GOLDEN MANDARIN(I1)
-
A N IMPROVED SINGLE-CHIP REAL-TIME
MANDARIN DICTATION MACHINE FOR CHINESE LANGUAGE WITH
VERY LARGE VOCABULARY
Lin-shan Lee's283, Chiu-yu Tseng', Keh-Jiann Chen', I-Jung Hung', Ming-Yu Lee', Lee-Feng Chien2, Yumin Lee', Renyuan Lyu'
,
Hsin-min Wang',
Yung-Chum Wu', Tung-Sheng Lin', Hung-yanGu',
Chi-ping Nee', Chun-Yi Liao', Yeng-Ju Yang', Yuan-Cheng Chang', Rung-chiung Y a n 2 National Taiwan University and Academia Sinica, Taipei, Taiwan, Republic
of
China *ABSTRACT
Golden Mandarin (11) is an improved single-chip real-time Mandarin dictation machine for Chinese language with very large vocabulary for the input of unlimited Chinese sentences into com- puters uaing voice. In this dictation machine only a single chip Motorola D S P 9 6 0 0 2 D on an Ariel D S P - 9 6 card is used, with a preliminary character correct rate around 95% in speaker depen- dent mode at a speed of 0 . 3 6 sec per character. This is achieved by many new techniquea, primarily a segmental probability mod- eling technique for syllable recognition specially considering the characteristics of Mandarin syllables, and a word-lattice-based Chinese character bigram for character identification specially conaidering the structure of Chinese language.
I. INTRODUCTION
Today, the input of Chinese characters into computers is still a very difficult and unsolved problem. This is the basic motiva- tion for the development of a Mandarin dictation machine. We defined the scope of this research by following limitations. The input speech is in the form of isolated syllables. The machine is speakcr dependent. Reasonable errors are acceptable because they can be found on the screen and corrected from the keyboard by the user very easily. But the machine has to be able to recog- nize Mandarin speech with very large vocabulary and unlimited texts, because the input to computers can be arbitrary Chinese texts. Also, the machine has to work in real-time for computer input applications. A previous version of such a machine, Golden Mandarin
(I),
has been developed in 1990 [1][2], but the high- ly computation-intensive algorithms for Golden Mandarin (I) re- quire 10 TMS 320C25 chips operating in parallel on 9 special hardware boards to meet the real time requirements. This is why the present machine is developed using completely different algorithms.There are at least lo5 commonly used Chinese words, each composed of one to several characters. There are at least 10
*
commonly used Chinese characters, all mono-syllabic. However, the total number of different syllables in Mandarin speech is on- ly 1302. Based on such observation, the use of syllable as the dictation unit becomes a very natural choice. Another very spe- cial feature of Mandarin Chinese is that it is a tonal language. '1. Dept. of Electrical Engineering, National Taiwan Univer- 2. Dept. of Computer Science and Information Engineering, 3. Institute of Information Science, Academia Sinica 4. Institute of History and Philology, Academia Sinica sityNational Taiwan University
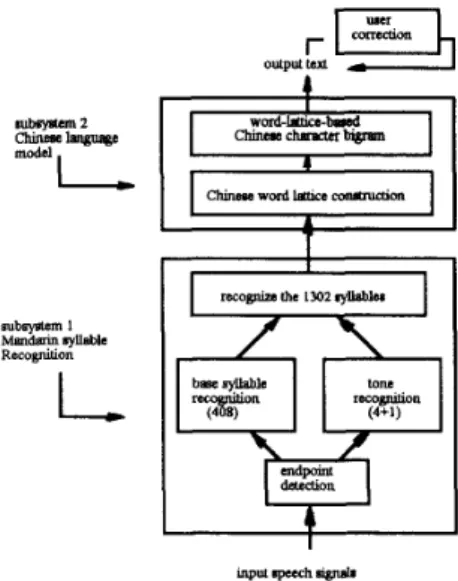
Every syllable is assigned a tone in general. There are basical- ly four lexical tones and one neutral tone in Mandarin. It has been shown that the primary difference for the tones is in the pitch contours, and the tones are essentially independent of the other acoustic properties of the syllables. If the differences in tones are disregarded, only 408 base syllables ( each bearing dif- ferent tones ) are required for Mandarin Chinese. This means the recognition of the syllables can be divided into two parallel proce- dures, the recognition of the tones, and of the 408 base syllables disregarding the tones. Based on the above considerations, the overall system structure for the Golden Mandarin (11) dictation machine is shown in Fig. 1. The system is basically divided into two subsystems. The first is to recognize the Mandarin syllables, and the second is to transform the series of syllables into Chi- nese characters, because every syllable can be shared by many homonym characters. For the first subsystem of syllable recog- nition, the base syllable (disregarding the tones) and the tone are recognized independently in parallel. For the second sub- system of language model, we need to first obtain all possible word hypothesis to construct a Chinese word lattice, and then use a word-lattice-based Chinese character bigram to select the most probable concatenation of word hypotheses as the output sentence.
