探索美國財務報表的主觀性詞彙與盈餘的關聯性:意見分析之應用 - 政大學術集成
92
0
0
全文
(2) 探索美國財務報表的主觀性詞彙與盈餘的關聯性:意見分 析之應用 Exploring the Relationships between Annual Earnings and Subjective Expressions in US Financial Statements: Opinion Analysis Applications. 研 究 生:陳建良. Student:Chien-Liang Chen. 指導教授:劉昭麟 張元晨. 立. Liu 政 治 Advisor:Chao-Lin 大 Yuan-Chen Chang. ‧ 國. 學 國立政治大學. ‧. 資訊科學系. n. al. A Thesis. y er. io. sit. Nat. 碩士論文. iv. prepared to Department of Computer Science C Un. hengchi. National Chengchi University for the degree of Master in Computer Science. 中華民國一百年七月 July 2011.
(3) 致謝 畢業的時刻就在忙碌之中悄悄到來,要感謝的人事物實在是太多。想當初從一個會計系 的學生到資科系時,受到許多的人提拔與照顧,才能順利完成碩士班的各種挑戰,深深 感受到陳之藩先生的「得之於人者太多,出之於己者太少」。首先,在碩士生涯中要深 深感謝我的兩位指導教授 劉昭麟老師和 張元晨老師能開拓我在學術上的視野並引領 我體會優秀學者應有的研究「真功夫」,更感謝他們兩人能包容我在專業和研究上的無 知與駑鈍,也謝謝他們讓我有勇於嘗試的勇氣。 感謝口試委員陳光華老師、柯淑津老師和張景新老師給予我論文上最真誠與無私的 建議,讓我受益無窮;感謝匿名的會議論文評審對我的磨練與建議,讓我的技術能力有 躍昇的機會;也謝謝 Moira Breen 女士協助我面對我英文寫作上的盲點。另外,特別感 謝蔡湘萍老師和劉文謙學長給予我財務學術的幫忙與建議,讓我有機會踏入財務的文獻 與研究。 陪我度過兩年半的 MIG 夥伴,是課業上也是生活上最大的助力。感謝實驗室畢業學 長姊家威、人豪、明欣、仁祥、智傑、家樑對我們的鼓勵,在進入到 MIG 後曾受到學長 姐禹勳、敏華、侃文、志斌、偉嘉、昭憲和育豪的照顧和協助我進入資訊科學的領域中, 讓我在資訊科學所中能有所成長,並能瞭解外面的社會;同一屆的怡軒和裕淇是我研究. 立. 政 治 大. ‧ 國. 學. ‧. 所戰場最重要的戰友兼朋友,協助我克服大大小小戰役並分享快樂的時間;學弟妹家琦、 柏廷、瑞平、瑋杰和孫暐提供很大的火力支援與及時幫助,也容忍了我經常性發牢騷的 習慣;大學部的專題生更是豐富我的生活,謝謝睿妤、韋狄、瑛澤、文霖、嘉玲、則維、 家佑和鴻源。感謝財管所的培雅和鈺屏曾經給予的協助。 在研究所兩年中感謝資科所的朋友們(景堯、彥崧、偉敦、建彪),大學時期的好朋 友(奕懷、健瑋、英峻、紀安、偉哲、汶軒、俞均和琇評,社團的崇孙和佳瑞,學弟妹 欣芳、啟鴻),會研所(若瑄、衛翎、咏平、佩珊、言修、佳卿、惠婷和藍萱)和財管所(至 冠)一起修課的朋友。在一起的日子,曾經一起趕報告、一起聊天、一起上課、一起辦 活動等等,永遠會是記憶中珍貴的一塊,難以忘記也很懷念。特別感謝藍萱在我想放棄. n. er. io. sit. y. Nat. al. Ch. engchi. i Un. v. 時,給我關鍵的建議和鼓勵。 最後也是最重要的,謝謝家人(祖母、父親和母親)無怨無悔地聽我說話,支持我渡 過風風雨雨的人生,有你們的支持我才有辦法茁長。 謝謝一路上曾經為我付出過的貴人!. 2011 八月 貓空山城 建良.
(4) 探索美國財務報表的主觀性詞彙與盈餘的關聯性:意見分 析之應用. 摘要. 政 治 大 財務報表中的主觀性詞彙往往影響市場中的參與者對於報導公司價值和獲 立. ‧ 國. 學. 利能力衡量的決策判斷。因此,公司的管理階層往往有高度的動機小心謹. ‧. 慎的選擇用詞以隱藏負面的消息而宣揚正面的消息。然而使用人工方式從. sit. y. Nat. 文字量極大的財務報表挖掘有用的資訊往往不可行,因此本研究採用人工. n. al. er. io. 智慧方法驗證美國財務報表中的主觀性多字詞 (subjective MWEs) 和公司. iv. 的財務狀況是否具有關聯性。多字詞模型往往比傳統的單字詞模型更能掌 C Un. hengchi. 握句子中的語意情境,因此本研究應用條件隨機域模型 (conditional random field) 辨識多字詞形式的意見樣式。另外,本研究的實證結果發現一些跡象 可以印證一般人對於財務報表的文字揭露往往與真實的財務數字存在有落 差的印象;更發現在負向的盈餘變化情況下,公司管理階層通常輕描淡寫 當下的短拙卻堅定地承諾璀璨的未來。.
(5) Exploring the Relationships between Annual Earnings and Subjective Expressions in US Financial Statements: Opinion Analysis Applications. Abstract. 立. 政 治 大. Subjective assertions in financial statements influence the judgments of. ‧ 國. 學. market participants when they assess the value and profitability of the reporting corporations. Hence, the managements of corporations may attempt to conceal. ‧. the negative and to accentuate the positive with "prudent" wording. To excavate. y. Nat. io. sit. this accounting phenomenon hidden behind financial statements, we designed an. er. artificial intelligence based strategy to investigate the linkage between financial. n. a. v. l Cearnings and subjective status measured by annual n i multi-word expressions. hengchi U. (MWEs). We applied the conditional random field (CRF) models to identify opinion patterns in the form of MWEs, and our approach outperformed previous work employing unigram models. Moreover, our novel algorithms take the lead to discover the evidences that support the common belief that there are inconsistencies between the implications of the written statements and the reality indicated by the figures in the financial statements. Unexpected negative earnings are often accompanied by ambiguous and mild statements and sometimes by promises of glorious future..
(6) TABLE OF CONTENTS. CHAPTER 1 Introduction .............................................................................. 1 1.1 Background ................................................................................................................... 1 1.2 Methodology overview ................................................................................................. 2 1.3 Contributions ................................................................................................................ 4 1.4 Organization ................................................................................................................. 5. CHAPTER 2 Literature Review ..................................................................... 7. 治 政 大 2.2 Computer science literature review .............................................................................. 9 立 2.1 Finance literature review .............................................................................................. 7. CHAPTER 3 Financial Data and Corpora .................................................. 16. ‧ 國. 學. 3.1 Annotated corpus: MPQA .......................................................................................... 16 3.2 Financial statements preprocessing ............................................................................ 19. ‧. 3.3 Quantitative financial data and data merging ............................................................. 20. y. Nat. CHAPTER 4 Models for Opinion Patterns Identification ......................... 23. sit. n. al. er. io. 4.1 Conditional random fields .......................................................................................... 24 4.2 Feature sets and linear chain CRF data view .............................................................. 28 4.2.1 Morphological and orthographical features ..................................................... 29 4.2.2 Predicate-argument structure features ............................................................. 32 4.2.3 Syntactic features ............................................................................................. 33 4.2.4 Simple semantic features ................................................................................. 38. Ch. engchi. i Un. v. CHAPTER 5 Linkages between Earnings and Subjective MWEs ........... 41 5.1 Dependent variable: standardized unexpected earnings ............................................. 41 5.2 Explanatory variables: MWEf-idf and control variables ............................................ 42 5.3 Multinomial logistic regression .................................................................................. 43 5.4 Strategies of discriminative MWE identification ....................................................... 45. CHAPTER 6 Experimental evaluation of CRF models ............................. 48 6.1 Design of the experiments .......................................................................................... 48 6.2 Experimental results ................................................................................................... 51. CHAPTER 7 Empirical study of earnings and subjective MWEs ............ 57 I.
(7) 7.1 Opinion patterns extraction from financial statements ............................................... 57 7.2 Empirical results of small dataset ............................................................................... 61 7.3 Robustness tests of large dataset ................................................................................ 62 7.4 Analysis of the economic meanings of subjective MWEs ......................................... 66. CHAPTER 8 Conclusions ............................................................................. 71 8.1 Discussions ................................................................................................................. 72 8.2 Future work ................................................................................................................ 73. References .......................................................................................................... 75 Appendix ............................................................................................................ 79. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. II. i Un. v.
