Efficient Remining of Generalized Association Rules
under Multiple Minimum Support Refinement
Ming-Cheng Tseng1, Wen-Yang Lin2 and Rong Jeng 3
1, 3 Institute of Information Management, I-Shou University, Kaohsiung 840, Taiwan 1 [email protected], 3 [email protected]
2 Department of Computer Science and Information Engineering, National University of
Kaohsiung, Kaohsiung 811, Taiwan [email protected]
Abstract. Mining generalized association rules among items in the presence of
taxonomy and with nonuniform minimum support has been recognized as an important model in the data mining community. In real applications, however, the work of discovering interesting association rules is an iterative process; the analysts have to continuously adjust the constraint of minimum support to dis-cover real informative rules. How to reduce the response time for each remin-ing process thus becomes a crucial issue. In this paper, we examine the prob-lem of maintaining the discovered multi-supported generalized association rules when the multiple minimum support constraint is refined and propose a novel algorithm called RGA_MSR to accomplish the work. By keeping and utilizing the set of frequent itemsets and negative border, and adopting vertical intersection counting strategy, the proposed RGA_MSR algorithm can signifi-cantly reduce the computation time spent on rediscovery of frequent itemsets and has very good performance.
1 Introduction
Mining association rules from a large database of business data, such as transaction records, has been a popular topic within the area of data mining [1, 2, 4, 8, 10, 13, 15]. This problem is originally motivated by application known as market basket analysis to find correlations among items purchased by customers.
An association rule is an expression of the form X ⇒ Y, where X and Y are sets of items. Such a rule reveals that transactions in the database containing items in X tend to contain items in Y, and the probability, measured as the fraction of transactions containing X also containing Y, is called the confidence of the rule. The support of the rule is the fraction of the transactions that contain all items in both X and Y. For an association rule to be valid, the rule should satisfy a user-specified minimum support, called ms, and minimum confidence, called mc, respectively.
In many applications, there are taxonomies (hierarchies), explicitly or implicitly, over the items. In some applications, it may be more useful to find associations at different levels of the taxonomy than only at the primitive concept level [5, 11]. For example, consider Fig. 1.
Fig. 1. An example of taxonomy T. It is likely to happen that the association rule,
Carrot ⇒ Apple (Support = 30%, Confidence = 60%),
does not hold when the minimum support is set to 40%, but the following association rule may be valid,
Vegetable ⇒ Fruit.
In our previous work, we have investigated the problem of, and proposed two ef-ficient algorithms, MMS_Cumulate and MMS_Stratify, for mining generalized asso-ciation rules across different levels of taxonomy with multiple minimum supports [14]. In real applications, however, the work of discovering interesting association rules is an iterative process; the analysts have to continuously adjust the constraint of minimum support and/or minimum confidence to discover real informative rules. How to reduce the response time for each remining process thus becomes a crucial issue.
In this paper, we consider the updating approach and propose an algorithm, called RGA_MSR (Remining Generalized Association rules under multiple Minimum Supports Refinement). Our algorithm, by utilizing the discovered frequent itemsets and infrequent candidate itemsets in the previous mining process, can significantly reduce the number of candidate itemsets as well as database rescanning. Empirical evaluation showed that our algorithm is very efficient.
The remaining of this paper is organized as follows. A description of related work is given in Section 2. In Section 3, we explain how to remine generalized association rules under multiple minimum support refinement and describe the proposed RGA_MSR algorithm. Evaluation of the RGA_MSR algorithm is described in Sec-tion 4. Finally, our conclusion is stated in SecSec-tion 5.
2 Related
Work
The problem of mining association rules in the presence of taxonomy information is first addressed in [6]and[11], independently. In [11], the authors aim at finding as-sociations among items at any level of the taxonomy under the ms and mc con-straints. In [6], they are primarily devoted to mining associations level-by-level in a fixed hierarchy, in which the uniform minimum support constraint is generalized to a form of level-wise assignment.
Another form of association rule model with multiple minimum supports is pro-posed in [7]. Their method allows users to specify different minimum supports to different item and can find rules involving both frequent and rare items. However, their model considers no taxonomy at all, and hence fails to find generalized associa-tion rules.
