國立高雄大學電機工程學系碩士班
碩士論文
以步態影像之貼片式區域紋理圖樣為基準的性別分類
Gender Classification from Gait-Based Images with
Three-Patch Local Texture Pattern
研 究 生: 李易叡
指導教授: 賴智錦 博士
i
以步態影像之貼片式區域紋理圖樣為基準的性別分類
指導教授:賴智錦 博士 國立高雄大學電機工程學系 研究生:李易叡 國立高雄大學電機工程學系碩士班 摘要 以電腦進行性別辨識是個相當具有挑戰性的問題,而且在視覺監控與人機互 動系統中具有相當多的應用。在本論文中,我們提出一個名為三貼片區域鋸齒圖 樣的新穎區域紋理描述子。我們將三貼片區域鋸齒圖樣應用在步態能量影像,以 此表達步態性別辨識中人類在行走時的特徵,辨識的程序則透過支持向量機予以 完成。我們以 CASIA dataset B 作為測試對象,實驗結果顯示我們所提出的方法 確實能獲得不錯的辨識效果。 關鍵字:步態性別辨識、步態能量影像、貼片式區域鋸齒圖樣ii
Gender Classification from Gait-Based Images with
Three-Patch Local Texture Pattern
Advisor: Dr. Chih-Chin Lai Department of Electrical Engineering
National University of Kaohsiung
Student: Yi-Jui Li
Department of Electrical Engineering National University of Kaohsiung
ABSTRACT
Computer vision-based gender classification is a challenging problem, and has a
variety of applications in visual surveillance and human-computer interaction systems.
In this paper, a novel local texture descriptor called three-patch local zigzag pattern
(TPLZP) is proposed. Furthermore, the TPLZP is applied to the gait energy images to
characterize human walking properties for gender recognition, and the recognition is
performed by using a support vector machine. Experimental results on the CASIA
dataset B are provided to illustrate the proposed approach is an effective method.
Keywords: Gait gender recognition, Gait energy image, Patch-based local zigzag pattern
iii
誌謝
能以兩年的時間順利完成學業,並且完成本論文的撰寫,首先得感謝我的指 導教授賴智錦老師。另外,感謝口試委員陳榮銘老師、吳志宏老師與潘欣泰老師 針對論文內容給予指正並提供許多意見,使本論文內容更加完整豐富。 在這段求學期間,承蒙賴老師的諄諄教誨,除了在課業上獲益良多,亦學習 到面對研究時應具有的態度,以及做人處事的道理。雖然我的資質駑鈍,也粗枝 大葉替您製造不少困擾,但您總是不厭其煩地機會教育、苦口婆心,一步一步的 帶領著我,讓我獲益匪淺。感謝老師處處為學生著想,讓我無後顧之憂並專注在 研究上,在此致上最深且最真誠的謝意。 感謝實驗室學長彥鈞,不論在就學期間或是畢業後在研究、課業方面提供許 多寶貴經驗。感謝同學思翰與學弟伯豪不遺餘力地幫我解決我所提出的問題,讓 我的學習過程十分順利。感謝學弟伯豪、致圻、信融協助處理實驗室的各項事務, 使我有更多的時間專心寫作論文。不管在哪方面,有實驗室各位的陪伴讓這兩年 增添許多回憶,更讓研究所生涯多了點色彩。 感謝 ICAL 的同學卡比與孟瑋,常敞開實驗室的大門讓我去串門子,也不厭 其詳地幫我解決課業上的問題。感謝朋友江瑜、政軒與鈺翔給予我論文上的指導 與幫助。因為有你們的幫助與支持,讓我能順利完成學業,且讓平凡的生活多采 多姿。 最後要感謝我的家人在背後為我的付出,從小到大一路學習的過程中,不斷 的包容我、支持我、鼓勵我,既使我並非非常會讀書,仍然接受我想讀碩士的想 法,並且支持我,讓我不受雜事的干擾,給我這兩年的時間專心完成我的碩士學 位。iv
目錄
摘要 ... i ABSTRACT ... ii 誌謝 ... iii 目錄 ... iv 圖目錄 ... v 表目錄 ... vi 第一章 緒論... 1 1.1 研究動機與目的 ... 1 1.2 研究方法與架構 ... 2 第二章 文獻探討 ... 3 2.1 以步態能量影像為基準的性別分類... 3 2.2 以其他步態影像為基準的性別分類... 4 第三章 研究方法 ... 6 3.1 植基於步態能量影像之性別辨識系統 ... 6 3.2 特徵擷取 ... 11 3.2.1 步態能量影像 ... 11 3.2.2 區域鋸齒圖樣 ... 12 3.2.3 三貼片區域二元圖樣 ... 14 3.2.4 三貼片區域鋸齒圖樣 ... 18 3.2.5 區塊式區域紋理特徵擷取 ... 22 3.3 支持向量機 ... 23 第四章 實驗結果 ... 28 4.1 實驗環境 ... 28 4.2 步態影像資料庫 ... 29 4.3 實驗結果與分析 ... 31 4.3.1 實驗一 ... 33 4.3.2 實驗二 ... 38 4.3.3 實驗三 ... 40 4.3.4 實驗四 ... 42 第五章 結論與未來工作 ... 44 參考文獻 ... 46v
圖目錄
圖 3.1:系統流程圖 ... 6 圖 3.2:CASIA 資料庫影像... 7 圖 3.3:陰影範例圖 ... 8 圖 3.4:原始影像(女) ... 9 圖 3.5:經背景相減與陰影去除後影像(女) ... 9 圖 3.6:原始影像(男) ... 9 圖 3.7:經背景相減法與陰影去除後影像(男) ... 9 圖 3.8:正規化 ... 10 圖 3.9:獲取步態能量影像示意圖 ... 11 圖 3.10:LZP 之編碼順序示意圖 ... 12 圖 3.11:原始影像範例、經過 LZP 處理後影像與相對應直方圖 ... 13 圖 3.12:LZP 編碼範例 ... 14 圖 3.13:以 Cp為中心之 TPLBP 各區域位置示意圖 ... 14 圖 3.14:LBP 編碼順序 ... 15 圖 3.15:原始影像範例、經過 TPLBP 處理後影像與相對應直方圖 ... 16 圖 3.16:TPLBP 範例 ... 17 圖 3.17:TPLBP 範例經過 LBP 處理後示意圖 ... 17 圖 3.18:TPLZP 範例 ... 18 圖 3.19:TPLZP 範例經過 LZP 處理後結果 ... 19 圖 3.20:TPLZP 範例經過加權後結果 ... 19 圖 3.21:原始影像範例、經過 TPLZP 處理後影像與相對應直方圖 ... 20 圖 3.22:男性的步態能量影像經各種不同圖樣處理之比較... 21 圖 3.23:女性的步態能量影像經各種不同圖樣處理之比較... 22 圖 3.24:以 3×3 為例之區塊式區域紋理特徵擷取與直方圖建構示意圖 ... 23 圖 3.25:二維平面 SVM 分類最佳超平面 ... 24 圖 3.26:利用核函數把資料投射到高維度空間[12] ... 24 圖 3.27:不同模式 LIBSVM 的效率比較圖[40] ... 26 圖 4.1:CASIA 資料庫不穿大衣與背包之影像 ... 29 圖 4.2:CASIA 資料庫穿著大衣之影像 ... 30 圖 4.3:CASIA 資料庫背背包之影像 ... 30 圖 4.4:CASIA 步態視訊拍攝環境示意圖 ... 31 圖 4.5:11 個角度行走之影像 ... 31 圖 4.6:10 次交叉驗證示意圖 ... 32 圖 4.7:資料庫中較男性化之女性原始影像與 GEI 處理後影像之範例 ... 38 圖 4.8:男性無穿著大衣與穿著大衣之影像比較 ... 41 圖 4.9:女性無穿著大衣與穿著大衣之影像比較 ... 41vi
表目錄