(8) LIST OF FIGURES. Figure 1.1 The system diagram .................................................................................................. 5 Figure 2.1 Syntactic templates and example patterns............................................................... 12 Figure 3.1 Procedures of MPQA corpus preprocessing ........................................................... 17 Figure 3.2 Procedures of financial statements preprocessing .................................................. 20. 政 治 大 Figure 4.1 The system diagram 立of the opinion patterns identification models ........................ 23 Figure 3.3 Procedures of data merging ..................................................................................... 21. ‧ 國. 學. Figure 4.2 Example sentence expressed in linear CRF data view ............................................ 30 Figure 4.3 The syntactic features in a parse tree ...................................................................... 33. ‧. Figure 4.4 Sample based chunk features (f13) ......................................................................... 36. Nat. sit. y. Figure 4.5 Strength and polarity category of subjective words ................................................ 39. n. al. er. io. Figure 5.1 Procedures of discriminative MWE identification.................................................. 47. i Un. v. Figure 6.1 Experimental procedures for the MPQA corpus ..................................................... 48. Ch. engchi. Figure 6.2 The diagram of the correct prediction of the opinion labels ................................... 49 Figure 7.1 The example of manually check whether the prediction is correct ......................... 59. III.
(9) LIST OF TABLES. Table 2.1 Features of Kim and Hovy ........................................................................................ 13 Table 2.2 Features of Choi et al. ............................................................................................... 15 Table 3.1 A sample sentence and annotations of the MPQA corpus ........................................ 18 Table 3.2 Annual quantitative financial data from the Compustat ........................................... 22. 治 政 大 Table 4.2 Feature sets of various linguistic features ................................................................. 27 立 Table 4.1 The example sentence of the feature sets.................................................................. 24. Table 4.3 Gidea’s statistical results of syntactic path and partial path ..................................... 35. ‧ 國. 學. Table 4.4 The descriptions of syntactic dependency ................................................................ 37. ‧. Table 5.1 Strategies of discriminative MWE identification ..................................................... 45. sit. y. Nat. Table 6.1 Results of “agent” identification with different feature sets ..................................... 51. io. er. Table 6.2 Performance with explicit expression sentences ...................................................... 54 Table 6.3 Performances achieved by the 1st and 2nd order CRF ............................................... 55. al. n. iv n C Table 6.4 Performance with and without ........................................................... 56 h e“target” i U n g c hlabel Table 7.1 Opinion patterns extracted from 10-K filings ........................................................... 58 Table 7.2 Opinion patterns combination in sentences .............................................................. 60 Table 7.3 Empirical results of small dataset ............................................................................. 62 Table 7.4 Robust estimation of standard error, g=0.5............................................................... 64 Table 7.5 Robust estimation of standard error, g=1.0............................................................... 67 Table 7.6 Economic meanings of the subjective MWEs .......................................................... 70. IV.
(10) CHAPTER 1. 1.1 Background. 立. Introduction. 政 治 大. As the data mining concept successfully applied in mining the relationships between diapers. ‧ 國. 學. and beer, many useful patterns that had never been imaged in financial applications have been discovered by various kinds of algorithms. Rather than only experimenting with financial. ‧. quantitative data that traditional empirical Finance and Accounting research methods merely. y. Nat. sit. cope with numeric data or nominal data, our work propose methods that combined financial. n. al. er. io. quantitative data and textual contents for examining the relationships between the annual. i Un. v. earnings and subjective expressions in U.S. financial statements. In today’s world, there are. Ch. engchi. huge of public available textual information rather than numeric data. Li concluded that textual information is much more costly to process which is not trivial amount of effort comparing with simple numeric data, and found that U.S. public companies annual financial statements contain thousands of words [14]. For retrieving relevant and important knowledge from the huge textual data, we use the methodology of information retrieval and knowledge discovery for extracting useful textual patterns. Furthermore, our work, which includes domain knowledge in Opinion Mining, Sentiment Analysis, Natural Language Processing, Machine Learning, Finance and Accounting, has been integrated comprehensively. 1.
(11) Opinion mining and sentiment analysis have been widely discussed in not only Computer Science but also Finance. We propose a way to automatically expand Loughran and McDonald’s single-word lists [18] that are linked to positive and negative financial statuses into subjective multi-word expressions (MWEs). Loughran and McDonald developed positive and negative single-word lists that better reflect the tones of the U.S. financial statements (10-K filings) than the words in traditional psychology dictionaries (e.g., Tetlock (2007) [34] and Tetlock et al. (2008) [35] used the weak. 政 治 大. word and the negative word categories in the Harvard-IV-4 psychological dictionary on. 立. General Inquirer’s web site for their researches), and they examined the linkage between the. ‧ 國. 學. textual statements and the financial figures which included 10-K filing returns, trading, and. ‧. unexpected earnings etc.. sit. y. Nat. Subjective assertions in financial statements influence the judgments of market. er. io. participants when they evaluate the value and profitability of the reporting corporations.. al. n. iv n C the positive statuses with “prudent” h wordings. i U the truth from the long reports and e n g cTohexcavate. Hence, the managements of the corporations may attempt to conceal the negative and to raise. the overwhelming amount of numbers, we integrated artificial intelligence techniques to investigate the linkage between financial statuses and subjective multi-word expressions (MWEs).. 1.2 Methodology overview We defined opinion patterns to include opinion holders and subjective multi-word expressions (MWEs). For instance, the opinion patterns in the sentence “The Company believes the profits 2.
(12) could be adversely affected” include opinion holder “The Company” and two subjective expressions: “believe” and “could be adversely affected”. Our work can be divided into two parts which include experiments of opinion patterns identification and empirical studies of investigating the relationships between annual earnings and U.S. textual contents. First, we propose a computational procedure to model the text in financial statements, and. 政 治 大 subjective opinion patterns extraction. We used a variety of linguistic features including 立. employ conditional random field (CRF) models for opinion patterns identification and. ‧ 國. 學. morphology, orthography, predicate-argument structure, syntax and simple semantics. For effectively tuning and evaluating the CRF models, we trained and tested the models with the. ‧. annotated MPQA corpus [21]. The goals of first part include identifying opinion holders and. sit. y. Nat. extracting subjective opinion patterns which are in the form of multi-word expressions. n. al. er. io. (MWEs). Besides, we employed the best performing CRF model that we found in a sequence. v. of experiments to identify opinion holders and extract subjective opinion patterns in U.S. financial statements.. Ch. engchi. i Un. Second, we examine whether the subjective MWEs in the U.S. financial statements reflect the firm’s annual unexpected earnings. We used multinomial logistic regression, which is one of the discriminative models, for explaining the relationships between annual earnings and subjective MWEs and identifying the discriminative subjective MWEs that have special economic meanings.. 3.
(13) 1.3 Contributions The major contribution of our work is to find a way to automatically expand the lists of words that are linked to positive and negative financial statuses into subjective multi-word expressions (MWEs). Unlike traditional models that considered individual words (unigrams) and “bag of words” [20], our methods attempt to automatically extract MWEs from textual statements. MWEs could capture the subjective evaluations of the financial statuses of the reporting corporations more precisely, so are potentially more informative than individual. 政 治 大. words to facilitate better decision makings of creditors and investors.. 立. ‧ 國. 學. The other contribution of our work is to provide the economic evidences that could interpret positive and negative financial statuses with subjective multi-word expressions. We. ‧. found that the companies inclined to use weaker expressions when mentioning negative. sit. y. Nat. results. For example, “seriously harmed” and “might be impaired” are negative words. al. er. io. expressing damages of something, but the word “seriously harmed” conveys stronger. iv n C h esome hide n gnegative c h i Uinformation. n. destructivity than “might be impaired” pragmatically. In reality, the managements of the companies have incentives to. but to promote positive. information. Hence, the analysis of the relationshipss between annual earnings and subjective expressions in financial statements is a tough problem while there is an information asymmetry between readers and reporters of financial statements. Last but the most important, we propose the comprehensive system that might shed light on discovering unseen knowledge and patterns and also facilitating the decision makers in evaluating the financial status of the company.. 4.
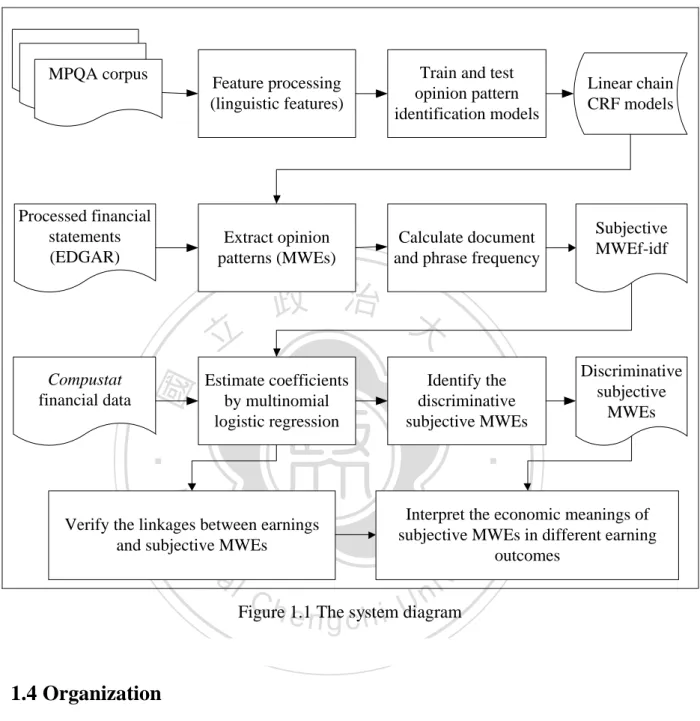
(14) MPQA corpus. Feature processing (linguistic features). Train and test opinion pattern identification models. Extract opinion patterns (MWEs). Calculate document and phrase frequency. Processed financial statements (EDGAR). 立. Estimate coefficients by multinomial logistic regression. Identify the discriminative subjective MWEs. Discriminative subjective MWEs. ‧. ‧ 國. Subjective MWEf-idf. 政 治 大. 學. Compustat financial data. Linear chain CRF models. y. Nat. sit. Interpret the economic meanings of subjective MWEs in different earning outcomes. n. al. er. io. Verify the linkages between earnings and subjective MWEs. iv n C h e1.1nThe Figure diagram hi U g csystem. 1.4 Organization The paper is organized as following. First, we propose a computational procedure to model the text in financial statements, which used conditional random field models for opinion patterns identification. Second, we trained and tested the models with the annotated MPQA corpus [21] for effectively tuning and evaluating the CRF models. Third, we employed the best performing CRF model that we found in a sequence of experiments to extract subjective opinion patterns 5.
