A Multi-level Ant-based Algorithm
for Fuzzy Data Mining
Tzung-Pei Hong Ya-Fang Tung Shyue-Liang Wang Yu-Lung Wu
Dept. of CSIE Dept. of Info. Management Dept. of Info. Management Dept. of Info. Management
Nat’l.University of Kaohsiung I-Shou University Nat’l.University of Kaohsiung I-Shou University
Kaohsiung, Taiwan Kaohsiung, Taiwan Kaohsiung, Taiwan Kaohsiung, Taiwan
[email protected] [email protected] [email protected] [email protected]
Abstract—In the past, we proposed a mining algorithm to find suitable membership functions for fuzzy association rules based on the ant colony systems. In that approach, the precision was limited since binary bits were adopted to encode the membership functions. The paper thus extends the original approach for increasing the accuracy of the results by adding multi-level processing. A multi-level ant colony framework is thus designed and an algorithm based on the structure is proposed to achieve the purpose. The proposed approach first transforms the fuzzy mining problem into a multi-stage graph, with each route representing a possible set of membership functions. The membership functions derived in a level will be refined in the next level. The final membership functions in the last level are then output to the rule-mining phase for finding fuzzy association rules. The experimental results show that the proposed multi-level ant colony systems mining approach can get better results than the previous one.
Keywords: data mining, ant colony system, fuzzy set, membership function, multi-stage graph.
I. INTRODUCTION
Due to the fast growing of data mining, many techniques and applications related to this field have appeared. Several kinds of knowledge may be derived, such as classification rules, clustering, association rules, and among others. Especially, inducing association rules from transaction data is very commonly applied in our life. It has received a great deal of attention in 1993 [1].
Besides, the fuzzy set theory has been used more and more frequently in intelligent systems because of its simplicity and similarity to human reasoning [11]. As to fuzzy data mining, Hong et al. integrated the fuzzy-set concepts and the Apriori mining algorithm to find fuzzy association rules [8]. It is important to define an appropriate set of membership functions, because it may have a critical influence on the final mining results in fuzzy data mining. A GA-based fuzzy data-mining method for extracting both association rules and membership functions from quantitative transactions was thus proposed [7].
Ant Colony System[2][5][6] has recently been successfully adopted to find nearly optimal solutions for difficult NP-hard problems, such as the Traveling Salesman Problem (TSP), Job Schedule Problem (JSP), Vehicle Routing Problems (VRP), etc
[3][6][15]. The Ant Colony System algorithm has also emerged as a promising technique to discovery useful and interesting knowledge from a database such as finding classification rules [10][12]. However, the researches about data mining based on the ant colony system are still rare. Parpinelli et al. proposed an ACS-based approach to find rules from medical data [13]. Cordon and Herrera also proposed the mining of classification rules [4]. In this paper, we propose a multi-layered ant colony algorithm to solve the problem in which the maximum quantity of an item in the transactions may be large. It is an extension of our previous approach [9] by adding multi-level processing. Numerical experiments on the proposed algorithm are also performed to show its effectiveness.
The remaining parts of the paper are organized as follows. The proposed multi-level ACS-based mining framework is presented in Section 2. The basic principle to use the ACS to fuzzy data mining is explained in Section 3. The proposed multiple-level ACS-mining algorithm is described in details in Section 4. Experimental results are shown in Section 5. Conclusion and future works are given in Section 6.
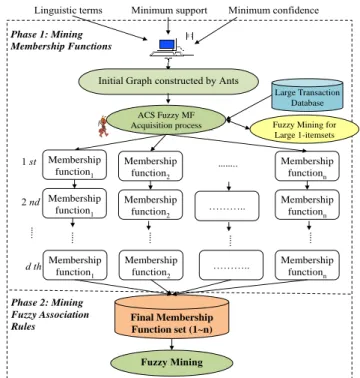
II. MULTI-LEVEL ACS-BASEDMININGFRAMWORK The proposed multi-level ACS-based framework for fuzzy data mining is shown in Fig. 1, where each item has its own set of membership functions. Each set of membership functions is then fed into the ant colony system to search for the final appropriate set. When the termination condition is reached, the best set of membership functions (with the highest fitness value) is then used to mine fuzzy association rules from a database.