3 The Proposed Method
3.1 Algorithm basics
Let a k-itemset denote an itemset with k items. The basic process of our generalized association rules remining algorithm under multiple minimum support update fol-lows the level-wise approach used by most Apriori-like algorithms. However, the well-known Apriori pruning technique based on the concept of downward closure does not work for multiple support specification. To solve this problem, we have adopted the sorted closure property [7] in our previous work for mining generalized association rules with multiple minimum supports. Hereafter, to distinguish from the traditional itemset, a sorted k-itemset denoted as 〈a1, a2, …, ak〉 is used.
Lemma 1 If a sorted k-itemset 〈a1, a2, …, ak〉, for k ≥ 2 and ms(a1) ≤ ms(a2) ≤ … ≤
ms(ak), is frequent, then all of its sorted subsets with k−1 items are frequent, except
the subset 〈a2, a3, …, ak〉.
Lemma 2 For k = 2, the procedure apriori-gen(L1) fails to generate all candidate 2-itemsets in C2.
Lemma 3 For k ≥ 3, any k-itemset A = 〈a1, a2, …, ak〉 generated by procedure
apri-ori-gen(Lk−1) can be pruned if there exists one (k−1) subset of A, say 〈ai1, ai2, …,
aik−1〉, such that 〈ai1, ai2, …, aik−1〉 ∉ Lk−1 and ai1 = a1 or ms(ai1) = ms(ai2). For more details, please refer to [14].
3.2 Algorithm RGA_MSR
Our RGA_MSR algorithm proceeds as follows. First, we load all 1-itemsets which are frequent or are infrequent but located at the negative border (NB) with respect to the old multiple minimum supports (msold) setting. Second, we create the frontier set
F and use it to generate the set of candidate 2-itemsets C2. Next, we create the set of new frequent 1-itemsets according to the new multiple minimum supports (ms
new
L1
new) setting. We then generate the set of frequent 2-itemsets by scanning some
part of C new L2 new k L
2 in DB. Finally, for k ≥ 3, we repeatedly generate the set of candidate
k-itemsets Ck from andcreate the set of frequent k-itemsets until no frequent
itemsets are generated. new k
L−1
Lemma 4 An itemset A is frequent with respect to msnew(A) if it is frequent with
re-spect to msold(A) and msnew(A)≤ msold(A), where ms(A) = min ai ∈A ms(ai).
Lemma 5 An itemset A is infrequent with respect to msnew(A) if it is infrequent with
In addition, an itemset A is uncertain of frequency with respect to msnew(A) if it is
frequent with respect to msold(A) and msnew(A)> msold(A),or if it is infrequent with
respect to msold(A) and msnew(A)< msold(A).
For itemsets satisfying Lemma 4, there is no need to rescan the database DB to determine whether they are frequent. For those satisfying Lemma 5, we already know itemsets are infrequent; therefore, they are just discarded. In addition, three cases are considered: one is that the itemsets which are frequent with respect to msold and msnew
> msold are not required to rescan the database DB, but they are required to be
calcu-lated to determine whether they are frequent, another case is that the itemsets which are infrequent with respect to msold and msnew < msold but found in NBare not required
to rescan the database DB; however, itemsets can be determined whether they are frequent by simply comparing with msnew, and the other case is that the itemsets
which are infrequent with respect to msold and msnew < msold but not found in NB need
to rescan the database DB.
The main steps of RGA_MSR Algorithm are presented as follows:
Inputs: (1) DB: the database; (2) the old multiple minimum support (msold) setting;
(3) the new multiple minimum support (msnew) setting; (4) T: the item taxonomy; (5)
: the set of old frequent itemsets; (6) : the set of old infre-quent candidate itemsets.
old k k
old L
L =U NB=UkNBk
Output: new: the set of new frequent itemsets with respect to ms k
k
new L
L =U new.
Steps:
1. LoadLoldand NB
1 1.
2. Divide the set of 1-itemsets C1 into two parts: one X1 consists of items in , and the other Y
old
L1 1 contains those in NB1.
3. Sort C1 in increasing order of their mss, and create frontier set F andLnew1 .
4. Generate the set of candidate 2-itemsets C2 from F.
5. Add generalized items in T into DB as ED, and convert ED into tidlist and bitmap.
6. Delete any candidate in C2 that consists of an item and its ancestor. 7. LoadLoldand NB
2 2.