表 3.1:核函數的定義 ... 25 表 4.1:實驗環境 ... 28 表 4.2:TPLZP 在 時,不同切割區塊數與門檻值對於辨識效能的影響 .... 33 表 4.3:TPLZP 在 時,不同切割區塊數與門檻值對於辨識效能的影響 .... 34 表 4.4:TPLZP 在 且 時,不同切割區塊數對於辨識效能的影響 ... 35 表 4.5:TPLZP 在 且 時,不同切割區塊數對於辨識效能的影響 ... 36 表 4.6:TPLZP 在 且 時,不同切割區塊數對於辨識效能的影響 ... 36 表 4.7: , Recognition rate (%) ... 37 表 4.8:所提方法與其他方法之辨識率比較... 39 表 4.9:穿著大衣與無配件影像混合時之辨識率 ... 40 表 4.10:在不同角度下與其它文獻之辨識率(%)比較 ... 421
第一章 緒論
1.1 研究動機與目的
科技日新月異且發達的原因不外乎有二:一是為了生活品質與便利性的提升, 二是為了商業利益。性別辨識的研究發展亦是如此,開發者將其廣泛的應用在生 活品質與便利性的提升方面,例如:安全監控就是個常見的議題。在公眾場所的 洗手間或是更衣室外,當有異性徘徊時,可透過性別辨識系統辨識出異性後發出 警告,再請維安人員多加留意,如此便能使意外發生的可能性降低。在商業利益 方面的應用則有:在大型電子廣告看板中嵌入隱藏式攝影機,或是在賣場中透過 監控攝影機系統觀察駐足停留的族群是男性或是女性較多、男性和女性的駐足時 間長短,以利判斷市場需求的族群與後續的銷售規劃。由此可知性別辨識系統不 僅帶給人們便利性,也帶來許多的商機。 不同的性別,在人臉的外觀上通常都會有顯著的差異,所以利用人臉特徵判 斷性別是很有效且最直覺的方法。人臉性別辨識系統已發展許久,已經是一個高 度發展的技術,但是人臉性別辨識系統必須在能夠擷取到臉部特徵的前提之下進 行辨識。在現實生活中,不管透過攝影機或是照相機,人們因為角度、配件、或 遮擋等問題,能夠完整地擷取臉部特徵實際上是不容易的;如此一來,辨識的準 確率便出現了問題。因此,取得人臉以外的資訊作為性別辨識的依據,是研究者 努力的課題。 不論是什麼膚色的人種,也不論生長在什麼背景環境,人類就是只有男性跟 女性兩種性別。人與人相處時,我們不但藉由觀察臉部外形來判斷此人的性別, 也觀察此人的身體特徵,甚至是行為模式,所以我們認為機器或許可以從人的身 體特徵與某種行為模式進行分析後判定被觀察者的性別。以往的研究多著重於從 臉部資訊判定性別,然而利用步態資訊當作性別判定依據的研究,在近年來有如 雨後春筍般的進展,但在辨識率的提升上仍然還有許多的進步空間,這是我們研2 究此主題的原因之一。步態泛指人類行走時,雙腳與身體其他部位的姿態,是一 種非常複雜的行為模式,採用此特徵作為性別辨識的依據是因為步態影像具有非 侵犯性、遠距獲取、影像畫質要求不高與偽裝困難等特性。如何使機器能精準的 從步態影像判斷所屬行人之性別,進而應用在相關領域與日常生活中,是本篇論 文主要的研究動機與目的。
1.2 研究方法與架構
一個辨識系統主要的程序分為三個步驟,第一步是前景偵測,第二步是特徵 擷取,第三步是使用分類器進行分類。在目前辨識系統的發展中,最重要的莫過 於特徵擷取技術的突破,因為前後兩者的研究已有很大的進展,出現了許多性能 良好的偵測與分類演算法,但是在特徵擷取的部分,不管是特徵的表示方式或是 運算的時間,仍然有許多可以進步的空間。本篇論文提出一套新穎的特徵表示方 法:以步態能量影像(gait energy image, GEI)為基準,結合三貼片區域鋸齒圖樣 (three-patch local zigzag pattern, TPLZP)做為影像特徵的表示,再將特徵送交支援向量機(support vector machine, SVM)進行性別的辨識。為了驗證所提方法的正確 性與效能,我們以 CAISA Gait Dataset B 資料庫[1]進行相關的實驗。
本論文共分成五個章節,第一章介紹研究動機與目的、研究方法與架構。第 二章為回顧本論文所使用之相關技術及文獻探討。第三章介紹本論文所提出的方 法。第四章是測試本論文方法的效能及相關實驗結果,並與其他方法的實驗進行 數據比較。第五章將則是本篇論文總結,及討論未來可改進及延伸的方向。
3
第二章 文獻探討
近年來,以自動化性別辨識已成為一個熱門的研究主題。為了使電腦認知人 類的性別,越來越多學者提出各種新穎的特徵擷取方法。隨著硬體的高度發展, 部分學者為了精確度與實用性,開始研究更複雜、資料量更大的分析方法。步態 分析有許多方式,大多數的論文,在前處理部份幾乎是大同小異,最大的差異在 於時間模板(temporal templates)對影像靜態與動態部分的結合方式不同,在第二 章中將介紹幾種既有的時間模板演算法與其變形。本章將針對不同特徵擷取的方 法應用於性別辨識之相關文獻進行探討。2.1 以步態能量影像為基準的性別分類
從一段行人行走的資料庫影片中,取其一段週期後,將此段週期中的前景影 像,皆對齊其質心,再除以週期中所包含影像的張數,最後即可得到 GEI 的值。 步態能量影像(gait energy image, GEI),亦稱為平均輪廓法,類似的概念最早是由 Bobick 和 Davis 提出[2],用於行為識別上,之後是 Zhou 和 Bhanu[3]與 Han 和Bhanu[4]以人的輪廓為基礎將其應用在步態辨識上,得到了很好的效果。此方法
獲取的影像通常會使用主成分分析法(principal component analysis, PCA)[5]或線 性鑑別分析法(linear discriminant analysis, LDA)[6]等方法進行分析特徵維度的降 維處理;此外,一般在使用 GEI 時,會以側面(90 度)影像進行分析,因為在 90 度以外的其它角度(例如:36 度),會有週期取得不易與 GEI 正規化等問題[7]。
Zhang 等人[8][9]在兩篇論文中提出一種很特別的方法,是在 GEI 的基礎上
延伸,將不同拍攝角度所得到的 GEI 融合之後,利用多重線性主成份分析法 (multilinear principal component analysis, MPCA)降低特徵資訊的維度當作特徵值,
最後應用在 CAISA Gait Dataset B 和自行蒐集的步態視訊上進行辨識。
Wang[10]以輪廓為基礎步行擷取出步態能量影像,再結合以紋理為基礎的區
4
是從多重區塊區域二元之圖樣(multi-block local binary pattern, MBLBP)[11]衍生 而來,計算方式是取得貼片的區域特徵資訊後,得到這些貼片的差異圖樣,計算 雖然看似比傳統的 LBP 和 MBLBP 複雜許多,但在計算的過程中,因為 LBDP 一次計算的像素點較多,所以即使一次的計算略為複雜,但總計算次數減少很多, 使得總計算時間也相對減少許多,效能有略微提高。
Fan[12]以紋理為基礎的區域二元圖樣(local binary pattern, LBP)[13]和以輪廓
為基礎的 GEI 結合,以此改善 GEI 在面臨非 90 度的拍攝影像時,會產生辨識率 明顯下降的不穩定情況。他們的方法是先將原始影像分割成頭部、身體、和腿部 三個區塊,然後分別進行區域膚色偵測與去除,再擷取各個區塊的 LBP 當特徵 值後利用一致圖樣理論[14]將此特徵值進行降維以減少後續的計算時間,此為紋 理 的 部 分 。 接 著 將 GEI 的 特 徵 向 量 使 用 變 異 數 分 析 (analysis of variance, ANOVA)[15]來進行降維得到輪廓的部分,最後再將降維後的 LBP 特徵值與降維
後的 GEI 值進行串接作為完整的特徵表示。
Shan 等人[16][17]認為 Lee and Grimson[18]提出的方法只考慮到步態影像的
動態資訊是不夠完善的,所以將重點擺在動態特徵與結構特徵,也就是將步態影 像與臉部紋理的特徵結合[19][20]。但是,單純的串接結合仍是不夠完善,因為 人臉與步態雖然具有某種程度上的關聯,但是本質上相異,所以需要使用典型相 關分析(canonical correlation analysis, CCA)建立兩者間有效的關聯性。因此 Shan 等人先將臉部紋理特徵與步態能量影像分別取出,再使用 CCA 建立關係並融合 特徵值,最後交由支援向量機(support vector machine, SVM)進行性別分類。
2.2 以其他步態影像為基準的性別分類
Lai 等人參考步態片刻影像(gait moment image, GMI)[21]的觀念提出一種全
新 的演 算法 ,稱為向 前 參考 差異歷 史 影像 (forward difference history image, FDHI)[22]。有別於 GMI 是將整段影片同時提取所有的週期進行分析,FDHI 則
5
是在一個步態週期上進行切割,將一個週期切成四等份來分析。相較之下,可以 在擷取週期的處理上節省較多的時間,之後再使用 K-最近鄰域分類演算法 (k-nearest neighbor, KNN)[23]進行分類。FDHI 與 GMI 在分析的程序中,當影像
經過前處理後,人體的上半部通常處於靜態,此兩種方法會因為前述理由而將人 體的上半部部分影像視為不需要的資訊予以去除以降低計算量。
Lu 等人[24]認為目前的性別分類方法普遍用於固定且受控制的條件下,例如:
背景固定,如此一來降低了實用性,因此提出新方法。他們參考[25]使用的背景 相減法,接著使用平均步態影像(averaged gait image, AGI),再使用 K-means 分群 演算法[26]尋找最佳特徵值,最後使用 K-最近鄰域分類演算法進行分類。
Sabir 等人[27]提出了一套結合空間域和頻率域的方法,首先在前處理的部分
採用[28]提出的背景相減法取出人形的輪廓,接著分別對手、腳、膝蓋、肩膀和 身高等部分進行間距的量測,再使用時空模型(spatio-temporal model, STM)[29] 來獲得第一組的特徵值,然後將背景相減法取出的輪廓影像再分別做一階哈爾小 波轉換(Haar wavelet filter)和三階哈爾小波轉換獲得頻率域的資訊,之後取水平 低頻與垂直低頻的部分當作第二組跟第三組的特徵值,最後將三組特徵混合串接, 再使用 LDA 來降低維度得到最後的特徵值。
6
第三章 研究方法
從文獻探討中我們得知,在性別辨識方法中以步態能量影像作為特徵擷取是 較廣為使用的方法,此方法在辨識率與穩定性上有不錯的表現且較易實作。因此, 本論文以步態能量影像為基礎,再以區域鋸齒圖樣(local zigzag pattern, LZP)[30] 與三貼片式區域二元圖樣(three-patch local binary pattern, TPLBP)[31,32,33]的觀 念提出一個新的紋理描述子,稱之為三貼片式區域鋸齒圖樣,作為紋理特徵進行 分析。本章節將依序介紹所用到的各種技術,及本論文所提之步態能量影像結合 三貼片式區域鋸齒圖樣表示方法。
3.1 植基於步態能量影像之性別辨識系統
本論文所提出的方法分為三個主要階段:影像前處理、特徵擷取及分類辨識。 完整方法的系統架構如圖 3.1 所示,各階段詳細說明如後。 圖 3.1:系統流程圖7 第一階段: 在影像前處理部分,我們使用步態資料庫中所提供只有單純背景的影像當作 絕對背景。接著,我們將有運動的目標擷取出來,因為背景是處於完全靜態的情 況下,所以我們選用簡單、效果佳且易於實現的背景相減法[34]予以完成步態輪 廓的提取。我們將輸入之行人影像與絕對背景影像進行相減,相減後的像素點之 灰階值若高於門檻值,則此點極可能為行人,我們將此點設為 1;反之,當相減 後的像素點之灰階值若低於門檻值,則為影像沒有變化,我們將此判定為背景且 此點設為 0。絕對背景影像與行人影像如圖 3.2 所示。 (a)絕對背景影像 (b)行人影像 圖 3.2:CASIA 資料庫影像 相關公式如公式(1)所示: , (1) 為第 t 秒時之輸出結果, 為第 t 秒時輸入影像在 座標時之像 素灰階值, 為絕對背景影像在 座標時之像素灰階值, 為門 檻值。 在進行運動目標偵測時,會遇到因受光不勻稱的關係而在執行背景相減法後, 影像會產生部分的陰影,這會影響之後的辨識效果,因此我們將依照 Cucchiara
8 等人[35]所提出的陰影偵測法偵測影像中的陰影。偵測陰影的原理是因為陰影部 分通常會較背景為暗,也就是像素的灰階值較低,所以我們利用此特性將輸入影 像除以絕對背景,當低於一個門檻值時,我們就可推斷此處即為陰影;之後將經 過背景相減處理後之影像減去陰影區域後,即可完成前處理部分。影像中的陰影 部分如圖 3.3 所示。 圖 3.3:陰影範例圖 陰影區域的判別如公式(2)所示: , (2) 為第 t 秒時的陰影區域, 為第 t 秒時輸入影像在 座標時之像 素灰階值, 為絕對背景影像在 座標時之像素灰階值, 、 為其門檻 值。 在本論文,我們使用 OpenCV 函式庫提供的背景相減法,對輸入影像進行步 態輪廓擷取,之後偵測出陰影區域並去除。我們以此方法對原始資料庫的影像圖 3.4 與 3.6 進行前處理分別得到圖 3.5 與 3.7 所示之影像。
9 圖 3.4:原始影像(女) 圖 3.5:經背景相減與陰影去除後影像(女) 圖 3.6:原始影像(男) 圖 3.7:經背景相減法與陰影去除後影像(男) 原始影像經過上述處理後,將變成一張 的影像,人影會出現在整 張影像的某個區域,這並不適合之後獲取步態能量影像之用,因此需把此影像進 行正規化處理,將多餘的黑色背景區域去除,並把影像縮放至同一大小 。 正規化處理如圖 3.8 所示。
10 (a)原始影像 (b)正規化後影像 圖 3.8:正規化 第二階段: 為了從經過前處理後的步態影像中取得足以代表性別紋理特徵的資訊,在第 二階段的資訊擷取方式,我們將採用以 GEI 為基準,並提出 TPLZP 的方法與採 用區塊式的方法建構整張影像的特徵資訊。 我們將輸入影像先經過 GEI 處理,將其切割成 個不重疊的子區塊,再 將各區塊以 TPLZP 運算擷取紋理特徵。然後,對每個子區塊求取其特徵影像直 方圖後將其依序串接,形成代表此張影像的特徵直方圖,最後以此特徵直方圖做 為步態性別影像的性別特徵進行後續辨識。 第三階段:
我們將第二階段產生的特徵資訊輸入支持向量機(support vector machine, SVM)進行分類辨識。此階段分成訓練及測試二部分進行:訓練部份,將每張訓
練影像依第二階段所產生之特徵直方圖作為特徵向量,並輸入至 SVM,以訓練 樣本進行 SVM 模型的建立。在測試部份,測試影像亦經相同的特徵擷取步驟取 得特徵向量,再將其輸入訓練完成的 SVM 模型中進行性別分類並獲得最終辨識 結果。
11
3.2 特徵擷取
男性與女性的步態影像之間存在著相當巧妙的差異,為了找出這看似細微且 不易觀察的差異,因此,本論文提出以 GEI 為基準,並以 TPLZP 作為紋理特徵 擷取的方法,以期達到有效的辨識結果。以下,我們先介紹 GEI 的基本觀念, 接著介紹 TPLZP 的方法原理,最後介紹分割區塊截取紋理特徵與 SVM 的基本 觀念。3.2.1 步態能量影像
步態能量影像,亦稱為平均輪廓法;相較於一般步態影像,其優點是不易受 到輪廓雜訊干擾,缺點是特徵維度高。此方法是從一段已經經過前處理後之行人 行走的影像中取其一段週期後,將此段週期所有影像中行人的輪廓皆對齊其質心 重疊並累加,再除以週期中所包含影像的張數,最後即可得到 GEI,其作法如公 式(3)所示: , (3) 其中 t 為週期內第 t 張影像,N 為一段週期內所有影像的張數, 為第 t 張 影像在 座標之 Boolean 值。一張步態能量影像如圖 3.9 所示。 GEI 圖 3.9:獲取步態能量影像示意圖12
3.2.2 區域鋸齒圖樣
區域鋸齒圖樣(local zigzag pattern, LZP)在定義特徵時,其鄰點比較順序的想 法源自離散餘弦轉換(discrete cosine transform, DCT)。有別於以往多數用於性別 辨識的圖樣是以中心點與其相鄰點作比較,區域鋸齒圖樣的原理是將影像內某個 區域的各個相鄰像素點之灰階值,以鋸齒狀的方向比較相鄰兩點之灰階值差並編 碼。這種作法相較於以往與中心點比較的方法,有更好的穩定性,因為若相鄰像 素點皆與中心像素點作比較,當中心像素點的灰階值過大或過小時,便會導致特 徵值極大或極小。當這種情況發生的次數頻繁,之後 SVM 訓練出的模型可能會 鑑別度不高,使辨識效果不佳;由於 LZP 是將像素點與相鄰像素點進行比較, 可以避免這類情況發生。LZP 的編碼順序如圖 3.10 所示。 P4 P0 P1 P2 P3 P5 P6 P7 P8 圖 3.10:LZP 之編碼順序示意圖 經由這種方式,可以得到 LZP 運算規則,定義如公式(4)與(5)所示: , (4) , (5) 其中,gn表示區域內某像素點的灰階值。如此可將該影像之像素點表示為一組二 位元編碼,最後將該編碼乘以相對權重值後進行加總,以此數表示為像素點 P4 的 LZP 編碼數值。利用上述方法得到的 LZP 特徵值維度為 28。
13 最後將影像中的每個像素點之灰階值經過 LZP 方法運算後,根據不同的 LZP 值進行累加即可統計出該張影像的特徵直方圖,並以此特徵直方圖表示該張影像 之紋理特徵。某影像經 LZP 運算後之相關結果如圖 3.11 所示。 (a)原始影像 (b)經 LZP 計算後影像 (c)特徵直方圖 圖 3.11:原始影像範例、經過 LZP 處理後影像與相對應直方圖 以圖 3.12 作為影像上某像素點及其八個鄰點的灰階值為例,利用公式(4)和 (5)進行 LZP 編碼運算可得此影像之 LZP 值。 1 10 100 1000 10000 100000 1 12 23 34 45 56 67 78 89 100 111 122 133 144 155 166 177 188 199 210 221 232 243 254 pi x el n um be r LZP value
14 乘上相對應之權重
15
7
23
18
19
21
4
4
1
1 0 1 0 0 1 1 1 1 2 4 8 16 32 64 128 LZP 二位元編碼=11100101 LZP 值= 1+4+32+64+128 = 229 圖 3.12:LZP 編碼範例3.2.3 三貼片區域二元圖樣