11. MANDARIN SYLLABLE RECOGNITION
The recognition of the Mandarin syllables includes two parts: recognition of the 408 base syllables (disregarding the tones) and recognition of the tones. The tone recognition is not too diffi- cult. Discrete Hidden Markov Models based on feature vectors of pitch frequency, difference pitch frequency, energy and differ- ence energy are used, and the syllable durational cues are further applied to distinguish the neutral tone from the 4 lexical tones. The recognitionof the 408 base syllables (disregarding the tones), however, is very difficult, because there exist 38 confusing sets in this vocabulary. A good example is the A-set, { a, ja, cha, sha, dsa, tsa, sa, ga, ka, ha, da, ta, na, la, ba, pa, ma, fa
}.
Specially trained continuous density Hidden Markov Models (HMM's)[3] [4] for cepstral coefficients were used in the previous version machine [1][2], which are highly computation-intensive. Considering the fact that Mandarin mono-syllables have relatively simple phonet- ic structure and the primary problem in base syllable recognition is to distinguish the very confusing initial consonants instead of matching the entire template, it is therefore believed that the time warping functions of the state transition probabilities of HMM's are not very important. Because state transition path searching process in HMM's is highly computation-intensive, a segmental probability model (SPM) specially for Mandarin base syllables was therefore developed, which is very similar to continuous den-11-503
subSyaan 1 Mandarin syWk Recognilion
I
7 I L " P ~ rpcch ngndrFigure 1: The overall system structure for
Mandarin(I1) dictation machine
training and recognition processes are simplified tremendously as compared to the continuous density HMM's.
The training data used in the experiments include 5 utter- ances for each of the 1302 syllables for each speaker, and the results below are the average scores obtained for two speakers. The recognition rates are listed in Table 1. The experiment (1) in the first row is for the continuous density HMM's used in the previous version machine [1][2], and experiment (2) in the sec- ond row is the initial test for SPM where N = 7 and M=3, such that the number of states and mixtures are exactly the same in experiments (1) and (2) for parallel comparison. It can be seen that SPM gives an top 1 rate more than 20% lower than con- tinuos density HMM's, apparently because SPM is a much more simplified version. However, the following series of improvements in experiments (3)-(6) in fact indicate the very high potential of SPM for Mandarin syllable recognition, if special characteris- tics of Mandarin syllables can be more carefully considered. Be- cause the primary problem for Mandarin syllable recognition is to distinguish the very confusing initial consonants and some er- rors are often caused by the syllable ending (such as /an/ and /ang/),in experiment (3) smaller shift between adjacent speech frames was used in the first 20% and last 10% of the syllable ut- terances, such that finer signal characteristics can be extracted for the initial consonants and syllable ending. In the third row of Table 1, the top 1 rate was improved in this way from 69.85% to 75.49%. In experiments (4) and (5) optimal values of N and M were further found empirically and the linear prediction order P was increased from 10 to 14. Note that 3 segments (N=3) gives
the Golden
sity HMM, but the state transition probabilities are deleted and the N states equally segment the syllable utterance.