(15) in U.S. financial statements. Fourth, we employed multinomial logistic regression to verify whether the opinion patterns are indicative of the earnings of the corporations, and also designed discriminative strategies to quantify the linkages between annual earnings and subjective MWEs. Finally, using the algorithmically identified MWEs, we examined whether companies indeed expressed in different strengths of positivity and negativity for different earning outcomes. The system diagram presents as Figure 1.1. Chapter 2 reviews related literatures in Finance and Computer Science; Chapter 3 briefly. 政 治 大. introduces the U.S. financial data and the corpora; Chapter 4 elaborates linguistic features and. 立. the CRF models that we used to mine the opinion patterns and subjective MWEs; Chapter 5. ‧ 國. 學. presents the method of the linkages between earnings and subjective MWEs; Chapter 6. ‧. discusses experimental results of evaluating the opinion patterns identification models by using the MPQA corpus; Chapter 7 interprets the empirical study result of the linkages between. y. Nat. n. al. er. io. sit. earnings and subjective MWEs; and Chapter 8 concludes and reviews the paper.. Ch. engchi. 6. i Un. v.
(16) CHAPTER 2. Literature Review. In this chapter, we review the recent studies from Finance aspect and Computer Science. 政 治 大. aspect. In the first part, we review the literatures that examined the linkage between financial. 立. opinion mining and sentiment analysis in Computer Science.. 學. ‧ 國. figures and textual contents; in the second part, we survey the literatures that worked on. ‧ y. Nat. er. io. sit. 2.1 Finance literature review. In recent years, researchers implemented quantitative methods to investigate the relationships. n. al. Ch. i Un. v. between financial performance and the text contents of financial press.. engchi. The recent studies identified the relationships between trading volume and measures of the Internet communication activity. Antweiler and Frank (2004) studied the influence of Internet stock message board on the stock markets by using both 1.5 millions messages posted on Yahoo! Finance and Raging Bull that talked about 45 companies in the Dow Jones Industrial Average. A naïve-Bayes algorithm was applied to measure bullishness in messages which characterized the contents of the messages as “buy,” “sell” or “hold” recommendations. The results concluded that the stock messages could help predict market return volatility and. 7.
(17) trading volume, but they did not find the evidence that the “bullish” messages would have statistically or economically significant effect on stock returns [1]. Li (2006) relied on the information in the texts of annual financial statements to examine the implications of risk sentiment of corporation’s 10-K filings for stock returns and future earnings. Risk sentiment of annual reports, which are related to the risk or uncertainty words “risk,” “risks,” “risky,” “uncertain,” “uncertainty,” and “uncertainties”, is measured by the frequencies of the individual words in the U.S. 10-K filings (section of the “Item 7A.. 政 治 大. Quantitative and Qualitative Disclosures about Market Risk” in the 10-K filings were extracted. 立. for analysis). Li found that the risk sentiment is negatively correlated with future earnings and. ‧ 國. 學. future stock returns which can be predicted by the risk sentiment under cross-sectional. ‧. situation. Furthermore, his research also provide an empirical study instance for market efficiency literature about examining whether the stock market reflects information in the text. y. Nat. er. io. sit. contents of publicly available documents [14].. al. n. iv n C h ethen gpsychology linkage with c h i Uof the. Casual observation implies that the textual contents of the news media about the stock market might have the. financial market participants. (especially invertors). Tetlock (2007) used principal components analysis to construct a simple measure of media pessimism from the content of the column “Abreast of the Market” in the Wall Street Journal over 16-year period 1984 through 1999, and estimated the linkage between the media pessimism measure and the stock market by using basic vector autoregressions. He concluded: (1) the high levels of the media pessimism predicts temporary decreases in stock return but does not be correlated with risk measures (risk aversion) while followed by a reversion to fundaments; (2) high or low values of the media pessimism forecasts well the high. 8.
(18) market trading volume; (3) low market returns would cause the media pessimism being high [34]. Tetlock et al. (2008) concluded that negative words contained in financial press about firms included in the S&P 500 capture some hard-to-be-quantified firms’ fundamentals, and they can forecast low earnings well. Although the markets underreacted to negative words in firm-specific news, the results showed that the negative words, especially those related to the fundamentals of corporations, are useful predicators for both earnings and returns. They found. 政 治 大. that the more negative words used in a firm-specific news story, the lower are the firm’s. 立. subsequent standardized unexpected earnings (SUE). That is to say, the proportion of the. ‧ 國. 學. negative words in a news article can predict the firm’s quarterly earnings [35].. ‧ y. Nat. er. io. sit. 2.2 Computer science literature review. Sentiment analysis and opinion analysis, which discuss the human emotions, sentiments,. n. al. Ch. i Un. v. affections, beliefs and opinions, have been studied in psychology for a long time before being. engchi. popular topics in Computer Science. Emotional intelligence has been thought as one of important aspects of the human intelligence. Since Piscard et al. proposed the concept of “affective computing”, the sentiment analysis and opinion mining researches have widely discussed in Human Machine Interaction, Artificial Intelligence, Robotics, and Natural Language Processing etc. They developed a feature-based machine that is able to recognize the human affection state given the four psychology signals [24]. Liu surveyed techniques in opinion mining and sentiment analysis that discussed identifying the text with opinions, sentiments or emotions from the corpora. Text roughly 9.
(19) belongs to two types: fact discourse or opinion discourse. The former provides objective information about the specific object (e.g., entities, events or topics). In contrast, the latter contains subjective evaluations, beliefs, judgments or comments about the objects. The main difference between them is whether or not subjective expressions are included in the discourses. Assuming that human’s subjective feelings about objects have only two extremes, i.e., pleasantness and unpleasantness, then the opinion expressions can be categorized into three kinds of polarities: positive, negative and neutral. For a given polarity, human beings. 政 治 大. may have different degrees of feelings about different things. For example, “wrong” and. 立. “might be inaccurate” are negative words expressing disapproval of someone or something,. ‧ 國. 學. but the word “wrong” conveys stronger disapproval than “might be inaccurate” pragmatically. He defined the basic components of an opinion. (1) Opinion holder: the person or organization. ‧. that holds a specific opinion on a particular object. (2) Target: on which an opinion is. y. Nat. er. io. sit. expressed. (3) Opinion: a view, attitude, or appraisal on an object from an opinion holder [17]. Researchers employed different machine learning techniques to determine the sentiment. n. al. Ch. i Un. v. in text of different granularities. Some worked at the document-level; others may work on the. engchi. paragraph-level, the sentence-level, the phrase-level or the word-level. Pang et al. found that machine learning methods outperformed the human-produced method in determining whether the sentiment polarity of the movie reviews is positive or negative. The human-produced method was conducting as choosing the indicator words for positive and negative sentiments in movie reviews. The machine learning methods, which included naïve Bayes, maximum entropy classification and support vector machines, classified the sentiment polarity of movie reviews at the document-level and utilized the features including unigrams, bigrams, part-of-speech and the word position in the text. They also 10.
(20) compared frequency based feature with presence based feature. Furthermore, they concluded that the sentiment classification problem is more challenging than topic classification problem (e.g., classifying whether a document is sports news or politics news) [22]. Weibe et al. manually annotated the sentence-level subjective sentences and objective sentence. After evaluating the disagreement between the different judges, they reported the results that using probabilistic classifier to classify subjective sentences based on syntactic features. Searches, which could be either forward or backward search, are performed to find. 政 治 大. the highest accuracy probability model that captures the important interdependencies among. 立. features while the system considered naïve Bayes, full independence, full interdependent. The. ‧ 國. 學. followings are features considered in the subjective and objective classification: the presence. ‧. in the sentence of the pronouns, adjectives, the cardinal numbers, modals other than “will”, adverbs other than “not”, whether or not to be the begin of the sentence, co-occurrence of word. y. Nat. er. io. sit. tokens and punctuation marks [36].. al. n. iv n C U list (known subjectivity vocabulary) h esubjectivity expressions from sentences. The initial n g c h iclues. Riloff and Wiebe used a bootstrapping machine learning process to extract the subjective. was used by the high-precision subjectivity classifier for labeling un-annotated text, and developing a bootstrapping process for the high-precision subjectivity classifier is because of three ideas: (1) to automatically identify the subjective and objective sentences in un-annotated texts and to automatically generate a large set of labeled subjective expressions, (2) to use such annotated data as training data for learning the extraction patterns which have richer linguistic information than single words and n-grams, (3) the learned patterns can be used to grow the labeled training set and make the whole processes as a bootstrap process. For automatically learning extraction patterns that correlated with the subjectivity, the learning algorithms are 11.
