1111
Mining Time-Interval Sequential Patterns Using Clustering
Analysis
Hao-En Chueh
1, Nancy P. Lin
21
Department of Information Management, Yuanpei University
2
Department of Computer Sciences and Information Engineering, Tamkang University
1
[email protected],
2[email protected]
Abstract
-A time-interval sequential pattern is asequential pattern with the information about the time intervals between itemsets. Most algorithms of mining time-interval sequential patterns find the time intervals between itemsets by predefining some non-overlap time partitions, however, a predefined set of non-overlap time partitions cannot be suitable for every pair of successive itemsets. Therefore, in this paper, we present a new algorithm to mine time-interval sequential patterns without defining any time partitions in advance. The algorithm first adopts the clustering analysis to automatically generate the suitable time partitions for frequent occurring pairs of successive itemsets, and then uses these generated time partitions to extend typical algorithms to discover the time-interval sequential patterns. Our result of experiment verifies that this algorithm outperforms than the algorithms which use some predefined and non-overlap time partitions.
Keywords: Data Mining, Sequential Pattern, Time
Interval, Clustering Analysis.
1. Introduction
Data mining is the procedure of discovering hidden, useful, previously unknown information from databases. The existing techniques of data mining include association analysis, classification, clustering, etc, and one of the important techniques is mining sequential patterns. Mining sequential patterns first introduced by Agrawal and Srikant (1995) is the task of finding frequently occurring patterns related to time or other sequences from a sequence database [1]. An example of a sequential pattern is “A customer who bought a digital camera will return to buy an extra memory card”. Mining sequential patterns is widely used in the field of retail business to assist in making various marketing decisions since many transaction records are stored as sequence data [3,5,7].
Many algorithms of mining sequential patterns
have been proposed [1,4,6,9], and most of these algorithms only focus on finding the order of the itemsets, but ignore the time intervals between successive itemsets. An example of a sequential pattern with time intervals between successive itemsets is “A customer who bought a digital camera will buy an extra memory card within one month”. In business field, actually, a sequential pattern which includes the time intervals between successive itemsets is more valuable than a traditional sequential pattern without any time information, because the time intervals between successive itemsets can offer useful information for businesses to sell the appropriate products to their customers at the right time. To this end, some researches start to propose algorithms to discover the sequential patterns with time intervals between itemsets, called time-interval sequential pattern [2].
To find the time intervals between every pair of successive itemsets, most proposed algorithms of mining time-interval sequential patterns usually predefine some non-overlap time partitions, and assume that the time interval between each pair of successive itemsets can match one time partition of this predefined set, but a predefined set of non- overlap time partitions, in fact, cannot be suitable for every pair of successive itemsets. Generating the suitable time partitions for every pair of successive itemsets directly from the real data is more reasonable. Accordingly, in this paper, we present a new algorithm to mine time-interval sequential patterns without predefining any time partitions. This algorithm tries to use the clustering analysis first to automatically generate the suitable time partitions between frequent occurring pairs of successive itemsets, and then uses these generated time partitions to extend typical algorithms to discover the time-interval sequential patterns.
The rest of this paper is organized as follows. Some researches related to time-interval sequential patterns are reviewed in section 2. The proposed time-interval sequential patterns mining algorithm is presented in section 3. A simple experiment is displayed in section 4. The conclusions are given
2222
in section 5.
2. Time-Interval Sequential Patterns
The problem of sequential patterns mining which can be described as the task of discovering frequently occurring ordered patterns from a given sequence database was first introduced by Agrawal and Srikant in the mid 1990s [1].
A sequence is an ordered list of itemsets. Let } ,..., , {i1 i2 im I = be a set of items, S =<s1,s2, > k s
..., is a sequence, wheresi⊆Iis called an itemset. Length of a sequence means the number of itemsets in the sequence, and a sequence contains k itemsets is called a k-sequence. The support of a sequence S is denoted by supp(S and ) means the percentage of total number of records containing sequence S in the sequence database. If supp(S is greater than or equal to a predefined ) threshold, called minimal support, than sequence S is considered as a frequent sequence and called a sequential pattern.