In more detail, each utterance of syllable a is equally di- vided into N segments (or states), and each segment is mod- eled by M Gaussian mixtures. Each of the mixture is character- ized by a mean vector p i j and a covariance matrix b;j
, where
i = 1,2,.
. .
,
N is the segment index, and j=
1,2,.. .
,
M
is the mixture index. The SPM of a syllable a is therefom represented byS N M ( U )
=
{(p;j,b;j),i = 1,2,.. .
,
N , j=
1,2,.. .
,
M)In the training phase, all training utterances for the syllable a are equally divided into N segments, and the feature vectors from the i-th segment of all training utterances are used togethcr to train the parameters (p;j , ~ ; j )
,
j=
1,2,..
.
, M
,
for the i-th segment. They are first vector quantized into M dusters, and the feature vectors in the j-th cluster are used to obtain( p
;j,8;j). The co- variance matrices ~ ; j are assumed diagonal. In the recognition phase, the observation probability function b ;(a) for an observed feature vector with respect to the i-th segment of the syllablea is simply
bi(fi) =j=l,Y.X,M {bij(a)I
where b;j (6) is the Gaussian distribution function defined by ( .iiij,#;j
)
.
In
the recognition phase, an unknown utterance U is first equally divided into N segments, assuming each with n feature vectors,U = {6ikr i = 1,2,
. . .
,
N , k = 1,2,.
. .
,
n}where i is the segment index and k is the vector number in a segment. The observation probability of this unknown utterance U with respect to the SPM model of a syllable ~ , S N M ( ~ )
,
is thenN
r n
1Apparently the syllable model giving the highest observation pr* bability for U is the recognition output. In this way, both the
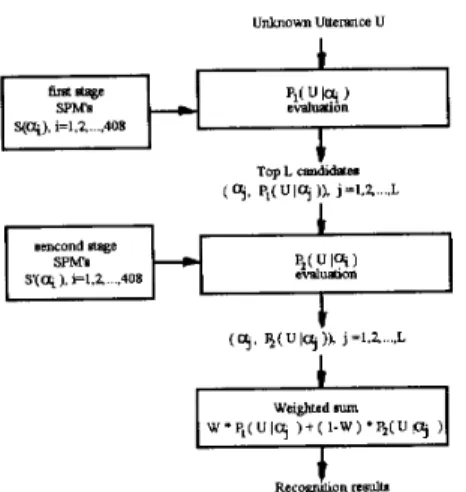
better results than 7 segments ( N = 7 ) , probably because all the Mandarin syllables have relatively simple structure, composed of at most 3 to 4 phonemes. Without the time warping function of the state transition probabilities, too many segments (or states) may in fact cause interference among adjacent segments in the SPM. Therefore roughly one phoneme per segment tums out to be the best choice for SPM, although in HMM's 7 states gives the best results. On the other hand, because the computation load for SPM recognitionis very low, increase of linear prediction order P from 10 to 14 can be easily achieved but is highly re- warding, as was indicated by the significant improvements in the top 1 rate, from 77.45% to 88.97%. Still further improvements can be achieved by a two-stage SPM approach in experiment ( 6 ) as shown in Fig. 2, in which the first stage SPM used cepstral coefficients, while the second stage SPM used regression coeffi- cients obtained from cepstral coefficients, and the parameters M , N for the two stages can be separately optimized. The first stage selected the top L candidates a l , a a ,
...,
a~ and passed them to the second stage, together with the corresponding observation probabilities P l ( U l a j ) , j=
1,2,...,
L
.
The final score of each of the L candidates is then the weighted s u m of the observation probabilities obtained in the two stages. The last row of Table 1 indicates that in this way the top 1 rate can be as high as 96.57%, and the top 3 rate can be 99.75%. Note that the computation requirements in experiment (6) are still much less than those of continuous density HMM's used in experiment (l), but the per- formance is muchmore better. These results are also summarized in Fig. 3.111. CHINESE LANGUAGE MODEL
After the base syllables and tones are recognized by the sub- system 1, the high degree of ambiguity caused by the large num- ber of homonym characters still remain to be solved. The subsys- tem 2 thus acts as a linguistic decoder to identify the characters using context information. In the previous versionmachine [1][2], a relatively simple Chinese character bigram trained by primary
I ‘
(5.