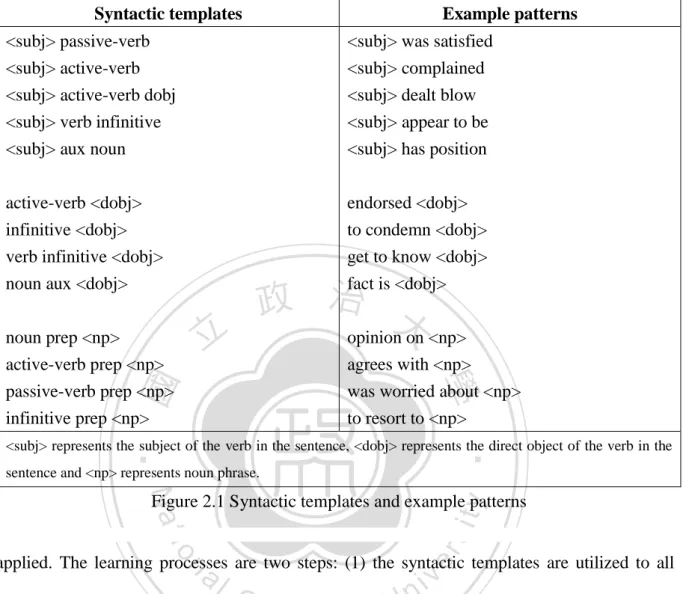
(21) Syntactic templates. Example patterns. <subj> passive-verb <subj> active-verb <subj> active-verb dobj <subj> verb infinitive <subj> aux noun. <subj> was satisfied <subj> complained <subj> dealt blow <subj> appear to be <subj> has position. active-verb <dobj> infinitive <dobj> verb infinitive <dobj> noun aux <dobj>. endorsed <dobj> to condemn <dobj> get to know <dobj> fact is <dobj>. 立. agrees with <np> was worried about <np> to resort to <np>. ‧ 國. 學. noun prep <np> active-verb prep <np> passive-verb prep <np> infinitive prep <np>. 政 治 大 opinion on <np>. ‧. <subj> represents the subject of the verb in the sentence, <dobj> represents the direct object of the verb in the sentence and <np> represents noun phrase.. Nat. er. io. sit. y. Figure 2.1 Syntactic templates and example patterns. al. applied. The learning processes are two steps: (1) the syntactic templates are utilized to all. n. iv n C training corpus. If the word sequence the description of the syntactic template, the h ematches ngchi U. word sequence would be viewed as an extraction patterns. The syntactic templates show in Figure 2.1. (2) The second step of the process tried to find the learned patterns that maximize the conditional probability. while the frequency of the pattern is. larger than the threshold. [27]. Kim and Hovy used syntactic features to indentify the opinion holders in the MPQA corpus by a ranking algorithm that considered maximum entropy. Their opinion holder identification system generated all possible holder candidates given a sentence and an opinion. 12.
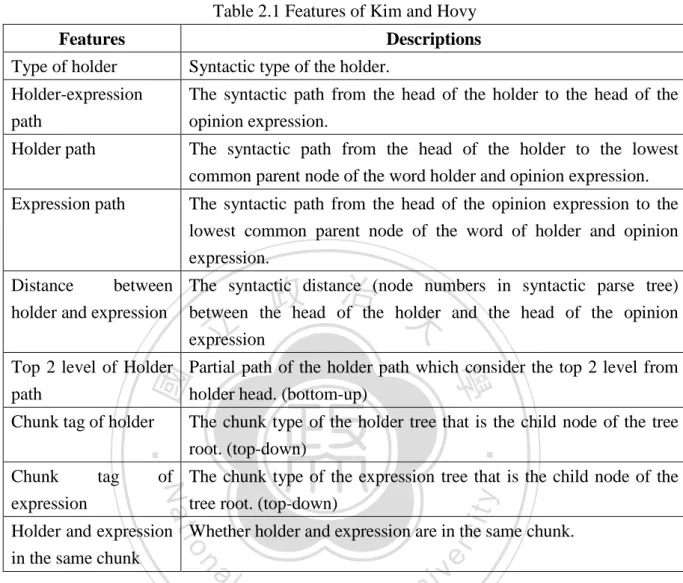
(22) Table 2.1 Features of Kim and Hovy Features. Descriptions. Type of holder. Syntactic type of the holder.. Holder-expression path. The syntactic path from the head of the holder to the head of the opinion expression.. Holder path. The syntactic path from the head of the holder to the lowest common parent node of the word holder and opinion expression.. Expression path. The syntactic path from the head of the opinion expression to the lowest common parent node of the word of holder and opinion expression.. 政 治 大. Distance between The syntactic distance (node numbers in syntactic parse tree) holder and expression between the head of the holder and the head of the opinion expression. 立. root. (top-down). of The chunk type of the expression tree that is the child node of the tree root. (top-down). sit. y. Nat. Chunk tag expression. The chunk type of the holder tree that is the child node of the tree. ‧. ‧ 國. Chunk tag of holder. 學. Top 2 level of Holder Partial path of the holder path which consider the top 2 level from path holder head. (bottom-up). er. io. Holder and expression Whether holder and expression are in the same chunk. in the same chunk. al. n. iv n C expression. The system modeled the opinion holder identification problem by selecting the he ngchi U most probable candidate that maximizes the conditional probability given a set of holder candidates and a specific opinion expression. The conditional probability would be calculated as feature functions to find the best of holder candidate which had the highest ranking from the results of the feature functions. The holder candidates were expected to be named entities or noun phrases in the sentence while excluding pronoun holders. The hypothesis of the system is that syntactic structure relation exists between an opinion holder and an opinion expression, so the features used in the work including full parsing features, partial parsing features and other features which are listed in Table 2.1. [12] 13.
(23) Choi et al. adopted two very different learning-based methods from information extraction that combined conditional random field (CRF) and the AutoSlog information extraction learning algorithm for identifying sources of opinions, emotions and sentiments in the MPQA corpus. While the CRFs were defined as a sequential tagging task and the AutoSlog was viewed as a pattern-matching task, they believed that combining the two techniques would perform better than either one alone. They considered three properties of opinion sources for selecting features of the CRFs: (1) the opinion sources are usually noun. 政 治 大. phrases, (2) the opinion sources would be semantic entities that can express opinion or hold. 立. the expression, (3) the opinion sources should be related with the opinion expression in the. ‧ 國. 學. sentence, since opinion sources expressed the expression, and the features are listed in Table 2.2. Their AutoSlog was a supervised extraction pattern learner that took heuristics looks at. ‧. the context surrounding each opinion source and extracted lexico-syntactic patterns for each. y. Nat. sit. opinion source, while the training was easily conducted by using a training corpus of texts and. n. al. er. io. their correspond opinion source and features. The extracted patterns of AutoSlog, which can. i Un. v. be produced as frequency-based (frequency of the patterns presence) or probability-based. Ch. engchi. (conditional probability of opinion source given the pattern), would be represented as the features of the CRF model. Finally, their hybrid opinion source identification system outperformed the three heuristic baseline systems which are (1) merely using semantic class as a feature, (2) using noun phrase information as a feature, and (3) combination (1), (2) with a heuristic rule [4].. 14.
(24) Table 2.2 Features of Choi et al. Features. Descriptions. Capitalization. Two Boolean features represent the capitalization of a word, including “all characters in a word are capital” and “the initial character of a word is capital”.. Part-of-speech. Each token in the sentences is classified into one of the POS: noun, verb, adverb, wh-word, determiner and punctuation etc. The neighboring tokens in the contextual windows (previous 1, previous 2, next 1 and next 2) are done for same things.. Opinion lexicon. 政 治 大 The purposes 立of the features are to capture structural information and to. 學. indicate whether each token is involved in any grammatical relations with an opinion word. The Collins dependency parser was used [6].. ‧ 國. Dependency tree. A sequence of binary features indicates whether each token in the sentence is presence in opinion lexicon list. (Weibe et al. collected [37]). Two preprocessing processes:. ‧. (1) Syntactic chunking: the first step traverses the dependency tree by breadth-first search for identifying and grouping syntactic related nodes into one chunk. The next step assigns each syntactic chunk a grammatical role (e.g., subject, object, verb, modifier, time, location, of-pp, by-pp). (2) Opinion word propagation: since the opinion words are all single words, the propagation was applied to expand the opinion words into multi-word phrases. This allows each token in the chunk to act as an opinion word for feature encoding.. n. er. io. sit. y. Nat. al. Ch. engchi. i Un. v. The features of each token include: the grammatical role of its chunk, the grammatical role of previous chunk, whether the parent node includes an opinion word, whether its chunk is in an argument position with respect to the parent chunk, whether current token represents a constituent boundary. Semantic class. 7 binary features encode whether each token belongs to one of the semantic classes which includes authority, government, human, media, organization, proper name and other.. 15.
