An Empirical Study of Lexical Variation Methods for Biomedical Information Retrieval
10
0
0
全文
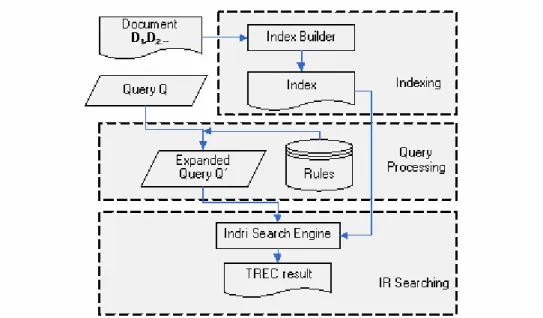
(2) lowing lexical variants: “NF-kappaB”, “NFkappa B”,. Section 2, we describe our lexical variation method. “NF-kB”, and “NFkB”. In the biomedical domain,. and its application to an IR system, and in Section 3. there are many lexical resources and databases, such. we deliberate over our experiments, including dataset,. as UMLS [3] and LocusLink [4], which provide a. settings, and results. The impact of expanded terms on. large number of aliases and alternative gene symbols.. the search results is discussed in Section 4. We wrap. However, they do not cover all the variants for the. up the paper with a brief conclusion and future work.. biomedical terms in Medline abstracts, which already. 2. number over ten million and are increasing rapidly.. Methods. Several methods have been proposed for generating. In this section, we introduce our lexical variation. lexical variants for query term expansion. Divita et al.. method and describe how its application to an IR. [5] used a large knowledge base (the SPECIALIST. system.. Lexicon [7]) to manage inflectional morphology.. 1.. More recently, Tsuruoka and Tsujii [6] proposed an. Information Retrieval System. Figure 1 presents an overview of our IR system for. automatic learning method for lexical variant genera-. retrieving biomedical documents. It is comprised of. tion. However, both approaches have some disadvan-. three stages. The first stage is document indexing,. tages. The first is based on a set of rules in [10] that. which stores all documents in an index file and. both cooperate with and depend on the SPECIALIST. transforms each document into a word list. The file. Lexicon, which contains over 100,000 entries, and. connects the query terms to the words in documents.. cannot be covered completely. The second approach. In addition, we remove all stop words, perform. must still be trained on a well-annotated corpus.. stemming on words, and convert words to lowercase.. In this paper, we propose a simple and efficient. The second stage is query preprocessing in which we. method of lexical variation for query expansion in. also remove stop words and perform stemming on. biomedical information retrieval. Based on the lexical. words that do not trigger lexical variation rules. To. variation method used by Büttcher et al. [7], our. guarantee that preprocessed query terms and words in. method includes eight new rules. To evaluate the ef-. the index file can be mapped correctly, all word. fectiveness of these lexical variation rules for bio-. processing methods in this stage should be consistent. medical information retrieval, we implement a bio-. with those in the document indexing stage. Unlike. medical information retrieval system using a very. stemming or lowercase conversion which changes the. large corpus that is composed of Medline abstracts. original terms, lexical variation rules merely expand. published from 1994 to 2003. We adopt the queries. terms from the original terms. Thus, we do not have to. provided by the Genomic Track 2004 for testing, and. apply lexical variation rules in both stages. In most. observe the frequency of the original query terms and. cases, the rules are applied in query preprocessing,. their lexical variants to evaluate the eight rules.. rather than document indexing, to avoid generating. The remainder of this paper is organized as follows. In. too many terms.. 2.
