國
立
交
通
大
學
電機與控制工程學系
碩
士
論
文
AshFS: 一個支援離線操作的輕量化行動檔案系統
AshFS: A Lightweight Mobile File System Supporting Disconnected
Operations
研 究 生 : 張立穎
指導教授 : 黃育綸 博士
AshFS:
一個支援離線操作的輕量化行動檔案系統
AshFS: A Lightweight Mobile File System Supporting Disconnected
Operations
研 究 生 : 張立穎 Student:Li-Ying Chang
指導教授 : 黃育綸 博士 Advisor:Dr. Yu-Lun Huang
國 立 交 通 大 學
電機與控制工程學系
碩 士 論 文
A Thesis
Submitted to Department of Electrical and Control Engineering College of Electrical Engineering and Computer Science
National Chiao Tung University in Partial Fulfillment of the Requirements
for the Degree of Master
in
Electrical and Control Engineering
July 2008
Hsinchu, Taiwan, Republic of China
AshFS: 一個支援離線操作的輕量化行動檔案
系統
學生:張立穎 指導教授:黃育綸 博士
國立交通大學電機與控制工程學系(研究所)碩士班
摘 要
隨著網際網路的蓬勃發展,有愈來愈多的服務都力求和網路結合,為數眾多的行動 裝置如手機和 PDA 等也開始強調其連網能力,以求達到機動性。在這種情況下,許許 多多的網路檔案系統也發展了起來,讓在網路另一端的使用者,可以像在操作本地端檔 案一般,透明化的存取遠端電腦上的檔案。以往許多的網路檔案系統,都是針對高頻寬 網路環境設計的,常預設使用者擁有一個穩定且高速的網路連線,然而這假設對於到處 漫遊的行動網路使用者來說並無法完全適用。行動網路有著不穩定的連接性,以及變動 性極大的頻寬;而這些檔案系統並無法自動處理這類的狀況,一旦與伺服器失去連結就 無法繼續使用。少數支援離線操作的檔案系統,由於是針對大型分散式環境所設計的, 相對來說比較耗資源,且花費了較多對使用者來說很有限的網路頻寬。在本論文中,我 們設計了一個適用於個人的行動檔案系統-- AshFS,希望能更讓移動使用者,透過其行 動裝置透明的存取自己個人電腦裡的檔案,並且不受外在網路環境變動的影響。AshFS 支援離線操作和自動同步,能在網路斷線的情況下繼續使用,並且在恢復連線後主動同 步客戶端和伺服器之間的檔案;此外,它也能有效的節省頻寬的使用。爲了驗證我們設 計的理念,在論文的最後我們設計了一連串的實驗。實驗結果顯示 AshFS 有著較高操作 速度和較低的頻寬使用量,並且在網路環境變動的情況下,其效能也能維持在一定的水 準。AshFS: A Lightweight Mobile File System
Supporting Disconnected Operations
Student: Li-Ying Chang Advisor: Dr. Yu-Lun Huang
Department of Electrical and Control Engineering
National Chiao Tung University
Abstract
Because of the pervasion of Internet, a large number of devices combined with Internet to enhance their functionalities. Under this background, many network file systems have been developed to allow people accessing files located on the remote host. Traditional network file systems usually assume that users have strong and steady connections. However this assumption is rarely true for the mobile users because of the unpredictable connectivity and widely-varying bandwidth of the mobile networks. Although some of previous works can function correctly in this circumstance, they are designed for larger distributed environments, and they consume too much bandwidth, which is very restricted for the mobile users. In this thesis, we describe the designs and implementations of a personal mobile file system, AshFS, which can mount users’ personal computers as a part of their devices’ local filesystem and can deal with the unsteady network status automatically. AshFS supports some advanced features including disconnected operations and automatic synchronization. Since AshFS is designed for the personal use, we simplify some complex mechanisms used in distributed file systems before. And this also reduces a user’s bandwidth consuming and resource usage. In the end we set up a series of experiments. The experiments show that AshFS has a higher operation speed and a lower protocol overhead. In addition, the variation of the network status doesn’t influence AshFS’s performance much.
誌謝
首先要感謝我的指導教授,黃育綸博士,由於她的細心指導與充分信任,讓我 能夠充分利用實驗室的資源,這篇論文以及相關作品才得以順利完成。以及何福軒 先生,在指導教授出國的這段時間,不辭辛勞的繼續指導我們完成論文。 再來要特別謝謝實驗室的同學陸培華和鍾興龍,在我們一起度過的兩年碩班生 涯裡,不論是碩一時修課讀書拼考試,亦或是當助教一起荼毒學弟妹,以及碩二時 一起互相鼓勵朝著自己的研究目標邁進,這些日子都將是我難以抹滅的回憶,也無 形中幫助我成長。此外感謝實驗室的學長姊楊志堅,黃詠文,蔡欣宜和鄭依文,雖 然偶爾礙於地位必須臣服於學長姊的淫威之下,但能在我徬徨無助時適時的給予了 指點,仍讓我獲益匪淺。感謝 RTES 實驗室的學弟妹們,因為你們的懵懂無知和天 真無邪,為實驗室帶來了不少的歡樂。感謝甄元彬,黃暉鈞,邵啟意及洪堃能等電 控系足的成員,因為你們適時的助攻讓我可以完成一球球漂亮的世界波,能和大家 一起快樂的踢球,是我忘卻所有壓力的最好方式。在我們一起征戰過的地方,都留 下了我們的足跡,歡笑和淚水。感謝許呈韶,潘彥承,陳慈樸,辛威虢,蔡承祐, 蔡旻諴,高豪佐,吳佩倫和陳玉婷等大學時代結識的好友們,雖然彼此的領域有所 差異,對未來的打算也不盡相同,也因為這樣和你們相處談心的時光,總是讓我增 廣見聞和放鬆自己的時候。 最後我要感謝我親愛的父母和弟弟,以及其他所有長輩們,還有家裡的狗狗 tokky,在求學生涯中給了我最大的物質和精神支持,讓我能衣食無虞並且滿心歡 喜的往每個目標邁進。謹以此論文,獻給所有愛我的人和我愛的人。Table of Contents
摘 要 ...i
Abstract ...ii
誌謝 ...iii
Table of Contents ...iv
List of Tables ...vi
List of Figures ...vii
Chapter 1 Introduction ... 1
1.1 Motivation ... 1
1.2 Contribution... 2
1.2 Synopsis ... 2
Chapter 2 Related Work ... 4
2.1 NFS... 4
2.2 SAMBA... 5
2.3 Coda ... 6
2.4 SSHFS ... 7
2.5 RSC Filesystem for Symbian OS... 8
2.6 MAFS... 9
2.7 Summary ... 10
Chapter 3 Design Issues ... 11
3.1 Read Issues ... 11 3.1.1 Cache design... 12 3.1.2 Cache consistency ... 13 3.1.3 Network manager ... 14 3.2 Write Issues ... 16 3.2.1 Upload manager... 18
3.2.2 Write optimization and read-write contention ... 19
3.2.3 Conflict detection and resolution ... 20
3.3 Other Issues... 21
3.3.1 Directory refresh... 21
3.3.2 Time stamp synchronization... 22
3.3.3 Improve operation speed and bandwidth consuming ... 23
Chapter 4 Implementation... 26
4.1 System Architecture... 26
4.2 Tools ... 27
4.2.1 FUSE ... 28
4.3 Current Status and System Requirements ... 30
Chapter 5 Experiments and Performance Evaluation ... 32
5.1 Experiment Environment and Tools ... 32
5.2 Frequencies of Filesystem Operations ... 33
5.2.1 List frequencies ... 33
5.2.2 Frequencies of a sequence of operations... 33
5.3 Write Throughput... 35
5.3.1 Write throughput under unlimited bandwidth... 35
5.3.2 Write throughput under lower bandwidth... 37
5.4 Synchronization Performance ... 40
5.4.1 Synchronization time... 40
5.4.2 Rewriting speedup ... 41
List of Tables
Table 1: Comparison of related works... 10
Table 2: Priorities of network accesses ... 20
Table 3: Single file throughput under high BW ... 39
Table 4: Separate files throughput under high BW ... 39
Table 5: Single file throughput under 512KBps... 40
Table 6: Separate files throughput under 512KBps... 40
List of Figures
Figure 1: Read flow... 11
Figure 2: Connection status and timeout... 16
Figure 3: Write flow... 17
Figure 4: Upload manager... 18
Figure 5: Readdir flow ... 22
Figure 6: AshFS system architecture ... 27
Figure 7: Path of stat request in FUSE... 28
Figure 8: Path of stat request in AshFS... 31
Figure 9: Frequencies of List operations... 34
Figure 10: Frequencies of a sequence of operations ... 34
Figure 11: Single file write throughput... 36
Figure 12: Separate files write throughput... 36
Figure 13: Write overhead... 37
Figure 14: Single file throughput in 512KBps... 38
Figure 15: Separate files throughput in 512KBps... 38
Figure 16: Write overhead in 512 KBps ... 39
Figure 17: Synchronization time... 41
Chapter 1
Introduction
1.1 Motivation
As computer networks became ubiquitous, many devices combine with Internet and focus on their connecting ability recently. Sharing files between two hosts has become more and more important. People used to utilize some client-side applications to download files from the server to their devices, but having multiple copies of one file causes many troublesome synchronization problems. What they really want is to keep only that file on the server, but it can be accessed by their devices everywhere. Therefore many network file systems have been developed to make users can access remote files as if they were on the local storage. However, most of them are designed for the LAN environment: they need a strong and consistent and connection, and usually are used under a high-bandwidth network environment. Apparently, this assumption is rarely true for the mobile users. For mobiles users who use 3G or WLAN, the connections are often intermittent, and the available bandwidth is much lower. Furthermore, network resources for them are precious, because sometimes the connection is closed manually to reduce power consumption or just save their connection cost. There should be a more suitable network file system under this circumstance, so we focus on these issues and implement an experimental solution.