In this paper, the ACS algorithm plays an important role in extracting the membership functions in Phase 1. In the past, Parpinelli et al. proposed the AntMiner to discover association rules [13]. They coped with categorical attributes and discrete values and showed that the ACS algorithm performed well on handling discrete values in a solution space. In this paper, we further discuss the issue of handling quantitative and fuzzy values.
III. USINGACSONFUZZYDATAMINING
This section shows how the ACS algorithm can be applied to fuzzy data mining. It includes the following subsections:
encoding representation, pheromone initialization, state transition rule, and pheromone updating rules of the ACS algorithm. d th 2 nd 1 st Linguistic terms Large Transaction Database ……... ACS Fuzzy MF
Acquisition process Fuzzy Mining for Large 1-itemsets Minimum confidence
Phase 1: Mining Membership Functions
Initial Graph constructed by Ants
Membership function1 Membership function2 Membership functionn …….. Minimum support Membership function1 Membership function2 Membership functionn ……….. … .. ….. ….. ….. Membership function1 Membership function2 Membership functionn ……….. … .. Final Membership Function set (1~n) Fuzzy Mining Phase 2: Mining Fuzzy Association Rules
Figure 1. The multi-level ACS-based framework for fuzzy data mining
A. Encoding Representation
As the same as the previous approach in [10], the membership functions of each item are encoded into a pair of binary strings. Each item has a set of membership functions, which are assumed to be the shape of an isosceles triangle for simplicity. The membership functions stand for linguistic terms, such as low, middle, high. Each membership function thus has two parameters, center and half the spread (called span). First, we use n binary-bits to encode the center and the span of a membership function for an item according to the quantity range of the item in the database. For example, if the quantity range of an item is among 0 to 15, we may use four bits to encode each center and the span of the item. Assume there are three linguistic terms (membership functions) for an item Ij. Let Cj1, Cj2, Cj3 denote the three centers of the linguistic terms and Sj1, Sj2, Sj3 represent their spans. The pair of binary strings for the centers of the item will thus be represented by 12 bits, such as {(0, 0, 1, 1) (0, 1, 1, 1) (1, 1, 0, 1)} in Fig. 2. Similarly, the spans of each linguistic term will be encoded as {(0, 0, 1, 1) (0, 1, 1, 0) (0, 1, 1, 1)}. 1 1 0 0 1 1 0 0 1 1 0 0 1 1 0 0 0 1 1 0 1 1 1 0 0 1 1 0 1 1 1 0 1 1 1 0 1 0 1 1 1 1 1 0 1 0 1 1 Center Span Ci1 Si1 Si2 Si3 Ci2 Ci3 23 22 21 20
Figure 2. The string representation of membership functions for an item
For the above case, the corresponding representation of membership functions for Item Ij and its function shape are showed in Fig. 3, where the three centers are {3, 7, 13} and the three spans are {3, 6, 7} from the coding scheme. However, there is a constraint on generating the span value. That is, if the span of a region spread over its neighboring regions, its value will be reduced to the boundary of the neighboring regions.
Figure 3. The representation of membership functions for an item After the membership functions are encoded, the ACS algorithm can then be applied to find the (nearly) optimal solution. As can be observed in Fig. 4, each position of a string includes two bits, one for the center and the other for the span. Thus there are four cases, namely (0, 0), (0, 1), (1, 0), (1, 1). If the decision of each pair of bits is thought of as a node, then the problem can be transformed into a multi-stage decision problem. Although it can be solved by the dynamical programming techniques, it is still NP-hard.
Figure 4. The multi-stage graph transformed for the proposed ACS-based mining algorithm
Since the problem has been converted into an optimization problem in a multi-stage graph, the ACS algorithm can thus be used here to solve it. Just like solving TSP (traveling salesman problem), each ant can choose one of the four alternatives as its node in every stage. Therefore for the above example, there are twelve nodes and four selections of each node. As shown in Figure 4, there are 12 stages and each stage has four nodes. An ant will thus pass through the nodes, each of which is composed of a pair of (Cj, Sj). For the example in Figure 2, the four nodes (0, 0), (0, 0), (1, 1), (1, 1) will form a path for the first membership function. When an ant finishes a route with twelve nodes, one possible set of membership functions of an item will be generated. Ants thus continue repeating this process until the termination condition is reached. The best set of membership functions (with the highest amounts of pheromone) obtained so far is thus output for fuzzy data mining.