(3) Figure 1 Our IR System In the final stage, we find the relevant documents by a. in [7], we propose eight lexical variation rules for. scoring algorithm, such as TFIDF, OKAPI, or boost-. obtaining the variants of biomedical terms in Medline. ing. Discussion of scoring algorithms is beyond the. abstracts. These rules, which we apply to all query. scope of this paper; however, a detailed assessment. terms, are designed specifically for biomedical terms,. can be found in [7].. and do not affect the standard English definition of words in those terms. The rules are listed below.. 2.2 Lexical Variants. z. In general, biomedical named entities (NEs), such as. Insert a hyphen at every transition between. Latin letters, Arabic numerals and Greek letters.. protein or gene names, do not follow any particular. z. nomenclature [8] and can comprise long compound. Convert the last Arabic numeral to a Latin letter.. For example, “Smad-4” would become “Smad-D”.. words and short abbreviations [9]. Some NEs also. z. contain various symbols and other spelling variations. Convert the last Latin letter to an Arabic nu-. meral. For example, “NFkappa B” would become. [10]. On average, biomedical name entities have five. “NFkappa 2”.. synonyms, most of which are generated by lexical. z. variations. These variations, generated by different. Convert the last Arabic numeral to a Roman. numeral. For instance, “Smad-4” would become. hyphenation/spacing rules and Greek-letter represen-. “Smad-IV”.. tations, make biomedical information retrieval a. z. challenging problem indeed. If they are not dealt with. Replace Greek transcriptions with their corre-. sponding Latin letters. For example, “alpha” becomes. carefully, many relevant documents containing a term. “a”, “gamma” becomes “g”, and so on.. that is a variation of the query term may be missed. To. Replace a hyphen with a space.. overcome this problem, we have, therefore, devised. z. several rules for obtaining the lexical variants of. Remove hyphens from terms. However, if the. characters preceding and following a hyphen are all. biomedical terms.. letters or all numerals, the hyphen should not be re-. Rules. moved.. Extending the lexical variation algorithms described 3.
(4) Figure 2 An example of matching the variant with the index z. words in Indri.. Remove hyphens and numbers at the end of the. term.. #combine (Ferroportin-1 humans Find articles #1. After lexical variation, all terms generated by the rules. (iron transporter)). are added to the original query. We also check if the. Next, we apply our lexical variation method to the. length of each variant is greater than one. If the length. query, which gives us:. is one, it should be omitted. For instance, after ap#combine (#syn (Ferroportin-1 Ferroportin1 Ferro-. plying Rule 8 to the term “p-53”, it becomes “p”.. portin-I Ferroportin-a) humans Find articles #od1(iron. Obviously, “p” is a harmful term for searching.. transporter)). 2.2.2 Rule Combinations. We put the original terms and their lexical variants into. The order of the rules is important, as different se-. a “#syn” block, which means that bracketed words are. quences may produce different lexical variants. Some. treated as synonyms.. rules may compensate for the effect of precedence Figure 2 shows how the lexical variation rule works.. rules. The rules and their permutations used in this. Suppose D1 is a document relevant to the query. It can. experiment are Rule 1 & 2, Rule 1 & 2 & 3, Rule 5 & 6. not be retrieved correctly without applying lexical. & 7, and so on.. variation rules to expand the query term from Fer-. 2.3 The query preprocessing stage. roportin-1 to Ferroportin1.. We use the following query to explain this stage:. 2.4 “Ferroportin-1 in humans Find articles about Ferro-. Dataset. We use the MEDLINE bibliographic database to. portin-1 an iron transporter in humans.”. evaluate the proposed method. The subset of MED-. After parsing and removing stop words, it becomes:. LINE used by Genomic Track in the Text Retrieval. “Ferrportin-1|humans|Find|articles|Ferroportin-1|iron. Conference (TREC) 2004 [12] includes 4,591,008. transporter|humans.”. abstracts of research papers from 1994 to 2003. For. Since we use the Indri Query Language [11] as our IR. evaluation purposes, Genomic Track also provides the. engine, these terms are used to generate an Indri query.. test data, queries, and relevant documents corre-. Note that “#combine” and “#1” are used as functional. sponding to each query. There are 50 queries and 4.
