Efficient Algorithms For Distributed Program Reliability Analysis
21
0
0
全文
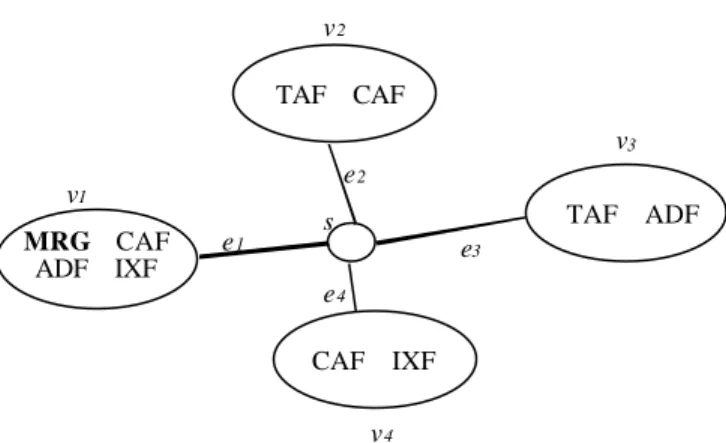
(2) 1. INTRODUCTION A distributed computing system (DCS), in general, is considered to be one in which the computing functions are distributed among several physically distinct computing elements [4]. These elements or resources (e.g. processing elements, data files, and programs) may be geographically separated or co-located. Thus, each program can run on one or more computers and may frequently access files stored in other sites. Banking systems, travel agency systems, and power control systems are just a few examples of such a distributed computing environment [15]. There are many measures to evaluate the performance of DCS's. Reliability is an important issue [5]. For traditional networks, many reliability indices have been proposed. They include two-terminal reliability, all-terminal reliability, and K-terminal reliability [1, 7, 12, 13, 18]. However, these measures are not applicable to practical DCS's since the reliability measure for DCS's should capture the effects of redundant distribution of data files. Kumar et al. [8, 9] introduce a new reliability measure, namely, distributed program reliability (DPR) to accurately model the reliability of DCS's. The DPR is defined as the probability that a program with distributed files can run successfully in spite of some faults occurring in the communication edges. A model used to represent such situations is a probabilistic graph. A probabilistic graph has a collection of nodes representing the processing elements (sites) which contain some data files and programs, together with a collection of edges representing communication links. Each edge fails independently with known failure probability. As an example, consider a possible DCS of a banking system [8, 15] shown in figure 1. Each local disk stores some of the following information: l. consumer accounts file (CAF),. l. automated teller machine accounts file (TAF),. l. administrative aids file (ADF), and. l. interest and exchange rates file (IXF).. Management report generation (MRG) in computer A indicates a query (program) to be executed for report generation. Figure 2 shows the graph model for this system. A node represents any computer 2.
(3) location and the links show the communication network. We assume that the query (program) MRG requires data files CAF, TAF, ADF and IXF to complete its execution, and it is running at node v 1, which holds data files CAF, ADF and IXF. Hence, it must access data file TAF, which is stored in both nodes v 2 and v 3. Therefore, the DPR of MRG shown in figure 2 can be formulated as: DPR = Prob[(v 1 and v 2 are connected) or (v 1 and v 3 are connected)]. TAF CAF. computer B MRG CAF ADF IXF. computer C. computer A. TAF ADF. Hub computer D. CAF IXF Figure 1: A distributed banking system.. v2 TAF CAF v3 e2. v1 MRG CAF ADF IXF. e1. TAF. s. ADF. e3 e4 CAF. IXF v4. Figure 2: The graph model for the distributed banking system in figure 1.. Most network reliability problems (e.g., K-terminal reliability) are #P-complete. The class of #P-complete problems was introduced by Valiant [16]. The class #P contains those problems that involve counting the accepting computations for problems in NP; the class of #P-complete problems contains the hardest problems in #P. As widely recognized, all known exact algorithms for these problems have exponential time complexity, thereby making it unlikely that efficient (polynomial time) algorithms can be 3.
(4) developed for this class of problems. Clearly, computing the DPR for general DCS's is also #P-complete. This complexity can be averted by considering only a restricted class of DCS's. Our overall objective will be to examine the boundary of problem classes separating the polynomially solvable cases from the #P-complete cases. However, polynomial-time algorithms have been developed for computing the DPR over the DCS's with linear and ring topologies [10]. Classes of interest here include star, 2-tree, serial-parallel, and planar topologies. The results of section 2 show that most of them continue to be #P-complete. In section 3, we propose a polynomially solvable case of the DPR problem for star topologies in which data files are restricted to a certain type of distribution. Section 4 shows a linear time algorithm to verify whether or not a star DCS has this restricted class of file distribution.. Assumptions 1. The nodes are perfect. 2. The edges are s-independent and either function or fail with known probabilities.. Acronyms & Abbreviations DCS. distributed computing system. DPR. distributed program reliability. KTR. K-terminal reliability. #EC. number of edge covers. FST. file spanning tree. Notation (General) G. a general graph (of a network).. D. a DCS graph. E. set of edges. V. set of nodes. ei. a component of E 4.