B. Pheromone initialization
The initial amount of pheromone deposited at each path is 0.5. While an ant goes through the path, it will deposit pheromone on the path between the two nodes.
C. State transition rule
Every ant selects the next node with a calculated probability. The state transition rule for an ant at node j to node
n at the next stage is given as follows:
otherwise P q q if i jn jn jn N m , , }, { max arg 0
where τjn(t) is the current pheromone left on the path between nodes j and n in time t, ηjn is the coefficient value depending on the problem domain, q is a random variable between [0, 1], and
q0 (0 ≦ q0 ≦ 1) is a predefined parameter. When the value of q is greater than the predefined parameter value, the formula shown below is used to decide the transition probability of each possible next node:
jm m jm jn jn jn t t t P
( ) ) ( ) ( where node m must be at the same stage with node n. In this paper, we assume the coefficients of η’s are the same for all the transitions for simplicity.
D. Pheromone updating rules
One of the differences between the ant colony system and the ant system is the pheromone updating rules. In our proposed method, there are two updating rules for artificial ants to update the pheromone amounts on the edges to search for (nearly) optimal solutions and to avoid the stagnating evolutionary process. One is the local updating rule and the other is the global updating rule. They are stated as follows.
1) The Local updating rule
The local updating rule prevents ants from falling into local optima while they are searching on the paths. It can appropriately adjust the amount of pheromone while ants construct the path. The local updating rule is given below:
0 ) ( ) 1 ( ) 1 (
jn t jn t where (1-ρ) is a parameter used to adjust the pheromone on the constructed edge and τ0 is the initial pheromone value of the edge.
2) The Global updating rule
The goal of the global updating rule is to allow that the good paths can be further exploited. While all ants in an iteration have completed their trails, the pheromone of the best path is increased and those of the others are decreased. The global updating rule used in this paper is iteration-best given below:
jn jn
jn
(1 ) where α is the pheromone decay parameter and △τjn is calculated as follows: path best iteration jn if path best iteration jn if value fitness jn , 0 ,
where the parameter β is used to adjust the fitness value to the pheromone change. An iteration-best path is the best path among the ones found by all the ants in each iteration. The fitness values of the tours constructed by the ants will be introduced in the next section. The one with the highest fitness value in each iteration will be the global best tour which is then applied to the global updating rule here.
IV. MULTI-LEVELACS-BASEDFUZZYMINING
In this section, the proposed multi-level ACS-based mining algorithm is described below. Some basic set-up is first introduced. A flow chart for the proposed algorithm is then designed and explained. The entire algorithm is finally given.
A. Initial Population and Fitness Functions
As mentioned above, each item will have a set of isosceles-triangular membership functions. The membership functions stand for the linguistic terms such as low, middle, and
high. The proposed approach would thus like to search for an
appropriate set of membership functions from a given set of quantitative dataset. Since the ant algorithm has to use some ants to search for the solutions, a population of ants is thus initialized and then updated during the evolution process.
The fitness value of a possible solution is according to the criteria proposed by Hong et al. [7], which is defined as follows:
y suitabilit
L f | 1| .
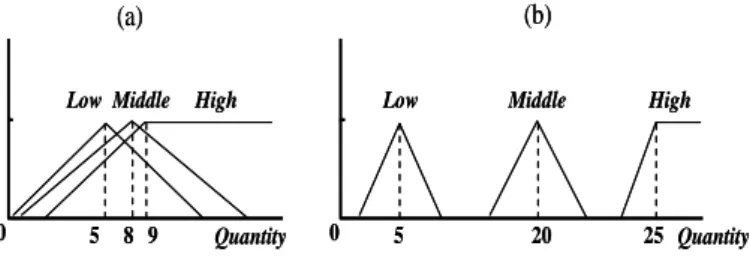
where |L1| is the number of large 1-itemsets obtained by using the set of membership functions in an ant. The suitability factor is designed to reduce the occurrence of the two bad kinds of membership functions shown in Fig. 5, where the first one is too redundant, and the second one is too separate.