Our goal is to design a personal mobile file system. Users outside can easily utilize it to access files on their personal computers at home or office without perceiving the changes of network status, and can use available bandwidth more efficient. Mobile access to shared data is complicated by unpredictable computing environment: the network or particular destination may be unavailable, or the throughput may be substandard [5]. In order to adapt to these
conditions, our new filesystem can support disconnected operations and automatic synchronization. Disconnected-operations means that the client can continually use cached data when the server is out of reach. After the connection recovers, the file system will automatically synchronize files between the client and the server. Previous works like Coda also supports disconnected operations and automatic synchronization. However, Coda was originally designed for large-scale distributed computing environments, so it paid much attention to maintain authentication and file consistency. It causes lower performance and consumes more bandwidth. Hence we are trying to make some compromises, and design a simpler and more efficient mobile file system.
1.2 Contribution
In this thesis, we developed a personal mobile network file system for accessing files on the remote SSH server. This file system is called AshFS now, which means advanced SSH file system. In combination with our designs and the OpenSSH client suite, AshFS makes users can easily mount the directories on the SSH server as a part of their local file system. AshFS fully supports disconnected operations, which means that it can work correctly even if the server is out-of-reach. In addition, AshFS has a higher operation speed and effectively reduces the bandwidth usage. When the network environment changes, it can adapt itself to different bandwidth with acceptable performance. AshFS is suitable for personal use or few clients’ use, since we relaxed some strict authentication and consistency methods used in previous works to achieve higher performance. In addition, AshFS is running on Linux OS now, and it looks like just a client-side application for the end users.
1.2 Synopsis
the Chapter 1, some related works will be showed in Chapter 2. Then we are going to interpret some important design issues in Chapter 3. Chapter 4 layouts AshFS’s system architecture and discusses our implementations. Several experiment results will be showed in Chapter 5, and finally, we will give our conclusions and outline the future work in Chapter 6.
Chapter 2
Related Work
File sharing is a common service as Internet became popular. People used client-side applications supporting interactive protocols like File Transfer Protocol (FTP) to download files from the server initially [18]. Such applications need their own network supporting code to make use of the remote server’s file resources [1]. However, what people really need is a file system that offers transparent accesses to remote files. From the application’s view, these files are indistinguishable from local files. Therefore many network filesystem were developed, and we are going to look these previous works here.
2.1 NFS
Network File System (NFS) is a network file system protocol originally jointly developed by Sun Microsystems and IBM in 1984. It is the first widely-deployed transparent file system [6]. NFS is almost the most common way to share files between UNIX-like servers since its simplicity and efficiency. The latest version of NFS is Version 4, but most sites currently implement Version 3(NFSv3). Because of its wide deployment and support (both by operating systems and by applications), features offered by NFSv3 can be considered a golden standard to which other network file systems can be compared.
NFS clients make no assumptions about server state and any caching of data is unofficial [1]. No server state means that the client is not aware of the server state. If the server crushes, the client can only wait until the server recovers, and file system operations will be blocked for a long time. Also NFS uses the minimal caching design. Although it means that there are few data consistency problems because almost every operation will see
the freshest result, it causes a long delay when the client is not in a low latency and high bandwidth network environment, because many messages of file system operations need to transfer over the network. Since NFS is originally designed for sharing files over a fast and reliable network[24], no server state and minimal caching make it a relatively easy implementation, excellent performance and easy error recover network file system. However, it is not suitable for the mobile networks.
Furthermore, NFS server uses IP address and subnet mask to identify its clients and limit the authority [9]. It is fine for sharing files over LAN because the range of IP is clear, and many clients have its own invariable IP addresses. Nevertheless, it’s not that condition for the mobile clients. It is hard to know where the client would go, so the scope of IP address cannot be definitely limited.
2.2 SAMBA
Samba is an open source software suite which makes UNIX and MS Windows can share files and print services with each other [14-15]. It is also a free software suite and was developed by many kinds of organizations since 1992. All manner of SMB/CIFS (Server Message Block/Common Internet File System) clients, including the numerous versions of Microsoft Windows operating systems, can use services provided by Samba. Current stable version of Samba is Version 3 (samba 3), and it’s also our comparison standard.
Samba identifies a user and limits its authority by using login name and password or some other more complex ways. Because of its cross-platform characteristic and safer authentication method, Samba is suitable for sharing files over the network. Although many authentication methods and options make Samba a secure and elastic network file system, theses options also let deployment cost higher. Problem-shooting also becomes more difficult because sometimes it’s not easy to find out the problem is on the client, the server, or just the
network environment.
Samba supports virtual memory cache, and can cache recently-used directories contents. But the cache is not persistent, and it doesn’t cache whole-file contents, hence it doesn’t support disconnected operations. Samba is usually used for sharing files between Linux and Windows machines over LAN nowadays since its original design purpose and the not fully-functional cache. Accessing files on a Samba server over Internet may not be a good idea, because it could cause a long delay.
2.3 Coda
Coda is a file system for a large-scale distributed computing environment composed of Unix workstations [4]. It has been developed at CMU since 1987 by the systems group of M. Satyanarayanan in the SCS department. Coda is still under development, and its current stable version is 6.9, though the focus has shifted from research to creating a robust product for commercial use.
The Coda file system started as an advancement of AFS and it introduced several new key features: disconnected operation, resolution of diverging replicas with bandwidth adaptation, and server replication. Each Coda client runs a process called Venus as the cache manager; Venus uses the local disk as a file cache and caches files and directories in their entirety. Once a file is cached, file system operations of this file will be redirected to the local file system without contacting to the server (if the cached file is fresh). When the server is out of reach, the client can still operate this file system and use the cached files, and Coda will switch to disconnected mode. In disconnected mode the updates are immediately applied to the local cached files and also logged. After the connection recovers, the log will be propagated to the server and will be replayed on the server. Before replaying the log, Coda examines if there is any confliction between the client and the server. If there are conflictions,
Coda will try to resolve these conflictions automatically (called “Conflict Resolution”). In case of server failure, server replication allows each volume (the storage unit in Coda) to have read-write replicas at more than one server. The set of replicas for a volume is its “volume storage group” (VSG). The subset of a VSG which permit a client can access is called “Accessible VSG” (AVSG) [25].
Besides disconnected mode, Coda has other two operation modes: strongly connected and weakly connected. During strongly connected mode, Coda will prefetch some files for future use (called “Hoarding”). It makes users can use more files when disconnect from the server. The remote servers can be replicated for higher performance and fault tolerance, i.e. Coda stores copies of a file at multiple servers. Even if some of servers are partitioned from the network, user can still fetch files from other servers. Because mechanisms listed above, Coda can achieve high availability.
