765965738.2884 * f12(y) + 0.0477 * f2(x)- 0.0001 * f22(x) + 503895107805.454 * f2(y)- 2108347731.4035 * f22(y) + 0.0505 * f3(x)- 0.0001 * f32(x) + 0.0115 * f4(x)- 0.0001 * f42(x) + 594109578711.428 * f4(y)- 1862412472.4495 * f42(y) -0.0235 * f5(x)+ 1E-05 * f52(x) + 0.1212 * f6(x)- 0.0003 * f62(x) - 0.1846 * f7(x)+ 0.0003 * f72(x)
• EXP(PL):exp(6.2867 + 1E-06 * f1(x)- 4E-05 * f1(y)- 1E-05 * f2(x)+ 0.0002 * f2(y)+ 0.0001 * f3(x)- 0.0001 * f3(y)+ 0.0001 * f4(x)- 0.0001 * f4(y)+ 0.0001 * f5(x)- 4E-05 * f5(y)+ 0.0009 * f6(x)- 0.0014 * f6(y)- 0.0007 * f7(x))
• EXP(PR):exp(5.2678 + 3E-05 * f1(x)- 4E-05 * f1(y)- 2E-06 * f2(x)+ 0.0001 * f2(y)- 3E-05 * f3(x)+ 0.0001 * f3(y)- 0.0002 * f4(x)+ 0.0001 * f4(y)- 4E-05 * f5(x)+ 0.0001 * f5(y)- 0.0008 * f6(x)+ 0.0014 * f6(y)+ 0.0007 * f7(x))
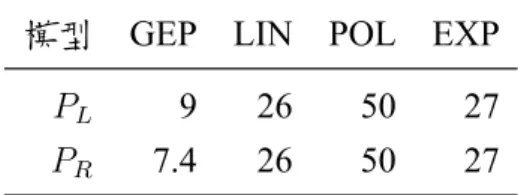
表 4.18: 各方法迴歸模型使用運算子數量 模型 GEP LIN POL EXP
PL 10 26 50 27
N a tio n al U niversity of Kao hsi un g 表 4.19: 各方法迴歸模型平均使用運算子數量 模型 GEP LIN POL EXP
PL 9 26 50 27
PR 7.4 26 50 27
表 4.20: 各方法迴歸模型不同次數的計算時間
計算次數 模型 GEP LIN POL EXP
1000 PL 0.015 0.016 0.014 0.016 PR 0.010 0.019 0.015 0.016 10000 PL 0.106 0.148 0.152 0.154 PR 0.106 0.154 0.152 0.157 100000 PL 0.931 1.420 1.448 1.476 PR 0.939 1.435 1.482 1.482 1000000 PL 9.057 14.047 14.376 14.614 PR 9.211 14.073 14.633 14.683
4.8
實驗 E–實機測試
實驗 E 主要目的為比較不同 GEP 訓練模型實際安裝於機器人測試效果,使 用實驗 D 的所有迴歸模型進行測試,測試場地共有 6 種類如圖4.6所示。表4.22、 表4.23為不同迴歸模型安裝於實體機器人的測試結果,表4.22為逆時針繞行路線的 測試結果,表4.23為逆時針繞行路線的測試結果。分別以時間、失誤次數 ρ、置中 程度 µm、平行程度 µp 作為實機測試的指標。 • 時間:代表機器人走完測試路徑耗費的時間,單位為秒。 • 失誤次數 ρ:指攝影機影像遺失軌道的次數,當影像中的有效特徵點個數少 於 Nl 2 時,即遺失軌道,此時機器人會後退直到再次感測到軌道為止,此處 的有效特徵點是指特徵點 fi座標不等於 (−1, −1) 的情況。N a tio n al U niversity of Kao hsi un g 圖 4.15: 紅外線模組安裝示意圖 圖 4.16: 平行程度 µm的模組編號設定 圖 4.17: 置中程度 µp 的模組編號設定 • 置中程度 µm:機器人中線與軌道的接近程度,其值越大,機器人偏離軌道 的程度越小。 • 平行程度 µp:機器人行走方向與軌道的平行程度,其值越大,機器人與軌 道的方向越一致。 其中,置中程度與平行程度需藉由額外安裝紅外線感測器量測,紅外線感測器安 裝於機器人下方,並以 2 列 7 排的陣列組成,如圖4.15所示。置中程度的計算方 式如下所述,各別將每列紅外線感測器編號成如圖4.16所示,當不同位置的模組 感測到軌道時,得到對應的 µm 值,對應關係如表4.21所示。 假設 3 號模組感測 到軌道,則 µm值為 0.75。若 3、4 號模組同時感測到軌道,則取平均值 0.875。對 每一列進行相同的計算後,將每列的 µm,i 值加總取均值即當下的置中程度 µm,t, 再將每一刻 µm,t 值取平均則是表4.22、表4.23中的置中程度 µm。平行程度的計算