8. Divide C2 into three parts: the itemsets in Lold2 , those in NB2, and those not in NB2. For the itemsets inLold2 , further divide them into two parts: X2a for
msnew ≤ msold andX2b for msnew > msold. For those in NB2, further divide them into two parts: Y2a for msnew < msold andY2b for msnew ≥ msold. For those not in
NB2, further divide them into two parts: Z2a for msnew < msold andZ2b for
msnew ≥ msold.
9. Count the supports of itemsets in Z2a over tidlist and bitmap. 10. Create Lnewby combining X
2 2a and those itemsets which are frequent in X2b,
Y2a and Z2a.
11. Generate candidates C3 fromLnew2 .
12. Repeat Steps 6-11 for new candidates Ck until no frequent k-itemsets
are created. new
k
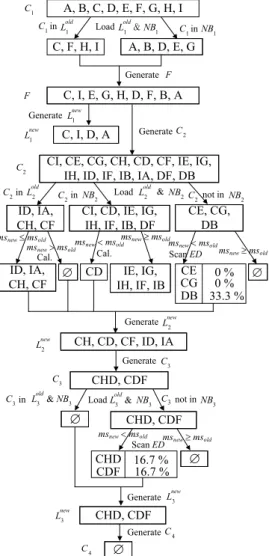
An example illustrating the RGA_MSR algorithm is provided in Appendix, where in Fig. 4, item “A” stands for “Vegetable”, “B” for “Non-root Vegetable”, “C” for “Kale”, “D” for “Carrot”, “E” for “Tomato”, “F” for “Fruit”, “G” for “Papaya”, “H” for “Apple”, and “I” for “Pickle”.
4 Experiments
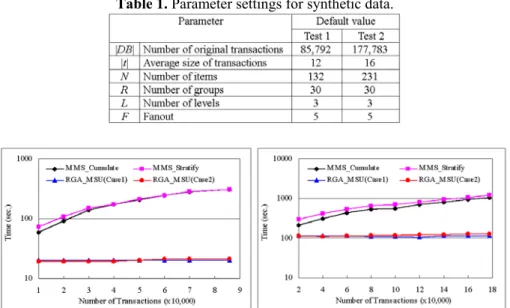
In this section, we describe the experiments conducted on evaluating the performance of algorithm RGA_MSR using two synthetic datasets generated by IBM data gen-erator [2]. In the implementation of RGA_MSR, we have kept and utilized the set of frequent itemsets and negative border [3, 9, 12, 13], and adopted the vertical inter-section counting strategy [1, 2, 4, 8, 10, 15]. The parameter settings for the two test sets are shown in Table 1. All experiments were performed on an Intel Pentium-IV 2.80GHz with 2GB RAM, running on Windows 2000.
First, the efficiency of RGA_MSR was compared to MMS_Stratify and MMS_Cummulate under various sizes of databases. The minimum supports were specified to items randomly, ranging from 0.4% to 5.5%. Besides, we adopted the ordinary case that the minimum support of an item a is no larger than any of its an-cestors , i.e., ms(a) ≤ ms( a ). The comparison was performed under two different cases: 1) all items having ms
aˆ ˆ
new > msold; and 2) all items having msnew < msold. As the
results depicted in Fig. 2 and 3 show, RGA_MSR significantly outperforms MMS_Stratify and MMS_Cumulate.
Table 1. Parameter settings for synthetic data.
Fig. 2. Execution time for various sizes of
5 Conclusions
We have investigated in this paper the problem of remining association rules under multiple minimum support refinement and presented an efficient algorithm, RGA_MSR. Empirical evaluation showed that the algorithm is very efficient to complete the remining process under multiple minimum support refinement, and su-perior to our previous proposed algorithms MMS_Cumulate and MMS_Stratify. In the future, we will continue this study to find more efficient algorithms. We will also consider applying our method to the problem of on-line discovery and maintenance of multi-dimensional association rules from data warehouses.