However, Coda was originally designed for large-scale distributed computing environments, and it has strict maintenance in authentication and file consistency. Therefore it will sacrifice some performance and consume more network resources. In order to manage disconnected operation and synchronize data between multiple servers, Coda extents the RPC protocol to RPC2. But RPC2 is different from RPC of NFS and NetBIOS of Samba; it’s not a standardized protocol. In addition, Coda’s deployment is marginal outside the academic community [3], and causes its deployment and establishment costs are much higher than other file systems.
2.4 SSHFS
Sshfs is an abbreviation of secure shell filesystem, it allows users mounting an SSH server as a part of local file system [16-17]. It is a file system client based on SSH file transfer protocol (SFTP) and FUSE, a user-space filesystem framework. Sshfs can be running on
many OSs with a FUSE implementation such as Linux, Mac OS X and FreeBSD.
Since most Linux servers already support SSH and SFTP protocols, sshfs’ deployment is not difficult. There is nothing to do on the server side and on the client side mounting the file system is as easy as logging into a server with an SSH application. Sshfs uses multithread programming technique, i.e. more than one request can be on its way to the server. In addition, it caches directory contents temporarily for faster responses. However, this cache isn’t persistent and sshfs needs a consistent connection to the server. Once the connection between the client and the server is lost, it cannot handle this situation automatically, and manually remount is needed. In other words, Sshfs doesn’t support disconnected operation. For a mobile user, it is painful to deal with this connection problem by himself/herself.
2.5 RSC Filesystem for Symbian OS
Four Finland researchers have developed a framework called Remote Storage Client (RSC) framework for accessing remote file systems with Symbian OS phones [3]. RSC was inspired and informed by Coda, many design aspects are similar to Coda, but it adapted some of aspects to make it faster and more efficient. It supports disconnected operation with whole-file caching and immediate file access. While whole-file caching is a natural consequence of the requirement to support disconnected operation, immediate file access makes it more suitable for multimedia applications. Because these applications sometimes only require quick access to a portion of data, without any intention to consume the whole file. Downloading the whole-file causes needless long delay.
Two protocol plug-in modules for RSC have been implemented: WebDAV and FTP. WebDAV is an HTTP extension which allows users to collaboratively edit and manage files on remote web servers. They tried to use standardized protocols and preferably not require server-side changes. In this framework, the server is a standard WebDAV or FTP server, the
whole procedure is conducted by the client.
Immediate file access with block-level caching reduces the delay when opening a file, and sometimes makes file access more efficient. But this design is for multimedia files only. When considering accessing normal files, RSC filesystem still needs to fetch the whole contents. Furthermore, RSC uploads the cached file in its entirety to the server for updating. This is somewhat wastes the network resources if only a little part of the file was modified.
2.6 MAFS
MAFS is a file system for mobile clients and is tailored for wireless networks by incorporating automatic adaptation to the available bandwidth [5]. Rather than specifying a threshold for switching between synchronous and asynchronous writeback modes, it uses asynchronous writeback at all bandwidth level. But delaying writes at high bandwidth sometimes causes severe inconsistency problems, so MAFS incorporates a new invalidation-based update propagation algorithm, SIRP, to ensure that file modifications are propagated to the clients who need them in time. In addition, it uses RPC priorities to reduce interference between read and write traffic at low bandwidth, and reduce a client’s contention for wireless bandwidth. In a word, MAFS reacts to bandwidth variations in a file-grained manner and permits a degree of consistency.
MAFS also supports disconnected operation with whole-file caching. Although MAFS uses several ways to eliminate the fundamental problem of contention for insufficient bandwidth, it doesn’t try to reduce the client-server network traffic for file transferring, which could be the most bandwidth-consuming operation. In addition, MAFS doesn’t resolve conflicts automatically, but we think it is necessary for better consistency.
2.7 Summary
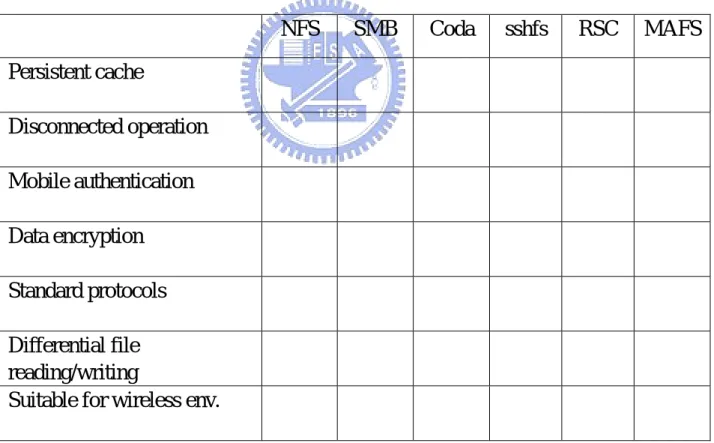
Now we list a table to describe our design goals and make a comparison of our related works. And we explain some terminologies listed in the table here.
z Mobile authentication: The target filesystem can recognize and authenticate a mobile user.
z Data encryption: All transferred data are encrypted for the security concerns.
z Differential file reading/writing: When updating a file, the target filesystem can compare the new and old files, and only transfer the modified portion of the file.
z Suitable for wireless environments: The target filesystem can tolerate the variation of wireless networks and consume less bandwidth.
NFS
SMB
Coda sshfs RSC MAFS
Persistent cache
╳
╳
○
╳
○
○
Disconnected operation
╳
╳
○
╳
○
○
Mobile authentication
╳
○
○
○
○
○
Data encryption
╳
╳
○
○
╳
╳
Standard protocols
○
○
╳
○
○
╳
Differential file
reading/writing
╳
╳
╳
╳
╳
╳
Suitable for wireless env.
╳
╳
╳
╳
○
○
Chapter 3
Design Issues
To realize a file system, there are some basic operations like read and write needed to be implemented. Because we want AshFS can support two key mechanisms: disconnected operation and automatic synchronization, these operations are slightly different than traditional ones. With a view to easing deployment, we adopt two design aspects used by RSC filesystem to develop AshFS: standardized protocol and no server-side changes, but we changed some designs. Here we are going to discuss them, and explain our design tenets.
3.1 Read Issues
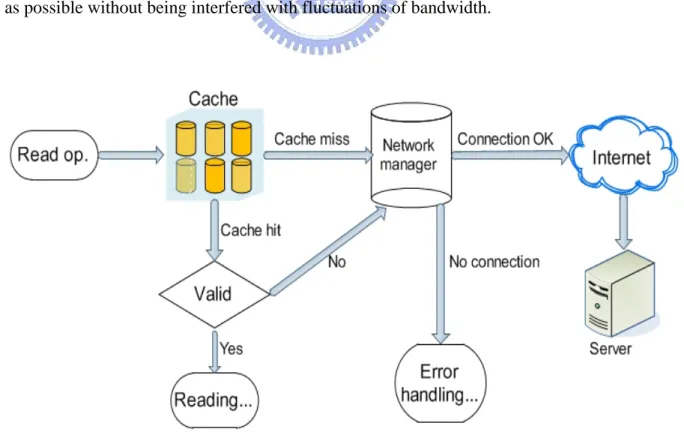
Most mobile users do lots of read operations than write, and want their readings as fast as possible without being interfered with fluctuations of bandwidth.
Figure 1 shows program flow of a read operation, and we are going to discuss some issues in detail. AshFS first search its cache for information of the requested object. At first time, there is a cache miss, AshFS will contact to server to get data. If the object has been read recently, it can be found in cache, so there is a cache hit. Then AshFS will check its validity, in order to make sure the cached data are fresh enough. Note that every network requests and replies will be sent to Network manager first. Because of unsteady connection of mobile networks, we have designed the network manager to facilitate administrating.
3.1.1 Cache design
In order to fully support disconnected operation, we designed a cache to store all necessary data and utilized whole-file caching; therefore user can still uses some files when there is no connection. Not only the object data are cached, but also its metadata are cached. The metadata includes filename, size, owner, assess rights, last modification time, etc. which are needed for a file system to interpret its data. When the client access a file for the first time, the entire file is fetched and cached in the local file system. So next time when the same object is requested again, AshFS can answer it directly without contacting server.