由於區域二元圖樣對於雜訊的容忍度非常低,易受到其影響,因此 Wolf 等 人提出了三貼片式區域二元圖樣(three-patch local binary pattern, TPLBP)的方法,用以改善區域二元圖樣的缺失。此方法共分為兩階段,第一階段先以 Cp為中心 切割出九個區域(如圖 3.13 所示),並對各區域進行區域二元圖樣之運算,第二階 段將經過 LBP 運算後的影像以三貼片的方式進行特徵運算與擷取,最後累加其 TPLBP 值並統計出該張影像的特徵直方圖。以下詳細說明此二階段的原理與做 法。
C
3C
4C
5C
6C
2C
7C
1C
0r
C
pα
w
w
圖 3.13:以 Cp為中心之 TPLBP 各區域位置示意圖15 第一階段: LBP 原理是將影像內某個 大小之區塊外圍的八個像素點( ), 其灰階值逐一與中心像素點 之灰階值比較並編碼,觀念如圖 3.14 所示。 P0 P1 P2 P3 P4 P5 P6 P7 Pc 圖 3.14:LBP 編碼順序 經由這種方式,可以得到 LBP 運算方式如公式(6)與(7): , (6) , (7) 其中 P 為相鄰像素點的個數,R 為相鄰點與中心點的距離, 為相鄰點之灰階值, 為中心點之灰階值。 第二階段: 經過第一階段運算後可得到以 Cp為中心之所有區塊之 LBP 值(C0, C1, C2, … , C7, Cp)。三貼片顧名思義就是三個區域,原理是尋找中心區域與兩塊距離中心區 域距離為 r 之區域之 LBP 值差,最後將兩個差值進行相減。TPLBP 運算公式如 (8)與(9)所示: , (8) , (9)
16 其中 r 是中心區塊中心點與另外八個區塊中心點的距離,S 是外環的區塊數目, w 是區塊大小,α 是用來決定哪兩塊距離中心區域距離為 r 之區域,τ 是一個略 大於零的門檻值(例如: ), 則是一個任意的距離函數。 最後將影像中經過 TPLBP 方法運算後不同的值進行累加,即可統計出該張 影像的特徵直方圖,並以此特徵直方圖表示該張影像之紋理特徵,其結果如圖 3.15 所示。 (a)原始影像 (b)經 TPLBP 計算後影像 (c)特徵直方圖 圖 3.15:原始影像範例、經過 TPLBP 處理後影像與相對應直方圖 考慮影像上某像素點及其八個相鄰區域的像素值分佈(以圖 3.16 為例),進行 TPLBP 的完整運算,假設 r = 2,S = 8,w = 3,α = 2,τ = 0.01。經使用公式(6) 與(7),可得到所有區域的 LBP 值,其運算結果如圖 3.17 所示。 1 10 100 1000 10000 1 12 23 34 45 56 67 78 89 100 111 122 133 144 155 166 177 188 199 210 221 232 243 254 pi x el n um be r TPLBP value
17 12 17 8 22 15 18 20 10 15 α = 2 w = 3 7 7 7 7 15 15 15 10 10 10 10 25 25 25 25 12 12 12 12 30 30 30 30 30 5 5 5 5 5 2 2 2 2 2 2 9 9 9 9 9 11 11 11 11 11 16 16 16 16 22 19 19 19 19 19 8 8 8 8 8 8 8 12 12 12 12 12 22 22 22 5 15 圖 3.16:TPLBP 範例 194 161 237 132 0 136 154 31 67 α = 2 w = 3 0 0 0 0 1 0 1 0 1 0 0 0 1 1 1 1 1 0 0 0 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 1 1 0 0 1 1 0 1 0 1 1 1 1 0 0 0 0 0 0 0 0 0 1 0 1 1 1 1 0 0 1+2+4+8+16=31 圖 3.17:TPLBP 範例經過 LBP 處理後示意圖 得到各 區域的 LBP 值後,套入三貼片的觀念;依據圖 3.17 之結果代入公式 (8)與(9)之運算可得
18
3.2.4 三貼片區域鋸齒圖樣
三貼片區域鋸齒圖樣(three-patch local zigzag pattern, TPLZP)是將 LZP 和 TPLBP 中貼片的觀念相結合所發展出的新方法,也是本篇論文的重點。有別於 以往多數的辨識系統使用 pixel-based 的圖樣進行特徵擷取,我們提出的方法是 以 patch-based 的圖樣進行,如此一次可以觀察的像素點則是前者的數倍,且是 區域特性,比較能呈現影像中區域間的特徵變化,整體來說,可以增加圖樣的穩 定性與宏觀性。TPLZP 跟 TPLBP 的差異在於第一階段會對所有區域進行 LZP 而 非 LBP 運算,再套用第二階段公式(8)與(9)的貼片差異運算得到影像中各像素的 TPLZP 值,最後將其分別累加得到 TPLZP 直方圖,以此作為最後的特徵值。 以圖 3.18 為例,首先對所有區域進行 LZP 的運算得到圖 3.19。 12 17 8 22 15 18 20 10 15 α = 2 w = 3 7 7 7 7 15 15 15 10 10 10 10 25 25 25 25 12 12 12 12 30 30 30 30 30 5 5 5 5 5 2 2 2 2 2 2 9 9 9 9 9 11 11 11 11 11 16 16 16 16 22 19 19 19 19 19 8 8 8 8 8 8 8 12 12 12 12 12 22 22 22 5 15 圖 3.18:TPLZP 範例
19 1 1 0 0 1 1 1 1 1 α = 2 w = 3 0 0 1 0 0 1 0 0 0 0 1 1 1 1 1 0 0 1 1 1 1 1 1 0 0 1 0 1 0 0 0 0 0 0 0 1 1 0 0 1 0 0 0 1 1 1 0 1 1 1 1 1 0 0 0 0 0 0 0 0 1 1 0 1+2+16+64=83 圖 3.19:TPLZP 範例經過 LZP 處理後結果 接著將圖 3.19 進行編碼與加權得其結果如圖 3.20 所示。 90 181 201 164 49 84 86 83 122 α = 2 w = 3 圖 3.20:TPLZP 範例經過加權後結果
20 接著將圖 3.19 進行公式(8)與(9)的運算可得方程式 246 即為代表中心區域的中心像素點的 TPLZP 值。某影像經 TPLZP 的運算結果 如圖 3.21 所示。 (a)原始影像 (b)經 TPLZP 計算後影像 (c)特徵直方圖 圖 3.21:原始影像範例、經過 TPLZP 處理後影像與相對應直方圖 1 10 100 1000 10000 1 12 23 34 45 56 67 78 89 100 111 122 133 144 155 166 177 188 199 210 221 232 243 254 pi x el n um be r TPLZP value
21 我們分析經由不同的區域圖樣,可獲取的特徵資訊差異。從圖 3.22 與圖 3.23, 圖(a)為步態能量影像,圖(b)為該步態能量影像經過 LZP 運算後的結果,圖(c)為 該步態能量影像經過 TPLBP 運算後的結果,而圖(d)為該步態能量影像經過 TPLZP 運算後的結果。從圖片的標示可看出,圖(b)與圖(c)和圖(d)的輪廓有很明 顯的不同,圖(b)的輪廓太粗使得身體的曲線不好判定,圖(c)雖然輪廓跟圖(d)差 不多粗,但是圖(d)的輪廓比較清楚,所以,以 TPLZP 描述步態影像的特徵,是 較為適當的。 (a)步態能量影像 (b)經過 LZP 處理後之影像 (c)經過 TPLBP 處理後之影像 (d)經過 TPLZP 處理後之影像 圖 3.22:男性的步態能量影像經各種不同圖樣處理之比較
22 (a)步態能量影像 (b)經過 LZP 處理後之影像 (c)經過 TPLBP 處理後之影像 (d)經過 TPLZP 處理後之影像 圖 3.23:女性的步態能量影像經各種不同圖樣處理之比較
3.2.5 區塊式區域紋理特徵擷取
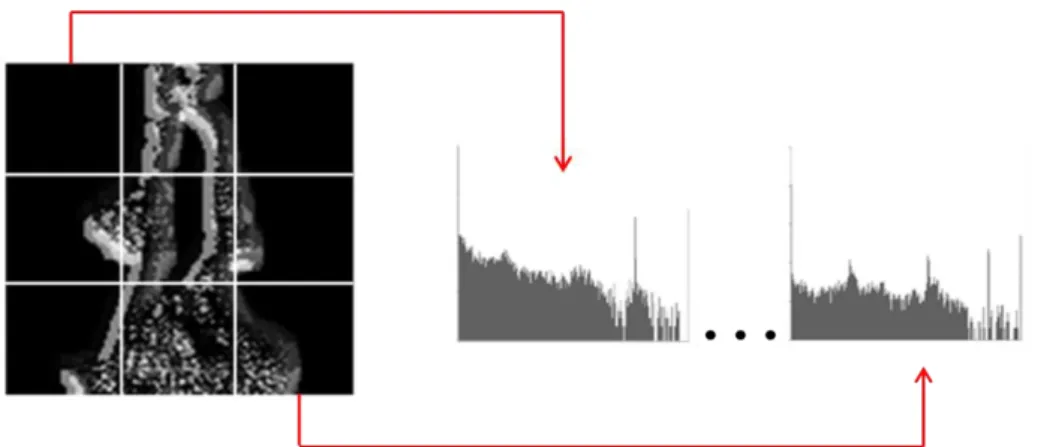
為 了 有 效 地 表 示 整 張 影 像 區 域 紋 理 的 分 布 情 形 , 我 們 使 用 區 塊 式 (block-based)的方法建構特徵影像直方圖,如此便可以較微觀的方式建構影像中 更細微的特徵,進而強化特徵的描述,以提升辨識效能。區塊式的特徵建構方法 是將影像切割成數個固定大小且不重疊的區塊{B1, B2, …, Bn},再依序對每個子 區塊進行特定紋理的運算並提取紋理特徵,最後將各個子區塊所獲得之直方圖 {H1, H2, …, Hn}依序串接起來,形成代表該張性別影像的特徵直方圖。以此概念, 我 們 將計 算 TPLZP 所形成之特徵資訊 , 分割成 個不重疊的區塊{B1, B2, …, },再將 TPLZP 運算所得的特徵直方圖{H1, H2, …, }依序串接起來 形成一個維度為 的特徵直方圖。區塊式區域紋理特徵的擷取與特徵直方 圖的建構觀念如圖 3.24 所示。23
圖 3.24:以 3×3 為例之區塊式區域紋理特徵擷取與直方圖建構示意圖
3.3 支持向量機
