Pergamon
Pattern Recognition, Vol. 30, No. 8. pp. 1339-1346, 1997
(l:" 1997 Pattern Recognition Society. Published by Elsevier Science Ltd Printed in Great Britain. All rights reserved 0031 3203/97 $17.00+.00
PIh S0031-3203(96)00154-9
A LANGUAGE MODEL BASED ON SEMANTICALLY
CLUSTERED WORDS IN A CHINESE CHARACTER
RECOGNITION SYSTEM
HSI-JIAN LEE* and CHENG-HUANG TUNG
Department of Computer Science and Information Engineering, National Chino Tung University, Hsinchu, Taiwan 30050, R.O.C.
(Received
16July
1996)Abstract--Tttis paper presents a new method for clustering the words in a dictionary into word groups. A Chinese character recognition system can then use these groups in a language model to improve the recognition accuracy. In the language model, the number of parameters we must train beforehand can be kept to a reasonable value. The Chinese synonym dictionary
Tong2yi4ci2 ci21in2
providing the semantic features is used to calculate the weights of the semantic attributes of the character-based word classes. The weights of the semantic attributes are next updated according to the words of the Behavior dictionary, which has a rather complete word set. Then, the word classes are clustered to m groups according to the semantic measurement by a greedy method. The words in the Behavior dictionary can finally be assigned to the m groups. The parameter space for the bigram contextual information of the character recognition system is m 2. From the experimental results, the recognition system with the proposed model has shown better performance than that of a character-based bigram language model ,~) 1997 Pattern Recognition Society. Published by Elsevier Science Ltd.Contextual postprocessing Language model Semantics Word group
1. INTRODUCTION
In a character recognition system, language models have been widely used for postprocessing to increase the recognition rate of the recognition system. In a language model, if the number of parameters used for describing contextual information is small, the ability for correcting the recognition errors in the character recognition stage will be insignificant. °-3) For example, if the words in a dictionary are clustered into about 30 parts-of-speech, only a few recognition errors can be corrected by using the contextual information. In contrast, if the number of parameters used for describing the contextual informa- tion is very large, the training process for the parameters will be difficult, and the memory required will make the execution of a language model impractical. (4-7) For instance, if a Chinese language model adopts a word bigram to describe contextual information, the language model may consume all available memory.
In this paper, we propose a new method to cluster the words in the Behavior dictionary (s) into a reasonable number of groups; we have 800 groups in our experi- ments. Semantic information will be used to cluster the words in the Behavior dictionary. Anyway, the Behavior dictionary does not contain the semantic features. We will accomplish the clustering task by using the Chinese synonym dictionary
Tong2yi4ci2 ci21in2, (9)
which pro- vides the necessary semantic information.* Author to whom correspondence should be addressed. Tel.: 886-35-711437; fax: 886-35-724176; e-mail: hjlee@csie.nc- tu.edu.tw.
In order to reduce the number of word classes, we first transtbrm the words into a character-based word class. Assume that the character set
C h s e t
includes the 5401 frequently used Chinese charactersChi,
which is denoted asCh_set = {Chl, Ch2,...,
Ch5401 }. We define that the character-based word classCh,#
includes the words with the prefixChg
and the postfix #, which represents a regular expression#---(Ch1+Ch2+...+Ch54oz)*.
Simi- larly, the word class#Chi
includes words with the suffixChi,
and the word class#Ch,#
includes words containing the characterChi.