(25) CHAPTER 3. Financial Data and Corpora. In this chapter, we introduce the financial data and corpora that we used in the experiments. 政 治 大. and empirical studies as following: (1) the MPQA corpus is a semantic annotated corpus that. 立. we used for training and testing our opinion patterns identification models; (2) the U.S.. ‧ 國. 學. Financial Statements is the textual corpus that we extracted the opinion patterns for being the. ‧. explanatory variables to examine the linkage between the annual earnings and subjective expressions; (3) the financial data is annual quantitative information about the companies that. y. Nat. er. io. sit. we employed as dependent variable and control variables to examine the linkages between the annual earnings and subjective expressions. Furthermore, we explain how we preprocessed. n. al. Ch. i Un. v. the financial statements, and how we merged the quantitative data and financial statements.. engchi. 3.1 Annotated corpus: MPQA Recently, many opinion mining works used MPQA (Multi-Perspective Question Answering) corpus for semantic annotation labels. MPQA corpus contains news articles, which cover different topics of news from different news sources, and other text documents manually annotated for opinions and private states (referring [21] for detail descriptions of the MPQA corpus). A subjective expression is any word or phrase used to express an opinion, emotion, evaluation, stance, speculation, etc. A general covering term for such states is private state. In 16.
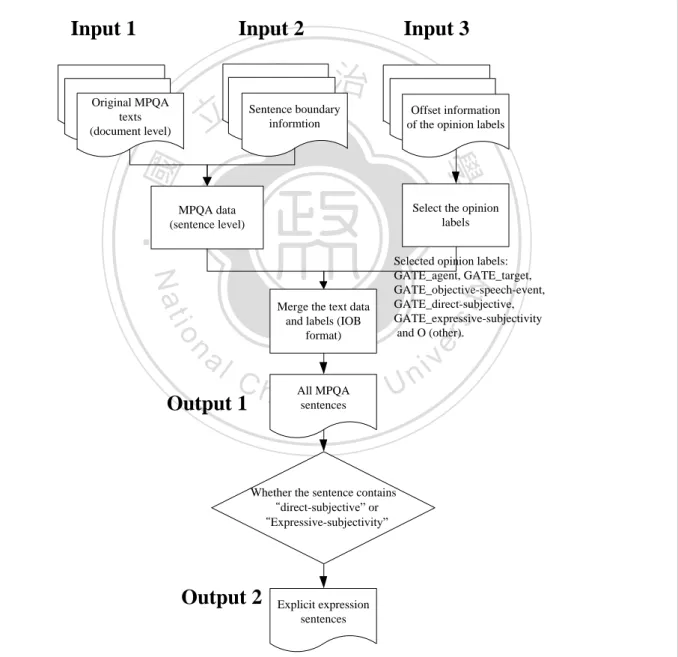
(26) MPQA Corpus, subjective expressions of varying lengths are marked, from single words to long phrases. Since the annotation unit of MPQA is one sentence per data, we focus on the sentence-level opinion patterns identification and opinion patterns extraction.. Input 1. Input 2. Original MPQA texts (document level). Input 3. 政 治 大. 立. Sentence boundary informtion. Offset information of the opinion labels. ‧ 國. 學 Select the opinion labels. ‧. MPQA data (sentence level). n. Ch. Output 1. MPQA e nAllsentences gchi. er. io. al. Merge the text data and labels (IOB format). sit. y. Nat. Selected opinion labels: GATE_agent, GATE_target, GATE_objective-speech-event, GATE_direct-subjective, GATE_expressive-subjectivity and O (other).. i Un. v. Whether the sentence contains “direct-subjective” or “Expressive-subjectivity”. Output 2. Explicit expression sentences. Figure 3.1 Procedures of MPQA corpus preprocessing. 17.
(27) Table 3.1 A sample sentence and annotations of the MPQA corpus According to Datanalisis' November poll, 57.4 percent of those polled feel as bad or worse than in the past and 55.3 percent believe their main problems are in the economic area. MPQA annotation labels Opinion. Datanalisis' November poll: agent;. holder 1. According to: objective speech event.. 立. 55.3 percent: agent; believe: direct-subjective;. 學. Opinion holder 3. 政 治 大. as bad or worse: expressive-subjectivity.. ‧ 國. Opinion holder 2. 57.4 percent of those polled: agent; feel: direct-subjective;. main problems: expressive-subjectivity.. ‧. sit. y. Nat. We explain the MPQA corpus preprocessing procedure in Figure 3.1 which produced the. io. al. n. original MPQA data.. er. all MPQA sentences and explicit sentences (referring Chapter 7 for detail descriptions) given. Ch. engchi. i Un. v. For training opinion patterns identification models, we used MPQA corpus to get the opinion patterns identification models and also selected part of annotation types as the tagging labels which included five different aspects of labels “agent”, “expressive-subjectivity”, “objective speech event”, “direct-subjective” and “target”. For better identifying opinion holders, the IOB format (Ramshaw and Marcus [26]) is used which has widely employed in NP chunking, word segmentation and named entity recognition research. In Table 3.1, “according to” would be tagged as “B-objective speech event” and “I-objective speech event”, which “B” stands for beginning word of phrase and “I” stands for continue word of phrase; the. 18.
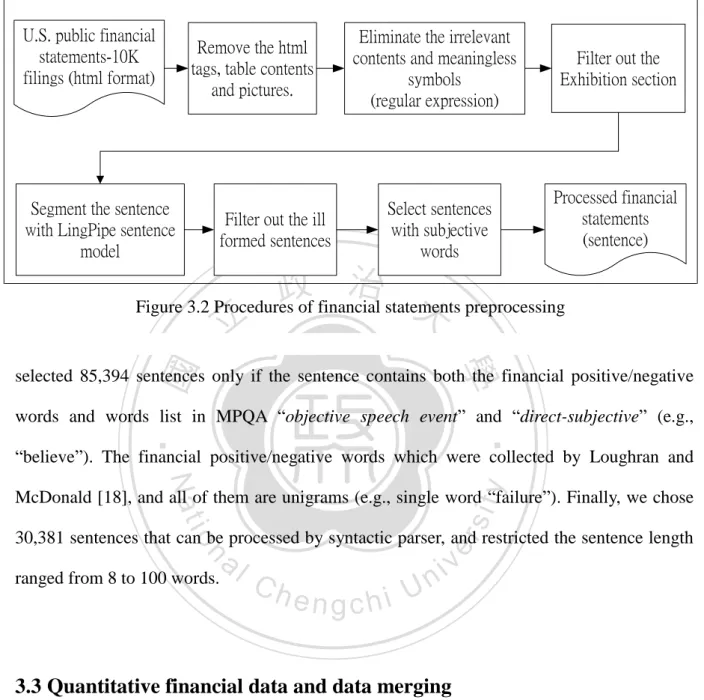
(28) single word “believe” in “direct-subjective” label which is both beginning and continue word would be tagged as “B-direct-subjective”. The labels are not overlapped and mutually embedded. We defined the opinion holders as a phrase with label “agent” in the corpus while the expression is implicit or explicit. Instead of limiting opinion holder to be a person, it can be any entity that expresses opinion, belief, speculation and private state to object directly or indirectly. The detail example is included in Table 3.1.. 政 治 大 3.2 Financial statements preprocessing 立. ‧ 國. 學. For both identifying and extracting the opinion patterns in the U.S. financial statements, the text in financial statements should be transferred into the format which our system can handle. ‧. with. Besides, the focus of our work is the textual contents of 10-K, so the process of. y. Nat. n. al. Ch. er. io. which is like climbing a steep peak without a guide.. sit. eliminating redundant contents and useless supplements is necessary. It is an experience. i Un. v. We preprocessed the filings for extracting footnote section and got rid of redundant. engchi. information (referring the procedure flow chart in Figure 3.2). The following is cleaning preprocesses: first of all, we removed the HTML tags, pictures, tables, front and ending matters and exhibitions for keeping the useful item sections; the next, we dropped the line contains too much white spaces, symbols, numbers or non-meaning words (e.g., fragment left after elimination) by regular expression; finally, we adopted LingPipe sentence model [15] to segment the filings into sentences for applying the opinion patterns identification model which is sentence-based method, and the total sentence number after preprocessing is 1.3 million. Instead of using 1.3 million sentences which are not all opinion sentences, we 19.