(5) vi. a component of V. K. subset of V. Ai. set of files available at node v i. pi. probability that edge ei functions. qi. probability that edge ei fails; ≡ 1 – pi. fi. data file i. Notation (Star DCS) D. a star DCS with n + 1 nodes {s, v1, v2, … , vn} and n edges {(s,v1), (s,v2), … ,(s, vn)}. n. number of edges in D. ei. ≡ edge (s, vi); 1 ≤ i ≤ n. m. number of distinct files in D. t. total number of files in D. A-1j. set of indexes of nodes which contain the file fj. Π. ≡ [π(1), π(2), … , π(n)] a permutation of numbers {1, 2, … , n} such that if file fd ∈ Aπ(i). and fd ∈ Aπ(j), then fd ∈ Aπ(k) for all k, i < k < j Φ. ordered set of all minimal file cutsets according to their minimal components. r. number of minimal file cutsets in Φ. Ci. the ith minimal file cutset in Φ; 1 ≤ i ≤ r. αi. ≡ min{k | eπ(k) ∈ Ci} , i.e. , the index of the minimal component in Ci; 1 ≤ i ≤ r. βi. ≡ max{k | eπ(k) ∈ Ci} , i.e. , the index of the maximal component in Ci; 1 ≤ i ≤ r. H(i, j). ≡{eπ(i), eπ(i+1), … , eπ(j)}; 1 ≤ i ≤ j ≤ n ( note that Ci ≡ H(αi, βi) ). X(i, j). event: all edges in H(i, j) fail. Wi Fi. ≡. i Υ X (α j , β j) j =1. ( note that the DPR of D can be expressed as 1 – Pr(Wr) ). event: the star DCS D' fails in which it consists of i + 1 nodes s, vπ(1), vπ(2), … , vπ(i) and i edges eπ(1), eπ(2), … , eπ(i). W. complement of event W. Definitions (Star DCS). 5.
(6) l. Consecutive file distribution: A star DCS D has the consecutive file distribution property iff its nodes can be linearly ordered such that, for each distinct file f d, the nodes containing file f d occur consecutively. More formally, a star DCS D has the consecutive file distribution property iff there exists a permutation Π = [π(1), π(2), … , π(n)] of numbers {1, 2, … , n} such that if file f d ∈ Aπ(i) and f d ∈Aπ(j), then f d ∈ Aπ(k) for all k, π(i) < π(k) < π(j).. l. File cutest: A set Cd of edges of D is referred to as a file cutset for file f d if it consists of all edges (s, v i) such that node v i contains file f d, i.e., Cd = {(s, v i) | f d ∈ Ai}.. l. Minimal file cutest: A file cutset C is referred to as minimal if there is no other file cutset C' such that C' ⊆ C. Without loss of generality, we reorder the minimal file cutsets, if necessary, by their minimal component, i.e., for two distinct minimal file cutsets Ci and Cj, i < j iff min{k | (s, vπ(k)) ∈ Ci} < min{k | (s, vπ(k)) ∈ Cj}.. 2. THE COMPUTATIONAL COMPLEXITY OF THE DPR PROBLEM In this section we assume that the reader is familiar with the basic notions of NP-completeness. We refer the reader to [6] for an excellent exposition of the theory of NP-completeness. First we state some known #P-complete problems. l. K-Terminal Reliability (KTR) [12] Input: an undirected graph G = (V, E) where V is the set of nodes and E is the set of edges that fail s-independently of each other with known probabilities. A set K⊆V is distinguished with |K| ≥ 2. Output: R(GK ), the probability that the set K of nodes of G is connected in G.. l. Number of Edge Covers (#EC) [2] Input: an undirected graph G = (V, E). Output: the number of edge covers for G ≡ |{EC ⊆ E: each node of G is an end of some edge in EC}|.. Theorem 1. The KTR problem is polynomially reducible to the DPR problem.. 6.