The basic idea of AshFS is caching information which is needed of each filesystem operation and redirecting these operations to local disk first. Usually the operation of reading a new object returns until all needed data are fetched. However, users are always impatient of waiting for a long time and think that the program is crashed when fetching a large file. Hence AshFS times each read operation and returns immediately when timeout occurs. Fetching process will continue in background, and a message will be showed when someone tries to read this incomplete file.
written into disk periodically in case of cache miss due to power shutdown or programs exits abnormally. Generally the user can use AshFS smoothly without being aware of the existence of cache, however we have make AshFS more flexible: The user can observe the caching state and control a part of cache.
3.1.2 Cache consistency
Because the client always refers to cached file preferentially, the freshness of the cached file becomes an important issue. If a cached file has been changed on the server, client should update this file before using it to prove data consistency; this process is called cache validation.
Traditionally cache validation can be avoided if the file in the server is locked. However, locking is overkill when the file is only opened for reading [3]. In fact, mobile clients usually perform much more reads than writes. Besides, file locking is not provided in the FUSE system [1], so the validity of the cache should be guaranteed by some other ways. One is server-side “callback”: The server actively notifies the client of changed files. This mechanism has been demonstrated to be a useful optimization in cache consistency management in many prior network file systems like Coda and NFSv4 [13]. Nevertheless, we have decided not to change server-side for easy deployment, also mobile network (like GPRS) operators do not typically allow active incoming packets form Internet [3]. So we have let the client to check validity actively: It check the last modification time of a file object on the server.
On the first time the client gets metadata of a file object (a file or a directory) from the server, it also records its last modification time, we say, time stamp in cache. Different from cache validation mechanism of RSC filesystem, we enhanced AshFS’s cache consistency by mixing both timeout (used in RSC) and check-on-demand mechanisms. The time stamp will be verified under two conditions: One is when the lifetime of the cached file object expires;
the other is when the object is requested. If the time stamp of a cached file object is different from server’s one, it means that server’s file have been modified since client have cached it last time. Maybe this cached file is out-of-date, and we call such file a “stale file”. If a cached file is marked as “stale”, AshFS will abandon it and try to download a fresher one.
Verifying cache needs to communicate with the server for every file operation, and it is bandwidth-consuming, so AshFS only perform it when it is in strongly connected state (discussed latter). In weakly connection state, AshFS’s control messages and file transfer deservedly take higher priority of network usage than cache validation. In addition, it’s apparent that such a communication process will take much more time than just deal with cached files. When considering the file operation speed, waiting until checking process finishes is unreasonable. So we do this process in parallel: create another thread to verify validity, and the main thread performs the real operation simultaneously. Main thread should detach his kid and returns quickly. If there is inconsistency, kid thread will mark this state on the file object, and update will be progressed next time. Checking validity in parallel sacrifices some consistency, but has a great advantage in operation speed. We used POSIX threads package (pthreads) [10] provided by the Linux OS to implement thread management and synchronization.
3.1.3 Network manager
AshFS is aware of the connection status, and divides it into three states: Strong, Weak, and Disconnected. When the connection to the server is lost, AshFS will switch to Disconnected mode automatically. In Disconnected mode, all file system operations will be served by cache, if there is a cache miss, an error message will be displayed. If the connection exists, but bandwidth is not strong enough, AshFS will switch to Weak mode. When AshFS is operated in Weak mode, it will still fetch the uncached file from the server, but all modifications will not be propagated to the server. Hence this stage is also called
write-disconnected mode.
As a matter of fact, AshFS’s every network accessing operation will past to Network manager first. Network manager is mainly responsible for identifying connection status, communicating with the server, and (re)connecting to the server. To classify connection status, Network manager uses timeout mechanism. Before Network manager connects to the server, a default timeout, say 20 seconds, was set. When it is connecting to the server, the response time of every request will be recorded. And their average pluses a little amount will be the new timeout. And the next network accesses will take the new timeout as reference. Once upon Network manager successfully connects to the server, it will use the “ping” utility to decide the current connection status is Strong or Weak. Network manager pings the server, and analyzes the response time to decide current status. The default margin of Strong and Weak is 10 ms. If the server doesn’t receive ICMP packets, i.e. it cannot be pinged, AshFS will set connection status as Strong first.
Adapting to variability of mobile networks, our timeout is dynamic. It means that the timeout may be changed in every communications. Please look at Figure 2. When Network manager sends requests to the connected server, it waits for responses in T seconds. If it can receive response, it will compare current response time with the T. If network manager cannot receive any message in T seconds, it will double current T and requests again. More details are described in the figure, and it shows how we define Weak and Disconnected. If AshFS doesn’t get respond in T over two times, it assumes that the server is out of reach and change to disconnected mode. By the way, all default values used here for Network manager can be changed manually by user.
Figure 2: Connection status and timeout
3.2 Write Issues
We have mentioned that all file operations will be redirected to local disk first, it’s also true for the writing. AshFS uses asynchronous writeback mechanism at all bandwidth levels, which means that AshFS will not propagate the update to server when the writing has just finished. This can reduce some unnecessary communications between client and server and utilize the limited bandwidth more efficiently.
Some of MAFS’s design aspects are adopted in AshFS: we utilized asynchronous writeback at all bandwidth levels and defined priorities for each kind of AshFS’s file operations. However we didn’t intend to adopt MAFS’s invalidation-based propagation
scheme, because it needs server-side changes and consumes more resources. Since AshFS is designed for personal use, we abandoned this propagation scheme which is useful in maintaining file consistency in a multi-client system. Besides using priorities like MAFS to make bandwidth-usage more efficient, we also focused on reducing client-server network traffic when transferring files.
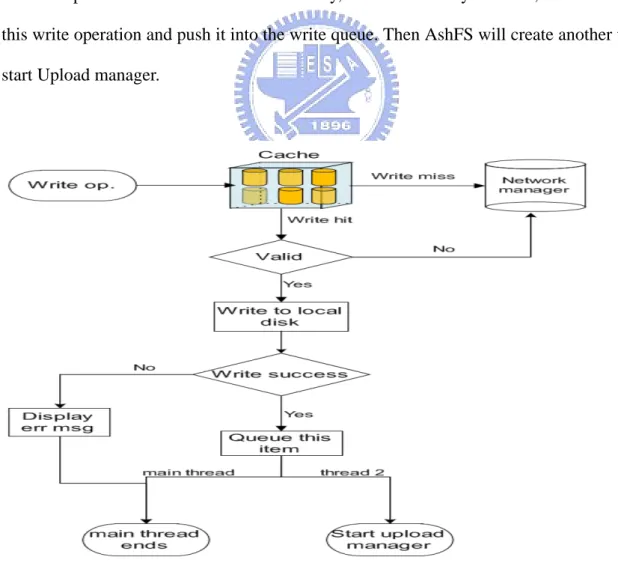
Please look at Figure 3. It illustrates how a write operation progresses. Here we omit the procedures of connecting to the server. In fact, when there is a write miss, AshFS will download it from the server first, and then remaining operations are redirect to the local files. Just similar to the read operation, before writing to the local file, the validity should be verified to prove consistency. If something causes write failure (like disk full or memory leak), the write process will aborts. On the contrary, if it successfully finished, AshFS will record this write operation and push it into the write queue. Then AshFS will create another thread to start Upload manager.