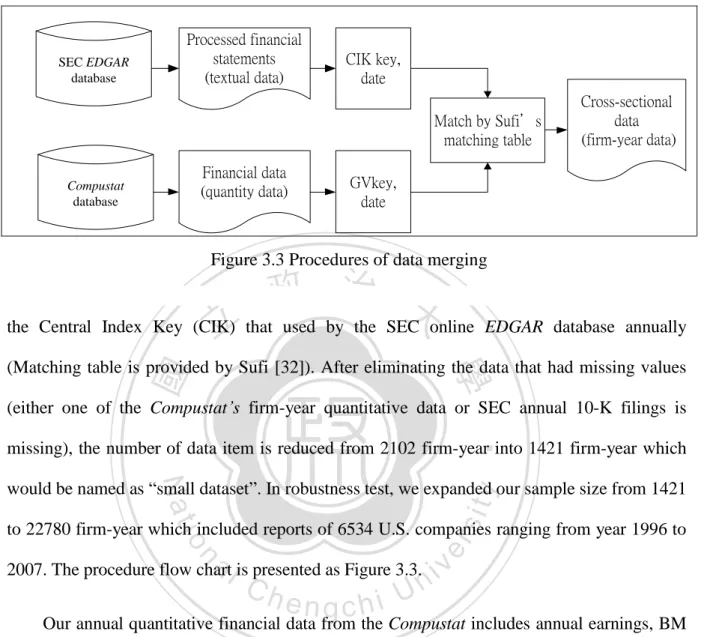
(29) U.S. public financial statements-10K filings (html format). Remove the html tags, table contents and pictures.. Segment the sentence with LingPipe sentence model. Eliminate the irrelevant contents and meaningless symbols (regular expression). Select sentences with subjective words. Filter out the ill formed sentences. Filter out the Exhibition section. Processed financial statements (sentence). 治 政 Figure 3.2 Procedures of financial statements 大 preprocessing 立 ‧ 國. 學. selected 85,394 sentences only if the sentence contains both the financial positive/negative words and words list in MPQA “objective speech event” and “direct-subjective” (e.g.,. ‧. “believe”). The financial positive/negative words which were collected by Loughran and. y. Nat. io. sit. McDonald [18], and all of them are unigrams (e.g., single word “failure”). Finally, we chose. n. al. er. 30,381 sentences that can be processed by syntactic parser, and restricted the sentence length ranged from 8 to 100 words.. Ch. engchi. i Un. v. 3.3 Quantitative financial data and data merging Financial statements used in this work are the U.S. SEC 10-K filings of public companies which were downloaded from the EDGAR database [7]. We needed annual quantitative information about the companies from the Compustat database [29]. Opinion patterns were extracted from the financial statements, for the years between 1996 and 2007, of 324 U.S. companies, and we merged two different data sources by matching GVKEY (Compustat) with 20.
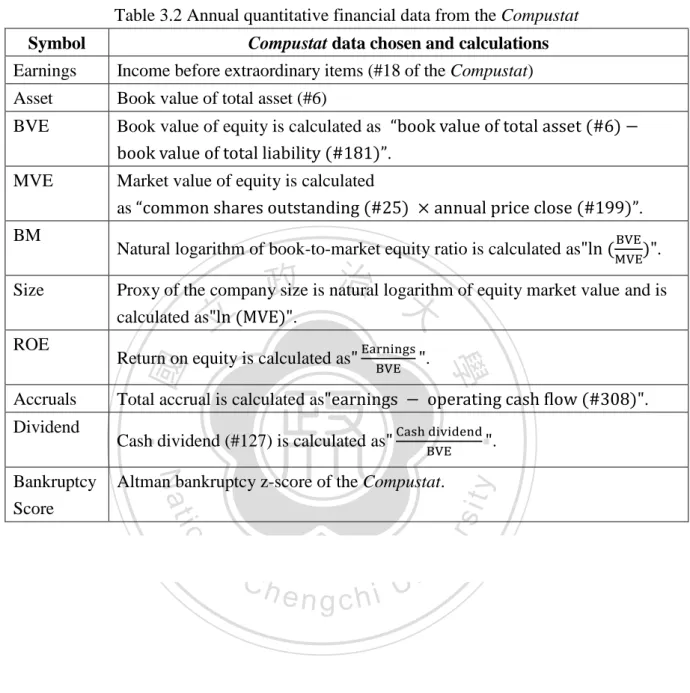
(30) Processed financial statements (textual data). SEC EDGAR database. CIK key, date Match by Sufi’s matching table. Financial data (quantity data). Compustat database. Cross-sectional data (firm-year data). GVkey, date. Figure 3.3 Procedures of data merging. 政 治 大 the Central Index Key (CIK) 立 that used by the SEC online EDGAR database annually. ‧ 國. 學. (Matching table is provided by Sufi [32]). After eliminating the data that had missing values (either one of the Compustat’s firm-year quantitative data or SEC annual 10-K filings is. ‧. missing), the number of data item is reduced from 2102 firm-year into 1421 firm-year which. Nat. sit. y. would be named as “small dataset”. In robustness test, we expanded our sample size from 1421. n. al. er. io. to 22780 firm-year which included reports of 6534 U.S. companies ranging from year 1996 to. i Un. 2007. The procedure flow chart is presented as Figure 3.3.. Ch. engchi. v. Our annual quantitative financial data from the Compustat includes annual earnings, BM ratio (natural log of dividing Book value by Market Value), ROE (return on equity), accruals (earnings minus operating cash flow), size (natural log of Market Value), Dividend (Cash dividend divided by Book value) and Bankruptcy Score (Z-score). For fairly representing the firm’s annual performance, we use the “the income before extraordinary items” as the proxy of the “annual earnings”. The calculations of our annual quantitative financial data are listed in Table 3.2.. 21.
(31) Table 3.2 Annual quantitative financial data from the Compustat Symbol. Compustat data chosen and calculations. Earnings. Income before extraordinary items (#18 of the Compustat). Asset. Book value of total asset (#6). BVE. Book value of equity is calculated as .. MVE. Market value of equity is calculated as. 立. calculated as. Total accrual is calculated as. .. Cash dividend (#127) is calculated as. .. Nat. Altman bankruptcy z-score of the Compustat.. io. sit. Bankruptcy Score. .. ‧. Dividend. Return on equity is calculated as. 學. Accruals. 政 治 大 .. ‧ 國. ROE. .. Proxy of the company size is natural logarithm of equity market value and is. y. Size. Natural logarithm of book-to-market equity ratio is calculated as. n. al. er. BM. .. Ch. engchi. 22. i Un. v.
(32) CHAPTER 4. Models for Opinion Patterns Identification. This Chapter explains how to attain our linguistic features and to build the opinion patterns. 政 治 大. identification with linear chain CRF models. The CRF models would be evaluated by the. 立. MPQA corpus in Chapter 6 and also be applied to the extraction of subjective expressions in. ‧ 國. 學. the financial statement in Chapter 7. The System diagram of Chapter 4 shows in Figure 4.1.. ‧. n. al. er. io. Preprocessing (Chapter 3). sit. y. Nat. MPQA corpus (sentence level). Feature processing PredicateMorphological argument features structure features. Ch. i Un. Syntactic features. engchi. v. Simple semantic features. Evaluate CRF models (Chapter 6) Linear-chain data view. Train opinion patterns identification model. CRF models. Extract opinion patterns in financial Statements (Chapter 7). Figure 4.1 The system diagram of the opinion patterns identification models. 23.
(33) Table 4.1 The example sentence of the feature sets Original sentence "We decided to make some bold decisions," he said. Annotation labels Opinion holder 1. he: agent, said: objective speech event.. Opinion holder 2. We: agent, decided: direct-subjective, to make some bold decisions: expressive-subjectivity.. 政 治 大. The main task of the chapter, opinion patterns identification, is viewed as a sequential. 立. tagging problem which uses features in morphology, orthography, predicate-argument. ‧ 國. 學. structure, syntax and simple semantics to train the linear-chain conditional random field. Although the relationship between surface manifestations and semantic role labeling is still. ‧. indeterminate, the linking theory proponents argue for prediction of semantic role labeling by. y. Nat. io. sit. syntactic information and predicate-argument structure is feasible [9]. Because the opinion. n. al. er. patterns identification is a sub-domain of semantic role labeling research, it is feasible and. Ch. i Un. v. reasonable to use general linguistic features for opinion patterns identification. Table 4.1 is the. engchi. example sentence and annotation labels that we explain our feature sets in this chapter.. 4.1 Conditional random fields Conditional random fields (CRF) are probabilistic frameworks which are suitable for labeling and segmenting sequential data. Rather than defining a joint probability label sequences. and observation sequences. trained to maximize a conditional probability. over both. , CRFs are undirected graphical models of the desired label sequences given. the corresponding observation sequences. The primary advantage of the CRF over hidden 24.
(34) Markov model is the relaxation of conditional independence assumptions of HMMs, and over the other conditional Markov model that based on directed graphical models is the avoidance of the label bias problems. (Referring Lafferty et al. [13] for the detail of the CRF model). Although the structure of CRF graph in theory can be arbitrary structure which would fit the real world application better, the linear chain CRF is a common special-case graph structure that widely applied in sequential labeling, such as Chinese word segmentation [23]. A linear chain CRF with parameters probability for label sequence. 立. defines a conditional. 政 治 大. given input observation sequences. , where labels indicate. the MPQA annotation labels which are in forms of IOB format (referring Section 3.1 for. ‧ 國. 學. detail descriptions) and input observation sequences indicate the feature sets (referring. ‧. Section 4.2 for detail descriptions) by assuming that the label sequence and observation sequence have the same length , and the form can be written as,. n. er. io. sit. y. Nat. al. where one;. i Un. engchi. v. is a normalization factor that makes the probability of all state sequences sum to is a transition feature function of the entire input observation sequences. and the label at position position. Ch. (1). and ;. is a state feature function of the label at. and the entire input observation sequences. ; and. and. are parameters that. estimated from training data with Maximum likelihood parameter estimation (maximizing the conditional probability of a set of label sequences, given each of their corresponding input observation sequences). To make the notation more uniform and general, we also rewrite (2) 25.
