Efficient Reversible Data Hiding for VQ-Compressed Images
Based on Index Mapping Mechanism
Chuan Qin1, Chin-Chen Chang2, 3 and Yen-Chang Chen2 1School of Optical-Electrical and Computer Engineering,
University of Shanghai for Science and Technology, Shanghai 200093, China E-mail: [email protected]
2Department of Information Engineering and Computer Science,
Feng Chia University, Taichung 40724, Taiwan E-mail: [email protected], [email protected]
3Department of Biomedical Imaging and Radiological Science,
China Medical University, Taichung 40402, Taiwan E-mail: [email protected]
Correspondence Address:
Prof. Chin-Chen Chang
Department of Information Engineering and Computer Science, Feng Chia University,
100 Wenhwa Road, Taichung 40724, Taiwan. E-mail: [email protected]
TEL: 886-4-24517250 ext. 3790 FAX: 886-4-27066495
Efficient Reversible Data Hiding for VQ-Compressed Images
Based on Index Mapping Mechanism
Chuan Qin, Chin-Chen Chang and Yen-Chang Chen
Abstract: In this paper, we propose a novel reversible data hiding scheme in the index tables of the
vector quantization (VQ) compressed images based on index mapping mechanism. On the sender side, the VQ indices with zero occurrence numbers in a given index table of an image are utilized to construct a series of index mappings together with some indices with the largest occurrence numbers. The indices in each constructed mapping correspond to the full binary representations with the length of the mapping bit number. Through the mapping optimization by index histogram, the optimal vector of mapping bit numbers can be obtained, which leads to the highest hiding capacity. Data embedding procedure can be easily achieved by the simple index substitutions according the current subset of secret bits for hiding. The same index mappings reconstructed on the receiver side ensure the correctness of secret data extraction and the lossless recovery of index table. Experimental results demonstrate the effectiveness of the proposed scheme.
Keywords: reversible data hiding, vector quantization, index mapping, hiding capacity
1. I
NTRODUCTIONAs a branch of data hiding [1], reversible data hiding has attracted many research interests recently [2-10]. The reversibility means that, after extracting the embedded secret information, the original cover data can be losslessly recovered from its stego version. Besides reversibility, the hiding capacity and the quality of stego data are also the main factors for the evaluation of reversible data hiding schemes. The commonly used cover medium for data hiding include text, audio, image, and video etc. Since digital images widely exist in Internet environment nowadays, a large amount of reversible data hiding schemes based on various image forms, such as gray image [3], color image [4], compressed image [5], and encrypted image [6], have been reported in recent years.
As a well-known data compression algorithm, vector quantization (VQ) can also be applied for digital images [11-12]. During the VQ compression process, the image is first segmented into
N non-overlapped blocks and each block consists of n2 pixels. A VQ codebook including Q
codewords is constructed and shared by the sender and the receiver. The length of each codeword is equal to n2. After calculating the similarity between the codewords and each image block using
Euclidean distance, the index of the codeword that has the smallest Euclidean distance with the block is recorded in the VQ index table. Thus, the output of VQ compression for a given gray image is one VQ index table consisting of N index values. Since only the index value of the codeword is stored for each block, and each index value requires log2Q for representation, the
compression ratio of VQ for the whole image is (8 n2) / log
2Q. In the decompression process,
according to index values in the VQ index table, the corresponding codewords in the codebook can be easily utilized to produce the decompressed image. Due to the representativeness of the VQ codewords, not only the high compression ratio can be obtained, but also the satisfactory visual quality of the decompressed image can be achieved [13]. In this work, we mainly discuss the reversible data hiding in the image compressed codes of VQ, i.e., VQ index table.
