Mining a Complete Set of Fuzzy Multiple-Level Rules
Tzung-Pei Hong1,2*, Chu-Tien Chiu3, Shyue-Liang Wang4, and Kuei-Ying Lin51
Department of Computer Science and Information Engineering National University of Kaohsiung, Kaohsiung, Taiwan
2
Department of Computer Science and Engineering National Sun Yat-sen University, Kaohsiung, Taiwan
3
Department of Information Management Cheng Shiu University, Kaohsiung, Taiwan
4
Department of Information Management National University of Kaohsiung, Kaohsiung, Taiwan
5
Telecommunication Laboratories
Chunghwa Telecom Co., Ltd, Taoyuan, Taiwan
[email protected], [email protected], [email protected], [email protected]
Abstract
Data mining is the process of extracting desirable knowledge or interesting patterns from existing databases for specific purposes. Most conventional data-mining algorithms identify relationships among transactions using binary values and find rules at a single-concept level. Transactions with quantitative values and items with hierarchical relationships are, however, commonly seen in real-world applications. In the past, we proposed a fuzzy multiple-level mining algorithm for extracting knowledge implicit in transactions stored as quantitative values. In that algorithm, each attribute uses only the linguistic term with the maximum cardinality in the mining process. The number of linguistic items is thus the same as that of the original attributes in the transaction database. This constraint allows the processing time as efficient as mining of non-fuzzy association rules. However, the fuzzy association rules derived in that way are not complete, as some possible fuzzy association rules might be missing. This paper proposes a new fuzzy data-mining algorithm for extracting all possible fuzzy association rules from transactions stored as quantitative values. The proposed algorithm can derive a more complete set of rules but with more computation time than the previous method. Trade-off thus exists between the computation time and the completeness of rules. Choosing an appropriate mining method thus depends on the requirement of the application domains.
Keywords: association rule, data mining, fuzzy set, multiple-level rule, quantitative value.
--- * Corresponding author
Introduction
Data mining has become a research area of great interest in recent years, as the amounts of data in many databases have grown explosively. It involves applying specific algorithms for extracting patterns or rules from data sets in a particular representation. Many successful applications of data mining have been demonstrated in marketing, business, medical analysis, product control, engineering design, bioinformatics and scientific exploration, among others. The technology promises opportunity to discover useful information and important patterns from large databases for assisting decision making.
Deriving association rules from transaction databases is most commonly seen in data mining [1-2, 6, 10-13, 15-16, 24, 31-32, 37]. It discovers relationships among items such that the presence of certain items in a transaction tends to imply the presence of certain other items. Most previous studies concentrated on discovering relationships between transaction items with binary values on single level of taxonomy. However, transaction data in real-world applications usually consist of quantitative values and items are often organized in taxonomy. Therefore designing a sophisticated data-mining algorithm, that is able to deal with quantitative data on multiple levels of items, presents a challenge in research.
In the past, Agrawal and his co-workers proposed several mining algorithms for finding
association rules from transaction data based on the concept of large itemsets [1-2, 31]. They
also proposed a method [32] for mining association rules from data sets with quantitative and
categorical attributes. Their proposed method first determined the number of partitions for
each quantitative attribute and then mapped all possible values of each attribute onto a set of
consecutive integers. Other methods had also been proposed to handle numeric attributes and
and permitted association rules to contain single uninstantiated conditions on the left-hand
side of the rules [12]. They also proposed schemes for determining conditions where rule
confidence or support values were maximized. However, their schemes were suitable only for
single optimal region. Rastogi and Shim extended the approach to more than one optimal
region and showed that the problem was NP-hard even for cases involving one un-instantiated
numeric attribute [28-29].
Fuzzy set theory has been used more and more frequently in intelligent systems because
of its simplicity and similarity to human reasoning [23, 39]. Several fuzzy learning algorithms
for inducing rules from given sets of data have been designed and well applied in certain
domains [3-4, 9, 14, 18-20, 30-31, 34-35]. Strategies based on decision trees were proposed in
[7-8, 26-27, 30, 36, 38]. Wang et al. proposed a fuzzy version space learning strategy for
managing vague information [34]. Hong et al. also proposed a fuzzy mining algorithm for
managing quantitative data [17].
In [22], we proposed a fuzzy multiple-level mining algorithm for extracting implicit
knowledge from transactions stored as quantitative values. In that algorithm, each attribute
uses only the linguistic term with the maximum cardinality in the mining process. The number
of linguistic items is thus the same as that of the original attributes in the transaction database.
This constraint allows the processing time as efficient as mining of non-fuzzy association
possible fuzzy association rules might be missing. In this work, we propose a new fuzzy
data-mining algorithm for extracting all possible fuzzy association rules from transactions
stored as quantitative values. The proposed algorithm considers all important linguistic terms
in the mining process. The main contribution is that it can derive a more complete set of rules
than the previous method. However, due to more linguistic terms are involved in the mining
process, it consumes more computation time. Trade-off thus exists between the computation
time and the completeness of rules generated.