There are a total of 3x5401 word classes defined.As the words in the Chinese dictionary
Tong2yi4ci2
ci21in2
contain hierarchical semantic features, we can assign the words in the dictionary into 3x5401 word classes according to the semantics of the words, and obtain the semantic attributes of the word classes. For example, the word E[-J ~ ~ inTong2yiaci2 ci21in2
can be contained in one of the five word classes ~']#, # ~ # , # ~ : , ~ ' ~ # , and #~0~' We will assign the word E~JT~,,__~[J~]nto one of the five word classes such that the semantic measurement among the semantic attributes of the word classes containing the word ~[J ~ ~ is minimal. After mapping all of the words inTong2yi4ci2
ci2lin2
into the word classes, the word classes are ranked according to the compactness of their semantic attributes, which will be defined later. After the word classes are ranked, the words in the Behavior dictionary will be clustered into the word classes. We cluster the word classes into a predefined number of m groups according to the semantic attributes. Then a language model based 13391340 H.-J. LEE and C.-H. TUNG
Collect semantic of ]
word classes
~
Updatethe occurrence
[counts of semantic I
attributes of word
classes
I
c,uge;
s &aod
ITrain alanguage [
model
I
Chinese OCRSystem
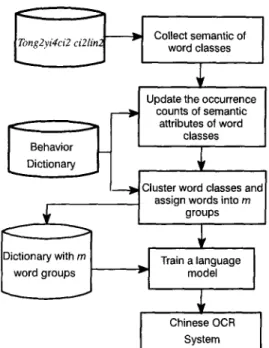
Fig. I. The flow diagram for clustering the words in the Behavior dictionary into m groups.
on the m word groups can be constructed for postproces- sing in a character recognition system.
The flow of our method is summarized in Fig. 1. First, we apply the synonym dictionary Tong2yi4ci2 ci21in2 to collect the semantic attributes of the character-based word classes and order the word classes. Second, the occurrence counts of the semantic attributes are updated according to the words in the Behavior dictionary. Third, the word classes are clustered to m groups according to their semantic measurement. According to the grouped word classes, the words in the Behavior dictionary can be assigned into the m groups. Fourth, a language model based on the grouped words can thus be constructed and used for postprocessing in a Chinese character recogni- tion system.
2. CONSTRUCTION OF SEMANTIC ATTRIBUTES OF WORD CLASSES
The Chinese dictionary Tong2yi4ci2 ci21in2 contains more than 50,000 words classified into 12 major, 94 medium, and 1428 minor categories. The 12 major categories are listed in Fig. 2. Each major category contains some medium categories and each medium category contains several minor categories. Each word in Tong2yi4ci2 ci21in2 has a semantic entry of major, medium, and minor categories. For example, the word ~ in Tong2yi4ci2 ci21in2 has the semantic entry Bn01, which represents object (=B), architect (=n), and architect and building (=01). In our system, we utilize the major and medium categories as the semantic entry. Thus the semantic entry of the word ~ ' ~ is Bn.
The semantic attributes of word classes are collected from that of the words in the dictionary Tong2yi4ci2 ci21in2. Figure 3 gives a simple example with words and
G H I J K L Fig. 2. The A Human B Object C Time and Space D Abstract E Characteristics F Action
Mental Activity Activity
Phenomena and State Association Auxiliary Honorary Words
12 major categories of the semantics.
semantic entries. In Fig. 3(a), we assume that a diction- ary contains only a total of 15 words, each of which has at least one semantic entry. If a word has several semantic entries, we distribute equally the weights among these semantic entries. For example, the words J-,-:[~ ~ , ;[~, and ~ have one, two, and three semantic entries,J"
respectively.
Figure 3(b) shows that the word ~ hasdistributed weight _~ to its semantic entry, denoted as (Di,l), (Ee,~), and (Hj,½). Similarly, the word ~ . ~ has the semantic entry (Hj, 1), and the word ~_~ has semantic entries (Hi,½) and (Hj,½), respectively.
The occurrence count of the word class Ch# is the sum of the weights of the words with the prefix Ch. In general, the semantic attributes of the word C l a s s i c a n be repre- sented as C lassi.att = ( att l , counq ), ( att2, count2 ), . . . ) ), where atti is the semantic entry, and count i is the occur- rence count of the semantic entry. Figure 4(a) gives the semantic attributes of the word classes in Fig. 3(a).