Recently, many researchers have studied on the techniques of reversible data hiding using VQ index table [14-22]. Du and Hsu proposed an adaptive data hiding method for VQ compressed images in [16], which can vary the embedding process according to the amount of the hidden data. In this method, the VQ codebook was partitioned into two or more subcodebooks, and the best match in one of the subcodebooks was found to embed secret data. In order to increase the embedding capacity, a VQ-based data hiding scheme by a codeword clustering technique was presented in [17]. The secret data were embedded into VQ index table by a codeword-order-cycle permutation. By the cycle technique, more possibilities and flexibility can be offered to improve the performance of this scheme. Chang et al. clustered the VQ codebook into three groups and used the VQ indices in the high-frequency cluster to hide secret data [18]. The other two clusters were used for the future recovery. Inspired by [16-17], Lin et al. adjusted the pre-determined distance threshold according to the required hiding capacity and arranged a number of similar codewords in one group to embed the secret sub-message [19]. A reversible data hiding method for VQ compressed images using locally adaptive coding was proposed in [20]. This method compressed the index table in the block-by-block manner and embedded secret message into VQ indices simultaneously. In [21], Yang and Lin sorted the VQ codebook using the referred counts, and then divided the codebook into several clusters. Half of these clusters were utilized to embed secret bits. Compared with [18], this method can embed more data. In order to further increase the hiding capacity, Yang and Lin replaced the traditional trace for processing index table with the fractal Hilbert curve, and during data embedding, the compression rate can also be improved by following the curve to process the index table [22].
The search-order coding (SOC) and the side match vector quantization (SMVQ) are the two most popular algorithms for the enhancement of VQ performance. SOC algorithm was proposed by Hsieh and Tsai, which can be utilized to further compress VQ index table and achieve better performance of the bit rate through searching nearby identical image blocks following a spiral path [23]. Some steganographic schemes were also proposed to embed secret data into the SOC compressed codes [24-25]. A group of works about embedding secret message by SMVQ were reported in [26-30]. In 2010, Chen and Chang proposed an SMVQ-based secret-hiding scheme using adaptive index [27]. The weighted squared Euclidean distance (WSED) was utilized to increase the probability of SMVQ for a high embedding rate. In order to make the secret data imperceptible to the interceptors, Shie and Jiang hided secret data into the SMVQ compressed codes of the image by using a partially sorted codebook [28]. The restoration of the original SMVQ-compressed image can be achieved on the receiver side.
In this work, we propose a data hiding scheme with reversibility for VQ-compressed images. The procedures of data embedding and extraction are both conducted in the VQ index table of the images. On the sender side, for a given VQ index table of an image, the most used and the unused indices of the codewords in the corresponding codebook are utilized to construct the mapping relationships. Through analyzing the histogram of the index table, the optimized mappings and the highest hiding capacity for the index table can be obtained. According to the secret bits for hiding and the mapping relationships, data embedding procedure can be easily achieved by index substitution. The extra information that represents the mapping relationships compactly should be shared by the receiver side to realize the data extraction and lossless recovery of index table.
The rest of the paper is organized as follows. Section 2 describes our proposed reversible data hiding scheme using index mapping mechanism. Experimental results and comparisons are given in Section 3, and Section 4 concludes the paper.
2. P
ROPOSEDS
CHEMEIn the proposed scheme, the VQ indices are first sorted according to their occurrence numbers in the index table. For the most natural images, there are often many indices of the corresponding VQ codebook that are not used in the index tables, i.e., the indices whose occurrence numbers are zero. We establish the mapping relationships between these unused indices and those indices with
the largest occurrence numbers for reversible data hiding. If the number of the unused indices is greater and the histogram of the index table is more concentrated, the hiding capacity of our scheme will be higher. The flowchart of the data embedding procedure is shown in Figure 1.
Figure 1 Flowchart of the data embedding procedure
2.1 Index Mapping Construction
Suppose that, in the proposed scheme, the codebook used for VQ compression consists of Q codewords. Denote the VQ index table of a given compressed image as T. We first sort all Q index values in the descending order according to their numbers of occurrences in T. Denote the sorted index values as V1, V2, …, VQ, and their corresponding occurrence numbers are x1, x2, …, xQ, respectively, where xi xj 0 (1 i j Q). Then, we find the index value, i.e., V, where
is the smallest existing number that makes x equal to 0, see Eq. (1).
, 1 subject to if 0 if 0 Q i x i x i i (1)
where i = 1, 2, …, Q. If the occurrence numbers of all index values are not equal to zero, i.e., xQ 0, it means that satisfying Eq. (1) doesn’t exist. In this case, we need choose the index table of another VQ compressed image. However, for most of the natural images, usually exists. In the following, we describe our scheme based on the assumption of the existence of .