References
1. Agrawal R., Imielinski T., Swami A.: Mining Association Rules between Sets of Items in Large Databases. In Proc. 1993 ACM-SIGMOD Intl. Conf. Management of Data (1993) 207-216
2. Agrawal R., Srikant R.: Fast Algorithms for Mining Association Rules. In Proc. 20th Intl. Conf. Very Large Data Bases (1994) 487-499
3. Ayan N.F., Tansel A. U., Arkun M.E.: An Efficient Algorithm to Update Large Itemsets with Early Pruning. In Proc. of the 5th ACM SIGKDD Intl. Conf. on Knowledge Discov-ery and Data Mining (KDD 1999), San Diego, CA, USA (1999) 287-291
4. Brin S., Motwani R., Ullman J.D., Tsur S.: Dynamic Itemset Counting and Implication Rules for Market Basket Data. SIGMOD Record, Vol. 26 (1997) 255-264
5. Cheung D.W., Lee S.D., Kao B.: A General Incremental Technique for Maintaining Dis-covered Association Rules. In Proc. DASFAA'97 (1997) 185-194
6. Han J., Fu Y.: Discovery of Multiple-level Association Rules from Large Databases. In Proc. 21st Intl. Conf. Very Large Data Bases, Zurich, Switzerland (1995) 420-431 7. Liu B., Hsu W., Ma Y.: Mining Association Rules with Multiple Minimum Supports. In
Proc. 5th Intl. Conf. Knowledge Discovery and Data Mining (1999) 337-341
8. Park J.S., Chen M.S., Yu P.S.: An Effective Hash-based Algorithm for Mining Associa-tion Rules. In Proc. 1995 ACM SIGMOD Intl. Conf. on Management of Data, San Jose, CA, USA (1995) 175-186
9. Sarda N.L., Srinivas N.V.: An Adaptive Algorithm for Incremental Mining of Associa-tion Rules. In Proc. 9th Intl. Workshop on Database and Expert Systems ApplicaAssocia-tions, (1998) 240-245
10. Savasere A., Omiecinski E., Navathe S.: An Efficient Algorithm for Mining Association Rules in Large Databases. In Proc. 21st Intl. Conf. Very Large Data Bases (1995) 432-444 11. Srikant R., Agrawal R.: Mining Generalized Association Rules. In Proc. 21st Intl. Conf.
Very Large Data Bases (1995) 407-419
12. Thomas S., Bodagala S., Alsabti K., Ranka S.: An Efficient Algorithm for the Incre-mental Updation of Association Rules in Large Databases. In Proc. 3rd Intl. Conf. Knowledge Discovery and Data Mining (1997)
13. Toivonen H.: Sampling Large Databases for Association Rules. In Proc. 22nd Intl. Conf. on Very Large Data Bases, Mumbai (India) (1996) 134-145
14. Tseng M.C., Lin W.Y.: Mining Generalized Association Rules with Multiple Minimum Support. In Proc. Intl. Conf. Data Warehousing and Knowledge Discovery (2001) 11-20 15. Zaki M.J.: Scalable Algorithms for Association Mining. IEEE Transactions on
Appedix
Fig. 4. An example for illustration of RGA_MSR.
CI, CD, IE, IG, IH, IF, IB, DF
msnew < msold msnew ≥ msold CE, CG, DB CD Scan ED ID, IA, CH, CF msnew ≤ msold msnew > msold Cal. ID, IA, CH, CF ∅ msnew < msold Cal. IE, IG, IH, IF, IB ∅ msnew ≥ msold
CI, CE, CG, CH, CD, CF, IE, IG, IH, ID, IF, IB, IA, DF, DB 2
C
2
NB
Load Lold2 &
2 NB in 2 C inLold2 2 C 2 C not inNB2 CH, CD, CF, ID, IA new L2 CHD, CDF 3 C msnew < msold Scan ED CHD, CDF CHD, CDF CHD 16.7 % CDF 16.7 % 3 C not inNB3 4 C Generate msnew ≥ msold ∅ GenerateLnew3 Generate new L2 GenerateC3
LoadLold3 &NB3
new L3 4 C ∅ ∅ & in 3 C Lold3 NB3 C, I, E, G, H, D, F, B, A C, I, D, A 1 C F new L1 A, B, C, D, E, F, G, H, I C, F, H, I A, B, D, E, G 1 C old L1 in 1 C inNB1 Load old L1 &NB1 GenerateLnew1 GenerateC2 Generate F CE 0 % CG 0 % DB 33.3 %