(35) and (3). Where the. can be either. or. . Then the. form can rewrite as,. (4). 立. Large positive values of. can be concluded as,. y. sit. io. is independent of. (5). , the decomposition above can efficiently find the most. er. Nat. Since the. make a state of the label unlikely. The most probable label. ‧. ‧ 國. sequence for an input. or. 學. large negative values of. 政 治 大 or indicate a preference for such a state of the label and. n. abyl using the Viterbi algorithm.i v n Ch U i e h n glabel c sequence given input observation sequences, In order to efficiently compute the best. probable label sequence. the features are restricted to depend only on local features of the output label. In first-order chain CRFs, the features may depend on the current position’s label and previous position label. Although the first-order assumption may make capturing less contextual information in one sentence which can result in not fitting to the real linguistic nature, the first-order assumption is necessary in practical experiments since the computation complexity would increase dramatically when the order goes up slightly.. 26.
(36) Table 4.2 Feature sets of various linguistic features Feature name. No.. Original token. Feature name. No.. f1. Syntactic category of phrase. A. f11. S. f2. Syntactic path and partial A path. f12. Initial words, all capital words or R. f3. Based chunk. C. f13. f4. Subordinate noun clause S followed verb and noun phrase before verb phrase. f14. S. f15. S. f16. its D. f17. Lemmatization. first character capitalized Word with alphabets and numbers R mixed. 立. Nat. Subjective polarity. word. and. A. f8. Verb-clusters of predicate. A. f18. A. f9. The frame of predicate in the A FrameNet. f19. A. f10. io. sit. Head word and its POS. f7. ‧. Sub-categorization of predicate. A. 學. Voice. ‧ 國. Before or after predicate. er. Position of predicate. R f5 治 Syntactic dependency 政 大 A f6 Named entity recognition. y. Punctuation. al. n. iv n C U parser in our research and can partial syntactic parser (the partialhparser e n gis cCGI h i Shallow. Rather than using the full syntactic parser, many information extraction systems used. correspond to based chunk feature). The reason of using the partial parser for the based chunk feature includes: (1) the number of the full syntactic parse tree for a given sentence would be greater than one (parse tree ambiguity problem), however, the number of the partial parse tree for a given sentence would certainly be equal to or less than the full parse tree; (2) The computation cost would be less expensive than full parser; (3) to recognize the best phrase boundary is practical difficult under the condition that we have only 10325 sentences of the MPQA corpus, and if we implement an algorithm to extract our based chunk would never be objective than the CGI Shallow parser which have been trained under the data fitting for 27.
(37) based chunk; that is to say, our research is lack of large-scale based chunk training data to implement our own algorithm that can extract the based chunk from the full parse tree. The main focus of our research is not to develop a new algorithm that can parse the best partial parse tree from the full parse tree, so the usage of the CGI Shallow parser is a practical discretion.. 政 治 大. 4.2 Feature sets and linear chain CRF data view. 立. The task of feature values processing were completed by Stanford NLP toolkits [30], ASSERT. ‧ 國. 學. semantic role labeler [3] [25] and CGI Shallow parser [11] for linguistic features. The following is the linguistic feature set being taken for CRF models. The feature sets that we use. ‧. in our work were presented as Table 4.2. We employed two kind of syntactic parsers which are. y. Nat. sit. Stanford Parser (included in Stanford NLP toolkits) and Charniak Parser [4] (embedded in. n. al. er. io. ASSERT semantic role labeler), and the features from two parser were merged by matching. i Un. v. each of original tokens and their part-of-speech sequentially for each sentence. However, the. Ch. engchi. agreement of two parsers is not 100%, so the feature which had the missing value would be represented as “O” if the mismatch happened. In Table 4.2, “S” stands for Stanford NLP toolkits; “R” for Java regular expression; “A” for ASSERT semantic role labeler; “C” for CGI Shallow parser; “D” for subjective word dictionary of Wiebe [37]. Since the data is divided into sentence unit, the granularity of the feature set which includes token-level, phrase-level, and sentence-level features but no cross-sentence features. Our linear CRF data view was presents as Figure 4.2, we use example sentence “We decided to make some bold decisions” and partially selected feature set which is consist of “f1, f2, f7, f8, 28.
(38) f9, f10, f11, f12 and f17” to clarify how the features of token-level, phrase-level and sentence-level are transformed into linear data view. The token-level feature value of each token in a sentence is extracted and recorded sequentially, but sentence-level feature value of a sentence is processed only once. In addition, the detail interpretation of phrase-level features that extracted from syntactic parse tree is explained at syntactic category feature (f11) and illustrated by syntactic parse tree in Figure 4.3.. 政 治 大 4.2.1 Morphological and orthographical features 立. ‧ 國. 學. Original token (f1): each character of original token reserves the morphological and orthographical form that might contain some linguistic features because of some syntactic or. ‧. semantic reason. We separated the words in the sentence by both the white space and. y. Nat. sit. punctuations and also kept its original form without further processed, so the single English. n. al. er. io. words, numbers, symbols and punctuation are viewed as one token respectively except for. i Un. v. taking named entity with periods or numbers as a single token.. Ch. engchi. 29.
(39) f1. We. decided. to. make. some. bold. decisions. f2. we. decide. to. make. some. bold. decision. f17. objective. weak, neutral. objective. objective. objective. strong, positive. objective. f7. before. after. after. after. DT: some. JJ: bold. NNS: decisions. DT. JJ. NNS. NP↑S. acitve. f9. VPVBD-S. VB: make. O. O. VP. O. VP↑VP↑S↑VP. acitve. acitve. VPVBD-S. VPVBD-S. a l BCh. n. f8. O. O. NNS: decisions. O. O. NP. O. O. NP↑VP↑ VP↑S↑VP. acitve. acitve. VPVBD-S. VPVBD-S. ‧. NP. PREDICATE. VB↑VP↑VP↑S↑ DT↑NP↑VP↑VP JJ↑NP↑VP↑VP↑ NNS↑NP↑VP↑VP VP ↑S↑VP S↑VP ↑S↑VP. y. PRP: we. TO↑VP↑S↑VP. sit. PRP↑NP↑S. io. Sentence level features. PRP. Nat. Phrase level features Syntactic f10 features f11 of leaf node's f12 parent. PRP: we. 學. f10 Syntactic features f11 of leaf node f12. after 治 政 大 TO: to VB: make 立TO VB after. acitve. er. Token Features level of leaf features node. Set # Feature-values (partially selected feature set). ‧ 國. Feature Level. IOB format. B-. B-. I-. LABELS. agent. direct-subjective expressive-subjectivity. engchi. i n U. v. VPVBD-S. Figure 4.2 Example sentence expressed in linear CRF data view. 30.
(40) Lemmatization (f2): the tokens above may contain many syntactic derivation and pragmatic variations. Since the different part of speech of words derived from the same lemma word would be semantically equivalent, and the lemma word usage can reduce the complexity of feature spaces. We used regular expression to recognize the following orthographical features which might indicate the named entities or specific symbols. In every sentence, we compared each. 政 治 大. character of each token with the following pattern and represented each feature values as binary value (true or false).. 立. ‧ 國. 學. Initial words, all capital words or first character capitalized (f3): in English, abbreviation words or words with all capital characters are probably the specific entities which can be. ‧. people name, organization name, location name or nation name. For example, the country. y. Nat. er. io. sit. name America and its abbreviation U.S.. Word with alphabets and numbers mixed (f4): It is observed some organization tends to. n. al. Ch. i Un. v. have a name with alphabets and numbers mixed for easily memorized. The famous American. engchi. company “3M” is an instance of such word that mixes numbers and alphabets into one word. Punctuation (f5): the punctuations in sentences are the best boundary of semantic unit that separate different phrases or clauses rather than engaging in dealing with the semantic unit segmentation. The tokens before or after the punctuation are reasonable to be the start or the end of the semantic unit which can be token-level, phrase-level, clause-level and sentence-level semantic unit. Besides, quotation mark is a punctuation that indicates the sentence of speech or subjective expressions, where indicating the words inside the quotation mark might be subjective expressions and the words outside might be opinion holders. 31.
(41) 4.2.2 Predicate-argument structure features Predicate-argument structure (PAS) has been successfully implemented in semantic role labeling. PAS is a structure that captures the events of interest and the participant entities involved in events that correspond to predicate and arguments respectively. Generally speaking, predicate is usually a verb that conveys the type of event. The types and numbers of arguments are totally different while each predicate is different in syntactical or pragmatic view, e.g. transitive verb vs. intransitive verb, and different types of the arguments tend to. 政 治 大. have different chances to be opinion holders.. 立. ‧ 國. 學. Position of predicate (f6): arguments usually get closed to the predicate, especially agent and patient (subject and object of verb). The word “said” in the beginning or ending part of. ‧. sentence possibly indicates the agent of speech event is located at beginning or ending part of. y. sit. n. al. er. io. sentence.. Nat. the sentence. It also can be taken as the distance of the token and the first token of the. i Un. v. Before or after predicate (relative position from predicate, f7): the arguments before or. Ch. engchi. after predicate are totally different types of semantic roles. For example, in sentence “Peter chases John.” Since the predicate is “chases” and two arguments Peter (arg0) and John (arg1) correspond to agent (Subject) and patient (object) respectively, it can be concluded the relative position of arguments from predicate impacts the semantic roles while syntactic categories are the same. Voice (f8): whether the predicate is active or passive voice that can affect the arguments type. In sentence “John is chased by Peter” the predicate changes the voice, not only the tense of verb is modified but both sequences of arguments are changed. If considering both relative 32.