The rest of this paper is organized as follows. Data mining with multiple-level taxonomy
is described in Section 2. Notation used in this paper is defined in Section 3. The algorithm
for mining a complete set of fuzzy association rules is proposed in Section 4. An example to
illustrate the proposed algorithm is given in Section 5. Conclusion is stated in Section 6.
2. Data mining with multiple-level taxonomy
Previous studies of data mining focused on finding association rules on a single-concept
level. However, mining multiple-concept-level rules may lead to discovery of more general
and important knowledge from data. Taxonomies of data items are usually predefined in
real-world applications and can be represented using hierarchy trees. Terminal nodes on the
trees represent actual items appearing in transactions. Internal nodes represent classes or
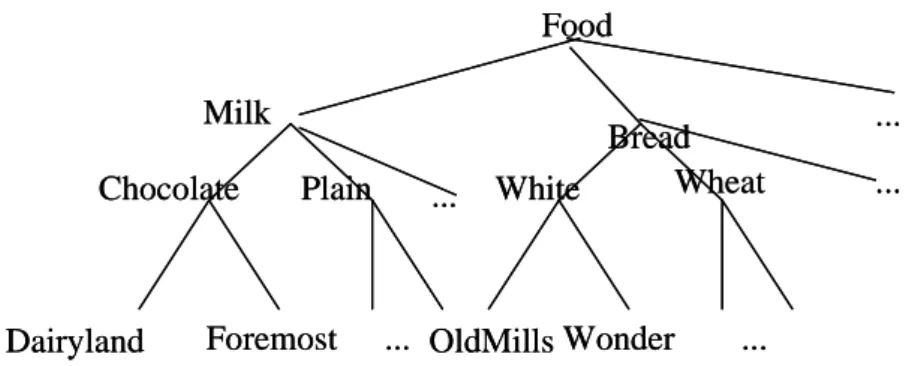
Figure 1: An example of taxonomy
In Figure 1, the root node is on level 0, the internal nodes representing categories (such
as “milk”) are on level 1, the internal nodes representing flavors (such as “chocolate”) are on
level 2, and the terminal nodes representing brands (such as “Foremost”) are on level 3. Only
terminal nodes appear in transactions.
Han and Fu first proposed a method for finding level-crossing association rules on
multiple levels of taxonomy [15]. Their method finds flexible association rules not confined
to strict, pre-arranged conceptual hierarchies. Nodes in predefined taxonomies are first
encoded using sequences of numbers and the symbol "*" according to their positions in the
hierarchy tree. For example, the internal node "Milk" in Figure 1 would be represented by 1**,
the internal node "Chocolate" by 11*, and the terminal node "Dairyland" by 111. A top-down
progressively deepening search approach is used and exploration of “level-crossing”
associational relationships is allowed. Candidate itemsets on certain levels may thus contain
items from other levels. For example, candidate 2-itemsets on level 2 are not limited to Food ... Milk Plain Chocolate ... ... White Wheat
Dairyland Foremost OldMills Wonder
Bread ... ... Food ... Milk Plain Chocolate ... ... White Wheat
Dairyland Foremost OldMills Wonder
Bread
... ...
containing only pairs of large items on level 2. Instead, large items on level 2 may be paired
with large items on level 1 to form candidate 2-itemsets on level 2 (such as {11*, 2**}). Han
and Fu’s concepts will be used in our approach to mine fuzzy association rules.
3. Notation
Notation used in this paper is stated as follows.
n: the number of transactions;
i
D : the i-th transaction, 1≤i≤n;
x: the number of levels in a given taxonomy.
k
m : the number of items (nodes) on level k, 1≤k≤x;
k j
I : the j-th item on level k, 1≤k≤x; 1≤j≤ mk;
k j
h : the number of fuzzy regions forIkj;
k jl
R : the l-th fuzzy region of Ikj, 1≤l≤ k j h ;
k ij
v : the quantitative value of Ikj inDi;
k ij
f
: the fuzzy set converted fromvijk;k ijl
f : the membership value of Di in regionRkjl;
k jl
count : the summation of fijlk, i=1 to n;
α
: the predefined minimum support value;k r
C : the set of candidate itemsets with r items on level k; k
r
L : the set of large itemsets with r items on level k.
4. Mining a complete set of fuzzy multi-level association rules
In [22], we proposed a fuzzy multiple-level mining approach where each attribute used
only the linguistic term with the maximum count in the mining process. In this work, all
linguistic terms are used. However, linguistic terms belonging to the same attribute cannot
belong to the same itemset. The computation is more complex than that in [22] since all
possible linguistic terms are involved in calculating large itemsets, but the derived set of
association rules is more complete.