支持向量機(support vector machine, SVM) [36]是一種功能非常強大的演算 法,它本質上是與類神經網路相似,應用層面很廣,包括:分類(classification)、 迴歸(regression)的演算及密度估計等。SVM 為一種根據統計學習理論提出的機 器學習(machine learning)演算法,亦為監督式學習法(supervised learning),但是目 前多數人都是將其應用於分類。基於可以處理線性與非線性分割問題、運算速度 快、分類的準確度高且當樣本數不平等時,仍然可以有良好的效果,種種的優點, 使我們在分類器的選用上選擇 SVM 進行分類。 SVM 的基礎觀念是如果有一堆已經分成類別 A 和類別 B 的數據,但是不知 其分類的依據是什麼,如圖 3.25 所示,SVM 可以在這些資料中找到一個超平面 (hyperplane),使之將不同類別的資料區隔開,兩類最接近超平面的所有資料點(圖 3.25 中黑色三角形與圓形)被稱為支持向量(support vector),超平面則由這些支持 向量所決定。兩類別資料各自與超平面間的最短距離之和則為邊界(margin),邊 界的大小代表不同類別資料間分離的程度,所以這超平面的邊界(margin)越大越 好,當邊界達到最大值時之超平面稱之為最佳超平面,之後經由訓練(training) 建立一個模型(model),當輸入未分類的新資料進行測試時,SVM 可利用訓練完 成的模型預測(predict)這筆新資料所屬的類別。
24 類別A(+1) 類別B(-1) Maximum Margin x2 x1 圖 3.25:二維平面 SVM 分類最佳超平面 假 設 我 們 有 一 堆 分 好 類 別 的 樣 本 集 合 且 ,接著我們需要找到超平面 使得當 的所有點 落在 這一邊,也同時使所有 的點落在 這一邊,如此一來 我們便可輕易的分類該點是屬於哪一類別。 SVM 有一重要的特點,就是可以解決線性與非線性資料的問題,而 SVM 解 決非線性資料問題的方法就是透過所謂的核函數(kernel function)把資料投射到 比原始資料高維度的空間上來改變其特徵空間分佈型態,使得資料變得可用線性 方法區分,如圖 3.26 所示。 圖 3.26:利用核函數把資料投射到高維度空間[12]
25
使用不同的核函數來減低複雜問題的分類難度,是影響 SVM 結果相當重要 的一環。基礎的核函數總共有四種[37],分別為線性(Linear) 、多項式(Polynomial)、 輻射基底函數(Radial Basis Function, RBF)和 Sigmoid,如表 3.1 所示,其中 、 和 是 kernel 的係數。我們因相關文獻中多以 RBF 作為核函數的選擇,且 Bing 等人 [38]比較了 Linear Kernel、Polynomial Kernel 和 RBF 的差異,Linear Kernel 雖然
較快,但 Polynomial Kernel 和 RBF 正確率較高,但 Polynomial Kernel 在較高維 度的空間時會有計算上的困難,所以選擇 RBF 會比選擇 Polynomial Kernel 來的 佳。Guo 等人[39]分析了 Sigmoid Kernel 和 RBF 的表現,認為 RBF 的效果較優 秀。綜合上述分析,本論文在 SVM 之核函數將使用 RBF 作為選擇。
表 3.1:核函數的定義
種類 function
Linear Kernel
Polynomial Kernel Radial Basis Function (RBF)
Sigmoid Kernel
本論文後續之實驗是以 Multimedia Knowledge and Social Media Analytics Laboratory[40] 提 供 的 GPU-accelerated LIBSVM(a library for support vector
machine) 作為測試系統效能之工具,選用在 2013 年更新的 version 1.2。我們將
性 別 訓 練 樣 本經 過 GEI 處 理後 , 透 過 TPLZP 方 法 取 得 之 特 徵 向量 輸 入 GPU-accelerated LIBSVM 進行模型訓練與分析。在使用 GPU-accelerated LIBSVM
之前我們必須要先安裝 python[41]與 gnuplot[42]兩套軟體,需要安裝 python 是因 為後面使用到的工具是以此程式語言撰寫而成,gunplot 是因使用的工具須以此
26 來繪製圖形。
GPU-accelerated LIBSVM version 1.2 是利用 CUDA 架構對 Chang 和 Lin 提 供的 LIBSVM version3.17[43]進行修改。在 CUDA 的架構下,我們可以使用 NVIDIA 顯卡內的多核心進行平行運算,如此可以顯著的縮短處理時間並產生相 同的結果。GPU 版本與原始版本效能差距如圖 3.27 所示。 圖 3.27:不同模式 LIBSVM 的效率比較圖[40] 一個完整的分類辨識階段是:輸入資料-資料正規化-參數選擇-訓練模型-測 試-辨識結果,其中除了參數選擇,我們可以全部直接呼叫 LIBSVM 完成。輸入 特徵資料後,我們先呼叫函式庫中的 svmscale 將資料調整到-1 至 1 的範圍內, 此作法可以避免特徵值中的某項特徵過大,在計算超平面時主導結果。接著在參 數選擇上,Chang 和 Lin 提供名為“grid.py”的 kernel function 參數選擇工具,此處 我們選擇 RBF 作為 kernel function,該工具在訓練階段會採用交叉驗證針對所有 訓練資料評估每一個聯合參數的準確性,最後自動找出一組最佳參數以此呼叫函 式庫中的 svmtrain 產生 SVM 分類模型,再將測試樣本以相同特徵擷取方法取得 之特徵向量一樣正規化後,呼叫函式庫中的 svmpredict,把資料輸入分類模型中
27
進行分類,即可從分類結果中得出我們所提方法之整體辨識效果。Chang 和 Lin 也為了方便他人使用,提供一個名為“easy.py”的簡易腳本,此腳本從資料正規化 -參數選擇-訓練模型-測試可以一次完成,我們也是使用此工具進行實驗。
28
第四章 實驗結果
本章節依序介紹實驗環境與所使用的步態影像資料庫,並依據本論文所提出 之步態性別辨識方法進行多組試驗與分析,其中包含:區塊數不同、貼片半徑不 同和資料庫樣本不同等實驗,並和其他論文所提之性別分類特徵擷取方法的實驗 數據進行比較。4.1 實驗環境
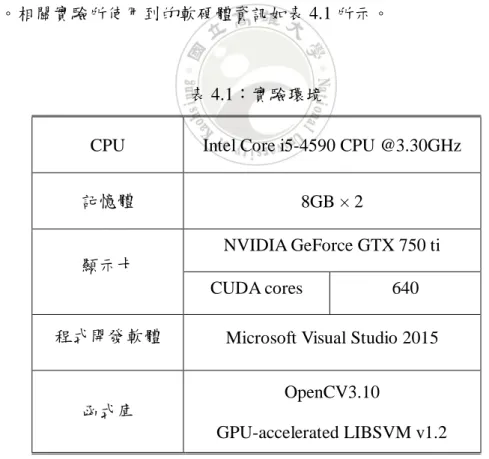
本論文以一台雙核心的電腦進行所有相關實驗。我們主要使用具有 640 CUDA cores 的 GTX 750 ti 顯示卡進行 GPU-LIBSVM 之實驗,在相關程式的撰寫與開發上,我們採用 Microsoft Visual Studio 2015 並搭配 OpenCV 與 LIBSVM 函式庫。相關實驗所使用到的軟硬體資訊如表 4.1 所示。
表 4.1:實驗環境
CPU Intel Core i5-4590 CPU @3.30GHz
記憶體 8GB × 2
顯示卡
NVIDIA GeForce GTX 750 ti
CUDA cores 640
程式開發軟體 Microsoft Visual Studio 2015
函式庫
OpenCV3.10
29
4.2 步態影像資料庫
我們所採用的 CASIA 資料庫是由中國科學院自動化研究所(The Institute of Automation, Chinese Academy of Sciences, CASIA)免費提供,此單位是中國最大
且專業從事生物特徵識別的研究機構。CASIA 步態資料庫總共有四個數據集: dataset A(小規模標準數據集)、dataset B(多視角步態數據集)、dataset C(紅外線步
態數據集)和 dataset D(步態和其對應的腳印數據集)。為了測試本論文所提之方法, 我們選用 CASIA dataset B 步態資料庫[1],此資料庫建立於 2005 年,總共有 124 位實驗者,年齡分布在 20 歲至 30 歲之間,包含 93 位男性和 31 位女性,其中有 123 位亞洲人和 1 位歐洲人,每位行人不穿大衣與背包自然的直線行走 6 次,穿 著大衣與背包自然的直線行走各 2 次,一共行走 10 次。資料庫內的影像範例如 圖 4.1 至圖 4.3 所示。 圖 4.1:CASIA 資料庫不穿大衣與背包之影像
30 圖 4.2:CASIA 資料庫穿著大衣之影像 圖 4.3:CASIA 資料庫背背包之影像 步態視訊的拍攝環境如圖 4.4 所示。拍攝角度從 0 度到 180 度,每間隔 18 度裝置一台攝影機,一共有 11 台攝影機同時拍攝 11 個角度,因此被拍攝者走一 次即可得到 11 段不同角度的影片,所以總共會有 13640 ( ) 段影片。 影片如圖 4.5 所示。
31 圖 4.4:CASIA 步態視訊拍攝環境示意圖 圖 4.5:11 個角度行走之影像