(42) position from predicate and voice, the resolution between opinion holders and the other labels become more feasible.. 4.2.3 Syntactic features Sub-categorization of predicate (f9): the feature is the verb phrase sub-structure that expressed the VP sub-parse tree structure where predicate located. Dash frame in Figure 4.3 indicates the. 政 治 大. sub-categorization of “decided” is “VPVBD-S”. The feature helps analysis the phrase or the. 立. clause that follows predicate, and increases the ability of discriminating between arguments.. ‧ 國. S. ‧. VP. io. al. n decided. We. 4. sit. y. Nat. S. VBD. PRP. TO. Ch. VP. engchi. er. NP. 學. 1. i Un. v. VP. 2 to. NP. VB. make. DT. JJ. some. bold. NNS. 3. Figure 4.3 The syntactic features in a parse tree. 33. decisions.
(43) Head word and its POS (f10): the features are syntactic head of the phrase and the syntactic category of the head. Different heads in noun phrase can be used to express different semantic roles. If the head word is “he” or “Bill” rather than “computer”, then the probability that the noun phrase is the opinion holder increases. The Collins’ head word algorithm is adopted for head word recognition [6]. Since the head of prepositional phrase (PP) is preposition and the significant semantic meaning in PP might be the noun phrase (NP), we also added the head of NP in PP as a feature which is called content word of PP. We also included. 政 治 大. the head word and head word’s POS of parent node and grandparent node for considering the. 立. contextual syntactic features in linear data.. ‧ 國. 學. Syntactic category of phrase (phrase type, f11): different semantic roles tend to be. ‧. realized by different syntactic categories. The opinion holders are usually the noun phrases and sometimes prepositional phrases, but labels “objective speech event” and “direct-subjective”. y. Nat. er. io. sit. tend to be verb phrases. Our opinion patterns identification models are realized by the linear CRF models, but the syntactic categories of the word or the phrase are not pure linear data. n. al. Ch. i Un. v. which has been expressed in tree structure, i.e., the phrase type of word “decisions” in Figure. engchi. 4.3 is NNS while the phrase type of “some bold decisions” is NP (i.e., the bold arrow). Instead of considering all syntactic categories in a syntactic parse tree which increases the space complexity dramatically, we traced upward only three syntactic categories of non-terminal nodes from the parent of leaf nodes if the head word of parent phrase is such leaf node. For example in Figure 4.3, because the head word of NP “some bold decisions” is “decisions” and the head of VP “make some bold decisions” is “make”, the noun “decisions” would have phrase type only NNS and NP without VP. In contrast, the verb “make” would contains VB, VP and VP in sequence (The detail data view is illustrated in Figure 4.2). Hence, we embedded 34.
(44) Table 4.3 Gidea’s statistical results of syntactic path and partial path Frequency proportion. Syntactic Path. Description. 14.2%. VB↑VP↓PP. PP argument / adjunct. 11.8. VB↑VP↑S↓NP↓. Subject. 10.1. VBD↑VP↑NP↓. Object. 7.9. VB↑VP↑ VP↑S↓NP↓. 4.1. VB↑VP↓ADVP. 3.0. NN↑NP↑NP↓PP. Prepositional complement of noun. 政 治 VB↑VP↑ VP↑ VP↑S↓NP↓ 大 立 Not matching. 1.6. Adverbial particle embedded VP. 學. Other. ‧. ‧ 國. 14.2. (embedded VP). Adverbial adjunct. VB↑VP↓PRT. 1.7. 31.4. Subject. the syntactic features of phrase in head word of phrase to solve linear data structure problem.. sit. y. Nat. Considering contextual syntactic features by tracing bottom-up from the leaf of parse tree. n. al. er. io. structure is better than by using sliding window method that merely adds POS of the previous. v. and next token linearly without capturing global view of syntactic tree structure.. Ch. engchi. i Un. Syntactic path and partial path (f12): according to Gidea’s statistical results [9] in Table 4.3, the path VB↑VP↓PP has 14.2% relative frequency to be PP argument or adjunct; path VB↑VP↑S↓NP↓ is 11.8% to be subject; path VBD↑VP↑NP↓ has 10.1% chance to be object of the sentence; and the VB↑VP↓ADVP is adverbial adjunct with 4.1%. The above path help predict the semantic labels. The syntactic path feature describes the syntactic relation from constituent to the predicate in the sentence with the syntactic categories of node passed through. In Figure 4.3, the path (i.e., the bold dash arrow) from “We” to “decides” can be represented as either “PRP↑NP↑S↓VP↓VBD” or “NP↑S↓VP↓VBD” depends on whether the 35.
(45) We. decided. B-NP B-VP. to. make some bold decisions. I-VP I-VP. B-NP I-NP I-NP. Figure 4.4 Sample based chunk features (f13) constituent is PRP or NP of word “We”. The deep parse tree can make the string of path too long, and would the data sparseness problem would happen. The partial path is part of syntactic path which contains the lowest common ancestor of constituent and predicate. (e.g., the lowest common ancestor is S in the sentence, so the partial path is reduced to. 政 治 大. “PRP↑NP↑S”) Using partial path feature can solve the sparseness problem.. 立. Based chunk (f13): the based chunk feature is similar to the phrase type feature but. ‧ 國. 學. without the phrase type overlapped. In Figure 4.4, the sentence S is consist of NP (We) and VP (decided to…), but this VP can be divided into non-overlapping sub-phrases which are. ‧. combined by VP (decided to make) and NP (some bold decisions). We represent the based. y. Nat. er. io. sit. chunk in IOB format which makes the segmentation of phrase boundary more precise.. al. Subordinate noun clause followed verb and noun phrase before verb phrase (f14): Since. n. iv n C our phrase type feature is only threeh levels of syntacticU e n g c h i category from the parents of parse tree leaf nodes, the whole sentence structure information may be omitted if the parse tree is constructed deeply. In sentence “The management believed that …,” the subordinate noun clause followed verb “believed” is usually embedded with subjective expressions and opinion targets. We used Stanford tregex toolkit to extract such pattern from the parse tree [30].. 36.
(46) Table 4.4 The descriptions of syntactic dependency Relation. Syntactic Subject relation subject+verb (nsubj). Descriptions Identifying the nominal subject and its corresponding verb (or adjective) in one sentence. A nominal subject is a noun that is a syntactic subject of one clause. The governor of the. subject+adjective. relation could be either a verb or an adjective. subject+passive verb. corresponding verb in a passive 政 治itssentence. 大. Identifying. (advmod). adverbs, which the adverb modifies the meaning of the verb.. verbs. and. the. n. er. io. Identifying the direct object and its corresponding verb (or adjective) in one sentence. The direct object is a noun that is the object of the verb.. sit. verb + direct object. al. the. y. Nat. Direct-object relation (dobj). adverb modifies verb. ‧. ‧ 國. 立. adjective modifies Identifying the nouns and the noun (amod) adjectives, which the adjective modifies the meaning of the noun.. 學. Modifying relation. Identifying the nominal subject and. Ch. engchi. i Un. v. Syntactic dependency (f15): the purpose of dependency feature is not only to encode the syntactic structural information but also to capture the grammatical relation that includes three type of Stanford grammar dependency “subject relationship”, “modifying relationship” and “direct-object relationship” (Table 4.4 shows the descriptions of syntactic dependency [30]). Subject relationship includes “nominal subject” and “passive nominal subject”, which correspond to the noun that is the syntactic subject of active and passive clause; when the governor of this relation is linking verb, the complement of the linking verb can be a noun or 37.
數據

+7


相關文件
The hashCode method for a given class can be used to test for object equality and object inequality for that class. The hashCode method is used by the java.util.SortedSet
All steps, except Step 3 below for computing the residual vector r (k) , of Iterative Refinement are performed in the t-digit arithmetic... of precision t.. OUTPUT approx. exceeded’
Using sets of diverse, multimodal and multi-genre texts of high quality on selected themes, the Seed Project, Development of Text Sets (DTS) for Enriching the School-based
• cost-sensitive classifier: low cost but high error rate. • traditional classifier: low error rate but
* All rights reserved, Tei-Wei Kuo, National Taiwan University, 2005..
第一課節:介紹成本會計和解釋成本概念及詞彙 第二課節:了解用於編製財務報表的不同成本分類
For a long time, 5×5 evaluation table is the tool used by Kano’s two dimensional model in judging quality attribute, but the judgment process might be too objective, plus
This article was compared with the survey results from the article, “Skills requirements for MIS staffs – the study of enterprises’ requirements for the high school,