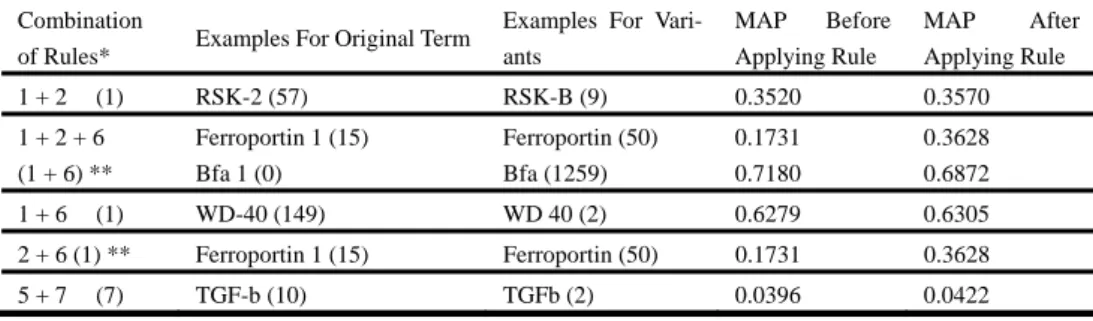
(5) Table 1. The difference in the MAP of each query for some special combinations of rules Combination of Rules* 1+2. Examples For Vari-. MAP. ants. Applying Rule. Before. MAP. RSK-2 (57). RSK-B (9). 0.3520. 0.3570. Ferroportin 1 (15). Ferroportin (50). 0.1731. 0.3628. (1 + 6) **. Bfa 1 (0). Bfa (1259). 0.7180. 0.6872 0.6305. (1). WD-40 (149). WD 40 (2). 0.6279. 2 + 6 (1) **. Ferroportin 1 (15). Ferroportin (50). 0.1731. 0.3628. 5+7. TGF-b (10). TGFb (2). 0.0396. 0.0422. (7). After. Applying Rule. 1+2+6 1+6. (1). Examples For Original Term. * The numbers in parentheses are the combinations of the rules compared. ** See the end of Discussions for explanation of the behavior of this rule.. vides MAP values, to evaluate the performance of our. 8,286 relevant documents in the test set.. system. MAP is widely used for evaluating the per-. 3. Experiments. formance of IR and QA systems, and can also be used to assess the effectiveness of lexical variation rules.. To compare the effectiveness of the eight lexical variation rules and their combinations described in. MAP is affected by the ranking of relevant articles. If. Sections 2.3.1 and 2.3.2, we built an information re-. the number of relevant articles is small, the MAP. trieval system and an IR engine based on the Indri. will be high if the most relevant articles are ranked. search engine. To evaluate our method, we used fifty. high. In contrast, the MAP will be low if most relevant. queries from 2004 Genomic Track for testing and. articles have lower rankings, even if the number of. measured the performance of the search results.. relevant articles is large.. 3.1 Experimental Design. However, for some applications, the volume of rele-. We use three indicators to evaluate our method,. vant articles is important. Therefore, we have to find. namely, the mean average precision (MAP), recall,. another evaluation measure, instead of ranking.. and term frequency. First, we use the TREC Evaluator [13], which pro-. 80 70. No Rule Rule 1. MAP (%). 60. Rule 6. 50. Rule 7 40. Rule 8 Rule 12. 30. Rule 26 20. Rule 126 Rule 167. 10. Rule 1268 0 Overall Average. Query 1. Query 12. Query 26. Query 35. Cases (Query Number) Figure 3 MAP chart for every rule 5. Query 46.