(7) Proof. Let G = (V, E) be a network graph with a subset of nodes K ⊆ V. Construct a DCS graph D = (V, E) from G such that node v i of D contains file f i iff node v i ∈ K in G. Clearly, all distinct files in D are interconnected iff all nodes of K are connected in G. In addition, let each edge of D have the same operational probability as the corresponding edge of G. Then, the DPR of D is equal to the KTR of G. In this case the DCS D can be obtained from G in polynomial time.. Q.E.D.. By Theorem 1, if we have a polynomial-time algorithm for computing the DPR of D, then we can obtain a polynomial-time algorithm for computing the KTR of G using this construction. However, Rosenthal [12] showed that the problem of computing the KTR in general is #P-complete, so computing the DPR in general is also #P-complete. Therefore, we have the following corollary. Corollary 1. Computing the DPR for a general DCS is #P-complete. Corollary 2. Computing the DPR for a planar DCS is #P-complete. Proof. From the proof of Theorem 1, it is clear that the KTR problem is just a special case of the DPR problem. It has been shown that computing the KTR over a planar network is #P-complete [11]. This also immediately implies that computing the DPR over a planar DCS is still #P-complete.. Q.E.D.. For the KTR problem, polynomial-time (or linear-time) algorithms have been developed for other restricted networks, such as a star network, a 2-tree network, and a series-parallel network [14]. If there are no replicated files in DCS's, i.e., if there is only one copy of each file in DCS's, the DPR problem can be transformed into the equivalent KTR problem in which the K set is the set of nodes that contain the data files needed for the program under consideration. However, data files are usually replicated and distributed in DCS's, so these two problems are different. In the remainder of this section, we will see that computing the DPR over a star DCS, a tree DCS, or a series-parallel DCS in general is still #P-complete. Theorem 2. The #EC problem is polynomially reducible to the DPR problem over a star DCS. Proof. Given a graph G with n edges e1, e2, … , en and nodes v 1, v 2, … , we shall construct a star DCS D such that the number of edge covers in G can be expressed as a function of the DPR of D. Construct a star 7.
(8) DCS D = (V', E') where V' = {s, v'1, v'2,… , v'n}, E' = {(s, v'1), (s, v'2), … , (s, v'n)} and node v'i contains files f g and f h iff ei = (v g, v h) in G. We now consider a file spanning tree (FST) T, which is a subgraph of D and its nodes hold all the needed data files, i.e., Υ { f j | v ′ 'i v ′'i ∈T. contains file f j} =. Υ { f j |v′ i v ′i ∈V ′. contains file f j} .. It is easy to see that there is a one-to-one correspondence between one of the sets of edge covers in G and one FST in D. The DPR of D can be expressed as DPR =. ∑ for all FST T in D. ∏ (1− pi ) ∏ p i ( v 0 ,v ′i ) ∈E ′− T ' ( v0 , v ′i ) ∈T . where pi is reliability of edge (s, v'i) of D, 1 ≤ i ≤ n. If we set each pi =. DPR =. 1 n ∑ ( ) for all FST 2. 1 for all 1 ≤ i ≤ n, then we have 2. , or. T in D. DPR ⋅ 2n =. ∑1 for all FST T in D. = # of FST's in D = # of edge covers in G Since D can be constructed from G in polynomial time, the number of edge covers in G can be solved in polynomial time if we have a polynomial-time algorithm for computing the DPR of D. Q.E.D. Corollary 3. Computing the DPR for a star DCS is #P-complete. Proof. Follows from Theorem 2 and the fact that #EC have been shown to be #P-complete [2]. Q.E.D. Now we shall show that computing the DPR remains difficult for a 2-tree topology. A 2-tree is defined recursively as follows: 8.
(9) l. The complete graph K2 (a single edge) is a 2-tree.. l. Given any 2-tree G on n ≥ 2 nodes, let (v i, v j) be an edge of G. Adding a new node v k and two edges (v k, v i) and (v k, v j) produces a 2-tree on n + 1 nodes.. Corollary 4. Computing the DPR for a 2-tree DCS in general is #P-complete. Proof. Let D be a star DCS with n + 1 nodes s, v 1 , v 2 , ..., v n and n edges (s, v 1 ), (s, v 2 ), … ,(s, v n ). We shall construct from D a 2-tree DCS D' such that D and D' have the same DPR. Embed the 2-tree DCS D' into the star DCS D by adding some virtual edges (v i , v i+1 ), 1 ≤ i ≤ n-1. Now, it is easy to see that D' is a 2-tree DCS on n + 1 nodes. If we stipulate that each virtual edge has operational probability 0, the DPR of D is reduced to the DPR of D' . By corollary 3, since computing the DPR over a star topology in general is #P-complete, computing the DPR over a 2-tree topology is also #P-complete.. Q.E.D.. Corollary 5. Computing the DPR over a series-parallel DCS is #P-complete. Proof. From [17], a 2-tree graph is a maximal series-parallel graph. A maximal series-parallel graph is a series-parallel graph with neither loops nor parallel edges. Since computing the DPR over a 2-tree topology is #P-complete, computing the DPR over a series-parallel DCS is also #P-complete.. Q.E.D.. 3. A POLYNOMIAL-TIME ALGORITHM FOR COMPUTING THE DPR OF STAR DCS's The results of the previous section indicate that computing the DPR over a star DCS is #P-complete. These results imply that polynomial algorithms unlikely exist for solving them. However, an efficient algorithm possibly exists for computing the DPR over a star DCS with a certain restricted class of file distribution. In this section we present a polynomial-time algorithm for computing the DPR of a star DCS with a consecutive file distribution. Let D be a star DCS with the consecutive file distribution property. Then, the minimal file cutsets can be ordered by their minimal component, i.e. for two distinct minimal file cutsets Ci and Cj, i < j iff min{k | (s, v π(k)) ∈ Ci} < min{k | (s, v π(k)) ∈ Cj}. By definition, D fails iff at least one event X(αi, βi), 1 ≤ i ≤ r, 9.