Many algorithms have been proposed to mine sequential pattern [1,4,6,9], and most algorithms only focus on finding the frequently occurring order of the itemsets, but ignore the time intervals between itemsets. The time intervals between itemsets, in fact, can offer useful information for businesses to sell the appropriate products to their customers at the right time. Due to the value of the time intervals between itemsets, some researchers start to propose algorithms to mine various sequential patterns with time information between itemsets recently [2,8,10,11].
Srikant et al. [10] utilize three restrictions, the maximum interval(max −interval),the minimum interval(min −interval),and the time window size
)
(window −size to find sequential patterns related to time intervals, and the discovered pattern is like ((A,B),(C,D)), where (A,B) and (C,D) are called subsequences of((A,B),(C,D)). Themax−
interval and the min −interval are respectively used to indicate the maximal and minimal interval within subsequence. Thewindow −sizeis used to indicate the interval among subsequences. For example, let the max −interval is set to 10 hours, the min −intervalis set to 3 hours, andwindow−
size is set to 24 hours. That is, the time interval between A and B lies in [2,10], the time interval between C and D also lies in [2,10], and the time interval between(A,B)and(C,D)lies in [0,24].
Mannila et al. [8] use a window width(win to )
find frequent episodes in sequences of events, and the discovered episode is like (A,B,C). Assume that the win is set to 3 days, then the episode
) , ,
(A BC means that, in 3 days, A occurs first, B follows, and C happens finally.
Wu et al. [11] utilize a window(d as well to ) find the sequential pattern likes(A,B,C),such that, in a sequential pattern, the interval between adjacent events is within the window d . Assume d is set to 5 hours, then the discovered pattern (A,B,C) means that A occurs first, B follows, and C happens finally and the interval between A and B , and between B and C is within 5 hours.
Chen et al. [2] use a predefined set of non- overlap time partitions to discover potential time-interval sequential patterns, and the discovered pattern is like (A,I0,B,I2,C),where
2 0, I
I belong to the non-overlap set of time partitions. Assume that, in the set of time partitions,
0
I denotes the time interval t satisfying0≤t≤1 day; I2 denotes the time interval t satisfying
7
3<t≤ days, and then the pattern(A,I0,B,I2,C) means thatA,Band C happen in this order, and the interval between A and B is within 1 day , and the interval between B and lies between 3 days and 7 days.
Although these preceding discussion researches can discover the sequential patterns with the time information between itemsets by using a or some predefined and fixed time partitions, the patterns whose intervals between itemsets lie outside these predefined time ranges cannot be found yet.
Therefore, this work presents a new algorithm to mine time-interval sequential patterns without defining any time partitions in advance, and the main concept of this algorithm is to generate the suitable time partitions directly from the real data. This algorithm first uses the clustering analysis to automatically generate the suitable time partitions for frequent occurring pairs of successive itemsets, and then adopts these generated time partitions to extend typical algorithms to mine the sequential patterns with time intervals between every pair of successive itemsets.
Details of the proposed time-interval sequential mining patterns algorithm are presented in the following section.
3. The Proposed Algorithm
The proposed time-interval sequential patterns mining algorithm is presented in this section. This
3333
algorithm uses clustering analysis to automatically generate the suitable time partitions directly from the real data for the frequent occurring pairs of successive itemsets, and then uses these generated time partitions to extend the typical algorithms to discover the sequential patterns with time intervals between every pair of successive itemsets. Steps of the algorithm are described as follows.
Notation:
} ,..., ,
{i1i2 im
I = : The set of items.
>
=< n
i s s s
S 1, 2,..., : A sequence, where each I sk ⊆ . } ,..., , {S1 S2 Sk
D = : The set of sequences.
supp(S : The support ofi) S . i supp
min − : The minimal support threshold.
k
CS : The set of candidate k-sequences.
k
FS : The set of frequent k-sequences.
k
CTIS : The set of candidate time-interval k-sequences.
k
FTIS : The set of frequent time-interval k-sequences.