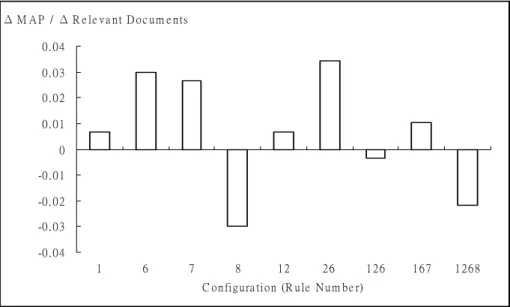
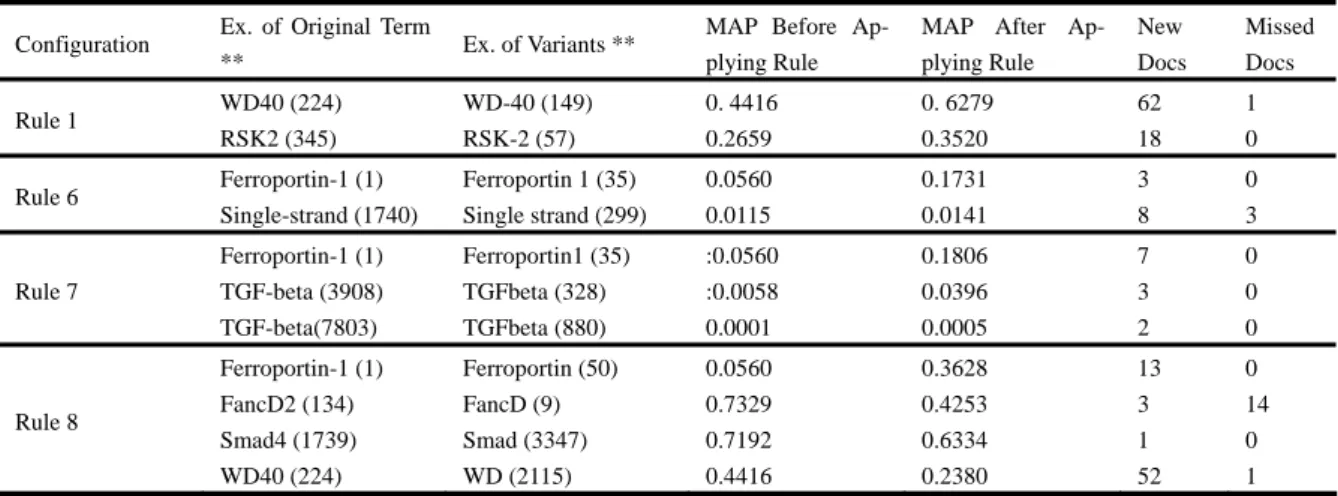
(6) Table 2. The effects of some special combinations Combinations of. Overall Average MAP. Examples For Original Term. Examples For Variants. 1+2. 0.2136. RSK2. RSK-2, RSK-B. 1+2+6. 0.2048. FancD2. FancD-2, FancD b. 2+6. 0.2144. Ferroportin-1. Ferroportin-a,Ferroportin 1. 1+6+7. 0.2188 (best). Gal1. Gal-1, Gal 1. 1+2+6+8. 0.1648 (worst). Smad4. Rules. Smad-4, Smad d, Smad. Second, we use the difference in the relevance of the. with the combination of Rules 1, 6, and 7, it is 21.88.. articles found by two rules as another measure. Al-. Thus, the combination of these three rules improves. though using two rules may retrieve an equal number. performance, while Rule 8 degrades it. The remaining. of relevant articles, the articles found using these two. rules are nearly neutral./do not affect the performance. articles may actually different. Thus, the difference. significantly.. between retrieved relevant articles is a good measure. Note that although Rule 2 does not affect MAP and. that gives us detailed information about the search. Rule 1 and Rule 6 are both beneficial, combining them. results. The third evaluation measure is the frequency. degrades performance. Table 2 shows the effects of. of expanded query terms. Only relevant documents are. some special combinations.. used to count the frequency, which is an intuitive way to observe the effectiveness of lexical variation. 3.2.2 Recall. methods. If our method can produce additional rele-. We compare the difference of each combination of the. vant query terms, the IR system should have better. rules. recall. For example, Ferroportin1 is the expanded. by. using. the. following. approach:. newfound = Rulei × Rule j − Rulei ∪ Rule j. query term of the original query Ferroportin-1. We. missed = Rulei ∪ Rule j − Rulei × Rule j. believe that the frequency of Ferroportin1 in the index. where. file is a good measure for evaluating the rule that. Rulei × Rule j means applying both.. generates Ferroportin1. We chose the number of relevant documents as one of. 3.2 Experimental Results. the indicators of our method, and the total numbers of. After conducting the experiments on all the possible. newfound and missed documents in each configura-. combinations of every rule, we get 2 = 256 results.. tion. Roughly speaking, albeit some relevant might. We now use the three indicators mentioned in Section. lost, the rules or their combination can achieve better. 3.1 to evaluate our lexical variation algorithm.. recall.. 3.2.1 MAP. In Figure 4 we show the ratio of the variance of MAP. In this subsection, we consider the overall average. to the variance of relevant documents we retrieved. As. MAP, and then investigate the MAP of each query. shown in this figure, for most of the rules the MAP and. separately. The overall average MAP of each con-. the relevant documents we retrieved are in positive. figuration is shown in Figure 2. The overall average is. correlation. But there are still exceptions, such as the. the average MAP of fifty queries.. configurations containing Rule 8, give negative ratios.. 8. The MAP of fifty queries with “no rule” is 20.82, but 6.