5 8 9
Low Middle High
Quantity
0
(a)
5 20 25
Low Middle High
Quantity
0
(b)
5 8 9
Low Middle High
Quantity
0
(a)
5 20 25
Low Middle High
Quantity
0
(b)
Figure 5. The two bad types of membership functions
The suitability of the membership functions includes two items, the overlap factor designed for avoiding the first bad case and the coverage factor designed for avoiding the second bad case. The calculation for the suitability for Item Ij is thus designed as follows: ). ( _ ) ( _ )
(Ij overlap factor Ij coverage factor Ij
y
suitabilit
The overlap factor is defined as follows:
. ] 1 ) 1 ), ) , ( ) , ( (( [ _ 1 1 1
k j jk jk j R R min R R overlap max factor overlapThe term overlap(Rjk, Rji) represents the overlap ratio of two membership functions Rjk and Rji, which is defined as the overlap length divided by the minimum span (half the spread) of the two functions. If the overlap length is larger than the span, then appropriate punishment must then be considered in this case. The coverage factor is defined as follows:
. ) ( ) ,... ( _ j jk j1 I max R R range 1 factor coverage
The term range (Rj1, Rj2, …, Rjk) is the coverage range of the membership functions, and max (Ij) is the maximum quantity of Ij in the transactions. The coverage factor of a set of membership functions for an item Ij is thus defined as the coverage range of the membership functions divided by the maximum quantity of that item in the transactions. The more the coverage ratio is, the better the derived membership functions are.
B. The design concept
In this paper, a fixed number of k bits are used for encoding membership functions. The maximum quantity value M of each item in the transactions is first found to decide the number of levels to run. The scale d used as the unit for the membership functions of an item in a level is calculated as follows:
Mk d 2
The best membership functions obtained after a level are then shown in Fig. 6.
0 d 2d 3d 4d
R1
5d
R2
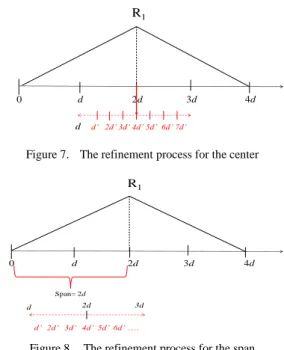
Figure 6. The membership functions obtained after a level The membership functions obtained at this level are then refined in the next level. A new scale d’ to refine the center and the span is then formed as follows:
dk d 2 2 '
The membership functions are then tuned using the new scale to get more precise values of each center and span of a fuzzy region in the ACS algorithm. The adjusting scope is 2d from the previous solutions, with the concept shown in Fig. 7. The center of a membership function is adjusted between d and 3d, the new scale d’ is the new unit for search.
The adjusting process for the span of a membership function is similar to that for the center. Assume the original span is s, then the search range for the next level will be from
s-d to s+d using the new scale d’. An example is shown in Fig.
8, where the original span is 2d and the adjusting range is from
d to 3d.
0 d 2d 3d 4d
R1
d’ 2d’ 3d’ 4d’ 5d’ 6d’ 7d’
d
Figure 7. The refinement process for the center
0 d 2d 3d 4d R1 d’ 2d’ 3d’ 4d’ 5d’ 6d’ …. Span= 2d 2d d 3d
Figure 8. The refinement process for the span
The scale d’ is then further shortened in the next level and the same steps are repeated again until some termination criterion for precision is reached.
C. The proposed multi-level ACS-based Mining algorithm
As mentioned above, the proposed approach applies the ACS algorithm to extract the rough membership functions and repeat the ACS algorithm to get more precise ones. The following parameters will be used in the approach, including the number of artificial ants, the minimum pheromone ratio of an ant, the evaporation ratio of pheromone, the local updating ratio, and the global updating ratio. In this section, the proposed multi-layered ant-colony algorithm is stated to solve the problem in which the maximum quantitative number in the transactions is large. It is an extension of the first approach with multi-level processing. The algorithm is described as follows.
The proposed algorithm: INPUT:
(1) n quantitative transaction data,
(2) a set of m items, each with l predefined linguistic terms (different items may have different l values),
(3) a support threshold α, (4) a confidence threshold λ,
(5) a maximum number G of iterations, and
(6) a number k of encoding bits for a membership function OUTPUT:
A set of fuzzy association rules with its associated set of membership functions.
STEP 1: Let p = 1, where p is used to keep the identity number of the item to be processed.