Algorithm:
Step 1: ProducingFS . Each itemset can be 1 regarded as a candidate 1-sequence. A candidate 1-sequence whose support is greater than or equal tomin −suppis a frequent 1-sequence, and the set of all frequent 1-sequences isFS . 1
Step 2: ProducingCS . For any two frequent 2 1-sequencess and1 s where2, s1,s2∈FS1ands ≠1 s2, then we can generate 2 candidate 2-sequences
> < 2 1, s s and< > 1 2, s s that belong toCS . 2
Step 3: ProducingFS . A candidate 2-sequence 2 whose support is greater than or equal to min−
supp is a frequent 2-sequence, and the set of all frequent 2-sequences isFS . 2
Step 4: Finding the set of all the suitable time partitions for each frequent 2-sequences ofFS . 2 For any frequent 2-sequence ofFS2<sp,sq>,all the time intervals betweens andp s appears inq D
are listed in increasing order, then the following clustering steps are used to find the suitable time partitions of all these intervals.
Step 4(a): Assume that T(1,z)=[t1,t2,L,tz] is the increasingly ordered list of the time intervals of
. , >
<sp sq LetT <sp,sq>={T(1,z)}be the set of all the suitable time partitions of <sp,sq>. The
first step of the clustering analysis is to find the maximal difference between two adjacent intervals from all partitions ofT<sp,sq>, and then divide the partition with the maximal difference into 2 partitions. At the beginning, only one partition is in T<sp,sq>, therefore, the chosen partition is
). , 1 ( z
T Assume that the different betweent and i
1 +
i
t is maximal, thanT( z1, )is divided into T( i1, ) andT(i+1,z), whereT(1,i)=[t1,L,ti], T(i+1,z) ]. , , [ti+1Ltz =
Step 4(b): The second step is to calculate the support of< >
q p s
s , that respectively includes time intervals within these two partitions. If the support of < >
q p s
s , that includes time intervals within )
, 1 ( i
T is greater than or equal tomin −supp, )
, 1 ( i
T is a suitable time partition of<sp,sq>, and then T( i1, )is reserved, otherwiseT( i1, )is deleted. Similarly, if the support of<sp,sq>that includes time intervals within T(i+1,z) is greater than or equal tomin −supp, T(i+1,z) is a suitable time partition, and then T( i1,) is reserved, otherwise
) , 1 ( i
T is deleted. Thus, the chosen partition is placed by the reserved partitions. If no partition is reserved, this chosen partition is considered as non-dividable. If all of the differences between two adjacent intervals in a partition are equal, this partition is considered as non-dividable as well.
Step 4(c): Repeating step 4(a) and step 4(b), until all time partitions in T<sp,sq> are non- dividable.
Step 5: ProducingFTIS . Each 2-sequence of 2 2
FS is extended by all its suitable time partitions to formFTIS . Let2 , { 1, 2,
T T s s T< p q >= , } R T L is
the set of all the suitable time partitions of the sequence <sp,sq>, thenT s ,Ti,sq ,i 1 R,
p > = L
<
is a frequent time-interval 2-sequences.
Step 6: ProducingCTISk, ≥k 3. For any two frequent time-interval (k-1)-sequencesS and1 S2, where S1=<s1,1,T1,1,s1,2,L,s1,k−2,T1,k−2,s1,k−1>, S2= ; , , , , , , 2,1 2,2 2, 2 2, 2 2, 1 1 1 , 2 − − − >∈ − <s T s L s k T k s k FTISk s1,2 ; , , , 1,3 2,2 1, 1 2, 2 1 , 2 = − = − = k k s s s s s L T1,2=T2,1,T1,3=T2,2, , ,T1,k−2=T2,k−3
L then we can generate a candidate time-interval k-sequences S =<1 s1,1,T1,1,s1,2,LL, . , , , , 1, 2 1, 1 2, 2 2, 1 2 , 1k− Tk− sk− T k− s k− > s
4444
time-interval k-sequence whose support is greater than or equal to min −suppis a frequent time- interval k-sequence, and the set of all frequent time-interval k-sequences isFTIS k.
Step 8: Repeating step 6 and step 7, until no next CTIS can be generated. k
According to these steps, an experiment using a simple sequence database will be displayed in the next section.