(7) Δ M A P / Δ R e le v a n t D o c u m e n ts 0.04 0.03 0.02 0.01 0 -0 . 0 1 -0 . 0 2 -0 . 0 3 -0 . 0 4 1. 6. 7. 8. 12. 26. 126. 167. 1268. C o n fig u ra tio n (R u le N u m b e r). Figure 4 The relationship between relevant documents and MAP By these ratios the relative effect of ranking of each. Relative Freq(q, r ) =. rule can be evaluated. In general, finding more rele-. Freqlexi Freq org + Freqlexi. ,. vant documents raises MAP, leading to a positive. where Freqorg denotes the frequency of q’s most. ratio. For those cases with negative ratios, we can. variant term, t, before applying r, while Freqlexi de-. refer these exceptions to incorrect ranking. Rule 8. notes t’s term frequency after applying r. Here, the. produces generalized variants, which retrieves more. most variant term means the term in q which has the. relevant document but also ruined the ranking and. highest frequency variance before and after applying r.. undermines MAP as well.. To measure the variance of MAP, we define the mar-. 3.2.3 The frequency of expanded query terms. ginal MAP as follows:. In this section, we discuss how a query’s change. MarginalMAP(q, r ) =. caused by a lexical variation rule influences that. MAPlexi -MAPorg. query’s retrieval result, which is usually measured by. MAPorg. , where. MAP. Given a query q and a lexical variation rule r is. MAPorg denotes the MAP of q’s retrieval result before. applied on q, we define the relative frequency as fol-. applying r, and MAPlexi denotes the MAP of q’s re-. lows:. trieval result after applying r.. 7.
(8) Table 3. The impact of different rules on the lexical variants.* Configuration Rule 1 Rule 6. Rule 7. Rule 8. Ex. of Original Term **. Ex. of Variants **. MAP Before Ap-. MAP After Ap-. New. Missed. plying Rule. plying Rule. Docs. Docs. WD40 (224). WD-40 (149). 0. 4416. 0. 6279. 62. 1. RSK2 (345). RSK-2 (57). 0.2659. 0.3520. 18. 0. Ferroportin-1 (1). Ferroportin 1 (35). 0.0560. 0.1731. 3. 0. Single-strand (1740). Single strand (299). 0.0115. 0.0141. 8. 3. Ferroportin-1 (1). Ferroportin1 (35). :0.0560. 0.1806. 7. 0. TGF-beta (3908). TGFbeta (328). :0.0058. 0.0396. 3. 0. TGF-beta(7803). TGFbeta (880). 0.0001. 0.0005. 2. 0. Ferroportin-1 (1). Ferroportin (50). 0.0560. 0.3628. 13. 0. FancD2 (134). FancD (9). 0.7329. 0.4253. 3. 14. Smad4 (1739). Smad (3347). 0.7192. 0.6334. 1. 0. WD40 (224). WD (2115). 0.4416. 0.2380. 52. 1. * Some rules are omitted cause the change is not conspicuous. ** The number in the parentheses stand for the term frequency.. In Figure 5, we use the x-axis to represent the relative. whether the rule is too aggressive. The relative fre-. frequency and y-axis to represent the marginal MAP.. quency made by Rule 1, 6, 7 are less than 0.5, which. Each point represents a query-rule pair. In addition, we. means the frequencies of lexical variants are less than. use different symbols to represent different rules. For. the frequency of the original term, while the relative. example, the points represented by △ means that we. frequency made by Rule 8 is close to 1, which means. apply Rule 1 on these queries and get lexical variants.. the frequencies of lexical variants are much more than. We observe that, in Rule 1, 6, and 7, the correlation. the frequency of the original term. This phenomenon. between relative frequency and marginal MAP is. explains why Rule 8 causes MAP decrease.. positive. It means the more frequent terms we ex-. 3.3 Discussion. panded, the higher MAP we can achieve. However, we. To analyze the impact of expanded terms on the search. also notice that, in Rule 8, the correlation between. results, we categorize the relationship between the. relative frequency and MAP is negative.. expanded term and the original query term as one of. Relative frequency of rules is another way to measure. two types:. Marginal5 MAP. Rule1 Rule6. 4 Rule7 3. Rule8. 2 1 0 -1 -2 0. 0.2. 0.4 0.6 Relative Frequency. 0.8. 1. Figure 5 The relationship between relative frequency and marginal MAP 8.