S(UlCq)). 1=LZ .LFigure
2:
The two-stage approach for SPM
school Chinese textbooks ( 5 ] [ 6 ] was used, whose function was in fact limited. In Chinese language every word is composed of from one to several characters and there is no blanks between two ad- jacent words, thus a sentence can be considered as a sequence of words, or a sequence of characters. The 10
’
characters or lo5words require a character bigram of 10
*
x 10’ probabilities or a word bigram of los xl o 5
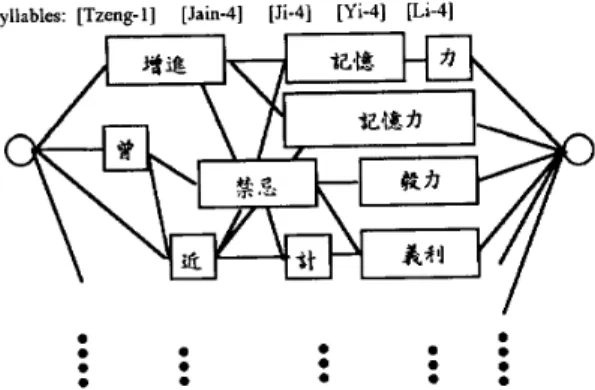
probabilities respectively. Preliminary tests indicated that the word bigram is much more powerful than the character bigram [5], probably because the Chinese sentences are really built by words rather than by characters. But the word bigram is difficult to train and implement on a single chip because of the much larger size. A new approach considering the special structure of Chinese language using a word-lattice-based Chinese character bigram was thus developed to solve this problem. In this approach, the sequence of syllables obtained from the sub- system 1 is first matched with the words in a lexicon of 10 words to find all possible word hypotheses to construct a word lattice, with the help of a set of lexical rules. A word lattice is a graph of all possible paths connecting all word hypotheses, a simple ex- ample is shown in Fig. 4. The paths on the word lattice are then searched through by a word-lattice-based character bigram. The path with the highest probability is then chosen as the result, just as shown in Fig. 1.Previous study [7][8] showed that grammatical information such as word formation are very helpful to statistical language models in grouping legal combinations of words while filtering out illegal ones. In Chinese language many compound words can be established by combining two or more words with simple rules, so they don’t have to be stored in the lexicon. For example, the words ” pig(
&
) ” and ” Meat( $q ) ” can form a new word”Pork( )
”,
etc. These are the lexical rules mentioned above to help reduce the size of the lexicon. By matching the input syl- lable sequence with the words in the lexicon with the help of the lexical rules, all possible word hypotheses can be obtained and constructed in the word lattice. The function of the statistical language model can then be significantly reduced and simplified. For example, many noisy syllables or characters such as incorrect- ly recognized syllables or homonym charactera which can’t form word hypotheses with adjacent syllables or characters or can’t be used as a mono-character word will be automatically deleted. On the other hand,if
a set of adjacent word hypotheses can be grouped together earlier into a single compound word hypothesisTable
1:
Base syllable recognition rates
for
the previous
HMM and the new SPM techniques
90 8 5 80 75 70
3
1 2 3 4 5Figure 3: Recognition rates for the base syllables
in the word lattice, the number of possible paths connecting the word hypothesis in the lattice can be reduced. Also, it has been observed in preliminary experiments that a longer word hypothe- sis is usually more reliable, and in fact very probably it is exactly the correct answer if it is really long. Therefore the establishment of such a word lattice can not only reject the interference from many noisy syllables and characters, but significantly reduce the search space of the statistical language model and improve the overall accuracy.After a word lattice was constructed as discussed above, a specially designed word-lattice-based Chinese character bigram was used to search through the word lattice to obtain the max- imum likelihood output sentence. For each word hypothesis se- quence W = Wl Wz
...