The proposed fuzzy mining algorithm first encodes items (nodes) in a given taxonomy
similar to Han and Fu's approach [15]. It then uses membership functions to transform each
quantitative value into a fuzzy set in linguistic terms. A top-down progressive deepening
approach is used to find large itemsets level-by-level. The algorithm then calculates the scalar
cardinality of each linguistic term on all transaction data. A mining process using fuzzy counts
is then performed to find fuzzy multiple-level association rules. Details of the proposed
The mining algorithm:
INPUT: A body of n quantitative transaction data, a set of membership functions, a predefined
taxonomy, a predefined minimum support value α, and a predefined minimum confidence valueλ.
OUTPUT: A complete set of fuzzy multiple-level association rules.
STEP 1: Encode each item in the predefined taxonomy using a sequence of numbers and the
symbol "*", with the t-th digit representing the branch number on level t.
STEP 2: Translate the item names in the transaction data according to the encoding scheme.
STEP 3: Set k = 1,where k is used to store the level number being processed.
STEP 4: Group the items with the same first k digits in each transaction datum Di, calculate
the count (occurring number) of each group in all the transactions, and remove the
groups with their counts less than α. Denote the amount of Di for the j-th group on
level k as vijk.
STEP 5: Transform the quantitative valuevijk of each encoded group name Ikj in transaction
datum Di into a fuzzy set fijk represented as + + + k jh k ijh k j k ij k j k ij R f R f R f .... 2 2 1 1 using the
given membership functions, where h is the number of fuzzy regions for Ikj, k jl
R is
the l-th fuzzy region of Ikj, 1≤l ≤h, and fijlk isvijk’s fuzzy membership value in
regionRkjl.
to form the candidate set C1k.
STEP 7: Calculate the scalar cardinality countkjl of each fuzzy region Rkjl in k
C1 from the
transaction data as:
∑
= = n i k ijl k jl f count 1 .STEP 8: Check whether the value countkjlof each region R kjl in Ck
1 is larger than or
equal to the predefined minimum support value α . If k jl
R is equal to or greater
than the minimum support value, put it in the large 1-itemsets ( k
L1) for level k. That
is,
{
k k}
jl k jl k jl k C R count R L1 = ≥α
, ∈ 1 .STEP 9: If k reaches the level number of the taxonomy, then go to STEP 17 to find association
rules; otherwise, if k
L1 is null, then set k = k + 1 and go to STEP 4; otherwise, do the
next step.
STEP 10: Generate the candidate set k
C2 from 1 1 L , 2 1 L , …, Lk 1 to find “level-crossing”
large itemsets. Each 2-itemset in k
C2 must contain at least one region in
k L1, and
the item name of the other region may not be its ancestor in the taxonomy. Also,
the two regions can not have the same item name. All the possible 2-itemsets are
collected as k C2.
STEP 11: Do the following substeps for each newly formed candidate 2-itemset s with regions
(s1, s2) in k C2:
(a) Calculate the fuzzy value of s in each transaction datum Di as fis = fis1Λfis2 ,
where j
is
f is the membership value of region sj inD If the minimum operator is i.
used for the intersection, then fis =min(fis1,fis2).
(b) Calculate the scalar cardinality of s in all the transaction data as:
counts =
∑
= n i is f 1 .(c) If counts is larger than or equal to the predefined minimum support value
α
, put s ink L2.
STEP 12: Set r = 2, where r is used to represent the number of regions stored in the current
large itemsets.
STEP 13: If k r
L is null, then set k = k + 1 and go to STEP 4; otherwise, do the next step.
STEP 14: Generate the candidate set k r
C+1 from
k r
L in a way similar to that in the apriori
algorithm. That is, the algorithm first joins k r
L and k r
L , assuming that r-1 regions
in the two itemsets are the same and the other one is different. Also the different
regions must not have a hierarchical relationship in the taxonomy. Store in k r C+1all
the itemsets with all their sub-r-itemsets in k r L .
STEP 15: Do the following substeps for each newly formed (r+1)-itemset s with regions (s1,
s2, …, sr+1) in Crk+1:
(a) Calculate the fuzzy value of s in each transaction datum Di as
r is is is is
f
f
f
f
=
Λ
Λ
...
Λ
2.
i
D If the minimum operator is used for the intersection, then
j is r j is
Min
f
f
1 1 + ==
.(b) Calculate the scalar cardinality of s in all the transaction data as:
counts =
∑
= n i is f 1 .(c) If counts is larger than or equal to the predefined minimum support value
α
, put s ink r L+1.
STEP 16: Set r = r + 1 and go to STEP 13.
STEP 17: Construct the fuzzy association rules for all large q-itemset s containing regions
(
s1, s2, ..., sq)
, q≥2, as follows.(a) Form all possible association rules thusly:
k q k k s s s s s1Λ...Λ −1Λ +1Λ...Λ → , k=1 to q.
(b) Calculate the confidence values of all association rules using the formula:
∑
∑
= = Λ Λ Λ Λ − + n i is is is is n i is q K K f f f f f 1 1 ) ... , ... ( 1 1 1 .STEP 18: Output the rules with confidence values larger than or equal to the predefined
confidence thresholdλ.