(9) 1) The expanded term has a higher-level concept meaning than the original term. useful to generate good lexical variants which im-. In this case, the expanded query term may be less. According to our evaluation on all lexical variation. specific than the original term. Thus, the MAP may. rules, we have found that the rules for dealing with. improve or deteriorate, depending on the semantic. hyphens improve the precision of information re-. meaning of the original query. For instance, adding the. trieval the most, which implies that biologists often. term “Ferroportin” (the original term is Ferroportin-1). insert hyphens in different positions. Also, the rule for. to query 1 increases the MAP by 31%. However, add-. manipulating Greek transcriptions substantially im-. ing “Samd” (the original term is Samd-4) to query 12. proves the MAP and recall of query terms with such. reduces the MAP by 30%. Generally, in this case the. transcriptions. Converting Greek transcriptions in. precision decreases, but the recall increases.. query terms to Latin letters and applying the hyphen. 2) The expanded term has a different meaning to the original term. variation rules improve both the MAP and recall rate. prove performance.. of biomedical information retrieval.. In this case, the search performance always deterio-. 5. rates, because the semantics of the original query are. Future Work. corrupted. The accuracy of the expanded term then. In the future, we will compare our lexical variation. depends on that of other terms in the query. However,. rules with other lexical variation systems, for example,. the performance will not decrease significantly if the. NLM’s LVG (Lexical Variant Generator) [14]. The. domains of the generated variations do not overlap too. LVG can generate inflectional lexical variants such as. much with the domain of the original term. For in-. “acting” and “acted” for the term “act”. When incor-. stance, applying Rule 4 and 6 to query 26 generates. porated into information retrieval engines, some en-. the variant BFA I, which is different to the original. gines do not use stemming on their term indexes and. term, BFA1. This reduces the MAP by 0.01%.. query terms. Therefore, when using these engines, we. 4. need to generate the inflectional variants of query. Conclusion. terms. On the other hand, as mentioned in Section 2.1,. In this paper, we conduct a series of experiments to. our methods incorporate the Indri Query Language,. investigate which lexical variation rule can help the. which does stem query terms and term indexes. We. retrieval of biomedical abstracts most. In traditional. will compare the MAP scores of our method, which. experiments, most researchers only use MAP or term. uses stemming, with those of LVG, which do not use. frequency to evaluate lexical variation rules’ effec-. stemming.. tiveness. We use MAP, recall, and term frequency to. We will also test our method on more queries to obtain. analyze the effectiveness of each rule. In addition, we. more cases of lexical variants from new query terms.. further define two indicators: relative frequency and. This would enhance our comprehension of the prop-. marginal MAP to measure how much a query’s change. erties of lexical variations and provide more precise. caused by a lexical variation rule influences that. evaluation.. query’s retrieval result, which is usually measured by. 6. MAP. According to our observation, if the correlation between these two indicators is positive, the rule is. Acknowledgement. We thank Dr. Chao-Lin Liu for his useful comments. 9.