(10) occurs, where αi and βi are the indexes of the minimal and maximal components in Ci, respectively. Clearly, if r = 1, the unreliability of D can be obtained as Pr[W1] = Pr[X(α1, β1)]. Next consider the case with r ≥ 2. The unreliability of D with the first i's file cutsets is Pr[Wi] = Pr[W i −1 Υ X (αi , βi)] This expression can be decomposed using conditional probability as Pr[Wi] = Pr[W i−1] + Pr[W i − 1 ∩ X ( a i , βi )] .. (1). Consider the event W i −1 ∩ X (αi , βi) , which implies l. E1: For each k, 1 ≤ k ≤ i − 1, at least one edge e ∈ H (αk , βk ) ≡ Ck functions and. l. E2: All edges ∈ H (αi , βi) ≡ Ci fail.. By event E2, event E1 can be rewritten as l. E1': For each k, 1 ≤ k ≤ i − 1, at least one edge e ∈ {H (αk , β k ) − H (αi , βi )} functions.. A fundamental difficulty in calculating Pr(E1' ) is that events in E1' are not, in general, disjoint. However, we can define events Sj's that are disjoint by Sj = { E1' occurs and edge e π( j) is the last good one}, for αi-1 ≤ j ≤ αi −1. Thus, E 1 ' Ι E 2 =. αi − 1 Υ (S j Ι j = αi −1. E 2 ) . and αi − 1. Pr[W i − 1 ∩ X ( a i , βi )] = Pr[ Υ. j = αi −1. ( S j Ι E 2 )]. (2). Since Sj's are disjoint events, we have αi − 1. Pr[ Υ. j = αi −1. ( S j Ι E 2 )] =. αi − 1. ∑ Pr( S j Ι E 2 ). j = αi −1. 10. (3).
(11) The event Sj 3 E2, αi-1 ≤ j ≤ αi−1, can be decomposed into three independent events:{no file cutset fails between edges e π(1) and e π( j −1) }, {edge e π( j) functions}, and {all edges between e π( j +1) and e π( βi ) fail}. So Pr( S j Ι E 2 ) = [1 − Pr( F j −1)] ⋅ p π ( j) ⋅ Pr[ X ( j + 1, βi )] .. (4). Therefore, according to Eqs. (1), (2), (3), and (4) , we have Pr(W i) = Pr(W i − 1) +. αi − 1. ∑. j = αi −1. {[1 − Pr( F j −1)] ⋅ pπ( j ) ⋅ Pr[ X ( j + 1, βi)]}. The following theorem can now be established.. Theorem 3. For 2 ≤ i ≤ r: Pr(W i) = Pr(W i − 1) +. αi − 1. ∑. j = αi −1. {[1 − Pr( F j −1)] ⋅ pπ( j ) ⋅ Pr[ X ( j + 1, βi)]} ,. (5). with the boundary conditions: Pr(W 1) = Pr[ X (α1 , β1)], and Pr( F k ) = 0 for 0 ≤ k < β1 .. Before applying Theorem 3, initially compute the values of Pr[ X ( j + 1, βi )] and Pr(Fj-1) for 2 ≤ i ≤ r and αi-1 ≤ j ≤ αi − 1. By noting that αg < αh whenever g < h, the recursive formula can be obtained as follows. βi 1 ⋅ Pr[ X (αi-1 , βi − 1)] ⋅ ∏ q π( k ) for j = αi-1 q k = βi −1+ 1 Pr[ X ( j + 1, βi )] = π (αi-1) 1 ⋅ Pr[ X ( j , β )] for αi -1 < j ≤ αi − 1 i q π( j ) β1. By starting with Pr[ X (α1 , β1)] = ∏ qπ( k ) , we successively determine that k =α1. 11. (6).