The rules output after STEP 18 can then serve as meta-knowledge concerning the given transactions.
5. An Example
In this section, an example is given to illustrate the proposed data-mining algorithm. This
is a simple example to show how the proposed algorithm generates fuzzy association rules
from quantitative transactions using taxonomy. The data set includes six transactions as
shown in Table 1.
Table 1. Six transactions in this example
TID ITEMS
T1 (Dairyland chocolate milk, 1); (Foremost chocolate milk, 4); (Old Mills white bread, 4); (Wonder white bread, 6);
(Present chocolate cookies, 7); (Linton green tea beverage, 7). T2 (Dairyland chocolate milk, 3);(Foremost chocolate milk, 3);
(Dairyland plain milk, 1); (Old Mills wheat bread, 5); (Wonder wheat bread, 3); (present lemon cookies, 4) (77 lemon cookies, 4).
T3 (Foremost chocolate milk, 2);(Old Mills white bread, 4); (Old Mills wheat bread, 4);(77 chocolate cookies, 5); (77 lemon cookies, 7)
T4 (Dairyland chocolate milk, 2); (Old Mills white bread, 5); (77 chocolate cookies, 5).
T5 (Old Mills white bread, 5); (Wonder wheat bread, 4). T6 (Dairyland chocolate milk, 3); (Foremost plain milk, 10);
(Wonder white bread, 4); (Nestle black tea beverage, 9)
Each transaction includes a transaction ID and purchased items. Each item is represented
by a tuple with two values (item name, item amount). For example, the fifth transaction
consists of five units of Old Mills white bread and four units of Wonder wheat bread. The
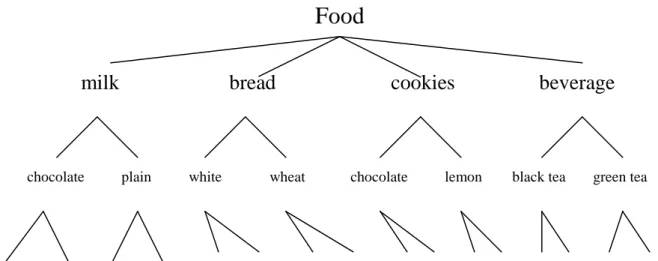
The food items in Figure 5 are first classified into four classes: milk, bread, cookie and
beverage, from top to bottom. Milk can be further classified into chocolate milk and plain
milk. There are two brands of chocolate milk, Dairyland and Foremost. Other nodes can be
classified similarly.
We also assume that the fuzzy membership functions are the same for all the items and
are as shown in Figure 6.
Figure 6. The membership functions used in this example
Food
milk
bread
cookies
beverage
chocolate plain white wheat chocolate lemon black tea green tea
Dairyland Foremost Dairyland Foremost Old Mills Wonder Old Mills Wonder Present 77 Present 77 Linton Nestle Linton Nestle
Figure 5. The predefined taxonomy in this example
0 1 6 11
Low Middle High
1
0 Membership value
In this example, amounts are represented by three fuzzy regions: Low, Middle and High.
Thus, three fuzzy membership values are produced for each item amount according to the
predefined membership functions. Note that the membership functions adopted are not
necessarily triangular. The proposed approach can also be used with other kinds of
membership functions. For the transaction data in Table 1, the proposed fuzzy mining
algorithm proceeds as follows.
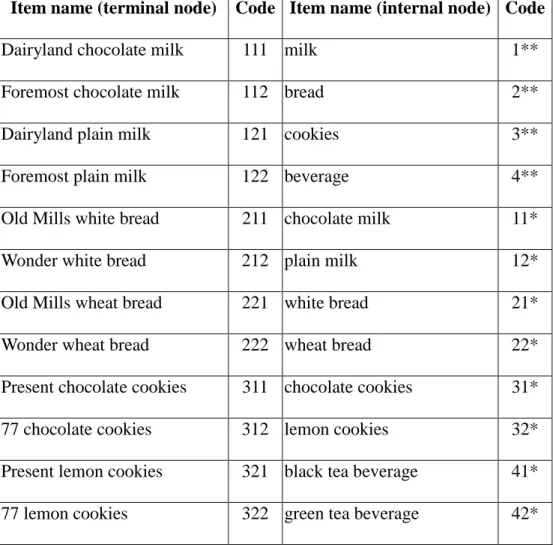
STEP 1: Each item name is first encoded using the predefined taxonomy. Results are
shown in Table 2.