In order to evaluate the similarity of semantic attri- butes in a word class, we will define the compact measurement, COMPACT, between two semantic attri- butes (atti,count~) and (attj,countj). Each semantic attri- bute (atti,counti) can be further represented as (C/,t Ci,2, counti), where Cij and Ci,2 represent the major and medium semantic categories. The compactness be- tween the two semantic attributes (atti, counti) and (att# countj) is defined as
COMPA CT ( ( atti, counti ) , ( attj, countj ) )
=- COMPA CT( ( Ci,1Ci,2, counti ), ( Cj,, , Cj,2, countj ) )
=- k • c o u n t i • c o u n t j ~
where k=2 if Cij ~ Cj,t, or k = l , otherwise. For exam- ple, the compactness between the two (Hi, 1) and (Aj,4), which are the semantic attributes of the word class # ~ , is 8 ( = 2 × 1 × 4). The average compactness of the semantic attributes in a word class can be defined as
A VG_ COMP(Classi)
{
~ j ~ k > i COMPACT( (on) . . . . tj) (attk,countk ) C(Classl.count,2)= if Classi.count > 1, 2, if Classi.count = 1,
where Clas&.count is the sum of the occurrence count of the semantic entries in Classi. It is used as a normal-
A language based on semantically clustered words in a Chinese character 1341
Hi, Hj
~
Aj
~[1 ~
Ed
Hj
Aj
Ed
Hj
~
Di, Ee, HJ
~~ ~
Hi
(a)
~ _ ~ -(H j, 1)
~_~
: (Hi, 1),
~_
"(Di, ½)
(b)
(Hi,
½)
(Ee, 1), (Hj, 1)
Fig. 3. A small example of words and semantic distributions. (a) The 15 words and their semantic entries. (b) The distribution of multiple semantic entries in a word.
#J~_ #.att=- ~_ #.att=
((Hi, 1), (Hi,9))#~fi~.#.att=- #~.att=
((Hi, 1), (Aj,4))#~#.att=-
((Di,½), (Ed, 3), (Ee,1),(Hi, 1),(Hj,4),(Ih, 1))#~.att=-((Di,1),
(Ed, 2), (Ee,1), (Hi, 1), (Hi,4), (Ih, 1))#~#.att=- #~.att=-
((Hi, 1))# ~ #.art=- # ~ .att=
((Hi, 1)) (a)A VG_COMP(#~gJ~_
#.art)=A VG_COMP(~_ #.att)--0.225
A VG_COMP(# ~
#.art)=A VG_COMP( #-~ .att)=0.8
A VG_COMP(# ~
#.art)= 1.49A VG_COMP(# ~ .att)=l.726
A VG_COMP( # {p~ #.att)= A VG_COMP( # ~ .att)=2
a VG_COMP(# ~1~ #.att)= a VG_COMP(# ~ .art)=2
(b)
Fig. 4. (a) The semantic attributes of the word classes. (b) The average compactness of character-based word classes.
1342 H.-J. LEE and C.-H. TUNG
ization factor. For example, we have #~.count=5 and
AVG_COMP(#)3~)=(8/C(5,2))=0.8.
Note that the range ofCOMPACT
is from 0 to 2. The word classes with similar semantic categories and large occurrence counts will have a small compactness. Since the class with a single count is generally not what we need, we assign it a rather large compactness. Figure 4(b) lists the average compactness for the character-based word classes.Among the word classes in Fig. 4(b), the word class
~
has the minimal average compactness for the semantic attributes. Therefore, the words with prefix ~_~ are grouped into the word class ~ . Because the average compactness for the semantic attributes of the word class ~ g # is the smallest, we assign the word class J ~ the first rank; that is,]~#.rank:l. The
words assigned into the word class ~ and the attributes of the word class ~ are shown in" " Fig. 5(a). After remov- ing the assigned words, we perform the same process to obtain the semantic attributes and the average compact- ness for word classes. The final word classes extracted from the 15 words are shown in Fig. 6.We perform the process to assign all words in the dictionary
Tong2yi4ci2 ci2lin2.
The word classes with semantic attributes are ordered sequentially. If a word class includes no words inTong2yi4ci2 ci2lin2,
the semantic attributes of the word class are set as null and the average compactness of the semantic attributes in the word class are defined to be infinite.Since the Behavior dictionary has more complete words than the dictionary
Tong2yi4ci2 ci21in2,
we will modify the occurrence count of the semantic entry according to the words in the Behavior dictionary. We ignore the word occurrence probability in this version.#.rank= 1
J ~ #.att=
((Hi,
½),
(Hi,9))AVG DIST( ~
#.att)--0.225
Hi, Hj
J~ ~J~ Hj
(a)
Hi z ~ ,--, Di, Ee, Hj (b)Fig. 5. (a) The words assigned into the word class ~ # . (b) The remaining words.