These Q + 1 index values with zero occurrence numbers and some index values with the largest occurrence numbers are utilized to construct a series of index mappings M sequentially. For example, the jth mapping, i.e., Mj, is constructed by the index Vj and a number of the indices with zero occurrence numbers. The number of the indices with zero occurrence numbers used in each mapping is determined by a mapping bit number. The possible maximum of the mapping bit numbers for all index mappings can be calculated:
log2( 2)
. Q (2) Index Mapping Construction Original VQ index table Embedded VQ index table Mapping Optimization Data Embedding by Index SubstitutionSuppose that the jth constructed index mapping Mj corresponds to kj mapping bits (j = 1, 2, …,
R), where R is the total number of the constructed mappings. Note that kp kq 1 (1 p < q
R, and R < ). In the jth constructed index mapping Mj, the index Vj and the 2kj 1 indices with
zero occurrence numbers map to the 2kjkinds of binary representations for k
j bits individually (j = 1, 2, …, R). Thus, besides Q + 1 indices with zero occurrence numbers, there are totally R indices with the largest occurrence numbers, i.e., V1, V2, …, VR, that are used for the mapping construction. It should be noted that kj, R, and Q + 1 should satisfy the relationship in Eq. (3):
. 1 ) 1 2 ( 1
Q R j kj (3)We define a function () as follows:
.0
,0
0
,)1
2(
)(
1i
R
i
i
i j kj
(4)Therefore, besides Vi + 1, the other 2ki +1 1 indices with zero occurrence numbers used in the (i +1)th constructed index mapping Mi + 1 are:
. 1 , , 1 , 0 }, , , , {V(i) V(i)1 V(i)2ki12 i R (5)
According to the above process of mapping construction, we can obtain a vector of mapping bit numbers, i.e., = [k1, k2, …, kR]. Note that the components in the vector must appear in the descending order. Evidently, by using the vector and the order of the sorted indices V1, V2, …, VQ, the R index mappings can be easily reconstructed.
2.2 Mapping Optimization
Usually, there is more than one vector of mapping bit numbers that can satisfy the relationship in Eq. (3). In order to achieve the highest hiding capacity of our scheme, we should choose the optimal vector of mapping bit numbers and conduct the mapping optimization. Assume that the vector = [k1, k2, …, kR] is utilized in the proposed data hiding scheme. The indices V1, V2, …, VR in T are searched in the raster-scanning order. If the index Vj is scanned, the current kj secret bits
can be embedded by substituting Vj with one of the 2kj indices in the mapping Mj (j = 1, 2, …, R). Thus, the total hiding capacity C is closely related to the occurrence numbers of the indices V1, V2, …, VR, i.e., x1, x2, …, xR, see Eq. (6).
. 1
R j j j x k C (6)By using dynamic programming strategy, we can find all eligible vectors (1), (2), …, (),
where is the number of the vectors that satisfy Eq. (3), (i) = [k
1(i), k2(i), …, kRi(i)], and Ri is the number of the constructed index mappings for the vector (i) (i = 1, 2, …, ). The corresponding
hiding capacities C under these vectors can be calculated easily by using Eq. (6), and the optimal vector is the one that achieves the largest hiding capacity among (1), (2), …, (), see
Eq. (7). . , , 2 , 1 , ] [ max arg ) ( max arg 1 ) ( ) ( ) (
i x k C i i i R j j i j (7)For convenience, in the following, we also use = [k1, k2, …, kR] to denote the found optimal vector. After the index mappings constructed in Subsection 2.1 are updated according to the optimal and Eqs (4)-(5), the data embedding procedure can be conducted, which is described detailedly in the next subsection.
2.3 Embedding Procedure
To enhance security, the secret bits are scrambled by a secret key before embedding. Based on R optimized index mappings, i.e., M1, M2, …, MR, the secret bits can be easily embedded into the index table T. The detailed steps are as follows:
Step 1: Traverse all indices of the index table T in the raster-scanning order to search the
indices V1, V2, …, VR.