Table 2. Codes of item names
Item name (terminal node) Code Item name (internal node) Code
Dairyland chocolate milk 111 milk 1**
Foremost chocolate milk 112 bread 2**
Dairyland plain milk 121 cookies 3**
Foremost plain milk 122 beverage 4**
Old Mills white bread 211 chocolate milk 11*
Wonder white bread 212 plain milk 12*
Old Mills wheat bread 221 white bread 21*
Wonder wheat bread 222 wheat bread 22*
Present chocolate cookies 311 chocolate cookies 31*
77 chocolate cookies 312 lemon cookies 32*
Present lemon cookies 321 black tea beverage 41*
Linton black tea beverage 411 Nestle black tea beverage 412 Linton green tea beverage 421 Nestle green tea beverage 422
For example, the item ”Foremost chocolate milk” is encoded as ‘112’, in which the first
digit ’1’ represents the code ‘milk’ on level 1, the second digit ‘1’ represents the flavor
‘chocolate’ on level 2, and the third digit ‘2’ represents the brand ‘Foremost’ on level 3.
STEP 2: All the transactions shown in Table 1 are encoded using the above coding
scheme. Results are shown in Table 3.
Table 3. Encoded transaction data in the example
TID ITEMS T1 (111, 1) (112, 4) (211, 4) (212, 6) (311, 7) (421, 7) T2 (111, 3) (112, 3) (121, 1) (221, 5) (222, 3) (322, 4) (321, 4) T3 (112, 2) (211, 4) (221, 4) (312, 5) (322, 7) T4 (111, 2) (211, 5) (312, 5) T5 (211, 5) (222 ,4) T6 (111, 3) (122, 10) (212, 4) (412, 9)
STEP 3: k is initially set at 1, where k is used to store the level number being processed.
STEP 4: All the items in the transactions are first grouped on level one. Take the items in
transaction T1 as an example. The items (111, 1) and (112, 4) are grouped into (1**, 5).
Table 4. Level-1 representation in the example TID ITEMS T1 (1**, 5) (2**, 10) (3**, 7) (4**, 7) T2 (1**, 7) (2**, 8) (3**, 8) T3 (1**, 2) (2**, 8) (3**, 12) T4 (1**,2) (2**, 5) (3**,5) T5 (2**, 9) T6 (1**, 13) (2**, 4) (4**, 9)
The count of each group is then calculated. Assume that in this example, α is set as 2.1. The group 4** is removed since its support count is only 2 (T1 and T6) which is less than α.
STEP 5: The quantitative values of the items on level 1 are represented as fuzzy sets.
Take the first item in transaction T5 as an example. The amount “9” is converted into the fuzzy set ) 4 . 0 6 . 0 0 . 0 ( High Middle Low+ +
using the given membership functions shown in Figure 6. This
step is repeated for all other items and the results are shown in Table 5, where the notation
item.term is called a fuzzy region.
Table 5. The level-1 fuzzy sets transformed from the data in Table 4
TID Level-1 fuzzy set
T1 ) *. * 3 2 . 0 *. * 3 8 . 0 )( *. * 2 8 . 0 *. * 2 2 . 0 )( *. * 1 8 . 0 *. * 1 2 . 0 ( High Midlle High Middle Midlle Low + + + T2 ) *. * 3 4 . 0 *. * 3 6 . 0 )( *. * 2 4 . 0 *. * 2 6 . 0 )( *. * 1 2 . 0 *. * 1 8 . 0 ( High Middle High Middle High Middle + + + T3 ) *. * 3 0 . 1 )( *. * 2 4 . 0 *. * 2 6 . 0 )( *. * 1 2 . 0 *. * 1 8 . 0 ( High High Middle Middle Low + + T4 ) *. * 3 8 . 0 *. * 3 2 . 0 )( *. * 2 8 . 0 *. * 2 2 . 0 )( *. * 1 2 . 0 *. * 1 8 . 0 ( Middle Low Middle Low Middle Low + + + T5 ) *. * 2 6 . 0 *. * 2 4 . 0 ( High Middle + T6 ) *. * 2 6 . 0 *. * 2 4 . 0 )( *. * 1 0 . 1 ( Middle Low High +
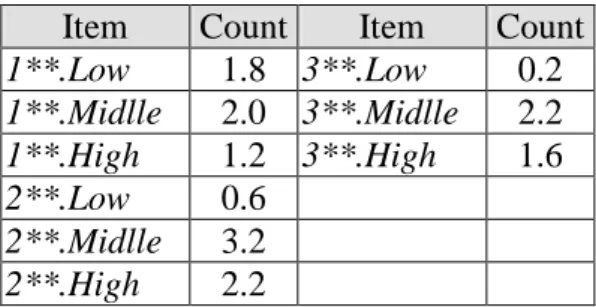
STEP 6. The fuzzy regions with membership values greater than zero are collected as
Table 6. The counts of the fuzzy regions for level 1
Item Count Item Count
1**.Low 1.8 3**.Low 0.2 1**.Midlle 2.0 3**.Midlle 2.2 1**.High 1.2 3**.High 1.6 2**.Low 0.6 2**.Midlle 3.2 2**.High 2.2
STEP 7: The scalar cardinality of each fuzzy region in 1 1
C is calculated as a count
value. Take the fuzzy region 1**.Middle as an example. Its scalar cardinality = (0.8 + 0.8 +
0.2 + 0.2 + 0.0 + 0.0) = 2.0. This step is repeated for all other regions and results are shown in
Table 6.