4.3 實驗結果與分析
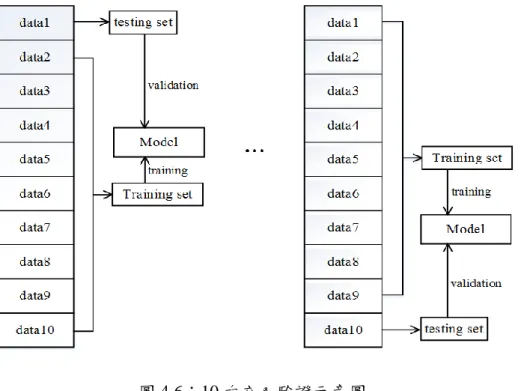
本節將介紹我們所進行之實驗,以測試本論文所提方法之效能。實驗一與實 驗二我們將分別比較在 TPLZP 步態特徵截取部份之相關參數與切割區塊數對於 辨識效能的影響。實驗三是從實驗一與實驗二的結果中,將我們所提方法之辨識32 率與其它文獻所提之方法進行比較,以證明我們所提之方法有良好的效果。接著 我們將評估所提方法的可行性,在實驗一至三中,我們皆是採用 CASIA dataset B 步態資料庫中 90 度且沒穿著大衣或背包的影像作為實驗的對象,但是在實驗四 中,我們將實驗對象從原本只使用到 90 度且無配件的影像,加入 90 度且穿著大 衣或是背包的影像進行測試。在實驗五中,我們則把 90 度且無配件的影像換成 其它拍攝角度且無配件的影像,以此兩個實驗證明我們所提之方法,在非理想(90 度且無配件)的條件下,亦有良好的效果。 為 了 評 估 我 們 的 方 法 之 辨 識 效 能 , 所 有 的 實 驗 皆 使 用 交 叉 驗 證 (cross-validation)作為判斷的基準。在統計學上,前述判斷基準也被稱為循環估計, 而 10 次交叉驗證(10-fold cross-validation)是最常被使用的形式,故本論文以此作 為評估基準。10 次交叉驗證其原理如圖 4.6 所示,是隨機將初始樣本分割成 10 個子樣本,其中 1 個單獨的子樣本被保留作為驗證模型的數據,稱為測試集 (testing set),其他 9 個樣本則被用來訓練模型,稱為訓練集(training set);將測試
集放入訓練集訓練出的模型中進行驗證,即為 1 次驗證,如此每個子樣本皆各驗 證 1 次,最後平均 10 次驗證所得之數據即為結果。
33
4.3.1 實驗一
在進行 TPLZP 的運算前,我們會先將經過 GEI 處理後的影像切割為 個 區塊,辨識效能的結果會隨著區塊數量變化而有所改變,且資料量與計算時間也 有密切的關係。隨著切割區塊數的增加,計算特徵值的次數也會增加,使得計算 時間上升,特徵直方圖維度亦會隨之變大成 ;如此一來,勢必會影 響後續在 SVM 訓練模型與性別分類的時間。本實驗我們以 CASIA dataset B 步態 資料庫作為測試對象,並將 n 值設定為 1 至 10 以觀察切割區塊數對辨識效能的 影響,同時,我們也改變了 TPLZP 中的 τ 值與 r 值,觀察其是否會影響辨識率, 其它 TPLZP 參數固定為 與 。相關實驗結果如表 4.2 至表 4.6 所示。 表 4.2:TPLZP 在 時,不同切割區塊數與門檻值對於辨識效能的影響 切割區塊數 85.62 87.10 84.75 84.42 85.14 92.68 91.05 90.46 90.99 90.70 91.99 92.81 91.94 91.93 91.41 95.03 93.95 94.23 93.69 94.23 96.85 95.82 95.77 95.63 95.42 96.71 96.84 96.78 95.63 95.50 97.25 96.98 96.77 97.11 96.97 97.98 98.04 97.45 97.65 97.10 97.85 97.05 96.91 97.01 97.44 95.19 90.56 95.98 96.17 95.6534 根據表 4.2 的實驗結果發現,當 時,隨著切割區塊數的遞增,擷取出的 辨識特徵資訊變多且辨識率有逐漸上升的趨勢,不論τ 值為多少,在切割區塊數 為 時,我們幾乎都獲得最高的辨識率。當切割區塊數繼續增加時,辨識率 開始些微的下降,當切割區塊數到達 時則開始出現明顯的下降情況,我 們推斷原因是因為區塊數過多,導致過多的多餘資訊使 SVM 無法準確的建立超 平面,進而造成辨識率的下降。而 τ 值在 時,不管其值為何,對於實驗結 果並不明顯。在 、 且切割區塊數為 時,我們得到了最高的辨識率 。 仿照前述實驗,我們繼續測試在不同的 r 值與區塊數目下,對於辨識效能有 何影響。相關實驗數據如表 4.3 至表 4.6 所示。 表 4.3:TPLZP 在 時,不同切割區塊數與門檻值對於辨識效能的影響 切割區塊數 88.04 89.72 87.24 85.09 86.09 93.14 93.11 91.40 91.27 91.51 93.47 93.96 92.06 93.54 92.01 94.22 94.22 94.69 94.76 94.49 96.57 96.78 96.64 96.10 96.64 96.98 97.18 96.70 96.97 96.70 97.45 97.31 97.58 97.24 97.85 98.03 98.20 97.71 97.85 98.12 98.05 97.58 97.78 97.71 98.02 98.09 95.90 96.97 97.78 97.98
35 根據表 4.3 的實驗結果發現,當 時,隨著切割區塊數的遞增,擷取出的 辨識特徵資訊變多且辨識率仍然與 時一樣有逐漸上升的趨勢,不論 τ 值為 多少,在切割區塊數為 時,我們幾乎都獲得最高的辨識率。當切割區塊數 繼續增加時,辨識率開始出現持平或些微的下降趨勢,而 τ 值在 時,不管 其值為何,對於實驗結果並不明顯;因此,從表 4.2 與表 4.3,我們推斷切割區 塊數對於辨識率是有幫助的,而τ 值對於實驗結果影響並不明顯。在 、 且切割區塊數為 時我們得到了最高的辨識率 。 表 4.4:TPLZP 在 且 時,不同切割區塊數對於辨識效能的影響 區塊數 直方圖維度 辨識率(%) 94.40
36 表 4.5:TPLZP 在 且 時,不同切割區塊數對於辨識效能的影響 區塊數 直方圖維度 辨識率(%) 94.41 表 4.6:TPLZP 在 且 時,不同切割區塊數對於辨識效能的影響 區塊數 直方圖維度 辨識率(%) 94.41
37 根據表 4.4 至表 4.6 的實驗結果可以發現,其辨識效能皆呈現隨著切割區塊 數的增加,擷取出的辨識特徵變多而使得辨識率逐漸上升的趨勢。當 時, 最佳辨識率落在切割區塊數為 ,與表 4.2 與 4.3 相比,雖然可以獲得相近的 辨識率,但需要達到最佳辨識率必然會因特徵直方圖維度較大的影響,導致在特 徵擷取、SVM 模型訓練、與 SVM 分類的耗費時間大於 與 時甚多。 所以在兼顧區塊數量、直方圖維度及訓練時間等因素的考量下,設定 所獲 取的系統成效必然會略遜一籌。當 時,雖然在切割區塊數 時就獲得了 最高辨識率 %,但略低於在表 4.3 所得到的 ,當 時,就相差更 多了。所以從表 4.2 至 4.6 的結果觀察,當 且切割區塊數為 時,我們可 以獲得最佳辨識率 %。 另外我們取出 且切割區塊數為 時之分類結果進行分析,統計出混 淆矩陣(confusion matrix)如表 4.7 所示。由表 4.7 可觀察到,女性誤判率明顯較高, 其原因可能是因為資料庫中有某幾位女性影像極為男性化(如圖 4.7),不管是原 始影像或是 GEI 處理後的影像,以肉眼判斷幾乎與男性影像沒有差異;此外也 有可能因為資料庫中男女的取樣數量比為 3:1,可能會使男性的模型的建構上 比較完整。 表 4.7: , Recognition rate (%) 男 女 男 99.32 0.68 女 5.19 94.81
38 圖 4.7:資料庫中較男性化之女性原始影像與 GEI 處理後影像之範例
4.3.2 實驗二
從實驗一的結果得知,為了兼顧區塊數量、直方圖維度及訓練時間等因素的 考量,我們將取出當 且切割區塊數為 時,其辨識率為 作為本篇 論文的代表數據。為了證明我們所提的方法在性別辨識上具有一定的準確性,因 此本實驗將我們的方法與其他文獻所提之以步態影像進行性別辨識的方法進行 比較。實驗從 CASIA dataset B 步態資料庫中取出 93 位男士與 31 位女士在 90 度 角拍攝下,無穿著大衣與背包之行人影像各 6 段,並以十次交叉驗證法進行驗證, 相關實驗數據如表 4.8 所示。 文獻[44]所提之方法是將影片所獲得的步態影像身體切割成 7 個區塊,再對 各區塊進行橢圓擬合,此方法直接使用影片中一個時間點的步態影像,而非考慮 一整段的步態影像。文獻[45]單純只使用 2D-DWT 的方法,之後以嵌入式隱藏馬 爾夫模型(embedded hidden Markov model, EHMM)進行模型訓練,此文獻主要強 調使用此分類器訓練模型可以達到不錯的效能。文獻[46]亦使用步態能量影像, 接著直接對影像使用他們所提的方法無關聯性單一分析(uncorrelated discriminant simplex analysis, UDSA)進行降維,當作其特徵值,之後使用 KNN 分類器進行分類。文獻[47]把 2D-DWT 結合小波能量的概念,每一階離散小波轉換皆計算一次 小波能量,一共做六階,之後將六個小波能量結合再使用主成分分析進行降維, 最後使用倒傳遞類神經網路進行模型訓練與分析。文獻[48]與文獻[44]相似,差