Step 2: If the index Vj is scanned and j{1, 2, …, R}, read kj bits sequentially from the secret
information for embedding. Denote these kj bits information as S.
Step 3: Search the jth constructed index mapping Mj, in which there are 2kj indices including
}. , , , || { 2 2 ) 1 ( 1 ) 1 ( ) 1 ( kj j j j j V V V V (8)
Step 4: Since the 2kj indices of M
j in Eq. (8) maps to all 2kj binary representations of kj bits correspondingly, we choose the one whose mapping result of binary representation is the same as
S from these 2kj indices.
Step 5: Substitute the current scanned index Vj with the chosen index in Step 4. Then, go back
to Step 1 for the iterative implementation until all indices in T are traversed.
After the embedding procedure finishes, in the embedded index table T’, all indices that belong to {V1, V2, …, VR} are conducted the index substitution according to their corresponding subsets of binary bits for embedding. It can be concluded from Eqs. (3) and (6) that, if the number of the indices with zero occurrence numbers, i.e., Q + 1, is greater and the histogram of all the indices occurred in T, i.e., V1, V2, …, V 1, is more concentrated, the hiding capacity of the
proposed scheme is higher.
2.4 Extraction and Recovery Procedures
To guarantee the correctness of secret data extraction and index table recovery, the optimal vector of mapping bit numbers and the order of the sorted indices V1, V2, …, VQ should also be transmitted to the receiver side as extra information together with the embedded index table T’. The detailed steps of data extraction and index table recovery are as follows:
Step 1: Reconstruct the R index mappings M1, M2, …, MR using {V1, V2, …, VR} and {V, V +
1, …, VQ} according to the vector . Note that the indices in the reconstructed Mj are the same as the 2kj ones in Eq. (8) (j = 1, 2, …, R).
Step 2: Traverse all indices of the embedded index table T’ in the raster-scanning order to
search the ones that belong to the R + (R) indices in M1, M2, …, MR.
Step 3: If the current scanned index belongs to one of the 2kj indices in M
j, the kj embedded secret bits in current index can be easily extracted according to its mapping binary representation, and the current index is recovered to its original value, i.e., Vj.
Step 4: Go back to Step 2 for the iterative implementation until all indices in T’ are traversed.
After the above steps are completed, the receiver can extract all embedded secret bits that can then be reversed to its original version by the same scrambling key shared with the sender, and the original index table T can be recovered losslessly.
3. E
XPERIMENTALR
ESULTSANDC
OMPARISONSExperiments were conducted on a group of gray-level images with different sizes to verify the effectiveness of the proposed scheme. In our experiment, the sizes of the divided non-overlapping image blocks for VQ compression were 4 4, i.e., n = 4. Thus, the length of each codeword in the used VQ codebooks was 16. We utilized MATLAB 7 to pseudo-randomly generate the binary sequences of different lengths that were used as the secret bits for embedding.
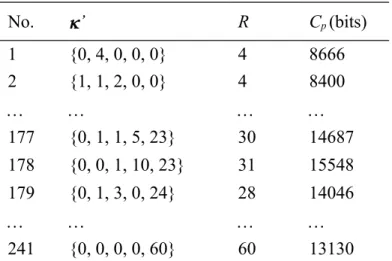
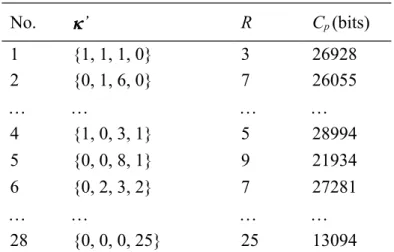
The six standard, 512 512 images that were used for testing, including Airplane, Goldhill, Lena, Peppers, Toys, and Zelda, are shown in Figure 2. We first conducted VQ compression for these six images, and the size of the used codebook, i.e., Q, was equal to 256. The histograms of the VQ index values in the six generated index tables are illustrated in Figure 3. The ordinates of Figure 3 are the occurrence numbers of corresponding index values in abscissas. The numbers of the indices with zero occurrence numbers, i.e., Q + 1, for the index tables of these six images are 32, 60, 59, 18, 25, and 129, respectively.