W ,,
wherew;
is the i-th component word hypothesis, let W ; = CilC;z...
C i s ,,
where Cik is the k-th com- ponent character ofW ;
and si is the number of characters in W;,
recalling that a Chinese word is composed of several characters. Thenp ( w ) = p(w1, W J , ...I w m )
= P(C1101p..
---
.
C I S 1 , . . . , C i l ..,c;si, , , . ,c,Ic,J...
CmS,)W1 w; W,
This probability can be approximated by
p ( w ) = ~ ( c 1 1 ) ~ ( ~ 2 1 ~ ~ 1 s l ) ~ , . ~ ( ~ m l ~ C ( n ~ - ~ ) s , , , - ~ )
.,.
syllables: [Tzeng-1] [Jab41 [Ji-4] [Yi-4] [Li-4] I -,-I 0 0 0 0 0 0 . 0 0 0 0 . 0 0 0 0 .
Figure
4:
A partial list of an example word lattice. Each
rectangle is
a
multi-character word, while each square
is
a
mono-character word.
As can b e f o u n d i n Fig.5, t h i s probability only considers t h e conditional probabilities for b o u n d a r y characters i n t h o s e adj, cent w o r d hypothesis, b u t ignores t h e conditional probabilities for characters w i t h i n a w o r d hypothesis, P ( C ik l C i ~ ~ - l ~ ) , 2
5
k5
S;w i t h i n W;
.
T h i s is b e c a u s e t h e c h a r a c t e r s w i t h i n a w o r d h y p o t h - esis a r e fixed and k n o w n , t h e conditional probability for adjacent characters c a n t h u s b e a s s u m e d t o b e unity, w h e n t h e w o r d hy- pothesis i s a l r e a d y c o n s t r u c t e d on t h e w o r d lattice. In this way, t h e sentence hypotheses including longer w o r d hypotheses will h a v e higher probabilities. Therefore t h e longer w o r d h y p o t h e - ses will a u t o m a t i c a l l y h a v e higher priority t o b e chosen, because t h e y a r e i n f a c t m o r e reliable as mentionedpreviously. T h e word- lattice-based c h a r a c t e r b i g r a m w a s t r a i n e d in a similar way, i.e., t h e words i n t h e t r a i n i n g c o r p u s were first segmented, and t h e b i g r a m probabilities for t h e b o u n d a r y c h a r a c t e r s were t h e n esti- m a t e d . N o t e t h a t such a c h a r a c t e r b i g r a m of 10‘
10‘ probabili- ties i s relatively easy to h a n d l e and relatively r o b u s t w i t h respect t o insufficient training corpus, b u t t h e w o r d l a t t i c e discussed pre- viously c a n effectively e n h a n c e t h e capabilities of t h e c h a r a c t e r b i g r a m t o a p p r o x i m a t e a w o r d bigram. In G o l d e n M a n d a r i n (11), t h e c h a r a c t e r b i g r a m was t r a i n e d b y a c o r p u s of 6 million char- acters t a k e n f r o m n e w s p a p e r s , magazines, and so o n , and t h e t o p several base syllables and t o n e s f r o m t h e s u b s y s t e m 1 a r e included i n t h e w o r d lattice.IV. REAL TIME IMPLEMENTATION AND
CONCLUDING REMARKS
In t h e real-time i m p l e m e n t a t i o n of t h e G o l d e n M a n d a r i n (11) all necessary c o m p u t a t i o n is p e r f o r m e d i n a single c h i p M o t o r o l a DSP 96002D, and t h e c o m p l e t e m a c h i n e is i m p l e m e n t e d on an Ariel DSP-96 c a r d i n s e r t e d i n t o an IBM PC/AT, while a P r o - P o r t Mode1/656 acts as t h e f r o n t e n d for acoustic signals. T h e waveform of t h e i n p u t u n k n o w n syllable is filtered and s a m p l e d i n P r o P o r t and t r a n s f o r m e d i n t o 16-bit integer f o r m a t , DSP96002D t h e n sponsors all t h e following processes including e n d p o i n t de- tection, pre-emphasis, M a n d a r i n syllable recognition and t h e Chi- nese language model. P r e l i m i n a r y t e s t s i n d i c a t e that i n average i t takes 0.36 sec f o r t h e m a c h i n e t o d i c t a t e a c h a r a c t e r , which is exactly real-time, and t h e c h a r a c t e r correct r a t e is a r o u n d 95%.