39 異只在於將步態影像的身體分割成 8 個區塊。文獻[49]先對影像進行步態能量影 像的運算,之後將影像分割成五個區塊,分別乘與相對應的權重即為特徵值。文 獻[50]的方法有點複雜,把步態影像分別計算身體各部位間的距離、一階小波轉 換、三階小波轉換,之後使用分數混合將前述三種特徵值混合起來,最後使用線 性判別分析進行降維。從表 4.8 的結果可發現,我們所提出的方法和其他方法相 較下可獲得較為不錯的辨識效果。 表 4.8:所提方法與其他方法之辨識率比較 方法 使用特徵 分類器 辨識率(%)
Martin et. al.[44] ellipse-fitting SVM
Chang and Wu[45] 2D-DWT EHMM
Lu and Tan[46] GEI+UDSA KNN
Arai and Asmara[47]
2D DWT+6 level
decomposition energy
BPNN
Martin et. al.[48]
realistic appearance-based representation SVM Yu et. al.[49] appearance-based features +human knowledge SVM
Sabir et. al.[50] STM+LMD+SWM SVM
40
4.3.3 實驗三
前述的兩個實驗中,我們皆是以無穿著大衣或背包之影像進行測試。在本實 驗中,我們將試驗我們的方法在加入背背包及穿大衣之影像後,是否仍然維持良 好的辨識率。本次實驗我們使用 CASIA dataset B 步態資料庫中,男性 93 人與女 性 31 人,拍攝角度是 90 度且無配件之影像每人 6 段、背背包之影像 2 段與穿大 衣之影像 2 段,每人共 10 段影片混合測試,測試方法為實驗一中辨識率最高的 方法,其結果如表 4.9 所示。雖然沒有其它文獻有做此方面的實驗,但是 CASIA dataset B 步態資料庫中提供這些類型的影片,因此我們決定進行實驗獲取結果, 以供他人日後比較參考使用。Nm 為無配件之影像、Bg 為背背包之影像、Cl 為 穿著大衣之影像。 表 4.9:穿著大衣與無配件影像混合時之辨識率 實驗對象 辨識率(%) Nm Nm + Bg Nm + Cl 5.91 Nm + Bg + Cl 96.37 從表 4.9 可以觀察到,穿著背包對於辨識率的影響並不大,而穿著大衣就有 較明顯的影響,原因可能是因為穿著大衣會遮蔽身體的曲線,這些曲線可能是性 別判定重要的特徵,所以才導致辨識率的下降。因為穿著大衣之影像使辨識率下 降幅度較大,所以我們從圖 4.8 與圖 4.9 進行分析,圖 4.8(a)與 4.9(a)分別為男性 無配件影像與女性無配件影像,圖 4.8(b)與圖 4.9(b)分別為男性穿著大衣影像與 女性穿著大衣影像。41 (a)無穿著大衣 (b)穿著大衣 圖 4.8:男性無穿著大衣與穿著大衣之影像比較 (a)無穿著大衣 (b)穿著大衣 圖 4.9:女性無穿著大衣與穿著大衣之影像比較 從圖片 4.8(a)與圖 4.9(a)可以觀察到,兩者在無配件時,頭髮(紅色標示處) 與胸部(黃色標示處)的曲線有較明顯的差異,而在圖 4.8(b)與圖 4.9(b)穿著大衣的 情況下時,頭髮與胸部的曲線變得較不明顯。如此一來,當一位男性穿著長大衣 時,將與下圖十分相似,因此就有可能會發生誤判的情況。
42
4.3.4 實驗四
因為在日常生活中,並非皆能拍攝到 90 度之行人影像,因此本實驗我們不 再只使用 90 度影像進行測試,而是測試在其它拍攝角度下,我們的方法效能為 何。我們分別以 CASIA dataset B 步態資料庫中拍攝角度從 0 度到 180 度,共 11 種角度且無穿著大衣與背包之影像進行測試,測試結果如表 4.10 所示。 表 4.10:在不同角度下與其它文獻之辨識率(%)比較 [12] [45] [46] [22] Ours 分類器 SVM 0 83.35 97.67 86.60 - 98.35 18 87.95 98.33 89.90 - 97.38 36 83.05 94.33 87.60 - 95.98 54 92.35 95.33 90.10 85.34 95.95 72 90.95 92.00 90.40 84.78 97.04 90 89.20 92.33 92.90 97.79 98.20 108 86.35 89.33 83.10 94.98 96.84 126 85.15 89.67 85.80 95.98 96.75 144 88.05 91.67 87.60 - 96.75 162 84.20 95.00 89.30 - 97.69 180 86.00 98.33 85.50 - 98.41 Avg. 87.05 94.00 87.99 92.77 97.05 文獻[12]的方法是先將原始影像分割成頭部、身體、和腿部三個區塊,然後 分別進行區域膚色偵測與去除,再擷取各個區塊的 LBP 當特徵值後利用一致圖 樣理論將此特徵值進行降維以減少後續的計算時間,接著將 GEI 的特徵向量使 用變異數分析進行降維,最後再將降維後的 LBP 特徵值與降維後的 GEI 值進行 串接作為完整的特徵表示。文獻[45]單純只使用 2D-DWT 的方法,之後以嵌入式 隱藏馬爾夫模型進行模型訓練,此文獻主要強調使用此分類器訓練模型可以達到 不錯的效能。文獻[46]亦使用步態能量影像,接著直接對影像使用他們所提的方 法 UDSA 進行降維,當作其特徵值,之後使用 KNN 分類器進行分類。文獻[22]43 提出的向前參考差異歷史影像,是把一個步態週期進行切割,將一個週期切成四 等份來分析。相較之下,可以在擷取週期的處理上節省較多的時間,此外此方法 在影像經過前處理後,人體的上半部通常處於靜態,所以會將人體的上半部部分 影像視為不需要的資訊予以去除以降低計算量,這有可能刪掉上半部影像看似微 不足道,實則蠻重要的資訊。 根據表 4.10 的結果,整體而言,我們的方法在較多的角度下有較佳的辨識 率,只有在 18 度略低於文獻[45]約 1%,但我們的方法在多數實驗中的辨識率與 整體辨識率皆優於另外四篇文獻。
44
第五章 結論與未來工作
性別辨識在電腦視覺的領域中逐漸受到重視,而且可以廣泛地應用在安全監 控、商業分析或人機互動識別等領域。由於步態性別辨識系統具有非侵犯性、遠 距獲取、影像畫質要求不高、與不易偽裝等特性,不僅是學術界的熱門研究主題, 也可為生活增加許多便利性。 步態是由許多不同且複雜的紋理組合而成,使得不同人所展現出的步態變化 細微與差異程度相當地複雜。本論文採用將影像先經過 GEI 處理後,結合 TPLZP 擷取步態影像的特徵,並以區塊式特徵擷取方法計算出子區塊內各個像素點的特 徵值後將其統計成特徵直方圖,並將各區塊所對應的特徵直方圖加以串聯後,以 此作為該張影像之特徵資訊。實驗結果顯示,相較於其他人提出的方法,我們的 方法擁有較好的性別辨識率。 針對本論文提出的方法,主要的結論有: 1. 在步態性別辨識系統中,擷取步態影像的特徵是影響步態性別辨識系統 其效能最重要的一環。本論文提出先將步態影像經過 GEI 處理後再使 用區塊式 TPLZP 擷取影像的特徵,實驗結果證實我們所提方法可以獲 得良好的效果。 2. 為了證實我們所提方法之可行性,我們亦分別使用 CASIA dataset B 步 態資料庫中不同配件與不同角度的影像進行實驗,亦獲得不錯的辨識結 果。 因為性別辨識領域的蓬勃發展,有許多學者投入研究在特徵擷取之方法之改 良,未來可以嘗試將我們的方法在特徵維度上進行改良,降低運算與縮短訓練時 間;或是在第一階段的處理,將步態能量影像替換成其他步態影像描述技術;或 是在第二階段使用不同的圖樣來描述,以提升性別辨識系統之效能。 本篇論文皆是使用整張步態影像進行辨識,並沒有將局部的特徵,例如:步 伐大小、胸部或臀部等部位分別擷取出再進行測試,若局部辨識的辨識結果具有45 良好的辨識率,則以此進行分析將會對性別辨識有更深的了解,或許可以降低特 徵擷取的時間。 在現實生活中,多數所拍攝的影像必定不會是 90 度或是無配件的行人,所 以我們未來可以多著重於其它幾度或是有佩戴配件的影響的分析與效能。 在實際應用層面,隨著科技的進步,無論在哪皆可廣泛地看到攝影裝置的設 立,例如:一般店家的攝影機、車上的行車紀錄器或 3C 產品上的相機等,若能 使步態性別辨識系統可以因此廣泛的被使用,將可大幅提高商業與科技發展,生 活亦趨便利。
46
參考文獻
[1] CASIA Gait Database, http://www.cbsr.ia.ac.cn/english/Gait%20Databases.asp. [2] A. F. Bobick and J. W. Davis, “The recognition of human movement using
temporal templates,” IEEE Transactions on Pattern Analysis and Machine
Intelligence, vol. 23, no. 3, pp. 257-267, 2001.