We attach each word class
Classi
a count Classi.Dict_-count,
initialized to zero, to record how many words in the Behavior dictionary are assigned to the word class, and then update the occurrence counts of the semantic features in word classes.Let the words in the Behavior dictionary be repre- sented a s W l , . . . ,
Wn,
where n > 80, 000. Assume that a word W/consists of characters Chi,,..., Chi~. The word will be assigned into the word class with the minimal rank among the word classes #Chij#,j = 1,..., k, Chi,#, and #Chik, For example, if the ranks of the word classes ~ # , # ~ # , # ~ # , and ~ # are 105,502, 416, and 376, respectively, the word ~ ~ will be clustered into the character-based word class ~l~# with the best rank, and then the count ~#.Dict_count is increased by one.After all words in the Behavior dictionary have been assigned into the word classes, we will modify the occurrence counts of the semantic attributes of the word classes. For each word class Classi, the occurrence count
countj of a semantic attribute attj
is updated asClassi.Dict_count
countj.
Classi .count
For instance, the original semantic attributes are ((Hi,½), (Hj,9)). If ~-#.Dict_count is 7, the new semantic attri- butes are
]~#.att=((Hi,7),
(Hj,~)).3. CLUSTERING WORD CLASSES INTO m GROUPS
After the occurrence counts of the semantic attributes in word classes have been modified, we will cluster the word classes into m groups• At the first step, we select m word classes Classl, Class2,..., Classm, with the largest
Classj.count, j
= 1 , . . . , m, among all word classes. Each groupGj, j -
1 , . . . , m, is initialized asGj = { (Class6,
(attl, count1 ), (att2, count2),...) }. We define the size of a group Gj asszzEIojl: Z
Ctas~,.count.
Classi in Gj
To make the sizes of the m groups as similar as possible, we apply a greedy method to update the m groups. First, a group
Gj
with the minimal size is selected from the m groups. The semantic attributes of each unclustered word class Class i are combined with the semantic attributes in the group G i. Then we measure the average compactness of the combined semantic attributes. For example, if the selected group G~!s Gj={(~a#,(Hi,7),(Hj,~0))}, and the classClassi=(#~j~#,(Hi, l),(Hj,1))
has not been clus- tered, we create the combined semantic attributes• 1 7 • 7 3
((HI,T6),(HJ if6))" The average compactness of the seman- tic attributes is
• • 1 7 • 7 3 1 7 7 3
Dtst((H1, F6),
(Hj, T6)) _ (10)" (To) _ 0.345.C(9,2) 36
If the group Gj has the minimal compactness for the combined semantic attributes, the unclustered
A language based on semantically clustered words in a Chinese character 1343
~
#.rank=l
#.art=- ((Hi, l ) , (Hi,9))
A VG_DIST( ~ _ #.att)=0.225
Hi, Hj# ~j~.rank=2
# ~ .att=
((Aj, 4))A VG_DIST( # ~}j,. .att)=O
Aj
~ - ~ A j# ~ #.rank=-3
#~!~-~#.att=-
( ( D i , 1 ) , ( E d , 3 ) , ( E e , 1 ) , ( H i , 1 ) , ( H j , 1 ) , ( I h , 1))AVG DIST( # ~ # . a t t ) = l . 4
Di, Ee, Hj~-~ ~
Hi
Fig. 6. The three words classes extracted from the 15 words.
word classes will be clustered into the selected group Gj. For example, if the unclustered class
Classi--
(#:I~#,(Hi,1),(Hj,1)) combined with group Gj has the minimal compactness, we have a new groupGj=
{(~#,(Hj,12)),(#J"J~#,(Hi,1),(Hj,1))}. The process is repeated until all word classes are clustered into m groups.Because the words
W1,..., Wn in the Behavior dic-
tionary have been assigned into the character-based word classes and the word classes have been clustered into m groups, the words WI, •. •, Wn can thus be assigned into m groups.4. MARKOV LANGUAGE BASED ON CLUSTERED WORDS
In this section, we will derive the language model based on the clustered words. In the procedure for training contextual information, a large training corpus is needed. Since the bigram POS (parts-of-speech) lan- guage model has shown high performance for word segmentation, (3) we apply the bigram POS language model to segment the sentences in a training corpus. Let the words in a segmented sentence be wl, w 2 , . . . , wk. Let
G(wi)
represent the group in which the wordG(wO
has been clustered. We transform the segmented sentence intoG(wl),G(w2),...,G(wk)
to train the transition probability, that is, the contextual informationP(G(wi)[G(wi_t)).