Golden Mandarin (11) is t h e second version p r o t o t y p e sys- t e m developed i n a l o n g t e r m p r o j e c t , in which t h e goal is to solve t h e difficult p r o b l e m of i n p u t of a r b i t r a r y Chinese t e x t i n t o
Figure
5:
The probability estimation in the word-
lattice-based Chinese character bigram
c o m p u t e r s using M a n d a r i n speech.
As
c o m p a r e d to t h e first ver- sion, t h i s m a c h i n e is b a s e d on a single c h i p w i t h all a l g o r i t h m s significantly simplified, but provides i m p r o v e d c h a r a c t e r correct r a t e at higher s p e e d . This i s achieved b y m a n y n e w techniques, p r i m a r i l y a s e g m e n t a l probability m o d e l i n g technique for syllable recognition specially considering t h e characteristics of M a n d a r i n syllables, and a word-lattice-based Chinese c h a r a c t e r b i g r a m for c h a r a c t e r identification specially considering t h e s t r u c t u r e of Chi- nese language.ACKNOWLEDGMENT
T h e work described in t h i s p a p e r i s s u p p o r t e d b y t h e N a t i o n a l Science Council of Republic of C h i n a f r o m 1984 t o 1993, and per- f o r m e d i n t h e S p e e c h L a b o r a t o r y of N a t i o n a l T a i w a n University i n Taipei.
References
L. S. Lee, C. Y. Tseng, H. Y. Gu, K. J. Chen, F. H. Liu, C. H. Chang, S. H. Hsieh, C. H. Chen, “A Real-time Mandarin Dictation Machine for Chinese Language with Unlimited Texts and Very Large Vocabulary,” ICASSP
,
Apr 1990, Albuquerque, NM, USA, pp.65-68.L. S. Lee, C. Y. Tseng, H. Y. Gu, F. H. Liu, C. H. Chang, Y. H. Lin, Y. Lee, S. L. Tu, S. H. Hsieh, C. H. Chen,“Golden Mandarin (I)
-
A Real-time Mandarin Speech Dictation Machine for Chinese Language with Very Large Vocabulary,” t o appear in IEEE !t’ranaactions on Speech and Audio Processing, Vol. 1, NO. 2, Apr 1993.L. S. Lee, C. Y. Tseng, F. H. Liu, C. H. Chang, H. Y. Gu, S. H. Haieh, C. H. Chen, “Special Speech Recognition Approaches for t h e Highly Confusing Mandarin Syllables Baaed on Hidden Markov Models,” Computer Speech and Language, Vol. 6, No. 2 , Apr 1991, pp.181-201.
B. H. Juang and L. R. Rabiner, “Mixture Autoregressive Hid- den Markov Models for Speech Signals,”IEEE Transactions on
A S S P , pp. 1404-1413, 1985.
H. Y. Gu, C. Y. Tseng and L. S. Lee, “Markov Modeling of Man- darin Chinese for Decoding t h e Phonetic Sequence into Chinese Characters,” Computer Speech and Language, Vol. 5, No. 4, Oct 1991, pp.368377.
S. M. Katz, “Estimation of Probabilities from Sparse D a t a for t h e Language Model component of a Speech Recognizer,” IEEE
Transactions on A S S P , Vol. 35, pp.4OCL 411, 1987.
L. F. Chien, K. C. Chen and L. S. Lee, “A Beat-firat Lan- guage Processing Model Integrating the Unification Grammar and Markov Language Model for Speech Recognition Applica. tions, ” t o appear on IEEE Transactions on Speech and Audio
Processing, Vol. 1, NO. 2 , Apr 1993.