STEP 8. The count of each region in Table 6 is checked against the predefined minimum
support value α . Assume that in this example,α is set at 2.1. Since the count values of
2**.Middle, 2**.High and 3**.Middle are larger than 2.1, they are put in 1 1
L (Table 7).
Table 7. The set of large 1-itemsets ( 1 1
L ) for level one in this example
Itemset
count
2**.Middle 3.2 2**.High 2.2 3**.Middle 2.2 STEP 9: Since 1 1L is not null, go to the next step.
STEP 10: The candidate set 1 2
C is generated from 1 1
L as (2**.Middle, 3**.Middle) and
STEP 11: The following substeps are done for each newly formed candidate 2-itemset
in 1 2
C :
(a) The fuzzy membership values of the candidate 2-itemsets are calculated for each
transaction data. Here, the minimum operator is used for intersection. Take (2**.Middle,
3**.Middle) as an example. The derived membership value of (2**.Middle, 3**.Middle)
for transaction T1 is calculated as: min(0.2, 0.8)=0.2. The results for all other transactions
are shown in Table 8.
Table 8. The membership values for 2**.MiddleΛ3**.Middle
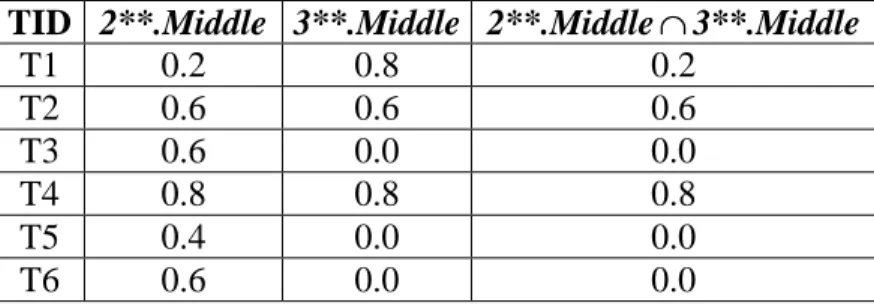
TID 2**.Middle 3**.Middle 2**.Middle∩3**.Middle
T1 0.2 0.8 0.2 T2 0.6 0.6 0.6 T3 0.6 0.0 0.0 T4 0.8 0.8 0.8 T5 0.4 0.0 0.0 T6 0.6 0.0 0.0
(b) The scalar cardinality (count) of each candidate 2-itemset in 1 2
C is calculated. Results are
shown in Table 9.
Table 9. The counts of the 2-itemsets on level 1
Itemset Count
2**.Middle, 3**.Middle 1.6
2**.High, 3**.Middle 1.2
(c) Since the counts of the above itemsets are not greater than the predefined minimum
support value 2.1, 1 2
STEP 12: r is set at 2, where r is used to store the number of regions kept in the current
itemsets.
STEP 13: Since L is null, k=k+1=2 and STEP 4 is done. The results for level 2 are 12
shown in Table 10.
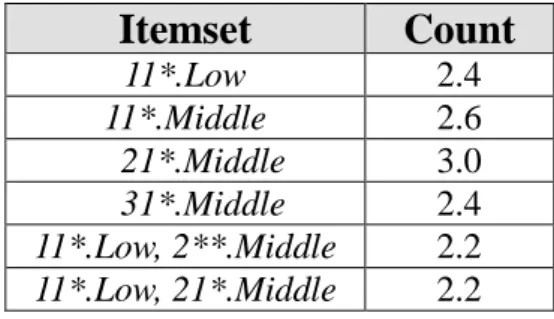
Table 10. The set of large itemsets for level 2 in this example
Itemset
Count
11*.Low 2.4 11*.Middle 2.6 21*.Middle 3.0 31*.Middle 2.4 11*.Low, 2**.Middle 2.2 11*.Low, 21*.Middle 2.2The results for level 3 are shown in Table 11.
Table 11. The set of large itemsets for level 3 in this example
Itemset
Count
111.Low 3.0
211.Middle 2.8
111.Low, 2**.Middle 2.2
111.Low, 3**.Middle 2.2
There are no large itemsets for level 4. STEP 17 is then done.
STEP 17: The association rules are constructed for each large itemset using the
following substeps.
(a) The possible association rules from the itemsets found are formed as follows:
If 11* = Low, then 2** = Middle;
If 11* = Low, then 21* = Middle;
If 21* = Middle, then 11* = Low;
If 2** = Middle, then 111 = Low;
If 111 = Low, then 2** = Middle;
If 3** = Middle, then 111 = Low;
If 111 = Low, then 3** = Middle.