The conditional probability of the wordwg, P(wilG(wi)), is trained similarly.
After a word transition graph is constructed, a new language model is applied for the contextual postproces- sing, which is described as follows. Let I --
1112... IL be
a sequence of character images, where ,I, is the ith character image in the input sentence /, and L is the length of the sentence. Each character image li is re- cognized as M candidate characters C i l , C i 2 , . . . , C i M . Eachcandidate character cik has a matching score M&k. In the candidate character sets, there are M L sentence hypoth- eses. The goal of the language model is to determine a sentence hypothesis S =
clic2j.., cr,k that has the max-
imum likelihood among all sentence hypotheses {S}. The occurrence likelihood of a sentence hypothesisS = clc2...cL
is given byP(SII),
whereci
is one of the candidate characters in the ith candidate set. Our goal can be represented asP(SI1) = m~x P(SII ).
Since the basic syntax-meaningful unit in Chinese is a word, a sentence S =
clc2...cL
can be represented asS=WlW2...WN,
where the wordwi
is com- posed of one or more characters. Then the bigram contextual probability at the word level, P ( w i [ w i _ l ) ,can be modified as
1344 H.-J. LEE and C.-H. TUNG
Fig. 7. The sentences segmented by the bigram POS language model.
The probability
P(SII )
can be computed asN
P(SII) ~ H P(G(wi)lG(wi-1))P(wi[G(wi)) ]-I P(ckllk)"
i 1 k
The term [Ik
P(ck[lk)
is the matching score of wordwi,
which is the product of the matching scores of the constituent characters c~. After a word transition graph is constructed for all candidate characters of the sentence, the dynamic programming method for the Markov lan- guage model can be applied to find the most promising sentence hypothesis.5. EXPERIMENTAL RESULTS
In the process of clustering the words, we defined the number of word groups m=800. In our experiments, the training corpus consisted of reports of local news. There were 178,027 sentences in the corpus, including a total of more than 2,000,000 Chinese characters. Some sentences in the corpus were segmented by the bigram POS lan- guage model for training contextual information, and the results are shown in Fig. 7.
In the following, we measure the performance of the language models based on character bigram, bigram POS, trigram POS, and semantically clustered word classes. An image file with 800 news sentences includ- ing 8136 characters are recognized by a Chinese character recognition system. The recognition rate is about 85.2%. After the character-based bigram language model is applied to perform contextual postprocess- ing, the recognition rate is increased to 89.2%. Similarly, the recognition rates for the bigram POS model and the trigram POS model are 87.3% and 87.5%, respec- tively, where the number of parts-of-speech is 30. When the language model based on clustered words is applied, the recognition rate is increased to 92.8%, which is higher than those for the other three language models.
Next, we discuss memory requirements of these lan- guage models. The memory required for contextual description in the bigram POS is 302 plus the number of words in the dictionary, and the memory required for the trigram POS language model is 303 plus the number of words in the dictionary. Their recognition rates in- creased by using these two models are relatively low. The largest memory requirement for contextual description the character-based bigram language model is 54019 and that for contextual description in our language model is the sum of 8002 and the number of words in the dic- tionary, which is much less than 54012.
An example which shows how a correct sentence hypothesis is selected from the candidate character sets
input characters
a candidate character set
characters selected by our language model
Fig. 8. An example showing how a correct sentence hypothesis is selected from the candidate character sets generated by a
A language based on semantically clustered words in a Chinese character 1345
e r r o n e o u s l y se- l e c t e d c h a r a c t e r
Fig. 9. Some more examples showing the performance of the language model.
is shown in Fig. 8. Each candidate character set contain- ing 10 candidate characters is generated by a character recognition system. The example shows that our lan- guage model can select the candidate character from each candidate set correctly. Figure 9 gives more examples of contextual postprocessing. The character bounded by a box is selected incorrectly.
meter space for the bigram contextual information can be reduced to m e . From the experimental results, we have shown that the language model based on the grouped word classes has better performance than a character- based bigram language model. For further improvement, we can modify the clustering criterion by considering the word occurrence probabilities.