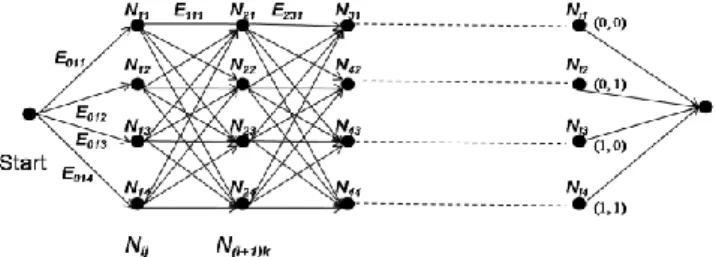
STEP 2: Let the multi-stage graph for the fuzzy mining problem be (N, E), where N is the set of nodes and E is the set of edges (Fig. 10). Also denote the j-node in the i-th stage as Nij, and the edge from Nij to N(i+1)k as Eijk. Initially set the pheromone on every edge Eijk as τ0 (usually set as 0.5).
Figure 9. The multi-stage graph for the fuzzy mining problem STEP 3: Find out the maximum quantitative value M of the
p-th item in the transactions.
STEP 4: Find the scale d for the searching process as follows: Mk d 2
where k is the number of encoding bits for a membership function of the p-th item. The unit used for the membership functions of the p-th item in this phase is then d (Fig. 10).
Figure 10. The unit used for the membership functions STEP 5: Let the initial generation g = 1.
STEP 6: Find a complete route for each artificial ant Antq by selecting the edges from start to end according to the state transaction rule.
STEP 7: Update the pheromone of the edges which an ant just passed through according to the local updating rule.
STEP 8: Evaluate the fitness value of the solution (membership functions) obtained by each artificial ant according to the criteria stated above.
STEP 9: Find the ant with the highest fitness value among all the ants and update the pheromone of the best route according to the global updating rule.
STEP 10: If the generation g is equal to the termination generation G, keep the current best membership functions of the p-th item and go to the next step; otherwise, g = g + 1 and go to STEP 6.
STEP 11: Find the new scale d’, which is more precise than the original one as follows:
dk d 2 2 '
STEP 12: If 2d is less than 2k and the previous d’’ is not 1, go to STEP 19 for processing the next item. Otherwise, set d =
d’, d’’ = d’, and go to Step 5 for getting more precise
membership functions.
STEP 13: If p ≠ m, set p = p + 1 and go to STEP 2 for processing the next item; otherwise, stop the algorithm and output the membership functions.
The final set of membership functions output in STEP 13 and the 1-itemsets obtained from the best ant are then used to mine fuzzy association rules from the given database.
V. EXPERIMENTS
In this section, experiments for a comparison of the multi-level ant-mining approach and the original approach are described. They were implemented in C/C++ on a personal computer with AMD Athlon(tm) 64 Processor 3200+ and 1 GB RAM. There were a total of 64 items and 10,000 transactions used in the experiments. The maximum quantities of the items among the transactions were up to 128. The proposed multi-level algorithm used four bits to encode a membership function. Each item had three linguistic terms and totally 12 bits were thus used for an item. Due to the short bits of encoding, three levels of execution were needed in the proposed approach to extract the accurate membership functions. The minimum support for association rules was set at 0.04. The proposed approach searched for the membership functions of each item by the ACS algorithm. The parameters in the ACS algorithm were set as follows. The initial size of ants was set at 10, the initial pheromone was 0.5, the evaporation ratio α was 0.9, the local updating ratio ρ was 0.1. and the parameter β was set 1. The average fitness values of the artificial ants along with different numbers of generations by the proposed and the previous ones are shown in Fig. 11. It can be easily observed that the proposed method had a better performance on the average fitness values than the original method in [10].
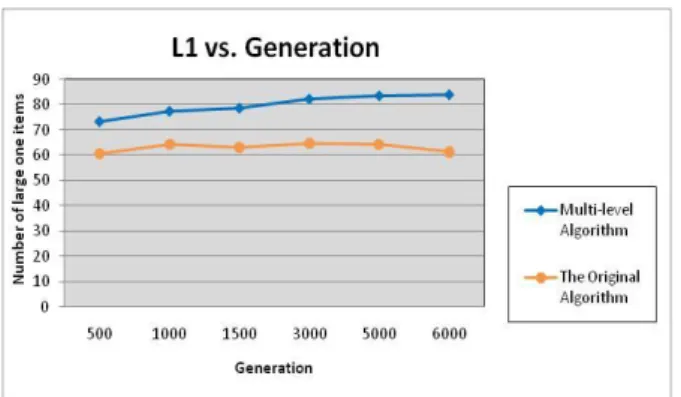
Figure 11. The average fitness values by the two algorithms Experiments were then made to show the numbers of large 1-itemsets along with different numbers of generations. The results are shown in Fig. 12. It can also be observed that the proposed approach could derive more amounts of knowledge than the original method.