(12) Pr[ X (α1 + 1, β2 )], Pr[ X (α1 + 2 , β2 )], . . ., Pr[ X (α2 , β2 )], Pr[ X (α2 + 1, β3)], Pr[ X (α2 + 3, β3)], . . ., Pr[ X (α3 , β3)], . . . Pr[ X (αr − 1 + 1, βr )], Pr[ X (αr − 1 + 2, βr )], . . ., and Pr[ X (αr , βr )]. To obtain the values of Pr(Fj-1) in Theorem 3, by definition, we have that Pr(W i − 1) Pr( F k ) = 0. for βi − 1 ≤ k ≤ βi − 1 for k ≤ β1 − 1. (7). Hence, while computing Pr(Wi) by Theorem 3, we can also obtain Pr(Fk), for βi-1 ≤ k ≤ βi−1.. 3.1 A Polynomial-Time Algorithm The major algorithm-related strategies to compute the DPR of star DCS's are outlined. Assume a given star DCS D and the file distributions Ai for each node. By assuming that D has the property of consecutive file distribution, let Π be a permutation of numbers {1, 2, … ,n} such that if file f d ∈ Aπ(i) and f d ∈ Aπ(j), then f d ∈ Aπ(k) for all k, i < k < j. All file cutsets can be enumerated from Ai in the following manner: if node v i contains file f d, then file cutset Cd contains edge ei. Subsequently, αi and βi values of Ci can be determined from the permutation Π such that αi = min{k| eπ(k) ∈ Ci } and βi = max{k| eπ(k) ∈ Ci }. The next step removes the file cutsets which are not minimal and rearranges the remaining minimal file cutsets according to their αi and βi values. Finally Theorem 3, Eqs. (6) and (7) are used to compute the DPR ( = 1 − Pr[Wr] ). The algorithm is formally described below.. Algorithm REL Input: A star DCS D with n +1 nodes { s, v 1, v 2, … , v n} and n edges {(s,v 1), (s,v 2), … ,(s,v n)}. A permutation Π = [π(1), π(2), … , π(n)] of numbers {1, 2, … , n} such that if file f d ∈ Aπ(i), f d ∈Aπ(j), then f d ∈ Aπ(k) for all k, i < k < j, where Ai represents the set of files available at node v i. Output : the DPR of D. 12.
(13) begin Step 1:. // find all file cutsets //. for i ß 1 to m do Ci ß ∅ ;. // initialization step; m is the number of distinct files //. for i ß 1 to n do for each f d ∈ Ai do Cd ß Cd ∪ {ei}; Step 2:. // For convenience, let ei denote edge (s, v i) //. // set the values of αi and βi for 1 ≤ i ≤ m //. for i ß 1 to m do begin αi ß min{k| eπ(k) ∈ Ci }; βi ß max{k| eπ(k) ∈ Ci }; end Step 3:. // find all minimal file cutset //. Φ ß ∅; for i ß 1 to m do Φ ∪ {Ci}; for 1 ≤ i, j ≤ m do if (αi ≥ αj and βi ≤ βj) then remove Cj from Φ;. // which implies Ci ⊆ Cj //. Step 4: reorder the minimal file cutsets in Φ for two distinct minimal file cutsets Ci and Cj, i < j iff αi < αj; Step 5: // compute Pr[ X ( j + 1, βi)] , for 2 ≤ i ≤ r and αi-1 ≤ j ≤ αi − 1, by Eq. (6) // β1. Pr[ X (α1 , β1)] ← ∏ q π( k ) ; k = α1. for i ß 2 to r do // r is the number of minimal file cutsets in Φ// begin Pr[X(αi-1+1, βi)] ß. 1 q π(αi −1). ⋅ Pr[ X (αi −1 , βi−1)] ⋅. 13. βi. ∏. k = βi −1+1. qπ( k ) ;.
(14) for j ß αi-1+2 to αi−1do Pr[X(j + 1, βi)] ß. 1 q π( j ). ⋅ Pr[ X ( j , βi)] ;. end Step 6:. // Apply Theorem 3 and Eq. (7) to compute Pr(Wi) and Pr(Fj) //. Pr(W 1) ← Pr[ X (α1 , β1)] ;. // boundary condition //. for k ß 0 to β1−1 do Pr(Fk) ß 0; // boundary condition // for i ß 2 to r do begin for k ß βi-1 to βi−1 do Pr(Fk) ß Pr(Wi-1); Pr(W i) ← Pr(W i −1) +. αi − 1. ∑. j = αi −1. {[1 − Pr( F j −1)] ⋅ p π( j ) ⋅ Pr[ X ( j + 1, βi )]} ;. end Step 7: DPR ß 1– Pr(Wr); Output(DPR); end REL. 3.2 Complexity Analysis The time complexity of Algorithm REL is analyzed as follows. Step 1 performs n. O( m + ∑ Aπ( i) ) = O( m + t ) = O(t ) time (since m < t) to identify all file cutsets, where t denotes the i =1. m. total number of files in D. Step 2 requires O( 2 ⋅ ∑ Ci ) ≈ O( t ) time to set αi and βi, 1 ≤ i ≤ m and step i =1. 3 takes O(m2) time to obtain all minimal file cutsets. Step 4 requires the reordering of all minimal file cutsets in a nondecreasing order of their index of the minimal component. This ordering can be executed in O(r⋅log r) using an efficient sorting algorithm, where r denotes the number of minimal file cutsets. In step 5, evaluating Pr[X(j+1, βi)] by making use of Eq. (6) requires that 14.