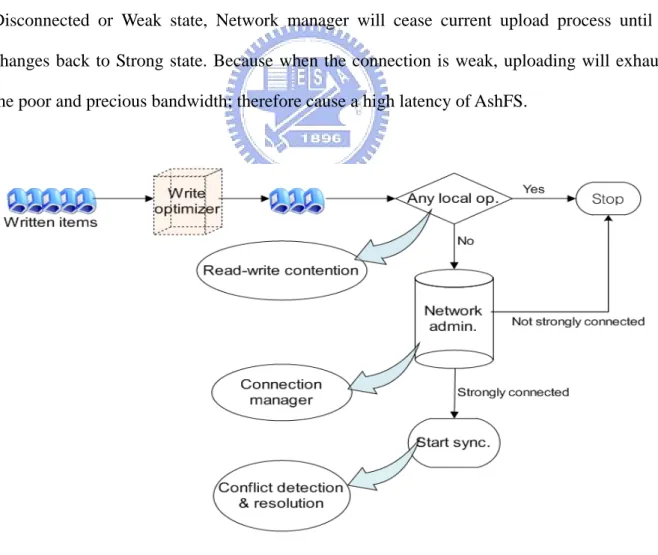
3.2.1 Upload manager
Upload manager is designed for uploading all the updates in write queue to the server. Figure 4 shows how Upload manager synchronizes these modified items to the server and some important mechanisms. To be briefly, it is responsible for all the updating process, including doing optimization, checking network status, resolving conflicts, avoiding read-write contention, labeling time stamp, and marking the upload status. We’ll discuss these processes soon. When an update has been uploaded to the server successfully, write manager will remove this item from the write queue. It is deserved to be mentioned that before processing each queue item, Upload manager will check the network status first. If it is in Disconnected or Weak state, Network manager will cease current upload process until it changes back to Strong state. Because when the connection is weak, uploading will exhaust the poor and precious bandwidth; therefore cause a high latency of AshFS.
3.2.2 Write optimization and read-write contention
Item in queue can be optimized because that some file operations could be canceled out. For example, if a user creates a new file, and after writing this file for several times, he finally removes the file. Operations to this file can all be canceled and it’s not necessary to upload it ever.
AshFS write updates asynchronously to the server. When upload manager propagates these updates in background, user can still use AshFS to do other read/write operations in foreground. So it’s usual that there are both read traffic and write traffic at the same time. This situation is called read-write contention [5]. However, most of update processes are deferrable, and they contest available bandwidth with foreground activities. Especially when the available bandwidth is poor, such competition will severely slow down the operation speed of file system. Using a network file system over such a low-bandwidth environment must consume less bandwidth, and avoid monopolizing network links in use for other purposes [26].
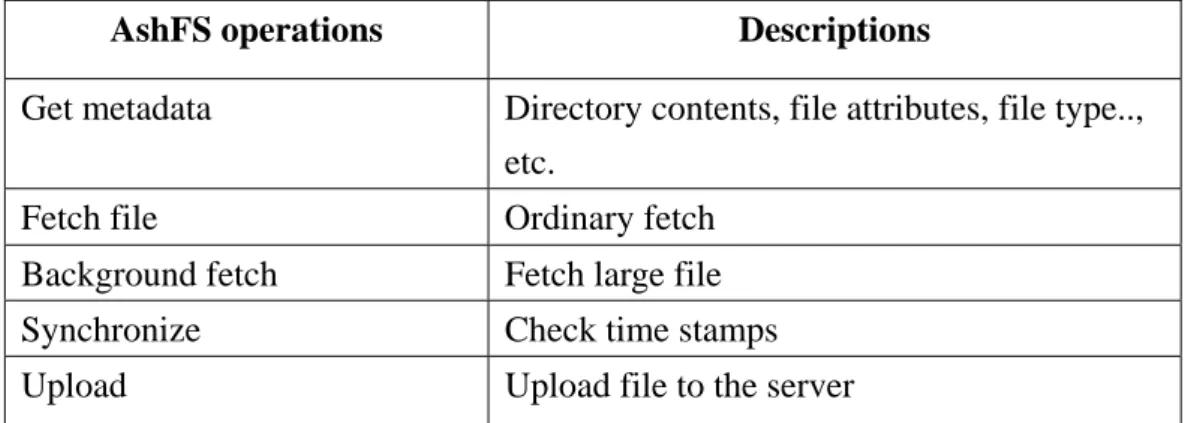
To smooth user’s file system operations without being interfered by minor tasks, we divided AshFS’s network operations into several classes, and sorted them based on their importance to the most users. Table 1 is the priorities of AshFS’s network operations. The most important operation is getting the metadata. Because it can let the user know quickly what contents an uncached directory has, or how large of an uncached file is. Fetching a file in background, which has been discussed in part B, we gave it a priority number 3, because the user may want to read it as soon as possible. Synchronization messages and upload are last two in our priority table. Although it may cause higher file inconsistency, it’s acceptable to do such a compromise.
AshFS operations Descriptions
Get metadata Directory contents, file attributes, file type.., etc.
Fetch file Ordinary fetch
Background fetch Fetch large file
Synchronize Check time stamps
Upload Upload file to the server
Table 2: Priorities of network accesses
3.2.3 Conflict detection and resolution
Because the server doesn’t positively notify its clients which files were changed, the consistency can only be checked by the client itself. There are two kinds of file inconsistency: one is Stale, and the other is Conflict, which we are going to discuss in this section. “Stale” means that the file on the server has been modified before the client writes it, so the cached file is out-of-date. We have talked about this in 3.1.2. Unfortunately, when Upload manager are trying to propagate a modified file to the server, and it finds that this file has already been changed on the server, then conflict occurs. It probably means that there are two clients have modified the same file simultaneously.
Let’s explain how AshFS detects a conflict here. We compare the time stamps. There are three kinds of time stamps which will be tracked by AshFS:
z Tm: time stamp of the file recorded by AshFS.
z Ts :time stamp of server’s file.
z Tc :time stamp of the file in AshFS’s cache now.
Case 1: Tc = Tm < Ts
Î Server’s file has been modified. Î Our client doesn’t modify (use) it yet. Î Stale.
Case 2: Tm < Ts and Tm < Tc
Î Server’s file has been modified.
Î Our client has also modified it but doesn’t upload it yet. Î Conflict.
In short, when these three time stamps are all unequal, we could say there is a conflict. To resolve a conflict, AshFS applies the “no lost update” principle [3]. It keeps both server’s and client’s new file, but rename client’s one. The new name of file is similar with old one, with a suffix and a time label appended to it. For example, the original file name is “hello.txt”, and its conflict copy could be renamed as “hello-conflict-20080521.txt”. So user can easily identify it as a conflict file. This principle may be a little conservative, but preserving both sides’ files let user can decide by himself / herself, could be the safest one. Resolution should be automatic and transparent without user intervention. In our implementation, users will not receive messages about conflicts. But they can perceive the existence of conflict files by the filename or the upload log.
3.3 Other Issues
Besides read and write issues, there are some other important mechanisms. We are going to interpret them here.
3.3.1 Directory refresh
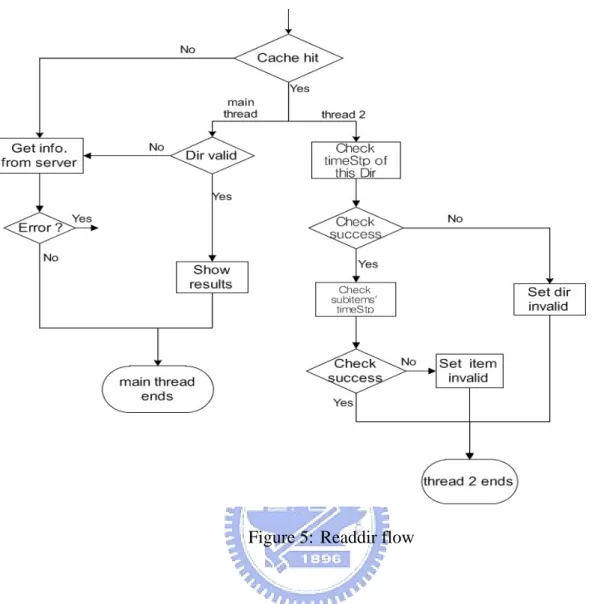
Listing is almost the most frequently-used function of a file system. User lists a directory and sees if there is something interesting. But how does AshFS know if the directory is updated or not? Let’s begin with an example.
Figure 5: Readdir flow
Figure 5 is a part of flowchart of customized Readdir() function. As we mentioned, the checking time stamp process will be done by another thread, thread 2. Thread 2 asks server for time stamp of the directory. If it is different from one in AshFS’s cache, it will know that something under the directory was deleted or newly added. So it will mark the directory as “invalid”. The original thread doesn’t check time stamp itself, but it inspects the valid bit of the directory. If the valid bit is set, main thread will contact to the server to reread the directory, and refresh the cache.