(a) Airplane (b) Goldhill (c) Lena
(d) Peppers (e) Toys (f) Zelda
Figure 2 Six standard test images
form. For example, if the possible maximum of the mapping bit numbers in Eq. (2) is equal to 5, and the vector = [4, 4, 4, 3, 3, 1, 1, 1, 1] (R = 9), we can represent in a new form, i.e., ’ = {0, 3, 2, 0, 4}, which means there are 0, 3, 2, 0, 4 constructed mappings correspond to 5, 4, 3, 2, 1 bits, respectively. In other words, the new representation of , i.e., ’, has components, and the
jth component in ’ denotes how many mappings correspond to j + 1 bits (j = 1, 2, …, ).
The values of calculated by Eq. (2) for the index tables of the six images in Figure 2 are 5, 5, 5, 4, 4, and 7, respectively. As mentioned in Subsection 2.2, more than one vector of mapping bit numbers may meet the relationship in Eq. (3). But, different vectors may lead to different hiding capacity for a given VQ index table. In order to obtain the pure hiding capacity of our scheme, we compressed the used extra information through a run-length coder. Denote the length of the compressed extra information as Ce. Because the total number of the embedded secret bits is C, the pure hiding capacity Cp can be defined as:
.
e p C C
C (9)
Tables 1-6 present some results of the eligible vectors and their corresponding hiding capacities. The 4th, 178th, 131th, 11th, 4th, and 197th ’ in Tables 1-6 are the optimal vectors for the corresponding images in Figure 2 to achieve the highest pure hiding capacities.
0 50 100 150 200 250 0 300 600 900 1200 1500 1800 2100 VQ Index Value O cc ur re nc e N um be rs 0 50 100 150 200 250 0 100 200 300 400 500 600 700 VQ Index Value O cc ur re nc e N um be rs
0 50 100 150 200 250 0 200 400 600 800 1000 1200 1400 1600 VQ Index Value O cc ur re nc e N um be rs 0 50 100 150 200 250 0 100 200 300 400 500 600 700 800 900 1000 VQ Index Value O cc ur re nc e N um be rs (c) Lena (d) Peppers 0 50 100 150 200 250 0 500 1000 1500 2000 2500 3000 3500 4000 4500 5000 VQ Index Value O cc ur re nc e N um be rs 0 50 100 150 200 250 0 200 400 600 800 1000 1200 VQ Index Value O cc ur re nc e N um be rs
(e) Toys (f) Zelda
Figure 3 Histograms of VQ index values (Q = 256)
Table 1 Results of the vectors of mapping bit numbers for Airplane ( = 5)
No. ’ R Cp (bits) 1 {0, 1, 2, 1, 0} 4 23665 2 {0, 0, 2, 6, 0} 8 24580 4 {0, 0, 4, 1, 1} 6 26275 5 {0, 1, 1, 3, 1} 6 24521 6 {0, 0, 1, 8, 1} 10 23049 47 {0, 0, 0, 0, 32} 32 12805