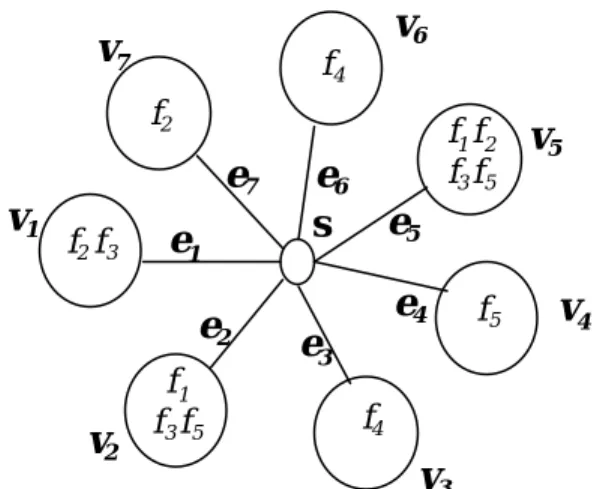
(15) r O{ ∑ [( βi − βi −1) + 2]} = O( βr − β1 + r ) ≈ O( n + r ), for j= αi − 1 i =r 2 O{ ∑ (1)} = O( r − 1) = O(r ), for αi − 1 ≤ j ≤ αi − 1 i = 2. Hence, the total time to evaluate all Pr[X(j+1, βi)] is therefore O(n + r). In step 6, computing all Pr(Fk) r. O[ ∑ ( βi − βi −1)] = O( βr − β1) ≈ O( n). takes. time. i =2. and. computing. all. Pr(Wi). takes. r. O{ ∑ [1 + (αi − αi − 1) ⋅ 3] = O[1 + 3 ⋅ (αr − α1)] ≈ O( n) time. Therefore, the total time in step 6 is O(n). i= 2. Clearly, step 7 performs in constant time. Finally, the entire algorithm has time complexity O[t + t + m2 + r⋅log r + (n + r) + n]. Since t ≤ m⋅n, and r ≤ n, the complexity of Algorithm REL can be obtained as O(m2 + m⋅n).. 3.3 An Example of Application of Algorithm REL To illustrate Algorithm REL as stated above, consider the star DCS in figure 3 in which there is a consecutive file distribution property and the associative permutation Π = [3, 6, 4, 2, 5, 1, 7]. (In Section 4, we will show how to identify the associative permutation when the star DCS has the consecutive file distribution property .) The overall procedure is as follows: Step 1: The file cutsets are found to be C1={e2, e5}, C2={e1, e5, e7}, C3={e1, e2, e5}, C4={e3, e6}, C5={e2, e4, e5}. Step 2: According to the permutation π(1) = 3, π(2) = 6, π(3) = 4, π(4) = 2, π(5) = 5, π(6) = 1, π(7) = 7 and the results of Step 1, we have α1 = 4, β1 = 5, α2 = 5, β2 = 7, α3 = 4, β3 = 6, α4 = 1, β4 = 2, α5 = 3, β5 = 5. Step 3: Since C1 ⊂ C3 and C1 ⊂ C5, remove C3 and C5. Thus, the set of minimal file cutsets is Φ = { C1, C2, C4}. 15.
(16) Step 4: Reorder the minimal file cutsets in such a manner that for Ci and Cj, i < j iff αi < αj, and we obtain C1={e3, e6}, α1 = 1, β1 = 2, C2={e2, e5}, α2 = 4, β2 = 5, C3={e1, e5, e7}, α3 = 5, β3 = 7. Step 5: By using Eq. (6), we have Pr[X(1,2)] = q3q6, Pr[X(2,5)] = q6q4q2q5, Pr[X(3,5)] = q4q2q5, Pr[X(4,5)] = q2q5, and Pr[X(5,7)] = q5q1q7. Step 6: We use Theorem 3 and Eq. (7) to compute Pr(Wi) and Pr(Fk) for 2 ≤ i ≤ 3 and βi-1 ≤ k ≤ βi−1, and obtain Pr(W1) = q3q6; Pr(F0) = Pr(F1) = 0 i =2:. (boundary condition). Pr(F2) = Pr(F3) = Pr(F4) = Pr(W1) = q3q6, Pr(W2). = Pr(W1) + [1−Pr(F0)] ⋅ p3 ⋅ Pr[X(2,5)]. (j=2). + [1−Pr(F1)] ⋅ p6 ⋅ Pr[X(3,5)]. (j=3). + [1−Pr(F2)] ⋅ p4 ⋅ Pr[X(4,5)]. (j=4). = q3q6 + p3q6q4q2q5 + p6q4q2q5 + (1−q3q6) ⋅ p4q2q5 i =3:. Pr(F5). = Pr(W2). Pr(W3). = Pr(W2) + [1−Pr(F3)] ⋅ p2 ⋅ Pr[X(5,7)]. (j = 5). = q3q6 + p3q6q4q2q5 + p6q4q2q5 + (1−q3q6) ⋅ p4q2q5 + (1−q3q6) ⋅ p2q5q1q7 Step 7: Therefore, DPR is DPR = 1 − Pr(W3) = 1 − {q3q6 + p3q6q4q2q5 + p6q4q2q5 + (1−q3q6) ⋅ p4q2q5 + (1−q3q6) ⋅ p2q5q1q7}. 16.