6. CONCLUSIONS
In this paper, we have proposed a new method to cluster the words in the Behavior dictionary into a reasonable n u m b e r of m groups. We performed the clustering task by applying the dictionary Tong2yi4ci2
ci21in2 to train the semantic attributes of character-based
word classes. The occurrence counts of the semantic attributes of word classes are updated by counting the words in the Behavior dictionary. The updated word classes are grouped into m groups according to the semantic measurement, and then the words in the Beha- vior dictionary are clustered into m groups. The para-
REFERENCES
1. L. E Chien, Some new approaches for language modeling and processing in speech recognition applications, Ph.D. Thesis, Institute of Computer Science and Information Engineering, National Taiwan University, Taipei, Taiwan (1991).
2. N. C. Wang, A handwritten Chinese text recognition system with a contextual postprocessing module, Master Thesis, Institute of Computer Science and Information Engineering, National Chiao Tung University, Hsinchu, Taiwan (1991).
3. H. J. Lee and C. H. C. Chien, A Markov language model in handwritten Chinese text recognition, Proc. 2nd 1CDAR, 72-75 (1993).
1346 H.-J. LEE and C.-H. TUNG
4. B. Merialdo, Multilevel decoding for very-large-size- dictionary speech recognition, IBM J. Res. Develop. 32, 227-237 (1988).
5. R. M. K. Sinha, Rule based contextual post-processing for Devanagari text recognition, Pattern Recognition 20, 475- 485 (1987).
6. E. J. Yannakoudakis, I. Tsomokos and P. J. Hutton, n- grams and their implication to natural language understanding, Pattern Recognition 23, 509-528 (1990).
7. C. H. Tung and H. J. Lee, Increasing character recognition accuracy by detection and correction of erroneously- identified characters, Pattern Recognition 27, 1259-1266 (1994).
8. Behavior Electronic Dictionary. Dehavior Design Corp.,
Taiwan (1994).
9. J.J. Mei, Y. M. Chu, Y. Q. Gau and H. X. Yin, Tong2yi4ci2
ci21in2--Chinese Synonym Dictionary (in Chinese). Shian-
ghai Publishing Co., Shianghai (1983).
About the A u t h o r - - HSI-JIAN LEE received the B.S., M.S., and Ph.D. degrees in Computer Engineering from National Chiao Tung University, Hsinchu, Taiwan, in 1976, 1980, and 1984, respectively. From 1981 to 1984, he was a lecturer in the Department of Computer Engineering, National Chiao Tung University, and from 1984 to 1989 an associate professor in the same department. Since August 1989, he has been with National Chiao Tung University as a professor. He is at present Chairman of the Department of Computer Science and Information Engineering, National Chiao Tung University. He has been a member of the Government Board of the Chinese Language Computer Society, a member of the Executive Committee of the Chinese Society on Image Processing and Pattern Recognition, and a member of the Executive Committee of R.O.C. Computational Linguistic Society. He is now the president of the Chinese Language Computer Society (CLCS), the Editor-in-Chief of the International Journal of Computer Processing of Oriental Languages (CPOL), and an Associate Editor of the International Journal of Pattern Recognition and Artificial Intelligence. He was responsible for the 1992 R.O.C. Computational Linguistic Workshop and 1993 R.O.C. Conference on Computer Vision, Graphics, and Image Processing. He was the program chair of the 1994 International Computer Symposium and the Fourth International Workshop on Frontiers in Handwriting Recognition (IWFHR). In 1992-1994, he was a winner of outstanding researchers of the National Science Council, R.O.C. His current research interests include document analysis, optical character recognition, image processing, pattern recognition, and artificial intelligence. He is a member of Phi Tau Phi.
About the Author - - CHENG-HUANG TUNG was born in Tainan city, Taiwan, R.O.C., on 28 May 1967. He
received the B.S. and Ph.D. degrees in Computer Science and Information Engineering from the National Chiao Tung University, Hsinchu, Taiwan, in 1989 and 1994. His research interests are in the areas of pattern recognition, artificial intelligence, and natural language processing.