No. ’ R Cp (bits) 1 {0, 4, 0, 0, 0} 4 8666 2 {1, 1, 2, 0, 0} 4 8400 177 {0, 1, 1, 5, 23} 30 14687 178 {0, 0, 1, 10, 23} 31 15548 179 {0, 1, 3, 0, 24} 28 14046 241 {0, 0, 0, 0, 60} 60 13130
Table 3 Results of the vectors of mapping bit numbers for Lena ( = 5)
No. ’ R Cp (bits) 1 {0, 3, 2, 0, 0} 5 16083 2 {1, 0, 4, 0, 0} 5 15961 130 {0, 1, 2, 5, 15} 23 21360 131 {0, 0, 2, 10, 15} 27 21709 132 {0, 1, 4, 0, 16} 21 20547 229 {0, 0, 0, 0, 59} 59 14470
Table 4 Results of the vectors of mapping bit numbers for Peppers ( = 4)
No. ’ R Cp (bits) 1 {1, 0, 1, 0} 2 5480 2 {0, 0, 6, 0} 6 8486 10 {0, 1, 1, 8} 10 9047 11 {0, 0, 3, 9} 12 9691 12 {0, 1, 0, 11} 12 8896 15 {0, 0, 0, 18} 18 9031
No. ’ R Cp (bits) 1 {1, 1, 1, 0} 3 26928 2 {0, 1, 6, 0} 7 26055 4 {1, 0, 3, 1} 5 28994 5 {0, 0, 8, 1} 9 21934 6 {0, 2, 3, 2} 7 27281 28 {0, 0, 0, 25} 25 13094
Table 6 Results of the vectors of mapping bit numbers for Zelda ( = 7)
No. ’ R Cp (bits) 1 {0, 0, 2, 4, 1, 0, 0} 7 24918 2 {0, 0, 3, 1, 3, 0, 0} 7 24239 196 {0, 1, 0, 2, 1, 9, 2} 15 28966 197 {0, 0, 0, 2, 10, 9, 2} 23 37653 198 {0, 0, 0, 6, 1, 10, 2} 19 34664 2881 {129, 0, 0, 0, 0, 0, 0} 129 16374
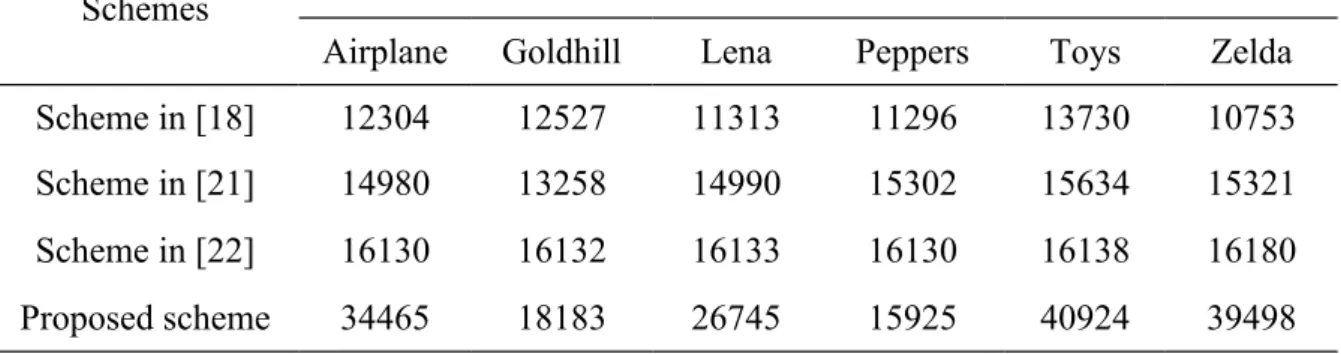
We compared our scheme with three recently reported schemes, i.e., the scheme in [18], the scheme in [21], and the scheme in [22]. During the comparisons, besides the codebook with 256 codewords (Q = 256), we also used the codebook with 512 codewords (Q = 512) for evaluation. Tables 7-8 give the comparison results of hiding capacity of the four schemes for the six standard images in Figure 2. Due to the good performance of the index mapping mechanism, it can be seen from Tables 7-8 that, in general, the proposed scheme can achieve higher pure hiding capacity than those of the other schemes in [18, 21-22]. We can also observe that, for the proposed scheme, Goldhill and Peppers are two images with the smallest hiding capacities among the six images in Figure 2. The reasons for this phenomenon are: 1) compared with other images, the histogram of the VQ indices for Goldhill is not concentrated, and more indices have similar occurrence numbers as shown in Figure 3(b); 2) the indices with zero occurrence numbers of Peppers is the least among the six images in Figure 2. Therefore, we can conclude from the
experimental results that, the distribution of the index histogram and the number of the indices with zero occurrence numbers are the two key factors to influence the hiding capacity of our scheme.