(17) v6. v7. f4 f2. e7 v1. f2 f 3. e1 e2. v2. f1 f3 f5. f1 f 2 f3 f 5. e6 s. v5. e5 e4. e3. f5. v4. f4. v3. Figure 3 : A star DCS with the consecutive file distribution property. 4. A LINEAR TIME ALGORITHM OF TESTING FOR THE CONSECUTIVE FILE DISTRIBUTION PROPERTY IN A STAR DCS The previous section has presented a polynomial-time algorithm for computing the DPR of a star DCS when it has the consecutive file distribution property. In this section, we are interested in testing whether or not a star DCS has the consecutive file distribution property. The problem statement would be: Input: A star DCS D with n + 1 nodes s , v 1, v 2, … , v n and file distributions Ai, 1 ≤ i ≤ n. Output: A permutation Π = [π(1), π(2), … , π(n)] of numbers {1, 2, … , n} such that if file f d ∈ Aπ(i) and f d ∈ Aπ(j), then f d ∈ Aπ(k) for all k, π(i) < π(k) < π(j). Note that a solution does not always exist. To facilitate our search for the correct ordering of Π, we use a data structure of a PQ-tree proposed by Booth and Leuker [3]. A PQ-tree is a rooted tree that has nodes of two varieties: P-nodes and Q-nodes. A P-node is a node whose children can be arbitrarily permuted. A Q-node is a node whose children are ordered or reverse ordered. The frontier of a PQ-tree is the permutation of leaves from left to right. Two PQ-trees are equivalent iff one can be transformed into the other by applying a sequence of the following transformation rules. l. arbitrarily permute the children of a P-node. l. reverse the children of a Q-node 17.
(18) Using a PQ-tree data structure, we have the following algorithm.. Algorithm Check_Consecutive_File_Distribution Input : A star DCS D with n + 1 nodes s, v 1, v 2, … , v n, n edges e1, e2, … , en, where ei = (s, v i) for 1 ≤ i ≤ n, and file-available set Ai = {f j | for each f j stored in node v i} for 1 ≤ i ≤ n. Output : A permutation Π = [π(1), π(2), … , π(n)] of numbers{1, 2, … , n}such that if file f d ∈ Aπ(i) and f d ∈Aπ(j), then f d ∈ Aπ(k) for all k, i < k < j. begin T ß universal tree; // a single P-node connected to all the leaf nodes of {1, 2, … , n} // for j ß 1 to m do A-1j ß ∅;. // m denotes the number of distinct files in D // // A-1j is the set of indexes of nodes that contain the file f j //. for i ß 1 to n do for each f j ∈ Ai do A-1j ß {i}; for j ß 1 to m do T ß REDUCE(T, A-1j); if T is a null tree then print out "D has no consecutive file distribution property" ; else print out the frontier of T ; end Check_Consecutive_File_Distribution. The routine REDUCE attempts to apply a set of eleven templates. Each template consists of a pattern to be matched against the current PQ-tree and the set A-1j and a replacement to be substituted for the pattern. The templates are applied from the bottom to the top of the tree. The null tree may be returned when no template applies. For details of the algorithm, the reader is directed to Booth and Leuker [3]. 18.
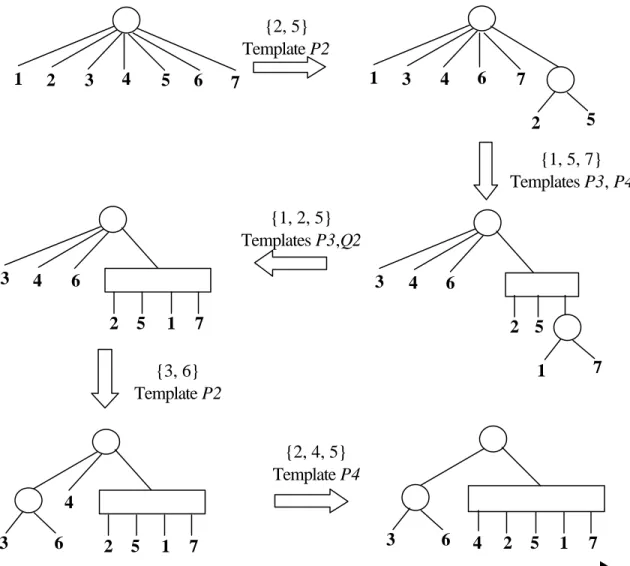
(19) Complexity Analysis: n. For A-1j, 1 ≤ j ≤ m, it can be obtained in O( m + ∑ Ai ) steps. According to [3], the loop of the i =1. m. n. j =1. i =1. REDUCE routine can be computed in O( m + n + ∑ A − 1 j ) steps. Further, ∑ Ai =. m. ∑ A −1 j = t. j =1. (the total number of files in D). Therefore, the time complexity for the above algorithm is O(m + t) + O(m + n + t) = O(m + n + t).. {2, 5} Template P2 1. 2. 4. 3. 5. 6. 1. 7. 3. 4. 6. 7 5. 2. {1, 5, 7} Templates P3, P4 {1, 2, 5} Templates P3,Q2 3. 4. 6. 3 2. 5. 1. 4. 6. 7. 2 5. {3, 6} Template P2. 7. 1. {2, 4, 5} Template P4 4 3. 6. 2. 5. 1. 3. 7. 6. 4. 2. Figure 4. The reduction steps by using a PQ-tree. An Illustrative Example: Consider the star DCS D shown in figure 3. Applying the above algorithm leads to 19. 5. 1. 7.