4. Experiment
In this section, we use the sequence database shown as in Table 1 to discover the time-interval sequential patterns. In Table 1, Id denotes the record number of a sequence, and each sequence is represented as <(s1,t1),(s2,t2),L,(sn,tn)>, where
i
s denotes an itemset, and t denotes the time i stamp that s occurs; i min −supp is set as 0.3.
Table 1: A sequence database.
Id Sequence 01 (s5,8), (s4,15), (s6,20) 02 (s1,2), (s3,7), (s2,11), (s6,18) 03 (s2,3), (s1,4), (s3,7), (s6,16), (s7,19) 04 (s1,2), (s2,8), (s6,10), (s7,15) 05 (s5,4), (s6,16), (s1,20), (s3,24) 06 (s7,7), (s1,13), (s5,18), (s2,25), (s6,28) 07 (s5,4), (s1,8), (s3,12), (s6,16), (s7,20) 08 (s1,3), (s5,6), (s2,9), (s4,18), (s6,21) 09 (s2,5), (s1,10), (s3,15), (s6,20), (s7,25) 10 (s6,2), (s7,8), (s5,12), (s2,17)
First, we need to calculate the supports of all itemsets to produce FS Supports of all itemsets 1. are shown in Table 2. Here, we can obtain =
1 FS }. , , , , , {s1 s2 s3 s5 s6 s7
Table 2: Supports of itemsets.
itemset supp s1 0.8 s2 0.7 s3 0.5 s4 0.2 s5 0.6 s6 1 s7 0.6
Next,CS is generated by jointing2 FS ×1 FS1; Supports of the sequences in CS are calculated 2 and shown in Table 3. Therefore, we obtainFS3=
, , , , , , , , , , {<s1 s2><s1 s3><s1 s6><s1 s7><s2 s6> , , , , , , , , , , 7 3 6 3 7 5 2 5 6 2 >< >< >< >< > <s s s s s s s s s s }. , 7 6 > <s s
Table 3: Supports of sequences inCS2.... 2 CS supp CS 2 supp <s1,s2> 0.4 <s5,s1> 0.2 <s1,s3> 0.5 <s5,s2> 0.3 <s1,s5> 0.2 <s5,s3> 0.2 <s1,s6> 0.7 <s5,s6> 0.5 <s1,s7> 0.4 <s5,s7> 0.1 <s2,s1> 0.2 <s6,s1> 0.1 <s2,s3> 0.2 <s6,s2> 0.1 <s2,s5> 0.0 <s6,s3> 0.1 <s2,s6> 0.6 <s6,s5> 0.1 <s2,s7> 0.3 <s6,s7> 0.5 <s3,s1> 0.0 <s7,s1> 0.1 <s3,s2> 0.1 <s7,s2> 0.2 <s3,s5> 0.0 <s7,s3> 0.0 <s3,s6> 0.4 <s7,s5> 0.2 <s3,s7> 0.3 <s7,s6> 0.1
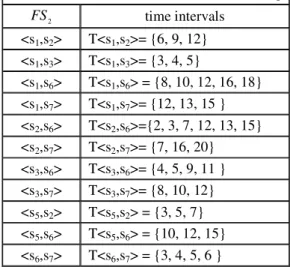
For each frequent 2-sequence of FS , all its 2 time intervals are recorded and listed in increasing order (Table 4).