(b) The confidence values of the above eight possible association rules are then
calculated. Take the first association rule as an example. The count of
2**.Middle∩11*.Low is 2.2 and the count of 2** is 3.2. The confidence value for
the association rule "If 2** = Middle, then 11* = Low" is calculated as:
∑
∑
= = ∩ 6 1 6 1 ) *. * 2 ( ) . * 11 *. * 2 ( i i Middle Low Middle =2
.
3
2
.
2
=0.69.Results for all the eight rules are shown below.
If 2** = Middle, then 11* = Low, with confidence 0.69;
If 11* = Low, then 2** = Middle, with confidence 0.92;
If 11* = Low, then 21* = Middle, with confidence 0.92;
If 21* = Middle, then 11* = Low, with confidence 0.73;
If 111 = Low, then 2** = Middle, with confidence 0.73;
If 3** = Middle, then 111 = Low, with confidence 1.0.
If 111 = Low, then 3** = Middle, with confidence 0.73.
STEP 18: The confidence values of the possible association rules are checked against the
predefined confidence thresholdλ. Assume that the given confidence thresholdλ is set at
0.75. The following three rules are thus kept:
1. If 11* = Low, then 2** = Middle, with confidence 0.92;
1. If 11* = Low, then 21* = Middle, with confidence 0.92;
2. If 3** = Middle, then 111 = Low, with confidence 1.0.
These three rules can then serve as meta-knowledge from the given transactions. In
comparison with the association rules generated in [22], there were only two possible rules:
If 3** = Middle, then 111 = Low, with confidence 1.0.
If 111 = Low, then 3** = Middle, with confidence 0.73.
If we set the confidence threshold λ as 0.7, there will be only one fuzzy association rule
generated by the algorithm in [22]. However, six fuzzy association rules are generated by the
proposed algorithm here. In fact, the final fuzzy rule set generated will depend on the
parameters such as minimum support, minimum confidence, and many other factors such as
number of regions stored in the current large itemsets. As most mining algorithms do, the
6. Conclusion
In this paper, we have proposed a fuzzy multiple-level mining algorithm, which can
process transaction data with quantitative values and discover association rules in taxonomy.
The proposed algorithm can derive a more complete set of rules than the method proposed in
[22] although it needs more computation time. Trade-off thus exists between the computation
time and the completeness of rules. Choosing an appropriate learning method thus depends on
the requirements of the application domains.
Although the proposed method works well in data mining for quantitative values, it is
just a beginning. There is still much work to be done in this field. Our method assumes that
the membership functions are known in advance. In [18-21], we proposed several fuzzy
learning methods to automatically derive the membership functions. In the future, we will
attempt to dynamically adjust the membership functions in the proposed mining algorithm to
avoid the bottleneck of membership function acquisition. We will also attempt to design
specific data-mining models for various problem domains.
References
[1] R. Agrawal, T. Imielinksi and A. Swami, “Mining association rules between sets of items
in large database,“ The 1993 ACM SIGMOD Conference on Management of Data, 1993,
[2] R. Agrawal, T. Imielinksi and A. Swami, “Database mining: a performance perspective,”
IEEE Transactions on Knowledge and Data Engineering, Vol. 5, No. 6, 1993, pp.
914-925.
[3] A. F. Blishun, “Fuzzy learning models in expert systems,” Fuzzy Sets and Systems, Vol. 22,
1987, pp. 57-70.
[4] L. M. de Campos and S. Moral, “Learning rules for a fuzzy inference model,” Fuzzy Sets
and Systems, Vol. 59, 1993, pp. 247-257.
[5] R. L. P. Chang and T. Pavliddis, “Fuzzy decision tree algorithms,” IEEE Transactions on
Systems, Man and Cybernetics, Vol. 7, 1977, pp. 28-35.
[6] M. S. Chen, J. Han and P. S. Yu, “Data mining: an overview from a database perspective,”
IEEE Transactions on Knowledge and Data Engineering, Vol. 8, No. 6, 1996, pp.
866-883.
[7] C. Clair, C. Liu and N. Pissinou, “Attribute weighting: a method of applying domain
knowledge in the decision tree process,” The Seventh International Conference on
Information and Knowledge Management, 1998, pp. 259-266.
[8] P. Clark and T. Niblett, “The CN2 induction algorithm,” Machine Learning, Vol. 3, 1989,
pp. 261-283.
[9] M. Delgado and A. Gonzalez, “An inductive learning procedure to identify fuzzy
[10] A. Famili, W. M. Shen, R. Weber and E. Simoudis, "Data preprocessing and intelligent
data analysis," Intelligent Data Analysis, Vol. 1, No. 1, 1997, pp. 3-23.
[11] W. J. Frawley, G. Piatetsky-Shapiro and C. J. Matheus, “Knowledge discovery in
databases: an overview,” The AAAI Workshop on Knowledge Discovery in Databases,
1991, pp. 1-27.