(20) A-11 = {2, 5}, A-12 = {1, 5, 7}, A-13 = {1, 2, 5}, A-14 = {3, 6}, A-15 = {2, 4, 5} Figure 4 displays the reduction steps. In an illustration of a PQ-tree, a P-node is drawn as a circle and a Q-node as a rectangle. From this figure, we can conclude that the star DCS D of figure 3 has the consecutive file distribution property and one of the associative permutations is: Π = [3, 6, 4, 2, 5, 1, 7]. REFERENCES [1]. K.K. Agrawal, S. Rai, "Reliability evaluation in computer-communication networks", IEEE Trans. Reliability, vol R-30, 1981 Apr, pp 32-35.. [2]. M.O. Ball, J.S. Provan, D.R. Shier, "Reliability covering problems", Networks, vol 21, 1991, pp 345-357.. [3]. K.S. Booth, G.S. Leuker, "Testing for the consecutive ones property, interval graphs, and graph planarity using PQ-tree algorithms", J. Comput. Syst. Sci., vol 13, 1976, pp 335-379.. [4]. P. Enslow, "What is a distributed data processing system", Computer, vol 11, 1978 Jan.. [5]. J. Garcia-Molina, "Reliability issues for fully replicated distributed database", IEEE Trans. Computer, vol 16, 1982 Sep, pp 34-42.. [6]. M.R. Garey, D.S. Johnson, Computers and intractability: a guide to the theory of NP-completeness, Freeman, San Francisco, 1979.. [7]. A.P. Grnarov, M. Gerla, "Multi-terminal reliability analysis of distributed processing system", Proc. 1981 Int. Conf. Parallel Processing, 1981 Aug, pp 79-86.. [8]. A. Kumar, S. Rai, D.P. Agrawal, "On computer communication network reliability under program execution constraints", IEEE JSAC, vol 6, 1988 Oct, pp 1393-1399.. [9]. V.K.P. Kumar, S. Hariri, C.S. Raghavendra, "Distributed program reliability analysis", IEEE Trans. Software Eng., vol SE-12, 1986 Jan, pp 42-50.. [10] M.S. Lin, D.J. Chen, "Two polynomial-time algorithms for computing reliability in a linear and a circular distributed system", PDPTA'97, 1997 Jun, Las Vegas, Nevada, USA. [11] J.S. Provan, "The complexity of reliability computations in planar and acyclic graphs", SIAM Journal on Computing, vol 15, 1986, pp 694-702.. 20.
(21) [12] A. Rosenthal, "A computer scientist looks at reliability computations in: reliability and fault tree analysis", SIAM, 1975, pp 133-153. [13] A. Satyanarayana, J.N. Hagstrom, "A new algorithm for the reliability analysis of multi-terminal networks", IEEE Trans. Reliability, vol R-30, 1981 Oct, pp 325-334. [14] A. Satyanarayana, R.K Wood, "A linear-time algorithm for computing k-terminal reliability in series-parallel networks", SIAM Journal of Computing, vol 14, 1985 Nov, pp 818-832. [15] D.A. Sheppard, "Standard for banking communication system", IEEE Trans. Computer, 1987 Nov, pp 92-95. [16] L.G. Valiant, "The complexity of enumeration and reliability problems", SIAM J. Computing, vol 8, 1979, pp 410-421. [17] P. Winter, "Steiner problem in networks: a survey", Networks, vol 17, 1987, pp 129-167. [18] R.K. Wood, "Factoring algorithms for computing k-terminal network reliability", IEEE Trans. Reliability, vol R-35, 1986 Aug, pp 269-278.. 21.
(22)
數據
相關文件
Most existing machine learning algorithms are designed by assuming that data can be easily accessed.. Therefore, the same data may be accessed
• The memory storage unit holds instructions and data for a running program.. • A bus is a group of wires that transfer data from one part to another (data,
2 Distributed classification algorithms Kernel support vector machines Linear support vector machines Parallel tree learning.. 3 Distributed clustering
2 Distributed classification algorithms Kernel support vector machines Linear support vector machines Parallel tree learning?. 3 Distributed clustering
In particular, we present a linear-time algorithm for the k-tuple total domination problem for graphs in which each block is a clique, a cycle or a complete bipartite graph,
The existence of transmission eigenvalues is closely related to the validity of some reconstruction methods for the inverse scattering problems in an inhomogeneous medium such as
Monopolies in synchronous distributed systems (Peleg 1998; Peleg
• The memory storage unit holds instructions and data for a running program.. • A bus is a group of wires that transfer data from one part to another (data,