3.3.2 Time stamp synchronization
Now we are going to discuss time stamp synchronization. When upload manager finishes propagating one file to the server, it’s intuitive to think that the server’s file is totally
the same as one in the client’s cache. However, their time stamps are rarely the same, since their finishing time are usually different. So when the client uses the file next time, AshFS will think that it was out-of-date, and try to update the cached file. Hence if a file is being uploading to the server, AshFS will temporarily turn off the synchronization of the file. And when the uploading has finished, AshFS will equalize their time stamps and their parent directory’s time stamps. Only when this process succeeds, the propagation of this item can be seen as completed.
3.3.3 Improve operation speed and bandwidth consuming
Because of the uncertainty and preciousness of the mobile networks, we are trying to accomplish most of operations in the local file system without going through Internet. When accessing Internet, we want to use it more efficiently. In addition, comparing with local operations, communicating with the server is time-consuming. There are four circumstances that AshFS consumes a large amount of network bandwidth:
z Retrieving metadata: especially after reading an uncached directory. z Cache validation: when checking time stamps.
z Time stamp synchronization: After uploading a file. z Fetching and storing files.
When a user lists an uncached directory, AshFS library will first try to link and call “readdir” function of AshFS process to find all entries under this directory. Then for each entry, the library will ask “stat” function for the metadata. After knowing what type of this entry is (file or directory), it finally shows the contents of the requested directory on the screen. During this process, stat function was called many times. Because each entry was uncached, the function needed to communicate with the server when it was called. Therefore a massive of send-receive pairs occurred here, and consumed bandwidth much. In order to be
more efficient, we decided not to request metadata one by one. Instead, we asked the server for all entries’ metadata in one time. So our readdir function is also responsible for filling all entries’ metadata. And our stat function will not contact to the server, just search AshFS’s cache.
The 2nd bandwidth-consuming case is cache validation. Look Figure 5 again. After thread 2 checks time stamp of request directory successfully, every entries’ time stamps will also be check. To avoid too many requests and replies happening, we decided to do it at once. Similarly, thread 2 will request all entries’ time stamp at once.
The 3rd bandwidth-consuming case is time stamp synchronization. As we talked in Part B, upload manager will make time stamp of a server’s newly-uploaded file equal one in client’s cache. It is unnecessary to change time stamp of server’s file one by one, we can also change them all at once. When upload manager finishes propagating a file, it record its time stamp. After upload manager completes a part of its work in write queue, it creates a shell script file, and appends commands to it. Then upload the shell script to the server and ask server to execute it. This method effectively reduces the communication times.
To sum up the first three cases, network accessing is unavoidable, and it usually slows down the speed of a network file system. We want that AshFS’s network accessing can be more efficient, so we request as more objects as possible in one time. This principle effectively decreases communications with the server, and reduces the bandwidth usage.
The 4th bandwidth-consuming circumstance is the most important one: fetching and storing files. When a user tries to download or upload a new file from/to the server, a large amount of bandwidth will be used to transfer file contents. Except doing some optimizations to cancel out unnecessary operations, there is nothing we can do to preserve our constrained bandwidth in tradition. However, if the user is updating an old file instead of a whole-new one, it is not the case. Since the updated file may be similar as the old one in server or client’s cache, we can avoid transferring the same parts of contents over the network but only the
different ones. By exploiting the similarities between the new and old files, the actual amounts of transferred packets will be much less than total file size. It indeed preserves the bandwidth consumption and makes our bandwidth-usage more efficient.
Chapter 4
Implementation
In Chapter 3, we discussed several design issues, and these mechanisms have been built in our AshFS file system. Now we are going to account for how they were implemented.
4.1 System Architecture
File systems have been implemented in the OS kernel traditionally, in order to obtain the fastest speed and the best integration with OS. Although computing power has a great improvement recently, the performance bottlenecks of the most network file systems are at the network transmission speed. So the speed improvement of a pure kernel-based network file system is no longer significant. When developing a mobile file system, we decided to create it in user space to achieve a good portability. In addition, such a user-space file system can corporate with other applications easily to enhance its own features.
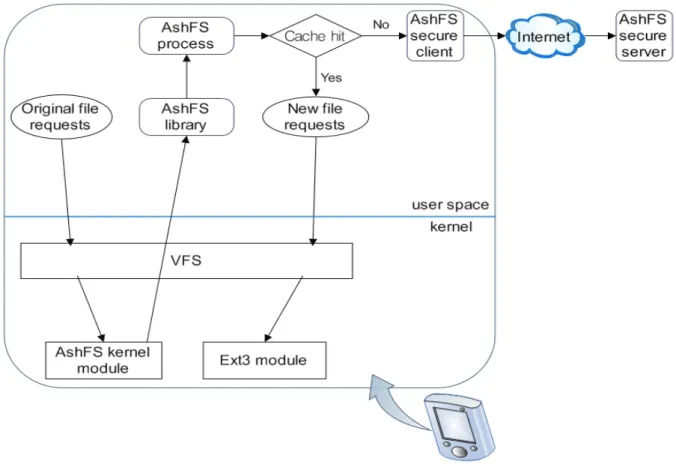
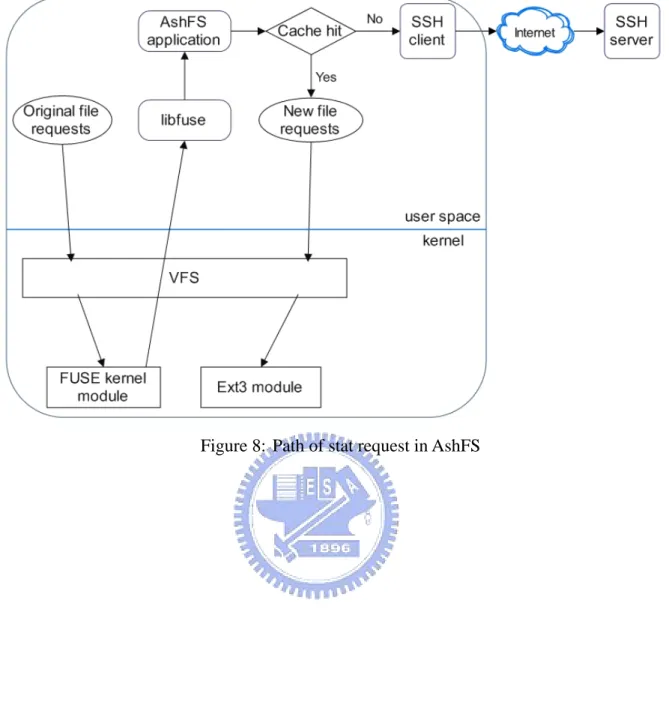
Figure 6 depicts AshFS's system architecture, where an ellipse represents a system call, a rounded rectangle represents an AshFS filesystem component, a rectangle represents a kernel interface, and a diamond represents an if-else statement. A complete AshFS system consists of a kernel module, a userspace library, a user application, a secure client and a secure server.
The figure also depicts the path of a file system request in AshFS. At the first time, the system call (request) enters the virtual file system (VFS) in the kernel, when it realizes that the request is for AshFS file system, the call is handled to the AshFS kernel module. Then AshFS kernel module passes the call to user-space AshFS library. Finally, the library communicates with the user-space AshFS process to know how to answer it. If the requested
file object is already in the cache and is fresh, the process will make a new request to the local file system. If the requested file object is uncached, AshFS process will ask the secure client for answers. Since mobile users usually roam around in less-reliable networks, we thought that our server and client should communicate with each other in a secure channel.
Figure 6: AshFS system architecture
4.2 Tools
To build a complete AshFS system, there are five components needed to be implemented (Figure 6). We planed not to do all of them by ourselves, but tried to combine with some powerful utilities in existence. We are going to introduce them and explain why they are adopted here.
4.2.1 FUSE
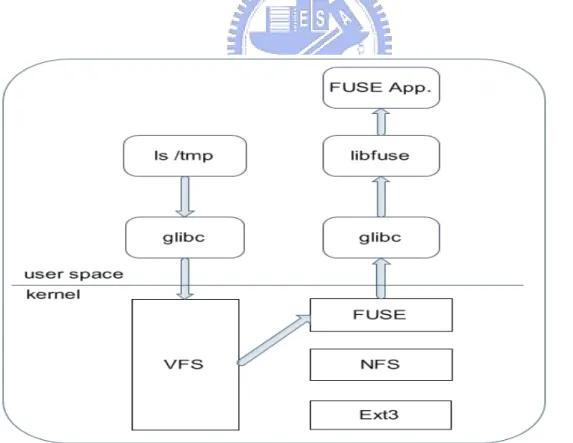
Conventional file systems which were implemented in the OS kernel take advantage of low overhead of accessing internal kernel services. However the speed improvement of a pure kernel-based network file system is no longer significant, because the network equipments are falling far behind the CPU and memory in speed. Recently efforts have made it become feasible to create a file system in user space, FUSE is one of it.