Figure 12. The average number of large 1-itemsets by the two algorithms
VI. CONCLUSIONANDFUTUREWORK
The paper has described a multi-level ACS-based mining algorithm to extract an appropriate set of membership functions in fuzzy data mining. It first transforms the mining problem into a multi-stage graph, with each route representing a possible set of membership functions. It also adopts multi-layer processing such that the precision of the final membership functions may be gradually improved. The approach is thus suitable for solving the problem in which the maximum quantity of an item in the transactions may be large. The experimental results show that the proposed multi-level ant-colony mining approach can get a better result than our previous approach. However, the experiments should be taken into more parameters and comparisons.
More works need to be done in the future. For example, we may attempt to study the effects of different encoding methods and different variant ant algorithms on the proposed algorithm. We may also apply the algorithm to solve some real-world mining problems. Defining more constraints about the center and the span of a membership function may also be worthy studying. The choice of fitness functions can be further discussed as well.
REFERENCES
[1] R. Agrawal, T. Imielinski, and A. Swami, ” Mining association rules between sets of items in large databases,” Proceedings of International Conference on the Management of Data ACM SIGMOD. USA: Washington, 1993.
[2] A. Colorni, M. Dorigo, and V. Maniezzo, “Distributed optimization by ant colonies,” The First European Conference on Artificial Life, pp. 134-142, 1991
[3] A. Colorni, M. Dorigo, V. Maniezzo, and M. Trubian, “Ant system for job-shop scheduling,” Belgian Journal of Operations Research, Statistics and Computer Science, vol. 34, pp. 39-53, 1994.
[4] J. C. Cordon, and F. Herrera, ”Learning fuzzy rules using ant colony optimization,” The Second International Workshop on Ant Algorithms, pp.13-21, 2002
[5] M. Dorigo, V. Maniezzo, and A. Colorni,, “Ant system: optimization by a colony of cooperating agents,” Transactions on Systems, Man, and Cybernetics-Part B, vol. 26, pp. 29-41, 1996.
[6] M. Dorigo, and L. M. Gambardella, “Ant colony system: a cooperative learning approach to the traveling salesman problem,” Transactions on Evolutionary Computation, vol. 1, pp. 53-66, 1997.
[7] T. P. Hong, C. H. Chen, Y. L. Wu and Y. C. Lee, “A GA-based fuzzy mining approach to achieve a trade-off between number of rules and suitability of membership functions,” Soft Computing: A Fusion of
Foundations, Methodologies and Applications, vol. 10, pp. 1091-1101, 2006.
[8] T. P. Hong, C. S. Kuo and S. C. Chi, “Trade-off between time complexity and number of rules for fuzzy mining from quantitative data. Uncertainty, Fuzziness, and Knowledge-Based Systems, vol. 9, pp. 587-604, 2001.
[9] T. P. Hong, Y. F. Tung, M. T. Wu, S. L. Wang and Y. L. Wu, ” Extracting membership functions in fuzzy data mining by ant colony systems,” Proceedings of The International Conference on Machine Learning and Cybernetics. China: Kunming, 2008.
[10] W. J. Jiang, Y. H. Xu and Y. S. Xu, “A novel data mining algorithm based on ant colony system,” Proceedings of the Fourth International Conference on Machine Learning and Cybernetics. Guangzhou., 2005. [11] A. Kandel, “Fuzzy expert systems,” CRC Press, Boca Raton, pp. 8-19,
1992.
[12] D. Martens, M. D. Backer, R. Haesen, J. Vanthienen, M. Snoeck and B. Baesens, “Classification with ant colony optimization,” Transaction on Evolutionary Computation, vol. 11, pp. 651-665, 2007.
[13] R. S. Parpinelli, H. S. Lopes and A. A. Freitas,, “An ant colony based system for data mining: application to medical data,” Proceedings of the Genetic and Evolutionary Computation Conference, pp. 791-798, 2001.
[14] T. Stützle, and H. H. Hoos, “MAX-MIN ant system,” Future Generation Computer System, vol. 16, pp. 889–914, 2000.