(10) We are grateful for the support of National Science. Linguistics (ACL), 2002.. Council under GRANT NSC94-2752-E-001-001.. [10] D. Hanisch, J. Fluck, H. Mevissen, and R. Zimmer, "Playing biology's name game: identifying. 7 [1]. References. protein names in scientific text," presented at Pacific Symposium on Biocomputing '03, 2003.. K. B. Cohen and L. Hunter, "Natural Language. Processing and Systems Biology," in Artificial Intel-. [11] T. Strohman, D. Metzler, H. Turtle, and W. B.. ligence and Systems Biology, Springer Series on. Croft, "Indri: A language-model based search engine. Computational Biology, W. Dubitzky and F. Azuaje,. for complex queries," presented at Internaional Con-. Eds.: Springer, 2005.. ference on Intelligence Analysis 2005, 2005.. [2]. [12] W. R. Hersh, R. T. Bhuptiraju, L. Ross, A. M.. G. Salton, Introduction to Modern Information. Retrieval: McGraw-Hill, 1983.. Cohen, and D. F. Kraemer, "TREC 2004 Genomics. [3]. Track Overview," presented at TREC 2004, 2004.. C. Lindberg, "The Unified Medical Language. System (UMLS) of the National Library of Medicine,". [13] C. Buckley, "trec eval IR evaluation package.". J. Am. Med. Rec. Assoc., pp. 40-42, 1990.. [14] NLM, "Lexical Variation Generator," 2005.. [4]. D. Maglott, "Locuslink: a directory of genes," in. NCBI Handbook, 2002, pp. 19-1 to 19-16. [5]. G. Divita, A. C. Browne, and T. C. Rindflesch,. "Evaluating Lexical Variant Generation to Improve Information Retrieval," presented at American Medical Informatics Association Annual Symposium 1998, 1998. [6]. Y. Tsuruoka and J. c. Tsujii, "Probabilistic Term. Variant Generator for Biomedical Terms," presented at Special Interest Group on Information Retrieval 2003, 2003. [7] S. Büttcher, C. L. A. Clarke, and G. V. Cormack, "Domain-Specific Synonym Expansion and Validation for Biomedical In-formation Retrieval (MultiText Experiments for TREC 2004)," presented at TREC 2004, 2004. [8]. H. Shatkay and R. Feldman, "Mining the bio-. medical literature in the genomic era: an overview," Journal of Computational Biology, vol. 10, pp. 821-855, 2003. [9]. S. Pakhomov, "Semi-supervised maximum. entropy based approach to acronym and abbreviation normalization in medical text," presented at the 40th Annual Meeting of the Association for Computational. 10.
(11)
數據


+3
相關文件
Hsinchu Biomedical Science Park Incubation Center,
Hsinchu Biomedical Science Park Incubation Center,
An Empirical Study of the Influences of Emotional Intelligence, Sex Discrimination, Change Leadership and LMX on Female Leadership Effectiveness.. 研 究
The presented methods for mining semantically related terms are based on either internal lexical similarities or external aspects of term occurrences in documents
• The abstraction shall have two units in terms o f which subclasses of Anatomical structure are defined: Cell and Organ.. • Other subclasses of Anatomical structure shall
• In the present work, we confine our discussions to mass spectro metry-based proteomics, and to study design and data resources, tools and analysis in a research
‘Basic’ liberty entails the freedoms of conscience, association and expression as well as democratic rights; … Thus participants would be moved to affirm a two-part second
PIV: parainfluenza virus, RSV: respiratory syncytial virus, MPV: metapneumovirus, Group A Strept: group A streptococcal disease.. Rhinovirus 鼻病毒