FUSE is a free filesystem framework and its name comes from “File system in user space”. It aims to provide the means by which file systems can be written in user space and exposed via the kernel to rest of the OS in a transparent way [1]. The infrastructure consists of an OS-dependent kernel module, portable user space libraries and a mount utility. Data and metadata of file system based on FUSE are provided by userspace process, and it makes this kind of file system can be more portable, since less functionality is bundled to the kernel.
The list (stat) call enters the VFS in the kernel, and when it identifies that the request is for FUSE file system, it passes the request to the FUSE kernel module. Then FUSE kernel module will pass the request to user-space FUSE libraries, by allowing these libraries to read a special device /dev/fuse. Finally, these libraries will communicate with the user space processes to know how to answer it.
4.2.2 SSH and OpenSSH
SSH (Secure Shell) original means a network protocol that allows data to be exchanged using a secure channel between two computers [8]. Another meaning of SSH is a very popular secure communication application. Users can remotely login to the SSH server with security protection [7]. With the support of SSH File Transfer Protocol and its application SFTP, user can store and download files to/from the server. Because SSH encrypts all data in transmission, it provides confidentiality and integrity of data over an insecure network. For mobile users, SSH can make their communications more secure. OpenSSH is one of the most widely used SSH implementations, and many Linux distributions have made it become one of the default installations. OpenSSH includes a set of applications for both server and client. Since its popularity and simplicity, we decided to use it as our secure client and secure server.
4.2.3 Rsync
Rsync is an open source utility that provides fast incremental file transfer [27-28]. It synchronizes files and directories from one location to another while minimizing data transfer using delta encoding when appropriate. Since it copies only the diffs of files that have actually changed, much bandwidth consumption can be preserved. Rsync can synchronize files and directories from/to a remote rsync daemon or via a remote shell such as RSH or SSH, which meets our security concerns. In addition, it supports some others functions like compression and recursion to facilitate synchronization processes. Because its flexibility, security and
efficiency in transferring files, we chose it to become one of AshFS’s synchronization utilities.
4.3 Current Status and System Requirements
AshFS is now implemented in C on Linux. The server is a standard OpenSSH server, and the client is a user-level process who will fork other process in background. Figure 8 shows the basic flow of current AshFS when a user carries out one file system operation. AshFS uses OpenSSH client applications to communicate with the server: “ssh” for passing control messages, and “sftp” for retrieving and updating files. AshFS will create two processes to individually execute these programs at initial and then return to the main procedure.
To realize AshFS, we implemented a set of functions like read(), write(), getattr(), readdir(), etc. FUSE uses a special structure which contains function pointers to this set of functions, and these functions will overlay a normal file system function [12]. These functions will access the special cache structure we designed for AshFS, and create other process or thread like Upload manager to start some mechanisms.
In order to run AshFS, besides AshFS client program we wrote, the client-side computers should have been installed the FUSE framework (both the FUSE kernel module and library) and the OpenSSH client suite which at least contains ssh and sftp command. Surely, you also need to prepare a SSH server.
Chapter 5
Experiments and Performance Evaluation
In this chapter, some experiments were set to test if AshFS is suitable for our proposed environment. For an objective comparison, we added some of our related works into the experiments. Since MAFS is implemented on FreeBSD and RSC filesystem is designed for the Symbian OS, they were not tested in these experiments. Here we listed the results and analyzed these data. In the end of each experiment, we tried to interpret the relationship between results and our design principles.
5.1 Experiment Environment and Tools
To explore how our file system performs, some experiments have been made. We connected two computers into a Gigabit network; one acted as our client and the other acted as our server. The client computer had an Athlon XP 2600+ CPU and 2GB ram. The server was a Pentium R computer with 3.0GHz clock rate and 1.5GB ram. Both client and server were running Linux with 2.6.17 kernel above. In our experiments, the server shared some parts of its local file system; the client mounted it and performed file system some operations under the mount point. Each experiment was repetitive running for 10 times and the data presented here were the average. Here are some tools and what they were doing for.
z time-1.7-29-fc7: It times a simple command or gives resource usage [21]. We used it to measure the finishing time of each experiment.
z bonnie++-1.03: Bonnie++ is an industry-standard file system benchmark used to benchmark ideal performance in a uniform and repeatable way [19-20]. We used it to evaluate write throughput of a single file.
z CBQ.init-v0.7.3: Cbq.init is a Linux shell script file which uses CBQ (class-based queuing) mechanism to control network traffic [22]. We used it to constrain the bandwidth between the client and the server.
z iftop-0.17-6.fc7: It listens to network traffic on a named interface and displays current bandwidth usage by pairs of hosts [23]. We used it to measure client’s bandwidth usage.
5.2 Frequencies of Filesystem Operations
In this section, we used several methods to test operation speed of our target file systems. Theses results should be close to how users really feel when using them.
5.2.1 List frequencies
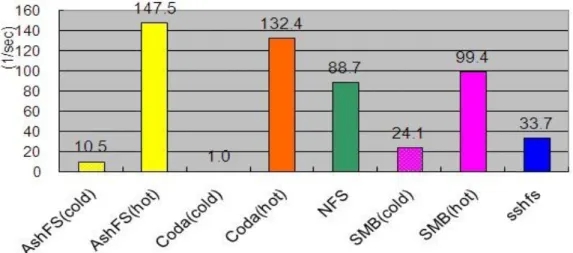
In these experiments we executed “list” operation and recorded execution time of each target file system. Because some file systems have permanent/temporary cache and the cache state affects its performance, we made measurements for both cold and hot cache. In the first experiment, the client listed every sub-directory under the mounted directory and measured the latencies. For easing comparison, we used frequency (1/second) instead of time (second). The result was shown in the Figure 9.
It is apparent that AshFS and Coda were slower than others when they listed the uncached directory. We thought that it is because of the cache overhead. But even under this circumstance, AshFS were 10 times faster than Coda. Nevertheless, if the client reads the directory again, Coda and AshFS will faster than others because they answer the request from cache directly without contacting to the server.
In this experiment, we measured the latencies of a series of file system operations: create, list (stat), and remove. First the client created a list of files, and then it listed these files, finally it deleted them in sequential order. Each kind of latency was measured and Figure 10 shows the result. We also performed the same operations on local file system (ext3), and the result was denotes as “Local” in Figure 10.
The operation speed of AshFS was faster than all other network file systems. Coda also did well in this experiment. Because in most of modifications, AshFS and Coda will write to local disk first without waiting responses from the server, and communications often take time.
Figure 9: Frequencies of List operations
5.3 Write Throughput
We were going to evaluate write throughput of each file system. To explore how bandwidth affects these file systems, we divided environments into two different network bandwidth. Furthermore, consumed bandwidth of each operation was measured for comparing protocol overheads of these file systems.
5.3.1 Write throughput under unlimited bandwidth
There are two kinds of write throughput benchmark, one is writing a single large file, and the other is writing separate small files. For testing the anterior one, we used Bonnie++ to benchmark our target file systems. For the latter one, we copied a directory with varied total size manually from the local file system to the target filesystem, and then measured its execution time. Each directory contains many small files with different sizes from 100B to 1MB.
Figure 11 and 12 show the write throughput benchmarks. Obviously, sshfs had a lower performance in both two benchmarks; it is because of its encryption. It stands to reason that client’s local file system has the best throughput. Coda and AshFS led others because they wrote to local file system first, and didn’t communicate with the server much at that time. When writing separate small files, all network file systems showed here are evidently slower than local, because much more time was spent on allocating space to files and file system itself (many stat and create actions were executed). Note that AshFS performed a little slower than Coda, and the gap was almost a constant in single file throughput, but it became smaller in separate files throughput. It could because that AshFS always transacts communications in batch (not individual and not synchronous for every file operation). Hence AshFS performed well in small files.