Table 4: Time intervals of the sequences ofFS2.... 2 FS time intervals <s1,s2> T<s1,s2>= {6, 9, 12} <s1,s3> T<s1,s3>= {3, 4, 5} <s1,s6> T<s1,s6> = {8, 10, 12, 16, 18} <s1,s7> T<s1,s7>= {12, 13, 15 } <s2,s6> T<s2,s6>={2, 3, 7, 12, 13, 15} <s2,s7> T<s2,s7>= {7, 16, 20} <s3,s6> T<s3,s6>= {4, 5, 9, 11 } <s3,s7> T<s3,s7>= {8, 10, 12} <s5,s2> T<s5,s2> = {3, 5, 7} <s5,s6> T<s5,s6> = {10, 12, 15} <s6,s7> T<s6,s7> = {3, 4, 5, 6 }
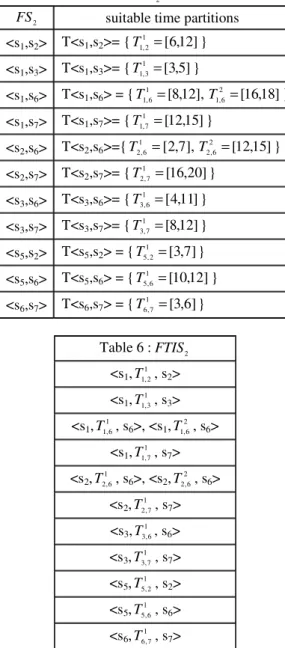
According to the step 4 described in the above section, the set of all suitable time partitions for
5555
each sequences of FS are obtained as in Table 5. 2 Next, each 2-sequence of FS is extended by all 2 its suitable time partitions to formFTIS (Table 6). 2
Table 5: The suitable time partitions of sequences ofFS . 2
2
FS suitable time partitions <s1,s2> T<s1,s2>= {T11,2=[6,12]} <s1,s3> T<s1,s3>= {T11,3=[3,5]} <s1,s6> T<s1,s6> = { [8,12], 1 6 , 1 = T 2 [16,18] 6 , 1 = T } <s1,s7> T<s1,s7>= {T11,7=[12,15]} <s2,s6> T<s2,s6>={T21,6=[2,7], [12,15] 2 6 , 2 = T } <s2,s7> T<s2,s7>= {T21,7=[16,20]} <s3,s6> T<s3,s6>= { [4,11] 1 6 , 3 = T } <s3,s7> T<s3,s7>= {T31,7=[8,12]} <s5,s2> T<s5,s2> = {T51,2=[3,7]} <s5,s6> T<s5,s6> = { [10,12] 1 6 , 5 = T } <s6,s7> T<s6,s7> = {T61,7=[3,6]} Table 6 :FTIS 2 <s1,T , s11,2 2> <s1, 1 3 , 1 T , s3> <s1,T , s11,6 6>, <s1, 2 6 , 1 T , s6> <s1,T , s11,7 7> <s2,T21,6, s6>, <s2, 2 6 , 2 T , s6> <s2,T21,7, s7> <s3,T , s31,6 6> <s3,T31,7, s7> <s5, 1 2 , 5 T , s2> <s5,T51,6, s6> <s6,T61,7, s7> 3
CTIS , the set of candidate time-interval 3- sequences is generated by jointingFTIS2×FTIS2. Supports of the sequences of CTIS are calculated 3 and shown in Table 7. A candidate time-interval 3-sequence whose support is greater than or equal to min −supp is called as a frequent time- interval 3- sequence. Therefore, we can obtain the set of all the frequent time-interval 3-sequences,
= 4 FTIS { <s1, 1 2 , 1 T ,s2, 1 6 , 2 T ,s6>, <s1, 1 3 , 1 T ,s3, 1 6 , 3 T ,s6>, <s1,T ,s11,3 3, 1 7 , 3 T ,s7>, <s1,T ,s11,6 6, 1 7 , 6 T ,s7>, <s3,T , 31,6 s6,T61,7, s7> }.