[12] T. Fukuda, Y. Morimoto, S. Morishita and T. Tokuyama, "Mining optimized association
rules for numeric attributes," The ACM SIGACT-SIGMOD-SIGART Symposium on
Principles of Database Systems, 1996, pp. 182-191.
[13] J. Galindo (Ed.), Handbook of Research on Fuzzy Information Processing in Databases,
Idea Group Inc. Hershey, PA, USA, 2008.
[14] A. Gonzalez, “A learning methodology in uncertain and imprecise environments,”
International Journal of Intelligent Systems, Vol. 10, 1995, pp. 57-371.
[15] J. Han and Y. Fu, “Discovery of multiple-level association rules from large databases,”
The International Conference on Very Large Databases, 1995, pp. 420 -431.
[16] T. P. Hong, M. J. Chiang and S. L. Wang, “Fuzzy weighted data mining from quantitative
transactions with linguistic minimum supports and confidences,” International Journal of
Fuzzy Systems, Vol. 8, No. 4, 2006, pp. 173-182.
[17] T. P. Hong, C. S. Kuo and S. C. Chi, "A data mining algorithm for transaction data
[18] T. P. Hong and J. B. Chen, "Finding relevant attributes and membership functions,"
Fuzzy Sets and Systems, Vol.103, No. 3, 1999, pp. 389-404.
[19] T. P. Hong and J. B. Chen, "Processing individual fuzzy attributes for fuzzy rule induction," Fuzzy Sets and Systems, Vol. 112, No. 1, 2000, pp. 127-140.
[20] T. P. Hong and C. Y. Lee, "Induction of fuzzy rules and membership functions from
training examples," Fuzzy Sets and Systems, Vol. 84, 1996, pp. 33-47.
[21] T. P. Hong and S. S. Tseng, “A generalized version space learning algorithm for noisy
and uncertain data,” IEEE Transactions on Knowledge and Data Engineering, Vol. 9,
No. 2, 1997, pp. 336-340.
[22] T. P. Hong and K.Y. Lin, “Fuzzy data mining using taxonomy”, The Eighth National
Conference on Fuzzy Theory and Its Application, 2000.
[23] A. Kandel, Fuzzy Expert Systems, CRC Press, Boca Raton, 1992, pp. 8-19.
[24] Chun-Wei Lin, Tzung-Pei Hong and Wen-Hsiang Lu, “An efficient tree-based fuzzy data
mining approach”, International Journal of Fuzzy Systems, Vol. 12, No. 2, 2010, pp.
150-157.
[25] E. H. Mamdani, “Applications of fuzzy algorithms for control of simple dynamic
plants,“ IEEE Proceedings, 1974, pp.1585-1588.
[26] J. R. Quinlan, “Decision tree as probabilistic classifier,” The Fourth International
[27] J. R. Quinlan, C4.5: Programs for Machine Learning, Morgan Kaufmann, San Mateo,
CA, 1993.
[28] R. Rastogi and K. Shim, "Mining optimized association rules with categorical and
numeric attributes," The 14th IEEE International Conference on Data Engineering,
Orlando, 1998, pp. 503-512.
[29] R. Rastogi and K. Shim, "Mining optimized support rules for numeric attributes," The
15th IEEE International Conference on Data Engineering, Sydney, Australia, 1999, pp.
206-215.
[30] J. Rives, “FID3: fuzzy induction decision tree,” The First International Symposium on
Uncertainty, Modeling and Analysis, 1990, pp. 457-462.
[31] R. Srikant, Q. Vu and R. Agrawal, “Mining association rules with item constraints,” The
Third International Conference on Knowledge Discovery in Databases and Data Mining,
1997, pp.67-73.
[32] R. Srikant and R. Agrawal, “Mining quantitative association rules in large relational
tables,” The 1996 ACM SIGMOD International Conference on Management of Data,
1996, pp. 1-12.
[33] R. Srikant and R. Agrawal, “Mining Generalized Association Rules," The International
Conference on Very Large Databases, 1995, pp. 407-419.
Fifth IEEE International Conference on Fuzzy Systems, 1996, pp. 13-18.
[35] C. H. Wang, J. F. Liu, T. P. Hong and S. S. Tseng, “A fuzzy inductive learning strategy
for modular rules,” Fuzzy Sets and Systems, Vol.103, No. 1, 1999, pp. 91-105.
[36] R. Weber, “Fuzzy-ID3: a class of methods for automatic knowledge acquisition,” The
Second International Conference on Fuzzy Logic and Neural Networks, 1992, pp.
265-268.
[37] C. A. Wu, W. Y. Lin and C. C. Wu, “An active multidimensional association mining
framework with user preference ontology,” International Journal of Fuzzy Systems, Vol.
12, No. 2, 2010, pp. 125-135.
[38] Y. Yuan and M. J. Shaw, “Induction of fuzzy decision trees,” Fuzzy Sets and Systems, Vol.
69, 1995, pp. 125-139.