Figure 11: Single file write throughput
Figure 12: Separate files write throughput
Figure 13 shows the write overheads. We measured total transferred and received flows. Then subtracted it from original size of the written file and took this value as the overhead. In both benchmarks, Coda’s overhead was much higher than others. It maybe means that Coda’s protocols are more talkative, so it needs more network resources for write operations. Sshfs took 2nd high overhead, because the encryption of SSH2. Nevertheless, AshFS also uses SSH2, but its overhead was 52-77% less than Coda and 32-34% less than sshfs. Here shows that our
design in reducing communications between client and server works.
Figure 13: Write overhead
5.3.2 Write throughput under lower bandwidth
To simulate mobile networks with usual transfer rate, we confined the experiment bandwidth to 4096kbps (512KB/s) for both downloading and uploading.
Figure 14 and 15 are our experiment results. NFS, SMB and sshfs performed notably worse than others, their throughputs were almost all equal to 0.46 MB/s (We have enlarged their data to make our figures more clear; original data displayed three overlapped lines lying on the x-axis). It shows that their performances were severely constrained by the available network bandwidth. It is because of they don’t have a persistent cache, and they usually need a steady, strong connection to the server. AshFS and Coda both take asynchronously write policy which means that files are written to local disk first, so their throughputs were similar to ones under unlimited bandwidth.
Figure 14: Single file throughput in 512KBps
Figure 15: Separate files throughput in 512KBps
Figure 16 are the write overheads in 512KBps bandwidth. There are no big differences except Coda’s overhead. Comparing with the overhead in unlimited bandwidth, even though coda’s overhead became less, it still used 51-52% more network resources than AshFS.
Figure 16: Write overhead in 512 KBps
Tables below are numeric benchmark data for reference.
AshFS Coda NFS SMB sshfs Local(ext3)
thruput-256M 37.314 42.007 28.086 30.660 10.446 47.482 thruput-384M 37.701 41.034 24.769 27.105 10.019 46.078 thruput-512M 37.703 40.251 21.453 23.549 10.257 44.299 thruput-640M 37.584 39.987 23.002 21.406 9.931 46.431 thruput-768M 36.753 39.840 22.138 19.738 9.181 43.542 overhead (%) 6.497 28.126 6.449 5.750 9.938 0.000 Table 3: Single file throughput under high BW
AshFS Coda NFS SMB sshfs Local(ext3)
thruput-256M 27.236 34.839 19.460 17.676 8.628 40.962 thruput-384M 28.197 31.457 18.941 17.844 8.615 42.025 thruput-512M 27.065 27.137 18.768 17.740 8.751 41.524 thruput-640M 27.356 28.938 19.468 17.776 8.745 42.875 thruput-768M 28.927 30.373 17.429 17.114 7.997 42.381 overhead (%) 6.483 13.467 6.820 8.275 9.648 0.000 Table 4: Separate files throughput under high BW
AshFS Coda NFS SMB sshfs Local(ext3) thruput-256M 33.066 40.751 0.4656 0.4679 0.4601 58.084 thruput-384M 35.071 39.795 0.4664 0.4675 0.4610 46.748 thruput-512M 35.664 38.294 0.4659 0.4688 0.4601 46.361 thruput-640M 34.229 39.587 0.4658 0.4676 0.4611 45.767 thruput-768M 35.026 40.243 0.4656 0.4672 0.4613 46.748 thruput-896M 35.256 40.687 0.4654 0.4671 0.4602 45.384 overhead (%) 6.297 12.825 6.406 5.719 9.516 0.000 Table 5: Single file throughput under 512KBps
AshFS Coda NFS SMB sshfs Local(ext3)
thruput-256M 24.267 33.810 0.4648 0.4655 0.4603 53.076 thruput-384M 25.120 33.550 0.4642 0.4651 0.4605 47.206 thruput-512M 24.700 29.922 0.4644 0.4660 0.4608 46.166 thruput-640M 23.917 28.693 0.4649 0.4656 0.4605 43.304 thruput-768M 23.358 24.710 0.4647 0.4653 0.4605 41.776 thruput-896M 23.210 26.963 0.4644 0.4659 0.4600 39.282 overhead (%) 6.375 13.375 6.750 6.219 9.766 0.000 Table 6: Separate files throughput under 512KBps
5.4 Synchronization Performance
5.4.1 Synchronization time
How long does it take to propagate all changed files to the server? We were going to measure it in this experiment. First we disconnected the network connection, and then wrote several files to our target file systems. As a result of lacking support of disconnected operations, just Coda and AshFS remained as our target file systems. After writing has finished, we reconnected the network. Once the target file system started to synchronize, we timed it. Figure 17 is our result; the horizontal coordinate denotes the total size of all written
files. Obviously, AshFS can finish synchronizing faster. The reason is because AshFS has a lower protocol overhead, and it transfers less data when synchronizing. In fact, we also recorded their transfer rates: The average transfer rate of AshFS was about 15MB/s, and one of Coda was about merely 9MB/s. It means that even they transfer the same amount of data, AshFS is more efficient.
Figure 17: Synchronization time
AshFS Coda time-128M (sec) 13.530 24.797 time-256M (sec) 22.518 39.820 time-384M (sec) 32.945 61.950 time-512M (sec) 42.483 75.86 time-640M (sec) 57.260 93.72 Table 7: Synchronization time
5.4.2 Rewriting speedup
Previous write throughputs are the measurements of writing new files to the mount point. In fact, users often deal with writing to existent files, and we used “rsync” utility to enhance rewriting performance of AshFS. In this experiment, we evaluated how it much faster than original writing methods. First we wrote a directory containing many files with different sizes
to the mount point. After these files are all successfully propagated to the server, we modified every file with a small change: we used a text editor to open them and appended two new lines of text to each file. Our target file systems will perceive the changes of cached files and then synchronize them with server’s ones. (For the file systems with no persistent cache, the changes are directly replayed on the server’s files.) After the synchronization has been finished, we appended these files again. Similar actions were repeated for three times, and the results shown here are the averages. The consumed bandwidth of each write/rewrite operation was measured and we compared it with the original file size. Here we invoke a new terminology “Speedup” used in rsync and follow its original definition.
z Speedup = Original file size / total transferred packet size
We can think that the number Speedup is a bandwidth-preserving factor. Obviously everyone wants it to be as greater as possible, since we can use a little bandwidth to finish synchronization. In a normal case, Speedup is usually less than 1 because of the protocol overhead (It costs more than N bytes to transfer an N bytes file).
The results are shown in Figure 18, where AshFS (z on) means AshFS with compress-enabled rsync; i.e. AshFS will compress some data when synchronizing. When all of our target file systems uploaded new files to the server, they transferred all contents of files. Hence all Speedups are a little less than 1, in a word, there is no speed improvement. Traditional cache-enabled network file systems usually upload every changed file to the server in their entirety, but AshFS will perceive that these files already exist on the server and will find the differences between the newer version and older version. When writing the same file again, AshFS will only propagate the modified contents. Since only a small part of file is transferred, Speedup is much bigger than 1 in the rewriting operation. Intuitively, with the support of compression, AshFS (z on) has larger Speedup. Note that Speedup of NFS is a little greater than 1 for the rewriting operation, and it means that NFS may compress the file data for rewriting. Samba and Sshfs performs notably worse than writing new files: their Speedups
are almost a half of the original ones, and we noticed that the amounts of their receiving packets were almost equal to sending packets (and almost equal to total directory size). This looks strange because the receiving packets are usually much less than sending packets for writing operations. We think this may because of the temporary cached files: Samba and Sshfs found that the user was writing to an existent file and thought it may be rewritten for several times in the future, so they downloaded the file to their memory caches first. After getting the file and writing to it, these file systems then uploaded the file to the server. This can explain why the amounts of sending packets and receiving packets were almost equal to the file size. But both of them don’t support persistent cache, so when the user wrote to the same file after a while (the cached file was invalidated or replaced), they needed to retrieve it from the server again. Therefore Samba and Sshfs transferred double amounts of packets in rewriting operations. Finally, lacking of synchronization algorithms similar to rsync, Coda’s Speedups are all the same in both write and rewrite benchmarks, because it transferred similar contents again and again.