Table 7 Comparison results of hiding capacity under the codebook size Q = 256
Schemes Pure Hiding Capacity (bits)
Airplane Goldhill Lena Peppers Toys Zelda
Scheme in [18] 13163 13209 12016 13248 14316 12012
Scheme in [21] 15457 14402 15405 15668 15961 15735
Scheme in [22] 16222 16226 16219 16223 16225 16248
Proposed scheme 26275 15548 21709 9691 28994 37653
Table 8 Comparison results of hiding capacity under the codebook size Q = 512
Schemes Pure Hiding Capacity (bits)
Airplane Goldhill Lena Peppers Toys Zelda
Scheme in [18] 12304 12527 11313 11296 13730 10753
Scheme in [21] 14980 13258 14990 15302 15634 15321
Scheme in [22] 16130 16132 16133 16130 16138 16180
Proposed scheme 34465 18183 26745 15925 40924 39498
4. C
ONCLUSIONSIn this work, we propose a reversible data hiding scheme for VQ compressed images using index mapping mechanism. The indices with zero occurrence numbers in VQ index table are counted to calculate the possible maximum of the mapping bit numbers. A series of index mappings are constructed sequentially by using the indices with zero occurrence numbers and the indices with the largest occurrence numbers. The indices in each constructed mapping correspond to the full binary representations with the length of its mapping bit number. In order to achieve the highest hiding capacity, the mapping optimization should be conducted by adjusting the vector of mapping bit numbers. Based on the optimal vector of mapping bit numbers, data embedding procedure can be achieved by the simple index substitutions according the current subset of secret bits for hiding. The same index mappings can be reconstructed on the receiver side, which
guarantees the correctness of secret data extraction and the lossless recovery of index table. The experimental results show that our scheme has better performance of hiding capacity than those of recently reported schemes.
R
EFERENCES[1] F. A. P. Petitcolas, R. J. Anderson and M. G. Kuhn, “Information Hiding — A Survey,”
Proceedings of the IEEE, vol. 87, no. 7, pp. 1062-1078, 1999.
[2] Z. C. Ni, Y. Q. Shi, N. Ansari and W. Su, “Reversible Data Hiding,” IEEE
Transactions on Circuits and Systems for Video Technology, vol. 16, no. 3, pp. 354-362,
2006.
[3] J. Tian, “Reversible Data Embedding Using a Difference Expansion,” IEEE Transactions
on Circuits and Systems for Video Technology, vol. 13, no. 8, pp. 890-896, 2003.
[4] A. M. Alattar, “Reversible Watermark Using the Difference Expansion of A Generalized Integer Transform,” IEEE Transactions on Image Processing, vol. 13, no. 8, pp. 1147-1156, 2004.
[5] C. C. Chang, C. C. Lin, C. S. Tseng and W. L. Tai, “Reversible Hiding in DCT-Based Compressed Images,” Information Sciences, vol. 177, no. 13, pp. 2768-2786, 2007.
[6] X. P. Zhang, “Reversible Data Hiding in Encrypted Image,” IEEE Signal Processing
Letters, vol. 18, no. 4, pp. 255-258, 2011.
[7] W. L. Tai, C. M. Yeh and C. C. Chang, “Reversible Data Hiding Based on Histogram Modification of Pixel Differences,” IEEE Transactions on Circuits and Systems for Video
Technology, vol. 19, no. 6, pp. 906-910, 2009.
[8] C. F. Lee, H. L. Chen and H. K. Tso, “Embedding Capacity Raising in Reversible Data Hiding Based on Prediction of Difference Expansion,” Journal of Systems and Software, vol. 83, no. 10, pp. 1864-1872, 2010.
[9] W. Hong and T. S. Chen, “Reversible Data Embedding for High Quality Images Using Interpolation and Reference Pixel Distribution Mechanism,” Journal of Visual
Communication and Image Representation, vol. 22, no. 2, pp. 131-140, 2011.
[10] C. Qin, C. C. Chang and L. T. Liao, “An Adaptive Prediction-Error Expansion Oriented Reversible Information Hiding Scheme,” Pattern Recognition Letters, vol. 33, no. 16, pp. 2166-2172, 2012.
[11] N. M. Nasrabadi and R. King, “Image Coding Using Vector Quantization: A Review,”
IEEE Transactions on Communications, vol. 36, no. 8, pp. 957-971, 1988.
[12] C. C. Chang and W. C. Wu, “Fast Planar-Oriented Ripple Search Algorithm for Hyperspace VQ Codebook,” IEEE Transactions on Image Processing, vol. 16, no. 6, pp. 1538-1547, 2007.