Table 7: Supports of sequences ofCTIS 3
3 CTIS supp <s1,T , s11,2 2, 1 6 , 2 T , s6> 0.3 <s1,T , s11,2 2, 2 6 , 2 T , s6> 0.1 <s1, 1 2 , 1 T , s2, 1 7 , 2 T , s7> 0.1 <s1,T , s11,3 3, 1 6 , 3 T , s6> 0.4 <s1,T , s11,3 3, 1 7 , 3 T , s7> 0.3 <s1,T , s11,6 6, 1 7 , 6 T , s7> 0.4 <s2,T21,6, s6, 1 7 , 6 T , s7> 0.1 <s2,T22,6, s6, 1 7 , 6 T , s7> 0.2 <s3,T , s31,6 6, 1 7 , 6 T , s7> 0.3 <s5,T51,2, s2, 1 7 , 2 T , s7> 0 <s5,T51,6, s6, 1 7 , 6 T , s7> 0.1
The set of candidate time-interval 4-sequences, ,
4
CTIS is generated by jointingFTIS3 ×FTIS3. Here, only one sequence, <s1,T , s11,3 3 ,
1 6 , 3
T , s6 ,T61,7, s7>, is generated. The support of the sequence <s1,T , s11,3 3 , 1 6 , 3 T , s6 ,T61,7, s7> is 0.3, thus <s1, 1 3 , 1 T , s3 ,T , s31,6 6 , 1 7 , 6 T , s7> is a frequent time-interval 4-sequences, and we obtain FTIS4={<s1,
1 3 , 1 T , s3 , 1 6 , 3 T , s6 , 1 7 , 6
T , s7>}. Because no nextCTIS can be 5 generated, the algorithm stops here.
According to the experimental results, we can clearly see that the suitable time partitions for every pair of successive itemsets are different and overlap, therefore, for every pair of successive itemsets, it is more reasonable to generate the suitable time partitions directly from the real data when mining time-interval sequential patterns.
5. Conclusions
A sequential pattern with the time intervals between successive itemsets is more valuable than a traditional sequential pattern without any time information. Most existing time-interval sequential pattern mining algorithms reveal the time-interval between itemsets by predefining some non-overlap time partitions, but a predefined set of non-overlap time partitions, in fact, cannot be suitable for every
6666
pair of successive itemsets.
In this paper, we present a new algorithm to mine time-interval sequential patterns without pre- defining any time partitions. This algorithm use the clustering analysis to automatically generate the suitable time partitions between frequent occurring pairs of successive itemsets, and then uses these generated time partitions to extend typical algorithms to discover the time-interval sequential patterns. The result of our experiment verifies that the concept of our algorithm is more reasonable than these algorithms which use some predefined and non-overlap time partitions.
References
[1] R. Agrawal, and R. Srikant, “Mining sequential patterns,” Proceedings of the International Conference on Data Engineering, pp. 3–14, 1995.
[2] Y. L. Chen, M. C. Chiang, and M. T. Ko, “Discovering time-interval sequential patterns in sequence databases,” Expert Systems with Applications, vol.25, no. 3, pp. 343–354, 2003. [3] M. S. Chen, J. Han, and P. S. Yu, “Data mining:
An overview from a database perspective,” IEEE Transactions on Knowledge and Data Engineering, vol.8, no.6, pp. 866–883, 1996. [4] M. S. Chen, J. S. Park, and P. S. Yu, “Efficient
data mining for path traversal patterns,” IEEE Transactions on Knowledge and Data Engineering, vol. 10, no. 2, pp. 209–221, 1998. [5] M. H. Dunham, Data mining, Introductory and
Advanced Topics, Pearson Education Inc., 2003.
[6] J. Han, G. Dong, and Y. Yin, “Efficient mining of partial periodic patterns in time series database,” Proceedings of 1999 International Conference on Data Engineering, pp. 106–115, 1999.
[7] J. Han, and M. Kamber, Data mining: Concepts and Techniques, Academic Press, 2001.
[8] H. Mannila, H. Toivonen, and A. Inkeri Verkamo, “Discovery of frequent episodes in event sequences,” Data Mining and Knowledge Discovery, vol. 1, no.3, pp. 259-289, 1997.
[9] J. Pei, J. Han, H. Pinto, Q, Chen, U. Dayal, and M.-C. Hsu, “PrefixSpan: Mining sequential patterns efficiently by prefix-projected pattern growth,” Proceedings of 2001 International Conference on Data Engineering, pp. 215–224, 2001.
[10] R. Srikant, and R. Agrawal, “Mining sequential patterns: Generalizations and performance improvements,” Proceedings of the 5th International Conference on Extending Database Technology, pp. 3–17, 1996.
[11] P. H. Wu, W. C. Peng, and M. S. Chen, “Mining sequential alarm patterns in a telecommunication database,” Proceedings of Workshop on Databases in Telecommunic- ations (VLDB 2001), pp. 37-51, 2001.