[3] X. Zhou and B. Bhanu, “Integrating face and gait for human recognition,” in
Proc. Conference on Computer Vision and Pattern Recognition Workshop, 2006,
p. 55.
[4] J. Han and B. Bhanu, “Individual recognition using gait energy image,” IEEE
Transactions on Pattern Analysis and Machine Intelligence, vol. 28, no. 2, pp.
316-322, 2006.
[5] K. Balci and V. Atalay, “PCA for gender estimation: which eigenvectors contribute?” in Proc. IEEE International Conference on Pattern Recognition, vol. 3, 2002, pp. 363-366.
[6] J. Wu, “A novel approach for discrimination of human gait using kernel learning algorithm,” in Proc. IEEE 6th International Conference on Natural Computation, 2010, vol. 6, pp. 3253-3256.
[7] S. Yu, D. Tan, and T. Tan, “A framework for evaluating the effect of view angle, clothing and carrying condition on gait recognition,” in Proc. IEEE 18th
International Conference on Pattern Recognition, 2006, vol. 4, pp. 441-444.
[8] D. Zhang, Y. Wang, and B. Bhanu, “Ethnicity classification based on gait using multi-view fusion,” in Proc. IEEE Computer Society Conference on Computer
Vision and Pattern Recognition Workshops, 2010, pp. 108-115.
[9] D. Zhang and Y. Wang, “Using multiple views for gait-based gender classification,” in Proc. IEEE Control and Decision Conference, 2014, pp. 2194-2197.
[10] Y. Wang, Y. Chen, H. Huang, and K. Fan, “Local block-difference pattern for use in gait-based gender classification,” Journal of Information Science and
Engineering, vol. 31, no. 6, pp. 1993-2008, 2015.
[11] L. Zhang, R. Chu, S. Xiang, and S. Z. Li, “Face detection based on multi-block LBP representation,” in Proc. International Conference on Biometrics, 2007, pp. 11-18.
[12] L.-C. Fan, View-insensitive Gender Recognition Using Local Binary Patterns, Master thesis, Dept. Computer Science and Information Engineering, National Central Univ., Taoyuan, Taiwan, 2009.
[13] H.-C. Lian and B.-L. Lu, “Multi-view gender classification using local binary patterns and support vector machine,” in J. Wang et al. (Eds): ISNN 2006, LNCS
47 3972, pp. 202-209, 2006.
[14] T. Ojala, M. Pietikainen, and T. Maenpaa, “Multiresolution gray-scale and rotation invariant texture classification with local binary patterns,” IEEE
Transactions on Pattern Analysis and Machine Intelligence, vol. 24, no. 7, pp.
971-987, 2002.
[15] H. H. Manap, N. M. Tahir, and A. I. M. Yassion, “Statistical analysis of parkinson disease gait classification using artificial neural network,” in Proc.
2011 IEEE International Symposium on Signal Processing and Information Technology, 2011, pp. 60-65.
[16] C. Shan, S. Gong, and P. W. McOwan, “Fusing gait and face cues for human gender recognition,” Neurocomputing, vol. 71, no. 10-12, pp. 1931-1938, 2008. [17] C. Shan, S. Gong, and P. W. McOwan, “Learning gender from gaits and faces,”
in Proc. IEEE Conference on Advanced Video and Signal Based Surveillance, 2007, pp. 505-510.
[18] L. Lee and W. E. L. Grimson, “Gait analysis for recognition and classification,” in Proc. 5th IEEE International Conference on Automatic Face and Gesture
Recognition, 2002, pp. 148-155.
[19] A. Kale, A. K. Roychowdhury, and R. Chellappa, “Fusion of gait and face for human identification,” in Proc. IEEE International Conference on Acoustics,
Speech, and Signal Processing, vol. 5, 2004, p. V-901-4.
[20] A. J. O’Toole, T. Vetter, N. F. Troje, and H. H. Bulthoff, “Sex classification is better with three-dimensional head structure than with image intensity information,” Perception, vol. 26, no. 1, pp. 75-84, 1997.
[21] Q. Ma, S. Wang, D. Nie, and J. Qiu, “Recognizing humans based on gait moment image,” in Proc. IEEE 8th International Association for Computer and
Information Science Conference on Software Engineering, Artificial Intelligence, Networking, and Parallel/Distributed Computing, 2007, vol. 2, pp. 606-610.
[22] S.-S. Lai, Human Identification Using Gait Features via Forward Difference
History Image, Master thesis, Dept. Computer Science and Information
Engineering, National Central Univ., Taoyuan, Taiwan, 2011. [23] Weka-KNN: https://sourceforge.net/projects/weka-knn/.
[24] J. Lu, G. Wang, and T. S. Huang, “Gait-based gender classification in unconstrained environments,” in Proc. 21st International Conference on Pattern
Recognition, 2012, pp. 3284-3287.
[25] S. Sarkar, P. Phillips, Z. Liu, I. Vega, P. Grother, and K. Bowyer, “The humanid gait challenge problem: data sets, performance, and analysis,” IEEE
Transactions on Pattern Analysis and Machine Intelligence, vol. 27, no. 2, pp.
48
[26] J. MacQueen, “Berkeley symposium on mathematical statics and probability,” in
Proc. 5th Berkeley Symposium on Mathematical. Statistics and Probability, 1967,
vol. 1, pp. 281-297.
[27] A. Sabir, N. Al-Jawad, S. Jassim, and A. Al-Talabani, “Human gait gender classification based on fusing spatio-temporal and wavelet statistical features,” in
Proc. 5th Computer Science and Electronic Engineering Conference, 2013, pp.
140-145.
[28] D. Migliore, M. Mattucci, and M. Nacca, “A revaluation of frame difference in fast and robust motion detection,” in Proc. 4th ACM International Workshop on
Video Surveillance and Sensor Networks, 2006, pp. 215-218.
[29] A. Sabir, N. Al-Jawad, and S. Jassim, “Gait recognition using spatio-temporal silhouette-based features,” in Proc. Mobile Multimedia/Image Processing,
Security, and Applications, 2013, vol. 8755, pp. 1-10.
[30] Y.-J. Li, C.-C. Lai, C.-H. Wu, S.-T. Pan, and S.-J. Lee, “Gender classification from face images with local texture pattern,” International Journal of Industrial
Electronics and Electrical Engineering, vol. 3, no. 11, pp. 15-17, 2015.
[31] L. Wolf, T. Hassner, and Y. Taigman, “Descriptor based methods in the wild,” in
Proc. Faces in Real-Life Images Workshop at The European Conference on Computer Vision, 2008, pp. 1-14.
[32] L. Wolf, T. Hassner, and Y. Taigman, “Effective unconstrained face recognition by combining multiple descriptors and learned background statistics,” IEEE
Transactions on Pattern Analysis and Machine Intelligence, vol. 33, no. 10, pp.
1978-1990, 2011.
[33] G. Mahalingam and K. Ricanek Jr., “LBP-based periocular recognition on challenging face datasets,” EURASIP Journal on Image and Video Processing, vol. 2013, no. 36, pp. 1-13, 2013.
[34] C. Stauffer and W. E. L. Grimson, “Adaptive background mixture models for real-time tracking,” in Proc. IEEE Computer Society Conference on Computer
Vision and Pattern Recognition, vol. 2, 1999, pp. 246-252.
[35] R. Cucchiara, C. Grana, M. Piccardi, A. Prati, and S. Sirotti, “Detecting moving objects, ghosts, and shadows in video streams,” IEEE Transactions on Pattern
Analysis and Machine Intelligence, vol. 25, no. 10, pp. 1337-1342, 2003.
[36] B. E. Boser, I. M. Guyon, and V. N. Vapnik, “A training algorithm for optimal margin classifiers,” in Proc. The 5th Annual Workshop on Computational Learning Theory, 1992, pp.144-152.
[37] C.-W. Hsu, C.-C. Chang, and C.-J. Lin, “A practical guide to support vector classification,” Technical report, Dept. of Computer Science, National Taiwan Univ., Taipei, Taiwan, 2003.