[13] A. Gersho and R. M. Gray, Vector Quantization and Signal Compression. Norwell, MA: Kluwer, 1992.
[14] W. J. Wang, C. T. Huang and S. J. Wang, “VQ Applications in Steganographic Data Hiding Upon Multimedia Images,” IEEE Systems Journal, vol. 5, no. 4, 528-537, 2011.
[15] Y. C. Hu, “High-Capacity Image Hiding Scheme Based on Vector Quantization,” Pattern
Recognition, vol. 39, no. 9, pp. 1715-1724, 2006.
[16] W. C. Du and W. J. Hsu, “Adaptive Data Hiding Based on VQ Compressed Images,” IEE
Proceedings - Vision, Image and Signal Processing, vol. 150, no. 4, pp. 233-238, 2003.
[17] C. C. Chang and W. C. Wu, “Hiding Secret Data Adaptively in Vector Quantisation Index Tables,” IEE Proceedings - Vision, Image and Signal Processing, vol. 153, no. 5, pp. 589-597, 2006.
[18] C. C. Chang, W. C. Wu and Y. C. Hu, “Lossless Recovery of a VQ Index Table with Embedded Secret Data,” Journal of Visual Communication and Image Representation, vol. 18, no. 3, pp. 207-216, 2007.
[19] C. C. Lin, S. C. Chen and N. L. Hsueh, “Adaptive Embedding Techniques for VQ-Compressed Images,” Information Sciences, vol. 179, no. 3, pp. 140-149, 2009.
[20] C. C. Chang, T. D. Kieu and Y. C. Chou, “Reversible Information Hiding for VQ Indices Based on Locally Adaptive Coding,” Journal of Visual Communication and Image
Representation, vol. 20, no. 1, pp. 57-64, 2009.
[21] C. H. Yang and Y. C. Lin, “Reversible Data Hiding of a VQ Index Table Based on Referred Counts,” Journal of Visual Communication and Image Representation, vol. 20, no. 6, pp. 399-407, 2009.
[22] C. H. Yang and Y. C. Lin, “Fractal Curves to Improve the Reversible Data Embedding for VQ-Indexes Based on Locally Adaptive Coding,” Journal of Visual Communication and
Image Representation, vol. 21, no. 4, pp. 334-342, 2010.
[23] C. H. Hsieh and J. C. Tsai, “Lossless Compression of VQ Index with Search-Order Coding,” IEEE Transactions on Image Processing, vol. 5, no. 11, pp. 1579-1582, 1996.
[24] C. C. Lee, W. H. Ku and S. Y. Huang, “A New Steganographic Scheme Based on Vector Quantisation and Search-Order Coding,” IET Image Processing, vol. 3, no. 4, pp. 243-248, 2009.
[25] S. C. Shie and S. D. Lin, “Data Hiding Based on Compressed VQ Indices of Images,”
Computer Standards Interfaces, vol. 31, no. 6, pp. 1143-1149, 2009.
[26] C. C. Chang, W. L. Tai and C. C. Lin, “A Reversible Data Hiding Scheme Based on Side Match Vector Quantization,” IEEE Transactions on Circuits and Systems for Video
Technology, vol. 16, no. 10, pp. 1301-1308, 2006.
[27] C. C. Chen and C. C. Chang, “High Capacity SMVQ-Based Hiding Scheme Using Adaptive Index,” Signal Processing, vol. 90, no. 7, pp. 2141-2149, 2010.
[28] S. C. Shie and J. H. Jiang, “Reversible and High-Payload Image Steganographic Scheme Based on Side-Match Vector Quantization,” Signal Processing, vol. 92, no. 9, pp. 2332– 2338, 2012.
[29] C. F. Lee, H. L. Chen and S. H. Lai, “An Adaptive Data Hiding Scheme with High Embedding Capacity and Visual Image Quality Based on SMVQ Prediction through Classification Codebooks,” Image and Vision Computing, vol. 28, no. 8, pp. 1293-1302, 2010.
[30] L. S. Chen and J. C. Lin, “Steganography Scheme Based on Side Match Vector Quantization,” Optical Engineering, vol. 49, no. 3, pp. 0370081-0370087, 2010.